Abstract
Achieving robust multi-object tracking in complex real-world scenarios remains a challenging task. Existing approaches often struggle to effectively handle occlusion, primarily because occlusion can result in unreliable appearance features, inaccurate motion estimation, and biased association cues. To address these challenges, this study proposes OATrack, a pedestrian multi-object tracking framework with explicit occlusion awareness. First, an occlusion perception module is introduced to estimate the occlusion rate and provide it as input for subsequent components. Subsequently, the Kalman Filter’s innovation gain is adaptively suppressed according to the target’s occlusion level, and association cues are assigned adaptive weights based on occlusion severity. Experimental results on the MOT17 benchmark dataset demonstrate that the proposed method achieves state-of-the-art performance in key tracking metrics. Specifically, on the MOT17 test set, the method achieves an IDF1 score of 80.6% and a HOTA score of 65.3%. On the MOT20 test set, it attains an IDF1 of 77.8% and a HOTA of 63.6%. The proposed algorithm offers an effective solution for multi-object tracking in environments characterized by frequent and complex occlusions.
1. Introduction
Pedestrian multi-object tracking is a fundamental task in computer vision, which aims to continuously detect and localize multiple individuals across video sequences while preserving their identity consistency. It has critical applications in various domains, including autonomous driving [1,2] and video surveillance [3]. Despite substantial advancements in recent years, achieving robust and reliable tracking performance in scenarios with frequent occlusions remains a significant challenge.
With the advancement of deep learning in representation learning [4,5,6], state-of-the-art tracking methods [7,8,9] have addressed the occlusion challenge by integrating motion cues with appearance feature cues. The Kalman Filter formulates pedestrian trajectory prediction as a linear estimation problem, thereby providing motion-based information. Meanwhile, pedestrian reidentification techniques enable the extraction of discriminative appearance features and facilitate cross-frame association. However, these approaches remain limited in handling occlusions due to the inherent unreliability of motion estimation and appearance features under occluded conditions, as well as suboptimal weighting strategies for fusing complementary cues.
In recent years, certain studies have identified occlusion by detecting abrupt changes in the target bounding box [9] or a decline in detection confidence [10], and have implemented specific strategies to alleviate the associated occlusion challenges. However, these approaches often lack precision in determining occlusion status and are susceptible to interference from the target’s intrinsic motion, such as pose variations, which can degrade overall tracking performance. Furthermore, attention-based methods [11,12,13] aim to model multi-frame contextual information to infer target motion patterns and thereby address occlusion. Nevertheless, compared to conventional techniques such as the Kalman Filter and appearance-based features, these methods demand significantly higher computational resources and present greater difficulties in scenario-specific optimization.
In occluded scenarios, object detectors often produce bounding boxes contaminated with noise, significantly degrading the discriminative capability of appearance features. Furthermore, severe occlusion typically indicates that the target is about to vanish from view. Under such conditions, unreliable detections during occlusion can mislead the Kalman Filter and exacerbate error accumulation throughout the period of target disappearance. Data association constitutes a core component of multi-object tracking, responsible for linking newly detected objects with existing trajectories to preserve identity consistency over time. Conventional tracking approaches generally combine motion and appearance cues using fixed weighting schemes [14,15] or predefined rules [7,8], lacking the ability to dynamically adapt the relative importance of these cues based on contextual scene variations. As a result, these methods are prone to identity switches (IDSw) in complex and dynamic environments.
To mitigate the challenges posed by occlusion, this study proposes OATrack, a framework that systematically enhances state estimation and data association through explicit modeling and effective utilization of the target occlusion rate (). Unlike approaches that model occlusion as a binary occurrence or depend on implicit cues such as detection confidence, OATrack introduces a unified, occlusion-aware control mechanism. This mechanism is driven by a continuously estimated occlusion ratio, facilitating smooth and context-sensitive adaptations within the tracking framework. The main contributions of this work are summarized as follows:
- Occlusion Perception Module (OPM): A lightweight component designed to directly regress the occlusion ratio of targets from the detector-generated bounding boxes, thereby providing essential occlusion-related information to enhance the performance of the Kalman Filter and data association processes. It provides an explicit and continuous occlusion severity signal, offering more granular information than binary indicators or detector scores.
- Occlusion-aware Adaptive Kalman Filter (OAKF): This module dynamically adjusts the Kalman gain based on the estimated occlusion ratio. Under conditions of severe occlusion, it reduces reliance on potentially noisy detection observations, thereby mitigating trajectory drift and minimizing error accumulation over time.
- Occlusion-aware Dynamic Data Association Strategy (ODA): By adaptively fusing the base association metric and motion-based distance through a weighting function governed by the occlusion ratio, this strategy significantly improves robustness in dynamic occlusion scenarios and effectively reduces identity switches during tracking.
2. Related Work
2.1. Multi-Object Tracking
Modern multi-object tracking systems predominantly adhere to the “tracking-by-detection” paradigm [10,16,17,18,19], in which object detection is performed independently on each frame, followed by cross-frame data association. This framework involves separate optimization of the detection and tracking stages. Early approaches primarily relied on motion-based cues for association, such as IoU distance. SORT [17] was among the first to incorporate the Kalman Filter [20] into multi-object tracking, utilizing it to predict object positions and enhance tracking continuity during occlusion periods. However, it relies entirely on motion cues, rendering it susceptible to identity switches in crowded and complex interaction scenarios. Building upon SORT [17], ByteTrack [10] significantly improved the tracking accuracy by associating not only high-confidence detections but also low confidence candidates, which often correspond to occluded objects, thereby achieving superior performance. Nevertheless, its association remains largely motion-driven and lacks the discriminative capability to reidentify targets after long term occlusion.
Relying solely on motion cues proves insufficient for addressing occlusion challenges. Appearance features serve as an additional and valuable source of information to mitigate such issues. DeepSORT [7] enhances the original SORT [17] framework by incorporating a ReID module to extract appearance features, thereby improving tracking accuracy through cascaded matching. Furthermore, BOT-Sort [8] employs an optimal selection strategy during data association to prioritize the most reliable matching cues. However, in densely crowded scenes where pedestrians wear similar clothing or under severe occlusion, appearance cues may introduce significant noise, increasing the likelihood of identity switches. Consequently, such methods still struggle to adequately address occlusion problems. Additionally, certain approaches adopt a shared network to jointly predict target positions and appearance features. While these methods offer lower computational complexity and enable real-time performance, they often fail to balance the focus between these two tasks, compromising tracking accuracy and neglecting the impacts of occlusion.
2.2. Occlusion Handling in MOT
In recent years, considerable research efforts have been devoted to addressing the challenge of occlusion in object tracking. OCSORT [21] mitigates error accumulation in standard Kalman Filter by resetting the uncertainty of state estimation upon target reappearance after occlusion, thereby improving robustness to short term occlusions. However, this approach primarily corrects trajectories post-reappearance and does not fundamentally address the issue of association failure during the occlusion period. As a result, inaccurate observations prior to target disappearance may still lead to trajectory drift, complicating subsequent reidentification. Transformer-based [11,12,13] approaches leverage the attention mechanism to model long range dependencies for inferring occluded targets, with methods such as MotionTrack [13] employing self-attention or cross-attention to capture long term motion patterns. Nevertheless, their high computational complexity and demanding optimization requirements limit their applicability in real-time deployment scenarios, particularly under dense occlusion conditions.
Some studies have attempted to explicitly detect or quantify occlusion events. For instance, OccluTrack [9] identifies occlusion based on geometric variations in detection bounding boxes. However, such heuristic strategies are sensitive to intrinsic target motions, such as pose changes, and often yield imprecise occlusion estimates. ORCTrack [22] improves detection performance under occlusion by enhancing the detector architecture; however, it still overlooks the impact of partial occlusion on state estimation and data association accuracy.
Despite these advancements, existing approaches lack an effective, lightweight, and seamlessly integrated occlusion awareness mechanism within the tracking pipeline. Most methods do not treat occlusion severity as a continuous, quantifiable signal that could be used to dynamically modulate the confidence in motion predictions and adaptively adjust the weighting of various cues in data association decisions.
2.3. Kalman Filter
The data association algorithm establishes a correspondence between the current observation and the predicted state derived from the previous frame. The Kalman Filter is employed to predict the motion state and recursively integrates predictions from the motion model with new observations on a frame-by-frame basis to update the system state. This process comprises two primary stages: the prediction step and the update step. The prediction steps are described in Equation (1).
The update procedure is described in Equation (2). During the update step, the Kalman gain is first computed, as it determines the weighting of the observations in the state update process. Subsequently, the updated state estimate and the updated covariance estimate are calculated.
2.4. Data Association
Given the complementary nature of motion and appearance cues, most tracking methods [7,8,14,15] integrate these two modalities to construct a cost matrix. However, appearance cues are typically prioritized, with motion cues either applied as a masking constraint to limit the cosine distance of appearance features [7,8] or combined through fixed weighting schemes [14,15], as illustrated in Equation (3). These strategies are fundamentally static and fail to account for the varying reliability of each clue under different conditions. In crowded scenes, however, partial occlusion often leads to significant noise in appearance-based representations, whereas motion cues may still provide a reliable spatial prior. Under such conditions, these fusion strategies fail to dynamically adjust the relative contributions of motion and appearance cues according to the extent of occlusion, thereby lacking adaptability and robustness.
As illustrated in Equation (4), BoT-Sort [8] introduced a novel fusion strategy. First, the IoU distance was employed to filter out candidate matches with excessive separation; subsequently, the association matrix was constructed by taking the minimum value of the IoU distance and the appearance-based distance.
As illustrated in Figure 1, this study conducts a statistical analysis of 700,000 potential matching pairs extracted from the MOT17 [23] validation set, revealing a significant discrepancy in magnitude between motion distance and appearance feature distance. Regardless of whether the existing trajectory and the detected object constitute potential matching candidates, the appearance distance consistently remains smaller than the motion distance. Consequently, in the BoT-Sort [8] matching strategy, the primary discriminative cue continues to be the cosine distance of appearance features.
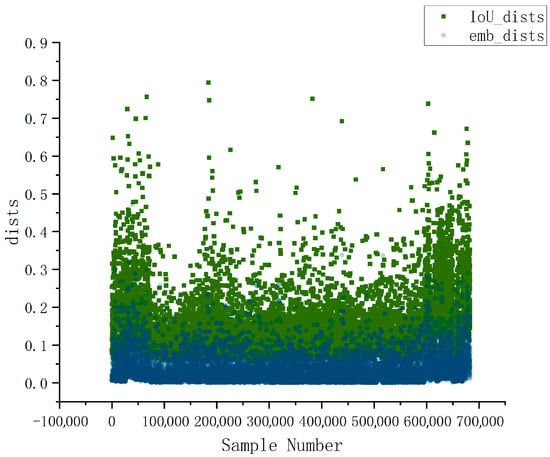
Figure 1.
Magnitude Difference Between Motion Distance and Appearance Feature Distance. Dark blue represents the appearance feature distance, formed by the superposition of light blue.
As illustrated in Figure 1, this study conducts a statistical analysis of 700,000 potential matching pairs extracted from the MOT17 [21] validation set, with results showing that the appearance distance has a mean of 0.05, while the motion distance has a mean of 0.17. The two exhibit significant distributional differences, the appearance distance is concentrated in the lower range (<0.15), whereas the motion distance is more widely distributed and skewed toward larger values. Thus, in the BoT-Sort association strategy, the appearance distance often dominates the matching decision; however, its reliability degrades in occlusion scenarios. Regardless of whether the existing trajectory and the detected object constitute potential matching pairs, the appearance distance consistently remains smaller than the motion distance. Consequently, the primary discriminative cue in the Bot-Sort matching strategy continues to be the cosine distance of appearance features.
3. Materials and Methods
3.1. Method Process
This section presents a comprehensive overview of three fundamental enhancements introduced by OATrack to the post-detection tracking paradigm. The overall workflow is illustrated in Figure 2a: an input frame is processed through the YOLOX detector [24] to generate target bounding boxes and corresponding detection scores; the high confidence detections are then fed into the OPM and ReID modules to estimate occlusion rates and extract appearance features, respectively. Low-confidence detections are conservatively treated as highly occluded and retained only for association. Subsequently, a dynamic correlation strategy is employed to construct the affinity cost matrix based on estimated occlusion levels. This matrix facilitates the matching of current detections with existing trajectories using the Hungarian algorithm. Successfully matched trajectories are updated via the trajectory update module, while the overall trajectory management strategy remains consistent with that of ByteTrack [10]. Figure 2b details the multistage association procedure: (1) active trajectories are first associated with high-confidence detections using ODA; (2) unmatched trajectories undergo appearance-based matching under stricter similarity thresholds; (3) any remaining trajectories are then associated with low-confidence detections based exclusively on IoU distance. Figure 2c illustrates the trajectory update mechanism.
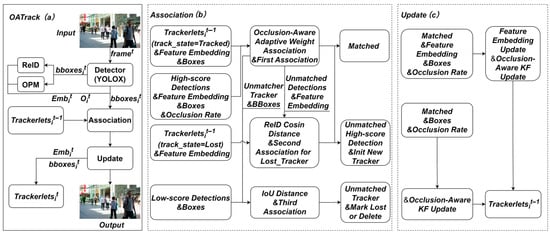
Figure 2.
Overall Framework Diagram of the Proposed Method in This study.
3.2. Occlusion Perception Module (OPM)
To accurately and efficiently estimate the occlusion rate of the target and provide reliable input for the subsequent two key modules, this study proposes an occlusion perception module. To minimize the impact of the occlusion perception module (OPM) on overall tracking efficiency, Mobilenetv3 (Large) was selected as the backbone network. This architecture achieves an optimal balance between inference speed and accuracy through neural architecture search within a lightweight framework.
As illustrated in Figure 3a, the Occlusion Perception Module is constructed based on an enhanced version of MobileNetV3 (large) [25]. The input consists of an image patch extracted from the pedestrian detection bounding box, while the output represents the occlusion rate, ranging from 0 to 1. To minimize model complexity without compromising performance, the last four layers of the original MobileNetV3—comprising three 1 × 1 convolutional layers and one global average pooling layer—were removed. Additionally, the final two and three inverted residual blocks from the fourth and fifth feature extraction stages, respectively, were eliminated. The OPM architecture adopts the streamlined MobileNetV3 (large) as its backbone, employing 12 network layers for feature extraction: one standard convolutional layer and 11 inverted residual modules. To improve the model’s ability to perceive occluded regions, the Spatial Attention Module (SAM) [24] and a modified version of the Efficient Channel Attention (ECA) mechanism [25] are incorporated. Among these modules, five retain their original structure, three incorporate Spatial Attention mechanisms, and three implement the Efficient Channel Attention (ECA) [26].
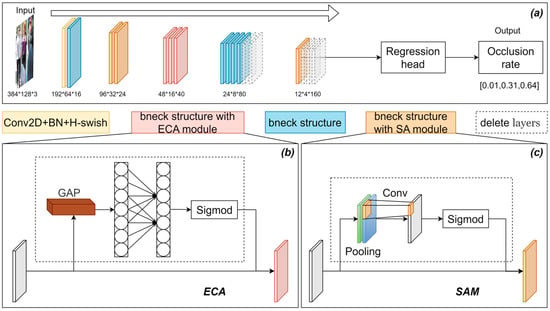
Figure 3.
Occlusion Perception Module Based on Improved MobileNetV3. (a) OPM architecture overview. (b) ECA module. (c) SAM.
The ECA module eliminates channel dimensionality reduction by substituting the fully connected layers of the conventional channel attention module—Squeeze-and-Excitation (SE)—with a one-dimensional convolution employing an adaptively determined kernel size, which enhances interaction between channels with almost no increase in parameters. The OPM integrates the ECA module in place of the SE module within the inverted residual block, thereby enhancing prediction accuracy while simultaneously reducing model parameters, as illustrated in Figure 3b.
The SAM enhances the model’s sensitivity to occluded regions, as illustrated in Figure 3c. To effectively balance local occlusion details with global occlusion states, such as occlusion ratio and spatial distribution, the OPM incorporates spatial attention mechanisms at both the shallow layer (the second feature extraction block) and the deep layer (the fifth feature extraction block).
The regression head first compresses the feature map into a fixed-length vector via adaptive average pooling, followed by a fully connected layer, a Hardswish activation function, and a Dropout layer employed to mitigate overfitting. Subsequently, a linear transformation and a Sigmoid activation function are applied to map the output values to the range [0, 1], yielding the final occlusion rate prediction. The overall process of the regression head can be formulated as:
Here, δ is the Hardswish activation function, and and are learnable parameters.
With regard to the loss function, we employ the Huber loss due to its superior robustness to noise and outliers in the training data compared to mean square error. This characteristic is particularly advantageous when learning from automatically generated occlusion rate labels.
3.3. Occlusion-Aware Adaptive Kalman Filter (OAKF)
The Kalman Filter is a recursive algorithm designed to estimate the state of a system from noisy observations. It primarily consists of two steps: prediction and update. In the prediction step, the algorithm forecasts the system’s state, including the target’s motion state. This prediction is subsequently refined in the update step by incorporating the most recently available, matched observations. The relative weighting between the predicted state and the current noisy measurements is governed by the Kalman gain, denoted as K. The Kalman gain acts as a dynamic weighting factor that adaptively balances the confidence in the predicted state versus the observed data during the state estimation process.
Traditional Kalman Filter encounters difficulties when the target undergoes partial occlusion, as occlusion may introduce errors in the observation data. Partial occlusion of the target introduces an anomalous error into the observed value of the Kalman Filter, resulting in a corrupted observation , where denotes the measurement affected by the error [9]. Consequently, the state update equation is modified as follows:
The state estimate incorporates the observation error associated with state estimation. The target state vector is defined as , where represents the object’s position and bounding box dimensions, and denotes the corresponding velocity components in each dimension.
An error in the target state vector, defined as , may arise during partial occlusion of the target. Target occlusion frequently indicates that the object of interest is about to become fully unobservable. Once the target disappears, the estimation error propagates through the state transition matrix , where τ denotes the total duration of occlusion, as illustrated in Figure 4a. Specifically, when the target begins to disappear at time t and remains occluded for a duration τ, the state update—as described by Equation (7)—is entirely governed by the Kalman Filter’s prediction, which relies on noisy observations recorded prior to the onset of occlusion.

Figure 4.
Comparison of Predicted Trajectories by the Kalman Filter. (a) The standard Kalman filter performance of BoT-Sort. (b) The performance of OAKF.
The error accumulated within a time interval τ can be expressed as , which is positively correlated with the Kalman gain K. The error induced by partial occlusion prior to complete occlusion tends to accumulate progressively over time.
Therefore, when the target is occluded, the standard Kalman Filter continuously incorporates noisy observations, such as detection offsets, into the state estimation, leading to trajectory drift (Figure 4a), with errors accumulating progressively throughout the occlusion period (Equation (7)). Hence, a KF variant capable of dynamically adjusting its reliance on observational data according to the extent of occlusion is required.
To mitigate the estimation error of the target during occlusion, the method proposed in this study incorporates a Kalman gain suppression mechanism guided by the occlusion rate. As shown in Equation (8), the occlusion rate is introduced as an adjustment factor in the Kalman Filter update process. By modulating the Kalman gain according to the occlusion rate, the influence of unreliable observations is effectively reduced. We employ piecewise functions rather than nonlinear functions to ensure consistent filter updates under low occlusion conditions, while applying strong suppression only in cases of confirmed high occlusion, thereby preventing the introduction of unnecessary deviations into normal tracking processes.
Among them, is the high occlusion threshold, and is the minimum suppression coefficient when there is high occlusion. The Kalman update formula after introducing the occlusion rate is:
When ≥ , the state update becomes more reliant on the predicted value. By reducing dependence on noisy observations, the proposed method enhances the accuracy of the target’s predicted trajectory during occlusion periods, as illustrated in Figure 4b.
3.4. Dynamic Data Association Strategy Based on Occlusion Rate (ODA)
The data association establishes an optimal correspondence between the detections in the current frame and the existing trajectory set . Conventional association methods typically combine motion cues (e.g., IoU distance ) and appearance cues (e.g., cosine distance of appearance features ) to construct the association cost matrix C, subsequently obtaining the optimal match via the Hungarian algorithm.
In the event of occlusion, the appearance features of the target undergo significant degradation. Although motion prediction uncertainty increases under such conditions, the spatial prior information remains relatively stable. Conventional fixed-weight fusion methods or simplistic “minimum selection” strategies are inadequate for addressing the dynamic variations in reliability between these two cues. As illustrated in Figure 1, the apparent distance is typically orders of magnitude smaller than the motion distance, leading to the latter being disproportionately overlooked during association decisions. Consequently, a robust association strategy capable of dynamically adjusting the weights of motion and appearance cues based on the target’s instantaneous state, particularly the extent of occlusion, is essential.
To mitigate the bias introduced by unreliable association cues, this study proposes a dynamic data association strategy based on the real-time occlusion rate of the target. The proposed Occlusion-aware Dynamic Association method leverages the occlusion rate to adaptively regulate the weighting of motion and appearance cues during the association process for each target , thereby enhancing the adaptability and robustness of the cost function.
The dynamic data association strategy is inspired by the preferential selection mechanism employed in BoT-Sort. First, the basic association distance between the trajectory and the detection is computed as , prioritizing the more reliable of the two metrics as the primary basis for association. This approach ensures that even if one modality becomes temporarily unreliable due to occlusion or other factors, the complementary cue can still provide effective matching information, thereby maintaining robustness in tracking performance.
To achieve a more precise balance between the contributions of the two types of cues under varying occlusion severity, this study proposes a dynamic weight function.
The parameter directly governs the dominance of motion cues in the final correlation cost. Under conditions of high occlusion, appearance cues tend to be highly noisy; therefore, the motion distance is used as the primary component of the final cost. To ensure smooth and controllable system behavior transitions and prevent abrupt changes in the associated strategy in response to minor variations in occlusion levels, a linear transition strategy is implemented within the moderately occluded region. The final correlation cost is computed through a dynamic fusion of the base correlation distance and the motion distance.
In tracking scenarios, when a previously mismatched trajectory reappears, its spatial position often significantly deviates from the prediction generated by the Kalman Filter. Under such circumstances, employing conventional trajectory association strategies may lead to failure in identity recovery due to excessive positional deviation. To address this issue, the proposed method in this study performs a dedicated appearance feature matching process for disappeared trajectories, applying more stringent matching thresholds, as illustrated in Figure 2b.
4. Experiments
4.1. Datasets and Evaluation Metrics
This study evaluates the proposed method using the multi-object tracking benchmark datasets MOT17 [23] and MOT20 [27], both of which feature complex scenarios including occlusions, crowded environments, and variations in lighting conditions. Following the baseline design [8], the training set is split into two equal parts: the first 50% is used for training, while the remaining 50% serves as the validation set for ablation studies. The final model performance is assessed on the official test set.
For the training and validation of the occlusion perception module, this study utilizes the pedestrian datasets CrowdHuman [28] and CityPersons [29], both of which provide full-body bounding box and visible-region bounding box annotations. Occlusion rate labels are derived from the discrepancy between these two types of annotations, and model performance is evaluated on the respective validation sets.
The tracking methods were evaluated using the CLEAR metrics [30], including MOTA, IDF1 [31], HOTA [32], IDSW, and AssA. MOTA primarily emphasizes detection performance, while IDF1 assesses overall tracking accuracy. HOTA provides a more balanced evaluation of both detection and tracking capabilities. AssA measures the tracker’s ability to correctly associate detection results across consecutive frames for the same target.
In this study, the Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) are employed to evaluate the occlusion perception module [32]. The MAE quantifies the average magnitude of prediction errors between the model outputs and the actual values, providing a measure of overall accuracy. The RMSE, on the other hand, assigns greater weight to larger errors due to the squared terms in its computation, thereby offering enhanced sensitivity to significant deviations and enabling a more rigorous assessment of model performance under conditions involving substantial prediction discrepancies.
4.2. Implementation Details
All experiments were conducted on a personal computer system equipped with a 13th Generation Intel (R) Core (TM) i7-13650HX 2.60 GHz processor and an NVIDIA GeForce RTX 4070 GPU. The training phase was performed on a server featuring an NVIDIA A100 GPU.
To maintain consistency with the baseline, this study adopts YOLOX [24] as the target detector and implements the same baseline training framework. The ReID model employs FastReID [33], which is trained on the MOT17 [23] and MOT20 [27] datasets. Based on the parameter sensitivity analysis presented in Figure 5, the Kalman gain suppression parameter is set to 0.3, while the occlusion thresholds are defined as and . All other parameters remain consistent with those used in the baseline approach [8].
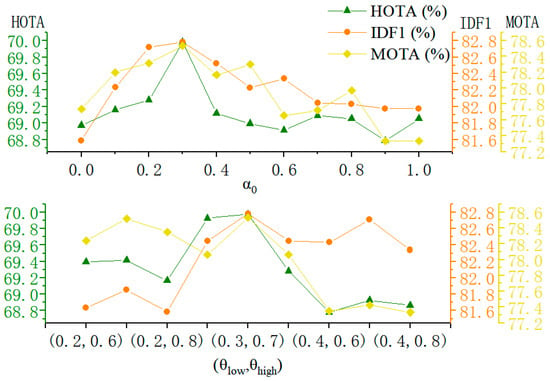
Figure 5.
Experimental results when adjusting the KF suppression parameters (top) and occlusion threshold (bottom).
The Occlusion Perception Module was trained on the CrowdHuman and CityPersons datasets. During training, the input consists of image patches cropped from pedestrian detection bounding boxes. These patches are first resized to 256 × 128 pixels. Data augmentation is performed using random horizontal flipping and standardization. To ensure alignment between the actual occluded regions and the corresponding occlusion rate labels, the random cropping strategy is omitted. The model employs the standard Huber loss as the loss function. Training is conducted using the AdamW optimizer with an initial learning rate of , the weight decay is and a batch size of 64. The learning rate was reduced to 0.1 times its initial value at the 30th and 40th training epochs, with a total of 50 training epochs completed.
4.3. Performance Comparison
4.3.1. Parameter Sensitivity Analysis
The Kalman gain suppression parameter and the occlusion thresholds and are critical hyperparameters in the proposed tracking framework. This study conducts a systematic evaluation of these key hyperparameters for OAKF and ODA on the MOT17 validation set to analyze their impact on tracking performance and identify optimal configurations.
First, is incrementally varied from 0 to 1, with results presented in Figure 5. The highest HOTA and IDF1 scores are achieved when = 0.3. A lower value leads to excessive suppression, resulting in an overly rigid motion model, whereas a higher value provides insufficient noise suppression, thereby degrading robustness to observation inaccuracies.
For the occlusion thresholds, as shown in Figure 6, an analysis of the MOT17 training data revealed that when the target occlusion rate exceeds approximately 0.6; moreover, the error distribution is more dispersed and has weak randomness, the discrepancy between the bounding box predicted by the detector and the ground truth annotation increases significantly. This suggests a sharp decline in observation quality beyond this threshold. Consequently, an initial high occlusion threshold value of 0.6 was established to systematically identify the optimal critical point for triggering Kalman gain suppression and switching data association strategies. Then, a joint grid search over and is performed within the range [0.2, 0.4] × [0.6, 0.8], with a step size of 0.1, yielding nine distinct combinations. As illustrated in Figure 5, the combination = 0.7 and = 0.3 delivers the most balanced and optimal performance across evaluation metrics.
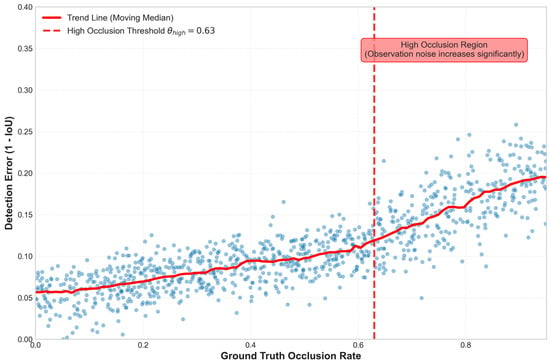
Figure 6.
Detection error analysis: Relationship with occlusion rate.
4.3.2. Comparative Study on Motion Models
To evaluate the performance of the proposed OAKF, the same detector YOLOX was employed to compare OAKF with other motion models on the MOT17 validation set. Additionally, the performance of Kalman gain suppression using both linear and piecewise functions—representing the method proposed in this study—was evaluated and compared.
The experimental results are presented in Table 1, where OAKF demonstrates superior performance. The performance advantage of OAKF primarily stems from its capability to mitigate the impact of noisy observations by leveraging the occlusion rate, effectively addressing the issue of abrupt variations in the predicted bounding box size under partial occlusion conditions.

Table 1.
Comparison results of different motion models on the MOT17 validation set. ↑ indicates the higher the value, the better.
To facilitate a more intuitive comparison of motion model performance, classic occlusion sequences exhibiting gradual occlusion and subsequent reappearance were selected from the MOT17 validation set to evaluate the trajectory prediction capabilities of OAKF in comparison with the traditional Kalman Filter. For consistency in analysis, predicted trajectories generated by the Kalman Filter during periods of complete target occlusion were retained.
The results are presented in Figure 7. In the traditional Kalman Filter, trajectory deviation arises due to observation errors following target occlusion, and identity switching occurs when the target reappears. In contrast, the OAKF is capable of maintaining a stable trajectory during occlusion periods, thereby enabling more accurate identity recovery. Furthermore, OAKF effectively mitigates trajectory deviations caused by noisy observations.
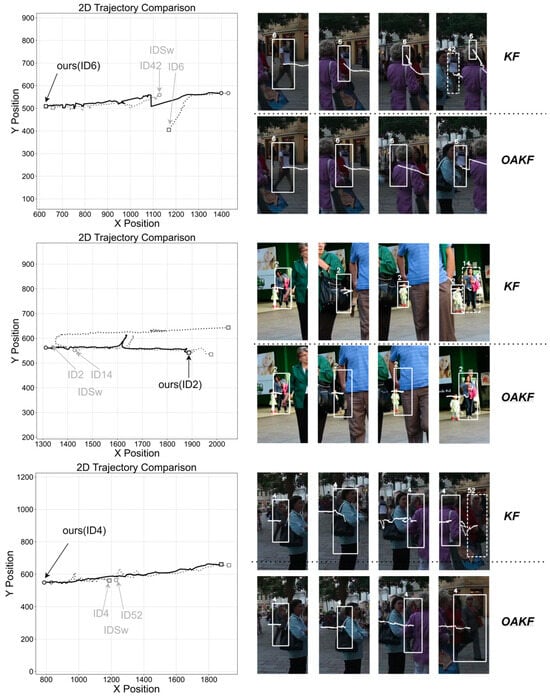
Figure 7.
Comparison of Performance Between OAKF and Traditional KF on Classic Occluded Targets. Circles and squares represent the starting and ending points of the trajectories, respectively.
4.3.3. A Comparative Study on Data Association Strategies
This study evaluates the performance of ODA in comparison with traditional association strategies on the MOT17 validation set, examining selection strategies based solely on IoU, solely on ReID, and those employed by BoT-Sort, as well as the motion fusion approach utilized in JDE. Additionally, a strategy that directly employs the occlusion rate as an adaptive weighting factor is also assessed.
As presented in Table 2, ODA attains the highest scores in both the HOTA and IDF1 metrics. Furthermore, the performance achieved by employing linear interpolation to smooth the transition weights significantly exceeds that of the association strategy using the occlusion rate directly as the weight.
Table 2.
Comparison results of different association strategies on the MOT17 validation set. ↑ indicates the higher the value, the better.
4.3.4. A Comprehensive Performance Comparison
Table 3 and Table 4 present the comparative results between the proposed method in this study and other tracking methods, respectively.
Table 3.
Comparison results with other methods on the MOT17 test set. ↑ indicates the higher the value, the better. ↓ indicates the lower the value, the better.
Table 4.
Comparison results with other methods on the MOT20 test set. ↑ indicates the higher the value, the better. ↓ indicates the lower the value, the better.
To ensure fairness in comparison and maintain baseline consistency, this study does not incorporate additional detector optimizations and consistently employs the publicly available YOLOX detector described in Section 3.2, using consistent baseline training configurations. All evaluation results are sourced from the official MOTChallenge website, where the unit for IDSw is expressed in occurrences. Table 3 presents a comparative analysis of OATrack against 13 existing tracking methods on the MOT17 test set. With respect to the key tracking metrics IDF1 and HOTA, OATrack achieves the highest performance, attaining scores of 80.6% and 65.3%, respectively.
The test results on MOT20 are presented in Table 4. Compared with ten other state-of-the-art tracking methods, OATrack achieves the highest IDF1 and HOTA scores (77.8% and 63.6%, respectively). Although OATrack does not achieve the top MOTA score, it demonstrates a well-balanced performance across IDF1, HOTA, and MOTA. In comparison with C-BIoU [19], which achieves the highest MOTA but lower overall metrics (IDF1: 79.7%, HOTA: 64.1%), and MotionTrack [13] (IDF1: 80.1%, HOTA: 65.1%), the proposed method exhibits superior overall tracking performance.
The IDSW metric quantifies the total number of identity switches by directly counting absolute occurrences; however, optimizing for this metric often involves a trade-off with overall tracking consistency, as measured by IDF1. The core design principle of the proposed method centers on addressing complex occlusion scenarios. To this end, its association strategy (ODA) and state update mechanism (OAKF) prioritize the reliability of associations over their continuity. In highly occluded environments, the approach emphasizes suppressing unreliable appearance cues and noisy observations. While this may result in a marginal increase in identity switches, it effectively mitigates more severe identity confusion, thereby achieving superior performance on higher-level evaluation metrics such as IDF1 and HOTA.
4.4. Ablation Experiment
This study introduces three components designed based on the baseline tracker and evaluates tracking performance using the official evaluation code provided by MOTChallenge. Experiments are conducted on the MOT17 validation set following the experimental protocol of ByteTrack [10]. Table 5 summarizes the performance improvements contributed by each component relative to the baseline, with the best results indicated in bold. FPS denotes frames per second.
Table 5.
Component Ablation Experiment Results on the MOT17 Validation Set. ↑ indicates the higher the value, the better.
The ablation study results demonstrate the effectiveness and synergistic contribution of the Occlusion Perception Module, the occlusion rate-based dynamic association strategy, and the Occlusion-Adaptive Kalman Filter within the OATrack framework and we also attempted to compare the use of detection confidence as the moderating factor for OAKF and ODA.
The addition of the OPM alone did not result in improvements in MOTA, HOTA, or IDF1 metrics in this experiment, as OPM is fundamentally a perception module designed primarily to provide occlusion rate information to the ODA and OAKF modules. The results indicate that, the integration of the OPM results in a moderate reduction in frame rate. This represents the expected computational overhead associated with incorporating a perceptual network. Crucially, this slight decrease in efficiency is justified by a significant improvement in tracking accuracy.
To quantitatively evaluate the robustness of the proposed method under occlusion conditions, we selected representative sequences from the MOT17 validation set for fine-grained analysis, including MOT17-09 (exhibiting mild occlusion) and MOT17-02 (featuring severe occlusion) as control cases. As presented in Table 6, on the MOT17-02 sequence with severe occlusion, OATrack achieves a notably higher performance improvement relative to the baseline method. This result demonstrates that the occlusion perception mechanism introduced in this study effectively addresses challenges posed by high levels of occlusion, with performance gains exhibiting a positive correlation with the severity of occlusion in the scene.
Table 6.
Performance Comparison on Sequences with Different Occlusion Levels.
This study further validates the prediction accuracy of OPM and the efficacy of its internal mechanisms. As presented in Table 7, the incorporation of spatial attention and channel attention modules leads to a significant reduction in both mean absolute error and root mean square error.
Table 7.
Ablation Study Results of the Occlusion Perception Module. ↓ indicates the lower the value, the better. ✓ indicates that this module has been used.
In addition, this study designed a baseline occlusion metric defined as 1-conf (conf is detection confidence) and evaluated it alongside OPM. The experimental results demonstrated that our method achieved superior performance, as detection confidence is influenced by multiple factors, such as occlusion, illumination variations, motion blur, and others. Furthermore, due to recent advancements in detector accuracy, certain heavily occluded objects may still yield relatively high confidence scores. In contrast, our OPM can more accurately estimate the occlusion ratio by directly learning from image patches, thus providing a more reliable input for downstream modules.
5. Discussion
The OATrack framework proposed in this study achieves high-performance multi-object tracking in complex occluded scenarios by explicitly modeling target occlusion rates and optimizing the processes of state estimation and data association. The experimental results demonstrate that the framework attains state-of-the-art performance in core metrics such as IDF1 and HOTA on the MOT17 and MOT20 datasets, verifying the effectiveness of the occlusion-aware mechanism in addressing key challenges of multi-object tracking.
The synergistic effect of the three core modules is crucial for enhancing performance. The Occlusion Perception Module, which is based on an improved MobileNetV3 architecture, achieves precise regression of occlusion rates by integrating spatial attention and Efficient Channel Attention mechanisms. This integration provides reliable input regarding occlusion states for subsequent modules. The Occlusion-Adaptive Kalman Filter dynamically adjusts the Kalman gain in response to the occlusion rate, effectively mitigating the impact of noisy observations on trajectory prediction and addressing the trajectory drift issue that commonly affects traditional Kalman Filter in occluded environments. Furthermore, the Occlusion-aware Dynamic Data Association Strategy moves away from a fixed-weight fusion approach. By dynamically modifying the contribution ratios of motion and appearance cues, it significantly enhances association robustness in scenarios with occlusions while reducing identity switches.
Compared with existing methods, OATrack’s advantages are concentrated in its targeted optimization for occluded scenarios: on the MOT17 test set, it outperforms both BoT-Sort and MotionTrack in terms of IDF1 and HOTA, while controlling IDSw at 1179 instances—demonstrating its superiority in maintaining identity consistency. Compared with BoT-Sort, the dynamic weighting mechanism in ODA addresses the issue where appearance cues become unreliable yet remain dominant under severe occlusion. In contrast to MotionTrack, OATrack effectively maintains trajectory prediction during short-term occlusion periods through explicit occlusion awareness and adaptive Kalman gain adjustment, achieving superior performance with lower computational complexity.
In the more challenging MOT20 dataset, OATrack still maintains a leading position, with IDF1 and HOTA reaching 77.8% and 63.6%, respectively, which validates its generalization capability in complex real-world scenarios.
Author Contributions
Methodology, H.W. and T.C.; Software, T.C.; Validation, Y.W.; Resources, H.W. and T.C.; Writing—original draft, T.C.; Writing—review & editing, T.C.; Visualization, Y.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Science and Technology Department of Henan Province Key Technology R&D Program (252102210030) and Key Scientific Research Project of Higher Education Institutions in Henan Province (25A520006).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Acknowledgments
We thank all those individuals who assisted us for their invaluable support, encouragement, and guidance throughout the research process.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Feng, D.; Haase-Schütz, C.; Rosenbaum, L.; Hertlein, H.; Gläser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep Multi-Modal Object Detection and Semantic Segmentation for Autonomous Driving: Datasets, Methods, and Challenges. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1341–1360. [Google Scholar] [CrossRef]
- Weng, X.; Wang, J.; Held, D.; Kitani, K. 3D Multi-Object Tracking: A Baseline and New Evaluation Metrics. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 10359–10366. [Google Scholar]
- Wang, X. Intelligent Multi-Camera Video Surveillance: A Review. Pattern Recognit. Lett. 2013, 34, 3–19. [Google Scholar] [CrossRef]
- Luo, H.; Gu, Y.; Liao, X.; Lai, S.; Jiang, W. Bag of Tricks and a Strong Baseline for Deep Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Wang, G.; Yuan, Y.; Chen, X.; Li, J.; Zhou, X. Learning Discriminative Features with Multiple Granularities for Person Re-Identification. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 274–282. [Google Scholar]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Omni-Scale Feature Learning for Person Re-Identification. In Proceedings of the IEEE/CVF International Conference On Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3702–3712. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple Online and Realtime Tracking with a Deep Association Metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3645–3649. [Google Scholar]
- Aharon, N.; Orfaig, R.; Bobrovsky, B.-Z. BoT-SORT: Robust Associations Multi-Pedestrian Tracking. arXiv 2022, arXiv:2206.14651. [Google Scholar]
- Gao, J.; Wang, Y.; Yap, K.-H.; Garg, K.; Han, B.S. Occlutrack: Rethinking Awareness of Occlusion for Enhancing Multiple Pedestrian Tracking. IEEE Trans. Intell. Transp. Syst. 2025, 26, 1524–9050. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. Bytetrack: Multi-Object Tracking by Associating Every Detection Box. In Computer Vision—ECCV 2022; Springer: Cham, Switzerland, 2022; pp. 1–21. [Google Scholar]
- Meinhardt, T.; Kirillov, A.; Leal-Taixe, L.; Feichtenhofer, C. TrackFormer: Multi-Object Tracking with Transformers. In Proceedings of the IEEE/CVF Conference On Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8844–8854. [Google Scholar]
- Zhang, Y.; Sheng, H.; Wu, Y.; Wang, S.; Lyu, W.; Ke, W.; Xiong, Z. Long-Term Tracking with Deep Tracklet Association. IEEE Trans. Image Process. 2020, 29, 6694–6706. [Google Scholar] [CrossRef]
- Qin, Z.; Zhou, S.; Wang, L.; Duan, J.; Hua, G.; Tang, W. Motiontrack: Learning Robust Short-Term and Long-Term Motions for Multi-Object Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 17939–17948. [Google Scholar]
- Wang, Z.; Zheng, L.; Liu, Y.; Li, Y.; Wang, S. Towards Real-Time Multi-Object Tracking. In Computer Vision—ECCV 2020; Springer: Cham, Switzerland, 2020; pp. 107–122. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. Fairmot: On the Fairness of Detection and Re-Identification in Multiple Object Tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar]
- Yu, F.; Li, W.; Li, Q.; Liu, Y.; Shi, X.; Yan, J. Poi: Multiple Object Tracking with High Performance Detection and Appearance Feature. In Computer Vision—ECCV 2016 Workshops; Springer: Cham, Switzerland, 2016; pp. 36–42. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple Online and Realtime Tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3464–3468. [Google Scholar]
- Bochinski, E.; Eiselein, V.; Sikora, T. High-Speed Tracking-by-Detection without Using Image Information. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Yang, F.; Odashima, S.; Masui, S.; Jiang, S. Hard to Track Objects with Irregular Motions and Similar Appearances? Make It Easier by Buffering the Matching Space. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 4799–4808. [Google Scholar]
- Brown, R.G.; Hwang, P.Y. Introduction to Random Signals and Applied Kalman Filtering: With MATLAB Exercises and Solutions; Wiley: New York, NY, USA, 1997. [Google Scholar]
- Cao, J.; Pang, J.; Weng, X.; Khirodkar, R.; Kitani, K. Observation-Centric Sort: Rethinking Sort for Robust Multi-Object Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 9686–9696. [Google Scholar]
- Su, Y.; Sun, R.; Shu, X.; Zhang, Y.; Wu, Q. Occlusion-Aware Detection and Re-Id Calibrated Network for Multi-Object Tracking. arXiv 2023, arXiv:2308.15795. [Google Scholar]
- Milan, A.; Leal-Taixé, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A Benchmark for Multi-Object Tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding Yolo Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for Mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE. In Proceedings of the CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11531–11539. [Google Scholar]
- Dendorfer, P.; Rezatofighi, H.; Milan, A.; Shi, J.; Cremers, D.; Reid, I.; Roth, S.; Schindler, K.; Leal-Taixé, L. Mot20: A Benchmark for Multi Object Tracking in Crowded Scenes. arXiv 2020, arXiv:2003.09003. [Google Scholar] [CrossRef]
- Shao, S.; Zhao, Z.; Li, B.; Xiao, T.; Yu, G.; Zhang, X.; Sun, J. Crowdhuman: A Benchmark for Detecting Human in a Crowd. arXiv 2018, arXiv:1805.00123. [Google Scholar] [CrossRef]
- Zhang, S.; Benenson, R.; Schiele, B. Citypersons: A Diverse Dataset for Pedestrian Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3213–3221. [Google Scholar]
- Bernardin, K.; Stiefelhagen, R. Evaluating Multiple Object Tracking Performance: The Clear Mot Metrics. EURASIP J. Image Video Process. 2008, 2008, 246309. [Google Scholar] [CrossRef]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance Measures and a Data Set for Multi-Target, Multi-Camera Tracking. In Computer Vision–ECCV 2016 Workshops; Springer: Cham, Switzerland, 2016; pp. 17–35. [Google Scholar]
- Luiten, J.; Osep, A.; Dendorfer, P.; Torr, P.; Geiger, A.; Leal-Taixé, L.; Leibe, B. Hota: A Higher Order Metric for Evaluating Multi-Object Tracking. Int. J. Comput. Vis. 2021, 129, 548–578. [Google Scholar] [CrossRef] [PubMed]
- He, L.; Liao, X.; Liu, W.; Liu, X.; Cheng, P.; Mei, T. Fastreid: A Pytorch Toolbox for General Instance Re-Identification. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 9664–9667. [Google Scholar]
- Zeng, F.; Dong, B.; Zhang, Y.; Wang, T.; Zhang, X.; Wei, Y. Motr: End-to-End Multiple-Object Tracking with Transformer. In Computer Vision—ECCV 2022; Springer: Cham, Switzerland, 2022; pp. 659–675. [Google Scholar]
- Yu, E.; Li, Z.; Han, S.; Wang, H. Relationtrack: Relation-Aware Multiple Object Tracking with Decoupled Representation. IEEE Trans. Multimed. 2022, 25, 2686–2697. [Google Scholar] [CrossRef]
- Liang, C.; Zhang, Z.; Zhou, X.; Li, B.; Zhu, S.; Hu, W. Rethinking the Competition between Detection and Reid in Multiobject Tracking. IEEE Trans. Image Process. 2022, 31, 3182–3196. [Google Scholar] [CrossRef] [PubMed]
- Sun, P.; Cao, J.; Jiang, Y.; Zhang, R.; Xie, E.; Yuan, Z.; Wang, C.; Luo, P. Transtrack: Multiple Object Tracking with Transformer. arXiv 2020, arXiv:2012.15460. [Google Scholar]
- Chu, P.; Wang, J.; You, Q.; Ling, H.; Liu, Z. Transmot: Spatial-Temporal Graph Transformer for Multiple Object Tracking. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 4870–4880. [Google Scholar]
- Du, Y.; Zhao, Z.; Song, Y.; Zhao, Y.; Su, F.; Gong, T.; Meng, H. Strongsort: Make Deepsort Great Again. IEEE Trans. Multimed. 2023, 25, 8725–8737. [Google Scholar] [CrossRef]
- Cui, Y.; Zeng, C.; Zhao, X.; Yang, Y.; Wu, G.; Wang, L. Sportsmot: A Large Multi-Object Tracking Dataset in Multiple Sports Scenes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 9921–9931. [Google Scholar]
- Qin, Z.; Wang, L.; Zhou, S.; Fu, P.; Hua, G.; Tang, W. Towards Generalizable Multi-Object Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024; pp. 18995–19004. [Google Scholar]
- Cao, X.; Zheng, Y.; Yao, Y.; Qin, H.; Cao, X.; Guo, S. TOPIC: A Parallel Association Paradigm for Multi-Object Tracking Under Complex Motions and Diverse Scenes. IEEE Trans. Image Process. 2025, 34, 743–758. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).