

Research on Tongue Image Segmentation and Classification Methods Based on Deep Learning and Machine Learning

 , ,
, ,
Abstract
1. Introduction
2. Materials and Methods
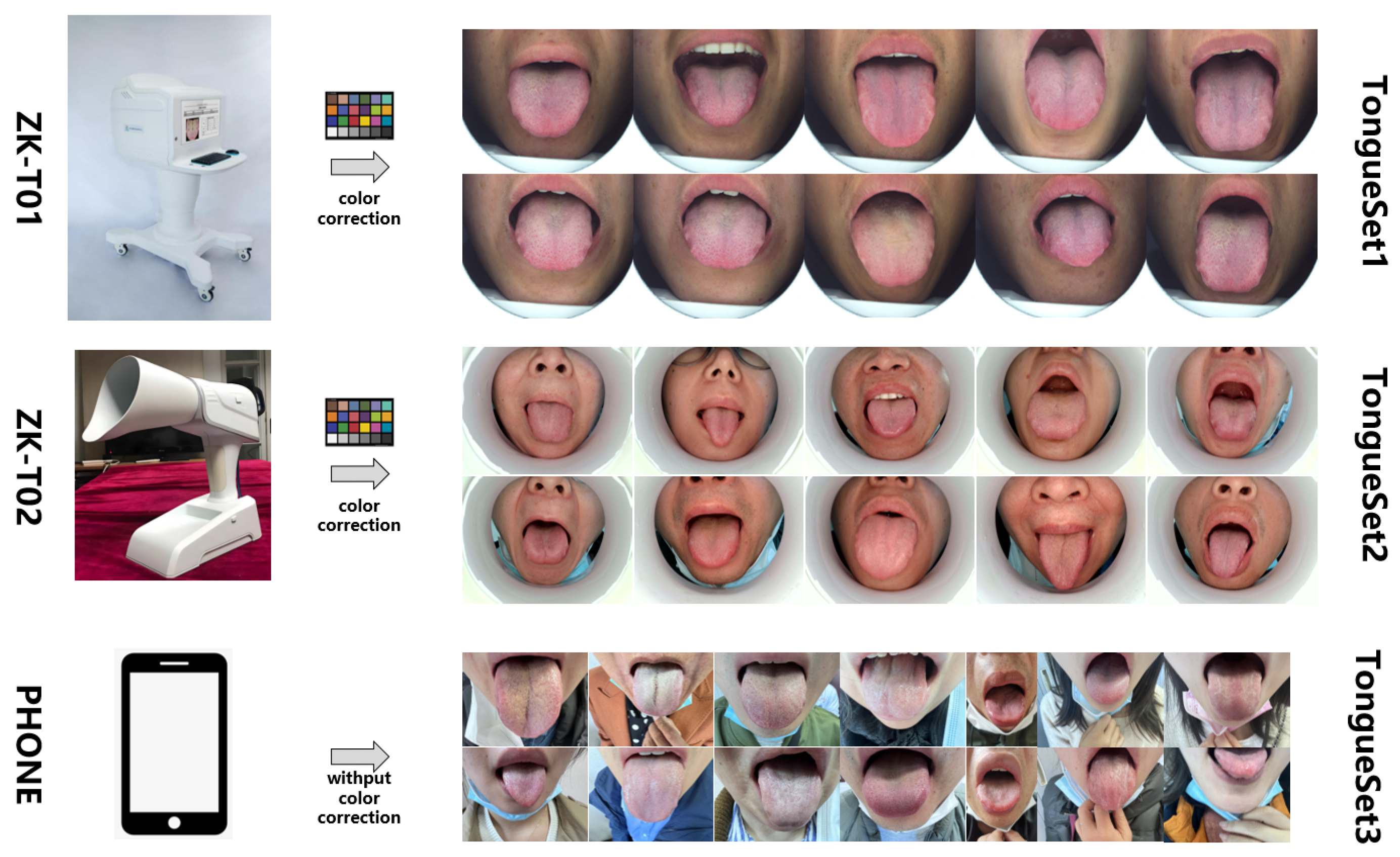
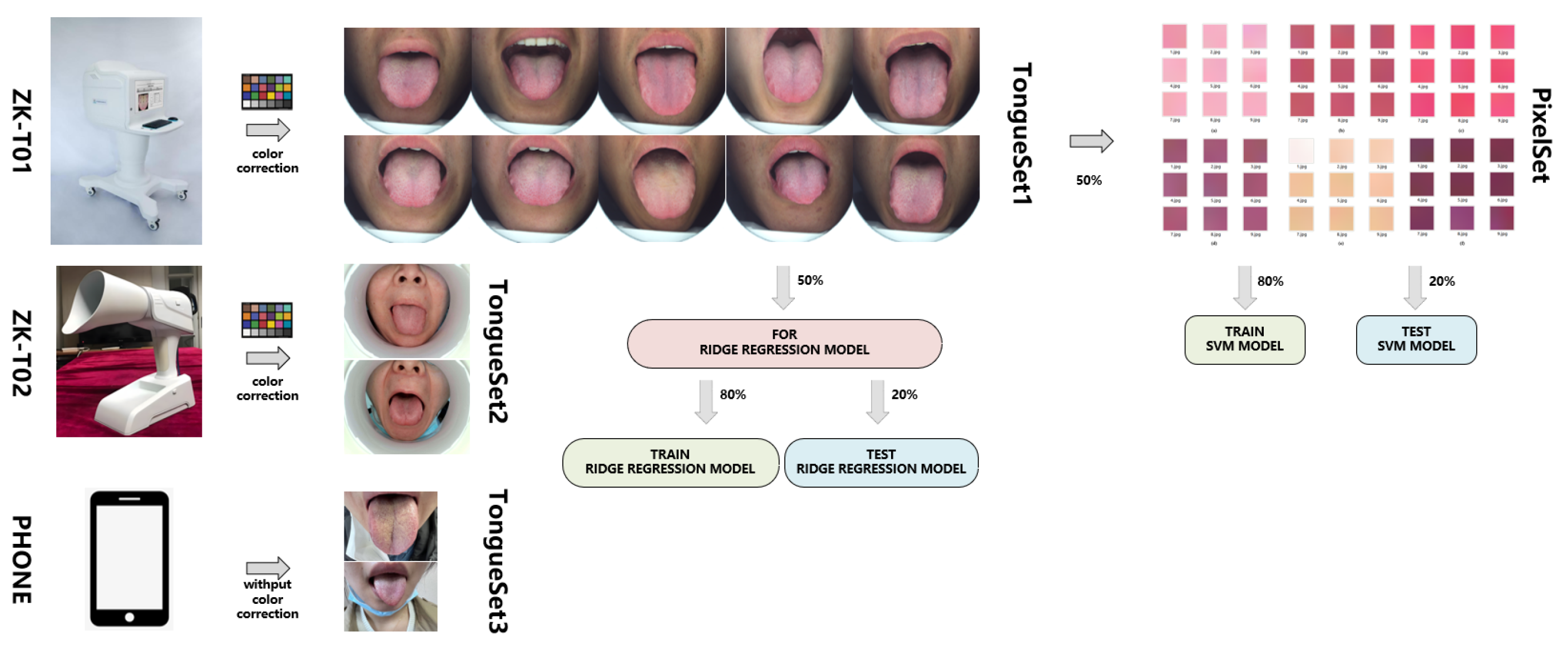
2.1. Datasets for Segmentation
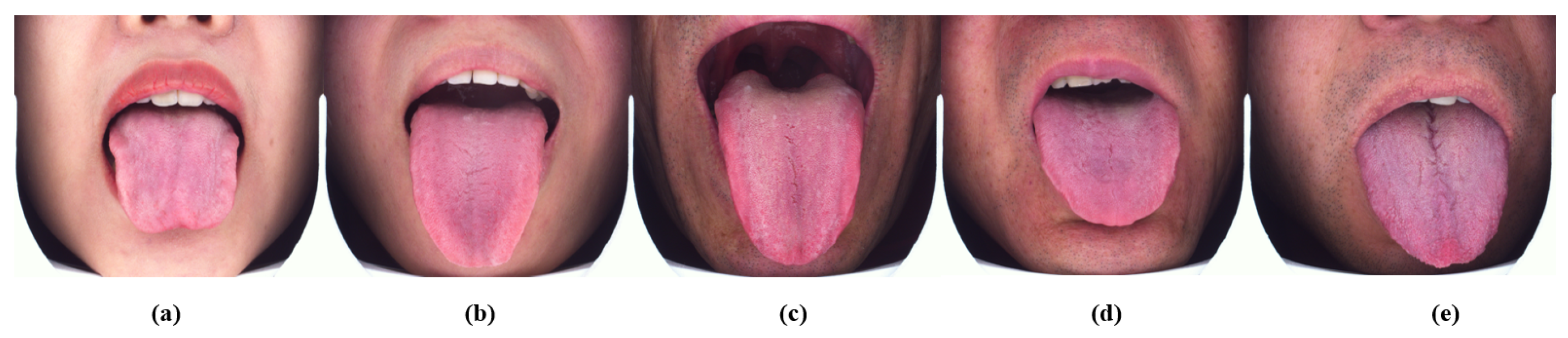
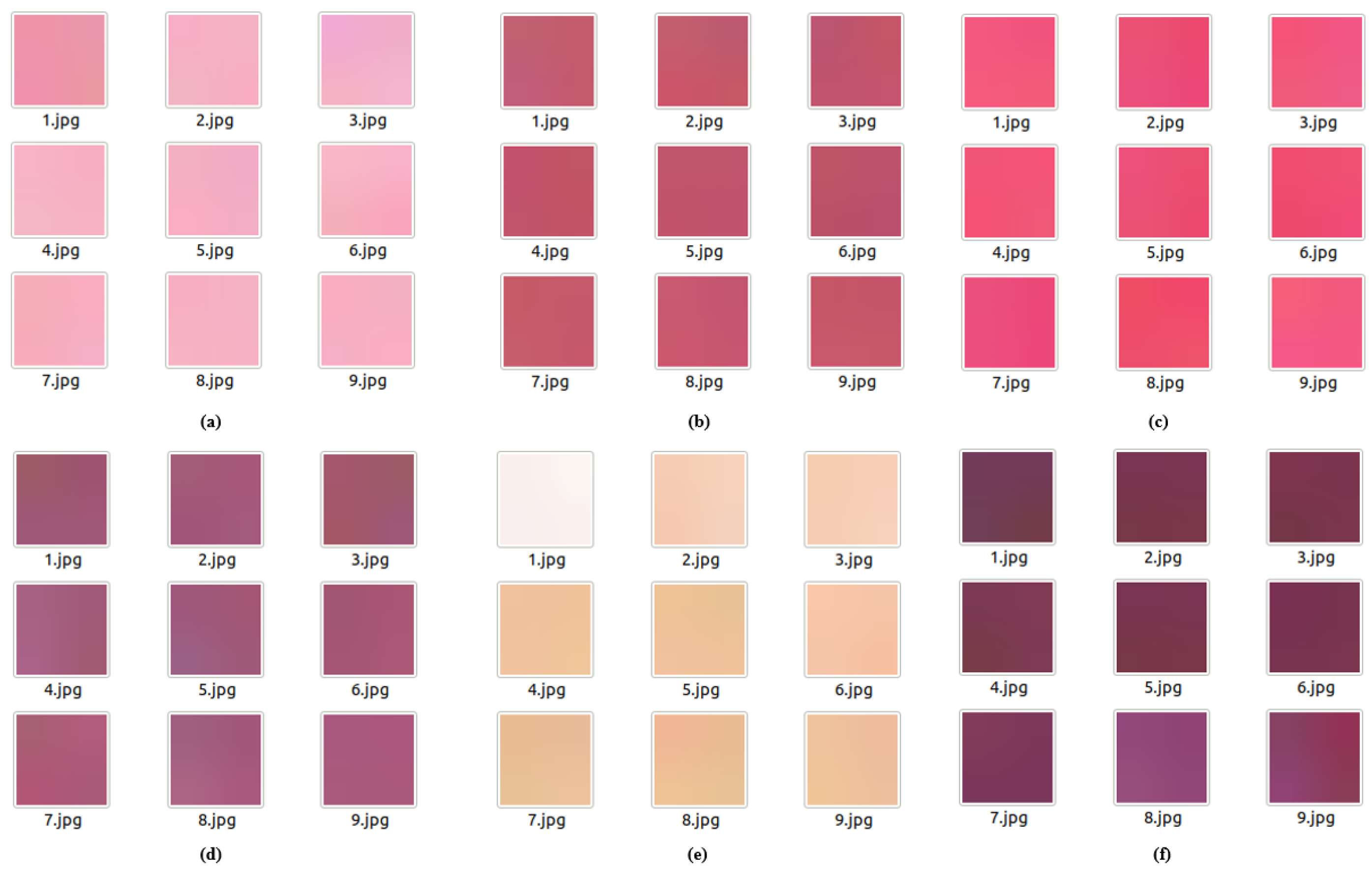
2.2. Datasets for Classification
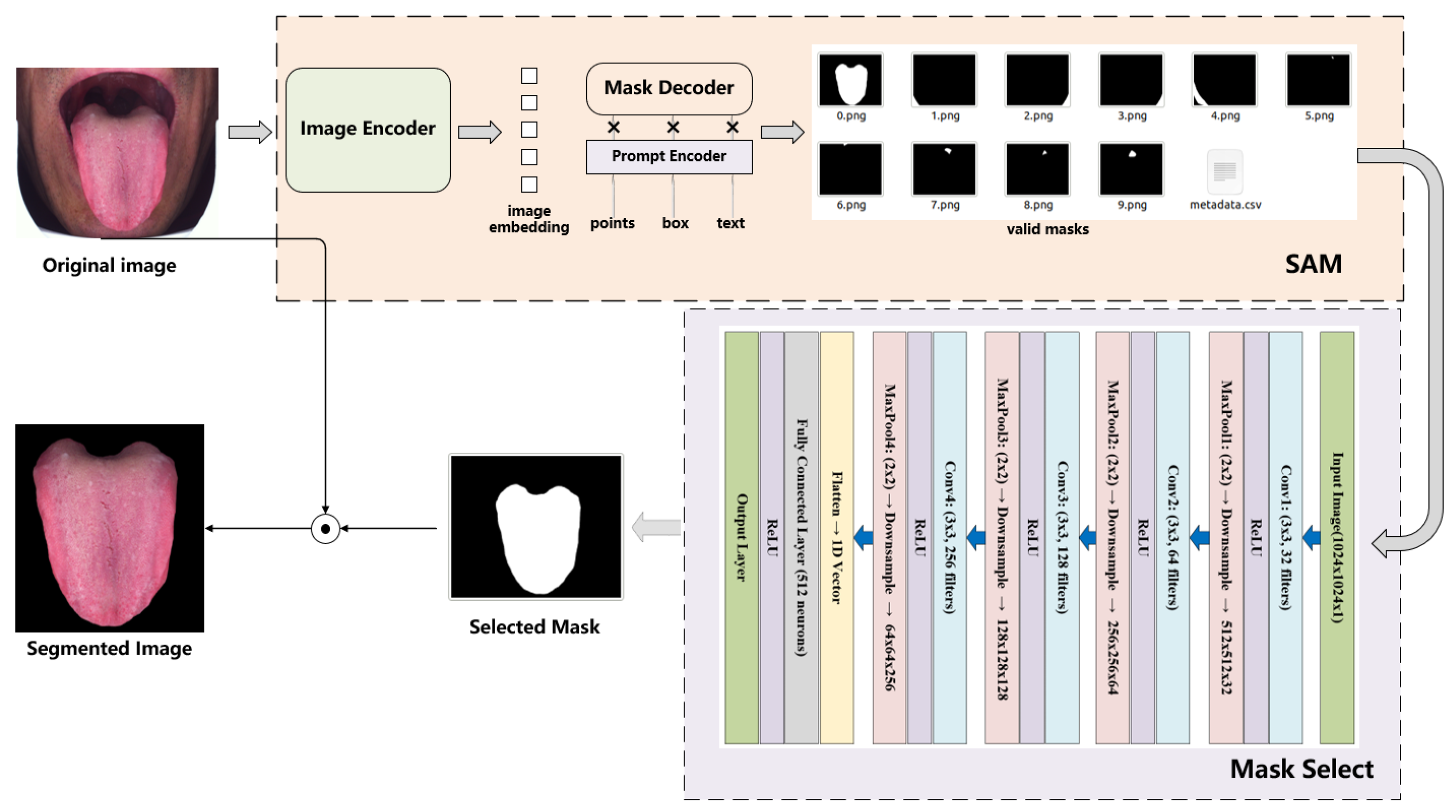
2.3. Proposed Segmentation Model
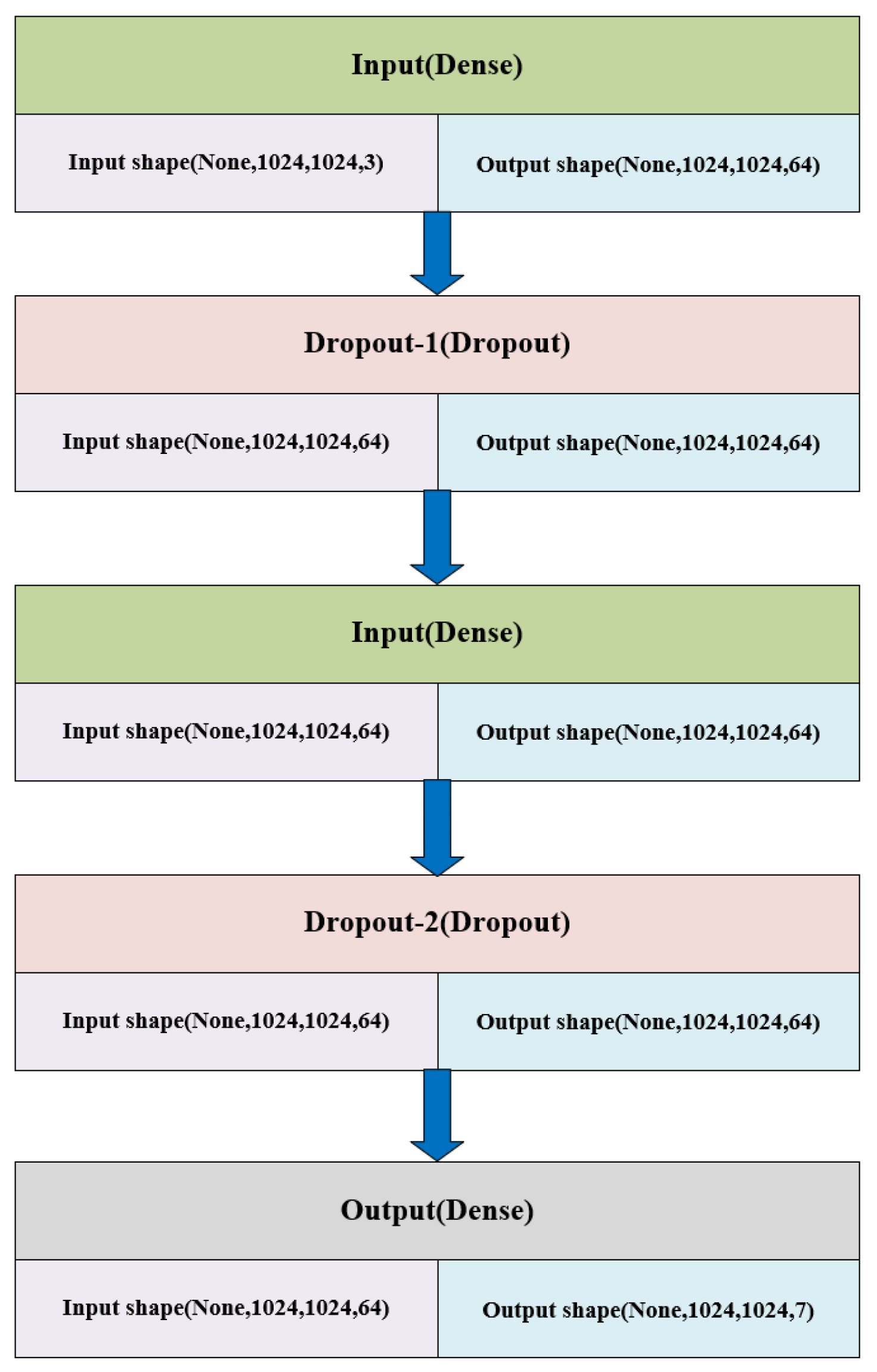
2.4. Proposed Classification Model
3. Results
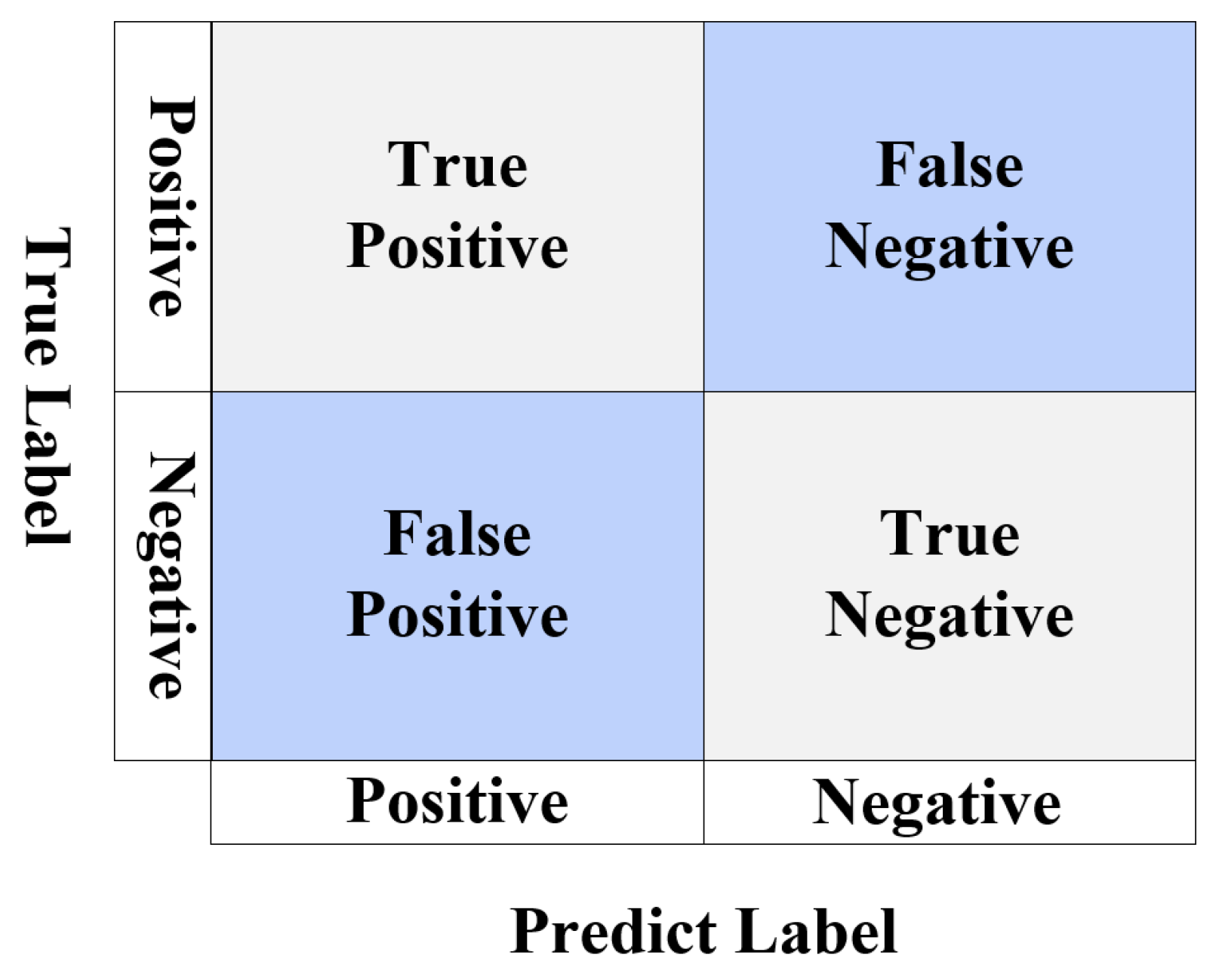
3.1. Evaluation Metrics
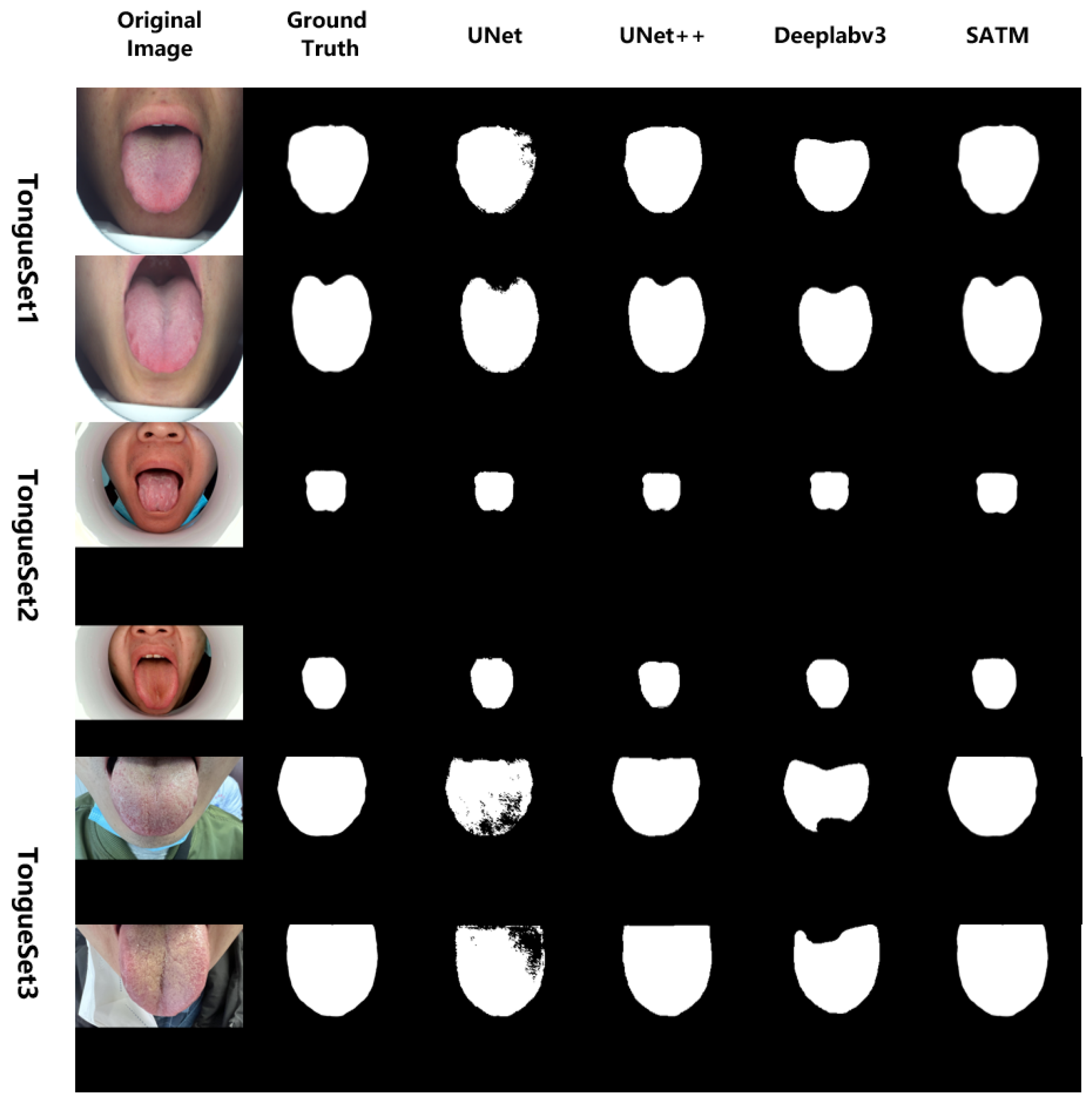
3.2. Experimental Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, J.; Zhang, Q.; Zhang, B.; Chen, X. TongueNet: A Precise and Fast Tongue Segmentation System Using U-Net with a Morphological Processing Layer. Appl. Sci. 2019, 9, 3128. [Google Scholar] [CrossRef]
- Huang, Z.; Miao, J.; Song, H.; Yang, S.; Zhong, Y.; Xu, Q.; Tan, Y.; Wen, C.; Guo, J. A novel tongue segmentation method based on improved U-Net. Neurocomputing 2022, 500, 73–89. [Google Scholar] [CrossRef]
- Zhang, X.; Bian, H.; Cai, Y.; Zhang, K.; Li, H. An improved tongue image segmentation algorithm based on Deeplabv3+ framework. IET Image Process. 2022, 16, 1473–1485. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, H.; Zhuo, L.; Li, X.; Zhang, J. TISNet-Enhanced Fully Convolutional Network with Encoder-Decoder Structure for Tongue Image Segmentation in Traditional Chinese Medicine. Comput. Math. Methods Med. 2020, 2020, 6029258. [Google Scholar] [CrossRef] [PubMed]
- Naveed, S.; Geetha, G.; Leninisha, S. Early Diabetes Discovery From Tongue Images. Comput. J. 2022, 65, 237–250. [Google Scholar] [CrossRef]
- Chen, J.M.; Chiu, P.F.; Wu, F.M.; Hsu, P.C.; Deng, L.J.; Chang, C.C.; Chiang, J.Y.; Lo, L.C. The tongue features associated with chronic kidney disease. Medicine 2021, 100, e25037. [Google Scholar] [CrossRef] [PubMed]
- Hsieh, S.F.; Shen, L.L.; Su, S.Y. Tongue color changes within a menstrual cycle in eumenorrheic women. J. Tradit. Complement. Med. 2016, 6, 269–274. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Liu, Z. Tongue color analysis and discrimination based on hyperspectral images. Comput. Med. Imaging Graph. 2009, 33, 217–221. [Google Scholar] [CrossRef] [PubMed]
- Kamarudin, N.D.; Ooi, C.Y.; Kawanabe, T.; Mi, X. Tongue’s substance and coating recognition analysis using HSV color threshold in tongue diagnosis. In Proceedings of the First International Workshop on Pattern Recognition, Tokyo, Japan, 11–13 May 2016. [Google Scholar] [CrossRef]
- Ni, J.; Yan, Z.; Jiang, J. TongueCaps: An Improved Capsule Network Model for Multi-Classification of Tongue Color. Diagnostics 2022, 12, 653. [Google Scholar] [CrossRef] [PubMed]
- Kawanabe, T.; Kamarudin, N.D.; Ooi, C.Y.; Kobayashi, F.; Mi, X.; Sekine, M.; Wakasugi, A.; Odaguchi, H.; Hanawa, T. Quantification of tongue colour using machine learning in Kampo medicine. Eur. J. Integr. Med. 2016, 8, 932–941. [Google Scholar] [CrossRef]
- Zhang, B.; Wang, X.; You, J.; Zhang, D. Tongue Color Analysis for Medical Application. Evid. Based Complement. Altern. Med. 2013, 2013, 264742. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Chen, J.; Liu, B.; Hu, W.; Wu, X.; Zhou, H. Tongue image segmentation and tongue color classification based on deep learning. Digit. Chin. Med. 2022, 5, 253–263. [Google Scholar] [CrossRef]
- Yan, B.; Zhang, S.; Yang, Z.; Su, H.; Zheng, H. Tongue Segmentation and Color Classification Using Deep Convolutional Neural Networks. Mathematics 2022, 10, 4286. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Segment Anything—Segment-Anything.com. Available online: https://segment-anything.com/ (accessed on 28 May 2024).
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Raschka, S.; Patterson, J.; Nolet, C. Machine Learning in Python: Main developments and technology trends in data science, machine learning, and artificial intelligence. arXiv 2020, arXiv:2002.04803. [Google Scholar] [CrossRef]
- Hoerl, A.; Kennard, R. Ridge regression-biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
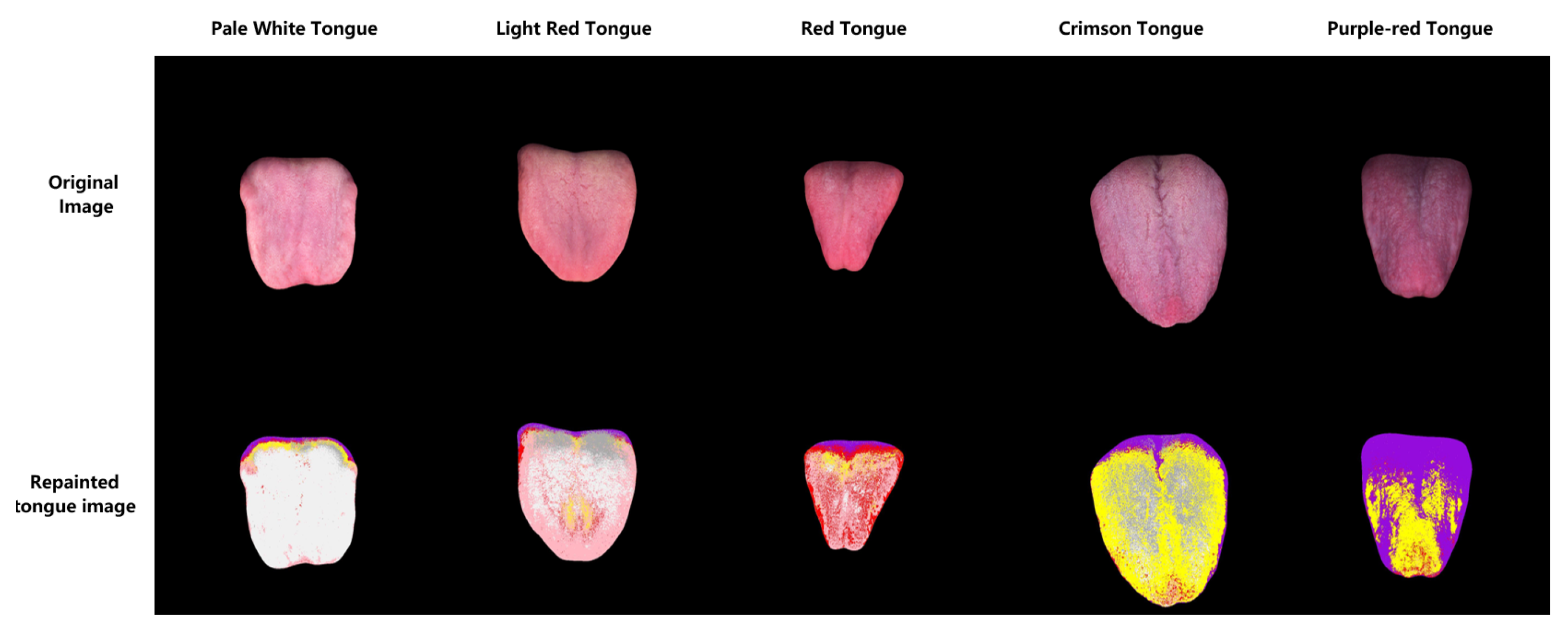
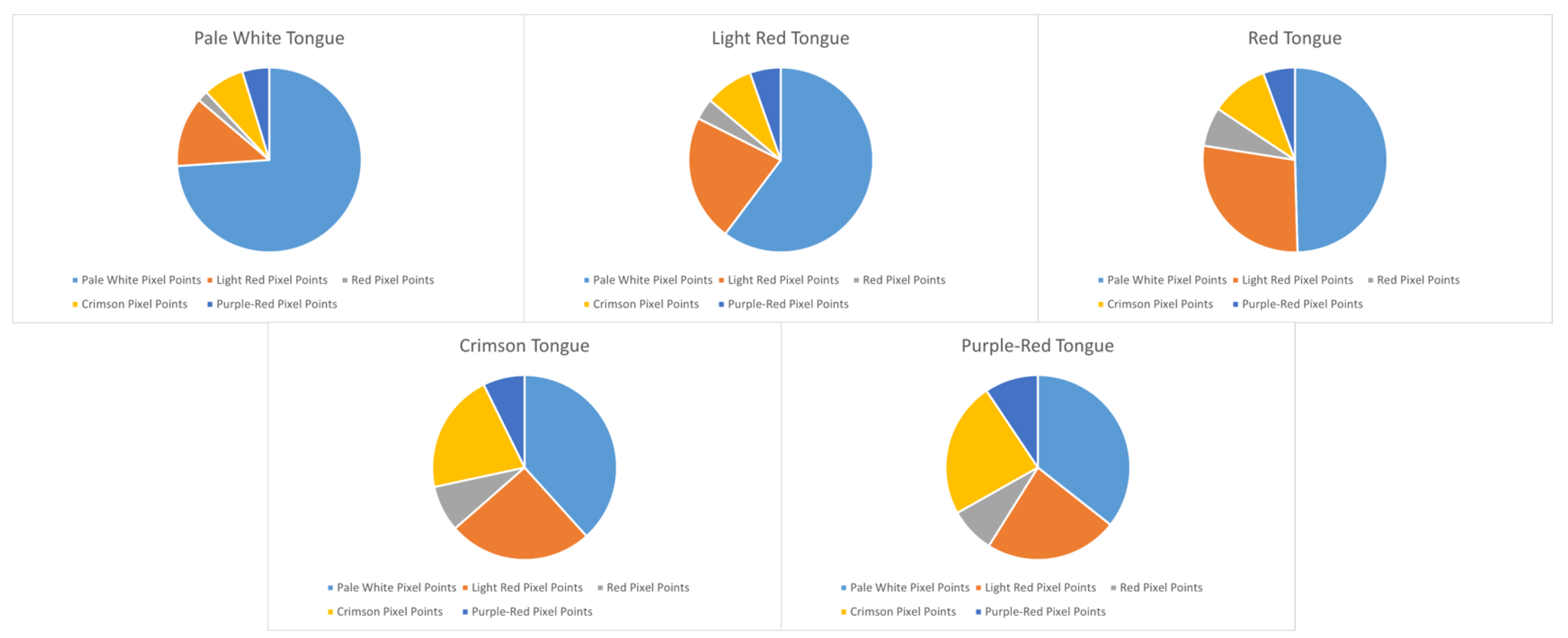

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TongueSet1 | TongueSet2 | TongueSet3 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| IoU | DSC | Acc | IoU | DSC | Acc | IoU | DSC | Acc | |
| U-Net | 0.8598 | 0.9212 | 0.9691 | 0.8782 | 0.9296 | 0.9924 | 0.8316 | 0.8816 | 0.9160 |
| U-Net++ | 0.9453 | 0.9719 | 0.9883 | 0.8910 | 0.9303 | 0.9930 | 0.9049 | 0.9369 | 0.9625 |
| DeepLabv3 | 0.7962 | 0.8309 | 0.9388 | 0.9091 | 0.9523 | 0.9950 | 0.8149 | 0.8795 | 0.9082 |
| SATM | 0.9707 | 0.9800 | 0.9907 | 0.9801 | 0.9877 | 0.9961 | 0.9544 | 0.9629 | 0.9695 |
| SVM-CPU | SVM-GPU | CNN | |
|---|---|---|---|
| Accuracy | 0.92 | 0.92 | 0.91 |
| Precision | 0.94 | 0.93 | 0.91 |
| Recall | 0.92 | 0.92 | 0.90 |
| F1-score | 0.93 | 0.93 | 0.90 |
| Run time (s) | 22.01 | 3.72 | 40.21 |
| 0.001 | 0.01 | 0.1 | 1 | 10 | 100 | |
|---|---|---|---|---|---|---|
| MSE | 0.1979 | 0.1971 | 0.1960 | 0.2036 | 0.4455 | 1.5651 |
| Accuracy | 0.9162 | 0.9177 | 0.9180 | 0.9018 | 0.8673 | 0.8238 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, B.; Wang, Z.; Yu, K.; Wang, Y.; Zhang, H.; Song, T.; Yang, H. Research on Tongue Image Segmentation and Classification Methods Based on Deep Learning and Machine Learning. Information 2025, 16, 357. https://doi.org/10.3390/info16050357
Liu B, Wang Z, Yu K, Wang Y, Zhang H, Song T, Yang H. Research on Tongue Image Segmentation and Classification Methods Based on Deep Learning and Machine Learning. Information. 2025; 16(5):357. https://doi.org/10.3390/info16050357
Chicago/Turabian StyleLiu, Bin, Zeya Wang, Kang Yu, Yunfeng Wang, Haiying Zhang, Tingting Song, and Hao Yang. 2025. "Research on Tongue Image Segmentation and Classification Methods Based on Deep Learning and Machine Learning" Information 16, no. 5: 357. https://doi.org/10.3390/info16050357
APA StyleLiu, B., Wang, Z., Yu, K., Wang, Y., Zhang, H., Song, T., & Yang, H. (2025). Research on Tongue Image Segmentation and Classification Methods Based on Deep Learning and Machine Learning. Information, 16(5), 357. https://doi.org/10.3390/info16050357