1. Introduction
After the Diffie–Hellman key agreement was proposed, two widely used public-key cryptographies (asymmetric cryptography) are RSA cryptography proposed by Ron Rivest, Adi Shamir, and Leonard Adleman in 1978 [
1] and elliptic curve cryptography (ECC) proposed by Koblitz [
2] and Miller [
3] in 1985. However, with the development of electronic information technology, the critical length of RSA is increasing to ensure security. In 2020, the recommendation proposed by the National Institute of Standards and Technology (NIST) [
4] compared various cryptographic algorithm families based on the security level and it reports that an ECC cryptosystem requires a smaller key length than an RSA cryptosystem for the same security level. For example, a 256-bit ECC cryptosystem over a prime field can provide an equivalent security level to a 3072-bit RSA cryptosystem with lower resource consumption and computational latency [
4,
5]. Thus ECC is suitable for both high-speed real-time cryptographic applications and lightweight cryptographic applications such as blockchain technology and the Internet of Things (IoT). Generally, an ECC cryptosystem can be divided into four hierarchical layers: top protocol layer, elliptic curve scalar multiplication (ECSM) execution layer, group operation layer, and bottom finite field operation layer. The protocol layer is usually implemented using software to provide functions of cryptographic protocols such as elliptic curve digital signature algorithm (ECDSA), elliptic curve Diffie–Hellman (ECDH), etc. The other three layers constitute the ECSM architecture, which is the most complicated and crucial operation for an ECC cryptosystem.
To accelerate ECSM, many existing designs have been implemented on the field programmable gate arrays (FPGAs) and application-specific integrated circuits (ASICs) targeting ECC over prime fields. For example, a simple and effective technique in literature [
6,
7,
8,
9,
10,
11,
12,
13] utilizes the five specific primes recommended by the NIST, which significantly reduces the time and hardware resources cost of modular reduction. However, high-speed ECSM can be achieved using these special primes, but it limits the flexibility and generality. In realistic applications, a flexible ECC cryptosystem that supports multiple security protocol standards is necessary. On the other hand, some designs utilized the specific DSP blocks in the FPGA such as [
7,
9,
12,
13,
14,
15,
16], which can accelerate multiplications without consuming logic resources. Nevertheless, these designs have low portability as they are difficult to rebuild on other FPGA platforms or ASICs.
The ECSM architecture in [
16] supports generic curves, which are based on the double-and-add always method and utilize two bit-length adjustable Montgomery multipliers to perform ECSM. In 2016, Hossain et al. [
11] developed an ECC processor based on both affine coordinates and mixed projective coordinates without using DSPs or BRAMs. Their design is implemented on both FPGA and ASIC platforms and supports two NIST recommended primes of
and
. The design in [
17] utilizes four modular multipliers based on interleaved modular multiplication algorithm and radix-4 optimization technique to perform ECSM. It supports general curves over
where
and is resistant to simple power analysis attacks. Marzouqi et al. [
12] took advantage of the redundant-signed-digit (RSD) technique to reduce the carry chain length of the adders used in their ECSM architecture. It is implemented on FPGA and supports only NIST recommended prime
.
In 2021, Awaludin et al. [
14] proposed a high-performance ECC processor over
. It utilizes a novel Montgomery ladder algorithm presented by Hamburg [
18] in 2020 and only takes 0.14 ms to perform a single ECSM, which is the fastest design in the literature for generic curves. Kudithi et al. [
6] developed a ECSM architecture with 7.4k slices consumption in FPGA. Their design has fairly high performance compared to other lightweight ECC cryptosystems but only supports two NIST recommended primes. Hu et al. [
19] proposed a low hardware consumption ECSM architecture that only uses LUT resources and supports all five NIST primes. In 2018, Shah et al. [
20] proposed a high-speed RSD-based flexible ECC cryptosystem. Their design utilizes the Montgomery ladder with (X,Y)-only common Z coordinate (Co-Z) arithmetic to perform ECSM and adopts the RSD technique to optimize all the finite filed calculations. This design achieves a speed of 0.84 ms for a single ECSM operation without using DSP for acceleration.
On the other hand, some application contexts place higher demands on the hardware area and power consumption of the cryptosystem than the computation speed, such as the IoT [
8]. The rise of IoT has sparked concerns about the security of data transmission between IoT devices. The ECC cryptosystem can solve the problems, but its complex calculation conflicts with the lightweight and flexible nature of IoT devices [
21]. Fortunately, it is possible to reduce the throughput rate and the required computation speed of IoT by versatile access control methods [
22]. Several ECSM architectures on the balance of hardware area and computational speed have been proposed for IoT devices. The designs in [
23,
24] utilize embedded ARM MCUs to execute ECSM, which allows their cryptosystems to have extremely low power consumption. However, the speed of software designs is not comparable to that of FPGAs or ASICs. In [
8], an FPGA-based ECC processor architecture for IoT applications combines various lightweight modular methods and a classic binary ECSM method to achieve the trade-offs between speed and area. In 2021, Di Matteo improved the double-and-add always method and proposed a higher security ECC processor for IoT applications [
25].
In general, most of the designs available in the literature for prime field ECSM architectures focus on improving the speed performance, resulting in a large circuit area. These designs are unfriendly to cryptosystems for small mobile devices that require a small area and low power consumption. Moreover, designs with low resource consumption generally have slow calculation speed or use DSPs at the expense of portability. In this paper, a lightweight ECSM architecture for random Weierstrass curves over a prime field is proposed. The major contributions are as follows:
An ECSM architecture based on four parallel modular multipliers and the Montgomery ladder with Co-Z arithmetic is implemented on FPGA using only 6.5k slices without DSPs or BRAMs. The modular multiplier and modular divider are optimized by the pre-calculation method to reduce the critical path while retaining a low resource consumption.
The point addition (PA) and point doubling (PD) methods in Co-Z arithmetic are modified to improve computation parallelism and accommodate four modular multipliers.
A compact scheduling method is proposed that includes appropriate scheduling of bottom finite field operations to reduce the clock cycles required and specific register connections to reduce the fan-out and path delay of the circuit.
The architecture is generic for random Weierstrass curves over a prime field and resistant to timing attacks, simple power analysis attacks, and safe-error attacks.
The rest of this paper is organized as follows:
Section 2 provides a review of the mathematical background of ECC as well as several ECSM methods and attack methods.
Section 3 presents all the technical details of our proposed ECSM architecture.
Section 4 analyzes the resistance of our proposed ECSM architecture against side-channel attacks. The hardware architecture and implementation results, as well as comparisons with other similar designs, are presented in
Section 5. Finally,
Section 6 concludes the paper.
3. ECSM Architecture Design Methods
This section presents the design methods of each unit in our proposed ECSM architecture. Firstly, the modular multiplier and divider in finite field arithmetic unit are proposed in
Section 3.1. Both components are optimized by the pre-calculation method to achieve performance gains with only a small resource consumption. Then, the co-Z arithmetic in
Section 3.2 is modified from computation parallelism and critical calculation path to shorten the critical calculation path and improve computing performance. Finally,
Section 3.3 presents the hardware designs of the finite field arithmetic unit and the ECSM scheduling unit. We analyze the impact of component count on the ECSM architecture performance and propose a compact hardware scheduling based on Algorithm 2.
3.1. Modular Components over
3.1.1. Modular Multiplier
Modular multiplication is the most crucial operation in an ECSM, which has led to a lot of literature on optimizing this operation to achieve faster speed and smaller resource consumption. Montgomery multiplication [
41] is a well-known method to solve the problem of the high latency caused by carrying propagation in modular multiplier design. This method avoids inversion operations by prime
p in the classic modular multiplication [
42]. However, it requires external circuits to transfer data to the Montgomery domain and correct the result to an acceptable range. Amanor et al. [
43] proposed a new modular multiplication method based on interleaved modular multiplication, utilizing carry-save adders instead of normal ones. It can efficiently solve the high latency generated by the series connection of adders. Nevertheless, the comparison between the output of the carry-save adder and prime
p requires additional symbol detection units.
In order to balance hardware resource occupation and performance, a modular multiplication algorithm based on the interleaved modular multiplication is proposed in [
11], shown in Algorithm 3. The algorithm uses the pre-calculation method to split the series adders for mod
p operation. However, the adder with multi-digit leads to a long carry chain, which affects the multiplier’s performance.
| Algorithm 3: Modular multiplication with pre-calculation |
![Electronics 11 02234 i003]() |
Algorithm 3 uses two comparators to select the per-calculation output as the final result of modular multiplication. As a further application of this latency reduction method, an improved architecture of modular multiplication is proposed based on Algorithm 3, which can further reduce the carry chain length and minimize the effect on the area.
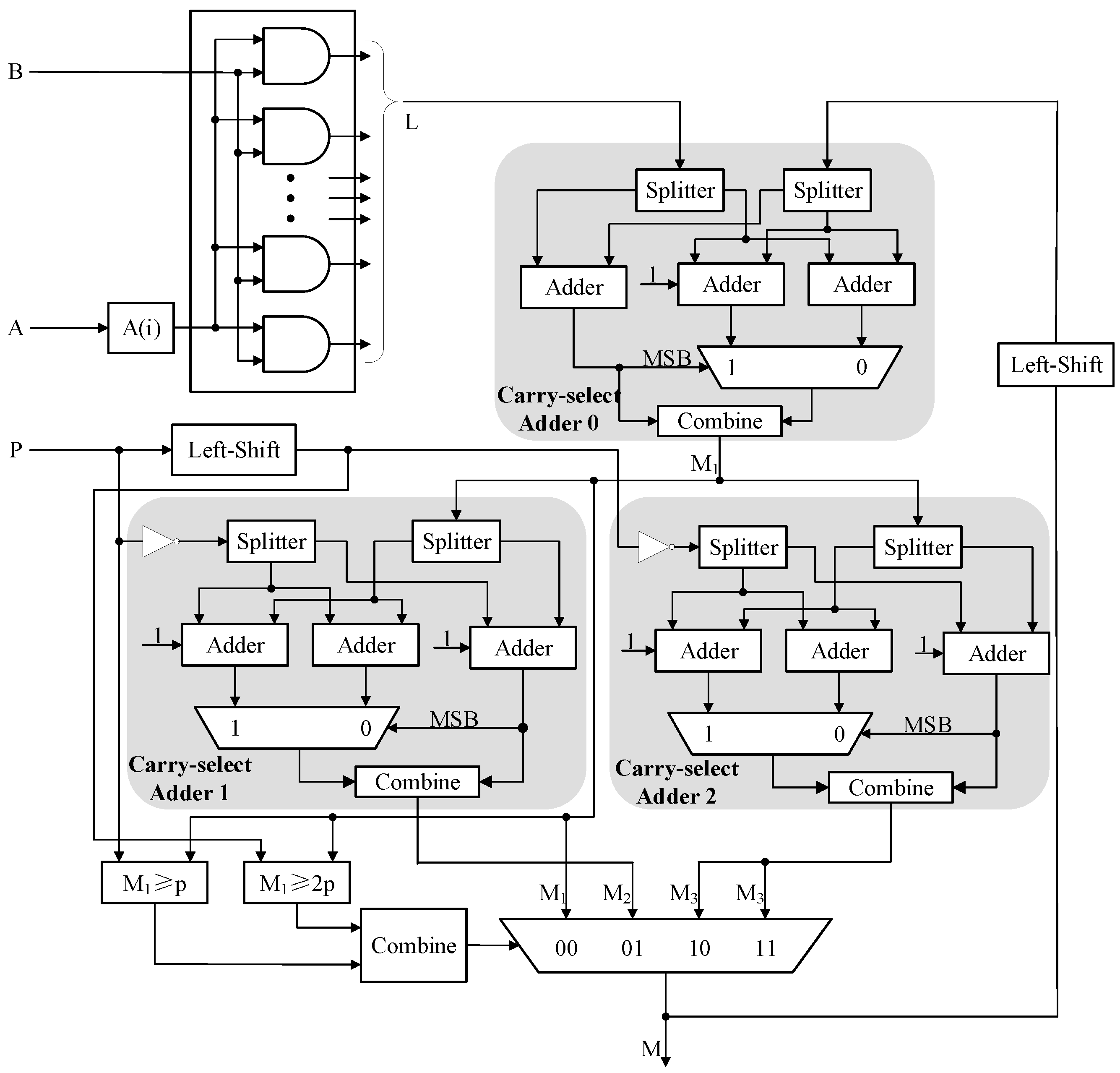
Figure 1 shows the architecture of our proposed modular multiplier.
Here, and are calculated by the left-shift operation. is calculated by AND operation bit-by-bit. Additionally, three carry-select adders are adopted in the architecture to perform addition and subtraction operands, where carry-select adder 0 performs , carry-select adder 1 performs , and carry-select adder 2 performs . The multiplexer selects the intermediate result by the output of the comparator in each iteration round.
The carry-select adder avoids the series connection of internal adders by the pre-calculation methods, efficiently reducing the circuit latency. Take the
operation as an example, the calculation process of carry-select Adder 0 in the modular multiplier is based on the following equations. Let
and
, the splitters divide each of them into two parts as
Then two adders perform the calculation
, assuming the carry-in is 0 and 1, respectively. Meanwhile, the third adder performs
in parallel, which dominates the correct carry-in.
The multiplexer selects the correct
between
and
, once the correct carry-in is known.
Finally, the result
is obtained by combining
and
as
In order to perform the subtraction, carry-select adder 1 and carry-select adder 2 require operands p and to be 2’s complement representation. Thus p and are inverted bit-by-bit, and an extra 1 is added to both carry-select adders.
In addition to modular multiplication, the modular square is also a complicated operation in ECSM. The circuit area of architecture designed explicitly for modular square is essentially the same as that of modular multiplication. However, according to Algorithm 2, except for the DBLU operation that was executed only once at the beginning of ECSM, all other operations require more multiplications than squares, leading to lower utilization of the specific modular square unit. Consequently, we use a modular multiplier to perform the modular square by entering identical operands to
A and
B shown in
Figure 1.
3.1.2. Modular Divider
In order to avoid the frequent modular division in the ECSM, Jacobian coordinates are used to represent the participating points and the intermediate processing results. However, the final result must be converted to the affine coordinate representation before the ECSM is finished, which requires a modular division according to Equation (
5).
To reduce computational complexity and area occupation, we use the binary inversion algorithm (BIA) [
26], which is accomplished by addition, subtraction, and shifting operations. The computation of BIA is based on the following equation.
where
x is the inverse of
A. In order to derive the Equation (
17), the BIA constructs an iteration with
A and
p. During the iterations, it can be obtained by performing divisions and subtractions on the following equations
Let
and
p be the inputs to the BIA, the Equation (
17) will become
So the inverse
x is
. Additionally, in the first iteration of the BIA,
,
, the Equation (
18) can be written as
By multiplying
B to both sides of the equation, the Equation (
20) becomes
where
,
,
, and
.
So we modify the initialization of the BIA with
, and implement the modular division operation
, as shown in Algorithm 4.
| Algorithm 4: Binary division algorithm over |
![Electronics 11 02234 i004]() |
The variables
u,
v,
, and
are updated in each iteration until the final output condition is satisfied. The
u and
v will remain in the range of 0 and
p, but
and
may be out of this range, so additional
operations are required. The equations to obtain
u,
v can be summarized as
In the implementation of Equation (
22), divisions are performed by right-shift units. A comparator is used to accomplish the comparison of
u and
v, and the output is used as one of the conditions for multiplexers. The parity determination for intermediate variables is performed by checking the least significant bit (LSB) value. LSB = 0 represents the variable is even, while LSB = 1 represents the variable is odd. The combine unit concatenates all the conditions for the multiplexer into a 2-bit input.
On the other hand,
,
can be evaluated as
To perform the
operation in Equation (
23), the pre-calculation method is used to reduce the carry chain length, which insert
and
calculations to the architecture. The architecture of the proposed modular divider is shown in
Figure 2.
3.2. Improvement in Co-Z Arithmetic
The computation parallelism and critical calculation path analysis are the basis for determining the hardware scheduling scheme of the ECSM in this paper. We expand ZADDC, ZADDU, and DBLU operations into a step-by-step form base on a single modular multiplier and use directed acyclic graphs (DAG) to represent the operational process of these algorithms.
The DAG of the ZADDC operation is shown in
Figure 3. The vertex number in the DAG corresponds to the step number in the corresponding algorithm. The SQ and M in solid vertices represent square and multiplication, while the A and S in dotted vertices represent addition and subtraction. Multiplication takes many more clock cycles than addition and subtraction in the prime finite field. Thus we select the number of multiplications as the critical calculation path length. Furthermore, the DAGs that omit A and S operations are also presented to facilitate observation.
As can be seen in
Figure 3, the critical calculation path contains 1 SQ, 2 M, and 5 A/S (1→2→3→7→8→21→22→23). While A and S are omitted, as shown in
Figure 3b, the critical path length is 3.
When ZADDC is executed for the first time in Algorithm 2, its input comes from the output of DBLU. Moreover, during the whole iteration, the output of ZADDC and ZADDU are used as each other’s input. Therefore, we improve the ZADDC operation by dividing part of incipient calculations to the end of DBLU and ZADDU. Part of the incipient calculations is inserted into the end of ZADDC. In the case of multiple multipliers, this modification improves the parallelism of ZADDC operation without affecting the critical path length of DBLU and ZADDU operations.
The DAG of improved ZADDC is shown in
Figure 4. S-INS and SQ-INS calculations are from the ZADDU operation. The improved ZADDC operation contains 13 multiplication paths with the same length and the critical path length is 2.
Meanwhile, ZADDU and DBLU operations are also redistributed. The DAGs are shown in
Figure 5. The improved ZADDU operation contains eight multiplication paths with the same length and the critical path length is two. DBLU operation is executed only once at the beginning of Algorithm 2. So the calculation time of DBLU is negligible compared to the whole algorithm execution time. The improved DBLU operation contains nine multiplication paths, and the critical path length is three.
3.3. Hardware Development of ECSM
Our proposed lightweight ECSM architecture consists of a finite field arithmetic unit and an ECSM scheduling unit based on Algorithm 2. This section presents a compact ECSM scheduling based on four modular multipliers, which reduces the overall clock cycles required for the ECSM.
3.3.1. Finite Field Arithmetic Unit
The finite field arithmetic unit (FFAU) performs all the essential finite field operations, consisting of the modular adder/subtracter, modular multiplier, and modular divider. The architecture of modular adder/subtracter in the FFAU uses the conventional design in [
8]. With this architecture, modular adder and subtracter are combined in the same module, and an external “a/s” input port is added to control which operation is performed by the module. The entire modular adder/subtracter is composed of combinational logic, thus the result can be cached directly at the adjacent clock after the operands are prepared. In contrast, both the modular multiplier and divider require an iterative calculation to complete the corresponding operation.
In the FFAU, multiple modular additions and subtractions can be performed during the process of modular multiplication and division. Besides, the modular division is performed only once in an ECSM according to Algorithm 2. So one modular adder/subtractor and one modular divider are sufficient for our design.
The critical path length can be reduced by analyzing the critical calculation path and rationally reformulating the algorithm. However, the corresponding number of modular multipliers may increase as well. The most frequently executed operations in Algorithm 2 are the ZADDC and ZADDU operations in the iteration.
Table 2 shows the calculation rounds and utilization efficiency with different numbers of modular multipliers based on the improved ZADDC and ZADDU operations in the
Section 3.2.
From
Table 2, it can be seen that four modular multipliers can complete a single iteration in an ECSM with the minimum calculation rounds. Moreover, when more than four multipliers are adopted, the utilization efficiency drops significantly with no increase in calculation speed. Therefore, to take full advantage of the improved ZADDC and ZADDU, four independent multipliers are integrated into the FFAU. This parallel design benefits from the low resource consumption of our proposed modular multiplier.
Consequently, the composition of FFAU and the functions of each component are shown in
Table 3. The FFAU can simultaneously perform up to four modular multiplications, one modular division, and one modular addition/subtraction.
3.3.2. ECSM Scheduling Unit
The ECSM scheduling unit (ECSM-SCU) controls the modular components in the FFAU to perform basic finite field operations with an efficient state machine and caches intermediate results with a register group. Our proposed ECSM-SCU is based on the Algorithm 2 and improved co-Z arithmetic in
Section 3.2.
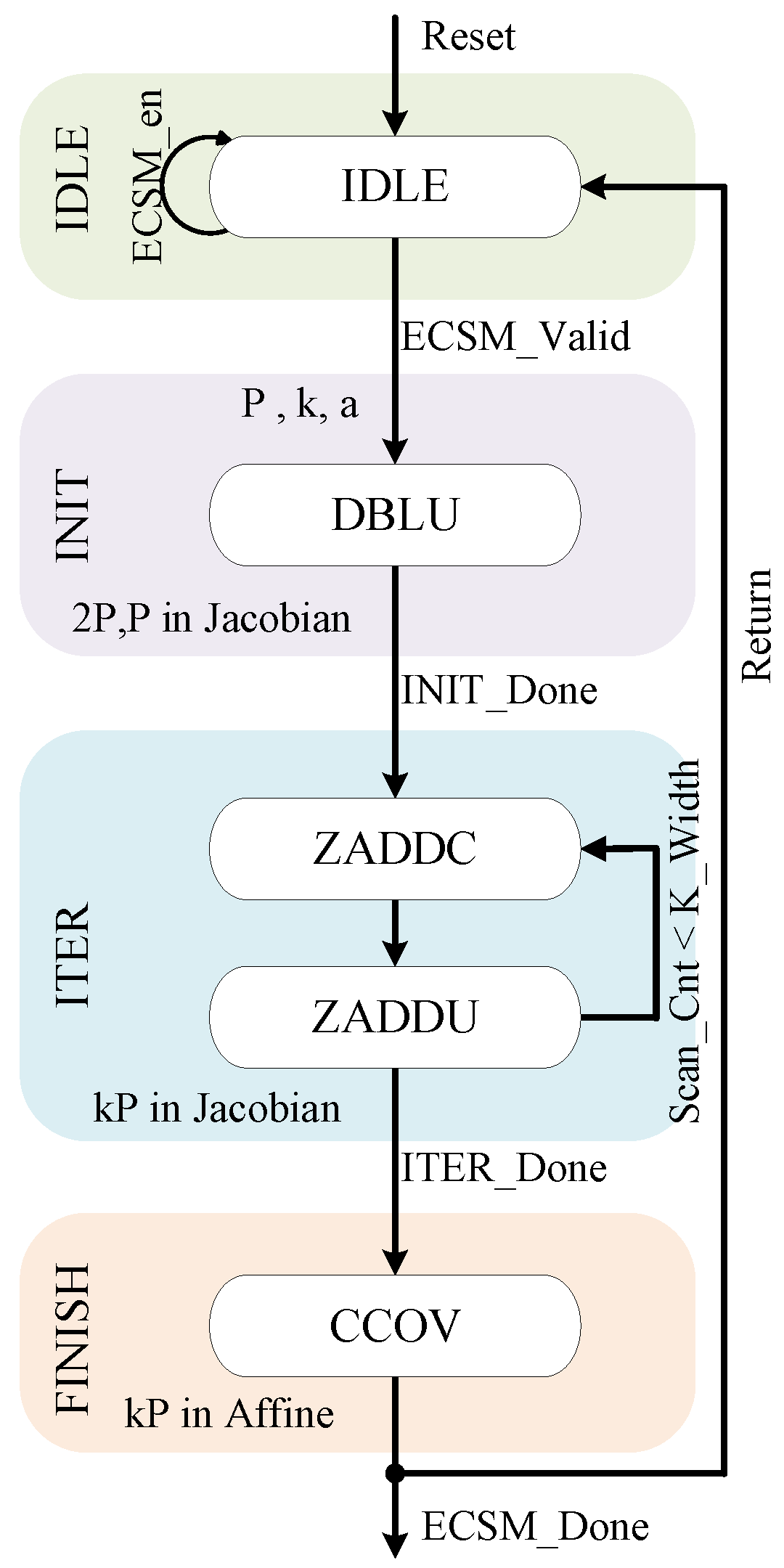
Figure 6 shows the transitions of the state machine used to execute the ECSM. It consists of idle state (IDLE), initialization state (INIT), iteration state (ITER), and finish state (FINISH). In IDLE, the ECSM-SCU is on standby, waiting for an ECSM request. It moves to the INIT after receiving an ECSM request, as well as the secret key and coordinates of point
P are cached. A DBLU operation generates
P and
in the Jacobian coordinate with the same Z coordinate. Then the ECSM-SCU executes a transition to ITER for the iteration of ZADDC and ZADDU operations.
P and
in INIT are used as the input to the ZADDC operation in the first iteration. Then the input–output connection between ZADDC and ZADDU operations in the following iterations will depend on the bit-by-bit scan of the secret key. In addition, ZADDU operations generate the results that satisfy the Montgomery ladder during the iteration. Finally, the state transitions to FINISH, and ECSM-SCU finishes the entire ECSM after converting the final results from Jacobian to affine coordinates. After completing the final output, the state returns to the IDLE, waiting for the next ECSM request.
The most prominent part of the ECSM-SCU is the scheduling of co-Z arithmetic which directly dominates the speed of the ECSM. Although the architecture and number of modular components have been determined, efficient coordination between the modular multiplier and modular adder/subtracter in hardware scheduling can still reduce the clock cycles. Our design principle is to reduce clock cycles, register usage, and keep the modular operations in the FFAU as parallel as possible.
Figure 7 shows the details of the co-Z arithmetic scheduling in ECSM-SCU.
MULTIPLICATION STAGE (MS) in
Figure 7 represents a stage where modular multipliers in FFAU complete 2~4 modular multiplications in parallel. In an MS, there is no correlation between the four modular multiplications, and each modular multiplier can perform at most one modular multiplication. Every MS starts with a modular multiplication and ends while operands of the first modular multiplication in the following MS are obtained. So the adjacent MS are interrelated and also gradually progressive. In addition, the coordinate conversion from Jacobian to affine coordinates needs to be completed after the last iteration. In order to further improve computational parallelism, two modular multiplications and one modular subtraction in the coordinate conversion are inserted into the MS of ZADDU without affecting the performance of ZADDU operations, as shown in
Figure 7c.
In the ECSM-SCU, nine n-bit registers are used to cache the intermediate results. As shown in
Table 3, a modular multiplication takes n clock cycles. Therefore the ECSM-SCU will select an unoccupied register to cache the operation result at the
th clock cycle after starting a modular multiplication. Additionally, for a modular addition/subtraction, the fastest operation for the modular adder/subtracter [
8] in the FFAU is to cache the result at the adjacent clock cycle after the operands are prepared. However, the modular adder/subtracter contains a longer carry chain than our proposed modular multiplier, which has an adverse effect on the timing.
In order to reduce the critical path length without consuming more area, we optimize it by scheduling and timing constraints. Firstly, and are designated as the modular addition and subtraction buffer, respectively, thus the multiplexer generated while transferring to different registers is eliminated, and the fan-out and path delay are reduced. Then, MulticyclePaths constraints are set from all registers to , improving the delay requirements of the modular adder/subtracter. Meanwhile, a modular addition/subtraction is executed with two clock cycles by ECSM-SCU. This optimization has a very small impact on the overall ECSM computing time since the modular addition/subtraction is scheduled to be executed during the modular multiplication which requires clock cycles in ECSM-SCU.
As a result, the DBLU operation is performed once with 3 MS and
clock cycles in INIT. Additionally, in ITER, the serial ZADDC and ZADDU operations are iterated
rounds, each iteration takes 4 MS and
clock cycles. Finally, COOV takes 5 modular multiplications and 1 modular division with
clock cycles. Therefore, the MS and total clock cycles (CC) consumed for a single ECSM can be calculated as
5. Overall Architecture and Implementation Results
This section presents the implementation results of our proposed lightweight ECSM architecture. The architecture consists of an ECSM-SCU and an FFAU, as shown in
Figure 8. The ECSM-SCU is responsible for controlling the entire ECSM process, and the FFAU is used to perform the bottom layer finite field operations over
. It supports the ECSM for random Weierstrass curves over
.
The implementation of our proposed design has been done in Verilog HDL and verified using the Synopsys VCS simulator. Synthesizing, mapping, placing, and routing are done using Xilinx Vivado 2022.
Table 4 shows the overall performance of the implementation achieved for a field size up to 256-bit on the Kintex-7 FPGA platform. It includes the latency for each ECSM ladder step over four standard ECC prime sizes: 160-bit, 192-bit, 224-bit, and 256-bit. In addition, our design is entirely based on the LUTs without using any integrated resources in FPGA such as DSP or BRAM. Thus it can be migrated to other FPGA platforms or even standard cells on ASIC technologies.
Moreover, for a comprehensive comparison with other similar works, our proposed design is implemented on several standard Xilinx 7-series FPGA platforms such as Virtex-7 (XC7VX690T), Kintex-7 (XC7K325T), and Zynq (XC7Z045), which supports ECSM operations for a field size up to 256-bit. The hardware resource consumption of the implementation results is shown in
Table 5. The implementation consumes similar resources in the three FPGA platforms. Therefore, in practical applications, our lightweight architecture can be easily integrated into other hardware designs that require ECC cryptosystem service.
Table 6 shows the implementation results and performance comparison analyses with similar designs. Our proposed design has similar implementation results on three 7-series platforms. A single ECSM operation is performed with 1.73 ms at 156.3 MHz, 1.70 ms at 158.7 MHz, and 1.80 ms at 149.7 MHz on Kintex-7, Virtex-7, and Zynq FPGA, respectively, and the resource consumption is around 6.5k slices in Kintex-7 FPGA, 6.4k slices in both Virtex-7 and Zynq FPGA. It is worth mentioning that the implementation result on Virtex-7 has the best performance with the area-time product (ATP) as low as 10.88. In
Table 6, designs in [
6,
8,
11,
12,
19,
20] are entirely LUTs-based. Additionally, designs in [
7,
9,
14,
15] use the integrated IPs in Xilinx FPGA to improve processor performance.
In the ECC cryptosystem design for IoT applications, Kudithi et al. [
8] proposed an area-efficient, high-speed implementation of ECC processor in affine coordinates over NIST prime fields
and
. It takes 2.70 ms and 3.73 ms for a single ECSM operation in
and
on Xilinx Kintex-7 FPGA, respectively. In 2020, Kudithi further improved the performance of prior design in [
6] by utilizing mixed-Jacobian coordinates, increasing the number of multipliers to four, and optimizing the scheduling of ECSM operation. The new design reduces the time to 2.44 ms with a 1k external slices consumption in
. However, the designs in [
6,
8] are based on the left-to-right binary method which is susceptible to SPA, and these designs only support NIST prime filed
and
. Our design reduces the time by 30% and increases the throughput rate by 41% with similar slices consumption. Furthermore, our design is resistant to side-channel attacks and supports random curves over a general prime field. Thus our proposed ECSM architecture is more suitable for the requirements of IoT applications.
The design in [
11] consumes 11.3k slices on Kintex-7 FPGA, and takes 3.27 ms at a frequency of 121.5 MHz to perform a single ECSM operation. Marzouqi et al. [
12] took advantage of the redundant-signed-digit (RSD) representation of operands to reduce the latency of the adders used in architecture. It consumes 34.6k LUTs, runs at a frequency of 160 MHz, and takes 2.26 ms to perform a single ECSM operation. Our design is superior in both area and time compared to this design. Hu et al. [
19] designed a lightweight ECC processor with 9.4k slices in Virtex-4 FPGA, which may achieve less resource consumption in a new FPGA platform. However, it takes a long time to perform ECSM operation due to its low frequency of 20.4 MHz and 610k clock cycle consumption. Compared with all these lightweight LUT-based ECC processors, our design achieves the fewest clock cycles and time through compact scheduling and has the highest throughput rate.
In terms of the area occupation, the processors in [
7,
9] consume relatively fewer resources in all the designs that use integrated IPs in Xilinx FPGA. Wu et al. [
7] designed a fast and unified ECC processor for five NIST primes. The authors proposed a word-based modular divider and used a scalable multiplication algorithm to support integers of different lengths. This design employs 8.4k slices and 32 DSPs and achieves a time of 0.53 ms in Virtex-7 FPGA. Loi et al. [
9] presented an ECC processor that supports 5 prime fields and 10 binary fields NIST curve. All the modular components in their design can be configured in two modes to support prime or binary fields operation. The design can perform an ECSM in 1.38 ms and occupy 2.3k slices, 25 DSPs, and 5 BRAM in Virtex-5 FPGA. Awaludin et al. [
14] proposed the fastest high-performance ECC processor over
. It only takes 0.14 ms to perform a single ECSM with 7.1k slices, 136 DSPs, and 15 BRAM. Asif et al. [
15] proposed an RSD-based ECC processor resort to a serial-parallel modular reduction architecture for the performance balance of time and area. Their design achieves 0.73 ms at a frequency of 86.6 MHz with the utilization of 18.8k LUTs and as many as 500 DSPs in Virtex-7 FPGA. It must be noted that there is no standard method to evaluate the equivalent resource occupation relationship between the DSPs and slices. We adopt the method with the lowest number of equivalent slices in [
6] to evaluate the area occupation. Additionally, our implementation in Virtex-7 FPGA has the smallest ATP compared to the other designs in
Table 6. Shah et al. [
20] also proposed an RSD-based ECC processor. A combination of the co-Z arithmetic and Montgomery ladder algorithm with four radix-4 RSD-based Montgomery multipliers is applied to perform ECSM operations. In Shah’s design, the RSD-based adder/subtractor, Montgomery multiplier, and divider make it possible to complete a single ECSM operation in just 0.84 ms without consuming any DSPs. However, these RSD-based components, especially the Montgomery multiplier which requires additional logic to convert operands to Montgomery form, lead to a high resources occupation with 13.3k slices. In contrast to this design, our proposed lightweight ECC processor achieved a 48% reduction in an area with similar ATP.
6. Conclusions
In this paper, we have proposed a novel lightweight ECSM architecture for random Weierstrass curves over prime field . To achieve low resource consumption, we utilized the adder-based modular multiplier, divider, and adder/subtracter to perform finite field operations. Furthermore, the architectures of modular multiplier and divider are optimized by pre-calculation technology, which decreases the critical path latency and improves the performance of ECSM architecture. Additionally, we also presented compact scheduling of the Montgomery ladder with co-Z arithmetic based on four modular multipliers, which only requires about clock cycles ( rounds modular multiplication) for a single ECSM. Our proposed design is implemented in Xilinx Kintex-7, Virtex-7, and Zynq FPGA platforms, utilizing 6.4~6.5k slices without DSPs or BRAMs and takes 1.73 ms, 1.70 ms, and 1.80 ms for an ECSM over , respectively. The design is based on the direction of low resource consumption, high security, and high portability, making it suitable for IoT applications or other lightweight embedded devices.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}