
On-Chip Bus Protection against Soft Errors



Abstract
1. Introduction
2. Protection of CPU Cores
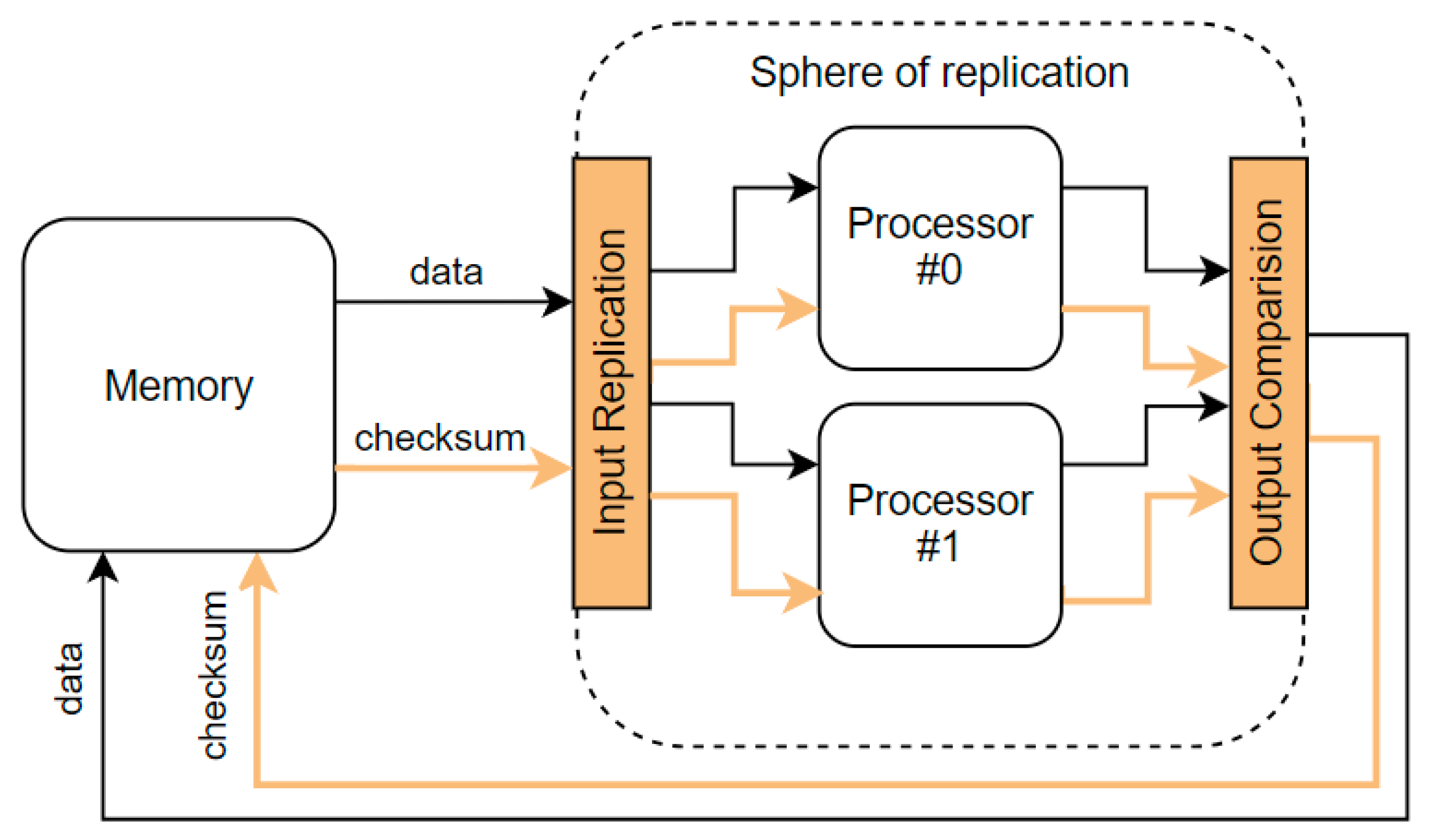
Sphere of Replication
3. Memory Protection
3.1. Information Redundancy
3.2. Hardening of Individual Memory Cells
3.3. State-of-the-Art of Memory Protection
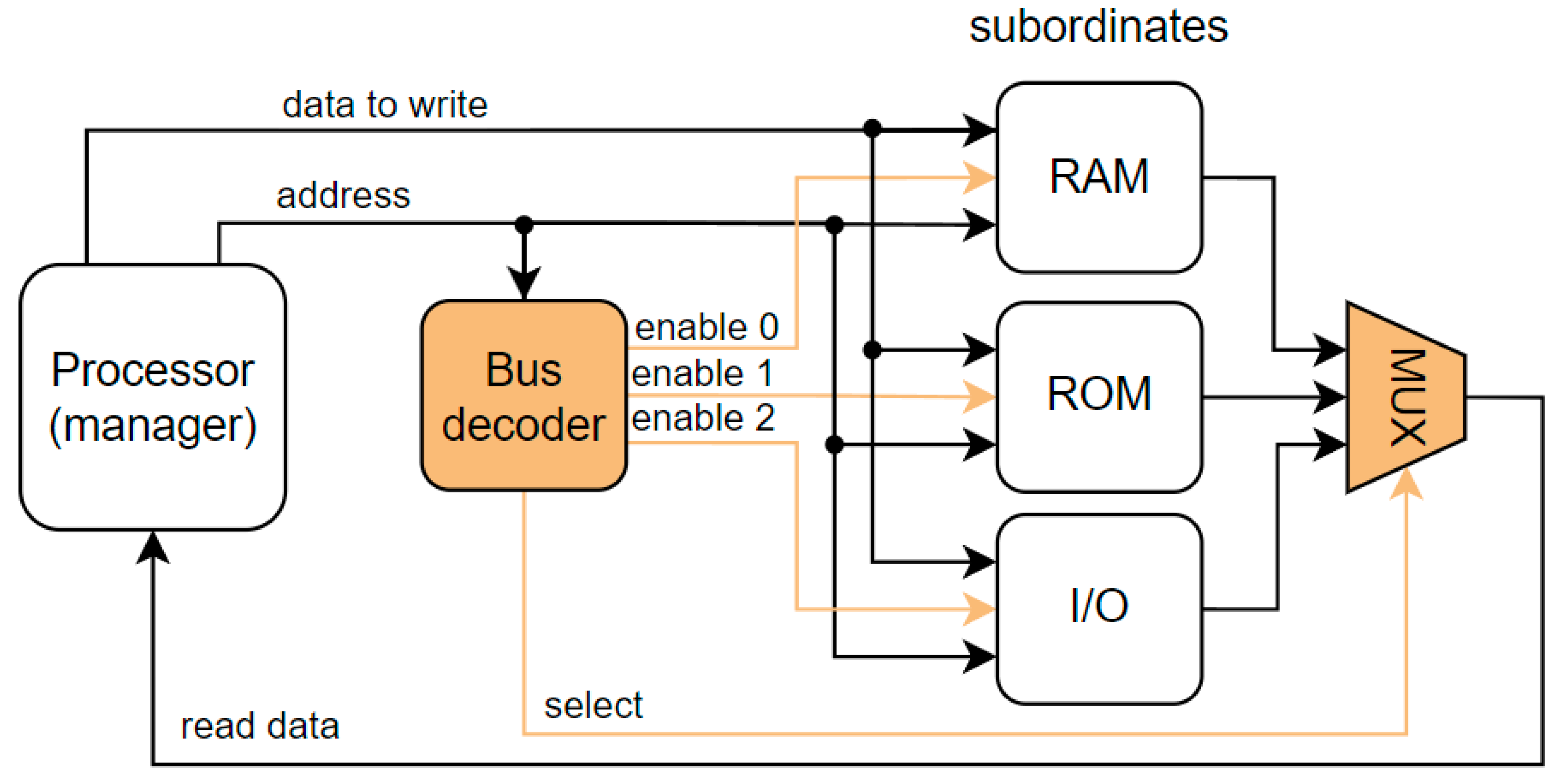
4. Bus Protection
4.1. Existing Protection Approaches
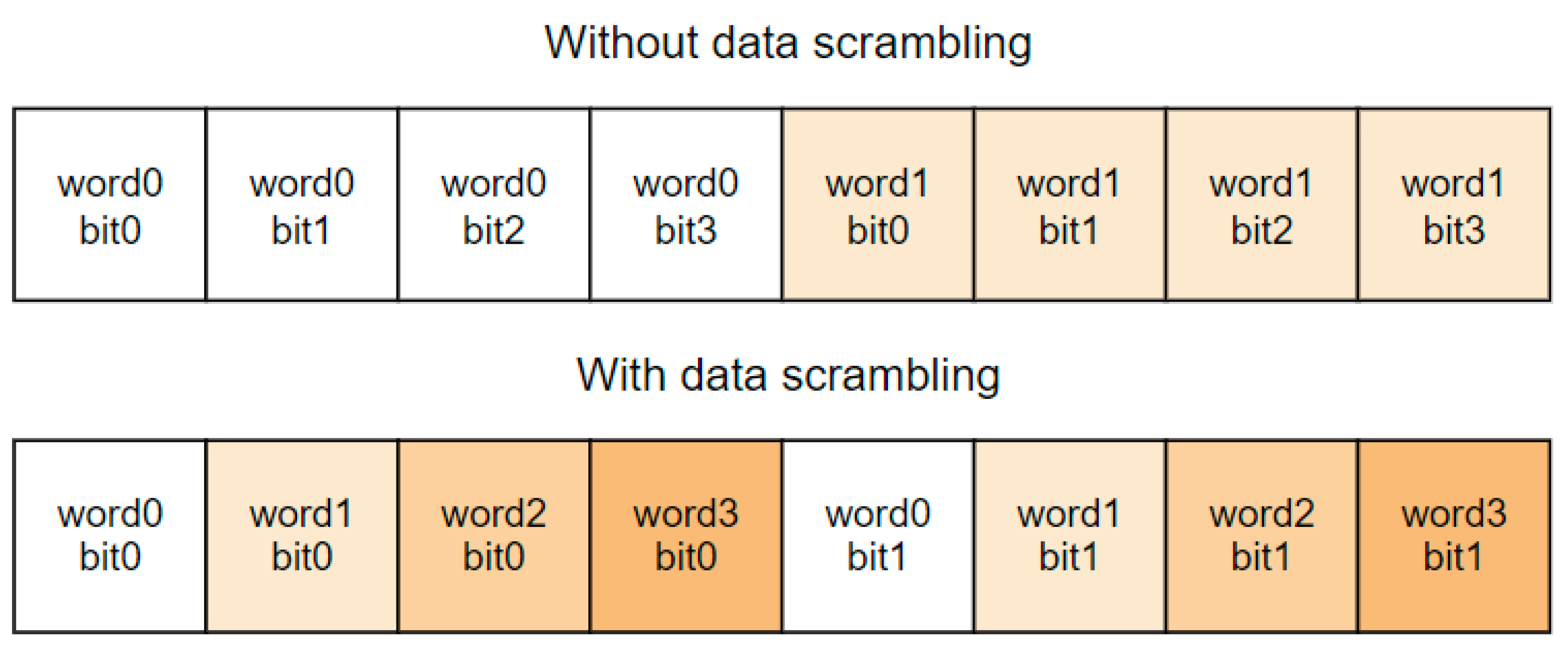
4.1.1. Information Redundancy
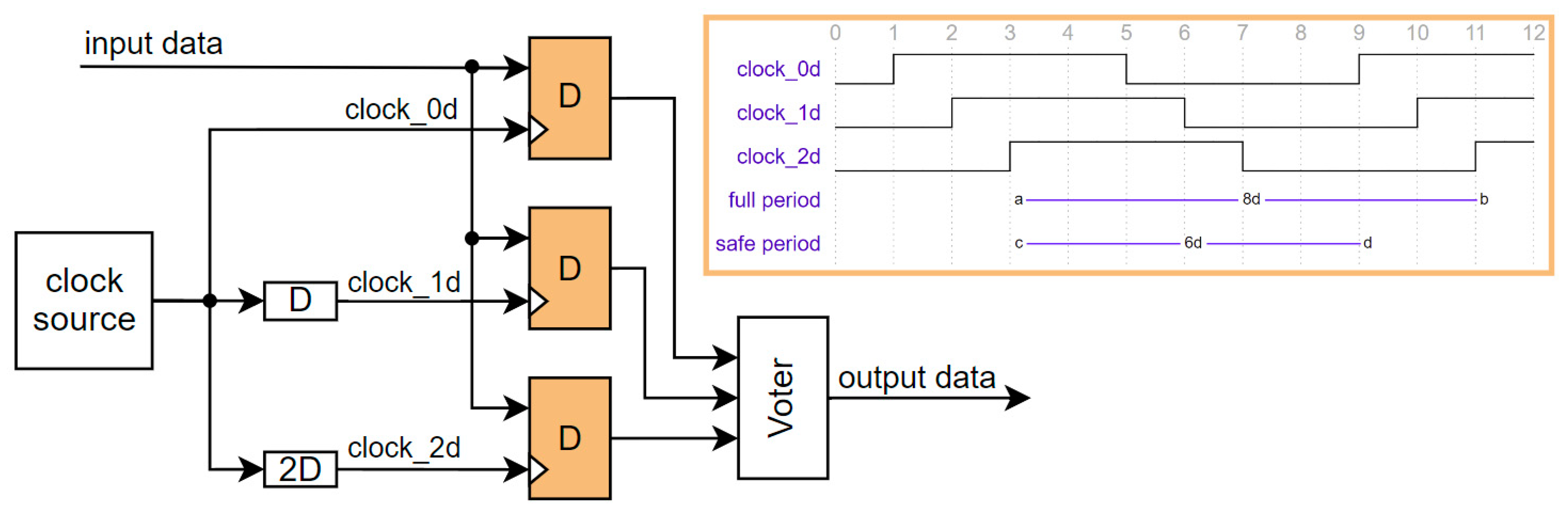
4.1.2. Temporal Redundancy
4.1.3. Spatial Redundancy
4.2. Summary
5. Conclusions
6. Future Directions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- ISO 26262-1:2018(E); Road Vehicles—Function Safety. Second edition 2018–12. International Standard ISO: Geneva, Switzerland, 2018.
- Battezzati, N.; Sterpone, L.; Violante, M. Reconfigurable Field Programmable Gate Arrays for Mission-Critical Applications; Springer: New York, NY, USA, 2011. [Google Scholar] [CrossRef]
- Baumann, R. Soft Errors in Advanced Computer Systems. IEEE Des. Test Comput. 2005, 22, 258–266. [Google Scholar] [CrossRef]
- Kobayashi, D. Scaling Trends of Digital Single-Event Effects: A Survey of SEU and SET Parameters and Comparison With Transistor Performance. IEEE Trans. Nucl. Sci. 2021, 68, 124–148. [Google Scholar] [CrossRef]
- Mach, J.; Kohútka, L.; Čičák, P. In-Pipeline Processor Protection against Soft Errors. J. Low Power Electron. Appl. 2023, 13, 33. [Google Scholar] [CrossRef]
- Microchip Technology Inc. SAMRH71 Rad-Hard 32-bit Arm® Cortex®-M7, Microcontroller for Aerospace Applications, Complete Data Sheet, DS60001593H; Microchip Technology Inc.: Chandler, AZ, USA, 2022. [Google Scholar]
- Haddad, N.F.; Brown, R.D.; Ferguson, R.; Kelly, A.T.; Lawrence, R.K.; Pirkl, D.M.; Rodgers, J.C. Second generation (200 MHz) RAD750 microprocessor radiation, evaluation. In Proceedings of the 2011 12th European Conference on Radiation and Its Effects on Components and Systems, Seville, Spain, 19–23 September 2011; pp. 877–880. [Google Scholar] [CrossRef]
- Cobham Gaisler AB. GR740 Radiation Summary, Test Report, Doc. No. GR740-RADS-1-1-3, Issue 1.3. 2020. Available online: https://gaisler.com/doc/gr740/GR740-RADS-1-1-3_GR740_Radiation_Summary.pdf (accessed on 18 November 2023).
- CAES. Gaisler NOEL-V SoC Applications and Ecosystem, RISC-V in Space 2022. Available online: http://microelectronics.esa.int/riscv/rvws2022/presentations/06_ESA_RISC-V_in_Space-NOEL-V.pdf (accessed on 23 April 2023).
- Iturbe, X.; Venu, B.; Ozer, E.; Poupat, J.-L.; Gimenez, G.; Zurek, H.-U. The Arm Triple Core Lock-Step (TCLS) Processor. ACM Trans. Comput. Syst. 2018, 36, 7. [Google Scholar] [CrossRef]
- de Oliveira, A.B.; Rodrigues, G.S.; Kastensmidt, F.L.; Added, N.; Macchione, E.L.A.; Aguiar, V.A.P.; Medina, N.H.; Silveira, M.A.G. Lockstep Dual-Core ARM A9: Implementation and Resilience Analysis Under Heavy Ion-Induced Soft Errors. IEEE Trans. Nucl. Sci. 2018, 65, 1783–1790. [Google Scholar] [CrossRef]
- Marcinek, K.; Pleskacz, W.A. Variable Delayed Dual-Core Lockstep (VDCLS) Processor for Safety and Security Applications. Electronics 2023, 12, 464. [Google Scholar] [CrossRef]
- Sim, M.T.; Zhuang, Y. A Dual Lockstep Processor System-on-a-Chip for Fast Error Recovery in Safety-Critical Applications. In Proceedings of the IECON 2020 the 46th Annual Conference of the IEEE Industrial Electronics Society, Singapore, 18–21 October 2020; pp. 2231–2238. [Google Scholar]
- Barbirotta, M.; Cheikh, A.; Mastrandrea, A.; Menichelli, F.; Vigli, F.; Olivieri, M. A Fault Tolerant soft-core obtained from an Interleaved-Multi-Threading RISC-V microprocessor design. In Proceedings of the 2021 IEEE International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems (DFT), Athens, Greece, 6–8 October 2021; pp. 1–4. [Google Scholar]
- Barbirotta, M.; Cheikh, A.; Mastrandrea, A.; Menichelli, F.; Ottavi, M.; Olivieri, M. Evaluation of Dynamic Triple Modular Redundancy in an Interleaved-Multi-Threading RISC-V Core. J. Low Power Electron. Appl. 2023, 13, 2. [Google Scholar] [CrossRef]
- Atmel Corporation. Rad-Hard 32 Bit SPARC V8 Processor AT697F, Rev. 7703E–AERO–08/11. 2011. Available online: https://ww1.microchip.com/downloads/en/DeviceDoc/doc7703.pdf (accessed on 23 April 2023).
- Clark, L.T.; Duvnjak, A.; Cannon, M.; Brunhaver, J.; Agarwal, S.; Manuel, J.E.; Wilson, D.; Barnaby, H.; Marinella, M. A Soft-Error Hardened by Design Microprocessor Implemented on Bulk 12-nm FinFET CMOS. IEEE Trans. Nucl. Sci. 2022, 69, 1602–1609. [Google Scholar] [CrossRef]
- Gupta, S.; Gala, N.; Madhusudan, G.S.; Kamakoti, V. SHAKTI-F: A Fault Tolerant Microprocessor Architecture. In Proceedings of the 2015 IEEE 24th Asian Test Symposium (ATS), Mumbai, India, 22–25 November 2015; pp. 163–168. [Google Scholar]
- Ginosar, R. Ramon Chips, Ltd. Survey of Processors for Space, DASIA. 2012. Available online: https://docs.wixstatic.com/ugd/418640_087c23c99df24aa8acbf01b96dcd281a.pdf?index=true (accessed on 23 April 2023).
- Reinhardt, K.S.; Mukherjee, S.S. Transient fault detection via simultaneous multithreading. In Proceedings of the 27th International Symposium on Computer Architecture (IEEE Cat. No.RS00201), Vancouver, BC, Canada, 10–14 June 2000; pp. 25–36. [Google Scholar]
- Mukherjee, S. Architecture Design for Soft Errors; Elsevier Inc.: Amsterdam, The Netherlands, 2008. [Google Scholar] [CrossRef]
- Greaves, D.J. System on Chip Design and Modelling. In University of Cambridge Computer Laboratory Lecture Notes; 2011; Available online: https://www.cl.cam.ac.uk/teaching/1011/SysOnChip/socdam-notes1011.pdf (accessed on 18 November 2023).
- Patterson, D.A.; Hennessy, J.L. Computer Organization and Design RISC-V Edition: The Hardware Software Interface, 1st. ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2017. [Google Scholar]
- Ottavi, M.; Gizopoulos, D.; Pontarelli, S. Dependable Multicore Architectures at Nanoscale; Springer International Publishing AG: Berlin/Heidelberg, Germany, 2018. [Google Scholar] [CrossRef]
- ECSS-Q-HB-60-02A; Techniques for Radiation Effects Mittigation in ASICs and FRGAs Hadbook. ECSS Secretariat ESA-ESTEC Requirements & Standards Division: Noordwijk, The Netherlands, 2016. Available online: http://microelectronics.esa.int/asic/ECSS-Q-HB-60-02A1September2016.pdf (accessed on 23 April 2023).
- van de Goor, A.; Schanstra, I. Address and data scrambling: Causes and impact on memory tests. In Proceedings of the First IEEE International Workshop on Electronic Design, Test and Applications 2002, Christchurch, New Zealand, 29–31 January 2002; pp. 128–136. [Google Scholar] [CrossRef]
- Chen, M.; Guo, C.; Chen, L.; Li, W.; Zhang, F.; Hu, X.; Xu, J. Research on EDAC Schemes for Memory in Space Applications. Electronics 2021, 10, 533. [Google Scholar] [CrossRef]
- Song, Y.; Park, S.; Sullivan, M.B.; Kim, J. SEC-BADAEC: An Efficient ECC with No Vacancy for Strong Memory Protection. IEEE Access 2022, 10, 89769–89780. [Google Scholar] [CrossRef]
- Sadler, N.N.; Sorin, D.J. Choosing an Error Protection Scheme for a Microprocessor’s L1 Data Cache. In Proceedings of the 2006 International Conference on Computer Design, San Jose, CA, USA, 1–4 October 2006; pp. 499–505. [Google Scholar] [CrossRef]
- Ko, Y.; Jeyapaul, R.; Kim, Y.; Lee, K.; Shrivastava, A. Protecting Caches from Soft Errors. ACM Trans. Embed. Comput. Syst. 2017, 16, 93. [Google Scholar] [CrossRef]
- Patel, M.; Kim, J.S.; Shahroodi, T.; Hassan, H.; Mutlu, O. Bit-Exact ECC Recovery (BEER): Determining DRAM On-Die ECC Functions by Exploiting DRAM Data Retention Characteristics. In Proceedings of the 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Athens, Greece, 17–21 October 2020; pp. 282–297. [Google Scholar] [CrossRef]
- Greb, K.; Pradhan, D. Texas Instruments, Hercules™ Microcontrollers: Real-Time MCUs for Safety-Critical Products; Texas Instruments: Dallas, TX, USA, 2011; Available online: https://www.ti.com/lit/fs/spry178/spry178.pdf?ts=1700302644823&ref_url=https%253A%252F%252Fwww.google.com%252F (accessed on 18 November 2023).
- GR740, Quad Core LEON4 SPARC V8 Processor, Version 2.6; Frontgrade Gaisler AB: Goteborg, Sweden, 2023.
- Su, C.-L.; Yeh, Y.-T.; Wu, C.-W. An integrated ECC and redundancy repair scheme for memory reliability enhancement. In Proceedings of the 20th IEEE International Symposium on Defect and Fault Tolerance in VLSI Systems (DFT’05), Monterey, CA, USA, 3–5 October 2005; pp. 81–89. [Google Scholar] [CrossRef]
- Santos, D.A.; Mattos, A.M.P.; Melo, D.R.; Dilillo, L. Enhancing Fault Awareness and Reliability of a Fault-Tolerant RISC-V System-on-Chip. Electronics 2023, 12, 2557. [Google Scholar] [CrossRef]
- Calin, T.; Velazco, R.; Nicolaidis, M.; Moss, S.; LaLumondiere, S.; Tran, V.; Koga, R.; Clark, K. Topology-related upset mechanisms in design hardened storage cells. RADECS 97. In Proceedings of the Fourth European Conference on Radiation and Its Effects on Components and Systems (Cat. No.97TH8294), Cannes, France, 15–19 September 1997; pp. 484–488. [Google Scholar] [CrossRef]
- Marinella, M.J. Radiation Effects in Advanced and Emerging Nonvolatile Memories. IEEE Trans. Nucl. Sci. 2021, 68, 546–572. [Google Scholar] [CrossRef]
- Cortex™-R5 and Cortex-R5F, Technical Reference Manual, Revision: r1p1, ARM DDI 0460C (ID021511). 2011. Available online: https://documentation-service.arm.com/static/5f042788cafe527e86f5cc83?token= (accessed on 18 November 2023).
- Cortex™-R4 and Cortex-R4F, Technical Reference Manual, Revision: r1p4, ARM DDI 0363G (ID041111). 2011. Available online: https://documentation-service.arm.com/static/5f0358e8dbdee951c1cd6f3b?token= (accessed on 18 November 2023).
- Graham, D.; Strid, P.; Roy, S.; Rodriguez, F. A low-tech solution to avoid the severe impact of transient errors on the IP interconnect. In Proceedings of the 2009 IEEE/IFIP International Conference on Dependable Systems & Networks, Lisbon, Portugal, 29 June–2 July 2009; pp. 478–483. [Google Scholar] [CrossRef]
- Lin, I.-C.; Srinivasan, S.; Vijaykrishnan, N.; Dhanwada, N. Transaction Level Error Susceptibility Model for Bus Based SoC Architectures. In Proceedings of the 7th International Symposium on Quality Electronic Design (ISQED’06), San Jose, CA, USA, 27–29 March 2006; pp. 6–780. [Google Scholar] [CrossRef]
- Cho, H.; Cher, C.-Y.; Shepherd, T.; Mitra, S. Understanding soft errors in uncore components. In Proceedings of the 52nd Annual Design Automation Conference (DAC ‘15). Association for Computing Machinery, New York, NY, USA, 8–12 June 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Postman, J.; Chiang, P. A Survey Addressing On-Chip Interconnect: Energy and Reliability Considerations. Int. Sch. Res. Not. 2012, 2012, 916259. [Google Scholar] [CrossRef][Green Version]
- Kahng, A.B.; Lienig, J.; Markov, I.L.; Hu, J. VLSI Physical Design: From Graph Partitioning to Timing Closure, 1st ed.; Springer Publishing Company, Incorporated: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Dash, R.; Garg, R.; Khatri, S.P.; Choi, G. SEU hardened clock regeneration circuits. In Proceedings of the 2009 10th International Symposium on Quality Electronic Design, San Jose, CA, USA, 16–18 March 2009; pp. 806–813. [Google Scholar] [CrossRef]
- Shen, J.P.; Lipasti, M.H. Moder Processor Design: Fundamentals of Superscalar Processors; Waveland Press, Inc.: Long Grove, IL, USA, 2013; ISBN 978-1-4786-0783-0. [Google Scholar]
- Pasricha, S.; Dutt, N. On-Chip Communication Architectures, 1st ed.; Elsevier: Amsterdam, The Netherlands, 2008; ISBN 978-0-12-373892-9. [Google Scholar]
- Introduction to AMBA AXI4, Issue 0101; ARM Limited: Cambridge, UK, 2020.
- IHI 0033C, AMBA® AHB Protocol Specification; ARM Limited: Cambridge, UK, 2021.
- Nikiema, P.R.; Kritikakou, A.; Traiola, M.; Sentieys, O. Design with low complexity fine-grained Dual Core Lock-Step (DCLS) RISC-V processors. In Proceedings of the 2023 53rd Annual IEEE/IFIP International Conference on Dependable Systems and Networks—Supplemental Volume (DSN-S), Porto, Portugal, 27–30 June 2023; pp. 224–229. [Google Scholar] [CrossRef]
- Rao, A.S.; Kudtarkar, A.; Harakuni, L.; Rao, G.N.; Sudeendra, K.K. A Generic On-Board Computer based on RISC-V Architecture Processor for Low Cost Nanosatellite Applications. In Proceedings of the 2023 2nd International Conference on Vision Towards Emerging Trends in Communication and Networking Technologies (ViTECoN), Vellore, India, 5–6 May 2023; pp. 1–6. [Google Scholar]
- Li, J.; Zhang, S.; Bao, C. DuckCore: A Fault-Tolerant Processor Core Architecture Based on the RISC-V ISA. Electronics 2022, 11, 122. [Google Scholar] [CrossRef]
- Silva, I.; do Espírito Santo, O.; do Nascimento, D.; Xavier-de-Souza, S. Cevero: A soft-error hardened soc for aerospace applications. In Anais Estendidos do X Simpósio Brasileiro de Engenharia de Sistemas Computacionais; SBC: Porto Alegre, Brasil, 2020; pp. 121–126. [Google Scholar]
- Bertozzi, D.; Benini, L.; De Micheli, G. Error control schemes for on-chip communication links: The energy-reliability tradeoff. IEEE Trans. Comput. -Aided Des. Integr. Circuits Syst. 2005, 24, 818–831. [Google Scholar] [CrossRef]
- Aurix Efficiency Platform TC21x/TC22x/TC23x User’s Manual, V1.1 2014-12; Infineon Technologies AG: Munich, Germany, 2014; Available online: https://community.infineon.com/gfawx74859/attachments/gfawx74859/AURIX/5399/1/Infineon-TC21x-TC22x-TC23x-UM-v01_01-EN.pdf (accessed on 18 November 2023).
- Mavis, D.; Eaton, P. Soft error rate mitigation techniques for modern microcircuits. 2002 IEEE International Reliability Physics Symposium Proceedings. In Proceedings of the 40th Annual (Cat. No.02CH37320), Dallas, TX, USA, 7–11 April 2002; pp. 216–225. [Google Scholar] [CrossRef]
- Rezgui, S.; Wang, J.J.; Tung, E.C.; Cronquist, B.; McCollum, J. New Methodologies for SET Characterization and Mitigation in Flash-Based FPGAs. IEEE Trans. Nucl. Sci. 2007, 54, 2512–2524. [Google Scholar] [CrossRef]
- Mitra, S.; Zhang, M.; Waqas, S.; Seifert, N.; Gill, B.; Kim, K.S. Combinational Logic Soft Error Correction. In Proceedings of the 2006 IEEE International Test Conference, Santa Clara, CA, USA, 22–27 October 2006; pp. 1–9. [Google Scholar] [CrossRef]
- Lázaro, J.; Astarloa, A.; Zuloaga, A.; Araujo, J.; Jiménez, J. AXI Lite Redundant On-Chip Bus Interconnect for High Reliability Systems. IEEE Trans. Reliab. 2023, 1–6. [Google Scholar] [CrossRef]
- Yao, J.; Okada, S.; Masuda, M.; Kobayashi, K.; Nakashima, Y. DARA: A Low-Cost Reliable Architecture Based on Unhardened Devices and Its Case Study of Radiation Stress Test. IEEE Trans. Nucl. Sci. 2012, 59, 2852–2858. [Google Scholar] [CrossRef]
- Naseer, R.; Draper, J. DEC ECC design to improve memory reliability in sub-100nm technologies. In Proceedings of the IEEE International Conference on Electronics, Circuits and Systems, St. Julien’s, Malta, 31 August–3 September 2008; pp. 586–589. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Property/Characteristic | Redundancy | ||
|---|---|---|---|
| Information | Temporal | Spatial | |
| Concurrent glitches in multiple wires can be undetected | Yes | No | Partially |
| Protection is limited by the duration of the glitch | No | Yes | No |
| Impacts bus clock frequency | Partially | Yes | Partially |
| Increases bus transfer latency (in clock cycles) | Partially | No | Partially |
| Increases area for the interconnection | Partially | Partially | Yes |
| Requires changes to the manager | Yes | No | Partially |
| Requires changes to the subordinates | Yes | No | No |
| Implementation is straightforward | No | Partially | Yes |
| Usable for data protection of data in memory | Yes | No | Yes |
| Some transactions may need several transfers | Yes | No | No |
| Fine-tunable for a specific interface | Yes | No | No |
| Used in state-of-the-art processors | Yes | Yes | Partially |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mach, J.; Kohútka, L.; Čičák, P. On-Chip Bus Protection against Soft Errors. Electronics 2023, 12, 4706. https://doi.org/10.3390/electronics12224706
Mach J, Kohútka L, Čičák P. On-Chip Bus Protection against Soft Errors. Electronics. 2023; 12(22):4706. https://doi.org/10.3390/electronics12224706
Chicago/Turabian StyleMach, Ján, Lukáš Kohútka, and Pavel Čičák. 2023. "On-Chip Bus Protection against Soft Errors" Electronics 12, no. 22: 4706. https://doi.org/10.3390/electronics12224706
APA StyleMach, J., Kohútka, L., & Čičák, P. (2023). On-Chip Bus Protection against Soft Errors. Electronics, 12(22), 4706. https://doi.org/10.3390/electronics12224706