
Multimodal Knowledge Distillation for Emotion Recognition


Abstract
1. Introduction
- A multimodal fusion module is designed to extract and integrate interactive and heterogeneous features, enabling the unimodal student model to learn from multimodal distributions.
- A dynamic feedback regulation mechanism is introduced, which continuously adjusts the teacher model based on the performance of the student model, thereby enhancing the effectiveness of knowledge transfer.
- Experimental results on the emotion datasets demonstrate that the proposed method achieves superior performance compared to baseline models, expanding the applicability of emotion recognition.
2. Related Work
2.1. Multimodal Physiological Signals
2.2. Emotion Recognition Utilizing Physiological Signals
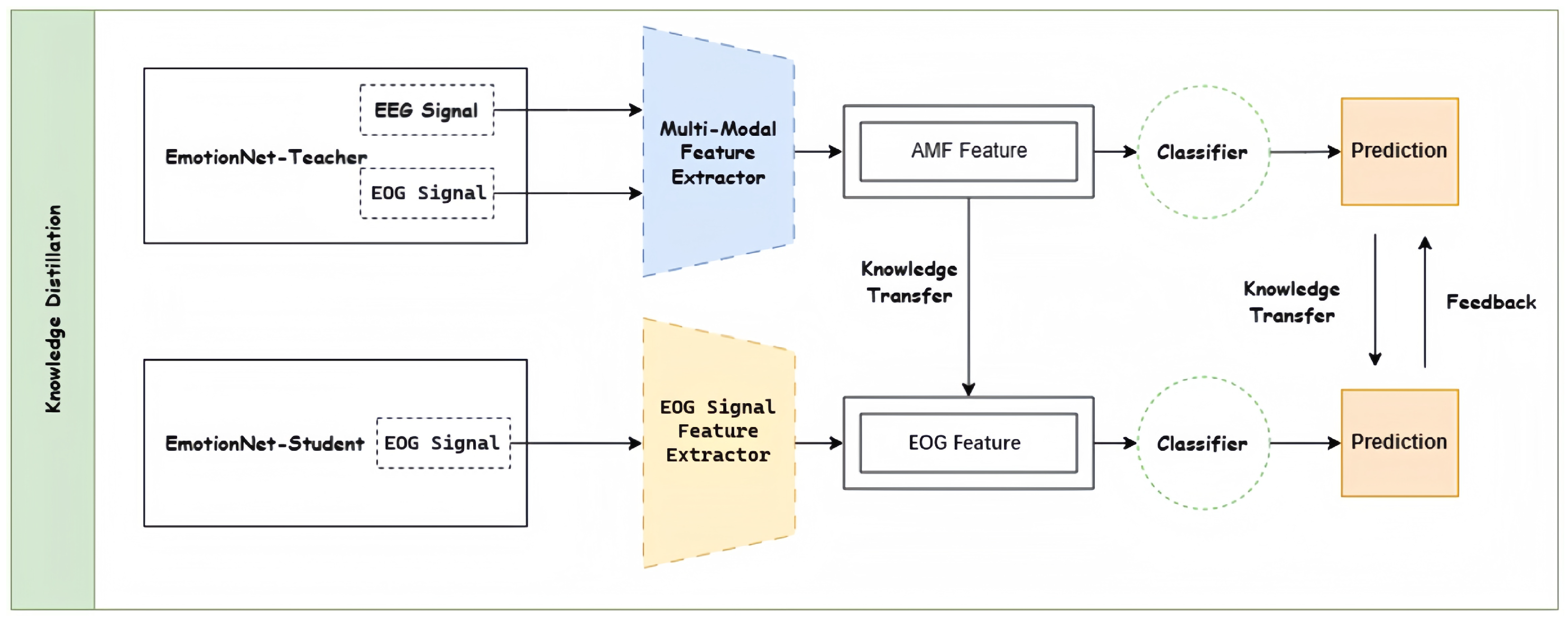
3. Proposed Methodology
3.1. Multimodal Teacher Model
3.1.1. Transformer-Based Feature Extraction for Modal Heterogeneity
3.1.2. Modal Fusion Module for Interactivity Features
3.2. Unimodal Student Model
3.3. Dynamic Feedback Mechanisms
3.3.1. Teaching Phase
3.3.2. Feedback Phase
4. Experimental Results and Analysis
4.1. Dataset Description
4.2. Emotional Dimensions and Evaluation Metrics
4.2.1. Arousal
4.2.2. Valence
4.2.3. Accuracy
4.2.4. F1 Score
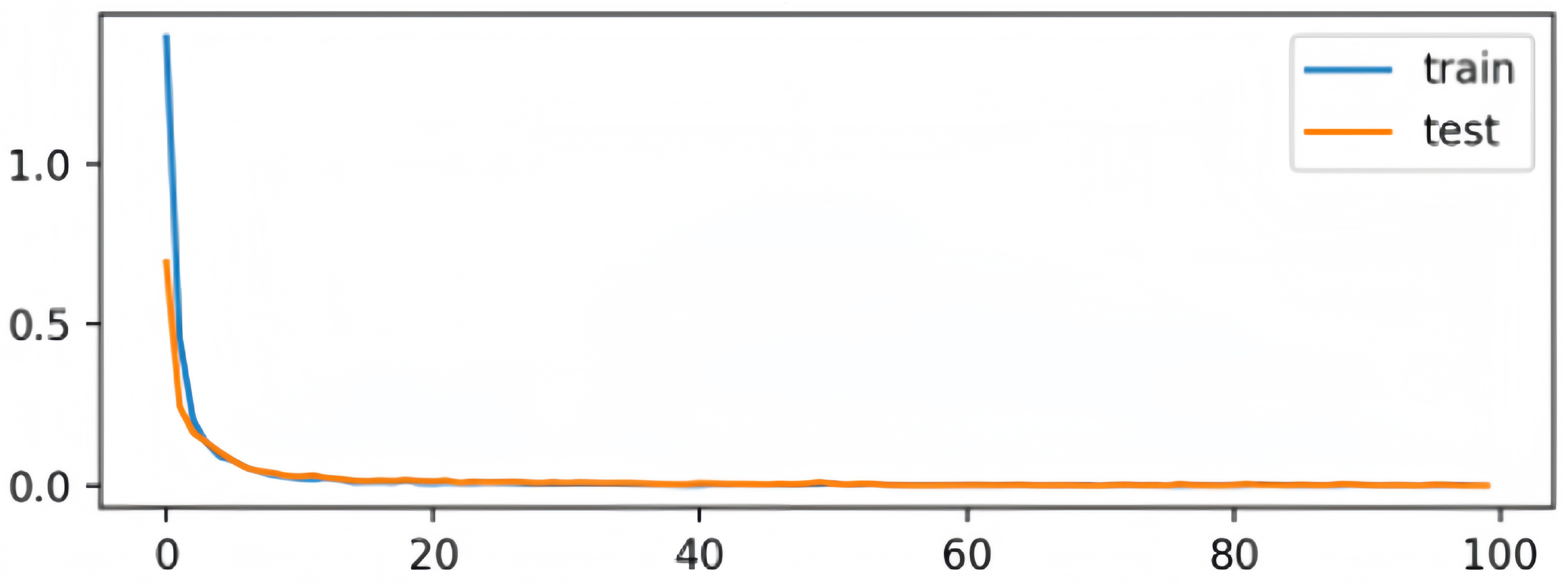
4.3. Experimental Setup
4.4. Experimental Results
4.5. Ablation Study
- Variation 1: Excluding multimodal fusion features and the feedback regulation mechanism. In this case, the Hinton-KD method is used as a baseline for knowledge distillation.
- Variation 2: Incorporating multimodal fusion features for distillation but without applying the feedback regulation mechanism.
- Variation 3: Including both multimodal fusion features and the feedback regulation mechanism.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abdullah, S.; Ameen, S.; Sadeeq, M.; Zeebaree, S. Multimodal Emotion Recognition using Deep Learning. J. Appl. Sci. Technol. Trends 2021, 2, 52–58. [Google Scholar] [CrossRef]
- Soleymani, M.; Pantic, M.; Pun, T. Multimodal Emotion Recognition in Response to Videos. IEEE Trans. Affect. Comput. 2012, 3, 211–223. [Google Scholar] [CrossRef]
- Tzirakis, P.; Trigeorgis, G.; Nicolaou, M.A.; Schuller, B.W.; Zafeiriou, S. End-to-End Multimodal Emotion Recognition Using Deep Neural Networks. IEEE J. Sel. Top. Signal Process. 2017, 11, 1301–1309. [Google Scholar] [CrossRef]
- Huang, C.; Jin, Y.; Wang, Q.; Zhao, L.; Zou, C. Multimodal Emotion Recognition Based on Speech and ECG Signals. Chin. J. Biomed. Eng. 2010, 40, 895–900. [Google Scholar] [CrossRef]
- Merzagora, A.C.; Izzetoglu, M.; Polikar, R.; Weisser, V.; Onaral, B.; Schultheis, M.T. Functional near-infrared spectroscopy and electroencephalography: A multimodal imaging approach. In Foundations of Augmented Cognition. Neuroergonomics and Operational Neuroscience, Proceedings of the 5th International Conference, FAC 2009 Held as Part of HCI International 2009, San Diego, CA, USA, 19–24 July 2009; Proceedings 5; Springer: Berlin/Heidelberg, Germany, 2009; pp. 417–426. [Google Scholar]
- Yang, Y.; Wang, Z.; Song, Y.; Jia, Z.; Wang, B.; Jung, T.-P.; Wan, F. Exploiting the Intrinsic Neighborhood Semantic Structure for Domain Adaptation in EEG-based Emotion Recognition. IEEE Trans. Affect. Comput. 2025, 1–13. [Google Scholar] [CrossRef]
- Wang, J.; Feng, Z.; Ning, X.; Lin, Y.; Chen, B.; Jia, Z. Two-stream Dynamic Heterogeneous Graph Recurrent Neural Network for Multi-label Multi-modal Emotion Recognition. IEEE Trans. Affect. Comput. 2025, 1–14. [Google Scholar] [CrossRef]
- Cheng, C.; Liu, W.; Wang, X.; Feng, L.; Jia, Z. DISD-Net: A Dynamic Interactive Network with Self-distillation for Cross-subject Multi-modal Emotion Recognition. IEEE Trans. Multimed. 2025, 1–14. [Google Scholar] [CrossRef]
- Cheng, C.; Liu, W.; Feng, L.; Jia, Z. Emotion Recognition Using Hierarchical Spatial-Temporal Learning Transformer From Regional to Global Brain. Neural Netw. 2024, 179, 106624. [Google Scholar] [CrossRef]
- Jia, Z.; Zhao, F.; Guo, Y.; Chen, H.; Jiang, T.; Center, B. Multi-level Disentangling Network for Cross-subject Emotion Recognition Based on Multimodal Physiological Signals. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI), Jeju, Republic of Korea, 3–9 August 2024; pp. 3069–3077. [Google Scholar]
- Ning, X.; Wang, J.; Lin, Y.; Cai, X.; Chen, H.; Gou, H.; Li, X.; Jia, Z. MetaEmotionNet: Spatial-Spectral-Temporal-Based Attention 3-D Dense Network with Meta-learning for EEG Emotion Recognition. IEEE Trans. Instrum. Meas. 2023, 73, 2501313. [Google Scholar] [CrossRef]
- Albanie, S.; Nagrani, A.; Vedaldi, A.; Zisserman, A. Emotion Recognition in Speech Using Cross-Modal Transfer in the Wild. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 292–301. [Google Scholar] [CrossRef]
- Saxena, A.; Khanna, A.; Gupta, D. Emotion Recognition and Detection Methods: A Comprehensive Survey. J. Artif. Intell. Syst. 2020, 2, 53–79. [Google Scholar] [CrossRef]
- Sharma, G.; Dhall, A. A Survey on Automatic Multimodal Emotion Recognition in the Wild. In Advances in Data Science: Methodologies and Applications; Phillips-Wren, G., Esposito, A., Jain, L.C., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 35–64. [Google Scholar] [CrossRef]
- Du, G.; Su, J.; Zhang, L.; Su, K.; Wang, X.; Teng, S.; Liu, P.X. A Multi-Dimensional Graph Convolution Network for EEG Emotion Recognition. IEEE Trans. Instrum. Meas. 2022, 71, 2518311. [Google Scholar] [CrossRef]
- Liu, S.; Wang, X.; Zhao, L.; Li, B.; Hu, W.; Yu, J.; Zhang, Y.D. 3DCANN: A Spatio-Temporal Convolution Attention Neural Network for EEG Emotion Recognition. IEEE J. Biomed. Health Inform. 2022, 26, 5321–5331. [Google Scholar] [CrossRef]
- Nguyen, D.; Nguyen, D.T.; Zeng, R.; Nguyen, T.T.; Tran, S.N.; Nguyen, T.; Sridharan, S.; Fookes, C. Deep Auto-Encoders with Sequential Learning for Multimodal Dimensional Emotion Recognition. IEEE Trans. Multimed. 2022, 24, 1313–1324. [Google Scholar] [CrossRef]
- Gou, J.; Yu, B.; Maybank, S.J. Knowledge Distillation: A Survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Zhou, T.; Ruan, S.; Canu, S. A Review: Deep Learning for Medical Image Segmentation Using Multi-Modality Fusion. Array 2019, 3–4, 100004. [Google Scholar] [CrossRef]
- Liu, W.; Qiu, J.L.; Zheng, W.L.; Lu, B.L. Comparing Recognition Performance and Robustness of Multimodal Deep Learning Models for Multimodal Emotion Recognition. IEEE Trans. Cogn. Dev. Syst. 2022, 14, 715–729. [Google Scholar] [CrossRef]
- Liu, W.; Zheng, W.L.; Lu, B.L. Emotion Recognition Using Multimodal Deep Learning. In Neural Information Processing; Hirose, A., Ozawa, S., Doya, K., Ikeda, K., Lee, M., Liu, D., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 521–529. [Google Scholar] [CrossRef]
- Guo, G.; Gao, P.; Zheng, X.; Ji, C. Multimodal Emotion Recognition Using CNN-SVM with Data Augmentation. In Proceedings of the 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Las Vegas, NV, USA, 6–8 December 2022; pp. 3008–3014. [Google Scholar] [CrossRef]
- Song, T.; Lu, G.; Yan, J. Emotion Recognition Based on Physiological Signals Using Convolution Neural Networks. In Proceedings of the 2020 ACM International Conference on Multimedia Retrieval, Dublin, Ireland, 8–11 June 2020; pp. 161–165. [Google Scholar] [CrossRef]
- Albera, L.; Kachenoura, A.; Comon, P.; Karfoul, A.; Wendling, F.; Senhadji, L.; Merlet, I. ICA-Based EEG Denoising: A Comparative Analysis of Fifteen Methods. Bull. Pol. Acad.-Sci.-Tech. Sci. 2012, 60, 407–418. Available online: https://api.semanticscholar.org/CorpusID:854211 (accessed on 28 May 2025). [CrossRef]
- Värbu, K.; Muhammad, N.; Muhammad, Y. Past, Present, and Future of EEG-Based BCI Applications. Sensors 2022, 22, 3331. [Google Scholar] [CrossRef]
- Dzedzickis, A.; Kaklauskas, A.; Bucinskas, V. Human Emotion Recognition: Review of Sensors and Methods. Sensors 2020, 20, 592. [Google Scholar] [CrossRef]
- Zhao, L.; Peng, X.; Chen, Y.; Kapadia, M.; Metaxas, D.N. Knowledge as Priors: Cross-Modal Knowledge Generalization for Datasets without Superior Knowledge. arXiv 2020, arXiv:2004.00176. [Google Scholar] [CrossRef]
- Fan, D.; Liu, M.; Zhang, X.; Gong, X. Human Emotion Recognition Based on Galvanic Skin Response Signal Feature Selection and SVM. arXiv 2023, arXiv:2307.05383. [Google Scholar] [CrossRef]
- Zhang, Q.; Lai, X.; Liu, G. Emotion Recognition of GSR Based on an Improved Quantum Neural Network. In Proceedings of the 2016 8th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 27–28 August 2016; Volume 1, pp. 488–492. [Google Scholar] [CrossRef]
- Susanto, I.Y.; Pan, T.Y.; Chen, C.W.; Hu, M.C.; Cheng, W.H. Emotion Recognition from Galvanic Skin Response Signal Based on Deep Hybrid Neural Networks. In Proceedings of the 2020 International Conference on Multimedia Retrieval, Dublin, Ireland, 8–11 June 2020; pp. 341–345. [Google Scholar] [CrossRef]
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep Mutual Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4320–4328. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar] [CrossRef]
- Mirzadeh, S.I.; Farajtabar, M.; Li, A.; Levine, N.; Matsukawa, A.; Ghasemzadeh, H. Improved Knowledge Distillation via Teacher Assistant. arXiv 2019, arXiv:1902.03393. [Google Scholar] [CrossRef]
- Park, D.Y.; Cha, M.H.; Jeong, C.; Kim, D.S.; Han, B. Learning Student-Friendly Teacher Networks for Knowledge Distillation. arXiv 2022, arXiv:2102.07650. [Google Scholar] [CrossRef]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive Representation Distillation. arXiv 2022, arXiv:1910.10699. [Google Scholar] [CrossRef]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.S.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. DEAP: A Database for Emotion Analysis Using Physiological Signals. IEEE Trans. Affect. Comput. 2012, 3, 18–31. [Google Scholar] [CrossRef]
- Soleymani, M.; Lichtenauer, J.; Pun, T.; Pantic, M. A Multimodal Database for Affect Recognition and Implicit Tagging. IEEE Trans. Affect. Comput. 2012, 3, 42–55. [Google Scholar] [CrossRef]
- Schirrmeister, R.; Gemein, L.; Eggensperger, K.; Hutter, F.; Ball, T. Deep Learning with Convolutional Neural Networks for Decoding and Visualization of EEG Pathology. In Proceedings of the 2017 IEEE Signal Processing in Medicine and Biology Symposium (SPMB), Philadelphia, PA, USA, 2 December 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Yan, X.; Zhao, L.M.; Lu, B.L. Simplifying Multimodal Emotion Recognition with Single Eye Movement Modality. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 1057–1063. [Google Scholar] [CrossRef]
- Liu, Y.; Jia, Z.; Wang, H. EmotionKD: A Cross-Modal Knowledge Distillation Framework for Emotion Recognition Based on Physiological Signals. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 6122–6131. [Google Scholar]
- Sun, T.; Wei, Y.; Ni, J.; Liu, Z.; Song, X.; Wang, Y.; Nie, L. Muti-modal Emotion Recognition via Hierarchical Knowledge Distillation. IEEE Trans. Multimed. 2024, 26, 9036–9046. [Google Scholar] [CrossRef]
- Mescheder, L.M.; Geiger, A.; Nowozin, S. Which Training Methods for GANs Do Actually Converge? In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Available online: https://api.semanticscholar.org/CorpusID:3345317 (accessed on 28 May 2025).


{kind=link}
{kind=link}
{kind=link}
| Aro | Val | |||
|---|---|---|---|---|
| Accuracy | F1-Score | Accuracy | F1-Score | |
| DeepConvNet [38] | 54.70 | 51.95 | 66.45 | 61.15 |
| CNN+RNN [30] | 54.17 | 40.37 | 67.97 | 64.17 |
| CGAN [39] | 54.43 | 48.82 | 55.17 | 35.66 |
| EmotionNet [38] | 56.06 | 55.50 | 69.18 | 68.33 |
| EmotionKD [40] | 56.56 | 56.18 | 69.38 | 68.63 |
| HKD-MER [41] | 58.75 | 58.38 | 69.73 | 69.03 |
| Proposed Method | 60.41 | 61.01 | 70.38 | 70.16 |
| Aro | Val | |||
|---|---|---|---|---|
| Accuracy | F1-Score | Accuracy | F1-Score | |
| DeepConvNet [38] | 56.56 | 42.55 | 46.32 | 48.69 |
| CNN+RNN [30] | 48.90 | 44.77 | 57.25 | 49.69 |
| CGAN [39,42] | 55.43 | 45.82 | 58.17 | 39.66 |
| EmotionNet [38] | 57.86 | 51.49 | 58.56 | 58.81 |
| EmotionKD [40] | 58.66 | 55.68 | 60.38 | 59.66 |
| HKD-MER [41] | 58.85 | 58.86 | 60.78 | 60.06 |
| Proposed Method | 60.41 | 59.81 | 61.31 | 60.61 |
| Aro | Val | |||
|---|---|---|---|---|
| Accuracy | F1-Score | Accuracy | F1-Score | |
| Variation 1 | 54.68 | 53.31 | 68.91 | 67.39 |
| Variation 2 | 55.89 | 53.60 | 69.70 | 68.41 |
| Variation 3 | 56.15 | 54.49 | 69.21 | 69.41 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Lu, G. Multimodal Knowledge Distillation for Emotion Recognition. Brain Sci. 2025, 15, 707. https://doi.org/10.3390/brainsci15070707
Zhang Z, Lu G. Multimodal Knowledge Distillation for Emotion Recognition. Brain Sciences. 2025; 15(7):707. https://doi.org/10.3390/brainsci15070707
Chicago/Turabian StyleZhang, Zhenxuan, and Guanyu Lu. 2025. "Multimodal Knowledge Distillation for Emotion Recognition" Brain Sciences 15, no. 7: 707. https://doi.org/10.3390/brainsci15070707
APA StyleZhang, Z., & Lu, G. (2025). Multimodal Knowledge Distillation for Emotion Recognition. Brain Sciences, 15(7), 707. https://doi.org/10.3390/brainsci15070707