Abstract
Hyperspectral images present significant challenges for conventional dimensionality reduction methods due to their high dimensionality, spectral redundancy, and complex spatial–spatial dependencies. While kernel-based sparse representation methods have shown promise in handling spectral non-linearities, they often fail to preserve spatial consistency and semantic discriminability during feature transformation. To address these limitations, we propose a novel semantic-guided kernel low-rank sparse preserving projection (SKLSPP) framework. Unlike previous approaches that primarily focus on spectral information, our method introduces three key innovations: a semantic-aware kernel representation that maintains discriminability through label constraints, a spatially adaptive manifold regularization term that preserves local pixel affinities in the reduced subspace, and an efficient optimization framework that jointly learns sparse codes and projection matrices. Extensive experiments on benchmark datasets demonstrate that SKLSPP achieves superior performance compared to state-of-the-art methods, showing enhanced feature discrimination, reduced redundancy, and improved robustness to noise while maintaining spatial coherence in the dimensionality-reduced features.
1. Introduction
Hyperspectral imaging (HSI) technology has revolutionized remote sensing by providing detailed spectral information across hundreds of contiguous bands, thus enabling precise material identification and classification [1,2]. This rich spectral characterization, however, comes with significant challenges, including the well-known curse of dimensionality [3], spectral redundancy [4], and complex non-linear mixing phenomena [5]. These issues necessitate effective dimensionality reduction (DR) techniques capable of transforming high-dimensional hyperspectral data into more compact and discriminative representations while simultaneously preserving essential spectral–spatial characteristics.
It is often acknowledged that images lie on a low-dimensional manifold, whose intrinsic structure can be effectively captured through manifold learning-based DR techniques [6]. Traditional linear approaches such as principal component analysis (PCA) [7], independent component analysis (ICA) [8], and linear discriminant analysis (LDA) [9] have been widely adopted but are limited in their ability to characterize the non-linear structures inherent in HSI data. To address this limitation, non-linear manifold learning techniques have been introduced, including kernel discriminant analysis (KDA) [10], Laplacian eigenmaps [11], neighborhood preserving embedding [12], locality linear embedding [13], and locality preserving projection (LPP) [14]. These methods attempt to preserve the local geometric structure of data in a reduced subspace. Building upon these foundations, Sugiyama [15] proposed local Fisher discriminant analysis, which combines LPP and LDA to enhance discriminative power while maintaining local structural preservation. Yan et al. [16] further advanced the field by establishing a unified graph embedding framework that generalizes various DR methods. Subsequent developments incorporated sparsity constraints into this framework. For instance, Cheng et al. [17] established the sparse graph embedding (SGE) model by incorporating HSI sparsity priors. To enhance land cover identification capabilities, Ly et al. [18] introduced a semi-supervised extension, sparse graph-based discriminant analysis, which integrates label information into graph construction.
However, despite these advancements, sparse representation methods primarily focus on achieving the sparsest reconstruction of individual samples, often overlooking semantic guidance during the learning process. In contrast to sparse representation approaches, low-rank representation (LRR) has emerged as a powerful framework for capturing global structures and handling data corruptions in high-dimensional domains [19,20]. The fundamental premise is that data samples from multiple subspaces can be represented as linear combinations of dictionary bases, resulting in a low-rank coefficient matrix that reveals global subspace membership. This paradigm demonstrates remarkable robustness to various corruptions, including noise, outliers, and occlusions, as evidenced by its successful applications in diverse domains such as face recognition [21], motion segmentation [22], and hyperspectral image analysis [23].
The theoretical foundation of LRR was significantly advanced by Liu et al. [20], who established robust subspace recovery through nuclear norm minimization. Subsequent developments have extended LRR in several directions that are particularly relevant to HSI analysis. For instance, Zhang et al. [24] introduced discriminative LRR that incorporates label information to enhance class separability. Similarly, Wong et al. [25] embedded low-rank constraints into orthogonal subspaces to reduce corruption impacts. Chen et al. [26] developed symmetric LRR constraints that improve representation accuracy. Furthermore, Du et al. [27] integrated low-rank representation with adaptive manifold learning to simultaneously capture local and global structures. While low-rank representation methods effectively capture global structures, they often overlook valuable local spatial information within and between classes. This is a critical aspect for hyperspectral image analysis, as adjacent pixels frequently share material compositions. This limitation has prompted research into methods that integrate discriminative and structural constraints. Jiang et al. [28] proposed Laplacian regularized collaborative representation projection (LRCRP) for unsupervised hyperspectral DR. LRCRP combines Laplacian regularization and local enhancement within collaborative representation to preserve local–global structures, thereby effectively exploring collaborative relationships among features.
Despite these advancements, current DR methods for HSI suffer from three fundamental limitations that hinder their effectiveness. First, they often neglect semantic consistency during feature transformation, leading to weakened discriminative power in the reduced subspace. Second, most approaches assume linear separability, which cannot adequately capture the complex non-linear relationships inherent in hyperspectral data. Third, existing methods frequently ignore crucial spatial neighborhood structures that provide complementary information to spectral features. This is particularly problematic for HSI analysis, as adjacent pixels often share similar material compositions. These limitations collectively result in suboptimal performance, characterized by weak semantic knowledge acquisition and the unrealized full potential of hyperspectral data.
To bridge these critical gaps and leverage the complementary strengths of both sparse and low-rank paradigms, we propose a novel semantic-guided kernel low-rank sparse preserving projection (SKLSPP) framework for hyperspectral image DR. The main contributions of this work are summarized as follows:
- (1)
- Semantic-aware kernel sparse representation. We propose a semantic guidance mechanism that integrates label information directly into the kernel sparse representation learning framework. This mechanism explicitly preserves semantic consistency during feature transformation via discriminative constraints in the kernel-induced feature space.
- (2)
- Spatially adaptive manifold regularization. We introduce a dynamically weighted graph Laplacian regularization term that captures both spectral similarity and spatial proximity among pixels. This adaptive manifold construction effectively preserves the local geometric structure of hyperspectral data while also accommodating the unique characteristics of different land cover types and overcoming the limitations of fixed neighborhood representations in conventional manifold learning methods.
- (3)
- Unified optimization framework with efficient computation. We establish a comprehensive optimization framework that jointly learns the sparse codes, projection matrix, and manifold structure through an iterative algorithm combining generalized power iteration and augmented Lagrangian methods.
By bridging the gaps between sparse representation, low-rank learning, and manifold embedding in a kernel-based framework, our approach offers a principled solution for extracting compact yet highly discriminative features from complex hyperspectral imagery. The remainder of this paper is organized as follows. Section 2 and Section 3 provide the theoretical background and detailed formulation of the proposed SKLSPP framework. Section 4 presents extensive experimental results and comparative analysis on benchmark hyperspectral datasets. Finally, Section 5 concludes the paper with a summary of the key findings and potential future research directions.
2. Theoretical Background
2.1. Sparse Representation
Assume that there is a set of samples from HSI, , where is the spectral dimension and is the total number of pixels. Provide a dictionary , where is the number of atoms in the dictionary and each represents a basic spectral signature. For an arbitrary pixel , the goal of sparse representation (SR) is to find a sparse coefficient vector such that . The sparseness of is typically enforced by minimizing its -norm or -norm. The -norm counts the number of non-zero elements in , while the -norm is its convex relaxation, which is computationally more tractable. Then, the sparse representation problem can be formulated as follows:
where is -norm and is a small positive constant that controls the reconstruction error. The dictionary can be constructed in various ways. In many applications, the training samples themselves are used as the dictionary, i.e., .
2.2. Low-Rank Representation
Following the understanding of local manifold structures provided by SR, low-rank representation (LRR) emerges as a complementary and often more robust technique, particularly when dealing with complex HSI data corrupted by various interferences. Given a dataset , LRR seeks to find a coefficient matrix , such that and has a low rank. The objective function for LRR is typically formulated as follows:
where denotes the nuclear norm of , which is a convex surrogate for the rank function. In practice, to account for noise, outliers, and corruptions inherent in real-world HSI data, the objective can be modified to explicitly handle these disturbances as follows:
Here, represents the error or corruption matrix. The -norm of promotes column-wise sparsity. The parameter balances the nuclear norm of and the -norm of .
2.3. Low-Rank Sparse Preserving Projections
In Ref. [29], Xie et al. propose low-rank sparse preserving projections for dimensionality reduction (LSPP) that unify low-rank, sparse, and manifold preservation. Mathematically, LSPP can be expressed as
Its objective typically includes a term , where is a projection matrix that maps high-dimensional data to a low-dimensional space and is a Laplacian matrix from a neighborhood graph. This term maintains local topological structure by ensuring points close in remain close in the projected space. , , are tradeoff parameters that balance the sparsity, low-rankness, and manifold term.
Despite its advancements, LSPP faces two primary limitations, particularly for complex HSI analysis. Firstly, its linear projection nature hinders its ability to capture the inherent non-linear structures and relationships within HSI data. Secondly, the manifold-preserving term relies on a static Laplacian matrix from a fixed neighborhood graph, precluding adaptation to evolving semantic relationships between classes and thus impeding optimal class separation during iterative learning.
To overcome these shortcomings and achieve more robust and discriminative dimensionality reduction for HSI, this paper proposes a novel framework that (1) leverages kernel methods to implicitly handle non-linear structures, mapping data into a high-dimensional feature space where linear separability is enhanced and (2) introduces a dynamic inter-class constraint, explicitly incorporating prior class label information into the optimization. This constraint, inspired by [30], enables the model to adaptively emphasize and refine inter-class semantic relationships throughout the iterative learning process, ensuring stronger class separability in the learned low-dimensional representation.
3. Methodology
This section details the proposed SKLSPP for DR. We first introduce kernel mapping to address the non-linear nature of HSI. Subsequently, a novel semantic-guided constraint is integrated to enhance inter-class separability by leveraging prior label information.
3.1. Kernel Low-Rank Sparse Preserving Projection (KLSPP)
LSPP is designed to find a low-dimensional subspace that simultaneously preserves data locality and global structural information through sparse reconstruction. However, HSI data often exhibit complex non-linear manifolds that linear projection models, like conventional LSPP, may fail to capture effectively. To address this, we extend LSPP into its kernelized form.
Let be the matrix of labeled training samples and be the matrix of unlabeled test samples, where is the original spectral dimensionality. Let be a non-linear mapping function that projects the original data from the input space to a high-dimensional space . The inner product in this feature space is implicitly defined by a chosen kernel function .
In this high-dimensional space, our objective is to learn a low-dimensional projection that captures the intrinsic structure of the data. Following the representer theorem, the optimal projection matrix (where is the potentially infinite dimension) in the feature space can be expressed as a linear combination of the mapped training samples as follows:
where is the coefficient matrix we aim to learn. Each column of corresponds to the coefficients for a specific projection direction in and is the desired reduced dimensionality. Thus, our primary goal is to optimize to define this effective projection.
The low-dimensional projections of the training samples and test samples can then be obtained by applying this projection operator . By substituting Equation (2) and employing the kernel trick (Equation (1)), we can avoid explicit computation in the high-dimensional space as follows:
where is the kernel matrix computed between all pairs of training samples , i.e., . Similarly, is the cross-kernel matrix between training samples and test samples , i.e., .
Incorporating these components and applying the kernel trick, the objective function for KLSPP is formulated as follows:
where is the kernelized orthogonality constraint, ensuring that the projection basis is orthonormal in the kernel space, thereby preventing trivial solutions and preserving the variance of the data. The term aims to learn a low-rank representation that links the projections of samples, serving to capture the underlying relationships between the projected training samples and test samples. The Laplacian matrix is defined as , where is a similarity matrix of and is a diagonal matrix with . This term encourages samples that are close in the original feature space to remain close in the projected space. and are regularization parameters.
3.2. Semantic-Guided Kernel Low-Rank Sparse Preserving Projection (SKLSPP)
To further enhance the discriminative power of the learned features and infuse prior semantic knowledge into the projection process, we strategically incorporate an intra-class regularization term within the SKLSPP framework. This term specifically aims to strengthen the correlation among samples belonging to the same class in the projected subspace. Let be a one-hot matrix, where denotes the number of training samples and is the total number of classes. For any training sample belonging to class , its corresponding entry in is , while for . The product then represents the class-wise averaged low-dimensional embeddings of the training samples. Each column of effectively provides a consolidated representation for a specific class, capturing the central tendency of its embedded samples, which in turn strengthens semantic consistency.
To encourage these class representations to exhibit strong internal coherence and a compact structure, we propose to minimize the nuclear norm of this class-wise averaged embedding term. This leads to the following constraint:
Minimizing the nuclear norm of is a powerful mechanism that directly enforces a low-rank intrinsic structure within these class-wise averaged representations. This operation compels the projected data within each class to be not only highly correlated but also to reside within a minimal low-dimensional subspace. Consequently, this significantly enhances intra-class compactness and crucially improves inter-class separability in the reduced-dimensional space. This mechanism provides potent semantic guidance by inherently ensuring that samples from the same class are projected into a more cohesive, distinctive, and semantically consistent region, directly addressing the challenge of preserving meaningful class structures during dimensionality reduction.
By strategically combining this semantic-guided low-rank constraint (Equation (6)) with the original KLSPP objective function from Equation (5), our final proposed model, semantic-guided kernel low-rank sparse preserving projection (SKLSPP), is formulated as follows:
where , and are regularization parameters controlling the weight of each term. This comprehensive objective function integrates sparse reconstruction of test data, robust sparsity regularization, semantic-guided class separation, and local manifold preservation, all within a kernelized framework.
3.3. Optimization
The objective function in Equation (7) is non-convex and involves multiple coupled variables with non-smooth norms, making its direct optimization challenging. We adopt the alternating direction method of multipliers (ADMM) for such problems. ADMM iteratively optimizes each variable while fixing the others, guaranteeing convergence to a local optimum. To decouple the variables and facilitate ADMM, we introduce auxiliary variables , , and . The problem in Equation (7) can be rewritten with auxiliary variables and corresponding constraints as follows:
The augmented Lagrangian function for this problem can be formulated as follows:
where are Lagrangian multiplier matrices for the respective constraints, and is a penalty parameter. The ADMM algorithm proceeds by iteratively updating each variable while holding the others fixed, followed by updating the Lagrangian multipliers and the penalty parameter.
- (1)
- Update A
When are fixed at their iteration values, the subproblem for at iteration is as follows:
Combining all constant terms as and , we define
Then, Equation (10) can be reformulated as follows:
To solve this problem, we introduce Lagrange multipliers . The augmented Lagrange function is as follows:
Taking the derivative of with respect to and setting it to zero yields the following:
Evidently, Equation (15) is not a standard generalized eigenvalue problem due to the existence of a linear term .
Considering computational efficiency for generalized eigenvalue problems involving linear terms, we adopt an approximation strategy: treating the linear term as a perturbation. Therefore, is considered a perturbation, and its influence is disregarded, retaining only the quadratic terms . Additionally, the Lagrangian multiplier is set to a diagonal matrix, where its diagonal entries are the eigenvalues . Under these conditions, Equation (15) can be transformed into a standard generalized eigenvalue problem as follows:
Let be an arbitrary column vector of . The update for then reduces to solving the following eigenvector problem:
The columns of are the eigenvectors corresponding to the smallest non-zero eigenvalues .
- (2)
- Update Z
By holding other auxiliary variables fixed, the optimization problem for simplifies into a quadratic minimization problem as follows:
To simplify, let and . This subproblem can be viewed as minimizing the sum of squared Frobenius norms. Taking the derivative with respect to and setting it to zero leads to a linear system as follows:
The update for is then given by the following:
The practical implementation of this update step involves solving a system of linear equations, which can be efficiently handled by standard numerical linear algebra routines.
- (3)
- Update B
The solution for emerges as a proximal operator problem. This formulation encapsulates the non-smooth -norm from the original objective function alongside the quadratic penalty term from the augmented Lagrangian function as follows:
The solution is obtained by applying the column-wise soft thresholding operation, specifically, for each column of , and the corresponding column of is calculated as follows:
If , then . This column-wise soft thresholding operation is instrumental in promoting column-wise sparsity in , thereby contributing to feature selection.
- (4)
- Update J
This particular subproblem involves the nuclear norm from the original objective function and the quadratic penalty term from the augmented Lagrangian function as follows:
Let . The solution is obtained by applying the singular value thresholding operator as follows:
If is the singular value decomposition of , then is given by the following:
- (5)
- Update G
Finally, by fixing all other variables, the subproblem for at iteration is as follows:
Then, we obtain the update rule as follows:
- (6)
- Updating Lagrangian Multipliers
When , , , , and are updated, the Lagrangian multipliers are updated using the following rules:
The penalty parameter is updated to accelerate convergence as follows:
where is an acceleration factor, which is fixed as 1.01 in this study, and is an upper bind for .
For easy observation, we summarize the pseudocodes of SKLSPP, as shown in Algorithm 1.
| Algorithm 1 SKLSPP | |
| Input: | : the training sample set; |
| : the one-hot matrix of training labels | |
| : the test sample set | |
| : the hyperparameters | |
| : the number of iteration times | |
| Output: | : the projection matrix |
| : the reconstruction coefficient | |
| while: | |
| + 1 | |
| Update by Equation (17) | |
| Update by Equation (20) | |
| Update by Equation (22) | |
| Update by Equation (25) | |
| Update by Equation (27) | |
| end while | (7) Updating Lagrangian Multipliers by Equations (28–31) |
Once the optimal projection matrix is learned through the iterative optimization process, the SKLSPP framework is fully established for subsequent dimensionality reduction and classification of unseen samples. For a new test sample , the first step involves implicitly mapping it into the high-dimensional kernel feature space via the kernel trick, which enhances the linear separability of data. Subsequently, this mapped sample is projected onto the learned low-dimensional subspace using the optimized projection matrix . This projection effectively transforms the complex, high-dimensional data into a more compact and discriminative representation. Finally, this low-dimensional representation can be directly fed into any standard classification algorithm for ultimate pixel-wise classification.
3.4. Time Complexity Analysis
In this section, we discuss the time complexity of SKLSPP. Assume the number of training samples to be , the target reduced dimension to be , the number of classes to be , and is the iteration number. Then, we have the following:
- (1)
- The time complexity of solving is (.
- (2)
- The time complexity of solving is (.
- (3)
- The time complexity of solving is (.
- (4)
- The time complexity of solving is (min(, .
- (5)
- The time complexity of solving is (.
Combining these, the dominant computational complexity per ADMM iteration is approximately (min(, ) ). Assuming that and the SVD term are the largest, the total computational complexity of our SKLSPP algorithm is (). It is worth noting that, benefiting from the kernel trick adopted in the projection process, SKLSPP generally exhibits faster performance in practical applications compared to algorithms without kernelization.
4. Experimental Results and Analysis
In this section, we conduct a set of experiments on three public hyperspectral image datasets, Indian Pines, University of Pavia, and Salinas, to verify the performance of the proposed SKLSPP.
4.1. Dataset Description
The Indian Pines dataset, captured by Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) sensor in 1992 over an agricultural area in northern Indiana, USA,, comprises 145 × 145 pixels. Originally, it had 220 spectral bands, but 20 water absorption bands were removed, leaving 200 bands for experiments. This dataset is known for its diverse land cover types and challenging characteristics.
The University of Pavia dataset, acquired by the Reflective Optics System Imaging Spectrometer (ROSIS) sensor in 2003, Italy, contains 610 × 340 pixels. From its initial 115 spectral bands, 12 noisy or atmospheric absorption-affected bands were discarded, resulting in 103 bands.
The Salinas dataset, also captured by the AVIRIS sensor, in the Salinas Valley, California, USA, covers an agricultural area and features 224 spectral bands with a spatial resolution of 3.7 m. Its rich and diverse land cover, including various crops, provides a realistic scenario for algorithm evaluation.
4.2. Experiment Setup
To evaluate the performance of the proposed SKLSPP methods in DR, image classification was conducted on the obtained low-dimensional features. For the Indian Pines, University of Pavia, and Salinas datasets, 5%, 2%, and 1% of pixels per class were randomly selected as training samples, with the remainder used for validation. This sample size ensured relatively stable classification accuracy. To verify the classification performance of SKLSPP, we compared it with RAW, PCA [7], NPE [12], LPP [7], modified tensor LPP (MTLPP [31]), LDA [9], kernel discriminant analysis (KDA [10]), LRCRP [28], multifeature structure joint-preserving embedding (MFS-PE [32]), and the RAW method, indicating that the OAs are obtained by the SVM classifier without DR. To better compare the classification results, we choose optimal parameters for each algorithm. For NPE and LPP, we set the number of neighbors to 12. The retained band number for PCA, LDA, and KDA is experimentally determined. For MTLPP, the window size for tensor partitioning is set to 9 × 9. For LRCRP, hyperparameters and are set to balance the contributions of the two regularization items. For MFS-PE, there are three important parameters, tradeoff parameter and hyperparameters , and we set to and .
For the kernelization step, a Gaussian kernel was utilized. Its scale factor, defined as , was determined through experimental tuning and subsequently set to 0.8. Additionally, there are four important parameters that should be determined for the proposed method, i.e., balance parameters , and , and the number of dimensions. These parameters can be determined by cross-validation experiments. , and control the effects of sparsity, weight of local structural, and inter-class semantic information in the objective function, respectively, which are tuned together and selected from {10−5, 10−4, 10−3, 10−2, 10−1, 1}. The corresponding experimental results of the HSI datasets are shown in Figure 1. It can be seen that the overall accuracy (OA) can reach the maximum values with some values of , and , which are common for the three experimental datasets. Accordingly, setting the values of , and as (0.01, 0.1, 0.1) is acceptable for all the datasets.
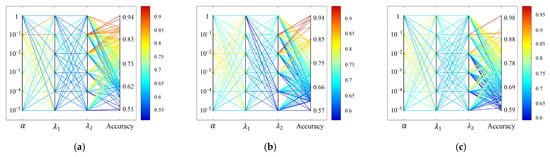
Figure 1.
Overall accuracy versus the parameters and on the three datasets of SKLSPP. (a) Indian Pines dataset. (b) University of Pavia dataset. (c) Salinas dataset.
Figure 2 illustrates the changes in OA corresponding to the retained number of dimensions (2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, and 30). For comparison, the classification results of the original image and the PCA, NPE, LPP, LDA, KLDA, LRCRP, MFS-PE, and SKLSPP dimension-reduced results were also generated. Across all methods and datasets, the classification accuracy stabilizes when the number of dimensions exceeds a certain threshold. Therefore, 14, 12, and 12 dimensions are reasonable values for the proposed SKLSPP methods for the three datasets in subsequent classifications. In particular, since the rank of the between-class scatter matrix is (where is the number of classes), the dimensionality of LDA- and KDA-transformed data is up to . Thus, the dimensionality of LDA and KDA is set to 15, 8, and 14 for the three test datasets. Finally, the extracted features from each method were used as input to a multiclass SVM classifier. A Gaussian kernel was employed for SVM, and the regularization and kernel parameters were optimized through cross-validation.
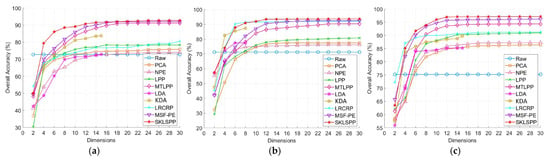
Figure 2.
Classification accuracy versus reduced dimensionality of the three HSI datasets using different DR methods. (a) Indian Pines dataset. (b) University of Pavia dataset. (c) Salinas dataset.
4.3. Experimental Results
In this section, we systematically evaluate the proposed SKLSPP method through comparative experiments with classical DR methods and several state-of-the-art baselines on three hyperspectral datasets. The classification performance across the three benchmark datasets is presented in Table 1, Table 2 and Table 3. To ensure statistical reliability, each model was independently executed ten times on each dataset. Specifically, the tables delineate the individual mean class accuracy, average accuracy (AA), OA, and Kappa coefficient (κ) for the datasets, with accompanying standard deviations providing insights into the classification model’s robustness and performance consistency.

Table 1.
Classification accuracy (%) for the Indian Pines dataset.
Table 2.
Classification accuracy (%) for the University of Pavia dataset.
Table 3.
Classification accuracy (%) for the Salinas dataset.
The proposed SKLSPP method achieved significantly improved classification performance compared to the existing DR techniques. On three test datasets, SKLSPP achieved overall accuracies of 94.54%, 94.28%, and 97.74% and Kappa coefficients of 93.17%, 92.49%, and 97.48%, respectively, representing substantial improvements over traditional methods. This superior performance was consistent across nearly all classes, with most achieving classification rates above 90%. Furthermore, previously challenging classes (e.g., C1 and C10 in the Indian Pines dataset) exhibited near-perfect classification rates. This enhancement is attributed to the novel local manifold learning strategy, which effectively captures intricate spatial–spectral relationships and overcomes limitations inherent in conventional DR approaches.
When compared to the baseline and classical methods, SKLSPP shows a significant performance gain. For instance, it substantially outperforms PCA and LDA by a large margin on all datasets, confirming the limitation of these linear techniques in handling complex spectral–spatial structures. Furthermore, against other strong non-linear or graph-based methods, such as KDA and LPP, SKLSPP consistently delivers better accuracy, highlighting the effectiveness of its novel structural constraints.
A detailed comparison with the best-performing existing techniques further validates the robustness of our approach. On the University of Pavia dataset, SKLSPP attains the highest AA of 93.40% and an OA of 94.28%, slightly edging out MFS-PE (OA: 93.74%) and notably outperforming LRCRP (OA: 88.34%) and MTLPP (OA:90.56). The advantage of SKLSPP is also evident at the class level across all datasets. It achieves perfect 100% accuracy in Class C8 of Indian Pines and Class C9 of University of Pavia and nears perfection in multiple Salinas classes (e.g., C2, C6, C7, C9, C12). While MFS-PE also shows remarkable class-wise performance, SKLSPP provides a more balanced and generalized solution, as evidenced by its superior OA and Kappa on complex scenes.
Figure 3, Figure 4 and Figure 5 present the classification maps produced by all considered methods on the test datasets, offering a more intuitive visualization of their performance. Visually, the proposed SKLSPP method yields significantly smoother homogeneous regions compared to other approaches. Notably, most of the classification errors highlighted by the rectangular boxes (Figure 3c–l, 4c–l, and 5c–l, respectively) are effectively corrected by SKLSPP. Furthermore, as observed in the area marked by the boxes in Figure 4i,l, both SKLSPP and the kernel-based KDA method achieve complete and accurate classification, successfully rectifying the misclassifications evident in other methods. This result underscores the advantage of kernel-based approaches in handling high-dimensional, non-linear hyperspectral data by mapping it into a more discriminative feature space. However, a more critical advantage of our method is revealed in more areas. While KDA exhibits significant classification noise and confusion among complex land cover types in this region, the proposed SKLSPP generates a markedly cleaner and more accurate map, closely resembling the ground truth. This superior performance can be attributed to the strategic integration of semantic label information directly into the sparse low-rank modeling process of SKLSPP. This design not only captures the non-linear data structure but also enhances the discriminative power of the resulting features by leveraging the supervisory signals from the training samples, thereby yielding more robust classification in complex scenarios.
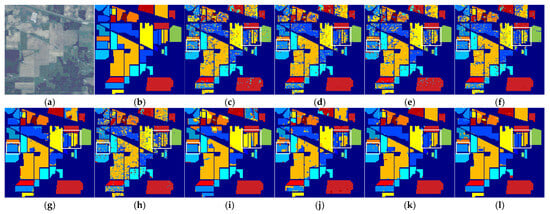
Figure 3.
Classification maps for the Indian Pines dataset using different DR methods. (a) Hyperspectral image. (b) Ground truth. (c) Raw spectral. (d) PCA. (e) NPE. (f) LPP. (g) MTLPP. (h) LDA. (i) KDA. (j) LRCRP. (k) MFS-PE. (l) SKLSPP.
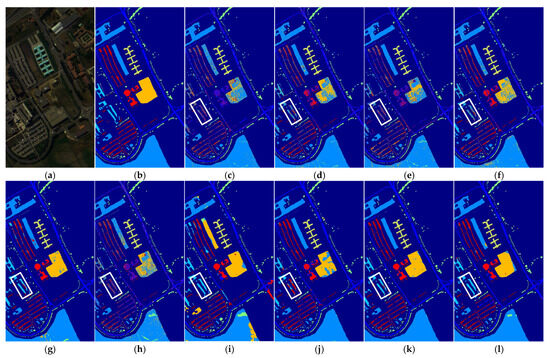
Figure 4.
Classification maps for the University of Pavia dataset using different DR methods. (a) Hyperspectral image. (b) Ground truth. (c) Raw spectral. (d) PCA. (e) NPE. (f) LPP. (g) MTLPP. (h) LDA. (i) KDA. (j) LRCRP. (k) MFS-PE (l) SKLSPP.

Figure 5.
Classification maps for the Salinas dataset using different DR methods. (a) Hyperspectral image. (b) Ground truth. (c) Raw spectral. (d) PCA. (e) NPE. (f) LPP. (g) MTLPP. (h) LDA. (i) KDA. (j) LRCRP. (k) MFS-PE. (l) SKLSPP.
5. Conclusions
This study introduces the semantic-guided kernel low-rank sparse preserving projection (SKLSPP), a novel dimensionality reduction framework designed to overcome the limitations of conventional manifold learning methods in hyperspectral image analysis. By integrating semantic-aware kernel representation with spatially adaptive manifold regularization, SKLSPP effectively preserves the intrinsic geometric structure of high-dimensional data while enhancing discriminative feature extraction. Key innovations include a semantic guidance mechanism that integrates labels to explicitly preserve semantic consistency during feature transformation, a dynamically weighted graph Laplacian regularization term that captures both spectral similarity and spatial proximity among pixels, and a unified optimization framework that jointly learns the sparse codes, projection matrix, and manifold structure. These advancements address critical challenges in spectral redundancy, spatial incoherence, and noise sensitivity observed in previous approaches. Our experimental results across various real-world hyperspectral datasets demonstrate the superiority of SKLSPP, which outperformed comparison methods on the test datasets.
Despite these promising results, we recognize several avenues for future research. One important direction involves a more in-depth investigation into the robustness of SKLSPP against various types and levels of noise, which are commonly present in hyperspectral imagery. While the inherent low-rank and sparse properties of our model offer a degree of noise resilience, a dedicated analysis and potential further enhancement of the model’s robustness under more challenging noisy conditions would be beneficial for practical applications.
Author Contributions
Conceptualization, J.L. and J.H.; methodology, J.L.; software, L.H.; validation, J.L., J.H., and L.H.; formal analysis, J.L. and C.H.; investigation, M.Z.; resources, J.H.; data curation, J.H.; writing—original draft preparation, J.L.; writing—review and editing, J.L.; visualization, J.H. and C.H.; supervision, M.Z.; project administration, J.L.; funding acquisition, J.L. and C.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the Natural Science Research Project of Anhui Educational Committee (No. 2022AH050796), the Scientific Research Foundation for High-level Talents of Anhui University of Science and Technology, and the National Natural Science Foundation of China (No. 424040015).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The hyperspectral datasets used in this study are publicly available through the Grupo de Inteligencia Computacional (GIC) at https://www.ehu.eus/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes (accessed on 1 January 2025.).
Acknowledgments
The authors would like to thank the anonymous reviewers for their helpful comments and valuable suggestions.
Conflicts of Interest
Author Lin Huang was employed by the company Anhui Cloud Spacial Information Technology Co., Ltd., Hefei, China. The remaining authors declare that there are no financial interests, commercial affiliations, or other potential conflicts of interest that could have influenced the objectivity of this research or the writing of this paper.
References
- Yu, W.B.; Zhang, M.; Huang, H.; Shen, Y.; Shen, G.X. Learning latent local manifold embeddings for hyperspectral feature extraction. J. Appl. Remote Sens. 2022, 16, 036513. [Google Scholar] [CrossRef]
- Liu, X.H.; Wang, T.M.; Wang, X.F. Joint Spectral-Spatial Representation Learning for Unsupervised Hyperspectral Image Clustering. Appl. Sci. 2025, 15, 8935. [Google Scholar] [CrossRef]
- Ghamisi, P.; Yokoya, N.; Li, J.; Liao, W.Z.; Liu, S.C.; Plaza, J.; Rasti, B.; Plaza, A. Advances in Hyperspectral Image and Signal Processing. IEEE Geosci. Remote Sens. Mag. 2017, 5, 37–78. [Google Scholar] [CrossRef]
- Kong, X.Y.; Zhao, Y.Q.; Chan, J.C.W.; Xue, J.Z. Hyperspectral Image Restoration via Spatial-Spectral Residual Total Variation Regularized Low-Rank Tensor Decomposition. Remote Sens. 2022, 14, 511. [Google Scholar] [CrossRef]
- Wu, L.; Huang, J.; Guo, M.S. Multidimensional Low-Rank Representation for Sparse Hyperspectral Unmixing. IEEE Geosci. Remote Sens. Lett. 2023, 20, 5502805. [Google Scholar] [CrossRef]
- de Morsier, F.; Borgeaud, M.; Gass, V.; Thiran, J.-P.; Tuia, D. Kernel Low-Rank and Sparse Graph for Unsupervised and Semi-Supervised Classification of Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3410–3420. [Google Scholar] [CrossRef]
- Geng, X.Y.; Guo, Q.; Hui, S.X.; Yang, M.; Zhang, C.M. Tensor robust PCA with nonconvex and nonlocal regularization. Comput. Vis. Image Underst. 2024, 243, 104007. [Google Scholar] [CrossRef]
- Reidl, J.; Starke, J.; Omer, D.B.; Grinvald, A.; Spors, H. Independent component analysis of high-resolution imaging data identifies distinct functional domains. Neuroimage 2007, 34, 94–108. [Google Scholar] [CrossRef]
- Wang, Q.; Meng, Z.T.; Li, X.L. Locality Adaptive Discriminant Analysis for Spectral-Spatial Classification of Hyperspectral Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2077–2081. [Google Scholar] [CrossRef]
- Huang, K.K.; Dai, D.Q.; Ren, C.X.; Lai, Z.R. Learning Kernel Extended Dictionary for Face Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 1082–1094. [Google Scholar] [CrossRef]
- Belkin, M.; Niyogi, P. Laplacian Eigenmaps for Dimensionality Reduction and Data Representation. Neural. Comput. 2003, 15, 1373–1396. [Google Scholar] [CrossRef]
- He, X.; Cai, D.; Yan, S.; Zhang, H.J. Neighborhood Preserving Embedding. In Proceedings of the Tenth IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005. [Google Scholar]
- Zhang, T.H.; Tao, D.C.; Li, X.L.; Yang, J. Patch Alignment for Dimensionality Reduction. IEEE Trans. Knowl. Data Eng. 2009, 21, 1299–1313. [Google Scholar] [CrossRef]
- Zheng, D.; Du, X.; Cui, L. Tensor Locality Preserving Projections for Face Recognition. In Proceedings of the IEEE International Conference on Systems Man & Cybernetics, Istanbul, Turkey, 10–13 October 2010; pp. 2347–2350. [Google Scholar]
- Sugiyama, M. Dimensionality reduction of multimodal labeled data by local fisher discriminant analysis. J. Mach. Learn. Res. 2007, 8, 1027–1061. [Google Scholar]
- Yan, S.C.; Xu, D.; Zhang, B.Y.; Zhang, H.J.; Yang, Q.; Lin, S. Graph embedding and extensions: A general framework for dimensionality reduction. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 40–51. [Google Scholar] [CrossRef]
- Cheng, B.; Yang, J.C.; Yan, S.C.; Fu, Y.; Huang, T.S. Learning With l1-Graph for Image Analysis. IEEE Trans. Image Process. 2010, 19, 858–866. [Google Scholar] [CrossRef]
- Ly, N.H.; Du, Q.; Fowler, J.E. Sparse Graph-Based Discriminant Analysis for Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3872–3884. [Google Scholar] [CrossRef]
- Candès, E.; Recht, B. Exact Matrix Completion via Convex Optimization. Commun. ACM 2012, 55, 111–119. [Google Scholar] [CrossRef]
- Liu, G.C.; Lin, Z.C.; Yan, S.C.; Sun, J.; Yu, Y.; Ma, Y. Robust Recovery of Subspace Structures by Low-Rank Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 171–184. [Google Scholar] [CrossRef]
- Liu, Y.F.; Chen, J.H.; Li, Y.Q.; Wu, T.S.; Wen, H. Joint face normalization and representation learning for face recognition. Pattern. Anal. Appl. 2024, 27, 64. [Google Scholar] [CrossRef]
- Baiju, P.S.; Jayan, P.D.; George, S.N. Tensor total variation regularised low-rank approximation framework for video deraining. Iet Image Process 2020, 14, 3602–3612. [Google Scholar] [CrossRef]
- Yan, W.Z.; Yang, M.; Li, Y.M. Robust Low Rank and Sparse Representation for Multiple Kernel Dimensionality Reduction. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 1–15. [Google Scholar] [CrossRef]
- Zhang, Z.; Xu, Y.; Shao, L.; Yang, J. Discriminative Block-Diagonal Representation Learning for Image Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3111–3125. [Google Scholar] [CrossRef]
- Wong, W.K.; Lai, Z.H.; Wen, J.J.; Fang, X.Z.; Lu, Y.W. Low-Rank Embedding for Robust Image Feature Extraction. IEEE Trans. Image Process. 2017, 26, 2905–2917. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Mao, H.; Sang, Y.S.; Yi, Z. Subspace clustering using a symmetric low-rank representation. Knowl. Based Syst. 2017, 127, 46–57. [Google Scholar] [CrossRef]
- Du, H.S.; Wang, Y.X.; Zhang, F.; Zhou, Y. Low-Rank Discriminative Adaptive Graph Preserving Subspace Learning. Neural Process. Lett. 2020, 52, 2127–2149. [Google Scholar] [CrossRef]
- Jiang, X.W.; Xiong, L.W.; Yan, Q.; Zhang, Y.S.; Liu, X.B.; Cai, Z.H. Unsupervised Dimensionality Reduction for Hyperspectral Imagery via Laplacian Regularized Collaborative Representation Projection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6007805. [Google Scholar] [CrossRef]
- Xie, L.F.; Yin, M.; Yin, X.Y.; Liu, Y.; Yin, G.F. Low-Rank Sparse Preserving Projections for Dimensionality Reduction. IEEE Trans. Image Process. 2018, 27, 5261–5274. [Google Scholar] [CrossRef]
- Teng, L.Y.; Tang, F.Y.; Zheng, Z.F.; Kang, P.P.; Teng, S.H. Kernel-Based Sparse Representation Learning With Global and Local Low-Rank Label Constraint. IEEE Trans. Comput. Soc. Syst. 2024, 11, 488–502. [Google Scholar] [CrossRef]
- Deng, Y.-J.; Li, H.-C.; Pan, L.; Shao, L.-Y.; Du, Q.; Emery, W.J. Modified Tensor Locality Preserving Projection for Dimensionality Reduction of Hyperspectral Images. IEEE Geosci. Remote Sens. Lett. 2018, 15, 277–281. [Google Scholar] [CrossRef]
- Chen, K.; Yang, G.G.; Wang, J.; Du, Q.; Su, H.J. Unsupervised Dimensionality Reduction With Multifeature Structure Joint Preserving Embedding for Hyperspectral Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 7585–7599. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.