Abstract
Multimodal emotion recognition has emerged as a prominent field in affective computing, offering superior performance compared to single-modality methods. Among various physiological signals, EEG signals and EOG data are highly valued for their complementary strengths in emotion recognition. However, the practical application of EEG-based approaches is often hindered by high costs and operational complexity, making EOG a more feasible alternative in real-world scenarios. To address this limitation, this study introduces a novel framework for multimodal knowledge distillation, designed to improve the practicality of emotion decoding while maintaining high accuracy, with the framework including a multimodal fusion module to extract and integrate interactive and heterogeneous features, and a unimodal student model structurally aligned with the multimodal teacher model for better knowledge alignment. The framework combines EEG and EOG signals into a unified model and distills the fused multimodal features into a simplified EOG-only model. To facilitate efficient knowledge transfer, the approach incorporates a dynamic feedback mechanism that adjusts the guidance provided by the multimodal model to the unimodal model during the distillation process based on performance metrics. The proposed method was comprehensively evaluated on two datasets based on EEG and EOG signals. The accuracy of the valence and arousal of the proposed model in the DEAP dataset are 70.38% and 60.41%, respectively. The accuracy of valence and arousal in the BJTU-Emotion dataset are 61.31% and 60.31%, respectively. The proposed method achieves state-of-the-art classification performance compared to the baseline method, with statistically significant improvements confirmed by paired t-tests (p < 0.05), and the framework effectively transfers knowledge from multimodal models to unimodal EOG models, enhancing the practicality of emotion recognition while maintaining high accuracy, thus expanding the applicability of emotion recognition in real-world scenarios.
1. Introduction
Emotion computing refers to the use of computational techniques to identify, analyze, interpret, and express human emotions. It is an interdisciplinary field encompassing artificial intelligence, computer science, psychology, and neuroscience. Emotion recognition, as a critical branch of emotion computing, focuses on identifying and classifying human emotional states through various signals. It plays an essential role in enhancing human–computer interaction and expanding the application scenarios of intelligent systems.
Emotion recognition methods can be broadly divided into two categories: physiological-signal-based methods and behavior-based methods. Physiological-signal-based methods use physiological data, such as electroencephalogram (EEG) and electrooculogram (EOG), as input features for emotion recognition. These signals are more stable than external behavioral features like facial expressions or speech. Consequently, physiological signals are increasingly used in emotion recognition systems due to their reliability in complex scenarios.
Human emotions involve intricate physiological processes, making single-modal signals insufficient for effective emotion recognition. As a result, researchers have increasingly investigated the use of multimodal data for emotion recognition [1,2]. These studies predominantly explore the interplay and diversity among various modalities. Regarding heterogeneity, the focus is on analyzing unique signal features within individual modalities. For interactivity, the emphasis lies on understanding the complementary aspects of physiological signals across different modalities. Findings from such studies indicate that multimodal data offer a more holistic representation of human emotions, enhancing recognition accuracy [3]. Consequently, multimodal emotion recognition has emerged as a pivotal area of interest in recent research.
Although multimodal physiological signals can improve the performance of models, the challenge lies in the complexity of the data collection process during experiments. For example, participants watching movie clips might be distracted, making it difficult for them to stay relaxed during testing, thereby affecting their psychological responses. Additionally, the collection of EEG signals imposes high environmental requirements, requiring a stable environment for data acquisition, which limits the application of emotion recognition in real-world scenarios. However, compared to the more challenging EEG signals, EOG signals can be collected with just one or a few simple sensors, making the data acquisition process much simpler. Moreover, EOG signals are less constrained by participants’ activities during the collection process, providing more authentic signals while being more cost-effective and efficient for experiments. However, relying solely on unimodal EOG signals for model construction is less effective than using multimodal data models. Therefore, how to leverage knowledge distillation techniques to transfer the rich knowledge from multimodal features (teacher model) to unimodal models (student model) becomes a critical issue. This approach helps enhance the generalization and practicality of unimodal models.
This paper proposes a novel emotion recognition framework based on physiological signals, which integrates a multimodal fusion module and a dynamic feedback regulation mechanism. The framework enables the unimodal student model to effectively learn interactive and heterogeneous knowledge from a multimodal teacher model. Specifically, the proposed method leverages EEG and EOG signals for emotion recognition. The primary contributions of this paper are as follows:
- A multimodal fusion module is designed to extract and integrate interactive and heterogeneous features, enabling the unimodal student model to learn from multimodal distributions.
- A dynamic feedback regulation mechanism is introduced, which continuously adjusts the teacher model based on the performance of the student model, thereby enhancing the effectiveness of knowledge transfer.
- Experimental results on the emotion datasets demonstrate that the proposed method achieves superior performance compared to baseline models, expanding the applicability of emotion recognition.
The remainder of this paper is structured as follows: Section 2 introduces related work, including multimodal emotion recognition and knowledge distillation. Section 3 describes the proposed method, detailing the multimodal fusion module and the dynamic feedback regulation mechanism. Section 4 presents experimental results and analysis, while Section 5 concludes the paper and discusses future research directions.
2. Related Work
2.1. Multimodal Physiological Signals
Multimodal physiological signals are a combination of various signals derived from different human physiological systems, including but not limited to electroencephalograms (EEG), electrooculograms (EOG), electromyograms (EMG), and others [4]. These signals encapsulate a wide spectrum of physiological states, such as emotions, cognitive conditions, and mental illnesses, making them invaluable in fields like medicine, psychology, and neuroscience. Multimodal physiological signals can be acquired through two primary methods: sensor-based acquisition and image processing techniques. For sensor-based acquisition, sensors are placed on the subject to collect physiological signals through electrodes or other devices. In contrast, image processing techniques extract physiological information such as facial expressions and eye movements by analyzing human body images.
The analysis and processing of multimodal physiological signals can be achieved using methods such as digital signal processing and machine learning [5]. For instance, signal processing techniques can be employed to preprocess data and extract features relevant to specific physiological states, which are then classified or predicted using machine learning algorithms. This enables the recognition and prediction of physiological states. Multimodal physiological signals are widely applied in medical diagnostics, neuroscience research, psychology, and human–computer interaction. One prominent application is emotion recognition, where different emotional states—such as joy, sadness, and anger—can be identified, supporting mental health assessment, emotional intervention, and interactive systems.
This study primarily uses EEG signals and EOG signals for emotion recognition. EEG signals refer to the bioelectrical signals of brain activity. These signals are obtained by placing electrodes on the scalp to measure and record the electrical activity of neurons in the cerebral cortex. EEG signals are widely used to study various physiological and pathological brain states, such as sleep, attention, epilepsy, and brain injuries. The frequency range of EEG signals generally lies between 0.5 Hz and 100 Hz, with the most prominent frequencies being in the 4 Hz to 30 Hz range, including alpha, beta, and gamma waves.
EOG signals, on the other hand, are bioelectrical signals that measure eye movements. These signals are generated by the difference in potential between the cornea and retina, allowing the tracking of horizontal and vertical eye movements. EOG is particularly useful for detecting visual attention, cognitive load, and emotional states, as eye movement patterns often reflect changes in these aspects. Compared to EEG signals, EOG signals are easier to acquire and require fewer electrodes, making them less intrusive and more practical for real-world applications.
By combining EEG and EOG signals, this study can achieve a more comprehensive understanding of participants’ emotional and psychological states, thereby enhancing the accuracy and applicability of emotion recognition systems.
Interactivity and heterogeneity are two key concepts in the analysis of multimodal physiological signals. Interactivity refers to the relationships and dependencies between different physiological signals. For example, EEG and ECG signals may interact due to the complex neurofeedback mechanisms between the brain and the heart. Such interactions require in-depth analysis and modeling to capture the dynamics of physiological systems. Heterogeneity, on the other hand, refers to the distinct characteristics of different physiological signals. For instance, EEG and EMG signals exhibit different frequency and amplitude features, necessitating tailored signal processing and modeling techniques. This heterogeneity introduces additional complexity to the analysis of multimodal physiological signals.
In multimodal physiological signal analysis, it is essential to account for both interactivity and heterogeneity. Modeling the interactivity between signals can reveal the intricate dynamics of physiological systems and enhance the overall analysis. Simultaneously, considering heterogeneity allows for the utilization of unique signal features, enriching the information and expressive power of the multimodal approach. In this study, we develop a neural network to model both the interactivity and heterogeneity of EEG and EOG signals, achieving superior performance. Additionally, we use knowledge distillation to transfer these properties, thereby enhancing the generalization ability of the unimodal model.
In conclusion, multimodal physiological signals hold immense potential due to their rich information content and wide applicability. With ongoing technological advancements and expanding use cases, the analysis and processing of these signals will continue to find broader and deeper applications across diverse fields.
2.2. Emotion Recognition Utilizing Physiological Signals
In recent years, emotion recognition has garnered increasing attention in the fields of brain–computer interfaces (BCIs) and intelligent healthcare. To address the challenges posed by individual variability and the complexity of multimodal signals, a range of advanced models have been proposed. Some studies exploit the intrinsic neighborhood semantic structure of EEG signals to facilitate domain adaptation for cross-subject generalization [6]. Others adopt dynamic heterogeneous graph recurrent neural networks to capture temporal dependencies and intermodal dynamics [7]. Techniques such as self-distillation and dynamic interaction have been introduced to enhance modality-specific feature learning and fusion [8]. Furthermore, hierarchical spatial–temporal learning frameworks based on transformers have been developed to model emotion-related patterns from local brain regions to global activity [9]. In addition, disentangling strategies and meta-learning mechanisms are employed to improve the robustness and adaptability of multimodal emotion recognition systems [10,11]. Collectively, these approaches reflect the current trend of integrating domain adaptation, graph learning, and attention mechanisms to tackle the challenges in cross-subject and multimodal emotion recognition [12].
In recent years, emotion recognition based on physiological signals has gained significant attention from researchers [13]. EEG signals, which directly reflect human brain activity, are widely used in emotional brain–computer interfaces. However, human emotions are complex physiological processes, and researchers have found that multimodal physiological signals, such as the combination of EEG with EOG, and ECG, can enhance emotion recognition performance [14]. Studies have shown that multimodal data fusion achieves better classification results compared to unimodal approaches [15,16,17,18]. This has led to extensive research on modeling the heterogeneity and interaction between multimodal signals [19]. For instance, Liu et al. [20,21] utilized a multimodal self-encoder and attention-based strategies to model interactions, while Guo et al. [22] and Song et al. [23] focused on modeling heterogeneity using CNN-based architectures and voting mechanisms.
Despite these advancements, most methods fail to simultaneously address the interaction and heterogeneity of multimodal data and predominantly rely on EEG signals combined with peripheral signals. This reliance on EEG presents practical challenges, as high-quality EEG data acquisition is cumbersome and costly [24,25]. EEG setups often require subjects to wear restrictive caps and maintain fixed positions in controlled environments, making real-world applications challenging. In contrast, EOG signals offer advantages such as easier acquisition and lower equipment costs while maintaining a strong correlation with human emotions [26,27]. Researchers have explored various methods to leverage EOG for emotion recognition, including wavelet-based denoising and SVM classification [28], quantum neural networks optimized with particle swarm algorithms [29], and deep hybrid neural networks [30].
Overall, sentiment recognition results using unimodal modalities are usually lower than those using multimodal modalities, due to the fact that multimodal data usually contain more latent knowledge. Therefore, it is important to know how to effectively transfer the knowledge captured in a large multimodal model to a lightweight unimodal model. The multimodal knowledge distillation proposed in this paper effectively extracts the intermodal heterogeneity and interaction and transfers them to the unimodal model through knowledge transfer. On the one hand, the multimodal information can be effectively utilized to better enhance the performance of the unimodal model, and on the other hand, it can alleviate the many limitations of multimodality in practical applications, and thus promote the grounded application of emotion recognition [31].
3. Proposed Methodology
As shown in Figure 1, the multimodal knowledge distillation framework proposed in this paper contains three main components: the multimodal teacher model, the unimodal student model, and the dynamically regulated knowledge-based distillation. The multimodal teacher model captures the knowledge of multimodal physiological signals and incorporates multimodal features to achieve better classification performance. In this paper, we propose a dynamic feedback-regulated knowledge distillation approach that transfers the knowledge captured by the multimodal teacher model to the unimodal student model.
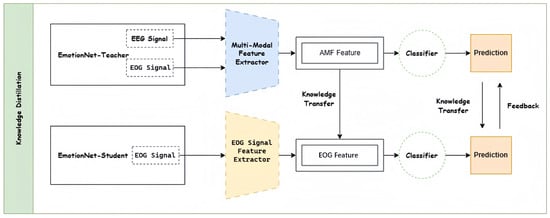
Figure 1.
The overall framework of multimodal knowledge distillation.
3.1. Multimodal Teacher Model
The multimodal teacher model starts by using two convolutional layers to process the raw physiological signals. For an input signal X with channels and a sampling rate of f, the convolutional filters are expressed as
In this equation, refers to a convolutional layer with a kernel size of . The resulting feature maps are then passed to a transformer encoder, which extracts the heterogeneous features from different modalities and uses fusion modules to strengthen interactions.
3.1.1. Transformer-Based Feature Extraction for Modal Heterogeneity
To effectively capture the heterogeneous characteristics across multiple modalities, this research utilizes a multi-layer transformer encoder to extract features, mathematically described as
where h indicates the number of attention heads, Q represents the query matrix, K is the key matrix, and V is the value matrix. Matrix provides the output weights. Each individual attention head is calculated as
where , , and are the respective weight matrices for Q, K, and V. The attention mechanism is further defined as
where , , and are the weight matrices for Q, K, and V, respectively. Furthermore, the attention mechanism is defined as
where indicates the size of the k-vector. The encoder’s output vectors are utilized to extract cross-modal interactive features, which are subsequently processed by the downstream transformer encoder for enhanced high-dimensional feature representation.
By implementing a dual-stream, multi-layer transformer encoder architecture, the model achieves more effective extraction of heterogeneous attributes across multiple modalities. This design uncovers hidden high-dimensional features from multimodal fusion, ultimately supporting unimodal models in delivering enhanced performance.
3.1.2. Modal Fusion Module for Interactivity Features
To effectively capture cross-modal interactions and organize multimodal features systematically, this study introduces a fusion module leveraging interaction fractions. Initially, high-dimensional features from various modalities are combined through concatenation to form unified representations. Interaction extractors are then employed to compute interaction fractions, with the outputs weighted and aggregated to produce the final fused features.
The four heterogeneous features in this module, denoted as and , correspond to the four inputs of the fusion module. The operation of this fusion module is formally defined as
where represents the l-th interaction extractor, Concat denotes the concatenation operation for tensors, and ⊕ represents the element-wise addition of two feature tensors. For , subscript i corresponds to one of the four inputs, and M represents the modality.
In this paper, an interaction extractor is utilized, where the input primarily consists of concatenated multimodal features. The computation in the interaction extraction module is defined as
where the interaction score is multiplied with the input features element-wise to generate the final output .
In summary, by effectively extracting heterogeneous and interactive features, the proposed model dynamically integrates multimodal fusion during training. This allows the extraction of high-quality features and improves the performance of downstream classification tasks, while also providing better guidance to unimodal models and enhancing their performance.
3.2. Unimodal Student Model
In this work, the process of distilling a unimodal student model introduces a fusion module based on heterogeneous feature extraction and weighting. This approach aims to reduce the structural gap between the unimodal student model and the multimodal teacher model.
The structure of the heterogeneous feature extractor is consistent with the interaction extractor introduced earlier. In this work, three features extracted from different positions of the transformer encoder output, denoted as , where , are input into the HDF (Heterogeneous Deep Fusion) module. The HDF module processes the inputs in a manner similar to the fusion module described previously. The calculation for the output of the HDF module is as follows:
where represents the m-th heterogeneous extractor. The heterogeneous score, , is computed using the same operations described in the interaction extractor, as follows:
Subsequently, the output of the heterogeneous extractor, , can be expressed as
In summary, this work designed a unimodal student model that is structurally more similar to the multimodal teacher model, facilitating better alignment with the outputs of the teacher model.
3.3. Dynamic Feedback Mechanisms
Traditional knowledge distillation methods often rely on a static teacher model, which limits adaptability during knowledge transfer [32]. To overcome this limitation, a dynamic feedback regulation mechanism is introduced, allowing the teacher model to adaptively adjust based on the student model’s performance. This enhances the overall efficiency of knowledge transfer. By extending the conventional student–teacher training framework, a feedback adjustment phase is incorporated to better align the teacher model with the student model, thereby improving knowledge transfer and facilitating the student’s learning process.
In this study, the teacher model is iteratively adjusted throughout the training process to produce knowledge that aligns more effectively with the student model, boosting its performance. The proposed training approach is divided into two main stages: the teaching phase and the feedback adjustment phase. During the teaching phase, the student model utilizes one-hot encoded labels from the pretrained teacher model for guidance. After a set number of iterations, the process shifts to the feedback adjustment phase, where the teacher model is updated based on feedback from the student. This iterative cycle alternates between the two phases until the unimodal student model achieves satisfactory performance. Finally, during the testing phase, the trained student model is evaluated to produce the final outcomes. Subsequent sections delve into the specifics of each training stage.
3.3.1. Teaching Phase
In this phase, the parameters of the student model are exclusively updated. The objective function is formulated using the cross-entropy loss , which serves to optimize classification accuracy. Given a one-hot encoded label , where K represents the total number of classes, and the predicted probabilities , the cross-entropy loss is expressed as
Simultaneously, the unimodal student model interacts with the teacher model to learn heterogeneous features and enhance classification performance. To ensure this, the output features of the student model, , must align as closely as possible with the heterogeneous features of the teacher model, , where N represents the number of data points for each feature. To achieve this alignment, a mean squared error (MSE) loss is incorporated into the objective function [33]:
Additionally, the output of the student model must align with that of the teacher model. To achieve this, Kullback–Leibler (KL) divergence is incorporated as an auxiliary loss term to optimize the student model’s learning process. In assuming that the classification output of the teacher model is , the KL divergence loss is defined as
The overall objective function combines three weighted loss terms:
where , , and are coefficients that balance the contributions of each loss term. Here, and represent the outputs of the teacher model and the student model, respectively, while x denotes the input data. Finally, the optimized parameters of the student model, , are determined by
3.3.2. Feedback Phase
In the feedback adjustment phase, the parameters of the student model remain fixed. A temporary student model is introduced as an auxiliary module, with its parameters copied from the original student model to ensure structural consistency [34]. The primary goal of this phase is to enable the teacher model to adapt its features dynamically according to feedback from the temporary student model, aligning more closely with the performance and characteristics of the student model.
The temporary student model does not directly affect the final student model, but it is vital for optimizing the teacher model. Specifically, it first learns from the teacher model with the help of the loss function . The updated parameters are computed as
where represents the learning rate. Subsequently, using the one-hot encoded labels, the teacher model output, and the IMF features of the updated temporary student model, the teacher model is adjusted to better guide the student model by refining multimodal feature representation. The definitions are as follows:
where represents a scaling factor. In practice, the updated temporary student model and teacher model utilize different training samples. To prevent data leakage, the updated teacher model leverages validation data instead of training data. Since the parameters of the original student model remain unchanged during this phase, there is no risk of data contamination throughout the training process.
In summary, the dynamic feedback adjustment method enables the continuous refinement of the teacher model during knowledge distillation. By selecting appropriate adjustment frequencies and iteration counts, the teacher model dynamically aligns with the evolving optimization needs of the student model [35]. This process effectively guides the student model to better learn multimodal features, ultimately improving its generalization ability and performance on unseen datasets.
4. Experimental Results and Analysis
4.1. Dataset Description
To comprehensively evaluate the effectiveness of the proposed model, this study uses the emotion datasets. These datasets are widely recognized in the field and provide a large amount of multimodal experimental data with annotated labels. Both datasets play a significant role in emotion computing and analysis.
The DEAP dataset provides various physiological signals and emotional evaluation data, serving as fundamental resources for research in affective computing and physiological signal analysis. Similarly, the BJTU-Emotion dataset also offers multimodal affective data, providing basic resources for affective analysis and data analysis studies. The public availability and standardization of these datasets facilitate advancements in affective computing and multimodal data analysis in related fields.
The DEAP dataset [36] is a multimodal dataset containing EEG, facial expressions, and peripheral physiological signals such as electrooculograms (EOG). It includes data collected from 32 participants while they watched music videos. Their EEG signals, facial expressions, and EOG signals were recorded during these sessions. Each participant completed 40 experiments, with each trial lasting one minute and including a 3 s baseline recording at the start. After each trial, participants provided self-reported ratings on arousal, valence, dominance, and liking on a nine-point scale [37].
BJTU-Emotion is a multimodal dataset we collected. It includes data from 30 participants who were recorded while watching movie clips. The recorded data comprise facial expressions, audio signals, eye gaze data, EEG signals, EOG signals, and other physiological signals. EEG signals were acquired from 32 electrodes following the international 10–20 system, with a sampling rate of 256 Hz. In each trial, participants provided self-reported annotations using integers from 1 to 9 for four dimensions: valence, arousal, dominance, and emotion keywords.
4.2. Emotional Dimensions and Evaluation Metrics
4.2.1. Arousal
In emotion recognition, arousal refers to the degree of physiological and psychological activation or stimulation in response to specific stimuli or emotional situations. It measures an individual’s perceived level of energy or excitement, which can range from low to high. A person’s level of arousal can influence their emotions, behavior, and cognition. For example, high arousal is often associated with feelings of anxiety, fear, or excitement, while low arousal is linked to feelings of relaxation or boredom. In emotion recognition tasks, arousal is typically evaluated alongside other dimensions, as it represents the activation level of emotional states, whether pleasant or unpleasant.
4.2.2. Valence
In emotion recognition, valence refers to the subjective experience of the positivity or negativity of an emotional state. It measures the qualitative aspect of an emotion, ranging from extremely positive to extremely negative. For instance, emotions such as happiness, joy, and contentment typically correspond to high valence, whereas emotions such as anger, sadness, and fear are associated with low valence. Valence is commonly evaluated in conjunction with other dimensions, such as arousal, to better understand an individual’s emotional state. Valence is crucial in applications related to mental health and well-being, as it provides insights into the balance of positive and negative emotional experiences over time.
4.2.3. Accuracy
Accuracy is a common evaluation metric in classification tasks. It measures the proportion of correctly classified samples to the total number of samples. For binary classification problems, accuracy is defined as
where TP represents true positives, TN represents true negatives, FP represents false positives, and FN represents false negatives.
4.2.4. F1 Score
The F1 score balances precision and recall to measure the accuracy of a model on a balanced dataset. When dealing with imbalanced labels, where the number of samples for each label is not equal, the F1 score becomes an important evaluation metric. It combines precision and recall to evaluate the classifier’s performance on imbalanced data. The F1 score is defined as
where TP, TN, FP, and FN are as defined above. The F1 score is also used in this paper as a performance metric for classification models.
4.3. Experimental Setup
For a fair comparison, the proposed method and baseline methods were evaluated under the same experimental setup. Specifically, since human emotions are a continuous process, the different phases within a single trial are highly correlated. If the dataset is split such that segments within the same trial appear in both the training and validation sets, the model may overfit to trial-specific patterns, causing the test performance to be artificially inflated. However, in real-world applications, a model often needs to predict data from unseen trials that differ significantly from the training data. To mimic this real-world scenario, this paper divides the dataset by trials, ensuring that the training, validation, and test sets are split at an 8:1:1 ratio. After this split, each trial is further segmented into 4 s slices (segments), with each segment treated as an independent sample for model training.
All physiological signals were downsampled to 128 Hz for consistency. Additionally, to prevent overfitting, the final test results were evaluated using the best model checkpoint from the validation phase. All models were implemented using TensorFlow. The HFE’s two fully connected layers had 512 and 256 units, with ReLU and sigmoid activations, respectively, and the IE’s two fully connected layers had 1024 and 512 units, with ReLU and sigmoid activations.
The models were optimized using the Adam optimizer. To improve generalization, all convolutional layers employed dropout regularization during training. Furthermore, in the knowledge distillation phase, the loss function weights were set to :: = 1:1:1, with the tuning factor during the feedback phase.
4.4. Experimental Results
This paper compares the unimodal student model utilizing EOG features with baseline models. As illustrated in Table 1 and Table 2, the results confirm the effectiveness of the proposed knowledge distillation approach in enhancing the performance of unimodal models. Specifically, the proposed method extracts both interactive and heterogeneous features from the multimodal teacher model through knowledge distillation. This enables the unimodal student model to learn multimodal distributions encompassing both interactive and heterogeneous attributes, leading to significant performance improvements.

Table 1.
Comparison of proposed unimodal student model and baseline models on DEAP.
Table 2.
Comparison of proposed unimodal student model and baseline models on BJTU-Emotion.
In contrast, methods such as DeepConvNet rely exclusively on single-modality signals and fail to utilize multimodal features, thereby limiting their overall performance. Similarly, while CGAN employs knowledge transfer techniques, it overlooks the extraction and integration of heterogeneous features for each modality, further constraining its capabilities. Compared to these approaches, the proposed unimodal student model benefits from joint learning with the multimodal teacher model on both datasets, leveraging the interactive and heterogeneous knowledge transferred from the teacher model. As a result, the proposed model achieves superior performance and delivers more consistent outcomes than the baseline models.
To further verify the stability and effectiveness of the proposed model, we visualized the learning curves during training, as shown in Figure 2 and Figure 3.
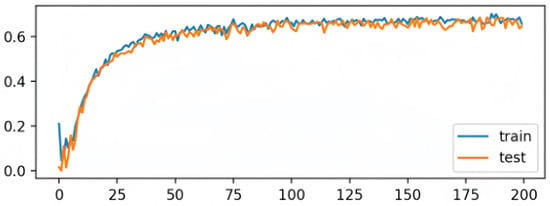
Figure 2.
Accuracy curve during training. The blue line represents training accuracy, and the orange line represents testing accuracy. The model shows rapid improvement during the first 45 epochs and gradually stabilizes, with training and testing accuracy closely aligned—indicating good generalization performance.
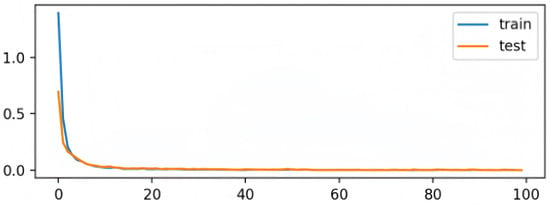
Figure 3.
Loss curve during training. Both training and testing loss values decrease rapidly and converge smoothly, suggesting a stable optimization process and no signs of overfitting.
As depicted in Figure 2, the model achieves rapid accuracy improvement within the first 45 epochs and gradually converges. The training and testing accuracy curves remain closely aligned, indicating strong generalization and resistance to overfitting.
In Figure 3, the loss curves for both training and testing sets show a fast decline and converge near zero within approximately 40 epochs. The consistent trends between the two curves further confirm that the model optimization is stable and that the proposed dynamic knowledge distillation framework is effective.
We conducted statistical significance tests between our proposed method and all baseline methods across both datasets to ensure the robustness and reliability of our results. Specifically, we applied paired t-tests to compare the performance metrics, and the results confirm that the improvements achieved by our method are statistically significant (p < 0.05). These findings further validate the effectiveness of our approach and support our claim of superior performance.
4.5. Ablation Study
To further evaluate the effectiveness of the multimodal fusion module and the dynamic feedback regulation mechanism in the unimodal student model, this study conducted an ablation study. The purpose of the ablation study was to assess the contribution of each proposed component by incrementally adding or removing features. The following variations were considered:
- Variation 1: Excluding multimodal fusion features and the feedback regulation mechanism. In this case, the Hinton-KD method is used as a baseline for knowledge distillation.
- Variation 2: Incorporating multimodal fusion features for distillation but without applying the feedback regulation mechanism.
- Variation 3: Including both multimodal fusion features and the feedback regulation mechanism.
This study builds upon the original knowledge distillation framework [22] and incorporates multimodal fusion features and feedback regulation mechanisms to assess their effectiveness. Table 3 demonstrates that integrating multimodal fusion features significantly enhances the performance of the unimodal student model. This improvement is attributed to the learning of multimodal distribution features, which strengthen the student model’s generalization ability.
Table 3.
Ablation study results on the DEAP dataset for different experimental configurations.
Furthermore, the introduction of the feedback regulation mechanism enhances the model’s performance by dynamically adjusting the teacher model based on the evolving characteristics of the student model, thereby promoting more efficient learning.
Additionally, this study explored the impact of data-splitting strategies on model performance. It was found that some models and methods achieved artificially high results on the DEAP dataset due to improper data preprocessing, which introduced severe biases. Specifically, when segments from the same trial appeared in both the training and test sets, the model could memorize trial-specific patterns, leading to inflated performance metrics.
To address this, this study employed strict data-splitting protocols to ensure no data leakage between the training and test sets. Under improper splitting, the multimodal teacher model achieved accuracies of 95.23% and 95.92% for valence and arousal, respectively. However, these results are not reflective of real-world scenarios. Therefore, strict preprocessing and evaluation methods were implemented to ensure realistic and reliable performance metrics.
5. Conclusions
This paper proposes a novel emotion recognition method that integrates a multimodal fusion module and a dynamic feedback regulation mechanism based on interactive features. By leveraging multimodal data and the transfer of interactive and heterogeneous features, the proposed approach effectively improves the performance of unimodal student models. The method addresses the challenges of emotion recognition using physiological signals such as EEG and EOG while enhancing the model’s performance through dynamic feedback refinement. Experimental results demonstrate that our method achieves superior performance and reduces the reliance on EEG signals, thereby expanding the applicability of emotion recognition models to broader scenarios. By focusing on EOG signals, this method widens the application scope of emotion recognition tasks and facilitates further advancements in the field. In summary, this method has significant potential for future development and application in emotion recognition. However, there is still room for improvement in several areas. This study considers only EEG and EOG signals as part of the multimodal input. In the future, incorporating additional modalities could lead to more comprehensive and robust multimodal emotion recognition models. Moreover, the proposed framework is based on a dual-stream transformer encoder architecture, which demands substantial computational resources. Exploring lightweight models for efficient real-time computation and deployment on edge devices remains a critical challenge. Despite these limitations, the proposed method represents a major improvement over current state-of-the-art models. Future research could focus on developing interpretable neural networks for physiological signal encoding and decoding, which remains a crucial direction for physiological signal classification. Future work will incorporate additional modalities such as GSR and facial expressions to enrich the multimodal feature space. We will consider structural pruning, compression after distillation, and deployment based on lightweight models in the future. And combining Bayesian deep learning can also introduce more interpretability into deep models in the future, which will contribute to the development of emotion recognition based on physiological signals.
Author Contributions
Conceptualization, Z.Z. and G.L.; methodology, Z.Z. and G.L.; validation, Z.Z. and G.L.; formal analysis, Z.Z.; investigation, Z.Z.; resources, G.L.; data curation, Z.Z.; writing—original draft preparation, Z.Z.; writing—review and editing, Z.Z. and G.L.; visualization, Z.Z.; supervision, G.L.; project administration, G.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The DEAP dataset used in this study is publicly available in the DEAP Dataset repository, https://www.eecs.qmul.ac.uk/mmv/datasets/deap/, accessed on 29 May 2025. The BJTU-Emotion dataset used in this study is available on request from the corresponding author due to privacy concerns regarding participant information.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Abdullah, S.; Ameen, S.; Sadeeq, M.; Zeebaree, S. Multimodal Emotion Recognition using Deep Learning. J. Appl. Sci. Technol. Trends 2021, 2, 52–58. [Google Scholar] [CrossRef]
- Soleymani, M.; Pantic, M.; Pun, T. Multimodal Emotion Recognition in Response to Videos. IEEE Trans. Affect. Comput. 2012, 3, 211–223. [Google Scholar] [CrossRef]
- Tzirakis, P.; Trigeorgis, G.; Nicolaou, M.A.; Schuller, B.W.; Zafeiriou, S. End-to-End Multimodal Emotion Recognition Using Deep Neural Networks. IEEE J. Sel. Top. Signal Process. 2017, 11, 1301–1309. [Google Scholar] [CrossRef]
- Huang, C.; Jin, Y.; Wang, Q.; Zhao, L.; Zou, C. Multimodal Emotion Recognition Based on Speech and ECG Signals. Chin. J. Biomed. Eng. 2010, 40, 895–900. [Google Scholar] [CrossRef]
- Merzagora, A.C.; Izzetoglu, M.; Polikar, R.; Weisser, V.; Onaral, B.; Schultheis, M.T. Functional near-infrared spectroscopy and electroencephalography: A multimodal imaging approach. In Foundations of Augmented Cognition. Neuroergonomics and Operational Neuroscience, Proceedings of the 5th International Conference, FAC 2009 Held as Part of HCI International 2009, San Diego, CA, USA, 19–24 July 2009; Proceedings 5; Springer: Berlin/Heidelberg, Germany, 2009; pp. 417–426. [Google Scholar]
- Yang, Y.; Wang, Z.; Song, Y.; Jia, Z.; Wang, B.; Jung, T.-P.; Wan, F. Exploiting the Intrinsic Neighborhood Semantic Structure for Domain Adaptation in EEG-based Emotion Recognition. IEEE Trans. Affect. Comput. 2025, 1–13. [Google Scholar] [CrossRef]
- Wang, J.; Feng, Z.; Ning, X.; Lin, Y.; Chen, B.; Jia, Z. Two-stream Dynamic Heterogeneous Graph Recurrent Neural Network for Multi-label Multi-modal Emotion Recognition. IEEE Trans. Affect. Comput. 2025, 1–14. [Google Scholar] [CrossRef]
- Cheng, C.; Liu, W.; Wang, X.; Feng, L.; Jia, Z. DISD-Net: A Dynamic Interactive Network with Self-distillation for Cross-subject Multi-modal Emotion Recognition. IEEE Trans. Multimed. 2025, 1–14. [Google Scholar] [CrossRef]
- Cheng, C.; Liu, W.; Feng, L.; Jia, Z. Emotion Recognition Using Hierarchical Spatial-Temporal Learning Transformer From Regional to Global Brain. Neural Netw. 2024, 179, 106624. [Google Scholar] [CrossRef]
- Jia, Z.; Zhao, F.; Guo, Y.; Chen, H.; Jiang, T.; Center, B. Multi-level Disentangling Network for Cross-subject Emotion Recognition Based on Multimodal Physiological Signals. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI), Jeju, Republic of Korea, 3–9 August 2024; pp. 3069–3077. [Google Scholar]
- Ning, X.; Wang, J.; Lin, Y.; Cai, X.; Chen, H.; Gou, H.; Li, X.; Jia, Z. MetaEmotionNet: Spatial-Spectral-Temporal-Based Attention 3-D Dense Network with Meta-learning for EEG Emotion Recognition. IEEE Trans. Instrum. Meas. 2023, 73, 2501313. [Google Scholar] [CrossRef]
- Albanie, S.; Nagrani, A.; Vedaldi, A.; Zisserman, A. Emotion Recognition in Speech Using Cross-Modal Transfer in the Wild. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 292–301. [Google Scholar] [CrossRef]
- Saxena, A.; Khanna, A.; Gupta, D. Emotion Recognition and Detection Methods: A Comprehensive Survey. J. Artif. Intell. Syst. 2020, 2, 53–79. [Google Scholar] [CrossRef]
- Sharma, G.; Dhall, A. A Survey on Automatic Multimodal Emotion Recognition in the Wild. In Advances in Data Science: Methodologies and Applications; Phillips-Wren, G., Esposito, A., Jain, L.C., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 35–64. [Google Scholar] [CrossRef]
- Du, G.; Su, J.; Zhang, L.; Su, K.; Wang, X.; Teng, S.; Liu, P.X. A Multi-Dimensional Graph Convolution Network for EEG Emotion Recognition. IEEE Trans. Instrum. Meas. 2022, 71, 2518311. [Google Scholar] [CrossRef]
- Liu, S.; Wang, X.; Zhao, L.; Li, B.; Hu, W.; Yu, J.; Zhang, Y.D. 3DCANN: A Spatio-Temporal Convolution Attention Neural Network for EEG Emotion Recognition. IEEE J. Biomed. Health Inform. 2022, 26, 5321–5331. [Google Scholar] [CrossRef]
- Nguyen, D.; Nguyen, D.T.; Zeng, R.; Nguyen, T.T.; Tran, S.N.; Nguyen, T.; Sridharan, S.; Fookes, C. Deep Auto-Encoders with Sequential Learning for Multimodal Dimensional Emotion Recognition. IEEE Trans. Multimed. 2022, 24, 1313–1324. [Google Scholar] [CrossRef]
- Gou, J.; Yu, B.; Maybank, S.J. Knowledge Distillation: A Survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Zhou, T.; Ruan, S.; Canu, S. A Review: Deep Learning for Medical Image Segmentation Using Multi-Modality Fusion. Array 2019, 3–4, 100004. [Google Scholar] [CrossRef]
- Liu, W.; Qiu, J.L.; Zheng, W.L.; Lu, B.L. Comparing Recognition Performance and Robustness of Multimodal Deep Learning Models for Multimodal Emotion Recognition. IEEE Trans. Cogn. Dev. Syst. 2022, 14, 715–729. [Google Scholar] [CrossRef]
- Liu, W.; Zheng, W.L.; Lu, B.L. Emotion Recognition Using Multimodal Deep Learning. In Neural Information Processing; Hirose, A., Ozawa, S., Doya, K., Ikeda, K., Lee, M., Liu, D., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 521–529. [Google Scholar] [CrossRef]
- Guo, G.; Gao, P.; Zheng, X.; Ji, C. Multimodal Emotion Recognition Using CNN-SVM with Data Augmentation. In Proceedings of the 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Las Vegas, NV, USA, 6–8 December 2022; pp. 3008–3014. [Google Scholar] [CrossRef]
- Song, T.; Lu, G.; Yan, J. Emotion Recognition Based on Physiological Signals Using Convolution Neural Networks. In Proceedings of the 2020 ACM International Conference on Multimedia Retrieval, Dublin, Ireland, 8–11 June 2020; pp. 161–165. [Google Scholar] [CrossRef]
- Albera, L.; Kachenoura, A.; Comon, P.; Karfoul, A.; Wendling, F.; Senhadji, L.; Merlet, I. ICA-Based EEG Denoising: A Comparative Analysis of Fifteen Methods. Bull. Pol. Acad.-Sci.-Tech. Sci. 2012, 60, 407–418. Available online: https://api.semanticscholar.org/CorpusID:854211 (accessed on 28 May 2025). [CrossRef]
- Värbu, K.; Muhammad, N.; Muhammad, Y. Past, Present, and Future of EEG-Based BCI Applications. Sensors 2022, 22, 3331. [Google Scholar] [CrossRef]
- Dzedzickis, A.; Kaklauskas, A.; Bucinskas, V. Human Emotion Recognition: Review of Sensors and Methods. Sensors 2020, 20, 592. [Google Scholar] [CrossRef]
- Zhao, L.; Peng, X.; Chen, Y.; Kapadia, M.; Metaxas, D.N. Knowledge as Priors: Cross-Modal Knowledge Generalization for Datasets without Superior Knowledge. arXiv 2020, arXiv:2004.00176. [Google Scholar] [CrossRef]
- Fan, D.; Liu, M.; Zhang, X.; Gong, X. Human Emotion Recognition Based on Galvanic Skin Response Signal Feature Selection and SVM. arXiv 2023, arXiv:2307.05383. [Google Scholar] [CrossRef]
- Zhang, Q.; Lai, X.; Liu, G. Emotion Recognition of GSR Based on an Improved Quantum Neural Network. In Proceedings of the 2016 8th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 27–28 August 2016; Volume 1, pp. 488–492. [Google Scholar] [CrossRef]
- Susanto, I.Y.; Pan, T.Y.; Chen, C.W.; Hu, M.C.; Cheng, W.H. Emotion Recognition from Galvanic Skin Response Signal Based on Deep Hybrid Neural Networks. In Proceedings of the 2020 International Conference on Multimedia Retrieval, Dublin, Ireland, 8–11 June 2020; pp. 341–345. [Google Scholar] [CrossRef]
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep Mutual Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4320–4328. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar] [CrossRef]
- Mirzadeh, S.I.; Farajtabar, M.; Li, A.; Levine, N.; Matsukawa, A.; Ghasemzadeh, H. Improved Knowledge Distillation via Teacher Assistant. arXiv 2019, arXiv:1902.03393. [Google Scholar] [CrossRef]
- Park, D.Y.; Cha, M.H.; Jeong, C.; Kim, D.S.; Han, B. Learning Student-Friendly Teacher Networks for Knowledge Distillation. arXiv 2022, arXiv:2102.07650. [Google Scholar] [CrossRef]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive Representation Distillation. arXiv 2022, arXiv:1910.10699. [Google Scholar] [CrossRef]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.S.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. DEAP: A Database for Emotion Analysis Using Physiological Signals. IEEE Trans. Affect. Comput. 2012, 3, 18–31. [Google Scholar] [CrossRef]
- Soleymani, M.; Lichtenauer, J.; Pun, T.; Pantic, M. A Multimodal Database for Affect Recognition and Implicit Tagging. IEEE Trans. Affect. Comput. 2012, 3, 42–55. [Google Scholar] [CrossRef]
- Schirrmeister, R.; Gemein, L.; Eggensperger, K.; Hutter, F.; Ball, T. Deep Learning with Convolutional Neural Networks for Decoding and Visualization of EEG Pathology. In Proceedings of the 2017 IEEE Signal Processing in Medicine and Biology Symposium (SPMB), Philadelphia, PA, USA, 2 December 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Yan, X.; Zhao, L.M.; Lu, B.L. Simplifying Multimodal Emotion Recognition with Single Eye Movement Modality. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 1057–1063. [Google Scholar] [CrossRef]
- Liu, Y.; Jia, Z.; Wang, H. EmotionKD: A Cross-Modal Knowledge Distillation Framework for Emotion Recognition Based on Physiological Signals. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 6122–6131. [Google Scholar]
- Sun, T.; Wei, Y.; Ni, J.; Liu, Z.; Song, X.; Wang, Y.; Nie, L. Muti-modal Emotion Recognition via Hierarchical Knowledge Distillation. IEEE Trans. Multimed. 2024, 26, 9036–9046. [Google Scholar] [CrossRef]
- Mescheder, L.M.; Geiger, A.; Nowozin, S. Which Training Methods for GANs Do Actually Converge? In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Available online: https://api.semanticscholar.org/CorpusID:3345317 (accessed on 28 May 2025).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).