Abstract
This paper presents a modular framework for character-coherent, emotion-aware role-playing dialogue with large language models (LLMs), centered on a novel Verifiable Emotion Reward (VER) objective. We introduce VER as a reinforcement-style signal derived from frozen emotion classifiers to provide both turn-level and dialogue-level alignment, effectively mitigating emotional drift across long interactions. To amplify VER’s benefits, we construct Character-Coherent Dialogues (CHARCO), a large-scale multi-turn dataset of over 230,000 dialogues, richly annotated with persona profiles, semantic contexts, and ten emotion labels. Our experiments show that fine-tuning LLMs on CHARCO significantly enhances VER’s impact, driving marked improvements in emotional consistency, role fidelity, and dialogue coherence. Through the evaluation that integrates lexical diversity metrics, automatic scoring with GPT-4, and human assessments, we demonstrate that the collaboration between a purpose-built multi-turn dataset and the VER objective leads to significant advancements in the field of persona-aligned conversational agents.
1. Introduction
The rapid development of artificial intelligence (AI) has profoundly reshaped human–computer interactions [1,2]. Large language models (LLMs) have emerged as a pivotal component of this transformation, demonstrating capabilities that enable the generation of text with a high degree of similarity to human language and the facilitation of interactions that are increasingly natural, complex, and emotionally nuanced [3,4]. These sophisticated AI systems are now widely deployed across diverse fields, including financial and medical customer service [5], psychological support [6], and emotional companionship [7]. Consequently, the personality traits exhibited by LLMs have become a focal point of interest among researchers in both technological and social science domains [8].
Conventionally, the concept of personality has been confined to the domain of human psychology. The extension of this application to AI systems introduces substantial ontological and methodological considerations. Empirical studies have demonstrated that distinct LLMs exhibit consistent personality profiles, which may vary based on language or usage context [9]. However, contemporary research predominantly conceptualizes personality as a static emergent property, measured in isolation, thus overlooking its dynamic role in multi-turn interactions. This limited perspective fails to consider the critical applications where personality expression, stability, and controllability are paramount, such as role-playing dialogue systems.
To endow LLMs with role-playing capabilities, researchers have proposed various technical approaches. Without additional training, zero-shot and few-shot prompting [10] use implicit model knowledge to achieve quick simulation of diverse roles, while often suffering from role drift and consistency loss in long dialogues. Supervised fine-tuning methods [11] trained on specifically constructed role-playing corpora significantly enhance role fidelity and emotional representation. Meanwhile, Yu et al. introduce the Beyond Dialogue framework, which employs fine-grained profile–dialogue alignment tasks to eliminate biases between predefined role profiles and their generated utterances [12]. To mitigate the necessity for extensive fine-tuning, Low-Rank Adaptation (LoRA) has emerged as a viable alternative [13]. LoRA adapts pre-trained models with minimal additional parameters, thereby enabling enhanced performance on role-playing tasks with reduced computational resources. The method incorporates trainable low-rank matrices into existing model weights, facilitating effective task adaptation while keeping the core model parameters frozen. This approach enhances efficiency and scalability for fine-tuning, making it a promising solution for machine learning systems. However, these models heavily depend on carefully curated data and a substantial amount of computational resources. Furthermore, their often closed-source nature limits transparency, reproducibility, and broader applicability. To mitigate issues of long-term consistency, retrieval augmentation and memory modules [14] have been explored for extended long-term memory and context windows through dynamically introduced character profiles or dialogue histories, while facing issues such as noise retrieval, index maintenance, and response latency. Furthermore, Man et al. propose a context-aware sentiment forecasting framework using multi-perspective role-playing agents built on large language models, which significantly improves predictions of social media users’ future sentiment trajectories [15]. It is noteworthy that research on cartography in data journalism has demonstrated that effective map-based storytelling is contingent on achieving an equilibrium between visual esthetics, narrative structure, and the integration of contextual data to facilitate audience comprehension [16]. This finding serves as a direct impetus for our semantic-enhanced retrieval design, which aims to ground dialogue context. Multi-agent simulations [17], as another solution perspective, balance strategy and emotion by promoting natural social dynamics through inter-character interactions. Another recent work, RolePlot, presents a systematic framework for evaluating and enhancing the plot progression capabilities of role-playing agents [18].
However, meeting these demands requires high-quality training data, which remains insufficient in existing public datasets. Popular resources such as UltraChat [19], Alpaca [20], and Baize [21] exhibit notable deficiencies in terms of multi-turn dialogue length, emotional diversity, and role conditionality. In the specialized domain of psychological counseling, the KokoroChat dataset was constructed via role-playing by trained counselors, ensuring high-quality, authentic Japanese counseling dialogues [22]. As summarized in Table 1, existing dialogue corpora exhibit widely varying scales, depths, and topical coverage; for example, UltraChat spans 146.8 k dialogues over 30 meta-topics, whereas RoleCraft [23] comprises only 27 k dialogues with low breadth.

Table 1.
Instruction/non-role-play and role-play-centric sets.
In summary, multi-turn dialogue and role-playing domains face several key challenges, characterized by the following bottlenecks:
- Inadequate Data Diversity, Dialogue Depth, and Role Conditioning: The majority of datasets and fine-tuning methods support dialogues of fewer than ten turns, which is inadequate for verifying model coherence and stability in scenarios exceeding 20–50 turns. Existing datasets predominantly feature a variety of topics with neutral emotions, which hinders the ability to regulate emotions in a nuanced manner and to generate emotions in a dynamic way under complex conditions. Moreover, prevalent fine-tuning methodologies such as zero-shot or few-shot prompting frequently neglect fine-grained character trait modeling due to the absence of systematic character profiles and behavioral guidelines. This oversight results in limitations in the long-term maintenance of consistent role identity and personality.
- Context Memory and Knowledge Updating Deficiencies: Despite the exploration of retrieval augmentation and memory modules, the majority of methods exhibit a lack of unified integration of retrieval, memory, and generation processes. This phenomenon leads to information redundancy, noise retrieval, and delayed responses, ultimately undermining the effective incorporation of dialogue history and external knowledge.
- Incomplete Evaluation Frameworks: Conventional evaluation metrics, such as BLEU [28] and ROUGE [29], exhibit a poor correlation with human subjective preferences. Furthermore, extant evaluation approaches frequently encounter limitations in terms of sample size, inadequate dialogue duration, and disparate evaluation dimensions, resulting in deficient assessments of coherence, role fidelity, and emotional dynamics.
To address the key limitations in existing role-playing dialogue systems, this work proposes a framework that advances the datasets, modeling techniques, and evaluation strategies. The construction of the CHARCO dataset is initiated with dialogues extending up to 50 turns, encompassing 28 roles, 40 meta-topics, and 10 emotional labels. This comprehensive dataset comprises a total of over 231,100 multi-turn interactions, thereby facilitating support for long-range dependencies, emotional evolution, and behavioral consistency. Additionally, a retrieval-augmented memory module is designed to enhance contextual awareness by dynamically incorporating knowledge from external sources such as Wikipedia and storing explicit memory traces of dialogue histories and role states, thus improving relevance and reducing irrelevant or repetitive information. Furthermore, this work introduces two multi-dimensional evaluation strategies, providing quantitative metrics such as Measure of Textual Lexical Diversity (MTLD) [30] and repetition rate for assessing dataset quality, as well as GPT-4 [31] automatic scoring and human assessments for evaluating the role-playing performance of different LLMs across perceptivity, adaptability, and interactivity. Our main contributions are summarized as follows:
- The CHARCO dataset offers a comprehensive collection of diverse, emotionally rich, and character-coherent dialogues designed for multi-turn role-playing with large language models. These dialogues are supported by a three-level quality filtering pipeline (heuristic rules, GPT-4 scoring, and human spot-checks) to ensure high data quality, minimal redundancy, and consistency in dialogue generation.
- A novel retrieval-augmented memory module improves contextual awareness by updating knowledge dynamically, reducing redundancy, and ensuring relevance in long-form dialogues.
- Fine-tuning on the CHARCO dataset enables smaller models to achieve role-playing capabilities comparable to GPT-4, significantly enhancing role fidelity, emotional diversity, and coherence in multi-turn dialogues.
2. Proposed Framework
This section describes our proposed framework in detail, outlining its core components and methodology. Please refer to the table of symbols in Table A1.
2.1. Preliminaries for Multi-Turn Dialogue in Large Language Models
Let denote a persona profile, represented as a tuple of sociodemographic attributes and background metadata, and let denote a dialogue goal, such as information retrieval, emotional support, or task completion. We write for the space of all utterances, i.e., token sequences. The inquirer policy is denoted by and the responder policy by . Then, the initialization of dialogue is presented as computing the inquirer’s first utterance:
where is an initialization function that maps the tuple to the initial prompt sequence. Based on the initialized dialogue , the responder generates the initial reply as follows:
where is a query extractor that produces the sub-prompt, yielding ⌀ if no valid query is found. Also, marks the immediate termination of the simulation, returning an empty dialogue. Following this, the utterance pair is recorded in the dialogue history D. Thereafter, for each turn , the inquirer input is formed by concatenating the previous inquirer utterance and a formatted version of the last responder reply:
where is a turn-forwarding function that reformats the previous responder utterance for inclusion in the subsequent context and ‖ denotes sequence concatenation. According to this, the responder applies the query extractor to generate the reply as follows:
Equation (4) forms a loop to support multi-turn dialogue, where the generated dialogue is appended to the complete multi-turn dialogue history D, capturing the full exchange driven by the configured persona, goal, and prompt design. The termination strategy is designed at or contains the termination token , also at t reaching the maximum allowed number of turns .
2.2. Emotion-Consistent Reward Optimization
To enhance emotional consistency in multi-turn role-playing dialogue, we extend beyond supervised fine-tuning and incorporate a reinforcement-style optimization objective inspired by Reward Learning from Verifiable Representations (RLVR) [32]. Specifically, we introduce a Verifiable Emotion Reward (VER), which leverages pre-trained emotion classifiers to provide turn-level and dialogue-level emotional alignment signals.
Given a generated dialogue
where is the generated utterance at turn t and is the ground-truth emotional label (or prompt-assigned target), we define the VER reward function as follows:
where is the output of a frozen emotion classifier (e.g., a RoBERTa or BERT-based model fine-tuned on emotion detection) and is the indicator function evaluating emotional correctness at each turn. This reward is normalized between 0 and 1 and reflects how well the generated utterances align with intended emotional trajectories. This binary reward formulation offers a stable and computationally efficient learning signal, which is paramount for the convergence of policy gradient algorithms in the high-dimensional and stochastic space of language generation. By providing a clear binary signal, it directly optimizes for emotional accuracy and effectively mitigates the risk of reward hacking that can arise from more complex, continuous reward functions.
To optimize this reward, we adopt a reinforcement learning with self-consistency objective, wherein multiple candidate completions
are sampled via stochastic decoding. The final reward is computed per sample, and the model is updated to maximize the expected reward via policy gradient [33]:
This objective is combined with the supervised loss:
where is a tunable coefficient that balances generation fidelity and emotional consistency.
In practice, this hybrid reward formulation enables the model to reinforce emotionally aligned behaviors over long dialogue trajectories, reducing emotion drift and enhancing character coherence. Our experiments show that incorporating VER consistently improves performance on interactivity metrics, especially in sentiment-sensitive tasks such as grounding reasoning and persona inference. For policy optimization, we employ Proximal Policy Optimization (PPO) [34], an on-policy algorithm suited for high-variance environments like language modeling. PPO maximizes the regularized expected reward objective while ensuring stable updates via a clipped surrogate loss. The benefits of PPO in our setting include safer exploration of diverse social–emotional strategies and smoother convergence when applied alongside the structured thinking scaffold. Additionally, to encourage reasoning compositionality and combat overfitting to surface cues, we evaluate the influence of Group Relative Policy Optimization (GRPO) [35], a more conservative baseline better suited for small-scale reward variance. This comparison helps assess how learning dynamics respond to different policy gradient estimators in emotionally keyed environments.
A more fundamental challenge lies in the inherent fallibility of the emotion classifier itself. The impact of such errors is mitigated, at least in part, by the configuration of the reward function. Firstly, the reward is calculated as an average over the entire dialogue trajectory. A single misclassification in an extensive dialogue exerts a diminished influence on the aggregate reward, thereby diminishing its capacity to impede the optimization process. Secondly, the reward is utilized in conjunction with the primary supervised loss, thereby anchoring the model to the high-quality ground-truth data from the CHARCO dataset. This hybrid approach ensures that the reinforcement learning process refines the model’s behavior without fundamentally diverging from coherent language generation, even in the face of occasional noisy rewards.
2.3. The Construction of the CHARCO Dataset
Existing multi-turn dialogue datasets exhibit limitations such as insufficient interaction depth, generic topics, limited emotional diversity, and inadequate control over character consistency. To overcome these challenges, we introduce CHARCO, a multi-turn dataset explicitly tailored to role-playing. CHARCO provides finely controlled, emotionally nuanced, and consistent character-driven interactions suitable for effective fine-tuning of LLMs.
Figure 1 illustrates the construction of CHARCO; the process commences with the creation of persona profiles, which involves the collection of metadata and background information to define role features. These profiles undergo further refinement through the application of language models (LLMs), which facilitate the generation of comprehensive role profiles and the identification of pertinent meta-topics. The subsequent step focuses on initializing the dialogue scenario, where the inquirer’s first utterance is generated, and subsequent turns are driven by related questions, ensuring that the dialogue maintains coherence and context. The integration of emotional dynamics is achieved through the classification of emotions such as joy, sadness, and excitement, which are then linked to role profiles. This linkage serves to shape the emotional tone throughout the conversation. The finalization of the dataset is achieved through the integration of the persona profiles, the scenario, and the emotional components. This results in multi-turn dialogues of over 50 turns, filtered and refined using GPT-4 to ensure high-quality, role-consistent, and emotionally rich interactions, making the dataset ideal for training language models in complex role-playing scenarios.
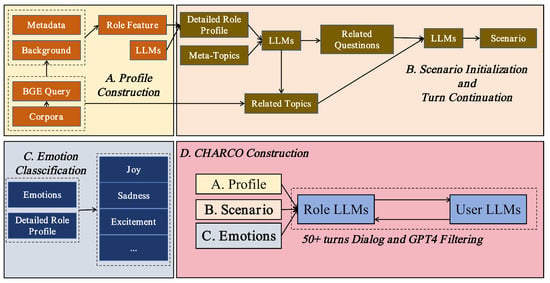
Figure 1.
Schematic diagram of the CHARCO dataset construction process.
2.3.1. Meta-Topic Selection
To ensure comprehensive and organized coverage of the content of conversations, we combined a thematic analysis of large-scale social media corpora with expert consultation in communication psychology. This resulted in 40 meta-topics drawn from widely recognized domains of human life, including personal and social life, professional and financial matters, culture and leisure, and social issues and well-being.
2.3.2. Semantic-Enhanced Retrieval for Context Grounding
To reduce hallucinations caused by missing background knowledge in synthetic dialogues, we adopt the BGE encoder [36], a lightweight semantic retrieval module capable of semantic matching between queries and candidate passages, achieving excellent performance in capturing the fine-grained semantic similarity across English and Chinese texts on the MTEB benchmark [37]. This retrieval-augmented design supports the LLM with factual or commonsense information relevant to the character and meta-topic, therefore improving coherence, informativeness, and real-world grounding of generated responses.
For each pair of character profile and meta-topic, a natural language query is generated to summarize contextual intent. The query is encoded via BGE and used to retrieve the top five semantically relevant passages based on cosine similarity in the embedding space. Retrieved contents, not exceeding 1024 tokens, are concatenated and prepended to the dialogue generation prompt to ground the model. If the maximum similarity between the query and the retrieved passages is below 0.25, the meta-topic is flagged as low-support and excluded to maintain topical relevance and factual grounding of the generated multi-turn dialogues.
2.3.3. Scenario-Driven Dialogue Generation
To simulate natural conversations, Algorithm 1 details our end-to-end dialogue generation pipeline. Rather than seeding exchanges with explicit questions, we prompt the LLM to draft an open-ended scenario embedding a latent conflict or event, around which the conversation unfolds organically. This design removes the rigid Q–A structure and enhances emotional depth, mirroring human interactions.
Table 2 summarizes the key prompts applied in our scenario-driven dialogue generation pipeline. Each prompt is designed to fulfill a specific functional role, ranging from topic selection to conversation termination, to ensure alignment with character profiles, emotional contexts, and dialogue requirements. The structured prompt design enhances coherence, emotional depth, and role consistency throughout the generated dialogues.
| Algorithm 1: Multi-turn dialogue generation with retrieval. |
 |
Table 2.
The key prompts applied in our scenario-driven dialogue generation pipeline.
2.3.4. Quality Control and Filtering
To ensure dialogue quality and consistency, a three-stage filtering pipeline is adopted by involving automated heuristics, model-based scoring, and manual verification. First, heuristic pre-filtering removes dialogues with obvious flaws such as underlength, overlength, duplicated content, profanity violations, or low semantic relevance measured by a cosine similarity lower than between the query and retrieved context. Next, GPT-4 evaluates each dialogue turn along four dimensions, fluency, coherence, emotional consistency, and character adherence, scoring each dialogue from 1 to 10. Dialogues averaging below 6 are discarded to maintain linguistic quality, emotional depth, and character consistency. In the end, human annotators review a random 20% sample of accepted dialogues, verifying coherence, emotion authenticity, and character portrayal accuracy. If any dialogue in a scenario cluster fails, the entire cluster is removed to prevent propagation of inconsistencies or lower-quality interactions.
This rigorous process produces around 230,000 multi-turn dialogues comprising around 4.9 million conversational turns, ensuring that the resulted CHARCO dataset achieves substantial improvements in emotional richness, character coherence, and interaction authenticity, robust for training sophisticated role-playing LLMs.
3. Experiment and Results
To assess the effectiveness of the proposed CHARCO dataset and fine-tuning framework, large-scale multi-turn dialogue evaluations across 13 fine-grained tasks are conducted. These experiments are designed to answer three key questions:
- How effective is CHARCO compared with existing datasets?
- Does CHARCO improves character coherence and emotional diversity?
- Why and how does the Verifiable Emotion Reward (VER) objective enhance emotional alignment and overall role-playing performance?
For the first question, we conduct a head-to-head benchmark in Section 3.3. CHARCO consistently outperforms leading role-play and instruction corpora in both vocabulary coverage and non-redundancy, showing a reduction in repetitive content.
In order to assess whether CHARCO enhances character coherence and emotional diversity, we applied the multi-turn role-playing evaluation strategy described in Section 3.4. This strategy combines GPT-4 auto-scoring and human validation across 13 fine-grained subtasks, which are organized into perceptivity, adaptability, and interactivity. As shown in Section 3.5, the model fine-tuned on CHARCO with the VER objective achieves an improvement over the untuned model, demonstrating significant enhancements in context memory, situational inference, and anaphora resolution.
Finally, we conduct reinforcement learning experiments with and without VER in Section 3.6 and complement these with a component-level ablation in Section 3.7. Integrating VER yields consistent gain improvement, whereas omitting VER leads to performance drops across all dimensions, underscoring its pivotal role in enhancing emotional alignment and overall role-playing quality.
3.1. A Summary of the CHARCO Dataset
Existing role-play corpora often emphasize celebrity or mythological figures, limiting the need for deep character reasoning. CHARCO addresses this gap by focusing on 28 diverse Chinese personas, ranging from high-school students and new parents to customer service agents and research assistants. Each persona profile averages 380 tokens and includes 45 fine-grained personality traits, providing ample context for maintaining long-range consistency in multi-turn interaction.
The dataset construction integrates three major sources: anonymized social media dialogues, curated customer service transcripts, and original screenplay-style exchanges. Each dialogue is driven by a latent scenario—often containing subtle emotional shifts or implicit conflict—and unfolds over up to 50 turns. Every utterance is tagged with one of ten emotion labels such as happy or sad, facilitating training of emotionally aware dialogue models. Table 3 provides key insights into the dataset.
Table 3.
Core statistics of the CHARCO dataset.
3.2. Implementation Details
As shown in Figure 2, Phase 1 involves the sequential execution of character profile construction, topic selection, semantic retrieval, and multi-turn dialogue generation, culminating in the creation of the CHARCO dataset. Phase 2 begins with Low-Rank Adaptation (LoRA) fine-tuning of the base large language model (LLM), followed by iterative policy optimization within a closed-loop framework of trajectory sampling and VER, ultimately yielding the final emotion-aware LLM. The LoRA fine-tuned model and the emotion-aware model are represented by yellow and green robot icons, respectively.

Figure 2.
Architecture of the emotion-aware LLM training pipeline.
All experiments were conducted on eight NVIDIA A800 GPUs using PyTorch 2.4.0 FSDP [38] for distributed training. For emotion classification, we employed the EmoBERTa [39] model. The semantic retrieval module utilizes the BGE-large-en-v1.5 [40] model to generate 1024-dimensional embeddings. These embeddings are then employed to retrieve the top five most relevant contexts from a corpus of emotion-related statements. A retrieval temperature of 0.7 was applied to balance diversity and relevance in the retrieved results.
The train–test ratio of the CHARCO dataset is set as 8:2, comprising approximately 184,902 dialogues for training and 46,226 for evaluation. In our experiments, we fine-tune both Qwen2-7B [41] and LLaMA2-7B [42] with LoRA hyperparameters set as rank 8, scaling factor 16, and dropout rate 0.1. The batch size is set with 64 sequences, each up to 512 tokens. The optimization is performed using AdamW for 10,000 optimization steps, where a linear learning rate warmup is arranged over 500 steps; then the learning rate decay is applied from , with the decay rate 0.01. Early stopping is used at plateaued validation loss.
After the supervised LoRA fine-tuning stage, we further refined the model via reinforcement learning under the Verifiable Emotion Reward (VER) objective using a self-consistency REINFORCE algorithm. For each prompt, we sampled candidate dialogue trajectories at a decoding temperature of to estimate the expected reward and balanced the cross-entropy generation loss against the emotion alignment signal with weight . Optimization proceeded with AdamW at an initial learning rate of , which was linearly warmed up over the first 100 RL steps and held constant until 90% of the maximum 5000 RL steps, after which it decayed linearly to zero. To stabilize training, we accumulated gradients over two mini-batches and applied early stopping if the average VER reward on the validation set failed to improve by at least over 500 consecutive RL steps. This two-stage pipeline maintained high language modeling fidelity while significantly enhancing both turn-level and dialogue-level emotional consistency.
3.3. Evaluation Strategy for the CHARCO Dataset
To quantitatively evaluate language diversity and generation quality, MTLD and repetition rate are applied as the two diagnostic metrics in this work, elaborated next.
3.3.1. Measure of Textual Lexical Diversity
The MTLD [30], formally defined as the mean length of word strings that maintain a fixed type–token ratio, measures how frequently new word types are introduced across a text. As a metric to assess the richness of vocabulary used in dialogue generation, higher MTLD values indicate greater lexical variability and reduced reliance on repetitive phrase templates. Unlike simpler metrics such as type–token ratio (TTR), MTLD is robust to variations in utterance length and genre.
3.3.2. Repetition Rate
Additionally, repetition rate is used, defined as the proportion of overlapping n-grams across adjacent utterances within the same dialogue or across similar contexts. High repetition rates often reflect either lack of data diversity or generation instability, such as text looping or semantic redundancy.
3.4. Evaluation Strategy for the Multi-Turn Role-Playing Capabilities
The evaluation strategy comprises GPT-4 auto-scoring and human assessment, providing both task-level granularity and dialogue-level robustness, enabling us to identify precise model capabilities and limitations in multi-turn, character-grounded interaction scenarios. To rigorously assess multi-turn role-playing capabilities, we adopt a fine-grained evaluation framework aligned with the taxonomy of multi-turn dialogue abilities proposed in MT-Bench-101 [43]. Each generated dialogue is evaluated across 13 tasks, hierarchically organized into three core dimensions: perceptivity, which examines the model’s ability to maintain context continuity and semantic coherence over multiple dialogue turns; adaptability, which assesses how the model adjusts to user constraints, corrections, or shifts in expectations; and interactivity, which captures the model’s responsiveness and engagement during dialogue. Table 4 tabulates the three core dimensions and the associated 13 distinct subtasks.
Table 4.
Dialogue model evaluation criteria. The best-performing aspects are highlighted in bold.
3.4.1. Scoring Protocol
A 1–10 score scale is applied to evaluate each response within a dialogue turn. This score reflects the degree to which the model fulfills the target ability, according to the following rubric:
- 1–3 (Poor): Major errors in comprehension, factuality, or consistency; clear failure to perform the task.
- 4–6 (Acceptable): Some minor issues or incomplete performance, but the response remains partially useful or coherent.
- 7–8 (Good): Fully correct or plausible responses that satisfy most task requirements.
- 9–10 (Excellent): Responses that are not only correct but also demonstrate fluency, emotional depth, and strong alignment with the persona and task.
3.4.2. Final Dialogue Score
For each dialogue, typically spanning 50 turns, we compute per-turn scores and define the final dialogue score as the minimum turn-level score across all turns in that session. A rigorous minimum score aggregation strategy has been implemented to address the fundamental challenges associated with maintaining character consistency in long-form role-playing dialogues. A single severe error, such as the inadvertent omission of character information or extreme emotional inconsistency, has the potential to disrupt the established sense of immersion and erode the trust that is fundamental to the narrative experience. The employment of minimum score tests as a direct penalty for critical errors serves to assess the model’s capacity to maintain high-quality performance throughout the dialogue. In comparison to the mean or median score, the minimum score has the capacity to more sensitively reveal critical gaps. It aligns more closely with human evaluation standards and ensures more accurate long-term consistency evaluations. This strategy penalizes brittle behaviors and reflects the intuition that a single critical failure can break the illusion of continuity and coherence in role-play. Examples of focused failure are forgetting persona details, producing contradictory facts, or ignoring user correction. As a strict evaluation strategy, the final dialogue score aligns closely with human evaluation preferences, as confirmed by our human-in-the-loop verification. In addition to the final score, we tabulate scores for each dimension evaluated across various individual tasks within the dialogue. The table shows these scores for different aspects, such as perceptivity, adaptability, and interactivity, as well as their averages. These individual scores contribute to the final score by reflecting the model’s strengths and weaknesses in different dialogue aspects. This granular evaluation provides a more comprehensive understanding of model performance. The final score integrates multiple task-specific measures, offering an objective overview of the model’s behavior throughout the entire dialogue.
3.4.3. Reliability Validation
To assess the validity of GPT-4 scoring, we conduct a blind annotation study over 100 dialogues, each independently reviewed by three expert annotators. GPT-4’s scores fall within ±1 point of the human consensus in over 91% of cases, suggesting that automatic evaluation is sufficiently reliable for large-scale benchmarking.
As shown in Table 5, CHARCO achieves an MTLD of 78.2, significantly outperforming other role-play and instruction datasets such as UltraChat (74.3) and Alpaca (42.8). This indicates that the proposed CHARCO dataset comprises a broader and more natural vocabulary distribution, beneficial for avoiding degenerative or templated outputs during generation. Moreover CHARCO maintains a remarkably low repetition rate of 6%. Compared with the 50% in UltraChat and 75% in SODA, this low redundancy in CHARCO highlights the quality of our scenario-driven prompting, semantic retrieval, and strict filtering pipeline.
Table 5.
Comparison of MTLD and repetition rate across datasets; best-performing ones are in bold.
Figure 3 presents a word cloud visualization of the personality traits extracted from the CHARCO dataset, where the font size of each term corresponds to its relative frequency across all character profiles. To generate this visualization, the occurrence of each trait label across all 28 character profiles was counted, and these counts were mapped to relative font sizes. The terms were then arranged using a layout algorithm that places higher-frequency traits centrally and with larger text. Prominent descriptors such as Collaborative, Innovative, and Empathetic highlight CHARCO’s emphasis on teamwork, creativity, and interpersonal sensitivity. Also, Figure 4 depicts the distribution of emotion labels among dialogue utterances, where Joy occupies the largest proportion, closely followed by Warmth, Calm, Excitement, and Chill. Surprise and Letdown appear less frequently, followed by Sadness, Fear, and Anger constituting the smallest shares. Overall, these visualizations highlight the diverse character personas and the balanced emotional landscape in CHARCO, supporting nuanced, character-driven interactions.

Figure 3.
Word cloud of frequently used personality descriptors in CHARCO character profiles. Larger font size indicates higher occurrence across the dataset.
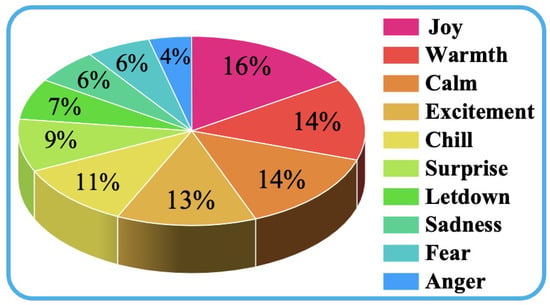
Figure 4.
Emotion label distribution in CHARCO dialogue utterances. The pie chart illustrates the relative proportions of ten predefined emotion categories annotated across all conversations.
3.5. Role-Playing Performance of Different LLMs on the CHARCO Dataset
To compute the role-playing performance of different LLMs, GPT-4 is applied as a unified judge to evaluate every turn of each held-out dialogue across the 13 fine-grained tasks, computing the final dialogue score. As aformentioned, human assessment is incorporated to validate the reliability of these automated judgments.
The proposed CHARCO dataset is benchmarked against a set of leading open-source and closed-source conversational models. The open-source models comprise Llama2-Chat, Qwen-Chat, and Mistral-Instruct, each selected for their strong multi-turn capabilities. The closed-source ones include GPT-3.5, GPT-4, and Anthropic Claude, chosen for their state-of-the-art performance on dialogue benchmarks. To provide comparative analysis, one Qwen2 model and one Llama2 model are fine-tuned on the CHARCO dataset based on combined supervised cross-entropy and reinforcement-based self-consistency objectives. Table 6, Table 7 and Table 8, respectively, summarize the performance for perceptivity tasks, adaptability tasks, and interactivity tasks on CHARCO, where LLMs fine-tuned with the CHARCO dataset are annotated in light blue. As shown in Table 6, Table 7 and Table 8, LLMs fine-tuned with the CHARCO dataset demonstrate three key advantages. The first is generality. These models transfer conversational behaviors to unseen personas and dialogue contexts, as reflected by their performance across diverse persona profiles. The second is granularity. The 13 distinct tasks spanning perceptivity, adaptability, and interactivity enable targeted insights into specific strengths and weaknesses rather than relying on a single aggregate score. The third is scalability and reliability. Automated GPT-4 scoring, cross-validated with human annotations, supports large-scale, reproducible experiments without sacrificing accuracy or reliability. These results highlight the dual role of the CHARCO dataset as a fine-tuning resource and a robust evaluation benchmark.
Table 6.
Role-playing performance of different LLMs for perceptivity tasks on CHARCO.
Table 7.
Role-playing performance of different LLMs for adaptability tasks on CHARCO.
Table 8.
Role-playing performance of different LLMs for interactivity tasks on CHARCO.
3.6. Comparison Study
To further validate the effectiveness of the Verifiable Emotion Reward (VER), we compare Proximal Policy Optimization (PPO) and Generalized REINFORCE Policy Optimization (GRPO) with and without the VER term. For a fair comparison, results are averaged over the three primary evaluation dimensions (perceptivity, adaptability, and interactivity) for the combined Qwen2-7b and Llama2-7b models. Table 9 shows the results.
Table 9.
Per-dimension scores for PPO and GRPO with/without VER on Qwen2-7b and Llama2-7b.
3.7. Ablation Study
To isolate the effects of key modules and dialogue depth on performance, we conduct two ablation experiments. For the component ablation study, we disable each component in turn while holding others constant. Table 10 reports the average perceptivity, adaptability, and interactivity scores.
Table 10.
Component ablation results.
For dialogue depth ablation, we truncate CHARCO to three dialogue depths—Short, Medium, and Full. Then we fine-tune Qwen2-7B under the same LoRA + VER settings. Table 11 shows the resulting average VER reward, persona recall rate, and GPT-4 overall score.
Table 11.
Dialogue depth ablation.
Table 10 shows that each key component, particularly semantic retrieval and VER, yields significant gains across all evaluated task dimensions. Furthermore, Table 11 shows that the depth of the dialogue, as measured by the number of turns, directly correlates with the richness of the multi-turn context. Meanwhile, it has been demonstrated that VER’s efficacy in enforcing emotional consistency and persona fidelity is amplified under these conditions.
3.8. Impact of Data Mixing on Role-Playing Performance
This section investigates the effects of mixing different proportions of CHARCO, reasoning-oriented, and general QA data on the multi-turn role-playing capabilities of LLMs. Three fixed data mixtures were constructed to fine-tune and test two LLMs, i.e., Qwen2-7B and LLaMA2-7B. More specifically, Mix-1 comprises 80% CHARCO and 20% reasoning data, Mix-2 contains 60% CHARCO, 20% reasoning, and 20% general QA data, while Mix-3 includes 50% CHARCO, 20% reasoning, and 30% general QA data. Evaluation was conducted across the three task dimensions: perceptivity, adaptability, and interactivity. Figure 5 presents the relative performance of both models under each data mixture configuration, depicting that Mix-1, i.e., 80% CHARCO + 20% reasoning data, leads to the highest perceptivity and adaptability for both models while preserving robust interactivity. Also, increasing the share of one-shot general QA data (Mix-2 or -3) leads to consistent performance declines, while the degradations are most notable in interactivity tasks. These findings confirm that a predominantly CHARCO-based curriculum lightly supplemented with reasoning data, and without general QA, is optimal for multi-turn role-playing performance.
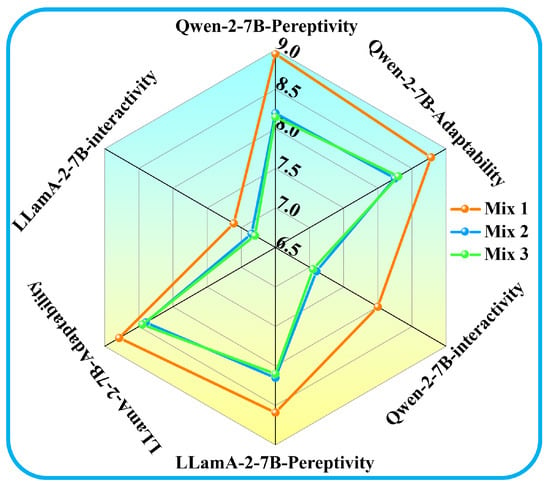
Figure 5.
Radar chart comparing perceptivity, adaptability, and interactivity scores of Qwen2-7B and LLaMA2-7B under three data mixture configurations.
4. Limitations
4.1. Dataset Dependency Consideration
The noteworthy efficacy of the proposed framework is intrinsically linked to the superior quality and extensive scale of the CHARCO dataset, underscoring a pivotal interdependence. As demonstrated by the ablation study in Table 10, the removal of the CHARCO-only component results in a substantial performance decline, thereby providing empirical evidence that the Verifiable Emotion Reward (VER) mechanism is contingent upon substantial, emotionally annotated, and character-consistent training data for effective long-range optimization. This dependency is further underscored by the dataset’s design, which features a low repetition rate of 6% and a high MTLD of 78.2. These characteristics are the direct result of a rigorous, multi-stage filtering pipeline that involves GPT-4 and human checks. While this approach ensures data quality, it also renders the framework’s replication and extension to new domains resource-intensive. Future research endeavors may involve the exploration of transfer learning from the VER mechanism or the utilization of synthetic data augmentation to mitigate the reliance on costly, specialized data curation.
4.2. Reward Signal Refinement Opportunity
The VER mechanism employs a frozen emotion classifier to generate a stable reinforcement signal, which has been demonstrated to enhance immediate emotional consistency, as evidenced by the substantial enhancement of the interactivity score when VER is implemented, as illustrated in Table 8. However, this design, while prioritizing training stability, presents a fundamental limitation: the reward signal is static and may fail to capture the full spectrum of context-dependent emotional nuances, particularly those rooted in specific cultural backgrounds or complex narrative arcs. This risk of bias is inherent in the reliance on a predefined classifier’s judgment. Since VER relies on a pre-trained classifier that may be biased by culture or datasets, the reward mechanism itself may introduce and reinforce these biases, limiting the model’s adaptability in cross-cultural dialogue scenarios. The binary nature of the reward for correct or incorrect emotion may inadvertently penalize creatively adaptive responses that deviate slightly from the expected label but enhance overall dialogue richness. Future research could integrate more sophisticated, adaptive evaluators that potentially integrate dynamic models fine-tuned on broader cultural datasets in order to create a more nuanced and empathetic reward signal that better bridges the gap between surface-level recognition and deeper engagement. Furthermore, the binary VER signal, while stable, could be refined to better capture the gradual transitions and subjective intensity of emotional expression. A natural extension is to replace the indicator function with a continuous reward based on the emotion classifier’s calibrated confidence scores or measures of emotional entropy. This would allow the model to learn not just what emotion to express but also how strongly to express it, leading to more nuanced and human-like interactions.
4.3. Long-Term Dynamics for Future Exploration
The present VER framework demonstrates notable proficiency in preserving short-term emotional consistency, effectively mitigating immediate emotional drift, and ensuring role fidelity on a turn-by-turn basis. This efficacy is substantiated by our evaluation metrics. However, this focus constitutes a deliberate scoping of the initial framework, as explicitly noted in the conclusion. The model falls short in its capacity to adequately simulate the long-term evolution of emotions and character states that occur over the course of extended conversations. While the retrieval-augmented memory module facilitates contextual awareness, the VER signal itself is devoid of an explicit temporal component necessary for long-term planning and dynamic adaptation. This domain represents a significant area for future exploration. Subsequent iterations could incorporate temporal modeling components to enable the model to reason about emotional arcs and character development over the entire dialogue trajectory, such as recurrent mechanisms or hierarchical reinforcement learning. This would preserve the method’s core strengths while unlocking more sophisticated, narrative-driven interactions.
5. Conclusions
In this work, we propose the CHARCO framework, which is designed to support long-range, character-coherent, and emotionally consistent multi-turn role-playing dialogue with large language models (LLMs). CHARCO uses structured persona profiles, emotionally grounded scenarios, and semantic-enhanced retrieval to enable LLMs to sustain nuanced, believable, and contextually rich interactions across up to 50 dialogue turns.
To improve emotional fidelity in character simulation and go beyond supervised learning, we introduced the Verifiable Emotion Reward (VER). VER is a reinforcement-style objective that uses frozen emotion classifiers to provide fine-grained alignment signals. Our ablation and comparison studies demonstrate that using VER yields consistent and significant improvements in perceptivity, adaptability, and interactivity, especially in emotionally sensitive dialogue tasks, such as persona inference and grounding reasoning. However, these gains depend critically on the availability of high-quality, emotionally labeled, character-consistent training data. Without a dataset like CHARCO, VER signals would be noisy or sparse, which would limit their effectiveness in long-range optimization.
Furthermore, we demonstrate the importance of the synergy between CHARCO and VER. CHARCO provides emotionally diverse and structurally consistent dialogue trajectories that reliably inform reward computation. Meanwhile, VER reinforces correct emotional behaviors during model learning, amplifying the effect of this data. Experiments on mixing data further confirm that introducing even modest proportions of unrelated QA data can degrade multi-turn coherence and emotional alignment. This underscores the importance of domain-targeted, high-fidelity corpora like CHARCO.
Together, CHARCO and VER form a scalable, transparent, and effective framework for developing role-playing agents capable of maintaining emotional and persona consistency during extended interactions. Meanwhile, the modular design of CHARCO and VER can be easily adapted to other conversational AI scenarios besides role-playing.
- Customer service and support: Maintaining a consistent brand voice and empathetic tone throughout lengthy conversations and resolving issues without causing emotional distress.
- Mental Health and Counseling Bots: Maintaining therapeutic alliances through aligned emotional responses throughout extended self-disclosure sessions.
- Interactive Storytelling and Game NPCs: Leveraging semantic-enhanced retrieval and long-turn coherence to craft richer, emotionally dynamic narratives.
Future work will involve extending CHARCO to multimodal and multilingual contexts and enhancing VER with continuous-valued emotional trajectories and memory-augmented fine-tuning to enable the simulation of persistent characters.
Author Contributions
Conceptualization, J.W. and Y.O.; methodology, J.W.; software, J.W. and K.W.; validation, J.W. and Y.O.; formal analysis, J.W. and K.W.; investigation, J.W. and K.W.; resources, Y.O.; data curation, K.W.; writing—original draft preparation, J.W.; writing—review and editing, K.W. and Y.O.; visualization, K.W.; supervision, Y.O.; project administration, Y.O.; funding acquisition, Y.O. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Data sharing is not applicable. Researchers can reproduce the data by applying the methods described in this article.
Acknowledgments
The authors would like to express their gratitude to the anonymous reviewers.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Table of Symbols
Table A1.
List of symbols.
Table A1.
List of symbols.
| Symbol | Description |
|---|---|
| Persona profile | |
| Dialogue goal (e.g., information retrieval and emotional support) | |
| Space of all utterances (token sequences) | |
| , | Inquirer/responder policies |
| Dialogue initialization function | |
| Utterances generated by inquirer/responder at turn t | |
| Extracted sub-prompt (query) | |
| Query extractor (returns ⌀ if no valid query) | |
| Turn-forwarding function (reformats previous reply) | |
| ‖ | Sequence concatenation |
| End-of-sequence token | |
| Maximum number of turns | |
| D | Dialogue history (all recorded pairs ) |
| Generated dialogue with emotion labels | |
| Utterance at turn t | |
| Corresponding emotion label (ground-truth or target) | |
| T | Total number of turns |
| Output of pre-trained emotion classifier | |
| Indicator function (1 if true, 0 otherwise) | |
| Verifiable Emotion Reward (VER) | |
| Parameterized generation policy | |
| Expected return of policy | |
| Policy gradient | |
| Supervised generation loss | |
| Weight coefficient for emotion reward | |
| Total objective: |
References
- Raikov, A.; Giretti, A.; Pirani, M.; Spalazzi, L.; Guo, M. Accelerating human–computer interaction through convergent conditions for LLM explanation. Front. Artif. Intell. 2024, 7, 1406773. [Google Scholar] [CrossRef]
- Sowmiya, R.; Revathi, P.; Ragunath, D.; Gokila, P.; Kalaivani, T. Multi-Modal LLM Driven Computer Interface. In Proceedings of the 2024 8th International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud)(I-SMAC), Kirtipur, Nepal, 3–5 October 2024; IEEE: New York, NY, USA, 2024; pp. 484–489. [Google Scholar]
- Kumar, P. Large language models (LLMs): Survey, technical frameworks, and future challenges. Artif. Intell. Rev. 2024, 57, 260. [Google Scholar] [CrossRef]
- Chen, J.; Liu, Z.; Huang, X.; Wu, C.; Liu, Q.; Jiang, G.; Pu, Y.; Lei, Y.; Chen, X.; Wang, X.; et al. When large language models meet personalization: Perspectives of challenges and opportunities. World Wide Web 2024, 27, 42. [Google Scholar] [CrossRef]
- Nazi, Z.A.; Peng, W. Large language models in healthcare and medical domain: A review. Informatics 2024, 11, 57. [Google Scholar] [CrossRef]
- Bolpagni, M.; Gabrielli, S. Development of a comprehensive evaluation scale for LLM-powered counseling chatbots (CES-LCC) using the Edelphi method. Informatics 2025, 12, 33. [Google Scholar] [CrossRef]
- Pinto-Bernal, M.; Biondina, M.; Belpaeme, T. Designing Social Robots with LLMs for Engaging Human Interaction. Appl. Sci. 2025, 15, 6377. [Google Scholar] [CrossRef]
- Jedrzejczak, W.W.; Kobosko, J. Do Chatbots Exhibit Personality Traits? A Comparison of ChatGPT and Gemini Through Self-Assessment. Information 2025, 16, 523. [Google Scholar] [CrossRef]
- Klinkert, L.J.; Buongiorno, S.; Clark, C. Evaluating the efficacy of LLMs to emulate realistic human personalities. In Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, Lexington, KY, USA, 18–22 November 2024; Volume 20, pp. 65–75. [Google Scholar]
- Chen, Y.C.; Lee, S.H.; Sheu, H.; Lin, S.H.; Hu, C.C.; Fu, S.C.; Yang, C.P.; Lin, Y.C. Enhancing responses from large language models with role-playing prompts: A comparative study on answering frequently asked questions about total knee arthroplasty. BMC Med. Inform. Decis. Mak. 2025, 25, 196. [Google Scholar] [CrossRef]
- Feng, Q.; Xie, Q.; Wang, X.; Li, Q.; Zhang, Y.; Feng, R.; Zhang, T.; Gao, S. EmoCharacter: Evaluating the Emotional Fidelity of Role-Playing Agents in Dialogues. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Albuquerque, NM, USA, 29 April–4 May 2025; pp. 6218–6240. [Google Scholar]
- Yu, Y.; Yu, R.; Wei, H.; Zhang, Z.; Qian, Q. Beyond Dialogue: A Profile-Dialogue Alignment Framework Towards General Role-Playing Language Model. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vienna, Austria, 27 July–1 August 2025; Che, W., Nabende, J., Shutova, E., Pilehvar, M.T., Eds.; pp. 11992–12022. [Google Scholar] [CrossRef]
- Dan, Y.; Zhou, J.; Chen, Q.; Tian, J.; He, L. P-React: Synthesizing Topic-Adaptive Reactions of Personality Traits via Mixture of Specialized LoRA Experts. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2025, Vienna, Austria, 27 July–1 August 2025; pp. 6342–6362. [Google Scholar]
- Huang, L.; Lan, H.; Sun, Z.; Shi, C.; Bai, T. Emotional RAG: Enhancing role-playing agents through emotional retrieval. In Proceedings of the 2024 IEEE International Conference on Knowledge Graph (ICKG), Abu Dhabi, United Arab Emirates, 11–12 December 2024; IEEE: New York, NY, USA, 2024; pp. 120–127. [Google Scholar]
- Man, F.; Wang, H.; Fang, J.; Deng, Z.; Zhao, B.; Chen, X.; Li, Y. Context-Aware Sentiment Forecasting via LLM-based Multi-Perspective Role-Playing Agents. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vienna, Austria, 27 July–1 August 2025; Che, W., Nabende, J., Shutova, E., Pilehvar, M.T., Eds.; pp. 2687–2703. [Google Scholar] [CrossRef]
- Gomes, A.; Brito, E.; Morais, L.; Ferreira, N. How do Data Journalists Design Maps to Tell Stories? arXiv 2025, arXiv:2508.10903. Available online: http://arxiv.org/abs/2508.10903 (accessed on 24 July 2025).
- Yu, T.; Shi, K.; Zhao, Z.; Penn, G. Multi-Agent Based Character Simulation for Story Writing. In Proceedings of the Fourth Workshop on Intelligent and Interactive Writing Assistants (In2Writing 2025), Albuquerque, NM, USA, 4 May 2025; pp. 87–108. [Google Scholar]
- Zhang, P.; An, S.; Qiao, L.; Yu, Y.; Chen, J.; Wang, J.; Yin, D.; Sun, X.; Zhang, K. RolePlot: A Systematic Framework for Evaluating and Enhancing the Plot-Progression Capabilities of Role-Playing Agents. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vienna, Austria, 27 July–1 August 2025; pp. 12337–12354. [Google Scholar]
- Ding, N.; Chen, Y.; Xu, B.; Qin, Y.; Zheng, Z.; Hu, S.; Liu, Z.; Sun, M.; Zhou, B. Enhancing chat language models by scaling high-quality instructional conversations. arXiv 2023, arXiv:2305.14233. [Google Scholar] [CrossRef]
- Taori, R.; Gulrajani, I.; Zhang, T.; Dubois, Y.; Li, X.; Guestrin, C.; Liang, P.; Hashimoto, T.B. Stanford Alpaca: An Instruction-Following LLaMA Model, 2023. Available online: https://github.com/tatsu-lab/stanford_alpaca (accessed on 24 July 2025).
- Xu, C.; Guo, D.; Duan, N.; McAuley, J. Baize: An open-source chat model with parameter-efficient tuning on self-chat data. arXiv 2023, arXiv:2304.01196. [Google Scholar]
- Qi, Z.; Kaneko, T.; Takamizo, K.; Ukiyo, M.; Inaba, M. KokoroChat: A Japanese Psychological Counseling Dialogue Dataset Collected via Role-Playing by Trained Counselors. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vienna, Austria, 27 July–1 August 2025; Che, W., Nabende, J., Shutova, E., Pilehvar, M.T., Eds.; pp. 12424–12443. [Google Scholar] [CrossRef]
- Tao, M.; Liang, X.; Shi, T.; Yu, L.; Xie, Y. RoleCraft-GLM: Advancing Personalized Role-Playing in Large Language Models. arXiv 2024, arXiv:2401.09432. Available online: http://arxiv.org/abs/2401.09432 (accessed on 24 July 2025).
- Kim, H.; Hessel, J.; Jiang, L.; West, P.; Lu, X.; Yu, Y.; Zhou, P.; Bras, R.L.; Alikhani, M.; Kim, G.; et al. SODA: Million-scale Dialogue Distillation with Social Commonsense Contextualization. arXiv 2022, arXiv:2212.10465. [Google Scholar]
- Ji, Y. Exploring the Impact of Instruction Data Scaling on Large Language Models: An Empirical Study on Real-World Use Cases. arXiv 2023, arXiv:2303.14742. [Google Scholar] [CrossRef]
- Tu, Q.; Fan, S.; Tian, Z.; Yan, R. Charactereval: A chinese benchmark for role-playing conversational agent evaluation. arXiv 2024, arXiv:2401.01275. [Google Scholar]
- Wang, Z.M.; Peng, Z.; Que, H.; Liu, J.; Zhou, W.; Wu, Y.; Guo, H.; Gan, R.; Ni, Z.; Yang, J.; et al. Rolellm: Benchmarking, eliciting, and enhancing role-playing abilities of large language models. arXiv 2023, arXiv:2310.00746. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; pp. 311–318. [Google Scholar]
- Lin, C.Y.; Hovy, E. Automatic evaluation of summaries using N-gram co-occurrence statistics. In Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology, Edmonton, AB, Canada, 27 May–1 June 2003; Association for Computational Linguistics: Stroudsburg, PA, USA, 2003; Volume 1, pp. 71–78. [Google Scholar]
- McCarthy, P.M.; Jarvis, S. MTLD, vocd-D, and HD-D: A validation study of sophisticated approaches to lexical diversity assessment. Behav. Res. Methods 2010, 42, 381–392. [Google Scholar] [CrossRef]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar] [CrossRef]
- Lambert, N.; Morrison, J.; Pyatkin, V.; Huang, S.; Ivison, H.; Brahman, F.; Miranda, L.J.V.; Liu, A.; Dziri, N.; Lyu, S.; et al. Tulu 3: Pushing frontiers in open language model post-training. arXiv 2024, arXiv:2411.15124. [Google Scholar] [CrossRef]
- Lehmann, M. The Definitive Guide to Policy Gradients in Deep Reinforcement Learning: Theory, Algorithms and Implementations. arXiv 2024, arXiv:2401.13662. Available online: http://arxiv.org/abs/2401.13662 (accessed on 24 July 2025). [CrossRef]
- Michailidis, P.; Michailidis, I.; Kosmatopoulos, E. Reinforcement learning for optimizing renewable energy utilization in buildings: A review on applications and innovations. Energies 2025, 18, 1724. [Google Scholar] [CrossRef]
- Shao, Z.; Wang, P.; Zhu, Q.; Xu, R.; Song, J.; Bi, X.; Zhang, H.; Zhang, M.; Li, Y.; Wu, Y.; et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv 2024, arXiv:2402.03300. [Google Scholar]
- Multi-Granularity, M.L.M.F. M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. In Proceedings of the ACL 2024, Bangkok, Thailand, 11–16 August 2024. [Google Scholar]
- Muennighoff, N.; Tazi, N.; Magne, L.; Reimers, N. Mteb: Massive text embedding benchmark. arXiv 2022, arXiv:2210.07316. [Google Scholar]
- Zhao, Y.; Gu, A.; Varma, R.; Luo, L.; Huang, C.C.; Xu, M.; Wright, L.; Shojanazeri, H.; Ott, M.; Shleifer, S.; et al. PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel. arXiv 2023, arXiv:2304.11277. Available online: http://arxiv.org/abs/2304.11277 (accessed on 24 July 2025). [CrossRef]
- Kim, T.; Vossen, P. EmoBERTa: Speaker-Aware Emotion Recognition in Conversation with RoBERTa. arXiv 2021, arXiv:2108.12009. Available online: http://arxiv.org/abs/2108.12009 (accessed on 24 July 2025).
- Xiao, S.; Liu, Z.; Zhang, P.; Muennighoff, N. C-Pack: Packaged Resources To Advance General Chinese Embedding. arXiv 2023, arXiv:2309.07597. Available online: http://arxiv.org/abs/2309.07597 (accessed on 24 July 2025).
- Yang, A.; Yang, B.; Hui, B.; Zheng, B.; Yu, B.; Zhou, C.; Li, C.; Li, C.; Liu, D.; Huang, F.; et al. Qwen2 Technical Report. arXiv 2024, arXiv:2407.10671. Available online: http://arxiv.org/abs/2407.10671 (accessed on 24 July 2025).
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv 2023, arXiv:2307.09288. Available online: http://arxiv.org/abs/2307.09288 (accessed on 24 July 2025). [CrossRef]
- Bai, G.; Liu, J.; Bu, X.; He, Y.; Liu, J.; Zhou, Z.; Lin, Z.; Su, W.; Ge, T.; Zheng, B.; et al. Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues. arXiv 2024, arXiv:2402.14762. [Google Scholar]
- Cai, Z.; Cao, M.; Chen, H.; Chen, K.; Chen, K.; Chen, X.; Chen, X.; Chen, Z.; Chen, Z.; Chu, P.; et al. InternLM2 Technical Report. arXiv 2024, arXiv:2403.17297. Available online: http://arxiv.org/abs/2403.17297 (accessed on 24 July 2025). [CrossRef]
- Jiang, A.Q.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot, D.S.; de las Casas, D.; Bressand, F.; Lengyel, G.; Lample, G.; Saulnier, L.; et al. Mistral 7B. arXiv 2023, arXiv:2310.06825. Available online: http://arxiv.org/abs/2310.06825 (accessed on 24 July 2025). [CrossRef]
- Li, A.; Gong, B.; Yang, B.; Shan, B.; Liu, C.; Zhu, C.; Zhang, C.; Guo, C.; Chen, D.; Li, D.; et al. Minimax-01: Scaling foundation models with lightning attention. arXiv 2025, arXiv:2501.08313. [Google Scholar] [CrossRef]
- GLM, T.; Zeng, A.; Xu, B.; Wang, B.; Zhang, C.; Yin, D.; Zhang, D.; Rojas, D.; Feng, G.; Zhao, H.; et al. Chatglm: A family of large language models from glm-130b to glm-4 all tools. arXiv 2024, arXiv:2406.12793. [Google Scholar]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).