
Automotive Vulnerability Analysis for Deep Learning Blockchain Consensus Algorithm

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- (1)
- Section 1 is platooned using an introduction.
- (2)
- Section 2 introduces automobile security, automobile security standards, and artificial intelligence algorithms as related studies.
- (3)
- Section 3 introduced LSTM’s Code Detection Model Design through Model Design.
- (4)
- Section 4 explains the love of experimental results.
- (5)
- Section 5 explains the conclusions and future studies.
2. Related Research
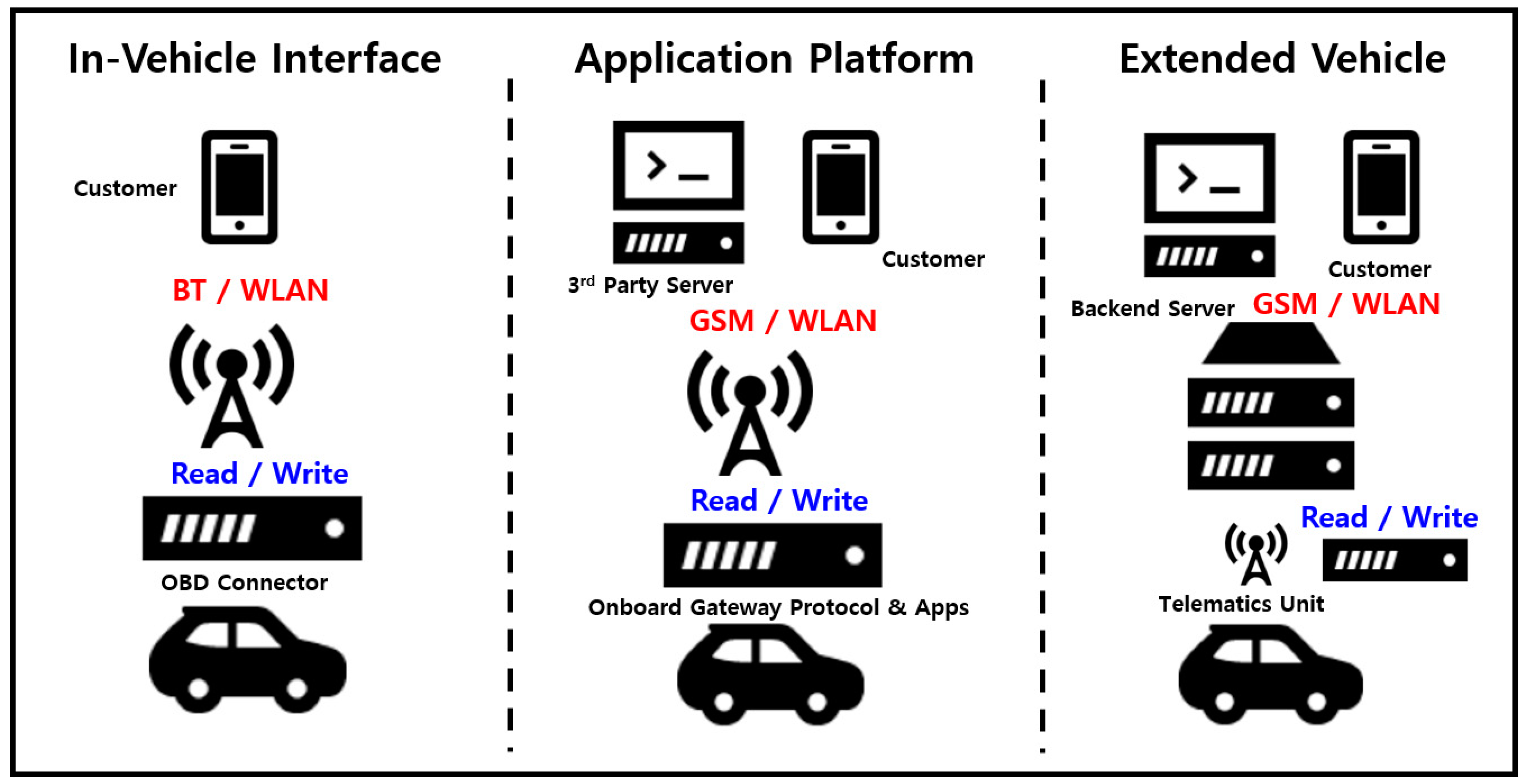
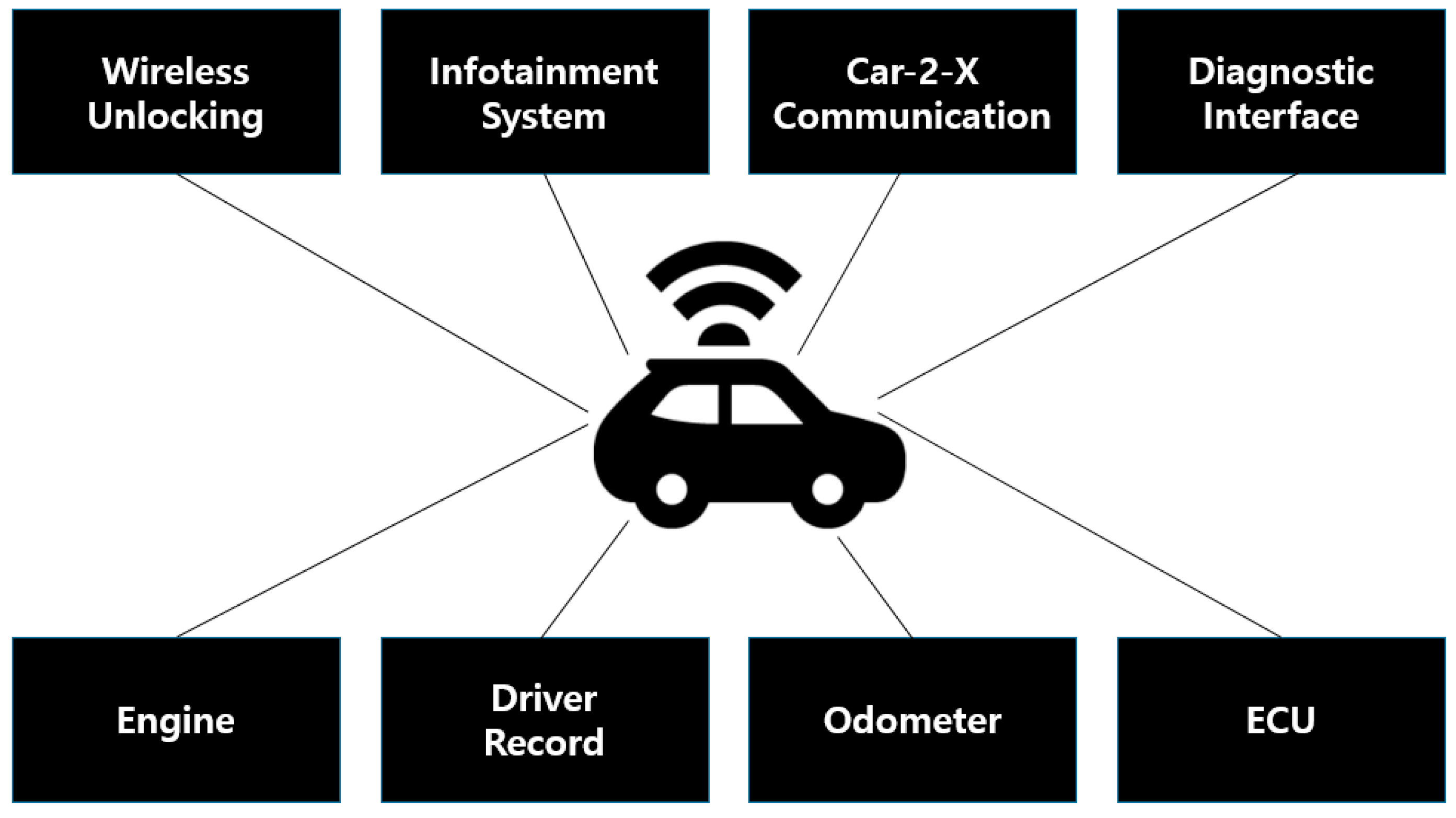
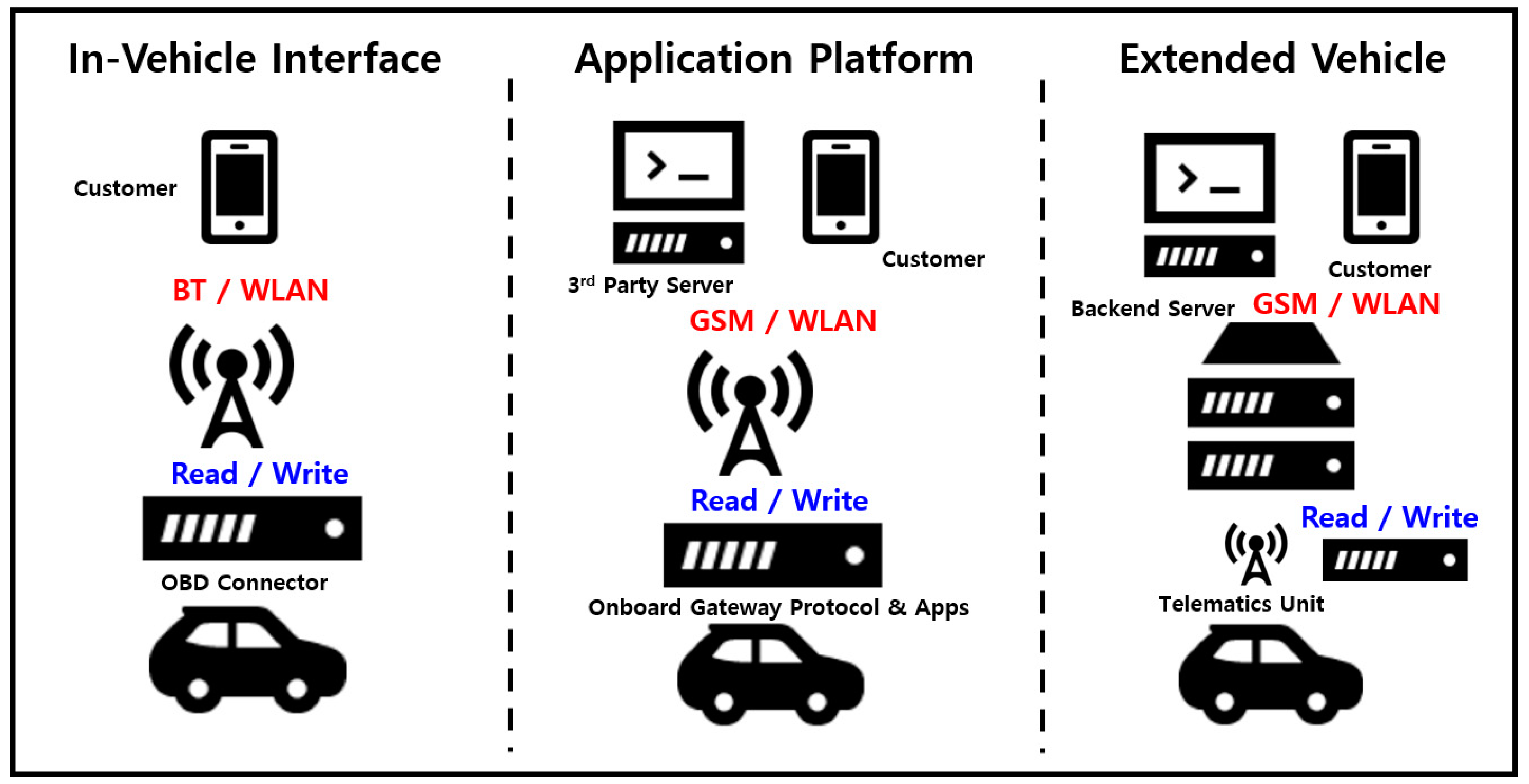
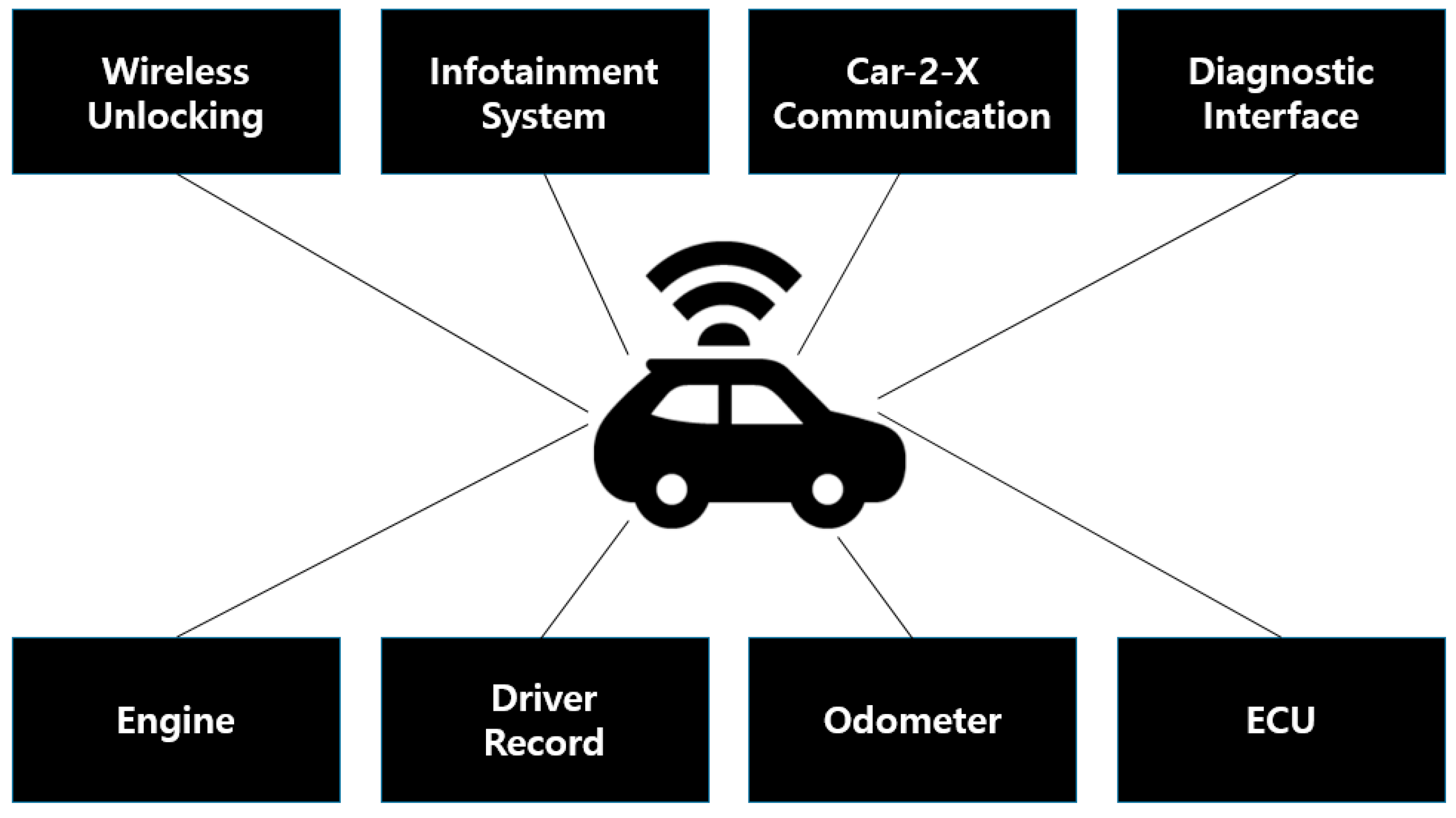
2.1. Automobile Security
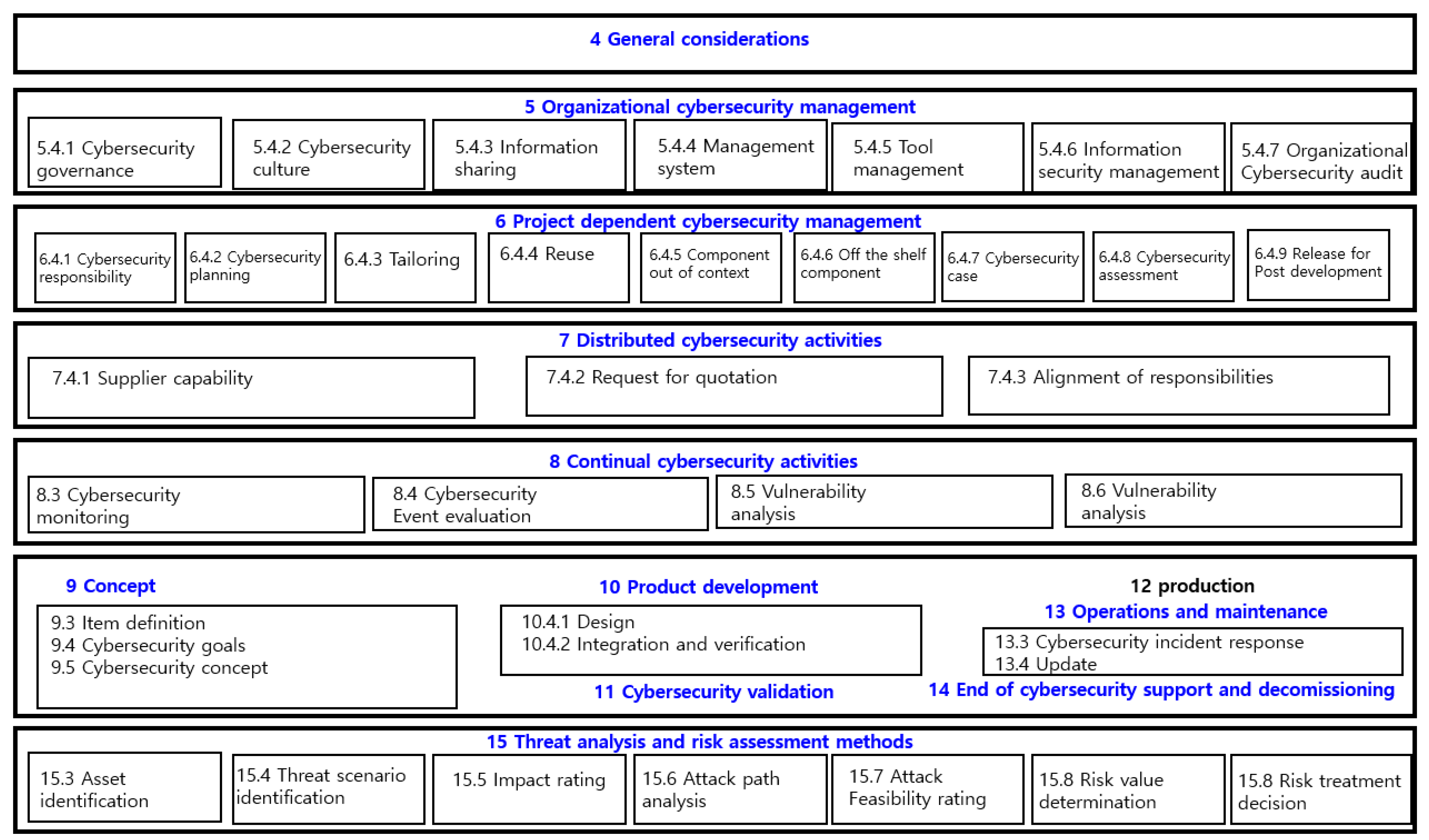
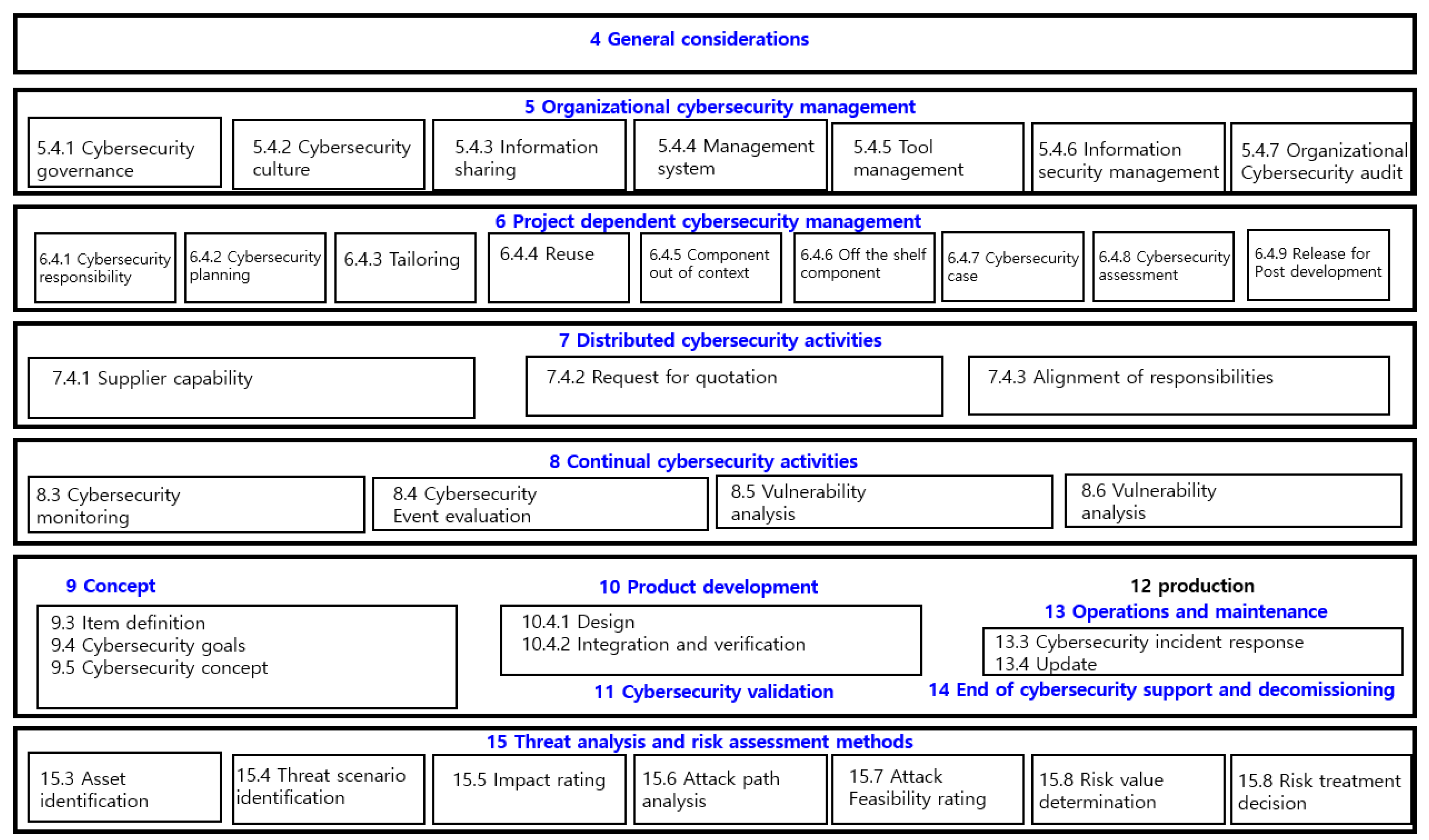
2.2. Automobile Security Standards
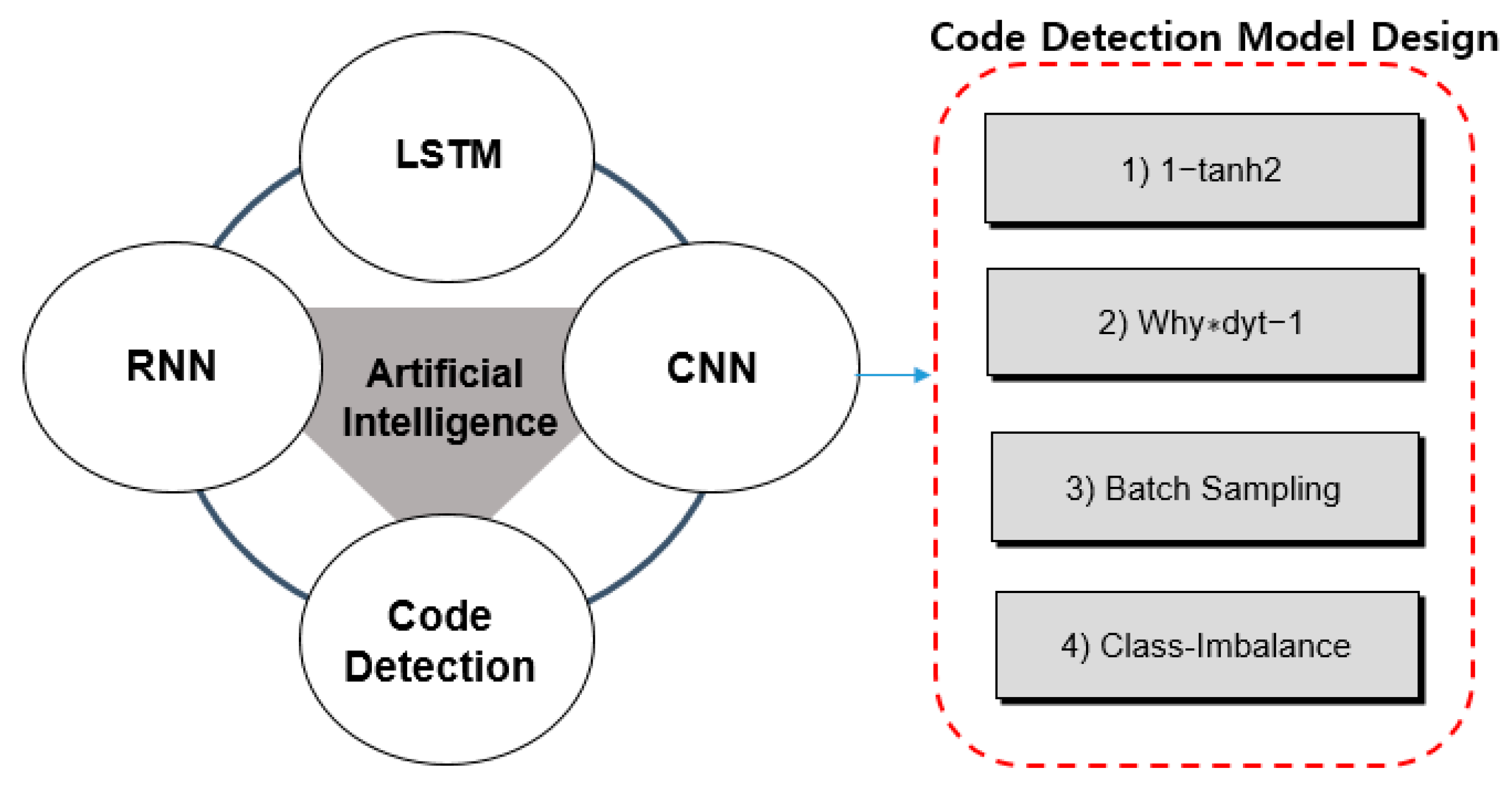
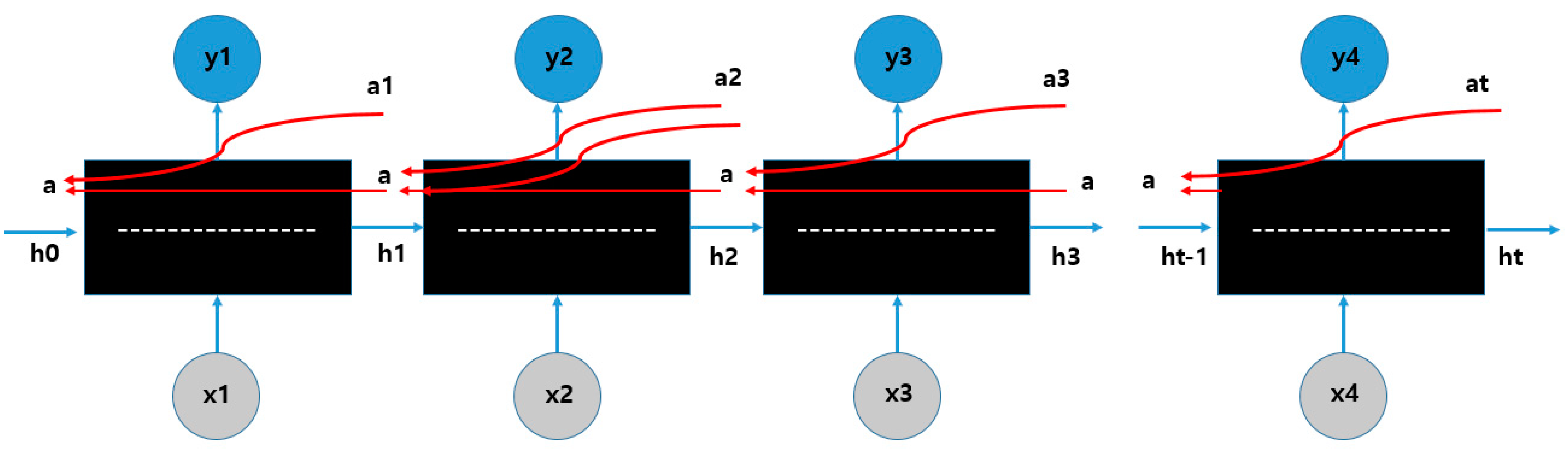
2.3. LSTM (Long Short-Term Memory)
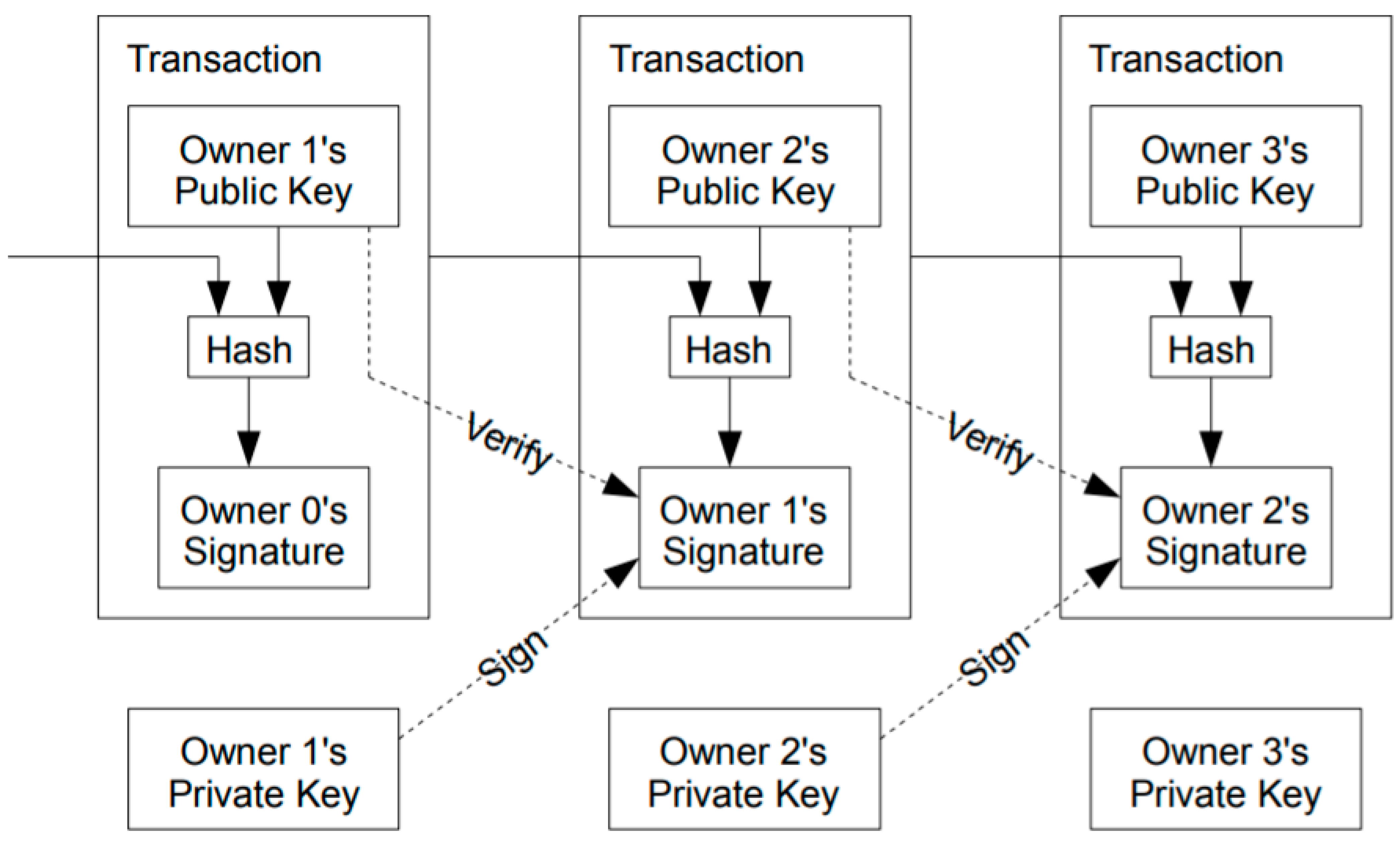
2.4. Blockchain Consensus Algorithm
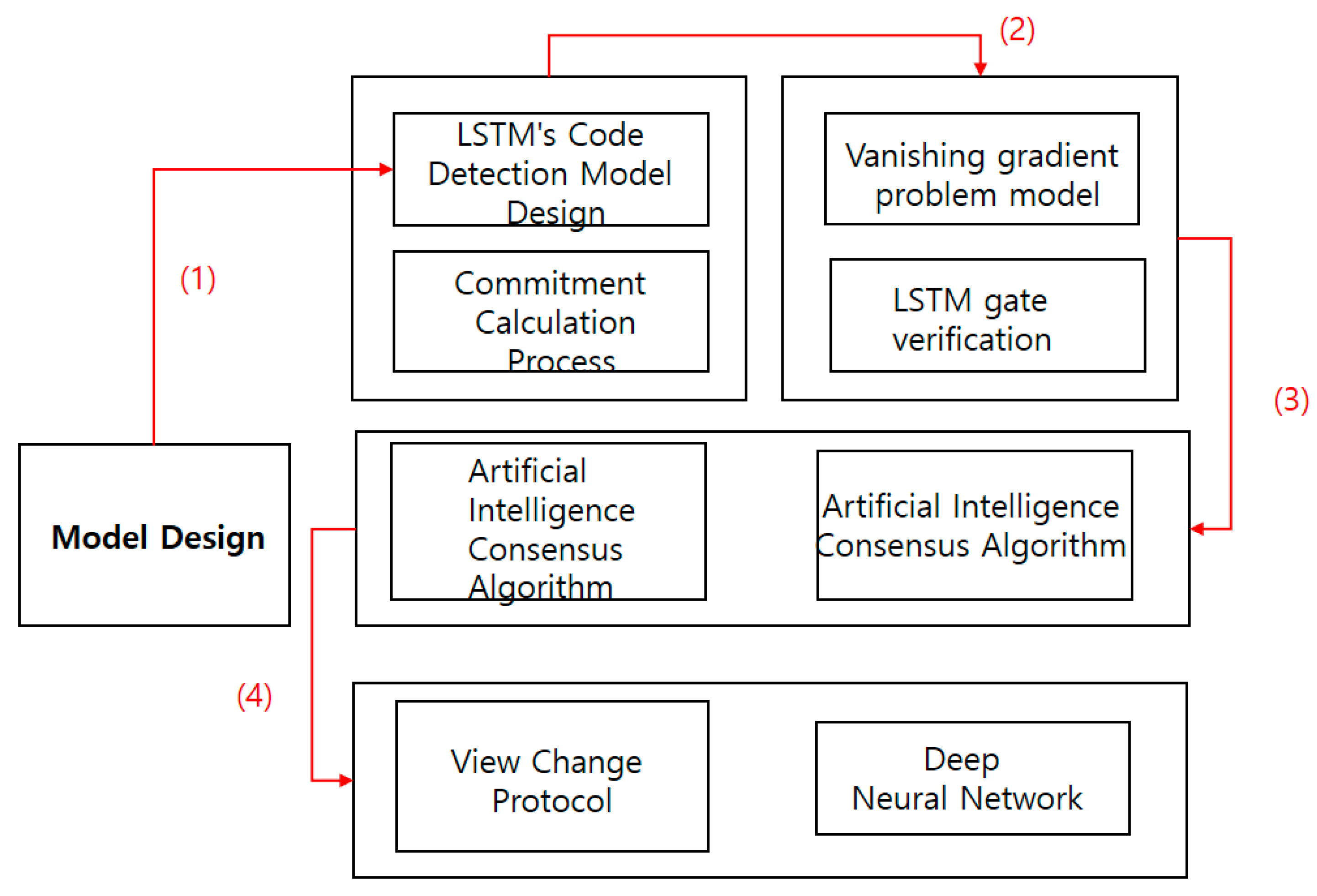
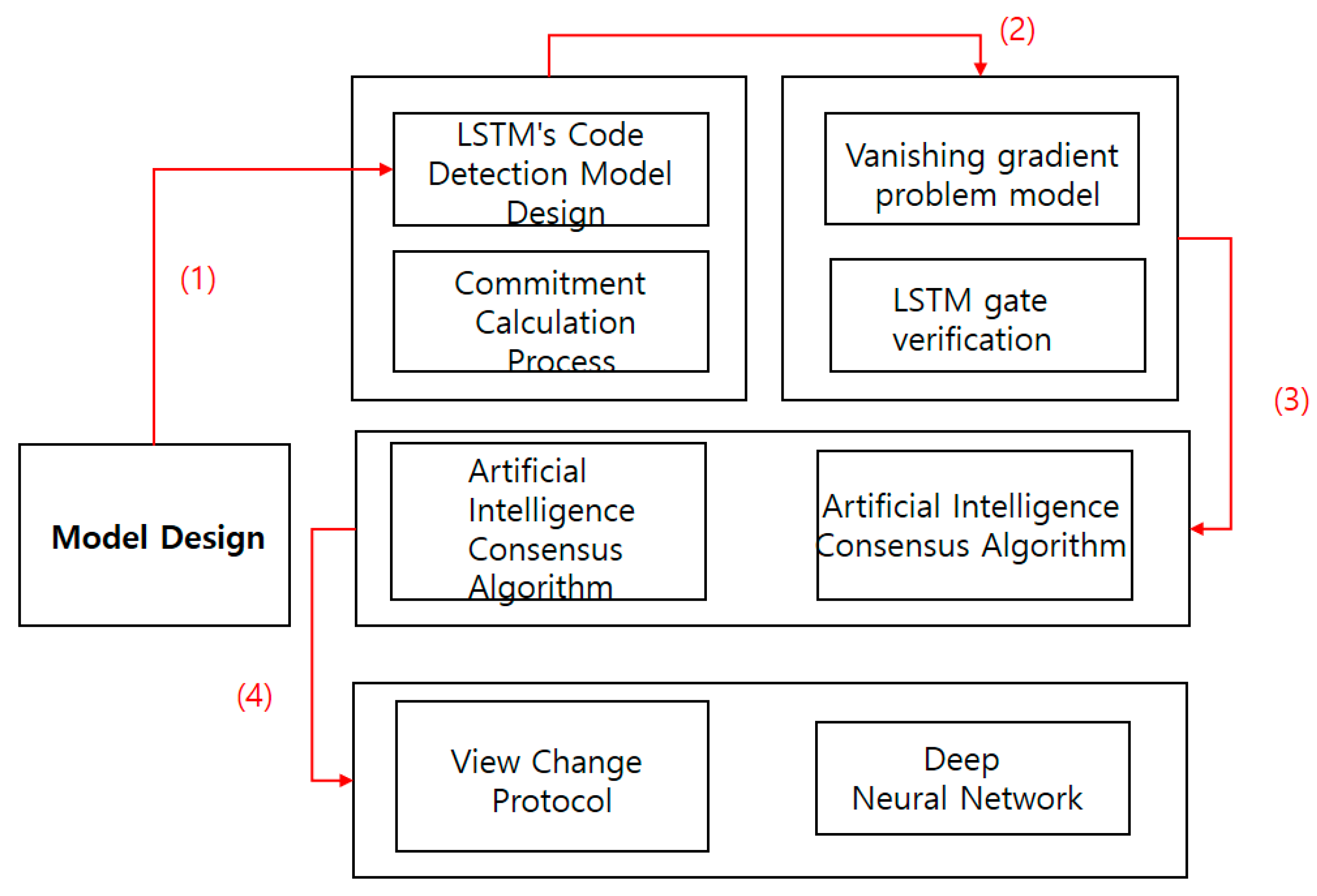
3. Model Design
3.1. Issue Raising
3.2. Research Methodology
3.3. LSTM’s Code Detection Model Design
3.3.1. Vanishing Gradient Problem Model
3.3.2. Commitment Calculation Process
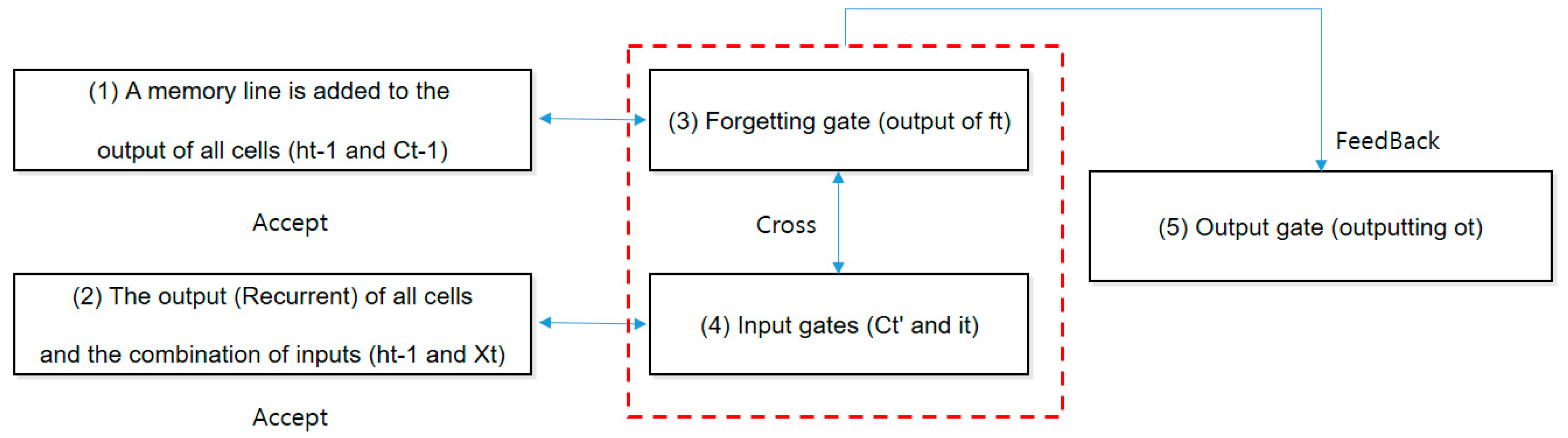
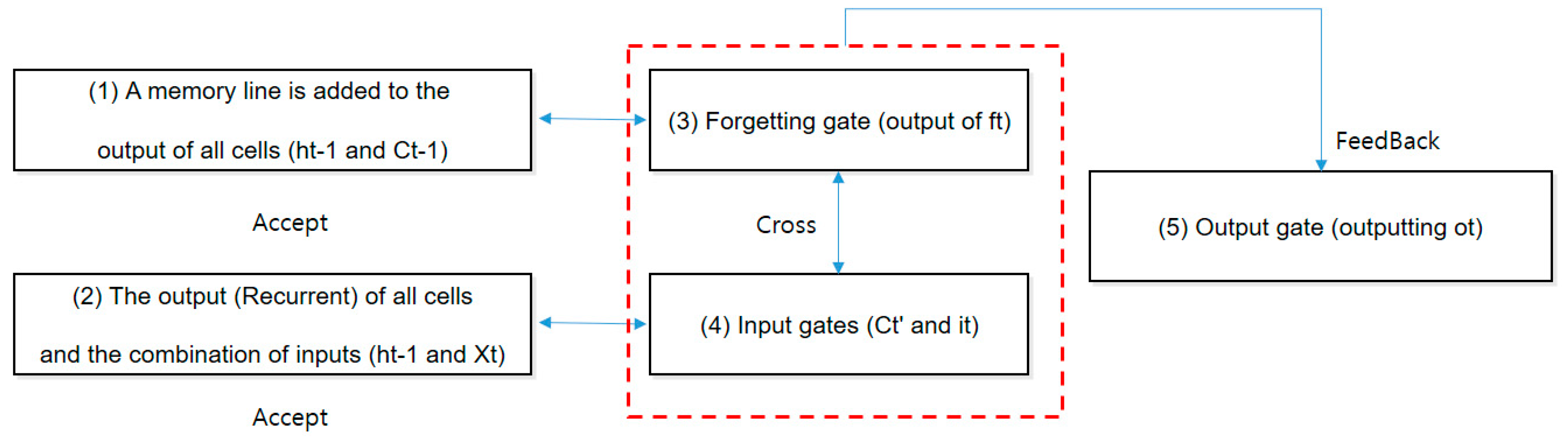
3.3.3. LSTM Gate Verification
- (1)
- A memory line is added to the output of all cells (ht − 1 and Ct − 1).
- (2)
- The output (Recurrent) of all cells and the combination of inputs (ht − 1 and Xt)
- (3)
- Forgetting gate (output of ft)
- (4)
- Input gates (Ct’ and it)
- -
- Transformation by tanh (outputting Ct’): Instead of flowing the information as it is, the amount of information can be reduced and is good to use. Further, tanh was said to be a useful function for determining candidate values added internally. For example, “I love you, unwilling” is replaced by a candidate for “I like you.” In this way, it is simply converted to output Ct’.
- -
- Screening by input gate (it): LSTM adjusts the weight by back propagation through time. Normal error backpropagation is the weight control of the input Xt, but synchronic error backpropagation is also affected by the information of the short-term memory ht − 1 in the previous cell. Therefore, in order to prevent the weight from being incorrectly updated by irrelevant information coming from ht − 1, the input gate is controlled to properly transmit only the required error signal. In addition, from the information “Younghee’s Unwilling Cake” made of ht − 1 + Xt, the input gate (sigmoid function) selects what to leave and what to let go.
- (5)
- Output gate (outputting ot)
- -
- Transformation by tanh: Tanh’s input is the long-term memory Ct − 1 in the previous cell plus the short-term memory Ct’ converted Xt. Each is selected as an oblivion gate and an input gate. Ct is to print this out as it is as long-term memory, but it is easier to convert than when there is only short-term memory because it also includes short-term memory.
- -
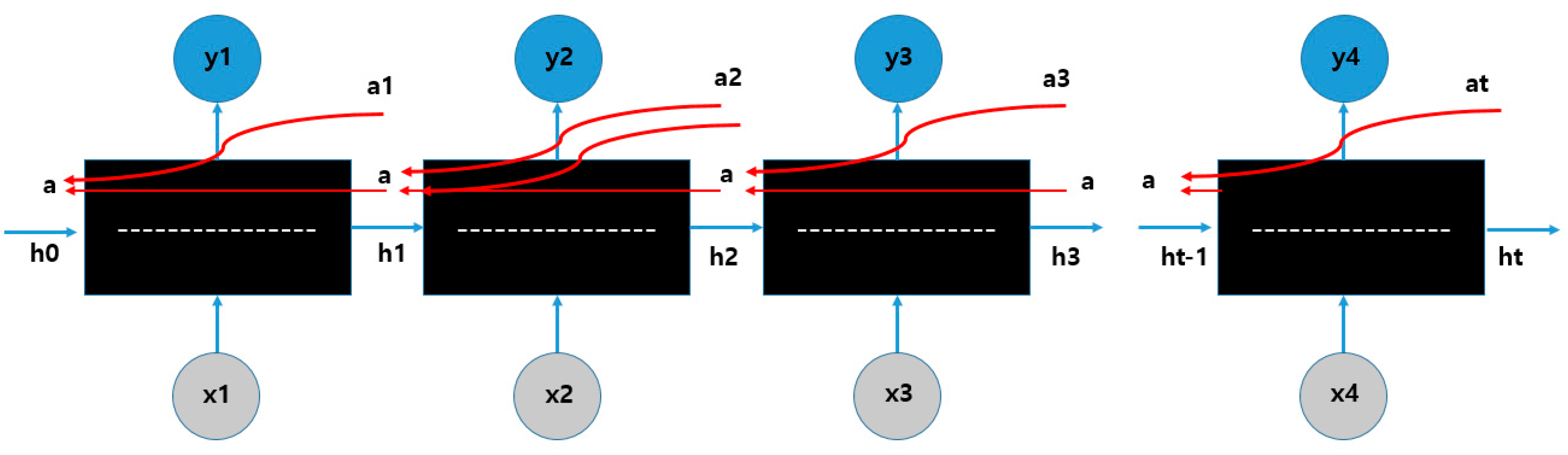
- Short-term memory selection: Just as the input gate protected the cell by itself, the output gate also prevented the propagation of bad information about the next cell. When updating the weight ht for activating the next cell, related information should be leaked so that it does not have a bad effect. Ot is output in the range from 0 to 1 by the output gate (Sigmoid function), and only the signal required for the short-term memory output ht is controlled to be properly transmitted (Figure 8).
3.4. Artificial Intelligence Consensus Algorithm
3.4.1. Artificial Intelligence Consensus Algorithm
3.4.2. View Change Protocol
3.5. Ant Colony
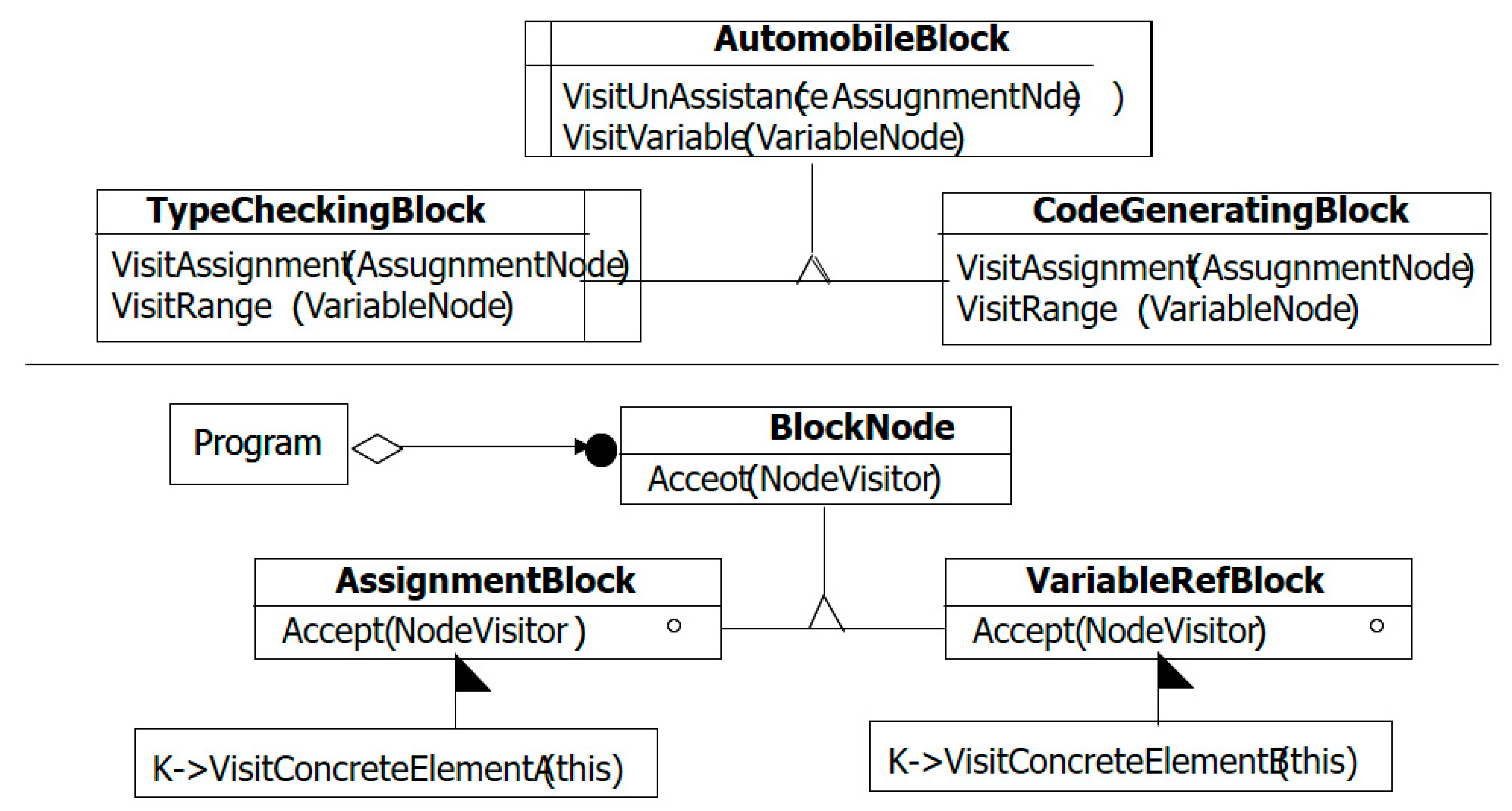
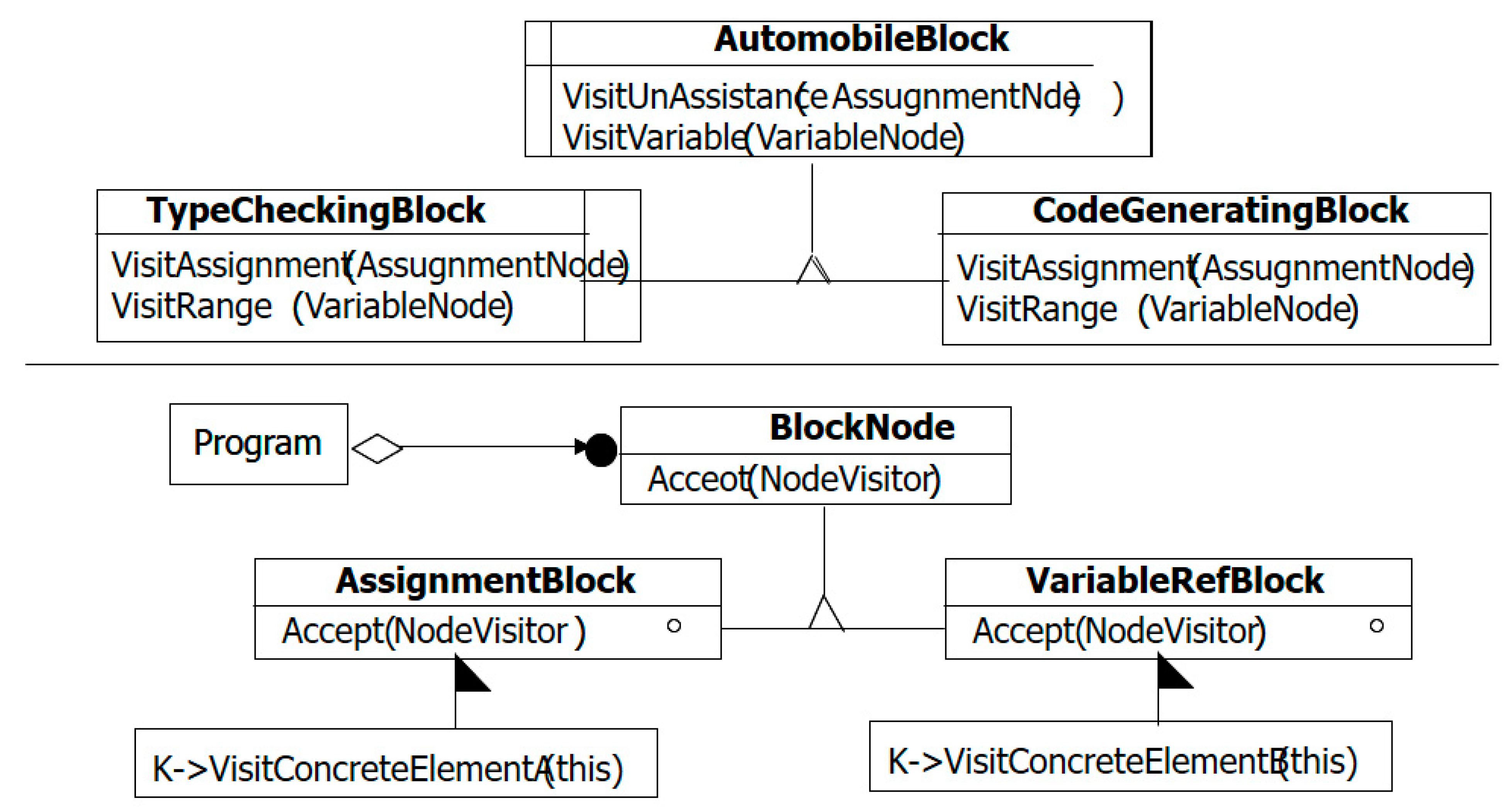
3.6. Automobile Malicious Code Verification Composite Diagram
3.6.1. Automobile Malicious Code Verification Composite Diagram
3.6.2. Automobile Malware Verification Source Code
4. Experiments and Results
4.1. Experiment Environment and Data Set
- -
- CPU Intel Core i9-9900
- -
- GPU GeForce RTX 2070
- -
- MEMORY 64GB
- -
- EngineVersion Unity 2019.2,13
- -
- Tensorflow Version 2.2.2
- -
- Unity ML ML release 2
4.2. Experimental Evaluation Method
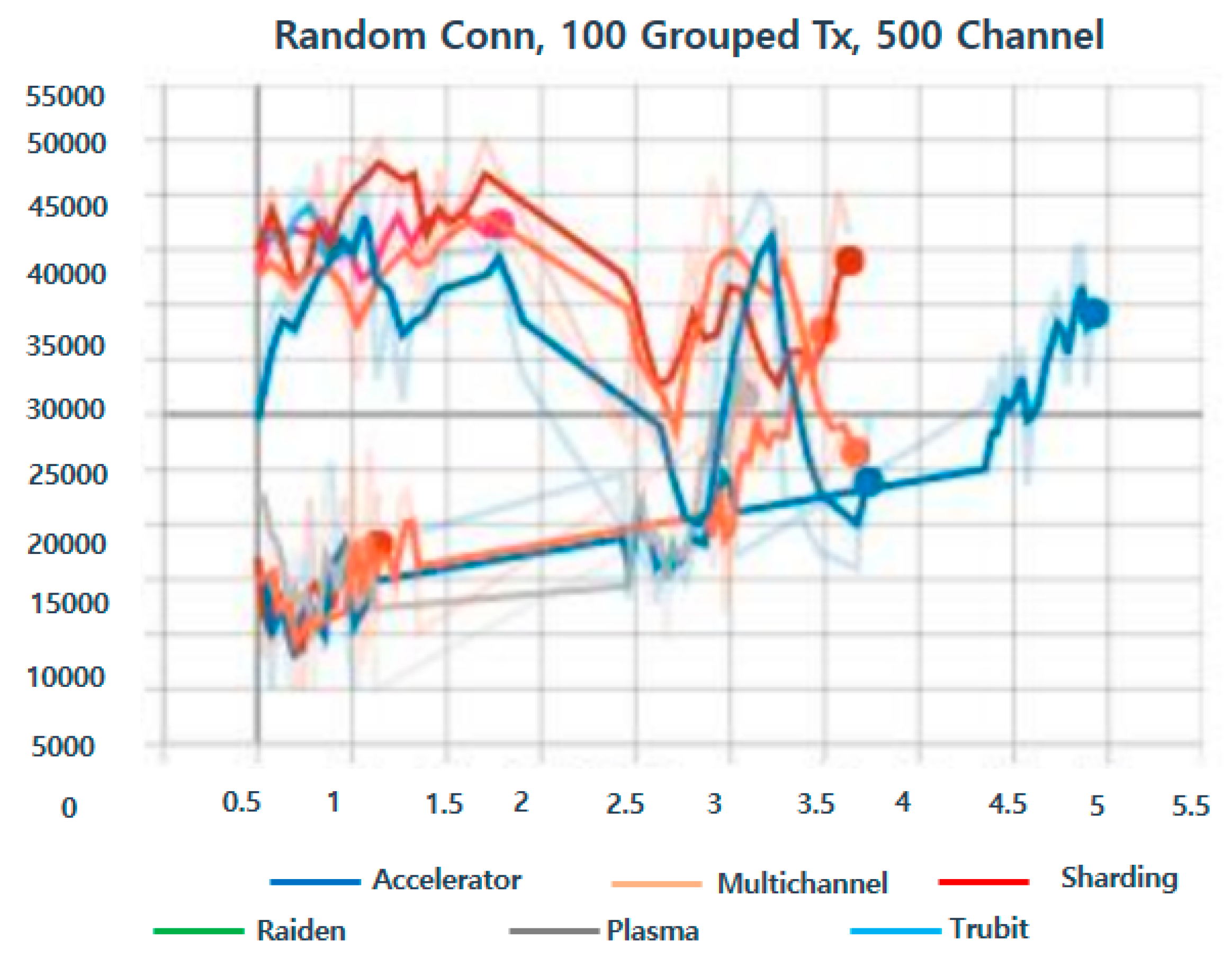
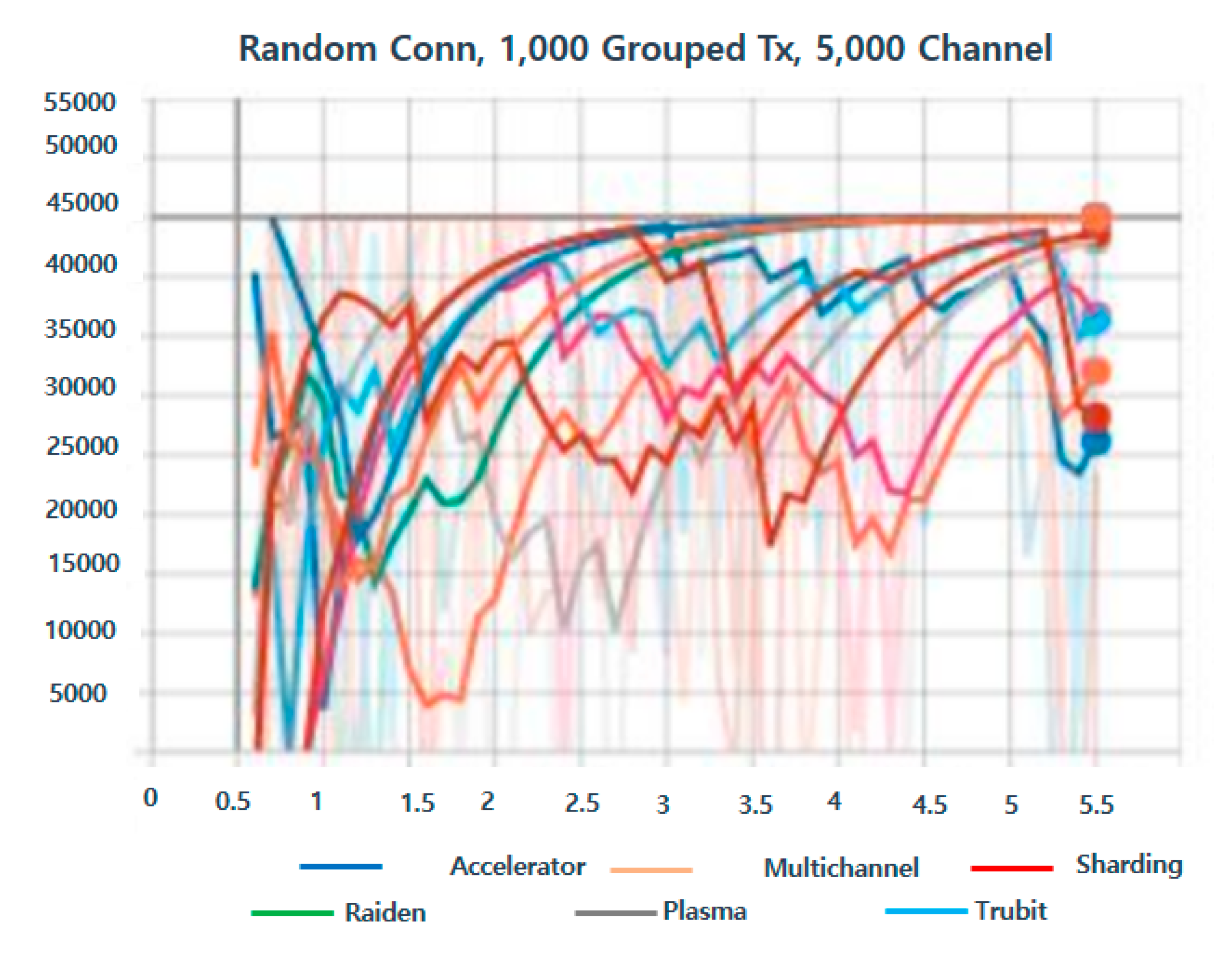
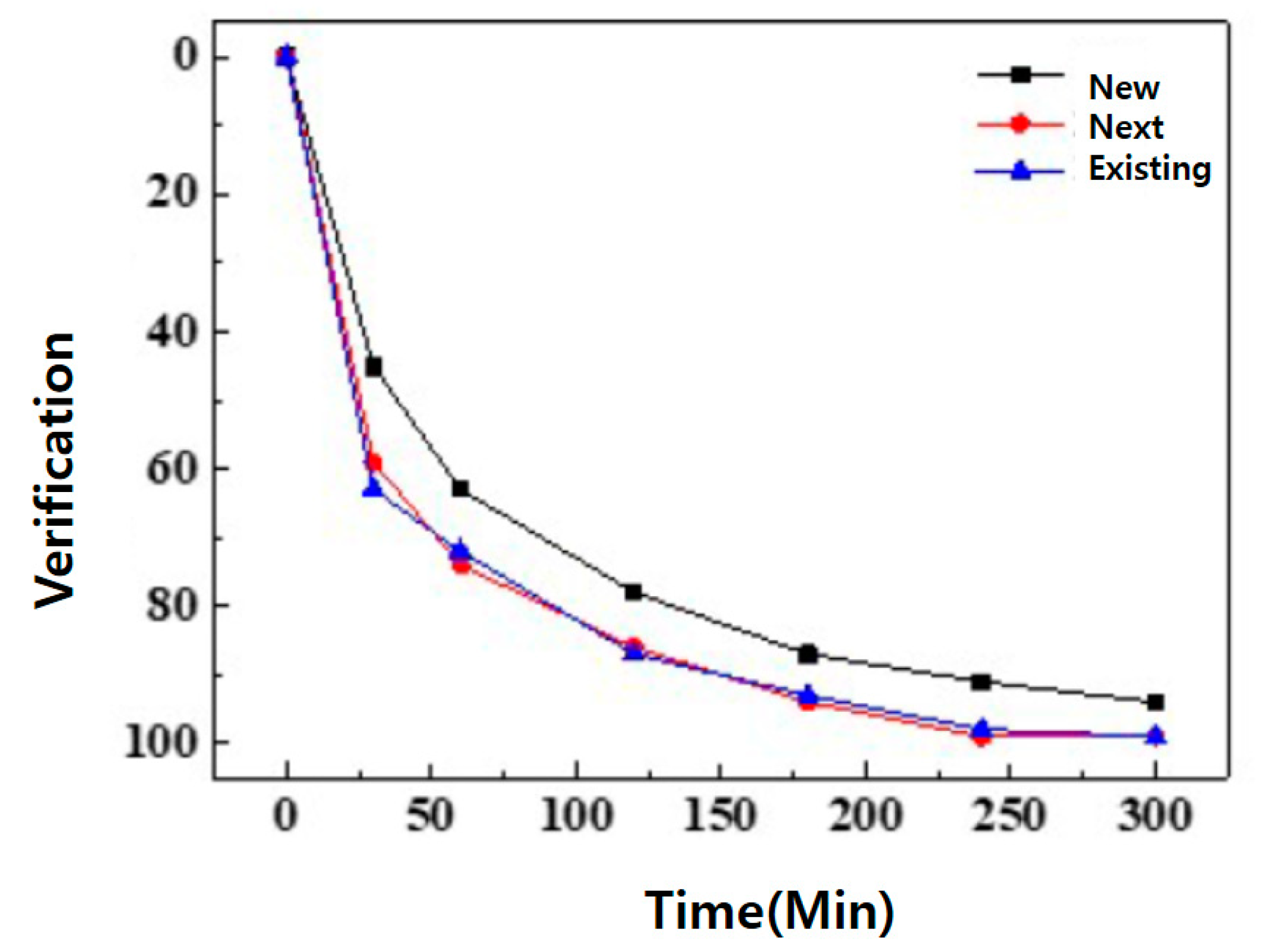
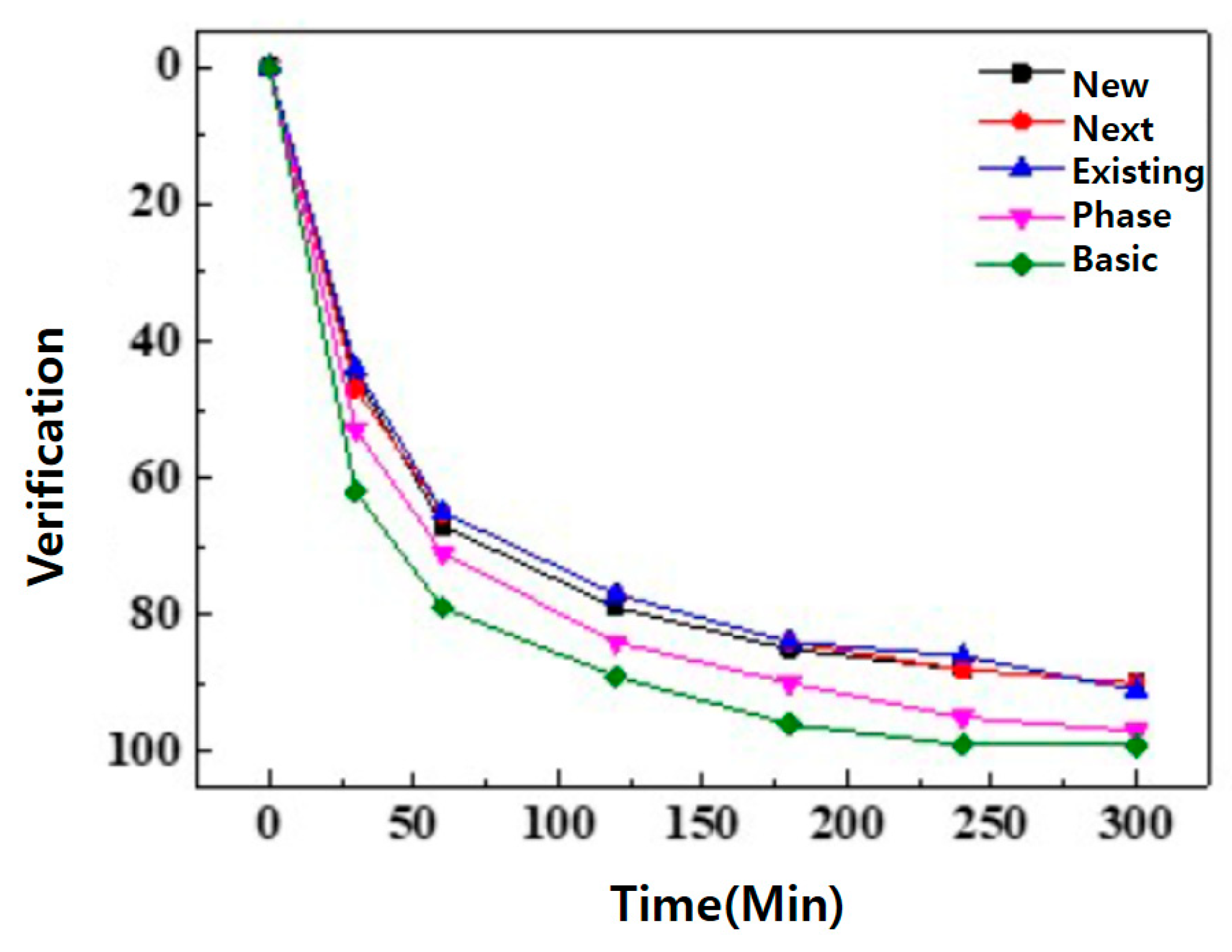
4.3. Experimental Results and Evaluation
4.4. Experimental Evaluation Method
5. Conclusions and Future Work
Funding
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| BPTT | Back Propagation Through Time |
| CAMP | Crash Avoidance. Metrics Partnership |
| CAN | Car Area Network |
| CTC | Connectionist Temporal Classification |
| DIS | Draft International Standard |
| DoS | Denial-of-Service |
| ECU | Electronic Control Unit |
| GPS | Global Positioning System |
| ICBM | IoT, Cloud, Big Data, Mobile |
| HIS | Internatinal Hybrid System |
| IT | Information Technology |
| IoT | Internet of Things |
| IDS | Intrusion Detection System |
| LSM | Linux security module |
| LSTM | Long short-term memory |
| NV | Night Vision |
| PCA | Principal Component Analysis |
| PoS | Proof of Stake |
| PoW | Proof of Work |
| RNN | Recurrent neural network |
| SCMS | Security Credential Management System |
| SOTA/FOTA | Software-Over-The-Air/Firmware-Over-The-Air |
| PKI | Public Key Infrastructure |
Appendix A
| Algorithms A1.pyc |
| def lossFun(inputs, targets, hprev, cprev): xs, hs, cs, is_, fs, os, gs, ys, ps= {}, {}, {}, {}, {}, {}, {}, {}, {} hs[−1] = np.copy(hprev) cs[−1] = np.copy(cprev) loss = 0 H = hidden_size # forward pass for t in range(len(inputs)): xs[t] = np.zeros((vocab_size, 1)) xs[t][inputs[t]] = 1 tmp = np.dot(Wxh, xs[t]) + np.dot(Whh, hs[t − 1]) + bh # hidden state is_[t] = sigmoid(tmp[:H]) fs[t] = sigmoid(tmp[H:2 * H]) os[t] = sigmoid(tmp[2 * H: 3 * H]) gs[t] = np.tanh(tmp[3 * H:]) cs[t] = fs[t] * cs[t − 1] + is_[t] * gs[t] hs[t] = os[t] * np.tanh(cs[t]) # compute loss for i in range(len(targets)): idx = len(inputs) − len(targets) + i ys[idx] = np.dot(Why, hs[idx]) + by # unnormalized log probabilities for next chars ps[idx] = np.exp(ys[idx]) / np.sum(np.exp(ys[idx])) # probabilities for next chars loss += −np.log(ps[idx][targets[i], 0]) # softmax (cross-entropy loss) # backward pass: compute gradients going backwards dWxh, dWhh, dWhy = np.zeros_like(Wxh), np.zeros_like(Whh), np.zeros_like(Why) dbh, dby = np.zeros_like(bh), np.zeros_like(by) dhnext, dcnext = np.zeros_like(hs[0]), np.zeros_like(cs[0]) n = 1 a = len(targets) − 1 for t in reversed(range(len(inputs))): if n > len(targets): continue dy = np.copy(ps[t]) dy[targets[a]] −= 1 # backprop into y dWhy += np.dot(dy, hs[t].T) dby += dy dh = np.dot(Why.T, dy) + dhnext # backprop into h dc = dcnext + (1 − np.tanh(cs[t]) * np.tanh(cs[t])) * dh * os[t] # backprop through tanh nonlinearity dcnext = dc * fs[t] di = dc * gs[t] df = dc * cs[t − 1] do = dh * np.tanh(cs[t]) dg = dc * is_[t] ddi = (1 − is_[t]) * is_[t] * di ddf = (1 − fs[t]) * fs[t] * df ddo = (1 − os[t]) * os[t] * do ddg = (1 − gs[t]^2) * dg da = np.hstack((ddi.ravel(),ddf.ravel(),ddo.ravel(),ddg.ravel())) dWxh += np.dot(da[:,np.newaxis],xs[t].T) dWhh += np.dot(da[:,np.newaxis],hs[t − 1].T) dbh += da[:, np.newaxis] dhnext = np.dot(Whh.T, da[:, np.newaxis]) n += 1 a −= 1 for dparam in [dWxh, dWhh, dWhy, dbh, dby]: np.clip(dparam, −5, 5, out = dparam) # clip to mitigate exploding gradients return loss, dWxh, dWhh, dWhy, dbh, dby, hs[len(inputs) − 1], cs[len(inputs) − 1] |
References
- Tellegen, A.; Watson, D.; Clark, L.A. On the Dimensional and Hierarchical Structure of Affect. Psychol. Sci. 1999, 10, 297–303. [Google Scholar] [CrossRef]
- Patra, B.G.; Maitra, P.; Das, D.; Bandyopadhyay, S. Mediaeval 2015: Music emotion recognition based on Feed-forward neural network. In Proceedings of the MediaEval 2015 Workshop, Wurzen, Germany, 14–15 September 2015. [Google Scholar]
- Chen, S.-H.; Lee, Y.-S.; Hsieh, W.-C.; Wang, J.-C. Music emotion recognition using deep Gaussian process. In Proceedings of the 2015 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Hong Kong, China, 16–19 December 2015; pp. 495–498. [Google Scholar]
- Bargaje, M. Emotion recognition and emotion based classification of audio using genetic algorithm-an opti-mized approach. In Proceedings of the 2015 International Conference on Industrial Instrumentation and Con-trol, Pune, India, 28–30 May 2015; pp. 562–567. [Google Scholar]
- Malik, M.; Adavanne, S.; Drossos, K.; Virtanen, T.; Ticha, D.; Jarina, R. Stacked Convolutional and recurrent neural networks for music Emotion Recognition. In Proceedings of the 14th Sound and Music Computing Conference, Espoo, Finland, 5–8 July 2017; pp. 208–213. [Google Scholar]
- Wang, Z.; Peterson, J.L.; Rea, C.; Humphreys, D. Special Issue on Machine Learning, Data Science, and Artificial Intelligence in Plasma Research. IEEE Trans. Plasma Sci. 2020, 48, 1–2. [Google Scholar] [CrossRef]
- Picard, R.W. Computer learning of subjectivity. ACM Comput. Surv. 1995, 27, 621–623. [Google Scholar] [CrossRef]
- Darwin, C. The Expression of Emotions in Animals and Man; University of Chicago Press: London, UK, 2015. [Google Scholar]
- Wang, Y.; Kwong, S.; Leung, H.; Lu, J.; Smith, M.H.; Trajkovic, L. Brain-Inspired Systems: A Transdisciplinary exploration on cognitive cybernetics, humanity, and systems science toward au-tonomous artificial intelligence. IEEE Syst. Man Cybern. Mag. 2020, 6, 6–13. [Google Scholar] [CrossRef]
- Watkins, T. Cosmology of artificial intelligence project: Libraries, makerspaces, community and AI litera-cy. ACM AI Matters 2019, 4, 134–140. [Google Scholar] [CrossRef]
- Seo, Y.-S.; Huh, J.-H. Automatic emotion-based music classification for supporting intelligent IoT applications. Electronics 2019, 8, 164. [Google Scholar] [CrossRef] [Green Version]
- Lee, Y.; Rathore, S.; Park, J.H.; Park, J.H. A blockchain-based smart home gateway architecture for preventing data forgery. Hum. Cent. Comput. Inf. Sci. 2020, 10, 1–14. [Google Scholar] [CrossRef]
- Seo, Y.-S.; Huh, J.-H. Context-aware auction solution of cooperative fish market monitoring system for intelligent user. Hum. Cent. Comput. Inf. Sci. 2020, 10, 1–36. [Google Scholar] [CrossRef]
- Park, J.S.; Park, J.H. Advanced technologies in Blockchain, machine learning, and big data. J. Inf. Processing Syst. 2020, 16, 239–245. [Google Scholar]
- Woo, H.; Jeong, S.-J.; Huh, J.-H. Improvement of ITSM it service efficiency in military electronic service. J. Inf. Processing Syst. 2020, 16, 246–260. [Google Scholar]
- Rahmadika, S.; Noh, S.; Lee, K.; Kweka, B.J.; Rhee, K.H. The dilemma of parameterizing propagation time in blockchain P2P network. J. Inf. Processing Syst. 2020, 16, 699–717. [Google Scholar]
- Yuan, Y.; Huh, J.-H. Automatic pattern setting system reacting to customer design. J. Inf. Processing Syst. 2019, 15, 1277–1295. [Google Scholar]
- Salim, M.M.; Shanmuganathan, V.; Loia, V.; Park, J.H. Deep learning enabled secure IoT handover authentication for blockchain networks. Hum. Cent. Comput. Inf. Sci. 2021, 11, 21. [Google Scholar]
- Kim, Y.; Chung, M.; Chung, A.M. An Approach to Hyperparameter Optimization for the Objective Function in Machine Learning. Electronics 2019, 8, 1267. [Google Scholar] [CrossRef] [Green Version]
- Huh, J.-H.; Kim, S.-K. The Blockchain Consensus Algorithm for Viable Management of New and Renewable Energies. Sustainability 2019, 11, 3184. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.-K.; Kwon, H.-T.; Kim, Y.-K.; Park, Y.-P.; Keum, D.-W.; Kim, U.-M. A Study on Application Method for Automation Solution Using Blockchain dApp Platform. In International Conference on Parallel and Distributed Computing: Applications and Technologies; Springer: Singapore, 2019; pp. 444–458. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation Learning: A Review and New Perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Luo, W.; Lu, J.; Li, X.; Chen, L.; Liu, K. Rethinking Motivation of Deep Neural Architectures. IEEE Circuits Syst. Mag. 2020, 20, 65–76. [Google Scholar] [CrossRef]
- Wang, X.; Lin, X.; Dang, X. Supervised learning in spiking neural networks: A review of algorithms and evaluations. Neural Netw. 2020, 125, 258–280. [Google Scholar] [CrossRef]
- Enríquez-Gaytán, J.; Gómez-Castañeda, F.; Flores-Nava, L.; Moreno-Cadenas, J. Spiking neural network approaches PCA with metaheuristics. Electron. Lett. 2020, 56, 488–490. [Google Scholar] [CrossRef]
- Liu, C.; Shen, W.; Zhang, L.; Du, Y.; Yuan, Z. Spike Neural Network Learning Algorithm Based on an Evolutionary Membrane Algorithm. IEEE Access 2021, 9, 17071–17082. [Google Scholar] [CrossRef]
- Al-Garadi, M.A.; Mohamed, A.; Al-Ali, A.K.; Du, X.; Ali, I.; Guizani, M. A Survey of Machine and Deep Learning Methods for Internet of Things (IoT) Security. IEEE Commun. Surv. Tutor. 2018, 22, 1646–1685. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Chen, X.; Li, E.; Zeng, L.; Luo, K.; Zhang, J. Edge intelligence: Paving the last mile of artificial intelli-gence with edge computing. Proc. IEEE 2019, 107, 1738–1762. [Google Scholar] [CrossRef] [Green Version]
- Bennis, F.; Bhattacharjya, R.K. Nature-Inspired Methods for Metaheuristics Optimization: Algorithms and Applications in Science and Engineering; Springer: Basingstoke, UK, 2020. [Google Scholar]
- Richard, B.; Levin, P.W.; Holly, L. Betting Blockchain Will Change Everything–SEC and CFTC Regulation of Blockchain Technology. In Handbook of Blockchain, Digital Finance, and Inclusion; Elsevier: Amsterdam, The Netherlands, 2017; Volume 2, pp. 187–212. [Google Scholar]
- Vogels, C.B.F.; Brito Anderson, F.; Wyllie, A.L.; Fauver, J.R.; Ott, I.M.; Kalinich, C.C.; Petrone, M.E.; Casano-vas-Massana, A.; Muenker, M.C.; Moore, A.J.; et al. Analytical sensitivity and efficiency comparisons of SARS-COV-2 qRT-PCR primer-probe sets. Nat. Microbiol. 2020, 5, 1299–1305. [Google Scholar] [CrossRef]
- Zhang, Y.; Odiwuor, N.; Xiong, J.; Sun, L.; Nyaruaba, R.O.; Wei, H.; Tanner, N.A. Rapid Molecular Detection of SARS-CoV-2 (COVID-19) Virus RNA Using Colorimetric LAMP. medRxiv 2020. [Google Scholar] [CrossRef]
- Notomi, T.; Okayama, H.; Masubuchi, H.; Yonekawa, T.; Watanabe, K.; Amino, N.; Hase, T. Loop-mediated isothermal amplification of DNA. Nucleic Acids Res. 2000, 28, E63. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kashir, J.; Yaqinuddin, A. Loop mediated isothermal amplification (LAMP) assays as a rapid diagnostic for COVID-19. Med. Hypotheses 2020, 141, 109786. [Google Scholar] [CrossRef] [PubMed]
- Rohaim, M.A.; Clayton, E.; Sahin, I.; Vilela, J.; Khalifa, M.E.; Al-Natour, M.Q.; Bayoumi, M.; Poirier, A.C.; Bra-navan, M.; Tharmakulasingam, M.; et al. Artificial intelligence-assisted loop mediated isothermal amplification (AI-LAMP) for rapid detection of SARS-CoV-2. Viruses 2020, 12, 972. [Google Scholar] [CrossRef]
- Sodhro, A.H.; Pirbhulal, S.; de Albuquerque, V.H.C. Artificial intelligence-driven mecha-nism for edge computing-based industrial applications. IEEE Trans. Ind. Inform. 2019, 15, 4235–4243. [Google Scholar] [CrossRef]
- Padmapriya, T.; Manikanthan, S.V. Implementation of Dual-Band Planar Inverted F- Antenna (PIFA) Using Machine Learning (ML) for 5G Mobile Applications. In Proceedings of the First International Conference on Computing, Communication and Control System, I3CAC 2021, Chennai, India, 7–8 June 2021. [Google Scholar]
- Dewi, K.C.; Harjoko, A. Kid’s Song Classification based on mood parameters using K-Nearest neighbor classification method and self organizing Map. In Proceedings of the 2010 International Conference on Distributed Frameworks for Multimedia Applications, Yogyakarta, Indonesia, 2–3 August 2010; pp. 1–5. [Google Scholar]
- Han, B.J.; Rho, S.M.; Dannenberg, R.B.; Hwang, E.J. SMERS: Music Emotion Recognition Using Support Vector Regression. In Proceedings of the 10th International Society for Music Information Retrieval Conference, Kobe, Japan, 26–30 October 2009; pp. 651–656. [Google Scholar]
- Lin, C.; Liu, M.; Hsiung, W.; Jhang, J. Music emotion recognition based on two-level support vector classification. In Proceedings of the 2016 International Conference on Machine Learning and Cybernetics, Jeju, Korea, 10–13 July 2016; pp. 375–389. [Google Scholar]
- Kim, B.-G.; Park, D.-J. Novel target segmentation and tracking based on fuzzy membership dis-tribution for vision-based target tracking system. Image Vis. Comput. 2016, 24, 1319–1331. [Google Scholar] [CrossRef]
- Huh, J.-H.; Seo, Y.-S. Understanding edge computing: Engineering evolution with artificial intelligence. IEEE Access 2019, 7, 164229–164245. [Google Scholar] [CrossRef]
- Chen, M.; Mao, S.; Liu, Y. Big Data: A Survey, Mobile Networks and Applications; Springer: Berlin/Heidelberg, Germany, 2014; pp. 171–209. [Google Scholar]
- Lee, S.; Woo, H.; Shin, Y. Study on Personal Information Leak Detection Based on Machine Learning. Adv. Sci. Lett. 2017, 23, 12818–12821. [Google Scholar] [CrossRef]
- Huh, J.-H.; Otgonchimeg, S.; Seo, K. Advanced metering infrastructure design and test bed experiment using intelligent agents: Focusing on the PLC network base technology for smart grid system. J. Supercomput. 2016, 72, 1862–1877. [Google Scholar] [CrossRef]
- Huang, X.; Yang, Q.; Qiao, H. Lightweight Two-Stream Convolutional Neural Network for SAR Target Recognition. IEEE Geosci. Remote Sens. Lett. 2021, 18, 667–671. [Google Scholar] [CrossRef]
- Huh, J.-H. PLC-based design of monitoring system for ICT-integrated vertical fish farm. Hum. Cent. Comput. Inf. Sci. 2017, 7, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Huh, J.-H. Smart Grid Test. Bed Using OPNET and Power Line Communication; IGI Global: Seoul, Korea, 2018; pp. 1–425. [Google Scholar]
- He, D.; Liu, C.; Quek, T.Q.S.; Wang, H. Transmit Antenna Selection in MIMO Wiretap Channels: A Machine Learning Approach. IEEE Wirel. Commun. Lett. 2018, 7, 634–637. [Google Scholar] [CrossRef]
- Huh, J.-H.; Lee, D.-G.; Seo, K. Design and Implementation of the Basic Technology for Realtime Smart Metering System Using Power Line Communication for Smart Grid. In Lecture Notes in Electrical Engineering; Springer: Singapore, 2015; pp. 663–669. [Google Scholar]
- Fraga-Lamas, P.; Fernandez-Carames, T.M. A Review on Blockchain Technologies for an Advanced and Cyber-Resilient Automotive Industry. IEEE Access 2019, 7, 17578–17598. [Google Scholar] [CrossRef]
- Suciu, G.; Nadrag, C.; Istrate, C.; Vulpe, A.; Ditu, M.-C.; Subea, O. Comparative Analysis of Distributed Ledger Technologies. In Proceedings of the 2018 Global Wireless Summit (GWS), Chiang Rai, Thailand, 25–28 November 2018; pp. 370–373. [Google Scholar]
- Praveen, G.; Chamola, V.; Hassija, V.; Kumar, N. Blockchain for 5G: A Prelude to Future Telecommunication. IEEE Netw. 2020, 34, 106–113. [Google Scholar] [CrossRef]
- Tran, T.-T.-Q.; Tran, Q.-T.; Le, H.-S. An Empirical Study on Continuance Using Intention of OTT Apps with Young Generation. In Lecture Notes in Electrical Engineering; Springer: Singapore, 2020; pp. 219–229. [Google Scholar]
- Seo, E.; Song, H.M.; Kim, H.K. GIDS: GAN based Intrusion Detection System for In-Vehicle Network. In Proceedings of the 16th Annual Conference on Privacy, Security and Trust, Belfast, UK, 28–30 August 2018; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Hanselmann, M.; Strauss, T.; Dormann, K.; Ulmer, H. CANet: An Unsupervised Intrusion Detection System for High Dimensional CAN Bus Data. IEEE Access 2020, 8, 58194–58205. [Google Scholar] [CrossRef]
- Lokman, S.F.; Othman, A.T.; Musa, S.; Abu Bakar, M.H. Deep Contractive Autoencoder-Based Anomaly Detection for In-Vehicle Controller Area Network (CAN). In Progress in Engineering Technology; Abu Bakar, M., Mohamad Sidik, M., Öchsner, A., Eds.; Advanced Structured Materials; Springer: Cham, Switzerland, 2019; pp. 195–205. [Google Scholar] [CrossRef]
- Huh, J.H.; Kwak, S.Y.; Lee, S.Y.; Seo, K. A design of small-size smart trash separation box using ICT technology. In Proceedings of the Asia-pacific Proceedings of Applied Science and Engineering for Better Human Life; In Proceedings of the 10th 2016 International Interdisciplinary Workshop Series at Jeju National University, Jeju, Korea, 16–19 August 2016; pp. 141–144. [Google Scholar]
- Kim, S.-K.; Huh, J.-H. Autochain platform: Expert automatic algorithm Blockchain technology for house rental dApp image application model. EURASIP J. Image Video Process. 2020, 2020, 1–23. [Google Scholar] [CrossRef]


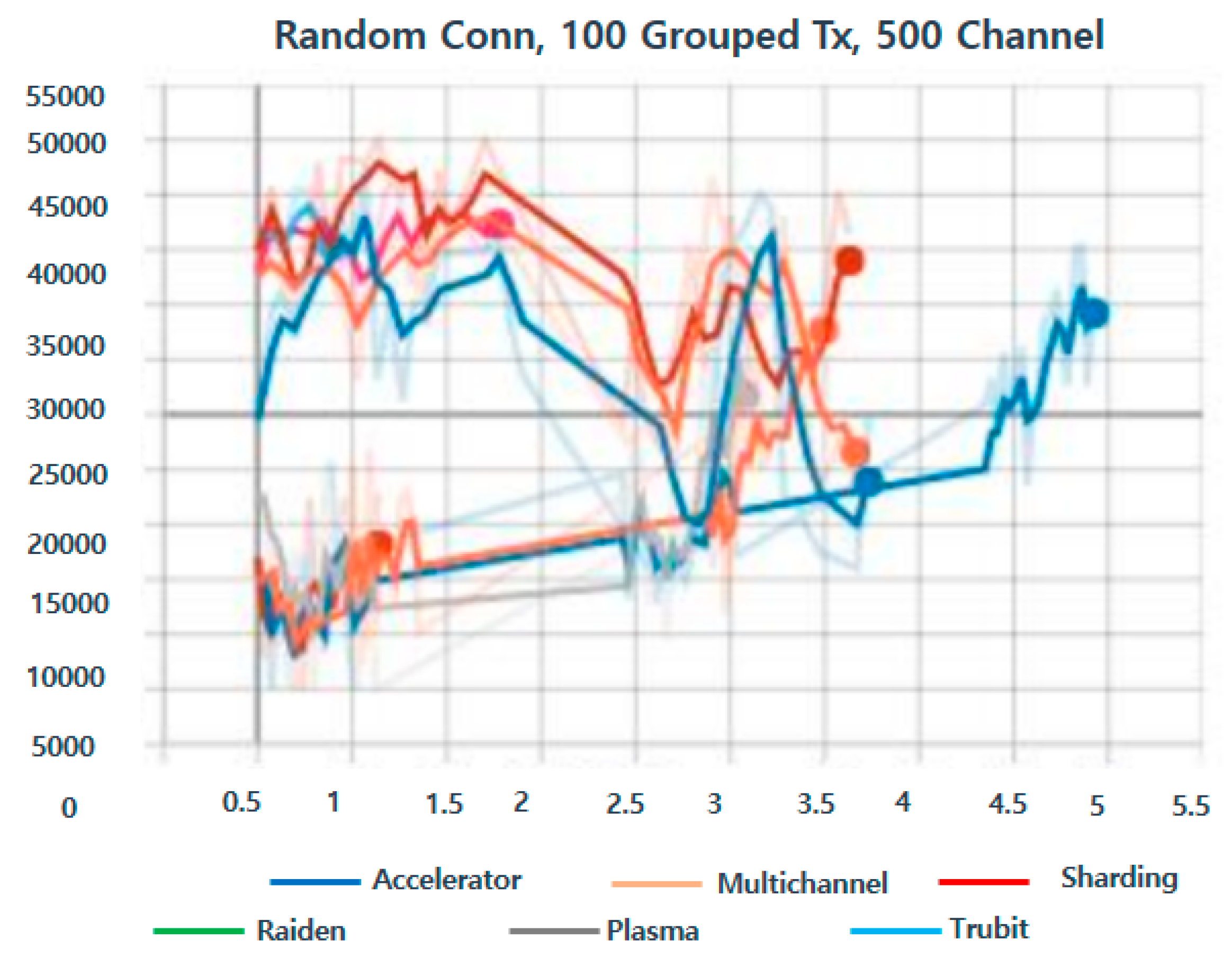
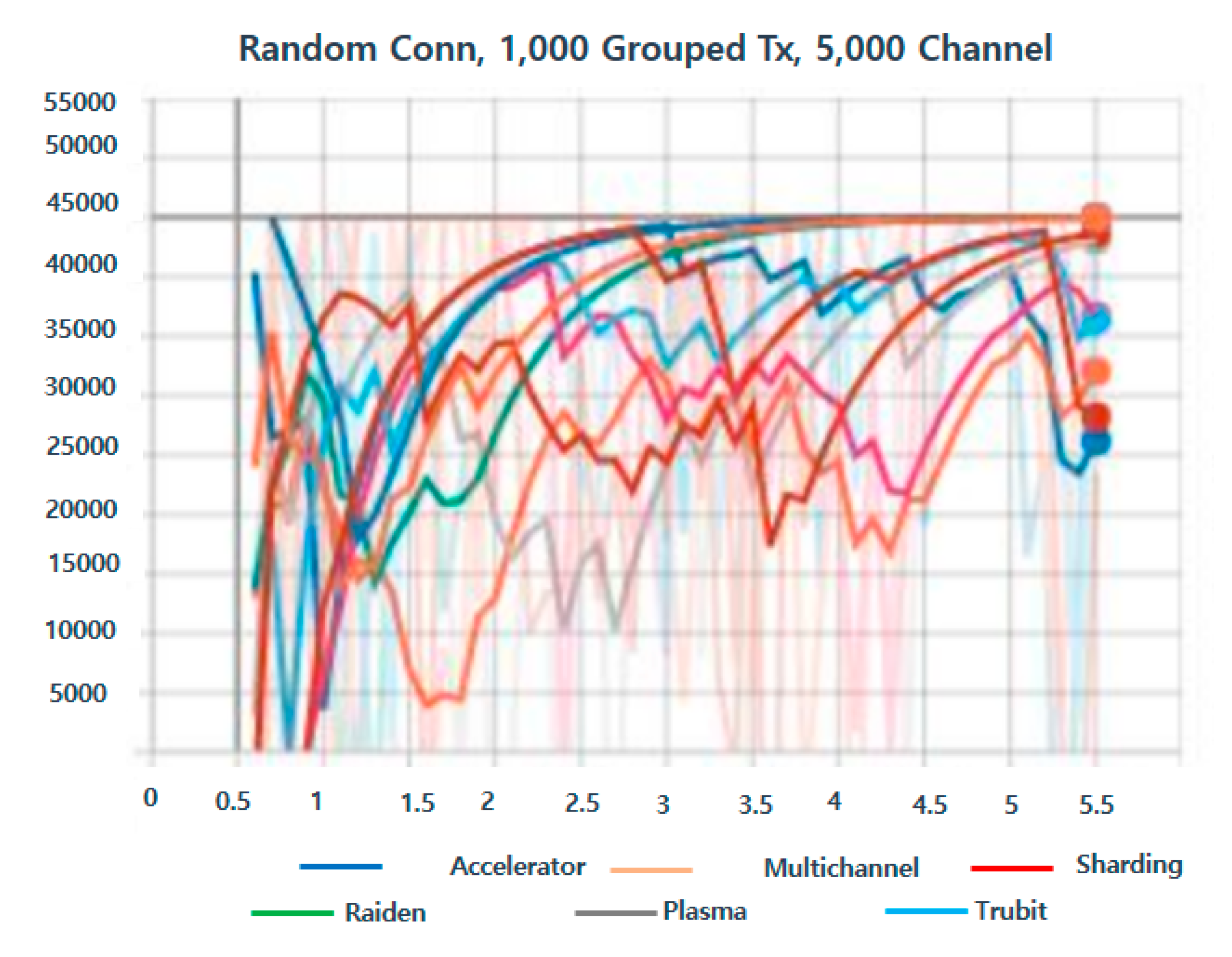
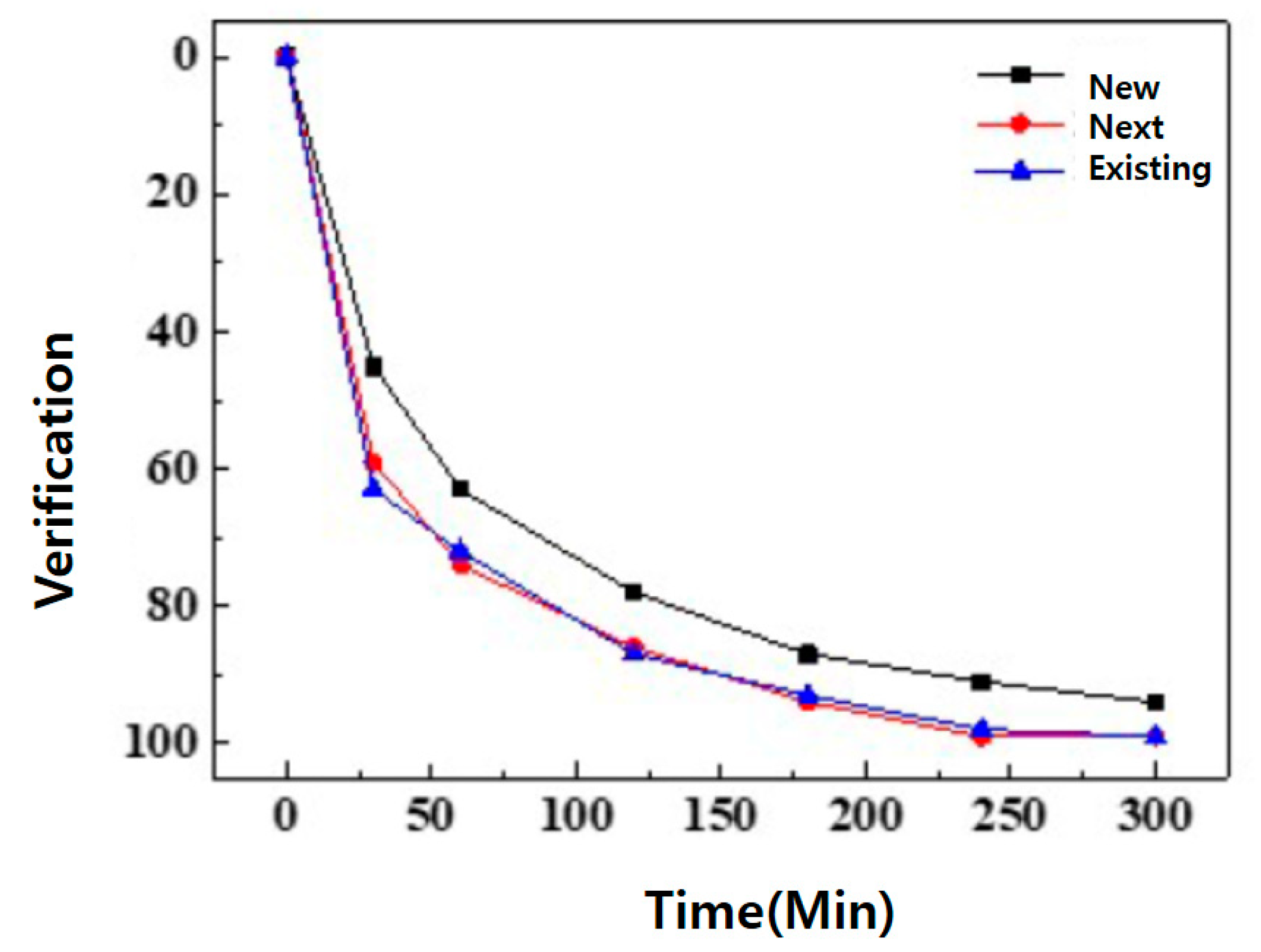
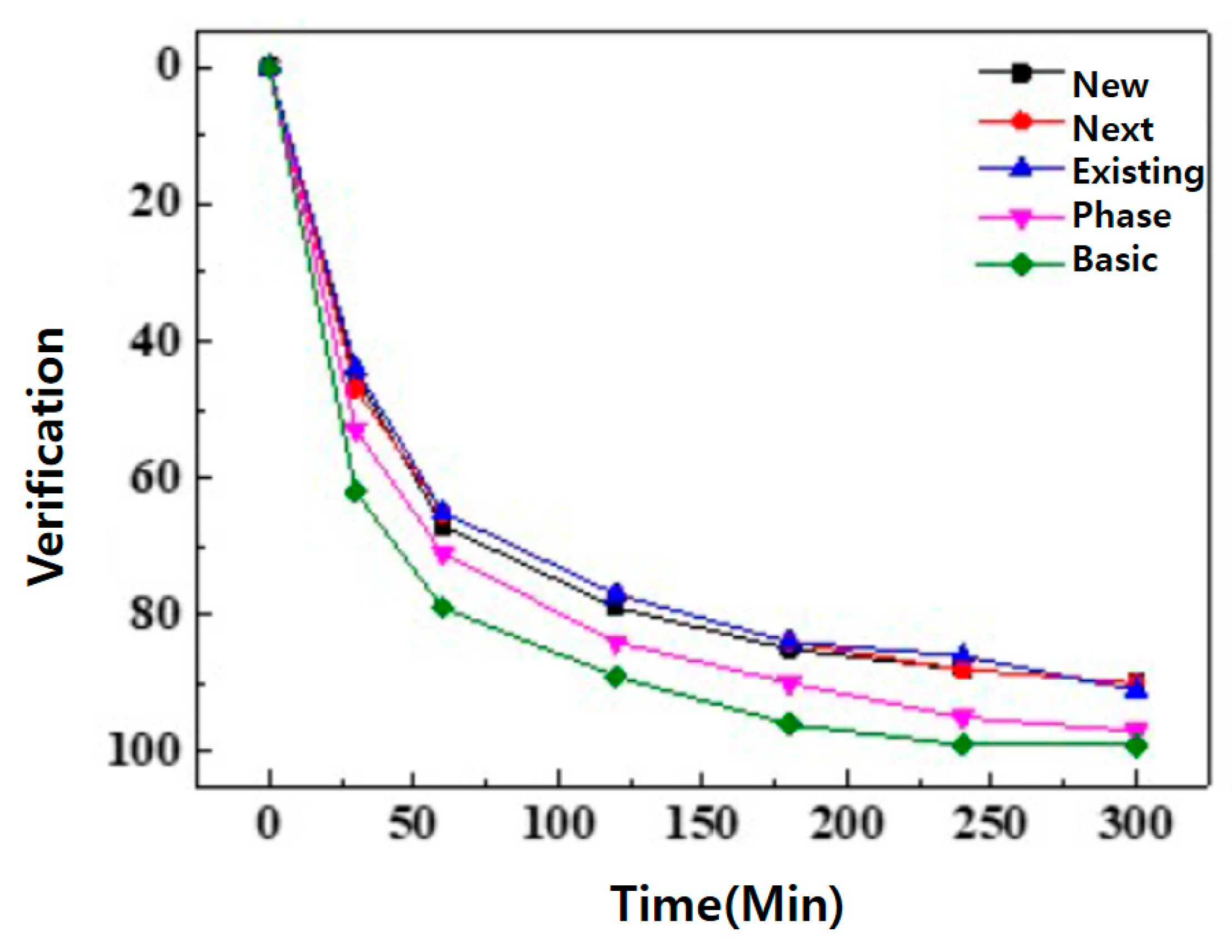
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.-K. Automotive Vulnerability Analysis for Deep Learning Blockchain Consensus Algorithm. Electronics 2022, 11, 119. https://doi.org/10.3390/electronics11010119
Kim S-K. Automotive Vulnerability Analysis for Deep Learning Blockchain Consensus Algorithm. Electronics. 2022; 11(1):119. https://doi.org/10.3390/electronics11010119
Chicago/Turabian StyleKim, Seong-Kyu. 2022. "Automotive Vulnerability Analysis for Deep Learning Blockchain Consensus Algorithm" Electronics 11, no. 1: 119. https://doi.org/10.3390/electronics11010119
APA StyleKim, S.-K. (2022). Automotive Vulnerability Analysis for Deep Learning Blockchain Consensus Algorithm. Electronics, 11(1), 119. https://doi.org/10.3390/electronics11010119