
Design and Implementation of an Intelligent Assistive Cane for Visually Impaired People Based on an Edge-Cloud Collaboration Scheme


Abstract
:1. Introduction
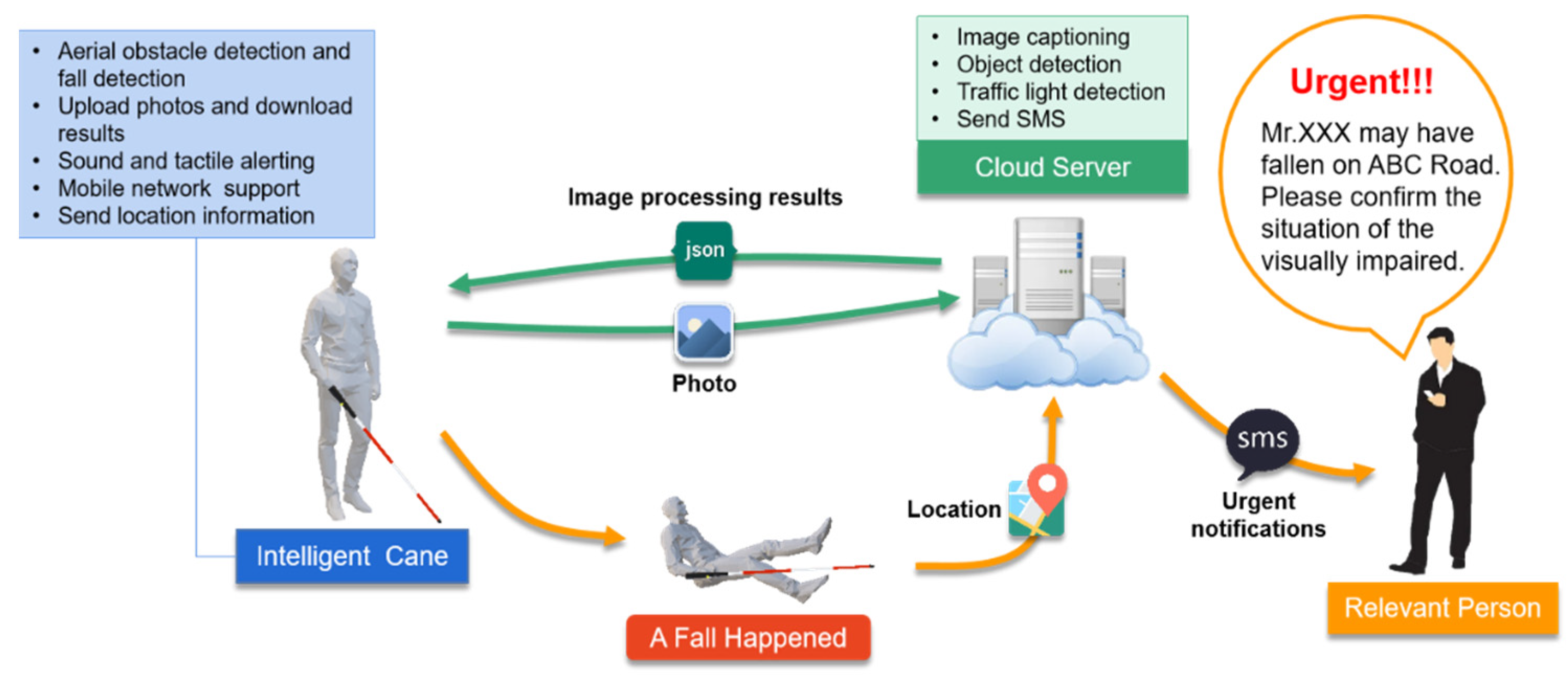
- The system has multiple functions and meets the needs of VIPs for assistive products from different perspectives, which facilitates the lives of the visually impaired.
- For the convenience of moving for VIPs, we designed and integrated aerial obstacle detection, fall detection, and traffic light detection functions. Experiments show that these functions can ensure the safety of the VIP efficiently.
- To help VIPs perceive more information about their surroundings, we have also designed an image captioning function and object detection function with high-speed processing capability based on an edge-cloud collaboration scheme.
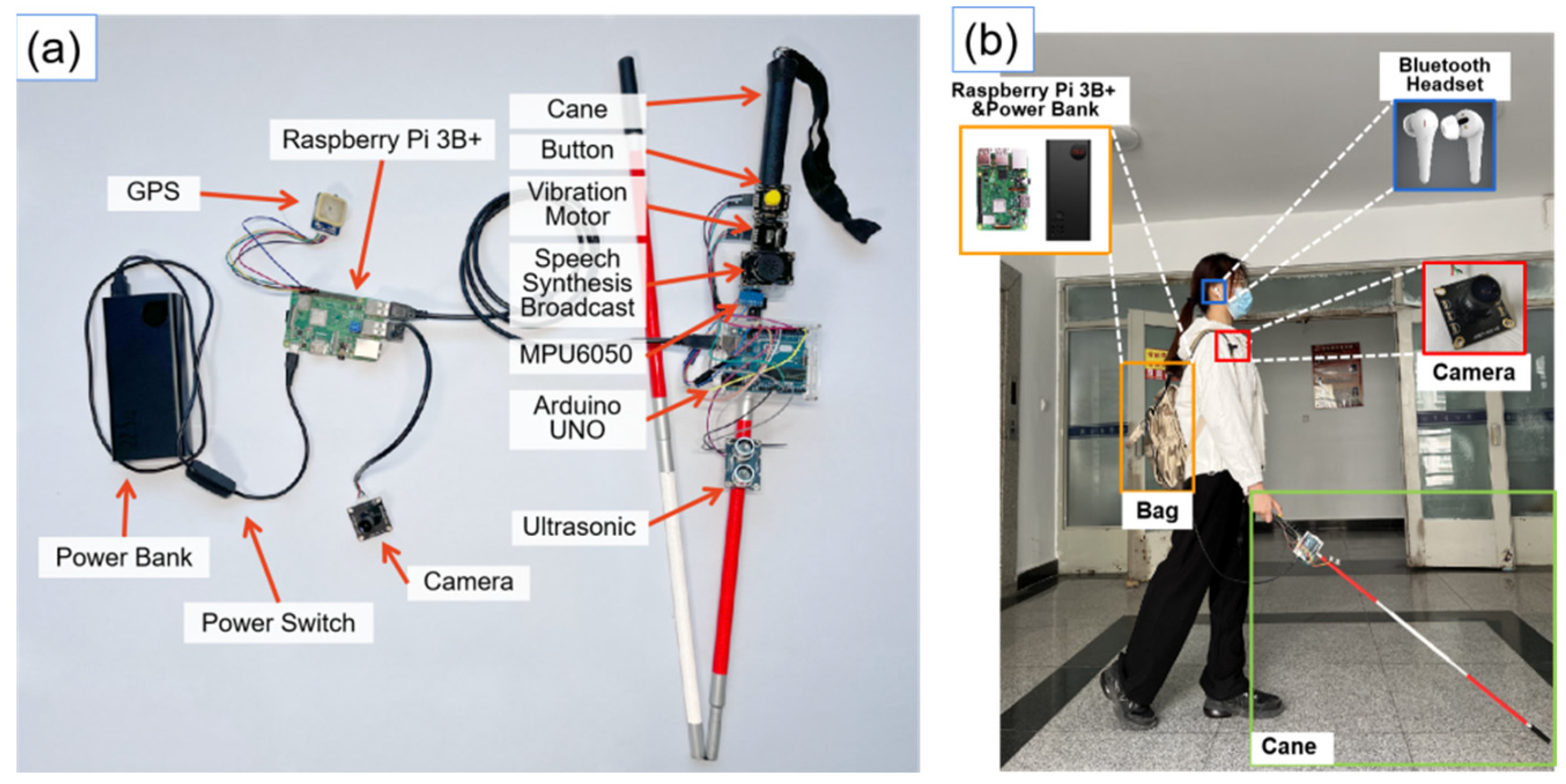
- The system is low cost, low power, and simple to operate. All functions are implemented using only Raspberry Pi and Arduino with some sensors. All interactive operations can be proceeded with one button.
2. Related Work
2.1. Non-Vision-Based Systems
2.2. Vision-Based Systems
3. The Proposed Assistance Cane
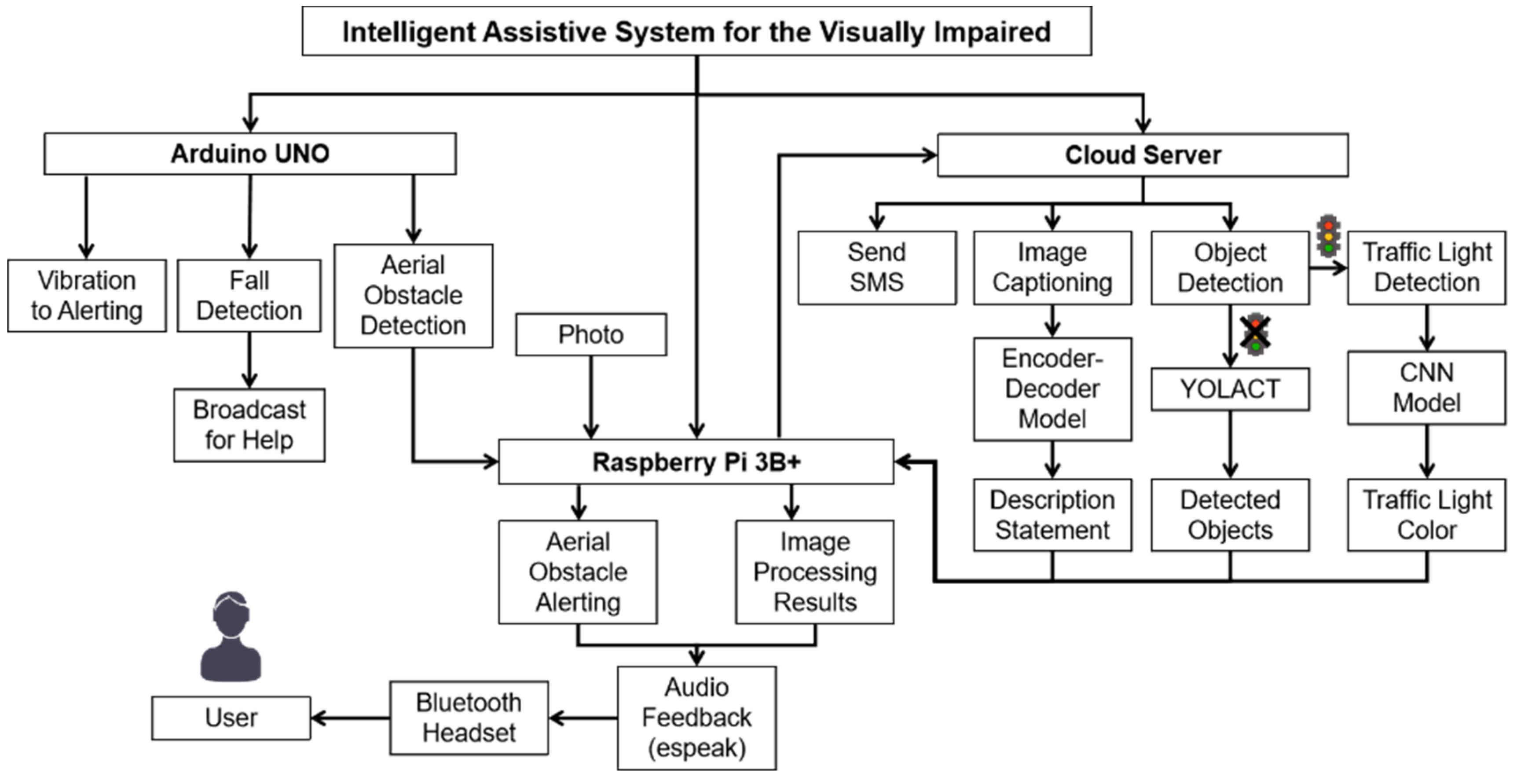
3.1. Overall Architecture and Functional Design
3.2. Functional Design of Assistive Mobility
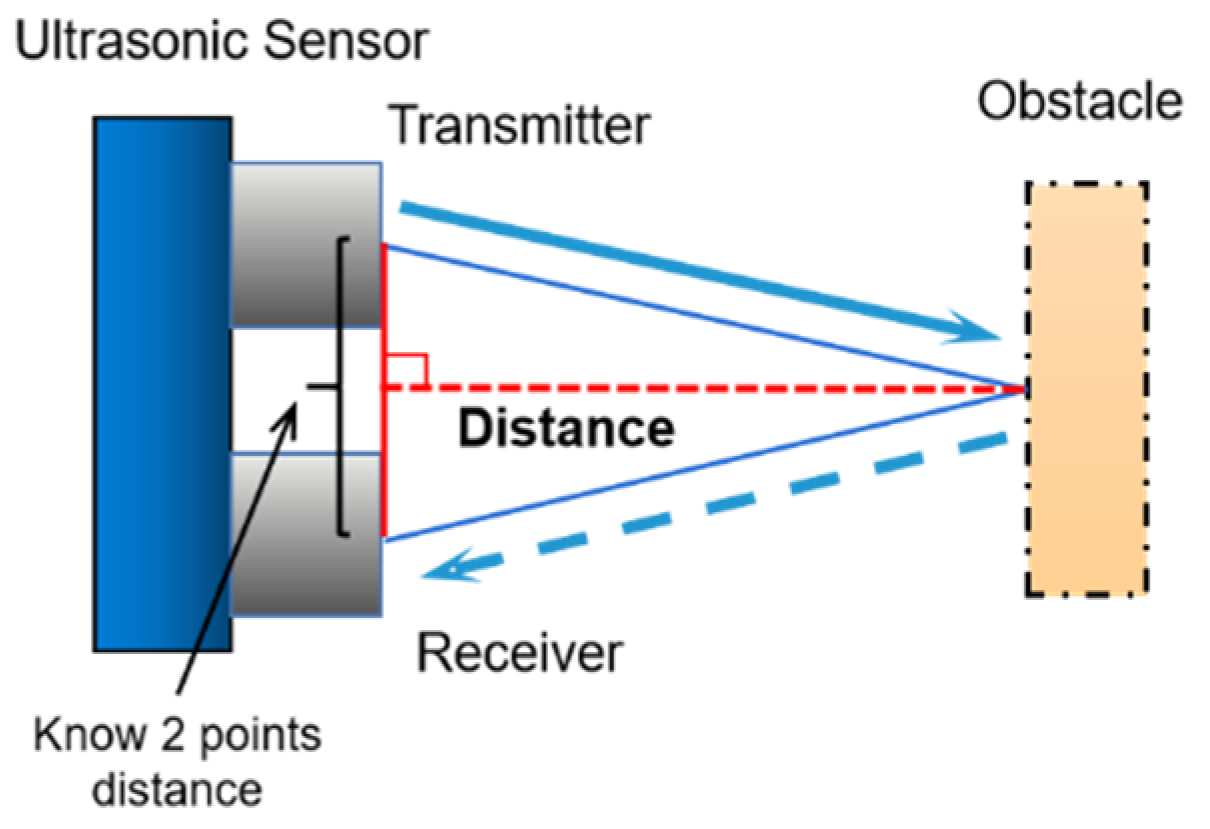
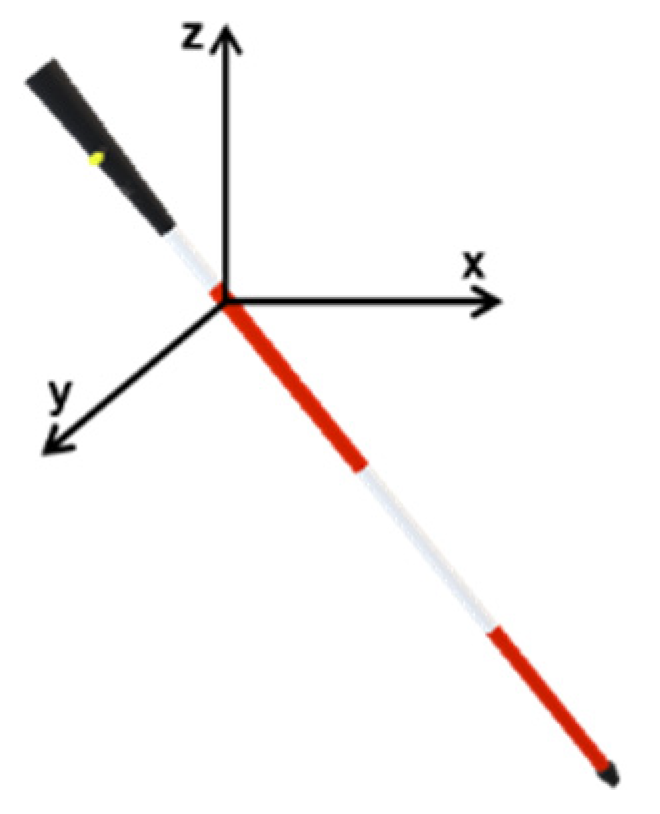
3.2.1. Aerial Obstacle Detection
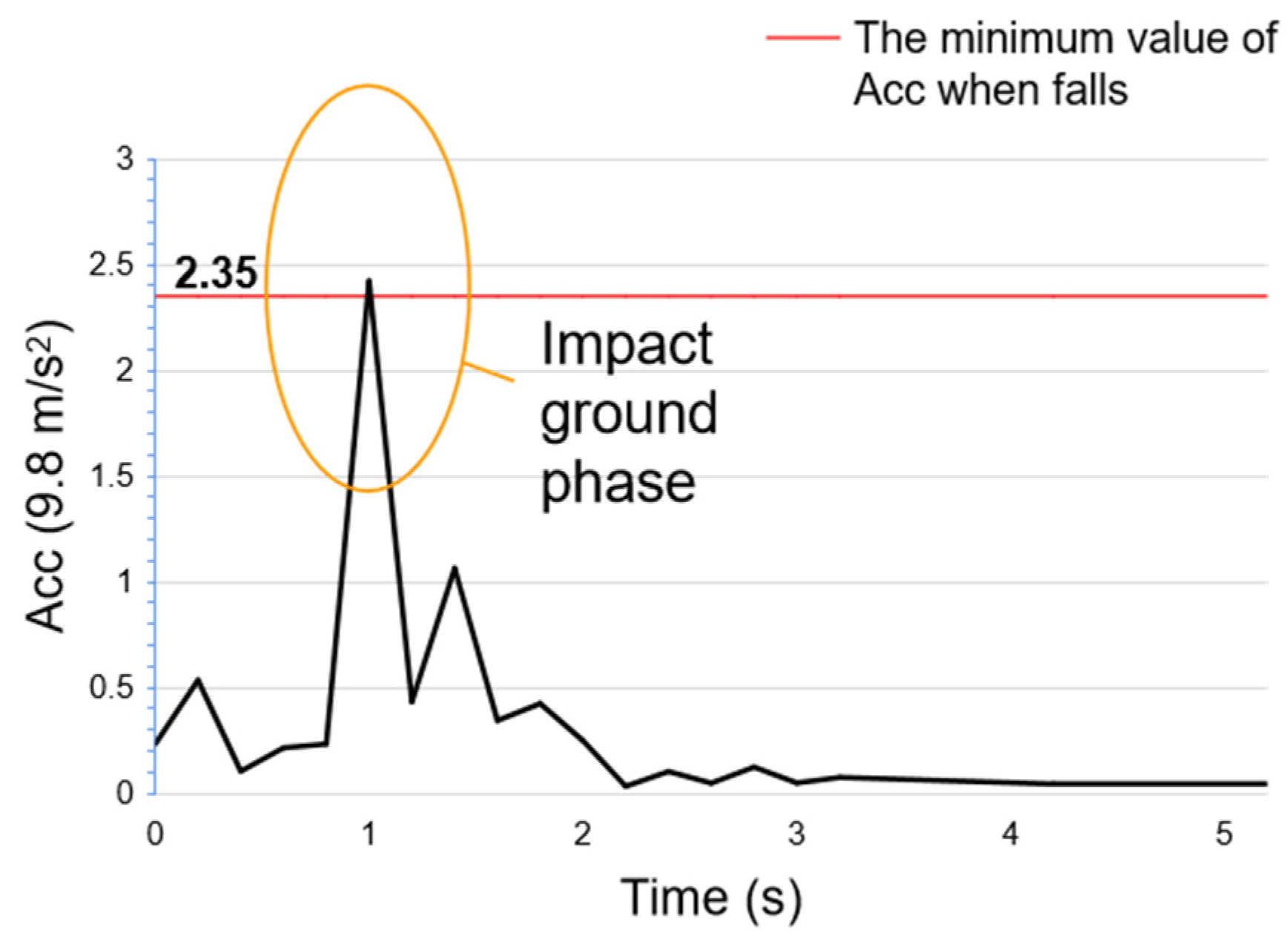
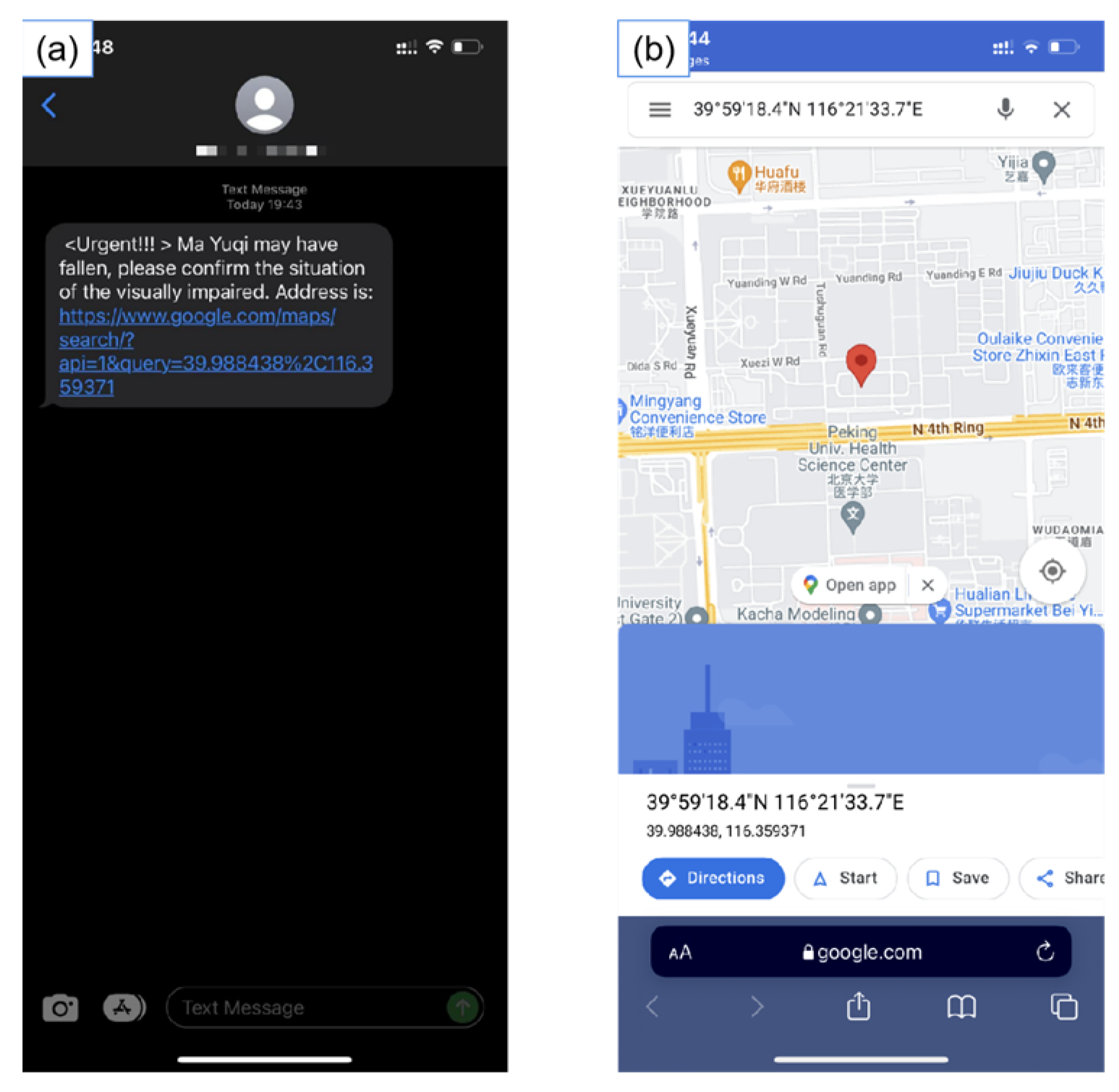
3.2.2. Fall Detection
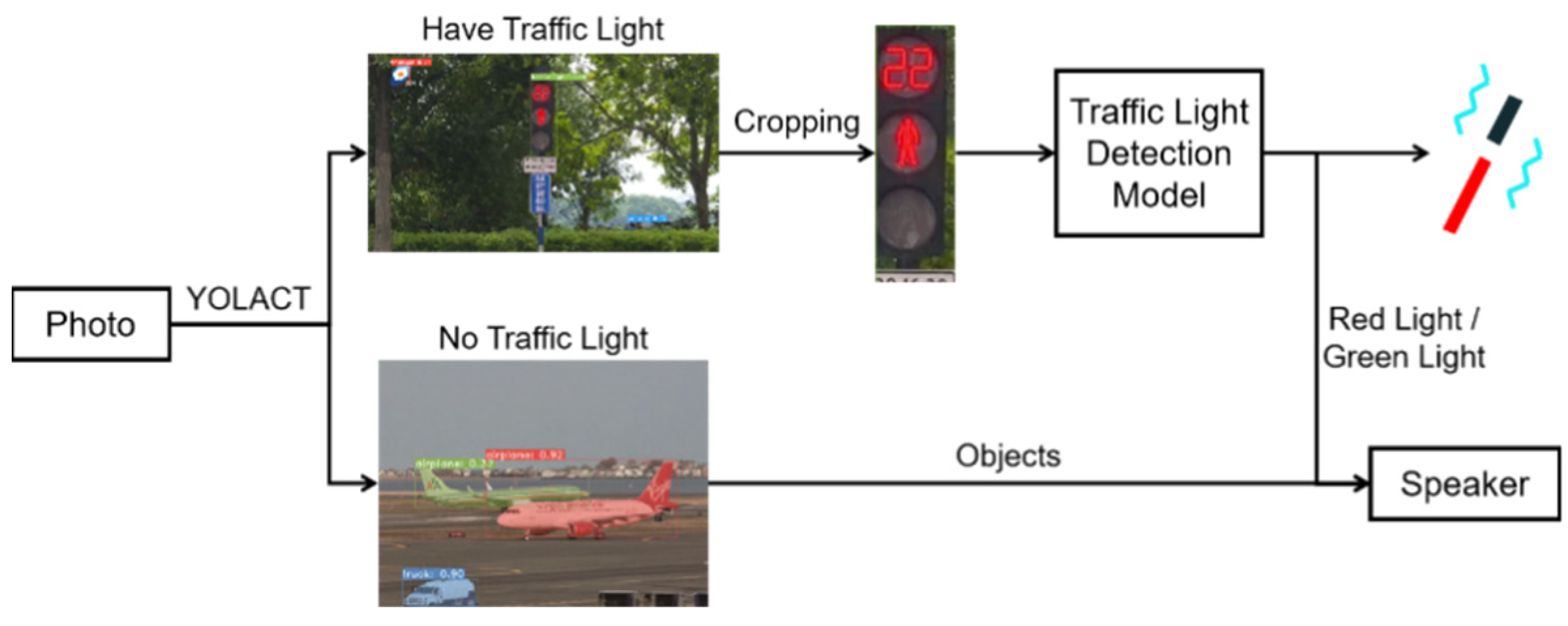
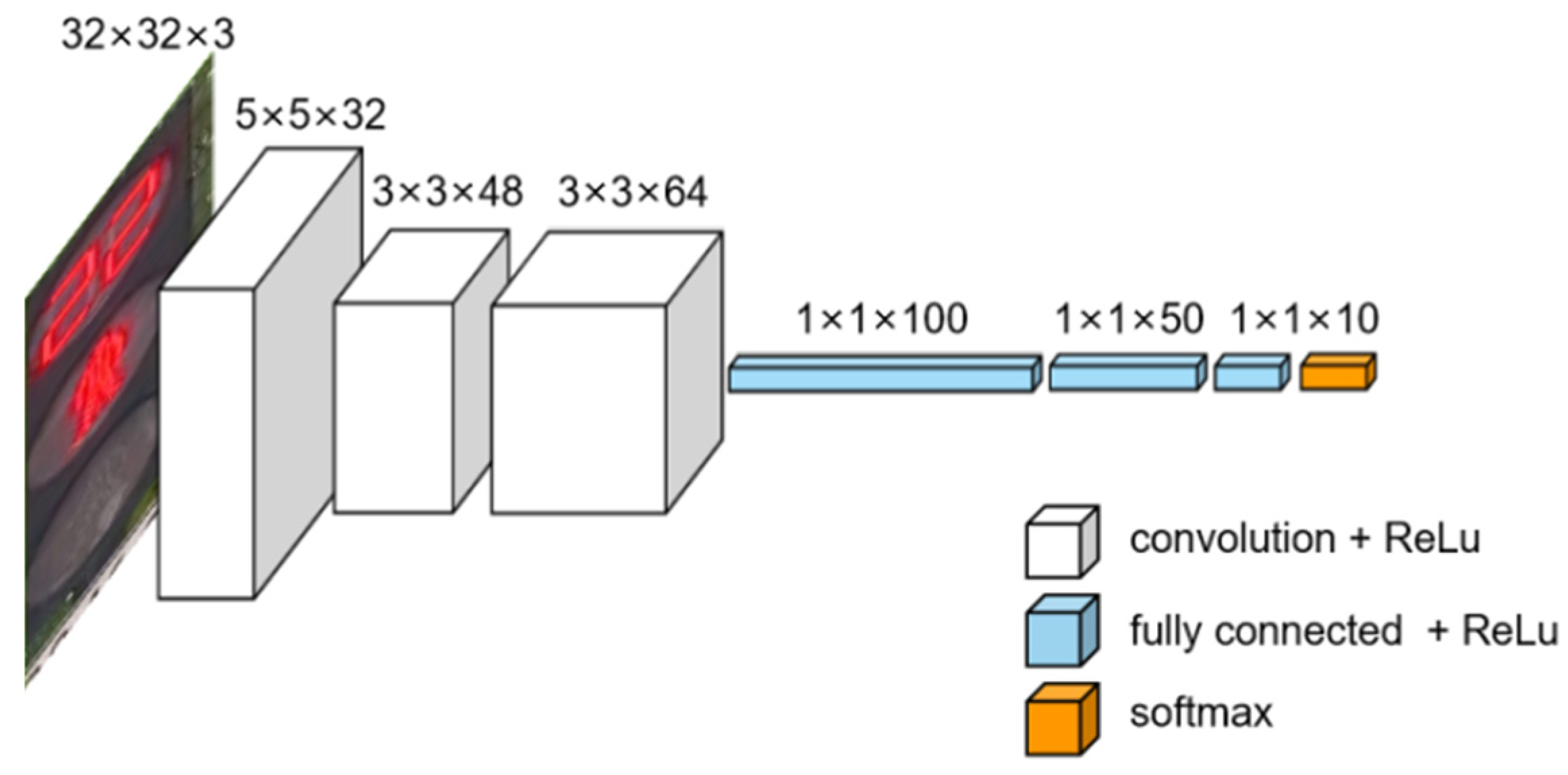
3.2.3. Traffic Light Detection
3.3. Functional Design of Auxiliary Visual Perception
3.3.1. Object Detection
3.3.2. Image Captioning
4. Experiment and Result Analysis
4.1. Experimental Environment
4.2. Result Analysis
4.2.1. Aerial Obstacle Detection
4.2.2. Fall Detection
4.2.3. Object Detection and Traffic Light Detection
4.2.4. Image Captioning
4.2.5. Overall Device Performance
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bourne, R.R.A.; Flaxman, S.R.; Braithwaite, T.; Cicinelli, M.V.; Das, A.; Vision Loss Expert Group. Magnitude, temporal trends, and projections of the global prevalence of blindness and distance and near vision impairment: A systematic review and meta-analysis. Lancet Glob. Health 2017, 5, e888–e897. [Google Scholar] [CrossRef] [Green Version]
- Sáez, J.M.; Escolano, F.; Lozano, M.A. Aerial Obstacle Detection With 3-D Mobile Devices. IEEE J. Biomed. Health Inform. 2015, 19, 74–80. [Google Scholar] [CrossRef] [Green Version]
- Plikynas, D.; Žvironas, A.; Gudauskis, M.; Budrionis, A.; Daniušis, P.; Sliesoraitytė, I. Research advances of indoor navigation for blind people: A brief review of technological instrumentation. IEEE Instrum. Meas. Mag. 2020, 23, 22–32. [Google Scholar] [CrossRef]
- Madrigal, G.A.M.; Boncolmo, M.L.M.; Santos, M.J.C.D.; Ortiz, S.M.G.; Santos, F.O.; Venezuela, D.L.; Velasco, J. Voice Controlled Navigational Aid With RFID-based Indoor Positioning System for the Visually Impaired. In Proceedings of the 2018 IEEE 10th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment and Management (HNICEM), Baguio City, Philippines, 29 November–2 December 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Zvironas, A.; Gudauskis, M.; Plikynas, D. Indoor Electronic Traveling Aids for Visually Impaired: Systemic Review. In Proceedings of the 2019 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 5–7 December 2019; pp. 936–942. [Google Scholar] [CrossRef]
- Plikynas, D.; Žvironas, A.; Budrionis, A.; Gudauskis, M. Indoor Navigation Systems for Visually Impaired Persons: Mapping the Features of Existing Technologies to User Needs. Sensors 2020, 20, 636. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.M.; Jung, J.Y.; Kim, J.J. Development of Walking Assistive Cane for Obstacle Detection and Location Recognition for Visually Impaired People. Sens. Mater. 2021, 33, 3623–3633. [Google Scholar] [CrossRef]
- Martinez-Sala, A.S.; Losilla, F.; Sánchez-Aarnoutse, J.C.; García-Haro, J. Design, Implementation and Evaluation of an Indoor Navigation System for Visually Impaired People. Sensors 2015, 15, 32168–32187. [Google Scholar] [CrossRef]
- Khan, S.; Nazir, S.; Khan, H.U. Analysis of Navigation Assistants for Blind and Visually Impaired People: A Systematic Review. IEEE Access 2021, 9, 26712–26734. [Google Scholar] [CrossRef]
- Al-Fahoum, A.S.; Al-Hmoud, H.B.; Al-Fraihat, A.A. A smart infrared microcontroller-based blind guidance system. Act. Passiv. Electron. Compon. 2013, 2013, 726480. [Google Scholar] [CrossRef] [Green Version]
- Wahab, M.H.A.; Talib, A.A.; Kadir, H.A.; Johari, A.; Noraziah, A.; Sidek, R.M.; Mutalib, A.A. Smart cane: Assistive cane for visually-impaired people. arXiv 2011, arXiv:1110.5156. [Google Scholar]
- Mustapha, B.; Zayegh, A.; Begg, R.K. Ultrasonic and Infrared Sensors Performance in a Wireless Obstacle Detection System. In Proceedings of the 2013 1st International Conference on Artificial Intelligence, Modelling and Simulation, Kota Kinabalu, Malaysia, 3–5 December 2013; pp. 487–492. [Google Scholar] [CrossRef]
- Khan, A.; Ashraf, M.A.; Javeed, M.A.; Sarfraz, M.S.; Ullah, A.; Khan, M.M.A. Electronic Guidance Cane for Users Having Partial Vision Loss Disability. Wirel. Commun. Mobile Comput. 2021, 2021, 1628996. [Google Scholar] [CrossRef]
- Zhangaskanov, D.; Zhumatay, N.; Ali, M.H. Audio-based Smart White Cane for Visually Impaired People. In Proceedings of the 2019 5th International Conference on Control, Automation and Robotics (ICCAR), Beijing, China, 19–22 April 2019; pp. 889–893. [Google Scholar] [CrossRef]
- Singh, B.; Kapoor, M. Assistive cane for visually impaired persons for uneven surface detection with orientation restraint sensing. Sens. Rev. 2020, 40, 687–698. [Google Scholar] [CrossRef]
- Swami, P.S.; Futane, P. Traffic Light Detection System for Low Vision or Visually Impaired Person Through Voice. In Proceedings of the 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 16–18 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Karthikayan, P.N.; Pushpakumar, R. Smart Glasses for Visually Impaired Using Image Processing Techniques. In Proceedings of the 2021 Fifth International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 11–13 November 2021; pp. 1322–1327. [Google Scholar] [CrossRef]
- Yang, K.; Wang, K.; Lin, S.; Bai, J.; Bergasa, L.M.; Arroyo, R. Long-Range Traversability Awareness and Low-Lying Obstacle Negotiation with RealSense for the Visually Impaired. In Proceedings of the 2018 International Conference on Information Science and System (ICISS ‘18). Association for Computing Machinery, New York, NY, USA, 27–29 April 2018; pp. 137–141. [Google Scholar] [CrossRef]
- Hakim, H.; Fadhil, A. Navigation system for visually impaired people based on RGB-D camera and ultrasonic sensor. In Proceedings of the International Conference on Information and Communication Technology (ICICT ‘19), Association for Computing Machinery, New York, NY, USA, 15–16 April 2019; pp. 172–177. [Google Scholar] [CrossRef]
- Chen, H.; Wang, K.; Yang, K. Improving RealSense by Fusing Color Stereo Vision and Infrared Stereo Vision for the Visually Impaired. In Proceedings of the 2018 International Conference on Information Science and System (ICISS ‘18), Association for Computing Machinery, New York, NY, USA, 27–29 April 2018; pp. 142–146. [Google Scholar] [CrossRef]
- Khan, M.A.; Paul, P.; Rashid, M.; Hossain, M.; Ahad, M.A.R. An AI-Based Visual Aid With Integrated Reading Assistant for the Completely Blind. IEEE Trans. Hum. Mach. Syst. 2020, 50, 507–517. [Google Scholar] [CrossRef]
- Sarwar, M.G.; Dey, A.; Das, A. Developing a LBPH-based Face Recognition System for Visually Impaired People. In Proceedings of the 2021 1st International Conference on Artificial Intelligence and Data Analytics (CAIDA), Riyadh, Saudi Arabia, 6–7 April 2021; pp. 286–289. [Google Scholar] [CrossRef]
- Zaman, S.; Abrar, M.A.; Hassan, M.M.; Islam, A.N.M.N. A Recurrent Neural Network Approach to Image Captioning in Braille for Blind-Deaf People. In Proceedings of the 2019 IEEE International Conference on Signal Processing, Information, Communication & Systems (SPICSCON), Dhaka, Bangladesh, 28–30 November 2019; pp. 49–53. [Google Scholar] [CrossRef]
- Al-Dahan, Z.T.; Bachache, N.K.; Bachache, L.N. Design and implementation of fall detection system using MPU6050 Arduino. In Proceedings of the International Conference on Smart Homes and Health Telematics, Wuhan, China, 25–27 May 2016; Springer: Cham, Switzerland, 2016; pp. 180–187. [Google Scholar]
- Kosobutskyy, P.; Ferens, R. Statistical analysis of noise measurement system based on accelerometer-gyroscope GY-521 and Arduino platform. In Proceedings of the 2017 14th International Conference The Experience of Designing and Application of CAD Systems in Microelectronics (CADSM), Lviv, Ukraine, 21–25 February 2017; pp. 405–407. [Google Scholar] [CrossRef]
- Heng, S.S.; Shamsudin, A.U.b.; Mohamed, T.M.M.S. Road Sign Instance Segmentation By Using YOLACT For Semi-Autonomous Vehicle In Malaysia. In Proceedings of the 2021 8th International Conference on Computer and Communication Engineering (ICCCE), Kuala Lumpur, Malaysia, 22–23 June 2021; pp. 406–410. [Google Scholar] [CrossRef]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT: Real-Time Instance Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 9156–9165. [Google Scholar] [CrossRef] [Green Version]
- YOLACT Model. Available online: https://github.com/dbolya/yolact (accessed on 8 July 2021).
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 2048–2057. [Google Scholar]
- Flickr8K Dataset. Available online: https://academictorrents.com/details/9dea07ba660a722ae1008c4c8afdd303b6f6e53b (accessed on 20 June 2021).
- Guo, Y.; Mi, Z.; Yang, Y.; Obaidat, M.S. An Energy Sensitive Computation Offloading Strategy in Cloud Robotic Network Based on GA. IEEE Syst. J. 2019, 13, 3513–3523. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aerial Obstacles | Height Range from the Ground | Number of Experiments | Accuracy Rate |
|---|---|---|---|
| Cabinet door | 51–163 cm | 20 | 100% |
| Eaves of low buildings | 104–110 cm | 20 | 100% |
| Fire hydrant doors | 104–176 cm | 20 | 95% |
| Strings | 126–126.5 cm | 20 | 65% |
| Sticks | 136–138 cm | 20 | 95% |
| Branches | 155–185 cm | 20 | 100% |
| Total | 51–185 cm | 120 | 92.5% |
| Fall Type | Number of Experiments | Correct Detection Times | Accuracy Rate |
|---|---|---|---|
| Fall to the ground | 50 | 45 | 90% |
| Type of Daily Activities | Number of Experiment | Error Detection Times | False-Positive Rate |
|---|---|---|---|
| Walk normally | 20 | 0 | 0% |
| Touch tactile paving by cane | 20 | 0 | 0% |
| Hit object by cane | 20 | 3 | 15% |
| Walk up and downstairs | 20 | 0 | 0% |
| Stand up and sit down | 20 | 0 | 0% |
| Bend down | 20 | 0 | 0% |
| TOTAL | 120 | 3 | 2.5% |
| Volunteer Number | Score |
|---|---|
| 1 | 8 |
| 2 | 8 |
| 3 | 9 |
| 4 | 9 |
| 5 | 7 |
| 6 | 10 |
| 7 | 8 |
| 8 | 6 |
| 9 | 9 |
| 10 | 9 |
| Average | 8.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Y.; Shi, Y.; Zhang, M.; Li, W.; Ma, C.; Guo, Y. Design and Implementation of an Intelligent Assistive Cane for Visually Impaired People Based on an Edge-Cloud Collaboration Scheme. Electronics 2022, 11, 2266. https://doi.org/10.3390/electronics11142266
Ma Y, Shi Y, Zhang M, Li W, Ma C, Guo Y. Design and Implementation of an Intelligent Assistive Cane for Visually Impaired People Based on an Edge-Cloud Collaboration Scheme. Electronics. 2022; 11(14):2266. https://doi.org/10.3390/electronics11142266
Chicago/Turabian StyleMa, Yuqi, Yanqing Shi, Moyu Zhang, Wei Li, Chen Ma, and Yu Guo. 2022. "Design and Implementation of an Intelligent Assistive Cane for Visually Impaired People Based on an Edge-Cloud Collaboration Scheme" Electronics 11, no. 14: 2266. https://doi.org/10.3390/electronics11142266
APA StyleMa, Y., Shi, Y., Zhang, M., Li, W., Ma, C., & Guo, Y. (2022). Design and Implementation of an Intelligent Assistive Cane for Visually Impaired People Based on an Edge-Cloud Collaboration Scheme. Electronics, 11(14), 2266. https://doi.org/10.3390/electronics11142266