4.1. Implementation Details
(1) Computation Platform: We ran our method in a NVIDIA Tesla V100 GPU (with 16G memory), CUDA 11.2, and cuDNN 7.6 on Ubuntu 16.04. Our method was implemented with an end-to-end PaddleDetection Suite.
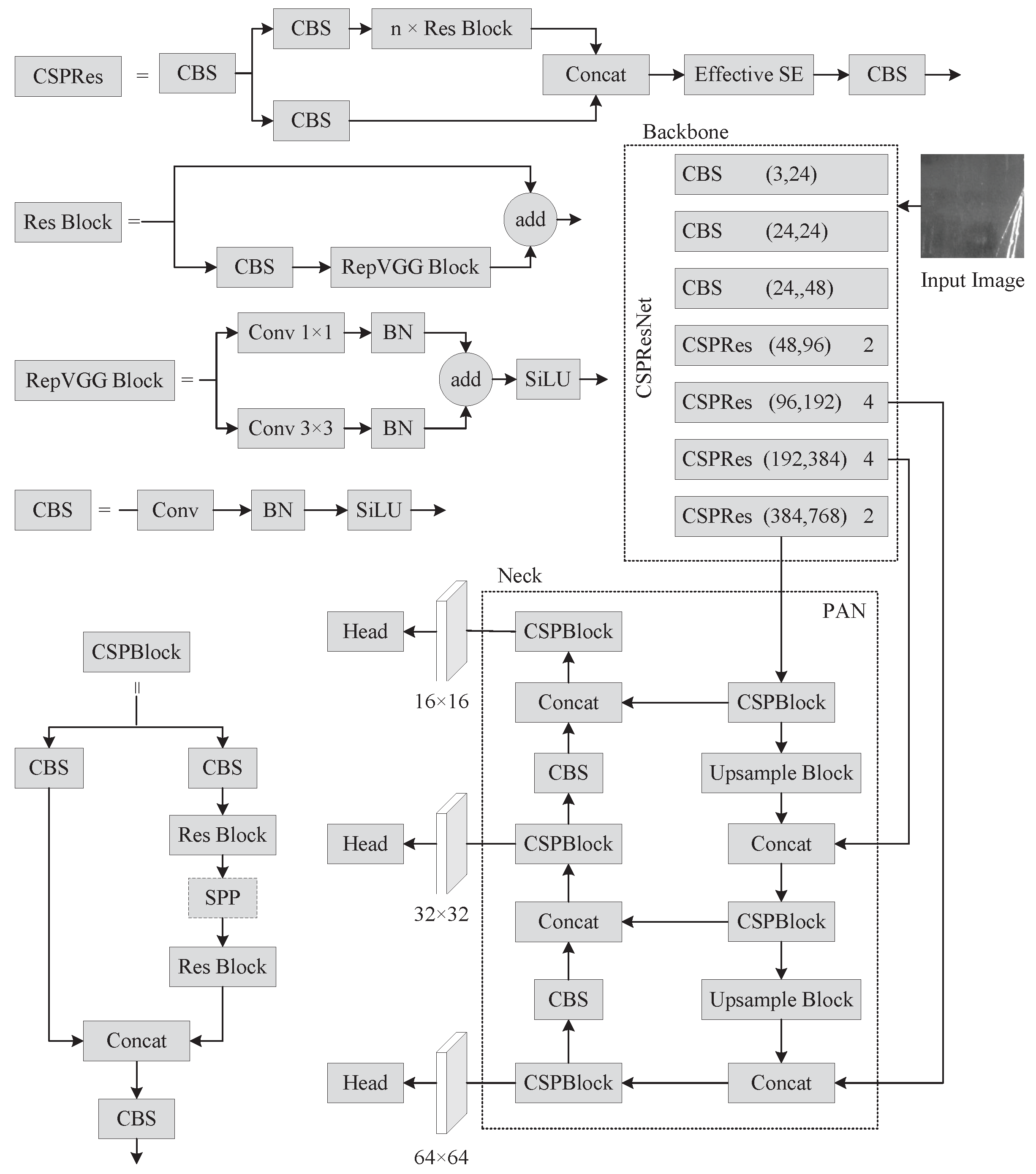
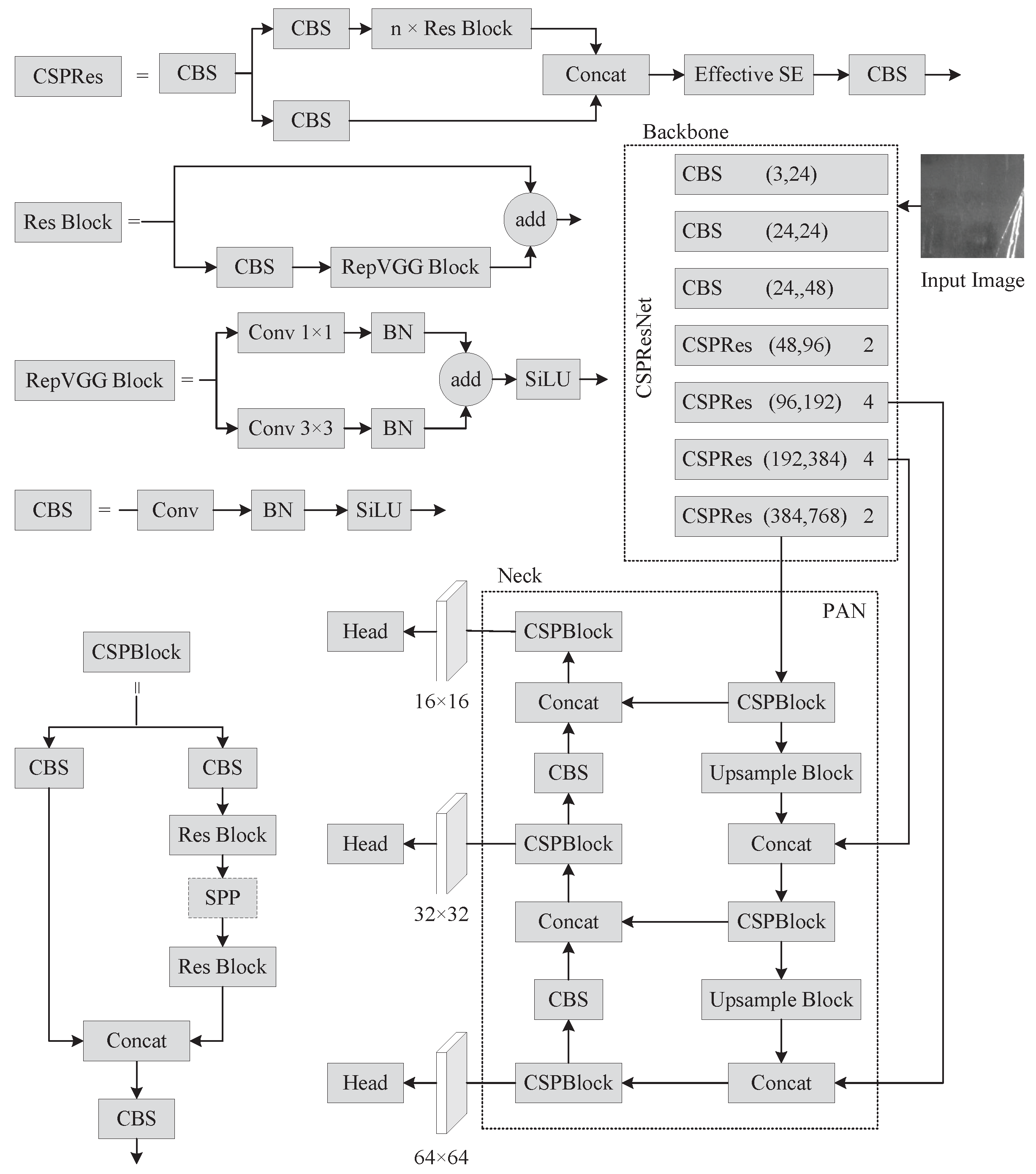
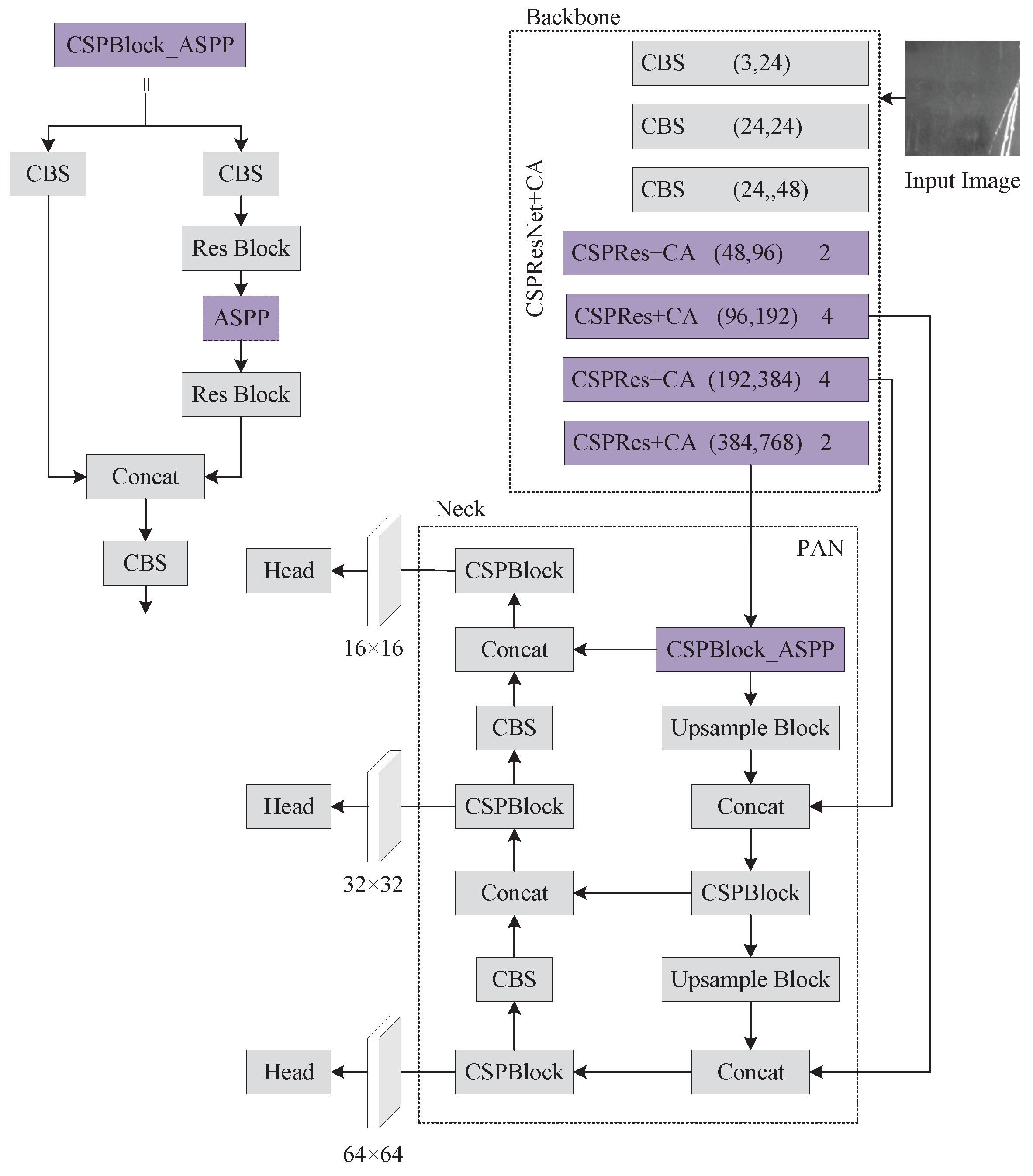
(2) Parameter Setting:The PP-YOLOE algorithm includes four network architectures with varying widths and depths, PP-YOLOE-s, PP-YOLOE-m, PP-YOLO-l, and PP-YOLO-x. We tested each of PP-YOLOE’s networks and found that PP-YOLOE-m performed the best.
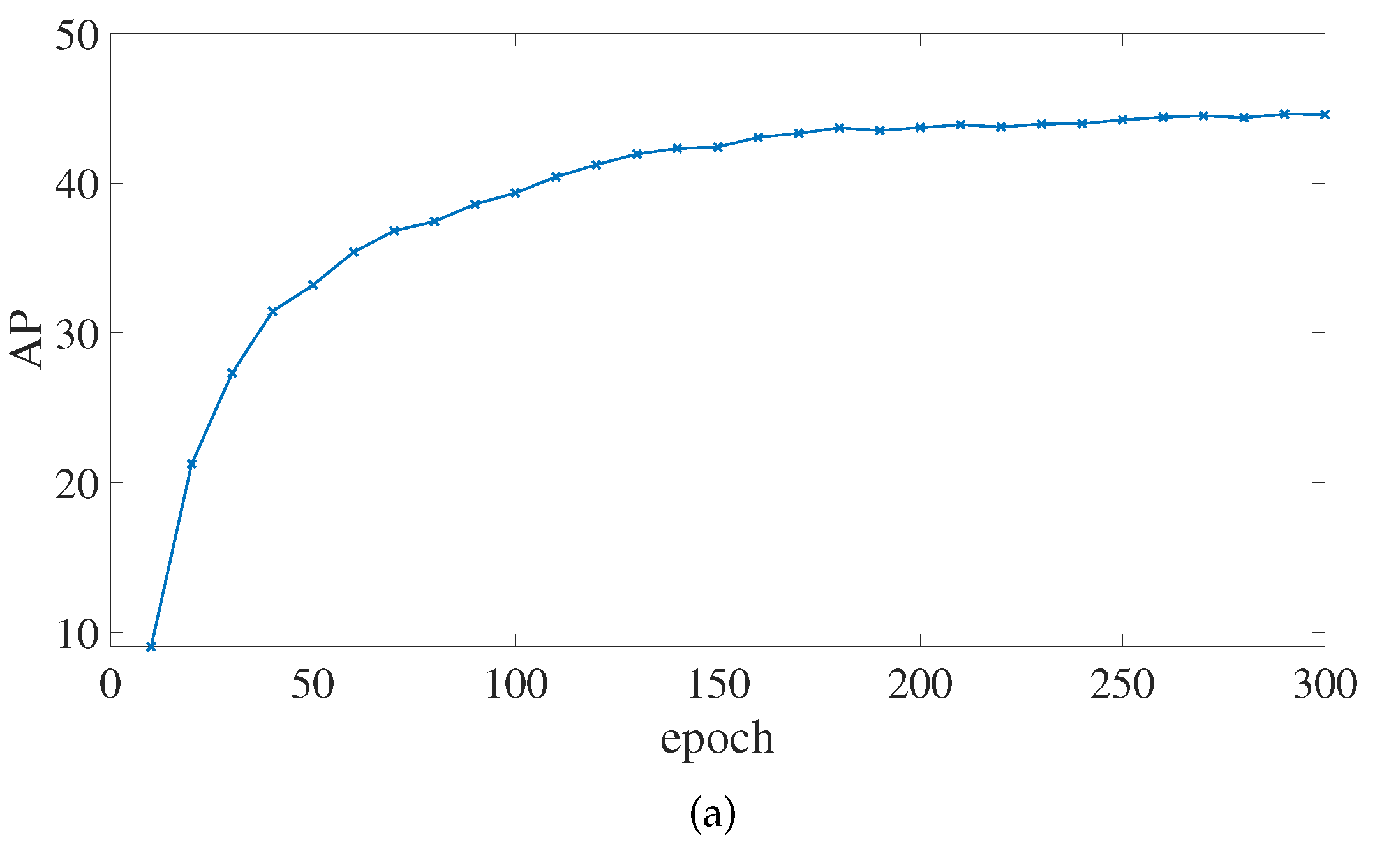
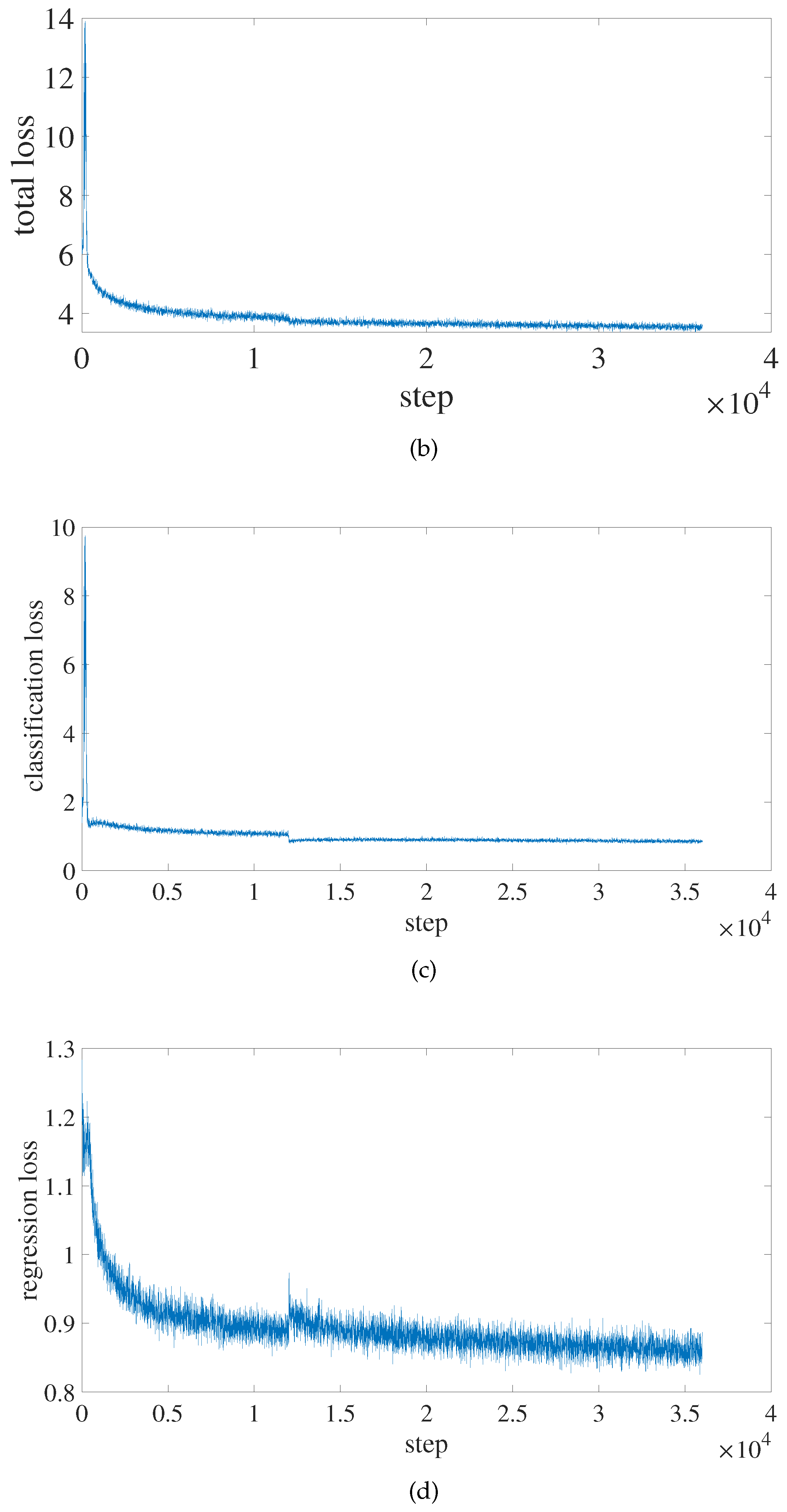
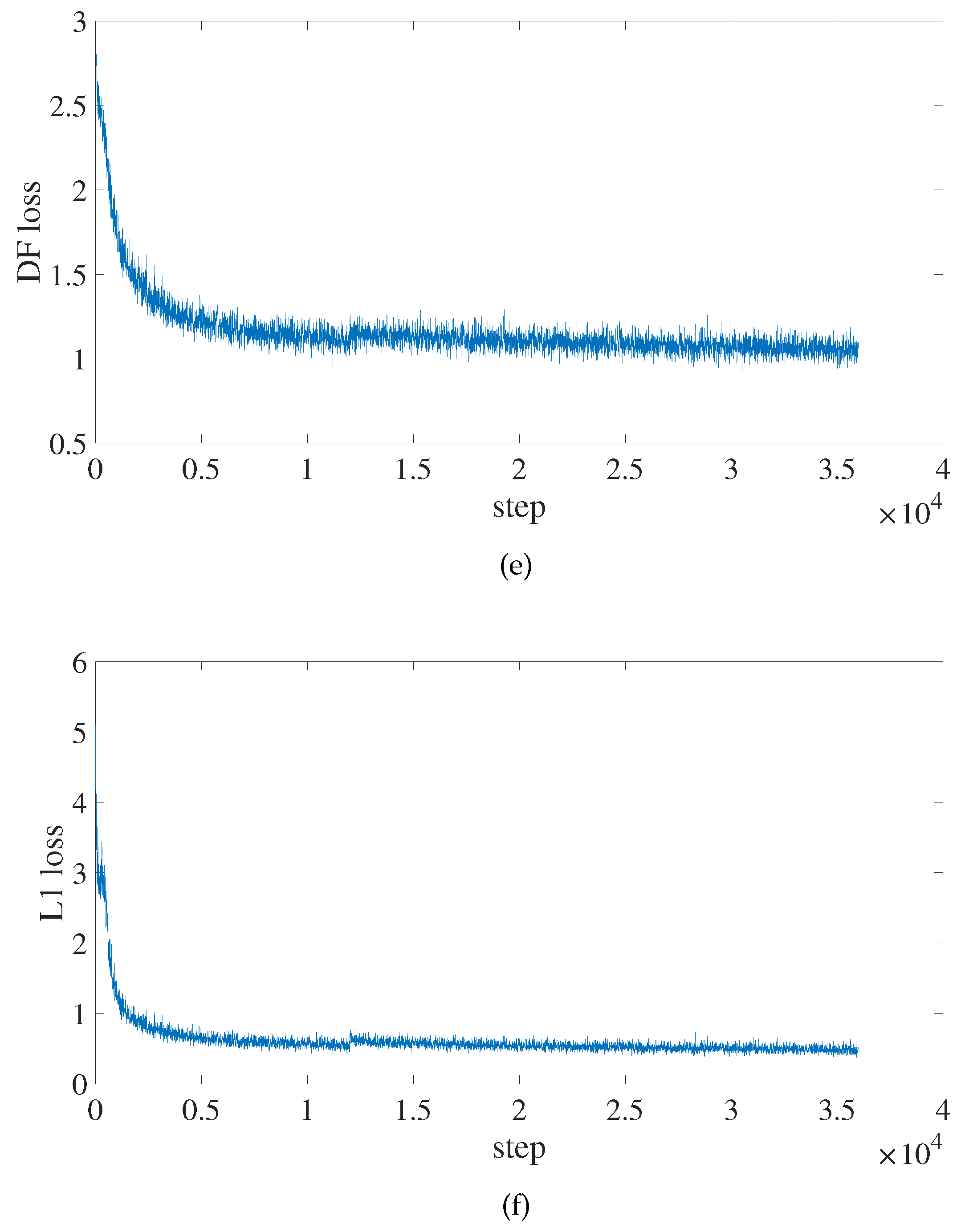
As a result, we chose PP-YOLOE-m as the baseline experiment, and all of the improvement trials in this study are based on it. During the training process, the input image be resized to , the CSPResNet backbone network be loaded with weights that had already been trained with the COCO2017 dataset, the network parameters are iteratively updated using the Momentum method with the initial momentum parameter set to 0.9, the initial learning rate set to 0.0035, the batch size set to 12, the trained epochs set to 300, and the model saved once every 10 epochs.
4.2. Defect Detection on NEU-DET
The NEU-DET dataset was divided into the training set and test set in an 8:2 ratio. 1440 pictures were fed to the network for training, and 360 pictures were used for testing the model. In terms of data augmentation, we attempted many tactics, including GridMask, Mixup, Mosaic, and AutoAugment; however, only AutoAugment was successful. In terms of network structure improvement, we attempted to add an additional detecting head; however, the experimental results were unsatisfactory.
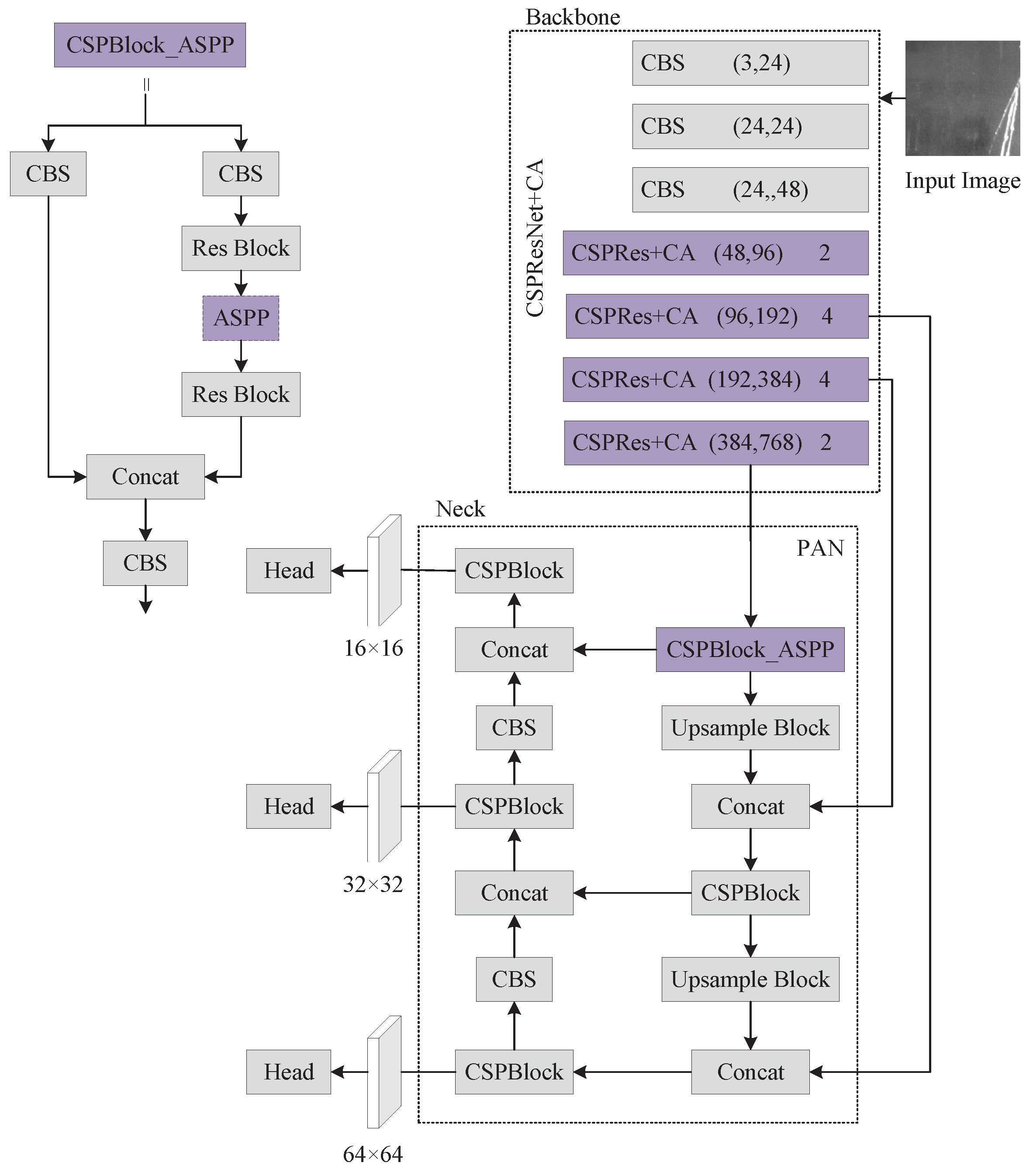
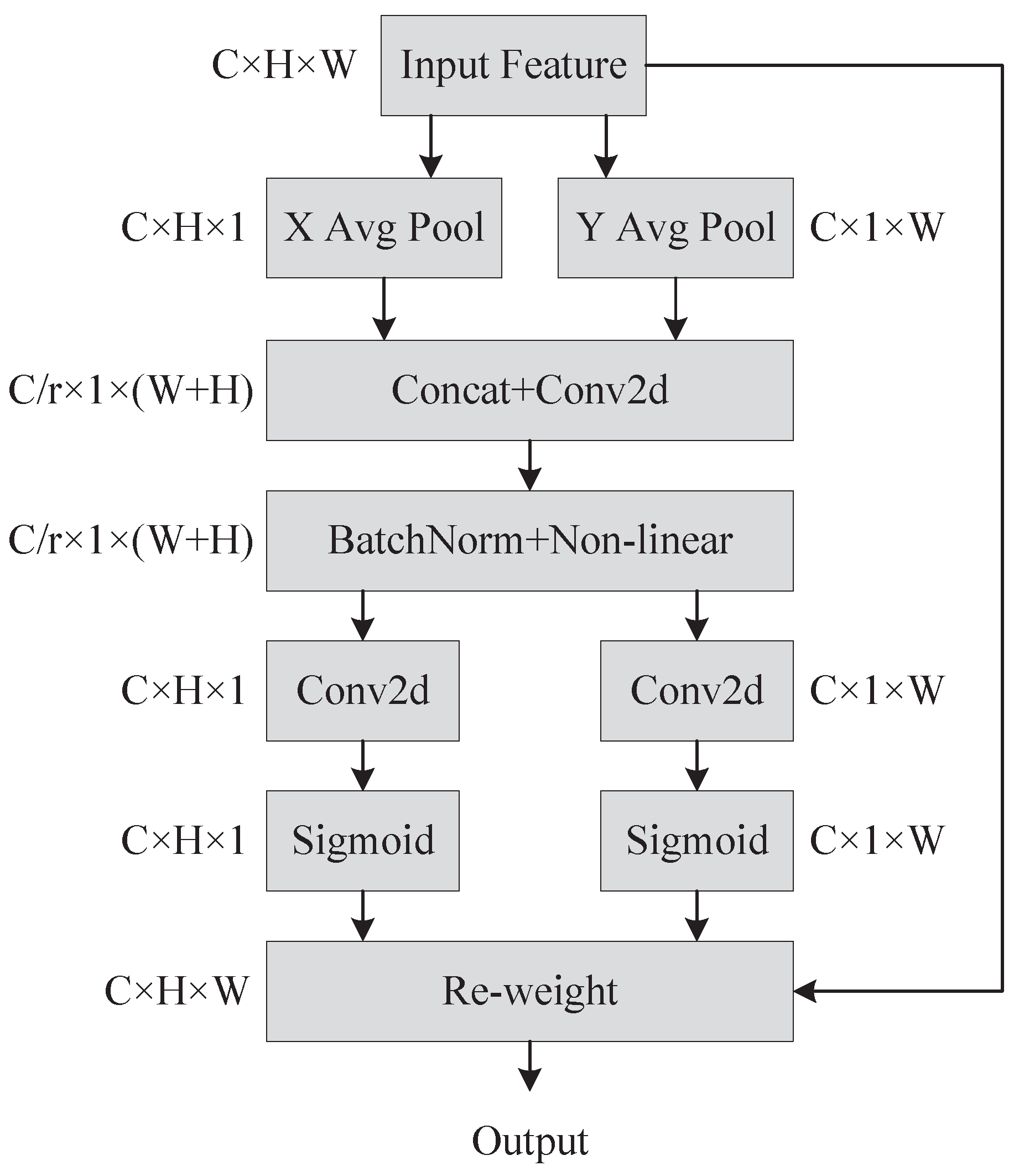
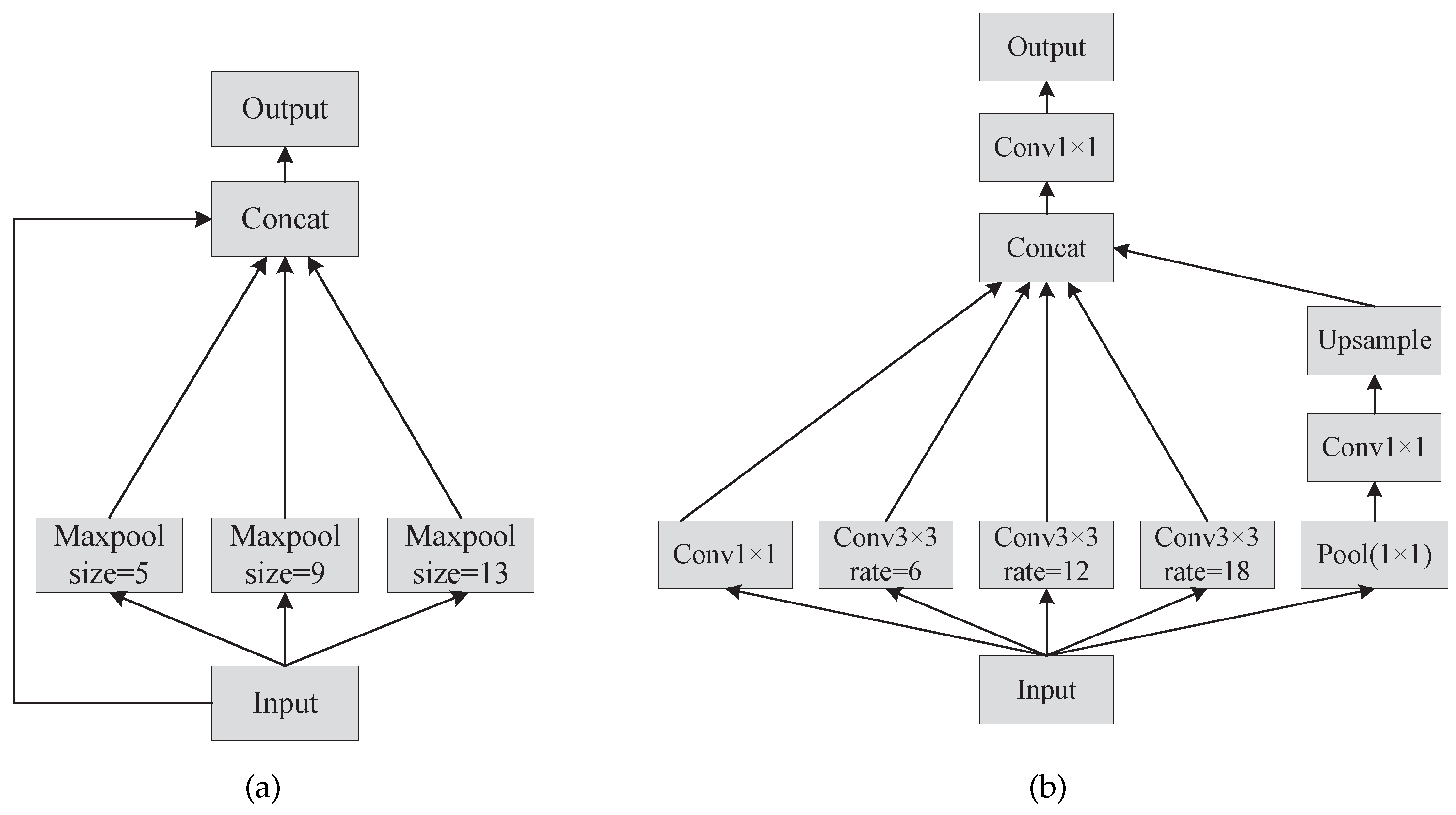
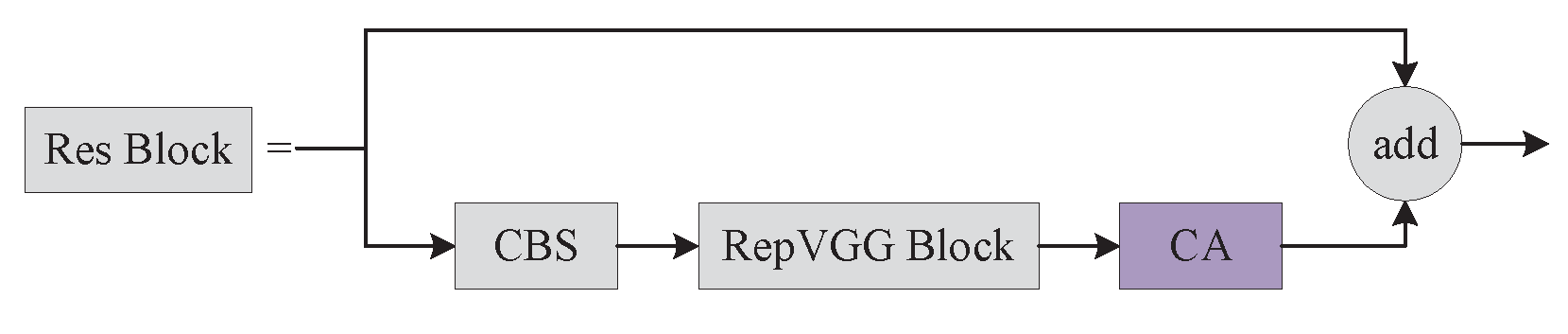
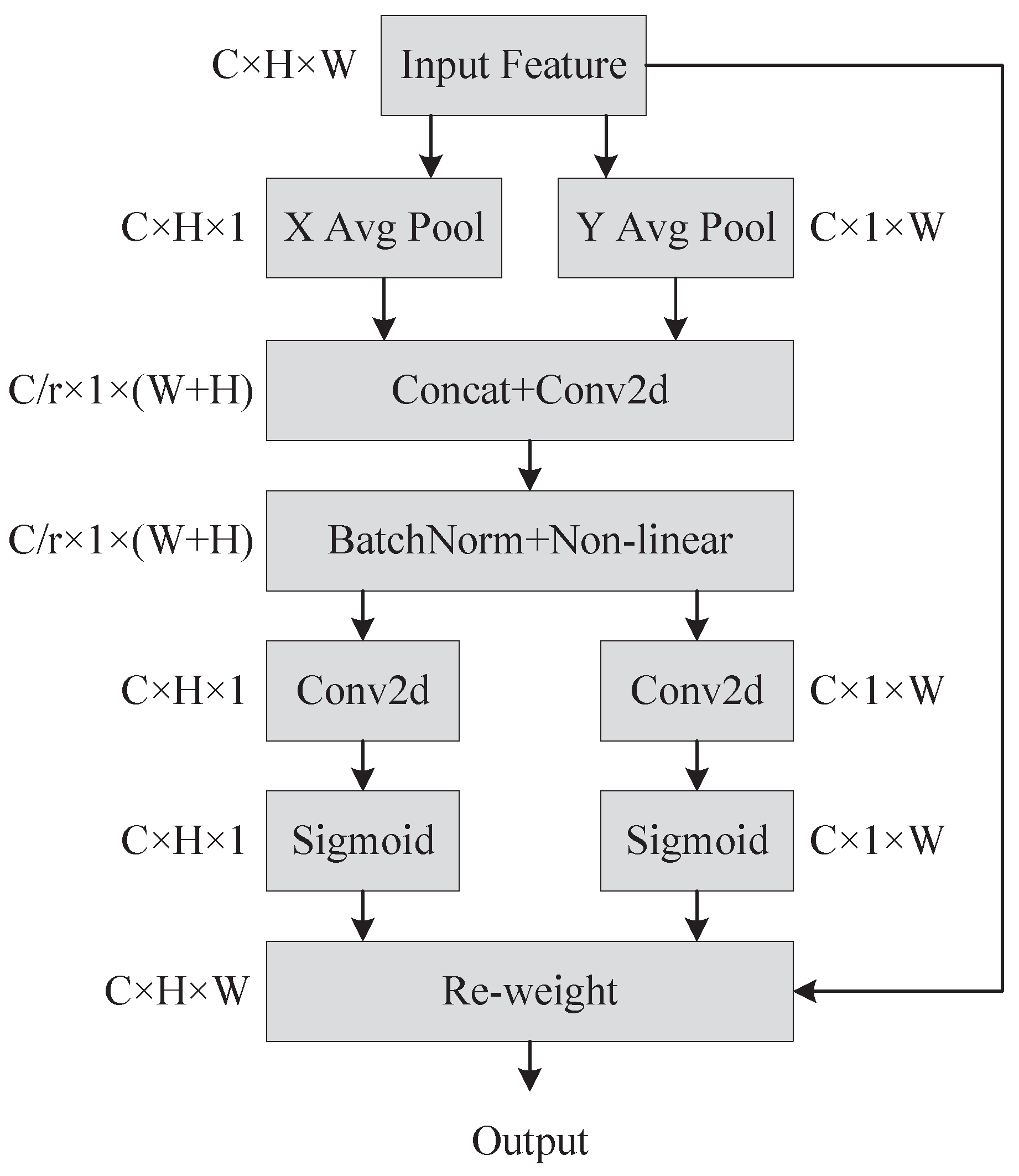
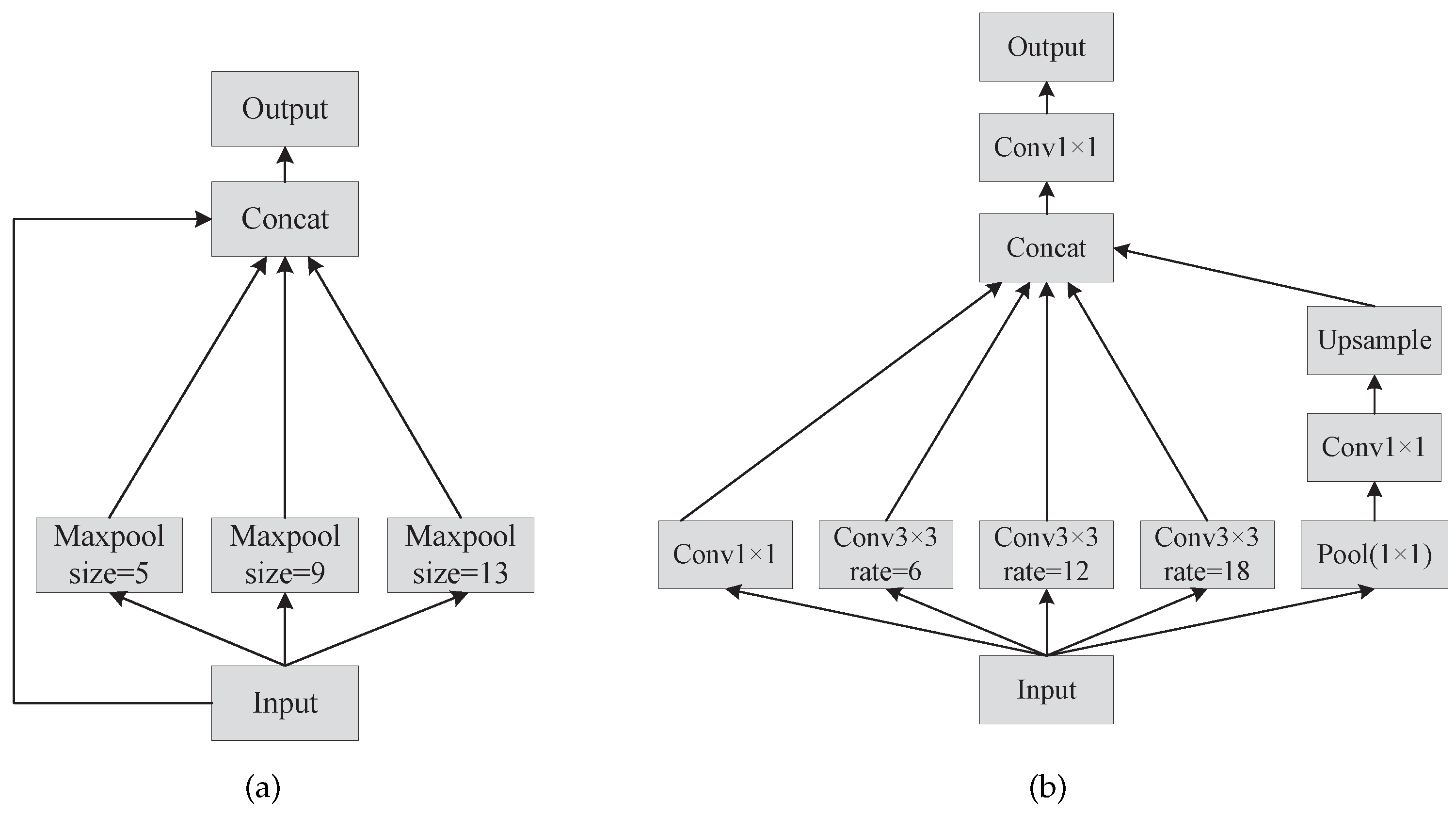
We attemptted to embed Coordinate Attention in various network locations with some success in the backbone network and the Neck. When we utilized ASPP pooling instead of SPP, we found that employing Coordinate Attention on PANet performed worse than not using it. Thus, we no longer embed coordinated attention in PANet. For the loss function, we used EIoU and SIoU loss functions, and SIoU outperformed EIoU in the experiment, which is the reason why we chose SIoU. Finally, we also conduct ablation experiments and compare the results of our improved approach to those of the most prevalent major object detection algorithms currently being used.
The Average Precision (AP) is used as an evaluation metric of experimental findings in this research. AP considers both precision and recall metrics. Precision and recall are defined as follows:
where
denotes the bounding box numbers of
,
denotes the bounding box numbers of
, and
denotes the ground truth that is not detected. For a continuous precision and recall relationship curve, AP is defined as follows:
In this paper, AP signifies the AP mean value of 0.5:0.05:0.95, AP signifies the AP value of , AP signifies the AP value of , AP signifies the AP value of 0.5:0.05:0.95 and for small objects, AP signifies the AP value of 0.5:0.05:0.95 and for medium objects, and AP signifies the AP value of 0.5:0.05:0.95 a and for large objects.
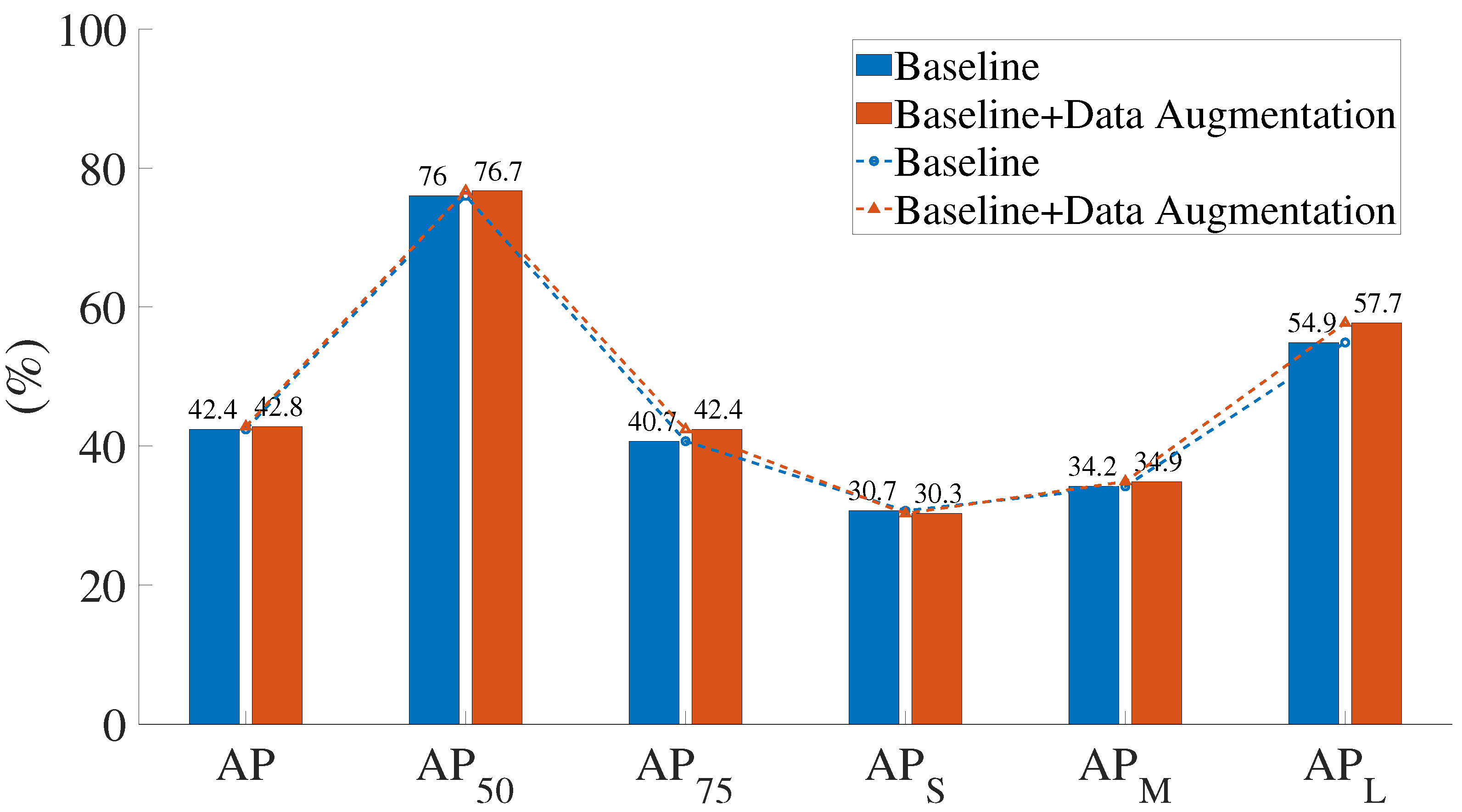
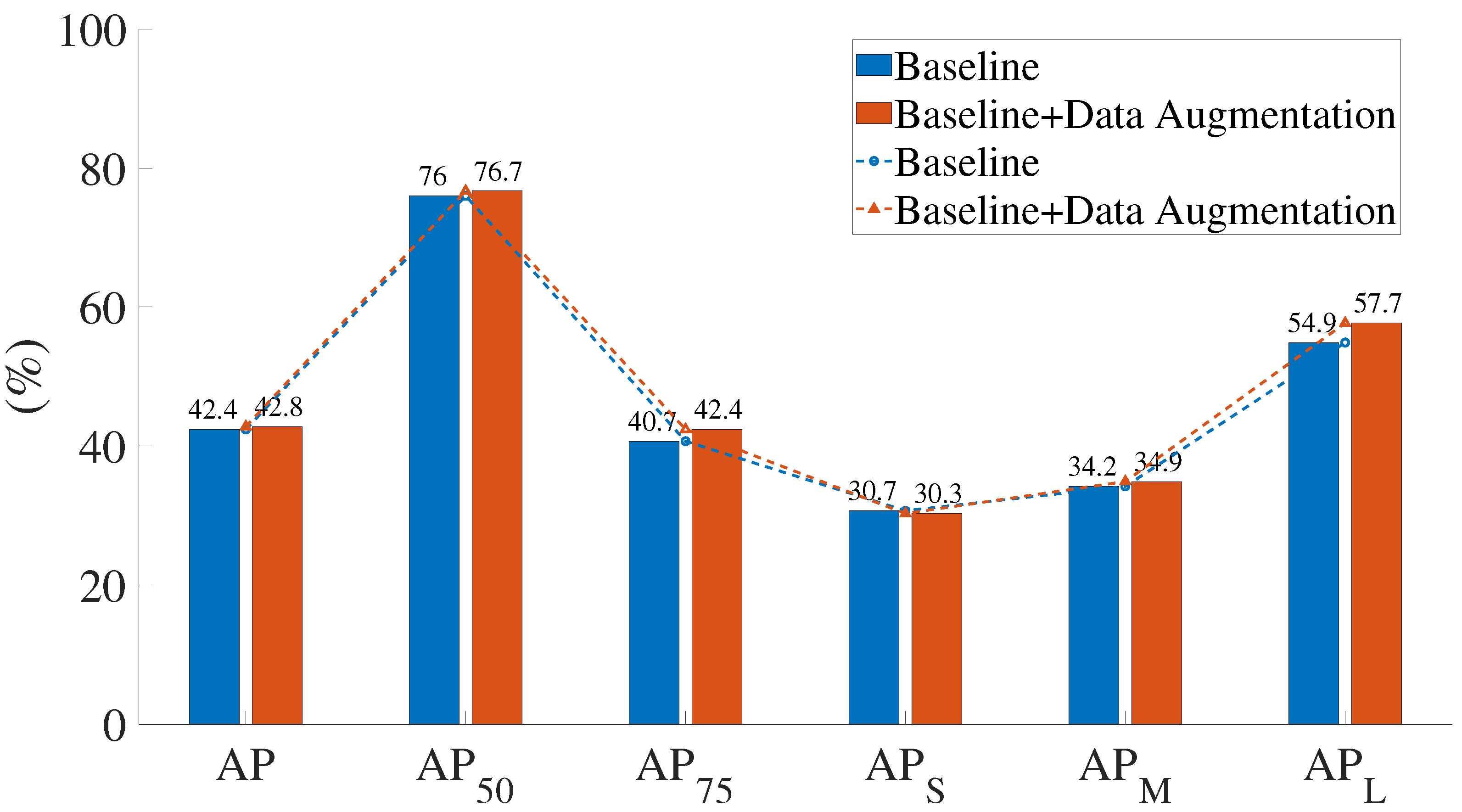
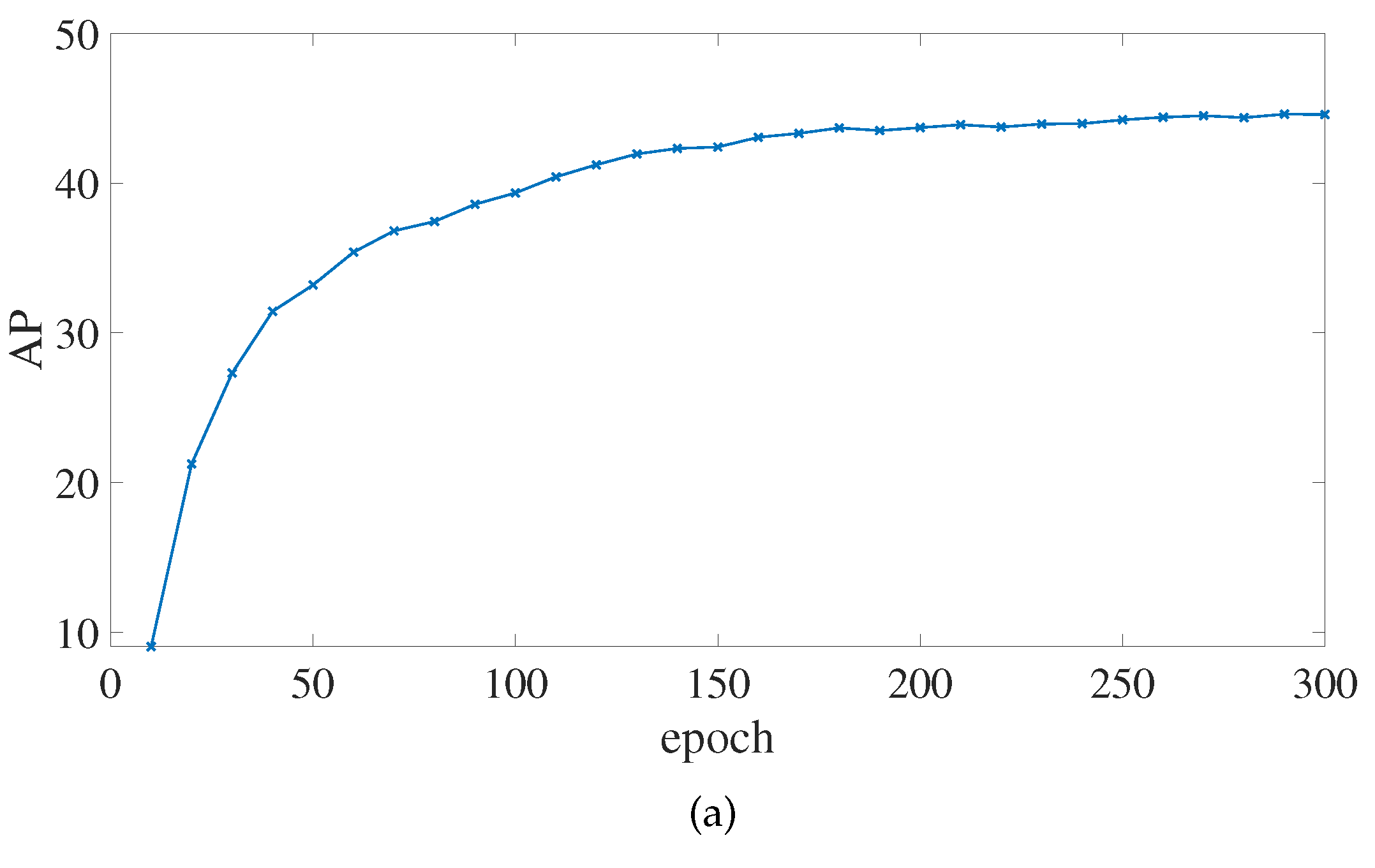
Figure 7 shows the comparison of the results before and after data augmentation of the PP-YOLOE-m network. When data augmentation is used, the AP
obviously improves by 1.7%. According to the AP
evaluation metrics, data augmentation does not boost the effectiveness of small object recognition. The AP
evaluation metrics show a significant improvement in detection precision for large objects, with a 2.8% improvement. With the exception of AP
, all indicators improved to varying degrees when the data augmentation was implemented.
Figure 8 shows a comparison of the heat map visualization results of the baseline experiment and embedding the Coordinate Attention’s network. The baseline network on the crazing (Cr) category defect did not concentrate on the defective region, and the embedding of Coordinate Attention was significantly improved. With the embedding of the Coordinate Attention, attention was primarily focused on areas with inclusion (In) category flaws rather than on extra regions with no faults as it had been in the baseline experiment.
On pitted surface (Ps) category defects, the embedding of Coordinate Attention focuses on the faulty area was more comprehensive than the baseline experiment’s focus on the defective region. The area of attention after embedding the Coordinate Attention was also better than the baseline experiment on patches (Pa), rolled-in scale (RS), and scratches (Sc) category defects. The experimental results show that the embedding Coordinate Attention strengthens the defect feature extraction capability of the backbone network and can obtain more defect location information.
We set up three separate sets of parameters for comparative studies in order to assess the influence of different rate expansion factors of ASPP modules on detection results. To avoid the impact of variable rate expansion factors on the detection results, this study directly replaced the SPP module with the ASPP module with varied rate expansion factors for experiments based on the baseline model. A large expansion factor step, as illustrated in
Table 2, is not as beneficial for detection precision as a small expansion factor step. When we increased the small step size by one more expansion factor, this had the opposite effect of improving detection. Thus, we chose (1,6,12,18) as the expansion factors of ASPP.
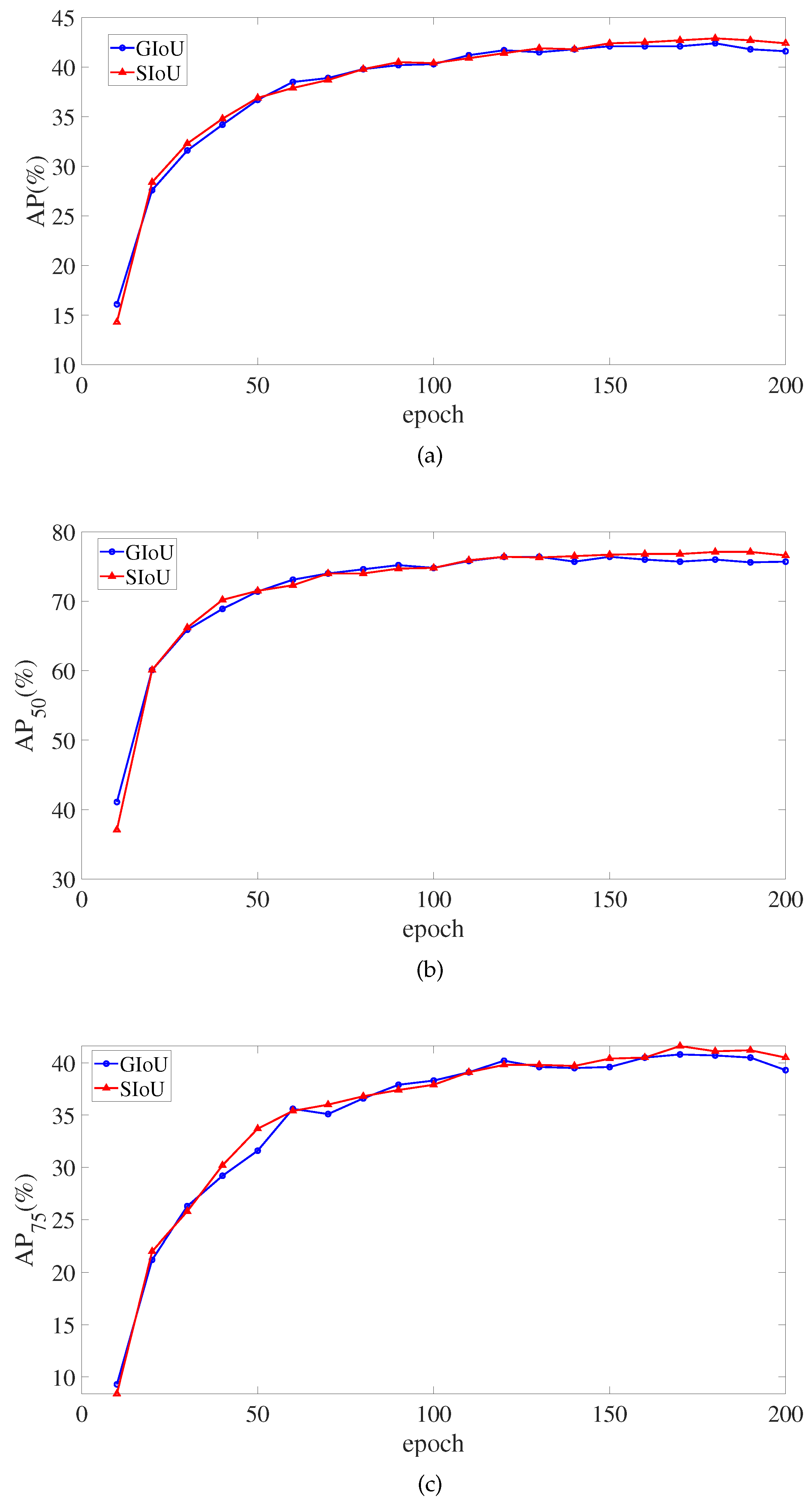
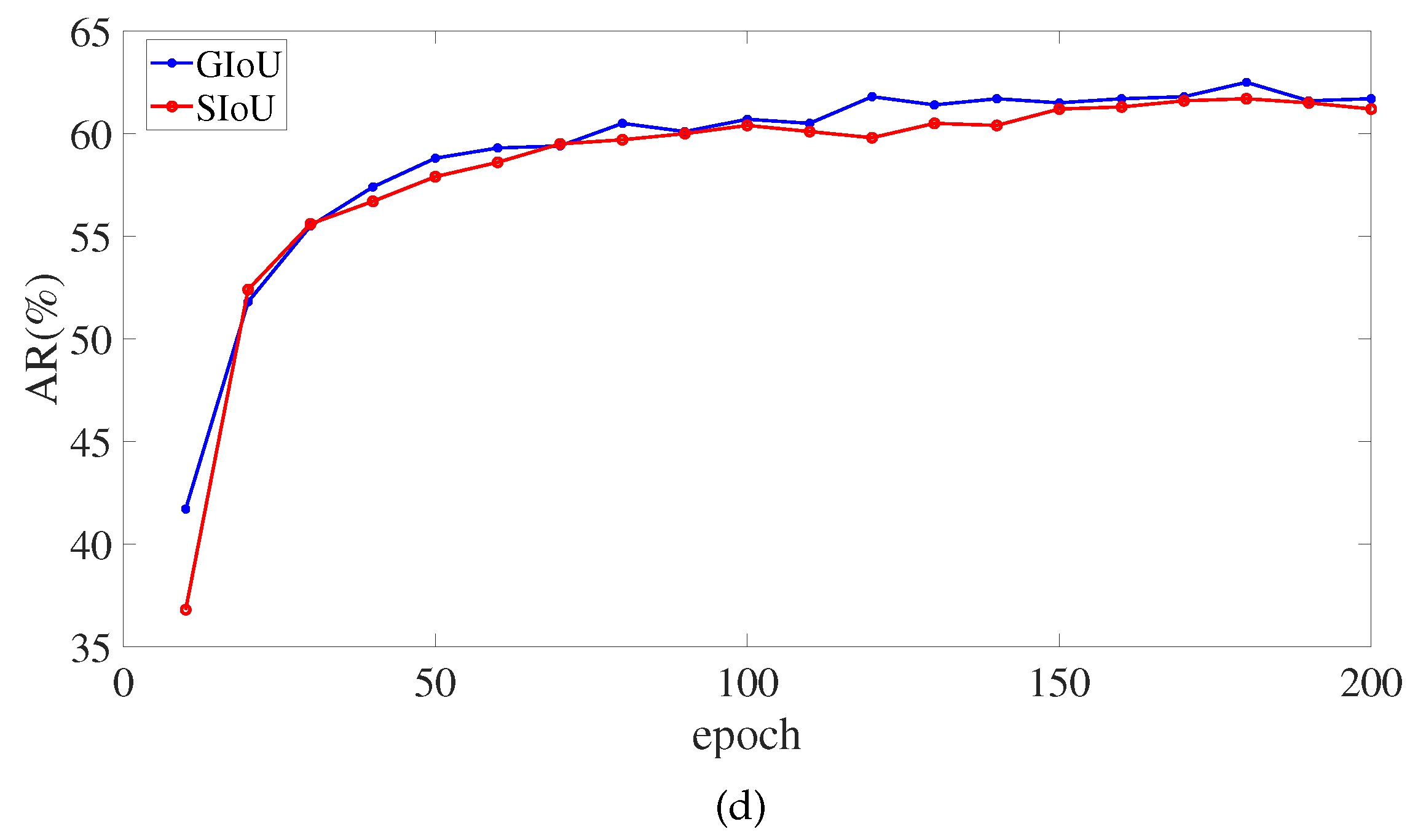
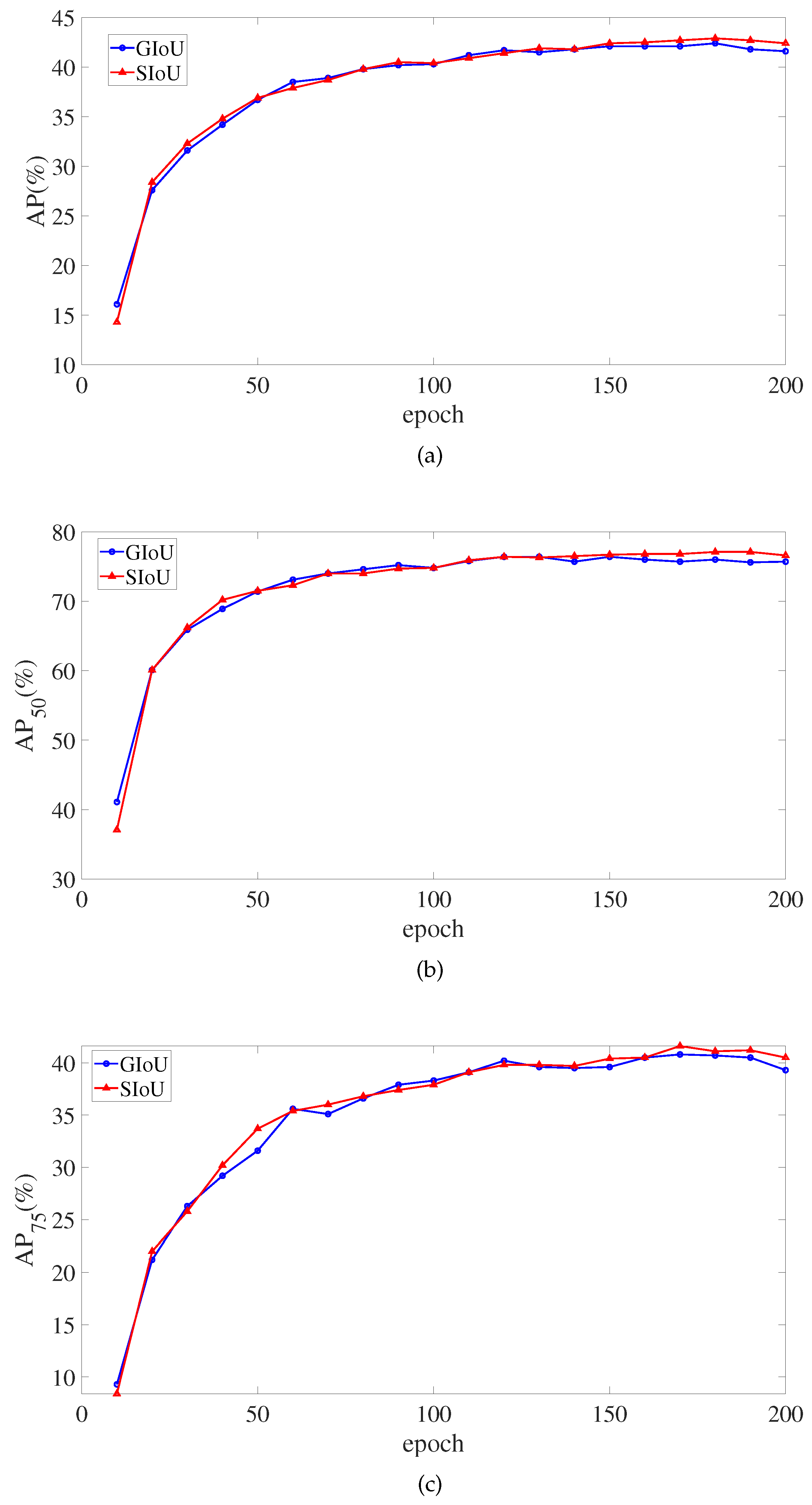
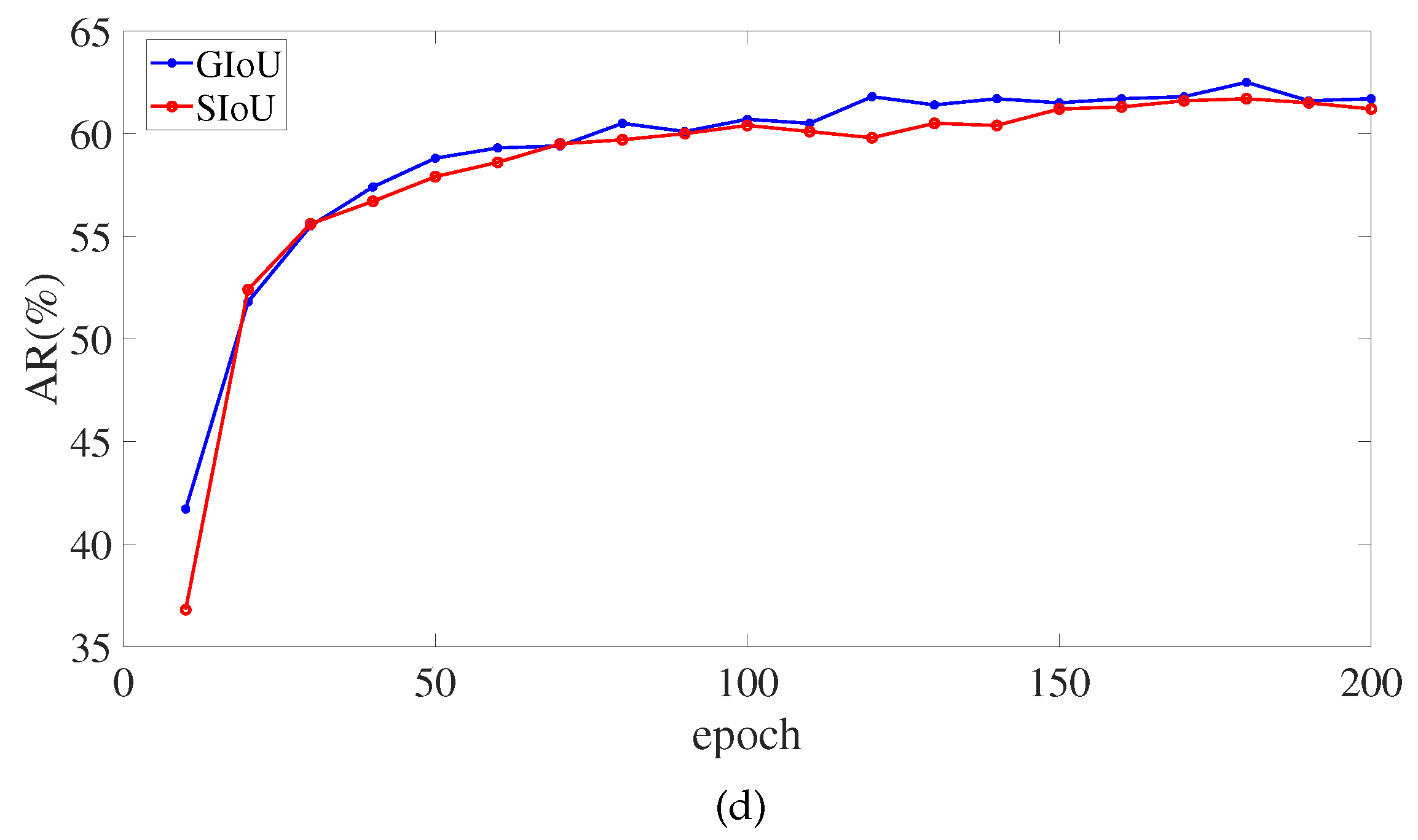
Figure 9 depicts the monitoring of critical SIoU and GIoU indicators in the training of the 200 epochs. In the around 150th epoch, the SIoU loss function’s AP, AP
, and AP
eventually surpasses the GIoU loss function. However, the SIoU loss function does not outperform GIoU loss function in Average Recall (AR) metrics. There, AR signifies the mean AR value of
0.5:0.05:0.95.
To verify the validity of the improvement on the baseline PP-YOLOE-m network, ablation experiments were conducted on the NEU-DET dataset in this paper. For each of the improvements in the baseline model PP-YOLOE-m, separate experiments were conducted, and from
Table 3, it can be seen that each improvement point improved the detection precision from the original. In particular, the average accuracy improvement is most obvious when the SPP module is replaced by the ASPP module, and AP, AP
, and AP
improved by 1.3%, 2.5%, and 1.6%, respectively.
The ASPP pooling approach expands the receptive fields and obtains more global information on strip defects. AP, AP, and AP are further improved by using the SIoU loss function based on the data enhancement. Embedding CA attention mechanism and the ASPP module replacing the SPP module are improvements belonging to the network structure, and we conducted experiments on the combination of these two.The average precision was better than the results of the experiments conducted separately, and the AP substantially improved.
The CA attention mechanism captures more information and enhances the backbone network for strip defect feature extraction ability. We conducted experiments with data augmentation and using SIoU loss function based on the improved network structure, respectively, and the average precision was improved to an extent.
Table 4 shows the detection results of the current mainstream algorithms on NEU-DET data. The improved PP-YOLOE-m has the best detection precision, with AP, AP
, and AP
reaching 44.6%, 80.3%, 45.3%, respectively. In terms of speed, it is slightly slower than the original PP-YOLOE-m. Compared with YOLOv4, the best performing one-stage algorithm on the NEU-DET dataset, AP, AP
, and AP
improved by 6.8%, 8%, and 10%, respectively.
AP, AP, and AP, respectively, improved by 6.5%, 7.7% and 9.1% compared to the best performing Cascade R-CNN in the two-stage algorithm. The above algorithms are anchor-based; however, this paper’s algorithm is based on anchor-free, which does not depend on the anchor setting.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}