


Making Images Speak: Human-Inspired Image Description Generation

Abstract
1. Introduction
2. Materials and Methods
2.1. Image Feature Extraction
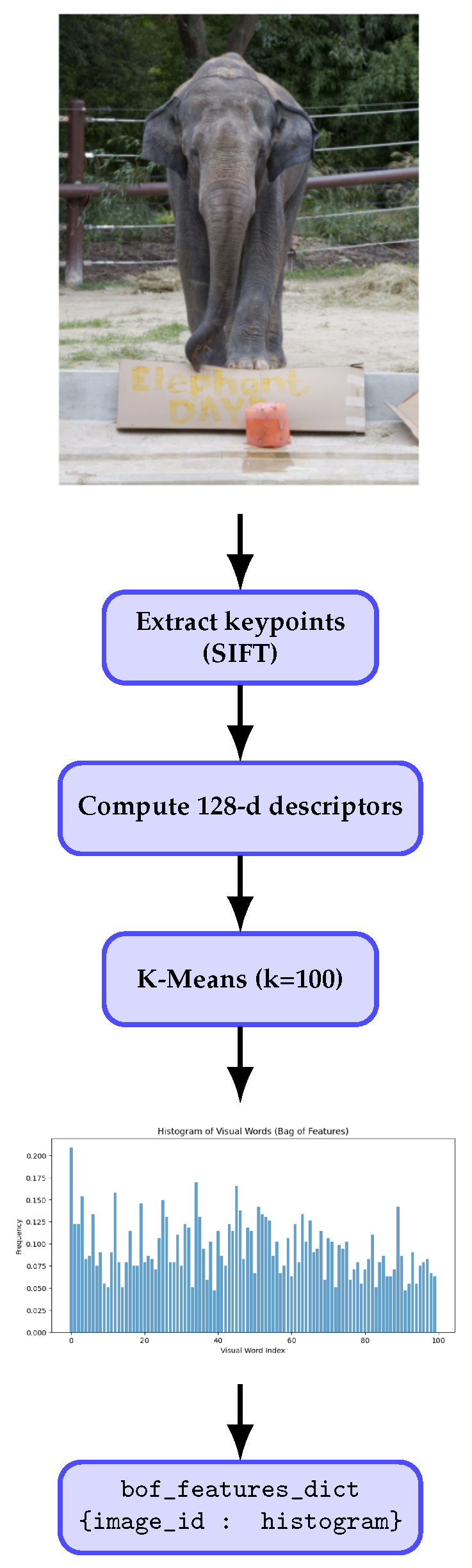
2.1.1. SIFT-Based Local Feature Extraction and Bag of Features Representation
SIFT for Local Feature Extraction
Descriptor Computation and BoF
2.1.2. ResNet50-Based Global Feature Extraction
Feature Processing Pipeline
- Preprocessing: All images are resized to 256 × 256 and normalized according to ResNet50’s training specifications.
- Extraction: Using ‘include_top=False’, we discard the fully connected layers and retain the final convolutional block, which produces an (8 × 8 × 2048) feature map encapsulating global semantics.
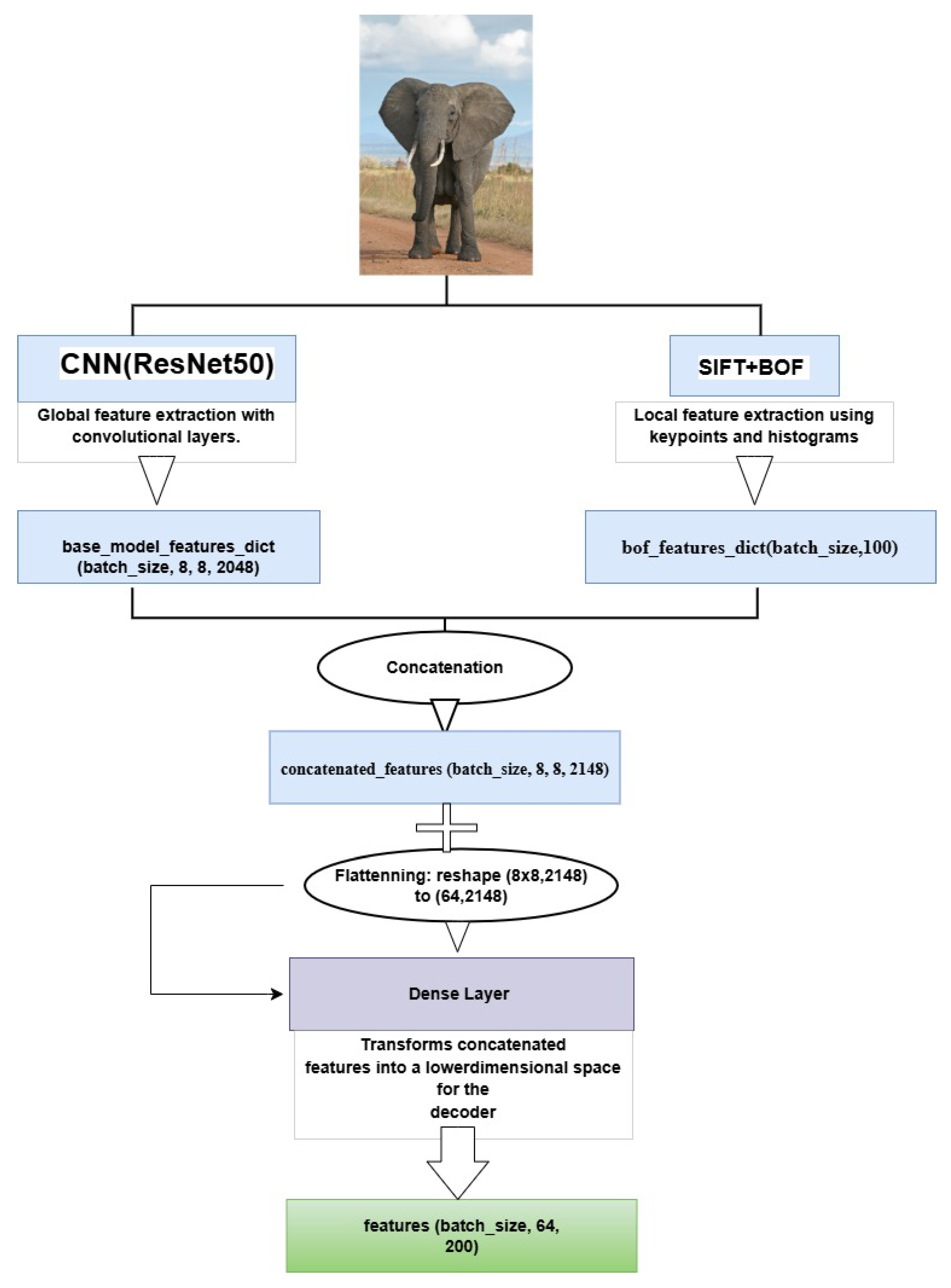
2.1.3. Feature Fusion and Alignment for Image Captioning
- Tiling (Alignment): The 1D BoF histogram is replicated to match ResNet50’s spatial resolution (e.g., 8 × 8), preserving its original frequency distribution without introducing additional learnable parameters.
- Channel Concatenation: The tiled BoF is concatenated along the channel dimension of the ResNet50 feature map (e.g., channels), merging local descriptors and global context into a single 3D tensor.
- Reshaping for Decoder Input: The resulting tensor is then flattened into a matrix to ensure compatibility with the attention-based decoder.
2.2. Data Preparation and Batch Construction
2.2.1. Image–Caption Mapping
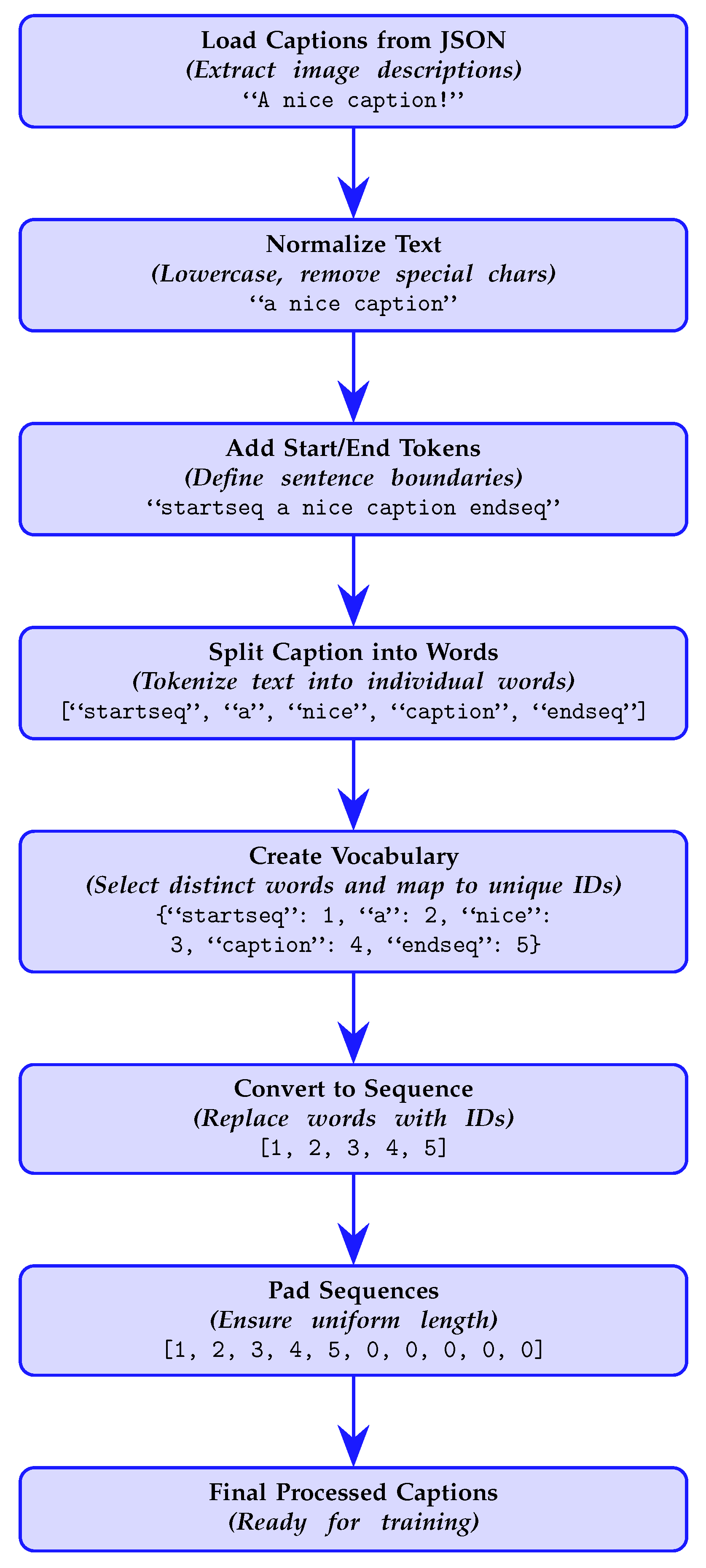
2.2.2. Text Preprocessing and Tokenization
- Before training: It converted raw captions into structured numerical sequences, ensuring consistent word representation.
- During caption generation: When the decoder predicted a word index, the Tokenizer mapped it back to the corresponding word to reconstruct a human-readable sentence.
2.2.3. Feature–Caption Alignment
2.2.4. Train–Test Splitting
- Training set: 200,000 image–caption pairs.
- Validation set: 50,000 image–caption pairs.
2.2.5. Optimized Batch Pipeline with TensorFlow
- Mapping: A custom function, map, is used to retrieve image features from the feature_dict and corresponding captions, casting all tensors to float32 for GPU compatibility.
- Dataset construction: A generator pipeline is built using tf.numpy_function, allowing for efficient data processing and integration with TensorFlow’s data pipeline.
- Shuffling and batching: The data is shuffled with a buffer size of 1000 and batched with a size of 64 to ensure balanced and efficient training.
- Prefetching: tf.data.experimental.AUTOTUNE is used to minimize idle GPU time and ensure that data is prepared ahead of time for the training process.
Batch Shapes
- Image features: . Each image is divided into 64 spatial patches (e.g., following an grid), and a hybrid feature vector of 2148 dimensions is extracted for each patch. This high-dimensional representation results from the concatenation of handcrafted local descriptors (SIFT) with deep visual features obtained from a pretrained ResNet50. By combining both local texture cues and semantic content, this representation provides a rich multimodal embedding of the visual input. Hence, the resulting shape per batch is , where 64 is the batch size, 64 the number of patches per image, and 2148 the feature dimensionality per patch.
- Captions: , representing the tokenized and padded textual sequences corresponding to each image.
2.3. Model Details
2.3.1. Encoder Architecture and Functionality
Dense Layer Functionality
Leaky ReLU Activation
Role in Caption Generation
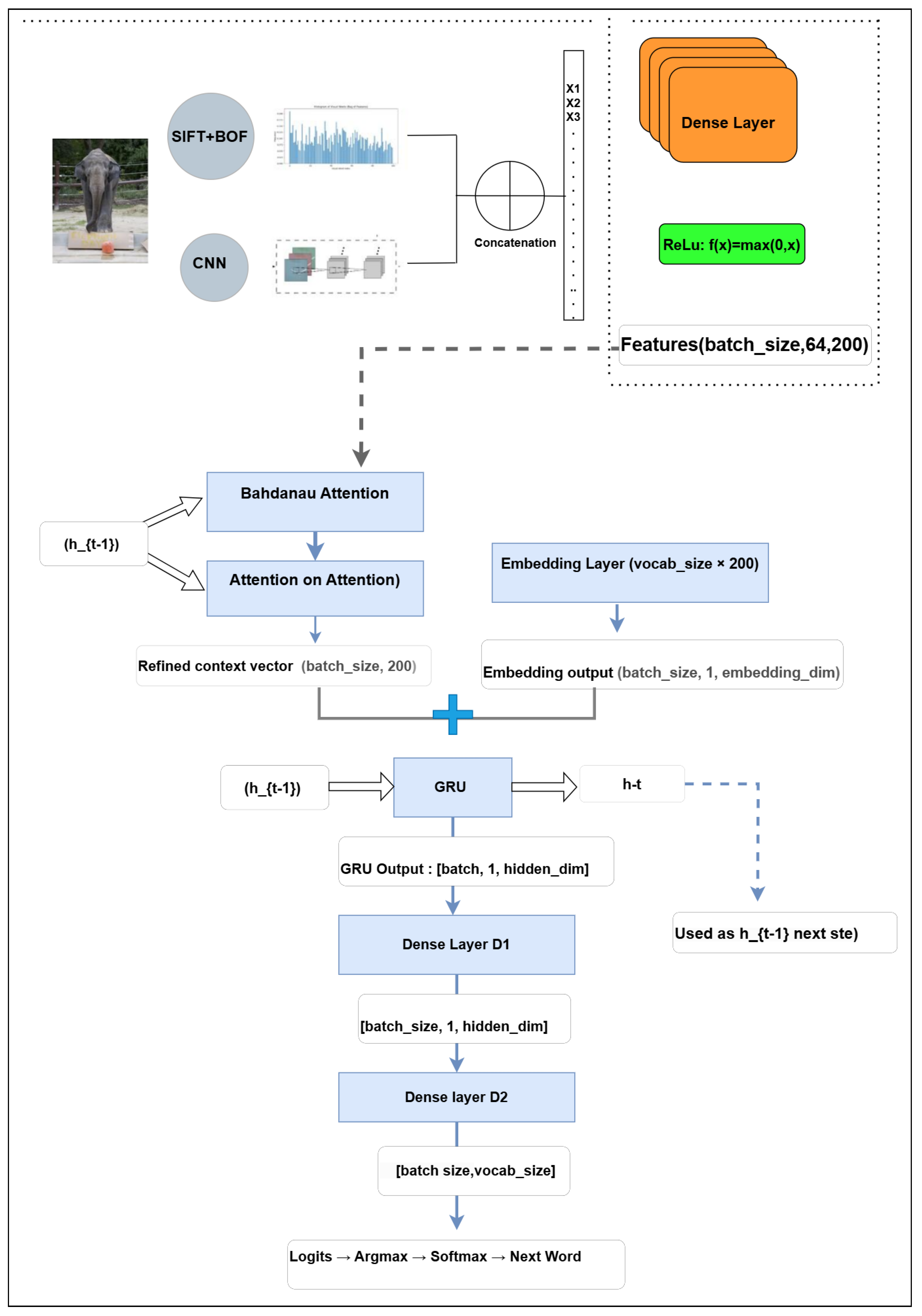
2.3.2. Decoder Architecture
Embedding Layer Preparation Using Pre-Trained GloVe Embeddings
- Load the vectors into an embeddings_index dictionary for efficient retrieval.
- Create an embedding_matrix of shape (vocab_size, embedding_dim), initialized with zeros.
- For each vocabulary word, insert its GloVe vector into the matrix; retain the zero vector if the word is not found.
- Training phase: Inputs are ground-truth word indices from the target captions.
- Inference phase: Inputs are word indices generated at the previous decoding step.
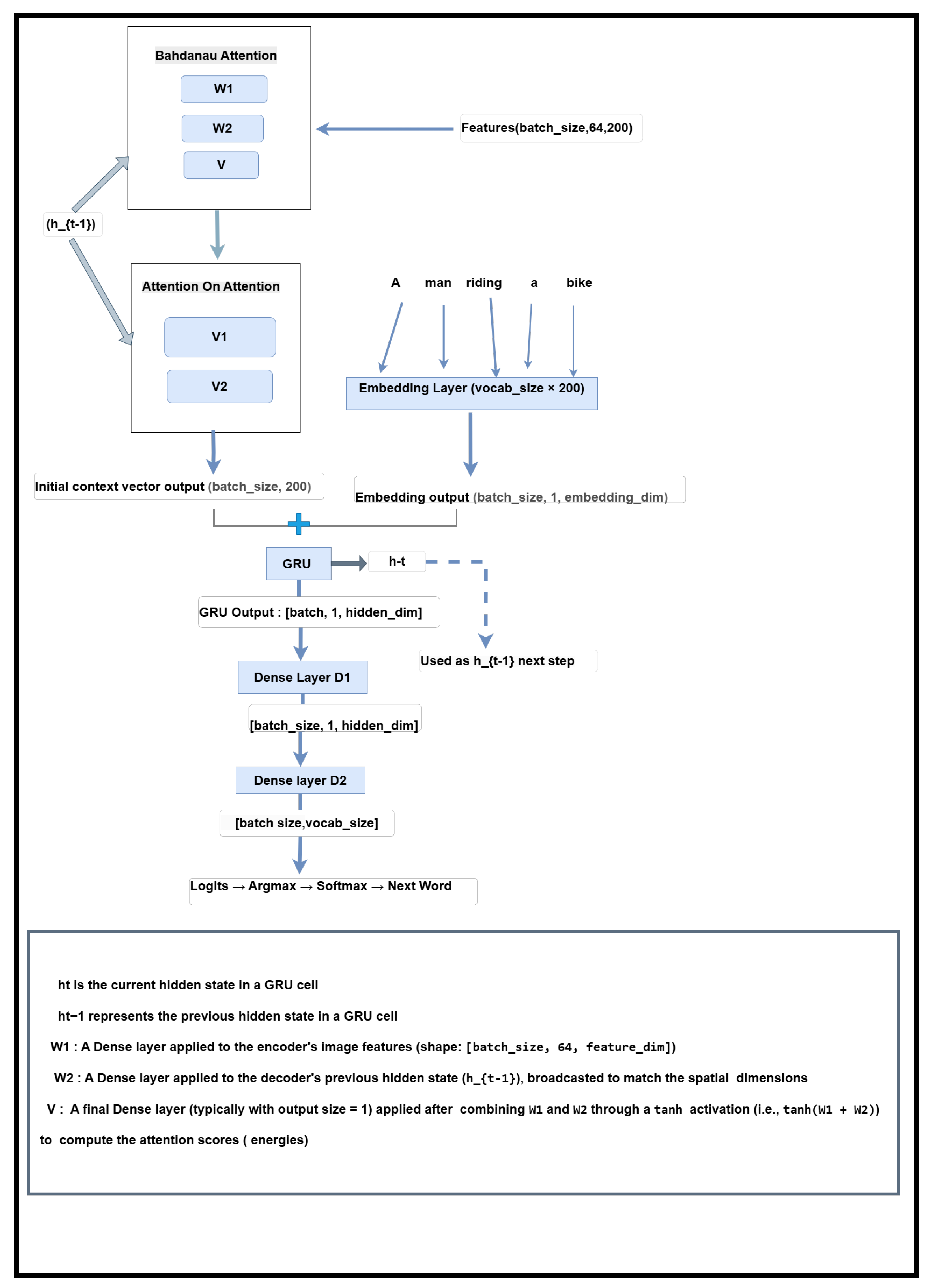
Enhanced Decoder with Bahdanau and Attention on Attention Mechanisms
- Improved feature selection: Irrelevant visual cues are more effectively suppressed.
- Enhanced fluency and coherence: Captions are more semantically consistent.
- Better modeling of object interactions: Particularly useful for complex, multi-object scenes.
- BLEU-4: 38.00 (vs. 0.19)
- CIDEr: 128.3 (vs. 12.89)
- ROUGE: 66.00 (vs. 21.61)
Recurrent Layer (GRU)—Details
- Refined context vector: produced by the AoA mechanism, summarizing salient visual features. Shape: (batch_size, embedding_dim).
- Embedded input word: representing the current token—either a ground-truth word (during training) or a previously generated one (during inference). Shape: (batch_size, 1, embedding_dim).
- Output vector (): a fused representation used by the dense layers for next-word prediction. Shape: (batch_size, 1, units).
- Hidden state (): a vector of shape (batch_size, units) that maintains temporal memory throughout caption generation.
Transition from GRU to Dense Layers in Decoder
- : GRU hidden state at time step t;
- , : learnable parameters;
- : non-linear activation function (e.g., ReLU);
- : refined representation.
- , : trainable parameters;
- : unnormalized logits over the vocabulary.
Data Processing Workflow in the Decoder (Summary)
- Inputs: The decoder receives:
- the current token x (ground truth during training, or the previous prediction during inference),
- the encoded image features from the encoder,
- and the current hidden state (initialized to zeros at the first decoding step).
- Attention Processing: Bahdanau attention computes an initial context vector by aligning the image features with the decoder’s hidden state. This context is then further refined via the Attention on Attention (AoA) module, enhancing focus on the most relevant visual regions.
- Embedding and Input Fusion: The input token x is embedded using a pre-trained GloVe-based embedding layer. The embedding is concatenated with the refined visual context (after expanding its temporal dimension), forming the input to the GRU layer.
- GRU and Vocabulary Projection: The GRU processes this fused input, updating its internal state and generating an output vector. This output is then passed through two dense layers, and , which project it into the vocabulary space. Finally, softmax is applied to obtain a probability distribution over possible next words.
2.4. Implementation Details
2.5. Training Strategy
2.5.1. Handling Padding and Custom Loss Function
2.5.2. Training and Evaluation Procedures
- Training: The train_step function is responsible for optimizing the model’s parameters. For each batch, it resets the decoder’s hidden state, feeds the ground truth captions word by word (teacher forcing), and computes the loss between the predicted and actual words at each time step. The total loss is then backpropagated to update the model weights. This step does not generate full image descriptions but helps the model learn to do so by improving its internal representations.
- Evaluation: The test_step function mirrors the training step but without any weight updates. It calculates the loss on the validation set using the model’s current parameters, providing a measure of generalization. The validation loss is monitored across epochs, and the model checkpoint with the lowest validation loss is saved automatically to preserve the best-performing version of the model.
2.5.3. Two-Phase Training and Checkpoint-Based Performance Monitoring
- Phase 1 (Epochs 1–20): The model is trained from scratch. Checkpoints are saved whenever a new lowest validation loss is observed, ensuring progressive refinement based on actual performance.
- Phase 2 (Epochs 21–40): Training resumes from the best checkpoint obtained in Phase 1. This fine-tuning stage allows the model to further optimize its representations while minimizing overfitting risks.
2.5.4. Robustness and Error Management
- Resource Management: The phased training strategy distributes computation over two stages, reducing memory overheads and mitigating resource exhaustion.
- Input Validation: Data integrity checks are applied to filter out erroneous captions, ensuring high-quality inputs for training.
- Padding Masking: The custom loss function ensures that training focuses solely on meaningful sequences, improving model precision.
2.6. Caption Generation Process
- Decoder Initialization: The decoder’s internal state is reset using reset_state(batch_ size=1) to prepare for caption generation.
- Local Feature Extraction (SIFT + K-Means):
- extract_sift_features(image_path) extracts keypoint descriptors using the SIFT algorithm.
- K-Means clustering transforms these descriptors into visual words, forming a Bag of Features (BoF) histogram.
- Global Feature Extraction (CNN): High-level semantic features are extracted using a pre-trained CNN via extract_base_model_features(image_path, new_base_model).
- Feature Preparation:
- Both feature types (BoF and CNN) are reshaped and aligned using np.tile() and np.reshape().
- Features are concatenated using np.concatenate() to create a unified representation.
- This combined feature tensor is fed into the encoder for dimensionality reduction.
- Caption Decoding:
- The decoding process begins with the special start token (startseq).
- The decoder, equipped with Bahdanau Attention, AoA, and a GRU, generates one word at a time.
- Generation continues until the endseq token is predicted.
- Output: The resulting caption is returned either as a list of words or as a TensorFlow tensor.
3. Results
3.1. Dataset Overview and Experimental Setup
3.2. Quantitative Performance Comparison Across Datasets
3.2.1. MS COCO Results Analysis

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Model | BLEU-1 (%) | BLEU-4 (%) | ROUGE (%) | CIDEr (%) | METEOR (%) |
|---|---|---|---|---|---|---|
| MS COCO | Our Model | 92.04 | 38.00 | 66.00 | 128.3 | 35.00 |
| SIFT + BoF + VGG16 + GloVe + Bahdanau + GRU (Baseline) | 12.94 | 0.19 | 21.61 | 12.89 | 7.34 | |
| Show, Attend and Tell [25] | 71.8 | 25.0 | - | - | 23.04 | |
| Attention on Attention [26] | 78.7 | 38.1 | 58.8 | 129.8 | - | |
| Bottom-Up and Top-Down [53] | 95.2 | 36.9 | 57.1 | 117.9 | 27.6 | |
| Semantic Attention [54] | 91.0 | 53.4 | 66.7 | 168.5 | 34.1 | |
| Adaptive Attention [55] | 74.2 | 33.2 | 54.9 | 108.5 | 26.6 | |
| GCN-LSTM [56] | 80.5 | 38.2 | 58.3 | 127.6 | 28.5 | |
| ViT-Attn [57] | - | 28.69 | - | 88.79 | 45.81 | |
| ViT-CNN-Attn [57] | - | 31.24 | - | 95.30 | 46.98 | |
| Object-Semantic Transformer [58] | 80.0 | 37.7 | 58.5 | 132.0 | 28.9 |
3.2.2. Flickr8K Results Analysis
3.3. Qualitative Evaluation of Caption Generation on the MS COCO and Flickr8K Datasets
4. Discussion and Conclusions
- Long-Range Dependency Modeling: GRUs are effective for local context but less suitable for capturing global dependencies. Replacing the decoder with a Transformer-based module may improve handling of complex spatial and semantic relationships.
- Attention Error Propagation: Misaligned initial attention from Bahdanau may propagate through AoA. Incorporating cross-modal regularization or uncertainty-aware mechanisms could help mitigate this.
- Feature Fusion Redundancy: Concatenating high-dimensional ResNet and BoF features can introduce redundancy. Adaptive gating or dimensionality reduction strategies may optimize this fusion.
- Generic or Repetitive Captions: Some outputs are overly generic due to dataset biases or decoder limitations. Techniques like diverse beam search or adversarial training could foster output diversity.
- Inference Overhead: The dual-attention mechanism introduces computational cost. Lightweight alternatives, such as attention pruning or knowledge distillation, could improve deployment feasibility.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Additional Captions Generated by the Proposed Method: Unseen Examples from the MS COCO and Flickr8K Datasets
Appendix A.1. Generated Captions for Unseen Images from the MS COCO Test Set








Appendix A.2. Generated Captions for Unseen Images from the Flickr8K Test Set







Appendix B. Comparison of Generated Captions (Our Model vs. Baseline: SIFT + BoF + VGG16 + GloVe + Bahdanau + GRU)
| Image | Baseline | Our Approach |
|---|---|---|
 | puppy figure. | The dog is standing in front of a fence in a grassy yard. |
 | a man stands in snow covered mountain house. | A group of people in snow skis. |
 | a young child is sitting outdoors. | A young child sitting in a car. |
 | a group of kids look on a couch. | A group of people are standing around a long wooden table with a group of people watch. |
| Image | Baseline | Our Approach |
|---|---|---|
 | a large tower with a clock tower | A large stone clock tower |
 | a man and woman staining looking at their phones | A couple of people standing in front of a wine glass |
References
- Gurari, D.; Zhao, Y.; Zhang, M.; Bhattacharya, N.; Bigham, J.P.; Grauman, K. Captioning Images Taken by People Who Are Blind. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 417–434. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Hossain, M.Z.; Sohel, F.; Shiratuddin, M.F.; Laga, H. A Comprehensive Survey of Deep Learning for Image Captioning. ACM Comput. Surv. (CSUR) 2019, 51, 1–36. [Google Scholar] [CrossRef]
- Mallat, S. A Theory for Multiresolution Signal Decomposition: The Wavelet Representation. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 674–693. [Google Scholar] [CrossRef]
- Daubechies, I. Ten Lectures on Wavelets; Society for Industrial and Applied Mathematics (SIAM): Philadelphia, PA, USA, 1992. [Google Scholar] [CrossRef]
- Rabiner, L.R. A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the Seventh IEEE International Conference on Computer Vision (ICCV), Corfu, Greece, 20–25 September 1999; pp. 1150–1157. [Google Scholar] [CrossRef]
- Csurka, G.; Dance, C.R.; Fan, L.; Willamowski, J.; Bray, C. Visual Categorization with Bags of Keypoints. In Proceedings of the ECCV Workshop on Statistical Learning in Computer Vision, Prague, Czech Republic, 16 May 2004; pp. 1–22. [Google Scholar]
- Farhadi, A.; Hejrati, M.; Sadeghi, M.A.; Young, P.; Rashtchian, C.; Hockenmaier, J.; Forsyth, D. Every Picture Tells a Story: Generating Sentences from Images. In Proceedings of the 11th European Conference on Computer Vision (ECCV 2010), Heraklion, Crete, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 15–29. [Google Scholar] [CrossRef]
- Kulkarni, G.; Premraj, V.; Ordonez, V.; Dhar, S.; Li, S.; Choi, Y.; Berg, A.C.; Berg, T.L. BabyTalk: Understanding and Generating Simple Image Descriptions. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2891–2903. [Google Scholar] [CrossRef]
- Mnih, A.; Hinton, G.E. Three New Graphical Models for Statistical Language Modelling. In Proceedings of the 24th International Conference on Machine Learning (ICML 2007); ACM: New York, NY, USA, 2007; pp. 641–648. [Google Scholar] [CrossRef]
- Kiros, R.; Salakhutdinov, R.; Zemel, R.S. Multimodal Neural Language Models. In Proceedings of the 31st International Conference on Machine Learning (ICML), Beijing, China, 21–26 June 2014; pp. II-595–II-603. Available online: https://dl.acm.org/doi/10.5555/3044805.3044959 (accessed on 19 March 2025).
- Kiros, R.; Salakhutdinov, R.; Zemel, R. Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models. arXiv 2014, arXiv:1411.2539. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. Available online: https://aclanthology.org/D14-1179 (accessed on 19 March 2025).
- Mikolov, T.; Karafiát, M.; Burget, L.; Černocký, J.; Khudanpur, S. Recurrent Neural Network Based Language Model. Proc. Interspeech 2010, 2, 1045–1048. Available online: https://www.isca-speech.org/archive/interspeech_2010/mikolov10_interspeech.html (accessed on 19 March 2025).
- Mao, J.; Xu, W.; Yang, Y.; Wang, J.; Huang, Z.; Yuille, A. Learning Like a Child: Fast Novel Visual Concept Learning from Sentence Descriptions of Images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 2533–2541. Available online: https://openaccess.thecvf.com/content_iccv_2015/papers/Mao_Learning_Like_a_ICCV_2015_paper.pdf (accessed on 19 March 2025).
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and Tell: A Neural Image Caption Generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NeurIPS 2015), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. Available online: https://proceedings.neurips.cc/paper_files/paper/2015/file/14bfa6bb14875e45bba028a21ed38046-Paper.pdf (accessed on 19 March 2025).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Karpathy, A.; Fei-Fei, L. Deep Visual-Semantic Alignments for Generating Image Descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Huang, L.; Wang, W.; Chen, J.; Wei, X.Y. Attention on Attention for Image Captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4634–4643. [Google Scholar] [CrossRef]
- Al-Malla, M.A.; Jafar, A.; Ghneim, N. Image Captioning Model Using Attention and Object Features to Mimic Human Image Understanding. J. Big Data 2022, 9, 20. [Google Scholar] [CrossRef]
- Fang, H.; Deng, L.; Mitchell, M.; Gupta, S.; Dollár, P.; Platt, J.C.; Iandola, F.; Gao, J.; Zitnick, C.L.; Srivastava, R.K.; et al. From Captions to Visual Concepts and Back. arXiv 2015, arXiv:1411.4952v3. [Google Scholar]
- Yang, X.; Wang, Y.; Wang, Z.; Xu, Y.; Bai, X.; Bai, S. Auto-Encoding Scene Graphs for Image Captioning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10685–10694. [Google Scholar] [CrossRef]
- Xu, D.; Zhu, Y.; Choy, C.B.; Fei-Fei, L. Scene Graph Generation by Iterative Message Passing. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5410–5419. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient Graph-Based Image Segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. Available online: https://arxiv.org/abs/2010.11929 (accessed on 19 March 2025).
- Liu, W.; Chen, S.; Guo, L.; Zhu, X.; Liu, J. CPTR: Full Transformer Network for Image Captioning. arXiv 2021, arXiv:2101.10804. Available online: https://arxiv.org/abs/2101.10804 (accessed on 19 March 2025).
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the International Conference on Machine Learning (ICML), Virtual, 18–24 July 2021; Available online: https://arxiv.org/abs/2103.00020 (accessed on 19 March 2025).
- OpenAI. GPT-4V(ision): Extending GPT-4 to Multimodal Inputs. OpenAI Technical Report, 2023. Available online: https://cdn.openai.com/papers/gpt-4.pdf (accessed on 12 October 2023).
- Alayrac, J.B.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Hasson, Y.; Lenc, K.; Mensch, A.; Millican, K.; Reynolds, M.; et al. Flamingo: A Visual Language Model for Few-Shot Learning. Adv. Neural Inf. Process. Syst. 2022, 35, 23716–23736. [Google Scholar]
- Kalimuthu, M.; Mogadala, A.; Mosbach, M.; Klakow, D. Fusion Models for Improved Visual Captioning. arXiv 2020, arXiv:2010.15251. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 1532–1543. Available online: https://aclanthology.org/D14-1162 (accessed on 19 March 2025).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- MacQueen, J.B. Some Methods for Classification and Analysis of Multivariate Observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 21 June–18 July 1965 and 27 December 1965–7 January 1966; University of California Press: Oakland, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. Available online: https://arxiv.org/abs/1409.1556 (accessed on 12 July 2021).
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier Nonlinearities Improve Neural Network Acoustic Models. In Proceedings of the 30th International Conference on Machine Learning (ICML 2013), Workshop on Deep Learning for Audio, Speech and Language Processing, Atlanta, GA, USA, 16–21 June 2013; Available online: https://ai.stanford.edu/~amaas/papers/relu_hybrid_icml2013_final.pdf (accessed on 19 March 2025).
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. Available online: https://aclanthology.org/N19-1423 (accessed on 19 March 2025).
- Quadrai. Image Captioning with Attention, ResNet and GloVe. Available online: https://www.kaggle.com/code/quadrai/image-captioning-with-attention-resnet-and-glove (accessed on 19 March 2025).
- Anundskås, L.H.; Afridi, H.; Tarekegn, A.N.; Yamin, M.M.; Ullah, M.; Yamin, S.; Cheikh, F.A. GloVe-Ing Attention: A Multi-Modal Neural Learning Approach to Image Captioning. In Proceedings of the 2023 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), Rhodes Island, Greece, 4–9 June 2023. [Google Scholar] [CrossRef]
- Muškardin, E.; Tappler, M.; Pill, I.; Aichernig, B.K.; Pock, T. On the Relationship Between RNN Hidden-State Vectors and Semantic Structures. In Findings of the Association for Computational Linguistics: ACL 2024; Association for Computational Linguistics: Bangkok, Thailand, 2024; pp. 5641–5658. Available online: https://aclanthology.org/2024.findings-acl.335/ (accessed on 22 February 2024).
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Banerjee, S.; Lavie, A. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures; Association for Computational Linguistics: Ann Arbor, MI, USA, 2005; pp. 65–72. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out: Proceedings of the ACL Workshop; Association for Computational Linguistics: Ann Arbor, MI, USA, 2004; pp. 74–81. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. CIDEr: Consensus-Based Image Description Evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar] [CrossRef]
- Anderson, P.; Fernando, B.; Johnson, M.; Gould, S. SPICE: Semantic Propositional Image Caption Evaluation. In European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2016; pp. 382–398. [Google Scholar] [CrossRef]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6077–6086. Available online: https://openaccess.thecvf.com/content_cvpr_2018/papers/Anderson_Bottom-Up_and_Top-Down_CVPR_2018_paper.pdf (accessed on 15 July 2023).
- You, Q.; Jin, H.; Wang, Z.; Fang, C.; Luo, J. Image Captioning with Semantic Attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4651–4659. [Google Scholar]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing When to Look: Adaptive Attention via a Visual Sentinel for Image Captioning. arXiv 2017, arXiv:1612.01887. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Exploring Visual Relationship for Image Captioning. arXiv 2018, arXiv:1809.07041. [Google Scholar]
- Cahyono, J.A.; Jusuf, J.N. Automated Image Captioning with CNNs and Transformers. arXiv 2024, arXiv:2412.10511. [Google Scholar]
- Hafeth, D.A.; Kollias, S. Insights into Object Semantics: Leveraging Transformer Networks for Advanced Image Captioning. Sensors 2024, 24, 1796. [Google Scholar] [CrossRef]
- Al Badarneh, I.; Hammo, B.H.; Al-Kadi, O. An Ensemble Model with Attention-Based Mechanism for Image Captioning. Information 2023, 14, 56. Available online: https://www.mdpi.com/2078-2489/14/1/56 (accessed on 10 October 2024). [CrossRef]
- Jiang, L.; Zhang, Z.; Huang, Z.; Tan, T. Incorporating Copying Mechanism in Image Captioning for Learning Novel Objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5263–5271. Available online: https://openaccess.thecvf.com/content_cvpr_2017/papers/Yao_Incorporating_Copying_Mechanism_CVPR_2017_paper.pdf (accessed on 10 October 2024).
- Patel, A.; Lakhotia, K.; Jain, N.; Bhattacharyya, C. Diversity-Promoting GAN for Generating Natural Image Descriptions. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11635–11642. Available online: https://ojs.aaai.org/index.php/AAAI/article/view/6800 (accessed on 10 October 2024).
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. Available online: https://openaccess.thecvf.com/content/ICCV2021/papers/Liu_Swin_Transformer_Hierarchical_Vision_Transformer_Using_Shifted_Windows_ICCV_2021_paper.pdf (accessed on 19 March 2025).
| Dataset | Model | BLEU-1 (%) | BLEU-2 (%) | BLEU-3 (%) | BLEU-4 (%) | ROUGE-L (%) | METEOR (%) | CIDEr (%) | SPICE (%) |
|---|---|---|---|---|---|---|---|---|---|
| Flickr8K | Our Model (Current Approach) | 73.15 | 63.02 | 47.57 | 37.51 | 43.60 | 42.98 | 53.00 | 20.89 |
| Our Baseline 1: SIFT + VGG16 + BOF + Learned Embeddings + Bahdanau + LSTM | 59.57 | 47.24 | 39.33 | 33.78 | 43.54 | 20.34 | 17.98 | 11.63 | |
| Our Baseline 2: SIFT + BoF + VGG16 + GloVe Embeddings + Bahdanau + LSTM | 59.42 | 0.61 | 0.11 | 0.04 | 43.63 | 20.94 | 0.17 | 12.75 | |
| Al Badarneh et al. (2023) [59] | 72.80 | 49.50 | 32.30 | 20.80 | 43.20 | 23.50 | 60.40 | 16.40 | |
| Jiang et al. (2019) [60] | 69.00 | 47.10 | 32.40 | 21.90 | 50.20 | 20.30 | 50.70 | - | |
| Patel et al. (2020) [61] | 60.10 | 41.40 | 27.40 | 18.10 | 43.30 | 18.30 | 45.20 | - | |
| Google NIC [19] | 63.00 | 41.00 | 27.00 | - | - | - | - | - | |
| Log Bilinear [12] | 65.60 | 42.40 | 27.70 | 17.70 | - | 17.31 | - | - | |
| Soft-Attention [25] | 67.00 | 44.80 | 29.90 | 19.50 | - | 18.93 | - | - | |
| Hard-Attention [25] | 67.00 | 45.70 | 31.40 | 21.30 | - | 20.30 | - | - | |
| CF [38] | 64.50 | 46.70 | 32.70 | 22.80 | - | 21.30 | - | - |
| Image | Generated Caption |
|---|---|
 | A large stone clock tower. |
 | A Delta airline taking off from the airport. |
 | A man in a suit and tie standing next to a large group of people. |
 | A man and a woman standing in a living room. |
 | An elephant standing next to a rock, directing something. |
| Image | Generated Caption |
|---|---|
 | The dog is standing in front of a fence in a grassy yard. |
 | A group of people in snow skis. |
 | A group of people are standing around a long wooden table with a group of people watch. |
 | A young child sitting in a car. |
 | A sheep is standing on a lush green field. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sebbane, C.; Belhajem, I.; Rziza, M. Making Images Speak: Human-Inspired Image Description Generation. Information 2025, 16, 356. https://doi.org/10.3390/info16050356
Sebbane C, Belhajem I, Rziza M. Making Images Speak: Human-Inspired Image Description Generation. Information. 2025; 16(5):356. https://doi.org/10.3390/info16050356
Chicago/Turabian StyleSebbane, Chifaa, Ikram Belhajem, and Mohammed Rziza. 2025. "Making Images Speak: Human-Inspired Image Description Generation" Information 16, no. 5: 356. https://doi.org/10.3390/info16050356
APA StyleSebbane, C., Belhajem, I., & Rziza, M. (2025). Making Images Speak: Human-Inspired Image Description Generation. Information, 16(5), 356. https://doi.org/10.3390/info16050356