
Stable Local Bit-Line 6 T SRAM Architecture Design for Low-Voltage Operation and Access Enhancement


 ,
, 

Abstract
1. Introduction
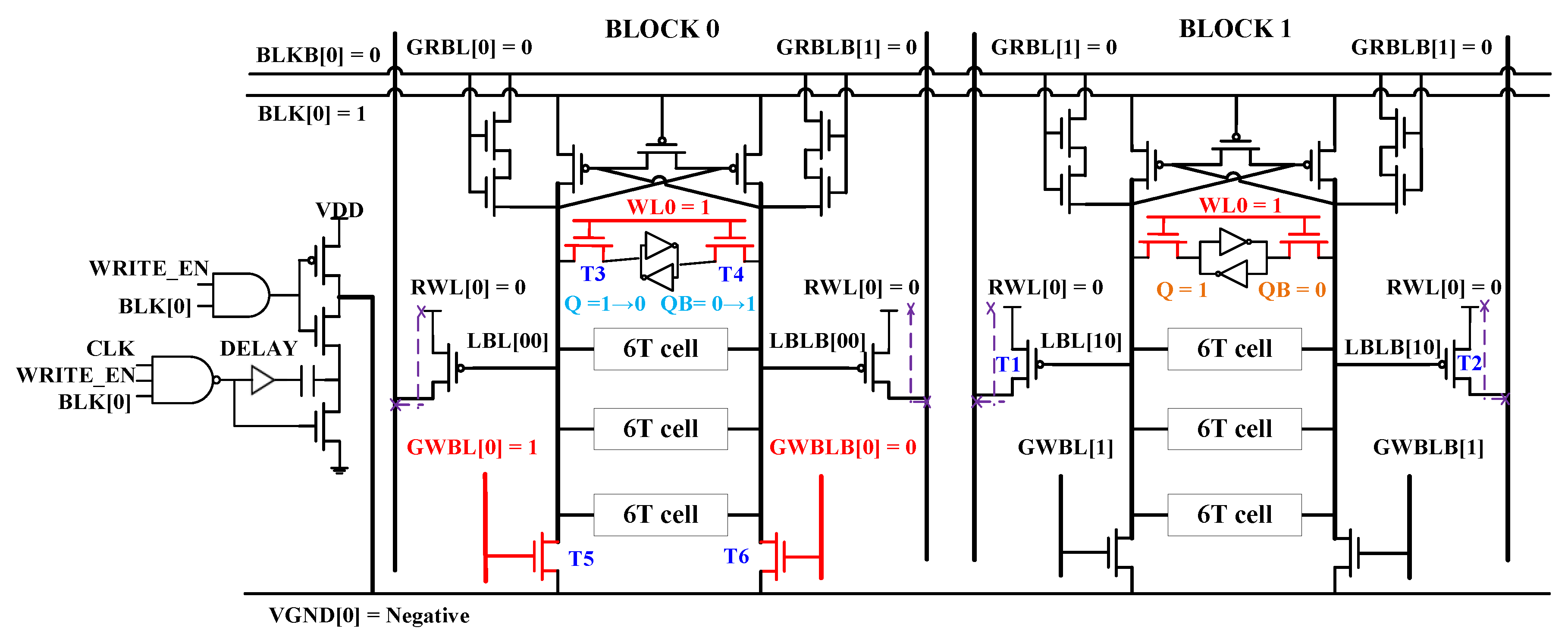
2. Proposed Local Bit-Line SRAM Architecture
2.1. Optimal Pre-Charge Circuit and Read Operation
2.2. Negative Local Bit-Line Scheme and Write Operation
2.3. Half-Select Condition Operation
3. Simulation Results
3.1. The Comparison of RSNM Simulation
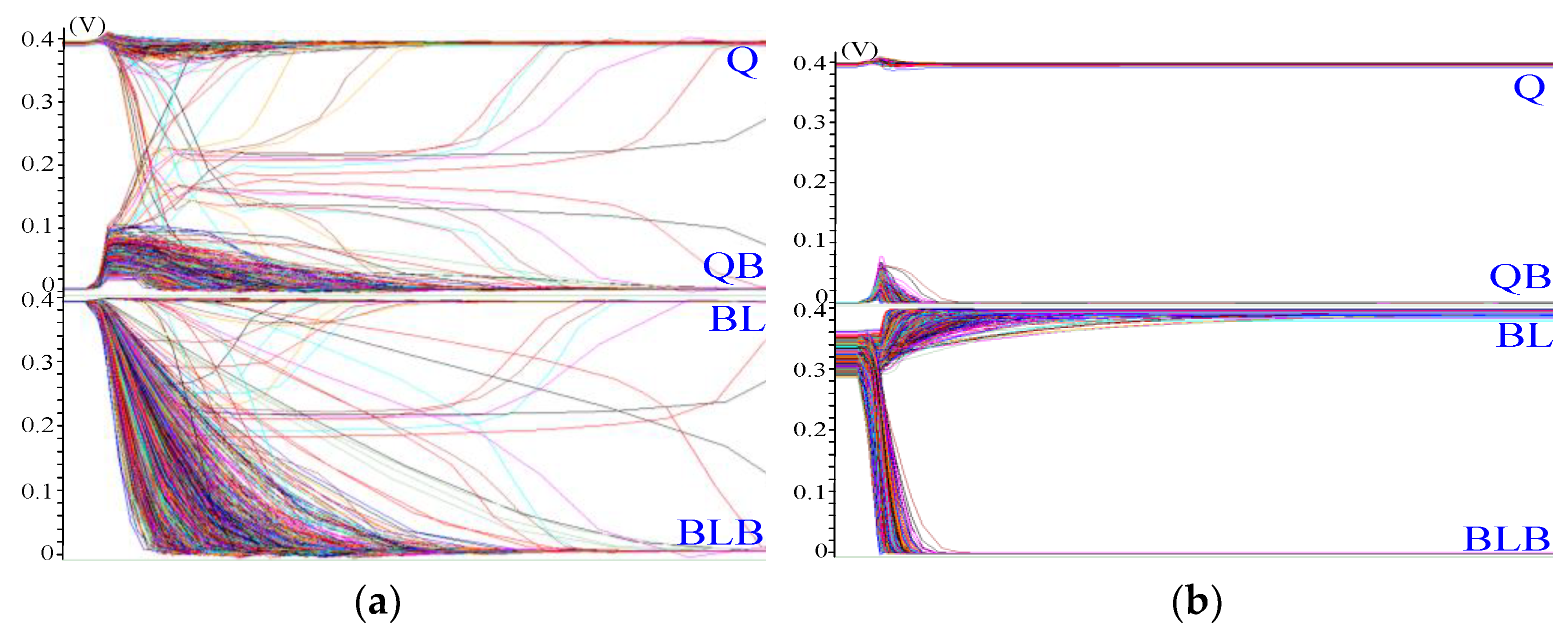
3.2. The Comparison of Monte Carlo Simulation
3.3. The Comparison of Write Ability Simulation
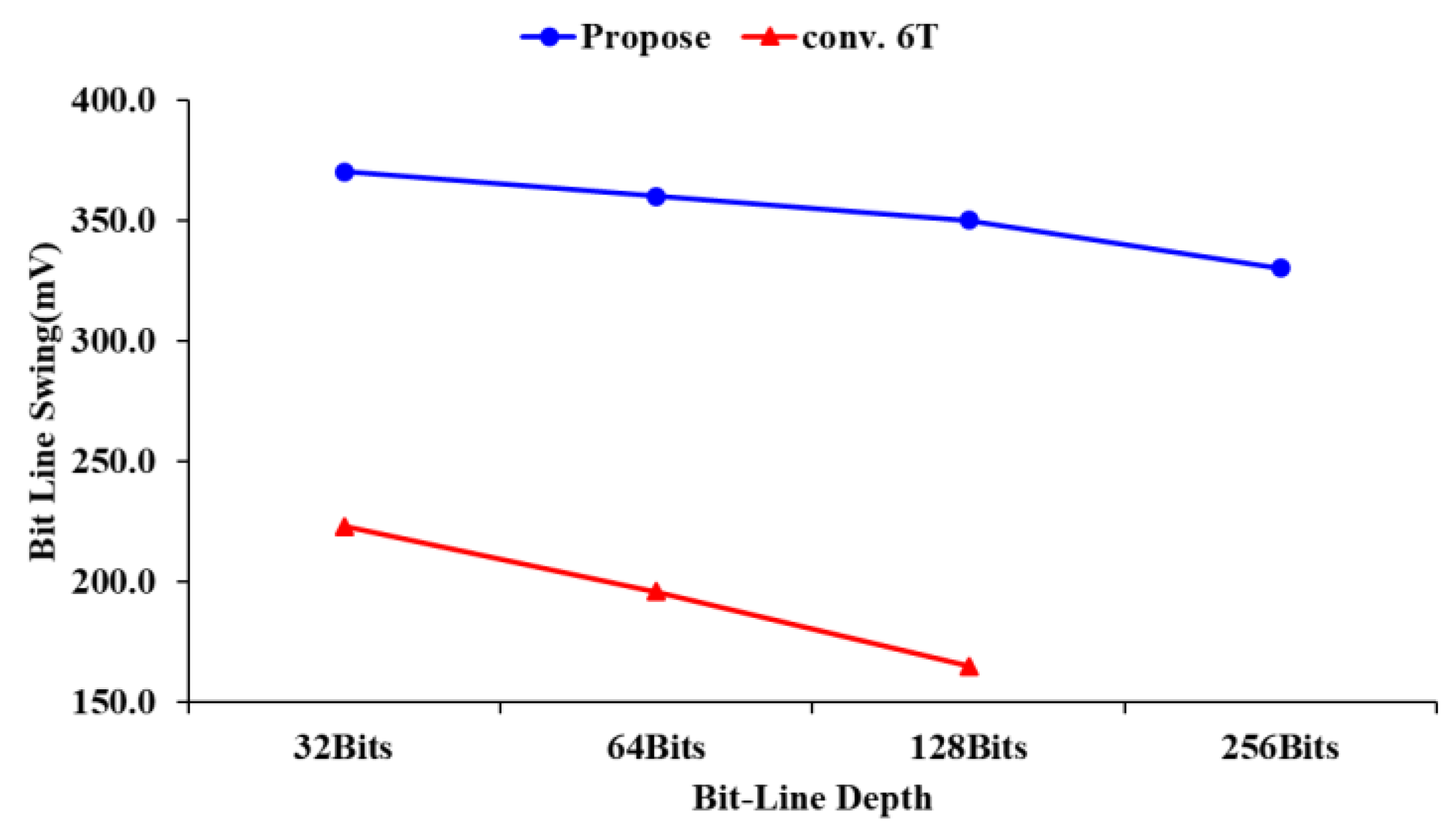
3.4. The Comparison of Bit-Line Swing Simulation
3.5. The Comparison of Leakage Power
4. Chip Implementation and Result Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Atzori, L.; Iera, A.; Morabito, G. The Internet of Things: A survey. Comput. Netw. 2010, 54, 2787–2805. [Google Scholar] [CrossRef]
- Frank, D.J.; Dennard, R.H.; Nowak, E.; Solomon, P.M.; Taur, Y.; Wong, H.-S.P. Device scaling limits of Si MOSFETs and their application dependencies. Proc. IEEE 2011, 89, 259–288. [Google Scholar] [CrossRef]
- Do, A.-T.; Low, J.Y.S.; Low, J.Y.L.; Kong, Z.-H.; Tan, X.; Yeo, K.-S. An 8T differential SRAM with improved noise margin for bit-interleaving in 65 nm CMOS. IEEE Trans. Circuits Syst. I Regul. Pap. 2011, 58, 1252–1263. [Google Scholar]
- Song, T.; Rim, W.; Jung, J.; Yang, G.; Park, J.; Park, S.; Kim, Y.; Baek, K.-H.; Baek, S.; Oh, S.-K.; et al. A 14 nm FinFET 128 Mb SRAM with VMIN Enhancement Techniques for Low-Power Applications. IEEE J. Solid-State Circuits 2015, 50, 158–169. [Google Scholar] [CrossRef]
- Chen, G.; Sylvester, D.; Blaauw, D.; Mudge, T.N. Yield Driven Near Threshold SRAM Design. IEEE Trans. Very Large Scale Integr. Syst. 2010, 18, 1590–1598. [Google Scholar] [CrossRef]
- Sinangil, M.E.; Mair, H.; Chandrakasan, A.P. A 28nm high-density 6T SRAM with optimized peripheral-assist circuits for operation down to 0.6V. In Proceedings of the IEEE 2011 International Solid-State Circuits Conference (INSPEC Acc. No. 11930802), San Francisco, CA, USA, 20–24 February 2011; pp. 260–261. [Google Scholar]
- Choi, W.; Park, J. A charge-recycling assist technique for reliable and low power SRAM design. IEEE Trans. Circuits Syst. I Regul. Pap. 2016, 63, 1164–1175. [Google Scholar] [CrossRef]
- Zhang, K.; Bhattacharya, U.; Chen, Z. A 3-GHz 70-Mb SRAM in 65-nm CMOS technology with integrated column-based dynamic power supply. IEEE J. Solid-State Circuits 2006, 41, 146–151. [Google Scholar] [CrossRef]
- Chang, L.; Fried, D.M.; Hergenrother, J.; Sleight, J.W.; Dennard, R.H.; Montoye, R.K.; Sekaric, L.; McNab, S.J.; Topol, A.W.; Adams, C.D.; et al. Stable SRAM cell design for the 32 nm node and beyond. In Proceedings of the IEEE 2005 Symposium on VLSI Technology (INSPEC Acc. No. 8615693), Kyoto, Japan, 14–16 June 2005; pp. 128–129. [Google Scholar]
- Chang, L.; Montoye, R.K.; Nakamura, Y.; Batson, K.A.; Eickemeyer, R.J.; Dennard, R.H.; Haensch, W.; Jamsek, D. An 8T-SRAM for variability tolerance and low-voltage operation in high-performance caches. IEEE J. Solid-State Circuits 2008, 43, 956–963. [Google Scholar] [CrossRef]
- Chang, M.-F.; Chang, S.-W.; Chou, P.-W.; Wu, W.-C. A 130 mV SRAM with Expanded Write and Read Margins for Subthreshold Applications. IEEE J. Solid-State Circuits 2011, 46, 520–529. [Google Scholar] [CrossRef]
- Tu, M.-H.; Lin, J.-Y.; Tsai, M.-C.; Lu, C.-Y.; Lin, Y.-J.; Wang, M.-H.; Huang, H.-S.; Lee, K.-D.; Shih, W.-C.; Jou, S.-J.; et al. A Single-Ended Disturb-Free 9T Subthreshold SRAM With Cross-Point Data-Aware Write Word-Line Structure, Negative Bit-Line, and Adaptive Read Operation Timing Tracing. IEEE J. Solid-State Circuits 2012, 47, 1469–1482. [Google Scholar] [CrossRef]
- Shin, K.; Choi, W.; Park, J. Half-Select Free and Bit-Line Sharing 9T SRAM for Reliable Supply Voltage Scaling. IEEE Trans. Circuits Syst. I Regul. Pap. 2017, 64, 2036–2048. [Google Scholar] [CrossRef]
- Chang, I.J.; Kim, J.-J.; Park, S.P.; Roy, K. A 32 kb 10T sub-threshold SRAM array with bit-interleaving and differential read scheme in 90 nm CMOS. IEEE J. Solid-State Circuits 2009, 44, 650–658. [Google Scholar] [CrossRef]
- Lo, C.-H.; Huang, S.-Y. P-P-N Based 10T SRAM Cell for Low-Leakage and Resilient Subthreshold Operation. IEEE J. Solid-State Circuits 2011, 46, 695–704. [Google Scholar] [CrossRef]
- Chiu, Y.-W.; Hu, Y.-H.; Tu, M.-H.; Zhao, J.-K. 40 nm Bit-Interleaving 12T Subthreshold SRAM with Data-Aware Write-Assist. IEEE Trans. Circuits Syst. I Regul. Pap. 2014, 61, 2578–2585. [Google Scholar] [CrossRef]
- Khayatzadeh, M.; Lian, Y. Average-8T Differential-Sensing Subthreshold SRAM With Bit Interleaving and 1k Bits Per Bitline. IEEE Trans. Very Large Scale Integr. (Vlsi) Syst. 2014, 22, 971–982. [Google Scholar] [CrossRef]
- Kang, K.; Jeong, H.; Yang, Y.; Park, J.; Kim, K.; Jung, S.-O. Full-Swing Local Bitline SRAM Architecture Based on the 22-nm FinFET Technology for Low-Voltage Operation. IEEE Trans. Very Large Scale Integr. (Vlsi) Syst. 2016, 24, 1342–1350. [Google Scholar] [CrossRef]
- Chien, Y.-C.; Wang, J.-S. A 0.2 V 32-Kb 10T SRAM with 41 nW Standby Power for IoT Applications. IEEE Trans. Circuits Syst. I Regul. Pap. 2018, 65, 2443–2454. [Google Scholar] [CrossRef]
- Wu, S.-L.; Li, K.-Y.; Huang, P.-T.; Hwang, W.; Tu, M.-H.; Lung, S.-C.; Peng, W.-S.; Huang, H.-A.; Lee, K.-D.; Kao, Y.-S.; et al. A 0.5-V 28-nm 256-kb Mini-Array Based 6T SRAM with Vtrip-Tracking Write-Assist. IEEE Trans. Circuits Syst. I Regul. Pap. 2017, 64, 1791–1802. [Google Scholar] [CrossRef]
- Oh, T.W.; Jeong, H.; Park, J.; Jung, S.-O. Pre-Charged Local Bit-Line Sharing SRAM Architecture for Near-Threshold Operation. IEEE Trans. Circuits Syst. I Regul. Pap. 2017, 64, 2737–2747. [Google Scholar] [CrossRef]
- Chen, S.-Y.; Wang, C.-C. Single-ended disturb-free 5T loadless SRAM cell using 90 nm CMOS process. In Proceedings of the IEEE 2012 International Conference on IC Design & Technology (INSPEC Acc. No. 12851100), Austin, TX, USA, 30 May–1 June 2012; pp. 1–4. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Supply Voltage for Operation | Optimal Voltage Range (mV) |
|---|---|
| 0.9 V | 600~650 |
| 0.8 V | 550~600 |
| 0.7 V | 500~550 |
| 0.6 V | 400~450 |
| 0.5 V | 350~400 |
| Layout | Conventional 6 T | 8 T [10] | Proposed 6 T |
|---|---|---|---|
| 1 Kb area(μm2) size | 1935.36 (1×) | 2466.20 (1.27×) | 2436.57 (1.26×) |
| Design Approach | Averge−8 T [17] | Full-Swing 6 T [18] | Pre-Charge 6 T [21] | Mini-Area 6 T [20] | Proposed |
|---|---|---|---|---|---|
| Technology | 130 nm | 22 nm | 22 nm | 28 nm HkMG | 40 nmGP |
| Area per block | 24.65 μm2 | 0.71 μm2 | 0.70 μm2 | 1.36 μm2 | 7.65 μm2 |
| Local Bit-Line | Pre-Discharged | Pre-Discharged | Pre-Charged | Pre-Charged | Low-Voltage Pre-Charged |
| Write mechanism | Single-ended | Differential | Differential | Differential | Differential + NLBL |
| VDDMIN | 260 mV *1 | 440 mV | 400 mV | 500 mV | 400 mV |
| Capacity | 64-kb | N. A | N. A | 256-kb | 1-kb |
| Area(mm2) | 0.512 | N. A | N. A | 0.397 | 0.00690 |
| Frequency @ VDDMIN | 245 kHz | N. A | N. A | 20 MHz | 25 MHz |
| Read energy (pJ) | 0.23 | 0.19 | 0.14 | N. A | 0.22 |
| Write energy (pJ) | 0.24 | 0.45 | 0.42 | N. A | 0.23 |
| Average Energy (pJ) | 0.23 | 0.32 | 0.28 | 0.468 | 0.22 |
| Leakage Power @VDDMIN | 0.88μW | N. A | N. A | 60μW *2 | 3.363μW |
| FoM *3 | 1× | 18× | 23.5× | 4.25× | 25× |
| Sim. /Meas. | Measured | Post-sim | Post-sim | Measured | Post-sim |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sheu, M.-H.; Morsalin, S.M.S.; Tsai, C.-M.; Yang, C.-J.; Hsia, S.-C.; Hsueh, Y.-H.; Lin, J.-F.; Chang, C.-Y. Stable Local Bit-Line 6 T SRAM Architecture Design for Low-Voltage Operation and Access Enhancement. Electronics 2021, 10, 685. https://doi.org/10.3390/electronics10060685
Sheu M-H, Morsalin SMS, Tsai C-M, Yang C-J, Hsia S-C, Hsueh Y-H, Lin J-F, Chang C-Y. Stable Local Bit-Line 6 T SRAM Architecture Design for Low-Voltage Operation and Access Enhancement. Electronics. 2021; 10(6):685. https://doi.org/10.3390/electronics10060685
Chicago/Turabian StyleSheu, Ming-Hwa, S M Salahuddin Morsalin, Chang-Ming Tsai, Cheng-Jie Yang, Shih-Chang Hsia, Ya-Hsin Hsueh, Jin-Fa Lin, and Chuan-Yu Chang. 2021. "Stable Local Bit-Line 6 T SRAM Architecture Design for Low-Voltage Operation and Access Enhancement" Electronics 10, no. 6: 685. https://doi.org/10.3390/electronics10060685
APA StyleSheu, M.-H., Morsalin, S. M. S., Tsai, C.-M., Yang, C.-J., Hsia, S.-C., Hsueh, Y.-H., Lin, J.-F., & Chang, C.-Y. (2021). Stable Local Bit-Line 6 T SRAM Architecture Design for Low-Voltage Operation and Access Enhancement. Electronics, 10(6), 685. https://doi.org/10.3390/electronics10060685