
Downlink MIMO-NOMA System for 6G Internet of Things


Abstract
1. Introduction
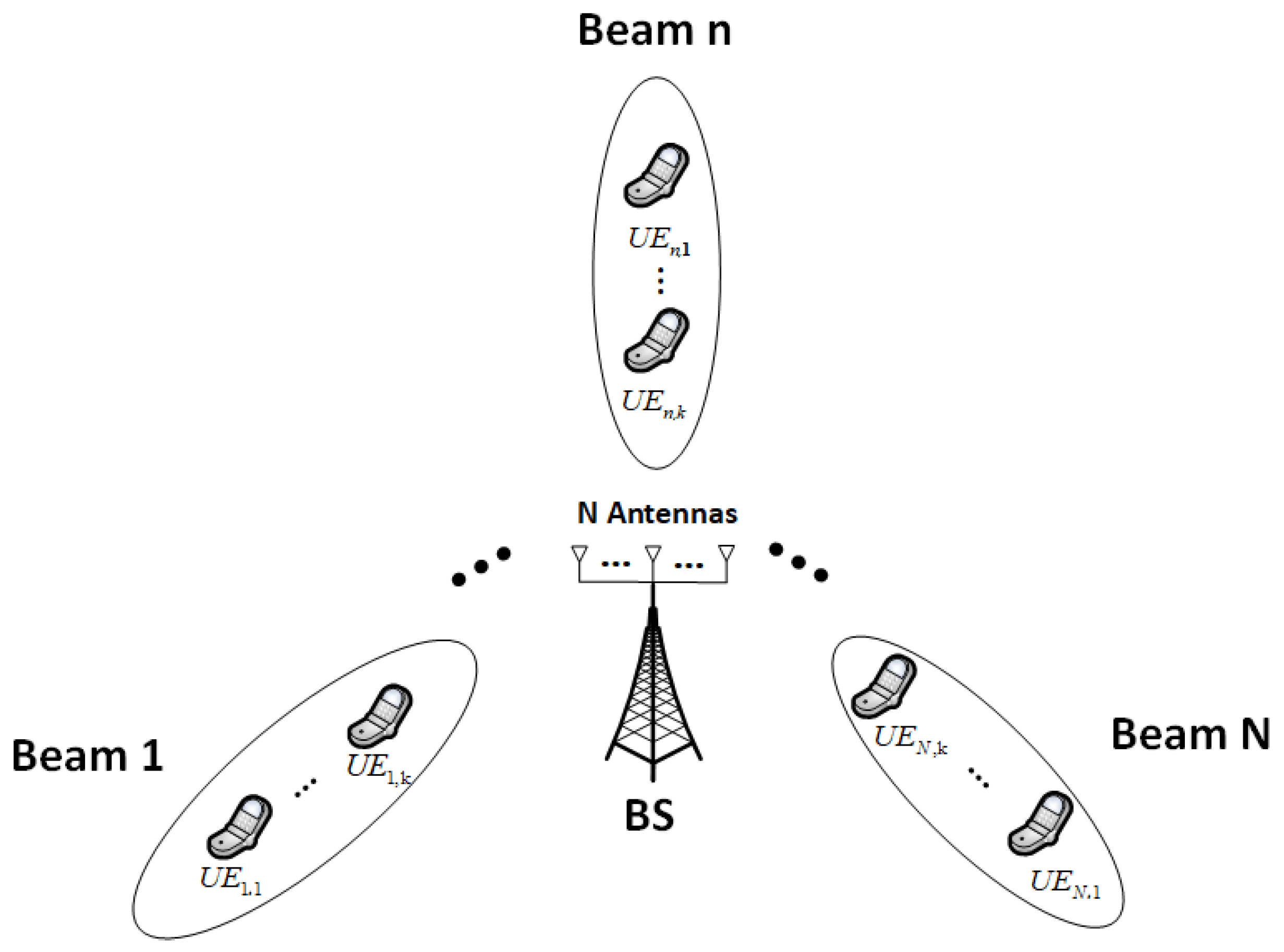
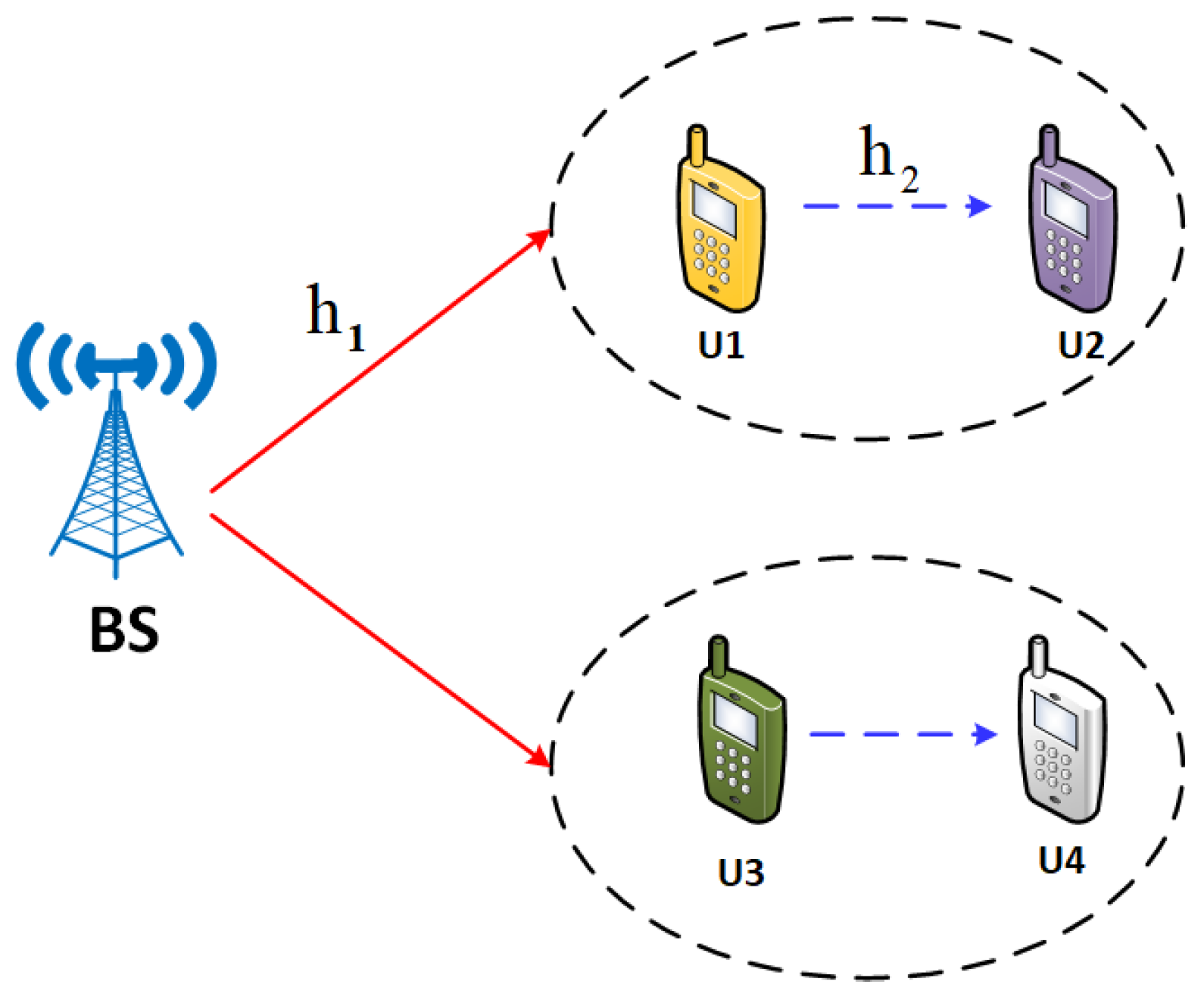
2. System Model
3. Methods
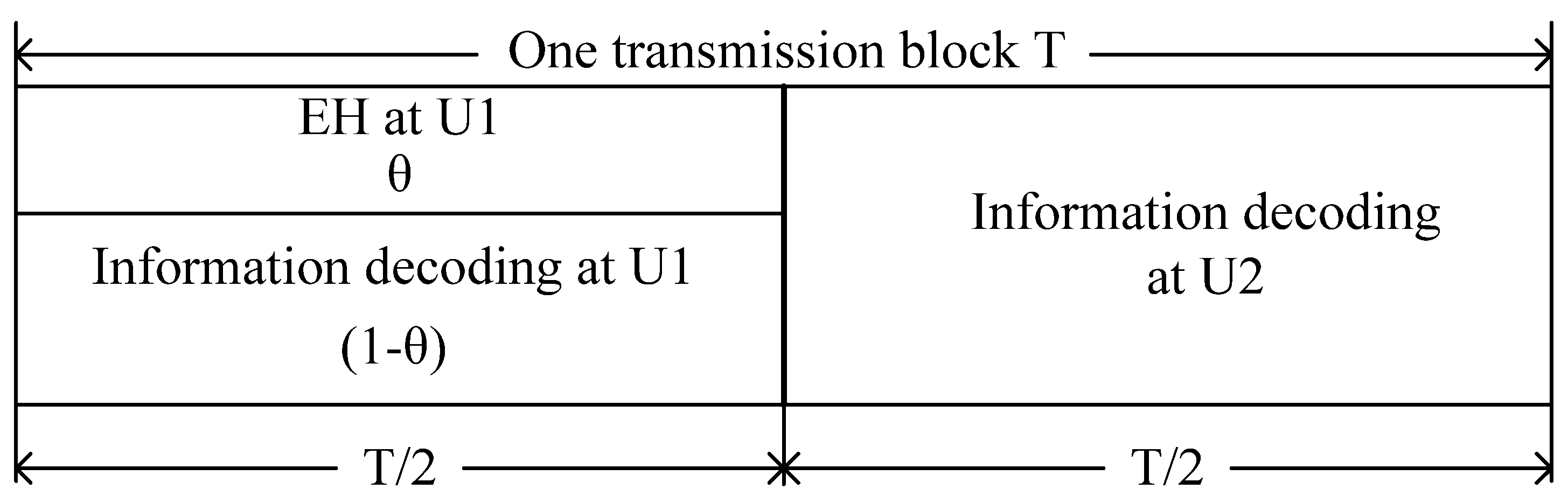
3.1. Transmission Protocol
3.2. Achievable Rates
4. DRL-Based User-Pairing NOMA Scheme
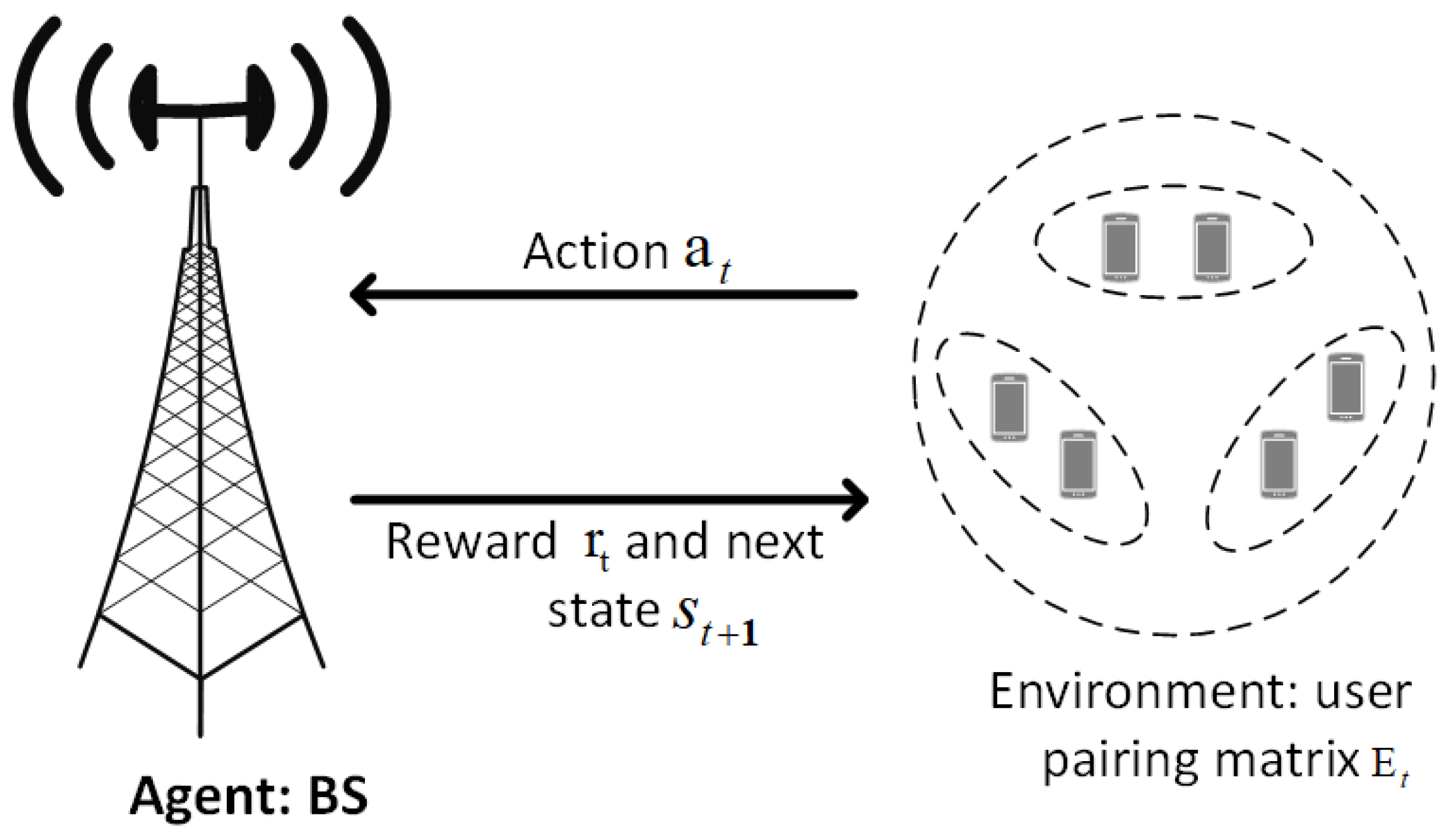
4.1. DRL Based Downlink SWIPT
4.2. Optimal Power Allocation and User Pairing Based on Q-Learning Algorithm
| Algorithm 1 The proposed NOMA system with the DRL |
| Input: iterations , action set , decay factor , Actor neural network , Critic neural network |
| Output: Actor network parameters , Critic network parameters |
| Initialize , |
| for from 1 to ( is not terminal): |
| , take action , observe |
| Collect and save sample |
| Calculate TD-error through Citric network |
| Update Critic network according to Mean square error loss function |
| Update Actor network |
| end for |
| return |
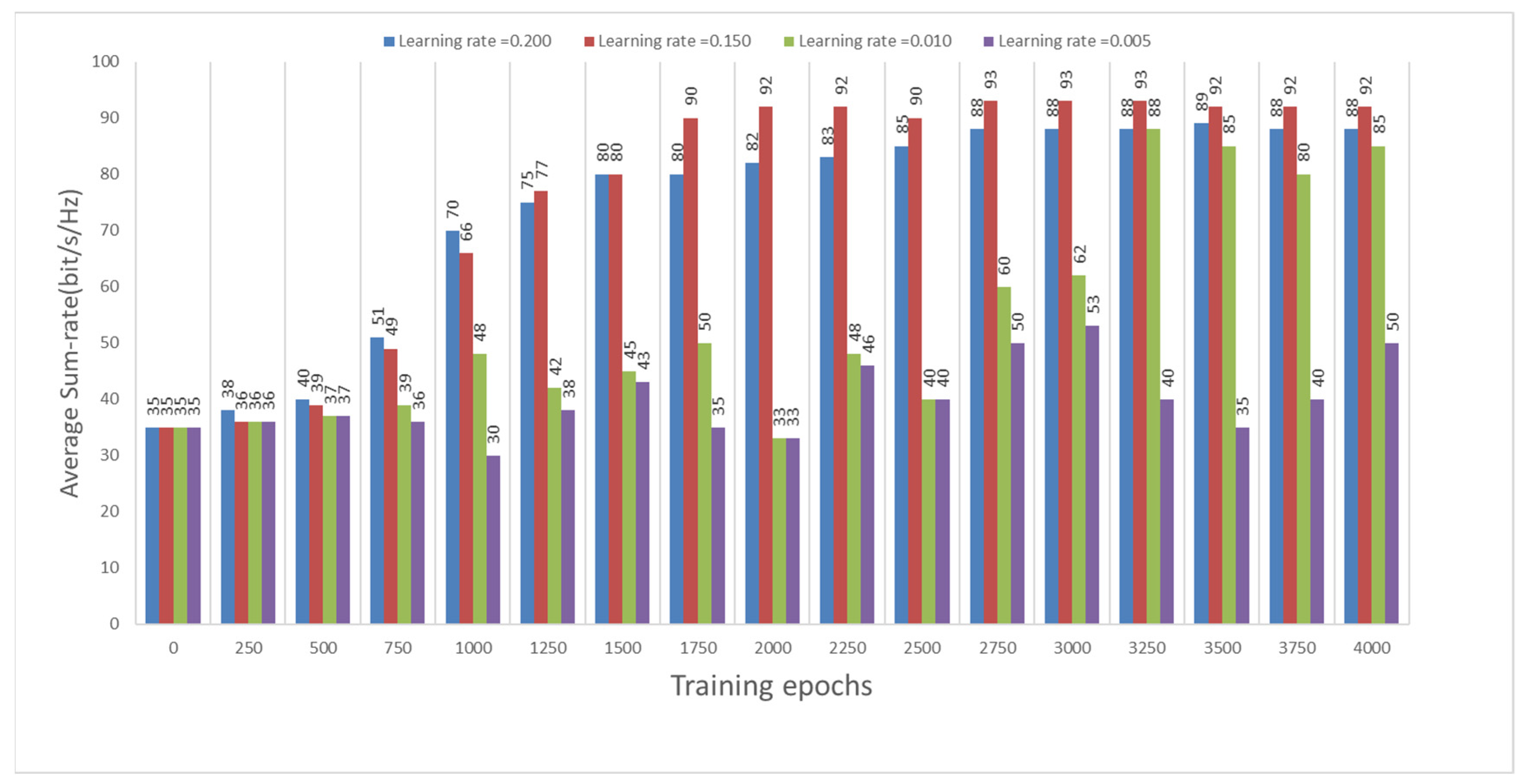
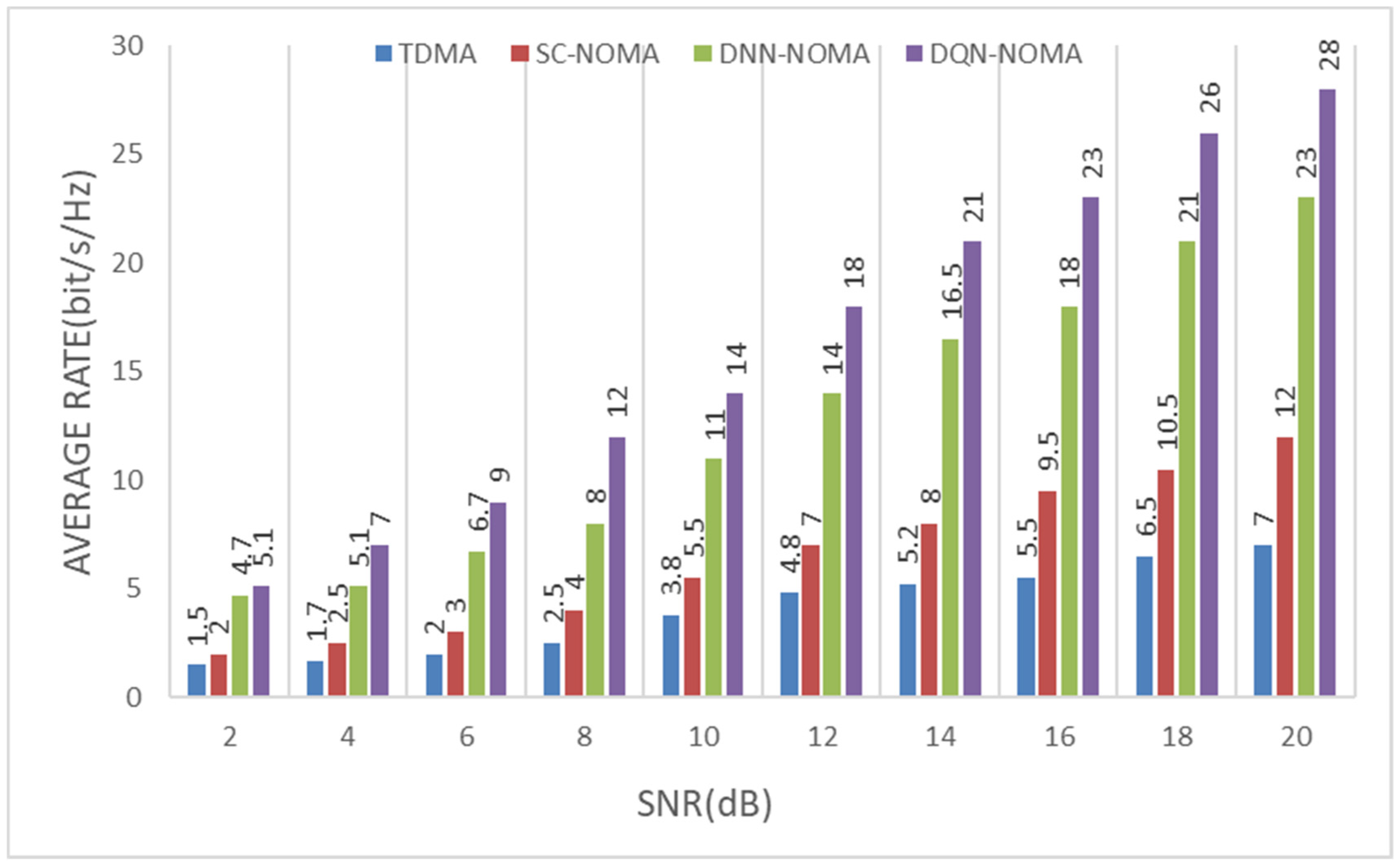
5. Simulation Results
5.1. Simulation Settings
5.2. Simulation Analysis by Considering Frequency Flat Fading Conditions without Node Mobility
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, C.-X.; Huang, J.; Wang, H.; Gao, X.; You, X.; Hao, Y. 6G Wireless Channel Measurements and Models: Trends and Challenges. IEEE Veh. Technol. Mag. 2020, 15, 22–32. [Google Scholar] [CrossRef]
- de Lima, C.; Belot, D.; Berkvens, R.; Bourdoux, A.; Dardari, D.; Guillaud, M.; Isomursu, M.; Simona Lohan, E.; Miao, Y.; Barreto, A.N.; et al. Convergent Communication, Sensing and Localization in 6G Systems: An Overview of Technologies, Opportunities and Challenges. IEEE Access 2021, 9, 26902–26925. [Google Scholar] [CrossRef]
- Tataria, H.; Shafi, M.; Molisch, A.F.; Dohler, M.; Sjöland, H.; Tufvesson, F. 6G Wireless Systems: Vision, Requirements, Challenges, Insights, and Opportunities. Proc. IEEE 2021, 109, 1166–1199. [Google Scholar] [CrossRef]
- Rezvani, S.; Jorswieck, E.A.; Joda, R.; Yanikomeroglu, H. Optimal Power Allocation in Downlink Multicarrier NOMA Systems: Theory and Fast Algorithms. IEEE J. Sel. Areas Commun. 2022, 40, 1162–1189. [Google Scholar] [CrossRef]
- Mothukuri, V.; Khare, P.; Parizi, R.M.; Pouriyeh, S.; Dehghantanha, A.; Srivastava, G. Federated-Learning-Based Anomaly Detection for IoT Security Attacks. IEEE Internet Things J. 2022, 9, 2545–2554. [Google Scholar] [CrossRef]
- Hui, H.; Zhou, C.; Xu, S.; Lin, F. A novel secure data transmission scheme in industrial internet of things. China Commun. 2020, 17, 73–88. [Google Scholar] [CrossRef]
- Tseng, L.; Wong, L.; Otoum, S.; Aloqaily, M.; Othman, J.B. Blockchain for Managing Heterogeneous Internet of Things: A Perspective Architecture. IEEE Netw. 2020, 34, 16–23. [Google Scholar] [CrossRef]
- Qiu, C.; Yao, H.; Jiang, C.; Guo, S.; Xu, F. Cloud Computing Assisted Blockchain-Enabled Internet of Thing. IEEE Trans. Cloud Comput. 2022, 10, 247–257. [Google Scholar] [CrossRef]
- Xiang, Z.; Yang, W.; Cai, Y.; Ding, Z.; Song, Y.; Zou, Y. NOMA-Assisted Secure Short-Packet Communications in IoT. IEEE Wirel. Commun. 2020, 27, 8–15. [Google Scholar] [CrossRef]
- Dai, L.; Wang, B.; Yuan, Y.; Han, S.; Chih-lin, I.; Wang, Z. Non-orthogonal multiple access for 5G: Solutions, challenges, opportunities, and future research trends. IEEE Commun. Mag. 2015, 53, 74–81. [Google Scholar] [CrossRef]
- Suo, L.; Li, H.; Zhang, S.; Li, J. Successive interference cancellation and alignment in K-user MIMO interference channels with partial unidirectional strong interference. China Commun. 2022, 19, 118–130. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, X. NOMA-Based Resource Allocation for Cluster-Based Cognitive Industrial Internet of Things. IEEE Trans. Ind. Inform. 2020, 16, 5379–5388. [Google Scholar] [CrossRef]
- Nezhadmohammad, P.; Abedi, M.; Emadi, M.J.; Wichman, R. SWIPT-Enabled Multiple Access Channel: Effects of Decoding Cost and Non-Linear EH Model. IEEE Trans. Commun. 2022, 70, 306–316. [Google Scholar] [CrossRef]
- Luo, Y.; Pu, L. Practical Issues of RF Energy Harvest and Data Transmission in Renewable Radio Energy Powered IoT. IEEE Trans. Sustain. Comput. 2021, 6, 667–678. [Google Scholar] [CrossRef]
- Ding, Z. Harvesting Devices’ Heterogeneous Energy Profiles and QoS Requirements in IoT: WPT-NOMA vs BAC-NOMA. IEEE Trans. Commun. 2021, 69, 2837–2850. [Google Scholar] [CrossRef]
- Baidas, M.W.; Bahbahani, Z.; Alsusa, E. User association and channel assignment in downlink multi-cell NOMA networks: A matching-theoretic approach. EURASIP J. Wirel. Commun. Netw. 2019, 2019, 220. [Google Scholar] [CrossRef]
- Mokhtari, F.; Mili, M.R.; Eslami, F.; Ashtiani, F.; Makki, B.; Mirmohseni, M.; Nasiri-Kenari, M.; Svensson, T. Download elastic traffic rate optimization via NOMA protocols. IEEE Trans. Veh. Technol. 2019, 68, 713–727. [Google Scholar] [CrossRef]
- Baghani, M.; Parsaeefard, S.; Derakhshani, M.; Saad, W. Dynamic non-orthogonal multiple access (NOMA) and orthogonal multiple access (OMA) in 5G wireless networks. IEEE Trans. Commun. 2019, 69, 1. [Google Scholar]
- Ghous, M.; Hassan, A.K.; Abbas, Z.H.; Abbas, G. Modeling and analysis of self-interference impaired two-user cooperative MIMO-NOMA system. Phys. Commun. 2021, 48, 101441. [Google Scholar] [CrossRef]
- Ghous, M.; Abbas, Z.; Hassan, A.; Abbas, G.; Baker, T.; Al-Jumeily, D. Performance Analysis and Beamforming Design of a Secure Cooperative MISO-NOMA Network. Sensors 2021, 12, 4180. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International conference on machine learning, PMLR 2019, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Huang, S.Y.; Chu, W.T. Searching by generating: Flexible and efficient one-shot NAS with architecture generator. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 983–992. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Numerical Value |
|---|---|
| Distance between two users | 12 m |
| Net transfer bandwidth | 800 MHz |
| Carrier frequency | 100 GHz |
| Transmit power of BS | 40–100 W |
| Path loss index of the channel | 3 |
| AWGN noise spectral density | −170 dBm/Hz |
| Quality of service threshold | 2.5 bps/Hz |
| Noise figure | 5 dB |
| Parameter | Minimum Epochs of Achieving Convergence (k) | Average Sum-Rate (bit/s/Hz) | |
|---|---|---|---|
| learning rate lr | lr = 0.005 | 2.7 | 53 |
| lr = 0.010 | 3.2 | 80 | |
| lr = 0.150 | 2.0 | 93 | |
| lr = 0.20 | 2.7 | 88 | |
| decay factor | 3.0 | 80 | |
| 2.5 | 90 | ||
| 3.2 | 82 | ||
| exploration rate | 2.0 | 93 | |
| 2.8 | 88 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, W.; Ding, X.; Cai, B.; Li, X.; Wei, M. Downlink MIMO-NOMA System for 6G Internet of Things. Electronics 2022, 11, 3233. https://doi.org/10.3390/electronics11193233
Xie W, Ding X, Cai B, Li X, Wei M. Downlink MIMO-NOMA System for 6G Internet of Things. Electronics. 2022; 11(19):3233. https://doi.org/10.3390/electronics11193233
Chicago/Turabian StyleXie, Weiliang, Xue Ding, Bowen Cai, Xiao Li, and Mingshuo Wei. 2022. "Downlink MIMO-NOMA System for 6G Internet of Things" Electronics 11, no. 19: 3233. https://doi.org/10.3390/electronics11193233
APA StyleXie, W., Ding, X., Cai, B., Li, X., & Wei, M. (2022). Downlink MIMO-NOMA System for 6G Internet of Things. Electronics, 11(19), 3233. https://doi.org/10.3390/electronics11193233