In this section, we start by presenting the results using the conventional loss function when training the LeNet network on the CIFAR-10 dataset, providing an intuitive comparison. We then evaluate the accuracy and CD of ResNet18/34/50, MobileNetV2, and BN-VGG16 on the ImageNet dataset using our proposed quantization scheme. Both the CIFAR-100 and ImageNet datasets have large and diverse image data with sufficient data for training and evaluating deep neural network models and have become widely used in academia as widely accepted benchmark sets. In addition, we compare and analyze the parameter distributions of the different quantized models. Finally, we compare the quantization of ResNet18/34/50 at different bit widths and present the changes in the accuracy and CD on the CIFAR-100 dataset.
4.1. Intuitive Comparison
The quantized model shown in
Figure 1b was trained using the conventional loss function
, which is the CE loss between the predictions of the quantized model and the labels. In contrast, we trained the quantized model using
, which is the MCL loss between the predictions of the quantized and floating-point models. The accuracy and CD values of the quantized model obtained using these two different methods on the 10-class labels of the CIFAR-10 dataset are shown in
Table 2.
The quantized model trained using achieved an accuracy of 81.58%, which was 0.49% lower than that of the original model and only 0.02% lower than that of the quantized model trained using . In addition, the quantized model trained using achieved a CD of 3.54%, which was 0.52% lower than that of the quantized model trained using . This means that the quantized model trained using is more equivalent to the original model.
The decrease in accuracy resulted from increased prediction accuracy in four out of ten classes but decreased accuracy in the remaining six. As a result, these changes caused a decrease in the similarity between the quantized and floating-point models. Compared to the quantized model trained using , the results varied when using to train the quantized model. Although quantization caused some loss, it reduced the CD by 0.49% while only decreasing the accuracy by 0.02%.
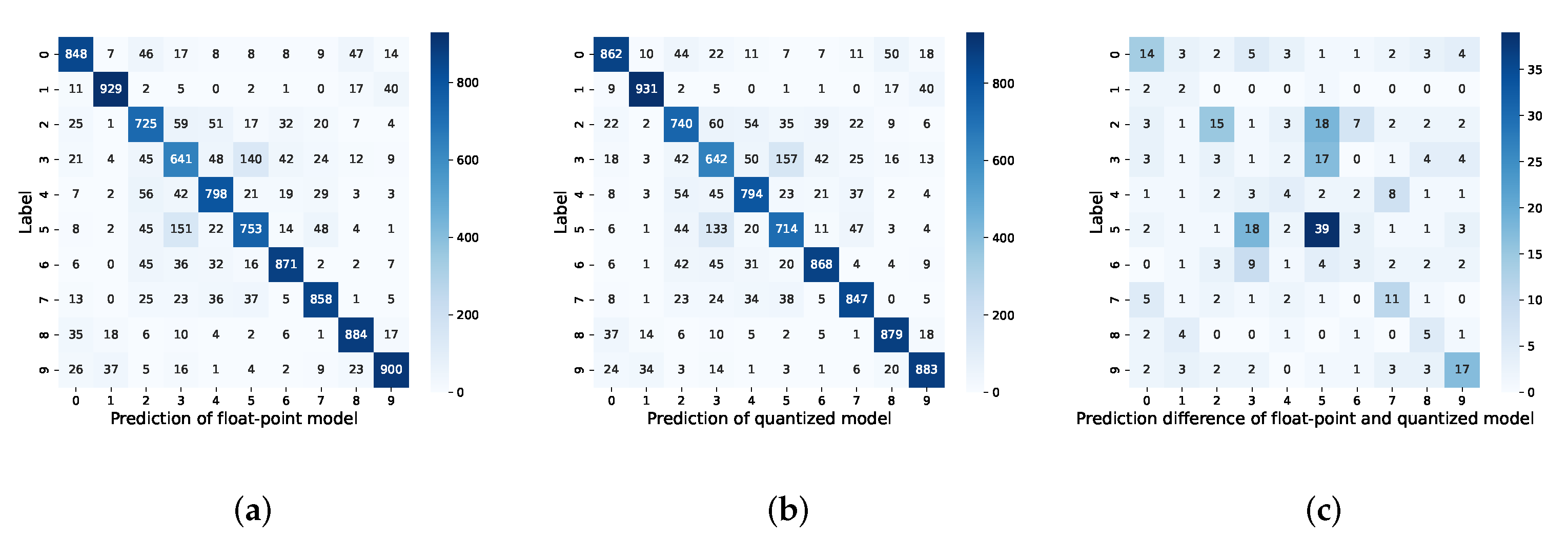
We show the confusion matrix of the outputs of the quantized model trained using the MCL and the floating-point model trained using
, which is presented in
Figure 9. The outputs of the quantized model trained using the MCL show smaller differences when compared to the floating-point model, indicating a reduced equivalence loss. When comparing the prediction difference in
Figure 9 with that in
Figure 1, it can be seen that the maximum discrepancy in the classification predictions decreased from 39 (in
Figure 1c) to 18 (in
Figure 9c), and the number of instances where the prediction discrepancy exceeds 10 was reduced from 8 (in
Figure 1c) to 5 (in
Figure 9c). These results demonstrate the advantages of employing MCL training in quantized models to reduce the equivalence loss.
4.2. Evaluation on ImageNet
To demonstrate the effectiveness of the proposed method, we quantized several representative models using the MCL loss, including ResNet18/34/50, MobileNetV2, and BN-VGG16. Additionally, we evaluated them using 8-bit-width quantization on the ImageNet dataset.
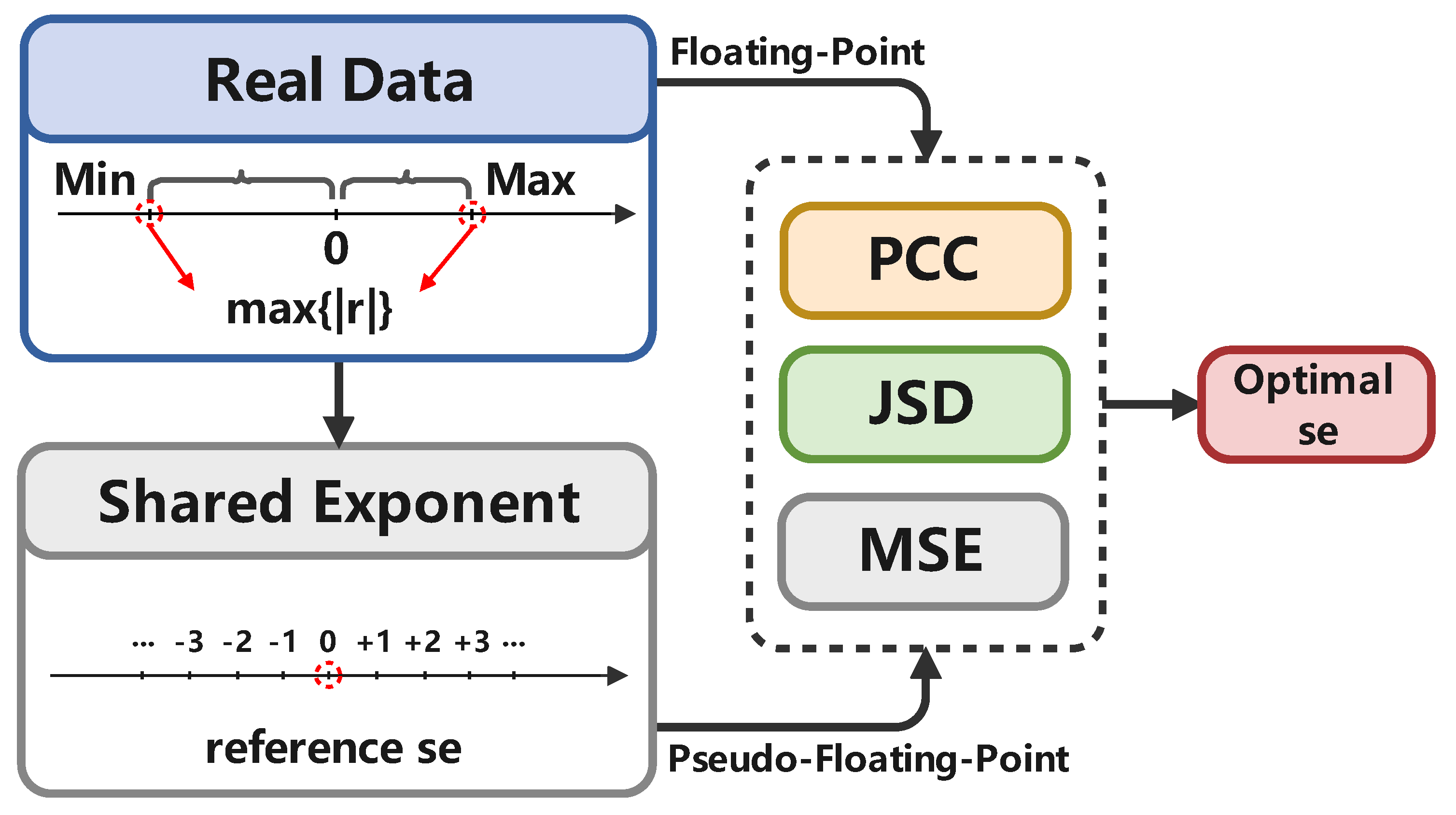
We followed the proposed quantization scheme. First, we trained a 32-bit floating-point model using as the full-precision model. Then, we used it as an initial model to train the quantized model, where two of the loss functions were used: and . Furthermore, we used identical training settings for pretraining and fine-tuning, including the learning rate, learning rate scheduler, batch size, optimizer, and weight decay.
For a better comparison, the initial learning rate in the training of the quantized model using remained unchanged in the training of the quantized model using . The learning rate was updated every 20 epochs with the learning rate scheduler. The parameters were quantized by 10% every two epochs, and by the 20th epoch, all parameters were transferred to the ISE type. We used the stochastic gradient descent (SGD) optimizer to adjust the parameters. The momentum remained at 0.9, and the weight decay was set to . For ResNet18/34 and MobileNetV2, the batch size was set to 128, and for ResNet50 and BN-VGG16, the batch size was set to 64 owing to their large size.
First, we compared the accuracy and CD of the quantized models obtained using different loss functions. The experimental results of these models on the ImageNet dataset are shown in
Table 3, where we list the Top-1 accuracy (Top-1 Acc.) and CD of the quantized models.
We also present the accuracy of the floating-point model as a baseline. The two quantized models were trained using two different loss functions and identical quantization settings. We found that the quantized model trained using achieved the lowest CD while maintaining comparable or even higher performance compared to the quantized model trained using . We can see that the network with the best performance is ResNet50 for 7-bit quantization, which achieved a CD of 12.90%, and the accuracy was higher than that of the quantized model trained using by 0.48%.
In addition, we compared the models quantized using many advanced methods, including FAQ [
48], regularization [
39], LSQ [
40], EQ [
41], QAT [
30], OCS [
42], ACIQ [
43], SSBD [
49], UNIQ [
44], Apprentice [
45], INQ [
38], RV-Quant [
46], 8-bit training [
50], and ZeroQ [
47]. The comparison was performed across different bit widths of the weights and activations. For most of these methods, bias quantization is not mentioned, whereas our method can support bias quantization at a low bit width. For all methods, the Top-1 accuracy (Top-1 Acc.) serves as the baseline for the floating-point model. The experimental results on the ImageNet dataset for these models are shown in
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8. To the best of our knowledge, model quantization using the MCL loss exhibited the best performance, particularly for ResNet18/34/50 networks.
However, the results for MobileNetV2 were significantly lower compared to those of the other models. The CD did not fall below 10% for the 8-bit setting and was close to 30% for the 7-bit setting. We presume that the reason for this is that MobileNetV2, as a lightweight model, contains inverted residuals and depth-wise convolution layers. These structures have far fewer parameters compared to conventional convolutional layers with kernel sizes of 3, 5, 7, etc. To a certain extent, this increased the impact of parameter quantization on the results. To further investigate the reasons, we generated a kernel density estimation (KDE) of the parameter distributions for the floating-point and quantized models in MobileNetV2. For comparative purposes, we also included KDE for BN-VGG16, as illustrated in
Figure 10.
For the MobileNetV2 and BN-VGG16 networks, we generated the weight distribution of the continuous convolution/linear layer and batch normalization layer of the network, which are located at the front and back layers of the model, respectively, as shown in
Figure 10. Owing to insufficient data, the impact of the bias was negligible. Conv/Linear-0/1 and BN-0/1 are two consecutive computing layers. It should be noted here that the weight of the batch normalization layer refers to the weight after fusing the variance of the input feature map. The black line represents the weight distribution of the floating-point model, whereas the blue and orange lines represent that of the quantized model trained using
and
, respectively. For the parameter distributions of the convolutional or linear layers, we observe an almost complete overlap, demonstrating an approximate normal distribution for both models. This is in line with the original purpose of quantization, which aims for the quantized weights to resemble floating-point weights as much as possible. However, the situation is slightly different for the parameter distribution in the batch normalization layer. On the one hand, there are generally fewer parameters in the batch normalization layer compared to the convolutional/linear layers, resulting in a greater difference in the data distribution. As shown in
Figure 10, the weight distribution of the 8-bit quantized model trained using
and
was challenging to approximate or match that of the 32-bit floating-point model. On the other hand, the fused weight of the batch normalization layer includes variance information from the feature map, which means that inadequate or incomplete feature extraction can significantly affect the overall data distribution.
For BN-VGG16, the convolution layer with a kernel size of three contained many weight parameters (Param = 1792 and 1,180,160), which extracted feature information well. As a result, the subsequent batch normalization layer approximated a normal distribution. Moreover, compared to the quantized model trained using
, the weight distribution of the quantized BN-VGG16 trained using
approached the floating-point BN-VGG16 model more closely. As shown in
Figure 10, the orange line is closer to the black line than the blue line.
In contrast, for MobileNetV2, the number of weight parameters was significantly smaller compared to BN-VGG16 (Param = 528 and 442,752). Insufficient feature information led to a feature distribution with a large variance, which further affected the distribution of the fused weight in the subsequent batch normalization layer. This impact became increasingly pronounced as the layer moved further back. As shown in
Figure 10, the weight distribution of BN-0 roughly resembles a normal distribution, whereas that of the BN-1 layer at the back deviates completely from a normal distribution.
Consequently, the 8-bit quantized model output differed significantly from that of the floating-point model for MobileNetV2. The quantized model trained using achieved a significant reduction in the CD of up to 13.32% while experiencing a notable increase in accuracy of 69.33%, which was higher than that of the quantized model trained using .
In summary, the results prove that in most cases, the quantized model trained using can further reduce the mode compression loss while maintaining or even improving the accuracy.
4.3. Evaluation on CIFAR-100
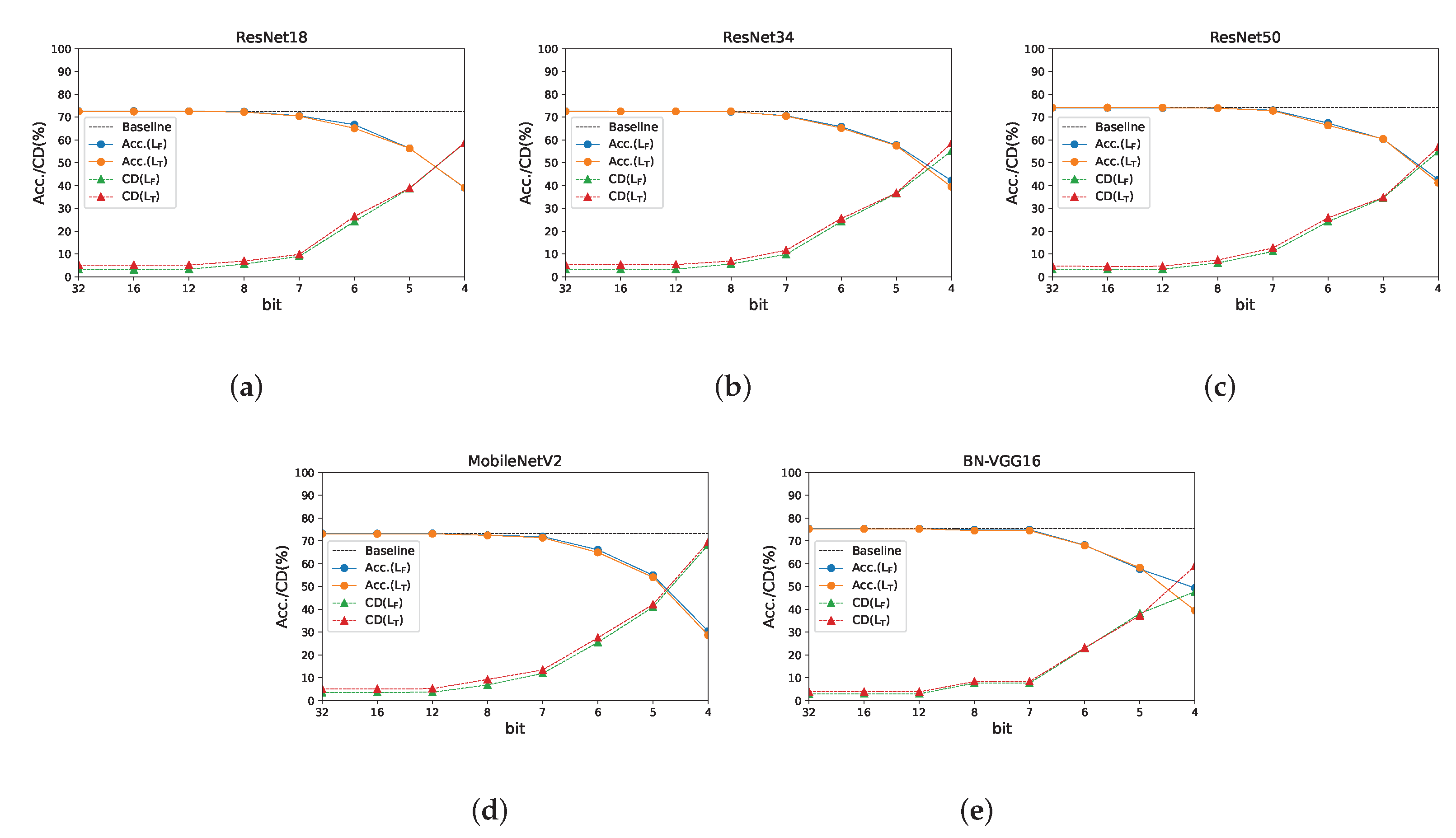
To evaluate the CD of the quantization model at various bit widths, we trained the ResNet18/34/50 network on the CIFAR-100 dataset at bit widths of 32, 16, 12, 8, 7, and 6. The loss functions we used were
and
. The Top-1 accuracy (Top-1 Acc.) and CD changes in the different network models at different quantization bit widths are illustrated in
Figure 11.
The use of different loss functions resulted in few differences in the networks’ accuracy values for the quantization models at different bit widths. This is evidenced by the similar orange and blue lines in the graph, with differences becoming more prominent only when the quantization bit width decreased. However, for the CD, training using the MCL loss function yielded a smaller compression loss, as indicated by the green line, which is lower than the red line in the graph. In addition, the CD increased with decreasing bit widths of quantization. Similarly, at lower bit widths, the difference in the CD became more pronounced. The quantized model trained using achieved higher accuracy compared to the one trained using when the bit width was lower than six. This was particularly evident for BN-VGG16 and ResNet34 with a 4-bit width. The quantization models with different bit widths not only resulted in different levels of performance but also lower bandwidths, thereby reducing the demand for storage and making deployment on resource-constrained devices more feasible. The CD of the quantization model fine-tuned using the MCL was lower, making it better suited to scenarios that require high equivalence between the quantization and floating-point models (such as intelligent face locks, etc.).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}