Abstract
Multimodal amed entity recognition (MNER) is a natural language-processing technique that integrates text and visual modalities to detect and segment entity boundaries and their types from unstructured multimodal data. Although existing methods alleviate semantic deficiencies by optimizing image and text feature extraction and fusion, a fundamental challenge remains due to the lack of fine-grained alignment caused by cross-modal semantic deviations and image noise interference. To address these issues, this paper proposes a dual-enhanced hierarchical alignment (DEHA) framework that achieves dual semantic and spatial enhancement via global–local cooperative alignment optimization. The proposed framework incorporates a dual enhancement strategy comprising Semantic-Augmented Global Contrast (SAGC) and Multi-scale Spatial Local Contrast (MS-SLC), which reinforce the alignment of image and text modalities at the global sample level and local feature level, respectively, thereby reducing image noise. Additionally, a cross-modal feature fusion and vision-constrained CRF prediction layer is designed to achieve adaptive aggregation of global and local features. Experimental results on the Twitter-2015 and Twitter-2017 datasets yield F1 scores of 77.42% and 88.79%, outperforming baseline models. These results demonstrate that the global–local complementary mechanism effectively balances alignment precision and noise robustness, thereby enhancing entity recognition accuracy in social media and advancing multimodal semantic understanding.
1. Introduction
Named entity recognition (NER) is a cornerstone task in natural language processing (NLP), a field of artificial intelligence focused on enabling computers to understand and process human language. NER involves identifying and extracting specific entities—such as people’s names, locations, or organizations—from unstructured text, like social media posts or news articles [1]. With the surge of multimodal content on social media, a vast amount of social media posts containing text, images, and audio have been generated, making social media an important source of multimodal data [2]. As internet technology continues to advance, user-generated social media content has become increasingly diverse and abundant. However, traditional named entity recognition methods primarily focus on entity recognition in a single text modality, often neglecting information from other modalities. This limitation frequently results in semantic loss and ambiguity in cross-modal information. To accurately and comprehensively interpret the vast amount of cross-modal information in the era of big data, multimodal named entity recognition (MNER) has been rapidly developing and is gradually becoming a core technology in downstream tasks such as knowledge graph enhancement and multimodal dialogue systems.
Multimodal named entity recognition (MNER) leverages cross-modal complementary information by integrating textual and visual features to enhance recognition accuracy [3], demonstrating superior performance and remarkable effectiveness in social media scenarios where noise interference is severe. However, existing MNER methods still face three key challenges: Firstly, semantic deviation between modalities leads to insufficient cross-modal alignment. Zhang [4] found that relying solely on cosine similarity for feature matching overlooks entity-level semantic consistency. As shown in Figure 1a, when the text mentions “apple”, the existing method UMT [5] fails to effectively distinguish between the fruit (which is not labeled as an entity) and the company (ORG) due to the lack of fine-grained semantic supervision, resulting in entity type misclassification. Secondly, the issue of visual noise interference is significant. Experiments by Gustavo Aguilar et al. [6] indicate that irrelevant image regions may mislead the model into incorrectly classifying textual entities. For instance, when the text describes the event “Washington is giving a speech” (Figure 1b), the Washington Monument in the background (visual noise) causes the model [7] to misclassify the person’s name (PER) as a location (LOC). Thirdly, existing contrastive learning methods primarily focus on global sample alignment (e.g., MoCo [8]) and lack supervision for local fine-grained semantic units, leading to ambiguous entity boundaries [9]. As illustrated in Figure 1c, CLIP-ner [10] struggles with long-tail entities such as “Springfield” (LOC); due to its single-scale feature matching mechanism, it fails to capture the hierarchical differences in multimodal semantics, misclassifying it as an organization (ORG).

Figure 1.
Three examples of multimodal named entity recognition on social media. (a) [Apple ORG] released a new product. (b) [Washington PER] is making a speech. (c) We had a great day in [Springfield LOC].
To tackle the challenges outlined above, this paper introduces the dual-enhanced hierarchical alignment (DEHA) framework, which leverages a global–local collaborative optimization strategy to achieve dual enhancement of semantics and spatial alignment. The framework’s novelty lies in two key innovations: (1) The Semantic-Augmented Global Contrast (SAGC) module innovatively constructs semantic similarity expansion and employs cross-modal nearest neighbor supervised contrastive learning to establish a dynamic queue of expanded positive and negative samples. By fostering semantic consistency within the global representation space at the sample level, this module effectively mitigates distribution shifts arising from modal heterogeneity. (2) The Multi-scale Spatial Local Contrast (MS-SLC) module designs a multi-scale visual feature pyramid and incorporates a gating mechanism to dynamically select visual regions most relevant to text tokens. This module establishes a fine-grained alignment mechanism at the local feature level, adeptly identifying and correcting biases that may emerge in global contrast due to textual semantic expansion. Particularly in social media contexts, where text augmented with noisy descriptions risks erroneous entity feature associations in SAGC’s global alignment, MS-SLC dynamically adjusts cross-modal weights through local spatial response analysis. Ultimately, during the CRF decoding phase, noise interference is eliminated via a visual constraint term. This bidirectional optimization approach of “global anchoring and local calibration” significantly bolsters robustness in complex noisy environments.
2. Related Work
2.1. Multimodal Named Entity Recognition
Multimodal named entity recognition (MNER) seeks to jointly extract entities, such as people’s names and locations, from social media text and image content. Early research primarily relied on attention mechanisms, a technique that emulates human visual “focusing” capabilities by computing weighted scores between text word vectors and image region features to facilitate cross-modal feature interaction. For instance, Moon et al. [1] proposed a multimodal disambiguation method that achieved initial alignment of image and text features using attention weights. However, it struggled to handle visual noise common in social media. With the advent of Transformer architectures, which leverage self-attention mechanisms to model global dependencies in parallel, Yu et al. [5] developed the Unified Multimodal Transformer (UMT) model, which enhanced fine-grained feature matching in cross-modal interactions through an entity span detection mechanism, thereby significantly improving entity classification accuracy. Building upon this, Zhang et al. [7] further proposed Unified Multimodal Graph Fusion (UMGF), which treats textual tokens and image regions as graph nodes and employs a Graph Convolutional Network (GCN) to model fine-grained semantic associations. Nevertheless, existing research methods still exhibit deficiencies in robustness under complex noisy conditions.
To address the unresolved issues of fine-grained semantic alignment and insufficient noise robustness in multimodal fusion, research on optimizing fine-grained alignment in noisy environments has been burgeoning. Wang et al. [11] were the first to propose a cross-modal contrastive learning framework (ITA) that maximizes the similarity between textual entities and image regions. Concurrently, Xu et al. [12] introduced a universal matching alignment framework (MAF) that employs a dynamic gating mechanism combined with text–region similarity scores, greatly enhancing alignment accuracy, although it did not resolve the issue of visual bias. Consequently, researchers have further explored dynamic noise suppression strategies. For example, Xin et al. [13] proposed a visual object debiasing method, which filters out low-relevance regions based on semantic relevance scoring to reduce noise. Zhai et al. [14] proposed a multi-level alignment architecture (MLNet) that aligns at the object level (e.g., “iPhone” with phone), scene level (e.g., “park” with lawn), and attribute level (e.g., “red” with color), thereby significantly enhancing the accuracy of complex entity recognition. Moreover, Zeng et al. [15] utilized an instruction template (ICKA) to guide the model to focus on key semantic generation regions, which improved accuracy in few-shot scenarios. Liu et al. [16] further proposed hierarchical alignment learning that jointly optimizes alignment at the word, phrase, and sentence levels, providing a novel perspective for addressing these challenges.
However, existing methods still face many other challenges. On one hand, global alignment strategies tend to overlook local semantic associations (e.g., the fine-grained matching between entities and image regions); on the other hand, the coupling effect between visual noise interference and cross-modal semantic alignment limits further improvement in model performance.
2.2. Contrastive Learning
Contrastive learning, as a foundational paradigm for multimodal semantic alignment, guides models to distinguish semantic consistency by constructing positive and negative sample pairs. Specifically, in the MNER task, representations of the same entity across different modalities—such as the textual mention of “Eiffel Tower” and its corresponding visual landmark features in an image—are defined as positive sample pairs, while cross-modal combinations of different entities serve as negative sample pairs. This technique optimizes a contrastive loss function, such as InfoNCE, to minimize the embedding distance between positive pairs while maximizing the distance between negative pairs, thereby enhancing the compactness of the cross-modal semantic space. Compared to traditional attention mechanisms, contrastive learning more robustly mitigates visual noise interference, making it a critical technical approach for addressing entity ambiguity in social media contexts. In the field of unimodal representation learning, the MoCo framework proposed by He et al. [8] enhances visual feature learning efficiency through a momentum encoder, while SimCSE by Gao et al. [9] optimizes text embeddings via sentence-level contrastive learning. However, these methods do not take into account the heterogeneous characteristics inherent in multimodal scenarios. To overcome this limitation, Radford et al. [10] introduced the CLIP model, which attempts to achieve cross-modal semantic alignment through large-scale image–text contrastive pre-training, yet its coarse-grained global matching mechanism is insufficient to capture entity-level semantic associations.
In recent years, multimodal contrastive learning has progressively evolved toward finer-grained and hierarchical approaches. These hierarchical semantic modeling strategies offer new perspectives with which to break through current technical bottlenecks. For example, Zhang et al. [17] proposed a text expansion-guided contrastive learning strategy that significantly enhances the model’s robustness to noise by augmenting positive and negative sample pairs through adversarial text generation. Meanwhile, in the task of drug–disease association prediction, a Dual-Modal Uniform Alignment [18] approach was proposed, which optimizes cross-modal representations by integrating global–local contrastive loss. However, existing contrastive methods (e.g., SHAN [19]) often adopt a progressive alignment strategy from local to global, lacking a multi-scale feature fusion mechanism, which results in ambiguous entity boundaries [9].
3. Methodology
In this section, we propose a dual-enhanced hierarchical alignment (DEHA) framework that addresses the challenges of semantic deviation, visual noise interference, and the coupling of fine-grained cross-modal alignment in multimodal named entity recognition (MNER) within social media scenarios. The core architecture consists of three main components, as shown in Figure 2: (1) a multimodal feature encoding layer; (2) a dual-enhanced hierarchical alignment module; and (3) cross-modal feature fusion and vision-constrained CRF prediction layer. We first extract text-augmented features and three-level visual pyramid features (with 64 × 64, 32 × 32, and 16 × 16 grids) via the multimodal feature encoding layer. To mitigate cross-modal semantic bias, the text and image features are processed by the dual-enhanced hierarchical alignment module, which optimizes fine-grained alignment in two stages. The Semantic-Augmented Global Contrast (SAGC) module ensures semantic alignment by maintaining global consistency in the cross-modal representation space, while the Multi-scale Spatial Local Contrast (MS-SLC) module achieves fine-grained calibration by correcting noise potentially introduced during global contrast through localized detail matching. Subsequently, the cross-modal feature fusion module employs a gated adaptive mechanism to enable complementary integration of the SAGC and MS-SLC modules. Finally, we innovatively incorporate both alignment matrices into the CRF decoding process, ensuring that entity boundary predictions align with visual spatial evidence, thereby enhancing the noise robustness of multimodal named entity recognition.
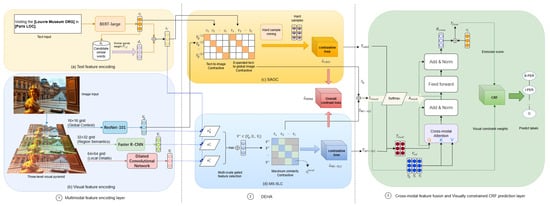
Figure 2.
Dual-enhanced hierarchical alignment (DEHA) framework. (1) Multimodal feature encoding using BERT-large for text and a three-level visual pyramid (ResNet-101, Faster R-CNN, Dilated Convolutional Network) for images; (2) DEHA alignment with Semantic-Augmented Global Contrast (SAGC) for global alignment and Multi-scale Spatial Local Contrast (MS-SLC) for local refinement; (3) cross-modal fusion and visual-constrained CRF for entity prediction, improving robustness against noise and misalignment.
3.1. Multimodal Feature Encoding Layer
3.1.1. Text Feature Encoding
Extraction of textual features is fundamental to the named entity recognition task. To mitigate the sparsity problem inherent in social media texts, we enhance text features via similar word expansion, as illustrated in Figure 2.
Specifically, we employ the BERT-large model [3] to encode each entity word into a semantic vector and then retrieve the top-m candidate words with the highest cosine similarity to from the social media corpus, denoted .
However, not every word in this similar set contributes beneficially to the prediction of entity outcomes; thus, it is necessary to differentiate the contributions of individual words within their context. By employing an attention mechanism for weighted fusion, we compute similarity word weights and subsequently obtain an augmented semantic vector through a weighted summation of the candidate word vectors. This is defined as
where denotes the word vector representation derived from the mapped similar word.
Finally, we integrate the original text features with the enhanced semantic features using a gating mechanism to yield the final vector representation for each word. The gating mechanism is formulated as
where gate represents the control gate parameter, and are weight matrices, and is the corresponding bias term.
3.1.2. Three-Level Visual Pyramid Feature Encoding
Social media images often contain a multitude of visual objects, yet in most cases only a subset of these objects is associated with the entities mentioned in the text. To address the complex distribution of visual objects and the sparse association with textual entities in social media images, we propose a three-level visual pyramid encoding structure that enhances the model’s ability to capture complex visual semantics through multi-scale, fine-grained representations.
The visual pyramid comprises three levels of features—grids of , , and , respectively—as illustrated in Figure 2. Visual features are extracted in three granularities: global context, region semantics, and local details. Denser grids cover smaller regions of the original image, yielding finer feature granularity that accommodates the multi-level semantic requirements of entity descriptions in text. Given the inherent differences in semantic demands and modality alignment objectives across varying visual granularities, a single architecture cannot simultaneously balance multi-scale feature extraction and noise suppression. Consequently, we employ distinct neural network architectures for each of the three hierarchical image encoding layers.
The global context features (a 16 × 16 grid) capture the overall image layout and scene semantics at a macro granularity, requiring high-level semantic abstraction to represent the entire scene. ResNet-101, through its deep convolutional layers and spatial pooling, naturally generates a 16 × 16 low-resolution feature map. The final convolutional layer of this deep network excels at extracting macro-level semantics, such as scene categories, while filtering out irrelevant detail noise, thereby aligning with the global descriptions in text. Consequently, we adopt the ResNet-101 [20] backbone to extract global image features , where denotes the feature dimension.
The region semantics features (a 32 × 32 grid) target meso-level granularity to localize primary objects directly associated with text entities, necessitating precise object-level detection and selection capabilities. Faster R-CNN [21] employs an object detection mechanism to accurately generate candidate regions, retaining the top k salient local visual objects based on classification confidence, which directly correspond to text entities such as person or brand names. This yields region-level features , where each region feature encapsulates the semantic information within a detection box, effectively covering key entity-related objects while filtering out low-relevance backgrounds.
The local detail features (a 64 × 64 grid) focus on micro-level granularity to capture auxiliary details, such as text or textures, requiring the preservation of high-resolution spatial information. We utilize a Dilated Convolutional Network [22] with its dilation property, setting a dilation rate (e.g., ) to expand the receptive field to 7 × 7, thereby capturing local context while maintaining a 64 × 64 high-resolution feature map. This approach avoids information loss from traditional pooling operations, preserving pixel-level features , where represents the spatial dimensions of the feature map. The large receptive field effectively models local contextual relationships.
The three-level features, after dimensionality alignment, are concatenated to form a spatial pyramid feature, denoted . Here, 1 represents the single vector of the global feature , k indicates the number of regional features (where comprises kd-dimensional vectors), and denotes the number of vectors obtained by flattening the local features (where is reshaped from into ), with d being the unified feature dimension.This hierarchical encoding mechanism overcomes the limitations of traditional single-scale visual representations and provides critical support for the subsequent Multi-scale Spatial Local Contrast (MS-SLC), as detailed in Section 3.2.2.
3.2. Dual-Enhanced Hierarchical Alignment (DEHA)
The core innovation of the DEHA framework lies in the design of a hierarchical contrastive learning architecture, where SAGC and MS-SLC construct complementary optimization pathways at the global sample level and local feature level, respectively. The former ensures cross-modal semantic consistency through knowledge-augmented contrastive learning while mitigating semantic deviation, whereas the latter leverages multi-scale visual features to achieve fine-grained alignment and automated noise filtering. The two modules work in tandem through gradient-gated dynamic error correction. This section provides a detailed introduction to Semantic-Augmented Global Contrast (SAGC) and Multi-scale Spatial Local Contrast (MS-SLC).
3.2.1. Semantic-Augmented Global Contrast (SAGC)
To address the issue of cross-modal semantic deviation caused by polysemous words in social media, we propose Semantic-Augmented Global Contrast (SAGC), which constructs a dynamic cross-modal positive sample queue through a knowledge-guided text augmentation strategy. By integrating nearest-neighbor supervised contrastive learning, the semantic disambiguation process is explicitly embedded into the contrastive objective function, thereby tackling the inherent challenges posed by polysemous words and ambiguous expressions in social media, as illustrated in Figure 3.
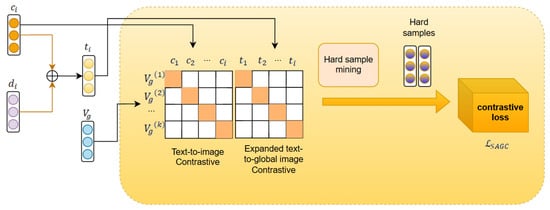
Figure 3.
Semantic-Augmented Global Contrast (SAGC) module in the DEHA framework for MNER.
Specifically, we first extract the global features of all image–text pairs in the training set to construct a cross-modal feature bank , as depicted in the leftmost contrast matrix in Figure 3, where represents the original text features extracted by BERT-large [3], and denotes the global visual features extracted by ResNet-101 [20]. We then retrieve the cross-modal nearest neighbors for each augmented text from the feature bank and compute the text–image similarity matrix using the cosine similarity function, formulated as
Images satisfying (where ) are selected as new positive samples , as highlighted by the yellow shaded regions in the contrastive similarity matrix shown in Figure 3 (second panel from the left). Each original pair may generate multiple new positive samples through text expansion, with the exact number depending on the count of matching images k under the similarity threshold .
Furthermore, to enhance the discriminability of contrastive learning, we mine hard negative samples, which, in contrast to randomly selected negatives, are chosen based on their high similarity to the positive samples while belonging to different categories. This forces the model to learn finer-grained decision boundaries. The hardest negative sample for each is selected as the non-matching sample with the highest similarity, forming the hard negative sample set:
where is the similarity threshold, denotes the global image features of sample j indexed in the feature bank, and represents the class label of sample j.
Finally, we perform supervised contrastive loss optimization, jointly optimizing the contrastive loss of the original positive samples, the additional positive samples, and the hard negative samples. The loss function for SAGC is defined as
where is the temperature coefficient that controls the distribution smoothness, K is the number of additional positive samples, and N denotes the batch size.
3.2.2. Multi-Scale Spatial Local Contrast (MS-SLC)
Although Semantic-Augmented Global Contrast (SAGC) alleviates cross-modal semantic deviation through knowledge injection, its global feature-based alignment is vulnerable to visual noise (such as background advertisements and irrelevant objects) and struggles to capture fine-grained entity–region associations. To address this, we propose a collaborative optimization framework with Multi-scale Spatial Local Contrast (MS-SLC); while global SAGC establishes modal consistency in a low-dimensional space to achieve semantic alignment, local MS-SLC leverages high-resolution features to preserve detail discriminability for boundary localization, thereby forming a complementary mechanism. Furthermore, the global module prevents overfitting by enforcing semantic consistency constraints, whereas the local module corrects global underfitting through maximum similarity-based spatial semantic validation, ultimately establishing a dynamic global–local coordination mechanism. As illustrated in Figure 4, MS-SLC dynamically selects the visual hierarchy most relevant to text tokens via multi-scale gating and employs a maximum similarity criterion to achieve noise filtering and fine-grained alignment.
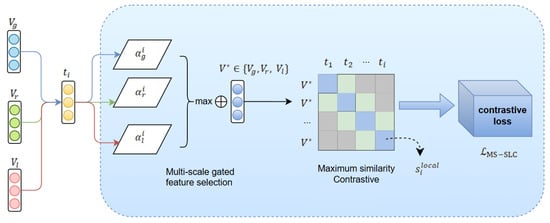
Figure 4.
Multi-scale Spatial Local Contrast (MS-SLC) module in the DEHA framework for MNER.
Specifically, we first perform multi-scale gated feature selection to obtain the association weights between each augmented semantic text (as defined in Equation (4)) and each level of the visual pyramid, computed as
where are learnable parameters and is the normalization factor. The visual level corresponding to the maximum weight is then selected as ; for example, entity nouns preferentially associate with region-level features (e.g., “apple” matching the detected apple region), whereas adjectives associate with pixel-level texture features (e.g., “red” corresponding to a color distribution).
Next, we focus on key regions through maximum similarity to match each text token with the most relevant local visual feature, thereby enhancing fine-grained alignment. Within the selected level , we compute the maximum similarity between and all visual features as
This maximization ensures that each text token aligns only with the most relevant visual region, after which a dynamic mask is generated to construct an adaptive noise filtering mechanism that counteracts global noise, defined as
where is a relaxation threshold (set to 0.6 in our experiments) that retains features with similarity close to the maximum.
We then define the local contrastive loss function as
where is the set of all visual features encompassing features from all levels (both positive and negative samples), with an explicit distinction between v (features from the selected level) and (all features), is the cosine similarity, and is the temperature coefficient controlling the sharpness of the similarity distribution (default 0.1).
Through the three-stage design of multi-scale gated selection, token-wise maximum alignment, and dynamic noise suppression, MS-SLC achieves fine-grained cross-modal alignment that effectively compensates for the limitations of SAGC’s global representations; simultaneously, the fusion of these two modules innovatively realizes a bidirectional enhancement mechanism of “global semantic constraint coupled with local fine-grained verification”, thereby providing a hierarchical alignment paradigm for multimodal named entity recognition.
3.3. Cross-Modal Feature Fusion and Vision-Constrained CRF Prediction Layer
This section serves as the final inference hub of the dual-enhanced hierarchical alignment framework, undertaking the core tasks of global–local feature aggregation and multimodal collaborative decoding, as illustrated in the third part of Figure 2.
3.3.1. Cross-Modal Feature Fusion
Through a visual signal-guided cross-modal interaction mechanism, we deeply integrate the semantic-enhanced global alignment capability of the SAGC module with the local fine-grained spatial alignment advantages of the MS-SLC module, achieving hierarchical complementarity between text and image features.
Specifically, we first concatenate the text–visual global alignment features and local alignment features: . These are then normalized to generate a visual prior mask, compelling the model to focus on high-confidence alignment regions: . This mask is subsequently input into a cross-modal attention mechanism, where the text acts as the query, and the visual features serve as the key and value, with the attention weights guided by the visual prior mask:
where denotes all visual features ().
Finally, we perform dynamic gated fusion of the cross-modal interaction features and the original text features :
where is a learnable parameter matrix, and represents the Sigmoid function, producing the gating weight .
This gating design mitigates the noise issues arising from fully connected interactions in traditional cross-modal attention; when the visual signal is reliable, g approaches 1, allowing significant contribution from the cross-modal features. Conversely, when the image is irrelevant to the text or heavily noisy, g nears 0, causing the fused features to predominantly consist of the text features, with minimal contribution from the cross-modal features.
3.3.2. Vision-Constrained CRF Prediction Layer
During the prediction phase, we innovatively incorporate the alignment matrix as a constraint in the Conditional Random Field (CRF) decoding process, enabling entity recognition decisions to be driven simultaneously by both textual semantics and visual evidence. This approach significantly enhances the precision of entity boundary discrimination and the credibility of type inference in multimodal social media scenarios, providing final decision support for the global–local collaborative optimization loop. Specifically, we integrate visual alignment information into the energy function of the CRF to dynamically enhance the semantic consistency of multimodal named entity recognition (MNER). The energy function of the CRF is expressed as
where represents the label emission scores, obtained by mapping the fused text features through a linear layer; denotes the label transition scores, calculated via the CRF transition matrix; and the visual constraint weights are provided by , which enhance the credibility of entity labels (). The indicator function activates the visual constraint when the label is not “O”, where “O” is the “non-entity” label in NER, used to filter out interference from irrelevant visual information on non-entity parts.
The innovation in constructing the visual constraint lies in two aspects: (1) dynamic modality adaptation, where visual alignment features quantify visual credibility to avoid the blind fusion of noise prevalent in traditional multimodal models, and (2) fine-grained alignment optimization, which achieves local alignment between visual and textual features at the entity level (rather than the sample level), thereby enabling precise correction of ambiguous labels.
4. Experiments
4.1. Datasets and Evaluation Metrics
We conducted experiments using two publicly available multimodal named entity recognition datasets: the Twitter-2015 dataset [4] and the Twitter-2017 dataset [23]. These datasets have been widely adopted in the fields of natural language processing and social media analysis. They are annotated with four entity types: Person (PER), Location (LOC), Organization (ORG), and Miscellaneous (MISC). The Twitter-2015 dataset contains 8257 tweets, while the Twitter-2017 dataset includes 4819 tweets, both enriched with extensive multimodal information. Table 1 provides a detailed breakdown of the number of entity types and the total number of tweets across the training, validation, and test sets for both datasets, laying the foundational data support for subsequent experimental analysis.

Table 1.
The statistics summary of two Twitter datasets.
To comprehensively evaluate the performance of multimodal named entity recognition models, this paper adopts Precision, Recall, and F1 score as the core evaluation metrics [1], with their computation accounting for fine-grained performance variations across different entity types, such as person names, locations, and organization names. Specifically, the F1 score is reported for each entity category, while the overall model performance is assessed using aggregated metrics. Given the imbalanced distribution of entity categories in the data, reporting individual F1 scores provides clearer insight into the model’s performance on each category, whereas the aggregated metrics offer a global perspective.
Precision measures the proportion of correctly identified positive samples among those predicted as positive, reflecting the accuracy of the predictions:
Recall quantifies the model’s ability to identify all true positive samples, indicating the completeness of detection:
The F1 score, as the harmonic mean of Precision and Recall, provides a balanced measure of the model’s accuracy and robustness:
Here, TP (True Positive) denotes the number of correctly identified entities, FP (False Positive) represents the number of non-entities incorrectly identified, and FN (False Negative) indicates the number of true entities missed [1].
This evaluation strategy effectively captures the model’s balanced recognition capabilities across various entity types, making it particularly suitable for social media scenarios characterized by uneven entity type distributions and ambiguous semantic boundaries.
4.2. Compared Baselines
To evaluate the advancements of the dual-enhanced hierarchical alignment (DEHA) framework in addressing cross-modal semantic bias, fine-grained alignment, and image noise suppression, a comprehensive comparison was conducted with both unimodal and multimodal baseline models. The unimodal baselines include a traditional sequence labeling model based on BiLSTM-CRF [2] (2018) and a BERT-CRF pretraining model [3] (2020), which serve to assess the necessity of multimodal information fusion. The multimodal baselines encompass several representative approaches: the Unified Multimodal Transformer (UMT) [5] (2020), which integrates global image features and text embeddings into Transformer layers for deep fusion via self-attention; ITA [11] (2022), an image–text alignment framework based on cross-modal contrastive learning that suppresses irrelevant visual noise by maximizing the similarity between text entities and related image regions; HVPNeT [24] (2022), a hierarchical visual prefix network that categorizes image features into scene, object, and attribute levels to guide text encoding through prefix attention; DebiasCL [13] (2023), which employs debiased contrastive learning to mitigate visual noise interference via dynamic negative sample sampling; MLNet [14] (2023), a multi-level cross-modal fusion architecture that aligns text with image features at object, scene, and attribute levels to address multi-granularity semantic matching; MPMRC-MNER [25] (2023), a machine reading comprehension framework leveraging multimodal prompt learning to guide the model toward image–text associated entities through learnable prompts; ICAK [15] (2024), an instruction-driven knowledge alignment framework that enhances cross-modal consistency using external knowledge graphs; and HamLearning [16] (2024), a hierarchical adaptive modality learning approach that dynamically integrates visual information across various granularities.
The experimental results, presented in Table 2, demonstrate that DEHA achieves the best performance on both the Twitter-2015 and Twitter-2017 datasets.
Table 2.
Performance comparison of different competitive unimodal and multimodal approaches.
These results highlight the significant breakthroughs and advantages of our method in several aspects.
- Compared to ITA [11] and HVPNeT [24], which rely on static alignment strategies and struggle to capture fine-grained semantic differences, DEHA introduces a dynamic multi-scale alignment module that integrates a three-level visual feature pyramid with a gated attention mechanism, enabling adaptive association of text entities with multi-granularity visual regions, including global scenes, regional semantics, and local details. In fine-grained entity recognition tasks, such as identifying brand-related ORG entities, the F1 scores on the two datasets improved by 2.75% and 2.76%, respectively, over HVPNeT. The recognition of ORG entities benefits from the cross-modal abstract association capability of the global semantic enhancement module (SAGC). Organization names often involve complex semantic compositions (such as abbreviations, aliases, and implicit associations with visual symbols). SAGC effectively addresses entity coreference ambiguity by modeling the global semantic consistency between textual descriptions and visual concepts through contrastive learning.
- Although MPMRC-MNER [25] and ICAK [15] excel in few-shot scenarios, markedly enhancing long-tail entity recognition (e.g., niche brands), their dependence on manual expertise and knowledge bases limits their generalizability. In contrast, DEHA dynamically updates cross-modal alignment knowledge through text similarity expansion, improving the F1 score for long-tail entity recognition, such as “Springfield” (LOC), by 1.11% over MPMRC-MNER, effectively mitigating semantic bias. Geographic entities are often strongly coupled with specific regions in images (such as landmarks and geographic boundaries), and MS-SLC precisely captures the fine-grained co-occurrence patterns between textual descriptions and visual spatial cues through local feature pyramid alignment.
- Compared to models like DebiasCL [13], MLNet [14], and HamLearning [16], which rely on predefined noise assumptions and fail to address dynamic noise interference, DEHA increases the F1 score on Twitter-2017 by 1.43% to 1.95%. Particularly in cases with complex image backgrounds, such as interference from the Eiffel Tower in Case 1, the MS-SLC module suppresses irrelevant regional feature responses through multi-scale spatial contrast, boosting the recall rate for the LOC category by 3.79%.
- Compared to the multi-level fusion architecture MLNet [14] and the MRC-based MPMRC-MNER [25], DEHA’s visual constraint CRF layer jointly optimizes label transition probabilities and visual consistency, achieving a precision of 78.09% on Twitter-2015, an improvement of 1.14%, demonstrating that adaptive feature aggregation effectively reduces misjudgments caused by image interference.
4.3. Ablation Study
To assess the contribution of each module within the DEHA framework, core components were progressively removed, and performance differences were compared, as shown in Table 3. The ablation settings are defined as follows.
- w/o SAGC removes the Semantic-Enhanced Global Contrastive Learning (SAGC) module, replacing it with traditional cross-modal contrastive learning (He et al., 2020 [8]), which relies solely on random negative samples for global alignment and disables the text semantic similarity-driven prototype expansion strategy;
- w/o MS-SLC removes the Multi-Scale Spatial Local Contrastive (MS-SLC) learning module, substituting it with single-scale (64×64 grid) local feature matching, eliminating the spatial pyramid structure and cross-scale contrast constraints;
- w/o Cross-Modal Fusion removes the adaptive cross-modal feature fusion layer, replacing it with simple concatenation followed by a fully connected layer;
- w/o Visual Constraint CRF removes the visual constraint CRF prediction layer, replacing it with a standard CRF that depends solely on text label transition probabilities without incorporating visual alignment strength as a decoding constraint.
According to the results in Table 3,
- Removing the SAGC module results in a 2.5% decrease in Precision and a 2.2% reduction in Recall on the Twitter-2017 dataset, indicating that traditional contrastive learning approaches, such as MoCo [8], struggle to address the semantic misalignment between images and text in social media contexts. This module enhances cross-modal semantic consistency by expanding prototypes through textual semantic similarity. Furthermore, the removal of this module leads to a 5.3% drop in Recall on the Twitter-2015 dataset, because the elimination of SAGC’s mechanism for selecting the hardest negative samples forces the model to rely solely on random negative samples, resulting in blurred discriminative boundaries and an inability to filter out irrelevant entities in images.
- When MS-SLC is removed, the F1 scores on Twitter-2015 and Twitter-2017 decline by 3.7% and 2.9%, respectively. MS-SLC captures multi-granularity visual contexts through a three-level spatial grid (64 × 64/32 × 32/16 × 16), whereas single-scale local contrast depends solely on text regions, resulting in a 4.5% drop in Recall due to the absence of multi-scale feature support.
- Removing the cross-modal fusion layer and resorting to simple concatenation also reduces F1 scores. In scenarios with conflicting text and image information, adaptive cross-modal fusion suppresses interfering visual features via a gating mechanism, whereas concatenation allows erroneous visual signals to contaminate text representations, increasing the misjudgment rate. The standard CRF, by ignoring visual evidence consistency, reduces Precision by 1.3% and Recall by 1.1% for image-dominant entities on Twitter-2017.
- The standard CRF overlooks the consistency of visual evidence, leading to a 1.3% decrease in Precision and a 1.1% decrease in Recall for “image-dominant entities” on the Twitter-2017 dataset. The visually constrained CRF suppresses entity probabilities based on low alignment intensity, whereas the standard CRF excessively relies on textual context, erroneously retaining such entities.
- Simultaneously removing SAGC and MS-SLC results in F1 score decreases of 4.7% and 4.4% on Twitter-2015 and Twitter-2017, respectively, significantly exceeding the sum of individual module ablation declines, underscoring a nonlinear synergistic effect between global semantic calibration and local spatial contrast.
Table 3.
Ablation experiment.
Table 3.
Ablation experiment.
| Model | Twitter-2015 | Twitter-2017 | ||||
|---|---|---|---|---|---|---|
| P (%) | R (%) | F1 (%) | P (%) | R (%) | F1 (%) | |
| DEHA | 85 | 83.9 | 84.9 | 86.8 | 85.7 | 86.5 |
| w/o SAGC | 82.5 | 81.7 | 82.1 | 84.3 | 83.5 | 83.9 |
| w/o MS-SLC | 83.8 | 82.2 | 83 | 85.2 | 84.2 | 84.7 |
| w/o Cross-Modal Fusion | 81 | 80.1 | 80.5 | 83.5 | 82.9 | 83.2 |
| w/o Visual Constraint CRF | 83.9 | 83 | 83.4 | 85.5 | 84.6 | 85 |
| w/o SAGC + MS-SLC | 79.8 | 78.6 | 79.2 | 82.3 | 81.9 | 82.1 |
4.4. Case Study
To further validate the effectiveness of the DEHA framework in addressing fine-grained alignment and image noise interference caused by cross-modal semantic bias, three typical social media cases were selected for comparison with baseline models, including DebiasCL [13], ICAK [15], and HamLearning [16].
As shown in Table 4, in Case-a, both DebiasCL [13] and ICAK [15] fail to correctly predict the entity “Yellowstone National Park”. These models do not account for multi-scale spatial features, leading to partial entity recognition and type misclassification. Although HamLearning [16] correctly identifies the entity, its type confidence remains low due to its inability to suppress image noise. In contrast, DEHA enhances the association of “Yellowstone” with geographic prototypes, such as “national park” and “mountain”, through text semantic enhancement and suppresses interference from the Eiffel Tower in the image via multi-scale spatial alignment, demonstrating effective cross-modal noise suppression. Case-b highlights the effectiveness of fine-grained alignment between text and multi-scale visual objects. DEHA captures more hierarchical features through a three-level spatial grid (64 × 64/32 × 32/16 × 16), enabling accurate predictions, whereas other methods produce erroneous predictions due to noise from multi-object images. In Case-c, HamLearning [16] and ICAK [15], by not incorporating visual constraints, erroneously weight conflicting text and image evidence, resulting in a bias toward visual dominance. DebiasCL [13] mitigates visual noise interference through dynamic negative sample sampling. DEHA, however, enhances the association of “Apple” with technology company prototypes through the text context “innovation”, reducing the weight of fruit-related prototypes. Additionally, the visual constraint CRF detects that the local response in the logo area (0.78) exceeds that in the fruit area (0.45), constraining the CRF to bias the type of “Apple” toward ORG, thus successfully resolving cross-modal ambiguity.
Table 4.
Performance comparison of entity recognition across different multimodal approaches.
5. Conclusions and Outlook
This paper tackles the challenges of multimodal named entity recognition (MNER) in social media, specifically addressing cross-modal semantic bias—leading to a lack of fine-grained alignment—and image noise. To tackle these problems, we propose a dual-enhanced hierarchical alignment (DEHA) framework. This framework leverages a global–local collaborative optimization strategy by integrating a dual-enhancement mechanism that combines semantic-enhanced global contrastive learning with multi-scale spatial local contrastive learning. These mechanisms strengthen the semantic consistency between image and text modalities at both the sample and feature levels. Furthermore, the framework incorporates a cross-modal fusion layer and a visual-constrained conditional random field (CRF) prediction layer to achieve multi-level fine-grained alignment and automated noise suppression through collaborative decision making. Experimental results demonstrate that DEHA significantly outperforms existing baseline models on mainstream social media datasets, exhibiting superior robustness particularly in complex noise scenarios and fine-grained entity localization tasks. The core innovation of DEHA lies in its seamless integration of global semantic expansion alignment with local spatial alignment, synchronously optimizing inter-modal semantic distributions and spatial associations through a hierarchical alignment strategy. Additionally, the introduction of a visual-guided CRF constraint mechanism ensures that entity recognition outcomes adhere to both textual contextual patterns and visual spatial evidence, thereby providing more reliable multimodal semantic understanding capabilities for downstream applications such as knowledge graph construction and intelligent question answering.
Despite the notable advancements achieved by DEHA in cross-modal fine-grained alignment and noise suppression, certain limitations persist. Firstly, the fine-grained semantic alignment still depends on predefined multi-scale divisions, which may overlook implicit cross-scale associations. Incorporating an adaptive scale selection mechanism or leveraging graph neural networks to model hierarchical semantic relationships could further enhance alignment precision. Secondly, the deep integration of contrastive learning with large language models (LLMs) represents an important future direction. Leveraging the semantic generation capabilities of LLMs could facilitate the construction of high-quality cross-modal supervision signals, thereby enhancing the robustness of global alignment.
In terms of cross-domain adaptability, the hierarchical alignment mechanism of DEHA demonstrates potential for transferability to other multimodal scenarios. For instance, in medical text analysis, global semantic enhancement could capture the complex relationships between medical images and diagnostic reports, while local spatial calibration could optimize fine-grained localization of anatomical structures. In e-commerce scenarios, the framework could support multimodal understanding of product images and textual descriptions, capturing deep associations between category features and attribute details through dual semantic–spatial enhancement, thereby offering a general paradigm for cross-domain multimodal modeling.
To address the challenge of computational complexity in practical deployments, future work will explore lightweight engineering optimization strategies. By employing multimodal feature caching mechanisms and model compression techniques, the computational load on the visual encoder can be effectively reduced, while dynamic feature pre-computation can help balance inference efficiency. Such complexity management strategies will promote the application of DEHA in resource-constrained environments and provide feasibility assurance for industrial-scale multimodal systems. Future research will focus on these directions to advance the practical deployment and generalization of multimodal named entity recognition technology in open-domain social media analysis.
Author Contributions
The authors confirm their contributions to the paper as follows: study conception and design: J.W. and Y.Z.; data collection: Y.Z. and W.Z.; analysis and interpretation of results: J.W. and Y.Z.; draft manuscript preparation: Y.Z. and Q.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the National Key Research and Development Program of China (Grant No. 2021YFC3101601).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data supporting the findings of this study are openly available in the Twitter-2015 and Twitter-2017 benchmark datasets for multimodal named entity recognition. These datasets can be accessed through the following channels: Twitter-2015, publicly available at https://github.com/CopotronicRifat/TwitterDataMABSA (accessed on 20 December 2024, reference implementation from [4]), and Twitter-2017, publicly available at https://github.com/CopotronicRifat/TwitterDataMABSA (accessed on 20 December 2024, reference implementation from [23]). Both datasets consist of anonymized public Twitter posts with manually annotated named entity labels containing text and associated images. The datasets were used in accordance with Twitter’s terms of service and academic research guidelines.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| BERT | Bidirectional Encoder Representations from Transformers |
| CLIP | Contrastive Language–Image Pretraining |
| CRF | Conditional Random Field |
| DEHA | Dual-Enhanced Hierarchical Alignment |
| Faster R-CNN | Faster Region-based Convolutional Neural Network |
| GCN | Graph Convolutional Network |
| HamLearning | Hierarchical Adaptive Modality Learning |
| HVPNeT | Hierarchical Visual Prefix Network |
| ICAK | Instruction Construction and Knowledge Alignment |
| ITA | Image–Text Alignments |
| MAF | Matching and Alignment Framework |
| MLNet | Multi-Level Network |
| MNER | Multimodal Named Entity Recognition |
| MoCo | Momentum Contrast |
| MPMRC-MNER | Machine Reading Comprehension for Multimodal Named Entity Recognition |
| MS-SLC | Multi-Scale Spatial Local Contrast |
| NLP | Natural Language Processing |
| ResNet | Residual Network |
| SAGC | Semantic-Augmented Global Contrast |
| SimCSE | Simple Contrastive Learning of Sentence Embeddings |
| UMGF | Unified Multimodal Graph Fusion |
| UMT | Unified Multimodal Transformer |
References
- Moon, S.; Neves, L.; Carvalho, V. Multimodal named entity disambiguation for noisy social media posts. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 2000–2008. [Google Scholar]
- Yadav, V.; Bethard, S. A Survey on Recent Advances in Named Entity Recognition from Deep Learning models. In Proceedings of the 27th International Conference on Computational Linguistics; Association for Computational Linguistics: Santa Fe, NM, USA, 2018; pp. 2145–2158. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MI, USA, 2019; pp. 4171–4186. [Google Scholar]
- Zhang, Q.; Fu, J.; Liu, X.; Huang, X. Adaptive co-attention network for named entity recognition in tweets. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32, pp. 5674–5681. [Google Scholar]
- Yu, J.; Jiang, J.; Yang, L.; Xia, R. Improving multimodal named entity recognition via entity span detection with unified multimodal transformer. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020. [Google Scholar]
- Chen, S.; Aguilar, G.; Neves, L.; Solorio, T. Can images help recognize entities? A study of the role of images for Multimodal NER. In Proceedings of the Seventh Workshop on Noisy User-generated Text (W-NUT 2021); Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 87–96. [Google Scholar]
- Zhang, D.; Wei, S.; Li, S.; Wu, H.; Zhu, Q.; Zhou, G. Multi-modal Graph Fusion for Named Entity Recognition with Targeted Visual Guidance. Proc. AAAI Conf. Artif. Intell. 2021, 35, 14347–14355. [Google Scholar] [CrossRef]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognitio, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Gao, T.; Yao, X.; Chen, D. SimCSE: Simple contrastive learning of sentence embeddings. arXiv 2021, arXiv:2104.08821. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; PMLR: Cambridge, MA, USA, 2021; pp. 8748–8763. [Google Scholar]
- Wang, X.; Gui, M.; Jiang, Y.; Jia, Z.; Bach, N.; Wang, T.; Huang, Z.; Huang, F.; Tu, K. ITA: Image-Text Alignments for Multimodal NER; Association for Computational Linguistics: Melbourne, Australia, 2022; pp. 3176–3189. [Google Scholar]
- Xu, B.; Huang, S.; Sha, C.; Wang, H. MAF: A general matching and alignment framework for multimodal named entity recognition. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Virtual, 21–25 February 2022; pp. 1215–1223. [Google Scholar]
- Zhang, X.; Yuan, J.; Li, L.; Liu, J. Reducing the Bias of Visual Objects in Multimodal Named Entity Recognition. In Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, Singapore, 27 February–3 March 2023; Association for Computing Machinery: New York, NY, USA, 2023; pp. 958–966. [Google Scholar]
- Zhai, H.; Lv, X.; Hou, Z.; Tong, X.; Bu, F. MLNet: Multi-level MNER Architecture. Front. Neurorobotics 2023, 17, 1181143. [Google Scholar] [CrossRef] [PubMed]
- Zeng, Q.; Yuan, M.; Wan, J.; Wang, K.; Shi, N.; Che, Q.; Liu, B. ICKA: Instruction Construction and Knowledge Alignment for MNER. Expert Syst. 2024, 255, 124867. [Google Scholar] [CrossRef]
- Liu, P.; Li, H.; Ren, Y.; Liu, J.; Si, S.; Zhu, H.; Sun, L. Hierarchical Aligned Multimodal Learning for NER on Tweet Posts. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 18680–18688. [Google Scholar]
- Wang, Y.; Liu, X.; Huang, F.; Xiong, Z.; Zhang, W. A multi-modal contrastive diffusion model for therapeutic peptide generation. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 3–11. [Google Scholar]
- Wang, Z.; Xiong, Z.; Huang, F.; Liu, X.; Zhang, W. ZeroDDI: A Zero-Shot Drug-Drug Interaction Event Prediction Method with Semantic Enhanced Learning and Dual-Modal Uniform Alignment. arXiv 2024, arXiv:2407.00891. [Google Scholar]
- Ji, Z.; Chen, K.; Wang, H. Step-wise hierarchical alignment network for image-text matching. arXiv 2021, arXiv:2106.06509. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Lu, D.; Neves, L.; Carvalho, V.; Zhang, N.; Ji, H. Visual attention model for name tagging in multimodal social media. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 1990–1999. [Google Scholar]
- Chen, X.; Zhang, N.; Li, L.; Yao, Y.; Deng, S.; Tan, C.; Huang, F.; Si, L.; Chen, H. Good Visual Guidance Make A Better Extractor: Hierarchical Visual Prefix for Multimodal Entity and Relation Extraction. In Findings of the Association for Computational Linguistics: NAACL 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 1607–1618. [Google Scholar]
- Bao, X.; Tian, M.; Zha, Z.; Qin, B. MPMRC-MNER: Unified MRC Framework for MNER. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, Birmingham, UK, 21–25 October 2023; Association for Computing Machinery: New York, NY, USA, 2023; pp. 47–56. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).