Featured Application
This work provides a computationally efficient and robust local feature extraction solution specifically optimized for real-time Visual Simultaneous Localization and Mapping (Visual SLAM) and mobile Augmented Reality (AR) systems. The proposed GCA-Net is particularly applicable to high-precision spatial computing and tracking on resource-constrained devices. By suppressing localization jitter and mitigating perceptual aliasing in complex environments, it enables stable trajectory estimation for applications such as indoor navigation, industrial AR maintenance, and collaborative SLAM, where maintaining sub-pixel accuracy and low latency is critical.
Abstract
Lightweight local feature extractors are essential for real-time SLAM. However, they frequently struggle with perceptual aliasing and low localization accuracy in texture-sparse or repetitive environments. This paper introduces the Geometric-Contextual Alignment Network (GCA-Net), a framework designed to address these instabilities through a Geometric-Contextual Alignment (GCA) module. The proposed GCA module integrates global contextual priors into the feature stream. By employing Context-based Feature-wise Linear Modulation (C-FiLM), the network mitigates perceptual aliasing by prioritizing structurally reliable regions. To enhance spatial precision, we incorporate a Depthwise Separable Atrous Spatial Pyramid Pooling (DS-ASPP) stage to expand the Effective Receptive Field (ERF). This design provides robust multi-scale anchoring, which significantly reduces localization jitter under large viewpoint shifts. Extensive evaluations on MegaDepth, ScanNet and HPatches demonstrate that GCA-Net achieves high sub-pixel precision and robust cross-domain generalization. On the MegaDepth benchmark, GCA-Net outperforms the vanilla XFeat by 8.0% in Area Under the Curve (AUC) at a 5° threshold (AUC@5°). Furthermore, it yields a 23.6% relative improvement over the SuperPoint baseline while using compact 64-floating-point (64-f) descriptors. These results indicate that the GCA mechanism helps capture complex spatial structures that typically require much heavier architectures. By balancing matching accuracy with computational efficiency, GCA-Net provides an effective framework for autonomous navigation on edge computing platforms.
1. Introduction
Visual Simultaneous Localization and Mapping (SLAM) and 3D reconstruction have undergone extensive development, driven by applications in autonomous navigation and augmented reality [1,2]. Recent assessments of the SLAM landscape highlight a shift from purely geometric methods to hybrid deep-learning-driven frameworks to meet the demands of high-stakes environments [3,4]. As the front-end foundation of these systems, local feature extraction determines the upper bound of robustness and accuracy [5]. Comprehensive surveys emphasize that the discriminability and sub-pixel precision of local features directly dictate the reliability of downstream pose estimation [6]. While recent lightweight models, such as XFeat [7], have achieved notable gains in computational efficiency, they often sacrifice geometric reliability in complex real-world environments [8]. Specifically, extreme architectural minimalism often leads to the neglect of mid-level structural cues, causing performance degradation in challenging lighting or texture-sparse scenes [9]. In particular, these models suffer from two fundamental bottlenecks. The first is perceptual aliasing, where geometric similarity leads to incorrect correspondences [10]. The second is localization instability, characterized by marked precision degradation under drastic scale variations or low-contrast conditions.
Most existing methods implicitly assume that geometrically repeatable patterns correspond to stable landmarks. However, this assumption frequently fails in scenes with repetitive structures, textureless surfaces, or dynamic objects. In such scenarios, networks generate multiple indistinguishable response peaks for distinct structural entities, leading to ambiguous matches. Furthermore, features extracted from low-contrast regions often lack well-defined intensity gradients. Limited receptive fields make sub-pixel localization highly sensitive to photometric noise. Limited effective receptive fields (ERF) in lightweight backbones further exacerbate this issue, as the network lacks the macroscopic spatial constraints necessary to anchor keypoints against photometric noise [11]. This sensitivity causes peak coordinates to fluctuate randomly, a phenomenon termed localization jitter. Integrating these contextually inconsistent or spatially drifting features into pose estimation pipelines introduces spurious motion noise. Consequently, this noise severely degrades trajectory consistency. To bridge this gap, we propose an end-to-end Geometric-Contextual Alignment Network (GCA-Net), designed to enhance the reliability of lightweight local features by introducing structural guidance into the feature extraction pipeline.
These limitations indicate that local geometric cues alone are insufficient for assessing feature validity. Robust frameworks must distinguish permanent landmarks from transient or ambiguous regions. Global structural context, even when coarse, provides critical priors for region-level consistency [12]. Rather than relying on explicit pixel-level annotations, the proposed context serves as adaptive guidance. It steers the extractor toward structurally salient regions while suppressing uninformative responses. Importantly, such guidance must be integrated with multi-scale geometric information to preserve the fine-grained precision necessary for stable localization.
While high-level semantic labels offer category information, we argue that mid-level structural context provides a more stable and computationally efficient prior for geometric verification in changing environments. Accordingly, GCA-Net is architecturally defined as a dual-stream framework that decouples geometric feature extraction from structural context modulation. This design allows global structural priors to guide local refinement without the heavy overhead typically associated with semantic-level understanding. By integrating global structural context with local geometric features, GCA-Net facilitates a coarse-to-fine refinement process within a single forward pass. This design is specifically optimized for deployment on edge computing devices where computational resources are limited but high localization precision is mandatory. It allows global contextual cues to guide local feature refinement without introducing additional inference stages. The ultimate goal of this work is to provide a reliable front-end solution for autonomous systems operating in low-compute environments. By resolving the instability of lightweight features, the proposed framework is highly applicable to long-term navigation tasks where persistent localization is required despite environmental changes. Our contributions are three-fold:
- (1)
- Geometric-Contextual Alignment (GCA): We introduce a decoupled contextual stream to modulate the geometric features via Context-based Feature-wise Linear Modulation (C-FiLM) [13]. This mechanism dynamically re-weights feature importance based on scene context. By doing so, it effectively resolves perceptual aliasing in repetitive or texture-sparse environments.
- (2)
- Lightweight Multi-scale Aggregation (DS-ASPP): To suppress localization jitter, we incorporate a lightweight Depthwise Separable Atrous Spatial Pyramid Pooling (DS-ASPP) module. By expanding the effective receptive field, this module provides robust multi-scale anchoring [14,15]. This mechanism mitigates coordinate drifting caused by local noise, ensuring stability across varying scene scales.
- (3)
- Unified Lightweight Architecture and Proven Applicability: We integrate these modules into an end-to-end pipeline tailored for resource-constrained platforms. Extensive evaluations on MegaDepth, ScanNet, and HPatches reveal that GCA-Net achieves a marked performance gain. Beyond standard benchmarks, we provide direct evidence of its applicability by integrating GCA-Net into the AirSLAM system, demonstrating its capacity to support robust trajectory estimation in complete navigation pipelines. In our experiments, it yields an 8.0% relative gain in Area Under the Curve (AUC) at a 5° threshold (AUC@5°) over the vanilla XFeat and a 23.6% improvement over SuperPoint on MegaDepth, while maintaining real-time efficiency on edge devices.
2. Related Work
2.1. Lightweight Local Feature Learning
Local feature extraction has evolved from handcrafted operators, such as Scale-Invariant Feature Transform (SIFT) and Oriented FAST and Rotated BRIEF (ORB) [16], to joint detection and description frameworks. Landmark models like SuperPoint [8] and D2-Net [10] established high benchmarks for robustness by learning invariance to diverse transformations through end-to-end architectures. However, these models often incur prohibitive computational costs when processing high-resolution images, and their performance frequently degrades in texture-sparse or repetitive environments. Recently, the field has shifted toward efficiency-focused architectures. ALIKE [17] and SiLK [18] achieved competitive performance but remain hindered by their reliance on high-resolution inputs, which inflate memory footprints. While competitors like ZippyPoint [19] pursue speed through binarization, they remain “context-agnostic,” failing to distinguish stable structural landmarks from transient textures.
XFeat addressed these constraints by employing a minimalist CNN architecture, enabling real-time inference on resource-limited devices. However, this extreme minimalism often limits the ERF. This restriction leads to ‘flat’ response maps in textureless regions and causes substantial localization jitter. To mitigate such performance degradation in texture-sparse environments, recent advancements have integrated 3D geometric cues into lightweight frameworks [20], aligning with our goal of enhancing structural reliability. Furthermore, the feasibility of hardware-efficient architectures has been validated through optimized local matching modules specifically designed for resource-constrained platforms [21]. Complementing our strategy of combining minimalism with contextual awareness, recent re-examinations of local perception mechanisms in lightweight Vision Transformers (ViTs) have further optimized the efficiency of feature extraction while maintaining high-fidelity localization [22].
2.2. Contextual Guidance and Feature Modulation
The integration of global context to guide local geometric extraction is an active area of research. However, current methods are often hindered by the trade-off between contextual depth and inference efficiency. Traditional approaches frequently rely on explicit semantic masking. For instance, certain models like AliNet [23] utilize pixel-level segmentation to filter dynamic outliers. Nevertheless, fine-grained supervision incurs prohibitive annotation costs, and the heavy computational overhead of segmentation renders these methods unsuitable for real-time SLAM. Furthermore, the binary nature of “hard-masking” may inadvertently discard valid geometric cues in texture-rich but non-static regions.
To mitigate these bottlenecks, attention mechanisms in Transformer models [24,25] have been employed to capture long-range dependencies. While Transformers show competitive robustness in cluttered scenes, their quadratic computational complexity remains a critical obstacle for high-frequency visual odometry. In contrast, Feature-wise Linear Modulation (FiLM) [13] provides a computationally efficient “soft” modulation alternative. By applying channel-level scaling and shifting parameters, FiLM achieves linear complexity, making it highly scalable for resource-constrained deployment.
While FiLM has seen success in vision-language tasks, its potential in local feature extraction remains under-explored. The proposed GCA leverages this principle by employing a decoupled contextual stream. This stream learns to prioritize structurally reliable landmarks using coarse contextual priors. Unlike methods requiring explicit labels, GCA enables the network to resolve perceptual aliasing by adaptively re-weighting feature responses. This modulation encourages the model to focus on stable geometric entities. Simultaneously, it suppresses unstable response peaks commonly found in repetitive or dynamic environments. The effectiveness of this strategy is echoed by recent multi-level contextual prototype modulation schemes, which demonstrate that adaptive feature weighting can significantly improve robustness in complex scenes [26]. Furthermore, the introduction of contextual gating mechanisms within Transformer architectures offers a synergistic approach to balancing global context with local details [27], providing a robust precedent for our demand for lightweight yet contextually guided modulation.
2.3. Multi-Scale Learning and Receptive Field Efficacy
Capturing multi-scale information is essential for handling large depth variations and drastic scale changes in 3D reconstruction. Unlike traditional methods that rely on computationally expensive image pyramids [28], modern architectures leverage dilated convolutions to expand the effective receptive field without sacrificing spatial resolution. Atrous Spatial Pyramid Pooling (ASPP) [14,15] has emerged as a robust mechanism for capturing multi-scale context by employing parallel atrous convolutions with varying dilation rates. In contrast to traditional pooling layers that discard fine-grained geometric details through pronounced downsampling [29], ASPP preserves high-resolution feature maps while integrating diverse receptive fields.
Despite its success in dense prediction tasks, the potential of ASPP for anchoring local features within lightweight pipelines remains under-explored. Minimalist backbones, such as XFeat and ALIKE, primarily utilize shallow filters restricted to localized gradients. These constrained receptive fields often lack the macroscopic structural context necessary to resolve geometric ambiguities in texture-sparse or low-contrast regions. This limitation frequently manifests as localization jitter and coordinate drifting in downstream SLAM tasks. While frameworks like GlueStick [30] and LoFTR [31] attempt to address these issues through global self-attention or point-line fusion, their high computational complexity often exceeds the budget of edge devices [32,33,34,35].
To address the computational complexity of expanding the ERF, recursive convolution mechanisms have been proposed to achieve multi-frequency representations without the overhead of large-kernel filters [36]. This is consistent with the design philosophy of our DS-ASPP module. Theoretical analyses further suggest that multi-scale message-passing can effectively expand the ERF without increasing the overall computational budget [37], supporting our emphasis on receptive field optimization. In parallel, multi-kernel correlation-attention frameworks have demonstrated the capacity to resolve geometric ambiguities by fusing global and local contexts [38]. Finally, the success of multi-scale adaptive learning networks in dynamic feature fusion [39] reinforces our design of utilizing a lightweight ASPP adaptation to stabilize keypoints against photometric noise. Consequently, our DS-ASPP module integrates these broad geometric constraints into the feature stream. This lightweight adaptation provides the necessary multi-scale spatial constraints to stabilize keypoints, thereby reconciling the trade-off between computational efficiency and geometric reliability.
3. Methodology
3.1. Overview of GCA-Net
The Geometric-Contextual Alignment Network (GCA-Net) is designed to integrate global contextual reasoning with local geometric precision. As illustrated in Figure 1, the input image is first processed by a shared backbone to generate hierarchical feature maps. The system adopts a multi-head paradigm consisting of a geometric stream for dense feature extraction, a decoupled contextual stream for structural guidance, and auxiliary branches for keypoint detection and reliability evaluation. The core design follows a coarse-to-fine refinement strategy that enhances both feature discriminative power and localization stability.
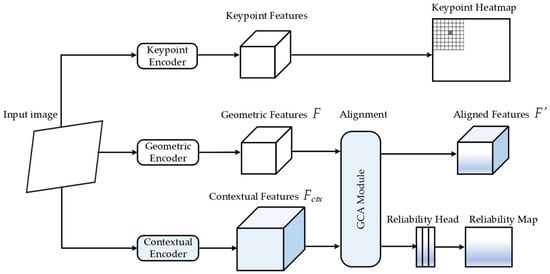
Figure 1.
Architecture of the proposed GCA-Net. The overall framework consists of a keypoint detection branch, a geometric extraction stream, and a contextual calibration stream. The GCA module integrates geometric features and contextual embeddings to produce a calibrated feature representation .
Geometric Foundation. To establish a robust geometric basis, the geometric stream produces dense features for precise localization. This is achieved by introducing the Depthwise Separable Atrous Spatial Pyramid Pooling (DS-ASPP) module (Figure 2), which aggregates multi-scale cues via parallel depthwise separable dilated convolutions. By expanding the Effective Receptive Field (ERF) to encode broad structural information and fusing upsampled representations from deeper layers (e.g., and scales), the geometric encoder constructs scale-aware features . This representation preserves both fine-grained details and global context.
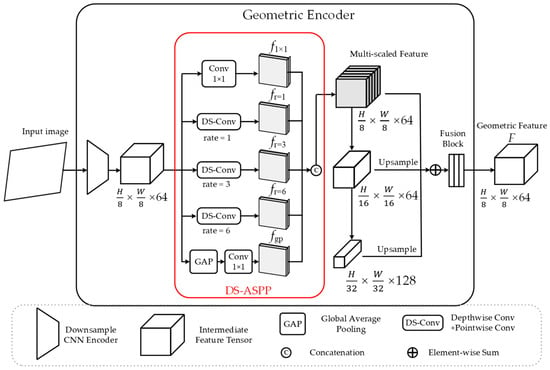
Figure 2.
Detailed architecture of the Geometric Encoder. The proposed DS-ASPP module utilizes parallel depthwise separable convolutions with various atrous rates to capture multi-scale context. The final geometric feature is constructed by fusing hierarchical features from multiple stages. Dimensions are indicated as .
Contextual Alignment and Auxiliary Branches. Concurrently, the decoupled contextual stream extracts mid-level feature maps , where is a compact bottleneck dimension (8 or 16) designed to prioritize structural regularities. Subsequently, the Geometric-Contextual Alignment (GCA) module (Figure 3) performs context-aware modulation on . The mid-level features are compressed via Global Average Pooling (GAP) to form a contextual embedding , which is then projected through a modulation layer. This process generates channel-wise modulation vectors, and , to perform an affine transformation on . This mechanism calibrates feature activations to effectively suppress perceptual aliasing and imaging artifacts, producing a unified and aligned feature representation .
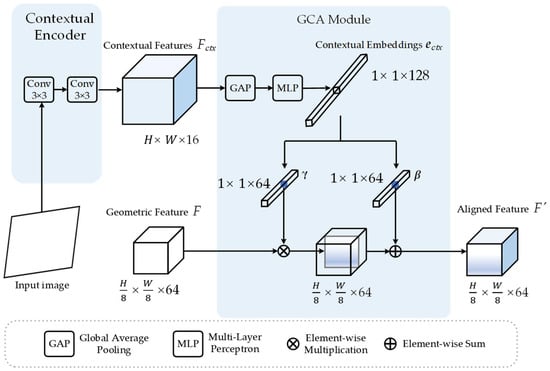
Figure 3.
Detailed architecture of the contextual stream and GCA module. The GCA mechanism performs channel-wise modulation between geometric features and contextual embeddings . Mid-level features are projected into modulation vectors (, ) to refine geometric responses via a channel-wise affine transformation, yielding the aligned feature . Dimensions are indicated as .
The keypoint detection and reliability evaluation branches adopt the architectural design of XFeat to maintain a complete and spatially robust framework [7]. By leveraging these established components, our system focuses on context-guided alignment while maintaining high-quality feature filtering under drastic viewpoint transformations.
3.2. Lightweight Multi-Scale Aggregation (DS-ASPP)
While the GCA module promotes contextual consistency, minimalist backbones often suffer from a constrained Effective Receptive Field (ERF). This architectural limitation results in feature responses derived from overly localized intensity gradients, which are susceptible to coordinate drifting under photometric noise. To suppress these instabilities while preserving real-time efficiency, we introduce the Depthwise Separable Atrous Spatial Pyramid Pooling (DS-ASPP) module. DS-ASPP establishes the geometric foundation by mitigating isolated feature extraction. This is achieved through the aggregation of multi-scale priors, which anchor keypoints within a broader spatial context. This mitigates the localization jitter inherent in lightweight architectures.
3.2.1. Dilated Convolution and Receptive Field
Dilated (atrous) convolution allows for the expansion of the ERF without increasing parameter density or compromising spatial resolution. Unlike standard downsampling or pooling operations that sacrifice resolution to capture context, dilated convolution introduces a sampling stride within the kernel support, defined by the dilation rate . For a 2D feature map , the output at location is:
where denotes the dilation rate that controls the sampling stride, signifies the learnable filter weights, and represents the discrete spatial index within the kernel support (e.g., for a filter). By modulating , the network effectively captures macroscopic structural patterns while maintaining high-fidelity spatial details.
This mechanism is particularly advantageous for GCA-Net for two reasons:
- Resolution Preservation: By avoiding aggressive pooling, the framework retains high-fidelity spatial information, which is essential for precise sub-pixel anchoring.
- Macroscopic Structural Awareness: It enables the detection of large-scale geometric primitives, such as long architectural lines or planar boundaries, which are inherently invisible to standard kernels.
By integrating these dilated kernels into a Depthwise Separable (DS) structure, the DS-ASPP module achieves extensive multi-scale context aggregation while adhering to the stringent computational constraints of edge computing platforms.
3.2.2. Scale-Space Anchoring via DS-ASPP
To implement geometric stability across various distances, the DS-ASPP module constructs a parallel multi-scale refinement stage (see Figure 2). This architecture processes the intermediate backbone features (where , ) through five specialized branches, effectively “anchoring” local keypoints within a broader geometric reference frame before subsequent contextual modulation. , and denote the height, width, and channel depth of the backbone’s intermediate output, respectively. As detailed in Figure 2, each branch maintains the spatial resolution to ensure sub-pixel alignment.
The augmented feature map is formulated as follows:
The DS-ASPP module employs a hierarchical set of dilation rates to capture geometric features across multiple spatial scales. According to the receptive field (RF) formula, these rates correspond to spatial supports of , , and pixels, respectively. This specific triplet is chosen to ensure a continuous sampling of the scale-space: preserves the highest spatial resolution for sub-pixel precision, while expands the context to capture mid-range structural primitives without introducing the “gridding effect” typically seen with larger, sparser dilation intervals.
In this formulation, the denotes a standard convolutional branch dedicated to preserving fine-grained local details. The represents the Depthwise Separable Dilated branch with a specific dilation rate , engineered to expand the ERF while minimizing parameter redundancy (as detailed in Section 4.6). In this data flow, each branch independently transforms the -channel input into a -channel representative feature map. Simultaneously, the global context is incorporated via , which employs Global Average Pooling to reduce to a vector, followed by bilinear interpolation to upsample it back to .
These five parallel outputs are concatenated along the channel dimension to form the high-dimensional aggregate . Finally, a learnable projection matrix (implemented as a convolution) compresses into the target geometric feature . By aggregating these multi-scale responses without spatial downsampling, the module provides a redundant and scale-invariant geometric foundation for the subsequent alignment stage.
Unlike standard ASPP which relies on dense convolutional kernels, DS-ASPP employs depthwise separable factorization in each dilated branch. This design ensures that the backbone captures extensive macroscopic cues while maintaining the lightweight profile required for real-time SLAM. By refining the geometric features at this stage, the module provides a multi-scale foundation that is more robust to scale variations and texture-sparse regions, which is subsequently fine-tuned by the GCA module for contextual reliability.
3.2.3. Mitigation of Localization Jitter
The primary objective of scale-space anchoring is the suppression of localization jitter—the non-physical fluctuation of feature coordinates. In lightweight backbones, jitter often arises because the localization function is derived from an overly narrow window, making it hypersensitive to pixel-level noise.
For sub-pixel spatial precision, DS-ASPP facilitates a high-fidelity localization gradient. Unlike traditional multi-scale methods that rely on spatial pooling (which destroys sub-pixel alignment), dilated convolutions expand the context while preserving the original feature map resolution. This allows the subsequent keypoint detection head to perform parabolic or soft-argmax interpolation on a feature map that is both spatially sharp and structurally informed. By anchoring the local gradient within an expanded receptive field (up to pixels for the branch), DS-ASPP ensures that the feature localization is informed by a broader structural context rather than isolated intensity changes. This multi-scale sampling allows the network to maintain a stable geometric reference even when the central patch is corrupted by noise. Consequently, the keypoint detection head can achieve higher sub-pixel precision by interpolating over a feature map that has been regularized by these macroscopic structural anchors.
3.3. Geometric-Contextual Alignment (GCA)
To resolve perceptual aliasing and prioritize structurally reliable regions, we introduce the Geometric-Contextual Alignment (GCA) mechanism. Conventional extractors—including handcrafted operators such as ORB [16] and standard deep convolutional backbones like VGG-based architectures [40]—typically learn a direct mapping . These conventional methods primarily focus on localized intensity gradients or local receptive fields. They assume that all spatial locations contribute equally to feature reliability, making them “context-agnostic”. Consequently, they often fail to distinguish between stable structural landmarks and transient textures in repetitive scenes. Here, represents the descriptor dimensionality, while denotes the network stride. However, discriminability is inherently context-dependent. To incorporate this dependency, we define a context-aware modulation function based on Context-based Feature-wise Linear Modulation (C-FiLM):
where represents a mid-level contextual embedding. Based on the overarching scene layout, this formulation enables the network to “softly” modulate geometric features . This approach avoids the binary nature of hard-masking strategies, thereby preserving the representational continuity of the feature stream.
At the heart of this approach is the GCA Module (see Figure 3), which modulates local geometric responses using global structural context. The context-aware modulation stage dynamically adjusts feature activations, balancing geometric precision with contextual consistency in the final descriptors. This process effectively “anchors” keypoints within a broader structural frame, filtering out noise in repetitive or transient environments.
3.3.1. Contextual Embedding Generation
The generation of the contextual embedding is motivated by the requirement for structural primitives—such as corners, edges, and local gradients—which serve as stable geometric anchors in visual localization. Unlike high-level semantic labels that are susceptible to class imbalance, these low-to-mid-level cues remain consistent across diverse environments.
- Lightweight Shallow Architecture ()
As illustrated in Figure 3, the Contextual Encoder adopts a lightweight, two-layer architecture () to extract the feature . This shallow design serves a dual purpose:
- Preserving Spatial Fidelity: By restricting the depth, the model avoids the aggressive spatial downsampling typical of deep networks. This ensures the capture of fine-grained descriptors that correlate directly with geometric reliability.
- Efficiency: Two layers of convolutions facilitate minimal computational overhead, satisfying the real-time requirements of resource-constrained applications.
- 2.
- Compact Dimensionality Constraint
The embedding dimension is set to 8 or 16. This compact dimensionality is a critical design choice that acts as a structural bottleneck. By forcing the high-dimensional backbone features into a significantly lower-dimensional latent space, the network is discouraged from memorizing transient, high-frequency photometric details. Instead, it is regularized to prioritize persistent geometric regularities (e.g., planar surfaces and architectural edges). This ensures that the generated “perceptual prior” is robust to noise and avoids the overfitting risks typical of high-dimensional contextual modules.
- 3.
- Global Aggregation
Finally, the contextual feature is aggregated via Global Average Pooling (GAP) to form the embedding . This embedding captures the overarching scene context, serving as the conditioning modulation signal for the GCA module to calibrate geometric features into .
3.3.2. Contextual Calibration via Context-Based Feature-Wise Linear Modulation (C-FiLM)
To achieve a more nuanced fusion than standard feature concatenation, the GCA module utilizes a Context-based Feature-wise Linear Modulation (C-FiLM). As illustrated in Figure 3, the contextual feature is first aggregated into a compact global descriptor, denoted as the contextual embedding , through GAP:
In this framework, the module treats as a conditional controller to calibrate the geometric feature (where , ) in a channel-wise manner. This mechanism enables the seamless alignment of global contextual priors with local geometric responses. The C-FiLM mechanism dynamically adjusts the weights of individual geometric channels. This modulation is driven by the overarching scene context to prioritize discriminative features.
Parameter Generation. The global contextual embedding acts as the conditional controller to determine the modulation intensity. It is projected into the modulation space through a Multi-Layer Perceptron (MLP) to generate the channel-wise parameters. The scaling vector and the shifting vector are derived as follows:
where denote the learnable weight matrices that project the -dimensional context into the 64-dimensional geometric space, and denote the corresponding bias vectors. The Sigmoid activation constrains to be non-negative to maintain the directional consistency of feature activations, while allows for an additive baseline adjustment based on the global context. This mechanism enables the network to learn a task-specific mapping that prioritizes specific geometric patterns based on the global scene context.
The C-FiLM mechanism operates as a context-dependent gating function. Unlike static extractors that treat all local patches equally, C-FiLM uses the global embedding to “inform” the local channels about the overarching scene type. Specifically, the scaling vector acts as a channel-wise attention mask: it magnifies the response of filters that are sensitive to the detected scene’s stable structures while dampening those prone to aliasing.
To resolve perceptual aliasing, where multiple local regions exhibit nearly identical photometric signatures (e.g., repetitive windows on a building facade), C-FiLM injects global structural constraints into the local descriptor. While two patches may look identical in isolation, their relative importance and “identity” are re-calibrated by the global context , effectively providing each local feature with a unique structural signature that distinguishes it from its visually similar counterparts.
Feature Alignment. Once the modulation parameters are generated, they are broadcast spatially to match the resolution of . The aligned feature map is computed via a channel-wise affine transformation. For each channel and spatial coordinate , the operation is defined as:
In this formulation, and carry distinct physical interpretations optimized for robust visual localization:
- as Channel-wise Reliability Weighting: The scaling factor acts as a soft-attention mechanism. It dynamically re-weights feature importance by assigning higher gains to channels that encode spatially consistent landmarks (e.g., rigid architectures) while suppressing unstable responses triggered by repetitive textures or transient entities. This adaptive weighting ensures that the final descriptor is anchored within a consistent global reference frame.
- as Context-aware Photometric Compensation: Unlike pixel-level white balance, which applies a fixed linear scaling to RGB intensities, the shifting term operates in the latent feature space and is conditioned on the global contextual embedding . In practice, illumination variations (e.g., overexposure or strong shadows) induce complex, non-linear shifts in the distribution of convolutional activations rather than simple intensity scaling. The term learns to compensate for these context-dependent activation shifts by adaptively recalibrating the feature baselines. As a result, the descriptors maintain numerical stability and consistency under varying lighting conditions. This mechanism goes beyond simple white balance, functioning as a learned photometric adaptation that preserves the integrity of underlying geometric representations.
The decoupled nature of this architecture facilitates that the backbone remains fundamentally geometry-driven. Meanwhile, the GCA module provides necessary contextual guidance. This sequential refinement integrates multi-scale geometric anchoring with context-aware calibration. Such a design encourages the extractor to prioritize structurally reliable feature candidates over transient textures. By re-weighting geometric responses, the framework effectively resolves perceptual aliasing and provides high-precision anchoring for downstream SLAM trajectory estimation.
Descriptor Dimensionality. Following the contextual calibration, the final aligned feature is projected to a dimensionality of 64. This descriptor size is selected to strike an optimal balance between matching discriminability and computational efficiency for edge devices. By condensing the multi-scale geometric cues and contextual priors into this compact vector, GCA-Net maintains a low memory footprint during the construction of large-scale SLAM map points while providing sufficient entropy to resolve matching ambiguities in complex environments.
4. Experimental Results
To evaluate the robustness, stability, and efficiency of GCA-Net, we conduct extensive experiments across diverse benchmarks. Our analysis evaluates the model’s performance under challenging environmental conditions and its adaptability to real-time SLAM pipelines.
Implementation Details. The proposed framework is implemented in PyTorch 2.4.1. Both the GCA and DS-ASPP modules are integrated into the pipeline and trained end-to-end. We utilize a self-supervised training strategy on the MegaDepth [41] and synthetically warped COCO [42] datasets (6:4 ratio). Optimization is performed using the Adam optimizer with a learning rate of and a batch size of 10. The training converges within 42 h on a single NVIDIA L20 GPU.
Evaluation Tasks. The assessment is categorized into several distinct tasks to validate different aspects of the extractor:
- Relative Pose Estimation: Evaluated on MegaDepth and ScanNet [43] to assess 3D geometry robustness.
- Homography Estimation: Conducted on HPatches [44] to measure descriptor discriminability under illumination and viewpoint shifts.
- Visual Localization: Tested on the Aachen Day-Night [45] dataset via the HLoc pipeline [46] to verify cross-domain reliability.
- System-Level SLAM Validation: Integrated into the AirSLAM framework and evaluated on the EuRoC MAV [47] dataset to demonstrate the practical utility and trajectory accuracy in a complete navigation pipeline.
- Qualitative Analysis and Interpretability: Visualizes feature activations and matching performance to provide an intuitive understanding of the context-guided mechanism.
- Ablation Study: Systematic experiments are performed on MegaDepth-1500 to isolate the quantitative contributions of the GCA and DS-ASPP modules.
- Efficiency and Computational Complexity: Benchmarks the architectural complexity and inference speed of DS-ASPP against standard ASPP implementations to validate the framework’s suitability for high-frequency, real-time SLAM on resource-constrained devices.
4.1. Relative Pose Estimation
Datasets. Camera pose estimation is a critical benchmark for evaluating the geometric-contextual consistency of local features. Following previous protocols [17], we evaluate GCA-Net on the MegaDepth and ScanNet test sets. MegaDepth comprises approximately one million internet images across 196 urban scenes and building facades. It provides sparse reconstructions and multi-view stereo depth maps, posing formidable challenges such as demanding illumination changes, aggressive viewpoint shifts, and repetitive structures. For this dataset, images are resized to a maximum dimension of 1200 pixels. For essential matrix estimation, we employ the PoseLib library as a robust and efficient alternative to OpenCV’s RANSAC. To ensure rigorous scientific reproducibility, PoseLib utilizes fixed internal random seeds, which yield deterministic pose estimates across repeated trials under identical configurations. To assess the generalizability and robustness of our framework, we conduct zero-shot evaluation on the ScanNet dataset using the model trained exclusively on MegaDepth v1. This cross-domain setup is designed to evaluate the performance of GCA-Net in indoor environments without scene-specific fine-tuning. For example, ScanNet v2 comprises over 1500 RGB-D sequences characterized by diverse challenges, including texture-less surfaces (e.g., white walls), repetitive architectural structures, and complex occlusion patterns. For this evaluation, all images are resized to Video Graphics Array (VGA) resolution ( pixels).
Metrics. To quantify the precision of camera pose estimation, we report the Area Under the Curve (AUC) of the rotation and translation errors at thresholds of . The pose error is defined as the maximum of the angular deviations in rotation and translation. We also report Acc@, representing the percentage of image pairs with a pose error below , which serves as a robust indicator of overall matching reliability. Furthermore, we denote the descriptor type (e.g., floating-point ‘f’ or binary ‘b’) and dimensionality (dim) to evaluate the trade-off between descriptor compactness and discriminability.
Results. Table 1 reports the relative camera pose estimation results on the MegaDepth-1500 dataset. Compared to the baseline XFeat and other competitive lightweight extractors, our GCA-Net exhibits considerable improvement across all evaluation metrics.

Table 1.
Megadepth-1500 relative camera pose estimation. The top results are highlighted in bold, the runner-up in underline, and categorized by method class (standard/fast).
Within the ‘Fast’ category, GCA-Net achieves a notable improvement in the most stringent metric, AUC@5°, improving from 42.7% to 46.1%. This represents an 8.0% relative gain over the original XFeat. Similar upward trends are observed in AUC@10° and AUC@20°, where our method consistently outperforms XFeat and ZippyPoint. These results indicate that integrating GCA with DS-ASPP effectively compensates for the representational limitations of lightweight backbones.
Despite its lightweight architecture and low-dimensional (64-f) descriptors, GCA-Net outperforms the widely used ‘Standard’ extractor SuperPoint by 23.6% relative gain in AUC@5°. This result indicates that contextual modulation improves the discriminative power of lightweight descriptors. Furthermore, GCA-Net successfully narrows the performance gap with state-of-the-art dense extractors like DISK, offering a compelling balance between computational efficiency and geometric robustness for resource-constrained platforms.
The marked improvement is attributed to the integration of multi-scale spatial anchoring and contextual modulation. In particular, the GCA module mitigates perceptual aliasing by resolving ambiguities in repetitive urban structures, such as symmetric facades and windows. Through context-aware modulation, the network prioritizes structurally reliable landmarks, yielding a 5.2% increase in Acc@10° over the baseline XFeat. Simultaneously, the DS-ASPP-based scale-space anchoring expands the effective receptive field to incorporate broader geometric context. This mechanism reduces coordinate drift and improves sub-pixel localization accuracy under large viewpoint shifts. The sequential refinement transitions from geometric anchoring to contextual calibration. This mechanism allows GCA-Net to maintain robust performance in scenarios where standard lightweight models often degrade.
Despite the narrowing gap, standard dense descriptors like DISK still maintain a performance lead over GCA-Net in scenarios involving extreme viewpoint transformations (e.g., >60° rotation) and highly repetitive, low-texture surfaces. The underlying reasons are twofold. First, the model capacity of the lightweight backbone in GCA-Net is inherently constrained compared to the deeper architectures used in DISK, which limits the extraction of high-order semantic abstractions necessary for resolving extreme geometric distortions. Second, there is a fundamental trade-off between descriptor dimensionality and discriminative power. DISK employs 128-dimensional floating-point descriptors, whereas GCA-Net utilizes a compact 64-dimensional representation to ensure real-time efficiency on edge devices. This lower dimensionality inevitably results in a lower feature entropy, which may lead to reduced matching scores in environments where subtle photometric nuances are the only distinguishing factors.
Table 2 highlights the indoor performance on ScanNet. While robust extractors like DISK and ALIKE are effective in their respective domains, they exhibit noticeable performance shifts when transitioning to indoor scenes, likely due to sensitivity to landmark distributions. In contrast, GCA-Net demonstrates robust zero-shot generalization, achieving an AUC@5° of 16.6%.
Table 2.
ScanNet-1500 relative pose estimation. The best results are in bold and the runner-up in underline. Methods are categorized into standard and fast approaches.
As shown in Table 2, GCA-Net outperforms the original XFeat, improving AUC@5° from 16.1% to 16.6%. This improvement validates the combined efficacy of multi-scale geometric refinement and contextual modulation in texture-sparse settings. It achieves a 32.8% relative gain over the SuperPoint model (from 12.5% to 16.6%), which is widely recognized for its indoor robustness. This substantial improvement indicates that the GCA strategy is more resilient to the “domain shift” between outdoor training and indoor testing. Such results suggest that GCA-Net effectively integrates global contextual priors with multi-scale refinement. This mechanism enables it to maintain high localization fidelity across diverse environments without the need for scene-specific fine-tuning.
4.2. Homography Estimation
Datasets. We evaluate descriptor discriminability using the HPatches [44] dataset, which includes 116 sequences under varying illumination and viewpoint conditions. Following standard protocols, we employ MAGSAC++ [48] to estimate the homography matrix from the established correspondences. For each sequence, the target image is warped back to the reference coordinate frame to assess geometric alignment.
Metrics. The Mean Homography Accuracy (MHA) is reported at thresholds of pixels. The error is quantified as the average distance between the four corners of the target image projected via the ground-truth homography and those projected via the estimated matrix . Higher MHA values at lower thresholds (e.g., @3px) reveal superior sub-pixel precision and matching reliability.
Results. Table 3 summarizes the performance across illumination and viewpoint splits. GCA-Net achieves competitive results against state-of-the-art dense descriptors such as DISK [29] and SuperPoint [8]. While traditional lightweight solutions like ORB and SiLK suffer considerable performance degradation under pronounced illumination shifts, our method maintains high accuracy.
Table 3.
Homography estimation on HPatches. The best results are in bold and the runner-up in underline. Methods are categorized into standard and fast approaches.
Regarding illumination robustness, GCA-Net achieves a high MHA@3px of 95.1%. While baseline methods like SiLK (78.5%) and ORB (74.6%) degrade sharply under photometric fluctuations, our method maintains stability. The slight but consistent improvements over XFeat (95.0% to 95.1%) suggest that the GCA module effectively leverages global structural context to suppress transient intensity noise and shadows, ensuring robust feature calibration. This demonstrates that the context-based calibration promotes more robust feature representation than purely geometric approaches.
In terms of viewpoint invariance, the benefits of GCA-Net are more apparent. Our method reaches an MHA@7px of 86.3%, surpassing the original XFeat (86.1%) and SuperPoint (83.9%). The improvement at the strict @3px threshold (68.6% to 68.8%) indicates that the DS-ASPP module provides finer geometric anchoring. By aggregating multi-scale receptive fields, DS-ASPP enables the model to perceive broader structural contexts. This capability is critical for maintaining localization accuracy during aggressive perspective shifts.
The results validate that GCA-Net offers a superior balance of efficiency and precision. The sequential integration of GCA and DS-ASPP allows the lightweight backbone to achieve performance comparable to much heavier models like SuperPoint.
4.3. Visual Localization
Datasets. We evaluate the localization robustness of GCA-Net using the Aachen Day-Night [45] dataset. We employ the HLoc [46] hierarchical localization pipeline, which triangulates an SfM map using ground-truth poses and query images. For a fair comparison, all query images are resized to a maximum dimension of 1024 pixels.
Metrics. Accuracy is reported as the percentage of successfully localized images within three distance/angular error thresholds: (0.25 m, 2°), (0.5 m, 5°), and (5 m, 10°). These metrics assess the precision of the estimated camera poses under extreme illumination changes between day and night.
Results. Table 4 details the visual localization performance on Aachen Day-Night. GCA-Net demonstrates a consistent performance advantage over the vanilla XFeat, particularly in the challenging night-time sequences.
Table 4.
Visual localization on Aachen day-night. The best results are in bold and the runner-up in underline. Methods are categorized into standard and fast approaches.
When examining the robustness to illumination fluctuations, GCA-Net achieves 79.2% accuracy at the strict (0.25 m, 2°) threshold in night-time scenes, marking a substantial improvement over the 77.6% achieved by XFeat. While traditional descriptors like ORB (10.2%) fail under low-light conditions, our model remains robust. This gain is primarily attributed to the GCA module, which leverages global structural context to ignore transient night-time artifacts such as strong artificial lights. By filtering these distractions, the model focuses on structurally permanent architectural features.
As for high-precision localization, GCA-Net also maintains a competitive edge in the day-time split, reaching 85.1% at the finest threshold. The integration of the DS-ASPP module provides enhanced geometric stability. By capturing multi-scale structural information, DS-ASPP facilitates precise keypoint localization even in texture-sparse nocturnal environments. This capability allows GCA-Net to narrow the performance gap with dense descriptors, such as DISK (83.7% vs. 79.2% in night scenes).
These results reveal that the sequential integration of contextual modulation and multi-scale refinement is critical. GCA-Net achieves high-accuracy localization, proving its reliability for long-term navigation in changing environments.
4.4. System-Level Validation on AirSLAM
Datasets. To evaluate the practical performance of GCA-Net in a complete SLAM pipeline, we integrated it into AirSLAM, a state-of-the-art lightweight visual-inertial SLAM system. We replaced the original feature extraction frontend with GCA-Net and conducted comparative experiments on the EuRoC MAV dataset. We specifically present the results of the representative V2_02 (Vicon Room 2 Medium) sequence, which features aggressive motion and complex textures, to demonstrate the system-level performance.
Metrics. The system accuracy is evaluated using the Absolute Trajectory Error (ATE). We report the Root Mean Square Error (RMSE), Mean error, Median error, and Standard Deviation (S.D.). These metrics collectively assess the global consistency and the tracking stability of the SLAM system under continuous motion.
Results. Table 5 compares the trajectory estimation performance of different frontends within the AirSLAM framework.
Table 5.
Absolute Trajectory Error (ATE) [m] comparison of different frontends integrated into AirSLAM on the EuRoC dataset for the V2_02 sequence. The best results are in bold and the runner-up in underline.
As demonstrated in Table 5, the integration of GCA-Net into the AirSLAM pipeline yields a significant reduction in RMSE (11.0%) and S.D. (7.4%) compared to the XFeat-based frontend. This concurrent improvement in both accuracy and precision is a direct result of our contextual modulation strategy. By suppressing unstable feature responses in regions with aggressive motion, GCA-Net not only minimizes large trajectory deviations (reflected in RMSE) but also enhances the temporal consistency of the tracking process (reflected in S.D.). Consequently, the system exhibits superior reliability during continuous, high-speed maneuvers in the Vicon Room environment.
4.5. Qualitative Analysis and Interpretability
4.5.1. Visual Comparison of Matching Performance
Robustness Analysis under Varied Viewpoints on MegaDepth. To further validate the effectiveness of GCA-Net, we visualize the matching results under challenging viewpoint changes and repetitive urban structures in Figure 4. For a comprehensive qualitative evaluation, we compare our framework with XFeat, the runner-up method on the MegaDepth dataset as reported in Table 1. These examples provide visual evidence consistent with the quantitative gains reported in our experiments. GCA-Net demonstrates robust performance in suppressing false matches and maintaining a balanced distribution of keypoints in complex environments.

Figure 4.
Qualitative comparison of feature matching on the MegaDepth dataset. Compared to the original XFeat, GCA-Net demonstrates superior resilience to repetitive patterns and viewpoint shifts, producing denser and more reliable correspondences.
The visual evidence highlights the specific contributions of our proposed modules. For the repetitive and fine structures shown in scene (a), XFeat fails to extract keypoints from the subtle architectural lettering on the frieze. In contrast, GCA-Net produces dense and accurate matches in these regions. This observation demonstrates that the DS-ASPP module enhances geometric anchoring for fine-grained architectural details.
In the low-light scenario of scene (b), the baseline struggles with information loss in the dark shadowed areas on the right. GCA-Net, however, maintains reliable correspondences even in near-zero texture environments. This validates that the GCA module effectively utilizes global structural context to calibrate features where local intensity gradients are insufficient.
In scene (c), which involves pronounced viewpoint shifts and potential overexposure, XFeat exhibits extensive perceptual aliasing. As indicated in the red box, it incorrectly matches features from the second statue to the third. GCA-Net effectively mitigates these outliers. This improvement demonstrates a sequential refinement process that transitions from context-aware calibration to spatial geometric anchoring. Such a mechanism enables the model to overcome the representational limitations inherent in lightweight backbones.
GCA-Net demonstrates superior resilience to repetitive patterns and environmental interference, offering a better balance of efficiency and robustness for complex real-world applications.
Evaluation of Spatial Consistency in Indoor Environments on ScanNet. Figure 5 presents the visual matching performance of GCA-Net across three representative indoor challenges from the ScanNet dataset. We compare our results with XFeat, the second-best performing method, in Table 2. This qualitative evidence aligns with the quantitative gains observed in our previous experiments.

Figure 5.
Qualitative matching results on the ScanNet dataset. We evaluate GCA-Net under three typical demanding scenarios: (a) Repetitive textures (e.g., furniture patterns), (b) Texture-sparse regions (e.g., smooth surfaces), and (c) Viewpoint changes.
In cases involving repetitive textures, such as the sofa and carpet scenario shown in Figure 5a, standard extractors often suffer from perceptual aliasing due to highly self-similar patterns. The GCA module effectively suppresses redundant activations in these ambiguous regions. By leveraging mid-level structural cues, GCA-Net prioritizes structurally unique boundaries, ensuring that keypoints are anchored to permanent geometric structures rather than unstable repetitive textures.
Figure 5b evaluates the precision in texture-sparse regions. Large textureless surfaces, such as tabletops and chair backs, typically lead to coordinate drifting or complete matching failures. The DS-ASPP module mitigates these issues by expanding the effective receptive field through multi-scale atrous convolutions. This wide-range geometric anchoring enables GCA-Net to recover precise matches even in low-gradient areas. For example, it can reliably capture distinct structural components, such as monitor stands, keyboards, and mice. As a result, the green match lines exhibit high consistency and parallelism, demonstrating consistent spatial stability.
The robustness of GCA-Net under pronounced perspective shifts is further validated in Figure 5c. Large-scale viewpoint variations often distort local geometric descriptors, particularly in non-salient regions such as beds or floors. GCA-Net addresses this through a context-guided alignment mechanism. By integrating the C-FiLM module, the framework leverages global contextual priors to identify stable geometric primitives and permanent landmarks, while effectively suppressing dynamic artifacts and illumination interference. Importantly, our framework maintains a spatially balanced distribution of high-quality matches—most prominently along the consistent contours of the lounge chairs—achieving a robust coarse-to-fine refinement that remains invariant to drastic viewpoint transformations.
4.5.2. Introspection of Context-Guided Feature Activations
To further explore the internal decision-making process of the proposed framework, we visualize the feature activation maps using Gradient-weighted Class Activation Mapping (Grad-CAM++). As illustrated in Figure 6, we compare the attention regions of GCA-Net with the baseline XFeat in complex urban environments containing heavy dynamic interference.
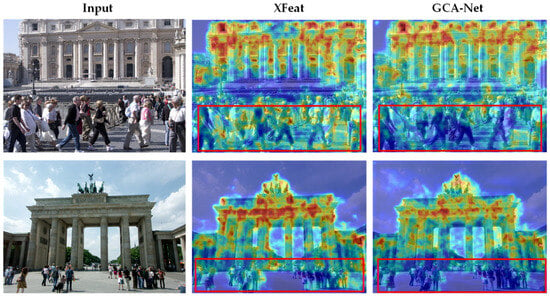
Figure 6.
Interpretability analysis of feature activations via Grad-CAM++. The warmer colors (red/yellow regions) indicate stronger feature activation, while cooler colors (blue/green regions) denote weaker activation. The red boxes highlight instances where XFeat is erroneously distracted by dynamic pedestrians. In contrast, GCA-Net consistently focuses on permanent architectural structures, demonstrating the impact of the GCA mechanism in filtering out transient noise.
When examining the structural stability of feature responses, the visualization reveals a fundamental shift in network attention. In the baseline XFeat (middle column), the high-response regions are fragmented and frequently cluster on transient objects, such as pedestrians and moving crowds (highlighted in red boxes). Such distractions often lead to unstable feature tracking in real-world localization. In contrast, GCA-Net (right column) exhibits a concentrated focus on permanent architectural structures, specifically along the salient geometric contours of buildings and arches.
This selective attention is facilitated by the context-aware calibration within the GCA module. By integrating global contextual priors, the network effectively suppresses the activations of non-stationary entities. The result is a more robust “perceptual anchor” that prioritizes stable geometric candidates, ensuring precise correspondence estimation even in densely populated urban scenes.
4.6. Ablation Study
We conduct ablation experiments on the MegaDepth-1500 dataset to isolate the quantitative contributions of the DS-ASPP and GCA modules. All variants are evaluated using the AUC@5° metric for the relative pose estimation task. The results, summarized in Table 6, validate the synergistic effect of the proposed modules in enhancing geometric robustness and spatial anchoring.
Table 6.
Ablation experiments on Megadepth-1500. The best results are in bold.
As shown in Table 6, integrating the DS-ASPP module yields a 1.9% relative improvement in AUC@5°. In the context of our proposal, this enhancement represents a significant reduction in localization jitter. While standard backbones often suffer from limited receptive fields, DS-ASPP captures multi-scale structural patterns. As qualitatively demonstrated in Figure 4a, this expanded awareness allows the model to anchor keypoints on fine-grained architectural details (e.g., subtle lettering) that are typically overlooked by baseline methods, ensuring sub-pixel precision under demanding viewpoint changes.
The addition of the GCA module improves the AUC@5° by 3.5%. This enhancement signifies a fundamental improvement in the model’s discriminability against perceptual aliasing. In the MegaDepth dataset, repetitive architectural elements often introduce matching ambiguities. The GCA stream addresses this by performing context-aware modulation. This is explicitly mitigated by the GCA stream, which suppresses the extensive perceptual aliasing observed in Figure 4c. By re-weighting feature responses based on contextual priors, GCA ensures that the matching process relies on contextually unique landmarks rather than being misled by repetitive structures (e.g., identical statues).
The full GCA-Net configuration achieves the highest accuracy of 46.1%, outperforming the baseline by 8.0%. This cumulative enhancement translates to a more robust pose estimation pipeline. The non-linear improvement indicates that contextual modulation and multi-scale refinement are highly complementary: the DS-ASPP module establishes a stable multi-scale search space, while the GCA module filters candidates to focus on the most reliable regions. Ultimately, the enhancement offered by our proposal means that GCA-Net maintains higher trajectory consistency and lower coordinate drift in challenging urban environments where baseline methods typically struggle.
4.7. Efficiency and Computational Complexity
4.7.1. Module-Level Complexity: DS-ASPP vs. Standard ASPP
Setup. To verify the lightweight nature of the proposed DS-ASPP module, we compare its architectural complexity against the standard ASPP implementation. All metrics are evaluated on an NVIDIA L20 GPU using a standard 640 × 480 input resolution.
Results. As reflected in Table 7, DS-ASPP achieves a significant reduction in both computational cost and memory footprint.
Table 7.
Complexity comparison between Standard ASPP and DS-ASPP.
By replacing dense convolutions with depthwise separable counterparts, DS-ASPP reduces the parameter count from 136.8 K to 42.5 K (a 69.0% reduction) and cuts FLOPs from 4.42 G to 1.29 G (a 70.7% reduction). This factorization decouples spatial filtering from channel mixing, allowing the module to capture a wider receptive field with minimal overhead.
Beyond theoretical complexity, the practical inference time on the GPU drops from 1.450 ms to 0.907 ms. This 37.5% speedup—representing a 0.543 ms reduction per frame—is essential for high-frequency SLAM systems. This efficiency validates that the additional geometric guidance from DS-ASPP does not become a computational bottleneck for the XFeat backbone.
These results demonstrate that DS-ASPP offers a superior trade-off between efficiency and representational power. The extensive savings in FLOPs and parameters make GCA-Net well-suited for deployment on resource-constrained edge devices where real-time processing and low power consumption are paramount.
4.7.2. End-to-End Efficiency on Edge-Simulated Platforms
To further validate the real-time capability of GCA-Net for edge applications, we provide an end-to-end efficiency benchmark. The model was exported to the ONNX format to simulate deployment on embedded inference engines. To ensure statistical significance, we conducted five independent runs for each model and report the mean value along with the standard deviation.
As shown in Table 8, GCA-Net maintains a highly competitive inference speed of 35.82 ms per frame (28.12 FPS), fulfilling the real-time requirements (typically >20 FPS) for high-frequency SLAM systems.
Table 8.
End-to-end performance comparison with state-of-the-art lightweight models (Input: 640 × 480).
Interestingly, while the integration of GCA and DS-ASPP modules introduces a marginal increase in parameters (+64.62 K) and theoretical FLOPs, the practical inference latency of GCA-Net is approximately 2.8% lower than the vanilla XFeat. This efficiency suggests that our architectural optimizations, particularly the depthwise separable factorizations, are highly compatible with the parallel execution patterns of modern hardware acceleration engines.
Furthermore, GCA-Net remains extremely compact with only 0.72 M parameters. It represents a minor 9.8% increase compared to the vanilla XFeat. This low memory footprint and stable frame rate (evidenced by the low standard deviation) make GCA-Net an ideal candidate for deployment on actual embedded hardware (e.g., NVIDIA Jetson or mobile NPUs) where real-time constraints and power efficiency are paramount.
5. Discussion and Limitations
Despite the significant performance gains achieved by GCA-Net across various benchmarks, certain limitations remain that warrant further discussion. These constraints provide a foundation for future improvements in lightweight feature extraction.
5.1. Performance in Highly Dynamic Scenes
GCA-Net relies on a global contextual stream to modulate local geometric features. While the Global Average Pooling (GAP) mechanism effectively captures macroscopic scene priors, it lacks the granularity to distinguish between static landmarks and large moving objects (e.g., dense crowds or vehicles) in highly dynamic environments. In such scenarios, the contextual guidance might be influenced by transient information, potentially leading to suboptimal feature re-weighting and degraded matching consistency. Future work will investigate the integration of temporal attention to filter out dynamic interferences.
5.2. Robustness in Unstructured Natural Environments
While DS-ASPP expands the receptive field to capture structural context, its efficacy is primarily optimized for environments with discernible geometric primitives. In unstructured natural scenes (e.g., dense vegetation, rocky terrain, or forest floors), the scene lacks the regular geometric structures (such as linear edges and planar surfaces) typically found in man-made environments. In these contexts, the global contextual priors captured by the GAP mechanism may become “noisy” or overly diffused. This is because natural textures are often stochastic and lack the predictable spatial layout that GCA-Net uses to modulate feature weights. Consequently, the alignment between local geometric anchors and global context may weaken, potentially leading the model to rely more on local photometric gradients, which are inherently less stable in complex natural settings.
5.3. Theoretical Trade-Offs of Contextual Modulation
While the Contextual Modulation strategy effectively suppresses ambiguous responses in repetitive textures, it introduces a theoretical trade-off between global consistency and sub-pixel precision. In certain high-precision 3D reconstruction tasks, the strong influence of global structural priors may cause minor coordinate drifting (sub-pixel offsets) in the interest point localization. Furthermore, while the fixed dilation rates in DS-ASPP provide substantial receptive field expansion, they may not be optimally suited for all motion conditions, such as acute motion blur, where adaptive dilation mechanisms might offer better resilience.
6. Conclusions
This paper presents GCA-Net, a lightweight local feature extractor designed to enhance geometric representations through GCA. By integrating a DS-ASPP module for spatial refinement and a GCA module for contextual modulation, the framework effectively addresses the instability inherent in lightweight backbones. Our approach leverages multi-scale geometric anchoring to mitigate coordinate drifting while utilizing global contextual priors to prioritize structurally reliable landmarks.
Experimental results on benchmarks including HPatches, MegaDepth, and ScanNet demonstrate that GCA-Net achieves a superior balance between precision and efficiency. Our framework consistently outperforms the original XFeat baseline while achieving a substantial 23.6% relative gain over SuperPoint on MegaDepth. These findings demonstrate that multi-scale geometric refinement and contextual modulation are highly complementary. Their integration effectively overcomes the representational limitations inherent in lightweight backbones. Consequently, GCA-Net is well-positioned for resource-constrained VIO and SLAM applications.
The performance gains of GCA-Net have direct implications for autonomous navigation. In visual SLAM, the suppression of unstable features on repetitive textures translates to more consistent trajectory estimation and reduced drift. Furthermore, the enhanced robustness to extreme illumination changes facilitates reliable loop closure detection, which is critical for long-term localization. Because the proposed contextual guidance operates without pixel-level annotations, it provides a cost-effective pathway for deployment on edge computing platforms. Such efficiency is particularly beneficial for lightweight drones and mobile robots.
Future iterations of this work will focus on addressing current limitations to further enhance robustness. To overcome the coarse nature of GAP-based context, we plan to integrate fine-grained attention mechanisms, such as spatial-temporal Transformers or cross-attention layers, to better resolve intricate spatial relationships in dynamic environments. Additionally, exploring adaptive dilation mechanisms within the multi-scale aggregation layer could provide better resilience to motion blur and extreme scale shifts. These advancements will aim to extend the applicability of GCA-Net to more complex, unstructured natural environments where the absence of regular geometry and the stochastic nature of textures pose unique challenges to fixed-scale contextual priors.
Author Contributions
Conceptualization, Y.D.; methodology, Y.D.; software, Y.W. and X.L. (Xingchao Liu); validation, Y.D., X.Z. and X.L. (Xin Liu); data curation, Y.D.; writing—original draft preparation, Y.D.; writing—review and editing, Y.D., X.H., L.T. and C.L.; visualization, Y.D.; supervision, C.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Research Projects of Department of Education of Hebei Province, grant number CXZX2025038.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data were created in this study. All datasets analyzed are publicly available from their original sources [MegaDepth, ScanNet, HPatches, Aachen Day-Night].
Acknowledgments
We thank the researchers who developed the COCO, MegaDepth, ScanNet, HPatches, and Aachen Day-Night datasets.
Conflicts of Interest
Author Xiaohui Hou was employed by HiScene Information Technology Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Cadena, C.; Tardós, J.D.; Castellanos, J.A.; Neira, J. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Trans. Robot. 2017, 32, 1309–1332. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Ibrayev, A.; Bektemessov, A. A Comprehensive Survey of Visual SLAM Technology: Methods, Challenges, and Perspectives. Int. J. Adv. Comput. Sci. Appl. 2025, 16, 10. [Google Scholar] [CrossRef]
- Rui, X. Visual SLAM methods for autonomous driving vehicles. Highlights Sci. Eng. Technol. 2024, 111, 234–241. [Google Scholar] [CrossRef]
- Ma, J.; Jiang, X.; Fan, A.; Jiang, J.; Yan, J. Image matching from handcrafted to deep features: A survey. Int. J. Comput. Vis. 2021, 129, 23–79. [Google Scholar] [CrossRef]
- Xu, S.; Chen, S.; Xu, R.; Li, Y.; Wang, R. Local feature matching using deep learning: A survey. Inf. Fusion 2024, 107, 102344. [Google Scholar] [CrossRef]
- Potje, G.; Cadar, F.; Araujo, A.; Martins, R.; Erickson, R. XFeat: Accelerated features for lightweight image matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 2682–2691. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 224–236. [Google Scholar]
- Lin, G.; Li, G. MogaDepth: Multi-Order Feature Hierarchy Fusion for Lightweight Monocular Depth Estimation. Sensors 2026, 26, 685. [Google Scholar] [CrossRef]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-net: A trainable cnn for joint detection and description of local features. arXiv 2019, arXiv:1905.03561. [Google Scholar] [CrossRef]
- Sarkar, S.; Hasan, M.A.; Shahriar, K.A.; Ray, S.K. EGD-YOLO: A Lightweight Multimodal Framework for Robust Drone-Bird Discrimination via Ghost-Enhanced YOLOv8n and EMA Attention under Adverse Condition. arXiv 2025, arXiv:2510.10765. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland; pp. 818–833.
- Perez, E.; Strub, F.; De Vries, H.; Dumoulin, V.; Courville, A. Film: Visual reasoning with a general conditioning layer. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2012; pp. 2564–2571. [Google Scholar]
- Zhao, X.; Wu, X.; Miao, J.; Chen, W.; Yeh, P.C.; Jia, Y. Alike: Accurate and lightweight keypoint detection and descriptor extraction. IEEE Trans. Multimed. 2022, 25, 3101–3112. [Google Scholar] [CrossRef]
- Gleize, P.; Wang, W.; Feiszli, M. Silk: Simple learned keypoints. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 22499–22508. [Google Scholar]
- Kanakis, M.; Maurer, S.; Spallanzani, M.; Lucchi, A.; Gool, L.V. Zippypoint: Fast interest point detection, description, and matching through mixed precision discretization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 6114–6123. [Google Scholar]
- Liu, Y.; Lai, W.; Zhao, Z.; Huang, X.; Zhang, L. LiftFeat: 3D geometry-aware local feature matching. In Proceedings of the 2025 IEEE International Conference on Robotics and Automation (ICRA), Panama City, Panama, 19–23 May 2025; IEEE: Piscataway, NJ, USA, 2025; pp. 11714–11720. [Google Scholar]
- Ying, S.; Zhao, J.; Li, G.; Wang, K.; Zhang, Y. LIM: Lightweight image local feature matching. J. Imaging 2025, 11, 164. [Google Scholar] [CrossRef] [PubMed]
- Fan, Q.; Huang, H.; Guan, J.; Zhang, G. Rethinking local perception in lightweight vision transformer. arXiv 2023, arXiv:2303.17803. [Google Scholar] [CrossRef]
- Sun, Z.; Wang, C.; Hu, W.; Chen, M.; Cheng, G.; Qu, Y. Knowledge graph alignment network with gated multi-hop neighborhood aggregation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 222–229. [Google Scholar]
- Jiang, H.; Karpur, A.; Cao, B.; Huang, B.; Tsou, C.K. Omniglue: Generalizable feature matching with foundation model guidance. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 19865–19875. [Google Scholar]
- Lindenberger, P.; Sarlin, P.E.; Pollefeys, M. Lightglue: Local feature matching at light speed. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 17627–17638. [Google Scholar]
- Liu, Y.; Wang, X.; Gao, X.; Li, J.; Zhao, M. Multi-Level Contextual Prototype Modulation for Compositional Zero-Shot Learning. IEEE Trans. Image Process. 2025, 34, 1245–1258. [Google Scholar] [CrossRef] [PubMed]
- Gameiro, M.A. Contextual Gating within the Transformer Stack: Synergistic Feature Modulation for Enhanced Lyrical Classification and Calibration. arXiv 2025, arXiv:2512.02053. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany; pp. 404–417.
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Pautrat, R.; Suárez, I.; Yu, Y.; Pollefeys, M.; Larsson, V. Gluestick: Robust image matching by sticking points and lines together. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 9706–9716. [Google Scholar]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-free local feature matching with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8922–8931. [Google Scholar]
- Xu, H.; Liu, X.; Liu, Y. Visual Inertial Odometry with Fusion of Point and Line Features in Low Illumination Environments. In Proceedings of the 2024 12th International Conference on Traffic and Logistic Engineering (ICTLE), Macau, China, 24–26 August 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 52–56. [Google Scholar]
- Li, S.; Gao, J.; Liu, Y.; Liu, H.; Tang, L.; You, H.; Zhu, Z.M. MambaMatch: SLAM Front-End Feature Matching with State Space Models. arXiv 2024, arXiv:2407.03781. [Google Scholar]
- Wang, Y.; He, X.; Peng, S.; Liu, J.; Wu, Y.; Sun, H.; Zhou, X. Efficient LoFTR: Semi-dense Local Feature Matching with Sparse-like Speed. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 21666–21675. [Google Scholar]
- Herrera-Granda, E.P.; Torres-Cantero, J.C.; Peluffo-Ordonez, D.H. Monocular visual SLAM, visual odometry, and structure from motion methods applied to 3D reconstruction: A comprehensive survey. Heliyon 2024, 10, e37713. [Google Scholar] [CrossRef]
- Zhao, M.; Luo, Y.; Ouyang, Y. RecConv: Efficient Recursive Convolutions for Multi-Frequency Representations. arXiv 2024, arXiv:2412.19628. [Google Scholar]
- Finder, S.E.; Weber, R.S.; Eliasof, M.; Treister, H.; Haber, E. Improving the effective receptive field of message-passing neural networks. arXiv 2025, arXiv:2505.23185. [Google Scholar] [CrossRef]
- Zhang, H.; Huang, S.L.; Kuruoglu, E.E.; Wang, Z. Multi-Kernel Correlation-Attention Vision Transformer for Enhanced Contextual Understanding and Multi-Scale Integration. In Proceedings of the 39th Annual Conference on Neural Information Processing Systems (NeurIPS 2025), San Diego, CA, USA, 7–13 December 2025. [Google Scholar]
- Yang, C.; Wei, C.; Zhao, Y.; Tan, X. MSALNet: A multi-scale adaptive learning network for high-resolution remote sensing scene classification. Geo-Spat. Inf. Sci. 2025, 29, 143–167. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Li, Z.; Snavely, N. Megadepth: Learning single-view depth prediction from internet photos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2041–2050. [Google Scholar]
- Rostianingsih, S.; Setiawan, A.; Halim, C.I. COCO (creating common object in context) dataset for chemistry apparatus. Procedia Comput. Sci. 2020, 171, 2445–2452. [Google Scholar] [CrossRef]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5828–5839. [Google Scholar]
- Balntas, V.; Lenc, K.; Vedaldi, A.; Mikolajczyk, K. HPatches: A benchmark and evaluation of handcrafted and learned local descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5173–5182. [Google Scholar]
- Sattler, T.; Maddern, W.; Toft, C.; Torii, A.; Hammarstrand, L.; Stenborg, E.; Pajdla, T.; Sivic, J.; Kosecka, J.; Pollefeys, M.; et al. Benchmarking 6dof outdoor visual localization in changing conditions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8601–8610. [Google Scholar]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4938–4947. [Google Scholar]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.W.; Siegwart, R. The EuRoC Micro Aerial Vehicle Datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]
- Barath, D.; Noskova, J.; Ivashechkin, M.; Matas, J. MAGSAC++, a fast, reliable and accurate robust estimator. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1304–1312. [Google Scholar]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.