Abstract
Human pose comparison involves measuring the similarities in body postures between individuals to understand movement patterns and interactions, yet existing methods are often insufficiently robust and flexible. In this paper, we propose a RotJoint-based pipeline for pose similarity estimation that is both fine-grained and generalizable, as well as robust. Firstly, we developed a comprehensive benchmark for action ambiguity that intuitively and effectively evaluates the robustness of pose comparison methods against challenges such as body shape variations, viewpoint variations, and torsional poses. To address these challenges, we define a feature representation called RotJoints, which is strongly correlated with both the semantic and spatial characteristics of the pose. This parameter emphasizes the description of limb rotations across multiple dimensions, rather than merely describing orientation. Finally, we propose TemporalRotNet, a Transformer-based network, trained via supervised contrastive learning to capture spatial–temporal motion features. It achieves 93.7% accuracy on NTU-RGB+D close set action classification and 88% on the open set, demonstrating its effectiveness for dynamic motion analysis. Extensive experiments demonstrate that our RotJoint-based pipeline produces results more aligned with human understanding across a wide range of common pose comparison tasks and achieves superior performance in situations prone to ambiguity.
1. Introduction
Human pose comparison, which entails inferring the similarity between two poses, has extensive application scenarios, with downstream applications such as rehabilitation medicine and sports fitness having significant market potential. For instance, in rehabilitation medicine, it is imperative to compare standard template poses with patient poses to facilitate accurate rehabilitation training [1,2,3]. Therefore, research on pose comparison algorithms holds substantial importance. Pose comparison serves as the foundation for motion comparison. Individual frames in action videos often encapsulate rich information, especially expressive poses, such as those in gymnastics. Similarity measures employed in pose comparison assess these individual poses without considering temporal aspects. This methodology can be utilized for the comparison and identification of key poses or, alternatively, for incorporating complex temporal and contextual information to develop a more comprehensive model [4].
Recent advancements in pose comparison methodologies can be broadly categorized into two main approaches. The first approach employs classification models to determine whether two poses are identical or distinct [5]. The conventional frameworks for action recognition and classification predominantly utilize skeletal data for prediction, including models such as ST-GCN [6], 2s-AGCN [7], MST-GCN [8], and Skeletal-GNN [9]. However, this method is evidently limited in granularity, as it merely offers a binary judgment rather than a detailed comparison [10]. Moreover, this approach is constrained by the finite set of actions in the training data, making it necessary to substantially modify both the dataset and model architecture to recognize new, unseen actions [11], making zero-shot action classification [12,13] particularly challenging. This limitation significantly impedes the straightforward customization of a standard action library [14,15]. The second approach focuses on the computation of similarity metrics based on extracted pose features [4,16]. These methods refer to articulated skeletal points capable of movement as joint nodes, such as shoulder and knee joints, and regard them as key pose representation features. During the pose estimation stage, these methods first predict the positional parameters of these joint nodes, which serve as the foundation for subsequent similarity computations. Traditional methods in this category predominantly rely on 2D and 3D skeleton-based models [17,18,19], where comparisons are made by calculating either the angular differences between corresponding joint vectors or the Euclidean distances between corresponding joint nodes [20,21,22,23]. However, as depicted in Figure 1, these methods are often hampered by variations in human body morphology and camera angles, which can alter both the angles between joint vectors and the spatial positions of joint nodes. Furthermore, the skeletal model’s inherent limitations in representing the full complexity of human poses can lead to significant ambiguities in the comparison process.
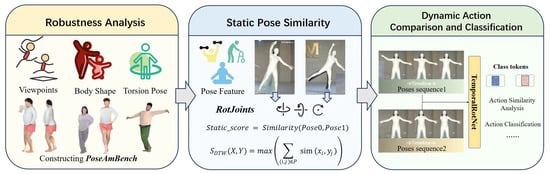
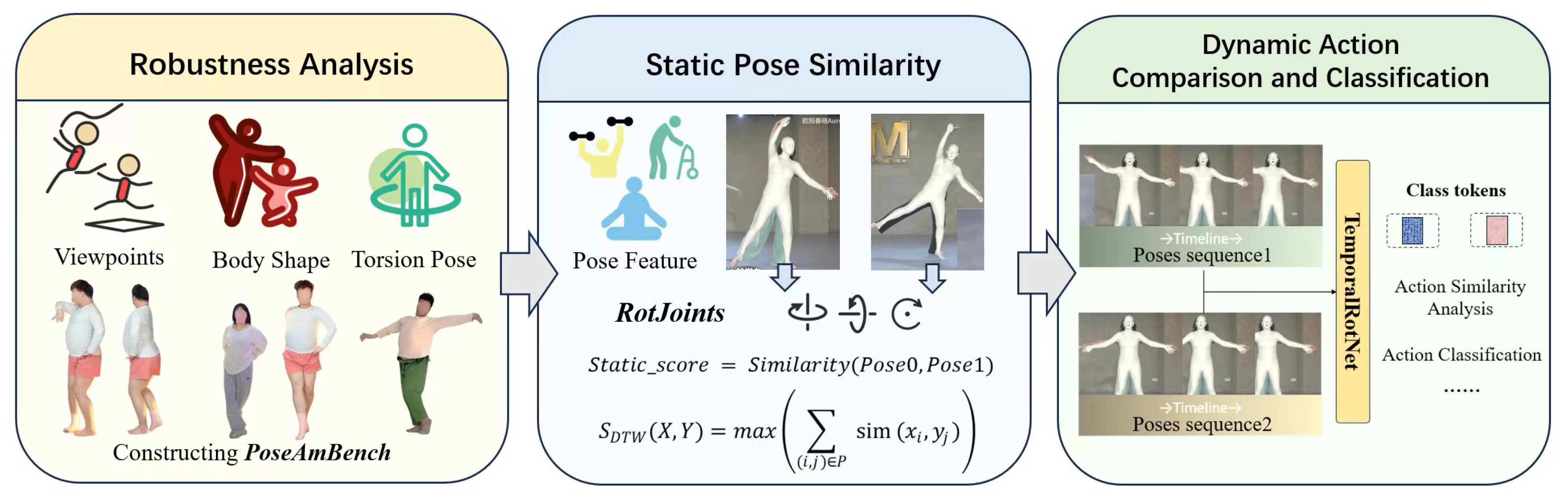
Figure 1.
Flowchart outlining the process of this study.
To evaluate the performance of existing methods in addressing ambiguities caused by shape variations, viewpoint variations, and torsional poses, with a particular focus on the robustness of action similarity measurement techniques, we develop PoseAMBench. This benchmark is organized into three categories, each designed to assess whether models can maintain strong discriminative capabilities when faced with significant ambiguities. In response to these challenges, we propose a novel protocol for pose comparison that aims to enhance both generalization and robustness [24].
To enable fine-grained generalization in our model, we developed a similarity evaluation method based on the conceptual framework of the second approach, utilizing pose features and incorporating human perceptual judgments of actions. To enhance the robustness of this method when confronting ambiguities, we introduce rotational parameters known as RotJoints, representing the rotations of joints. As a result, the similarity evaluation can benefit from RotJoint-based feature extraction implementations, effectively addressing ambiguities caused by variations in body shape, multiple viewpoints, and limb rotations.
In our method, RotJoints are derived from a 3D mesh-based evaluation model; they not only represent the skeletal orientation but also guide the twisting of joint nodes and represent muscle rotations, or in other words, restore muscle rotations. And human actions are defined based on the rotations of joint nodes. This definition provides higher interpretability and aligns more closely with human understanding in the task of pose similarity measurement. This rotation is multi-dimensional, involving not only the orientation of the joint nodes relative to their parent nodes but also the rotation of joint nodes relative to the joint vectors. With this definition above, pose estimation is not affected by variations in human body shape and image perspectives. Moreover, it can more accurately identify and distinguish poses that are primarily characterized by rotational movements around axes. In our method, human actions are understood as rotations of joint nodes [25,26]. Experimental validation has demonstrated that the static pose similarity represented by RotJoints is highly aligned with human judgments.
Building on this, we propose TemporalRotNet, a Transformer-based model that introduces a class token to action recognition. Through extensive pre-training, it learns high-dimensional spatiotemporal features of dynamic actions, enabling classification and similarity judgment without the need for retraining during inference. Compared to skeleton-based networks such as ST-GCN [6], TemporalRotNet exhibits superior robustness in handling ambiguous action assessments.
The organization of this paper is as follows. Section 2 reviews the related works in the fields of human pose estimation and action comparison. Section 3 introduces the benchmark designed in this paper, namely, PoseAMBench, which evaluates a pipeline’s ability to differentiate poses prone to ambiguity. Section 4 provides a detailed description of the proposed method, including the definition of RotJoints, the static pose comparison method and the dynamic pose comparison method based on RotJoints. Section 5 presents a comprehensive analysis of the experimental process and the results of the proposed method, comparing it with other similar models in terms of accuracy, precision, and other metrics. Finally, Section 6 summarizes our work in this paper and provides a future outlook.
2. Related Work
2.1. Human Pose Estimation
Pose estimation can be categorized into two main types. The first one is skeleton representation [27,28,29], which further comprises 2D and 3D variants. Represented by VitPose [17] and Simple Baseline [30], the 2D type is limited to planar representations, capturing only joint and skeleton positions in images. In contrast, the 3D type, exemplified by Simple Baseline-3D [30] and VideoPose3D [31], extends to spatial representations, incorporating richer angular and spatial information. The second category is whole-body mesh recovery. Unlike skeletons, parametric models focus on mesh rotation around joints, influenced by motion and shape, making them ideal for comprehensive motion analysis. SMPL is a vertex-based model representing diverse body shapes and poses. Its parameters, learned from data, include a rest pose template, blend weights, pose, and a vertex-to-joint regressor [32]. Recently, several outstanding methods for whole-body mesh recovery have emerged. For instance, OSX [33] introduces a one-stage pipeline for expressive whole-body mesh recovery, eliminating the need for separate networks for each component. Hand4Whole [34] leverages both body and hand joint features to achieve accurate 3D wrist rotation and ensure smooth connectivity between the body and hands. Despite the clarity and interpretability of SMPL’s parameters for pose similarity comparison, existing methods have not integrated it.
2.2. Action Comparison
In the context of pose estimation, distance metrics or learning-based methods are often used to directly measure and assess pose similarity [35,36]. The accuracy of these metrics is critical for tasks built upon pose similarity, such as action recognition. Common pose distance functions include the Manhattan distance, Euclidean distance [37], and cosine similarity [38]. Advanced methods use deep learning, representing body joints as graph nodes and connections as edges. Through spatiotemporal graph convolution, they capture joint spatial dependencies and frame-to-frame temporal dynamics. ST-GCN [6] applies graph convolutional networks [39] to human skeleton data, representing body joints as nodes in a graph and the connections between joints as edges. 2s-AGCN [7] introduces an adaptive graph convolution mechanism that learns a data-driven adjacency matrix, enhancing the model’s ability to capture subtle relationships between joints. Methods for directly modeling the human body utilize voxel-based or point-cloud-based techniques. By analyzing the local structure of points in 3D space, they model the dynamic characteristics of point clouds, capturing the relationship between body dynamics and actions. PointNet++ [40] operates on 3D point clouds to capture detailed spatial relationships. 3DV (motion) [41] uses voxel representations to model the dynamics of human motion. 3DV-PointNet++ [41] combines the strengths of PointNet++ and 3DV, leveraging both point cloud and voxel representations to better capture dynamic motion characteristics.
3. Benchmark
To address ambiguities in existing pose comparison methods, as depicted in Figure 2, we design the PoseAMBench collection based on three main sources of ambiguity: viewpoint ambiguity [42,43], torsional ambiguity, and body shape-induced ambiguity [44]. The collection process involves expert annotation and similarity scoring to ensure comprehensive and accurate data.
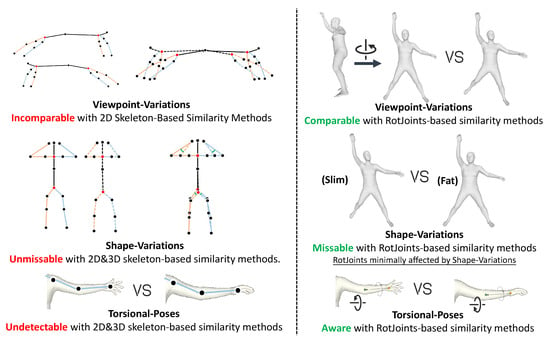
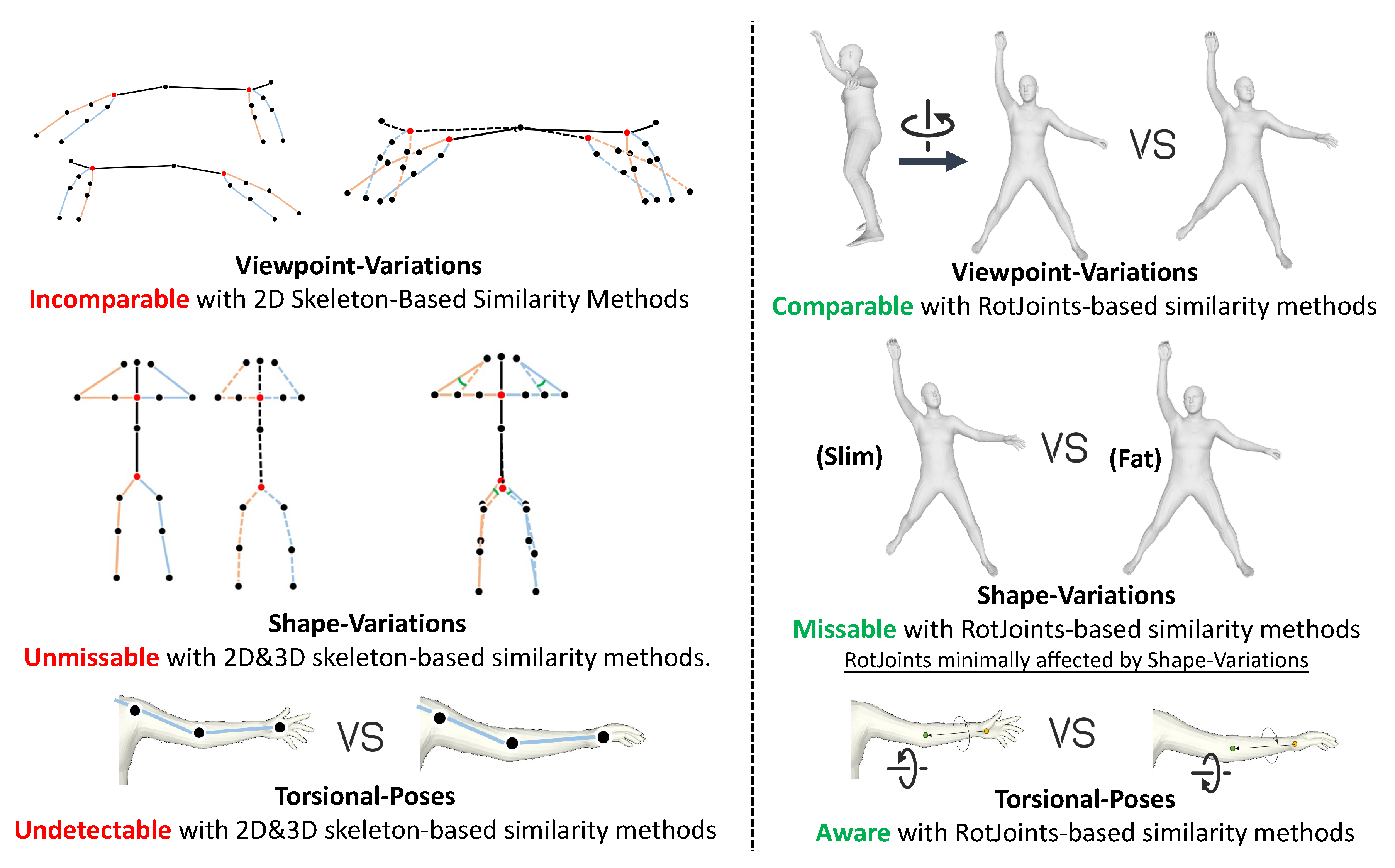
Figure 2.
(Left) Pose comparison method based on skeleton features. (Right) Pose comparison method based on RotJoints. Comparison of their robustness in pose matching tasks under shape variation, viewpoint changes, and torsional poses. The red text highlights ambiguities inherent to traditional methods, while the green text demonstrates how our approach resolves these ambiguities.
3.1. Ambiguity Pose Definition
Viewpoint ambiguity: Variations in camera viewpoints can distort action recognition in 2D pose estimation. Movements may appear similar when projected onto a 2D plane, especially from side views, making it difficult to distinguish forward and backward actions, such as forward and backward kicks.
Shape ambiguity: Differences in human body shapes, such as limb lengths and body proportions, can cause variations in skeletal angles for identical movements. This leads to ambiguity in pose comparisons, as actions may be interpreted differently based on an individual’s anatomy.
Torsional ambiguity: Rotational changes in joints (e.g., torso or wrist rotations) are difficult to perceive and are often overlooked by skeletal-based methods. This results in ambiguity when comparing poses with torsional movements.
Thus, we propose three tasks to evaluate pose recognition: Invariance to body shape variations, invariance to viewpoint changes, and sensitivity to twisting variations in limb movements. These tasks are assessed through three sub-benchmarks: the Shape-Variations Set, which compares pose pairs with different body shapes; the Viewpoint-Variations Set, which compares pose pairs from different viewpoints; and the Torsional-Pose Set, which tests the ability to distinguish torsional variations in limb movements rather than just limb movement types.
3.2. PoseAMBench Collection
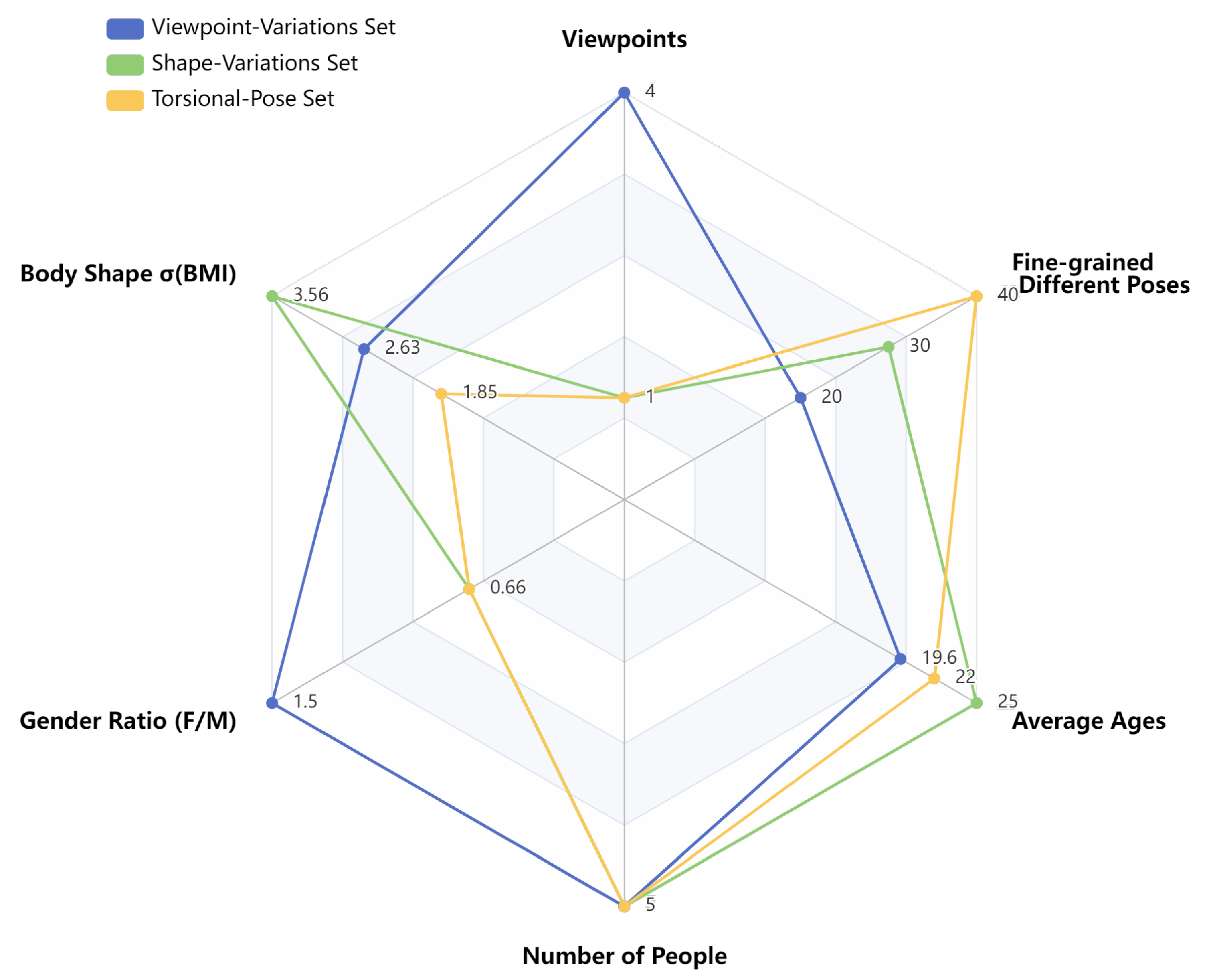
Based on the design guidelines, we categorize the data into three sets: (1) Shape-Variations Set, (2) Viewpoint-Variations Set, and (3) Torsional-Pose Set. The target data are selected and defined according to standards that best reflect the ambiguities in pose similarity differentiation methods. For the Shape-Variations Set, we select 30 action groups, with full-body frontal photos taken by five individuals of varying body types (tall, short, lean, and stocky). The same action performed by different individuals is labeled as having consistent poses. For the Viewpoint-Variations Set, we select 20 action groups, each performed by five individuals with full-body photos taken from different angles, including front, side, 45° oblique, and top-down views. The same individual performing the same action is defined as having consistent poses across different viewpoints. For the Torsional-Pose Set, we first design 10 basic actions, upon which we introduce varying degrees of arm and leg torsion. Five individuals are photographed performing these actions from consistent viewpoints. The labeling for this set is more complex and will be elaborated on in the metrics section. After filtering, a total of 980 action pairs are selected. Detailed statistical information is shown in Table 1 and Figure 3.

Table 1.
Data statistics of PoseAMBench.
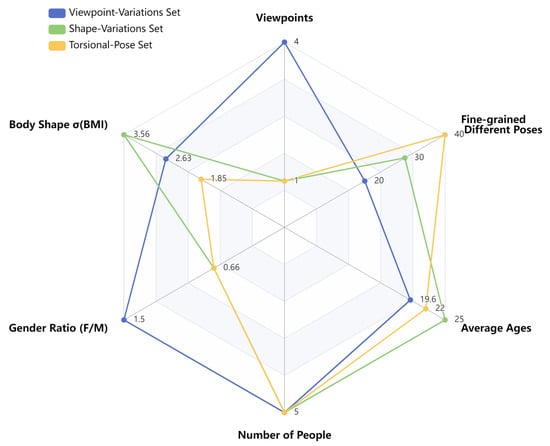
Figure 3.
Comparison of statistical measures across different sets in PoseAMBench. means standard deviation.
3.3. PoseAMBench Metric
We define the Torsion-Ambiguity-Aware Similarity Metric (TAASM) to measure action similarity in the Torsion-Ambiguity Pose set, extending the limb torsion metric (LTM) for body segments (torso, arms, and legs). The TAASM accounts for torsion differences even when body shape and joint angles are identical. By evaluating torsion separately for each segment, the metric provides a more interpretable similarity score, focusing on torsion-induced variations.
Torsion metric calculation: The body is divided into five parts: torso (including the head), left arm, right arm, left leg, and right leg. For each body part g, the torsional difference is given by
where and are the actual and reference torsion angles for body part g at frame i.
Normalized similarity calculation: The torsional difference for each body part is normalized as
where represents the maximum torsion angle (180° or radians), and ranges from 0 (maximum difference) to 1 (perfect similarity).
Overall similarity: The overall action similarity is the average of the individual body part similarities:
where , and are the similarity scores for the torso, left arm, right arm, left leg, and right leg, respectively.
We assign labels of 0 (dissimilar) and 1 (similar) to pose pairs. In the Shape-Variations and Viewpoint-Variations Sets, label 1 is used when actions are the same but other conditions differ, and label 0 otherwise. For the Torsional-Pose Set, labels are based on TAASM: if the value exceeds 0.6, the label is 1; otherwise, it is 0.
4. RotJoint-Based Pipeline
We designed the pipeline according to the following three questions.
4.1. What Are RotJoints?
RotJoints, which represent the characterization of three rotational parameters for the 21 joints of the human body, are designed to circumvent the ambiguities, and allow for the parameters to be effectively visualized and interpreted meanwhile. The 21 joints include the head, neck, collarbone, shoulders, elbows, wrists, hands, spine, pelvis, hips, knees, ankles, and feet, with each joint’s rotation characterized by pitch, yaw, and roll. The fundamental concept of Euler angles involves decomposing angular displacement into a sequence of three rotations around three mutually perpendicular axes. This decomposition makes Euler angles more intuitive and easier to interpret for understanding human motion. In the human pose estimation stage, the relative rotations of joint points can be obtained by sequentially rotating around the three axes (roll, pitch, yaw). We adopted the rotation order commonly used in the field of human pose estimation: roll → pitch → yaw. This sequence places the axis least likely to rotate by 90 degrees (pitch) in the middle, thereby minimizing the occurrence of gimbal lock issues and reducing the introduction of additional ambiguities.
The distinction between our approach and traditional skeletal vector-based methods for action representation lies in our use of joint rotations in 3D space to define human posture and motion. Traditional methods, which use skeletal representations for similarity matching, are limited by inherent ambiguities. Our approach, on the other hand, is designed to circumvent these ambiguities, allowing for the parameters to be effectively visualized and interpreted.
Given a human image , we adopt a framework to perform full-body mesh recovery, estimating the corresponding body parameters . These parameters are then fed into an SMPL layer to obtain the final 3D whole-body human mesh. In detail, contains the 3D body joint rotations .
In other works, various networks have been designed to generate pose and body shape parameters as inputs for the SMPL model. Here, we adopt the architecture of the OSX model, simplifying it by removing the shape and unnecessary facial parameter regression parts. To generate the Q parameters essential for our RotJoint-based pose comparison, we process human images by dividing the input image I into fixed-size patches of M, creating patches . These patches undergo linear projection and are combined with position embeddings to form feature tokens . To incorporate body prior information, we concatenate these feature tokens with learnable body tokens . The concatenated tokens are then processed by a Transformer encoder, yielding updated tokens . The body parameters are finally regressed from using fully connected layers.
In 2D pose estimation, viewpoint changes distort action recognition, while differences in body shapes and torsional movements can lead to misinterpretations. RotJoints, derived from a 3D mesh-based evaluation model, capture joint rotations relative to their parent nodes and joint axes, making the representation invariant to viewpoint changes and body shape variations. Additionally, by explicitly modeling rotational degrees of freedom around joint axes, RotJoints effectively capture torsional movements, improving the robustness and accuracy of pose comparison across diverse scenarios.
4.2. How to Use RotJoints in Static Pose Comparison?
The simplest and most intuitive method for measuring pose similarity is to quantify the position changes between the given and ground truth (GT) poses. However, current pose estimation metrics, such as MPJPE for skeleton-based methods, only consider joint position differences or angular differences, while metrics like MPVPE for mesh recovery mainly focus on vertex position differences, neglecting rotational information and both local and global pose differences. We separate the body parts physiologically. The joints in a skeleton are grouped into five categories: torso (including the head), arms, and legs. The structural representation is then calculated for each body part. Inspired by the IQM approach, the joint angles are normalized using the perceptually relevant mean-subtracted contrast normalization (MSCN) procedure. The MSCN coefficients of the jth joint in each pth body part can be obtained as
where is the normalized rotation angle, is the original angle from , and and are the mean and standard deviation. The global structure is represented by a rotation angle vector , where is the rotation of the jth joint. Local and global similarities are defined as
The overall similarity combines both:
where and weight local and global contributions, providing a comprehensive pose similarity measure while taking into account both fine-grained joint rotations and overall structural consistency. A higher emphasizes local differences, making the metric more sensitive to variations in individual limb rotations. A higher prioritizes global structural alignment, reducing sensitivity to minor limb rotations while maintaining overall pose similarity.
4.3. How to Use RotJoints in Dynamic Action Comparison?
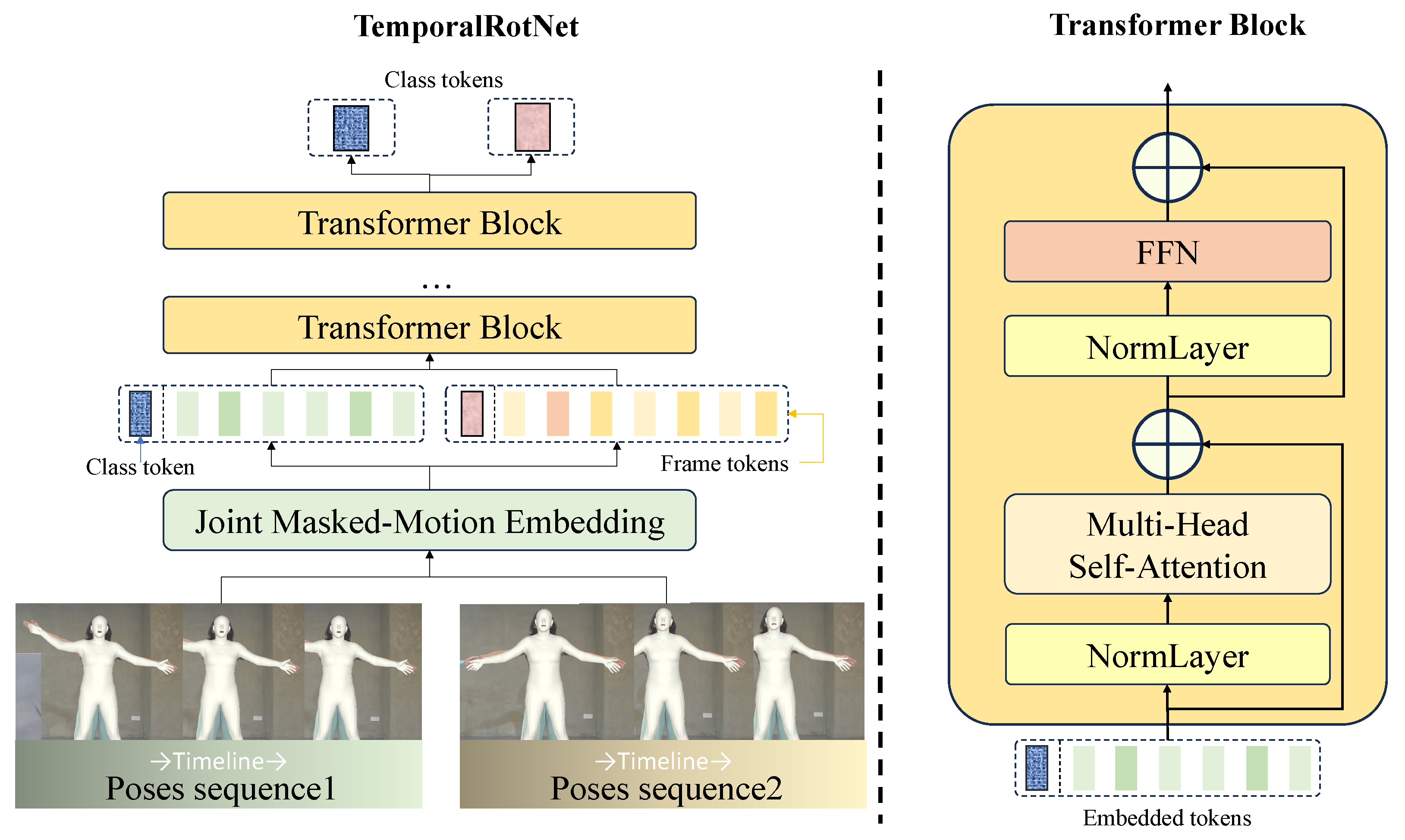
To extend the application of RotJoints in dynamic motion analysis, we propose TemporalRotNet, a novel framework that integrates motion features with temporal dynamics by utilizing a Transformer architecture to aggregate motion sequence information into a class token, which is further optimized through contrastive learning. As illustrated in Figure 4, the framework operates through the following structured pipeline.
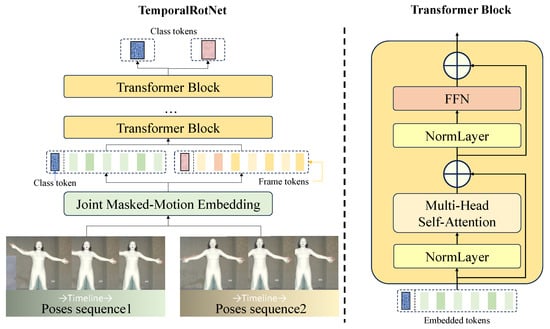
Figure 4.
Model overview. To enhance the model’s robustness and generalization capabilities while simulating the increased attention on partial joint information in real-world scenarios, we apply a joint masking mechanism to each motion sequence, followed by linear embedding to obtain the class token and frame tokens. The resulting sequence of vectors is then fed into a standard Transformer block. The structure of the Transformer block is inspired by ViT [45].
Firstly, the model employs an attention-based architecture to capture semantic and temporal dependencies within motion sequences. By utilizing a Transformer encoder, TemporalRotNet efficiently processes sequential data and extracts multi-level feature representations. Second, to enhance the model’s robustness and generalization capabilities, we introduce a joint masking mechanism. This mechanism randomly masks certain joints in the input motion data, simulating real-world scenarios where partial joint information may be missing or noisy, thereby improving the model’s adaptability to incomplete data.
In the model design, inspired by the CLIP network [46], the class token, a learnable special marker, is prepended to the input sequence. Through multiple layers of the Transformer encoder, the class token aggregates global information from the entire motion sequence, capturing its semantic and structural features, and outputs a fixed-dimensional vector. This design not only simplifies the model architecture but also provides a unified representation for downstream tasks.
During the training phase, TemporalRotNet adopts a supervised contrastive learning framework. Specifically, the model normalizes feature vectors and computes a similarity matrix to capture relationships between different motion sequences. The supervised contrastive loss function is designed to maximize similarity within the same class while minimizing similarity across different classes. This training strategy ensures that the model can effectively distinguish between different motion categories while maintaining consistency within the same category.
5. Experiment
5.1. Subjective Pose Similarity Assessment
To qualitatively validate the effectiveness of the RotJoint pipeline in estimating pose similarity, we conducted a subjective pose similarity assessment to evaluate the similarity of pose pairs. To ensure fairness, we applied the same weight parameter configuration when calculating similarity for the same body parts. The only difference was that one method used the ground truth directional vector of the 3D skeleton, while the other used RotJoints.
We collected 500 representative pose samples from the Human3.6M [21,47] dataset’s test samples, each containing 120 consecutive frames. From these, we created 1000 pose pairs. We selected 50 qualified participants for the experiment, all with normal vision and expertise in sports and medical fields. Ensuring the participants’ conditions and the experimental setup met strict standards was crucial for this subjective testing. Poses were displayed on a 65-inch ultra-high-definition monitor, and participants rated the quality of pose samples using a score range from 0 to 1, with completely identical (1) and very dissimilar (0). The numeric values in parentheses represent the labels.
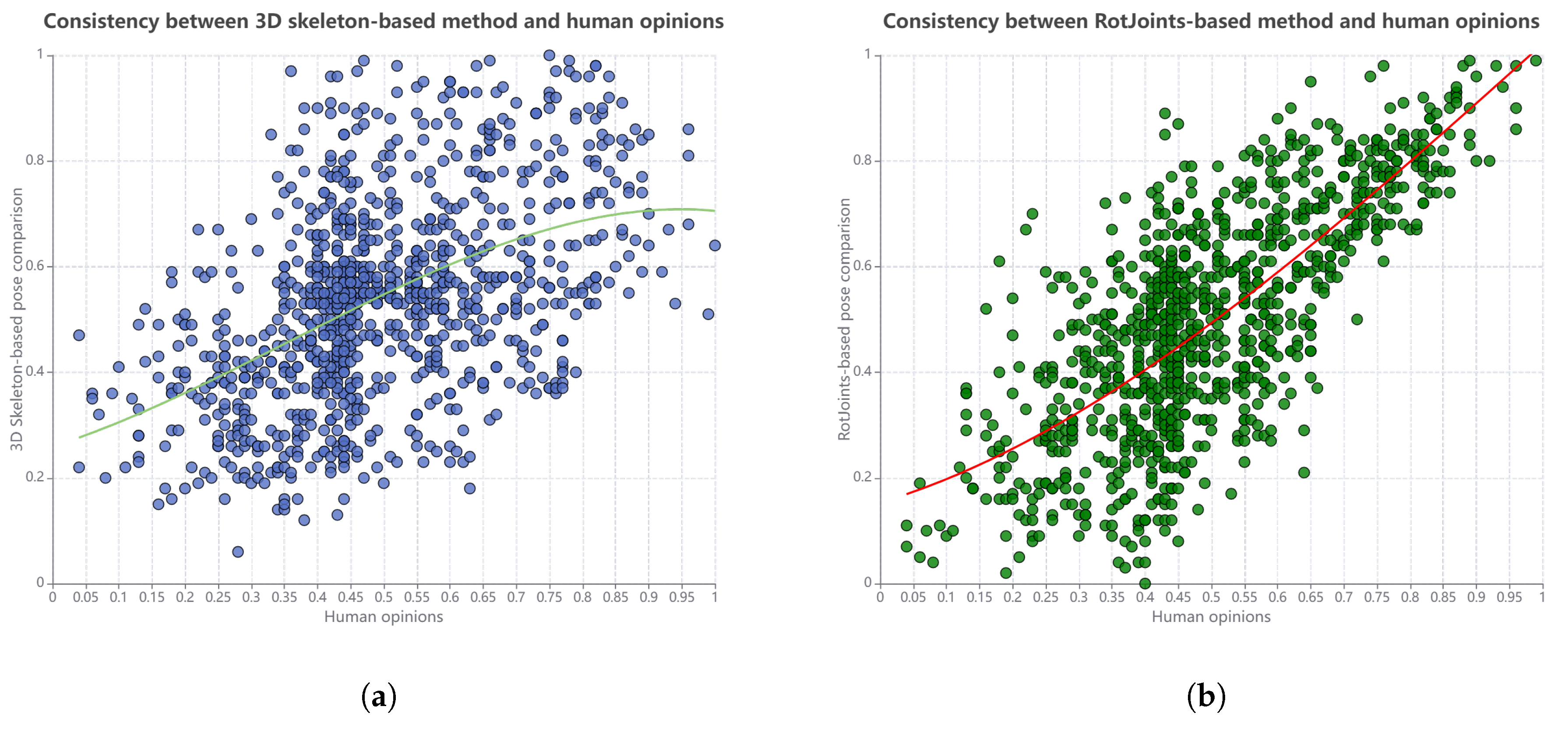
After all participants rated the pose sequences, we calculated the mean opinion score for the pose pair similarity. Each test session lasted 50 min, followed by a 10 min break to reduce dizziness from prolonged screen use. Each participant spent a total of 180 min on the task. The results are shown in Figure 5. Using a third-order polynomial fitting method, curves are fitted to the data, revealing that the RotJoint-based approach demonstrates higher consistency with human evaluations. The Pearson correlation coefficient is calculated, showing a value of 0.745 for the RotJoint-based method and 0.487 for the 3D skeleton-based method. This indicates that the RotJoint-based approach aligns more closely with human perception of pose similarity, making it a more accurate measure according to human cognitive standards.
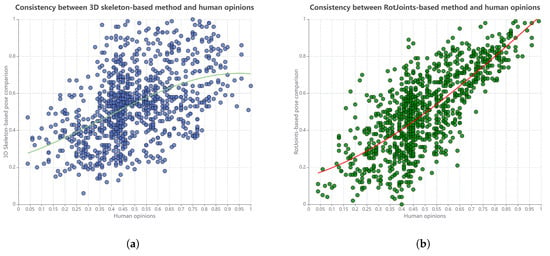
Figure 5.
Relationship between the results of (a) 3D skeleton-based and (b) RotJoint-based methods and human opinions on pose similarity, presented in the form of a scatter plot with a third-degree polynomial fit.
5.2. Performance on PoseAMBench
Based on the design principles of the pose ambiguity benchmark described earlier, we evaluate the performance of three methods on the PoseAMBench dataset, where the 2D and 3D skeleton-based action features are both generated by VitPose [17]. Since the labels in all three sets are binary (0 or 1) and thresholds significantly affect similarity score classification, we determine the optimal threshold for each method by testing 0.1 increments of similarity scores, enabling accurate comparison of their performance.
As shown in the Table 2, for the Viewpoint-Variation Set, the 3D skeleton-based method and the RotJoint-based method achieve accuracies of 84.6% and 93.5%, respectively, both of which are significantly higher than the performance of the 2D skeleton-based method. This indicates that both 3D-based methods demonstrate some resistance to viewpoint interference when assessing pose similarity.
Table 2.
Performance comparison of 2D skeleton-based, 3D skeleton-based, and RotJoint-based methods on different sets of PoseAMBench. The underlined values indicate the maximum results for each method across different thresholds within a single dataset, while the bolded values represent the absolute maximum values across all methods and settings in the entire study.
In the Shape-Variation Set and Torsional-Pose Set, the RotJoint-based method outperforms the others, highlighting its ability to effectively measure pose similarity even in the presence of body shape variations and limb torsion.
To compare the impact of different rotation parameter choices, we conducted an ablation study. In the first stage, we extracted features from identical pose images using axis-angle, quaternion, and rotation matrix representations. In the second stage, we employed two methods for similarity estimation: (1) computing the difference followed by normalization (to maintain consistency with the referenced work), and (2) calculating the cosine similarity. We then computed the average accuracy across the three sets. As shown in Table 3, the results indicated minor differences among representations, with our chosen approach achieving the best performance on the benchmark. Additionally, the parameter exhibits a relatively small data footprint.
Table 3.
The performance of different rotation parameter representations in PoseAMBench. The bolded values represent the maximum values across all settings.
These results clearly demonstrate the superior performance of the RotJoint-based pipeline compared to traditional skeleton-based models. The RotJoint-based approach consistently shows higher correlation coefficients across all benchmarks, particularly excelling in handling body shape variations, viewpoint changes, and limb twisting. These findings validate the robustness and precision of our pipeline under diverse conditions, confirming its efficacy in addressing action ambiguity.
5.3. Action Sequence Similarity Identification Based on Frame-Matching Integration
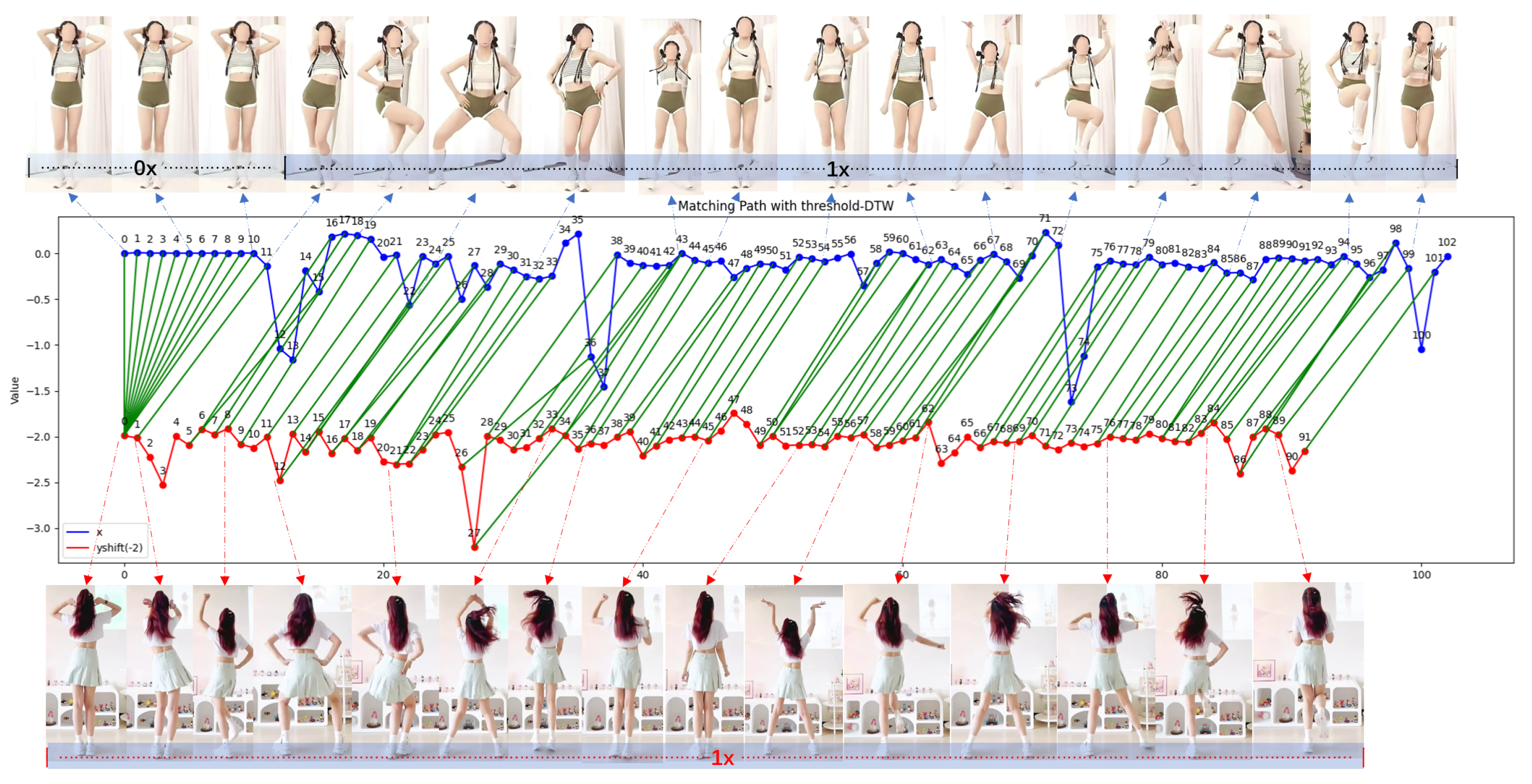
To validate the effectiveness of our method on dynamic actions, we applied a frame-matching technique to transfer pose-level similarity comparison methods to action matching [48]. Here, we employed the dynamic time warping (DTW) method [49,50] to match features extracted using the aforementioned RotJoint-based approach. Based on Section 5.2, we utilized the RotJoint-based method with a threshold set at 0.72 to measure the similarity of single-frame images. In this simplified experiment, we did not account for the speed of the action, focusing solely on the sequence of movements and the similarity between poses in individual frames. DTW measures the distance between two sequences by calculating the maximum similarity and the formula is
where represents the similarity between pose pairs and , and P is the set of alignment paths. The matching path P is obtained by selecting the alignment path that maximizes the total similarity:
where i and j are the indices corresponding to points in sequences X and Y, respectively, and the path is chosen to maximize similarity. To demonstrate the reliability of the RotJoint-based method in temporal action matching, we conducted tests on videos of the same individual performing the same action at varying speeds, recorded from different viewpoints. Fifty single-person motion videos, each with an average duration of 2 min and a frame rate of 1 fps, were used. The original videos played at 1× speed, while the comparison videos were divided into 4–5 segments, with speeds ranging from 0.1× to 2×. The average score achieved was 0.996. In a more complex scenario involving different individuals performing the same action at varying speeds and viewpoints, like Figure 6, we obtained a score of 0.909 using the same setup.
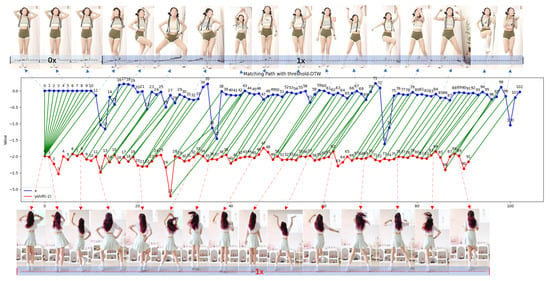
Figure 6.
The video case study compares two 30 s fitness routines performed by different individuals from distinct perspectives and at varied speeds. The upper section shows a freeze frame of the first video, while the lower section displays the original-speed video from a rear view. After matching, a similarity score of 93.9 is achieved, enabling movement comparison and synchronization.
These results highlight the strong transferability and robustness of the RotJoint-based method for action sequence matching, demonstrating its effectiveness under both simple and complex conditions, including variations in speed and viewpoint. The high average scores in these tests underscore the method’s potential for broad application in video-based action comparison tasks, ensuring accurate matching across dynamic conditions.
5.4. TemporalRotNet-Based Action Recognition and Similarity Assessment
We conducted training and testing of TemporalRotNet on the single-person subset of the NTU-RGB+D [51,52] dataset. We performed two types of classification tasks, one was a closed-set classification task. In cross-subject evaluation, 40 performers were split into two groups of 20 for training and testing. In cross-view evaluation, camera 1’s data were used for testing, and cameras 2 and 3’s data were used for training. As shown in Table 4, we observe that the training performance of TemporalRotNet based on RotJoint features is excellent in the classification task, surpassing that of the classical skeleton-based networks like SGN and 2s-AGCN.
Table 4.
Comparison of action recognition methods on NTU RGB+D 60 and NTU RGB+D 120 datasets’ test sets. The bolded values represent the maximum values across all settings.
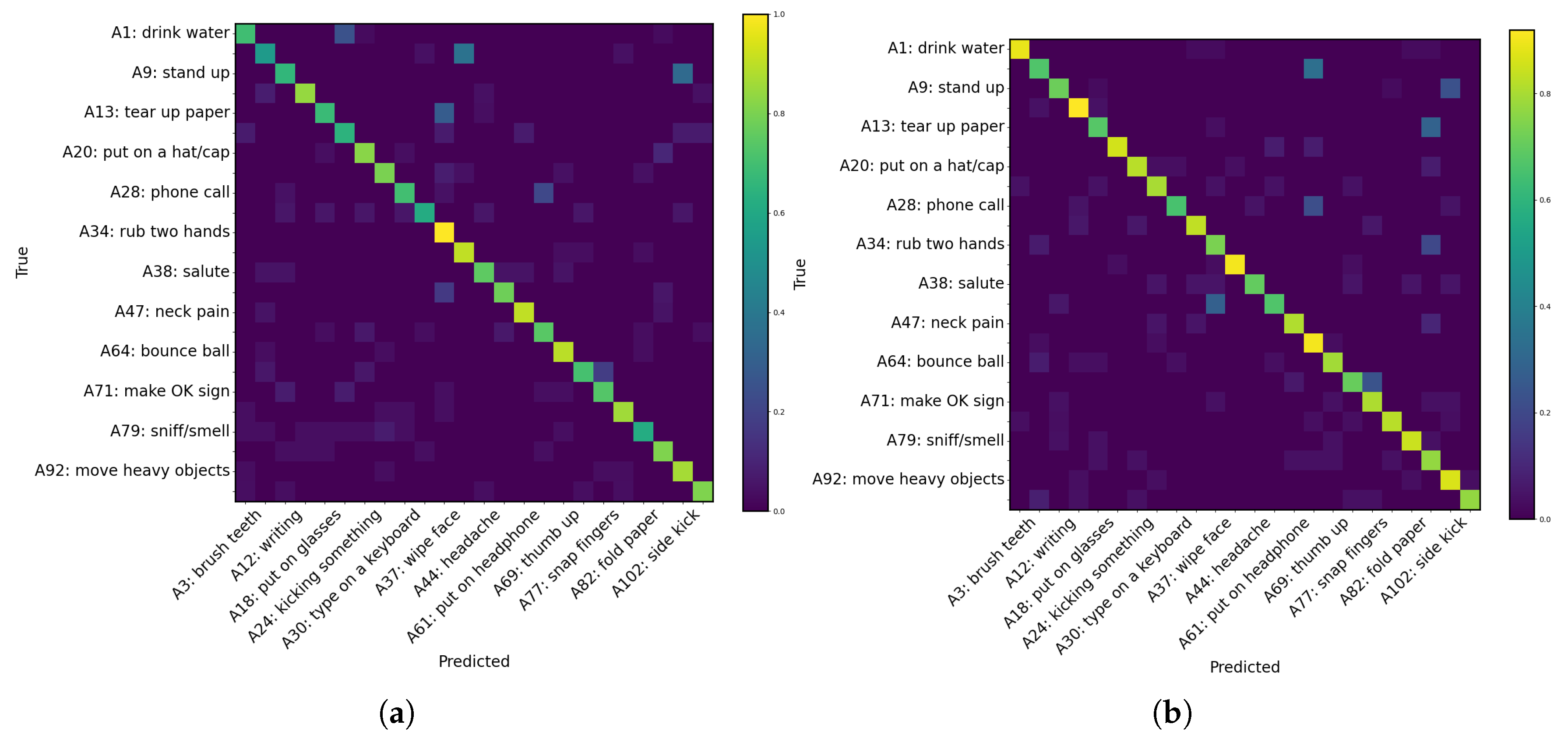
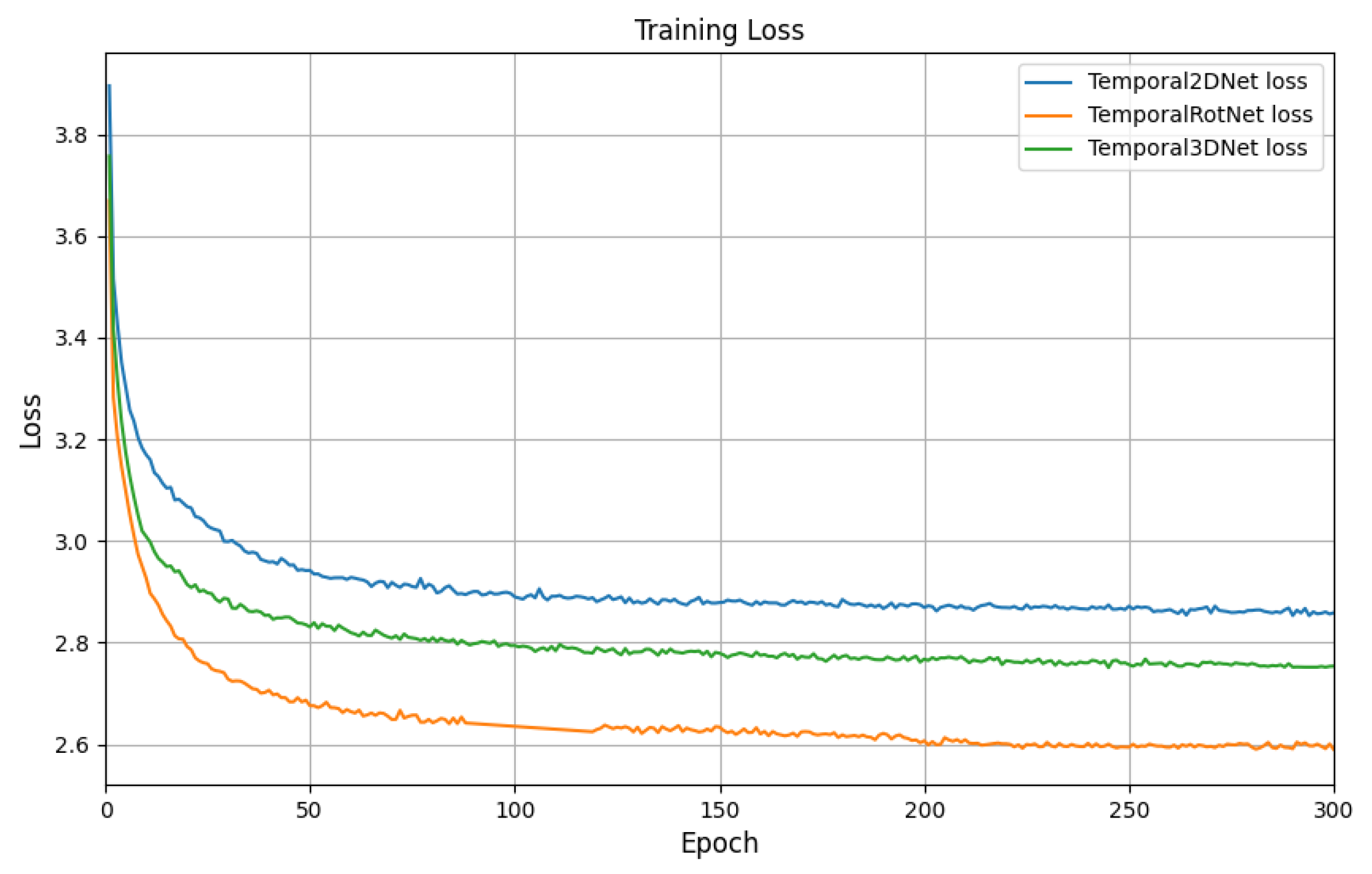
Furthermore, as shown in Table 5, we conducted a series of ablation experiments by utilizing both 2D and 3D skeleton-based features (provided as ground truth) as inputs. It can be observed that the performance of the skeleton-based networks is suboptimal. Additionally, the confusion matrix shown in Figure 7 reveals that these networks exhibit significant confusion, particularly when dealing with ambiguous actions. As shown in Figure 8, we compared the convergence of three baseline networks for TemporalNet. Among them, TemporalRotNet demonstrated the best convergence, reaching a loss value of approximately 2.600 within 300 epochs.
Table 5.
Ablation study of Temporal*Net with different feature bases. The bolded values represent the maximum values across all settings.
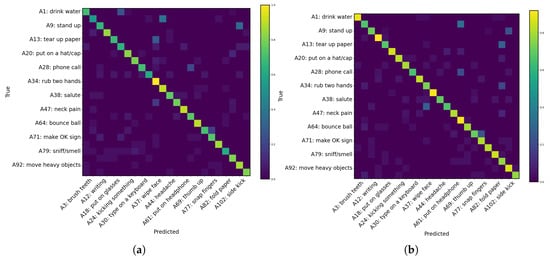
Figure 7.
The confusion matrices on the left and right, respectively, represent the ablation experiments conducted using (a) 2D and (b) 3D skeleton features. For clarity, 24 randomly selected samples are displayed. The vertical axis indicates the labels at odd positions, while the horizontal axis indicates the labels at even positions.
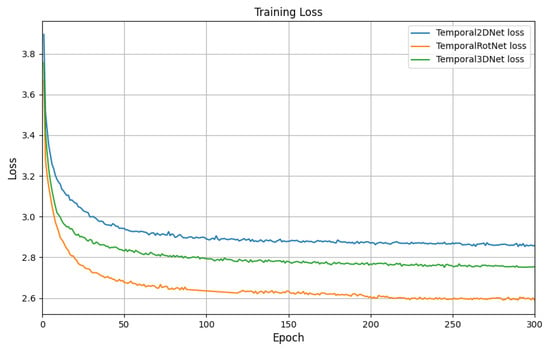
Figure 8.
Comparison of the training loss between Temporal2DNet, Temporal3DNet, and TemporalRotNet.
The other task is open-set classification. After excluding multi-person samples, 66,360 motion videos from 70 action classes were used for training, and 22,752 samples from 24 action classes were used for testing. The action classes in the test set did not overlap with those in the training set. During testing, for the classification task, 24 target actions were randomly selected, and the test set, after being processed by TemporalRotNet, was fed into a similarity comparison classifier to achieve a training-free classification task. Other models took the tensor from the layer preceding the final activation layer as the feature.
As shown in the confusion matrix in Figure 9 and the results in Table 6, the accuracy was 88%, indicating that the dynamic training based on RotJoint features performed well, and the network was able to effectively integrate information from both static and dynamic aspects. Even for unseen actions, the model can extract sufficient motion and temporal features for classification. We note that while 2s-AGCN achieves the same accuracy as our method, both 2s-AGCN and TRNet have computational complexity proportional to the square of the sequence length. However, with the specific optimization of the Transformer’s FlashAttention module [55], our method completes inference in 22.8 ms on an NVIDIA 3090 GPU (NVIDIA, Santa Clara, CA, USA) for a 2 s video at 60 fps, whereas 2s-AGCN, which lacks hardware acceleration for specific components, requires 40.2 ms. Additionally, 2s-AGCN is constrained by a fixed sequence window length, while TemporalRotNet can adapt to sequences of varying lengths, making it more effective for large-scale sequence data. Under the open-set setting, 2s-AGCN converged after 320 epochs, while TemporalRotNet required only 250 epochs.
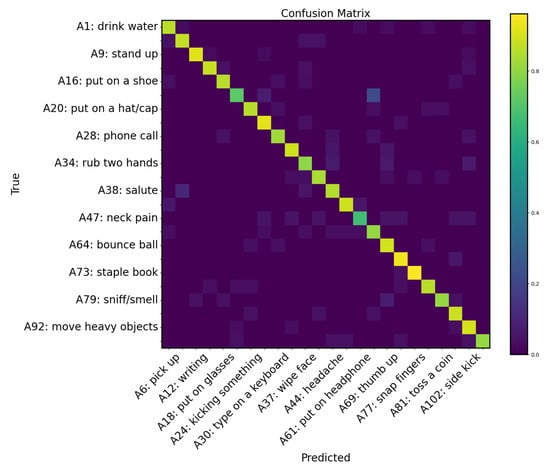
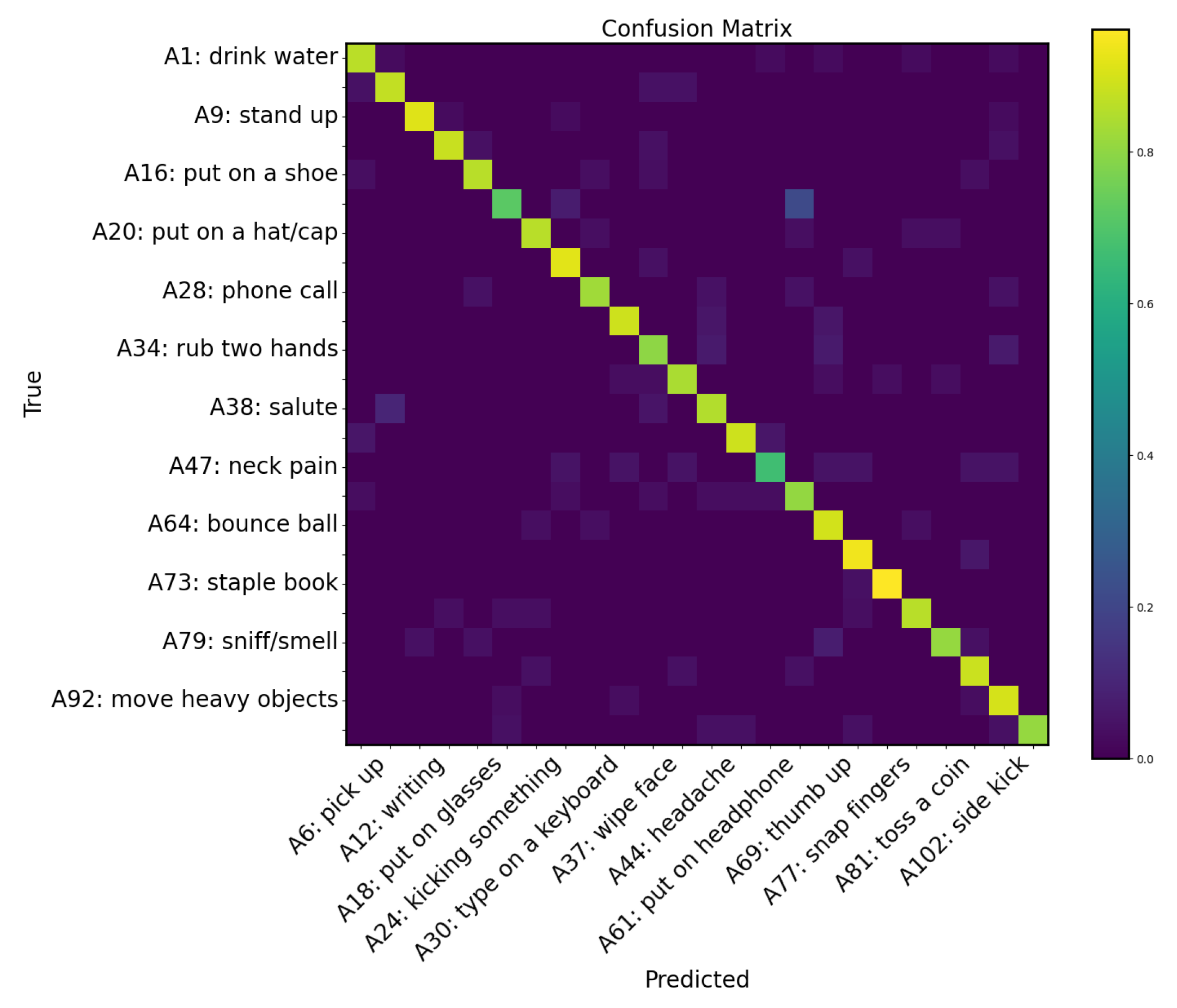
Figure 9.
To facilitate visualization, we plotted the confusion matrix for the 24 categories in the test set of the open-set classification task.
Table 6.
The performance of different base network architectures in open-set action recognition. The bolded values represent the maximum values across all settings.
In addition to the above conclusions, we find that the performance on the closed-set task is generally better than that on the open-set task, with a closed-set accuracy of 93.7% compared to an open-set accuracy of 88%. Although TemporalRotNet can effectively capture dynamic motion features, its feature representation may not be sufficient to fully support accurate classification when faced with entirely new classes, resulting in a performance gap between the two tasks. This task is analogous to face recognition tasks, where having a larger amount of data could potentially improve the performance of open-set classification.
6. Conclusions
This paper summarizes the common ambiguities present in existing pose comparison methods and introduces a new benchmark, PoseAMBench, which is divided into three sets based on the source of ambiguity: the Shape-Variations Set, the Viewpoint-Variations Set, and the Torsional-Pose Set. A robust pose similarity estimation method capable of overcoming these ambiguities should perform well on this benchmark. To address these ambiguities, we propose a RotJoint-based human pose comparison pipeline, leveraging RotJoint parameters for action similarity measurement. On PoseAMBench, our method achieves scores of 92.7 on the Shape-Variations Set, 93.5 on the Viewpoint-Variations Set, and 91.6 on the Torsional-Pose Set, while the best results from 2D and 3D skeleton-based methods on these three sets are 78.0, 84.6, and 77.6, respectively. The experimental results demonstrate that, compared to traditional skeleton-based approaches, our method aligns more closely with human judgments and achieves state-of-the-art performance in distinguishing ambiguous poses. Furthermore, to validate the potential of our current work in extending to multi-frame continuous actions in the temporal dimension, we conduct a preliminary verification by extending the pipeline to the spatiotemporal domain using dynamic time warping. This approach achieves 0.996 similarity for the same individual performing actions at different speeds and 0.909 similarity for different individuals under varying speeds and viewpoints. Our experiments demonstrate the robustness and transferability of the RotJoint-based method for action sequence matching. Additionally, we introduce TemporalRotNet, a Transformer-based network designed for dynamic action comparison. Through the integration of class tokens, it supports tasks such as action classification, recognition, and similarity evaluation, achieving outstanding results, including 93.7% accuracy on closed-set recognition with the NTU RGB+D dataset.
In summary, this paper identifies the ambiguities in existing pose comparison methods, proposes a RotJoint-based pose comparison pipeline, and introduces the PoseAMBench benchmark. The experimental results demonstrate the superior performance of the proposed method in pose similarity estimation, while its capability in dynamic action comparison is further validated through dynamic time warping and TemporalRotNet.
Author Contributions
Conceptualization, G.G., R.X. and H.Z.; Methodology, G.G.; Software, G.G.; Validation, G.G. and Z.Z.; Data curation, G.G., G.Y., Z.L. and Y.Q.; Writing—original draft, G.G.; Writing—review and editing, Y.Y.; Funding acquisition, G.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the “Leading Goose + X” Science and Technology Program of Zhejiang Province of China (2025C02104).
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki, and the protocol was approved by the Ethics Committee of College of Biomedical Engineering & Instrument Science, Zhejiang University of [2022]51, approved on 5 December 2022.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The data used in this study are not fully open access. Partial datasets can be accessed from https://rose1.ntu.edu.sg/dataset/actionRecognition/ (accessed on 12 May 2024) and http://vision.imar.ro/human3.6m/ (accessed on 8 May 2024). For additional data requests, please contact the corresponding author.
Conflicts of Interest
Authors Guang Yang and Zhengrong Liu were employed by the company Hangzhou Sunrise Technology Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as potential conflicts of interest.
References
- Garg, S.; Saxena, A.; Gupta, R. Yoga pose classification: A CNN and MediaPipe inspired deep learning approach for real-world application. J. Ambient Intell. Humaniz. Comput. 2023, 14, 16551–16562. [Google Scholar]
- Wang, J.; Tan, S.; Zhen, X.; Xu, S.; Zheng, F.; He, Z.; Shao, L. Deep 3D human pose estimation: A review. Comput. Vis. Image Underst. 2021, 210, 103225. [Google Scholar]
- Lee, S.; Lee, K. CheerUp: A Real-time Ambient Visualization of Cheerleading Pose Similarity. In Proceedings of the Companion Proceedings of the 28th International Conference on Intelligent User Interfaces, Sydney, Australia, 27–31 March 2023; pp. 72–74. [Google Scholar]
- Sebernegg, A.; Kán, P.; Kaufmann, H. Motion similarity modeling—A state of the art report. arXiv 2020, arXiv:2008.05872. [Google Scholar]
- Li, K.; Wang, S.; Zhang, X.; Xu, Y.; Xu, W.; Tu, Z. Pose recognition with cascade transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1944–1953. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12026–12035. [Google Scholar]
- Chen, Z.; Li, S.; Yang, B.; Li, Q.; Liu, H. Multi-scale spatial temporal graph convolutional network for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 1113–1122. [Google Scholar]
- Zeng, A.; Sun, X.; Yang, L.; Zhao, N.; Liu, M.; Xu, Q. Learning skeletal graph neural networks for hard 3D pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11436–11445. [Google Scholar]
- Krüger, B.; Tautges, J.; Weber, A.; Zinke, A. Fast local and global similarity searches in large motion capture databases. In Proceedings of the Symposium on Computer Animation, Madrid, Spain, 2–4 July 2010; pp. 1–10. [Google Scholar]
- Mazzia, V.; Angarano, S.; Salvetti, F.; Angelini, F.; Chiaberge, M. Action transformer: A self-attention model for short-time pose-based human action recognition. Pattern Recognit. 2022, 124, 108487. [Google Scholar]
- Estevam, V.; Pedrini, H.; Menotti, D. Zero-shot action recognition in videos: A survey. Neurocomputing 2021, 439, 159–175. [Google Scholar]
- Sun, B.; Kong, D.; Wang, S.; Li, J.; Yin, B.; Luo, X. GAN for vision, KG for relation: A two-stage network for zero-shot action recognition. Pattern Recognit. 2022, 126, 108563. [Google Scholar]
- Mishra, A.; Pandey, A.; Murthy, H.A. Zero-shot learning for action recognition using synthesized features. Neurocomputing 2020, 390, 117–130. [Google Scholar]
- Gao, J.; Zhang, T.; Xu, C. Learning to model relationships for zero-shot video classification. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3476–3491. [Google Scholar]
- Lei, J.; Song, M.; Li, Z.N.; Chen, C. Whole-body humanoid robot imitation with pose similarity evaluation. Signal Process. 2015, 108, 136–146. [Google Scholar]
- Xu, Y.; Zhang, J.; Zhang, Q.; Tao, D. Vitpose: Simple vision transformer baselines for human pose estimation. Adv. Neural Inf. Process. Syst. 2022, 35, 38571–38584. [Google Scholar]
- Xu, Y.; Zhang, J.; Zhang, Q.; Tao, D. Vitpose++: Vision transformer for generic body pose estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 1212–1230. [Google Scholar] [CrossRef]
- Fang, H.S.; Li, J.; Tang, H.; Xu, C.; Zhu, H.; Xiu, Y.; Li, Y.L.; Lu, C. Alphapose: Whole-body regional multi-person pose estimation and tracking in real-time. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 7157–7173. [Google Scholar] [CrossRef]
- Ngan, P.T.H.; Hochin, T.; Nomiya, H. Similarity measure of human body movement through 3D chaincode. In Proceedings of the 2017 18th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Kanazawa, Japan, 26–28 June 2017; pp. 607–614. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1325–1339. [Google Scholar] [CrossRef]
- Zhou, J.; Feng, W.; Lei, Q.; Liu, X.; Zhong, Q.; Wang, Y.; Jin, J.; Gui, G.; Wang, W. Skeleton-based human keypoints detection and action similarity assessment for fitness assistance. In Proceedings of the 2021 IEEE 6th International Conference on Signal and Image Processing (ICSIP), Nanjing, China, 22–24 October 2021; pp. 304–310. [Google Scholar]
- Lee, J.J.; Choi, J.H.; Chuluunsaikhan, T.; Nasridinov, A. Pose evaluation for dance learning application using joint position and angular similarity. In Proceedings of the Adjunct Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers, Virtual, 14–17 September 2020; pp. 67–70. [Google Scholar]
- Lee, K.; Kim, W.; Lee, S. From human pose similarity metric to 3D human pose estimator: Temporal propagating LSTM networks. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1781–1797. [Google Scholar] [CrossRef]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A skinned multi-person linear model. In Seminal Graphics Papers: Pushing the Boundaries; ACM: New York, NY, USA, 2023; Volume 2, pp. 851–866. [Google Scholar]
- Pavlakos, G.; Choutas, V.; Ghorbani, N.; Bolkart, T.; Osman, A.A.; Tzionas, D.; Black, M.J. Expressive body capture: 3d hands, face, and body from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10975–10985. [Google Scholar]
- Chen, W.; Jiang, Z.; Guo, H.; Ni, X. Fall detection based on key points of human-skeleton using openpose. Symmetry 2020, 12, 744. [Google Scholar] [CrossRef]
- Kendall, A.; Grimes, M.; Cipolla, R. Posenet: A convolutional network for real-time 6-dof camera relocalization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 2938–2946. [Google Scholar]
- Maji, D.; Nagori, S.; Mathew, M.; Poddar, D. Yolo-pose: Enhancing yolo for multi person pose estimation using object keypoint similarity loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2637–2646. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 466–481. [Google Scholar]
- Charles, J.; Pfister, T.; Magee, D.; Hogg, D.; Zisserman, A. Personalizing human video pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 3063–3072. [Google Scholar]
- Tang, W.; Li, Y.; Osimiri, L.; Zhang, C. Osteoblast-specific transcription factor Osterix (Osx) is an upstream regulator of Satb2 during bone formation. J. Biol. Chem. 2011, 286, 32995–33002. [Google Scholar] [CrossRef]
- Lin, J.; Zeng, A.; Wang, H.; Zhang, L.; Li, Y. One-stage 3d whole-body mesh recovery with component aware transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 21159–21168. [Google Scholar]
- Moon, G.; Choi, H.; Lee, K.M. Accurate 3D hand pose estimation for whole-body 3D human mesh estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2308–2317. [Google Scholar]
- Huynh, D.Q. Metrics for 3D rotations: Comparison and analysis. J. Math. Imaging Vis. 2009, 35, 155–164. [Google Scholar]
- Switonski, A.; Michalczuk, A.; Josinski, H.; Polanski, A.; Wojciechowski, K. Dynamic time warping in gait classification of motion capture data. In Proceedings of the World Academy of Science, Engineering and Technology, World Academy of Science, Engineering and Technology (WASET), Paris, France, 22–23 August 2012; Number 71. p. 53. [Google Scholar]
- Abdulghani, M.M.; Ghazal, M.T.; Salih, A.B.M. Discover human poses similarity and action recognition based on machine learning. Bull. Electr. Eng. Inform. 2023, 12, 1570–1577. [Google Scholar] [CrossRef]
- Chan, J.; Leung, H.; Tang, K.T.; Komura, T. Immersive performance training tools using motion capture technology. In Proceedings of the 1st Intenational ICST Conference on Immersive Telecommunications & Workshops, Verona, Italy, 10–12 October 2010. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations, Online, 25–29 April 2022. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30, 5105–5114. [Google Scholar]
- Wang, Y.; Xiao, Y.; Xiong, F.; Jiang, W.; Cao, Z.; Zhou, J.T.; Yuan, J. 3DV: 3D dynamic voxel for action recognition in depth video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 511–520. [Google Scholar]
- Tang, J.; Luo, J.; Tjahjadi, T.; Guo, F. Robust arbitrary-view gait recognition based on 3D partial similarity matching. IEEE Trans. Image Process. 2016, 26, 7–22. [Google Scholar] [CrossRef]
- Sweeney, C.; Kneip, L.; Hollerer, T.; Turk, M. Computing similarity transformations from only image correspondences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3305–3313. [Google Scholar]
- Huang, P.; Hilton, A.; Starck, J. Shape similarity for 3D video sequences of people. Int. J. Comput. Vis. 2010, 89, 362–381. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Ionescu, C.; Li, F.; Sminchisescu, C. Latent Structured Models for Human Pose Estimation. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Wang, L.; Liu, J.; Zheng, L.; Gedeon, T.; Koniusz, P. Meet JEANIE: A Similarity Measure for 3D Skeleton Sequences via Temporal-Viewpoint Alignment. Int. J. Comput. Vis. 2024, 132, 4091–4122. [Google Scholar] [CrossRef]
- Slama, R.; Wannous, H.; Daoudi, M. 3D human motion analysis framework for shape similarity and retrieval. Image Vis. Comput. 2014, 32, 131–154. [Google Scholar] [CrossRef]
- Rybarczyk, Y.; Deters, J.K.; Gonzalo, A.A.; Esparza, D.; Gonzalez, M.; Villarreal, S.; Nunes, I.L. Recognition of physiotherapeutic exercises through DTW and low-cost vision-based motion capture. In Proceedings of the Advances in Human Factors and Systems Interaction: Proceedings of the AHFE 2017 International Conference on Human Factors and Systems Interaction, Los Angeles, CA, USA, 17–21 July 2017; Springer: Berlin/Heidelberg, Germany, 2018; pp. 348–360. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.Y.; Kot, A.C. Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2684–2701. [Google Scholar] [CrossRef]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Yang, L.; Huang, J.; Feng, T.; Hong-An, W.; Guo-Zhong, D. Gesture interaction in virtual reality. Virtual Real. Intell. Hardw. 2019, 1, 84–112. [Google Scholar]
- Fan, H.; Yu, X.; Ding, Y.; Yang, Y.; Kankanhalli, M. Pstnet: Point spatio-temporal convolution on point cloud sequences. In Proceedings of the ICLR 2021—9th International Conference on Learning Representations, ICLR, Virtual, 3–7 May 2021. [Google Scholar]
- Shah, J.; Bikshandi, G.; Zhang, Y.; Thakkar, V.; Ramani, P.; Dao, T. Flashattention-3: Fast and accurate attention with asynchrony and low-precision. Adv. Neural Inf. Process. Syst. 2024, 37, 68658–68685. [Google Scholar]
- Chen, Y.; Zhang, Z.; Yuan, C.; Li, B.; Deng, Y.; Hu, W. Channel-wise topology refinement graph convolution for skeleton-based action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 13359–13368. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).