Abstract
Recommender systems are used as effective information-filtering techniques to automatically predict and identify sets of interesting items for users based on their preferences. Recently, there have been increasing efforts to use sentiment analysis of user reviews to improve the recommendations of recommender systems. Previous studies show the advantage of integrating sentiment analysis with recommender systems to enhance the quality of recommendations and user experience. However, limited research has been focused on recommender systems for Arabic content. This study, therefore, sets out to improve Arabic recommendation systems and investigate the impact of using sentiment analysis of user reviews on the quality of recommendations. We propose two collaborative filtering recommender systems for Arabic content: the first depends on users’ ratings, and the second uses sentiment analysis of users’ reviews to enhance the recommendations. These proposed models were tested using the Large-Scale Arabic Book Reviews dataset. Our results show that, when the user review sentiment analysis is combined with recommender systems, the quality of the recommendations is improved. The best model was the singular value decomposition (SVD) with the Arabic BERT–mini model, which yielded minimum errors in terms of RMSE and MAE values and outperformed the performance of other previous studies in the literature.
1. Introduction
Recommender systems are filtering systems designed to produce helpful recommendations about items or products based on a user’s interests. Recommender systems help users find items in which they are interested, and they can help companies to boost their sales and maintain user satisfaction [1,2,3]. People can face a problem referred to as “choice overload”, which occurs when someone has difficulty making decisions due to there being too many options. Recently, various filtering approaches have been used in recommender systems, including collaborative filtering, content-based filtering, and hybrid filtering. Collaborative filtering is one of these techniques that is most frequently used [4]. Collaborative filtering delivers its recommendations based on the user’s “neighbors”, or those with a similar history of preferences; it uses two main approaches: memory- and model-based methods. Collaborative filtering faces “cold start” problems, which occur when there is not enough data for a new item or new user. Content-based filtering requires knowledge of both items and users so that it can recommend items that are similar to those that a user has liked previously. Hybrid filtering is a combination of collaborative and content-based filtering. Researchers have recently been paying more attention to recommender systems; however, most studies have concentrated on systems designed for languages other than Arabic. Although Arabic is one of the most commonly spoken languages, with over a billion speakers worldwide, research on recommender systems for Arabic content is limited [5].
People frequently ask for advice from others when making decisions. In most cases, a user’s rating for an item or service will reveal whether they were satisfied or dissatisfied with a specific feature. Therefore, while selecting whether to buy a product, read a book, or go to a restaurant, online reviews are quite helpful. Reviews have become increasingly important and are used by both businesses and individuals for decision-making. Sentiment analysis is typically employed to determine users’ opinions about certain topics. Sentiment analysis, also referred to as opinion mining, is a text analysis technique that uses natural language processing, machine learning, and artificial intelligence to automatically identify, extract, and detect sentiments or opinions (positive, negative, or neutral) [6]. It can be used to help gather insights from unstructured text from various sources, such as emails, posts, reviews, webchats, and social media channels. Recently, sentiment analysis has been incorporated with recommender systems to improve the quality of recommendations and user satisfaction. However, few studies focus on integrating sentiment analysis with recommender systems for Arabic content [3].
A book recommender system recommends books to readers that are similar to those in which the readers have previously been interested. Book recommendation systems are used by websites that provide e-books through services such as Google Play Books, Goodreads, and Open Library. This paper presents an examination of current collaborative recommender systems using the Large-Scale Arabic Book Reviews (LABR) dataset, which is considered to be the largest Arabic sentiment analysis dataset for books. This study fills a gap in the literature by investigating the use of recommender systems for Arabic content. Since few studies have been conducted specifically on Arabic content, we propose a new efficient approach for Arabic content that uses collaborative filtering algorithms and sentiment analysis models of user reviews to overcome present challenges and increase the accessibility of Arabic content. For sentiment analysis of user reviews, we investigate the use of three sentiment analysis approaches: the Mazajak tool, an online Arabic sentiment analyzer, and two pre-trained models: the Arabic Bidirectional Encoder Representations from Transformers (BERT)–mini model and Arabic bidirectional encoder representations from transformers (AraBERT) model [7,8,9]. These transformer-based models demonstrated superior results in sentiment analysis, improved sentiment analysis performance, and produced state-of-the-art results for various NLP tasks [9,10]. The main objectives of this study are enhancing the performance of recommendation systems in the Arabic language, contributing to quick decision-making and quickly obtaining the favorite item for the user. The main contributions of our research are the following:
- Proposed a new approach that combines collaborative recommender system algorithms with different sentiment analysis models and compares their performance;
- Applied Arabic BERT–mini model, AraBERT model, and Mazajak tool for Arabic sentiment analysis of user reviews;
- Investigated the impact of using sentiment analysis models with a collaborative recommender algorithm on recommendation quality;
- Improved the performance of Arabic recommendation systems.
2. Related Works
As noted in the previous section, there has been much research in the field of recommender systems for non-Arabic content. There are now many recommender systems available for English material; however, there is limited research on Arabic-based recommender systems. The present authors [3] surveyed the literature in the field of recommender systems and found that few studies specifically addressed Arabic material, and some of these studies integrated the recommender system with sentiment analysis to increase the accuracy of recommendations. In addition, Sundermann et al. [11] surveyed the current state of recommender systems focusing on both contextual information and opinion mining and they emphasized the importance of integrating users’ reviews opinion mining in recommendation systems, especially when combined with contextual information. Additionally, multiple studies, such as [12,13], have surveyed the current state of the recommender systems field including models, techniques, and applications. In this section, we discuss some related studies in the field of recommender systems.
Srifi et al. [14] investigated the use of recommender systems with Arabic content. They used five recent recommendation systems (ALFM, A3NCF, PARL, CARL, and CARP) to extract semantic contextual data from reviews for rating predictions. Additionally, they translated four distinct datasets from Amazon’s English datasets into Arabic (based on the Googletrans library in Python): these were the Musical Instruments dataset, Patio Lawn and Garden dataset, the Automotive dataset, and the Instant Video dataset. Subsequently, they preprocessed datasets. Then, they compared the accuracy of multiple recommender systems on Arabic and English datasets and found that these systems demonstrated high accuracy. The accuracy of recommender systems with Arabic content was found to be comparable to those used with English content.
Harrag et al. [15] used a collaborative recommender system with sentiment analysis of Arabic reviews to solve the issue of data sparsity. They used text mining and natural language processing techniques to predict product ratings based on user reviews. They used the Opinion Corpus Arabic (OCA) dataset, which includes 500 film reviews, to evaluate the model. The sentiment analysis used the Arabic review dataset as input, and the results were then used as input for the recommender system. During the sentiment analysis phase, they used a support vector machine (SVM) model and a term frequency–inverse document frequency (TF–IDF) matrix. In the recommendation phase, they employed singular value decomposition (SVD). Their model achieved an accuracy of 85%.
Sallam et al. [16] used two methods: item-based collaborative filtering and singular value decomposition-based collaborative filtering. In item-based collaborative filtering, the degree of similarity between the target item and any other item is determined, and the items that have the greatest degree of similarity are subsequently recommended. The variability and scalability issues raised by collaborative filtering were addressed by a single-value analysis-based technique, which also enhances the effectiveness of item-based collaborative filtering. The LABR dataset, which contains over 63,000 book reviews, each with a star rating of 1 to 5, was used to evaluate the suggested method based on the two most popular metrics employed in collaborative filtering: MAE and RMSE. Their methods achieved good performance, with a low RMSE value of 1.019 and an MAE equal to 0.808.
Kurmashov et al. [17] proposed a book recommendation web service using collaborative filtering that generates high-speed recommendations for users based on their preferences, which they provide when registering. The dataset contains about 25,000 popular books, focusing on the Russian language. They used neighborhood-based algorithms to calculate the similarity between two items. The system was able to achieve an 89% recommendation speed and a 77% recommendation quality.
Kommineni et al. [18] introduced new techniques to build book recommendations that help recommend appropriate books to a reader. They applied user-based collaborative filtering and applied it to the Goodreads book dataset from Kaggle. They used a k-nearest neighbors (kNN) algorithm and several similarity methods, including the Pearson correlation coefficient (PCC), constrained PCC (CPCC), Jaccard, and cosine, to calculate a similarity matrix for each user and compare these methods. They showed that the CPCC measure was the best for computing similarities between users.
Gong et al. [19] noted that researchers face two main problems when using only memory-based collaborative filtering: sparsity and scalability. Model-based collaborative filtering has been proposed to solve these problems, but this approach tends to limit the range of users. They combined two collaborative filtering approaches (memory-based and model-based) in one recommender system. First, they employed memory-based collaborative filtering to fill in the vacant ratings of the user–item matrix. They then used item-based collaborative filtering to extract the nearest neighbors of every item. The method was applied to the MovieLens dataset, from which they made random selections (100,000 ratings of 1680 movies by 1000 users, where every user contributed at least 20 ratings). Subsequently, they compared the proposed method with traditional collaborative filtering by applying the MAE metric. The results showed that their proposed collaborative filtering showed better performance than traditional collaborative filtering in terms of MAE scores.
Parvatikar and Joshi [20] proposed a recommendation system based on collaboration-based filtering and the mining of association rules. Collaborative filtering was used to find similarities between items that would help the system recommend other items, and association mining was used to fill empty categories when necessary. Collaborative filtering uses the item-based algorithm. The modified cosine vector similarity method has also been used in this method to find the similarity among items, where each user’s rating is considered. The proposed solutions showed better performance and solved data sparsity and scalability challenges.
Dubey et al. [21] proposed a method consisting of two modules. The first module analyzes reviews and determines overall sentiments about products using a logistic regression algorithm. The second module applies a collaborative filtering (item-based) algorithm for recommendations, with the sentiment score as an input. The sentiment analysis phase is divided into four significant phases: data collection, preprocessing, construction of a bag of words, and finally, frequency measurement. They used an Internet Movie Database (IMDb) review dataset containing 25,000 reviews rated “1” for positive and “0” for negative and the MovieLens 100 k dataset that consists of 100,000 ratings of 1700 movies by 1000 users. In the frequency measurement stage, the TF–IDF model was used. The model was tested on logistic regression, and the training data yielded an accuracy of 92%. The model was used to predict the positive sentiment probabilities of the reviews of the items from the MovieLens dataset. Finally, they found that when the recommender system was combined with sentiment analysis, the quality of the recommender system improved.
D’Addio and Manzato [22] proposed a collaborative recommender that uses users’ reviews to produce recommendations. They used the MovieLens dataset, and the Stanford CoreNLP tools were applied to produce a sentiment analysis of these reviews, producing scores to represent the overall feeling (positive, neutral, or negative). The Stanford CoreNLP sentiment analysis tool uses a deep-learning model to provide sentiment analysis at the sentence level. In the recommendation stage, they used a kNN algorithm. The key benefit of this method is that it may suggest items to users that are similar to ones they have previously liked. This similarity is driven by public opinion about the quality of various products determined using positive reviews. They used the precision-at10 (Prec@10) and mean average precision (MAP) metrics to evaluate the model.
Miao and Lang [23] proposed a collaborative recommendation system based on sentiment analysis. This system uses enhanced logistic regression to create sentiment ratings for different users in the Chinese language. In the recommender system, they used an item-based algorithm. In the evaluation, the MAE was used. They then compared this system (which includes sentiment analysis) with a traditional recommender (without sentiment analysis) that had been used in another study. Their proposed system produced good results and enhanced the quality of the recommendations.
Kumar et al. [24] proposed a hybrid recommendation system for films that took advantage of collaborative filtering and content-based filtering (user–item matrix), along with sentiment analysis of tweets from microblogging sites. They used two types of databases. One was a user-rated movie database featuring ratings for related movies, while the other was user tweets from Twitter (MovieLens 100 k, MovieLens 20 M, IMDb, and MovieTweetings). They used the MovieTweetings database for sentiment analysis. During the tweet preprocessing step, they relied on filtering out useless data and unhelpful elements of the tweets, such as stop words, punctuation, web links, and repetitive phrases, which do not provide much value in sentiment analysis. For the sentiment analysis, they used the Valence Aware Dictionary and sEntiment Reasoner (VADER) sentiment analysis system. In the movie recommendation rating stage, they used a kNN algorithm and a user–item matrix. This matrix was used to predict a user’s rating of a particular item by analyzing the ratings of other users in their neighborhood. The proposed model produced more accurate recommendations than the other models.
All of the studies reviewed here support collaborative filtering recommender systems, and the most popular dataset was MovieLens. These studies applied several algorithms, the most frequent of which was kNN. We also note that some of the studies used sentiment analysis to improve the quality of their recommendation systems. Most of these studies aim to solve numerous difficulties such as scalability, cold start problem, and data sparsity. Moreover, there are few studies that support recommender systems for Arabic content. Table 1 presents a summary of these studies.

Table 1.
Summary of related studies.
This paper aimed to address the gap in the literature by proposing a new approach that uses collaborative filtering algorithms and sentiment analysis of user reviews to improve the recommendation process. Since Arabic BERT–mini model and the AraBERT model have been successfully used in sentiment analysis, we will use them in the sentiment analysis phase to analyze users’ reviews.
3. Dataset and Methodology
3.1. Dataset
We used the largest Arabic sentiment analysis dataset for books, the LABR dataset, which consists of over 63,000 reviews submitted by 16,486 users for 2131 different books [25]. The data were extracted from the Goodreads website. After non-Arabic reviews were filtered out and several preprocessing procedures were used to remove HyperText Markup Language (HTML) elements and other unnecessary data, the total dataset included 63,257 Arabic reviews [25]. The dataset includes the following elements:
- Rating: user ratings on a scale of one to five;
- Review ID: the goodreads.com review ID;
- User ID: the goodreads.com user ID;
- Book ID: the goodreads.com book ID;
- Review: the text of the review.
Table 2 shows some statistics relating to the LABR dataset [25], and Table 3 shows a subset of the LABR dataset.
Table 2.
LABR dataset statistics.
Table 3.
Subset of the LABR dataset.
3.2. Data Preprocessing and Cleaning
Data preprocessing is an essential step in building the model. We performed text preprocessing and data normalization. For example, Arabic letters were normalized by replacing [إأآاٱ] with “ا”, “ى” with “ي”, “ة” with “ه”, and “گ” with “ك”. Repeated letters were also removed. Next, links such as www.* and https://* were removed, along with all punctuation marks and diacritics. Reviews were then divided into three categories: positive, negative, and neutral. Ratings of 4 or 5 stars were categorized as positive, 3 star ratings were categorized as neutral, and 1 or 2 star ratings were categorized as negative.
3.3. Proposed Method
We proposed a collaborative filtering recommender system for Arabic content. We used two different methods to build the model and then compared the results of the two methods, as shown in Figure 1. In the first method, we used users’ ratings from the LABR dataset as input to collaborative filtering (memory- and model-based) algorithms that produce recommendations. In the second method, we used users’ reviews from the LABR dataset as input to opinion mining (sentiment analysis) models and we integrated the results of opinion mining with users’ ratings from the LABR dataset as input to (memory- and model-based) collaborative filtering algorithms to produce recommendations. We then evaluated and compared the performance of the two methods.
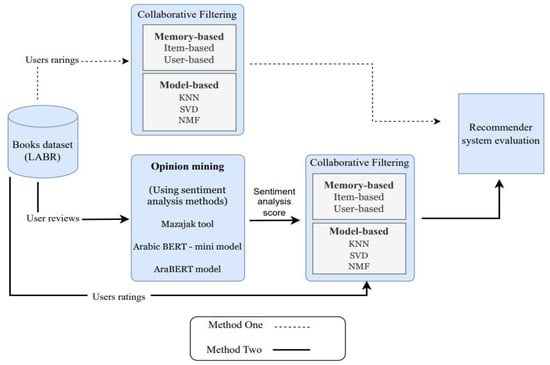
Figure 1.
Our proposed solution.
3.3.1. Building a Collaborative Recommender System
Collaborative filtering is a technique for filtering data using user interactions and data that the system has already collected from other users. It is a method of developing automatic predictions (filtering) about a user’s interests based on the preferences or tastes of many users [4]. For this step, we used model- and memory-based techniques for collaborative filtering, and we applied several different algorithms to determine the best one.
We used two memory-based collaborative filtering approaches: user–user collaborative filtering and item–item collaborative filtering. We experimented with different k values (k = number of nearest neighbors) from 25 to 150; k was changed in increments of 25 for each experiment. For user–user collaborative filtering, we calculated the similarity of the active user to all other users. To make predictions for the active user, we then ranked and filtered the top N users; this meant recommending a small set of N items to each user from a large collection of items. This approach is usually quite effective, but it requires a significant amount of time and resources. Item–item collaborative filtering is similar to user–user collaborative filtering; in this approach, we computed item similarity and recommended similar items. To calculate user–user and item–item similarity, we used three similarity metrics: cosine similarity, Euclidean distance, and Manhattan distance [26]. We then compared the models’ performance using each similarity metric.
For model-based collaborative filtering, we used dimensionality reduction to improve the model’s capabilities and accuracy. We compressed the user–item matrix into a low-dimensional matrix. To do this, we used algorithms such as SVD, a low-rank factorization method, and kNN. We tuned kNN, SVD, and non-negative matrix factorization (NMF) using cross-validation with a grid search to determine the optimal values for a given model, resulting in the lowest possible RMSE and MAE values [27,28,29]. We used three similarity metrics on these algorithms: mean squared distance similarity, cosine distance similarity, and Pearson baseline distance similarity. We then used these similarity metrics to evaluate and compare the models.
3.3.2. Building Sentiment Analysis Models
To test the value of applying sentiment analysis of users’ reviews in the recommendation process, we integrated memory-based and model-based collaborative filtering recommender systems that we built in the previous phase with three sentiment analysis approaches: the Mazajak tool, an online Arabic sentiment analyzer, and two pre-trained models: Arabic BERT–mini model and AraBERT [7,8]. As noted, our models were trained and tested using the LABR dataset.
The Mazajak Application Programming Interface (API) is the first online Arabic sentiment analysis tool [30,31]. It uses a convolutional neural network and a long short-term memory recurrent neural network architecture. The Mazajak model was evaluated on three different datasets: the SemEval-2017 Task 4—a benchmark dataset [32], the Arabic Sentiment Tweets Dataset (ASTD) benchmark dataset [33], and an Arabic Speech-Act and Sentiment Corpus of Tweets (ArSAS), the largest Arabic sentiment analysis dataset. We used the Mazajak tool for the sentiment analysis phase. Table 4 shows the results of the Mazajak tool using average recall and accuracy metrics. is the macro-average F-score for the positive and negative categories [30].
Table 4.
Performance result of the Mazajak tool.
We also conducted a sentiment analysis using the Arabic BERT–mini model. The Arabic BERT–mini model [7,34], was trained on 8.2 billion words extracted from the Arabic version of the Open Super-Large Crawled ALMAnaCH Corpus (OSCAR) [35], a recent dump of Arabic Wikipedia [36], and other Arabic resources, for a total of 95 GB of text. We trained the model on four datasets: SS2030 [37], 100 k reviews [38], ArSAS [39], and the Arabic Sentiment Twitter Corpus. The fourth dataset led to the best performance. Thus, we used this public dataset to tune the model [40]. This dataset contains 58,000 Arabic tweets (47 k training, 11 k test) categorized as positive or negative. After this training, the model was ready to classify the LABR dataset. Figure 2 shows the receiver operating characteristic (ROC) curve for the Arabic BERT–mini sentiment analysis model. We used the Python programming language for implementing our models and Google Colaboratory (also known as Colab) platform.
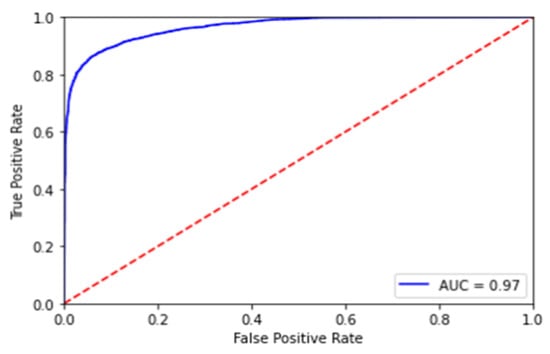
Figure 2.
ROC curve of the Arabic BERT–mini model.
The third sentiment analysis approach uses AraBERT. This is a pre-trained Arabic-language model based on Google’s BERT architecture. AraBERT uses the BERT base configuration. The AraBERT model was trained on 8.6 billion words (95 GB) of unshuffled, filtered text extracted from OSCAR [35], the Arabic Wikipedia dump from 1 September 2020 [41], the Arabic Corpus (1.5 B words) [42], the OSIAN Corpus [43], and Assafir news articles. We also used the Arabic Sentiment Twitter Corpus to tune the AraBERT model. Training the AraBERT model on the Arabic Sentiment Twitter Corpus resulted in better performance than that of the Arabic BERT–mini model.
3.3.3. Integrating Sentiment Analysis into the Recommender System
To integrate the sentiment analysis models into the recommender system, we used the average scores of user ratings and sentiment analysis of user reviews to produce a new rating. This score was calculated using:
Average score = ((LABR_rating + Sentiment_rating))/((Scale of LABR rating + Scale of sentiment rating)) × Rating_scale
Table 5 shows an example of how our model produces a new rating from previous user ratings and the sentiment analysis score. When we calculated the new rating for the first case in this table, (4 + 1)/(5 + 3) × 5 = 3.1, where 4 = previous user rating, 1 = sentiment score, 5 = rating scale (scale of LABR rating), and 3 = sentiment scale (scale of sentiment rating).
Table 5.
Examples of how the new rating depends on the previous user rating and the sentiment analysis score.
4. Results and Discussion
4.1. Performance Measures
Our proposed collaborative recommender systems were evaluated using rating prediction indicators that measure how near a recommender’s estimated ratings are to actual user ratings. Metrics commonly used to evaluate the accuracy of predicted ratings are the RMSE and MAE [44]. The advantage of using RMSE over MAE is that it penalizes the term more when the error is high.
To evaluate the sentiment analysis models, we considered the most important performance measures used for the classification models: accuracy, precision, recall, and F1 [4].
4.2. Results
In this section, we discuss the results of our experiments. First, we show the results of memory-based collaborative filtering. We then present the results of model-based collaborative filtering. We then obtained the results of combining the recommendation models with the sentiment analysis models.
4.2.1. Memory-Based Model Results
For memory-based collaborative filtering, we calculated the user–user and item–item similarity using three metrics: cosine similarity, Euclidean distance, and Manhattan distance. Table 6 shows the results for the memory-based model.
Table 6.
Memory-based model results.
Our models performed best on cosine similarity; this is because cosine similarity is frequently used for sparse matrices and is calculated using only the dot product and magnitude of each vector. Therefore, it is affected only by the terms the two vectors have in common. Our models also performed better using the item–item algorithm than the user–user algorithm; the item–item algorithm is also faster than the user–user algorithm. In addition, user profiles change frequently, and the entire model must be recomputed to account for these changes. The average rating for a given item does not change frequently, leading to more stable rating distributions in the model, so it does not have to be rebuilt as often.
4.2.2. Model-Based Model Results
For model-based collaborative filtering, we calculated the similarity using three metrics: mean squared distance, cosine distance, and Pearson baseline distance. We tuned these models using a grid search. Table 7 shows the results of the model-based system.
Table 7.
Model-based models results.
The SVD model performed best on mean squared distance and cosine similarity, as shown in Table 7. The SVD algorithm works well with recommender systems and solves several challenges such as scalability, the cold start problem, and sparsity [4]. The computational cost of the five models is shown in Table 8.
Table 8.
Our models’ computational cost in seconds.
4.2.3. Recommendation Models with Sentiment Analysis (Mazajak Tool)
We combined the recommendation models with the Mazajak tool. Table 9 shows the combination of the memory-based (item- and user-based) algorithms with the Mazajak sentiment analysis score.
Table 9.
Memory-based algorithm with the Mazajak tool.
The Mazajak-integrated user–user model obtained the best results with Euclidean distance similarity and k = 150. For the item–item model, the best results were obtained for cosine similarity with k = 25. Table 10 shows the results of integrating the model-based (machine learning algorithm) system with the Mazajak tool. Here, the RMSE is lower than in previous methods. The best integrated results for this model were obtained with the SVD algorithm and mean squared distance.
Table 10.
Model-based algorithm with Mazajak.
4.2.4. Recommendation Models with Sentiment Analysis (Arabic BERT–Mini Model)
Table 11 shows the results of integrating the memory-based model with the Arabic BERT–mini model. The best results for the item–item model combined with the Arabic BERT–mini model were obtained for cosine similarity.
Table 11.
Memory-based algorithm with the Arabic BERT–mini model.
Table 12 shows the results of the model-based (machine learning algorithm) system combined with the Arabic BERT–mini model. Here, we noticed significant reductions in RMSE and MAE, indicating that our recommender system is more effective when it is combined with sentiment analysis. The best result for this integration was obtained using the SVD algorithm and mean squared distance.
Table 12.
Model-based algorithm with BERT.
4.2.5. Recommendation Models with Sentiment Analysis (AraBERT Model)
Table 13 shows the results of the memory-based model combined with the AraBERT model. For this integration, the best results were obtained for the item–item algorithm with cosine similarity.
Table 13.
Memory-based algorithm with AraBERT.
Table 14 shows the results of the model-based (machine learning algorithm) system combined with the AraBERT model. The best results for this integration were obtained using the SVD algorithm. For this integration, SVD with AraBERT performed better than SVD with the Mazajak tool.
Table 14.
Model-based algorithm with AraBERT.
4.3. Discussion
The performances of five recommendation models were evaluated before and after they were combined with sentiment analysis models. During the evaluation phase, we compared five models without sentiment analysis and then compared 15 models with sentiment analysis (five models with Mazajak, five models with the Arabic BERT–mini model, and five models with AraBERT). Of the compared models, the best performance was obtained by the SVD algorithm combined with the Arabic BERT–mini model, as shown in Table 15. These results demonstrate the usefulness of integrating sentiment analysis of user reviews into a recommender system to produce better recommendations. The Arabic BERT–mini model leads to better performance than AraBERT when combined with recommender system models because the BERT model was trained on a larger dataset than AraBERT. Our proposed method considers two factors: user ratings and sentiment analysis of user reviews, which leads to better recommendations by avoiding rating bias, a risk when the rating is based on a single factor.
Table 15.
Best performing recommendation system models.
Previous works have used different datasets, so our discussion focuses on one particular previous study using the LABR dataset. Our item–item and SVD results for recommender system models are similar to those of Sallam et al. [16], who achieved an RMSE of 1.19 with an item–item algorithm, compared to our RMSE of 1.13. For SVD models, they achieved an RMSE of 1.019; our RMSE for SVD models was 1.015. We used several different algorithms from those used in [16], and we combined our algorithms with sentiment analysis of user reviews, leading to an even lower RMSE of 0.58. Table 16 compares our results to those of Sallam et al. [16].
Table 16.
Comparison of our proposed methods with another study from the literature.
5. Conclusions
The aim of our study is to examine the impact of using user reviews sentiment analysis to improve the quality of recommendations. We focus on Arabic recommender systems since only a few studies have focused on Arabic content. We proposed an Arabic-language collaborative filtering recommender system that uses sentiment analysis of user reviews to produce better recommendations. We tested five different recommender system algorithms: item–item, user–user, kNN, SVD, and NMF. For sentiment analysis of user reviews, we used the Mazajak tool, the Arabic BERT–mini model, and AraBERT. We then developed 15 models by integrating each recommender system with each of the three sentiment analysis models. The best performance was obtained when combining the recommender system with sentiment analysis of user reviews using the SVD technique and the Arabic BERT–mini model, which achieves an improvement over other previous studies in the literature. The results of this study confirmed that using user reviews sentiment analysis enhances the quality of recommender systems, improves performance, and helps users to make better decisions. In future work, we plan to apply our integrated recommender system with sentiment analysis to a new Arabic dataset, taking into account users’ experiences of recommender systems.
Author Contributions
Conceptualization, A.A.-A. and N.A.; methodology, A.A.-A. and N.A.; software, N.A.; validation, A.A.-A. and N.A.; formal analysis, A.A.-A. and N.A.; investigation, A.A.-A. and N.A.; data curation, A.A.-A. and N.A.; writing—original draft preparation, N.A.; writing—review and editing, A.A.-A.; visualization, A.A.-A. and N.A.; supervision, A.A.-A.; project administration, A.A.-A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Not applicable.
Acknowledgments
This research project was supported by a grant from the “Research Center of the Female Scientific and Medical Colleges”, Deanship of Scientific Research, King Saud University.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Fleder, D.M.; Hosanagar, K. Recommender Systems and Their Impact on Sales Diversity. In Proceedings of the 8th ACM Conference on Electronic Commerce, San Diego, CA, USA, 11 June 2007; ACM: San Diego, CA, USA, 2007; pp. 192–199. [Google Scholar]
- Chen, H.; Jung, H.; Suhm, A. Impact of Recommender Systems on Consumers’ Purchase Intention. Available online: https://www.munich-business-school.de/insights/en/2021/impact-of-recommender-systems-on-consumers-purchase-intention/ (accessed on 27 May 2023).
- Al-Ajlan, A.; AlShareef, N. A Survey on Recommender System for Arabic Content. In Proceedings of the 2022 5th International Conference on Computing and Informatics (ICCI), New Cairo, Egypt, 9 March 2022; IEEE: New Cairo, Egypt, 2022; pp. 316–320. [Google Scholar]
- Aggarwal, C.C. Recommender Systems; Springer International Publishing: Cham, Germany, 2016; ISBN 978-3-319-29657-9. [Google Scholar]
- Al-Kabi, M.N.; Abdulla, N.A.; Al-Ayyoub, M. An Analytical Study of Arabic Sentiments: Maktoob Case Study. In Proceedings of the 8th International Conference for Internet Technology and Secured Transactions (ICITST-2013), London, UK, 9–12 December 2013; IEEE: London, UK, 2013; pp. 89–94. [Google Scholar]
- Mouthami, K.; Devi, K.N.; Bhaskaran, V.M. Sentiment Analysis and Classification Based on Textual Reviews. In Proceedings of the 2013 International Conference on Information Communication and Embedded Systems (ICICES), Chennai, India, 21–22 February 2013; IEEE: Chennai, India, 2013; pp. 271–276. [Google Scholar]
- Safaya, A. Alisafaya/Arabic-BERT: Arabic Edition of BERT Pretrained Language Models. Available online: https://github.com/alisafaya/Arabic-BERT (accessed on 28 May 2023).
- Antoun, W.; Baly, F. Aub-Mind/Arabert: Pre-Trained Transformers for the Arabic Language Understanding and Generation (Arabic BERT, Arabic GPT2, Arabic Electra). Available online: https://github.com/aub-mind/arabert (accessed on 28 May 2023).
- Chouikhi, H.; Chniter, H.; Jarray, F. Arabic Sentiment Analysis Using BERT Model. In Advances in Computational Collective Intelligence; Wojtkiewicz, K., Treur, J., Pimenidis, E., Maleszka, M., Eds.; Communications in Computer and Information Science; Springer International Publishing: Cham, Germany, 2021; Volume 1463, pp. 621–632. ISBN 978-3-030-88112-2. [Google Scholar]
- Mohamed, O.; Kassem, A.M.; Ashraf, A.; Jamal, S.; Mohamed, E.H. An Ensemble Transformer-Based Model for Arabic Sentiment Analysis. Soc. Netw. Anal. Min. 2022, 13, 11. [Google Scholar] [CrossRef]
- Sundermann, C.; Domingues, M.; Sinoara, R.; Marcacini, R.; Rezende, S. Using Opinion Mining in Context-Aware Recommender Systems: A Systematic Review. Information 2019, 10, 42. [Google Scholar] [CrossRef]
- Duraisamy, P.; Yuvaraj, S.; Natarajan, Y.; Niranjani, V. An Overview of Different Types of Recommendations Systems—A Survey. In Proceedings of the 2023 4th International Conference on Innovative Trends in Information Technology (ICITIIT), Kottayam, India, 11–12 February 2023; IEEE: Kottayam, India, 2023; pp. 1–5. [Google Scholar]
- Ko, H.; Lee, S.; Park, Y.; Choi, A. A Survey of Recommendation Systems: Recommendation Models, Techniques, and Application Fields. Electronics 2022, 11, 141. [Google Scholar] [CrossRef]
- Srifi, M.; Oussous, A.; Ait Lahcen, A.; Mouline, S. Evaluation of Recent Advances in Recommender Systems on Arabic Content. J. Big Data 2021, 8, 35. [Google Scholar] [CrossRef]
- Harrag, F.; Al-Salman, A.S.; Alquahtani, A. Arabic Opinion Mining Using a Hybrid Recommender System Approach. arXiv 2020, arXiv:2009.07397. [Google Scholar] [CrossRef]
- Sallam, R.; Hussein, M.; Mousa, H. An Enhanced Collaborative Filtering-Based Approach for Recommender Systems. Int. J. Comput. Appl. 2020, 176, 9–15. [Google Scholar] [CrossRef]
- Kurmashov, N.; Latuta, K.; Nussipbekov, A. Online Book Recommendation System. In Proceedings of the 2015 Twelve International Conference on Electronics Computer and Computation (ICECCO), Almaty, Kazakhstan, 27–30 September 2015; IEEE: Almaty, Kazakhstan, 2015; pp. 1–4. [Google Scholar]
- Kommineni, M.; Alekhya, P.; Vyshnavi, T.M.; Aparna, V.; Swetha, K.; Mounika, V. Machine Learning Based Efficient Recommendation System for Book Selection Using User Based Collaborative Filtering Algorithm. In Proceedings of the 2020 Fourth International Conference on Inventive Systems and Control (ICISC), Coimbatore, India, 8–10 January 2020; IEEE: Coimbatore, India, 2020; pp. 66–71. [Google Scholar]
- Gong, S.; Ye, H.; Tan, H. Combining Memory-Based and Model-Based Collaborative Filtering in Recommender System. In Proceedings of the 2009 Pacific-Asia Conference on Circuits, Communications and Systems, Chengdu, China, 16–17 May 2009; IEEE: Chengdu, China, 2009; pp. 690–693. [Google Scholar]
- Parvatikar, S.; Joshi, B. Online Book Recommendation System by Using Collaborative Filtering and Association Mining. In Proceedings of the 2015 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Madurai, India, 10–12 December 2015; IEEE: Madurai, India, 2015; pp. 1–4. [Google Scholar]
- Dubey, A.; Gupta, A.; Raturi, N.; Saxena, P. Item-Based Collaborative Filtering Using Sentiment Analysis of User Reviews. In Applications of Computing and Communication Technologies; Deka, G.C., Kaiwartya, O., Vashisth, P., Rathee, P., Eds.; Communications in Computer and Information Science; Springer: Singapore, 2018; Volume 899, pp. 77–87. ISBN 9789811320347. [Google Scholar]
- D’Addio, R.M.; Manzato, M.G. A Collaborative Filtering Approach Based on User’s Reviews. In Proceedings of the 2014 Brazilian Conference on Intelligent Systems, Sao Paulo, Brazil, 18–22 October 2014; IEEE: Sao Paulo, Brazil, 2014; pp. 204–209. [Google Scholar]
- Miao, D.; Lang, F. A Recommendation System Based on Text Mining. In Proceedings of the 2017 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), Nanjing, China, 12–14 October 2017; IEEE: Nanjing, China, 2017; pp. 318–321. [Google Scholar]
- Kumar, S.; De, K.; Roy, P.P. Movie Recommendation System Using Sentiment Analysis From Microblogging Data. IEEE Trans. Comput. Soc. Syst. 2020, 7, 915–923. [Google Scholar] [CrossRef]
- Aly, M.; Atiya, A. LABR: A Large Scale Arabic Book Reviews Dataset. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4 August 2013; pp. 494–498. [Google Scholar]
- The SciPy Community Scipy.Spatial.Distance.Euclidean—SciPy v1.8.1 Manual. Available online: https://docs.scipy.org/doc/scipy/reference/generated/scipy.spatial.distance.euclidean.html (accessed on 29 May 2023).
- scikit-learn Developers Sklearn.Model_selection.GridSearchCV—Scikit-Learn 1.2.1 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html (accessed on 29 May 2023).
- Hug, N. Matrix Factorization-Based Algorithms—Surprise 1 Documentation. Available online: https://surprise.readthedocs.io/en/stable/matrix_factorization.html (accessed on 29 May 2023).
- scikit-learn Developers Sklearn.Decomposition.NMF—Scikit-Learn 1.2.1 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.NMF.html (accessed on 29 May 2023).
- Abdelgwad, M.M.; Soliman, T.H.A.; Taloba, A.I. Arabic Aspect Sentiment Polarity Classification Using BERT. J. Big Data 2022, 9, 115. [Google Scholar] [CrossRef]
- Abu Farha, I.; Magdy, W. Mazajak: An Online Arabic Sentiment Analyser. In Proceedings of the Fourth Arabic Natural Language Processing Workshop; Association for Computational Linguistics: Florence, Italy, 2019; pp. 192–198. [Google Scholar]
- SemEval-2017 Task 4 Full Training Data for SemEval-2017 Task. Available online: https://alt.qcri.org/semeval2017/task4/?id=download-the-full-training-data-for-semeval-2017-task-4 (accessed on 10 April 2023).
- El-Dien Aly, M.A. ASTD: Arabic Sentiment Tweets Dataset. Available online: http://www.mohamedaly.info/datasets/astd (accessed on 10 April 2023).
- Metatext Asafaya/Bert-Mini-Arabic Model—NLP Hub. Available online: https://metatext.io/models/asafaya-bert-mini-arabic (accessed on 10 April 2023).
- The OSCAR Project (Open Super-Large Crawled Aggregated coRpus). Available online: https://oscar-corpus.com/ (accessed on 10 April 2023).
- Wikimedia Foundation Wikimedia Downloads. Available online: https://dumps.wikimedia.org/backup-index.html (accessed on 10 April 2023).
- Alyami, S. Arabic Sentiment Analysis Dataset SS2030 Dataset. Available online: https://www.kaggle.com/snalyami3/arabic-sentiment-analysis-dataset-ss2030-dataset (accessed on 10 April 2023).
- A Khooli Arabic 100k Reviews. Available online: https://www.kaggle.com/abedkhooli/arabic-100k-reviews (accessed on 10 April 2023).
- Elmadany, A.A.; Mubarak, H.; Magdy, W. ArSAS: An Arabic Speech-Act and Sentiment Corpus of Tweets. 2018. Available online: lrec-conf.org/workshops/lrec2018/W30/pdf/book_of_proceedings.pdf#page=30 (accessed on 10 April 2023).
- Arabic Sentiment Twitter Corpus. Available online: https://www.kaggle.com/mksaad/arabic-sentiment-twitter-corpus (accessed on 10 April 2023).
- Wikimedia Foundation Wikimedia Database Dump of the Arabic Wikipedia on 1 February 2019. Available online: https://archive.org/details/arwiki-20190201 (accessed on 10 April 2023).
- El-khair, I.A. 1.5 Billion Words Arabic Corpus. arXiv 2016, arXiv:1611.04033. [Google Scholar] [CrossRef]
- Zeroual, I.; Goldhahn, D.; Eckart, T.; Lakhouaja, A. OSIAN: Open Source International Arabic News Corpus—Preparation and Integration into the CLARIN-Infrastructure. In Proceedings of the Fourth Arabic Natural Language Processing Workshop; Association for Computational Linguistics: Florence, Italy, 2019; pp. 175–182. [Google Scholar]
- Jannach, D.; Zanker, M.; Felfernig, A.; Friedrich, G. Recommender Systems: An Introduction; Jannach, D., Ed.; Cambridge University Press: New York, NY, USA, 2011; ISBN 978-0-521-49336-9. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).