Abstract
Power equipment detection is a critical component in power transmission line inspection. However, existing power equipment detection algorithms often face problems such as large model sizes and high computational complexity. This paper proposes a lightweight power equipment detection algorithm based on large receptive field and attention guidance. First, we propose a lightweight large receptive field feature extraction module, CRepLK, which reparameterizes multiple branches into large kernel convolution to improve the multi-scale detection capability of the model; secondly, we propose a lightweight ELA-guided Dynamic Sampling Fusion (LEDSF) Neck, which alleviates the feature misalignment problem inherent in conventional neck networks to a certain extent; finally, we propose a lightweight Partial Asymmetric Detection Head (PADH), which utilizes the redundancy of feature maps to achieve the significant light weight of the detection head. Experimental results show that on the Insplad power equipment dataset, the number of parameters, computational cost (GFLOPs) and the size of the model weight are reduced by 46.8%, 44.1% and 46.4%, respectively, compared with the Baseline model, while the mAP is improved by 1%. Comparative experiments on three power equipment datasets show that our model achieves a compelling balance between efficiency and detection performance in power equipment detection scenarios.
1. Introduction
With the rapid advancement of the power industry, the use of drones for intelligent inspection of transmission lines has become widespread, wherein the detection of power equipment is a critical task [1,2]. In recent years, with the rapid progress of computer vision and deep learning technology, image-based object detection algorithms have demonstrated significant potential in the field of power equipment inspection. However, owing to the large size of the inspection objects and the variable shooting distance of the drone, these objects show substantial scale variations in the captured image. This difference in scale places extremely high demands on the robustness of detection models, and conventional models often struggle to accurately identify large, medium, and small targets simultaneously. Furthermore, although existing deep learning models achieve high detection accuracy, their network structures are complex, entailing a massive number of parameters and computational complexity. This complexity imposes stringent requirements on computing resources and hardware platforms. Consequently, their direct deployment on resource-constrained edge computing devices or mobile platforms such as drones is challenging, which to a certain extent limits their widespread application in practical inspection scenarios.
To address these two issues, this paper proposes a lightweight power equipment detection algorithm designed for multi-scale power equipment detection scenarios, aiming to achieve a better balance between model lightweighting and detection performance, thereby facilitating intelligent, unmanned, and real-time power equipment inspections. Specifically, the model incorporates a lightweight feature extraction module (CRepLK), a neck network (LEDSF), and a detection head (PADH). While significantly reducing model parameters and computational complexity, it maintains detection accuracy on par with or even exceeding that of prevailing methods. The effectiveness of the proposed model is validated on three power equipment datasets, demonstrating its potential as a practical and efficient solution for the intelligent inspection of power equipment.
The main contributions of this paper are summarized as follows:
- (1)
- We propose a lightweight feature extraction module, CRepLK, which effectively establishes long-distance dependencies between features through the large receptive field of large kernel convolution, enhances the model’s capacity for global context modeling, thereby improving its multi-scale detection capabilities.
- (2)
- We propose a lightweight neck network, LEDSFN, which refines and modulates the multi-scale features from the backbone through ELA attention, it also employs the dynamic upsampling DySample module to better preserve boundary and texture details of the image, thereby alleviating the feature conflict issue inherent in traditional FPN fusion to a certain extent.
- (3)
- We propose a lightweight detection head, PADH, which mitigates channel redundancy in the feature map from the neck network to a certain extent. This is achieved by simplifying the classification branch and applying convolution to only a subset of channels within the localization branch.
The rest of this paper is organized as follows: Section 2 introduces the latest developments in object detection models. Section 3 introduces the structure and improvements of the proposed LRA-YOLO in detail. Section 4 introduces comparative experiments, ablation experiments, and visualization analysis. Section 5 introduces the summary of our research and future prospects.
2. Related Work
2.1. Object Detection Methods
Existing object detection algorithms can primarily be categorized into CNN-based and transformer-based detection approaches. CNN-based detection algorithms are further divided into one-stage detection and two-stage detection approaches. Prominent one-stage detection algorithms including the SSD [3], FCOS [4], RetinaNet [5], and YOLO [6] series, while two-stage detection algorithms are exemplified by the R-CNN series [7,8,9]. By performing detailed classification and regression on candidate regions, two-stage algorithms generally achieve superior detection accuracy, particularly for small objects and precise localization. However, this process, which involves generating and independently processing each region, results in higher computational complexity. In contrast, one-stage detection algorithms bypass the candidate region generation step, instead performing dense sampling across the entire image and completing both object classification and localization in a single pass. Consequently, they exhibit lower computational requirements and faster inference speeds, rendering them more suitable for applications with high real-time performance demands.
Object detection algorithms based on Transformers emerged with DETR [10], which revolutionarily introduced the Transformer architecture into this field, establishing an end-to-end process that does not require anchor boxes or non-maximum suppression (NMS). Its core is to treat detection as a set prediction problem, directly outputting the final set of predicted boxes through the Transformer’s encoder–decoder and unique bipartite graph matching. Early DETR had problems such as slow training convergence and poor detection of small objects. Subsequent work has evolved around these challenges: Deformable DETR [11] introduced deformable attention, accelerating convergence and improving attention to multi-scale objects; DAB-DETR [12] introduced coordinates as dynamic anchors in queries, enhancing positional awareness; DINO [13] significantly accelerated model convergence and improved detection accuracy by improving query representations and iterative optimization methods; RT-DETR [14] reduced model complexity by performing self-attention calculations on a small portion of features, enabling real-time performance.
Additionally, as model scale and data volume grow, large-scale visual foundation models such as the Segment Anything Model (SAM) [15] and its successor, Segment Anything 2 (SAM2) [16], have demonstrated unprecedented zero-shot segmentation capabilities. SAM2 maintains SAM’s strong generalization capabilities while further improving segmentation performance and efficiency in complex scenarios. Although these models primarily focus on segmentation tasks, the rich world knowledge and strong visual generalization capabilities they acquire through pre-training on massive datasets have pointed the way toward new directions in object detection research. For example, recent work such as WeakSAM [17] leverages the prior knowledge learned by SAM to address weakly supervised object detection problems, demonstrating the immense potential of transferring the prior knowledge of foundational models to specific detection tasks. This suggests that future object detection systems may increasingly integrate with such foundational models to achieve stronger zero-shot/few-shot detection capabilities.
However, the powerful performance of these advanced algorithms often relies on a large number of model parameters and significant computational resources. This makes them difficult to deploy on resource-constrained platforms, thereby limiting their lightweight applications. Therefore, we will review the progress made in the field of lightweight object detection and then discuss existing research on power equipment detection.
2.2. Lightweight Object Detection Methods
In recent years, achieving real-time, lightweight object detection on resource-constrained platforms has become a major research focus in the field of computer vision. Traditional object detection networks, while highly accurate, are difficult to deploy on such devices due to their massive computational requirements and large parameter counts. To address this issue, researchers have proposed a series of lightweight methods aimed at optimizing the balance between model speed, size, and accuracy. In this context, the YOLO series of architectures has emerged as a representative paradigm for lightweight object detection. YOLO-NAS employs neural architecture search to automatically identify quantization-friendly detection architectures, introducing quantization-aware base modules and selective quantization to achieve a better accuracy-latency trade-off with minimal accuracy loss during inference. YOLOv10 [18] achieves end-to-end training without NMS through Consistent Dual Assignments and adopts an integrated design driven by efficiency and accuracy to optimize each component, thereby significantly reducing latency and redundancy while maintaining accuracy. MHAF-YOLO [19] designs a multi-branch auxiliary FPN (MAFPN) to enhance the fusion of high- and low-level features, and combines a heterogeneous multi-scale module (RepHMS) that can flexibly select convolution kernels to expand the receptive field, achieving extremely high parameter efficiency. YOLOv11 [20] designs a lightweight feature extraction block (C3K2) and uses DW convolution in the detection head to significantly reduce the number of model parameters and improve detection performance. YOLOv12 [21] introduces efficient region attention A2 and residual efficient layer aggregation R-ELAN, combined with architectural simplifications like FlashAttention, to further improve accuracy while maintaining real-time speed. Recently, a Transformer-based real-time object detection model RT-DETR [14] optimizes computational efficiency through a designed efficient hybrid encoder and improves initial queries with high-quality query selection, achieving end-to-end real-time detection.
Unlike current mainstream lightweight detectors, which either focus on finding optimal topologies through neural architecture search (such as YOLO-NAS) or explore new architectural paradigms (such as RT-DETR introducing end-to-end detection with Transformers into the real-time domain), our work returns to the model architecture itself, proposing an end-to-end collaborative lightweight design. We do not optimize individual components in isolation but instead systematically overhaul the backbone network, neck network, and detection head as an integrated system: our proposed CRepLK enhances global perception capabilities through large-core convolutions; LEDSFN refines feature fusion through attention and dynamic upsampling; and PADH specifically addresses the channel redundancy issue in neck outputs. This collaborative optimization allows the advantages of each module to accumulate, ultimately achieving efficient detection with extremely low parameter counts.
2.3. Power Equipment Object Detection Method
In recent years, object detection algorithms have been increasingly applied to intelligent inspection of transmission lines. For one-stage algorithms targeting power equipment detection, Maduako et al. [22] utilized high-resolution oblique images from drones and an optimized one-stage model SSD to achieve automatic detection and inventory of faulty components in the transmission network, offering a low-cost and timely power asset management solution. Huang et al. [23] proposed an improved YOLOv5-based insulator defect detection algorithm. This method reduces computational overhead by constructing a lightweight backbone network, enhances the recognition accuracy of small defects by incorporating a small-scale detection layer, and replaces the original SPP module with a newly designed receptive field module to enhance feature extraction and network performance. Bao et al. [24] proposed BC-YOLO for the detection of transmission line dampers and insulators. This model incorporates Coordinate Attention (CA) mechanism to accurately capture long-range spatial interactions and replaces PANet with BiFPN for feature fusion. The BiFPN assigns learnable weights to different feature maps, enabling the network to prioritize features with greater contributions and thus optimizing the feature fusion process. Souza et al. [25] proposed Hybrid-YOLO, a hybrid version of YOLO that utilizes a ResNet-18 classifier for the classification of transmission line insulator defects. Panigrahy et al. [26] applied YOLOv8 and integrated it with image enhancement technology to monitor high-voltage insulators, specifically to prevent overfitting. Their implementation utilized a six-axis UAV equipped with an airborne camera and a Raspberry Pi to achieve real-time detection and automated inspection. Furthermore, Wan et al. [27] proposed the YOLO-SRSA anomaly detection algorithm. They enhanced the model’s detection accuracy and the anti-interference performance under complex weather conditions through several modifications, including data augmentation, the integration of ACmix and BiFormer modules, and the adoption of the MPDIoU loss function.
Notable advancements have also been made in two-stage algorithms. Dong et al. [28] proposed a relative average accuracy index to accurately evaluate small objects and employed multi-scale transformation data enhancement to alleviate the scale problem. Concurrently, enhanced the Cascade R-CNN by integrating Swin-v2, a balanced feature pyramid, and side-aware boundary positioning to improve feature representation and localization accuracy. Li et al. [29] proposed a power equipment detection network, PEDNet, which constructs a global information aggregation module (GIAM) to focus on the object regions, introduced an improved spatial transformer network (ISTN) to mitigate the influence of rotated objects, and fully integrated salient areas, rotated objects and strong semantic information through the multi-scale feature cross-fusion structure of the feature enhancement fusion network FEFN. Ou et al. [30] proposed an improved Faster R-CNN model, which achieved fast and high-precision detection of five types of electrical equipment by optimizing the VGG16 feature extraction network and increasing the proportion of specific anchor frames. Furthermore, the model demonstrates robustness against noise and variations in illumination.
Although the aforementioned studies have achieved notable accuracy in power equipment detection by introducing complex components and strategies, these approaches have also led to a significant increase in the number of model parameters and computational complexity. To address this trade-off between high accuracy and lightweight deployment, this paper proposes a brand-new power equipment detection model.
3. The Proposed Methods
To ensure detection accuracy in power transmission line inspection while realizing a lightweight model, this study introduces a lightweight architecture based on YOLOv11. As illustrated in Figure 1, the proposed LRA-YOLO comprises a backbone, a neck, and a detection head. The backbone is primarily composed of Conv, CRepLK, SPPF, and C2PSA modules. Specifically, an input image is first processed by a sequence of two Conv layers, one CRepLK module, and another Conv layer for initial feature extraction. Subsequently, P3 and P4 feature maps are generated via alternating Conv and CRepLK modules. Finally, the P5 feature map is extracted following a sequence of Conv, CRepLK, SPPF, and C2PSA modules. These feature maps (P3, P4, and P5) are then fed into the Lightweight ELA-guided Dynamic Sampling Fusion (LEDSF) neck for multi-scale feature fusion. The resulting features are subsequently passed to the Partial Asymmetric Detection Head (PADH) for bounding box and category prediction.
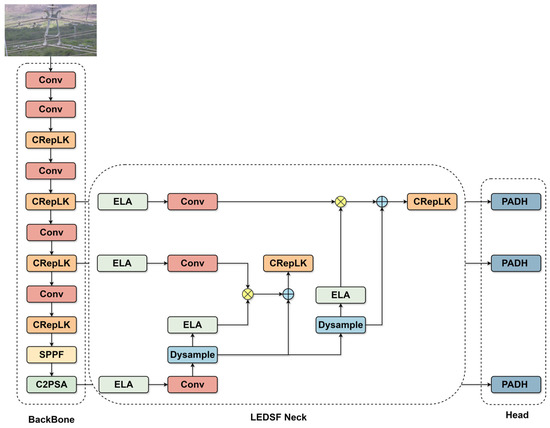
Figure 1.
The structure of LRA-YOLO. The model consists of three main parts: CRepLK Feature Extraction Module, Lightweight ELA-guided Dynamic Sampling Fusion (LEDSF) Neck, and Partial Asymmetric Detection Head (PADH).
3.1. CRepLK Feature Extraction Module
Due to the variations in flying altitude and shooting angle during the inspection of power transmission lines via drones, the same type of power equipment often exhibits significant scale variations across images, rendering the model’s multi-scale capability particularly important. However, the large receptive field of large kernel convolution can cover a wider range of image features at one time, making it insensitive to the absolute scale of the object. A large convolution kernel can still cover the primary structure of the object and its critical contextual environment despite variations in the object’s size, thereby facilitating the identification of structurally similar objects at different scales. Although traditional methods employ multi-scale feature extraction to address scale issues, the inherent capability of large kernel convolution to capture contextual information can simplify such complex multi-scale processing modules to a certain extent while providing them with richer initial features. Therefore, we designed a CRepLK module to enhance the multi-scale feature extraction capability of the model while being lightweight.
The structure of the CRepLK module is shown in Figure 2. The CSP structure [31] of the CRepLK module can integrate the gradient flow information of each branch while maintaining lightweight, remaining or even enhancing the model’s learning ability. Specifically, the input features are first processed by a convolution layer to adjust channel dimension and are subsequently split into two parts. One part undergoes processing by a RepLK Block [32] and a convolution layer. The resulting feature is then fed into an additional RepLK Block and Conv layer for multi-scale feature extraction. The three resulting features are concatenated, and their channel dimension is adjusted by a final Conv layer to match the input. The RepLK Block consists of DilatedReparam and convolution. DilatedReparam is designed to efficiently obtain a large receptive field, mitigating the substantial computational and parametric overhead associated with using large, dense convolution kernels. It consists of a primary 5 × 5 convolution branch and two parallel 3 × 3 convolution branches with dilation rates of 1 and 2, respectively. Dilated convolution expands the kernel’s receptive field without increasing its parameters or computational cost. DilatedReparam employs structural reparameterization: during training, its three branches are trained in parallel; during inference, they are fused into a single, equivalent 5 × 5 kernel, thereby significantly reducing the parameter count and computational load.
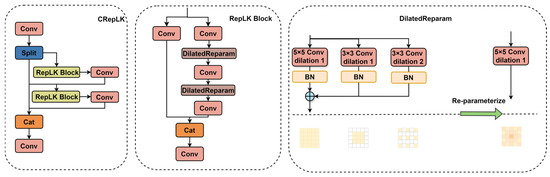
Figure 2.
The structure of the CRepLK feature extraction module. The module employs a lightweight CSP design and RepLK Blocks to enhance multi-scale feature extraction by efficiently acquiring large receptive fields.
3.2. LEDSF Neck Network
Li et al. [33] argued that existing low-level feature maps tend to retain the representation of small objects (local features in small receptive fields), while high-level feature maps are more suited for the representation of large objects (global features in large receptive fields). Directly fusing them point-to-point may lead to feature conflicts and information dilution. This misalignment is particularly prominent when the representations from different levels of the pyramid are forced to be directly fused point-to-point after upsampling or downsampling. Moreover, most of the existing FPN structures have large computational complexity. The top-down and bottom-up structures used in the Panet [34] neck, as utilized by the YOLO series, exhibit feature redundancy and are not suitable for power transmission line inspection tasks. Inspired by MFDS-DETR [35], we depart from the Panet neck and propose a Lightweight ELA-guided Dynamic Sampling Fusion (LEDSF) Neck.
As shown in Figure 3, LEDSF first employs ELA [36] for feature selection and enhancement on the P3, P4, and P5 layers from the backbone network. Subsequently, the P5 feature map is resized to match the spatial dimensions of P4 via dynamic upsampling (Dysample) [37]. This upsampled feature map is then refined by the ELA attention module and modulated by the P4 features. The core of this process involves utilizing high-level features to gate low-level features. This gating mechanism enables the network to adaptively weight or select information from different scales. For instance, when high-level features indicate the existence of an object, it can enhance the details related to the edge of the object in low-level features. This mechanism makes the fusion no longer a blind point-to-point superposition, but a selective fusion, thereby mitigating the interference and misalignment from irrelevant features. The selected features are aggregated with the high-level features, and a CRepLK module is then applied for the final feature extraction before input to the detection head. A similar procedure is applied to the P3 feature. This design effectively addresses computational redundancy of Panet. By being lightweight and leveraging high-level features to filter and integrate low-level information, the proposed neck architecture enhances multi-scale feature interaction and the overall learning capacity of the model.
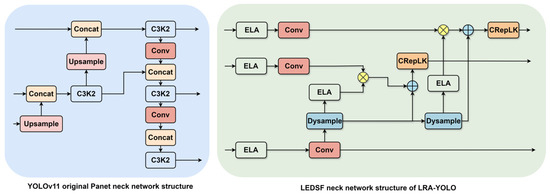
Figure 3.
Neck network structure of YOLOv11 and LRA-YOLO. Our LEDSF neck is a lightweight alternative to Panet, enhances multi-scale feature interaction by employing ELA and Dysample to selectively fuse high-level and low-level features through a gating mechanism.
3.2.1. ELA Module
The ELA module [36] effectively captures long-range spatial dependencies. When applied to P3, P4, and P5, it enables each feature layer to integrate a wider range of contextual information. For instance, features from P3, typically associated with smaller objects, can benefit from comprehending more of the surrounding scene, while features from P5, associated with larger objects, can further optimize their already large receptive fields to focus on the most relevant dependencies. By applying the ELA module to the P3, P4, and P5 feature maps independently, the network can better lock important object locations within each specific scale before these features are combined. This process enables more accurate spatial information to be fed into the feature fusion stage of the neck.
As shown in Figure 4, the ELA module aims to enhance feature representation via decoupled horizontal and vertical high-order spatial attention mechanisms. The module first utilizes adaptive average pooling to aggregate the global contextual information from the input feature maps along the height and width directions, respectively. Subsequently, these 1D feature vectors are processed by a shared attention branch containing depthwise separable 1D convolutions and sigmoid activation functions to learn and generate local high-order spatial attention weights along their respective directions. Finally, these attention weights are expanded and element-wise multiplied with the original feature map, achieving adaptive feature enhancement of key areas. A key characteristic of ELA is its ability to efficiently capture high-order spatial dependencies using 1D depthwise separable convolutions, thereby avoiding complex 2D convolution calculations, significantly improving the efficiency and feature selection capabilities of the model.
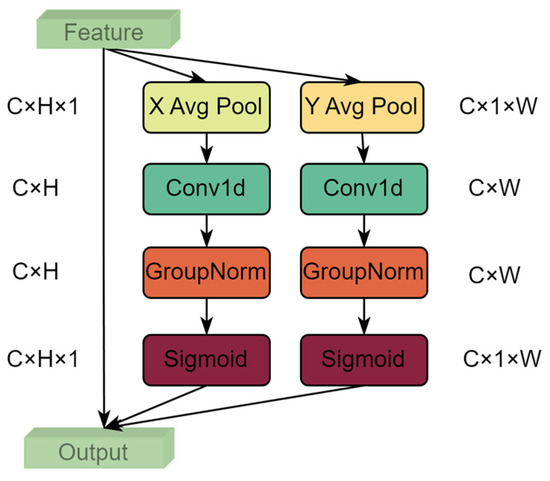
Figure 4.
The structure of ELA module. The module enhances feature representation by efficiently capturing long-range spatial dependencies through decoupled horizontal and vertical high-order spatial attention.
3.2.2. Dysample Module
The structure of DySample [37] is shown in Figure 5, different from traditional fixed upsampling methods such as bilinear interpolation, DySample proposes a dynamic, content-aware upsampling scheme. Traditional methods often lead to blurred edges and detail loss due to their fixed averaging mechanism. DySample can adaptively adjust the sampling position according to input feature content by learning adaptive sampling point offsets, thereby more accurately retaining object boundaries and texture details. This adaptive mechanism mitigates the problem of feature space misalignment and information ambiguity caused by traditional methods. It enables the semantic information in low-resolution feature maps to be converted to the high-resolution space with higher fidelity, providing higher-quality feature inputs for subsequent feature fusion and detection tasks. Furthermore, a major advantage of DySample is its lightweight design. It employs an efficient point sampling method to avoid generating large dynamic convolution kernels or complex convolution operations, thus achieving excellent performance with minimal parameters and computational costs.
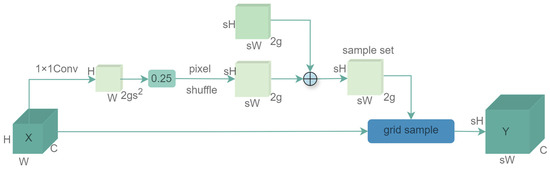
Figure 5.
The structure of Dysample module. DySample dynamically adjusts the sampling position by learning content-aware sampling point offsets, thereby accurately preserving object boundaries and texture details.
The neck of the YOLO model fuses feature maps from different stages of the backbone network to create representations suitable for multi-scale object detection. The quality of upsampling directly affects the effectiveness of this fusion. By providing higher quality, more detailed upsampled features, the model can more effectively integrate semantic and spatial information, thereby enhancing the detection performance for objects across various scales.
3.3. PADH
Yolov11 introduces DW convolution based on the decoupled detection head of Yolov8 for classification and localization, further lightweighting the model. However, the entire detection head still suffers from large number of parameters and high computational complexity. Fasternet [38] argues that significant redundancy exists among the feature maps of different channels. We argue that similar feature redundancy exists between the channels of multi-scale features from the neck network. Therefore, we proposed the PADH detection head.
The structure of the PADH detection head is shown in Figure 6. For the classification branch, we employ two 1 × 1 convolutions for classification regression. For the localization branch, we utilize three Pconv [38] and one 1 × 1 convolution for localization regression.
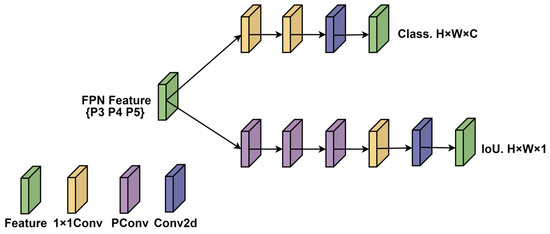
Figure 6.
The structure of PADH. PADH aims to address multi-scale feature redundancy and achieve efficient lightweighting through two 1 × 1 convolutional classification branches and a PConv-based localization branch.
As our backbone network and neck network have completed sufficient spatial feature extraction and multi-scale feature fusion, the design of the classification branch prioritizes computational efficiency and a minimal parameter count. Two consecutive 1 × 1 convolutions provide a lightweight way for channel-wise information interaction and dimensions adjustment and quickly map features to classification scores.
Feature redundancy persists in the channels of the multi-scale feature maps generated by the neck network. Therefore, the localization branch focuses on extracting sufficient spatial features and establishing a suitable receptive field for the bounding box regression task, while maintaining high efficiency through Pconv, and learning more complex spatial relationships. PConv, as shown in Figure 7, mitigates computational redundancy and memory access by processing only some channels, thereby achieving superior actual computing speed compared to convolution. A stack of three PConv layers helps to extract and refine spatial information in layers and gradually expand the receptive field. Finally, a 1 × 1 convolution efficiently projects these refined spatial features onto the final bounding box coordinates.
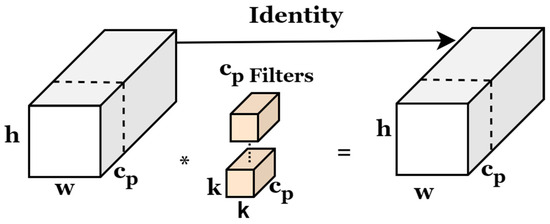
Figure 7.
The structure of Pconv. Where * denotes convolution operation. Pconv reduces computational redundancy by processing only a subset of channels.
4. Experimental Results and Analysis
4.1. Experimental Environment Setup and Evaluation Metrics
The experiments were conducted on a Windows 11 system with 128 GB memory, a 12th Gen Intel Core i9-12900K CPU and NVIDIA GeForce RTX4090 graphics card. The software environment consisted of Python 3.11, PyTorch 2.3.1, CUDA12.7. The training hyperparameters for the ablation experiment included a batch size of 16, 200 epochs, an initial learning rate of 0.01, and a final learning rate of 0.0001.
To comprehensively evaluate the performance of the proposed model, we adopted a set of standard metrics that combine accuracy and efficiency for object detection. For detection accuracy, we adopted precision, recall, and mean average precision (mAP). Precision refers to the proportion of instances predicted as positive that are actually positive. Recall refers to the proportion of all actual positive instances that are correctly detected by the model. AP refers to the area under the P-R curve, which refers to the precision of a single category, and mAP refers to the average precision of multiple categories.
A true positive (TP) refers to a successful detection, that is, the model’s predicted box matches the category of a real box, and their intersection over union (IoU) is greater than the preset threshold. A false positive (FP) represents an incorrect detection, which includes misidentifying the background as the object, incorrect category prediction, or IoU below the threshold due to inaccurate positioning. A false negative (FN) represents a missed detection, that is, a real object in the image is not effectively detected by the model.
In terms of model complexity and deployment efficiency, we evaluated three key metrics: the number of parameters (Params, M), an important metrics for measuring model complexity; computational complexity (GFLOPs, G), the amount of computation required to evaluate the model forward propagation at 640 × 640 input resolution; model size (Size, MB); and inference speed (FPS, frames per second), tested on GPU and CPU platforms, directly reflects the model’s real-time processing capabilities and operational efficiency in actual deployment environments. which directly reflects the file size when the model is deployed. This set of evaluation metrics enables us to conduct a balanced and in-depth analysis of the accuracy and practicality of the model.
4.2. Datasets
The Insplad dataset [39] is a dataset of power line assets captured by drone images. It consists of 10,607 images and contains 17 power line asset categories. Its training set and test set consist of 7935 and 2626 images, respectively.
The Furnas dataset [40] is a dataset of power equipment in the transmission line scenario. The dataset consists of five parts: baliser, bird nest, insulator, spacer, and stockbridge, which have different states. There is a total of 6295 images. Its training set and test set consist of 5667 and 628 images, respectively.
Our private dataset is a dataset of power equipment captured by drones. It consists of three categories: knife switches, drop-out fuses, and transformers. It has a total of 4189 images. Its training set and test set consist of 3257 and 932 images, respectively.
4.3. Comparative Experiment and Analysis
In order to verify the effectiveness of the improvement of our model, we conducted comparative experiments with the current mainstream models on the insplad dataset, the private dataset of power equipment, and the furnas dataset. The comparison models are: YOLOv5s, YOLOv6s [41], YOLOv8s, YOLOv10s [18], YOLOv11s [20], YOLOv12s [21], MHAF-YOLO [19], YOLO-NAS-s and RT-DETR-R18.
As shown in Table 1, LRA-YOLO exhibits significant advantages over other advanced models. It achieved the best mAP result with the lowest Params, GFLOPs, and Size. Specifically, LRA-YOLO attained a precision of 88.1% and a recall of 87.5%, requiring only 5.0 M Params, 11.9 GFLOPs, and a model weight of 9.8 MB. Compared with the next-best model, YOLOv11s, the mAP metrics increased by 1% while the number of parameters, computational complexity, and model weight size were significantly reduced by 46.8%, 44.1%, and 46.4%, respectively. Furthermore, its mAP surpassed that of YOLOv5s, YOLOv6s, YOLOv8s, YOLOv10s, YOLOv12s, MHAF-YOLO, YOLO-NAS-s and RT-DETR-R18 by 2.8%, 2.3%, 1.2%, 1.3%, 1.2%, 2.2%, 8.2%, and 2.5%, respectively. Compared to YOLO-NAS-s and RT-DETR-R18, which have much higher Params and GFLOPs than our model, our model demonstrates a significant advantage in the mAP metric, outperforming them by 8.2% and 2.5%, respectively.

Table 1.
Comparative experiments on the Insplad dataset.
In addition, we also use a furnas dataset and private dataset of power equipment to verify the superiority of LRA-YOLO. The experimental results are shown in Table 2 and Table 3. Our LRA-YOLO can achieve good performance on the Furnas dataset. The mAP index of our proposed LRA-YOLO reached 93.7% On our private dataset of power equipment. Compared with other mainstream models, LRA-YOLO has achieved competitive performance with much lower Params, GFLOPs, and size than other models.
Table 2.
Comparative experiments on the Furnas dataset.
Table 3.
Comparative experiments on a private dataset of power equipment.
4.4. Ablation Experiment and Analysis
To evaluate the effectiveness of the proposed modules, we conducted ablation experiments on the insplad dataset by integrating CRepLK, LEDSF and PADH into the Baseline model. The results are shown in Table 4. The baseline model achieved a good mAP of 89.0%, but its number of parameters, computational complexity and model weight size are still large. The integration of CRepLK and PADH into the baseline individually increased the mAP by 0.9% and 0.8%, respectively, while also reducing computational complexity. Our proposed LRA-YOLO, which integrates all three components, attained a 1.0% improvement in mAP. Its number of parameters, computational complexity and model weight size were reduced by 4.4 M, 9.4 G and 8.5 MB, respectively. This result indicates that the model achieved a significant lightweight while maintaining high accuracy, demonstrating the effectiveness of the proposed component modules of LRA-YOLO.
Table 4.
Ablation experiments on the Insplad dataset.
4.5. Visual Analysis
A qualitative visual visualization analysis of the Baseline model and LRA-YOLO was conducted on the insplad dataset. We selected three typical scenes for visualization analysis: a long-distance scale-variable object scene, a tilted view detection scene, and a complex background scene. As shown in Figure 8, the first scene contains multi-category objects of varying sizes, where the baseline model exhibits several missed detections. The second scene is a tilted view, in which objects undergo perspective distortion, that is, the effect of near big and far small. The scales of different positions on the image are inconsistent, and the size and shape of the same object in the image will be different. Our LRA-YOLO enhances the model’s multi-scale detection capability through the designed CrepLK module, which mitigates the missed detection in such multi-scale scene to a certain extent. The third scene involves detection in a complex background, where dense weeds interfere with the object detection task. Our LRA-YOLO refines and modulates the multi-scale features through the designed LEDSF neck, enabling the model can pay more attention to the object rather than the background, enhancing the object detection performance.


Figure 8.
Visual analysis of baseline and LRA-YOLO on the Insplad dataset. This figure shows three typical scene types in the Insplad dataset: scenes with long distances and variable object scales, detection scenes with tilted perspectives, and scenes with complex backgrounds.
As shown in Figure 9, to visually validate the performance improvement of our proposed LRA-YOLO, we employ heatmap visualization to analyze the model’s attention mechanism at the feature level. Three representative complex scenes with multiple objects were selected to compare LRA-YOLO with the baseline model. The experimental results clearly show that when the Baseline model processes these scenes, its attention area is relatively scattered, and even largely mistakenly focuses on the background area that is irrelevant to the detection task, which will undoubtedly interfere with the subsequent prediction process. In sharp contrast, thanks to our innovatively designed LEDSF neck network, LRA-YOLO shows excellent focusing ability. LEDSF effectively filters background noise and enhances the semantic information and saliency of object features through its efficient feature refinement and fusion mechanism. Therefore, the heatmap of LRA-YOLO can accurately and centrally cover each object in the scene, rather than the background. This observation visually corroborates the enhanced feature extraction capabilities of LRA-YOLO and offers a qualitative explanation for its reduced rates of missed and false detections in complex environments.

Figure 9.
Heatmap analysis of Baseline and LRA-YOLO. This figure shows the heat maps of Baseline and LRA-YOLO in multi-object scenes on the insplad dataset.
4.6. Analysis of Failure Cases and Limitations
To systematically analyze the failure cases and limitations of the proposed method, we employed the object detection evaluation tool TIDE [42] to conduct error analysis on the Insplad dataset, as shown in Figure 10. This tool decomposes the model’s total error into six fine-grained categories: Classification Error, Localization Error, Both Classification and Localization Error, Duplicate Detection Error, Background Error, and Missed GT Error. It quantifies the impact of each error type by calculating the potential improvement in mAP (ΔAP) after independently eliminating each category of error. It is important to note that TIDE does not sequentially correct errors until the end but instead calculates ΔAP separately for each error category starting from the original model. Overall, our LRA-YOLO achieves significantly lower missed ground truth (Missed GT) errors compared to the baseline model YOLOv11 (1.30 < 2.24). Additionally, TIDE’s analysis results clearly indicate that the performance bottlenecks of our model primarily stem from three types of errors: Localization error, Missed GT Error, and Background Error. If these errors could be ideally eliminated, they could, respectively, contribute to mAP improvements of 2.67%, 1.3%, and 1.02% for the model.
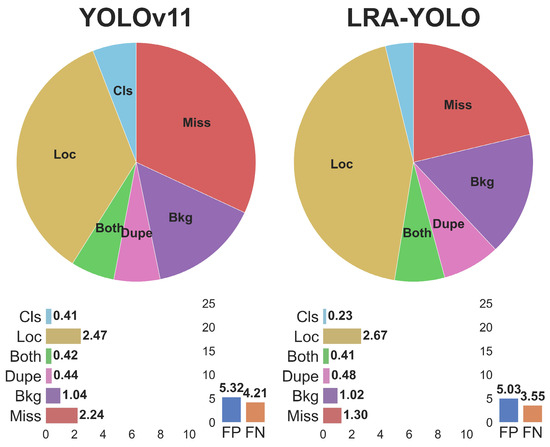
Figure 10.
TIDE error decomposition results for YOLOv11 and LRA-YOLO. This figure presents the six main error components analyzed using the TIDE tool for the YOLOv11 and LRA-YOLO models. The specific error types are defined as follows: Classification Error (Cls): The object is correctly located but classified incorrectly. Localization Error (Loc): The object is correctly classified but the localization is inaccurate. Both Classification and Localization Error (Both): The object has both classification and localization errors. Duplicate Detection Error (Dupe): Multiple detection boxes are generated for the same real object. Background Error (Bkg): Background is mistakenly detected as an object. Missed GT Error (Miss): The real object is not detected.
By examining specific error cases, we further discovered that the fundamental causes of these performance bottlenecks lie in object truncation and complex backgrounds in real-world scenarios. These two challenges are precisely what lead to the aforementioned errors in the model’s detection process. As shown in Figure 11, for the first group of close-range object truncation scenarios, the model exhibited three typical errors for the three objects from left to right: the left object had a classification error (Classification Error), which was due to truncation causing highly similar features between different subcategories of the same major category, making it difficult for the model to distinguish them and resulting in low-confidence predictions; The middle object has a localization error, as the identification of certain components (e.g., the polymer insulator lower shackle) depends on contextual information. The truncation disrupts contextual integrity, forcing the model to output a bounding box larger than the ground truth to ensure the object is fully enclosed; The object on the right is completely missed (Missed GT Error) because the object (such as the glass insulator) is severely truncated, and its incomplete visual information does not match the complete object features learned by the model. The same issue caused by object truncation is also evident in the second set of images, where the background at the image boundary is mistakenly identified as the object by the model due to its similarity to some features of the glass insulator big shackle, resulting in background misclassification (Background Error). In the third set of images, the challenge comes from detecting small objects in a complex background. Although our CrepLK module enhances the model’s multi-scale capabilities, the features of small objects such as hanging rings, which occupy a relatively small proportion of pixels, are easily lost after sampling in the deep layers of the network. In addition, the dense trees and intricate steel frame of the tower cause the objects to blend in with the background. these two factors together led to the failure to detect four smaller hanging ring objects.
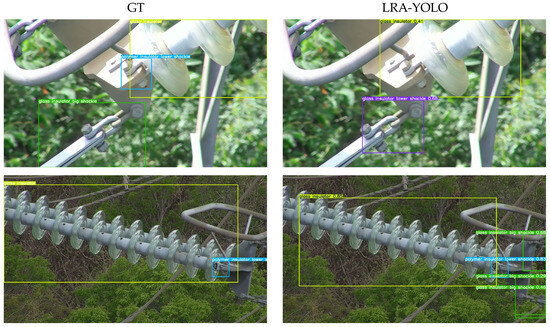

Figure 11.
Failure case scenario. The figure shows the main types of errors in the model in object truncation and complex background scenes from top to bottom: First group: Classification Errors, Localization Errors, and Missed GT Error. Second group: Background Errors. Third group: Missed GT Error.
The analysis of the above failure cases reveals potential areas for improvement in the model in two key aspects. First, the object truncation issue highlights that the current model still has limitations in extracting and identifying fine-grained features when only partial visual information is available. A promising direction for future exploration is to further enhance the model’s ability to perceive subtle differences in local textures of the target, thereby improving accuracy in distinguishing similar categories under truncated conditions. The false negative issue in complex backgrounds indicates that relying solely on spatial domain learning may make it difficult for the model to filter out background noise. Therefore, introducing new perspectives such as frequency domain analysis could be an effective way to enhance detection robustness. By enhancing the distinction between targets and backgrounds through such methods, the model may be able to separate target features from distractions such as trees and steel frames, thereby significantly improving detection performance in complex environments.
5. Conclusions
This paper proposes a lightweight LRA-YOLO algorithm for power equipment detection. First, we propose a lightweight feature extraction module CRepLK, which captures global context information through a large receptive field to enhance the multi-scale detection capability of the model. Furthermore, a lightweight neck network, LEDSF, is proposed to alleviate the feature misalignment problem caused by the original neck network’s direct fusion of low-level and high-level features by refining the backbone features and modulating the features and more efficiently fusing multi-scale features. Additionally, the proposed PADH addresses the channel redundancy problem of the neck network output features to a certain extent, further reducing the model’s complexity. To verify the superiority of our model, we conducted experiments on three power equipment datasets. The experimental results show that our LRA-YOLO achieves excellent detection performance with the lowest number of parameters, computational complexity, and model weight sizes compared with mainstream models on the three datasets. Ablation experiments were conducted to confirm the effectiveness of each proposed module. In summary, LRA-YOLO performs well in power equipment detection and has strong generalization, providing a better solution for the field of power transmission line inspection.
Future work will focus on constructing a more comprehensive and complex power equipment dataset, which will include images under extreme weather conditions such as rain, snow, and dense fog, as well as complex lighting environments, such as strong backlight and night, to continuously improve the robustness of the model. Furthermore, we will explore lightweighting and hardware optimization of the LRA-YOLO model, aiming to efficiently deploy it on edge computing devices such as drones and inspection robots to achieve true real-time, online intelligent inspection. The research will also be extended from detection to diagnosis. By integrating multimodal data, such as infrared thermal imaging and ultraviolet imaging, the model will not only be able to identify equipment but also intelligently judge its potential fault states, such as abnormal heating and partial discharge, thereby providing richer data support for predictive maintenance. We argue that these studies will inject strong impetus into the sustainable development and intelligence of smart grids and provide solid and reliable technical support.
Author Contributions
Conceptualization, J.Y. and L.H.; methodology, J.Y. and L.H.; software, J.Y.; validation, L.H. and Q.H.; investigation, L.H.; resources, L.H. and J.Y.; data curation, J.Y.; writing—original draft preparation, J.Y., L.H., and Q.H.; writing—review and editing, L.H., J.Y., and Q.H.; visualization, J.Y. and Q.H.; supervision, L.H.; project administration, L.H.; funding acquisition, L.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (grant number: 62362040 and 61662033) and the Natural Science Foundation of Jiangxi Province under Grant (grant number: 20242BAB25080).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The Insplad dataset can be accessed publicly at https://github.com/andreluizbvs/InsPLAD (accessed on 3 July 2025), the Furnas dataset can be accessed publicly at https://github.com/freds0/PTL-AI_Furnas_Dataset (accessed on 3 July 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Shakiba, F.M.; Azizi, S.M.; Zhou, M.; Abusorrah, A. Application of machine learning methods in fault detection and classification of power transmission lines: A survey. Artif. Intell. Rev. 2023, 56, 5799–5836. [Google Scholar] [CrossRef]
- Qian, X.; Luo, L.; Li, Y.; Zeng, L.; Chen, Z.; Wang, W.; Deng, W. Real-Time Object Detection Model for Electric Power Operation Violation Identification. Information 2025, 16, 569. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27–28 October 2019; pp. 9627–9636. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 26 June 26–1 July 2016; pp. 779–788. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4–8 May 2021. [Google Scholar]
- Liu, S.; Li, F.; Zhang, H.; Yang, X.; Qi, X.; Su, H.; Zhu, J.; Zhang, L. DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.; Shum, H.-Y. DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 4–6 October 2023; pp. 4015–4026. [Google Scholar]
- Ravi, N.; Gabeur, V.; Hu, Y.-T.; Hu, R.; Ryali, C.; Ma, T.; Khedr, H.; Rädle, R.; Rolland, C.; Gustafson, L. Sam 2: Segment anything in images and videos. arXiv 2024, arXiv:2408.00714. [Google Scholar]
- Zhu, L.; Zhou, J.; Liu, Y.; Hao, X.; Liu, W.; Wang, X. Weaksam: Segment anything meets weakly-supervised instance-level recognition. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, Australia, 28 October–1 November 2024; pp. 7947–7956. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. Yolov10: Real-time end-to-end object detection. In Proceedings of the Advances in Neural Information Processing Systems, San Diego, CA, USA, 14 May 2025; pp. 107984–108011. [Google Scholar]
- Yang, Z.; Guan, Q.; Yu, Z.; Xu, X.; Long, H.; Lian, S.; Hu, H.; Tang, Y. MHAF-YOLO: Multi-Branch Heterogeneous Auxiliary Fusion YOLO for accurate object detection. arXiv 2025, arXiv:2502.04656. [Google Scholar]
- Glenn, J.; Jing, Q. Ultralytics YOLO11. Available online: https://github.com/ultralytics/ultralytics (accessed on 5 March 2025).
- Tian, Y.; Ye, Q.; Doermann, D. Yolov12: Attention-centric real-time object detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Maduako, I.; Igwe, C.F.; Abah, J.E.; Onwuasaanya, O.E.; Chukwu, G.A.; Ezeji, F.; Okeke, F.I. Deep learning for component fault detection in electricity transmission lines. J. Big Data 2022, 9, 81. [Google Scholar] [CrossRef]
- Huang, Y.; Jiang, L.; Han, T.; Xu, S.; Liu, Y.; Fu, J. High-accuracy insulator defect detection for overhead transmission lines based on improved YOLOv5. Appl. Sci. 2022, 12, 12682. [Google Scholar] [CrossRef]
- Bao, W.; Du, X.; Wang, N.; Yuan, M.; Yang, X. A defect detection method based on BC-YOLO for transmission line components in UAV remote sensing images. Remote Sens. 2022, 14, 5176. [Google Scholar] [CrossRef]
- Souza, B.J.; Stefenon, S.F.; Singh, G.; Freire, R.Z. Hybrid-YOLO for classification of insulators defects in transmission lines based on UAV. Int. J. Electr. Power Energy Syst. 2023, 148, 108982. [Google Scholar] [CrossRef]
- Panigrahy, S.; Karmakar, S. Real-time condition monitoring of transmission line insulators using the YOLO object detection model with a UAV. IEEE Trans. Instrum. Meas. 2024, 73, 2514109. [Google Scholar] [CrossRef]
- Wan, Z.; Jiang, Y.; Wenlong, L.; Songhai, F.; Yang, Y.; Hou, J.; Tang, H. YOLO-SRSA: An Improved YOLOv7 Network for the Abnormal Detection of Power Equipment. Information 2025, 16, 407. [Google Scholar] [CrossRef]
- Dong, C.; Zhang, K.; Xie, Z.; Shi, C. An improved cascade RCNN detection method for key components and defects of transmission lines. IET Gener. Transm. Distrib. 2023, 17, 4277–4292. [Google Scholar] [CrossRef]
- Li, J.; Xu, Y.; Nie, K.; Cao, B.; Zuo, S.; Zhu, J. PEDNet: A lightweight detection network of power equipment in infrared image based on YOLOv4-tiny. IEEE Trans. Instrum. Meas. 2023, 72, 5004312. [Google Scholar] [CrossRef]
- Ou, J.; Wang, J.; Xue, J.; Wang, J.; Zhou, X.; She, L.; Fan, Y. Infrared image target detection of substation electrical equipment using an improved faster R-CNN. IEEE Trans. Power Deliv. 2022, 38, 387–396. [Google Scholar] [CrossRef]
- Li, A.; Zhang, L.; Liu, Y.; Zhu, C. Feature modulation transformer: Cross-refinement of global representation via high-frequency prior for image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 12514–12524. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31x31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- Li, H. Rethinking Features-Fused-Pyramid-Neck for Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Milan, Italy, 29 September–4 October 2024; pp. 74–90. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Chen, Y.; Zhang, C.; Chen, B.; Huang, Y.; Sun, Y.; Wang, C.; Fu, X.; Dai, Y.; Qin, F.; Peng, Y. Accurate leukocyte detection based on deformable-DETR and multi-level feature fusion for aiding diagnosis of blood diseases. Comput. Biol. Med. 2024, 170, 107917. [Google Scholar] [CrossRef] [PubMed]
- Xu, W.; Wan, Y. ELA: Efficient local attention for deep convolutional neural networks. arXiv 2024, arXiv:2403.01123. [Google Scholar] [CrossRef]
- Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to upsample by learning to sample. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023; pp. 6027–6037. [Google Scholar]
- Chen, J.; Kao, S.-h.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, Canada, 18–22 June 2023; pp. 12021–12031. [Google Scholar]
- Vieira e Silva, A.L.B.; de Castro Felix, H.; Simões, F.P.M.; Teichrieb, V.; dos Santos, M.; Santiago, H.; Sgotti, V.; Lott Neto, H. Insplad: A dataset and benchmark for power line asset inspection in UAV images. Int. J. Remote Sens. 2023, 44, 7294–7320. [Google Scholar] [CrossRef]
- De Oliveira, F.S.; De Carvalho, M.; Campos, P.H.T.; Soares, A.D.S.; Júnior, A.C.; Quirino, A.C.R.D.S. PTL-AI Furnas dataset: A public dataset for fault detection in power transmission lines using aerial images. In Proceedings of the 2022 35th SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Natal, Brazil, 24–27 October 2022; pp. 7–12. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Bolya, D.; Foley, S.; Hays, J.; Hoffman, J. Tide: A general toolbox for identifying object detection errors. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 558–573. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).