Abstract
With the rapid advancement of deepfake technology, the detection of low-quality synthetic facial images has become increasingly challenging, particularly in cases involving low resolution, blurriness, or noise. Traditional detection methods often exhibit limited performance under such conditions. To address these limitations, this paper proposes a novel algorithm, YOLOv9-ARC, which is designed to enhance the accuracy of detecting low-quality fake facial images. The proposed algorithm introduces an innovative convolution module, Adaptive Kernel Convolution (AKConv), which dynamically adjusts kernel sizes to effectively extract image features, thereby mitigating the challenges posed by low resolution, blurriness, and noise. Furthermore, a hybrid attention mechanism, Convolutional Block Attention Module (CBAM), is integrated to amplify salient features while suppressing irrelevant information. Extensive experiments demonstrate that YOLOv9-ARC achieves a mean average precision (mAP) of 75.1% on the DFDC (DeepFake Detection Challenge) dataset, representing a 3.5% improvement over the baseline model. The proposed YOLOv9-ARC not only addresses the challenges of low-quality deepfake detection but also demonstrates significant improvements in accuracy within this domain.
1. Introduction
With the rapid advancement of deepfake technologies, particularly Generative Adversarial Networks (GANs), image generation techniques have achieved remarkable progress, enabling the synthesis of highly realistic forged images indistinguishable from authentic faces []. Recent enhancements in GANs have significantly increased both visual fidelity and detection difficulty []. Such high-quality synthetic images pose unprecedented challenges to facial recognition and security systems, creating significant risks in political and financial domains, thus emphasizing the urgent need for improved forgery detection methods [].
To address those demanding situations, researchers have proposed various methods for detecting artificial snapshots. For instance, Zhao et al. [] delivered a multi-attention community that considerably stepped forward detection accuracy by integrating a couple of spatial attention heads and texture enhancement modules. Lee et al. [] demonstrated exceptional performance in detecting high-quality forgeries using a Transfer Learning-based Autoencoder with Residual Blocks (TAR). TAR outperformed other methods on the FaceForensics++ dataset []. Wang et al. [] proposed an attention-guided records augmentation approach to enhance the functionality of CNN-based detectors in detecting solid faces. While those strategies have superior detection accuracy to a point, their effectiveness remains constrained for low-quality images.
However, despite recent progress, current deepfake detection techniques still exhibit significant performance degradation when processing low-quality forged images. These images, characterized by blur, noise, and low resolution, severely obscure critical facial features, making traditional CNN-based methods ineffective. Existing approaches predominantly address high-quality forgeries, while those targeting low-quality scenarios either rely on computationally intensive super-resolution or lack generalization capabilities. Consequently, there is an urgent need for an efficient detection method specifically designed to handle the complexities associated with low-quality deepfakes.
As image generation technologies have advanced, conventional forgery detection methods have shown massive performance degradation on low-quality photos [], specifically those stricken by noise, low resolution, or blur. Low-quality image snapshots normally include considerable noise and reduced resolution, which significantly degrade the overall performance of existing brand new, deep, ultra-modern techniques in detecting artificial content material []. The similarity between low-quality synthetic and authentic images further complicates the differentiation system of traditional detection strategies []. Although state-of-the-art deep learning models excel in processing high-quality images, they often fail to deliver satisfactory results on low-quality inputs [].
In recent years, researchers have introduced several novel tactics to deal with the demanding situation of detecting low-quality counterfeit pictures, particularly the ones stricken by low resolution and noise. Those techniques aim to enhance the accuracy and robustness of contemporary forgery detection by leveraging superior strategies consisting of feature extraction, amazing resolution healing, and current deep techniques. For example, Zou et al. [] proposed the DIFLD technique, which employs high-frequency invariance and excessive-dimensional function distribution learning to enhance detection performance on low-quality compressed images. While effective, this approach restrained generalization abilties. Kiruthika et al. [] proposed a counterfeit face detection approach based totally on photograph assessment features, accomplishing stepped forward accuracy through frequency and spatial area analysis. But its performance on non-widespread datasets remains suboptimal.
Sohaib et al. [] developed a video forgery detection system using a Convolutional Neural Network–Long Short-Term Memory (CNN-LSTM) model, integrating facial feature extraction via a Multi-task Cascaded Convolutional Neural Network (MTCNN) and Extreme Inception (Xception) with temporal feature capture through Long Short-Term Memory (LSTM). Although this model performed well on the Google Deepfake AI dataset [], it struggled with issues such as color inconsistency.
In addition, advancements include those by Wang et al. [], who mixed sparse coding with deep learning for super-resolution image restoration. Despite achieving high restoration accuracy and subjective quality, their method incurs significant computational overhead and has limited applicability. Herrmann et al. [] enhanced local matching techniques by integrating multi-scale Local Binary Pattern (LBP) features with time fusion, demonstrating success in low-resolution surveillance video face recognition. However, its accuracy declines under extremely low resolution and complex backgrounds. Heinsohn et al. [] introduced the blur-ASR method, which leverages sparse representation with dictionaries tailored to various blur levels to improve low-resolution image recognition. While effective, its performance is highly dependent on dataset representativeness, limiting its applicability in real-world scenarios. Kim et al. [] introduced an adaptive feature extraction technique effective for blurred face images, though it struggles with severe blur and high computational complexity. Lin et al. [] proposed a two-stage pipeline using the pix2pix network for low-resolution face image enhancement, which is coupled with a multi-quality fusion network to improve recognition performance. Despite its strengths, the method is limited in restoring extremely low-quality data and suffers from high computational complexity. Mu et al. [] presented a lightweight convolutional model combining multi-resolution feature fusion and spatial attention modules, outperforming traditional CNNs on the Lock3DFace dataset []. Nevertheless, its ability to handle extremely low-quality data remains constrained.
Many existing methods focus on a single technique, such as super-resolution restoration or feature extraction, and often exhibit limited performance on extremely low-quality images or incur significant computational overhead. Consequently, current research has yet to provide a comprehensive solution for addressing the combined challenges of noise, blur, and low resolution in low-quality forged images.
To address these limitations, this paper proposes the YOLOv9-ARC algorithm, which significantly enhances the detection performance of low-quality forged images through the introduction of two key components: the Adaptive Kernel Convolution (AKConv) module and the Convolutional Block Attention Module (CBAM). Unlike previous approaches, the core innovation of this work lies in the synergistic integration of dynamically adjustable convolution kernels (AKConv) and multi-level attention mechanisms (CBAM), which optimize feature extraction and feature representation, respectively. The AKConv module dynamically adjusts the size of the convolution kernel, enabling the model to effectively handle low resolution, noise, and blur, thereby enhancing its feature extraction capability on low-quality images. Simultaneously, the CBAM mechanism dynamically recalibrates feature importance across both channel and spatial dimensions, amplifying critical regions while suppressing noise and irrelevant features.
Compared to existing techniques that rely solely on feature extraction or super-resolution restoration, the proposed approach combines adaptive convolution kernel adjustment with attention-guided feature optimization. This dual strategy not only improves the model’s adaptability to low-quality images but also achieves higher accuracy in addressing challenges such as low resolution and noise. Furthermore, the model demonstrates enhanced robustness by focusing on discriminative regions and reducing the impact of irrelevant information.
In summary, this paper builds upon existing technologies and introduces significant improvements to overcome the limitations of traditional methods in detecting low-quality forged images. The proposed YOLOv9-ARC algorithm offers a more efficient and adaptable solution, advancing the state-of-the-art in forgery detection under challenging conditions.
The key contributions of this paper are outlined below:
- We propose YOLOv9-ARC, which is an improved detection framework specifically designed for low-quality deepfake images characterized by noise, blur, and low resolution.
- We introduce Adaptive Kernel Convolution (AKConv) to enhance the model’s ability to extract meaningful features under degraded visual conditions.
- We incorporate the Convolutional Block Attention Module (CBAM) to emphasize critical facial regions and suppress irrelevant noise, improving detection accuracy.
- Extensive experiments demonstrate that YOLOv9-ARC achieves superior performance and generalization on low-quality datasets compared to baseline methods.
Compared to existing techniques, the innovations of this paper include the following:
- Combining adaptive convolution and attention mechanisms to improve detection performance: Unlike methods that rely only on super-resolution restoration (e.g., Wang et al. []) or feature extraction (e.g., Sohaib et al. []), YOLOv9-ARC integrates both adaptive convolution and attention mechanisms, achieving more robust low-quality forgery detection.
- Better generalization and adaptability: While the DIFLD method [] mainly relies on high-dimensional feature distribution learning, AKConv enables the model to optimize feature extraction across varying resolutions and noise levels, improving its adaptability to complex datasets.
- Optimized computational efficiency: Compared to computationally expensive super-resolution methods (e.g., Lin et al. [], who used a pix2pix network for low-resolution face enhancement), YOLOv9-ARC reduces computational complexity through its lightweight AKConv design, making it more suitable for real-time applications.
This paper is structured as follows: Section 1 reviews related works on deepfake detection with a focus on challenges posed by low-quality synthetic images. Section 2 introduces the proposed YOLOv9-ARC model in detail, including the AKConv and CBAM modules. Section 3 presents the experimental setup and evaluation results on the DFDC dataset. Section 4 discusses the implications of the findings, current limitations, and future research directions. Finally, Section 5 concludes the paper by summarizing the key contributions and outcomes.
2. Materials and Methods
2.1. Model Overview
In the field of object detection, YOLOv9 [] emerged as a new breakthrough in 2024, setting a new benchmark for efficiency and accuracy. However, when dealing with low-quality facial images, the YOLOv9 model begins to show inefficiencies, leading to a decline in detection performance.
To address these issues, this paper proposes the YOLOv9-ARC algorithm for counterfeit detection in low-quality facial images. The full network architecture is depicted in Figure 1. This framework is composed of three primary components.
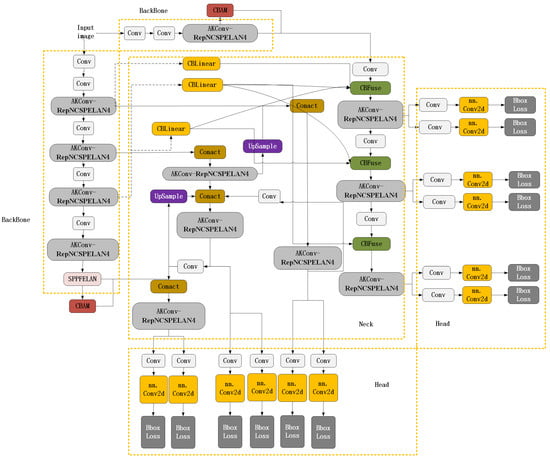
Figure 1.
YOLOv9-ARC architecture diagram. The model introduces a hybrid attention mechanism based on the baseline model, updating the feature extraction module by replacing standard convolutional layers.
The Backbone is responsible for extracting initial features from the input image. The Convolutional Block Attention Module (CBAM) [] is integrated into the Backbone to focus on important regions of the image. By leveraging both spatial and channel attention mechanisms, CBAM enhances critical information while suppressing noise and irrelevant regions, thereby improving the feature extraction capability for low-quality images. The Adaptive Kernel Convolution (AKConv) [] is combined with the RepNCSPELAN4 module to expand the receptive field and enable the network to capture finer spatial features, enhancing its adaptability to images of varying quality and size. Additionally, the SPPFELAN module further aggregates and refines these features.
The Neck connects the Backbone and the Head, primarily processing and fusing the features extracted by the Backbone to enhance multi-scale feature representation. This is particularly beneficial for detecting objects of varying sizes in low-quality images. The Neck also employs AKConv to dynamically adjust the convolution kernel size, enabling it to handle feature maps at different scales. Through CBFuse operations, multiple feature maps are fused, integrating information from different levels into a unified feature representation. Furthermore, UpSample and Concat operations upsample and concatenate feature maps of different resolutions, generating higher-dimensional feature maps and ensuring effective multi-scale information fusion.
Finally, the Head utilizes the refined features from the Neck to generate the final detection results. This component includes multiple Conv layers to further refine the features, ensuring precise detection outputs. Multiple Conv2d layers are used to generate target location and category information, while the Bbox Loss is computed to optimize the model through bounding box regression.
By integrating the CBAM attention mechanism, AKConv adaptive convolution, and multi-scale feature fusion techniques, YOLOv9-ARC significantly enhances object detection capabilities in low-quality images. It effectively addresses challenges such as noise and blur, providing accurate forgery detection results.
As illustrated in Figure 1 and Figure 2, the proposed YOLOv9-ARC model demonstrates significant advantages over the original YOLOv9 model when processing low-quality facial images, owing to the integration of the CBAM attention mechanism and AKConv adaptive convolution. The CBAM mechanism enables the model to focus on critical regions of the image, particularly edge and texture features that are essential for low-quality images. Meanwhile, AKConv dynamically adjusts the convolution kernel size to adapt to multi-scale feature extraction, effectively capturing fine-grained details in the images. In terms of feature fusion, the proposed model employs the CBFuse operation to better integrate features from different levels, enhancing the ability to combine multi-scale information. This is particularly crucial for low-quality images, where facial features may be fragmented or blurred. In contrast, although the original YOLOv9 model also utilizes Conv layers and concatenation operations, its lack of the CBAM attention mechanism limits its ability to prioritize key features in low-quality images, resulting in inferior performance compared to the proposed model. Overall, the proposed model, with its more sophisticated feature processing and fusion techniques, is better equipped to handle noise and blur in low-quality facial images, delivering higher detection accuracy.
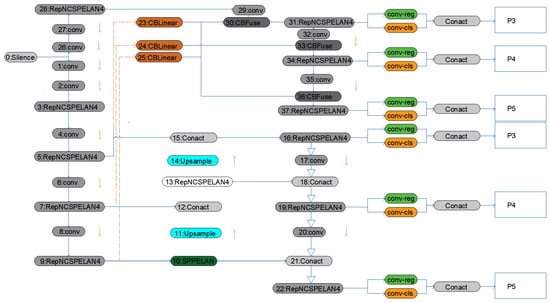
Figure 2.
YOLOv9 architecture diagram. The model demonstrates the YOLOv9 architecture’s processing flow for input images.
2.2. YOLOv9 Algorithm
YOLOv9 [] introduces the concept of Programmable Gradient Information (PGI) and designs a supplementary supervision structure that incorporates PGI. As shown in Figure 3, the framework consists of featuring three essential components: the primary branch, a supplementary reversible branch, and a multi-level framework During the logical conclusion phase, the network only utilizes the main transition toward avoid increasing inference costs. However, during training, the complementary reversible route provides reliable gradient-based information for help the primary pathway learn effective features, preventing the loss of important feature information. This design ensures that the loss function is computed using the full input data, thereby supplying stable and reliable gradient feedback for fine-tuning the model parameters.
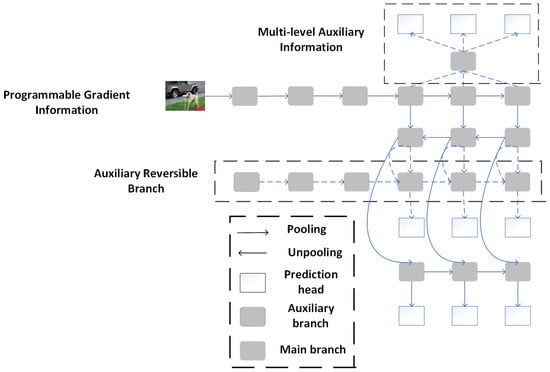
Figure 3.
Programmable gradient information architecture diagram. This structure optimizes gradient flow and adjusts gradient utilization, improving training efficiency, stability, and object detection accuracy, especially in complex input environments.
In addition, the research team proposed a newly designed, low-complexity network architecture, the General Efficient Layer Aggregation Network (GELAN), as demonstrated in Figure 4c. The General Efficient Layer Aggregation Network (GELAN) is built upon the Efficient Layer Aggregation Network (ELAN) architecture in Figure 4b by integrating the Cross-Stage Partial Network (CSPNet) from Figure 4a. Firstly, balancing computational complexity and detection accuracy is at the core of the design. GELAN optimizes the model’s computational requirements through modular design, ensuring that even under limited computational resources, high detection accuracy can still be maintained. Secondly, lightweight convolution operations are introduced between each convolutional layer, reducing computation, which is particularly suitable for edge devices or low-power environments, thus lowering the computational cost during inference and improving processing speed. The authors also improve computational efficiency by incorporating the Cross-Stage Partial Network (CSPNet), which distributes the computational load across different stages and network blocks, preventing excessive computation at any single stage and enabling flexible adjustment of computation based on hardware conditions. Dynamic resource adjustment allows GELAN to dynamically optimize the allocation of computational resources according to hardware conditions, ensuring high inference efficiency even when resources are limited. Finally, the modular design of the model, through the rational combination and integration of different network layers and modules, maintains high detection accuracy without adding excessive computational burden. The design of this architecture considers the balance between computational complexity and detection performance, ensuring that the model maintains high inference efficiency even with limited computational resources.
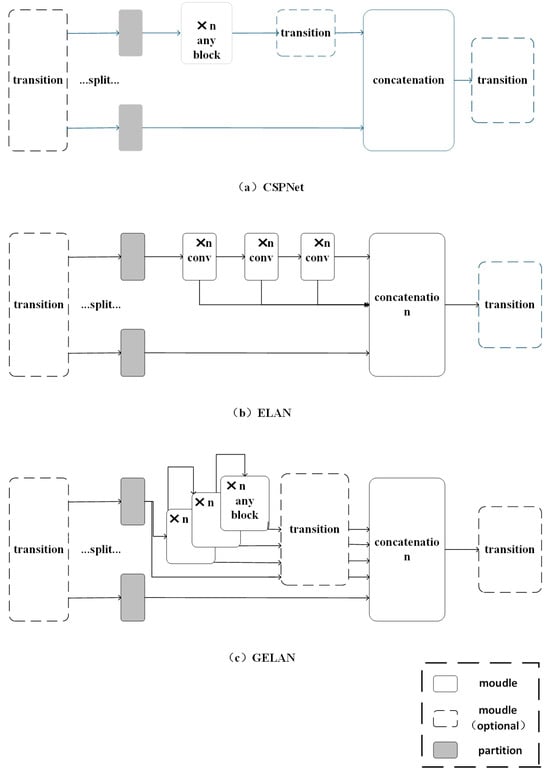
Figure 4.
General efficient layer aggregation network structure diagram. This structure improves the model’s computational efficiency and detection accuracy by optimizing feature extraction, reducing computational resource consumption, and enhancing multi-scale detection capabilities, especially demonstrating stronger adaptability in complex and dynamic environments.
The incorporation of these two innovative technologies is crucial for mitigating information loss during training while also optimizing efficiency and inference speed. These advancements strengthen the model’s competitiveness and practical relevance in real-world situations.
2.3. CBAM Hybrid Attention Mechanism
In terms of low-quality facial images, the dataset contains low-resolution or noisy images; that is, images where the boundaries between the facial features and the background are blurred. Hence, this is helpful for cases where it is difficult to interpose features in the same image with multiple types of facial features, even leading to large-magnitude variations at different in the same cases of image types. To address these problems, in this paper, the CBAM Hybrid Attention Mechanism is embedded into the detection framework. This mined and integrated feature information, which are crucial for facial detection, allows the model to concentrate more on these key features, enabling feature fusion.
A deep learning attention mechanism CBAM [] is based on the idea of inferring attention maps in channel and spatial dimensions independently from the input feature map. Attention maps are then applied on the input feature map to refine the features based on the attention.
The CBAM embodies two main components: the Channel Attention Module and the Spatial Attention Module (as shown in Figure 5a. The channel attention is followed by a spatial attention.
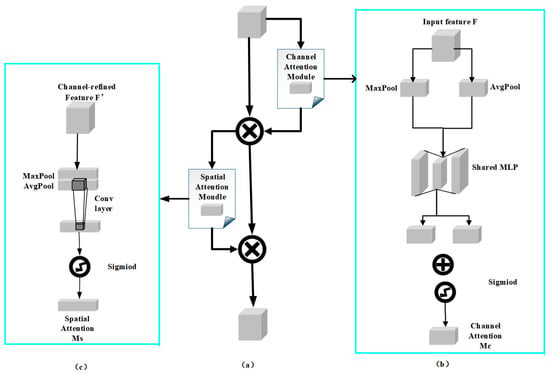
Figure 5.
CBAM attention mechanism architecture diagram. (a) The CBAM (Convolutional Block Attention Module) combines channel and spatial attention mechanisms to enhance model performance by highlighting important features and suppressing irrelevant ones. It consists of two modules: (b) the Channel Attention Module, which models channel dependencies and generates the channel attention map; (c) and the Spatial Attention Module, which models spatial dependencies and generates the spatial attention map. The input features are element-wise multiplied by the two attention maps to produce enhanced output features.
This sequence enables the model to effectively capture and utilize feature information from multiple dimensions, enhancing its capacity to recognize relevant characteristics within images.
The entire process of the attention mechanism can be represented by the following equation:
In the above expression, denotes the element-wise multiplication operation. F indicates the input feature representation at the beginning of the process, refers to the feature map generated after passing through the channel attention mechanism, and denotes the resulting feature map obtained following passing through the attention across spatial dimensions module. indicates the output produced by the attention mechanism for channel-wise features after processing the visual feature matrix F, while represents the output generated through the spatial attention mechanism after processing the visual feature matrix .
As shown in Figure 5b, this part is the channel attention module. Initially, the input visual feature matrix F, characterized by dimensions of (where C represents the channel count, while and denote the image’s height and width, respectively), is processed. Then, global pooling is applied individually to each channel of the input visual feature matrix F, including both max pooling across the entire spatial dimension and pooling by computing the mean over the entire spatial dimension, which results in two distinct feature maps. These include then passed into a fully connected layer (MLP), which learns the attention weights for each channel. After processing, the feature maps are integrated to produce a new activation map. At the final stage, the channel attention features are computed by applying a activation function. These features are then integrated with the input feature map F by applying multiplication on an element-by-element basis, generating the updated channel attention visual feature grid .
The process of channel attention is expressed as shown below:
In the equation above, stands for the activation function, denotes the global max pooling operation, and corresponds to global average pooling. The terms and refer to the learnable weights and variables of the network.
As shown in Figure 5c, this section represents the spatial feature focusing module. After being processed via the channel attention mechanism module, the output feature representation undergoes the global max pooling procedure followed by global average pooling, resulting in two sets of feature maps of measurements . The concatenated results are then processed through a convolutional layer to produce the spatial attention weights . Subsequently, the attention weights are processed using the function, after which they are applied to the feature map for spatial attention weighting, ultimately producing the final the resulting feature map generated as the output .
The formula for the focus on spatial information within the feature map process can be expressed as shown below:
In the expression, refers to the function, represents a convolutional filter with dimensions 7 × 7, represents max pooling, refers to average pooling, represents the extracted feature representation generated by the channel-based attention mechanism, denotes the result produced by the spatial attention module, and refers to the final result produced by the CBAM attention mechanism.
The authors of this paper have decided to integrate the CBAM hybrid attention mechanism to the backbone network of the baseline model. By amplifying important information through both channel and spatial attention, it suppresses the expression of irrelevant information. Additionally, since this attention mechanism is a lightweight module, it does not noticeably add to the system’s computational complexity.
3. Results
3.1. Dataset Introduction
The dataset used in this experiment comes from the largest publicly available deepfake dataset, the DFDC (DeepFake Detection Challenge) dataset [], which was released by the Facebook AI team in 2020. This dataset contains 128,154 videos, of which 104,500 are deepfake videos. Each video is approximately 10 s long with frame rates and resolutions ranging from low to high. The individuals in the dataset are actors from diverse backgrounds, genders, ages, and ethnicities, ensuring the dataset’s diversity. In contrast to earlier deepfake datasets, all individuals in the DFDC dataset have given their consent for their images to be included and have authorized alterations to their images during the dataset creation process. The purpose of this dataset is to train and test deepfake detection models, conduct related research and analysis, promote the development of deepfake detection technology, and organize corresponding deepfake detection competitions.
Based on the DFDC dataset, this paper selected a portion of real videos and fake videos. To ensure a sufficient number of image samples for analysis, it is a common practice to extract multiple frames per second from video data. For instance, frames can be sampled at regular intervals such as every second, or a subset of frames, for example, 10 frames per second, can be systematically selected. This approach enhances the richness and diversity of the dataset, which is particularly crucial for deepfake detection tasks. A large and varied sample size is essential to effectively capture the diverse forgery patterns present in deepfake images. The videos were processed frame by frame to generate a collection of real and fake face images, amounting to nearly 22,000 images in total with approximately 11,000 real faces and 11,000 fabricated faces. The selected images include low-quality images caused by factors such as high light intensity leading to overexposure, low light intensity leading to underexposure, low resolution, and different shooting angles. Deepfake images frequently exhibit abnormal lighting conditions, which can result in overexposure or underexposure due to excessively strong or weak illumination. Additionally, low-resolution deepfake images often lose significant details, leading to blurry facial features. Furthermore, deepfake techniques may introduce unnatural distortions or misalignments in key facial attributes, such as the eyes, mouth, and nose. In some cases, discrepancies in facial angles between deepfake images and real videos may arise due to imperfections in image synthesis. These subtle artifacts serve as critical indicators for deepfake detection models. The labeling was completed using the Labelimg annotation software, classifying the images into two labels: “true” (real) and “fake” (fake). The total of approximately 22,000 face images was split into training, testing, and validation sets: around 18,000 images were designated for the training set, 2000 images were assigned to the testing set, and an additional 2000 images were designated for the validation set. These divisions not only ensure the adequacy of the training data but also guarantee that the model can undergo effective validation and testing.
3.2. Configuration of the Experimental Environment
The entirety of the experiments in this study were carried out on a system operating Windows 11 64-bit. The deep learning framework employed in this study is PyTorch version 1.13.1, and the Python environment is version 3.8. The computer’s GPU configuration is an NVIDIA GeForce RTX 3090, and the system is equipped with a 14-core Intel(R) Xeon(R) Gold 6330 CPU, running at a clock speed of 2.00 GHz. During model training, the hyperparameters for training were configured as detailed below: the model used a batch size of 16 for each iteration with a total of 120 iterations, the model was trained with an initial learning rate of 0.01, and SGD was chosen as the network optimizer during the training process.
3.3. Metrics for Experimental Evaluation
The evaluation of the model’s effectiveness was evaluated using the following quantitative indicators in this experiment: mean average precision (mAP), which provides an overall assessment of the detection model’s performance; precision (P), which evaluates the correctness of the model’s outputs, providing insight into how closely the anticipated results align with the ground truth; recall (R), which indicates whether the model is comprehensive in identifying relevant data; and F1-score (F1), which reflects the harmonic mean of precision and recall, providing a balanced assessment of both the model’s accuracy and its capacity to correctly identify relevant instances.
The formulas used to compute these evaluation metrics are outlined below:
In the equations above, TP refers to the frequency of instances where the model accurately identifies the class being predicted, FP denotes the count of instances in scenarios where the model incorrectly labels the negative class as positive, and FN represents the quantity of examples where the classifier mistakenly classifies the positive class as negative.
3.4. Experimental Data Analysis
3.4.1. Feature Visualization of the Dataset
As illustrated in Figure 6a, the dataset utilized in this experiment maintains an equal distribution between real and fake face images. This balance enables the detection model to capture more nuanced features, reducing the risk of bias toward either real or fake images, and ultimately enhancing both the accuracy and fairness of the model. Figure 6b depicts the spread of the central points of the forged components inside the manipulated face images, highlighting that the forged parts are primarily concentrated in the center region of the image. The analysis of the distribution pattern of aspect ratios of the manipulated components, as depicted in Figure 6c, provides valuable insights into their structural variations and patterns within the dataset. It is evident that the aspect ratios of the forged elements in the majority of fake face images tend to cluster into two distinct extremes: one with smaller aspect ratios and the other with larger ones.
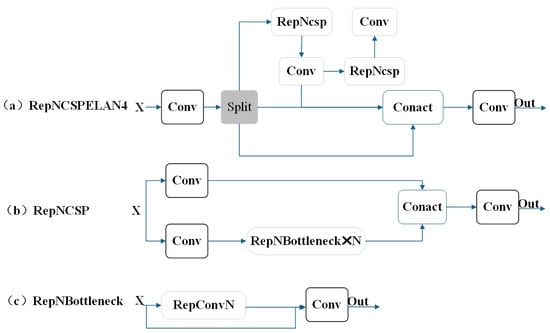
Figure 6.
Feature map of the dataset. This diagram analyzes the proportions of real and forged facial images, the distribution of the center coordinates of the forged parts in the facial images, and the aspect ratio analysis of the forged parts.
3.4.2. Training Loss
The performance measure of YOLOv9-ARC is composed of three segments: classification loss (cls_loss), bounding box regression loss (box_loss), and distribution focal loss (dfl_loss).
Classification loss quantifies the inconsistency in comparison to the object identified by the model class and the actual class label.
Bounding box regression loss assesses the magnitude of similarity connecting the model’s forecasted bounding box and the reference values box, refining the model’s effectiveness in localizing and providing a more accurate fit of the predicted bounding box around the target object.
Distribution focal loss models the distribution of each coordinate, enhancing the accuracy of bounding box regression.
As illustrated in Figure 7, after roughly training conducted over 10 epochs, tangible improvements in model performance were realized with the help of numerous adjustments to the model parameters. In the next phase, the loss reduction rate progressively diminished and reached a steady state, making the detection process more well-calibrated and productive.
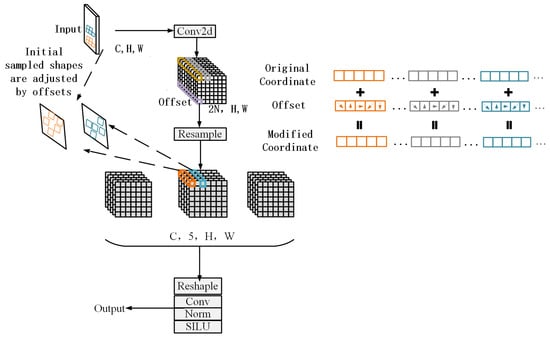
Figure 7.
Training loss graph of the model. The model training loss curve demonstrates the changes in the loss value during the training process, showing how the model improves or converges over time.
3.4.3. Ablation Experiment
To assess the impact of each individual module, this study conducts a series of ablation experiments for comparative evaluation, providing valuable insights and methods for understanding the role of specific modules or combinations of modules within the overall model.
The outcomes achieved by the ablation investigations are presented in Table 1. The changes in evaluation metrics such as mean average precision (mAP), precision (P), recall (R), and F1-score for the YOLOv9 baseline model and the proposed improved model for deepfake face detection are shown in Figure 8.

Table 1.
Ablation experiment results with efficiency metrics.
Figure 8.
Experimental results graph. This diagram shows the changes in evaluation metrics, such as average accuracy, precision, and recall, for the YOLOv9 baseline model and the improved model proposed in this paper, applied to the forged face detection task.
Building upon the YOLOv9 baseline model, this paper updates the feature extraction module and adds the CBAM attention mechanism to the backbone architecture, resulting in the YOLOv9-ARC deepfake face detection model. Enhancements to the feature extraction module improve the network’s capability to comprehend relevant features, reducing the adverse effects of noise, artifacts, and other elements present in low-quality face images within the dataset. Although this modification slightly decreases precision (P), recall (R), and F1-score, the mean average precision (mAP) improves by 2.1%.
Additionally, by adding the CBAM attention mechanism to the baseline model, the detection model places greater emphasis on key information in fake face images, reducing the weight given to irrelevant information. As a result, the mAP, precision (P), recall (R), and F1-score are improved by 1.4%, 6.8%, 8.3%, and 7.5%, respectively.
In addition to performance improvements, efficiency metrics also reflect the advantages of the proposed model. Specifically, the YOLOv9-ARC model reduces the inference time from 45 ms to 32 ms per image, indicating a 28.9% improvement in processing speed. Despite the architectural enhancements, the FLOPs only slightly decrease from 130 G to 128 G, demonstrating that the model maintains computational efficiency while delivering stronger detection performance.
Through the improvements in these aspects, the detection model’s accuracy in detecting deepfake faces is enhanced, leading to increases of 3.5%, 4.6%, 5.2%, and 4.9% in the final evaluation metrics.
3.4.4. Comparative Experiment
Comparative experiments are a research methodology used to evaluate the performance variations between different models by applying them to the same task under controlled, consistent conditions. This helps to determine the most cost-effective detection model based on a comprehensive evaluation of factors such as processing cost and benefits.
To evaluate the usefulness of the model under consideration, this study conducts a comparison with prominent object detection models, including those from the YOLOv series, using the same dataset. The conclusions drawn from the comparative investigations are shown in Table 2.
Table 2.
Comparative experiment results table.
Table 2 presents a comprehensive comparison of deepfake face detection models across both performance and efficiency metrics. YOLOv9-ARC achieves the best overall performance, attaining the highest mAP (0.751), recall (0.925), and F1-score (0.849), while maintaining a high precision (0.784), second only to YOLOv3. These results suggest that YOLOv9-ARC is highly effective at detecting positive samples (i.e., forged images) with minimal compromise in misclassification control.
From an efficiency perspective, YOLOv9-ARC records an inference time of just 32 ms and 128 GFLOPs—substantially faster and lighter than many competing models, including YOLOv5x and EfficientNet-B0. This indicates that the proposed architectural enhancements, such as AKConv and CBAM, improve feature extraction and attention without imposing additional computational burden.
Furthermore, compared to lightweight models like MobileNetV3-Large and YOLOv8n, YOLOv9-ARC delivers significantly better detection accuracy while maintaining comparable computational cost. This trade-off demonstrates that YOLOv9-ARC is not only suitable for high-performance systems but also adaptable to real-time or resource-constrained environments.
Overall, these results underscore the effectiveness of the proposed modules in enhancing robustness to low-quality deepfake images and validate the model’s suitability for practical deployment scenarios where both speed and accuracy are critical.
3.4.5. Statistical Testing Section
In this study, we propose a novel method for detecting low-quality fake facial images based on the YOLOv9-ARC model, which is validated on a comprehensive dataset. The core research question is whether the introduction of the Adaptive Kernel Convolution (AKConv) module and the Convolutional Block Attention Module (CBAM) can significantly enhance the detection accuracy of low-quality fake facial images. To address this, we formulate two hypotheses: the null hypothesis (H0) posits that there is no significant difference in detection accuracy between the YOLOv9-ARC model and other models, while the alternative hypothesis (H1) asserts that the YOLOv9-ARC model significantly improves detection performance.
The experiment utilizes a dataset comprising various types of fake facial images, particularly those affected by low resolution, blurring, and noise. The primary evaluation metric is the mean average precision (mAP). To ensure the reliability of the experimental results, three non-parametric statistical methods—the Mann–Whitney U test, Kruskal–Wallis H test, and Wilcoxon signed-rank test—are employed to compare model performance with a significance level set at = 0. 05.
Given that the detection data may not follow a normal distribution and may contain outliers, non-parametric statistical methods are chosen to avoid the assumptions required for parametric tests. The Mann–Whitney U test is used to compare two independent samples, evaluating whether the YOLOv9-ARC model exhibits significantly higher detection accuracy than other models. The Kruskal–Wallis H test extends this analysis to multiple independent samples, determining whether at least one group shows a significant difference in detection accuracy among all models, though it does not identify the specific source of the difference. Additionally, the Wilcoxon signed-rank test is applied to paired sample data to assess whether the detection accuracy on the same test data differs significantly between different models, further confirming the stability of the YOLOv9-ARC model’s performance improvement.
The results of these statistical tests are presented in Table 3. The Mann–Whitney U test reveals that all p-values are below 0.05, indicating a significant difference in detection accuracy between the YOLOv9-ARC model and other models. The Kruskal–Wallis H test further confirms that there is at least one significant difference among all models, demonstrating that detection accuracy is not uniformly distributed. Moreover, the Wilcoxon signed-rank test results show that the YOLOv9-ARC model significantly outperforms other models on the same test data, validating the effectiveness of the proposed approach.
Table 3.
Statistical test results table.
In conclusion, the statistical analysis supports the effectiveness of the YOLOv9-ARC model in detecting low-quality fake facial images with statistically significant improvements. The results demonstrate that the YOLOv9-ARC model exhibits significantly better detection performance compared to other models. The integration of the AKConv kernel convolution module and the CBAM attention mechanism has indeed enhanced detection accuracy, and this improvement is statistically significant (p < 0.05). Consequently, the statistical test results support the alternative hypothesis (H1), affirming the superior detection capability of the YOLOv9-ARC model, while rejecting the null hypothesis (H0). These findings validate the effectiveness and practical value of the proposed method.
4. Discussion
This study proposes a novel method for detecting low-quality fake facial images based on the YOLOv9-ARC model and validates its effectiveness through extensive experiments. The experimental results demonstrate that YOLOv9-ARC achieves a mean average precision (mAP) of 75.1% on the DFDC (DeepFake Detection Challenge) dataset, representing a 3.5% improvement over the baseline model, highlighting the model’s superior detection performance in complex environments.
The primary advantage of YOLOv9-ARC lies in the integration of the Adaptive Kernel Convolution (AKConv) module, which dynamically adjusts the receptive field to enable more effective multi-scale feature extraction. Additionally, the Convolutional Block Attention Module (CBAM) enhances the model’s ability to focus on critical regions, further improving detection accuracy. Experimental results confirm that CBAM significantly boosts both precision and recall, validating its effectiveness in optimizing feature representation.
A deeper analysis reveals that the combination of AKConv and CBAM plays a critical role in the model’s success on low-quality images. AKConv allows adaptive kernel size adjustment based on local features, which helps mitigate challenges caused by noise, blur, and reduced resolution. Meanwhile, CBAM refines feature representation by emphasizing discriminative regions and suppressing redundant or noisy features. This synergy is particularly beneficial for detecting visually degraded or compressed deepfakes, which are prevalent in the DFDC dataset.
However, the DFDC dataset still contains challenging conditions such as extreme lighting, occlusion, and large pose variations, which may affect detection outcomes. Although YOLOv9-ARC improves most performance metrics, it can sometimes generate false positives due to its high sensitivity to subtle artifacts, resulting in slightly lower precision in specific cases.
The current evaluation is limited to a single dataset, and the model’s generalizability requires further validation on diverse datasets such as FaceForensics++ and Celeb-DF. Potential data bias and lack of adversarial robustness testing also present limitations. Future work will address these issues through cross-dataset evaluation, deployment optimization, and the integration of explainable AI techniques to improve interpretability and transparency.
Compared to prior research, YOLOv9-ARC demonstrates superior performance in detecting low-quality fake facial images. Traditional methods such as Faster R-CNN [] and EfficientNet [] excel on high-quality facial image datasets but exhibit significant performance degradation under conditions of low resolution, noise, or blur. Faster R-CNN, with its region proposal-based detection mechanism, offers strong accuracy but suffers from high computational complexity, making it unsuitable for real-time applications. EfficientNet, while effective for standard image classification tasks, struggles with low-resolution and high-noise environments due to its limited feature extraction capabilities. Recent advancements in YOLO series models [,,] have made them popular for face detection tasks due to their efficiency and robust feature extraction. However, studies reveal that YOLOv3 and YOLOv5 still face challenges such as false positives and missed detections in low-quality fake face detection. This is primarily due to the limitations of standard convolution in capturing multi-scale information and the lack of mechanisms to focus on key regions. While YOLOv3 employs a fixed-size receptive field, limiting its effectiveness for small-object detection, YOLOv5 improves computational efficiency through depth-wise separable convolution but remains constrained in feature extraction for high-noise data.
In contrast, YOLOv9-ARC introduces the AKConv variable convolution kernel and CBAM attention mechanism, significantly enhancing the model’s detection capability for low-quality images. Experimental results show that YOLOv9-ARC achieves a 3.5% improvement in mAP over the baseline model on the DFDC dataset and outperforms YOLOv5 and EfficientNet in noisy and low-resolution conditions. Analysis indicates that AKConv adaptively adjusts the receptive field based on input scales, improving the model’s ability to capture fine details, while CBAM enhances focus on key regions, reducing false detections. These advancements enable YOLOv9-ARC to maintain high detection accuracy even in complex environments, addressing gaps in existing research on low-quality fake face detection.
Despite the strong performance of YOLOv9-ARC in detecting low-quality forged facial images, several research opportunities remain across different levels of difficulty and innovation. As shown in Figure 9, future work can be structured into three progressive layers.
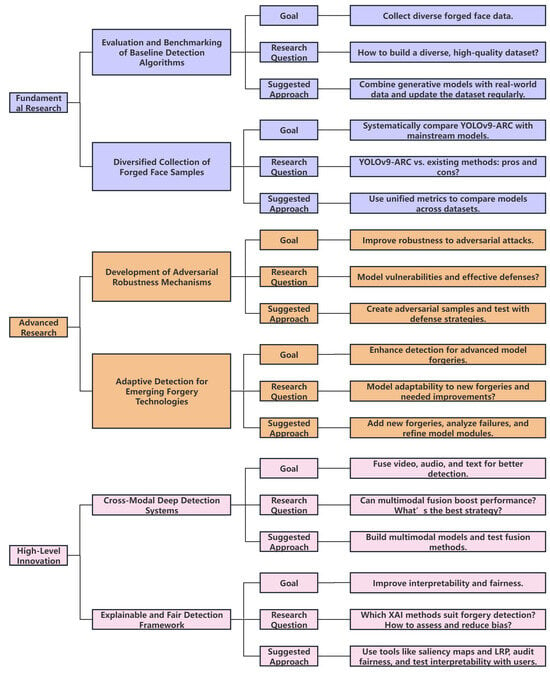
Figure 9.
YOLOv9-ARC future research roadmap. This diagram outlines a three-stage research framework to improve low-quality deepfake face detection: data enhancement, adversarial defense, and cross-modal innovations.
At the fundamental level, efforts should focus on constructing diverse and representative datasets. This includes collecting and synthesizing forged samples under extreme lighting, occlusion, and demographic variations, using both generative models and real-world data. Benchmarking across multiple datasets with standardized evaluation metrics (e.g., accuracy, recall) is also essential for understanding YOLOv9-ARC’s strengths and limitations compared to other state-of-the-art detectors.
In the advanced research stage, model robustness must be strengthened through adversarial training strategies and stress testing with examples generated by attacks like FGSM and PGD. Furthermore, adapting the model to detect forgeries created by emerging techniques such as diffusion models and advanced GANs requires structural enhancements in feature extraction and classification modules.
Moving into high-level innovation, future directions include the development of cross-modal detection systems that fuse video, audio, and text information to enhance robustness. Additionally, the integration of explainable AI (XAI) tools such as saliency maps and Layer-wise Relevance Propagation (LRP) can provide transparency and accountability, while fairness audits are crucial to ensure equitable model performance across demographic groups.
Future research should focus on optimizing computational efficiency to enable deployment in resource-constrained environments, such as mobile devices or embedded systems. Specifically, we plan to integrate lightweight neural network architectures (e.g., MobileNet, ShuffleNet) into the backbone of YOLOv9-ARC. These architectures are specifically designed to reduce the number of parameters and floating-point operations (FLOPs), which are key factors influencing model efficiency. For example, MobileNet uses depthwise separable convolutions, which significantly reduce the computational load by breaking the convolution operation into two parts: depthwise convolution (for each input channel) and pointwise convolution (to combine the outputs).
In addition to using lightweight backbones, we also consider applying model pruning techniques to remove redundant connections and neurons that do not significantly contribute to the model’s performance. This will help further reduce the model size and increase inference speed. Additionally, we plan to use knowledge distillation to transfer the knowledge from a larger, more complex model (teacher model) to a smaller, more efficient model (student model). By leveraging the student model’s compactness, we aim to maintain detection accuracy while significantly reducing computational overhead.
These strategies (lightweight architecture, pruning, and distillation) are specifically targeted at reducing inference time, memory footprint, and power consumption, all of which are critical when deploying models in resource-constrained environments such as mobile devices and embedded systems.
In future experiments, we will benchmark the optimized models on low-power hardware, such as Jetson Nano or ARM-based devices, and evaluate their practical deployment feasibility by measuring key performance indicators, including inference time (latency), memory usage, frames per second (FPS), and detection accuracy (mAP) on benchmark datasets. These metrics will help assess the model’s efficiency, resource consumption, and performance in real-time applications. The evaluations will help us determine the trade-off between model size, accuracy, and real-time processing capability, ensuring that YOLOv9-ARC remains efficient and effective even in environments with limited computational resources.
In summary, this study demonstrates the effectiveness of the YOLOv9-ARC model in detecting low-quality fake facial images, achieving significant improvements through the integration of AKConv and CBAM. However, future research must address challenges related to dataset diversity, computational efficiency, robustness in complex environments, and adaptability to emerging deepfake technologies. By focusing on these areas, the practical application value of fake facial image detection models can be further enhanced, contributing to the development of more reliable and scalable solutions.
5. Conclusions
In order to solve the problem of poor detection accuracy of deepfake face detection models in the real environment due to the inclusion of low-quality facial images, this paper presents a detection model YOLOv9-ARC. A low-quality face image usually contains loads of noise, artifacts, and other deleterious elements; thus, after we improve the feature extraction module (shown in Figure 2) in YOLOv9’s baseline architecture, the model has better performance in feature extraction and feature fusion. Moreover, the CBAM attention mechanism is integrated with the backbone network of the original model, fostering the model’s attention on necessary information and minimizing the occurrence of irrelevant or repetitive information. The YOLOv9-ARC detection models show better performance on low-quality images than existing alternatives, as evidenced by the results of a number of comparative and ablation studies on the DFDC dataset. Nevertheless, there remains room for enhancement regarding detection performance and model efficiency. In future work, we plan to optimize the speed of detection and lower the computational cost of the model.
Author Contributions
Conceptualization and design: G.W.; data collection and experimentation: G.W., Y.H. and F.X.; data analysis: G.W., Y.G. and W.S.; writing and revision: G.W. and Y.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Shandong Provincial Science and Technology-Based Small and Medium-Sized Enterprises Innovation Capacity Improvement Project, grant number 2024TSGC0158, and supported by Mr. Liu Qiang, an employee of Shandong Xinhua’an Information Technology Co., Ltd.
Institutional Review Board Statement
This study used the publicly released DeepFake Detection Challenge (DFDC) dataset. Ethical review and approval were waived due to the fact that all video materials in the dataset were collected by Meta (formerly Facebook) from contracted actors under signed informed consent. Meta explicitly states that the dataset is intended solely for non-commercial academic research, and prior to its public release, all data were processed for identity anonymization and use restriction. Therefore, ethical clearance was obtained by Meta during data acquisition, and the dataset includes appropriate legal and ethical safeguards.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study. The DFDC dataset consists of video materials collected from contracted actors who provided informed consent for participation. Written informed consent has been obtained from the participants to publish the associated data.
Data Availability Statement
The data presented in this study are available in the DFDC dataset. These data were derived from the following resources available in the public domain: https://ai.meta.com/datasets/dfdc/ (accessed on 22 June 2025).
Acknowledgments
I would like to sincerely thank the students from Shandong University of Science and Technology for their diligence, intelligence, and relentless pursuit throughout the research process. Their contributions have been crucial to the successful completion of this study. Once again, I express my heartfelt gratitude to all the individuals and organizations who have supported and assisted this research.
Conflicts of Interest
The authors declare that this study received funding from Shandong Xinhua’an Information Technology Co., Ltd. The funder was not involved in the study design, collection, analysis, interpretation of data, the writing of this article or the decision to submit it for publication.
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Nguyen, T.T.; Nguyen, Q.V.H.; Nguyen, D.T.; Nguyen, D.T.; Huynh-The, T.; Nahavandi, S.; Nguyen, T.T.; Pham, Q.-V.; Nguyen, C.M. Deep learning for deepfakes creation and detection: A survey. Comput. Vis. Image Underst. 2022, 223, 103525. [Google Scholar] [CrossRef]
- De Ruiter, A. The distinct wrong of deepfakes. Philos. Technol. 2021, 34, 1311–1332. [Google Scholar] [CrossRef]
- Zhao, H.; Zhou, W.; Chen, D.; Wei, T.; Zhang, W.; Yu, N. Multi-attentional deepfake detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 2185–2194. [Google Scholar]
- Lee, S.; Tariq, S.; Kim, J.; Woo, S.S. TAR: Generalized forensic framework to detect deepfakes using weakly supervised learning. In Proceedings of the IFIP International Conference on ICT Systems Security and Privacy Protection, Oslo, Norway, 22–24 June 2021; Springer: Cham, Switzerland, 2021; pp. 351–366. [Google Scholar]
- Rössler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. FaceForensics++: Learning to detect manipulated facial images. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1–11. [Google Scholar]
- Wang, C.; Deng, W. Representative forgery mining for fake face detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 14923–14932. [Google Scholar]
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Morales, A.; Ortega-Garcia, J. Deepfakes and beyond: A survey of face manipulation and fake detection. Inf. Fusion 2020, 64, 131–148. [Google Scholar] [CrossRef]
- Dolhansky, B.; Bitton, J.; Pflaum, B.; Lu, J.; Howes, R.; Wang, M.; Ferrer, C.C. The Deepfake Detection Challenge (DFDC) Dataset. arXiv 2020, arXiv:2006.07397. [Google Scholar]
- Zhou, Y.; Liu, D.; Huang, T. Survey of face detection on low-quality images. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 769–773. [Google Scholar]
- Yu, P.; Xia, Z.; Fei, J.; Lu, Y. A survey on deepfake video detection. IET Biom. 2021, 10, 607–624. [Google Scholar] [CrossRef]
- Zou, Y.; Luo, C.; Zhang, J. DIFLD: Domain invariant feature learning to detect low-quality compressed face forgery images. Complex Intell. Syst. 2024, 10, 357–368. [Google Scholar] [CrossRef]
- Kiruthika, S.; Masilamani, V. Image quality assessment based fake face detection. Multimed. Tools Appl. 2023, 82, 8691–8708. [Google Scholar]
- Sohaib, M.; Tehseen, S. Forgery detection of low quality deepfake videos. Neural Netw. World 2023, 33, 85. [Google Scholar] [CrossRef]
- Masood, M.; Nawaz, M.; Malik, K.M.; Javed, A.; Irtaza, A.; Malik, H. Deepfakes generation and detection: State-of-the-art, open challenges, countermeasures, and way forward. Appl. Intell. 2023, 53, 3974–4026. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, D.; Yang, J.; Han, W.; Huang, T. Deep networks for image super-resolution with sparse prior. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 370–378. [Google Scholar]
- Herrmann, C. Extending a local matching face recognition approach to low-resolution video. In Proceedings of the 2013 10th IEEE International Conference on Advanced Video and Signal Based Surveillance, Krakow, Poland, 27–30 August 2013; pp. 460–465. [Google Scholar]
- Heinsohn, D.; Villalobos, E.; Prieto, L.; Mery, D. Face recognition in low-quality images using adaptive sparse representations. Image Vis. Comput. 2019, 85, 46–58. [Google Scholar] [CrossRef]
- Kim, H.-I.; Lee, S.H.; Ro, Y.M. Adaptive feature extraction for blurred face images in facial expression recognition. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 5971–5975. [Google Scholar]
- Lin, S.; Jiang, C.; Liu, F.; Shen, L. High quality facial data synthesis and fusion for 3D low-quality face recognition. In Proceedings of the 2021 IEEE International Joint Conference on Biometrics (IJCB), Shenzhen, China, 4–7 August 2021; pp. 1–8. [Google Scholar]
- Mu, G.; Huang, D.; Hu, G.; Sun, J.; Wang, Y. LED3D: A lightweight and efficient deep approach to recognizing low-quality 3D faces. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5773–5782. [Google Scholar]
- Zhang, J.; Huang, D.; Wang, Y.; Sun, J. Lock3DFace: A large-scale database of low-cost Kinect 3D faces. In Proceedings of the 2016 International Conference on Biometrics (ICB), Halmstad, 13–16 June 2016; pp. 1–8. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. YOLOv9: Learning what you want to learn using programmable gradient information. In Proceedings of the European Conference Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 1–21. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, X.; Song, Y.; Song, T.; Yang, D.; Ye, Y.; Zhou, J.; Zhang, L. AKConv: Convolutional kernel with arbitrary sampled shapes and arbitrary number of parameters. arXiv 2023, arXiv:2311.11587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Tan, M.; Le, Q. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).