
Taxonomy and Survey of Current 3D Photorealistic Human Body Modelling and Reconstruction Techniques for Holographic-Type Communication



Abstract
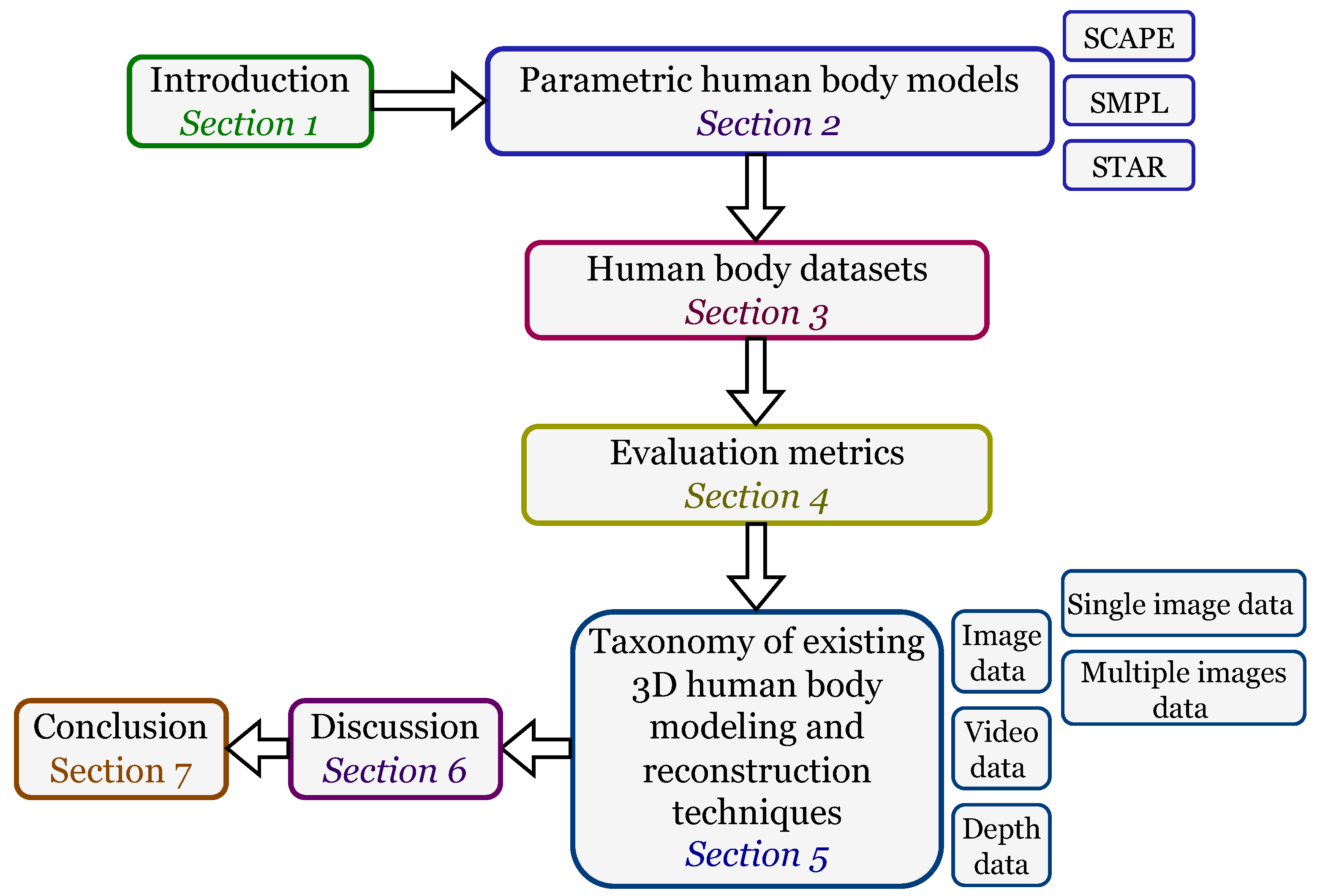
:1. Introduction
2. Parametric Human Body Models
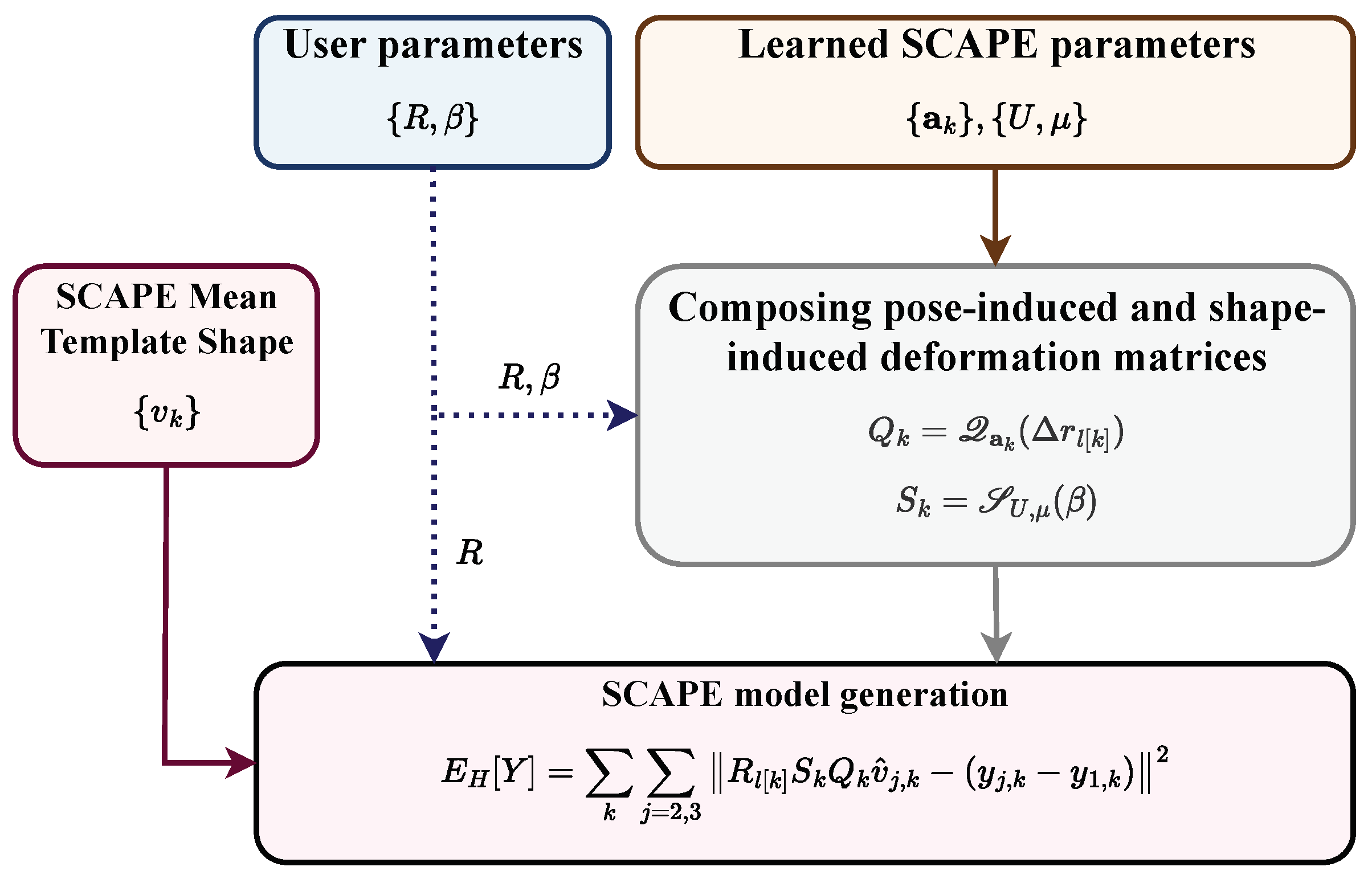
2.1. SCAPE
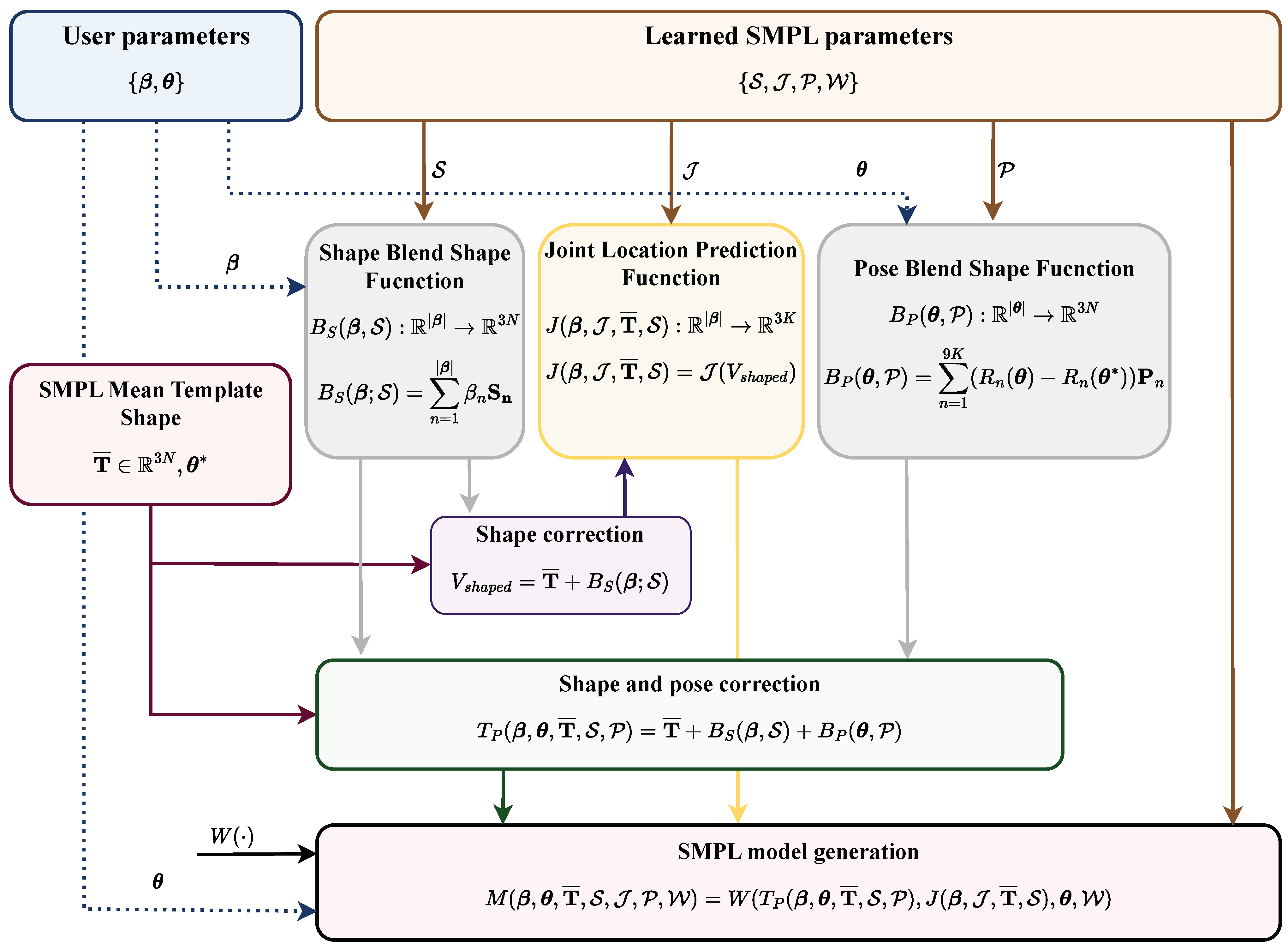
2.2. SMPL
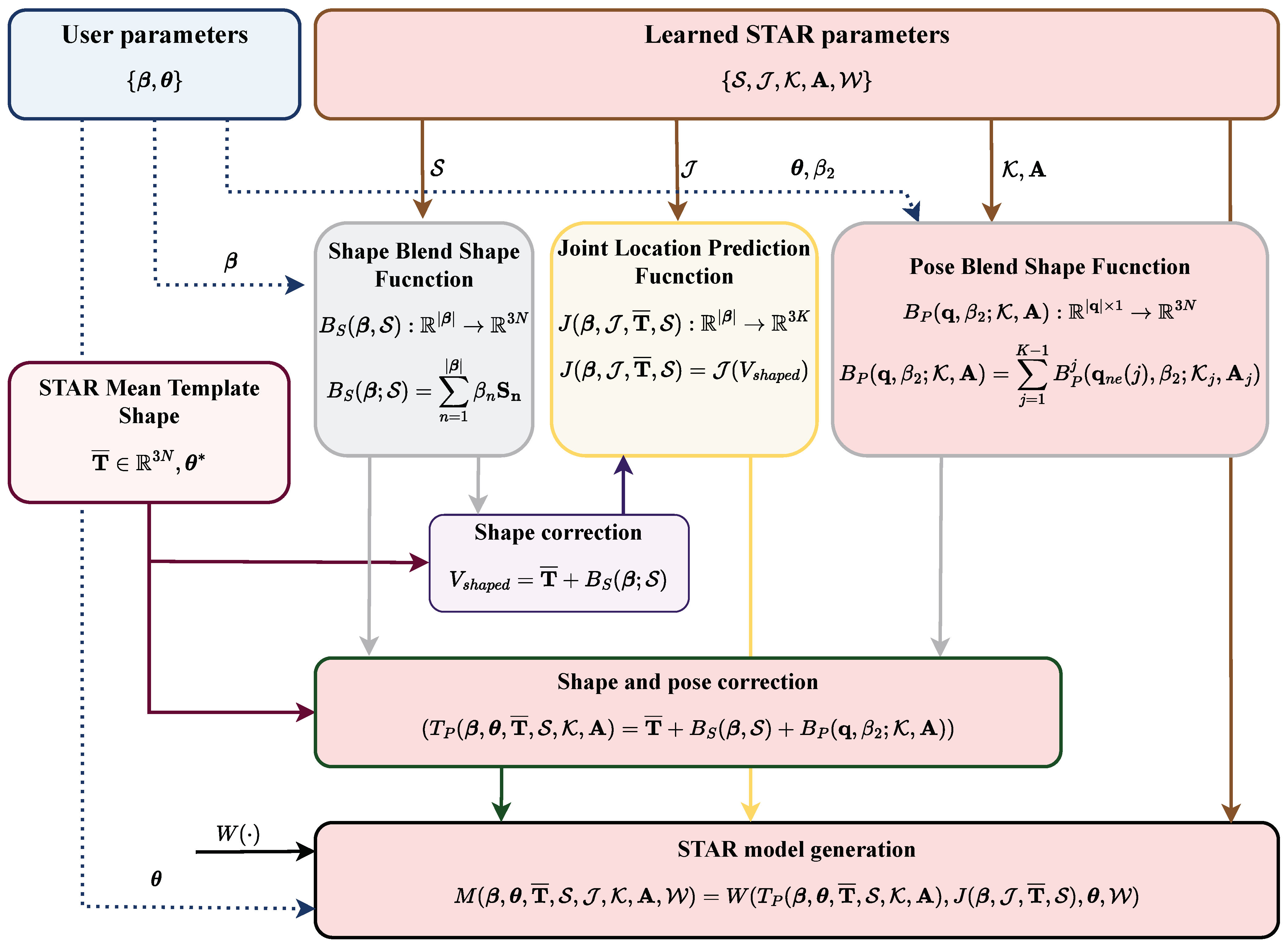
2.3. STAR
3. Human Body Datasets
4. Evaluation Metrics
- Mean Per-Joint Position Error (MPJPE)
- Mean Average Vertex Error (MAVE)
- Chamfer Distance
- Vertex-to-Surface Distance (VSD)
5. Taxonomy of Existing 3D Human Body Modelling and Reconstruction Techniques
5.1. Image Data
5.1.1. Single Image
5.1.2. Multiple Images
5.2. Video Data
5.3. Depth Map Data
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 3DOH | 3D Occlusion Human |
| 3DPW | 3D Poses in the Wild |
| AIST | Advanced Industrial Science and Technology |
| AR | Augmented Reality |
| AUC | Area Under the Curve |
| BMI | Body Mass Index |
| BUFF | Bodies Under Flowing Fashion |
| CAPE | Clothed Auto Person Encoding |
| CMU | Carnegie Mellon University |
| DFAUST | Dynamic Fine Alignment Using Scan Texture |
| EHF | Expressive Hands and Faces |
| FOF | Fourier Occupancy Field |
| HHOI | Human-Human-Object Interaction |
| HTC | Holographic-Type Communication |
| HUMBI | HUman Multiview Behavioral Imaging |
| IoU | Intersection over Union |
| ITOP | Invariant-Top View |
| LSP | Leeds Sports Pose |
| LSPe | Leeds Sports Pose extended |
| MAE | Mean Angle Error |
| mAP | mean Average Precision |
| MAVE | Mean Average Vertex Error |
| MMT | Multi-view human body Mesh Translator |
| MoSh | Motion and Shape capture |
| MPII | Max Planck Institute for Informatics |
| MPJPE | Mean Per Joint Position Error |
| MR | Mixed Reality |
| MS COCO | MicroSoft Common Objects in COntext |
| MuPoTS-3D | Multiperson Pose Test Set in 3D |
| NeRF | Neural Radiance Field |
| OPlanes | Occupancy Planes |
| PA-MPJPE | Procrustes Aligned MPJPE |
| PA-V2V | Procrustes-Aligned Vertex-to-Vertex |
| PCA | Principal Component Analysis |
| PCK | Percentage of Correct Key points |
| PHSPD | Polarization Human Shape and Pose Dataset |
| POCO | Pose and shape estimation with confidence |
| PRISMA | Preferred Reporting Items for Systematic Reviews and Meta-Analyses |
| PSNR | Peak Signal-to-Noise Ratio |
| PVE | Per-Vertex Error |
| PVE-T-SC | Per-Vertex Euclidean error in a neutral (T) pose |
| RGB | Reed Green Blue |
| RGB-D | Reed Green Blue—Depth |
| ROM | Range of Motion |
| RSC | Resolution-aware network, a Self-supervision loss, and a Contrastive learning scheme |
| S3D | SAIL-VOS 3D |
| SCAPE | Shape Completion and Animation of People |
| SSIM | Structural Similarity Index |
| SMPPL | Skinned Multi-Person Linear Model |
| SSP3D | Sports Shape and Pose 3D |
| STAR | Sparse Trained Articulated Human Body Regressor |
| SURREAL | Synthetic hUmans foR REAL tasks |
| UBC | University of British Columbia |
| VR | Virtual Reality |
| VSD | Vertex to Surface Distance |
References
- Manolova, A.; Tonchev, K.; Poulkov, V.; Dixir, S.; Lindgren, P. Context-aware holographic communication based on semantic knowledge extraction. Wirel. Pers. Commun. 2021, 120, 2307–2319. [Google Scholar] [CrossRef]
- Haleem, A.; Javaid, M.; Khan, I.H. Holography applications toward medical field: An overview. Indian J. Radiol. Imaging 2020, 30, 354–361. [Google Scholar] [CrossRef] [PubMed]
- Jumreornvong, O.; Yang, E.; Race, J.; Appel, J. Telemedicine and medical education in the age of COVID-19. Acad. Med. 2020, 95, 1838–1843. [Google Scholar] [CrossRef] [PubMed]
- Nayak, S.; Patgiri, R. 6G communication technology: A vision on intelligent healthcare. Health Inform. Comput. Perspect. Healthc. 2021, 1–18. [Google Scholar] [CrossRef]
- Ahmad, H.F.; Rafique, W.; Rasool, R.U.; Alhumam, A.; Anwar, Z.; Qadir, J. Leveraging 6G, extended reality, and IoT big data analytics for healthcare: A review. Comput. Sci. Rev. 2023, 48, 100558. [Google Scholar]
- Ahad, A.; Tahir, M. Perspective—6G and IoT for Intelligent Healthcare: Challenges and Future Research Directions. ECS Sens. Plus 2023, 2, 011601. [Google Scholar] [CrossRef]
- Bucioli, A.A.; Cyrino, G.F.; Lima, G.F.; Peres, I.C.; Cardoso, A.; Lamounier, E.A.; Neto, M.M.; Botelho, R.V. Holographic real time 3D heart visualization from coronary tomography for multi-place medical diagnostics. In Proceedings of the 2017 IEEE 15th International Conference on Dependable, Autonomic and Secure Computing, 15th International Conference on Pervasive Intelligence and Computing, 3rd International Conference on Big Data Intelligence and Computing and Cyber Science and Technology Congress (DASC/PiCom/DataCom/CyberSciTech), Orlando, FL, USA, 6–10 November 2017; pp. 239–244. [Google Scholar]
- Sirilak, S.; Muneesawang, P. A new procedure for advancing telemedicine using the HoloLens. IEEE Access 2018, 6, 60224–60233. [Google Scholar] [CrossRef]
- Choi, P.J.; Oskouian, R.J.; Tubbs, R.S.; Choi, P.J.K. Telesurgery: Past, present, and future. Cureus 2018, 10, e2716. [Google Scholar] [CrossRef]
- Barkhaya, N.M.M.; Abd Halim, N.D. A review of application of 3D hologram in education: A meta-analysis. In Proceedings of the 2016 IEEE 8th International Conference on Engineering Education (ICEED), Kuala Lumpur, Malaysia, 7–8 December 2016; pp. 257–260. [Google Scholar]
- Ramachandiran, C.R.; Chong, M.M.; Subramanian, P. 3D hologram in futuristic classroom: A review. Period. Eng. Nat. Sci. 2019, 7, 580–586. [Google Scholar] [CrossRef]
- Ahmad, A.S.; Alomaier, A.T.; Elmahal, D.M.; Abdlfatah, R.F.; Ibrahim, D.M. EduGram: Education Development Based on Hologram Technology. Int. J. Online Biomed. Eng. 2021, 17, 32–49. [Google Scholar] [CrossRef]
- Yoo, H.; Jang, J.; Oh, H.; Park, I. The potentials and trends of holography in education: A scoping review. Comput. Educ. 2022, 186, 104533. [Google Scholar] [CrossRef]
- Hughes, A. Death is no longer a deal breaker: The hologram performer in live music. Future Live Music 2020, 114–128. Available online: https://books.google.bg/books?id=QB3LzQEACAAJ (accessed on 20 October 2023).
- Matthews, J.; Nairn, A. Holographic ABBA: Examining Fan Responses to ABBA’s Virtual “Live” Concert. Pop. Music Soc. 2023, 1–22. [Google Scholar] [CrossRef]
- Rega, F.; Saxena, D. Free-roam virtual reality: A new avenue for gaming. In Advances in Augmented Reality and Virtual Reality; Springer: Berlin/Heidelberg, Germany, 2022; pp. 29–34. [Google Scholar]
- Fanini, B.; Pagano, A.; Pietroni, E.; Ferdani, D.; Demetrescu, E.; Palombini, A. Augmented Reality for Cultural Heritage. In Springer Handbook of Augmented Reality; Springer: Berlin/Heidelberg, Germany, 2023; pp. 391–411. [Google Scholar]
- Banfi, F.; Pontisso, M.; Paolillo, F.R.; Roascio, S.; Spallino, C.; Stanga, C. Interactive and Immersive Digital Representation for Virtual Museum: VR and AR for Semantic Enrichment of Museo Nazionale Romano, Antiquarium di Lucrezia Romana and Antiquarium di Villa Dei Quintili. ISPRS Int. J. Geo Inf. 2023, 12, 28. [Google Scholar] [CrossRef]
- Meng, Y.; Mok, P.Y.; Jin, X. Interactive virtual try-on clothing design systems. Comput. Aided Des. 2010, 42, 310–321. [Google Scholar] [CrossRef]
- Santesteban, I.; Otaduy, M.A.; Casas, D. Learning-based animation of clothing for virtual try-on. Proc. Comput. Graph. Forum 2019, 38, 355–366. [Google Scholar] [CrossRef]
- Zhao, F.; Xie, Z.; Kampffmeyer, M.; Dong, H.; Han, S.; Zheng, T.; Zhang, T.; Liang, X. M3d-vton: A monocular-to-3d virtual try-on network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 13239–13249. [Google Scholar]
- Cheng, Z.Q.; Chen, Y.; Martin, R.R.; Wu, T.; Song, Z. Parametric modeling of 3D human body shape—A survey. Comput. Graph. 2018, 71, 88–100. [Google Scholar] [CrossRef]
- Chen, L.; Peng, S.; Zhou, X. Towards efficient and photorealistic 3d human reconstruction: A brief survey. Vis. Inform. 2021, 5, 11–19. [Google Scholar] [CrossRef]
- Correia, H.A.; Brito, J.H. 3D reconstruction of human bodies from single-view and multi-view images: A systematic review. Comput. Methods Programs Biomed. 2023, 239, 107620. [Google Scholar] [CrossRef]
- Tian, Y.; Zhang, H.; Liu, Y.; Wang, L. Recovering 3D human mesh from monocular images: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 1–25. [Google Scholar] [CrossRef]
- Sun, M.; Yang, D.; Kou, D.; Jiang, Y.; Shan, W.; Yan, Z.; Zhang, L. Human 3D avatar modeling with implicit neural representation: A brief survey. In Proceedings of the 2022 14th International Conference on Signal Processing Systems (ICSPS), Zhenjiang, China, 18–20 November 2022; pp. 818–827. [Google Scholar]
- Page, M.; McKenzie, J.; Bossuyt, P.; Boutron, I.; Hoffmann, T.; Mulrow, C.; Shamseer, L.; Tetzlaff, J.; Akl, E.; Brennan, S.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. Syst. Rev. 2021, 10, 89. [Google Scholar] [PubMed]
- Christoff, N. Modeling of 3D Human Body for Photorealistic Avatar Generation: A Review. In Proceedings of the iCEST, Ohrid, North Macedonia, 27–29 June 2019. [Google Scholar]
- Zhou, S.; Fu, H.; Liu, L.; Cohen-Or, D.; Han, X. Parametric reshaping of human bodies in images. ACM Trans. Graph. 2010, 29, 1–10. [Google Scholar] [CrossRef]
- Omran, M.; Lassner, C.; Pons-Moll, G.; Gehler, P.; Schiele, B. Neural body fitting: Unifying deep learning and model based human pose and shape estimation. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 484–494. [Google Scholar]
- Anguelov, D.; Srinivasan, P.; Koller, D.; Thrun, S.; Rodgers, J.; Davis, J. Scape: Shape completion and animation of people. ACM SIGGRAPH Pap. 2005, 408–416. [Google Scholar] [CrossRef]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A skinned multi-person linear model. ACM Trans. Graph. 2015, 34, 1–16. [Google Scholar] [CrossRef]
- Osman, A.A.; Bolkart, T.; Black, M.J. Star: Sparse trained articulated human body regressor. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part VI 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 598–613. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1325–1339. [Google Scholar]
- Mehta, D.; Rhodin, H.; Casas, D.; Fua, P.; Sotnychenko, O.; Xu, W.; Theobalt, C. Monocular 3d human pose estimation in the wild using improved cnn supervision. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 506–516. [Google Scholar]
- Varol, G.; Romero, J.; Martin, X.; Mahmood, N.; Black, M.J.; Laptev, I.; Schmid, C. Learning from synthetic humans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 109–117. [Google Scholar]
- Bogo, F.; Romero, J.; Pons-Moll, G.; Black, M.J. Dynamic FAUST: Registering human bodies in motion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6233–6242. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Johnson, S.; Everingham, M. Clustered pose and nonlinear appearance models for human pose estimation. Proc. BMVC 2010, 2, 5. [Google Scholar]
- Johnson, S.; Everingham, M. Learning effective human pose estimation from inaccurate annotation. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1465–1472. [Google Scholar]
- Zhang, C.; Pujades, S.; Black, M.J.; Pons-Moll, G. Detailed, accurate, human shape estimation from clothed 3D scan sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4191–4200. [Google Scholar]
- Sigal, L.; Balan, A.O.; Black, M.J. Humaneva: Synchronized video and motion capture dataset and baseline algorithm for evaluation of articulated human motion. Int. J. Comput. Vis. 2010, 87, 4–27. [Google Scholar]
- Shu, T.; Ryoo, M.S.; Zhu, S.C. Learning social affordance for human-robot interaction. arXiv 2016, arXiv:1604.03692. [Google Scholar]
- Haque, A.; Peng, B.; Luo, Z.; Alahi, A.; Yeung, S.; Fei-Fei, L. Towards viewpoint invariant 3d human pose estimation. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 160–177. [Google Scholar]
- Bozhilov, I.; Tonchev, K.; Manolova, A.; Petkova, R. 3d human body models compression and decompression algorithm based on graph convolutional networks for holographic communication. In Proceedings of the 2022 25th International Symposium on Wireless Personal Multimedia Communications (WPMC), Herning, Denmark, 30 October–2 November 2022; pp. 532–537. [Google Scholar]
- Von Marcard, T.; Henschel, R.; Black, M.J.; Rosenhahn, B.; Pons-Moll, G. Recovering accurate 3d human pose in the wild using imus and a moving camera. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 601–617. [Google Scholar]
- Kanazawa, A.; Black, M.J.; Jacobs, D.W.; Malik, J. End-to-end recovery of human shape and pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7122–7131. [Google Scholar]
- Zhu, H.; Zuo, X.; Wang, S.; Cao, X.; Yang, R. Detailed human shape estimation from a single image by hierarchical mesh deformation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4491–4500. [Google Scholar]
- Gao, R.; Wen, M.; Park, J.; Cho, K. Human Mesh Reconstruction with Generative Adversarial Networks from Single RGB Images. Sensors 2021, 21, 1350. [Google Scholar]
- Xu, X.; Chen, H.; Moreno-Noguer, F.; Jeni, L.A.; De la Torre, F. 3D human pose, shape and texture from low-resolution images and videos. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4490–4504. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, W.; Liu, T.; Liu, X.; Xie, J.; Zhu, S.C. Monocular 3d pose estimation via pose grammar and data augmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6327–6344. [Google Scholar] [CrossRef] [PubMed]
- Dwivedi, S.K.; Schmid, C.; Yi, H.; Black, M.J.; Tzionas, D. POCO: 3D Pose and Shape Estimation with Confidence. arXiv 2023, arXiv:2308.12965. [Google Scholar]
- Jiang, X.; Nie, X.; Wang, Z.; Liu, L.; Liu, S. Multi-view Human Body Mesh Translator. arXiv 2022, arXiv:2210.01886. [Google Scholar]
- Pavllo, D.; Feichtenhofer, C.; Grangier, D.; Auli, M. 3d human pose estimation in video with temporal convolutions and semi-supervised training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7753–7762. [Google Scholar]
- Kolotouros, N.; Pavlakos, G.; Black, M.J.; Daniilidis, K. Learning to reconstruct 3D human pose and shape via model-fitting in the loop. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2252–2261. [Google Scholar]
- Shi, M.; Aberman, K.; Aristidou, A.; Komura, T.; Lischinski, D.; Cohen-Or, D.; Chen, B. Motionet: 3d human motion reconstruction from monocular video with skeleton consistency. ACM Trans. Graph. 2020, 40, 1–15. [Google Scholar]
- Makarov, I.; Chernyshev, D. Real-time 3D model reconstruction and mapping for fashion. In Proceedings of the 2020 43rd International Conference on Telecommunications and Signal Processing (TSP), Milan, Italy, 7–9 July 2020; pp. 133–138. [Google Scholar]
- Liu, L.; Wang, K.; Yang, J. 3D Human Body Shape and Pose Estimation from Depth Image. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Shenzhen, China, 14–17 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 410–421. [Google Scholar]
- Baradel, F.; Brégier, R.; Groueix, T.; Weinzaepfel, P.; Kalantidis, Y.; Rogez, G. PoseBERT: A Generic Transformer Module for Temporal 3D Human Modeling. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 1–16. [Google Scholar] [CrossRef]
- Varol, G.; Ceylan, D.; Russell, B.; Yang, J.; Yumer, E.; Laptev, I.; Schmid, C. Bodynet: Volumetric inference of 3d human body shapes. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 20–36. [Google Scholar]
- Zou, S.; Zuo, X.; Qian, Y.; Wang, S.; Xu, C.; Gong, M.; Cheng, L. 3D human shape reconstruction from a polarization image. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XIV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 351–368. [Google Scholar]
- Alldieck, T.; Magnor, M.; Xu, W.; Theobalt, C.; Pons-Moll, G. Video based reconstruction of 3d people models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8387–8397. [Google Scholar]
- Venkat, A.; Jinka, S.S.; Sharma, A. Deep textured 3d reconstruction of human bodies. arXiv 2018, arXiv:1809.06547. [Google Scholar]
- Jinka, S.S.; Chacko, R.; Sharma, A.; Narayanan, P. Peeledhuman: Robust shape representation for textured 3d human body reconstruction. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020; pp. 879–888. [Google Scholar]
- Marin-Jimenez, M.J.; Romero-Ramirez, F.J.; Munoz-Salinas, R.; Medina-Carnicer, R. 3D human pose estimation from depth maps using a deep combination of poses. J. Vis. Commun. Image Represent. 2018, 55, 627–639. [Google Scholar]
- Lu, Y.; Chen, G.; Pang, C.; Zhang, H.; Zhang, B. Subject-Specific Human Modeling for Human Pose Estimation. IEEE Trans. Hum.-Mach. Syst. 2022, 53, 54–64. [Google Scholar] [CrossRef]
- Jena, R.; Chaudhari, P.; Gee, J.; Iyer, G.; Choudhary, S.; Smith, B.M. Mesh Strikes Back: Fast and Efficient Human Reconstruction from RGB videos. arXiv 2023, arXiv:2303.08808. [Google Scholar]
- Lassner, C.; Romero, J.; Kiefel, M.; Bogo, F.; Black, M.J.; Gehler, P.V. Unite the people: Closing the loop between 3d and 2d human representations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6050–6059. [Google Scholar]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2d human pose estimation: New benchmark and state of the art analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3686–3693. [Google Scholar]
- Zou, S.; Zuo, X.; Qian, Y.; Wang, S.; Guo, C.; Xu, C.; Gong, M.; Cheng, L. Polarization human shape and pose dataset. arXiv 2020, arXiv:2004.14899. [Google Scholar]
- Yu, T.; Zheng, Z.; Guo, K.; Liu, P.; Dai, Q.; Liu, Y. Function4D: Real-time human volumetric capture from very sparse consumer rgbd sensors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5746–5756. [Google Scholar]
- Feng, Q.; Liu, Y.; Lai, Y.K.; Yang, J.; Li, K. FOF: Learning fourier occupancy field for monocular real-time human reconstruction. Adv. Neural Inf. Process. Syst. 2022, 35, 7397–7409. [Google Scholar]
- Zhang, T.; Huang, B.; Wang, Y. Object-occluded human shape and pose estimation from a single color image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7376–7385. [Google Scholar]
- Pavlakos, G.; Choutas, V.; Ghorbani, N.; Bolkart, T.; Osman, A.A.; Tzionas, D.; Black, M.J. Expressive body capture: 3d hands, face, and body from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10975–10985. [Google Scholar]
- Zioulis, N.; O’Brien, J.F. KBody: Towards General, Robust, and Aligned Monocular Whole-Body Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6214–6224. [Google Scholar]
- Sengupta, A.; Budvytis, I.; Cipolla, R. Synthetic training for accurate 3d human pose and shape estimation in the wild. arXiv 2020, arXiv:2009.10013. [Google Scholar]
- Vlasic, D.; Baran, I.; Matusik, W.; Popović, J. Articulated mesh animation from multi-view silhouettes. ACM Siggraph Pap. 2008, 1–9. [Google Scholar] [CrossRef]
- Li, Z.; Oskarsson, M.; Heyden, A. Learning to Implicitly Represent 3D Human Body From Multi-scale Features and Multi-view Images. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 8968–8975. [Google Scholar]
- Ma, Q.; Yang, J.; Ranjan, A.; Pujades, S.; Pons-Moll, G.; Tang, S.; Black, M.J. Learning to dress 3d people in generative clothing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6469–6478. [Google Scholar]
- ECCV 2022 WCPA Challenge: From Face, Body and Fashion to 3D Virtual Avatars. Available online: https://tianchi.aliyun.com/competition/entrance/531958/introduction (accessed on 20 October 2023).
- Chen, J.; Yi, W.; Wang, T.; Li, X.; Ma, L.; Fan, Y.; Lu, H. Pixel2ISDF: Implicit Signed Distance Fields Based Human Body Model from Multi-view and Multi-pose Images. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–24 October 2022; Springer: Berlin/Heildeberg, Germany, 2022; pp. 366–375. [Google Scholar]
- Yu, Z.; Yoon, J.S.; Lee, I.K.; Venkatesh, P.; Park, J.; Yu, J.; Park, H.S. Humbi: A large multiview dataset of human body expressions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2990–3000. [Google Scholar]
- De la Torre, F.; Hodgins, J.; Bargteil, A.; Martin, X.; Macey, J.; Collado, A.; Beltran, P. Guide to the Carnegie Mellon University Multimodal Activity (Cmu-Mmac) Database. 2009. Available online: https://www.ri.cmu.edu/pub_files/pub4/de_la_torre_frade_fernando_2008_1/de_la_torre_frade_fernando_2008_1.pdf (accessed on 20 October 2023).
- Habermann, M.; Liu, L.; Xu, W.; Zollhoefer, M.; Pons-Moll, G.; Theobalt, C. Real-time deep dynamic characters. ACM Trans. Graph. 2021, 40, 1–16. [Google Scholar]
- Zheng, Z.; Huang, H.; Yu, T.; Zhang, H.; Guo, Y.; Liu, Y. Structured local radiance fields for human avatar modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 8–24 June 2022; pp. 15893–15903. [Google Scholar]
- Habermann, M.; Xu, W.; Zollhofer, M.; Pons-Moll, G.; Theobalt, C. Deepcap: Monocular human performance capture using weak supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5052–5063. [Google Scholar]
- Mehta, D.; Sotnychenko, O.; Mueller, F.; Xu, W.; Sridhar, S.; Pons-Moll, G.; Theobalt, C. Single-shot multi-person 3d pose estimation from monocular rgb. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 120–130. [Google Scholar]
- Tsuchida, S.; Fukayama, S.; Hamasaki, M.; Goto, M. AIST Dance Video Database: Multi-Genre, Multi-Dancer, and Multi-Camera Database for Dance Information Processing. Proc. ISMIR 2019, 1, 6. [Google Scholar]
- Shafaei, A.; Little, J.J. Real-time human motion capture with multiple depth cameras. In Proceedings of the 2016 13th Conference on Computer and Robot Vision (CRV), Victoria, BC, Canada, 1–3 June 2016; pp. 24–31. [Google Scholar]
- Xu, W.; Chatterjee, A.; Zollhöfer, M.; Rhodin, H.; Mehta, D.; Seidel, H.P.; Theobalt, C. Monoperfcap: Human performance capture from monocular video. ACM Trans. Graph. 2018, 37, 1–15. [Google Scholar]
- Hu, Y.T.; Wang, J.; Yeh, R.A.; Schwing, A.G. Sail-vos 3D: A synthetic dataset and baselines for object detection and 3D mesh reconstruction from video data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1418–1428. [Google Scholar]
- Zhao, X.; Hu, Y.T.; Ren, Z.; Schwing, A.G. Occupancy planes for single-view rgb-d human reconstruction. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 3633–3641. [Google Scholar]
- Peng, S.; Zhang, Y.; Xu, Y.; Wang, Q.; Shuai, Q.; Bao, H.; Zhou, X. Neural body: Implicit neural representations with structured latent codes for novel view synthesis of dynamic humans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9054–9063. [Google Scholar]
- Shen, J.; Cashman, T.J.; Ye, Q.; Hutton, T.; Sharp, T.; Bogo, F.; Fitzgibbon, A.; Shotton, J. The phong surface: Efficient 3D model fitting using lifted optimization. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part I 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 687–703. [Google Scholar]
- Guan, P.; Weiss, A.; Balan, A.O.; Black, M.J. Estimating human shape and pose from a single image. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1381–1388. [Google Scholar]
- Zhu, H.; Su, H.; Wang, P.; Cao, X.; Yang, R. View extrapolation of human body from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4450–4459. [Google Scholar]
- Smith, B.M.; Chari, V.; Agrawal, A.; Rehg, J.M.; Sever, R. Towards accurate 3D human body reconstruction from silhouettes. In Proceedings of the 2019 International Conference on 3D Vision (3DV), Quebec City, QC, Canada, 16–19 September 2019; pp. 279–288. [Google Scholar]
- Robinette, K.M.; Blackwell, S.; Daanen, H.; Boehmer, M.; Fleming, S.; Brill, T.; Hoeferlin, D.; Burnsides, D. Civilian American and European Surface Anthropometry Resource (CAESAR), Final Report, Volume I: Summary. Sytronics Inc Dayton Oh. 2002. Available online: https://www.humanics-es.com/CAESARvol1.pdf (accessed on 20 October 2023).
- Beacco, A.; Gallego, J.; Slater, M. Automatic 3D character reconstruction from frontal and lateral monocular 2d rgb views. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2785–2789. [Google Scholar]
- Kanazawa, A.; Zhang, J.Y.; Felsen, P.; Malik, J. Learning 3d human dynamics from video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5614–5623. [Google Scholar]
- Mahmood, N.; Ghorbani, N.; Troje, N.F.; Pons-Moll, G.; Black, M.J. AMASS: Archive of motion capture as surface shapes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5442–5451. [Google Scholar]
- Sarbolandi, H.; Lefloch, D.; Kolb, A. Kinect range sensing: Structured-light versus Time-of-Flight Kinect. Comput. Vis. Image Underst. 2015, 139, 1–20. [Google Scholar]
- Petkova, R.; Poulkov, V.; Manolova, A.; Tonchev, K. Challenges in Implementing Low-Latency Holographic-Type Communication Systems. Sensors 2022, 22, 9617. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | RGB Image | Frame Sequence | Depth | Multi-View | 2D Pose | 3D Pose | 3D Mesh | Used in References |
|---|---|---|---|---|---|---|---|---|
| Human 3.6 M [34] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | [47,48,49,50,51,52,53,54,55,56,57,58] |
| MPI-INF-3DHP [35] | ✓ | ✓ | - | ✓ | - | ✓ | - | [47,48,49,50,55,59] |
| Synthetic Humans for Real Tasks (SURREAL) [36] | ✓ | ✓ | ✓ | - | ✓ | ✓ | ✓ | [49,58,60,61] |
| Dynamic Fine Alignment Using Scan Texture (DFAUST) [37] | ✓ | ✓ | ✓ | ✓ | - | ✓ | ✓ | [58,62,63] |
| Microsoft Common Objects in Context (MS COCO) [38] | ✓ | - | - | - | - | - | - | [47,48,49,50,52,57] |
| Leeds Sports Pose (LSP) [39] | ✓ | - | - | - | ✓ | - | - | [47,48,49,50,55] |
| Leeds Sports Pose Extended (LSPe) [40] | ✓ | - | - | - | ✓ | - | - | [47,48,49,50,52,55] |
| Bodies Under Flowing Fashion (BUFF) [41] | ✓ | ✓ | - | ✓ | - | - | ✓ | [62,64] |
| HumanEva [42] | ✓ | ✓ | - | ✓ | - | ✓ | - | [51,54,56] |
| Human–Human–Object Interaction (HHOI) [43] | ✓ | ✓ | ✓ | ✓ | - | ✓ | - | [51] |
| Invariant Top View (ITOP) [44] | - | ✓ | ✓ | ✓ | - | ✓ | - | [65] |
| 3D Poses in the Wild Dataset (3DPW) [46] | ✓ | ✓ | - | - | - | ✓ | ✓ | [50,52,55,59] |
| People Snapshot [62] | ✓ | ✓ | - | - | - | ✓ | ✓ | [66,67] |
| Unite the People [68] | ✓ | - | - | - | ✓ | ✓ | ✓ | [48,60] |
| Max Planck Institute for Informatics (MPII) [69] | ✓ | ✓ | - | - | ✓ | ✓ | ✓ | [47,48,50,52,55] |
| Polarization Human Shape and Pose Dataset (PHSPD) [70] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | [61] |
| Thuman2.0 [71] | - | - | - | - | - | - | ✓ | [72] |
| 3D Occlusion Human (3DOH) [73] | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | [52] |
| Expressive Hands and Faces (EHF) [74] | ✓ | - | - | - | ✓ | - | ✓ | [75] |
| Sports Shape and Pose 3D (SSP3D) [76] | ✓ | ✓ | - | - | ✓ | ✓ | ✓ | [75] |
| Articulated dataset [77] | ✓ | ✓ | - | ✓ | - | ✓ | ✓ | [63,78] |
| Clothed Auto Person Encoding (CAPE) [79] | ✓ | ✓ | - | ✓ | - | ✓ | ✓ | [78] |
| WCPA [80] | ✓ | - | ✓ | - | - | ✓ | ✓ | [81] |
| Human Multiview Behavioral Imaging (HUMBI) [82] | ✓ | ✓ | - | ✓ | ✓ | ✓ | ✓ | [53] |
| Carnegie Mellon University (CMU) [83] | ✓ | ✓ | - | ✓ | ✓ | - | - | [56] |
| Dynacap [84] | ✓ | ✓ | - | ✓ | ✓ | ✓ | ✓ | [85] |
| DeepCap [86] | ✓ | ✓ | - | ✓ | - | ✓ | ✓ | [85] |
| Multiperson Pose Test Set in 3D (MuPoTS-3D) [87] | ✓ | ✓ | - | ✓ | ✓ | ✓ | - | [59] |
| Advanced Industrial Science and Technology (AIST) [88] | ✓ | ✓ | - | ✓ | - | - | - | [59] |
| University of British Columbia (UBC 3V) [89] | - | ✓ | ✓ | ✓ | - | ✓ | - | [65] |
| MonoPerfCap [90] | ✓ | ✓ | - | ✓ | - | - | ✓ | [64] |
| SAIL-VOS 3D (S3D) [91] | ✓ | ✓ | ✓ | ✓ | - | - | ✓ | [92] |
| ZJU-MoCap [93] | ✓ | ✓ | - | ✓ | - | - | - | [67,85] |
| Research | Year | Main Focus | Assets | Constraints | Parametric Model | Dataset | Evaluation Metric |
|---|---|---|---|---|---|---|---|
| [95] | 2009 | Computing parametric body shape from shading | Minimal human intervention; extracting body shape from paintings | Limited lighting conditions; impossibility of recovering hair and clothes | SCAPE | Not specified | Not specified |
| [47] | 2018 | Human mesh recovery of 3D joint angles and body shape | Precise joints locations; no requirement for 2D to 3D paired data | Additional processing requirement for obtaining better results; impossibility of recovering hair and clothes | SMPL | LSP, LSPe, MPII, MS COCO, Human 3.6 M, MPI-INF-3DHP | MPJPE, PA-MPJPE |
| [60] | 2018 | Inference of volumetric human body shape directly from a single image | Fully automated end-to-end prediction system; functioning as a trainable building block | Impossibility of recovering hair; low results accuracy after the segmentation step | SMPL (only for evaluation purposes) | SURREAL, Unite the People | Voxel IoU, Silhouette IoU, Surface error |
| [48] | 2019 | Coarse-to-fine refinement of parametric 3D model composed from a single image | Exploitation of custom build datasets | Pose ambiguities; Large errors in body mesh prediction | SMPL | Human 3.6 M, MS COCO, LSP, LSPe, MPII, MPI-INF-3DHP, Unite the People, RECON, SYN | Silhouette IoU, 2D joint error, 3D error (MAVE but with nearest neighbors) |
| [61] | 2020 | 3D human body model reconstruction from a polarized image using synchronized cameras | Providing geometric details of the surface; Obtaining more reliable depth maps | Need of a polarization cameras; Limited datasets with polarized images | SMPL | SURREAL, PHSPD | MAE, MPJPE |
| [49] | 2021 | Introduction of Generative Adversarial Networks for human mesh reconstruction | Detailed body shape; Real-time solution; Possibility for use with video data; Discriminator used for reality check | Impossibility of recovering hair and clothes; Getting faster and better results with a pre-trained generator | SMPL | LSP, LSPe, MS COCO, MPI-INF-3dHP, MoSh, SURREAL, Human 3.6 M | MPJPE |
| [50] | 2021 | 3D model reconstruction from low-resolution images | Possibility for training with all kinds of image resolutions; textured 3D model in color | Impossibility of recovering long or voluminous hair; easily affected by noise | SMPL | Human 3.6 M, MPI-INF-3DHP, LSP, LSPe, MPII, MS COCO | MPJPE, PA-MPJPE |
| [51] | 2021 | Introduction of a pose grammar for achieving better 3D human body model representation | Enforcing high-level constraints over human poses | Not specifying body shape recovering; requirement for different types of data for achieving better results | Not used | Human 3.6 M, HumanEva, HHOI | Average Euclidean Distance |
| [72] | 2022 | 3D geometry representation for monocular real-time and accurate human reconstruction | FOF for representing high-quality 3D human geometries using a 2D map aligned with images | FOF inability for representing too-thin objects | SMPL (partially) | Thuman2.0, Twindom | VSD, Chamfer distance |
| [52] | 2023 | 3D pose and shape estimation with confidence | 3D human pose and shape estimation from 2D images, while providing a measure of pose uncertainty | Not providing shape uncertainty | SMPL | MS COCO, Human 3.6 M, MPI-INF-3D, MPII, LSPe, 3DPW, 3DOH, 3DPW-OCC | MPJPE, PA-MPJPE, PVE |
| [75] | 2023 | Framework for estimating whole-body human parameters from a single image | 3D estimation on human body shape and pose; handling images with missing information | Image-based appearance-prior technique for completion coming with limitations for non-frontal facing images | SMPL-X | EHF, SSP3D | PA-V2V, PVE-T-SC, IoU |
| Research | Year | Main Focus | Assets | Constraints | Parametric Model | Dataset | Evaluation Metric |
|---|---|---|---|---|---|---|---|
| [97] | 2019 | 3D human body reconstruction from silhouettes | A supervised-learning-based approach utilizing CNNs for 3D human body recovering | Need to increase the range of acceptable poses and camera viewpoints while maintaining the same performance | SMPL | CAESAR | Mean distance |
| [99] | 2020 | Reconstruction from two points of view: frontal and lateral | Processing one body side at a time; tackling the problem of self-occlusions | Negative effect of lighting over the accuracy of the reconstructed model; custom dataset | SMPL | Custom dataset | Not specified |
| [78] | 2021 | 3D human body reconstruction from multiple images | Learning model-free implicit function for 3D human body representation relying on multi-scale features | Not optimised generalization results due to training set limitations | Not used | Articulated dataset, CAPE | VSD, Chamfer distance, IoU |
| [53] | 2022 | 3D human body mesh recovery via MMT model | Utilization of a non parametric deep-learning-based model (MMT) leveraging a Vision Transformer and applying feature-level fusion | Exploited evaluation metrics—still rough to appropriately assess the reconstruction ability of the model; slower performance than the parametric models | Not used | Human 3.6 M, HUMBI | MPJPE, PA-MPJPE, MPVE |
| [66] | 2022 | Meta-optimization technique for 3D human rendering and reconstruction | The approach—designed for scenarios where accurate initial guesses are not available | Long execution time and slow convergence | SMPL | People-Snapshot Dataset, Human3.6. | Reprojection errors, MPJPE |
| [81] | 2022 | 3D clothed human body reconstruction based on multiple views and pose | Deep-learning approach incorporating the SMPLX model and non-parametric implicit function learning | Not specified | SMPLX | WCPA | Chamfer distance |
| Research | Year | Main Focus | Assets | Constraints | Parametric Model | Dataset | Evaluation Metric |
|---|---|---|---|---|---|---|---|
| [54] | 2018 | Temporal convolutions and semi-supervised training on video for 3D pose estimation | Training with a small amount of labeled data; using the model when motion capture is challenging | Complicated because of the number of the model’s layers; not estimating body shape | Not used | Human 3.6 M, HumanEva-I | MPJPE |
| [62] | 2018 | Obtaining a textured 3D model from a monocular video of a moving person | Reconstructing 3D model with detailed hair, body, clothes, and kinematic skeleton | Limited reconstruction of self-occluded zones; less accurate results due to fast movements | SMPL | DFAUST, BUFF | VSD |
| [55] | 2019 | SMPL model optimization in the loop | Self-improving training process; possibility for training in the absence of 3D annotations | High complexity and impossibility of real-time implementations | SMPL | Human 3.6 M, MPI-INF-3DHP, LSP, LSPe, 3DPW, MPII, COCO | Mean reconstruction error, MPJPE, AUC, PCK |
| [56] | 2020 | Generating an accurate skeleton from monocular videos | Creation of a more natural human motion movement; tackling the self-occlusion problem | No body shape estimation; large effects of camera movements over the global positioning of the joints | Not used | CMU, Human 3.6 M, HumanEva | MPJPE |
| [57] | 2020 | System functionality for real-time garment overlay | Possibility of real-time reconstruction; framework for garment overlay | Impossibility of recovering hair and clothes; limited body mesh projection optimization | SMPL | MS COCO, Human 3.6 M | Not specified |
| [50] | 2021 | 3D human model reconstruction from low-resolution videos | Applicable to low-resolution videos; better accuracy compared to the case with an image as input | Impossibility of recovering long or voluminous hair; limited textured 3D model in color; slower implementation | SMPL | 3DPW, Human36M, InstaVariety, MPI-INF-3DHP | MPJPE, PA-MPJPE, ACC. |
| [59] | 2022 | 3D pose estimation from monocular RGB videos | Exploiting a generic transformer module | Performance degradation in case of fast human motion or long-term occlusions | SMPL | AMASS, 3DPW, MPI-INF-3DHP, MuPoTS-3D, AIST | MPJPE, PA-MPJPE, MPVE |
| [85] | 2022 | A methodology for modelling animatable human avatars with dynamic garments | Recreating appearance and motion by leveraging neural scene representation while explicitly accounting for the motion hierarchy of clothes | Method performance depending on pose variance of the training data; assumption of accurate body pose estimation for the training images | SMPL | Dynacap, DeepCap, ZJU-MoCap | PSNR, SSIM |
| [67] | 2023 | A methodology for human geometry and realistic textures recovering from a monocular RGB video | SMPL+D mesh optimization and utilization of a multi-resolution texture representation using RGB images, binary silhouettes, and sparse 2D keypoints | Not specified | SMPL | ZJU-MoCap, People-Snapshot, Self-Recon | Chamfer distance, VSD |
| Research | Year | Main Focus | Assets | Constraints | Parametric Model | Dataset | Evaluation Metric |
|---|---|---|---|---|---|---|---|
| [63] | 2018 | Textured 3D human body reconstruction from a single RGB image and co-learning with Microsoft Kinect depth images | Considering depth information during the training process | Partially handling non-rigid deformations | Not used (not used for reconstruction, but SMPL dataset is used) | MPI-INF-3DHP, DFAUST, the Articulated dataset | IoU |
| [65] | 2018 | 3D human pose estimation from depth maps using a Deep Learning approach | Possibility for using data from both single and multiple viewpoints; no demands on pixel-wise segmentation and temporal information | No body shape estimation; additional noise when using images in the wild | Not used | ITOP and UBC 3V Hard-pose | MPJPE, mAP, AUC |
| [58] | 2020 | 3D human body pose and shape estimation from a single depth image | Possibility of using the model with real depth data achieved by the incorporated weakly supervised mechanism | Complicated with several functionality stages | SMPL (in the training process) | SURREAL, Human 3.6 M, DFAUST | MAVE |
| [64] | 2020 | Creating 3D human body representation from a set of Peeled Depth and RGB maps | Tackling severe self-occlusions; handling images wide assortment of shapes, poses, and textures | Not providing full body shape | Not used | BUFF, MonoPerfCap, Custom dataset | Chamfer distance |
| [92] | 2023 | 3D reconstruction from a single-view RGB-D image through creating multiple image-like planes (OPlanes) | Exploitation of spatial correlations between adjacent locations within a plane, appropriate particularly for occluded or partially visible humans | Not specified | Not used | S3D | IoU, Chamfer distance, Normal Consistency |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Petkova, R.; Bozhilov, I.; Nikolova, D.; Vladimirov, I.; Manolova, A. Taxonomy and Survey of Current 3D Photorealistic Human Body Modelling and Reconstruction Techniques for Holographic-Type Communication. Electronics 2023, 12, 4705. https://doi.org/10.3390/electronics12224705
Petkova R, Bozhilov I, Nikolova D, Vladimirov I, Manolova A. Taxonomy and Survey of Current 3D Photorealistic Human Body Modelling and Reconstruction Techniques for Holographic-Type Communication. Electronics. 2023; 12(22):4705. https://doi.org/10.3390/electronics12224705
Chicago/Turabian StylePetkova, Radostina, Ivaylo Bozhilov, Desislava Nikolova, Ivaylo Vladimirov, and Agata Manolova. 2023. "Taxonomy and Survey of Current 3D Photorealistic Human Body Modelling and Reconstruction Techniques for Holographic-Type Communication" Electronics 12, no. 22: 4705. https://doi.org/10.3390/electronics12224705
APA StylePetkova, R., Bozhilov, I., Nikolova, D., Vladimirov, I., & Manolova, A. (2023). Taxonomy and Survey of Current 3D Photorealistic Human Body Modelling and Reconstruction Techniques for Holographic-Type Communication. Electronics, 12(22), 4705. https://doi.org/10.3390/electronics12224705