Abstract
Background: In healthcare education, understanding and managing cognitive load is crucial for enhancing learning outcomes for students, healthcare professionals, patients, and the general public. Despite numerous studies developing cognitive load classification models, there is a lack of comprehensive guidelines on how to effectively utilize these models in healthcare education. This study reviews cognitive load classification models using physiological data to provide insights and guidelines for their development in healthcare contexts. Methods: A scoping review was conducted on studies published between 2015 and 2024, identified through databases including Scopus, Web of Science, PubMed, EMBASE, and PsycINFO. The search terms included “cognitive load,” “physiology,” “data,” and “classification.” Inclusion criteria were peer-reviewed journal articles in English, focused on the healthcare context, utilizing experimental physiological data, and developing classification models. After screening 351 articles, ten studies met the inclusion criteria and were analyzed in detail. Results: Task design predominantly focused on measuring intrinsic cognitive load by adjusting task difficulty. Data collection mainly utilized EEG (electroencephalogram) and body movement data. SVM (support vector machine) algorithms were the most frequently used for model development, with cross-validation and feature selection employed to prevent overfitting. This study derived the importance of clearly defining cognitive load types, designing appropriate tasks, establishing reliable ground truths with multiple indicators, and selecting contextually relevant data. Conclusions: This study provides a comprehensive analysis of cognitive load classification models using physiological data in healthcare education, offering valuable guidelines for their development. Despite the study’s limitations, including a small number of analyzed papers and limited diversity in educational contexts, it offers critical insights for using and developing cognitive load classification in healthcare education. Future research should explore the applicability of these models across diverse educational settings and populations, aiming to enhance the effectiveness of healthcare education and ultimately improve learning and healthcare outcomes.
1. Introduction
To effectively achieve the goal of education in the healthcare field, it is essential to provide educational materials tailored to the learners’ levels. Given that learners’ comprehension and learning abilities vary, it is important to consider cognitive load related to these differences [1,2]. Cognitive load refers to the mental effort required to process information and is closely linked to the learner’s level of understanding [3,4]. For instance, novice learners must focus on grasping basic concepts, thus maintaining a lower cognitive load is essential. Conversely, advanced learners benefit from engaging with complex problem-solving tasks that appropriately challenge their cognitive capacities. Therefore, while appropriate cognitive load can enhance learning outcomes, excessive cognitive load can impede learning [5,6].
In this aforementioned context, efforts have been made to accurately categorize cognitive load and provide tailored education accordingly. Personalized education is designed considering the learner’s cognitive load level, thereby improving learning efficiency and increasing learner satisfaction [7,8]. In the past, various models for classifying cognitive load have been actively researched and developed in the educational field to provide such personalized education [5,9]. The importance of personalized education lies in its ability to meet the individual needs and capabilities of learners, facilitating more effective acquisition and application of knowledge. This approach enhances the overall learning experience and contributes to better long-term learning outcomes [10,11].
Recently, research on developing models to measure and classify cognitive load in healthcare contexts has been increasing. The objective of this research is to accurately measure and classify cognitive load during physicians’ surgical procedures or patients’ rehabilitation activities, thereby providing more effective education and training [6]. Particularly, the use of physiological data to measure cognitive load has gained significant attention. Utilizing physiological data allows for more objective and precise measurement of cognitive load, greatly aiding in the provision of personalized education. For example, by monitoring real-time physiological indicators such as heart rate, brainwaves, and skin conductance, immediate feedback can be provided based on the learner’s cognitive load status, helping them maintain optimal learning conditions [12,13].
However, existing research primarily focuses on the development of cognitive load classification models. That is, most studies emphasize the process and performance evaluation of developing these models, but there is a lack of concrete guidelines on how to effectively develop these models. A scoping review of cognitive load classification models for healthcare education, based on substantial evidence, is needed to provide comprehensive guidance on model development. This approach is critical in devising educational methodologies tailored to the specific requirements and contexts of the healthcare sector, thereby maximizing educational effectiveness.
The aim of this study is to analyze the characteristics of cognitive load classification models developed in healthcare contexts. By doing so, we seek to provide guidelines for effectively developing these models in educational programs for medical students, professionals, patients, and the general public. This study aims to answer the following research questions: Firstly, how has the task design been conducted to develop cognitive load classification models in healthcare contexts? Secondly, what types of data have been collected to develop cognitive load classification models in healthcare contexts? Thirdly, how has the development of cognitive load classification models been carried out in healthcare contexts?
2. Method
This scoping review was structured and reported following the standards set by the updated PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) 2020 statement [14].
2.1. Search Strategy
We conducted comprehensive searches in five databases: Scopus (2004~), Web of Science (1990~), PubMed (National Library of Medicine; 1781~), EMBASE (1947~), and PsycINFO (1887~), chosen for their relevance to our study. The searches covered the literature published over the past ten years, covering the period from May 2014 to May 2024. Our search strategy utilized a combination of key terms across four categories: cognitive load, data, classification, and physiology. Detailed search queries for each database are documented in Table 1. Additionally, we conducted a hand search using Google Scholar. A professional research librarian advised on the development and implementation of our search strategies.

Table 1.
Search queries.
2.2. Inclusion and Exclusion Criteria
Our inclusion criteria encompassed original research articles published in peer-reviewed journals, written in English, that utilized physiological data to develop models for classifying cognitive load within a healthcare context. We included studies that did not rely on pre-existing data but instead used physiological data collected from experiments to develop classification models. Only full-text research papers were included. We excluded commentaries, editorials, book chapters, and letters. Our inclusion criteria are detailed in Table 2. After removing duplicates, three authors independently assessed the titles, abstracts, and full texts of all articles. Any disagreements between the authors were resolved by reaching a consensus through discussion.
Table 2.
Inclusion and exclusion criteria.
2.3. Data Extraction
Data were extracted from all the eligible studies; our research focus was on methodological aspects of how cognitive load tasks were designed, what data was collected, and how classification models were developed. We developed a framework of classification model development (Figure 1) and coding scheme (Table 3) through supporting literature investigation and iterative testing and revision.
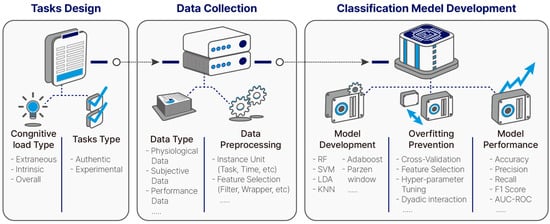
Figure 1.
Framework of classification model development.
Table 3.
Coding scheme.
Regarding cognitive load task design, we examined what cognitive load type each study selected. The cognitive load type was categorized into intrinsic load, extraneous load, and overall load. Cognitive load is generally defined as the load imposed on working memory when performing a task. Among these, intrinsic and extraneous load are derived from Sweller’s cognitive load theory. Intrinsic cognitive load is related to the complexity of the task and is determined by the number of elements in the task and their interactions [15,16,17]. Extraneous cognitive load refers to the cognitive load that arises from processing information not directly related to the task, often due to the way the task is presented or the use of unnecessary cognitive resources [18,19,20]. The remaining element, germane load, was not included in the classification scheme. Unlike intrinsic and extraneous load, germane cognitive load does not result from the task itself but refers to the cognitive resources used to handle these loads [18,19,20].
Among these three cognitive loads, only intrinsic and extraneous cognitive load are included in our framework due to both conceptual ambiguity and practical challenges in operationalizing germane load within the reviewed studies. Conceptually, there has been ongoing debate over whether germane load should even be considered a distinct type of cognitive load. First, it is difficult to distinguish intrinsic cognitive load (arising from the inherent complexity of learning material) from germane load (arising from the cognitive effort used to organize, abstract, and integrate that material). As [21,22] note, the processing complexity involved in learning is conceptually intertwined with content complexity, making it difficult to isolate germane load from intrinsic load in empirical studies. Additionally, the operational definitions of germane load found in some studies are controversial. For instance, in [23], germane load was inferred post hoc through transfer test performance—i.e., higher test scores were interpreted as reflecting higher germane load, based on the assumption that successful learners must have allocated more working memory resources to deep processing. However, this post hoc logic stands in contrast to more direct, task-based manipulations used to define other cognitive load types [24]. For these reasons, while theoretical exploration of germane cognitive load remains meaningful, and its role in learning processes is supported conceptually, its use in the engineering of classification models based on physiological data is currently less practical.
Therefore, this study classified cognitive load into intrinsic load, extraneous load, and overall load, which measures the total load caused by the task without distinguishing between the intrinsic load and extraneous load. Cognitive load validation serves as the standard for classifying cognitive load. Methods for setting the ground truth for cognitive load classification models include using task design, subjective measurement, or a combination of both. We also examined how each ground truth was validated. In relation to tasks, we extracted information that could aid in cognitive load task design. Task manipulation is important as it divides the levels of cognitive load through the task. Therefore, we categorized task manipulation into controlling task difficulty, using secondary tasks. Additionally, we checked whether the tasks were authentic or experimental, which tasks were used, and how tasks were categorized according to Bloom’s Taxonomy.
To provide insights into how many participants are needed for data collection and what type of data are appropriate to collect, we gathered information on participants (healthcare professionals/patients/general public), number of participants (total participants, usable participants after exclusion, percentage of usable data), type of collected cognitive load data (physiological/subjective/performance), subcategories of physiological data (e.g., physiological—brain—EEG), and data preprocessing (instance unit, instance number, feature selection). Among the schemes, the type of cognitive load data can be categorized into physiological, subjective, and performance data [25]. Physiological data capture information from our bodies to assess cognitive load. Subjective data measure cognitive load based on individual perception, and performance data are based on the expectation that the task performance level represents cognitive load level [25]. Among these, physiological data are more objective than subjective data and more directly connected to body status in real-time [26]. Therefore, this study focused on physiological data. Data related to the brain, body, heart, eyes, and skin are utilized to assess cognitive load. In this study, physiological data were primarily classified based on these body parts, and their subcategories were identified (e.g., brain—electroencephalogram (EEG), functional near-infrared spectroscopy, fNIRS). Feature selection methods were categorized into filter, wrapper, and embedded methods [27,28]. The filter method involves identifying highly relevant features based on statistical methods such as correlation analysis. Wrapper methods search for the most efficient combinations within subsets of features, while embedded methods, like penalized regression analysis, filter out irrelevant features within the classification model itself.
Regarding model development, to identify information necessary for creating robust models, we extracted data on classification models (specific model, feature fusion techniques, overfitting prevention methods), and model performance (performance metrics reported, accuracy, performance compared to baseline). Among the schemes, methods to prevent overfitting include cross-validation, data augmentation, feature selection, and hyperparameter tuning. Cross-validation involves splitting the entire dataset into multiple subsets, using one subset as the validation set while training the model on the remaining subsets, and repeating this process iteratively to each subset. Data augmentation refers to creating new datasets in various ways to increase the amount of training data available. Feature selection excludes unnecessary features to prevent the model from overfitting. Hyperparameter tuning adjusts hyperparameters deliberately to simplify the model (for example, pruning in decision trees).
2.4. Assessment of Study Quality
In order to assess the quality of the selected studies, the QualSyst Standard Quality Assessment Criteria [15,16,17] were employed (Appendix A). The selected assessment tool was chosen for its applicability to the evaluation of the quality of quantitative studies, including non-randomized controlled trials. The criteria for evaluating quantitative studies are as follows: (1) clear objective, (2) appropriate study design, (3) proper subject, (4) detailed subject characteristics, (5) random allocation in interventional studies, (6) investigator blinding, (7) subject blinding in interventional studies, (8) robust outcome and exposure measures, (9) appropriate sample size, (10) adequate analytic methods, (11) variance estimates for results, (12) control of confounding, (13) detailed results reporting, and (14) evidence-supported conclusions. The 14 criteria for quantitative studies are scored on a scale from 0 (lowest quality) to 2 (highest quality). The quality of the study was defined using a final mean score, with a value below 0.50 indicating inadequate quality, a value between 0.50 and 0.70 indicating adequate quality, a value between 0.71 and 0.80 indicating good quality, and a value above 0.80 indicating strong quality [18,19,20]. A cutoff point of 0.71 was selected as a conservative threshold for inclusion. The final quality scores ranged from 0.91 to 1.00, indicating that all included studies were of good quality.
3. Results
3.1. Trial Flow and Features of Reviewed Studies
A total of 389 articles were identified in the five academic databases, with none found in gray literature. After removing 181 duplicates, 208 studies remained for title screening. Title review eliminated 106 studies, leaving 102 for abstract screening. Abstract review excluded 88 more, resulting in 14 studies for full-text assessment. Four studies were excluded during full-text review, leaving ten studies for final inclusion in this scoping review. Figure 2 details the exclusion process and reasons at each stage.
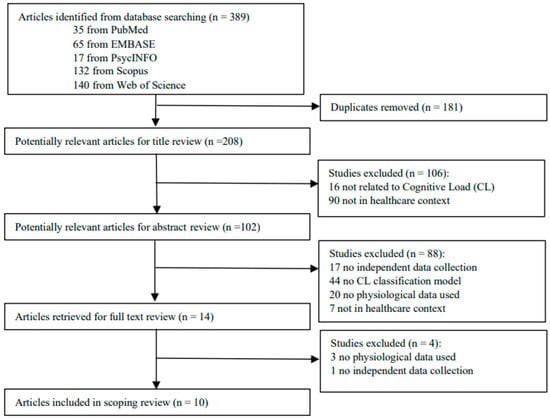
Figure 2.
Trial flow.
The ten studies included in the review were published between 2017 and 2023, encompassing a total of 311 participants. All of these studies were quantitative. Of the total studies, three engaged patients, another three involved healthcare professionals, and the remaining four had participants from the general public. The studies investigated the classification of cognitive load across various groups and conditions. They explored how cognitive load can be categorized in patients with stroke, autism, and cognitive impairments. Additionally, research examined the classification of cognitive demands during surgical operations and drug classification tasks for healthcare personnel. Finally, studies also assessed how cognitive load in the general public can be classified under stress conditions and in sedentary work environments. Detailed information on each study’s participant characteristics and context can be found in Appendix B.
3.2. How Has the Task Design Been Conducted to Develop Cognitive Load Classification Models in Healthcare Contexts? (RQ1)
- (1)
- Cognitive load of interest and task design
Among the ten studies reviewed, seven measured intrinsic load, two measured extraneous load, and one measured overall load as shown in Table 4 and Figure 3. Studies measuring intrinsic load manipulated the task difficulty by altering the components of the task to distinguish between high and low cognitive load. In contrast, studies employing extraneous load aimed primarily to induce fatigue or cognitive pathology by disrupting cognitive activities. These studies used secondary tasks unrelated to the primary task to induce extraneous load. Participants were required to perform commonly used cognitive load tasks such as the Operation Span Task (OSPAN) or elementary arithmetic tasks alongside the primary task to create irrelevant load. The study focusing on overall load did not manipulate the task difficulty or add additional tasks; instead, it aimed to measure the total cognitive load experienced by learners performing the task. It used subjective measurements to assess the learners’ overall effort and mental demands throughout the task, rather than manipulating tasks.
Table 4.
Type of cognitive load and task manipulation.
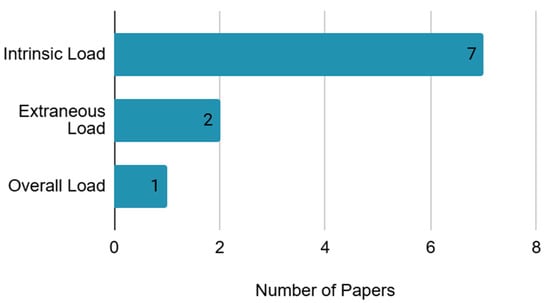
Figure 3.
Types of cognitive load.
- (2)
- Validation of cognitive load
Out of the ten studies, three used only task design to measure cognitive load, the others validate the cognitive load with additional methods. Five used subjective measurement, and one of each used a mixed method, as shown in Table 5 and Figure 4. Of the five studies that used subjective measurement to verify whether the measured cognitive load is validated, four measured cognitive load with the NASA Task Load Index (NASA-TLX). The reason for using subjective measurement instead of task design was the concern that cognitive load levels of the same tasks could vary greatly depending on the individual and situation [5,29]. Lastly, there is one study using the mixed method based on the perceived task difficulty, task performance, and task design.
Table 5.
Validation of cognitive load.
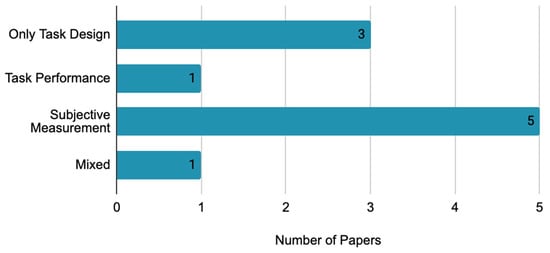
Figure 4.
Validation of cognitive load.
- (3)
- Task type
The tasks used in the reviewed studies can be divided into authentic tasks relevant to the context in which the classification model is applied and experimental tasks used solely in experimental contexts. Out of the ten studies, five utilized authentic tasks, while the remaining studies used experimental tasks. Authentic tasks included walking, pill sorting, surgery, and driving, depending on the research purpose as shown in Table 6 and Figure 5. Experimental tasks included commonly used cognitive load tasks such as the OSPAN, multiple object tracking (MOT) task, N-back task, and elementary arithmetic tasks.
Table 6.
Task type of cognitive load.
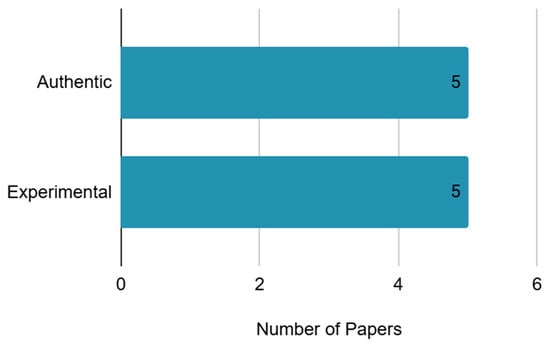
Figure 5.
Task type of cognitive load.
Additionally, the tasks used in the studies were categorized based on Bloom’s Taxonomy of cognitive learning [5,9], as shown in Table 6 and Figure 6. According to Bloom’s Taxonomy, tasks are divided into six levels: remembering, understanding, applying, analyzing, evaluating, and creating. Among the tasks, seven fell under the “applying” level, and two fell under the “remembering” level, and one fell under the “analyzing” level. The prevalence of tasks at the “applying” level is due to the inclusion of arithmetic tasks, which fall into this category.
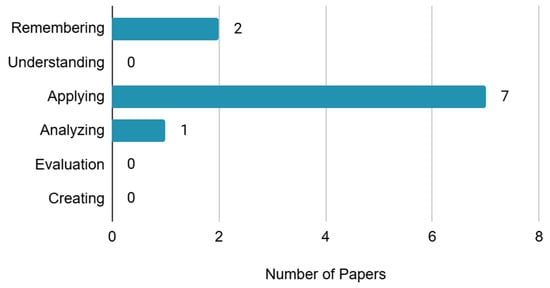
Figure 6.
Categorization of cognitive load tasks based on Bloom’s Taxonomy.
3.3. What Types of Data Have Been Collected to Develop Cognitive Load Classification Models in Healthcare Contexts? (RQ2)
- (1)
- Participant
The number of participants in the studies ranged from a minimum of 8 to a maximum of 154. However, excluding the study that collected data from 154 participants, all other studies collected data from fewer than 35 participants. The criteria for recruiting participants were set according to the purpose and conditions of the tasks. For instance, studies aimed at assisting patients or healthcare professionals involved participants who had the relevant medical conditions or were actual healthcare professionals. Additionally, tasks involving physical activity considered factors such as age and physical condition [1,2]. Even after excluding data with noise, at least approximately 85% of participant data were utilized for the model.
- (2)
- Data collection
Cognitive load data can be categorized into physiological data, subjective measurement data, and behavioral data (Table 7). The collected physiological data were organized by related body parts, with each type counted separately when multiple types were employed in a single study. Among these, brain-related data were the most frequently utilized, appearing in seven studies. These included electroencephalography (EEG), functional magnetic resonance imaging (fMRI), and functional near-infrared spectroscopy (fNIRS). Body-related data, used in five studies, involved measurements from various body parts such as the hand, hip, head, leg, and muscle. Eye-related data, reported in two studies, encompassed blink frequency (BL), eye movement (EM), and pupil dilation (PU). Heart-related data, also found in two studies, included electrocardiogram (ECG), heart rate variability (HRV), respiration rate (RSP), and photoplethysmogram (PPG). Skin-related data, appearing in two studies, comprised galvanic skin response (GSR; also referred to as electrodermal activity, EDA) and skin temperature (ST).
Table 7.
Collected cognitive load data.
Other than physiological data, the data utilized for developing classification models are subjective data and performance data. Subjective data were obtained from cognitive load questionnaires after the task, while performance data were derived from the process or results of tasks. Subjective data were employed as criteria for classifying cognitive load in five studies. NASA-TLX was used in four studies, and perceived task difficulty was used in the other study. Subjective data were considered as classification criteria instead of task design when significant individual differences in task response were anticipated or when task differentiation by difficulty level was challenging. Lastly, performance data were utilized in two studies.
3.4. How Has the Development of Cognitive Load Classification Models Been Carried out in Healthcare Contexts? (RQ3)
- (1)
- Data preprocessing and feature selection
Instance refers to a vector of features, and the creation units of instances can be classified into participant, task, event, and time. Among all studies, eight generated instances at the task level, while two studies created instances at the time level as shown in Table 8 and Figure 7. The studies that created instances at the time level all utilized brain data. Excluding the two studies where instances were not reported, the total number of instances varied widely, from 16 to 16,291. The study that utilized the most instances employed a walking task, with each step serving as an instance, resulting in the highest instance despite having only 10 participants [1,2].
Table 8.
Instance type and feature selection method.
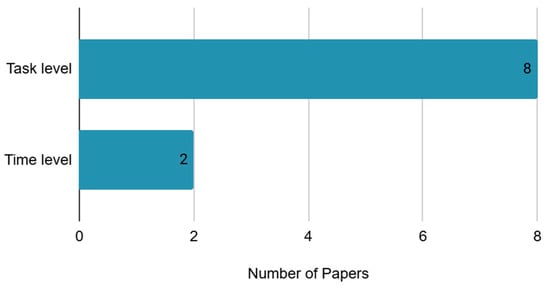
Figure 7.
Instance type.
In terms of feature selection, five utilized only the filter method, three used both filter and wrapper methods, and the remaining two did not use any feature selection method, as shown in Table 8 and Figure 8. Specific filter methods employed included correlation analysis, Mann–Whitney-U test, principal component analysis (PCA), and independent component analysis (ICA). Wrapper methods used included recursive feature elimination (RFE) and forward feature selection (FFS).
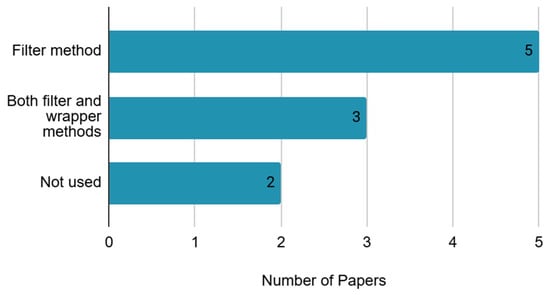
Figure 8.
Feature selection method.
- (2)
- Classification model
Among all studies, five employed SVM, while the remaining studies used random forest (RF), k-nearest neighbors (KNN), adaptive boosting (AdaBoost), linear discriminant analysis (LDA), and distribution-based classifier (Parzen Window) as shown in Table 9. To combine features for model utilization, methods include feature-level fusion, which combines all features together, decision-level fusion, which builds models for individual features and integrates their results, and hybrid fusion, which uses both approaches [30]. All 10 studies in this research employed feature-level fusion.
Table 9.
Classification model.
- (3)
- Overfitting Method
When developing classification models, one critical consideration is to avoid overfitting to the training data alone. Methods to prevent overfitting include cross-validation, data augmentation, feature selection, and hyperparameter tuning. In Table 10, all 10 studies in this research utilized cross-validation. Additionally, data augmentation was used in one study, and feature selection was employed in eight studies.
Table 10.
Overfitting method.
- (4)
- Model Performance
Classification models are evaluated using various metrics to assess performance. While accuracy is a prominent metric, it is essential to consider multiple metrics such as precision, recall, F1 score, and area under the curve-receiver operating characteristic (AUC-ROC). Among all studies, five focused solely on accuracy, while others reported a combination of metrics including F1 score and AUC-ROC. However, one study did report accuracy as a range (0.93–1), as shown in Table 11.
Table 11.
Model performance.
All studies demonstrated performance improvements above baseline accuracy. Given the varying number of classification categories across studies, comparing model performance relative to baseline accuracy provides insight into their effectiveness. Excluding the study that did report accuracy range, the highest performance improvement among the studies was a 251.2% increase, while the lowest improvement was 39.6%.
4. Discussion
This study analyzed the characteristics of ten cognitive load classification models developed within the healthcare context using a scoping review methodology. The results in this study can be discussed in terms of different forms of validity relevant to utilizing or developing cognitive load classification models in healthcare education.
First, to develop a usable and valid cognitive load classification model, it is imperative to clearly define the specific type of cognitive load the model quantifies. This ensures the model’s applicability for its intended purpose and guides appropriate utilization. However, the majority of the analyzed studies did not refer to the exact definition of their measured cognitive load. Only the study of [27] classified its cognitive load as an intrinsic task. For the remaining studies, the target cognitive load type could only be inferred by examining the task and classifying it according to cognitive load theory. To prevent inappropriate use, the target cognitive load type should be explicitly stated in reference to established theory. Distinguishing the type of cognitive load also enables researchers and developers of cognitive load classification models to align their measurement objectives with the appropriate cognitive load type. This can increase content validity, the extent to which a measurement covers all the important aspects of the concept it is intended to measure.
Also, clearly defining the types of cognitive load informs task design and data selection, which in turn enhances construct validity, the extent to which the measurement actually captures the theoretical concept it claims to measure, by ensuring task manipulation to distinguish different types of cognitive load or high–low level of cognitive load and chosen data to properly reflect the target cognitive load. Considering the definition of cognitive load and alignment between the target cognitive load, task, and data enables all stakeholders to assess content and construct validity of the cognitive load classification model.
Secondly, the cognitive load classification model should be developed using real tasks rather than experimental contexts. This is because the actual situation in which the cognitive load classification model is used is not in a laboratory but in a real context. The model that is valid only in a laboratory context may have low validity in a real situation. Therefore, in order to ensure the consistency of measurement of cognitive load in diverse real-world contexts, it is imperative to employ authentic tasks, a point that has been underscored by [2]. This can enhance ecological validity, the extent to which the findings (or the measurement process) reflect real-world settings, tasks, and conditions. The utilization of authentic tasks enables models to capture the complexity of real-world contexts and increases their applicability in diverse healthcare settings.
Thirdly, a multimodal approach should be considered when measuring cognitive load with physiological data. The objective of the cognitive load classification model is to objectively measure cognitive load [12,13]. To this end, recent attempts have been made to develop a cognitive load classification model using objective and time-based physiological data instead of self-report questionnaires. While physiological data are sensitive to moment-to-moment changes in cognitive load, they can also capture other states unrelated to cognitive load. To validate the use of such data, comparisons should be made with established instruments such as cognitive load questionnaires, which—despite their retrospective nature—are supported by rigorous validation processes. References [6,27,31,32] examined cognitive load occurrence through both self-report and physiological measures. This approach is consistent with criterion validity, which assesses whether results from one measure relate to those from an accepted criterion. Collecting comparative data from validated tools ensures that physiological measures validly capture cognitive load.
Fourthly, the data collected should be closely aligned with the target cognitive load type and the task. For example, in the study of [2], physical data from the legs, not the hands, were collected to measure the cognitive load that occurs in a walking task. Conversely, the study by [4] utilized physiological data from the hands to assess the cognitive load in a drug classification task. While both studies measured extraneous cognitive load, the nature of the collected data varied according to the specific task. Ensuring such alignment strengthens validity by excluding irrelevant data and focusing on variables directly related to the task context. The design of the measurement tool (collecting data) must align with the core characteristics (extraneous cognitive load) of the task.
In considering the practical implementation of cognitive load classification models in real-time healthcare settings, several challenges must be addressed. Latency in processing high-frequency physiological data (e.g., EEG, ECG) has the potential to impede real-time feedback, thus necessitating the development of efficient algorithms and the use of edge computing solutions. The collection of sensitive physiological data gives rise to concerns regarding privacy and data security, particularly in patient-facing environments, thus emphasizing the significance of ethical data governance and robust security infrastructure. The integration of these systems into clinical workflows is hindered by hardware limitations, including the necessity for non-intrusive, wearable, and cost-effective sensors. Addressing these challenges is critical for the successful deployment and adoption of cognitive load models in healthcare education and training environments.
5. Conclusions
This study conducted a scoping review of related studies published from 2015 to 2024 to analyze cognitive load classification models using physiological data in the healthcare field. The results showed that, in terms of task design, tasks that adjusted difficulty to measure intrinsic load were most commonly used, while EEG and body movement data were the most frequently utilized for data collection. In terms of model development, SVM algorithms were most frequently employed, with cross-validation and feature selection being the primary methods to prevent model overfitting. Based on these findings, guidelines for the development of cognitive load classification models were proposed, emphasizing the importance of clear definitions of cognitive load, appropriate task design, reliable ground truth establishment, and contextually relevant data collection.
The primary contribution of this study lies in addressing a critical gap in the existing literature: while numerous studies focus on developing cognitive load classification models, there is a lack of comprehensive, evidence-based guidelines on their development within healthcare education. Unlike previous reviews that primarily summarize model performance, our scoping review provides actionable insights for educators, researchers, and developers. By systematically analyzing the methodologies behind task design, data collection, and model development in healthcare contexts, we offer a unique framework for understanding and optimizing the practical utility of these models. This includes emphasizing the necessity of clearly defining cognitive load types, designing contextually relevant tasks, establishing reliable ground truths, and selecting appropriate physiological data. This practical, guideline-oriented approach significantly advances the field by bridging the gap between model development and real-world application in healthcare education.
Ultimately, the insights derived from this review are fundamental for advancing personalized education within the healthcare domain. By accurately classifying cognitive load through physiological data, educators can adapt instructional strategies in real-time, ensuring that learning materials and activities are optimally challenging—neither overwhelming novice learners nor underutilizing the capacities of advanced students. This adaptive approach aligns with core principles of cognitive load theory [33,34], promoting deeper understanding and retention. For instance, in clinical training, a classification model could identify when a medical student is experiencing excessive extraneous cognitive load during a complex procedure, allowing for immediate intervention and adjustment of training methods. Similarly, for patients and the general public learning about health management, tailoring information delivery based on their cognitive state can significantly improve comprehension and adherence. Thus, the effective use of these models is poised to enhance the effectiveness of healthcare education, leading directly to better learning outcomes for students and professionals, and ultimately, improved health literacy and clinical practice across all populations.
Despite these aforementioned contributions, this study is subject to limitations. Notably, the small number of included papers (n = 10) significantly restricts the generalizability of our findings. This is primarily because our stringent inclusion criteria focused solely on studies that directly collected physiological data and subsequently developed classification models. The process of both physiological data collection and classification model development is inherently complex and resource-intensive, leading to a limited number of studies that satisfy both conditions. This scarcity highlights the emerging nature of research at the intersection of cognitive load classification and healthcare education, making broader generalizations challenging. Future research should address this by actively expanding the scope of reviews to include a larger and more diverse body of literature, potentially by incorporating additional fields (e.g., cognitive science, human–computer interaction) and literature databases beyond those used in this study. This approach is expected to enhance the effectiveness of healthcare education, leading to better learning outcomes and improved healthcare services.
Author Contributions
H.K. conceptualized and designed the study. M.K., H.K. and Y.H. conducted the review of literature and prepared the first draft. M.K., H.K. and Y.H. contributed to the review and revision in the first draft and approved the final version. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the 2025 Yeungnam University Research Grant.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no competing interests.
Abbreviations
| AdaBoost | adaptive boosting |
| AUC-ROC | area under the curve-receiver operating characteristic |
| BL | blink frequency |
| CL | cognitive load |
| ECG | electrocardiogram |
| EDA | electrodermal activity |
| EEG | electroencephalogram |
| EM | eye movement |
| FFS | forward feature selection |
| fMRI | functional magnetic resonance imaging |
| fNIRS | functional near-infrared spectroscopy |
| GSR | galvanic skin response |
| HRV | heart rate variability |
| ICA | independent component analysis |
| KNN | k-nearest neighbors |
| LDA | linear discriminant analysis |
| MOT | multiple object tracking |
| NASA-TLX | NASA Task Load Index |
| OSPAN | Operation Span Task |
| PCA | principal component analysis |
| PPG | photoplethysmogram |
| PRISMA | Preferred Reporting Items for Systematic Reviews and Meta-Analyses |
| PU | pupil dilation |
| RFE | recursive feature elimination |
| RSP | respiration rate |
| ST | skin temperature |
| SVM | support vector machine |
Appendix A. Details of Reviewed Studies
| Study | Q1. Cognitive Load Task Design | Q2. Data Collection | Q3. Model Development | ||||||||||||||||||
| Cognitive Load | Tasks | Participants | Data | Data Preprocessing | Classification Model | Performance of Model | |||||||||||||||
| CL Type | CL Validation | Task Manipulation | Task Type | Task Name | Bloom Taxonomy | Type | Total | Usable | % of Usable | Type | Sub-type | Instance Unit | Instance Num | Feature Selection | Specific Model | Feature Fusion Techniques | Overfitting Prevention Methods | Performance Metrics Reported | Accuracy | Performance Compared to Baseline | |
| Dasgupta et al. (2018) [2] | Extraneous | N | Using Secondary Tasks | Authentic | Walking + Elementary Arithmetic | Applying | Patient | 10 | 10 | 100 | Physiological Data | Body (Leg) | Task | 16,291 | Filter (Correlation), Wrapper (Recursive Feature Elimination (RFE)) | RF, SVM | Feature- Level | Cross-Validation, Feature Selection | Reporting Another Index | Ranged of 0.93–1 | N |
| Dorum et al. (2020) [13] | Intrinsic | N | Controlling Difficulty | Experimental | Multiple Object Tracking (MOT) Task | Remembering | Patient | 154 | 144 | 93.5 | Physiological Data | Brain (fMRI) | Task | 432 | Unused | LDA | Feature- Level | Cross-Validation | Reporting Only Accuracy | 95.8 | 187.8 |
| Kohout et al. (2019) [4] | Extraneous | Task Performance | Using Secondary Tasks | Authentic | Pill Sorting + OSPAN | Applying | Healthcare Professional | 8 | 8 | 100 | Physiological Data | Body (Hand, Hip) | Task | 16 | Filter (Mann–Whitney-U Test), Wrapper (Forward Feature Selection (FFS)) | SVM | Feature- Level | Cross-Validation, Feature Selection | Reporting Another Index | 90.0 | 80 |
| Keles et al. (2021) [6] | Overall | Subjective Measurement (NASA-TLX) | N | Authentic | Laparoscopic Surgery tasks | Applying | Healthcare Professional | 33 | 28 | 84.9 | Physiological, Subjective Data | Brain (fNIRS) | Time | Unreported | Filter (Pearson Correlation) | SVM | Feature- Level | Cross-Validation, Feature Selection | Reporting Only Accuracy | 90.0 | 80 |
| Zhang et al. (2017) [29] | Intrinsic | Subjective Measurement (Perceived Task Difficulty), Task Performance | Controlling Difficulty | Authentic | Driving | Applying | Patient | 20 | 20 | 100 | Physiological, Subjective, Performance Data | Brain (EEG), Eye (BL, EC, EM, PU), Heart (ECG, RSP, PPG), Skin (GSR, ST), Body (Muscle) | Task | 286 | Filter (Principal Component Analysis (PCA)) | KNN | Feature- Level | Cross-Validation, Feature Selection | Reporting Only Accuracy | 84.4 | 68.9 |
| Zhou et al. (2020) [27] | Intrinsic | Subjective Measurement (NASA-TLX) | Controlling Difficulty | Authentic | Surgery | Applying | Healthcare Professional | 12 | 12 | 100 | Physiological, Subjective Data | Brain (EEG), Heart (HRV), Body (Hand, Muscle), Skin (GSR) | Task | 119 | Filter (Independent Component Analysis (ICA)) | SVM | Feature- Level | Cross-Validation, Feature Selection | Reporting Another Index | 83.2 | 66.4 |
| Beiramvand et al. (2023) [8] | Intrinsic | N | Controlling Difficulty | Experimental | N-Back Task | Remembering | General Public | 15 | 15 | Unreported | Physiological Data | Brain (EEG) | Time | Unreported | Unused | AdaBoost | Feature- Level | Cross-Validation, Data Augmentation | Reporting Another Index | 80.9 | 61.7 |
| Chen & Epps (2019) [35] | Intrinsic | Subjective Measurement (Unspecified) | Controlling Difficulty | Experimental | Elementary Arithmetic | Applying | General Public | 24 | 24 | 100 | Physiological Data | Body (Head) | Task | 336 | Filter | Parzen Window | Feature- Level | Cross-Validation, Feature Selection | Reporting Only Accuracy | 69.8 | 39.6 |
| Gogna et al. (2024) [31] | Intrinsic | Subjective Measurement (NASA-TLX) | Controlling Difficulty | Experimental | Game (spotting the differences in similar-looking pictures) | Analyzing | General Public | 15 | 15 | 100 | Physiological Data | Brain (EEG) | Task | 45 | Wrapper (Recursive Feature Elimination, RFE) | SVM | Feature- Level | Cross-Validation, Feature Selection, Hyperparameter Tuning | Reporting Another Index | 91.2 | 173.9 |
| Yu et al. (2024) [32] | Intrinsic | Subjective Measurement (NASA-TLX) | Controlling Difficulty | Experimental | Elementary Arithmetic | Applying | General Public | 20 | 20 | 100 | Physiological, Subjective Data | Brain (fMRI), Eye (BL, EM, PU) | Task | 300 | Filter | RF | Feature- Level | Cross-Validation, Feature Selection | Reporting Only Accuracy | 87.8 | 251.2 |
Appendix B. Distribution of Quality Assessment Scores (QualSyst) Across Included Studies
| Element | Chen & Epps (2019) [35] | Dasgupta et al. (2018) [2] | Dorum et al. (2020) [13] | Keles et al. (2021) [6] | Kohout et al. (2019) [4] | Zhang et al. (2017) [29] | Zhou et al. (2020) [27] | Beiramvand et al. (2023) [8] | Gogna et al. (2024) [31] | Yu et al. (2024) [32] |
| 1. Objective | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 2. Study design | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 3. Group selection | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 4. Subject characteristics | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 5. Random allocation | . | . | . | . | . | . | . | . | . | . |
| 6. Investigator blinding | . | . | . | . | . | . | . | . | . | . |
| 7. Subject blinding | . | . | . | . | . | . | . | . | . | . |
| 8. Outcome/exposure measures | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 9. Sample size | . | . | . | 1 | . | . | . | . | . | . |
| 10. Analytical methods | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 11. Variance estimates | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 12. Confounding control | 1 | 1 | 1 | 1 | 1 | 2 | 1 | 1 | 1 | 1 |
| 13. Results detail | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 14. Conclusions | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Total | 19 | 19 | 19 | 20 | 19 | 20 | 19 | 19 | 19 | 19 |
| Average | 0.95 | 0.95 | 0.95 | 0.91 | 0.95 | 1.00 | 0.95 | 0.95 | 0.95 | 0.95 |
References
- Brüggemann, T.; Ludewig, U.; Lorenz, R.; McElvany, N. Effects of mode and medium in reading comprehension tests on cognitive load. Comput. Educ. 2023, 192, 104649. [Google Scholar] [CrossRef]
- Dasgupta, P.; VanSwearingen, J.; Sejdic, E. “You can tell by the way I use my walk.” Predicting the presence of cognitive load with gait measurements. Biomed. Eng. Online 2018, 17, 122. [Google Scholar] [CrossRef]
- Sweller, J. Cognitive load theory. In International Encyclopedia of Education, 4th ed.; Elsevier: Amsterdam, The Netherlands, 2023; pp. 127–134. [Google Scholar] [CrossRef]
- Kohout, L.; Butz, M.; Stork, W. Using Acceleration Data for Detecting Temporary Cognitive Overload in Health Care Exemplified Shown in a Pill Sorting Task. In Proceedings of the 32nd IEEE International Symposium on Computer-Based Medical Systems (IEEE CBMS), Cordoba, Spain, 5–7 June 2019; pp. 20–25. [Google Scholar]
- Skulmowski, A.; Xu, K.M. Understanding Cognitive Load in Digital and Online Learning: A New Perspective on Extraneous Cognitive Load. Educ. Psychol. Rev. 2021, 34, 171–196. [Google Scholar] [CrossRef]
- Keles, H.O.; Cengiz, C.; Demiral, I.; Ozmen, M.M.; Omurtag, A.; Sakakibara, M. High density optical neuroimaging predicts surgeons’s subjective experience and skill levels. PLoS ONE 2021, 16, e0247117. [Google Scholar] [CrossRef]
- Kucirkova, N.; Gerard, L.; Linn, M.C. Designing personalised instruction: A research and design framework. Br. J. Educ. Technol. 2021, 52, 1839–1861. [Google Scholar] [CrossRef]
- Beiramvand, M.; Lipping, T.; Karttunen, N.; Koivula, R. Mental Workload Assessment Using Low-Channel Pre-Frontal EEG Signals. In Proceedings of the 2023 IEEE International Symposium on Medical Measurements and Applications, Jeju, Republic of Korea, 14–16 June 2023; pp. 1–5. [Google Scholar]
- Anderson, L.W.; Krathwohl, D.R. A Taxonomy for Learning, Teaching, and Assessing: A Revision of Bloom’s Taxonomy of Educational Objectives; Complete edition; Addison Wesley Longman: New York, NY, USA, 2021. [Google Scholar]
- Reddy, L.V. Personalized recommendation framework in technology enhanced learning. J. Emerg. Technol. Innov. Res. 2018, 5, 746–750. [Google Scholar]
- Mu, S.; Cui, M.; Huang, X. Multimodal Data Fusion in Learning Analytics: A Systematic Review. Sensors 2020, 20, 6856. [Google Scholar] [CrossRef]
- Wu, C.; Liu, Y.; Guo, X.; Zhu, T.; Bao, Z. Enhancing the feasibility of cognitive load recognition in remote learning using physiological measures and an adaptive feature recalibration convolutional neural network. Med. Biol. Eng. Comput. 2022, 60, 3447–3460. [Google Scholar] [CrossRef] [PubMed]
- Dørum, E.S.; Kaufmann, T.; Alnæs, D.; Richard, G.; Kolskår, K.K.; Engvig, A.; Sanders, A.-M.; Ulrichsen, K.; Ihle-Hansen, H.; Nordvik, J.E.; et al. Functional brain network modeling in sub-acute stroke patients and healthy controls during rest and continuous attentive tracking. Heliyon 2020, 6, 11. [Google Scholar] [CrossRef] [PubMed]
- Page, M.J.; McKenzie, J.; Bossuyt, P.; Boutron, I.; Hoffmann, T.; Mulrow, C.; Moher, D. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. arXiv 2020. [Google Scholar] [CrossRef]
- Dong, H.; Lio, J.; Sherer, R.; Jiang, I. Some Learning Theories for Medical Educators. Med. Sci. Educ. 2021, 31, 1157–1172. [Google Scholar] [CrossRef] [PubMed]
- Kmet, L.M.; Lee, R.C.; Cook, L.S. Standard Quality Assessment Criteria for Evaluating Primary Research Papers From a Variety of Fields. (HTA Initiative #13); Alberta Heritage Foundation for Medical Research: Edmonton, AB, Canada, 2004. [Google Scholar]
- Sweller, J. Element interactivity and intrinsic, extraneous, and germane cognitive load. Educ. Psychol. Rev. 2010, 22, 123–138. [Google Scholar] [CrossRef]
- Sarkhani, N.; Beykmirza, R. Patient Education Room: A New Perspective to Promote Effective Education. Asia Pac. J. Public. Heal. 2022, 34, 881–882. [Google Scholar] [CrossRef]
- Lee, L.; Packer, T.L.; Tang, S.H.; Girdler, S. Self-management education programs for age-related macular degeneration: A systematic review. Australas. J. Ageing 2008, 27, 170–176. [Google Scholar] [CrossRef]
- Sweller, J.; Ayres, P.; Kalyuga, S. Cognitive Load Theory; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- de Jong, T. Cognitive load theory, educational research, and instructional design: Some food for thought. Instr. Sci. 2010, 38, 105–134. [Google Scholar] [CrossRef]
- Sweller, J.; Ayres, P.; Kalyuga, S. The Expertise Reversal Effect. In Cognitive Load Theory, Explorations in the Learning Sciences; Instructional Systems and Performance Technologies; Sweller, J., Ayres, P., Kalyuga, S., Eds.; Springer: New York, NY, USA, 2011; pp. 155–170. [Google Scholar]
- Zu, T.; Hutson, J.; Loschky, L.C.; Rebello, N.S. Using eye movements to measure intrinsic, extraneous, and germane load in a multimedia learning environment. J. Educ. Psychol. 2020, 112, 1338. [Google Scholar] [CrossRef]
- Paas, F.; Renkl, A.; Sweller, J. Cognitive Load Theory: Instructional Implications of the Interaction between Information Structures and Cognitive Architecture. Instr. Sci. 2004, 32, 1–8. [Google Scholar] [CrossRef]
- Haapalainen, E.; Kim, S.; Forlizzi, J.F.; Dey, A.K. Psycho-Physiological Measures for Assessing Cogni-Tive load. In Proceedings of the 12th ACM international conference on Ubiquitous computing, Copenhagen, Denmark, 26–29 September 2010; pp. 301–310. [Google Scholar]
- Guo, J.; Dai, Y.; Wang, C.; Wu, H.; Xu, T.; Lin, K. A physiological data-driven model for learners’ cognitive load detection using HRV-PRV feature fusion and optimized XGBoost classification. Softw. Pr. Exp. 2020, 50, 2046–2064. [Google Scholar] [CrossRef]
- Zhou, T.; Cha, J.S.; Gonzalez, G.; Wachs, J.P.; Sundaram, C.P.; Yu, D. Multimodal Physiological Signals for Workload Prediction in Robot-assisted Surgery. ACM Trans. Hum. Robot. Interact. 2020, 9, 12. [Google Scholar] [CrossRef]
- Kumar, V.; Minz, S. Feature selection. SmartCR 2014, 4, 211–229. [Google Scholar] [CrossRef]
- Zhang, L.; Wade, J.; Bian, D.; Fan, J.; Swanson, A.; Weitlauf, A.; Warren, Z.; Sarkar, N. Cognitive Load Measurement in a Virtual Reality-Based Driving System for Autism Intervention. IEEE Trans. Affect. Comput. 2017, 8, 176–189. [Google Scholar] [CrossRef]
- Atrey, P.K.; Hossain, M.A.; El Saddik, A.; Kankanhalli, M.S. Multimodal fusion for multimedia analysis: A survey. Multimedia Syst. 2010, 16, 345–379. [Google Scholar] [CrossRef]
- Gogna, Y.; Tiwari, S.; Singla, R. Evaluating the performance of the cognitive workload model with subjective endorsement in addition to EEG. Med. Biol. Eng. Comput. 2024, 62, 2019–2036. [Google Scholar] [CrossRef] [PubMed]
- Yu, R.; Chan, A. Effects of player–video game interaction on the mental effort of older adults with the use of electroencephalography and NASA-TLX. Arch. Gerontol. Geriatr. 2024, 124, 105442. [Google Scholar] [CrossRef] [PubMed]
- Kalyuga, S. Cognitive Load in Adaptive Multimedia Learning. In New Perspectives on Affect and Learning Technologies; Springer: New York, NY, USA, 2011; pp. 203–215. [Google Scholar]
- Mihalca, L.; Salden, R.J.; Corbalan, G.; Paas, F.; Miclea, M. Effectiveness of cognitive-load based adaptive instruction in genetics education. Comput. Hum. Behav. 2011, 27, 82–88. [Google Scholar] [CrossRef]
- Chen, S.; Epps, J. Atomic Head Movement Analysis for Wearable Four-Dimensional Task Load Recognition. IEEE J. Biomed. Health Inform. 2019, 23, 2464–2474. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).