
A Transformer-Based Reinforcement Learning Framework for Sequential Strategy Optimization in Sparse Data

Abstract
1. Introduction
- High-dimensional heterogeneous state modeling and long short-term return balancing: A DRL-based pricing framework is proposed that effectively addresses the challenges of modeling high-dimensional heterogeneous states and balancing short- and long-term returns using large-scale economic behavior data.
- Reward enhancement via price perturbation and delayed-feedback revisitation: A novel reward enhancement mechanism is designed based on price perturbation and delayed-feedback tracing, significantly improving model stability and applicability in real-world big data environments, especially under delayed-feedback and sparse-data conditions.
- Comprehensive empirical validation and multi-scenario applicability: Extensive experiments on multiple real-world economic datasets demonstrate the proposed method’s superior performance in terms of revenue growth rate, pricing stability, and policy generalization compared to existing baseline approaches.
2. Related Works
2.1. Traditional Pricing Models and Strategies
2.2. Applications of Deep Reinforcement Learning in Pricing Scenarios
2.3. Revenue Prediction and Economic Behavior Modeling
3. Materials and Method
3.1. Dataset Collection
3.2. Data Preprocessing and Augmentation
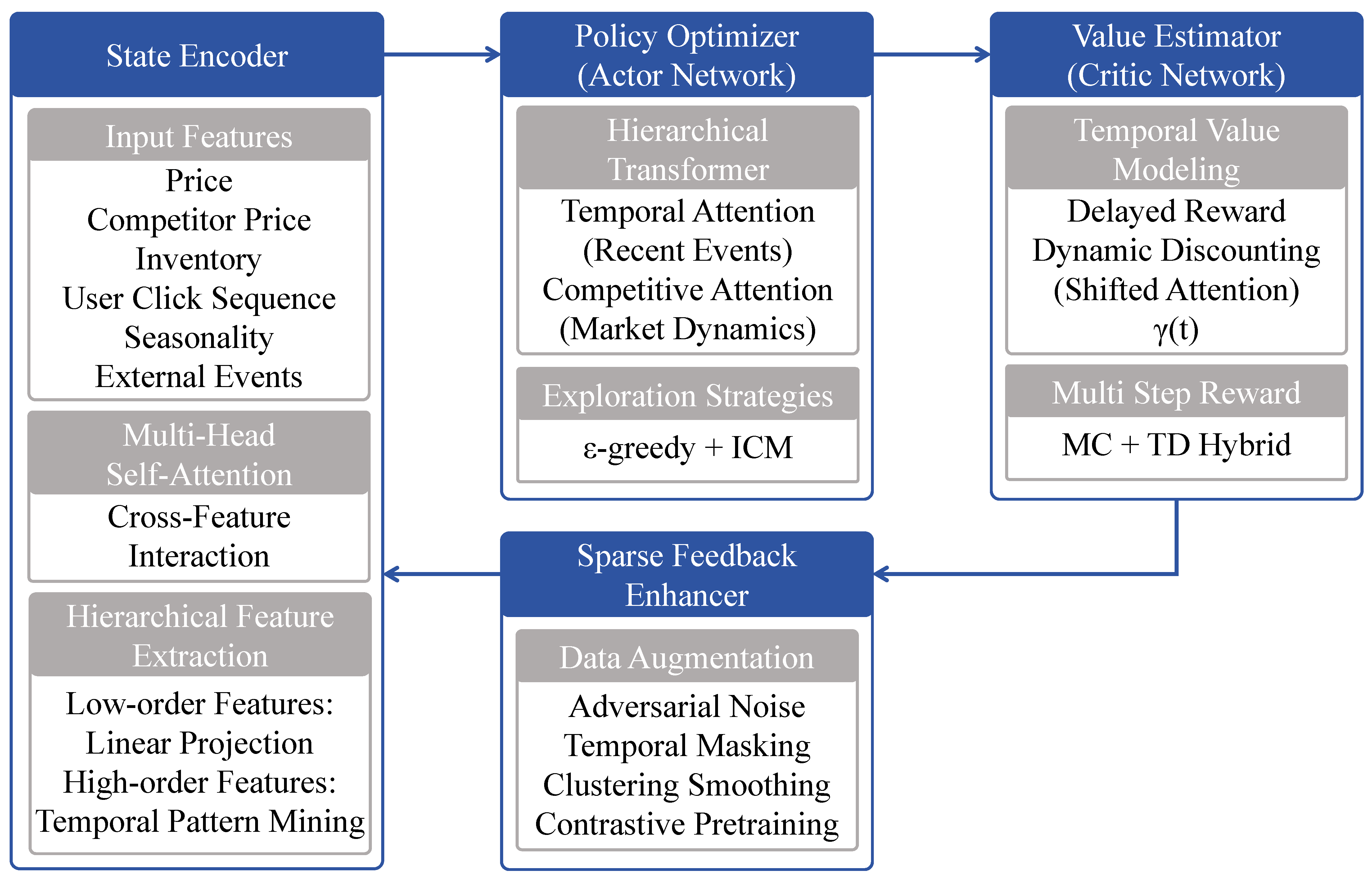
3.3. Proposed Method
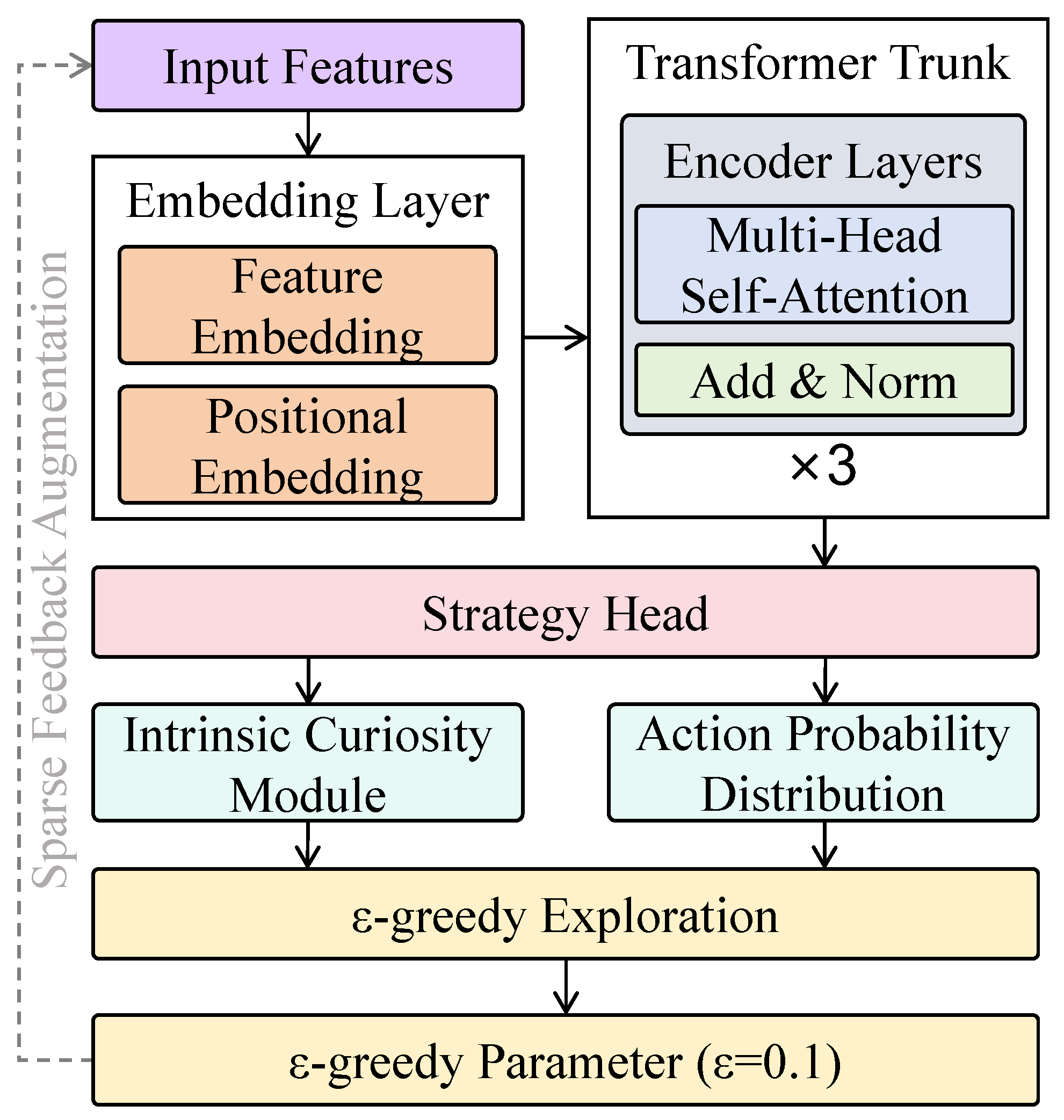
3.3.1. Policy-Learning Module
3.3.2. Reward Estimation Module
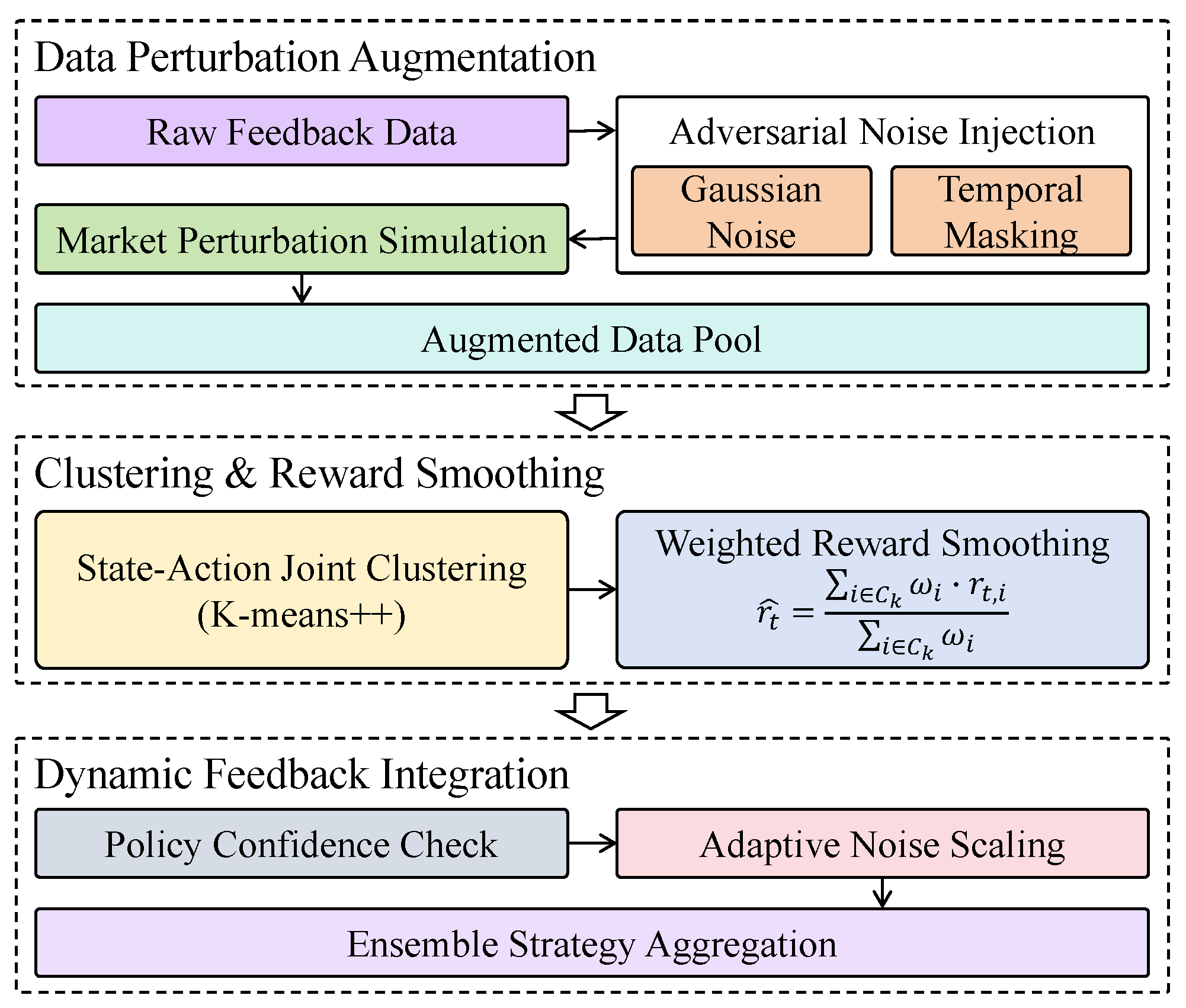
3.3.3. Sparse-Feedback-Enhancement Module
4. Results and Discussion
4.1. Experimental Setup and Evaluation Metrics
4.1.1. Hardware and Software Platform
4.1.2. Hyperparameter Settings
4.1.3. Evaluation Metrics
4.2. Comparative Experiments and Baselines
4.3. Results and Analysis
4.3.1. Experimental Results of Different Pricing-Strategy Models
4.3.2. Performance Evaluation on Different Subsets of Economic Behavior Data
4.3.3. Ablation Study of Key Modules in the Proposed Method
4.3.4. Cross-Stock Domain Transfer Evaluation
4.4. Discussion
4.4.1. Empirical Findings and Behavioral Insights
4.4.2. Computational Complexity Analysis
4.5. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sedliacikova, M.; Moresova, M.; Alac, P.; Drabek, J. How do behavioral aspects affect the financial decisions of managers and the competitiveness of enterprises? J. Compet. 2021, 13, 99–116. [Google Scholar] [CrossRef]
- Umapathy, T. Behavioral Economics: Understanding Irrationality In Economic Decision-Making. Migr. Lett. 2024, 21, 923–932. [Google Scholar]
- Zhou, X.; Chen, S.; Ren, Y.; Zhang, Y.; Fu, J.; Fan, D.; Lin, J.; Wang, Q. Atrous Pyramid GAN Segmentation Network for Fish Images with High Performance. Electronics 2022, 11, 911. [Google Scholar] [CrossRef]
- Das, P.; Pervin, T.; Bhattacharjee, B.; Karim, M.R.; Sultana, N.; Khan, M.S.; Hosien, M.A.; Kamruzzaman, F. Optimizing real-time dynamic pricing strategies in retail and e-commerce using machine learning models. Am. J. Eng. Technol. 2024, 6, 163–177. [Google Scholar] [CrossRef]
- Alwan, A.A.; Ciupala, M.A.; Brimicombe, A.J.; Ghorashi, S.A.; Baravalle, A.; Falcarin, P. Data quality challenges in large-scale cyber-physical systems: A systematic review. Inf. Syst. 2022, 105, 101951. [Google Scholar] [CrossRef]
- Yin, C.; Han, J. Dynamic pricing model of e-commerce platforms based on deep reinforcement learning. Comput. Model. Eng. Sci. 2021, 127, 291–307. [Google Scholar] [CrossRef]
- Izaret, J.M.; Sinha, A. Game Changer: How Strategic Pricing Shapes Businesses, Markets, and Society; John Wiley & Sons: Hoboken, NJ, USA, 2023. [Google Scholar]
- Zhang, L.; Zhang, Y.; Ma, X. A New Strategy for Tuning ReLUs: Self-Adaptive Linear Units (SALUs). In Proceedings of the ICMLCA 2021; 2nd International Conference on Machine Learning and Computer Application, VDE, Shenyang, China, 17–19 December 2021; pp. 1–8. [Google Scholar]
- Nagle, T.T.; Müller, G.; Gruyaert, E. The Strategy and Tactics of Pricing: A Guide to Growing More Profitably; Routledge: London, UK, 2023. [Google Scholar]
- Gast, R.; Solla, S.A.; Kennedy, A. Neural heterogeneity controls computations in spiking neural networks. Proc. Natl. Acad. Sci. USA 2024, 121, e2311885121. [Google Scholar] [CrossRef]
- Mehrjoo, S.; Amoozad Mahdirji, H.; Heidary Dahoei, J.; Razavi Haji Agha, S.H.; Hosseinzadeh, M. Providing a Robust Dynamic Pricing Model and Comparing It with Static Pricing in Multi-level Supply Chains Using a Game Theory Approach. Ind. Manag. J. 2023, 15, 534–565. [Google Scholar]
- Jalota, D.; Ye, Y. Stochastic online fisher markets: Static pricing limits and adaptive enhancements. Oper. Res. 2025, 73, 798–818. [Google Scholar] [CrossRef]
- Cohen, M.C.; Miao, S.; Wang, Y. Dynamic pricing with fairness constraints. SSRN 2021, 09, 3930622. [Google Scholar] [CrossRef]
- Sari, E.I.P.; Aurachman, R.; Akbar, M.D. Determination Price Ticket Of Airline Low-cost Carrier Based On Dynamic Pricing Strategy Using Multiple Regression Method. eProceedings Eng. 2021, 8, 6881–6892. [Google Scholar]
- Skiera, B.; Reiner, J.; Albers, S. Regression analysis. In Handbook of Market Research; Springer: Berlin/Heidelberg, Germany, 2021; pp. 299–327. [Google Scholar]
- Li, Q.; Ren, J.; Zhang, Y.; Song, C.; Liao, Y.; Zhang, Y. Privacy-Preserving DNN Training with Prefetched Meta-Keys on Heterogeneous Neural Network Accelerators. In Proceedings of the 2023 60th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 9–13 July 2023; pp. 1–6. [Google Scholar]
- Anis, H.T.; Kwon, R.H. A sparse regression and neural network approach for financial factor modeling. Appl. Soft Comput. 2021, 113, 107983. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, Y.; Ren, J.; Li, Q.; Zhang, Y. You Can Use But Cannot Recognize: Preserving Visual Privacy in Deep Neural Networks. arXiv 2024, arXiv:2404.04098. [Google Scholar]
- Li, D.; Xin, J. Deep learning-driven intelligent pricing model in retail: From sales forecasting to dynamic price optimization. Soft Comput. 2024, 28, 12281–12297. [Google Scholar] [CrossRef]
- Chuang, Y.C.; Chiu, W.Y. Deep reinforcement learning based pricing strategy of aggregators considering renewable energy. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 6, 499–508. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, Y. Confidential Federated Learning for Heterogeneous Platforms against Client-Side Privacy Leakages. In Proceedings of the ACM Turing Award Celebration Conference, Changsha, China, 5–7 July 2024; pp. 239–241. [Google Scholar]
- Massahi, M.; Mahootchi, M. A deep Q-learning based algorithmic trading system for commodity futures markets. Expert Syst. Appl. 2024, 237, 121711. [Google Scholar] [CrossRef]
- Park, M.; Kim, J.; Enke, D. A novel trading system for the stock market using Deep Q-Network action and instance selection. Expert Syst. Appl. 2024, 257, 125043. [Google Scholar] [CrossRef]
- Liang, Y.; Hu, Y.; Luo, D.; Zhu, Q.; Chen, Q.; Wang, C. Distributed Dynamic Pricing Strategy Based on Deep Reinforcement Learning Approach in a Presale Mechanism. Sustainability 2023, 15, 10480. [Google Scholar] [CrossRef]
- Zhu, X.; Jian, L.; Chen, X.; Zhao, Q. Reinforcement learning for Multi-Flight Dynamic Pricing. Comput. Ind. Eng. 2024, 193, 110302. [Google Scholar] [CrossRef]
- Paudel, D.; Das, T.K. Tacit Algorithmic Collusion in Deep Reinforcement Learning Guided Price Competition: A Study Using EV Charge Pricing Game. arXiv 2024, arXiv:2401.15108. [Google Scholar] [CrossRef]
- Alabi, M. Data-Driven Pricing Optimization: Using Machine Learning to Dynamically Adjust Prices Based on Market Conditions. J. Pricing Strategy Anal. 2024, 12, 45–59. [Google Scholar]
- Avramelou, L.; Nousi, P.; Passalis, N.; Tefas, A. Deep reinforcement learning for financial trading using multi-modal features. Expert Syst. Appl. 2024, 238, 121849. [Google Scholar] [CrossRef]
- Yan, Y.; Zhang, C.; An, Y.; Zhang, B. A Deep-Reinforcement-Learning-Based Multi-Source Information Fusion Portfolio Management Approach via Sector Rotation. Electronics 2025, 14, 1036. [Google Scholar] [CrossRef]
- Wang, C.H.; Wang, Z.; Sun, W.W.; Cheng, G. Online regularization toward always-valid high-dimensional dynamic pricing. J. Am. Stat. Assoc. 2024, 119, 2895–2907. [Google Scholar] [CrossRef]
- Chen, Y.; Wu, J.; Wu, Z. China’s commercial bank stock price prediction using a novel K-means-LSTM hybrid approach. Expert Syst. Appl. 2022, 202, 117370. [Google Scholar] [CrossRef]
- Liu, D.; Wang, W.; Wang, L.; Jia, H.; Shi, M. Dynamic pricing strategy of electric vehicle aggregators based on DDPG reinforcement learning algorithm. IEEE Access 2021, 9, 21556–21566. [Google Scholar] [CrossRef]
- He, Y.; Gu, C.; Gao, Y.; Wang, J. Bi-level day-ahead and real-time hybrid pricing model and its reinforcement learning method. Energy 2025, 322, 135316. [Google Scholar] [CrossRef]
- Khedr, A.M.; Arif, I.; El-Bannany, M.; Alhashmi, S.M.; Sreedharan, M. Cryptocurrency price prediction using traditional statistical and machine-learning techniques: A survey. Intell. Syst. Accounting, Financ. Manag. 2021, 28, 3–34. [Google Scholar] [CrossRef]
- Kenyon, P. Pricing. In A Guide to Post-Keynesian Economics; Routledge: London, UK, 2023; pp. 34–45. [Google Scholar]
- Ali, B.J.; Anwar, G. Marketing Strategy: Pricing strategies and its influence on consumer purchasing decision. Int. J. Rural. Dev. Environ. Health Res. 2021, 5, 26–39. [Google Scholar] [CrossRef]
- Gerpott, T.J.; Berends, J. Competitive pricing on online markets: A literature review. J. Revenue Pricing Manag. 2022, 21, 596. [Google Scholar] [CrossRef]
- Zhao, Y.; Hou, R.; Lin, X.; Lin, Q. Two-period information-sharing and quality decision in a supply chain under static and dynamic wholesale pricing strategies. Int. Trans. Oper. Res. 2022, 29, 2494–2522. [Google Scholar] [CrossRef]
- Zhao, C.; Wang, X.; Xiao, Y.; Sheng, J. Effects of online reviews and competition on quality and pricing strategies. Prod. Oper. Manag. 2022, 31, 3840–3858. [Google Scholar] [CrossRef]
- Basal, M.; Saraç, E.; Özer, K. Dynamic pricing strategies using artificial intelligence algorithm. Open J. Appl. Sci. 2024, 14, 1963–1978. [Google Scholar] [CrossRef]
- Chen, P.; Han, L.; Xin, G.; Zhang, A.; Ren, H.; Wang, F. Game theory based optimal pricing strategy for V2G participating in demand response. IEEE Trans. Ind. Appl. 2023, 59, 4673–4683. [Google Scholar] [CrossRef]
- Patel, P. Modelling Cooperation, Competition, and Equilibrium: The Enduring Relevance of Game Theory in Shaping Economic Realities. Soc. Sci. Chron. 2021, 1, 1–19. [Google Scholar] [CrossRef]
- Ghosh, P.K.; Manna, A.K.; Dey, J.K.; Kar, S. Supply chain coordination model for green product with different payment strategies: A game theoretic approach. J. Clean. Prod. 2021, 290, 125734. [Google Scholar] [CrossRef]
- Bekius, F.; Meijer, S.; Thomassen, H. A real case application of game theoretical concepts in a complex decision-making process: Case study ERTMS. Group Decis. Negot. 2022, 31, 153–185. [Google Scholar] [CrossRef]
- Li, C.; Zheng, P.; Yin, Y.; Wang, B.; Wang, L. Deep reinforcement learning in smart manufacturing: A review and prospects. CIRP J. Manuf. Sci. Technol. 2023, 40, 75–101. [Google Scholar] [CrossRef]
- Zhou, S.K.; Le, H.N.; Luu, K.; Nguyen, H.V.; Ayache, N. Deep reinforcement learning in medical imaging: A literature review. Med. Image Anal. 2021, 73, 102193. [Google Scholar] [CrossRef]
- Shakya, A.K.; Pillai, G.; Chakrabarty, S. Reinforcement learning algorithms: A brief survey. Expert Syst. Appl. 2023, 231, 120495. [Google Scholar] [CrossRef]
- Elbrächter, D.; Perekrestenko, D.; Grohs, P.; Bölcskei, H. Deep neural network approximation theory. IEEE Trans. Inf. Theory 2021, 67, 2581–2623. [Google Scholar] [CrossRef]
- Liang, Z.; Yang, R.; Wang, J.; Liu, L.; Ma, X.; Zhu, Z. Dynamic constrained evolutionary optimization based on deep Q-network. Expert Syst. Appl. 2024, 249, 123592. [Google Scholar] [CrossRef]
- Ke, D.; Fan, X. Deep reinforcement learning models in auction item price prediction: An optimisation study of a cross-interval quotation strategy. PeerJ Comput. Sci. 2024, 10, e2159. [Google Scholar] [CrossRef] [PubMed]
- Xiao, Y.; Tan, W.; Amato, C. Asynchronous actor-critic for multi-agent reinforcement learning. Adv. Neural Inf. Process. Syst. 2022, 35, 4385–4400. [Google Scholar]
- Sumiea, E.H.; Abdulkadir, S.J.; Alhussian, H.S.; Al-Selwi, S.M.; Alqushaibi, A.; Ragab, M.G.; Fati, S.M. Deep deterministic policy gradient algorithm: A systematic review. Heliyon 2024, 10, e30697. [Google Scholar] [CrossRef]
- Shen, H.; Zhang, K.; Hong, M.; Chen, T. Towards understanding asynchronous advantage actor-critic: Convergence and linear speedup. IEEE Trans. Signal Process. 2023, 71, 2579–2594. [Google Scholar] [CrossRef]
- Wang, X.; Wang, S.; Liang, X.; Zhao, D.; Huang, J.; Xu, X.; Dai, B.; Miao, Q. Deep reinforcement learning: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 5064–5078. [Google Scholar] [CrossRef] [PubMed]
- Arthur, W.B. Foundations of complexity economics. Nat. Rev. Phys. 2021, 3, 136–145. [Google Scholar] [CrossRef]
- Vishnevskaya, O.; Irtyshcheva, I.; Kramarenko, I.; Popadynets, N. The influence of globalization processes on forecasting the activities of market entities. J. Optim. Ind. Eng. 2022, 15, 261–268. [Google Scholar]
- Ghimire, S.; Yaseen, Z.M.; Farooque, A.A.; Deo, R.C.; Zhang, J.; Tao, X. Streamflow prediction using an integrated methodology based on convolutional neural network and long short-term memory networks. Sci. Rep. 2021, 11, 17497. [Google Scholar] [CrossRef]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Zhang, W.; Luo, C. Decomposition-based multi-scale transformer framework for time series anomaly detection. Neural Netw. 2025, 187, 107399. [Google Scholar] [CrossRef] [PubMed]
- Dixit, A.; Jain, S. Contemporary approaches to analyze non-stationary time-series: Some solutions and challenges. Recent Adv. Comput. Sci. Commun. (Former. Recent Patents Comput. Sci.) 2023, 16, 61–80. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Osband, I.; Blundell, C.; Pritzel, A.; Van Roy, B. Deep exploration via bootstrapped DQN. Adv. Neural Inf. Process. Syst. 2016, 29, 231–245. [Google Scholar]
- Koroteev, M.V. BERT: A review of applications in natural language processing and understanding. arXiv 2021, arXiv:2103.11943. [Google Scholar]
- Wang, C.; Chen, Y.; Zhang, S.; Zhang, Q. Stock market index prediction using deep Transformer model. Expert Syst. Appl. 2022, 208, 118128. [Google Scholar] [CrossRef]
- Bhandari, H.N.; Rimal, B.; Pokhrel, N.R.; Rimal, R.; Dahal, K.R.; Khatri, R.K. Predicting stock market index using LSTM. Mach. Learn. Appl. 2022, 9, 100320. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Source Platforms | Number of Records | Collection Period |
|---|---|---|---|
| Product Pricing Records | JD, Taobao, Suning | 205,890 | April–December 2023 |
| Sales Feedback | Taobao, Suning, Vipshop | 280,312 | July–December 2023 |
| User Browsing Behavior | Taobao, Suning | 279,034 | January–June 2023 |
| Inventory Levels | JD, Taobao | 348,910 | February–October 2023 |
| Total | —— | 1,000,000+ | Daily Time Series |
| Layer | Input Dim | Output Dim | Param |
|---|---|---|---|
| Input Embedding | 4 | 128 | 512 |
| Positional Encoding | – | 128 | 0 |
| Multi-Head Attention (4 heads) | 128 | 128 | 49,152 |
| Feed-Forward Network (FFN) | 128 | 128 | 65,536 |
| LayerNorm × 2 | 128 | 128 | 256 |
| Dropout | – | – | 0 |
| GRU-based Value Head | 128 | 1 | 98,432 |
| Policy Head (MLP) | 128 | 3 | 384 |
| Total | – | – | 214,272 |
| Model | Total Profit Gain | Average Reward | Std. of Actions | Sharpe Ratio | Max Drawdown | |
|---|---|---|---|---|---|---|
| XGBoost [61] | 0.12 | 3.25 | 0.97 | 0.61 | 0.64 | 0.43 |
| BERT [63] | 0.17 | 3.56 | 0.89 | 0.68 | 0.68 | 0.39 |
| LSTM-based [65] | 0.21 | 3.72 | 0.85 | 0.72 | 0.72 | 0.36 |
| Transformer-based [64] | 0.24 | 4.01 | 0.79 | 0.77 | 0.77 | 0.33 |
| DQN [62] | 0.28 | 4.23 | 0.66 | 0.80 | 0.80 | 0.28 |
| Proposed method | 0.34 | 4.78 | 0.41 | 0.88 | 0.86 | 0.21 |
| Model | Total Profit Gain | Average Reward | Std. of Actions | Sharpe Ratio | Max Drawdown | |
|---|---|---|---|---|---|---|
| XGBoost [61] | 0.13 | 3.38 | 0.92 | 0.62 | 0.65 | 0.41 |
| BERT [63] | 0.17 | 3.67 | 0.86 | 0.69 | 0.69 | 0.37 |
| LSTM-based [65] | 0.20 | 3.88 | 0.79 | 0.73 | 0.73 | 0.34 |
| Transformer-based [64] | 0.24 | 4.09 | 0.73 | 0.78 | 0.78 | 0.31 |
| DQN [62] | 0.28 | 4.33 | 0.61 | 0.82 | 0.81 | 0.27 |
| Proposed method | 0.36 | 4.91 | 0.38 | 0.90 | 0.87 | 0.19 |
| Model | Total Profit Gain | Average Reward | Std. of Actions | Sharpe Ratio | Max Drawdown | |
|---|---|---|---|---|---|---|
| XGBoost [61] | 0.12 | 3.31 | 0.94 | 0.60 | 0.63 | 0.44 |
| BERT [63] | 0.16 | 3.62 | 0.87 | 0.67 | 0.67 | 0.39 |
| LSTM-based [65] | 0.22 | 3.91 | 0.78 | 0.74 | 0.74 | 0.33 |
| Transformer-based [64] | 0.25 | 4.13 | 0.72 | 0.78 | 0.78 | 0.30 |
| DQN [62] | 0.29 | 4.36 | 0.60 | 0.83 | 0.82 | 0.25 |
| Proposed method | 0.37 | 4.85 | 0.37 | 0.91 | 0.89 | 0.18 |
| Model | Total Profit Gain | Average Reward | Std. of Actions | Sharpe Ratio | Max Drawdown | |
|---|---|---|---|---|---|---|
| XGBoost [61] | 0.14 | 3.41 | 0.90 | 0.63 | 0.66 | 0.42 |
| BERT [63] | 0.18 | 3.71 | 0.85 | 0.70 | 0.70 | 0.38 |
| LSTM-based [65] | 0.21 | 3.93 | 0.77 | 0.74 | 0.74 | 0.35 |
| Transformer-based [64] | 0.25 | 4.07 | 0.70 | 0.79 | 0.79 | 0.29 |
| DQN [62] | 0.29 | 4.26 | 0.60 | 0.83 | 0.82 | 0.26 |
| Proposed method | 0.33 | 4.66 | 0.43 | 0.87 | 0.85 | 0.20 |
| Model | Total Profit Gain | Average Reward | Std. of Actions | Sharpe Ratio | Max Drawdown | |
|---|---|---|---|---|---|---|
| XGBoost [61] | 0.15 | 3.43 | 0.93 | 0.64 | 0.67 | 0.40 |
| BERT [63] | 0.19 | 3.74 | 0.84 | 0.69 | 0.70 | 0.36 |
| LSTM-based [65] | 0.23 | 3.96 | 0.75 | 0.75 | 0.75 | 0.32 |
| Transformer-based [64] | 0.26 | 4.11 | 0.67 | 0.78 | 0.79 | 0.28 |
| DQN [62] | 0.30 | 4.30 | 0.55 | 0.82 | 0.81 | 0.24 |
| Proposed Method | 0.32 | 4.72 | 0.44 | 0.86 | 0.84 | 0.22 |
| Configuration | Total Profit Gain | Average Reward | Std. of Actions | Sharpe Ratio | Max Drawdown | |
|---|---|---|---|---|---|---|
| w/o All (Only Backbone) | 0.19 | 3.42 | 0.91 | 0.65 | 0.66 | 0.45 |
| w/o Perturbation | 0.23 | 3.88 | 0.75 | 0.72 | 0.72 | 0.37 |
| w/o Profit Backtracking | 0.26 | 4.10 | 0.68 | 0.77 | 0.76 | 0.32 |
| w/o Strategy Stabilizer | 0.29 | 4.21 | 0.57 | 0.80 | 0.80 | 0.27 |
| Proposed (Full Model) | 0.34 | 4.78 | 0.41 | 0.88 | 0.86 | 0.21 |
| Model | Total Profit Gain | Average Reward | Std. of Actions | R2 Score | Sharpe Ratio |
|---|---|---|---|---|---|
| XGBoost | 0.08 | 2.91 | 1.03 | 0.52 | 0.64 |
| LSTM-based | 0.14 | 3.45 | 0.84 | 0.67 | 0.71 |
| Transformer-based | 0.18 | 3.88 | 0.74 | 0.75 | 0.76 |
| DQN | 0.21 | 4.01 | 0.60 | 0.78 | 0.79 |
| Proposed | 0.27 | 4.49 | 0.42 | 0.85 | 0.83 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Z.; Zhang, L.; Liu, X.; He, S.; Zhang, J.; Zhu, J.; Pang, Y.; Lv, C. A Transformer-Based Reinforcement Learning Framework for Sequential Strategy Optimization in Sparse Data. Appl. Sci. 2025, 15, 6215. https://doi.org/10.3390/app15116215
Zhou Z, Zhang L, Liu X, He S, Zhang J, Zhu J, Pang Y, Lv C. A Transformer-Based Reinforcement Learning Framework for Sequential Strategy Optimization in Sparse Data. Applied Sciences. 2025; 15(11):6215. https://doi.org/10.3390/app15116215
Chicago/Turabian StyleZhou, Zizhe, Liman Zhang, Xuran Liu, Siyang He, Jingxuan Zhang, Jinzhi Zhu, Yuanping Pang, and Chunli Lv. 2025. "A Transformer-Based Reinforcement Learning Framework for Sequential Strategy Optimization in Sparse Data" Applied Sciences 15, no. 11: 6215. https://doi.org/10.3390/app15116215
APA StyleZhou, Z., Zhang, L., Liu, X., He, S., Zhang, J., Zhu, J., Pang, Y., & Lv, C. (2025). A Transformer-Based Reinforcement Learning Framework for Sequential Strategy Optimization in Sparse Data. Applied Sciences, 15(11), 6215. https://doi.org/10.3390/app15116215