Abstract
The emotional well-being of a child is crucial for their successful integration into society as a productive individual. While technology has made significant strides in enabling machines to decipher human emotional signals, current research in emotion recognition primarily prioritizes adults, disregarding the fact that children develop emotional awareness at an early stage. This highlights the need to explore how machines can recognize facial expressions in children, although the absence of a standardized database poses a challenge. In this study, we propose a system that employs Convolutional-Neural-Network (CNN)-based models, such as VGG19, VGG16, and Resnet50, as feature extractors, and Support Vector Machine (SVM) and Decision Tree (DT) for classification, to automatically recognize children’s expressions using a video dataset, namely Children’s Spontaneous Facial Expressions (LIRIS-CSE). Our system is evaluated through various experimental setups, including 80–20% split, K-Fold Cross-Validation (K-Fold CV), and leave one out cross-validation (LOOCV), for both image-based and video-based classification. Remarkably, our research achieves a promising classification accuracy of 99% for image-based classification, utilizing features from all three networks with SVM using 80–20% split and K-Fold CV. For video-based classification, we achieve 94% accuracy using features from VGG19 with SVM using LOOCV. These results surpass the performance of the original work, which reported an average image-based classification accuracy of 75% on their LIRIS-CSE dataset. The favorable outcomes obtained from our research can pave the way for the practical application of our proposed emotion recognition methodology in real-world scenarios.
1. Introduction
The shift from computer-centered to human-centered computing has opened up opportunities for computer vision research to propose solutions and innovative applications [1]. Understanding and responding to social and emotional signals, such as facial expressions, is a crucial aspect of human-centered computing. Facial expressions convey important emotional information in human communication, and the ability to distinguish between genuine and posed expressions is important for social interactions. Human’s real-time recognition of facial expressions can benefit both humans and computer algorithms [2,3]. Automated facial expression recognition is gaining attention in computer vision research due to its diverse applications, including social humanoid robots, video transcription, online recommendations, autism and developmental disability diagnosis, telemedicine for pain detection, smart homes, driver fatigue monitoring, and entertainment. Human activity recognition (HAR) is a significant research area that identifies human activities in real-life settings and plays a crucial role in interpersonal interactions [4]. Computer vision technology, powered by AI algorithms, can analyze data from wearable sensors, cameras, and CCTV systems to recognize emotional states through facial expressions by analyzing features such as the nose, eyes, and lips.
Recognizing facial expressions in children aged 6–12 is crucial for their physical and mental development, as it lays the foundation for lifelong well-being. Accurate facial expression recognition algorithms hold value in gaining insights into children’s emotional well-being, promoting healthy lifestyles, and enhancing their perception of the world. The pressing demand to address these practical needs has motivated the study and development of facial expression recognition in children. However, the challenge persists due to limited availability of accurate expression databases with sufficient facial images. The lack of natural, spontaneous expression data hinders real-world application development [5]. Existing databases mostly have posed expressions, with limited spontaneous expressions, which is problematic as children’s spontaneous expressions differ significantly from posed expressions. Additionally, research often focuses on adult faces, overlooking facial expressions in children.
Facial Emotion Recognition (FER) in children involves detecting and interpreting facial expressions of six basic emotions (anger, disgust, fear, happiness, sadness, and surprise) from children’s faces. It typically involves three stages: pre-processing, feature extraction, and classification. Pre-processing involves extracting frames from videos, removing the background, and detecting the face area. Feature extraction focuses on extracting useful feature representations from the face area, which can be conducted using traditional hand-crafted features such as Local Binary Pattern (LBP), Scale-Invariant Feature Transform (SIFT), Gabor wavelets, etc., or representation learning which automatically extracts features from the input data with Convolutional Neural Networks (CNN) [6]. The extracted features can then be fed to a classifier such as SVM or Decision Tree for classification. Transfer Learning, where a pre-trained network is fine-tuned for the experimental setup, is another approach used in FER [7,8]. Nowadays, many networks are trained on the ImageNet database. ImageNet-trained networks have been trained on over a million images and can classify diverse classes. Studies indicate that using pre-trained networks as feature extractors is faster, cheaper, and produces quality results. However, complex network architectures may not be suitable for simpler tasks, and if the target dataset is small and similar to the dataset on which the network is pre-trained, network fine-tuning could cause over-fitting [3].
This study proposes an automated system for classifying the facial expressions of children using pre-trained CNN models such as VGG16, VGG19, and Resnet50 as feature extractors. Approximately 19,000+ frames from 185 videos in the LIR-IS-CSE dataset [1] are used for feature extraction. This step has been carried out for video and image-based classification. However, the methodology deployed for the division of frames into train and test sets in both approaches is different. The extracted features are then used to train two image classifiers, Support Vector Machine (SVM) [9,10] and Decision Tree (DT) [11,12], to test their representational power. SVM and DT are chosen for their robustness and ability to perform well with complex datasets [13]. The system is unique, as deep features specific to the data are learned and then independent classifiers are used for classification. To our knowledge, the proposed system has not been used on such kind of child emotional speech datasets.
2. Related Work
The ability of human-centered computing interfaces to comprehend, understand the meaning of, and react to human expressions is one of the most important and challenging jobs [14,15]. Current studies in the field of emotion recognition have mainly focused on adult facial expressions. Several traditional and deep learning approaches have been deployed for the recognition of facial emotions using databases containing adult faces, as there is ample data on adult emotions. However, there is a lack of literature on FER in children due to many reasons; one of them is the dearth of children’s emotional datasets. State-of-the-art approaches have not yet been trained with standardized databases that provide 100% “unbiased” or spontaneous and natural emotions of children [16]. The existing databases also offer unevenness in pose, lightning, and variations in expression by subjects across different areas of the world [17]. A similar issue with publicly available databases is that it only contains adult facial expressions and ignores the children’s [18]. Therefore, limited work has been performed on spontaneous child facial expression recognition [19].
Child FER Datasets
To draw accurate conclusions for understanding children’s way of giving expressions, it is important to consider many factors that differentiate datasets from each other, such as the number of participants or volunteers, modality (audio or video), age group, elicitation techniques (posed or spontaneous), the number of categories, and the environment in which the participants gave the emotion.
The NIMH Child Emotional Faces Picture Set (NIMH-ChEFS) [20] considers different emotions such as ‘anger’, ‘fear’, ‘happy’, and ‘sad’ with averted and directed gaze presented by volunteers of the age group 10–17 years. The Dartmouth Database [21] of Children’s faces considers six basic universal emotions expressed by children around 6 to 16 years. Child Affective Facial Expression (CAFE) [22] is an image dataset considering seven emotions, i.e., six basic and one neutral. The age group of the culturally diverse volunteers is around 2–8 years. The Radboud Face Database (RaFD) [23] is a picture dataset that considers eight emotional states including anger, disgust, fear, happiness, sadness, surprise, dislike, and neutral presented by 67 children between 8 and 12 years. The EmoReact [24] is a multimodal dataset containing the emotions of children around the age group of 4–14 years. The volunteers presented six universal emotions and nine complex emotions, neutral, valence, uncertainty, and frustration. The JEMImE dataset [25] falls in the posed category. It contains four different kinds of emotions: anger, happiness, neutral, and sadness. LIRIS-CSE [1] is an emotional dataset for children that contains 208 videos of culturally varied children. The database was created involving videos of twelve children; five are male and seven are female of age group 6 to 12 years (average 7.3 years).
For assessing and benchmarking various algorithms designed for facial emotion recognition problems, there must exist standardized databases. The existing emotional datasets for children display exaggerated emotions of children with proper camera positions and illumination setups, which is different compared with the spontaneous expressions children give in real life. The LIRIS-CSE dataset presents 100% spontaneous emotions of children that can be used as a benchmark for the task of Facial Emotion Recognition (FER) in children.
The present studies on facial emotion recognition in children have been conducted through deep analysis of a child’s psyche and way of interpreting facial emotions. This is accompanied by experimental evaluations using traditional and deep learning methodologies such as Convolutional Neural Networks (CNN). The traditional feature extraction approach is often compared with CNN-based feature extractors. The difference between the two is that traditional feature-based techniques focus on using hand-crafted features, whereas CNN can learn such features automatically during training. These studies not only put forth the significance but the weaknesses that need to be dealt with in this field.
Khan et al. [1] proposed a novel emotion dataset for children, namely LIRIS-CSE, which considers six emotions; happiness, sadness, anger, disgust, and fear. They used a pre-trained VGG16 with a transfer learning approach. The last fully connected layer of their VGG16 architecture was interchanged with a dense layer with five outputs. The authors performed image-based classification using only 80% of the frames for training and 10% of the frames for the validation process. Their system achieved an average accuracy of 75%. Uddin et al. [26] focused on the recognition of dynamic facial expressions from videos by deploying their proposed approach on four datasets, Oulu-CASIA, AFEW, CK+, and LIRIS-CSE. They introduced a novel approach based on Spark distributed computing environment for efficiently processing the video data. They presented a dynamic feature descriptor known as LDSP-TOP that gives an established description of facial dynamics. Moreover, for capturing additional features of a face, they designed a 1D CNN that consisted of residual connections. Lastly, for learning spatiotemporal features, they used a long short-term memory auto-encoder. Their proposed methodology performed remarkably well on three of the above-mentioned datasets, achieving accuracies of 86.6%, 98.6%, and 84.2% on the Oulu-CASIA, CK+, and LIRIS-CSE datasets, respectively. Their proposed method did not perform well on the AFEW dataset, achieving a classification accuracy of 50.3%. C. Florea et al. [27] presented a method that used labeled and unlabeled data for the task of facial expression recognition by combining transfer learning and semi-supervised learning with the proposed framework known as Annealed Label Transfer (ALT). They made use of AlexNet and VGG16 networks in their work as well. They set up four scenarios for evaluation; the first two were facial expressions in the wild and the other two were FER in children along with anxiety-based expressions in the wild. They used RAF-DB and FER+ datasets (for labeled data) and MegaFace dataset (for unlabeled data) for the first two scenarios. They reported the performance of AlexNet with ALT on the CAFÉ dataset in a purely supervised manner, where it achieved 99.29% accuracy. To summarize, ALT used learned knowledge and transferred it to a labeled dataset in the wild to unlabeled datasets for the generation of pseudo labels. Zhao et al. [28] proposed a Mobile-Edge-Computing (MEC)-based hierarchical emotion recognition model. Their system used a pre-trained feature extraction and localization module on a remote cloud. The difficulty imposed by environmental issues was addressed by a mechanism called perturbation-aware defense. Using the proposed MEC-based hierarchical emotion recognition model with VGG16 in conjunction with the localization module, they achieved 95.67% accuracy on the LIRIS-CSE dataset.
Alejandro et al. [29] considered six basic emotions for the classification of facial expressions in children using the NAO robot. In their study, they compared AFFDEX SK and a CNN with Viola-Jones, which was trained on AffectNet and tuned on the NIMH-ChEF dataset, with a transfer learning approach. Moreover, they tested their system via comparison on another dataset, CAFÉ. Lastly, they compared both systems with the NAO robot using subsets of the AMFED and EmoReact datasets. Guiping Yu [30] proposed a face and emotion recognition multi-modal system based on deep learning methods for monitoring the emotions of preschool children. Their model combined face, context, and action for emotion recognition. They used the FLAW, FER2013, and CK+ datasets for facial recognition. Their work specified that face-tracking algorithms can make the system more resilient to complications such as pose, angle, and dynamic blur. Thus, they proposed an algorithmic model that detects face blur. They combined LSTM and CNN model algorithms. Resultantly, they used the VGG19 network in their proposed system. Weiqing et al. [31] combined the online course platforms with a deep learning CNN-based model for constructing a framework for analyzing students’ emotions during online classes. The goal of their system is that teachers change their teaching style by reading the results presented in the form of a histogram. Their model was trained on CK+, Jaffe, and FER2013 datasets while considering eight basic emotions. They also used online augmentation techniques to increase the number of images in the dataset. The proposed framework showed good performance and proved that it is likely to perform well in practical applications. Megan et al. [32] showed the benefit of using transfer learning for learning the general facial expressions from adult faces for performing multi-class classification on children’s facial expressions. In their research, they deployed a closed-mouth subset of the CAFÉ and CK+ datasets. Initially, they performed preprocessing on the images of the datasets. They designed a CNN model and trained it for classifying six basic emotions, including neutral emotion, in children and adults. Amir et al. [33] developed an affect recognition system for young children using a deep convolutional neural network. Their DCNN is an emotion recognition prototype that effectively extracts refined facial features. For training their model, they used an enhanced FER dataset (FER+) which consists of 35,887 facial images considering eight emotions, namely anger, disgust, fear, happiness, neutral, surprise, sadness, and contempt. They tested their model with kindergarten children, as they naturally interact with each other in a classroom. The prototype achieved an effective prediction accuracy of 93%.
Children with autism may encounter behavioral challenges and difficulties in recognizing emotions. Therefore, automatic facial emotional recognition systems could be valuable in helping children with autism infer and interpret human emotions, leading to more intuitive, genuine, and natural interactions. Awatramani et al. [34] focused on the emotion recognition ability of children with an autism spectrum disorder. In their work, they explained how this disorder can pose behavioral challenges for children and how they suffer from an inability to recognize emotions. They implemented a basic CNN for teaching children with ASD to recognize emotions. Their system achieved an accuracy of 67.50% on an existing dataset.
Qing et al. [35] performed facial expression recognition on babies. They introduced a novel dataset, namely, BabyExp. This dataset contains 12,000 images of babies aged around 1–2 years. The dataset presents three expressions: happy, normal, and sad. This dataset acts as a benchmark for facial expression recognition in babies and paves the way for further research. They tested their dataset by proposing a feature-guided CNN, where they also introduced a new loss function, named distance loss for optimization of inter-class distance. Their methodology accomplished a promising accuracy of 87.90% on the BabyExp dataset.
Arnaud et al. [25] focused on understanding facial emotions, especially in children, by proposing classification and regression systems. It was specified that existing databases for FER are limited in terms of the number of participants, recording environment, or simply the nature of annotation. They created their own children’s FE dataset, JEMImE, which included many modalities. The modalities are marked with categorical and qualitative FEs. Furthermore, for classification and regression, they deployed an FER pipeline, which uses a random forest trained on a mixture of geometric and appearance features. The results proved that random forest models that are trained on the JEMImE dataset generalize much better on children’s data for classification and regression.
Due to CNNs’ amazing ability to perform well and give robust results even for complex tasks, many researchers are inclined to use them to extract image features. The reason for selecting CNNs as feature extractors in our research is because of their amazing ability to extract useful features from the data based on their learning [36]. VGGNets such as VGG16 and VGG19 are considered state-of-the-art and they have an appealing framework due to their uniform architecture. Another type of residual network, known as ResNets, is also very effective in training deep networks, as it stacks additional layers and builds a deeper network. This network makes use of skip connections and solves the vanishing gradient problem [37,38]. Fortunately, pre-trained models of these networks are publicly available, making it practical for researchers to test even small-sized databases. This is accomplished by using a previously trained network that is qualified to extract useful features [39] and can be put to use in any of the three following ways: classification, feature extraction, and transfer learning. Table 1 gives a brief description of the ways a pre-trained network can be used.

Table 1.
Uses of a pre-trained network.
3. Materials and Methods
This section explains our proposed methodology in detail. The primary steps include: pre-processing (frame extraction, face detection), feature extraction, and classification. Our emotion recognition system utilizes a uni-model approach, focusing solely on visual content extracted from video clips in the emotional corpuses. In the initial stage, preprocessing is necessary to prepare the visual data for input into the neural network. This involves extracting frames from the video corpuses and isolating the face area within those frames. Next, distinct feature sets are extracted from the frames using three networks, namely VGG16, VGG19, and Resnet50. This step is performed for both video- and image-based classification, although the methodology for dividing the samples (i.e., frames) into train and test sets differs between the two approaches. The features extracted from these frames are then used to train two image classifiers, namely Support Vector Machine and Decision Tree, in order to evaluate the representational power of these features. Figure 1 represents a visual representation of our proposed methodology.
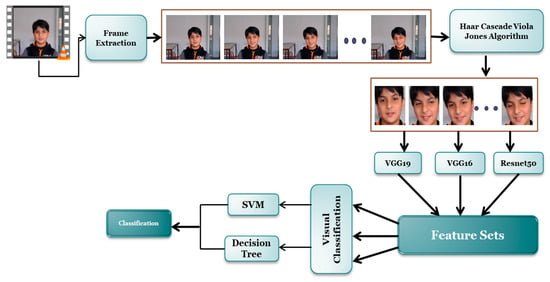
Figure 1.
Proposed Visual Emotion Recognition System.
3.1. LIRIS-CSE Dataset
Our study uses an emotional dataset, LIRIS-CSE [1], that contains 208 videos of 12 culturally varied children showing natural expressions in two setups; one is a classroom/lab setup and the second is a home setup. This dataset was created involving videos of 12 children, 5 males and 7 females, of age groups between 6 and 12 years (average 7.3 years). Table 2 presents the main characteristics of the participants involved in the study. Basically, children are exposed to different settings, showing six universal or prototypic emotional expressions. The recordings are captured in an unconstrained environment, with no limitations on head or hand movements, and the children are allowed to sit freely. This unrestricted setting enables the collection of spontaneous and natural expressions from the children. The validity of the database has been verified by 22 human raters. The evaluators for the database validation were divided into two groups: university students and university faculty members. Prior to starting the validation process, the human raters were briefed about the experiment. To facilitate the validation, software was created that played segmented videos in a random order and recorded the expression label choices made by the evaluators. The evaluators had the option to replay videos multiple times before making their final choice for each specific video.
Table 2.
Fundamental characteristics of the individuals involved in the LIRIS-CSE dataset.
The participants were shown animated emotional videos for inducing stimuli in children. The children’s expressions were recorded using a webcam attached to the top of a laptop along with a speaker output 50 cm apart. Upon stimulation, the children showed six basic emotions, i.e., anger, disgust, fear, happiness, sadness, and surprise. Although there were six basic universally accepted emotions, including anger, during the creation of the dataset, the stimuli (movies, video clips) to induce ‘negative’ emotions in young children were selected keeping many ethical and moral reasons in mind so that the selected stimuli should not have any long-term negative impact on young children. Therefore, there are more videos of ‘positive’ emotions, i.e., happiness and surprise, and very few videos of negative emotions, i.e., fear, sadness, disgust, and only one video of anger. Even though children were not shown any anger-inducing video, one child was still recorded displaying this emotion. Thus, there is only one video of anger in the dataset. Figure 2 shows the environmental setup, illumination changes, and spontaneous expressions presented by children in the LIRIS-CSE dataset.

Figure 2.
Emotional images of children from the movie clips of LIRIS-CSE dataset.
3.2. Pre-Processing
LIRIS-CSE is a video dataset with 208 videos in total. Out of 208, 185 videos are of 5 basic emotions, namely disgust, fear, happiness, sadness, and surprise, and the remaining 23 videos are of mixed emotions, namely happy-aloud, fear-surprise, happy-disgust, and happy-surprise. Since the emotion anger has a single video it was not considered in our experiment. Moreover, the mentioned mixed emotions have also not been considered. Since the dataset contains videos, the first step was frame extraction. After extraction, we had approximately 19,000 frames in total. The second step of this preprocessing stage was face area detection. In this step, we removed the unnecessary background and extracted only the face area from these frames via Haar Cascade Classifier [40]. The new image set was composed of gray-scale images containing solely the face area.
3.2.1. Image-Based Approach
In the image-based approach, the new set was divided into two subsets for training and testing the classifier. In this approach, each frame was considered separately or independently labeled and the decision was made on each frame individually.
3.2.2. Video-Based Approach
In the video-based approach, the videos were divided into train and test sets. In this approach, the whole video was considered for labeling, i.e., a majority voting-based decision was made on all the frames of a single complete video. Unlike the image-based approach, the frames were not considered independently; instead, they belonged to the specific video from which it was extracted. This helped in preserving the sequence and the temporal information of a video.
3.3. Feature Extraction
This section explains the method to extract learned image features from the data subsets via pre-trained CNN. Initially, the images were of different sizes and gray-scale in color, but the pre-trained networks required input images to be of size 224 × 224 × 3, where 3 is the number of color channels. Input images were resized and converted into 3 channel-colored images before they were fed to the network. We conducted our first experiment using VGG19, then VGG16, and lastly ResNet50. These networks were trained on more than a million images and can classify up to 1000 classes.
VGG19 is a convolutional neural network consisting of 47 layers in total, with 19 layers with learnable weights [41]. It is composed of 16 convolutional layers with stride [11] and 3 fully connected layers. Here, we have considered the output of a fully connected layer ‘fc8′ as features of size 1 × 1 × 1000.
VGG16 is another network that we have used in our work [42]. It has 41 layers, having 16 layers with learnable weights. There are 13 convolutional layers, and 3 fully connected layers. In our work, we have considered a fully connected layer ‘fc7′ of a pre-trained VGG16, which returns a feature vector of size 1 × 1 × 4096.
ResNet50 is another powerful Convolutional Neural Network that we have deployed in our research [43,44]. It has 177 layers in total and 50 layers with learnable weights. We have considered the layer ‘fc1000’, which returns a feature vector of size 1 × 1 × 1000.
The features from all three networks were forwarded to models for classification. Feature vector (FV) size and the learnable parameters of the selected layers from all three networks are shown in Table 3. The layer ‘fc8′ of VGG19 has 4,097,000 learnable parameters, while for VGG16 the fully connected layer ‘fc7′ has 16,781,312 parameters. Similarly, the fully connected layer (fc1000) of Resnet50 contains 2,049,000 parameters.
Table 3.
Feature vector size per layer.
3.4. Classification
LIRIS-CSE is a relatively smaller dataset in terms of the number of videos, so instead of training the network entirely from scratch on this dataset, we used the extracted features from these networks to train two different types of classifiers, i.e., Support Vector Machine (SVM) and Decision Tree (DT). In terms of performance, there does not exist much difference in using a CNN’s Softmax function for classification or using the above-mentioned classifiers with features extracted by a CNN, as it is empirically proven that SVM performs well with features from a CNN [45], especially when the dataset is a small size [3].
- Support Vector Machine
A multi-class SVM is a combination of multiple binary SVMs which performs classification on multiple states [46]. When labeled data is provided to SVM for training, it generates a hyperplane that categorizes various observations. In SVM, the hyperplane acts as a decision boundary and the goal is to maximize the margin between support vectors, which are data points closer to the hyperplane. The hyperplane with w and b parameters is presented as: f(x) = sign (wt x + b) This model uses K (K − 1)/2 binary support vector machine (SVM) models or binary learners and a one-versus-one coding design, where K is the number of unique class labels (levels). A coding design presents a matrix in which elements denote which classes are trained by the binary learner. In one-versus-one coding design, each binary learner has one positive class, one negative, and the rest is ignored.
- 2.
- Decision Tree
For classification and prediction problems, a decision tree is a commonly used model [47]. The structure of a decision tree is like a flowchart; it consists of the root node, branches, and leaf nodes. The root node is the parent node in the tree, located at the top. In a decision tree, each internal node indicates a test on a feature and every branch shows the result of the test, where the terminal or leaf node holds the class label. Based on the features given as input to the model, the model gives a fitted binary decision tree that splits the branch nodes based on the input features.
4. Experimental Results
This section explains our experimental results on feature sets from VGG19, VGG16, and Resnet50 with two classifiers, SVM and DT. We employed three kinds of experimental setups, i.e., 80–20% split, K-Fold cross-validation (CV), and leave one out cross-validation (LOOCV) for both image-based and video-based approaches.
4.1. Image-Based Results
For the image-based approach, we tested the representational power of the extracted features by first deploying the 80–20% split techniques, then K-Fold cross-validation.
4.1.1. 80–20% Split
In this methodology, the classifiers are trained on feature vectors extracted from 80% of the frames and then tested on remaining 20%. As discussed earlier, the division of the datasets in image-based and video-based approaches is slightly different from each other. However, the 80–20% split ratio is followed for both approaches.
In the image-based approach, the dataset is divided into two subsets for training and testing the classifier. The train set contains 80% of the frames, and the test set contains the remaining 20%. The key point in the image-based approach is that the division of the frames is conducted randomly. Table 4 reports the results for the frame- or image-based approach. In this setup, SVM with VGG16 features for image-based classification gives the best result, providing a classification accuracy of 99.9%. With VGG19 (fc8) and Resnet50 features, we achieved a classification accuracy of 99.5% and 99.8%, respectively. DT also performed remarkably well on the three sets of features extracted from VGG16, VGG19, and Resnet50, giving classification accuracies of 97.8%, 97.5%, and 96.9%, respectively. This proves that the combination of SVM with VGG16 features is a very powerful one, as it accomplishes extremely high classification accuracies.
Table 4.
Classification results for image-based approach.
4.1.2. K-Fold Cross-Validation
In this experimental setup, we deployed 10-fold cross-validation. The dataset is randomly split into 10 approximately equal parts. Out of 10 folds, 9 are used for training the classifier and the remaining 1 is used for testing. This process is repeated 10 times so that each of the 10 sub-samples are tested and the entire dataset is covered completely. Lastly, the obtained accuracies are averaged and a final average accuracy is obtained.
In this approach, each bin contains approximately 1927 samples and each bin is used for training and testing by the classifier. We achieved the highest classification accuracy of 99.8% with the combination of VGG16 features and SVM, as reported in Table 4. For the other two sets of features by VGG19 and Resnet50 with SVM, we achieved an accuracy of 99.0% and 99.5%, respectively. Similarly, DT also performed extremely well on the three sets of features from VGG16, VGG19, and Resnet50, giving classification accuracies of 94.8%, 94.2%, and 93.2%, respectively.
4.2. Video-Based Results
For the video-based approach, similar to the image-based approach, we deployed the 80–20% split and K-Fold cross-validation techniques, and we used LOOCV in order to improve the results.
4.2.1. 80–20% Split
In the video-based approach, the videos are divided into train and test sets, i.e., 80% of the videos belong to the train set and the remaining 20% belong to the test set. The key point in video-based classification is that the division of the frames is not random; rather, all frames belonging to their respective videos are in the same set. For this approach, the results are not as promising. It can be seen in Table 5 that SVM gives a classification accuracy of 57% for VGG19 features and 55% for both VGG16 and Resnet50 features. As expected, DT also performed poorly for this approach, giving 52%, 47%, and 45% accuracy for VGG16, VGG19, and Resnet50 features, respectively.
Table 5.
Classification results for video-based approach.
4.2.2. K-Fold Cross-Validation
In this setup, each bin consists of 18 videos and each bin is used for training and testing by the classifier; thus, every video sample is used. In Table 5, it can be seen that for the video-based approach, the results slightly improved with this setup. SVM resulted in achieving classification accuracies of 69%, 73%, and 71% for VGG16, VGG19, and Resnet50 features, respectively. DT accomplished 65%, 64%, and 63% for VGG16, VGG19, and Resnet50 features, respectively.
4.2.3. Leave One Out Cross-Validation
This setup is deployed in order to improve the classification results of the video-based approach. As the name suggests, in leave one out cross-validation, one instance of the dataset, i.e., one video of a child presenting an emotion becomes part of the test set once, while all remaining instances are part of the training set (in each iteration). This process is repeated corresponding to the total number of instances (videos) in the dataset. This method helped the SVM classifier in achieving improved classification accuracies of 91%, 94%, and 93% for VGG16, VGG19, and Resnet50 features, respectively. These results are given in Table 5. DT also accomplished remarkable results of 89%, 91%, and 88% for VGG16, VGG19, and Resnet50 features, respectively.
In the 80–20% split, the image-based approach gave better results compared with the video-based approach, as there existed sufficient frames of the same video in the training and testing set, but in the video-based approach all frames of the same video were present in either of two sets. In other words, the video-based approach considered a single video as one sample, which led to an insufficient amount of training samples. It can be seen in the other two setups that accuracies had improved due to the sufficient amount of data available for training. With K-fold cross-validation, such decent performance by the classifiers for the image-based approach was anticipated, because it is a very powerful method that covers the entire dataset. Finally, the accuracy of the video-based approach was significantly enhanced with the implementation of LOOCV, particularly as the number of training videos increased. LOOCV involves using all frames of a single video for testing in each iteration, while the frames of the remaining videos are used for training. Decision-making is performed through applying majority voting on the testing frames of a video. The entire dataset was evaluated using LOOCV.
To summarize, our proposed framework achieved the highest accuracy of 99% for image-based classification via features of all three networks with SVM using 80–20% split and K-Fold CV. Table 6 reports the confusion matrix of 80–20% split using VGG16 features with SVM as a classifier, resulting in 99.9% accuracy. The confusion matrix of this setup depicts only one misclassification of surprise emotion predicted as fear. Table 7 reports the confusion matrix of K-Fold CV using VGG16 features with SVM as a classifier, resulting in 99.8% accuracy. From the confusion matrix, it can be seen that the emotion disgust was misclassified as happy twice, and four samples of fear were mis-predicted as happy and five as surprise. Similarly, seven samples of happiness were wrongly predicted, one as sad and six as surprise. Moreover, one sample of sad was mis-predicted as happy and four as surprise. Lastly, surprise suffered the most misclassifications: four as fear, seven as happy, and two as sad.
Table 6.
Confusion matrix image-based approach. Eighty–twenty percent split with VGG16 features and SVM.
Table 7.
Confusion matrix image-based approach. K-fold CV with VGG16 features and SVM.
Similarly, Table 8 reports the confusion matrix for the video-based approach, in which SVM achieved the highest classification accuracy of 94% with VGG19 features using leave one out cross-validation. The number of samples of each emotion represents the number of videos for that emotion, i.e., a majority voting-based decision was made on all the frames of a single video. It can be seen that the classifier reported zero misclassifications for happy, whereas fear had the most misclassified videos. Two samples of disgust were misclassified as happy and surprise, whereas five samples of fear were predicted wrong: one as disgust, one as happy, and three as surprise. Lastly, three samples of surprise were misclassified as happy and one as fear. In both setups, overall surprise suffered the most misclassifications; surprise was especially mis-predicted as happy. This is understandable, as children tend to combine these emotions and present mixed emotions. Furthermore, to detect any indications of over-fitting, two validation metrics, namely accuracy and loss, were employed. The results showed that the loss on the test set was comparable to that on the training set, indicating minimal signs of over-fitting.
Table 8.
Confusion matrix video-based approach. LOOCV with VGG19 features and SVM.
5. Discussion
Our study utilizes the LIRIS-CSE emotional dataset [1], which consists of 208 videos featuring 12 children from diverse cultural backgrounds exhibiting natural expressions in different setups. The children were shown animated emotional videos to elicit emotional responses, and their expressions were recorded. The dataset contains more videos depicting ‘positive’ emotions, such as happiness and surprise, and fewer videos depicting ‘negative’ emotions, such as fear, sadness, and disgust, with only one video capturing the emotion anger.
In our study, each setup resulted in a different set of accuracies; however, it is important to note that feature representations have a more important role in the overall performance. As discussed, we used pre-trained networks which were trained on the ImageNet dataset, which is very different from our dataset. For the image-based approach, it was observed that VGG16 performs better in comparison with the other two networks in every case. From the results of the video-based approach, it was observed that VGG19 features outperformed VGG16 and ResNet50 features in the majority of the experiments carried out. Furthermore, in all tests carried out, SVM beat DT with a huge difference, proving that it is one of the best classifiers available. Our experiments have also demonstrated that the combination of pre-trained networks as feature extractors with models such as SVM and DT is a fine starting point to learn a new task and can guarantee promising results on a smaller dataset.
We have also compared our results with previous results computed on the LIRIS-CSE dataset. Table 9 reports this comparison. Khan et al. [1] achieved an average image-based classification accuracy of 75% using VGG16 architecture based on a transfer learning approach. Uddin et al. [26] reported an accuracy of 84.2% using deep spatiotemporal LDSP on spark. Zhao et al. [28] used an MEC-based hierarchical emotion recognition model with VGG16 in conjunction with the localization module and achieved 95.67% accuracy on the LIRIS-CSE dataset. In our work, we performed image- and video-based classification on this dataset and managed to achieve promising results. With the frame-based approach, our achieved recognition rates are higher as compared with the results reported in the literature. This shows that our proposed framework is effective in recognizing the facial expressions of children from images present in the LIRIS-CSE dataset.
Table 9.
Comparison with other works on LIRIS-CSE.
As far as computational cost is concerned, pre-trained models were utilized to extract features from the data. These models come with optimized weights that can effectively detect important features in the data and reduce the computation time, eliminating the need to modify the weights of the pre-trained model.
The LIRIS-CSE dataset is relatively new and poses a challenge due to the lack of controlled head movements. Moreover, children tend to express themselves subtly, resulting in significant variations among individuals and populations, unlike adults. Other datasets focusing on facial expressions in children tend to have restrictions, featuring minimal head movement and exaggerated or acted expressions. For example, the proposed framework by Khan et al. in [48] yielded results of 78.9% with SVM for the Dartmouth database of children’s faces and 68.4% for NIMH-ChEFS, whereas an accuracy of 75% has been reported by him on LIRIS-CSE. Therefore, despite the challenges presented by the demanding LIRIS-CSE dataset, which requires careful consideration, our proposed method demonstrated exceptional performance, surpassing the results already reported in the literature.
The limitations of our proposed approach are that the proposed system has been tested on single dataset due to unavailability of more child FE datasets. In the future, the methodology can be tested on more datasets for a comparative study. Additionally, both subject-dependent and independent experimental setups can be compared for performance analysis. Moreover, in light of the COVID-19 pandemic, there has been a shift in the focus of some recent studies towards detecting emotions on faces that are wearing masks [49]. Our approach could be expanded and tested to include masked children’s faces as well.
6. Conclusions
Facial expressions play a crucial role in social cognition, which refers to the mental processes involved in perceiving, interpreting, and responding to social information. They encompass emotion recognition, social perception, nonverbal communication, and social decision-making. They are fundamental to understanding and navigating social interactions and relationships. Facial emotion recognition is a very active area of research and, still, various frameworks are being deployed to improve the machine’s ability to accurately classify several emotions presented by children purely and spontaneously. In this paper, we used pre-trained convolutional neural networks as feature extractors on the LIRIS-CSE video dataset for facial expression recognition on five universal spontaneous emotions of children. In our experiment, image-based classification achieved the exceptionally high accuracy of 99.9% with an 80–20% split and 99.8% with K-Fold cross-validation. For video-based classification, the achieved accuracy was 57% with an 80–20% split, 73% with K-Fold cross-validation, and an impressive 94% with leave one out cross-validation (LOOCV). Our experiments demonstrated that the deep features extracted from these networks are a powerful representation of the input data, and they perform very well when classified using SVM and DT. The effectiveness of this approach is proven by our achieved results, as it outperformed the frameworks applied on the same dataset in the literature for the image-based approach. Using our framework, the difficulty posed by small datasets can be avoided, especially using the feature representations from pre-trained networks. Our proposed methodology also proved its worth by performing extremely well for video-based classification. In the future, emotions shown by children other than the six universal emotions can also be considered for recognition. A dataset with a mixture of several modalities, such as audio and video, can also be used in the future to achieve dynamic results. The proposed methodology can also be extended and tested on masked children’s facial emotions.
Author Contributions
Conceptualization, U.L., A.S. and R.A.K.; data curation, R.A.K. and U.A.; formal analysis, U.L. and Z.M.; investigation, U.L. and U.A.; methodology, U.L. and A.S.; project administration, A.S., R.A.K. and M.U.A.; resources, Z.M. and M.U.A.; software, U.L.; supervision, A.S. and R.A.K.; validation, A.S. and R.A.K.; visualization, U.L. and M.U.A.; writing—original draft, U.L.; writing—review and editing, A.S., Z.M. and U.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
This article does not contain any studies with human participants or animals performed by any of the authors.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Khan, R.A.; Crenn, A.; Meyer, A.; Bouakaz, S. A novel database of children’s spontaneous facial expressions (LIRIS-CSE). Image Vis. Comput. 2019, 83, 61–69. [Google Scholar] [CrossRef]
- Pantic, M.; Pentland, A.; Nijholt, A.; Huang, T.S. Human computing and machine understanding of human behavior: A survey. In Artifical Intelligence for Human Computing; Springer: Berlin/Heidelberg, Germany, 2007; pp. 47–71. [Google Scholar]
- Ravi, A. Pre-trained convolutional neural network features for facial expression recognition. arXiv 2018, arXiv:1812.06387. [Google Scholar]
- Bibbo’, L.; Cotroneo, F.; Vellasco, M. Emotional Health Detection in HAR: New Approach Using Ensemble SNN. Appl. Sci. 2023, 13, 3259. [Google Scholar] [CrossRef]
- Zahid, Z.; Shaukat, A.; Khan, R.A.; Akram, U.; Byun, Y.C. Emotion Recognition in Video Clips Using Simple and Extended Center Symmetric LBP. In Proceedings of the 2019 IEEE Transportation Electrification Conference and Expo, Asia-Pacific (ITEC Asia-Pacific), Seogwipo, Republic of Korea, 8–10 May 2019; IEEE: Manhattan, NY, USA, 2019; pp. 1–6. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ding, S.F.; Qi, B.J.; Tan, H.Y. An overview on theory and algorithm of support vector machines. J. Univ. Electron. Sci. Technol. China 2011, 40, 2–10. [Google Scholar]
- Tian, Y.; Shi, Y.; Liu, X. Recent advances on support vector machines research. Technol. Econ. Dev. Econ. 2012, 18, 5–33. [Google Scholar] [CrossRef]
- Song, Y.Y.; Ying, L.U. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 27, 130. [Google Scholar]
- Liu, H.; Cocea, M.; Ding, W. Decision tree learning based feature evaluation and selection for image classification. In Proceedings of the 2017 International Conference on Machine Learning and Cybernetics (ICMLC), Ningbo, China, 9–12 July 2017; IEEE: Manhattan, NY, USA, 2017; Volume 2, pp. 569–574. [Google Scholar]
- Cervantes, J.; Li, X.; Yu, W.; Li, K. Support vector machine classification for large data sets via minimum enclosing ball clustering. Neurocomputing 2008, 71, 611–619. [Google Scholar] [CrossRef]
- Pantic, M. Machine analysis of facial behaviour: Naturalistic and dynamic behaviour. Philos. Trans. R. Soc. B Biol. Sci. 2009, 364, 3505–3513. [Google Scholar] [CrossRef] [PubMed]
- Ko, B.C. A brief review of facial emotion recognition based on visual information. Sensors 2018, 18, 401. [Google Scholar] [CrossRef] [PubMed]
- Ekman, P.; Friesen, W.V. A new pan-cultural facial expression of emotion. Motiv. Emot. 1986, 10, 159–168. [Google Scholar] [CrossRef]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; IEEE: Manhattan, NY, USA, 2010; pp. 94–101. [Google Scholar]
- Pantic, M.; Valstar, M.; Rademaker, R.; Maat, L. Web-based database for facial expression analysis. In Proceedings of the 2005 IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, 6–9 July 2005; IEEE: Manhattan, NY, USA, 2005; p. 5. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Egger, H.L.; Pine, D.S.; Nelson, E.; Leibenluft, E.; Ernst, M.; Towbin, K.E.; Angold, A. The NIMH Child Emotional Faces Picture Set (NIMH-ChEFS): A new set of children’s facial emotion stimuli. Int. J. Methods Psychiatr. Res. 2011, 20, 145–156. [Google Scholar] [CrossRef]
- Dalrymple, K.A.; Gomez, J.; Duchaine, B. The Dartmouth Database of Children’s Faces: Acquisition and validation of a new face stimulus set. PLoS ONE 2013, 8, e79131. [Google Scholar] [CrossRef]
- LoBue, V.; Thrasher, C. The Child Affective Facial Expression (CAFE) set: Validity and reliability from untrained adults. Front. Psychol. 2015, 5, 1532. [Google Scholar] [CrossRef]
- Langner, O.; Dotsch, R.; Bijlstra, G.; Wigboldus, D.H.; Hawk, S.T.; Van Knippenberg, A.D. Presentation and validation of the Radboud Faces Database. Cogn. Emot. 2010, 24, 1377–1388. [Google Scholar] [CrossRef]
- Nojavanasghari, B.; Baltrušaitis, T.; Hughes, C.E.; Morency, L.P. Emoreact: A multimodal approach and dataset for recognizing emotional responses in children. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo Japan, 12–16 November 2016; pp. 137–144. [Google Scholar]
- Dapogny, A.; Grossard, C.; Hun, S.; Serret, S.; Grynszpan, O.; Dubuisson, S.; Cohen, D.; Bailly, K. On Automatically Assessing Children’s Facial Expressions Quality: A Study, Database, and Protocol. Front. Comput. Sci. 2019, 1, 5. [Google Scholar] [CrossRef]
- Uddin, M.A.; Joolee, J.B.; Sohn, K.A. Dynamic Facial Expression Understanding Using Deep Spatiotemporal LDSP On Spark. IEEE Access 2021, 9, 16866–16877. [Google Scholar] [CrossRef]
- Florea, C.; Florea, L.; Badea, M.A.; Vertan, C. Annealed label transfer for face expression recognition. In Proceedings of the British Machine Vision Conference (BMVC), Cardiff, UK, 9–12 September 2019. [Google Scholar]
- Zhao, Y.; Xu, K.; Wang, H.; Li, B.; Qiao, M.; Shi, H. MEC-Enabled Hierarchical Emotion Recognition and Perturbation-Aware Defense in Smart Cities. IEEE Internet Things J. 2021, 8, 16933–16945. [Google Scholar] [CrossRef]
- Lopez-Rincon, A. Emotion recognition using facial expressions in children using the NAO Robot. In Proceedings of the 2019 International Conference on Electronics, Communications and Computers (CONIELECOMP), Cholula, Mexico, 27 February–1 March 2019; IEEE: Manhattan, NY, USA, 2019; pp. 146–153. [Google Scholar]
- Yu, G. Emotion Monitoring for Preschool Children Based on Face Recognition and Emotion Recognition Algorithms. Complexity 2021, 2021, 6654455. [Google Scholar] [CrossRef]
- Wang, W.; Xu, K.; Niu, H.; Miao, X. Emotion Recognition of Students Based on Facial Expressions in Online Education Based on the Perspective of Computer Simulation. Complexity 2020, 2020, 4065207. [Google Scholar] [CrossRef]
- Witherow, M.A.; Samad, M.D.; Iftekharuddin, K.M. Transfer learning approach to multiclass classification of child facial expressions. In Proceedings of the Applications of Machine Learning, Long Beach, CA, USA, 9–15 June 2019; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 11139, p. 1113911. [Google Scholar]
- Farzaneh, A.H.; Kim, Y.; Zhou, M.; Qi, X. Developing a deep learning-based affect recognition system for young children. In Proceedings of the International Conference on Artificial Intelligence in Education, Chicago, IL, USA, 25–29 June 2019; Springer: Cham, Switzerland; pp. 73–78. [Google Scholar]
- Awatramani, J.; Hasteer, N. Facial Expression Recognition using Deep Learning for Children with Autism Spectrum Disorder. In Proceedings of the 2020 IEEE 5th International Conference on Computing Communication and Automation (ICCCA), Greater Noida, India, 30–31 October 2020; IEEE: Manhattan, NY, USA, 2020; pp. 35–39. [Google Scholar]
- Lin, Q.; He, R.; Jiang, P. Feature Guided CNN for Baby’s Facial Expression Recognition. Complexity 2020, 2020, 8855885. [Google Scholar] [CrossRef]
- Shaheen, F.; Verma, B.; Asafuddoula, M. Impact of automatic feature extraction in deep learning architecture. In Proceedings of the 2016 International conference on digital image computing: Techniques and Applications (DICTA), Goldcoast, Australia, 30 November–2 December 2016; IEEE: Manhattan, NY, USA, 2016; pp. 1–8. [Google Scholar]
- Li, B.; Lima, D. Facial expression recognition via ResNet-50. Int. J. Cogn. Comput. Eng. 2021, 2, 57–64. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Cuimei, L.; Zhiliang, Q.; Nan, J.; Jianhua, W. Human face detection algorithm via Haar cascade classifier combined with three additional classifiers. In Proceedings of the 2017 13th IEEE International Conference on Electronic Measurement & Instruments (ICEMI), Harbin, China, 9–11 August 2017; IEEE: Manhattan, NY, USA, 2017; pp. 483–487. [Google Scholar]
- Ramalingam, S.; Garzia, F. Facial expression recognition using transfer learning. In Proceedings of the 2018 International Carnahan Conference on Security Technology (ICCST), Montreal, QC, Canada, 22–25 October; IEEE: Manhattan, NY, USA, 2018; pp. 1–5. [Google Scholar]
- Tammina, S. Transfer learning using vgg-16 with deep convolutional neural network for classifying images. Int. J. Sci. Res. Public 2019, 9, 143–150. [Google Scholar] [CrossRef]
- Akhand, M.A.H.; Roy, S.; Siddique, N.; Kamal, M.A.S.; Shimamura, T. Facial Emotion Recognition Using Transfer Learning in the Deep CNN. Electronics 2021, 10, 1036. [Google Scholar] [CrossRef]
- Scherer, D.; Müller, A.; Behnke, S. Evaluation of pooling operations in convolutional architectures for object recognition. In Proceedings of the International Conference on Artificial Neural Networks, Thessaloniki, Greece, 15–18 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 92–101. [Google Scholar]
- Agarap, A.F. An architecture combining convolutional neural network (CNN) and support vector machine (SVM) for image classification. arXiv 2017, arXiv:1712.03541. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Myles, A.J.; Feudale, R.N.; Liu, Y.; Woody, N.A.; Brown, S.D. An introduction to decision tree modeling. J. Chemom. A J. Chemom. Soc. 2004, 18, 275–285. [Google Scholar] [CrossRef]
- Khan, R.A.; Meyer, A.; Bouakaz, S. Automatic affect analysis: From children to adults. In Proceedings of the Advances in Visual Computing: 11th International Symposium, ISVC 2015, Las Vegas, NV, USA, 14–16 December 2015; Springer International Publishing: Berlin/Heidelberg, Germany, 2015. Part II 11. pp. 304–313. [Google Scholar]
- Farkhod, A.; Abdusalomov, A.B.; Mukhiddinov, M.; Cho, Y.I. Development of Real-Time Landmark-Based Emotion Recognition CNN for Masked Faces. Sensors 2022, 22, 8704. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).