Abstract
Community Question-Answering (cQA) sites have an urgent need to be increasingly efficient at (a) offering contextualized/personalized content and (b) linking open questions to people willing to answer. Most recent ideas with respect to attaining this goal combine demographic factors (i.e., gender) with deep neural networks. In essence, recent studies have shown that high gender classification rates are perfectly viable by independently modeling profile images or textual interactions. This paper advances this body of knowledge by leveraging bimodal transformers that fuse gender signals from text and images. Qualitative results suggest that (a) profile avatars reinforce one of the genders manifested across textual inputs, (b) their positive contribution grows in tandem with the number of community fellows that provide this picture, and (c) their use might be detrimental if the goal is distinguishing throwaway/fake profiles. From a quantitative standpoint, ViLT proved to be a better alternative when coping with sparse datasets such as Stack Exchange, whereas CLIP and FLAVA excel with a large-scale collection—namely, Yahoo! answers and Reddit.
1. Introduction
Social networks are structures composed of actors, dyadic ties, and interactions between these actors. In actuality, one can find assorted communities in conformity to the different active interests of their memberships: image sharing, discussion fora, blogging, video hosting, etc. Notably, question-answering platforms including Yahoo! Answers (https://archive.fo/agAtD accessed on 30 October 2025), Reddit (https://www.reddit.com/), and Stack Exchange (https://stackexchange.com/), as well as Quora (https://www.quora.com/), are online social venues that offer the opportunity to browse and ask complex, subjective and/or context-dependent questions. A critical factor in their success is their ability to deliver timely responses tailored to specific real-world situations. As a matter of fact, their competitive advantage is that these types of answers can seldom be discovered via querying of top-notch Web search engines such as Google (https://www.google.com) and Bing (https://www.bing.com/).
At its heart, the study of social networks sets its sights on unearthing local/global patterns, finding influential members, and examining their intrinsic dynamics. Take, for example, the spread of misinformation or the analysis of influential figures within these services. In the realm of cQAs, it is vital to quickly establish fruitful connections between unresolved questions and peers that can and are willing to help.
More specifically, gender profiling of community members is instrumental not only in establishing effective communications between community peers but also in enforcing security policies (see details in the Related Work Section 2.1). In achieving this, recent advances in machine learning, especially deep neural networks, have played a pivotal role in enhancing user experience across cQA sites. In the realm of cQAs, research has focused its attention on automatically and independently detecting gender via avatars and textual inputs. Thus, our work deals with this task by exploring bimodal transformers to combine signals from both these kinds of sources. Concisely, the main contribution of our work to this research field is three-fold:
- A performance comparison of nine text-based encoders with four frontier bimodal transformers was conducted on the basis of four assessment metrics (i.e., accuracy, recall, precision, and F1 score).
- This contrast of systems was conducted via experiments on three dissimilar datasets, each of them belonging to a sharply different cQA website—namely, Yahoo! Answers, Reddit, and Stack Exchange.
- Ergo, the corpora considered in our empirical framework do not only have distinct gender distributions and purposes but they are also of various sizes, which means a dissimilar number of users available for this study.
Succinctly, our discoveries lead us to understand that images are likely to stress the gender most prominently exhibited by linguistic traits, and for this reason, it is better to depend entirely on text when the target application is detecting throwaway/fake accounts. Eventually, the larger the collection of images, the more noticeably the classification rate grows.
The roadmap of this work is described as follows. First, Section 2 fleshes out the works of our forerunners. Subsequently, Section 3 and Section 4 deal at length with our methodology and experimental results, respectively. Eventually, Section 5 and Section 6 set forth our key findings, as well as the limitations of our approach, and outlines some future research directions.
2. Related Work
By and large, ongoing research into cQA sites shows that the automatic distinguishing of demographic factors (e.g., gender) serves a crucial function not only in keeping their vibrancy but also in enforcing their policies [1,2,3,4,5]. By the same token, the rise of pre-trained models (PTMs) such as BERT has made it much easier for researchers to develop innovative and cost-efficient solutions for knotty problems. Essentially, PTMs are built on massive corpora and adapted to a particular task afterwards. In other words, they yield a starting set of weights and biases that can be adjusted to specific downstream tasks later [6,7,8,9]. In the realm of cQAs, PTMs have aided in producing encouraging results in many tasks, including automatic gender identification [10,11].
2.1. Gender Recognition
Assorted computer vision-oriented approaches, including PTMs, have been applied to the prediction of gender based on profile pictures on cQA websites [12,13]. For the most part, multifarious low-resolution, non-facial images present a tough but interesting challenge, even for ocular inspections [12].
When it comes to text analysis, the study reported in [14] looked into isolated questions (i.e., wording, metadata, demographics, and Web searches) in order to automatically tag askers’ genders. Based on large-scale data and vector spaces, the most informative features were found to comprise age, industry, and second-level categories, regardless of whether provided by the community member when singing up or deduced via textual semantics and dependency analyses.
In general, masculine members are likely to be neutral, while women tend to be positive on Yahoo! Answers [15]. Furthermore, females are more sentimental when responding and more likely to tackle questions seeking opinions in graphic design communities [15,16]. In contrast, it is more plausible that men deal with factual questions and that they use a distinctly negative tone when reacting.
Feminine members belonging to Stack Overflow are more willing to engage earlier when they come across other women [17]. On this platform, males focus primarily on answering, whereas women primarily focus on asking. As a consequence, females get fewer thumb-ups and lower average reputation scores [18,19,20], not to mention that women score lower when responding despite devoting greater effort to their contributions. According to [21], this bias puts forward the demand for strategies to increase women’s participation. Above all, these discoveries point toward the fact that automatically detecting genders is vitally important, especially in cases of anonymity and/or when gender information is unavailable [18].
Analogously to [11], ref. [10] assessed assorted cutting-edge PTMs on large-scale Yahoo! Answers collections. Like other demographic variables, such as age, best gender recognizers accounted for full questions and answers, but in their case, DeBERTa and MobileBERT eclipsed other architectures. Unlike age, fine tuning on user-generated content was affected by pre-training on clean corpora when tackling gender.
2.2. Multimodal Pre-Trained Encoders
In actual fact, transformers represent a real breakthrough in artificial intelligence. Their revolutionary idea consists of pre-training language model objectives using large neural networks and large-scale unlabeled material. Since the major introduction of OpenAI’s GPT and BERT [22,23], PTMs have become the default cost-efficient solution for many tasks [7]. However, they still face numerous challenges despite their considerable improvements during the last few years [7,24,25], including the design of effective architectures, capitalizing on rich contexts, generalization, enhancing computational efficiency, conducting interpretation and theoretical analysis, and temporality [26,27,28].
To a considerable degree, multimodal contexts are rich contexts. They are normally defined, detected, and experienced by a set of distinct sensors. Most people usually relate modalities to our primary sensory channels of communication and sensation, e.g., voice and vision. Thus, a task is perceived as multimodal when it copes with multiple modalities. The heterogeneity of this kind of data brings about unique challenges, such as capturing correspondences between distinct modalities and gaining a deeper understanding of natural phenomena [28,29].
In the event of visual–textual bimodal tasks, some multimodal PTMs leverage cross-modal attention modules for each modality [30], while others fuse unimodal embeddings as an initial step [31]. The approach described in [32] modifies BERT and XLNet to accept multimodal nonverbal data during fine tuning. Generally speaking, fully different transformer-based vision–text models can be built in an end-to-end fashion by considering several vision encoders (e.g., CLIP-ViT and Swin Transformer), text encoders (e.g., RoBERTa and DeBERTa), multimodal fusion modules (e.g., merged attention and co-attention), architectural designs (e.g., encoder-only and encoder–decoder architectures), and pre-training objectives like masked image modeling [33,34,35,36]. Furthermore, ref. [37] showed that a single model can not only support multiple input modalities but also perform multi-task learning across different combinations of these modalities.
As for embeddings, ref. [38] presented a model that learned to predict visual representations jointly with linguistic features for a limited array of words. As a result, visual information was disseminated to embeddings of terms with no direct visual evidence when training. Along the same lines, the proposal described in [39] merged visual–textual representations of concepts at different levels: objects, attributes, relations, and full scenes.
As a matter of fact, ref. [40] pioneered efforts in amalgamating image and text information to output gender probability scores for Twitter users. On the same platform, the work of Vicente et al. [41] automatically distinguished genders by exploiting three modalities: user-generated context (text), profile pictures, and network graphs (user activity). By analyzing images and text of the same users across Twitter and Pinterest, Ottoni et al. [42] discovered remarkably different patterns of activity: members post items first on Pinterest, then on Twitter, and they engage in more content categories on Pinterest than on Twitter. On Facebook, Farnadi et al. [43] profiled members and their genders based on a deep learning approach that mixes three modalities: textual posts, profile pictures, and relational data (page likes). In so doing, they capitalized upon a shared representation that merges the data at the level of features and, when making a final decision, combines the outputs of separate networks working on each source combination.
In the field of cQA, ref. [44] reported a multimodal dataset including textual questions, tables, and images. Later, ref. [45] proposed a strategy to integrate these three modalities. Conversely, ref. [46] answered open questions based on images and text only. From another angle, ref. [47] studied different visual and textual representations for table question answering. Another approach devised a multimodal question-answering system that integrates text, tables, and images in a text-to-text format for PTMs via position-enhanced table linearization and diversified image captioning [45].
3. Methodology
The contribution of images to text-only gender detection is quantified by comparing the performance of (a) state-of-the-art multimodal models—namely, models combining image and text data—with (b) cutting-edge unimodal text-based classifiers. In the event of the latter, we adapted the following nine well-known pre-trained frontier deep neural networks [22,23]:
- ALBERT (A Lite BERT) cuts down on memory consumption and training time via a factorized embedding parametrization and a share scheme for cross-layer parameters [48].
- BERT (Bidirectional Encoder Representations from Transformers) is the inspiration for most current top-notch models. Grounded in the linguistic principle that words are broadly defined by their company [49], it encompasses a multi-layer bidirectional encoder built for masking words and forecasting the next sentence [8,23]. Its core comprises twelve transformer blocks and twelve self-attention heads with a hidden state of 768.
- Knowledge distillation is a pre-training technique capitalized upon by DistillBERT to significantly diminish the size of the BERT model, preserving almost all its language-understanding capabilities. Coupled with a triple loss, it achieves a speedup of 60%, remaining competitive on many downstream tasks [50].
- In the same spirit as the previous encoder, DistilRoBERTa distills RoBERTa-base. This architecture has 6 layers, 768 dimensions, and 12 heads, decreasing the number of parameters from 125 million to 82 million. On average, it is twice as fast as its predecessor.
- Apart from masking some input tokens, ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately) determines, via a transformer, whether each token is an original or a replacement [51]. Another distinguishing feature of this approach is its neural network-based generator that masks and substitutes tokens to produce corrupted elements. This boosts the efficiency of BERT, since it demands substantially less computation while achieving competitive accuracy in several applications.
- The underlying idea behind Nyströmformer is to substitute the standard self-attention with a matrix approximation. This replacement offers scalability to cope with sequences encompassing thousands of tokens, thereby weakening the impact of the quadratic explosion that characterizes BERT-inspired encoders [52].
- RoBERTa enhances the robustness of BERT by extending training times and sequences, using bigger batches, and adding one order of magnitude more data [53]. Furthermore, it removes the goal of guessing the next sentence and dynamically changes masking patterns during training.
- As for multilinguality, XLMRoBERTa is a masked language model rivaling frontier monolingual encoders [54]. Built upon texts in one hundred languages, it achieves cutting-edge performance in cross-lingual classification, sequence labeling, and question answering. It is renowned for its strong performance on low-resource languages.
- XLNet is a generalized autoregressive pre-training strategy that learns bidirectional contexts. Instead of exploiting a fixed forward or backward factorization order, it maximizes the expected likelihood over all permutations of the factorization order [55].
Of course, the implementations offered by Hugging Face (https://huggingface.co/) were utilized during fine tuning. By and large, we chose default parameter settings to level the grounds and reduce the experimental workload. The number of epochs was set to four; hence, the time for fine tuning was restricted to one week in the case of the most computationally demanding models (e.g., LongFormer). The maximum sequence length was equal to 64. The batch size was set to ensure that the corresponding GPU memory usage reached its limit—namely, 32—allowing for convergence. In our experiments, we used sixteen NVIDIA A16 (16gb) Tesla GPU cards and two Nvidia DGX A100 40gb GPUs.
Generally speaking, bimodal visual–language techniques target the capture of rich semantics within images and their corresponding texts. This synergy assists in establishing relations between complementary, supplementary, and redundant cross-modal patterns in order to cope with complex downstream tasks. By and large, multimodal approaches leverage impressively engineered architectures that amalgamate a handful of pre-trained subsystems (e.g., an image feature model, a region/object detection model, and a pre-trained masked language model). Accordingly, these subsystems are jointly adapted by means of a battery of training objectives on image–text pairs. With that in mind, we fine-tuned the following four bimodal approaches:
- CLIP simultaneously builds a visual encoder and a language encoder. During testing, the latter synthesizes a zero-shot linear classifier by embedding the names/descriptions of the target categories. The only interaction between the two domains is a single dot product in the learned joint embedding space [56].
- In juxtaposition, FLAVA is an alignment model that concurrently aims at vision, language, and their multimodal combination. It infers strong representations through simultaneous pre-training on top of both unimodal and bimodal material while encompassing cross-modal “alignment” and bimodal “fusion” objectives [57].
- With regard to simple and efficient bimodal vision–language architectures, ViLT extracts and processes image features in place of a separate deep visual embedder by exploiting a transformer module. It handles both modalities in a single unified manner. This, together with its shallow, convolution-free embedding of pixel-level inputs, makes it sharply different from its predecessors [58].
- By using self-attention, VisualBERT piles transformer layers as a way of implicitly aligning elements of input texts and associated regions across related images. It integrates BERT and pre-trained object proposal systems such as Faster-RCNN [59]. Both types of inputs are processed in unison by multiple Transformer layers [60].
Like their unimodal counterparts, we fine-tuned the weights and biases published through Hugging Face based largely on their default parameter settings. Due to their computational demands, we reduced the number of epochs from four to one with respect to unimodal approaches. Nevertheless, the maximum sequence length remained equal to 64. However, in the event of FLAVA, the batch size was decreased to four to make it possible to work on the aforementioned hardware.
4. Experiments
Our empirical settings take into account three sharply different bimodal collections—namely, vision–language corpora. More specifically, each one was extracted from a distinct cQA site (i.e., Yahoo! Answers, Stack Exchange or Reddit). All three contain gender-tagged members encompassing their fictitious names and questions and answers, as well as their profile images in some cases (see Table 1).

Table 1.
Description of datasets.
Accordingly, these corpora are described below as follows:
- Yahoo! Answers (YA) comprises 53 million question–answer pages plus 12 million user profiles compiled for demographic analysis [61,62,63]. Note that this collection originally provides genders for 548,375 community fellows [10,11,13,64,65,66]. However, 55 records were removed due to stricter filters being applied for HTML sequences.
- Stack Exchange (SE) regularly offers data dumps for public consumption (https://archive.org/download/stackexchange/, accessed on 30 October 2025). According to previous studies [66], this corpus yields 525 community peers labeled with their gender. Like YA, this number was reduced to 512 due to a more complete removal of HTML sequences.Given the fact that its small size and its large imbalance dramatically hurt the learning process [66], we employed oversampling as a way of balancing the two classes. In so doing, we benefited from random sampling with replacement for the minority class across training instances only. It is worth noting here that without oversampling, models produced outcomes almost identical to the majority baseline.
- Reddit comprises more than 1.3 billion submissions (questions) and almost 350 billion answers (comments). This material was posted before July 2021 [67]. We extended the repository supplied by [66] from 68,717 to 317,001 gender-tagged profiles by exploiting their automatic labeling strategy.
In our experimental framework, each of these datasets was randomly split into training, (60%), evaluation (20%), and testing (20%) sets. Held-out evaluations were then conducted by keeping all three folders fixed. Note also that the test material was exploited only to obtain unbiased assessments of final model fits on the training/evaluation splits. As a means of analyzing the results from different angles, we report the respective outcomes in terms of accuracy, precision, recall, and F1 score.
4.1. Unimodal: Text-Based Models
Table 2 displays the experimental results obtained by the aforementioned nine text-based models (cf., Section 3). In this light, we can conclude the following:
Table 2.
Results obtained by text-based strategies. Best figures in bold.
- A bird’s eye view of the outcomes signals that ELECTRA emerged as the best performing alternative. To be more precise, it reaped the top results for YA and Reddit in terms of accuracy and precision. For these two platforms, this encoder also finished with F1 scores competitive with those of the respective top systems: 0.8233 → 0.8240 (YA) and 0.5782 → 0.5922 (Reddit). On the flip side, ELECTRA achieved an average or below-average recall, generally speaking.In juxtaposition, ELECTRA achieved the best recall and F1 score when aiming at SE. Three transformers accomplished the highest score (0.6897)—namely, DistilRoBERTa, ELECTRA, and XLMRoBERTa. These figures suggest that this might be the “upper bound” for these models when exploiting this small dataset. Nevertheless, ELECTRA surpassed the other two encoders because of its better precision (i.e., 0.4255 → 0.3922 and 0.4255 → 0.4167). In this scenario, ALBERT served the role that ELECTRA played on YA and Reddit by surpassing all other systems when it comes to accuracy and precision. Note also that ALBERT ended in third place in terms of F1 score.
- Despite its size and an entropy similar to that of YA (i.e, 0.9532 and 0.9687), models had a hard time distinguishing the minority class across Reddit members (see matrices in Figure 1c,f). The amount of females tagged as males is comparable to the number of correctly identified feminine peers—namely, 19.40% out of 39.7% instances (ca. 49.67%). This, in turn, means that the set of masculine fellows automatically labeled by ELECTRA is very noisy: 27.98% of male predictions were, indeed, women. Feminine members seen as masculine obtain quite similar figures when adapting RoBERTa: 44.11% and 27.10% out of all instances were automatically recognized as women and men, respectively.
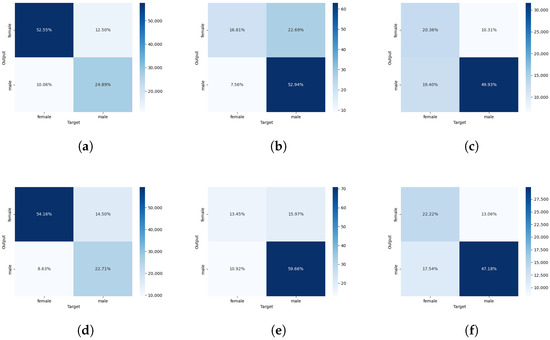 Figure 1. Confusion matrices corresponding to the best approaches grounded solely in texts. (a) YA—ELECTRA; (b) SE—ELECTRA; (c) Reddit—ELECTRA; (d) YA—XLMRoBERTa; (e) SE—ALBERT; (f) Reddit—RoBERTa.In the case of YA, analogously, these ratios tend to be lower. For instance, the fraction of males (minority class) perceived as females relative to the total number of predicted men was 12.50% of a total of 37.39% (33.43%) in the case of ELECTRA and 14.5% of 37.21% (38.97%) for XLMRoBERTa. As a logical consequence, we can conclude that finding women across Reddit poses a tougher challenge for frontier machine learning-based gender recognizers grounded only in text inputs.With regards to SE, the distribution of correctly classified masculine/feminine users by ALBERT was close to that observed across the real labels (see Table 1). This result leads to the conclusion that oversampling is a cost-efficient solution to improve fine tuning.
Figure 1. Confusion matrices corresponding to the best approaches grounded solely in texts. (a) YA—ELECTRA; (b) SE—ELECTRA; (c) Reddit—ELECTRA; (d) YA—XLMRoBERTa; (e) SE—ALBERT; (f) Reddit—RoBERTa.In the case of YA, analogously, these ratios tend to be lower. For instance, the fraction of males (minority class) perceived as females relative to the total number of predicted men was 12.50% of a total of 37.39% (33.43%) in the case of ELECTRA and 14.5% of 37.21% (38.97%) for XLMRoBERTa. As a logical consequence, we can conclude that finding women across Reddit poses a tougher challenge for frontier machine learning-based gender recognizers grounded only in text inputs.With regards to SE, the distribution of correctly classified masculine/feminine users by ALBERT was close to that observed across the real labels (see Table 1). This result leads to the conclusion that oversampling is a cost-efficient solution to improve fine tuning. - On the flip side, Nyströmformer was the least effective alternative. More precisely, it achieved the lowest F1 score on the YA and Reddit collections and, in the event of the former, the worst accuracy and recall as well. By the same token, its precision on both corpora, as well as its accuracy and recall on the Reddit corpus, was close to that of the worst performing models. Nevertheless, its outcomes on SE are competitive with those of the top architectures, regardless the assessment metric.
- In the same vein, average accuracies neatly summarize the finding outlined in the prior point. This score was 0.7587 on the YA dataset, which is approximately 13% higher than the portion of instances belonging to the majority category (females). With respect to Reddit, this value was about 7% greater than the fraction of the class corresponding to the lion’s share of users (males). Conversely, the average accuracy was 7% lower than the majority baseline on the SE corpus. In a nutshell, these figures encapsulate the differences across the three investigated collections, especially as they relate to how challenging they actually are.
In summary, ELECTRA surpassed its counterparts on the two largest collections—namely, Reddit and YA—but it performed poorly on SE. In contrast, Nyströmformer outclassed its rivals on SE while underperforming on the other two corpora. It is also worth highlighting that oversampling aided models in inferring some useful patterns when fine-tuned on few data. Curiously enough, the average accuracy declined from 75.87% (YA) to 67.24% (Reddit) despite dealing with collections of similar size and entropy. On top of that, our experiments revealed that a significant fraction of the errors were essentially due to females automatically being tagged as males. We hypothesize that the reason for this detriment has to do, in part, with the following features of Reddit:
- Although Reddit is not a completely anonymous service, it still operates predominantly on the grounds of pseudonyms. Ergo, its members are identified by persistent usernames instead of their real names. As a logical consequence, this spirit of anonymity makes any heuristic-based tagger considerably error-prone, especially in comparison with other sites, such as SE and YA, where community members are more likely to identify themselves as something closer to their actual names, including any of their potential diminutives. In our study, this sort of invisibility entails that we tackled a noisy and therefore more challenging working corpus.
- While it is true that Reddit does not require personal information to create a new account (e.g., real name and gender), it certainly collects some private data, such as IP addresses. At any rate, Reddit allows its community fellows to communicate without revealing their real name or identity. For instance, when enrolling, most Redditors pick an alias that represents them as a substitute for their real name, with the express purpose of hiding their true identity. Consequently, this site is attractive to individuals that are more concerned about being anonymous to their peers in conversation than its administration.
- This dynamic greenlights its members to anonymously post via throwaway accounts, which are normally abandoned or deleted after a short period of time. Thus, this type of activity allows Redditors to participate in this social network while keeping themselves totally unknown and/or running misleading/fake profiles. This prevents an average person from readily knowing who users really are when reading their comments.
In conclusion, we conjecture that people who dislike flying under the radar pose a difficult but interesting challenge for gender recognition across Reddit. We envisage that a plausible way of coping with this could be to single out throwaway accounts. However, this does not seem to be a straightforward task, since their set of characterizing features is yet to be studied and, hence, determined. Needless to say, it is uncertain whether it is better to filter this kind of account entirely from the corpus or whether it might be a better idea to devise a smart way of considering their input signals during training. Future studies are required to settle which option yields more robust machine learning gender identifiers. Needless to say, automatically detecting throwaway accounts could play a pivotal role in the discovery of malicious activities across Reddit.
With this in mind, a revision of the confusion matrices presented in Figure 1c,f leads us to believe that these throwaway accounts belong to, for the most part, male fellows pretending to be female. It is easy to conceive here that these Redditors intentionally convey misleading pieces of information regarding their gender as a means of being effective at deceiving their community peers or readers in general about their true identity. The bottom line is that this type of deception can easily fool a heuristic-based gender detector grounded largely in lists of names and morphologies such as the one used in [66].
4.2. Bimodal Models
Table 3 underscores the empirical outcomes accomplished by four bimodal approaches (cf., Section 3). Given these figures, we are able to state the following:
Table 3.
Performance achieved by bimodal approaches. Best figures in bold.
- First all, the impact of images on the classification rate is negligible when it comes to SE. To be more concrete, accuracies signal that a few extra women were correctly classified to the detriment of the number of properly recognized men (see Table 4 and the confusion matrices in Figure 1e and Figure 2b). Nevertheless, this is still positive, since females are under-represented across this strongly unbalanced dataset.
Table 4. Best text-based vs. bimodal outcomes. Best figures in bold.
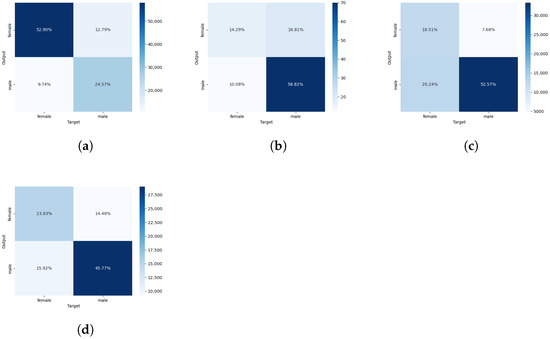 Figure 2. Confusion matrices for the best bimodal strategies. (a) YA—CLIP; (b) SE—ViLT; (c) Reddit—FLAVA; (d) Reddit—CLIP.
Figure 2. Confusion matrices for the best bimodal strategies. (a) YA—CLIP; (b) SE—ViLT; (c) Reddit—FLAVA; (d) Reddit—CLIP. - As a natural consequence, the increase in precision obtained by ViLT came at the expense of recall and F1-score performance (cf., Table 4). In fact, this sort of improvement is better suited for applications where detecting few but very accurate results is required, e.g., targeting cellphone screens. Regarding SE, the reliable identification of more feminine members is pertinent to its rewarding policies [20,21].
- While ViLT outperformed all three other encoders when operating on the smallest collection (SE), FLAVA finished with the best overall performance on YA and Reddit. In relation to bimodal transformers only, FLAVA reaped the top accuracy and precision for both YA and Reddit, and the former also achieved the highest F1 score. It is also worth highlighting here that CLIP ended with the highest recall for both datasets and the best F1 score on the Reddit collection.
- Despite showing some noticeable enhancements on both the YA and Reddit collections, bimodal encoders performed substantially better on Reddit. We interpret this as a result of its larger amount of community fellows that provide an avatar (see Table 1). Regardless the metric, a bimodal architecture always exists that significantly surpasses all its text-only rivals.
- When comparing the confusion matrices in Figure 2c,d with those in Figure 1c,f, we discover that FLAVA and CLIP accomplished their improvements in different ways. FLAVA correctly distinguished a higher number of masculine peers while missing a comparatively lower amount of feminine fellows. On the other hand, CLIP correctly recognized a higher number of feminine members while missing a relatively lower number of masculine members. It worth also noting that both types of errors are more evenly distributed in the event of CLIP.
- To some extent, the figures obtained by CLIP point towards images as a tool for conveying consistency. Put differently, they are aligned with the way users intend to present themselves in the network. Take, for instance, a case in which a male member wants to run a deceptive throwaway account as a woman; he will likely employ a profile picture that can be easily attributed to any female peer. This would strengthen the evidence for the intended gender, assisting in deceiving and, at the same time, in lessening the weigh of the linguistic discrepancies that help to distinguish between the two genders.
- It is worth noting here that avatars are small, diverse, low-resolution pictures (i.e., 96 × 96 or 128 × 128 pixels), e.g., facial and non-facial images, and some are automatically generated as well. This means that some visual regularities attributed to a specific gender are hard to detect, even by ocular inspection. Errors were found to be partly due to the presence of ambiguous images, like images of couples, someone near a car, symbols, or animals. Consider also that visual pre-trained networks are built on top of ImageNet (http://www.image-net.org/), which has a large distribution of image sizes, the most common of which is 500 × 500 pixels.
In brief, the results indicate that ViLT performed better on SE by dealing more effectively with the minority class, whereas FLAVA and CLIP shone particularly on Reddit by capitalizing upon its larger amount of avatars. In other words, our experiments signal that a substantial share of community members must provide their profile pictures in order for bimodal encoders (i.e., encoders incorporating text and image data) to be able to materially improve the classification rate.
4.3. Unimodal or Bimodal Models?
However, these findings must be taken with a pinch of salt (see a summary of the experimental outcomes displayed in Table 4). On the positive side, our outcomes show that avatars reinforce the linguistic evidence for one of the genders—normally, the genuine one. Needless to say, this reinforcement is desirable, since it contributes to enhanced performance. But on the negative side, this reinforcement makes it easier for community fellows to go unnoticed when running a fake profile or, in some cases, using the platform for malicious activities. In this case, setting a profile image accordingly will assist not only in deceiving community peers but also in decreasing the relevance of gender discrepancies that might surface from linguistic analysis of the corresponding text exchanges.
As a means of verifying the statistical significance between the best model for each case and the rest in their respective dataset/group, we bootstrap-sampled their results twenty times and carried out a two-tailed t-test afterwards (p < 0.025). All tests showed statistically significant differences.
The key here is that visual evidence is extracted from exclusively one avatar, whereas linguistic information is typically distilled from several inputs. Thus, it is almost impossible to search for visual patterns that might indicate gender discrepancies when there is only one picture available. But on the bright side, it is easier to find these discrepancies in textual inputs that extend across long periods of time. The longer the time span or the larger the amount of these inputs, the harder it is to maintain consistency.
Last but not least, it is worth stressing here that all this depends on the application at hand, i.e., whether our need is to identify the actual gender of a user, that intended by a community fellow, or both.
4.4. Caveats
The annotation process is grounded solely in textual inputs provided by each community fellow. However, this class of input can sometimes be misleading, since it is based on how community fellows identify themselves at a particular moment on the site. For instance, some individuals run fake profiles and seek to deceive.
Prior works have roughly estimated the accuracy of this automatic labeling strategy as 90% [61,62,63]. On the one hand, the 10% error rate is due partly to its intrinsically shallow nature, not showing a noticeable bias towards any gender (see details in Section 4.2 and Section 4.3 on [61]). On the other hand, it is also caused by members that willingly/unwillingly lie or pretend to belong to another gender—at least occasionally. It goes without saying that all these aspects make any manual labeling approach hard as well.
Incidentally, non-binary sexual orientations showed a negligible participation rate, probably due to the discretion of such users. It is worth noting here that YA dates back to 2018 and Reddit dates back to 2021.
5. Limitations and Future Research
Besides the unbalanced nature and limited size of the SE collection, there are some additional aspects that must be weighed carefully. As a starting point, consider the marked bias in favor of programmers—in particular, masculine programmers—exhibited by the SE platform, which makes it hard to effectively adapt models to related downstream tasks. Instead of oversampling, one could think of devising new and more sophisticated heuristics (cues) to manually and/or automatically find additional female members.
On top of that, our current computing infrastructure limited the size of the transformers that we could use in our experimental settings. In actuality, more refined meanings for frequent community jargon, spellings, aliases, entities, and acronyms could be learned from large-scale cQA training data if the necessary computational power were available to reconstruct state-of-the-art encoders from scratch.
Similarly, regenerating visual architectures by utilizing a massive corpus of avatars might assist in lessening the adverse effects of their low resolution and multifariousness. But on the flip side, the coverage of profile pictures is very narrow for some cQA networks (i.e., YA and SE); thus, in these cases their contribution, though valuable and positive, is highly plausible to be modest.
Furthermore, one promising idea capitalizes upon multilingual pre-trained transformers and material written in other languages in order to tackle data sparseness head-on, especially across individuals who have published very little textual content in English.
Another essential aspect to bear in mind is that what is considered to be masculine/feminine differs from one society to another. In the context of designing cost-efficient machine learning solutions, gender classification is cast as a binary classification task. Nonetheless, it can also be conceived as a continuum of male and female; this means one can be more or less man or woman (see chapter 12 in [68]). Needless to say, this interpretation dramatically increases the difficulty of acquiring an automatically (or manually) annotated corpus.
Additionally, we should consider the inherent bias pertaining to each collection. Table 1 discloses that some platforms seem to be favored by women (e.g., YA), whereas others are favored by men (e.g., SE and Reddit). Whether these biases are harmful or not remains an open research question whose answer depends largely on the underlying purpose of each community. For instance, research into gender behavior across SE has led to the implementation of reward policies that encourage female participation [17,18,19,20,21].
Finally yet importantly, gender refers to an array of cultural traits and behaviors deemed appropriate for men/women by a particular society (see chapter 12 in [68]). Women may give each other compliments on their appearance, while men exchange ritual insults, speech acts which draw on stereotypes of women seeking solidarity and men constructing hierarchy in conversation. Hence, profound differences between definitions of genders might entail striking variations on the best fit models.
6. Conclusions
In summary, this paper dissects the use of bimodal (i.e., text and images) encoders for gender recognition across distinct cQA services. More specifically, this study contrasts their contribution with strategies grounded solely in text. Essentially, our results support the following conclusions: (a) images emphasize the gender revealed by users’ associated linguistic traits; (b) text is a much more reliable source of information when the objective is the discovery of throwaway/fake accounts; and, as one can expect, (c) the larger the collection of images, the greater the contribution of images to the enhancement of the classification rate.
For the purpose of improving gender detection, the findings of this research reasonably suggest the exploitation of automatic filters for throwaway/fake profiles prior to capitalizing on automatic gender identifiers. We envisage that future works could focus their attention on supporting/disputing our outcomes that seem to indicate that the optimization of both objectives cannot be achieved simultaneously.
Aside from the research directions mentioned in the previous section, we envisage that studying patterns informative of throwaway accounts holds promise, as such research could have a considerable impact in terms of improving the safety of cQA platforms—in particular, assisting in monitoring some malicious activities.
Author Contributions
Conceptualization, A.F.; methodology, A.F.; software, E.M.; validation, A.F. and E.M.; formal analysis, A.F.; investigation, A.F. and E.M.; resources, A.F.; data curation, A.F.; writing—original draft preparation, A.F.; writing—review and editing, A.F.; supervision, A.F.; project administration, A.F.; funding acquisition, A.F. All authors have read and agreed to the published version of the manuscript.
Funding
This work was, in part, supported by the Fondecyt project titled “Multimodal Demographics and Psychographics for Improving Engagement in Question Answering Communities” (1220367) funded by the Chilean Government.
Institutional Review Board Statement
This research was reviewed, approved, and funded by Agencia Nacional de Investigación y Desarrollo—ANID (3691/2022, 1220367).
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data were created for this work. Accordingly, download links corresponding to the publicly available data used in this research are provided in Section 4.
Acknowledgments
This work was, in part, supported by the Fondecyt project titled “Multimodal Demographics and Psychographics for Improving Engagement in Question Answering Communities” (1220367) funded by the Chilean Government. Additionally, this research was partly supported by the Patagón supercomputer of Universidad Austral de Chile (FONDEQUIP EQM180042).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Srba, I.; Bielikova, M. A Comprehensive Survey and Classification of Approaches for Community Question Answering. ACM Trans. Web 2016, 10, 1–63. [Google Scholar] [CrossRef]
- Ahmad, A.; Feng, C.; Ge, S.; Yousif, A. A survey on mining stack overflow: Question and answering (Q&A) community. Data Technol. Appl. 2018, 52, 190–247. [Google Scholar] [CrossRef]
- Bouziane, A.; Bouchiha, D.; Doumi, N.; Malki, M. Question Answering Systems: Survey and Trends. Procedia Comput. Sci. 2015, 73, 366–375. [Google Scholar] [CrossRef]
- Jose, J.M.; Thomas, J. Finding best answer in community question answering sites: A review. In Proceedings of the 2018 International Conference on Circuits and Systems in Digital Enterprise Technology (ICCSDET), Kottayam, India, 21–22 December 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Roy, P.K.; Saumya, S.; Singh, J.P.; Banerjee, S.; Gutub, A. Analysis of community question-answering issues via machine learning and deep learning: State-of-the-art review. CAAI Trans. Intell. Technol. 2022, 8, 95–117. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained Models for Natural Language Processing: A Survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to Fine-Tune BERT for Text Classification? arXiv 2019, arXiv:1905.05583. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Schwarzenberg, P.; Figueroa, A. Textual Pre-Trained Models for Gender Identification Across Community Question-Answering Members. IEEE Access 2023, 11, 3983–3995. [Google Scholar] [CrossRef]
- Figueroa, A.; Timilsina, M. Textual Pre-Trained Models for Age Screening Across Community Question-Answering. IEEE Access 2024, 12, 30030–30038. [Google Scholar] [CrossRef]
- Lin, B.; Serebrenik, A. Recognizing Gender of Stack Overflow Users. In Proceedings of the 13th International Conference on Mining Software Repositories, MSR’16, Austin, TX, USA, 14–22 May 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 425–429. [Google Scholar] [CrossRef]
- Peralta, B.; Figueroa, A.; Nicolis, O.; Trewhela, Á. Gender Identification From Community Question Answering Avatars. IEEE Access 2021, 9, 156701–156716. [Google Scholar] [CrossRef]
- Figueroa, A. Male or female: What traits characterize questions prompted by each gender in community question answering? Expert Syst. Appl. 2017, 90, 405–413. [Google Scholar] [CrossRef]
- Kucuktunc, O.; Cambazoglu, B.B.; Weber, I.; Ferhatosmanoglu, H. A Large-scale Sentiment Analysis for Yahoo! Answers. In Proceedings of the Fifth ACM International Conference on Web Search and Data Mining, WSDM’12, Seattle, WA, USA, 8–12 February 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 633–642. [Google Scholar] [CrossRef]
- Dubois, P.M.J.; Maftouni, M.; Chilana, P.K.; McGrenere, J.; Bunt, A. Gender Differences in Graphic Design Q&As: How Community and Site Characteristics Contribute to Gender Gaps in Answering Questions. Proc. ACM Hum.-Comput. Interact. 2020, 4, 1–26. [Google Scholar]
- Ford, D.; Harkins, A.; Parnin, C. Someone like me: How does peer parity influence participation of women on stack overflow? In Proceedings of the 2017 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC), Raleigh, NC, USA, 11–14 October 2017; pp. 239–243. [Google Scholar] [CrossRef]
- May, A.; Wachs, J.; Hannák, A. Gender differences in participation and reward on Stack Overflows. Empir. Softw. Eng. 2019, 24, 1997–2019. [Google Scholar] [CrossRef]
- Wang, Y. Understanding the Reputation Differences between Women and Men on Stack Overflow. In Proceedings of the 2018 25th Asia-Pacific Software Engineering Conference (APSEC), Nara, Japan, 4–7 December 2018; pp. 436–444. [Google Scholar] [CrossRef]
- Blanco, G.; Pérez-López, R.; Fdez-Riverola, F.; Lourenço, A.M.G. Understanding the social evolution of the Java community in Stack Overflow: A 10-year s tudy of developer interactions. Future Gener. Comput. Syst. 2020, 105, 446–454. [Google Scholar] [CrossRef]
- Brooke, S. Trouble in programmer’s paradise: Gender-biases in sharing and recognising technical knowledge on Stack Overflow. Inf. Commun. Soc. 2021, 24, 2091–2112. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://www.semanticscholar.org/paper/Improving-Language-Understanding-by-Generative-Radford-Narasimhan/cd18800a0fe0b668a1cc19f2ec95b5003d0a5035 (accessed on 30 October 2025).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Brauwers, G.; Frasincar, F. A General Survey on Attention Mechanisms in Deep Learning. IEEE Trans. Knowl. Data Eng. 2021, 35, 3279–3298. [Google Scholar] [CrossRef]
- Tay, Y.; Dehghani, M.; Bahri, D.; Metzler, D. Efficient transformers: A survey. ACM Comput. Surv. 2020, 55, 109. [Google Scholar] [CrossRef]
- Han, X.; Zhang, Z.; Ding, N.; Gu, Y.; Liu, X.; Huo, Y.; Qiu, J.; Zhang, L.; Han, W.; Huang, M.; et al. Pre-Trained Models: Past, Present and Future. arXiv 2021, arXiv:2106.07139. [Google Scholar] [CrossRef]
- Röttger, P.; Pierrehumbert, J. Temporal Adaptation of BERT and Performance on Downstream Document Classification: Insights from Social Media. In Findings of the Association for Computational Linguistics: EMNLP 2021; Moens, M.F., Huang, X., Specia, L., Yih, S.W.T., Eds.; Association for Computational Linguistics: Punta Cana, Dominican Republic, 2021; pp. 2400–2412. [Google Scholar] [CrossRef]
- Mogadala, A.; Kalimuthu, M.; Klakow, D. Trends in integration of vision and language research: A survey of tasks, datasets, and methods. J. Artif. Intell. Res. 2021, 71, 1183–1317. [Google Scholar] [CrossRef]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal Machine Learning: A Survey and Taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 423–443. [Google Scholar] [CrossRef]
- Tsai, Y.H.H.; Bai, S.; Liang, P.P.; Kolter, J.Z.; Morency, L.P.; Salakhutdinov, R. Multimodal Transformer for Unaligned Multimodal Language Sequences. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Korhonen, A., Traum, D., Màrquez, L., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 6558–6569. [Google Scholar] [CrossRef]
- Sahu, G.; Vechtomova, O. Dynamic Fusion for Multimodal Data. arXiv 2019, arXiv:1911.03821. [Google Scholar] [CrossRef]
- Rahman, W.; Hasan, M.K.; Lee, S.; Bagher Zadeh, A.; Mao, C.; Morency, L.P.; Hoque, E. Integrating Multimodal Information in Large Pretrained Transformers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 2359–2369. [Google Scholar] [CrossRef]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the 28th International Conference on International Conference on Machine Learning, ICML’11, Bellevue, WA, USA, 28 June–2 July 2011; Omnipress: Madison, WI, USA, 2011; pp. 689–696. [Google Scholar]
- Zhang, C.; Yang, Z.; He, X.; Deng, L. Multimodal Intelligence: Representation Learning, Information Fusion, and Applications. IEEE J. Sel. Top. Signal Process. 2019, 14, 478–493. [Google Scholar] [CrossRef]
- Guo, W.; Wang, J.; Wang, S. Deep Multimodal Representation Learning: A Survey. IEEE Access 2019, 7, 63373–63394. [Google Scholar] [CrossRef]
- Dou, Z.Y.; Xu, Y.; Gan, Z.; Wang, J.; Wang, S.; Wang, L.; Zhu, C.; Zhang, P.; Yuan, L.; Peng, N.; et al. An Empirical Study of Training End-to-End Vision-and-Language Transformers. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 18145–18155. [Google Scholar] [CrossRef]
- Pramanik, S.; Agrawal, P.; Hussain, A. Omninet: A unified architecture for multi-modal multi-task learning. arXiv 2019, arXiv:1907.07804. [Google Scholar]
- Lazaridou, A.; Pham, N.T.; Baroni, M. Combining Language and Vision with a Multimodal Skip-gram Model. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; Mihalcea, R., Chai, J., Sarkar, A., Eds.; Association for Computational Linguistics: Denver, CO, USA, 2015; pp. 153–163. [Google Scholar] [CrossRef]
- Wu, H.; Mao, J.; Zhang, Y.; Jiang, Y.; Li, L.; Sun, W.; Ma, W.Y. Unified visual-semantic embeddings: Bridging vision and language with structured meaning representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6609–6618. [Google Scholar]
- Sakaki, S.; Miura, Y.; Ma, X.; Hattori, K.; Ohkuma, T. Twitter user gender inference using combined analysis of text and image processing. In Proceedings of the Third Workshop on Vision and Language, Dublin, Ireland, 23–29 August 2014; Dublin City University and the Association for Computational Linguistics: Dublin, Ireland, 2014; pp. 54–61. [Google Scholar]
- Vicente, M.; Batista, F.; Carvalho, J.P. Gender Detection of Twitter Users Based on Multiple Information Sources. In Interactions Between Computational Intelligence and Mathematics; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Ottoni, R.; Las Casas, D.; Pesce, J.P.; Meira, W., Jr.; Wilson, C.; Mislove, A.; Almeida, V. Of pins and tweets: Investigating how users behave across image-and text-based social networks. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8, pp. 386–395. [Google Scholar]
- Farnadi, G.; Tang, J.; De Cock, M.; Moens, M.F. User profiling through deep multimodal fusion. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; pp. 171–179. [Google Scholar]
- Talmor, A.; Yoran, O.; Catav, A.; Lahav, D.; Wang, Y.; Asai, A.; Ilharco, G.; Hajishirzi, H.; Berant, J. Multimodalqa: Complex question answering over text, tables and images. arXiv 2021, arXiv:2104.06039. [Google Scholar]
- Luo, H.; Shen, Y.; Deng, Y. Unifying Text, Tables, and Images for Multimodal Question Answering; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023. [Google Scholar]
- Chen, W.; Hu, H.; Chen, X.; Verga, P.; Cohen, W.W. Murag: Multimodal retrieval-augmented generator for open question answering over images and text. arXiv 2022, arXiv:2210.02928. [Google Scholar]
- Zhou, W.; Mesgar, M.; Adel, H.; Friedrich, A. Texts or Images? A Fine-grained Analysis on the Effectiveness of Input Representations and Models for Table Question Answering. arXiv 2025, arXiv:2505.14131. [Google Scholar] [CrossRef]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Taylor, W.L. “Cloze Procedure”: A New Tool for Measuring Readability. J. Mass Commun. Q. 1953, 30, 415–433. [Google Scholar] [CrossRef]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar] [CrossRef]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. In Proceedings of the ICLR, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Xiong, Y.; Zeng, Z.; Chakraborty, R.; Tan, M.; Fung, G.; Li, Y.; Singh, V. Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention. arXiv 2021, arXiv:2102.03902. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar] [CrossRef]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. arXiv 2019, arXiv:1911.02116. [Google Scholar] [CrossRef]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’ Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. arXiv 2021, arXiv:2103.00020. [Google Scholar] [CrossRef]
- Singh, A.; Hu, R.; Goswami, V.; Couairon, G.; Galuba, W.; Rohrbach, M.; Kiela, D. FLAVA: A Foundational Language And Vision Alignment Model. arXiv 2021, arXiv:2112.04482. [Google Scholar] [CrossRef]
- Kim, W.; Son, B.; Kim, I. ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision. arXiv 2021. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef]
- Li, L.H.; Yatskar, M.; Yin, D.; Hsieh, C.; Chang, K. VisualBERT: A Simple and Performant Baseline for Vision and Language. arXiv 2019, arXiv:1908.03557. [Google Scholar] [CrossRef]
- Figueroa, A.; Timilsina, M. What identifies different age cohorts in Yahoo! Answers? Knowl.-Based Syst. 2021, 228, 107278. [Google Scholar] [CrossRef]
- Figueroa, A.; Peralta, B.; Nicolis, O. Coming to Grips with Age Prediction on Imbalanced Multimodal Community Question Answering Data. Information 2021, 12, 48. [Google Scholar] [CrossRef]
- Figueroa, A.; Gómez-Pantoja, C.; Neumann, G. Integrating heterogeneous sources for predicting question temporal anchors across Yahoo! Answers. Inf. Fusion 2019, 50, 112–125. [Google Scholar] [CrossRef]
- Timilsina, M.; Figueroa, A. Neural age screening on question answering communities. Eng. Appl. Artif. Intell. 2023, 123, 106219. [Google Scholar] [CrossRef]
- Figueroa, A.; Peralta, B.; Nicolis, O. Gender screening on question-answering communities. Expert Syst. Appl. 2023, 215, 119405. [Google Scholar] [CrossRef]
- Figueroa, A. Less Is More: Analyzing Text Abstraction Levels for Gender and Age Recognition Across Question-Answering Communities. Information 2025, 16, 602. [Google Scholar] [CrossRef]
- Baumgartner, J.; Zannettou, S.; Keegan, B.; Squire, M.; Blackburn, J. The Pushshift Reddit Dataset. arXiv 2020. [Google Scholar] [CrossRef]
- Wardhaugh, R.; Fuller, J.M. An Introduction to Sociolinguistics; John Wiley & Sons: Hoboken, NJ, USA, 2021. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.