Abstract
Intelligent traffic systems represent one of the crucial domains in today’s world, aiming to enhance traffic management efficiency and road safety. However, current intelligent traffic systems still face various challenges, particularly in the realm of target detection. These challenges include adapting to complex traffic scenarios and the lack of precise detection for multiple objects. To address these issues, we propose an innovative approach known as YOLOv8-SnakeVision. This method introduces Dynamic Snake Convolution, Context Aggregation Attention Mechanisms, and the Wise-IoU strategy within the YOLOv8 framework to enhance target detection performance. Dynamic Snake Convolution assists in accurately capturing complex object shapes and features, especially in cases of target occlusion or overlap. The Context Aggregation Attention Mechanisms allow the model to better focus on critical image regions and effectively integrate information, thus improving its ability to recognize obscured targets, small objects, and complex patterns. The Wise-IoU strategy combines dynamic non-monotonic focusing mechanisms, aiming to more precisely regress target bounding boxes, particularly for low-quality examples. We validate our approach on the BDD100K and NEXET datasets. Experimental results demonstrate that YOLOv8-SnakeVision excels in various complex road traffic scenarios. It not only enhances small object detection but also strengthens the ability to recognize multiple targets. This innovative method provides robust support for the development of intelligent traffic systems and holds the promise of achieving further breakthroughs in future applications.
1. Introduction
In today’s society, due to the continuous advancement of urbanization and rapid economic development, the number of motor vehicles is consistently increasing. This trend is leading to a more complex and congested road traffic environment [1,2,3]. This increased traffic complexity poses significant challenges to urban residents’ mobility and escalates the risks of traffic accidents and violations [4,5]. In light of these issues, the development of intelligent traffic systems becomes particularly critical. Such systems not only have the potential to enhance traffic flow efficiency but also hold the promise of substantially improving road safety. At the core of intelligent traffic system technologies lies the accurate identification of motor vehicles, pedestrians, and other entities on the road, which is one of the most vital tasks [6,7]. Target detection technology, as a key component of intelligent traffic systems, provides an effective means to automatically recognize and track various entities in complex road traffic environments. In recent years, the emergence of deep learning has gained widespread attention in the field of target detection due to its exceptional performance. Deep learning models not only achieve highly accurate target detection but also possess strong adaptability and excellent generalization capabilities, making them an ideal choice for addressing intricate road traffic challenges [8,9].
In the domain of object detection, despite the remarkable progress achieved through deep learning techniques, several pivotal issues remain unresolved. Firstly, current object detection algorithms still grapple with challenges when dealing with intricate scenarios such as occlusions, variations in illumination, and changes in target scale [10,11]. Additionally, the robustness and versatility of the algorithms demand further enhancement to ensure effective operation across diverse environments and tasks [12,13]. To address these challenges, researchers have recently proposed a plethora of innovative object detection algorithms, including DETR, EfficientDet, and YOLOv8. To begin with, the Transformer-based DETR model offers a novel perspective for object detection [14]. This model successfully integrates the self-attention mechanism of Transformers into object detection, facilitating more efficient processing of contextual information within images. It circumvents the traditional anchor box design, directly outputting the location and category of the target. Such a design promotes simplicity and robustness but requires more computational resources and extended training periods, potentially posing challenges for real-time applications. Next, EfficientDet, which integrates EfficientNet as its backbone, embodies an object detection model that achieves efficiency and precision in object detection tasks through a compound scaling strategy [15]. Its adaptive nature ensures exemplary performance across devices with varying computational capabilities. However, in certain specific and complex scenarios, EfficientDet may require more in-depth fine-tuning to achieve outstanding performance. Lastly, our attention turns to YOLOv8. As a fresh entrant in the YOLO family, YOLOv8 further refines the detection speed and accuracy built upon YOLOv5 [16]. Yet, in scenarios with overlapping multi-targets or when certain targets are obscured, the absence of an attention mechanism might impede YOLOv8’s ability to recognize and pinpoint the obstructed sections. Concurrently, traditional convolution operations are similarly constrained in their capability to detect small targets and capture intricate patterns and structural information within images. The bounding box loss function, being an integral part of the object detection loss function, plays a crucial role in the object detection task. However, YOLOv8’s loss function overly emphasizes bounding box regression for low-quality examples and lacks a dynamic non-monotonic focusing mechanism along with a more judicious gradient gain allocation strategy [17]. These shortcomings evidently jeopardize potential enhancements in the model’s detection performance.
Given the identified constraints of YOLOv8, this study introduces an advanced model named YOLOv8-SnakeVision. Inspired by the segmentation of tubular structures based on topological geometric constraints, we incorporated Dynamic Snake Convolution (DSConv) into YOLOv8. This allows the model to adeptly capture slender and tortuous structural attributes when handling obscured or overlapping targets, thereby offering heightened precision in delineating their forms and characteristics, especially in scenarios with overlapping multiple targets. Furthermore, by integrating the Context Aggregation Attention Mechanisms (CAAM), the model is better positioned to focus on pivotal segments of the image, facilitating effective information amalgamation, thus bolstering the recognition of obscured objects, small targets, and intricate patterns. Ultimately, we refined YOLOv8’s loss function, adopting the Wise-IoU strategy. This approach amalgamates a dynamic non-monotonic focusing mechanism with a judicious gradient gain allocation strategy, aiming to more accurately regress bounding boxes, particularly for low-quality examples. Through this strategy, the model emphasizes on anchor boxes of average quality in the training data, rather than solely accentuating high- or low-quality examples, effectively enhancing the model’s detection and localization capabilities for targets.
The following are the three contributions of this paper:
- This paper introduces the YOLOv8-SnakeVision model, which exhibits significant innovation in the field of object detection. By incorporating DSConv and CAAM on top of YOLOv8, we are able to capture the shapes and features of complex objects more accurately, especially in cases of multiple overlapping or occluded objects. This innovation not only enriches the toolbox of object detection techniques but also enhances the performance and usability of intelligent traffic systems.
- In scientific research, adaptability to multiple scenarios has always been a key concern. Our study underscores the versatility of the YOLOv8-SnakeVision model across various road traffic scenarios. The model can handle complex situations including occlusions, overlapping objects, small targets, and intricate patterns, providing crucial support for practical intelligent traffic applications. This multi-scenario adaptability represents a significant contribution to this research, offering effective tools for tackling complex traffic issues.
- Our research also highlights the Wise-IoU strategy employed in the YOLOv8-SnakeVision model. This strategy combines a dynamic non-monotonic focusing mechanism, enabling more accurate regression of object-bounding boxes, particularly for low-quality examples. The improvement in this loss function is expected to significantly enhance the performance of object detection algorithms, making them more reliable in real-world road traffic environments.
2. Related Work
2.1. Research on Two-Stage Approaches in Object Detection
In the field of object detection, two-stage object detection algorithms are renowned for their high accuracy. These algorithms divide the object detection task into two key steps: region proposal and object classification. They excel in handling complex scenes and small object detection. The earliest model, R-CNN (Region-based Convolutional Neural Network) [18], employed selective search to generate region proposals, followed by feature extraction and classification using convolutional neural networks (CNNs). While it demonstrated excellent accuracy, it incurred high computational costs due to the need to process a large number of region proposals independently [19]. SPPNet (Spatial Pyramid Pooling Network) improved upon R-CNN by introducing spatial pyramid pooling, allowing for variable-sized input images and reducing computational costs [20]. Fast R-CNN integrated the region of interest (RoI) pooling layer directly into the network architecture, eliminating the need for external region proposal methods, and resulting in improved speed and accuracy. Faster R-CNN introduced a Region Proposal Network (RPN) that learned to generate region proposals within the network, enabling end-to-end training and striking a balance between high accuracy and speed [21]. Mask R-CNN extended Faster R-CNN by adding a mask prediction branch, enabling instance segmentation in addition to object detection [22]. Sparse R-CNN introduced a sparse-aware learning framework, enhancing inference speed by dynamically pruning unimportant regions during inference. Each two-stage object detection model has its unique strengths and limitations, necessitating a careful choice to meet specific requirements such as accuracy, speed, and computational resources in different application scenarios.
Although two-stage object detection algorithms excel in various domains, including road scene object detection, they also exhibit certain drawbacks [23]. Firstly, these algorithms often come with high computational complexity due to their multi-step nature, involving region proposal and object classification. This results in significant demands for computational resources and time, limiting their application in real-time scenarios. Secondly, some two-stage algorithms may experience instability when generating region proposals, leading to inconsistent region selection and subsequently causing issues such as false positives or missed detections, especially in scenarios with complex backgrounds or multi-scale objects [24]. Additionally, these algorithms may not perform well in the detection of small-sized objects, potentially leading to missed detections or inaccurate localization, which poses a challenge in applications like detecting tiny objects [25,26]. Table 1 illustrates the advantages and disadvantages of two-stage object detection algorithms.

Table 1.
Advantages and disadvantages of two-stage object detection algorithms.
2.2. Research on One-Stage Approaches in Object Detection
In the field of object detection, one-stage object detection algorithms have gained widespread attention. Their core idea is to simultaneously perform object localization and classification in a single pass. Compared to two-stage methods, one-stage algorithms offer higher speed and real-time performance, making them well-suited for applications that require rapid responses, especially in road scene object detection [29,30].
Among them, the YOLO (You Only Look Once) series of models represents a set of classical one-stage object detection algorithms. YOLOv1 was the initial version, introducing the concept of anchor boxes, dividing images into grid cells, and assigning multiple anchor boxes to each grid cell for simultaneous object localization and classification [31]. While it achieved high speed, it struggled with inaccuracies in localizing small objects and missed detections in complex scenes. YOLOv2 (YOLO9000) improved upon this by introducing Anchor Boxes and adopting the Darknet-19 backbone network, enhancing the detection of small objects. However, it still faced challenges in handling occlusion and multi-scale objects [32]. YOLOv3 further improved performance by introducing more anchor boxes and multi-scale detection to enhance detection accuracy [33]. Nevertheless, issues with detection accuracy in occluded and complex scenes persisted. YOLOv4 introduced innovative technologies like PANet, the CIOU loss function, and the SAM module, significantly boosting both accuracy and speed, though at the cost of increased complexity and computational resources [34]. YOLOv5 is further optimized for speed and accuracy, incorporating lightweight backbone networks and model compression techniques, suitable for applications requiring high-speed and high-accuracy performance [35]. EfficientDet stands as another outstanding one-stage object detection model, integrating EfficientNet as its backbone network and employing composite scaling strategies to achieve efficient and high-precision object detection [36]. DETR (Data-efficient Object Transformer) is a Transformer-based object detection model that successfully introduced self-attention mechanisms to handle contextual information in images [37]. Additionally, Deformable DETR builds upon DETR by introducing deformable attention mechanisms to further enhance object detection performance, especially in scenarios involving multiple overlapping or complex objects [38].
Road scene object detection presents a challenging domain where trade-offs must be made between the strengths and weaknesses of different models to meet the requirements of real-time performance, accuracy, and robustness [39]. A comparison of the pros and cons of one-stage object detection algorithms is presented in Table 2.
Table 2.
Advantages and disadvantages of one-stage object detection algorithms.
3. Method
3.1. Overview of Our Network
In this study, we propose an innovative object detection method known as YOLOv8-SnakeVision to address the challenges in intelligent traffic systems. This method incorporates three key components into the YOLOv8 framework:
DSConv: We integrate DSConv into the backbone network of YOLOv8s for the following reasons. First, traditional convolutional kernels have fixed weights, resulting in the same receptive field size when processing different regions of an image. However, objects of different scales or deformations may correspond to different locations in feature maps, requiring the model to adaptively adjust its receptive field. Second, DSConv closely matches the size and shape of objects, making it more robust during sampling compared to regular convolution. Lastly, small objects often have smaller sizes and varying shapes, which traditional convolution may struggle to detect accurately. DSConv effectively enhances the detection performance of small objects. This innovation endows the backbone network with adaptability, allowing it to better capture features of objects with different sizes and shapes, thereby improving overall model performance.
CAAM: We introduce the CAAM into the neck of YOLOv8s. This choice is based on the module’s ability to adaptively select and adjust channel and spatial weights in feature maps, thus effectively capturing and representing crucial image features. Furthermore, CAAM requires relatively lower computational overhead, making it computationally efficient compared to other attention mechanisms. In the YOLOv8 network, the neck plays a critical role in connecting the backbone network and prediction output heads. Due to its unique bottom-up and top-down construction, it facilitates a comprehensive fusion of features at different scales, laying the foundation for subsequent predictions. Hence, the network structure in the neck significantly influences the algorithm’s performance.
Wise-IoU Loss: Training data often includes low-quality examples, where conventional geometric metrics may overly penalize these instances, reducing model generalization. To address this issue, we introduce the Wise-IoU loss, which dynamically adjusts bounding box regression loss while reducing penalties for metrics like distance and aspect ratio. This approach better considers multiple factors between predicted and ground truth boxes, including IoU, position, size, and shape, resulting in improved detection accuracy.
By combining these three key components, the YOLOv8-SnakeVision method excels in complex traffic scenarios. It not only enhances the detection of small objects but also improves the recognition of multiple targets. This innovative approach provides robust support for the development of intelligent traffic systems, with the potential for further breakthroughs in future applications. It aims to enhance urban traffic safety and efficiency, reduce traffic accidents, and alleviate congestion, offering increased convenience and safety for future intelligent traffic systems. Figure 1 illustrates the overall network architecture of YOLOv8-SnakeVision.
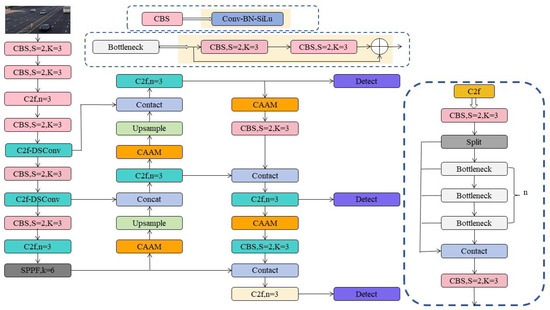
Figure 1.
The overall network architecture of YOLOv8-SnakeVision.
3.2. Dynamic Snake Convolution
DSConv is an innovative convolution method designed to capture complex geometric features in images with greater accuracy [40]. The fundamental concept behind DSConv is to introduce deformation offsets to provide more flexibility to the convolution kernel in standard 2D convolution operations. While the idea of incorporating deformation offsets was inspired by prior related work, DSConv has made significant key improvements in this domain. In traditional convolution operations, the receptive field remains fixed, which may pose challenges for the model in capturing certain detailed features, particularly those associated with slender tubular structures. DSConv addresses this issue by allowing the model to learn deformation offsets. However, to prevent excessive deviation of the receptive field from the target, DSConv employs an iterative strategy, ensuring that only one target is processed at a time, thus maintaining the continuity of attention [41]. Figure 2 illustrates the network architecture of DSConv. Below, we delve into the mathematical derivation of DSConv.
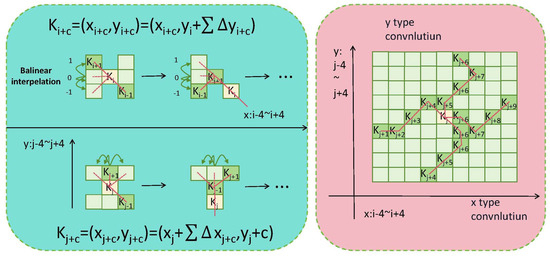
Figure 2.
Left: Illustration of the coordinates calculation of the DSConv. Right: The receptive field of the DSConv.
Firstly, we have the standard 2D convolution with coordinates denoted as K, where the central coordinate is represented as . For a 3 × 3 convolution kernel K and dilation rate set to 1, it can be expressed as:
To grant the convolution kernel more flexibility in focusing on the target’s intricate geometric features, we introduce a deformation offset, . However, allowing the model to learn these offsets freely might lead the receptive field astray from the target. To address this, DSConv adjusts the convolution kernel in both x-axis and y-axis directions.
For the x-axis direction, the coordinates are:
For the y-axis direction, the coordinates are:
where signifies the accumulated deformation.
Given that is often fractional, we handle it using bilinear interpolation, as illustrated by:
Here, B is the bilinear interpolation kernel, which can be decomposed into two one-dimensional interpolation kernels:
where b represents the one-dimensional interpolation function.
Based on the analysis of the aforementioned mathematical formulas, DSConv can dynamically adjust in the x and y-axis directions. As shown in Figure 3, DSConv covers a 9 × 9 area during its deformation process. The main purpose of this algorithm is to more accurately match slender tubular structures based on dynamic structures, thereby capturing key features more precisely.
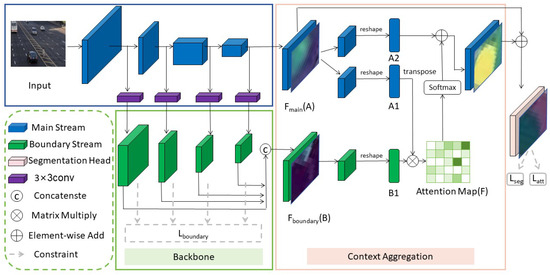
Figure 3.
The semantic embedding boundary features generated by the multi-scale boundary module are subjected to CAAM to achieve more accurate contextual aggregation.
3.3. Context Aggregation Attention Mechanism
CAAM is an advanced deep-learning technique specifically designed for image processing. Its core feature lies in the adoption of a unique attention mechanism, allowing the model to dynamically focus on specific regions or features within an image, thus capturing key contextual information relevant to the current task with greater precision [42]. In complex image processing tasks such as image segmentation, object detection, or scene classification, contextual information often plays a crucial role in overall interpretation and understanding, especially in the presence of multiple overlapping objects or objects similar to the background. Figure 3 illustrates the network structure of the CAAM.
Through CAAM, the model not only identifies fine structures and patterns within the image more accurately but also maintains high performance in challenging scenarios [43]. The introduction of this approach highlights the paramount importance of intelligently aggregating contextual information in image processing. Below is an overview of the derivation of this method:
In the implementation, we first extract two types of feature maps, and , from the given input. Next, these feature maps undergo deformation and are further subjected to two convolution operations, resulting in the generation of two new feature maps, A and B, both in the form of .
To capture the semantic similarity of boundaries, we define a similarity function, . This function is given by the following formula:
where represents the association between the i-th position of boundary feature map B and the j-th position of semantic feature map A.
Using the obtained boundary semantic similarity, we further compute the enhanced feature D, given by the formula:
Considering that boundary regions of the same class are typically assigned higher weights, this formula can be approximated as:
The significant role of CAAM in optimizing YOLOv8 cannot be underestimated. Within YOLOv8, there may be a multitude of objects in the image, appearing in varying scales, shapes, and positions. This necessitates the model’s ability to make full use of contextual information within the image for more precise object detection and localization. By introducing CAAM, YOLOv8 is better equipped to comprehend the relationships among different objects within the image and their connections to the background during image processing. This understanding of interrelatedness helps reduce false positives and false negatives, thereby enhancing the accuracy and robustness of detection. Furthermore, CAAM also enhances the detection of small-scale objects as it allows the model to better leverage the contextual information of these objects in the image, thus improving detection stability. Figure 2 illustrates the network architecture of CAAM.
3.4. Wise-IoU
Wise-IoU introduces a novel Bounding Box Regression (BBR) loss function, with its core principle being the utilization of a dynamic non-monotonic focusing mechanism to enhance object localization performance [17]. This approach emphasizes handling low-quality and average-quality samples, rather than solely relying on high-quality ones, offering a more comprehensive training guidance for the model. Compared to the conventional IoU loss function, WIoU’s primary innovation lies in its dynamic non-monotonic focusing mechanism. This mechanism employs the degree of anomaly instead of IoU to assess the quality of anchor boxes, determining the attention level for each sample. Such an evaluation method enables a more accurate distinction among high-, medium-, and low-quality samples, allocating appropriate gradients to them. This strategy not only reduces the competitiveness of high-quality anchor boxes but also diminishes the detrimental gradient generated by low-quality samples. Next, we introduce the mathematical derivation process of Wise-IoU:
First, we considered a version of IoU based on the distance between the center points of the anchor box and the ground truth box, called Distance IoU (DIoU). It is defined as
where are the coordinates of the center point of the anchor box, while are the coordinates of the center point of the ground truth box. and represent the width and height of the ground truth box respectively.
Further, to consider the offset between the center points of the anchor box and the ground truth box, we introduced the Enhanced IoU (EIoU):
Additionally, in order to comprehensively consider the consistency of the box size and the aspect ratio, we proposed the Complete IoU (CIoU):
where is defined as , and the consistency of the aspect ratio v is defined as:
Lastly, in order to further improve the quality assessment of the anchor box, we proposed the third version of Wise-IoU, which allocates appropriate gradient gains for the anchor box through a dynamic non-monotonic focal mechanism:
where represents the degree of outlier, and is a small constant to ensure that the denominator is not zero.
Integrating Wise-IoU into YOLOv8 holds significant importance. YOLOv8 is renowned for its speed and accuracy, and it can benefit even more from the refined gradient updates provided by Wise-IoU. During the training phase, the dynamic non-monotonic focal mechanism of Wise-IoU ensures that anchor boxes receive appropriate gradient gains. This mechanism helps reduce common issues faced when training deep neural networks for object detection, such as gradient vanishing or gradient explosion. Moreover, by emphasizing the quality of bounding box predictions, Wise-IoU assists YOLOv8 in handling complex scenes with overlapping objects of varying sizes and aspect ratios. Integrating Wise-IoU into YOLOv8 not only enhances the model’s performance but also sets a new benchmark for future object detection frameworks.
4. Experiment
In the experimental section, we first introduced the characteristics of the two major datasets, BDD100K and NEXET. Subsequently, we described the experimental environment setup and detailed procedures, including data preprocessing, model selection, model training, and evaluation methods. Ultimately, we delved deeply into the performance results of the model and validated the effectiveness of the algorithm through ablation studies.
4.1. Materials
4.1.1. Dataset
BDD100K is a large-scale driving scene dataset released by the Berkeley AI Research Laboratory (BAIR) [44]. This dataset provides annotations for object detection on 100,000 images, including vehicles, pedestrians, traffic signs, and more. To enhance the dataset’s diversity, each image is annotated multiple times, each with different angles, scales, transformations, and occlusions to simulate real-world visual scenes.
The NEXET dataset is released by the Nexar company, mainly for training and validating autonomous driving algorithms [45]. It comprises 500,000 images for vehicle detection, with five categories. All images in the dataset come with detailed annotations, including bounding boxes for vehicles, pedestrians, traffic signs, and other targets.
The emergence of datasets like BDD100K and NEXET provides valuable data support for the development of intelligent transportation systems. While BDD100K is designed to emulate real-world visual scenarios, NEXET offers a wealth of detailed annotations, enabling training and validation of autonomous driving algorithms in more realistic and challenging environments. These two datasets provide abundant training data for deep learning models, assisting researchers and developers in further refining and optimizing object detection techniques to adapt to the increasingly complex road traffic environment.
4.1.2. Experimental Environment
Our experimental setup is configured as follows, with detailed information provided in Table 3. In terms of hardware, we have chosen high-performance components, including the Intel i9 14900k as the central processing unit (CPU) and the RTX 4090 as the graphics processing unit (GPU). Additionally, we have equipped our setup with a robust video random-access memory (VRAM) with a capacity of 24 GB and 64 GB of RAM. On the software side, we have selected Ubuntu as the operating system and utilized Python 3.9.18 as our primary programming language. Furthermore, we have adopted PyTorch 1.10.0 as the deep learning framework, CUDA 11.2 for accelerated computations, and cuDNN 7.6.5 for deep learning tasks. These detailed configuration specifications are crucial for ensuring the accuracy and reproducibility of our experimental results.
Table 3.
Experiment configuration environment.
4.2. Experimental Details
Step 1 (data preprocessing): To comprehensively evaluate the performance of object detection algorithms in traffic scenarios, we selected two substantial datasets: BDD100K, which encompasses 100,000 images, and NEXET, which is specifically designed for vehicle detection and contains 500,000 images. Within the BDD100K set, we randomly culled 25,000 images, each bearing at least two object categories, from a pool of 50,000 images for model training. Out of these, 17,500 were allocated for the training set, 3750 for the validation set, and the remaining 3750 for the testing set. For NEXET, we employed 20,000 images, each marked by more than two categories, for training, distributing 15,000 for training, 2700 for testing, and the residual 2300 for validation. Confronted with images harboring missing labels or erroneous annotations, we harnessed tools like LabelImg for manual rectification and tagging to ensure dataset accuracy and integrity.
Before formal model training, all images undergo a series of preprocessing steps aimed at ensuring that the model can more effectively learn features from them. Firstly, we normalize the images, scaling the pixel values to the range [0, 1] to reduce variations in pixel values across different images. Secondly, we resize the images to the fixed size required by the model to ensure consistency in input image sizes. During this step, we typically use bilinear interpolation methods to maintain image quality and choose to either crop or pad the image to meet the model’s input size requirements. Finally, for images with issues such as overexposure or low contrast, we employ image enhancement techniques for correction. For overexposed images, we use exposure correction methods to recover lost details, while for low-contrast images, we apply techniques like contrast stretching or histogram equalization to enhance the contrast. These enhancement techniques contribute to improving the quality of the images, thereby enhancing the accuracy of object detection.
Step 2 (model selection): Within the domain of object detection, numerous advanced algorithms have been developed and progressively applied to the task of traffic scene detection. These algorithms, each with their own unique design and attributes, possess respective strengths and weaknesses. When choosing algorithms for our experiment, it is paramount not only to consider the inherent performance of the algorithm but also its adaptability to specific datasets. In this study, we delve into an extensive exploration and empirical validation of seven cutting-edge object detection algorithms, namely YOLOv5n, SSD, YOLOv7-Tiny, EfficientDet, VitDet, RTMet, and YOLOv8n. Notably, this paper also introduces and incorporates an innovative object detection method—YOLOv8-SnakeVision. While these algorithms have showcased exemplary performance in their respective fields and practical applications, our primary objective is to discern the disparities in their performance in traffic scenarios. To achieve this, we benchmark them against a unified dataset, aiming to determine the most apt model for traffic scene object detection tasks.
Step 3 (model training): In the context of our research framework, the YOLOv8-SnakeVision model underwent a rigorous training regimen based on transfer learning methodologies. Specifically, we initialized the model using the widely acknowledged pre-trained weights from the COCO dataset. Subsequently, this model was meticulously fine-tuned on our dedicated dataset. Throughout the training process, we adopted a batch size of 32 with an initial learning rate of 0.01 and carried out a total of 1000 training epochs. Table 4 provides an exhaustive list of the configuration parameters pertaining to YOLOv8-SnakeVision. Moreover, we employed the PyTorch deep learning framework to facilitate the model’s training, which furnishes comprehensive tools and libraries essential for constructing and training neural networks. Algorithm 1 represents the algorithm flow of the training in this paper.
| Algorithm 1: YOLOv8-SnakeVision training algorithm with transfer learning |
 |
Table 4.
YOLOv8-SnakeVision configuration parameters.
Figure 4 displays the overall results of the model proposed in this study for road detection. By comprehensively considering various performance metrics, our model demonstrates outstanding performance in various aspects. Particularly noteworthy is that in complex road scenarios, our model not only achieves high-precision object detection but also maintains stable performance when dealing with blurry backgrounds and objects of varying scales.
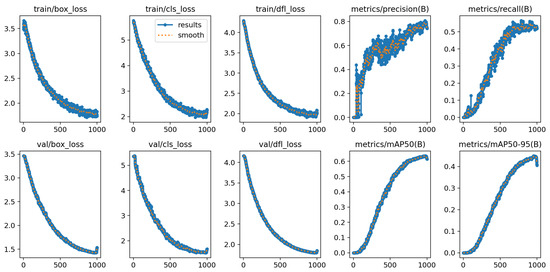
Figure 4.
The results of the proposed model.
Step 4 (model evaluation): To thoroughly and systematically evaluate the performance of the model on traffic scene object detection tasks, we employed a set of standardized evaluation metrics, including accuracy, precision, recall, and the F1 score. These metrics provide a quantitative overview of the model’s comprehensive performance in complex traffic scenarios. If the model underperforms in certain areas, we may consider optimizing the hyperparameters or expanding the training dataset to further enhance its capabilities. Ensuring a balance between overfitting and underfitting is paramount, contributing to superior generalization on unseen data. In the following section, we will delve into the specific evaluation metrics utilized in this study:
The Accuracy metric gives an overall measure of the model’s performance across all classes:
where denotes the number of true positives, denotes the number of true negatives, is the number of false positives, and is the number of false negatives.
Building upon accuracy, Precision specifically quantifies the model’s performance concerning false positives:
where denotes the number of true positives and is the number of false positives.
Another essential metric, Recall, measures the model’s ability to correctly detect positive instances:
where denotes the number of true positives and is the number of false negatives.
To strike a balance between precision and recall, the F1 Score acts as their harmonic mean:
where Precision is the precision of the model and Recall is the recall of the model.
Lastly, to account for multi-class detection tasks, the mean Average Precision (mAP) calculates the mean of average precisions across all classes:
where is the average precision for the class and N is the total number of classes.
4.3. Results
As shown in Table 5 and Figure 5, the performance comparison experiments between YOLOv8-SnakeVision and several other well-known object detection algorithms on two benchmark datasets, BDD100K and NEXET, are presented. The evaluation metrics employed include mAP50 (Mean Average Precision at IoU = 0.5), mAP50-95 (Mean Average Precision across IoU thresholds from 0.5 to 0.95), APs (Average Precision for small objects), and APm (Average Precision for medium-sized objects). First and foremost, YOLOv8-SnakeVision exhibits significant superiority over other algorithms on the BDD100K dataset. It outperforms other algorithms with remarkable scores in mAP50, mAP50-95, APs, and APm, reaching 0.63, 0.44, 0.19, and 0.37, respectively, far exceeding the performance of other algorithms. Furthermore, the same algorithm excels on the NEXET dataset as well. It achieves outstanding scores in mAP50, mAP50-95, APs, and APm, with values of 0.69, 0.50, 0.27, and 0.43, respectively, once again outpacing other algorithms. It is worth noting that YOLOv8-SnakeVision particularly excels in small object detection (APs) and medium-sized object detection (APm), demonstrating its exceptional performance in complex scenarios. This comparison vividly underscores the outstanding performance of YOLOv8-SnakeVision in the field of object detection. In summary, YOLOv8-SnakeVision demonstrates exceptional performance in object detection within traffic scenes, whether it be in the detection of vehicles, pedestrians, traffic signs, or bicycles, establishing a clear advantage. It contributes significantly to achieving safer and more efficient urban transportation.
Table 5.
Comparative experimental results between YOLOv8-SnakeVision and other object detection algorithms. Bold represents the best result.
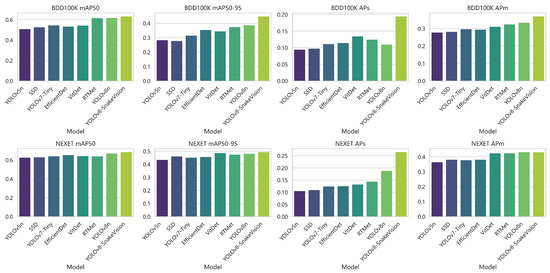
Figure 5.
Comparison of model performance on different datasets.
In this study, we conducted a comprehensive analysis of the performance of the YOLOv8-SnakeVision model on the BDD100K and NEXET datasets based on the data in Table 6, including comparisons of metrics such as Precision, Recall, F1 Score, and FPS. On the BDD100K dataset, YOLOv8-SnakeVision exhibited significant advantages, with a Precision value of 0.743, markedly higher than other algorithms. This indicates that the model excels in accuracy in predicting positive class instances, which is crucial for object recognition in traffic scenarios. While the Recall is slightly lower than some other algorithms, a recall rate of 0.520 is still relatively high, suggesting that YOLOv8-SnakeVision effectively captures most relevant objects. Furthermore, an F1 Score of 0.611 demonstrates a good balance between precision and recall. It is worth noting that YOLOv8-SnakeVision performs exceptionally well in Frames Per Second (FPS), processing image frames at speeds of up to 68 FPS, showcasing outstanding performance in real-time applications. On the NEXET dataset, YOLOv8-SnakeVision similarly leads in Precision, achieving a high Precision score of 0.753. Although its Recall value is relatively lower, with a recall rate of 0.531, it still falls within a relatively high range, indicating its capability to effectively identify relevant target instances. Additionally, an F1 Score of 0.625 shows that the model maintains a reasonable balance between precision and recall on this dataset. Similar to the BDD100K dataset, YOLOv8-SnakeVision also performs well in Frames Per Second (FPS) on the NEXET dataset, achieving speeds of 67 FPS, making it suitable for real-time applications with high demands.
Table 6.
Comparative experimental results between YOLOv8-SnakeVision and other object detection algorithms. Bold represents the best result.
Taking efficiency into consideration, we directly compared the number of parameters and the floating-point operations executed during inference between the baseline and our model in Table 7. Although our model is not the fastest, it generally ranks among the top in terms of efficiency, making it acceptable. Additionally, we provide a detailed comparison of model performance relative to computational efficiency in Figure 6. For our model, the research findings are compelling. Particularly, in most cases, the effectiveness of our model often surpasses faster models. These results further validate the consistent and outstanding performance of our model.
Table 7.
Comparison of Model Parameters (PARAMS) and Floating Point Operations (FLOPs) on BDD100K and NEXET datasets.
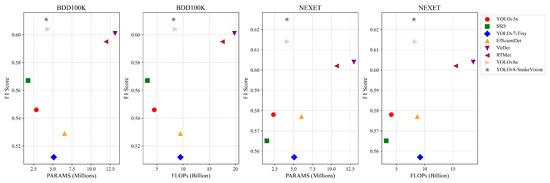
Figure 6.
Performance comparison of computational efficiency and F1 scores.
4.4. Ablation Study
To validate the effectiveness of algorithmic improvements, this section presents a series of ablation experiments, including YOLOv8n, YOLOv8n-1, YOLOv8n-2, YOLOv8n-3, YOLOv8n-4, YOLOv8n-5, and YOLOv8-SnakeVision. YOLOv8n-1 introduces DSConv into the backbone network of YOLOv8n. YOLOv8n-2 extends the YOLOv8n backbone network with the CAAN. The YOLOv8n-3 model replaces the original YOLOv8n’s loss function with Wise-IoU. YOLOv8n-4 combines DSConv and CAAM in the original YOLOv8n, while YOLOv8n-5 incorporates CAAM and replaces the loss function with Wise-IoU in the original YOLOv8n. Additionally, YOLOv8-SnakeVision is a novel algorithm proposed in this study, which integrates DSConv, CAAM, and Wise-IoU.
The comparative results of the ablation experiments are presented in Table 8. In the context of complex road scene object detection, each stage of the improved algorithms demonstrated significant performance enhancements, which were readily apparent. The YOLOv8n-1 model, modified with DSConv, exhibited improvements of 1.1 percentage points and 1 percentage point in mAP50 and mAP50-95, respectively, compared to YOLOv8n. This suggests that the DSConv module is more effective in extracting rich gradient flow information during feature extraction. The YOLOv8n-2 model, which introduced the CAAM, also showed relative improvements in mAP compared to the original YOLOv8n. This indicates that the addition of the CAAM effectively addressed challenges related to feature extraction when dealing with objects at different scales and in blurry backgrounds. Furthermore, the yolov8-3 model, which involved a change in the loss function, exhibited an improvement of approximately 1.22 percentage points over the original YOLOv8n. Finally, our model outperformed the original YOLOv8n by 1.5 percentage points, demonstrating the effectiveness of the various improvements in enhancing performance. These results underscore the significance and practical value of algorithmic enhancements in the context of object detection in complex road scenes.
Table 8.
Experiment results for each component.
4.5. Presentation of Results
Our object detection model has been extensively compared with YOLOv8n in terms of performance, as shown in Figure 7. The comparative results highlight the significant advantages of our model: Firstly, compared to YOLOv8n, our model has effectively reduced unnecessary false detections, substantially improving result reliability and reducing false positive rates. This bears crucial practical significance in the field of scientific research. Secondly, our model exhibits remarkable robustness in scenarios with target occlusion. For instance, our model can accurately differentiate between occluded cars and trucks, a vital performance characteristic for object detection in complex real-world scenarios. Furthermore, our model excels in detecting small targets, eliminating the risk of missing small objects. This reliability in detecting small-scale targets is pivotal for capturing fine details, which is indispensable for scientific research and applications. When dealing with overlapping targets, our model also performs exceptionally well, significantly reducing the occurrence of missed detections and enhancing the precision of object detection. This contributes to a more reliable foundation for scientific research. Most importantly, in contrast to YOLOv8n, our model does not misclassify non-target objects such as stones as cars. This further elevates the accuracy and credibility of detection results, aligning them more closely with the requirements of scientific research. In summary, our model demonstrates outstanding performance in multiple critical aspects, providing reliable technical support for solving complex real-world problems. It offers a more precise object detection solution for intelligent traffic applications and holds great potential for future scientific research and applications.

Figure 7.
Performance analysis of YOLOv8-SnakeVision detection and YOLOv8n detection results comparison.
However, our model also exhibits some instances of detection failures, as shown in Figure 8. Firstly, under the conditions of blurred rainy weather, we observed that the model’s detection confidence is relatively low, particularly for small objects, with a confidence level as low as 0.26. This phenomenon may be attributed to the degraded image quality caused by the blurry rainy environment, resulting in unclear edges and details of the target objects. Similarly, in overcast conditions, we also noticed lower detection confidence in our model. This could be due to relatively poor lighting conditions, resulting in reduced image contrast and less distinct features of the target objects. Consequently, the model may face greater visual challenges in accurately detecting targets, necessitating the ability to overcome limitations posed by lighting conditions. Additionally, when images are exposed to intense glare, we observed that the model failed to detect distant cars. This might be attributed to overexposure caused by strong light, making it challenging to distinguish and detect objects in the distant background. In such scenarios, the model may naturally focus its attention on the brighter areas, potentially overlooking distant objects. However, it is essential to note that despite these specific challenges observed in certain scenarios, our model continues to demonstrate outstanding performance in various other scenes and conditions. These instances do not imply that the model is subpar overall but rather highlight that, like any object detection model, it may encounter certain limitations in extreme or complex environments. In the majority of cases, our model maintains its remarkable performance, providing an efficient solution for target detection in various applications.

Figure 8.
Detection failures in YOLOv8-SnakeVision.
5. Conclusions
Our experimental results have fully demonstrated the effectiveness and innovation of the YOLOv8-SnakeVision model in the field of object detection for intelligent traffic systems. By introducing DSConv, CAAM, and the Wise-IoU strategy into the YOLOv8 framework, we have successfully achieved significant improvements in accurately capturing complex object shapes and features, even in scenarios involving occlusion, overlap, small objects, and intricate patterns. The adaptability of this model to diverse road traffic situations makes it a valuable addition to the toolbox of intelligent traffic systems.
However, we must also acknowledge that the model still has some limitations. Firstly, target detection under extreme weather conditions remains a challenge, and this is one of the issues that need to be addressed in the future. In this regard, we suggest that future research focus on the use of multi-modal sensor fusion methods to enhance the model’s robustness in target detection under conditions such as rain, snow, and heavy fog. By integrating information from multiple sources such as radar, infrared, and cameras, the model can have a more comprehensive perception of the environment, thereby improving the robustness of target detection. Secondly, issues such as changes in the orientation of objects, viewing angles, and lighting conditions may significantly impact detection accuracy. For this reason, future research could explore advanced visual attention mechanisms and lighting invariance techniques. Attention mechanisms help the model focus more specifically on critical areas, improving its ability to perceive details of the target. At the same time, lighting invariance techniques can assist the model in better adapting to different lighting conditions, mitigating the negative impact of these variations on detection performance. In conclusion, this research is of great practical significance for improving urban traffic safety and efficiency, reducing traffic accidents, and alleviating traffic congestion. We believe that through continuous efforts and research, we can further advance the development of intelligent traffic systems, bringing more convenience and safety to future urban transportation.
Author Contributions
Q.L. contributed to the conception and design of the study and completed various sections of the manuscript. Y.L. conducted the statistical analysis, and D.L. revised the manuscript, read, and approved the submitted version. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhu, Y.; Yan, W.Q. Traffic sign recognition based on deep learning. Multimed. Tools Appl. 2022, 81, 17779–17791. [Google Scholar] [CrossRef]
- Du, W.; Chen, L.; Wang, H.; Shan, Z.; Zhou, Z.; Li, W.; Wang, Y. Deciphering urban traffic impacts on air quality by deep learning and emission inventory. J. Environ. Sci. 2023, 124, 745–757. [Google Scholar] [CrossRef]
- Fakhrurroja, H.; Pramesti, D.; Hidayatullah, A.R.; Fashihullisan, A.A.; Bangkit, H.; Ismail, N. Automated License Plate Detection and Recognition using YOLOv8 and OCR With Tello Drone Camera. In Proceedings of the 2023 International Conference on Computer, Control, Informatics and its Applications (IC3INA), Bandung, Indonesia, 4–5 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 206–211. [Google Scholar]
- Yang, Z.; Zhang, W.; Feng, J. Predicting multiple types of traffic accident severity with explanations: A multi-task deep learning framework. Saf. Sci. 2022, 146, 105522. [Google Scholar] [CrossRef]
- Hameed, A.; Violos, J.; Leivadeas, A. A deep learning approach for IoT traffic multi-classification in a smart-city scenario. IEEE Access 2022, 10, 21193–21210. [Google Scholar] [CrossRef]
- Babbar, S.; Bedi, J. Real-time traffic, accident, and potholes detection by deep learning techniques: A modern approach for traffic management. Neural Comput. Appl. 2023, 35, 19465–19479. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, T.; Gao, S.; Raubal, M. Incorporating multimodal context information into traffic speed forecasting through graph deep learning. Int. J. Geogr. Inf. Sci. 2023, 37, 1909–1935. [Google Scholar] [CrossRef]
- Sattar, K.; Chikh Oughali, F.; Assi, K.; Ratrout, N.; Jamal, A.; Masiur Rahman, S. Transparent deep machine learning framework for predicting traffic crash severity. Neural Comput. Appl. 2023, 35, 1535–1547. [Google Scholar] [CrossRef]
- Bisio, I.; Garibotto, C.; Haleem, H.; Lavagetto, F.; Sciarrone, A. A systematic review of drone based road traffic monitoring system. IEEE Access 2022, 10, 101537–101555. [Google Scholar] [CrossRef]
- Ortataş, F.N.; Kaya, M. Performance Evaluation of YOLOv5, YOLOv7, and YOLOv8 Models in Traffic Sign Detection. In Proceedings of the 2023 8th International Conference on Computer Science and Engineering (UBMK), Burdur, Turkiye, 13–15 September 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 151–156. [Google Scholar]
- Huangfu, Z.; Li, S. Lightweight You Only Look Once v8: An Upgraded You Only Look Once v8 Algorithm for Small Object Identification in Unmanned Aerial Vehicle Images. Appl. Sci. 2023, 13, 12369. [Google Scholar] [CrossRef]
- Shokri, D.; Larouche, C.; Homayouni, S. A Comparative Analysis of Multi-Label Deep Learning Classifiers for Real-Time Vehicle Detection to Support Intelligent Transportation Systems. Smart Cities 2023, 6, 2982–3004. [Google Scholar] [CrossRef]
- Iftikhar, S.; Asim, M.; Zhang, Z.; Muthanna, A.; Chen, J.; El-Affendi, M.; Sedik, A.; Abd El-Latif, A.A. Target Detection and Recognition for Traffic Congestion in Smart Cities Using Deep Learning-Enabled UAVs: A Review and Analysis. Appl. Sci. 2023, 13, 3995. [Google Scholar] [CrossRef]
- Wei, H.; Zhang, Q.; Qin, Y.; Li, X.; Qian, Y. YOLOF-F: You only look one-level feature fusion for traffic sign detection. Vis. Comput. 2023, 1–14. [Google Scholar] [CrossRef]
- Gupta, M.; Miglani, H.; Deo, P.; Barhatte, A. Real-time traffic control and monitoring. e-Prime-Adv. Electr. Eng. Electron. Energy 2023, 5, 100211. [Google Scholar] [CrossRef]
- Aboah, A.; Wang, B.; Bagci, U.; Adu-Gyamfi, Y. Real-time multi-class helmet violation detection using few-shot data sampling technique and yolov8. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 5349–5357. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Mittal, U.; Chawla, P.; Tiwari, R. EnsembleNet: A hybrid approach for vehicle detection and estimation of traffic density based on faster R-CNN and YOLO models. Neural Comput. Appl. 2023, 35, 4755–4774. [Google Scholar] [CrossRef]
- Li, X.; Xie, Z.; Deng, X.; Wu, Y.; Pi, Y. Traffic sign detection based on improved faster R-CNN for autonomous driving. J. Supercomput. 2022, 78, 7982–8002. [Google Scholar] [CrossRef]
- Ghahremannezhad, H.; Shi, H.; Liu, C. Object Detection in Traffic Videos: A Survey. IEEE Trans. Intell. Transp. Syst. 2023, 24, 6780–6799. [Google Scholar] [CrossRef]
- Arora, N.; Kumar, Y.; Karkra, R.; Kumar, M. Automatic vehicle detection system in different environment conditions using fast R-CNN. Multimed. Tools Appl. 2022, 81, 18715–18735. [Google Scholar] [CrossRef]
- Fang, S.; Zhang, B.; Hu, J. Improved mask R-CNN multi-target detection and segmentation for autonomous driving in complex scenes. Sensors 2023, 23, 3853. [Google Scholar] [CrossRef]
- Sun, Y.; Su, L.; Luo, Y.; Meng, H.; Li, W.; Zhang, Z.; Wang, P.; Zhang, W. Global Mask R-CNN for marine ship instance segmentation. Neurocomputing 2022, 480, 257–270. [Google Scholar] [CrossRef]
- He, D.; Qiu, Y.; Miao, J.; Zou, Z.; Li, K.; Ren, C.; Shen, G. Improved Mask R-CNN for obstacle detection of rail transit. Measurement 2022, 190, 110728. [Google Scholar] [CrossRef]
- Qiu, Z.; Bai, H.; Chen, T. Special Vehicle Detection from UAV Perspective via YOLO-GNS Based Deep Learning Network. Drones 2023, 7, 117. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, Y.; Wang, Z.; Jiang, Y. YOLOv7-RAR for Urban Vehicle Detection. Sensors 2023, 23, 1801. [Google Scholar] [CrossRef] [PubMed]
- Othmani, M. A vehicle detection and tracking method for traffic video based on faster R-CNN. Multimed. Tools Appl. 2022, 81, 28347–28365. [Google Scholar] [CrossRef]
- Varesko, L.; Oreski, G. Performance comparison of novel object detection models on traffic data. In Proceedings of the 2023 8th International Conference on Machine Learning Technologies, Stockholm, Sweden, 10–12 March 2023; pp. 177–184. [Google Scholar]
- Soylu, E.; Soylu, T. A performance comparison of YOLOv8 models for traffic sign detection in the Robotaxi-full scale autonomous vehicle competition. Multimed. Tools Appl. 2023, 1–31. [Google Scholar] [CrossRef]
- Chen, J.; Hong, H.; Song, B.; Guo, J.; Chen, C.; Xu, J. MDCT: Multi-Kernel Dilated Convolution and Transformer for One-Stage Object Detection of Remote Sensing Images. Remote Sens. 2023, 15, 371. [Google Scholar] [CrossRef]
- Zou, H.; Zhan, H.; Zhang, L. Neural Network Based on Multi-Scale Saliency Fusion for Traffic Signs Detection. Sustainability 2022, 14, 16491. [Google Scholar] [CrossRef]
- Taouqi, I.; Klilou, A.; Chaji, K.; Arsalane, A. Yolov2 Implementation and Optimization for Moroccan Traffic Sign Detection. In Proceedings of the International Conference on Artificial Intelligence and Smart Environment, Errachidia, Morocco, 24–26 November 2022; Springer: Cham, Switzerland, 2022; pp. 837–843. [Google Scholar]
- Guillermo, M.; Francisco, K.; Concepcion, R.; Fernando, A.; Bandala, A.; Vicerra, R.R.; Dadios, E. A Comparative Study on Satellite Image Analysis for Road Traffic Detection using YOLOv3-SPP, Keras RetinaNet and Full Convolutional Network. In Proceedings of the 2023 8th International Conference on Business and Industrial Research (ICBIR), Bangkok, Thailand, 18–19 May 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 578–584. [Google Scholar]
- Li, Y.; Li, J.; Meng, P. Attention-YOLOV4: A real-time and high-accurate traffic sign detection algorithm. Multimed. Tools Appl. 2023, 82, 7567–7582. [Google Scholar] [CrossRef]
- Chen, X. Traffic Lights Detection Method Based on the Improved YOLOv5 Network. In Proceedings of the 2022 IEEE 4th International Conference on Civil Aviation Safety and Information Technology (ICCASIT), Dali, China, 12–14 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1111–1114. [Google Scholar]
- Tarun, R.; Esther, B.P. Traffic Anomaly Alert Model to Assist ADAS Feature based on Road Sign Detection in Edge Devices. In Proceedings of the 2023 4th International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 6–8 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 824–828. [Google Scholar]
- Krishnendhu, S.; Mohandas, P. SAD: Sensor-based Anomaly Detection System for Smart Junctions. IEEE Sens. J. 2023, 23, 20368–20378. [Google Scholar]
- Xia, J.; Li, M.; Liu, W.; Chen, X. DSRA-DETR: An Improved DETR for Multiscale Traffic Sign Detection. Sustainability 2023, 15, 10862. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, B.; Liu, N. CAST-YOLO: An Improved YOLO Based on a Cross-Attention Strategy Transformer for Foggy Weather Adaptive Detection. Appl. Sci. 2023, 13, 1176. [Google Scholar] [CrossRef]
- Qi, Y.; He, Y.; Qi, X.; Zhang, Y.; Yang, G. Dynamic Snake Convolution based on Topological Geometric Constraints for Tubular Structure Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 6070–6079. [Google Scholar]
- He, L.; Wang, M. SliceSamp: A Promising Downsampling Alternative for Retaining Information in a Neural Network. Appl. Sci. 2023, 13, 11657. [Google Scholar] [CrossRef]
- Liu, Z.; Li, J.; Song, R.; Wu, C.; Liu, W.; Li, Z.; Li, Y. Edge Guided Context Aggregation Network for Semantic Segmentation of Remote Sensing Imagery. Remote Sens. 2022, 14, 1353. [Google Scholar] [CrossRef]
- Ma, H.; Yang, H.; Huang, D. Boundary guided context aggregation for semantic segmentation. arXiv 2021, arXiv:2110.14587. [Google Scholar]
- Huang, K.; Lertniphonphan, K.; Chen, F.; Li, J.; Wang, Z. Multi-Object Tracking by Self-Supervised Learning Appearance Model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 3162–3168. [Google Scholar]
- Unal, D.; Catak, F.O.; Houkan, M.T.; Mudassir, M.; Hammoudeh, M. Towards robust autonomous driving systems through adversarial test set generation. ISA Trans. 2023, 132, 69–79. [Google Scholar] [CrossRef]
- Chen, Z.; Guo, H.; Yang, J.; Jiao, H.; Feng, Z.; Chen, L.; Gao, T. Fast vehicle detection algorithm in traffic scene based on improved SSD. Measurement 2022, 201, 111655. [Google Scholar] [CrossRef]
- Li, S.; Wang, S.; Wang, P. A small object detection algorithm for traffic signs based on improved YOLOv7. Sensors 2023, 23, 7145. [Google Scholar] [CrossRef] [PubMed]
- Fang, Z.; Zhang, T.; Fan, X. A ViTDet based dual-source fusion object detection method of UAV. In Proceedings of the 2022 International Conference on Image Processing, Computer Vision and Machine Learning (ICICML), Xi’an, China, 28–30 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 628–633. [Google Scholar]
- Chen, S.; Sun, P.; Song, Y.; Luo, P. Diffusiondet: Diffusion model for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 19830–19843. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).