Abstract
Overlapping communities are key characteristics of the structure and function analysis of complex networks. Shared or overlapping nodes within overlapping communities can either form subcommunities or act as intersections between larger communities. Nodes at the intersections that do not form subcommunities can be identified as overlapping nodes or as part of an internal structure of nested communities. To identify overlapping nodes, we apply a threshold rule based on the number of nodes in the nested structure. As the threshold value increases, the number of selected overlapping nodes decreases. This approach allows us to analyse the roles of nodes considered overlapping according to selection criteria, for example, to reduce the effect of noise. We illustrate our method by using three small and two larger real-world network structures. In larger networks, minor disturbances can produce a multitude of slightly different solutions, but the core communities remain robust, allowing other variations to be treated as noise. While this study employs our own method for community detection, other approaches can also be applied. Exploring the properties of shared nodes in overlapping communities of complex networks is a novel area of research with diverse applications in social network analysis, cybersecurity, and other fields in network science.
1. Introduction
Detecting communities in complex networks is an essential aspect of analysing network structures, as it helps identify clusters or modules of complex systems, such as social and biological networks, and cyber–physical systems. In networks, a community consists of nodes that are tightly linked to each other because of shared attributes. In social contexts, members of a community typically interact with each other more frequently than with individuals outside their group. Several reviews on community detection methodologies have been published in the literature [1,2]. In this study, our objective is not to analyse or compare different community detection methods but instead to treat the detected communities and their structures as given.
Communities can be categorised as non-overlapping, overlapping, or hierarchical. Non-overlapping communities assign each node to exactly one community, reflecting structures where the roles or associations of nodes are mutually exclusive. In contrast, overlapping communities allow nodes to belong simultaneously to multiple communities, as in social networks as members of different social circles, such as family, school, hobbies, etc. [3,4,5]. Hierarchical communities present a nested structure, with communities organised at multiple levels such that larger groups encompass smaller subcommunities, revealing multi-scale patterns within the network. These distinctions are crucial for tailoring community detection methods to the specific characteristics of real-world networks [4].
In network communities, the overlapping nodes play a crucial role in the structure and function of the network, as they frequently act as bridges that facilitate the flow of information or influence between different communities [6]. Identifying and analysing overlapping nodes is therefore essential to understand how complex systems operate. Studying them can reveal, e.g., critical points of vulnerability in infrastructure networks or improve predictions of spreading processes, such as opinion diffusion or contagion [7,8]. Moreover, overlapping nodes tend to exert stronger spreading influence than their non-overlapping counterparts [9,10]. In summary, overlapping nodes reveal how local communities connect, cooperate, and collectively shape the behaviour of the network as a whole [7].
Overlapping community detection methods can identify nodes that participate in multiple groups, but they face several limitations in handling such overlaps. It is often difficult to distinguish genuine multi-membership from artefacts caused by noise or high-degree nodes, and there is no universally accepted definition of what constitutes meaningful overlap. The resulting assignments can be sensitive to parameter choices and heavy overlap can reduce the interpretability of the detected structure. Moreover, validating overlapping communities remains challenging due to the lack of clear ground truth, thus complicating the assessment of the reliability of overlapping node assignments. These limitations are well documented in reviews of community detection methods, highlighting issues such as ambiguous definitions of overlap, sensitivity to parameters, challenges in validation, and difficulties in separating true overlaps from structural noise [11,12,13,14].
In order to identify the building blocks that form network communities, we apply the method presented in our previous study [15]. Here, we will demonstrate how small and cohesive substructures can be used to identify shared or overlapping nodes belonging to multiple communities. At the intersections of these communities, there are shared nodes, which, according to our definition, do not form distinct subcommunities. By applying a sequential selection rule to these nodes, we can distinguish the remaining overlapping nodes from those that make up the internal structure of nested communities. We also discuss the potential effects of ambiguously assigned nodes, i.e., noise, that can occur in detected communities. By applying threshold rules, we can determine which nodes to retain as overlapping nodes and which ones to exclude.
In complex networks, inherently overlapping structures and dense interconnections between communities can be found, making it necessary to apply filtering to detect and isolate the most influential overlapping nodes [6]. However, detecting overlapping nodes and distinguishing them from noise has received limited attention, in part because there is no universally accepted definition of what constitutes a community [14]. Here, our aim is to improve the reliability of community structure analysis and provide a deeper understanding of how nodes interact and influence each other. Regarding the community detection method, our approach to analyse shared and overlapping nodes can also be applied to other community detection methods, provided that they can identify overlapping communities.
In the present study, we compare the number of nodes in the outer layer with the inner layer of the nested structures. The overlapping nodes are selected by comparing this ratio with a threshold parameter value. As the threshold value increases, the criterion becomes stricter, resulting in more exclusions and fewer overlapping nodes remaining. In the end, increasing the threshold can lead to only one overlapping node. In the case of larger networks, minor disturbances can result in numerous slightly varied theoretical solutions [16]. However, core communities typically maintain their stability, indicating the robustness of our method. Our results show that for all network sizes, the number of overlapping nodes gradually decreases as the threshold parameter increases. This illustrates a key property of our model, namely that it can effectively limit or exclude potential overlapping nodes, even when community detection methods initially identify large sets of overlapping communities [17].
In this study, we apply our method to five real-world networks. For three of them, we compare empirical observations with the theoretical results on overlapping nodes derived from our model. In all cases, the findings indicate a trend that as the threshold value of the selection rule increases, the number of selected overlapping nodes decreases. This suggests that the influence of these overlapping nodes grows both in empirical observations and in theoretical calculations. Additionally, two of the example cases illustrate our model’s performance in larger network structures where empirical data is unavailable. In these instances, we focus solely on demonstrating how our model works in these larger networks.
The research objective of the present study is to develop a threshold-based method that identifies overlapping nodes in complex networks by filtering out noise-induced overlaps and internal subcommunity structures This allows the analysis to focus on the remaining nodes whose role and influence as overlapping connectors become increasingly pronounced.
The following sections first review related works on overlapping community detection, after which we present our model and the threshold-based selection rule to identify overlapping nodes. We then demonstrate the method using several real-world network datasets and analyse how thresholding influences the resulting overlaps. Finally, we discuss the implications of the approach and conclude with a summary of the findings and directions for the future research.
2. Related Work
The study of overlapping communities with nodes belonging to multiple groups has become an important topic of network science. Early community detection methods assumed disjoint community partitions, but subsequent research revealed that social, biological, and information networks frequently exhibit shared or ambiguous nodal memberships. One of the first major contributions was made in [18], which introduced the clique percolation method, allowing communities to overlap through shared nodes. Later, the study in [19] proposed link communities, shifting the focus from nodes to edges to better capture multi-scale relationships. The study in [20] introduced a local statistical fitness optimisation framework to detect hierarchical and overlapping communities. It evaluates candidate communities against a null model (pseudo-community) that preserves the degree distribution of the network, allowing statistically significant structures to be distinguished from noise. Other probabilistic models, such as the mixed membership stochastic block model in [21], further formalised overlapping membership of nodes through statistical inference. Complementary structural approaches address the issue of high overlap with merging and noise filtering. For example, in [22], a model identifies partial community cores, merges those that represent the same underlying community, and subsequently treats the remaining weakly affiliated nodes as noise. However, these approaches tend to struggle with hierarchical or nested structures, which can cause them to overestimate overlap or misinterpret subcommunities as genuine multi-memberships.
More recently, machine learning approaches have been extended to the aforementioned frameworks. Popular methods such as BigCLAM [23] and CESNA [8], and related generative approaches, frame overlapping memberships through learnable statistical parameters. Deep learning has further advanced the field by enabling unsupervised representations of the network structure, for example through autoencoder-based approaches [24,25], as well as generative adversarial approaches specifically designed for overlapping community detection, such as CommunityGAN [26]. Subsequently, graph neural network approaches, including Graph Convolutional Networks (GCN) and Graph Attention Networks (GAT), have proven particularly effective, as they propagate information between local neighbourhoods while preserving complex dependency patterns [27]. However, deep learning–based methods often introduce the challenge that their performance being highly dependent on hyperparameters, training heuristics, and model architecture selection. This can make the detection of overlapping nodes less transparent, less reproducible, and more difficult to interpret. Moreover, the learned representations may obscure the structural reasons why particular nodes are classified as overlapping, which makes the models less interpretable. For further details and timeline of machine learning models in community detection, see [28] for a comprehensive survey.
Many community detection methods are based on dividing the network into two factions. Another approach is to investigate the structure of the network by dividing it into the core and the periphery [29]. The core nodes are densely connected to each other, but also have connections to the periphery nodes. In contrast, the periphery nodes have only sparse connections among themselves. An alternative definition could be that the core nodes are located a short distance from all other nodes.
The study presented in [8] extends the detection of overlapping communities to include attributed networks by integrating both the characteristics of the nodes and the structure of the network. In [30], a comprehensive survey of community detection is provided, covering both overlapping and temporal community structures. Recently, advances have been made in the study of overlapping communities and their intersections. One study [31] investigates new methods that utilise neighbour similarity metrics to detect overlaps and subtle communities. Another study [32] emphasises the importance of tie strength in distinguishing between overlapping and non-overlapping nodes, which is useful for exploring structural criteria related to overlaps. In addition, an adaptive density-based method [33] has been introduced to detect overlaps, which employs iterative partitioning and is effective for networks with varying scales. Collectively, these studies highlight the detection of overlapping communities as an essential framework to understand the complex and multifaceted organisation of real-world networks.
Despite these advances, several important research gaps still remain. Existing overlapping community-detection methods identify shared nodes but offer limited guidance on distinguishing true overlapping nodes from noise or internal subcommunity structures, leaving their post-processing largely unresolved [12,14,34]. Although structural, probabilistic, and deep-learning approaches provide diverse ways to detect overlaps [18,19,21,23,28], the literature still lacks a unified threshold-based framework capable of controlling noise, handling nearly identical community structures, and revealing the increasing influence of the remaining overlapping nodes [20,35,36]. Furthermore, evaluation practices remain inconsistent, particularly due to the mismatch between attribute-driven social circles and topological communities, which highlight the need for clearer methodological criteria and more robust analysis of the structural roles of overlapping nodes [37,38,39].
3. Model
In Section 3.1, we present an overview of our community detection model [15], as it helps to understand the new contributions in the current paper. Our community detection method is effective for demonstrations because it can generate different overlapping structures based on the link weights used in the calculations. Higher link weights improve network cohesion, resulting in the detection of fewer communities and, typically, fewer overlapping communities. In Section 3.2, we focus on identifying and categorising shared nodes in overlapping communities. In Table 1, we list the key concepts of this study.

Table 1.
Definitions of key concepts used in this study.
3.1. Community Detection Method Used in Demonstrations
In our community detection model, community detection involves identifying local maximum values of the quality function (Equation 3 in [15]), as shown in Equation (1), calculated using the elements of the influence-spreading matrix for :
In Equation (1), we represent a node influencing as s (source) and a node influenced as t (target). The number of nodes in the network is N. The elements in the matrix describe the probabilities of directed influence between any two nodes in the network. Equation (1) measures the strength of the division between the two factions V and in the network G. A higher value of q indicates stronger cohesion, enabling comparisons between different network divisions. An advantage of our approach is its ability to identify multiple overlapping community structures without the need for a predetermined number of communities, unlike some methods currently found in the literature [4].
When a local maximum is identified for a subset of nodes V, it indicates that V and its complement are recognised as distinct communities. The two terms in Equation (1) represent the cohesion values of these communities. This method is based on the principle that a local optimum serves as a valid solution among its neighbouring candidates. Depending on the clarity of the division between the communities, there may be nodes that are not definitively associated with either community, or moving a node from one community to another may not significantly affect the value of q in Equation (1). Often, groups of these ambiguous nodes create overlapping regions between communities, which can be seen as optimal solutions when merged with one of the larger structures. Whether these intersections form separate subcommunities depends on whether they also satisfy the maximisation condition of Equation (1).
3.2. Model for Overlapping Nodes
In this section, we outline the scope of our study, which focuses on identifying and classifying shared nodes of overlapping communities within complex network structures. We do not describe any specific community detection methods in detail, as our approach to identifying shared or overlapping nodes is general and can incorporate any method capable of producing overlapping communities. To demonstrate this, we apply the overlapping community detection method we previously presented in [15].
Our approach in identifying overlapping nodes involves two main phases. First, we detect all intersections between communities, which we refer to as building blocks. Second, we evaluate each building block to determine whether it qualifies as a subcommunity. In our community detection model, this means that it is an optimal solution of the objective function defined in [15].
Intersections of communities that do not qualify as individual subcommunities are candidates for overlapping nodes. In our analysis, we apply a selection rule (see Appendix B) to determine which nodes to retain as overlapping nodes and which to exclude. Our rule of classifying nodes as overlapping nodes is not definitive and should only be considered as an example. The flow chart in Figure 1 shows the main steps of the procedure.
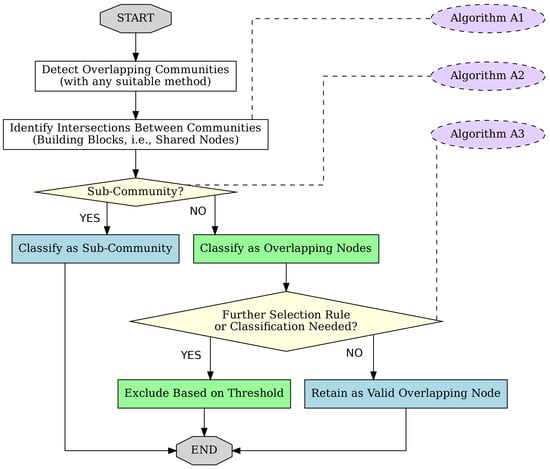
Figure 1.
Diagram showing the process by which the building blocks of overlapping communities are generated and shared nodes are identified using a threshold. The purple boxes indicate the algorithms in Appendix A and Appendix B that describe each phase.
Our proposed technique addresses the issue of ambiguously assigned nodes and noise. The definition of noise can vary according to the specific application. In the context of community detection in complex networks, noise refers to any disturbance or uncertainty that obscures the true community structure. Noise can also arise from various sources, including data errors, random connections, incomplete sampling, intrinsic randomness in the network generation process, or limitations inherent to the community detection method itself. In our approach, we exclude noise and do not classify it as a valid overlapping region.
As the first selection criterion in our algorithm, we assess all intersections of communities to determine whether they should be recognised as separate communities. This involves checking if they are inner parts of nested communities and meet the criteria for a community, such as maximising an objective function used in community detection methods. Next, we need to define another criterion for intersections that are not categorised as subcommunities. The nodes in these intersections can all be considered overlapping nodes, but we may want to exclude some of them based on a threshold value that takes into account the number of nodes or the cohesion values [17] of the intersections. In this study, we use the number of nodes as a basis for our selection rule.
In a nested community structure, we compare the number of nodes in the outer layer with the number of nodes in the inner layer of the nested structure. As this ratio increases, the rule becomes more restrictive, resulting in more nodes being excluded and fewer nodes being counted as remaining overlapping nodes. When we increase this threshold value, only a small number of nodes, or even just a single node, may be retained as overlapping. The selection criterion indicates that, in a nested system of nearly equal-sized sets of nodes, these excluded nodes can be considered internal structures rather than overlapping nodes of different communities.
Figure 2 illustrates a case in which community detection involves dividing the network into two segments. The figures on the left and middle show two different solutions of the community detection method. The figure on the right combines these segments and depicts various intersecting and overlapping regions: , , , and . The nodes in these regions can be used to define the inclusion and exclusion criteria for overlapping nodes. In Appendix B, we provide an example based on the number of nodes in the sets and (or and ). The threshold value for an overlap is defined by the condition that the ratio r in Equation (2) must be greater than a specified threshold parameter value, denoted by , in Appendix B.
Note that in our case, the set in (or ) is empty because the procedure in Appendix A has conducted pre-processing and classified the building blocks as valid subcommunities and other intersections of the detected communities. If this kind of pre-processing is not conducted, these sets can also be used in the selection rule.

Figure 2.
An illustrative example of two divisions of the network into two communities and (left) and and (middle). Nodes in are almost the same as in . The interception of these communities is marked as (right).
4. Data & Demonstrations
In this section, we demonstrate the practical use of our method for identifying overlapping nodes in overlapping communities. We evaluate the method by applying it to five real-world social networks, shown in Table 2. Four of the networks are drawn from the prior literature, while the dataset in Section 4.3 is derived from a large mobile phone call detail record (CDR) database [40]. Data are represented as social networks in which nodes denote individuals, and edges represent social ties between them. Next, we describe the datasets and their key characteristics, followed by the corresponding results. For each network, we compare the empirically observed community structures with the theoretical structures suggested by the network topology. For example, both Zachary’s Karate Club and the Dolphin Social Network are known to divide into two main groups, providing useful reference points to evaluate the results of our method. However, it should be noted that these ground truths are not necessarily definitive, and thus it is not possible to determine with certainty whether our method successfully converges towards the community structures agreed in the literature. In the case of Facebook, the comparison against a ground truth is particularly challenging because the labels are manually assigned and may themselves contain inconsistencies or subjective judgments. For the mobile phone network, no ground truth is available due to the private and anonymous nature of the data, making direct validation infeasible. For Zachary’s Karate club and Dolphin Social networks, we provide tables to compare our approach against selected studies in the literature.
Table 2.
Five social networks used in our demonstrations.
In Table 2, we present the network statistics, including the number of nodes and edges, the average clustering coefficient , and the values of the corresponding threshold parameters used in our analysis. These threshold values have been specifically chosen to highlight the significant changes in the set of overlapping nodes as the threshold increases above zero. It is important to note that these values are influenced by the results of the overlapping community detection methods and the characteristics of the studied network. Consequently, there is no universally applicable set of threshold values.
4.1. Zachary’s Karate Club Social Network
In the Zachary’s Karate Club network (Figure 3), which illustrates friendships between 34 club members, a dispute between the instructor (node 1) and the administrator (node 34) resulted in the club splitting into two factions that closely reflected the structure of the network. Both leaders were highly central nodes with numerous connections, and members generally sided with the leader to whom they were more closely connected. Node 3, which had strong ties to both leaders, eventually joined the instructor’s faction, according to Zachary’s analysis [41]. The only member whose choice did not align with the prediction of the model was node 9, which sided with the administrator instead of the instructor. This case highlights how the structure of social networks can effectively predict real-world group divisions.
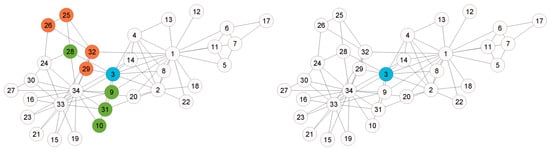
Figure 3.
Zachary’s Karate Club network overlapping nodes identified for two threshold parameter values ( and ).
Several studies have applied different methods to detect overlapping communities in the Zachary Karate Club network [42] and found that although the original division was clearly binary, certain nodes consistently appear at the boundary between communities. Across different algorithms, nodes and 31 are most frequently identified as overlapping, indicating their connections to members of both factions. For example, the study in [43] discovered that nodes and 31 belong to multiple groups according to the self-correcting algorithm. Similarly, the study in [44] identified the nodes and 31 as the boundary nodes. The study in [45] reported nodes 3 and 10, as well as node 10 separately, as overlapping nodes. Furthermore, the study in [46] characterised node 9 as an overlapping node. These results consistently indicate that a small group of individuals, particularly the nodes and 31, act from a structural point of view as bridges or connectors between the two main communities. This shows how certain members’ social ties can blur strict community boundaries within the club. The comparison of nodes identified as overlapping in the literature is summarised in Table 3. These examples represent only a small subset of the available studies and are not intended to be exhaustive.
Table 3.
Comparison of overlapping nodes (denoted by ×) in the Zachary’s Karate Club identified across studies.
Next, we compare the results of our model with the results of other theoretical models. Nodes and 31 are identified as overlapping nodes, consistent with the theoretical models mentioned above. Furthermore, node 28 is also recognised as an overlap node. Nodes and 31 exist consistently within the same subcommunity, as indicated in [15]. When they change subcommunities, they do so together, which is represented by the dark green colour in Figure 3. Similarly, nodes and 32 form a similar group, but are typically not identified as overlapping nodes in the existing literature. This is because our community detection method [15] identifies more subcommunities. However, these four nodes are classified as one of the four communities in the study [45]. This highlights the challenge of making clear distinctions between communities and the potential for overlap among communities in different models. In our model, node 3 remains classified as an overlapping node even for high values of the threshold parameter, which is consistent with other theoretical findings in the literature. In contrast to the other theoretical models, node 14 is not considered to overlap in our model. Figure 3 illustrates the overall situation in which overlapping nodes are distributed between the peripheral parts of the network.
4.2. Les Misérables Social Network
Several studies have used the Les Misérables social network, which consists of 77 fictitious characters from Victor Hugo’s book, as a benchmark for detecting overlapping or mixed-membership communities [35,47]. network illustrates character co-occurrences, such that each node represents a character and each edge connects two characters who appear together in a scene or chapter. The social network within the narrative features several distinct groups: Valjean’s group (nodes , and 27), the revolutionary students (nodes ), and the Thenardier family (nodes , and 30). Together, these groups consist of 17 nodes out of the total of 77 characters in the book who engage in social interactions and contribute to the community structure.
The community structure does not strictly reflect these groups, except perhaps for the revolutionary group, because the story revolves primarily around the social interactions between various characters. The communities and their overlapping nodes encompass all the families and other individuals, highlighting the author’s broader storyline that extends beyond mere interactions among these families. Some characters in the narrative function as overlapping or boundary nodes, serving as bridges between different communities and connecting various social groups. In Figure 4, the overlapping nodes are highlighted in different colours, illustrating the relationships that reflect the author’s story development in the book.
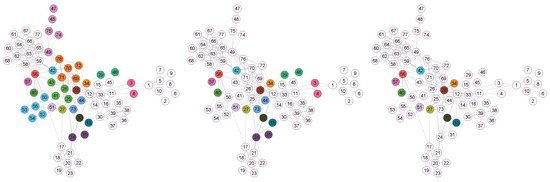
Figure 4.
Les Misérables network overlapping nodes identified for three increasing threshold parameter values (, and ).
To study the community structure of the Les Misérables social network, Riola and Newman used an information-theoretic approach [35]. Applying techniques such as information compression-based network partitioning, they identified “building blocks” of communities—groups of characters that frequently interact and form cohesive substructures within the overall network, as shown in Figure 5. The structure of the eight blocks at the mutual information peak includes both communities and their intersections. We compare this structure with our first figure, which uses the parameter value of , as shown in Figure 4. In our model, the white nodes are identified as members of the subcommunities or their internal structure, and the coloured nodes represent the overlapping nodes for different threshold values. The study in [35] demonstrated how information theory can reveal the hierarchical and modular organisation of complex social systems.
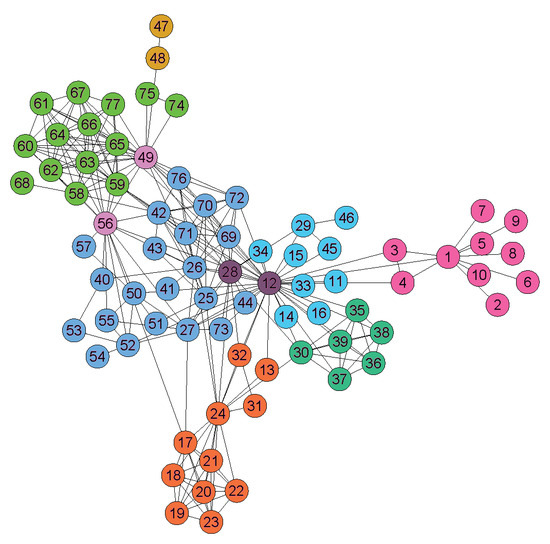
Figure 5.
Building blocks identified by Riolo and Newman using the information-theoretic method in their study [35]. These building blocks include both communities and their intersections.
As a result of this comparison, we conclude that although there are minor differences, the largest building block, indicated by the dark blue colour in Figure 5, corresponds to the overlapping nodes in Figure 4. The other five larger blocks, represented by shades of light green, dark green, light blue, orange, and purple, correspond to distinct subcommunities in our model.
4.3. Empirical Mobile Phone Call Network
The empirical dataset analysed in this section is based on data collected from a large mobile phone call detail records (CDRs) database. This dataset has been used to study human communication patterns, its social structure, and behavioural dynamics [48]. Derived from large-scale anonymised call detail records that cover millions of interactions, the data capture ego-centric social networks where nodes represent individuals and weighted edges indicate intensity or frequency of communication. Research based on this dataset has explored a variety of topics, including the strength of social links and gender- or age-related differences in communication patterns [49], mobility and internal migration in social interactions [50], and the evolution of statistically validated motifs and temporal communication structures. Collectively, these studies demonstrate how large-scale mobile phone data reveal consistent behavioural regularities, such as the persistence of close social bonds, demographic trends in calling behaviour, and stable network patterns, while offering valuable insights into human social organisation and communication dynamics at multiple scales.
Here, we focus solely on the topological properties of a subset of the mobile phone call network. The four panels in Figure 6 that show the effects of increasing the value of the threshold parameter of our model reveal a pattern that is consistent with other cases in this study. We observe that the number of overlapping nodes decreases as the value of the threshold parameter increases. In the fourth panel, only three small groups remain as overlapping. Compared to the other networks examined, the network is sparse: communities are clearly separated and typically connected by only one inter-community edge. This results in disjoint building blocks even when the threshold parameter is set to zero. As expected, a small increase in the threshold further reduces the remaining overlaps. In certain applications, even these few remaining overlapping groups can be further analysed to determine the most central focal node of them. An example of this is the problem of optimal sensor placement in a communication network, where it is feasible to have only one sensor for each of these groups.

Figure 6.
An example of overlapping nodes in a mobile phone call network, shown for four progressively increasing threshold values ( and ).
4.4. Dolphin Social Network
The following example highlights an undirected social network of 62 bottlenose dolphins in Doubtful Sound, New Zealand, between 1994 and 2001 [51]. In this network, nodes represent individual dolphins, while edges connect pairs observed together more often than expected by chance, indicating significant social associations. Analysed by Lusseau and Newman [52], the dataset reveals a cohesive, yet modular, community structure.
During this study, one dolphin, SN100, temporarily disappeared, causing the network to split into two subgroups [52]. When SN100 returned, the groups reunited, demonstrating how the presence or absence of a central individual can affect social cohesion. This dataset has become a key example in social network analysis, particularly for studying community structure and the influence of individuals on group dynamics.
Several studies have applied mixed-membership and overlapping community detection methods to the Dolphin Social Network. Although the network naturally divides into two main social groups, certain dolphins consistently appear at the boundary between communities, suggesting overlapping social affiliations. For example, the study in [34] identified overlapping individuals that included Beak, Kringel, MN105, Oscar, PL, SN4, SN9, and TR99, while the study in [53] found Beak, Bumper, Fish, Oscar, PL, SN89, SN96, and TR77 as boundary dolphins under a mixed membership model. The original analysis by Lusseau and Newman in [51] highlighted SN100 as the key bridge individual on the dolphin social network. Together, these results illustrate that certain dolphins, particularly Beak, Oscar, PL, and SN100, play crucial connector roles between subgroups, emphasising the importance of overlapping and bridging individuals in maintaining social cohesion. Next, we compare the results of our model with those previously mentioned.
Table 4 summarises our findings alongside a small selection of results from the literature. First, we examine the middle and bottom panels in Figure 7. The dolphins Beak, Kringel, MN105, Oscar, PL, and TR99 are consistent with the results reported in [34]. In contrast, SN4 and SN9 are not identified as overlapping nodes in our model, although they appear as overlapping nodes at a low threshold value in the upper panel of Figure 7. Our method identifies two groups: one consisting of five dolphins—Beak, Bumber, Fish, SN96, and TR77, and another containing two—Oscar and PL. The grouping in this way is similar to the findings in [53]. In our model, these groups remain together even when they change subcommunities, which is indicated by the brown shades in the figure. Furthermore, SN89 is identified in both cases, although it was not recognised in [34]. SN100 is still identified with a high threshold value in the bottom panel of Figure 7, highlighting its bridging role in the network structure. Zap is identified as an overlapping node across all threshold values, but not in the two models discussed in the literature.
Table 4.
Comparison of overlapping and boundary dolphins identified across selected studies (denoted by ×).
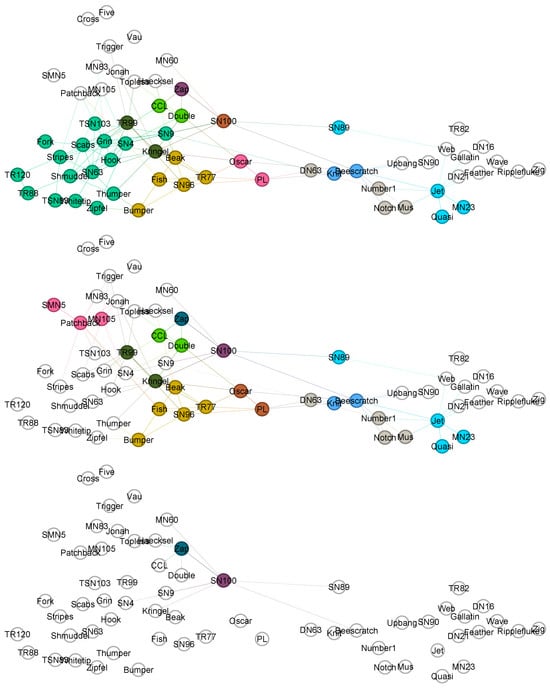
Figure 7.
The dolphin network overlapping nodes identified for three increasing threshold parameter values (, and ). The dolphin names are shown in the figure.
4.5. Facebook Social Circles Network
The Facebook ego network of 4039 nodes and 88,234 edges is an undirected social network extracted from user friendship circles, first introduced in [37] as part of the SNAP dataset collection [54]. Each node represents a Facebook user, and edges denote mutual friendships among friends of a single ego-centric user. The dataset includes ground-truth social circles that are derived through manual annotation, in which the ego user assigned friends to overlapping social groups based on real-life relationships and shared attributes, including school, workplace, location, or political affiliation. This makes it a popular benchmark for overlapping circle, community detection, and link prediction algorithms, including, for example, the methods in [8,23]. The analysis of these circles also raises an issue: The distinction between circles and communities is somewhat vague, and the terms are often used interchangeably in the science of social networks [39]. This is problematic because circles, although they reflect some structural properties, e.g., triadic closures and cliques, are attribute driven, while communities are more a topological phenomenon [9]. The overlapping community detection algorithms are often benchmarked against these circles and not the communities. Subsequent studies, including [55], have used this dataset to assess the quality of detected communities versus the memberships of known circles. The correlation between circles and communities is addressed in [39]. Investigating how our detected overlapping nodes align with known circle intersections is left for future work.
The Facebook ego-centric network serves as an example of a larger social network structure, illustrating our method for identifying overlapping nodes and groups of nodes. In Figure 8, we show nodes that overlap in six different scenarios, each of which is represented by an increasing value of the threshold parameter. When the threshold is low, almost all nodes are classified as overlapping. This is because in dense networks, most nodes participate in multiple intersections, leading to a high overlapping rate. Increasing the threshold value reduces the number of overlapping nodes, ultimately resulting in only a few nodes being classified as overlapping within the network structure. Interestingly, as the threshold is increased, the nodes that remain classified as overlapping are not necessarily the ego nodes themselves; rather, they may be located anywhere within the network. This indicates that influential bridging nodes often reside within communities rather than at their boundaries, a pattern observed also, e.g., in [56], in analysis of Twitter networks. Most importantly, our method can reveal such key bridging nodes even in densely interconnected subgroups. Such nodes would be difficult to identify using traditional community detection approaches.

Figure 8.
Overlapping nodes detected in the Facebook network [54]. The visualization shows the overlapping nodes identified at six different threshold parameter values. The rows correspond to thresholds , , and .
5. Discussion
In this study, we focus on identifying and filtering overlapping nodes of detected overlapping communities. The key question is how to distinguish genuinely overlapping nodes from those that appear to overlap due to noise or highly similar community structures. Fine-grained methods for detecting overlapping communities often produce many closely related communities, especially in social networks where individuals belong to several social circles [6]. In such dense settings, traditional methods may struggle to draw meaningful boundaries, and communities may share most of their members. In these cases, identifying true bridging nodes becomes more informative than analysing community structure alone.
Misclassifying too many nodes as overlapping obscures the influence of those that genuinely connect distinct network regions. Our approach addresses this by controlling structural noise with a threshold, reducing overlap caused by near-identical community compositions. This highlights nodes that function as real connectors and supports a more accurate analysis of influence, information flow, and key actors in complex networks. Furthermore, a topic not covered so far is the relation between the threshold parameter values and the network structure. Our empirical results indicate that the maximum threshold required to remove overlapping nodes is not arbitrary, but appears to be systematically related to the network characteristics including the size, density, and extent of local clustering (see Table 2. Small and moderately sized social networks such as Les Misérables, the Zachary’s Karate Club, and Dolphin Social Networks require only low to moderate thresholds, reflecting their relatively simple community structures and limited community overlap. In contrast, the large and dense Facebook network requires a much higher threshold, implying a far richer pattern of overlapping communities. Subsequently, the similarly large but very sparse Mobile Phone Network exhibits the lowest threshold, suggesting that sparsity suppresses the overlap despite scale. Although these findings are preliminary and subject to future work, they empirically suggest that the interplay between network size, density, and clustering jointly governs the sensitivity of overlapping nodes to the chosen threshold parameter.
Ego-centric networks are typically analysed by focusing on a single ego and its alters, which can challenge the capability of community detection algorithms. In our analysis of the Facebook ego-centric network, we have used a relatively low link weight to identify all major communities as distinct (Figure 8). This produced numerous communities with only minor overlaps, making bridging nodes harder to detect. The number of overlapping nodes can be controlled by fine-tuning the threshold: as it increases, the number of overlapping nodes decreases. This shift from a granular to a clearer structural representation aids the interpretation of the community organisation and influences the dynamics, as also demonstrated in the mobile phone call network.
In future algorithm development, we can introduce selection rules that are specifically tailored to meet the needs of different applications. These rules could take into account factors such as the size and coherence of intersections between communities, the number of communities to which a node belongs, and the strength of those memberships. By incorporating these criteria, the algorithm could better prioritise overlapping behaviours, allowing it to identify key bridging nodes and model patterns of multi-membership. A further point concerns the threshold rule applied in our approach. Although it serves as a practical heuristic, it lacks a solid theoretical basis. This limitation reflects a broader issue in community detection: there is no universally accepted definition of what constitutes a community. The absence of a clear conceptual foundation complicates the development of a cohesive theoretical framework for any method that detects overlapping nodes. Therefore, we argue that selection criteria should be based on specific use cases, since different analytical goals lead to various ways of prioritising overlaps.
6. Conclusions
This study introduced a framework for classifying shared nodes within overlapping communities of complex networks. By differentiating overlapping nodes from noise or subcommunity structures, our method improves the interpretation of community overlaps and reduces the ambiguity arising from nearly identical community divisions. The approach integrates a selection rule and a tunable threshold parameter to adjust the level of overlap, allowing the analysts to concentrate on structurally the most significant bridging nodes.
Applications to several real-world networks, based on social, communication, and empirical datasets, demonstrated that increasing the threshold progressively filters out spurious overlaps while preserving core connector nodes. These results confirm the robustness and adaptability of our method across various types of networks. Importantly, the approach is compatible with any community detection algorithm capable of producing overlapping partitions, thus providing a flexible post-processing tool for network analysis.
Future studies should focus on investigating how sensitive the results are to different threshold choices, as their effects are influenced by community structures generated by specific detection methods. Variations in threshold levels can also serve as a diagnostic tool to better understand both the behaviour of the detection methods and the underlying network structure. Since the framework is not limited to any particular algorithm—our own model served only as an example—it would be beneficial to evaluate it using additional overlapping community detection techniques. Conducting benchmarks on synthetic or ground-truth networks, along with analyses that link identified overlapping nodes to such metrics as influence or centrality, will deepen our understanding of when the framework provides the most insightful perspectives on overlapping structures.
Author Contributions
Conceptualization, V.K. and K.K.; Methodology, V.K. and K.K.; Software, V.K. and K.K.; Validation, V.K. and K.K.; Formal Analysis, V.K. and K.K.; Writing—Original Draft Preparation, V.K. and K.K.; Writing—Review & Editing, V.K., K.K. and K.K.K.; Visualization, V.K. and K.K.; Supervision, K.K.K.; Project Administration, K.K.K.; Funding Acquisition, K.K.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The Zachary’s Karate Club friendship network used in Section 4.1 is a standard benchmark dataset in community detection research. It is publicly available, for example, in https://networkrepository.com/soc-karate.php (accessed on 1 August 2025). In Section 4.2, we examine the Les Misérables character co-appearance network. It is publicly available from repositories such as https://networkrepository.com/lesmis.php (accessed on 1 August 2025) and appears in multiple open-source network libraries. The mobile phone call network studied in Section 4.3 is proprietary and cannot be shared publicly due to contractual and privacy restrictions. Access may be granted only under a data-sharing agreement with the provider and subject to applicable ethical and legal constraints. The Dolphin Social Network analysed in Section 4.4 is publicly available from several online repositories, including the https://networkrepository.com/soc-dolphins.php (accessed on 1 August 2025). The ego-Facebook social circles network analysed in Section 4.5 is publicly available through the Stanford Large Network Dataset Collection (SNAP): https://snap.stanford.edu/data/ego-Facebook.html (accessed on 1 August 2025).
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Appendix A.1. Building Blocks
These algorithms evaluate the input community structures by comparing them with a set of previously detected network divisions, each consisting of two communities. It first computes a cohesion score for each division, representing the strength of influence or connectivity among the nodes within each community (Algorithm A1). Then these divisions are sorted by their cohesion values. From the top divisions, the algorithm constructs building blocks that are used to classify nodes in the input communities (Algorithm A2).
| Algorithm A1 Compute And Rank Partition | |
| Require: | |
| ▹ number of nodes | |
| ▹ weight matrix | |
| ▹ number of iterations/partitions | |
| ▹ row t is the indicator vector at iteration t | |
| ▹ whether to apply normalization | |
| Ensure: | |
| ▹ agreement score per iteration | |
| ▹ indices sorted by s in descending order | |
| 1: Initialization | |
| 2: | |
| 3: | |
| 4: for to do | |
| 5: | ▹ indicator at iteration |
| 6: | |
| 7: for to N do | |
| 8: | |
| 9: | |
| 10: end for | |
| 11: if then | |
| 12: | ▹ fraction of zeros in v |
| 13: | |
| 14: end if | |
| 15: | ▹ avoid symmetric double-counting |
| 16: end for | |
| 17: Sort by s in descending order |
| Algorithm A2 Build Blocks | |
| Require: | |
| ▹ number of nodes | |
| ▹ membership indicators over T iterations | |
| ▹ number of iterations | |
| ▹ number of iterations in each segment | |
| ▹ ranking from Algorithm A1 over | |
| ▹ number of top-ranked segment anchors to process | |
| Ensure: | |
| For each anchor and segment index : | |
| : distinct membership-signature blocks | |
| : node → block assignments | |
| : block sizes | |
| 1: for to K do | ▹ process top-K ranked anchors |
| 2: | ▹ score index from Algorithm A1 |
| 3: | |
| 4: for to do | |
| 5: ; | |
| 6: ; | |
| 7: | |
| 8: | |
| 9: for to N do | |
| 10: | ▹ Set the Pattern |
| 11: index of a block in equal to (if any; else 0) | |
| 12: if then | |
| 13: ; | |
| 14: else | |
| 15: | |
| 16: Add to | |
| 17: ; | |
| 18: end if | |
| 19: end for | |
| 20: Output for anchor r and segment | |
| 21: end for | |
| 22: end for |
Appendix A.2. Patterns
Table A1 illustrates how the 34 nodes, , of the Karate Club network are categorised into patterns (used in Algorithm A2).
Table A1.
Nodes and their corresponding divisions and patterns.
Table A1.
Nodes and their corresponding divisions and patterns.
| N | Div1 | Div2 | Div3 | Div4 | Div5 | Div6 | Div7 | Pattern |
|---|---|---|---|---|---|---|---|---|
| 1 | x | x | x | x | x | x | x | xxxxxxx |
| 2 | x | x | x | x | x | x | x | xxxxxxx |
| 3 | x | x | x | x | o | x | x | xxxxoxx |
| 4 | x | x | x | x | x | x | x | xxxxxxx |
| 5 | o | x | x | x | o | o | o | oxxxooo |
| 6 | o | x | x | x | o | o | o | oxxxooo |
| 7 | o | x | x | x | o | o | o | oxxxooo |
| 8 | x | x | x | x | x | x | x | xxxxxxx |
| 9 | x | o | o | x | o | o | x | xooxoox |
| 10 | x | o | o | x | o | o | x | xooxoox |
| 11 | o | x | x | x | o | o | o | oxxxooo |
| 12 | x | x | x | x | x | x | x | xxxxxxx |
| 13 | x | x | x | x | x | x | x | xxxxxxx |
| 14 | x | x | x | x | x | x | x | xxxxxxx |
| 15 | x | o | o | o | o | o | o | xoooooo |
| 16 | x | o | o | o | o | o | o | xoooooo |
| 17 | o | x | x | x | o | o | o | oxxxooo |
| 18 | x | x | x | x | x | x | x | xxxxxxx |
| 19 | x | o | o | o | o | o | o | xoooooo |
| 20 | x | x | x | x | x | x | x | xxxxxxx |
| 21 | x | o | o | o | o | o | o | xoooooo |
| 22 | x | x | x | x | x | x | x | xxxxxxx |
| 23 | x | o | o | o | o | o | o | xoooooo |
| 24 | x | o | o | o | o | o | o | xoooooo |
| 25 | x | o | x | x | o | x | x | xoxxoxx |
| 26 | x | o | x | x | o | x | x | xoxxoxx |
| 27 | x | o | o | o | o | o | o | xoooooo |
| 28 | x | o | o | x | o | o | x | xooxoox |
| 29 | x | o | x | x | o | x | x | xoxxoxx |
| 30 | x | o | o | o | o | o | o | xoooooo |
| 31 | x | o | o | x | o | o | x | xooxoox |
| 32 | x | o | x | x | o | x | x | xoxxoxx |
| 33 | x | o | o | o | o | o | o | xoooooo |
| 34 | x | o | o | o | o | o | o | xoooooo |
Seven network divisions, denoted , have been identified using a community detection method. Partitions are indicated by ‘x’ and ‘o’ for each node, where ‘x’ denotes membership in the partition and ‘o’ indicates non-membership (or membership in the two distinct communities). The cumulative patterns derived from these columns are displayed in the last column of the table. In the first pattern, ’xxxxxxx’, there are ten nodes: 1, 2, 4, 8, 12, 13, 14, 18, 20, 22. The second pattern, ’xxxxoxx’, contains one node: 3. Additional patterns continue in this manner. In particular, the nodes identified in patterns 2, 4, and 6 overlap when the threshold . Table A2 summarises the patterns. Additionally, node 3 overlaps at a threshold of (according to Algorithm A3).
Table A2.
The six patterns found in the Karate Club network.
Table A2.
The six patterns found in the Karate Club network.
| Pattern No | Pattern | No Nodes |
|---|---|---|
| 1 | xxxxxxx | 10 |
| 2 | xxxxoxx | 1 |
| 3 | oxxxooo | 5 |
| 4 | xooxoox | 4 |
| 5 | xoooooo | 10 |
| 6 | xoxxoxx | 4 |
Appendix B. Overlapping Nodes
Each input community is analysed by assigning its nodes to building blocks and checking their alignment with the detected patterns using a tolerance threshold. Unmatched nodes are identified, i.e., overlapping nodes are identified.
| Algorithm A3 Community Evaluation | |
| Require: | |
| ▹ number of nodes | |
| ▹ number of communities | |
| ▹ community assignment per node | |
| , | ▹ anchor and segment index chosen from Algorithm A2 |
| ▹ node → block assignment for the chosen | |
| ▹ sizes of the B distinct blocks for | |
| ▹ Threshold-parameter | |
| ▹ output flags: match (=1) or not matched (=−1) | |
| ▹ accumulator for nodes in communities that fail matching | |
| Ensure: | |
| ▹ Set of nodes belonging to communities not matching any block | |
| ▹ Number of such nodes (total size of unmatched communities) | |
| 1: | |
| 2: Compute community sizes: | |
| 3: for to K do | |
| 4: | |
| 5: end for | |
| 6: | ▹ initialize all blocks as unmatched |
| 7: | ▹ initialize accumulator |
| 8: for to B do | |
| 9: | ▹ indicator for nodes in block k |
| 10: for to N do | |
| 11: if then | |
| 12: | |
| 13: end if | |
| 14: end for | |
| 15: | ▹ size of block k |
| 16: for to K do | ▹ iterate over communities from Algorithm A2 |
| 17: | ▹ community size |
| 18: if then | |
| 19: if then | |
| 20: | ▹ no match on this block |
| 21: else | |
| 22: | ▹ community matches this block |
| 23: break | |
| 24: end if | |
| 25: else | |
| 26: | ▹ (S = 0) |
| 27: end if | |
| 28: if and then | |
| 29: | ▹ accumulate nodes of unmatched community |
| 30: end if | |
| 31: end for | |
| 32: end for | |
| 33: | ▹ final set of overlapping nodes |
| 34: |
References
- Souravlas, S.; Sifaleras, A.; Tsintogianni, M.; Katsavounis, S. A classification of community detection methods in social networks: A survey. Int. J. Gen. Syst. 2021, 50, 63–91. [Google Scholar] [CrossRef]
- Li, J.; Lai, S.; Shuai, Z.; Tan, Y.; Jia, Y.; Yu, M.; Song, Z.; Peng, X.; Xu, Z.; Ni, Y.; et al. A comprehensive review of community detection in graphs. Neurocomputing 2024, 600, 128169. [Google Scholar] [CrossRef]
- Barabási, A.L. Network science. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2013, 371, 20120375. [Google Scholar] [CrossRef] [PubMed]
- Newman, M.E.J. Networks: An Introduction; Oxford University Press: Oxford, NY, USA, 2018. [Google Scholar]
- Latapy, M.; Magnien, C.; Del Vecchio, N. Basic Notions for the Analysis of Large Two-Mode Networks. Soc. Netw. 2008, 30, 31–48. [Google Scholar] [CrossRef]
- Shang, J.; Liu, L.; Li, X.; Xie, F.; Wu, C. Epidemic spreading on complex networks with overlapping and non-overlapping community structure. Phys. A Stat. Mech. Its Appl. 2015, 419, 171–182. [Google Scholar] [CrossRef]
- Ghalmane, Z.; Hassouni, M.E.; Cherifi, C.; Cherifi, H. Centrality in complex networks with overlapping communities. PLoS ONE 2019, 14, e0210003. [Google Scholar] [CrossRef]
- Yang, J.; Leskovec, J. Community Detection in Networks with Node Attributes. IEEE Trans. Knowl. Data Eng. 2014, 26, 1650–1663. [Google Scholar] [CrossRef]
- Koistinen, K.; Kuikka, V.; Kaski, K. Importance of Overlapping Network Nodes in Influence Spreading. arXiv 2025, arXiv:2510.24360. [Google Scholar] [CrossRef]
- Hurley, N.; Reid, F. Diffusion in Networks with Overlapping Community Structure. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining Workshops, Los Alamitos, CA, USA, 7–10 December 2011; pp. 969–978. [Google Scholar] [CrossRef]
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef]
- Xie, J.; Kelley, S.; Szymanski, B.K. Overlapping community detection in networks: The state-of-the-art and comparative study. Acm Comput. Surv. 2013, 45, 1–35. [Google Scholar] [CrossRef]
- Yang, Z.; Algesheimer, R.; Tessone, C.J. A comparative analysis of community detection algorithms on artificial networks. Sci. Rep. 2016, 6, 30750. [Google Scholar] [CrossRef]
- Fortunato, S.; Hric, D. Community detection in networks: A user guide. Phys. Rep. 2016, 659, 1–44. [Google Scholar] [CrossRef]
- Kuikka, V. Detecting Overlapping Communities Based on Influence-Spreading Matrix and Local Maxima of a Quality Function. Computation 2024, 12, 85. [Google Scholar] [CrossRef]
- Leskovec, J.; Lang, K.J.; Dasgupta, A.; Mahoney, M.W. Community structure in large networks: Natural cluster sizes and the absence of large well-defined clusters. Internet Math. 2009, 6, 29–123. [Google Scholar] [CrossRef]
- Kuikka, V.; Kaski, K.K. Detailed-level modelling of influence spreading on complex networks. Sci. Rep. 2024, 14, 28069. [Google Scholar] [CrossRef]
- Palla, G.; Derényi, I.; Farkas, I.; Vicsek, T. Uncovering the Overlapping Community Structure of Complex Networks in Nature and Society. Nature 2005, 435, 814–818. [Google Scholar] [CrossRef]
- Ahn, Y.Y.; Bagrow, J.P.; Lehmann, S. Link Communities Reveal Multiscale Complexity in Networks. Nature 2010, 466, 761–764. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Radicchi, F.; Ramasco, J.J.; Fortunato, S. Finding statistically significant communities in networks. PLoS ONE 2011, 6, e18961. [Google Scholar] [CrossRef]
- Airoldi, E.M.; Blei, D.M.; Fienberg, S.E.; Xing, E.P. Mixed Membership Stochastic Blockmodels. J. Mach. Learn. Res. 2008, 9, 1981–2014. [Google Scholar]
- Xu, E.H.W.; Hui, P.M. Uncovering complex overlapping pattern of communities in large-scale social networks. Appl. Netw. Sci. 2019, 4, 27. [Google Scholar] [CrossRef]
- Yang, J.; Leskovec, J. Overlapping Community Detection at Scale: A Nonnegative Matrix Factorization Approach. In Proceedings of the Sixth ACM International Conference on Web Search and Data Mining (WSDM ’13), New York, NY, USA, 4–8 February 2013; pp. 587–596. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the 2nd International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Jia, Y.; Zhang, Q.; Zhang, W.; Wang, X. CommunityGAN: Community Detection with Generative Adversarial Nets. In WWW’2019, Proceedings of the World Wide Web Conference, New York, NY, USA, 13–17 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 784–794. [Google Scholar] [CrossRef]
- Sismanis, K.; Potikas, P.; Souliou, D.; Pagourtzis, A. Overlapping community detection using graph attention networks. Future Gener. Comput. Syst. 2025, 163, 107529. [Google Scholar] [CrossRef]
- Su, X.; Xue, S.; Liu, F.; Wu, J.; Yang, J.; Zhou, C.; Hu, W.; Paris, C.; Nepal, S.; Jin, D.; et al. A Comprehensive Survey on Community Detection with Deep Learning. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 4682–4702. [Google Scholar] [CrossRef]
- Yanchenko, E.; Sengupta, S. Core-periphery structure in networks: A statistical exposition. Stat. Surv. 2023, 17, 42–74. [Google Scholar] [CrossRef]
- Rossetti, G.; Cazabet, R. Community Discovery in Dynamic Networks: A Survey. ACM Comput. Surv. 2018, 51, 1–37. [Google Scholar] [CrossRef]
- Khawaja, F.R.; Zhang, Z.; Ullah, A. Common-neighbor based overlapping community detection in complex networks. Soc. Netw. Anal. Min. 2025, 15, 61. [Google Scholar] [CrossRef]
- Guo, L.; Zhang, M. Overlapping Community Detection Based on Strong Tie Detection and Non-Overlapping Link Clustering. Math. Probl. Eng. 2022, 2022, 5931727. [Google Scholar] [CrossRef]
- Niu, Y.; Kong, D.; Liu, L.; Wen, R.; Xiao, J. Overlapping community detection with adaptive density peaks clustering and iterative partition strategy. Expert Syst. Appl. 2023, 213, 119213. [Google Scholar] [CrossRef]
- Shen, H.; Cheng, X.; Guo, J.; Hu, B. Quantifying and Identifying the Overlapping Community Structure in Networks. J. Stat. Mech. Theory Exp. 2009, 2009, P07042. [Google Scholar] [CrossRef]
- Riolo, M.A.; Newman, M. Consistency of community structure in complex networks. Phys. Rev. E 2020, 101, 052306. [Google Scholar] [CrossRef]
- Cherifi, H.; Palla, G.; Szymanski, B.K.; Lu, X. On community structure in complex networks: Challenges and opportunities. Appl. Netw. Sci. 2019, 4, 1–35. [Google Scholar] [CrossRef]
- McAuley, J.; Leskovec, J. Learning to Discover Social Circles in Ego Networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; Volume 25, pp. 548–556. [Google Scholar]
- Yang, J.; Leskovec, J. Defining and Evaluating Network Communities Based on Ground-Truth. Knowl. Inf. Syst. 2015, 42, 181–213. [Google Scholar] [CrossRef]
- Brauer, S.; Schmidt, T.C. Are Circles Communities? A Comparative Analysis of Selective Sharing in Google+. In Proceedings of the 2014 IEEE 34th International Conference on Distributed Computing Systems Workshops (ICDCSW), Washington, DC, USA, 30 June–3 July 2014; pp. 8–15. [Google Scholar] [CrossRef]
- Onnela, J.; Saramäki, J.; Hyvönen, J.; Szabó, G.; Lazer, D.; Kaski, K.; Kertész, J.; Barabási, A. Structure and tie strengths in mobile communication networks. Proc. Natl. Acad. Sci. USA 2007, 104, 7332–7336. [Google Scholar] [CrossRef]
- Zachary, W.W. An Information Flow Model for Conflict and Fission in Small Groups. J. Anthropol. Res. 1977, 33, 452–473. [Google Scholar] [CrossRef]
- Newman, M.E.J. Modularity and Community Structure in Networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef]
- Chen, M.; Nguyen, L.; Szymanski, B.K. A Fast Overlapping Community Detection Algorithm with Self-Correcting Ability. PLoS ONE 2014, 9, e91444. [Google Scholar] [CrossRef]
- Zhang, W.; Zhao, H.; Hu, M.; Liu, Q. Detecting Overlapping Communities Based on Vital Nodes in Complex Networks. Chin. Phys. B 2018, 27, 100504. [Google Scholar] [CrossRef]
- Dehghan, T.; Fathalikhani, S.; Dastjerdi, M. Overlapping Community Discovery Method Based on Two Expansions of Seeds. Symmetry 2021, 13, 18. [Google Scholar] [CrossRef]
- Duan, Y.; Liu, H.; Dong, J.; Sun, X. Multi-Type Node Detection in Network Communities. Entropy 2019, 21, 1237. [Google Scholar] [CrossRef]
- Knuth, D.E. The Stanford GraphBase: A Platform for Combinatorial Computing; Addison-Wesley: Boston, MA, USA, 1993. [Google Scholar]
- Li, M.X.; Palchykov, V.; Jiang, Z.Q.; Kaski, K.; Kertész, J.; Miccichè, S.; Tumminello, M.; Zhou, W.X.; Mantegna, R.N. Statistically validated mobile communication networks: Evolution of motifs in European and Chinese data. New J. Phys. 2014, 16, 063038. [Google Scholar] [CrossRef][Green Version]
- Fudolig, M.I.; Monsiváis, D.; Bhattacharya, K.; Jo, H.H.; Kaski, K. Different patterns of social closeness observed in mobile phone communication. R. Soc. Open Sci. 2020, 7, 191379. [Google Scholar] [CrossRef]
- Fudolig, M.I.; Monsiváis, D.; Bhattacharya, K.; Jo, H.H.; Kaski, K. Internal migration and mobile communication patterns among pairs with strong ties. EPJ Data Sci. 2022, 11, 40. [Google Scholar] [CrossRef]
- Lusseau, D.; Schneider, K.; Boisseau, O.J.; Haase, P.; Slooten, E.; Dawson, S.M. The bottlenose dolphin community of doubtful sound features a large proportion of long-lasting associations: Can geographic isolation explain this unique trait. Behav. Ecol. Sociobiol. 2003, 54, 396–405. [Google Scholar] [CrossRef]
- Newman, D.; Lusseau, D. Identifying the role that individual animal play in their social network. Proc. Biol. Sci. 2003, 271, S477–S481. [Google Scholar] [CrossRef]
- Ouyang, G.; Dey, D.K.; Zhang, P. A Mixed-Membership Model for Social Network Clustering. arXiv 2017, arXiv:1708.07604. [Google Scholar]
- Leskovec, J.; Krevl, A. SNAP Datasets: Stanford Large Network Dataset Collection. 2014. Available online: http://snap.stanford.edu/data (accessed on 1 August 2025).
- Shin, S.j.; Jeong, Y.j.; Kim, C.M.; Han, Y.H.; Park, C.Y. Study on Relation between Social Circles and Communities in Facebook Ego Networks. In Ubiquitous Information Technologies and Applications; Jeong, Y.S., Park, Y.H., Hsu, C.H.R., Park, J.J.J.H., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 567–572. [Google Scholar] [CrossRef]
- Cha, M.; Haddadi, H.; Benevenuto, F.; Gummadi, K.P. Measuring User Influence in Twitter: The Million Follower Fallacy. In Proceedings of the 4th International AAAI Conference on Weblogs and Social Media (ICWSM), Washington, DC, US, 23–26 May 2010; pp. 10–17. [Google Scholar] [CrossRef]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).