
Hybrid EEG Feature Learning Method for Cross-Session Human Mental Attention State Classification



Abstract
1. Introduction
- We propose a hybrid EEG feature learning framework for cross-session mental attention state classification, which integrates short-time Fourier transform (STFT) features with multiple brain connectivity representations, including functional and effective connectivity, enhanced through a two-stage feature selection strategy.
- We systematically investigate the influence of key signal segmentation parameters—such as window length and overlap ratio on classification performance—providing practical insights for EEG-based system design.
- Extensive experiments on two benchmark EEG datasets demonstrate the effectiveness of our method, achieving average accuracies of 84.3% and 96.61% for intra-subject cross-session classification, and 86.27% and 94.01% for inter-subject classification on Dataset 1 and Dataset 2, respectively, validating its generalizability under realistic conditions.
2. Related Works
2.1. EEG-Based Mental Attention State Experiments
2.2. Feature Engineering-Based Mental Attention State Classification
2.3. Deep Learning-Based Mental Attention States Classification
3. Materials and Methods
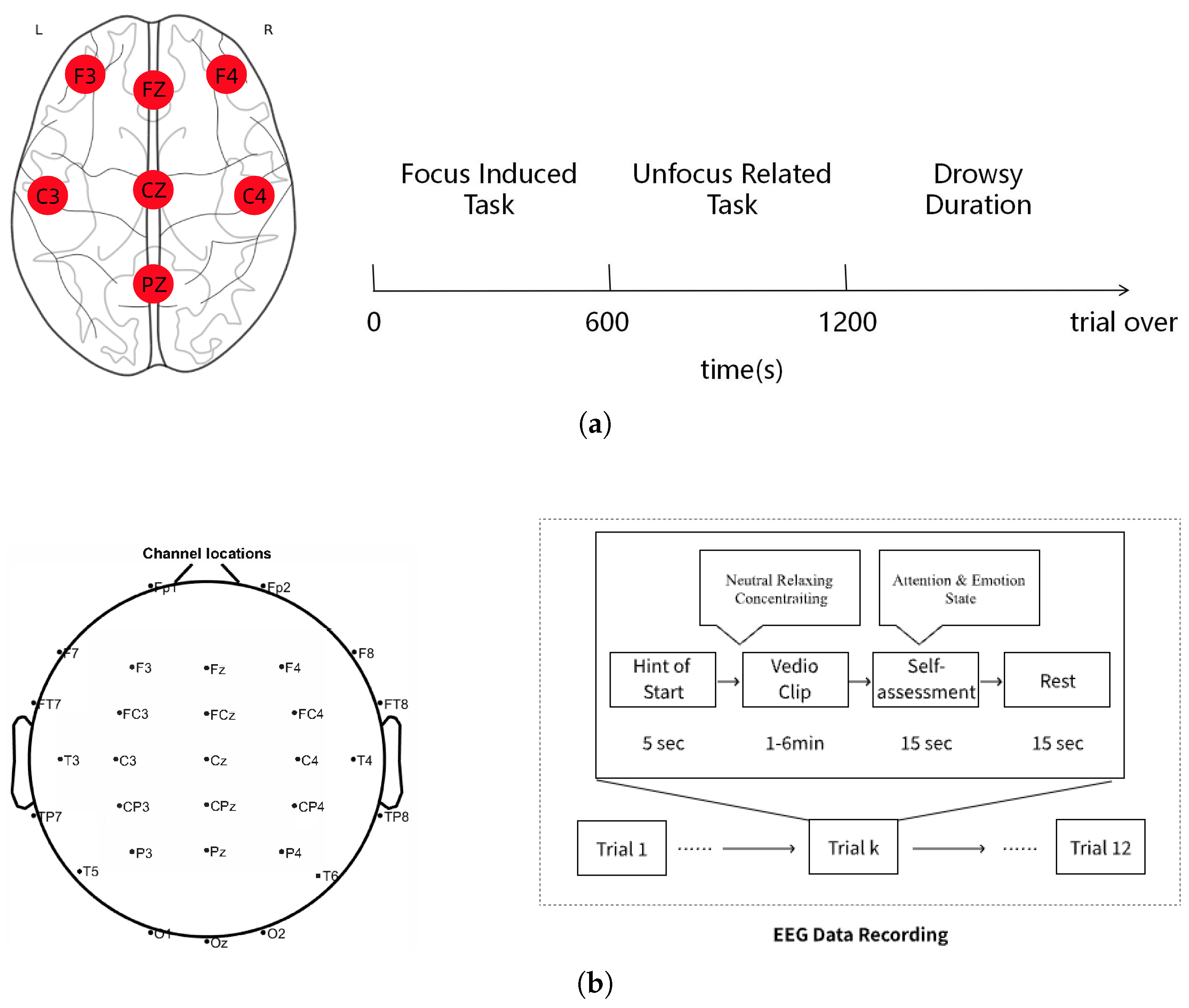
3.1. Dataset Description
3.2. Data Preprocessing
3.3. Feature Extraction
3.3.1. Brain Connectivity
- Structural Brain Connectivity Phase Locking Value (PLV) and Phase Lag Index (PLI) are widely employed metrics for quantifying phase synchronization between neural signals. PLV measures the consistency of phase locking between two time series within a given frequency band and temporal window [37], while PLI quantifies the asymmetry of phase differences, reflecting the directional consistency of phase lead or lag between signals [38].Let denote phase differences between two time series, and the is defined as follows:where denotes temporal averaging and N is the number of samples. A value approaching 1 indicates strong phase synchronization.The PLI is defined as follows:where sign denotes signum.In our work, the band width is determined based on the frequency range after filtering. The S index quantifies synchronization between two time series [39]. Given two simultaneously recorded signals and , delay phase-space embedding projects them into a higher-dimensional space using time-delay vectors:Delay phase-space vector is defined as follows:where d is the embedding dimension and the time delay.Let and denote the time indices of the k nearest neighbors of and . The mean Euclidean distance of to its k nearest neighbors isAdditionally, Y-conditioned mean squared Euclidean distance can be obtained:Then, the S index is defined as follows:An S index close to 1 indicates strong synchronization between x and y.
- Effective Brain ConnectivityTo assess directional influence between signals, Granger Causality (GC) determines whether past values of signal x improve prediction of signal y, indicating that x influences y [40,41]. Partial Directed Coherence (PDC) extends this by evaluating such influence across frequency bands [42].A Multivariate Autoregressive (MAR) model with M channels and order p is defined as follows:where are coefficient matrix, and denotes residuals. represents the vector of EEG signals for channel i at time k. In the MAR model, the value of each time series is expressible as a function of its own previous values and past values of all other time series involved.To compute GC, let and denote models using only and both and , respectively. The from to is defined as follows:By applying the Fourier transform to the MAR coefficients, the frequency-domain representation is obtained:The transfer function matrix is then defined as follows:Let , with being the -th element of , being the i-th column of the matrix . The from channel j to channel i is given by the following:For each sample, matrices were computed across multiple frequencies and averaged to form the final representation.
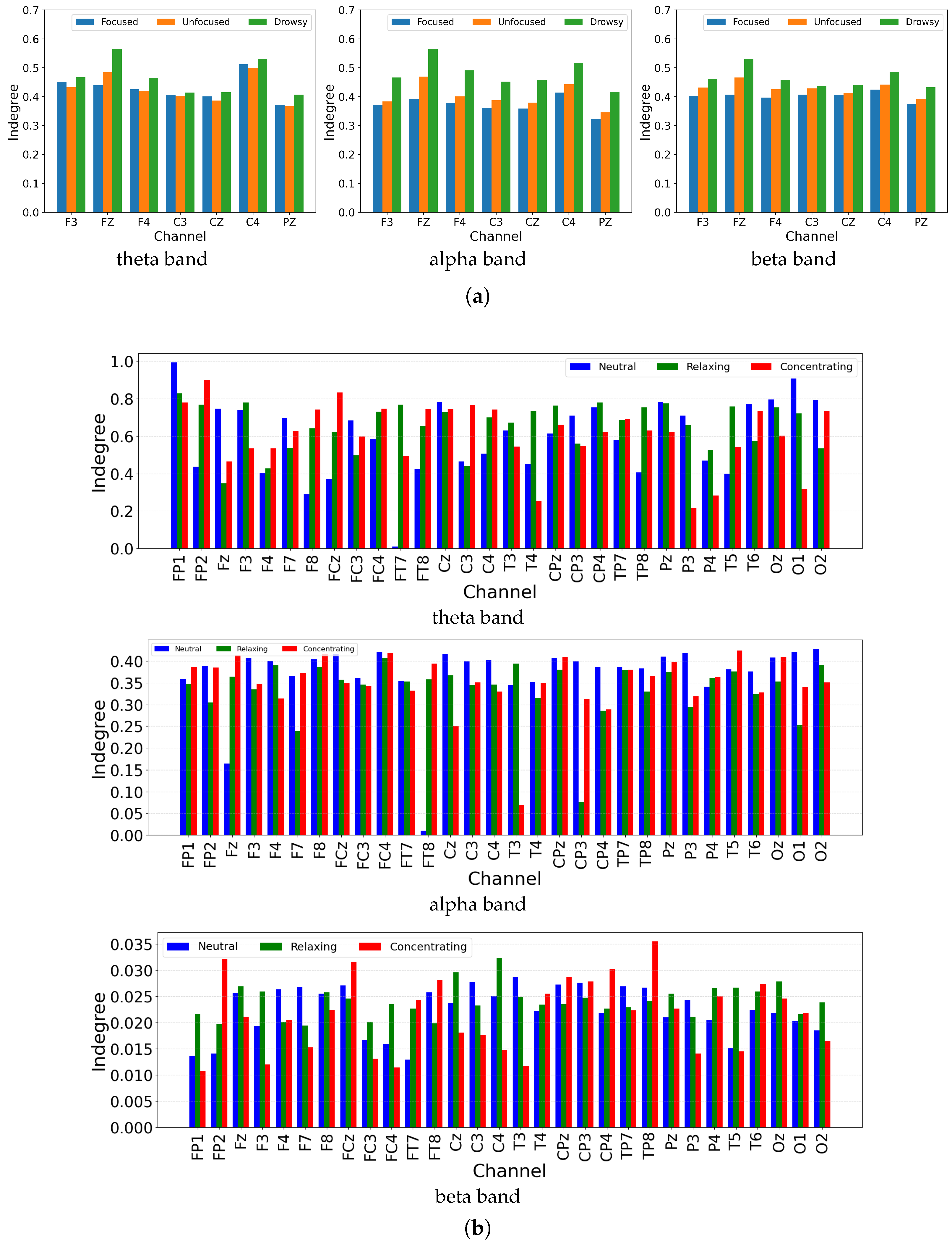
- Network PropertiesWe extracted five connectivity indicators—, , , , and S index—across three frequency bands (theta, alpha and beta), yielding 15 weighted connectivity matrices per trial (5 indicators × 3 bands). To derive global network features, each weighted matrix was thresholded at 130 linearly spaced values between 0 and 1. For each threshold, values above the threshold were binarized to form adjacency matrices, from which four graph-theoretic metrics were computed: global efficiency, local efficiency, clustering coefficient, and node degree. These metrics were aggregated (summed and averaged) across thresholds, resulting in 10 selected features per matrix, and a total of 150 global features (3 bands × 5 indicators × 10 features) for the dataset with 21 EEG channels. To capture local connectivity patterns and address potential feature sparsity, we also extracted the upper triangular elements (excluding the diagonal) from each original 21 × 21 weighted connectivity matrix, yielding 21 values per matrix and 315 local features in total (15 matrices × 21 values).The same processing pipeline was applied to Dataset 2 containing 32 EEG channels, ensuring consistency across datasets. Due to the increased number of nodes, the dimensionality of derived features increased accordingly. For each thresholded binary matrix, 35 graph-theoretic features were selected (expanding the metric set beyond the initial four), resulting in 525 global features (3 bands × 5 indicators × 35 features). Similarly, extracting the upper triangular values from each 32 × 32 weighted matrix yielded 496 values per matrix, leading to 7440 local connectivity features (15 matrices × 496 values).
3.3.2. STFT
3.3.3. Statistical Feature Construction
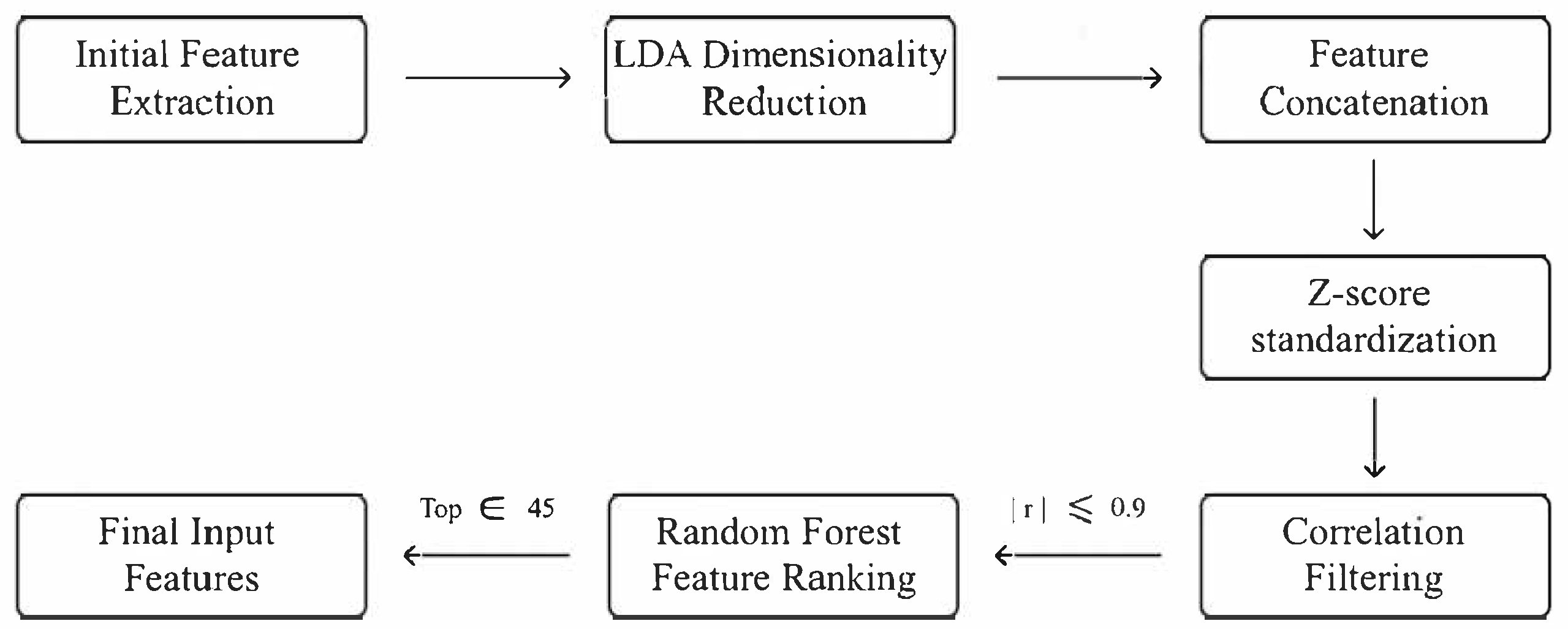
3.4. Feature Selection
3.5. Classifier
4. Results
4.1. Comparison with State-of-the-Art Methods
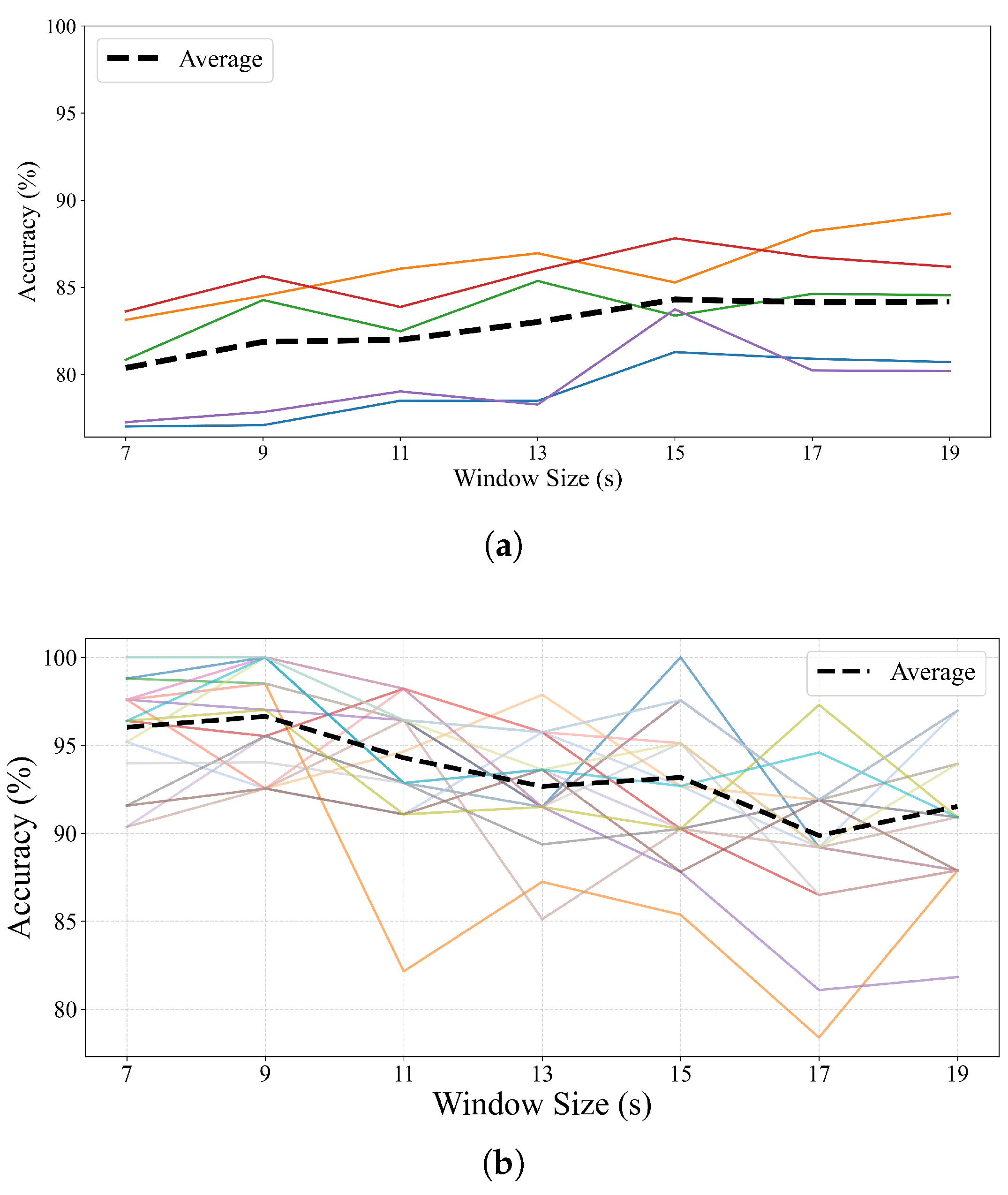
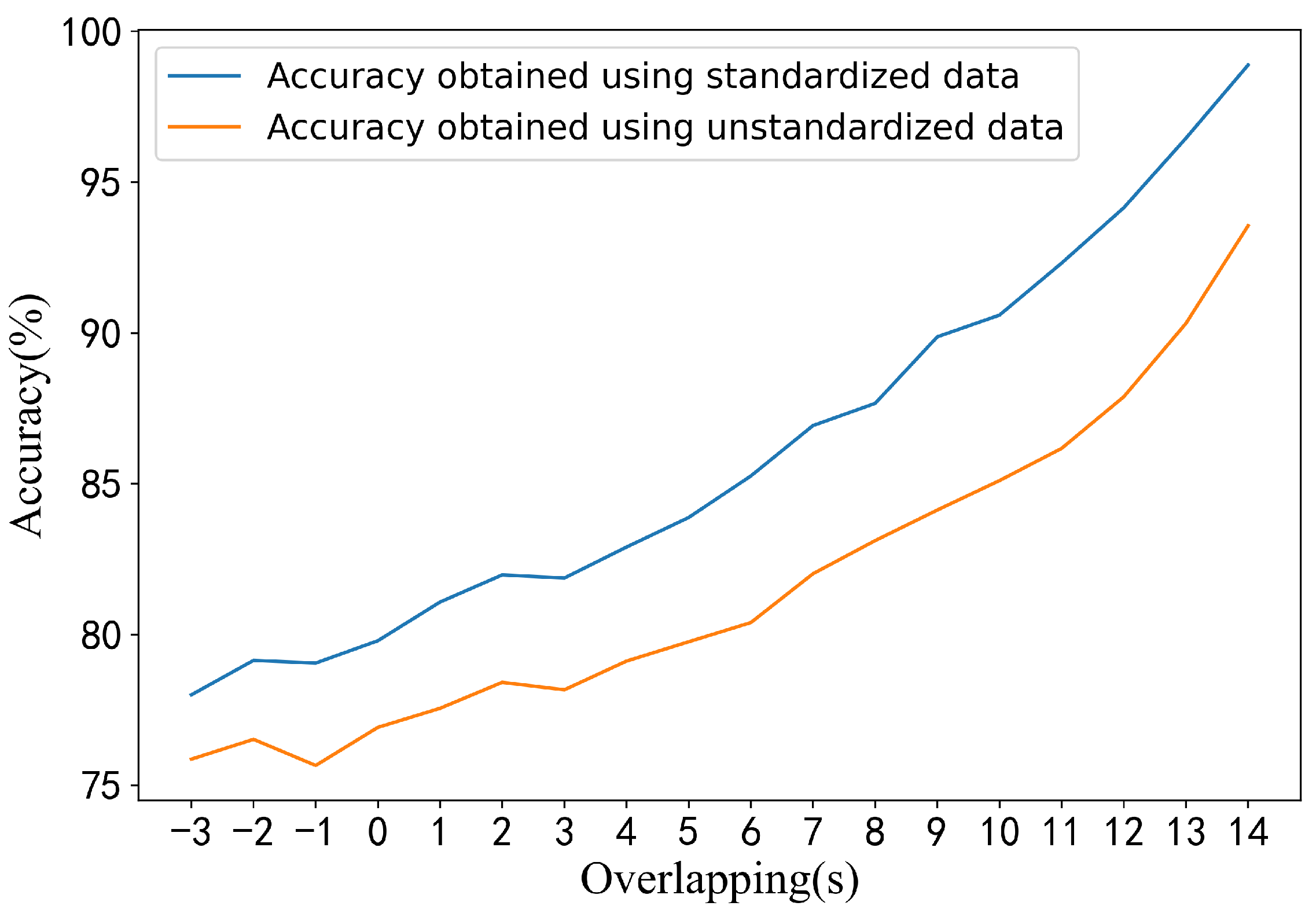
4.2. Effect of Window Size on Performance
4.3. Method Performance Without Data Shuffling
5. Discussion
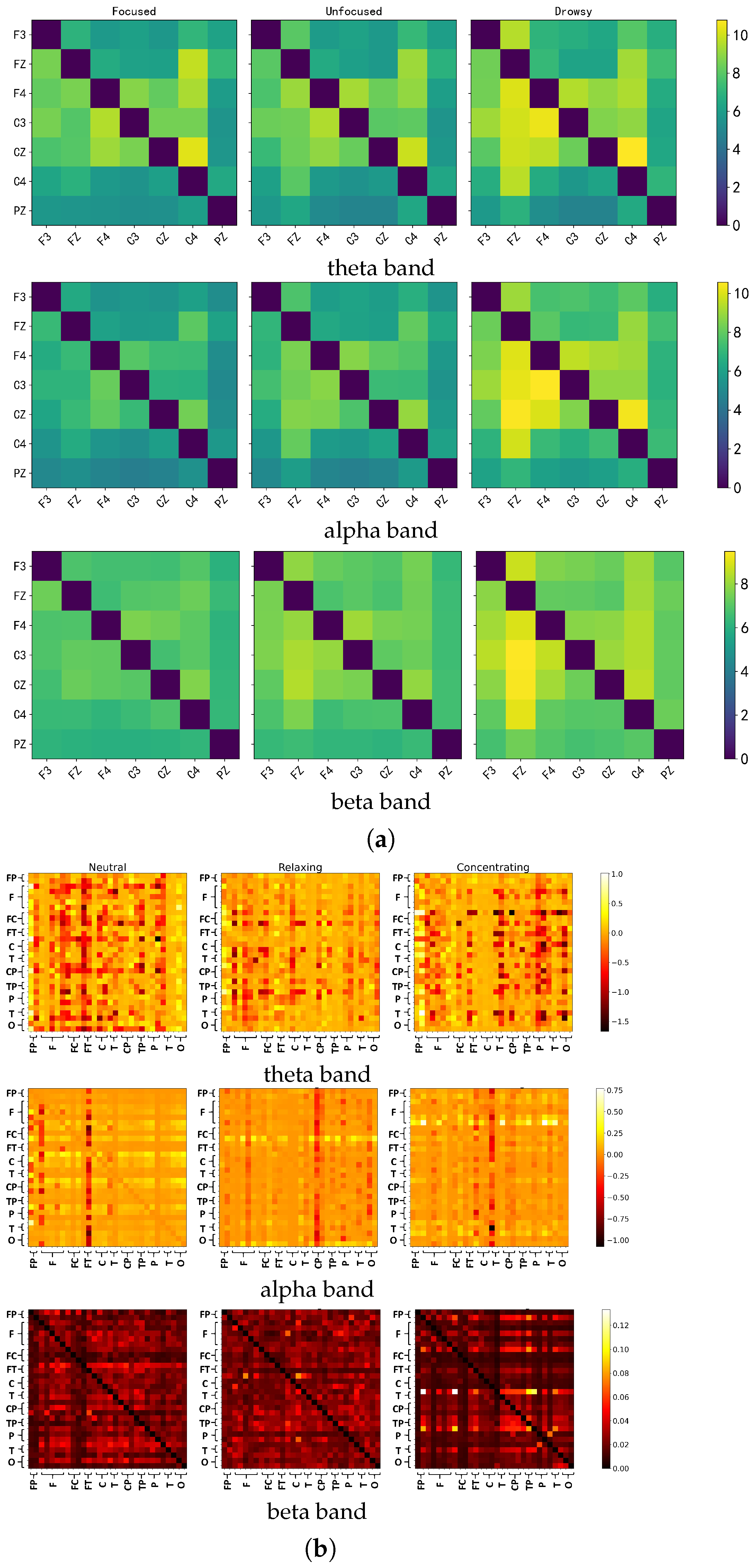
5.1. Discriminative Patterns of Granger Causality
5.2. Re-Evaluating “Excellent” Performance in Previous Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| EEG | Electroencephalography |
| ICA | Independent Component Analysis |
| STFT | Short-Time Fourier Transform |
| PLV | Phase Locking Value |
| PLI | Phase Lag Index |
| GC | Granger Causality |
| PDC | Partial Directed Coherence |
| SVM | Support Vector Machine |
References
- James, W. The Principles of Psychology; Cosimo, Inc.: New York, NY, USA, 2007; Volume 1. [Google Scholar]
- Kuo, Y.C.; Chu, H.C.; Tsai, M.C. Effects of an integrated physiological signal-based attention-promoting and English listening system on students’ learning performance and behavioral patterns. Comput. Hum. Behav. 2017, 75, 218–227. [Google Scholar] [CrossRef]
- Schmidt, M.; Benzing, V.; Wallman-Jones, A.; Mavilidi, M.F.; Lubans, D.R.; Paas, F. Embodied learning in the classroom: Effects on primary school children’s attention and foreign language vocabulary learning. Psychol. Sport Exerc. 2019, 43, 45–54. [Google Scholar] [CrossRef]
- Kountouriotis, G.K.; Merat, N. Leading to distraction: Driver distraction, lead car, and road environment. Accid. Anal. Prev. 2016, 89, 22–30. [Google Scholar] [CrossRef]
- Cheng, W.; Fu, R.; Yuan, W.; Liu, Z.; Zhang, M.; Liu, T. Driver attention distraction detection and hierarchical prewarning based on machine vision. J. Comput.-Aided Des. Comput. Graph. 2016, 28, 1287–1296. [Google Scholar]
- Corbetta, M.; Shulman, G.L. Control of goal-directed and stimulus-driven attention in the brain. Nat. Rev. Neurosci. 2002, 3, 201–215. [Google Scholar] [CrossRef]
- Ferrari, M.; Quaresima, V. A brief review on the history of human functional near-infrared spectroscopy (fNIRS) development and fields of application. NeuroImage 2012, 63, 921–935. [Google Scholar] [CrossRef]
- Posner, M.I.; Petersen, S.E.; Fox, P.T.; Raichle, M.E. Localization of cognitive operations in the human brain. Science 1988, 240, 1627–1631. [Google Scholar] [CrossRef]
- Klimesch, W. EEG alpha and theta oscillations reflect cognitive and memory performance: A review and analysis. Brain Res. Rev. 1999, 29, 169–195. [Google Scholar] [CrossRef] [PubMed]
- Liu, N.H.; Chiang, C.Y.; Chu, H.C. Recognizing the degree of human attention using EEG signals from mobile sensors. Sensors 2013, 13, 10273–10286. [Google Scholar] [CrossRef] [PubMed]
- Niu, J. Feature Extraction and Classification of Attention Related EEG. Master’s Thesis, Xidian University, Xi’an, China, 2013. [Google Scholar]
- Mohamed, Z.; El Halaby, M.; Said, T.; Shawky, D.; Badawi, A. Characterizing focused attention and working memory using EEG. Sensors 2018, 18, 3743. [Google Scholar] [CrossRef]
- Chen, D.; Huang, H.; Bao, X.; Pan, J.; Li, Y. An EEG-based attention recognition method: Fusion of time domain, frequency domain, and non-linear dynamics features. Front. Neurosci. 2023, 17, 1194554. [Google Scholar] [CrossRef]
- Suhail, T.; Indiradevi, K.; Suhara, E.; Poovathinal, S.A.; Ayyappan, A. Distinguishing cognitive states using electroencephalography local activation and functional connectivity patterns. Biomed. Signal Process. Control 2022, 77, 103742. [Google Scholar] [CrossRef]
- Hu, B.; Li, X.; Sun, S.; Ratcliffe, M. Attention recognition in EEG-based affective learning research using CFS+ KNN algorithm. IEEE/ACM Trans. Comput. Biol. Bioinform. 2016, 15, 38–45. [Google Scholar] [CrossRef] [PubMed]
- Saeidi, M.; Karwowski, W.; Farahani, F.V.; Fiok, K.; Taiar, R.; Hancock, P.A.; Al-Juaid, A. Neural decoding of EEG signals with machine learning: A systematic review. Brain Sci. 2021, 11, 1525. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Shi, Y.; Du, J.; Lin, Y.; Wang, Q. A CNN-based personalized system for attention detection in wayfinding tasks. Adv. Eng. Inform. 2020, 46, 101180. [Google Scholar] [CrossRef]
- Hassan, R.; Hasan, S.; Hasan, M.J.; Jamader, M.R.; Eisenberg, D.; Pias, T. Human attention recognition with machine learning from brain-EEG signals. In Proceedings of the 2020 IEEE 2nd Eurasia Conference on Biomedical Engineering, Healthcare and Sustainability (ECBIOS), Tainan, Taiwan, 29–31 May 2020; pp. 16–19. [Google Scholar]
- Toa, C.K.; Sim, K.S.; Tan, S.C. Electroencephalogram-based attention level classification using convolution attention memory neural network. IEEE Access 2021, 9, 58870–58881. [Google Scholar] [CrossRef]
- Acı, Ç.İ.; Kaya, M.; Mishchenko, Y. Distinguishing mental attention states of humans via an EEG-based passive BCI using machine learning methods. Expert Syst. Appl. 2019, 134, 153–166. [Google Scholar] [CrossRef]
- Polich, J. Updating P300: An integrative theory of P3a and P3b. Clin. Neurophysiol. 2007, 118, 2128–2148. [Google Scholar] [CrossRef]
- Jap, B.T.; Lal, S.; Fischer, P.; Bekiaris, A.J. Using EEG spectral components to assess algorithms for detecting fatigue. Expert Syst. Appl. 2009, 36, 2352–2359. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, Y.; Liu, G.; Du, X.; Wang, H.; Zhang, D. A Multi-Label EEG Dataset for Mental Attention State Classification in Online Learning. In Proceedings of the ICASSP 2025–2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 6–11 April 2025; pp. 1–5. [Google Scholar]
- Subasi, A.; Alkan, M.H.; Koklukaya, E.; Kiymik, M. Wavelet neural network classification of EEG signals by using AR model with MLE preprocessing. Neural Netw. 2005, 18, 985–997. [Google Scholar] [CrossRef]
- Jung, T.P.; Makeig, S.; Stensmo, M.; Sejnowski, T.J. Estimating alertness from the EEG power spectrum. IEEE Trans. Biomed. Eng. 1997, 44, 60–69. [Google Scholar] [CrossRef]
- Acharya, U.R.; Sree, S.V.; Swapna, G.; Martis, R.J.; Suri, J.S. Automated EEG analysis of epilepsy: A review. Knowl.-Based Syst. 2015, 88, 85–96. [Google Scholar] [CrossRef]
- Zheng, W.L.; Lu, B.L. Identifying stable patterns over time for emotion recognition from EEG. IEEE Trans. Affect. Comput. 2017, 10, 417–429. [Google Scholar] [CrossRef]
- Seshadri, N.G.; Singh, B.K.; Pachori, R.B. Eeg based functional brain network analysis and classification of dyslexic children during sustained attention task. IEEE Trans. Neural Syst. Rehabil. Eng. 2023, 31, 4672–4682. [Google Scholar] [CrossRef]
- Zhang, C.; Tang, Z.; Guo, T.; Lei, J.; Xiao, J.; Wang, A.; Bai, S.; Zhang, M. SaleNet: A low-power end-to-end CNN accelerator for sustained attention level evaluation using EEG. In Proceedings of the 2022 IEEE International Symposium on Circuits and Systems (ISCAS), Austin, TX, USA, 27 May–1 June 2022; pp. 2304–2308. [Google Scholar]
- Atilla, F.; Alimardani, M. EEG-based classification of drivers attention using convolutional neural network. In Proceedings of the 2021 IEEE 2nd International Conference on Human-Machine Systems (ICHMS), Magdeburg, Germany, 8–10 September 2021; pp. 1–4. [Google Scholar]
- Zhang, W.; Tang, X.; Wang, M. Attention model of EEG signals based on reinforcement learning. Front. Hum. Neurosci. 2024, 18, 1442398. [Google Scholar] [CrossRef]
- Kamrud, A.; Borghetti, B.; Schubert Kabban, C.; Miller, M. Generalized deep learning EEG models for cross-participant and cross-task detection of the vigilance decrement in sustained attention tasks. Sensors 2021, 21, 5617. [Google Scholar] [CrossRef] [PubMed]
- Åkerstedt, T.; Gillberg, M. Subjective and objective sleepiness in the active individual. Int. J. Neurosci. 1990, 52, 29–37. [Google Scholar] [CrossRef] [PubMed]
- Lee, T.W.; Lee, T.W. Independent Component Analysis; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Delorme, A.; Makeig, S. EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 2004, 134, 9–21. [Google Scholar] [CrossRef] [PubMed]
- Niso, G.; Bruña, R.; Pereda, E.; Gutiérrez, R.; Bajo, R.; Maestú, F.; Del-Pozo, F. HERMES: Towards an integrated toolbox to characterize functional and effective brain connectivity. Neuroinformatics 2013, 11, 405–434. [Google Scholar] [CrossRef]
- Lachaux, J.P.; Rodriguez, E.; Martinerie, J.; Varela, F.J. Measuring phase synchrony in brain signals. Hum. Brain Mapp. 1999, 8, 194–208. [Google Scholar] [CrossRef]
- Stam, C.J.; Nolte, G.; Daffertshofer, A. Phase lag index: Assessment of functional connectivity from multi channel EEG and MEG with diminished bias from common sources. Hum. Brain Mapp. 2007, 28, 1178–1193. [Google Scholar] [CrossRef] [PubMed]
- Arnhold, J.; Grassberger, P.; Lehnertz, K.; Elger, C.E. A robust method for detecting interdependences: Application to intracranially recorded EEG. Phys. D Nonlinear Phenom. 1999, 134, 419–430. [Google Scholar] [CrossRef]
- Wiener, N. The theory of prediction. In Modern Mathematics for Engineers; McGraw-Hill: New York, NY, USA, 1956. [Google Scholar]
- Granger, C.W. Investigating causal relations by econometric models and cross-spectral methods. Econom. J. Econom. Soc. 1969, 37, 424–438. [Google Scholar] [CrossRef]
- Baccalá, L.A.; Sameshima, K. Partial directed coherence: A new concept in neural structure determination. Biol. Cybern. 2001, 84, 463–474. [Google Scholar] [CrossRef]
- Lobos, T.; Rezmer, J. Real-time determination of power system frequency. IEEE Trans. Instrum. Meas. 1997, 46, 877–881. [Google Scholar] [CrossRef]
- Almeida, L.B. The fractional Fourier transform and time-frequency representations. IEEE Trans. Signal Process. 1994, 42, 3084–3091. [Google Scholar] [CrossRef]
- Khare, S.K.; Bajaj, V.; Sengur, A.; Sinha, G. Classification of mental states from rational dilation wavelet transform and bagged tree classifier using EEG signals. In Artificial Intelligence-Based Brain-Computer Interface; Elsevier: Amsterdam, The Netherlands, 2022; pp. 217–235. [Google Scholar]
- Zhang, D.; Cao, D.; Chen, H. Deep learning decoding of mental state in non-invasive brain computer interface. In Proceedings of the International Conference on Artificial Intelligence, Information Processing and Cloud Computing, Sanya, China, 19–21 December 2019; pp. 1–5. [Google Scholar]
- Wang, Y.; Nahon, R.; Tartaglione, E.; Mozharovskyi, P.; Nguyen, V.T. Optimized preprocessing and tiny ml for attention state classification. In Proceedings of the 2023 IEEE Statistical Signal Processing Workshop (SSP), Hanoi, Vietnam, 2–5 July 2023; pp. 695–699. [Google Scholar]
- Li, R.; Johansen, J.S.; Ahmed, H.; Ilyevsky, T.V.; Wilbur, R.B.; Bharadwaj, H.M.; Siskind, J.M. The perils and pitfalls of block design for EEG classification experiments. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 316–333. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Experimental Condition | Dataset | Accuracy (%) | F1 Score | Recall | Precision |
|---|---|---|---|---|---|---|
| STFT+SVM [20] | Intra-subject | Dataset 1 | 76.45 | / | / | / |
| RDWT+Ensemble ML [45] | Inter-subject | Dataset 1 | 85.64 | / | / | / |
| STFT+CNN [46] | Inter-subject, leave-one-trial-out | Dataset 1 | 53.22 | / | / | / |
| STFT+DNN [47] | Leave-one-subject-out | Dataset 1 | 71.10 | / | / | / |
| SVM [23] | Intra-subject/Inter-subject | Dataset 2 | 78.71/62.28 | 54.82/43.35 | / | / |
| RF [23] | Intra-subject/Inter-subject | Dataset 2 | 80.55/56.03 | 59.56/45.21 | / | / |
| EEGNet [23] | Intra-subject/Inter-subject | Dataset 2 | 85.12/64.84 | 59.64/64.84 | / | / |
| DGCNN [23] | Intra-subject/Inter-subject | Dataset 2 | 82.14/63.91 | 47.59/43.65 | / | / |
| Proposed Method | Intra-subject | Dataset 1 | 84.30 | 83.90 | 84.00 | 84.30 |
| Dataset 2 | 96.61 | 94.77 | 93.34 | 97.35 | ||
| Inter-subject | Dataset 1 | 86.27 | 86.22 | 86.26 | 86.40 | |
| Dataset 2 | 94.01 | 90.74 | 88.51 | 93.74 | ||
| Inter-subject, leave-one-trial-out | Dataset 1 | 67.99 | 65.31 | 68.05 | 72.44 | |
| Dataset 2 | 83.27 | 62.14 | 65.32 | 73.21 | ||
| Intra-subject, no shuffling | Dataset 1 | 77.61 | 77.22 | 77.92 | 81.37 | |
| Dataset 2 | 92.14 | 82.15 | 81.39 | 88.33 | ||
| Leave-one-subject-out | Dataset 1 | 72.27 | 70.75 | 72.37 | 71.03 | |
| Dataset 2 | 48.00 | 41.99 | 42.48 | 49.74 |
| Dataset | Subject | s | 1 s | 3 s | Subject | s | 1 s | 3 s |
|---|---|---|---|---|---|---|---|---|
| Dataset 1 | 1 | 79.41 | 80.40 | 84.61 | 2 | 83.18 | 85.31 | 88.72 |
| 3 | 80.33 | 80.19 | 85.80 | 4 | 82.88 | 87.21 | 92.01 | |
| 5 | 75.68 | 79.29 | 84.31 | – | – | – | – | |
| Average | 80.30 | 82.48 | 87.09 | F1 score | 80.33 | 82.39 | 87.72 | |
| Recall | 80.34 | 82.36 | 87.71 | Precision | 80.53 | 82.55 | 87.76 | |
| Dataset 2 | 1 | 99.11 | 100.00 | 100.00 | 2 | 96.43 | 98.80 | 100.00 |
| 3 | 93.75 | 98.19 | 99.09 | 4 | 98.21 | 100.00 | 99.09 | |
| 5 | 99.11 | 98.80 | 100.00 | 6 | 95.54 | 97.59 | 100.00 | |
| 7 | 90.18 | 99.40 | 96.37 | 8 | 97.32 | 100.00 | 100.00 | |
| 9 | 99.11 | 100.00 | 100.00 | 10 | 92.86 | 96.99 | 100.00 | |
| 11 | 93.75 | 98.80 | 99.40 | 12 | 91.07 | 97.59 | 99.40 | |
| 13 | 100.00 | 100.00 | 99.70 | 14 | 98.21 | 100.00 | 100.00 | |
| 15 | 99.11 | 99.40 | 100.00 | 16 | 98.21 | 98.80 | 99.70 | |
| 17 | 96.43 | 96.99 | 99.40 | 18 | 98.21 | 100.00 | 100.00 | |
| 19 | 99.11 | 100.00 | 100.00 | 20 | 96.43 | 100.00 | 100.00 | |
| Average | 96.61 | 99.07 | 99.61 | F1 score | 94.77 | 98.12 | 99.21 | |
| Recall | 93.37 | 97.69 | 99.31 | Precision | 97.35 | 98.87 | 99.26 |
| Dataset | Subject | Avg | Max | Min | Subject | Avg | Max | Min |
|---|---|---|---|---|---|---|---|---|
| Dataset 1 | 1 | 72.99 | 87.68 | 54.16 | 2 | 80.79 | 98.66 | 57.21 |
| 3 | 73.90 | 91.66 | 50.72 | 4 | 85.68 | 90.57 | 81.59 | |
| 5 | 75.97 | 84.78 | 66.66 | – | – | – | – | |
| Dataset 2 | 1 | 96.22 | 98.59 | 90.77 | 2 | 98.92 | 100.00 | 97.18 |
| 3 | 94.84 | 100.00 | 89.55 | 4 | 96.27 | 98.51 | 94.03 | |
| 5 | 98.15 | 100.00 | 95.38 | 6 | 98.57 | 100.00 | 95.77 | |
| 7 | 95.75 | 100.00 | 84.51 | 8 | 93.07 | 98.46 | 88.73 | |
| 9 | 96.69 | 98.51 | 94.03 | 10 | 93.25 | 98.59 | 89.55 | |
| 11 | 91.13 | 96.92 | 86.57 | 12 | 96.02 | 98.51 | 90.14 | |
| 13 | 95.89 | 98.51 | 93.85 | 14 | 95.10 | 98.59 | 90.77 | |
| 15 | 99.23 | 100.00 | 96.92 | 16 | 96.18 | 100.00 | 87.69 | |
| 17 | 93.68 | 97.01 | 89.23 | 18 | 95.56 | 100.00 | 93.85 | |
| 19 | 90.96 | 97.18 | 83.08 | 20 | 98.20 | 100.00 | 95.77 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Bao, X.; Jitian, K.; Li, R.; Zhu, L.; Kong, W. Hybrid EEG Feature Learning Method for Cross-Session Human Mental Attention State Classification. Brain Sci. 2025, 15, 805. https://doi.org/10.3390/brainsci15080805
Chen X, Bao X, Jitian K, Li R, Zhu L, Kong W. Hybrid EEG Feature Learning Method for Cross-Session Human Mental Attention State Classification. Brain Sciences. 2025; 15(8):805. https://doi.org/10.3390/brainsci15080805
Chicago/Turabian StyleChen, Xu, Xingtong Bao, Kailun Jitian, Ruihan Li, Li Zhu, and Wanzeng Kong. 2025. "Hybrid EEG Feature Learning Method for Cross-Session Human Mental Attention State Classification" Brain Sciences 15, no. 8: 805. https://doi.org/10.3390/brainsci15080805
APA StyleChen, X., Bao, X., Jitian, K., Li, R., Zhu, L., & Kong, W. (2025). Hybrid EEG Feature Learning Method for Cross-Session Human Mental Attention State Classification. Brain Sciences, 15(8), 805. https://doi.org/10.3390/brainsci15080805