1. Introduction
In recent years, the rapid development of technologies such as the Internet, artificial intelligence, and big data has helped usher in the era of educational informatization 2.0, and smart education has emerged as the times require. At present, online learning has been widely used in distance education, assisted classroom teaching, etc., providing a strong guarantee for promoting the reform of modern education. Online learning breaks the time and space constraints in the traditional teaching process and provides learners with a new form of learning. However, compared with traditional teaching forms, its shortcomings cannot be ignored. There is a lack of interaction between teachers and learners. Teachers cannot perceive learners’ learning status and emotions. Students’ emotions and expressions reflect their learning status and the degree of classroom participation, and teachers need to understand these emotional changes in time in order to adjust teaching strategies in a timely manner [
1]. At present, facial recognition technology has achieved remarkable results in areas such as attendance and security, which provides new ideas for smart online education. Deep learning can analyze students’ learning status, improve learning effects, and optimize teaching strategies [
2]. Therefore, by capturing the completeness and expression changes of students’ faces through expression recognition technology and counting and analyzing students’ classroom concentration, teachers can understand and manage students’ learning status and promote the improvement of teaching quality.
This system innovatively combines deep learning with classroom expression recognition technology. By capturing and analyzing students’ expressions, it accurately identifies students’ emotional states such as concentration, confusion, and fatigue in the classroom. The system uses spatial attention, channel attention, and self-attention mechanisms to extract deep features from students’ expression data and further optimizes the recognition accuracy of key areas through attention mechanisms. Teachers can adjust the teaching rhythm in a timely manner and enhance classroom interaction based on these recognition results. The system can not only objectively and accurately feedback students’ emotional states but also provide personalized data support for education, enabling teachers to improve teaching methods more effectively. Through this system, students’ emotions and learning states can be monitored, thereby achieving a more efficient and personalized classroom experience.
In summary, student expression recognition in the classroom environment is of great significance and can provide better support for teachers’ teaching and students’ learning:
- (1)
Optimizing teaching strategies: Through student expression recognition in the classroom environment, teachers can timely understand students’ emotional state and learning state, so as to adjust teaching strategies and make teaching more targeted and effective.
- (2)
Improving teaching quality: Teachers can analyze students’ learning behaviors, such as concentration and learning motivation, based on their expressions, so as to better help students learn and improve teaching quality.
- (3)
Improving students’ self-awareness and emotional management ability: Through expression recognition technology, students can better understand their emotional state and learning state, so as to timely adjust their learning state and improve their self-awareness and emotional management ability.
- (4)
Promoting educational informatization: Student expression recognition in the classroom environment requires the help of advanced computer technology, which can promote the development of smart education informatization.
However, with the widespread application of recognition technology, ethical issues have also become increasingly prominent. In particular, in terms of personal data protection, the regulations of different countries may vary. For example, compliance with the General Data Protection Regulation (GDPR) is mandatory in Europe, and in some countries and regions, data privacy regulations may become more and more extensive. Therefore, when applying such technology, the legality and scope of data collection must be clarified. Educational institutions should ensure that they obtain informed consent from students and their parents before collecting facial data and take necessary measures to anonymize the data to prevent data leakage. At the same time, ensure that the data are used only for educational purposes and avoid being used for other commercial or non-educational purposes.
In short, recognition technology has great potential in improving the quality of education and personalized learning experience, but it also needs to pay full attention to data privacy and ethical issues. Globally, educational institutions should strictly manage students’ personal data in accordance with the laws and regulations of their regions, ensure that the application of technology complies with ethical standards, and protect students’ privacy rights.
2. Related Works
2.1. Classroom Student Expression Dataset
Student expression datasets are fundamental to expression recognition, providing the necessary image samples for both training and testing. The quality of these datasets directly impacts recognition accuracy and the reliability of research findings.
Wei et al. constructed a multimodal student expression dataset (BNU-LSVED2.0), which consists of 2117 image sequences representing the classroom expressions of 81 students across 12 subjects, including mathematics, physics, and politics. This dataset identifies nine typical expressions: pleasure, surprise, disgust, confusion, fatigue, concentration, confidence, distraction, and frustration [
3]. Ramón et al. developed a student emotion dataset that categorizes emotional states based on real-time EEG signals. They designed activities and video viewing sessions to induce 25 participants to spontaneously express six emotions: boredom, engagement, excitement, concentration, enjoyment, and relaxation [
4]. Additionally, Bian et al. simulated an online learning environment to create an online classroom expression dataset, which includes 1274 video clips and 30,184 images from 82 students [
5].
Table 1 below summarizes the existing classroom student expression datasets and their key characteristics.
The schematic diagram of classic expression datasets is shown in
Figure 1. The RAF-DB dataset contains a vast collection of real-world facial images, representing a variety of expressions, ages, genders, races, and other conditions [
10]. FER2013 is a dataset specifically designed for facial expression recognition, containing seven basic facial expressions: anger, disgust, fear, happiness, neutrality, sadness, and surprise [
11]. Each sample in the CK+ dataset typically includes a continuous expression sequence, made up of multiple static frames, which captures the complete transition from a neutral expression to a specific emotion (such as happiness, sadness, surprise, etc.) [
12]. AffectNet comprises images sourced from the internet and natural scenes, annotated with extensive emotion and mood information, including expression categories, intensity, and attributes [
13]. These four datasets have been widely used in expression recognition research, and each offers distinct characteristics and advantages.
2.2. Expression Recognition Methods
2.2.1. Based on Traditional Expression Recognition Methods
Traditional expression recognition methods usually focus on extracting expression features, which may be geometric features of the facial region or facial features. Cai et al. [
13] proposed a new island loss (IL) to enhance the discriminative ability of deep learning features. The island loss can enlarge the difference between classes while reducing the intra-class variation. Zhang et al. [
14] proposed a chain code-based facial expression geometric feature extraction algorithm. The algorithm encodes the position of feature points on the face with a circular chain code to extract the geometric features of the face shape. In addition, Fabian Benitez-Quiroz et al. [
15] improved the accuracy of the model and optimized the algorithm time complexity by fusing different geometric feature extraction methods. The limitation of the geometric feature method is that it can only extract static information of expression and cannot handle dynamic changes of expression. Therefore, the geometric feature method is usually used for the recognition of static expression images.
In the field of face recognition, facial feature methods mainly extract feature vectors by filtering the entire or partial facial image data. Zheng H. [
16] proposed an expression recognition method based on two-dimensional Gabor filters and sparse representation. The 2D Gabor filter is used to enhance the robustness of changes. Since sparse representation can be used to handle subtleties, the recognition problem is reduced to a sparse approximation problem. However, after being processed by the Gabor filter, the feature dimension is excessive, and the data are redundant. To solve this problem, Mahmood et al. [
17] proposed an image sequence facial expression recognition method combining Radon transform and Gabor wavelet transform. This method first uses the ellipse parameter method for face detection, then extracts variable features through Radon transform and Gabor transform filters, and finally, uses self-organizing maps and neural networks as recognition engines to measure six basic facial expressions. The recognition accuracy is higher than many algorithms at the time. In 2020, Ramos et al. [
18] proposed an expression recognition algorithm based on Gabor filters. The algorithm uses feature extraction methods such as Haar-Cascade classifiers for face detection, Gabor filters and Eigenface API for feature extraction, and has an accuracy of 80.11% when training the model. The results are analyzed and linked to appropriate teaching methods for educators, and intervention measures related to emotion prediction observed in lectures or classes are recommended.
2.2.2. Expression Recognition Method Based on Deep Learning
With the increasing application of deep learning in expression recognition, many scholars have devoted themselves to studying and improving deep learning algorithms for expression recognition. Among them, Andre Teixeira Lopes et al. [
19] extracted expression-specific features from facial images based on convolutional neural networks and explored the influence of sample presentation order. In 2014, Liu et al. [
20] proposed a boosted deep belief network (BDBN). The joint fine-tuning process proposed by the network can enhance the discrimination ability of the selected features. Since expression is a short-term action, Hariri et al. [
21] proposed a three-dimensional facial expression recognition method based on the Riemann manifold kernel method. This method uses 3D data to process the inter-class and intra-class variability of human facial expressions and focuses on the variation factors in the data by focusing on the manifold-based classification. In addition, Farkhod et al. [
22] proposed a CNN method for facial expression recognition based on real-time landmarks in 2022. Since wearing a mask is indispensable during the COVID-19 pandemic, this method uses landmarks on the upper part of the face to extract facial expression features from key points of the face, uses Haar-Cascade for face detection, and completes expression recognition through the media pipeline face mesh model. In order to solve the problem of redundant information, Chang and Lin [
23] proposed a generative adversarial network (WGAN), which extracts expression features irrelevant to user information through adversarial learning and can complete occluded expression images. In general, the expression recognition process is shown in
Figure 2.
Although the accuracy and speed of deep learning methods in facial expression recognition tasks are constantly improving, and the transfer ability is also constantly increasing, compared with traditional expression recognition technology, its accuracy has also been greatly improved after the feature extraction method has been improved. However, in the facial expression recognition task, there are still challenges such as lack of data, poor network feature extraction capabilities, and low utilization rate of extracted features. In addition, in the real classroom environment, there are still problems such as light influence and foreign object occlusion. Therefore, the problem of deep learning expression recognition is still a very meaningful research topic, which requires scholars to continue to explore and improve.
2.3. Educational Applications of Facial Expression Recognition
The topic of this paper is the expression recognition algorithm in the classroom environment. In order to solve the problems of complex background and facial occlusion in the classroom environment and insufficient information of facial expression features extracted using a single attention mechanism in the expression recognition process, an expression recognition algorithm integrating multiple attention mechanisms is proposed. This algorithm is based on the ResNet-34 residual network and integrates channel attention, spatial attention, and self-attention mechanisms. First, the channel attention and spatial attention mechanisms are introduced to the front end of the network to process image information and extract expression features. Then, the self-attention mechanism processes the expression features to achieve the effect of model strengthening. Compared with the classical algorithm, it can more accurately complete the task of student expression recognition in a learning environment.
2.3.1. Application in Online Teaching
For multiple participants in online classes, it is often difficult for teachers to detect students’ emotional changes one by one. This expression recognition system provides teachers with emotion recognition to help them better understand students’ emotional states and optimize classroom interactions. Specific application scenarios include:
Personalized teaching: Students’ facial expressions can be monitored. By analyzing students’ emotional fluctuations (such as anxiety, confusion, boredom, etc.), teachers can understand students’ learning status and adjust the classroom rhythm and teaching content. For example, the system will display students’ emotions in the form of graphs on the screen. If multiple students show anxiety or confusion when explaining a certain knowledge point, the teacher can adjust the teaching content or involve students through interactive question-and-answer sessions to improve classroom interaction and learning outcomes.
Emotional monitoring: By analyzing facial expressions in the classroom environment, students’ concentration can be judged. For classes with a large number of students, teachers can understand the emotional state of the entire class through the system, providing more data support and help for teachers, students, and parents.
2.3.2. Educational Value
Traditional face recognition technology, despite significant progress in identifying facial features, often ignores subtle changes in emotions. For example, when faced with complex classroom environments (such as changes in students’ perspective, facial occlusion, lowering their heads, etc.), it is impossible to stably identify students’ emotional states. In addition, many existing systems lack effective feedback mechanisms in multi-student situations and cannot provide teachers with specific information about each student’s emotions. Therefore, existing technologies are difficult to cope with the personalized teaching needs faced in online education. The model can accurately capture changes in students’ facial expressions and help analyze students’ emotional fluctuations. Compared with traditional emotion recognition technology, the algorithm proposed in this article is more adaptable to complex classroom environments, can overcome problems such as bowing and occlusion, and provides more accurate emotional feedback.
3. Theoretical Framework of Facial Expression Recognition
3.1. Research Methods
This study aims to develop a classroom concentration analysis system based on deep learning. The system automatically identifies students’ head-up rates and facial expressions from classroom images and analyzes classroom concentration using a concentration model to determine the current level of student engagement. The system architecture is shown in
Figure 3. The primary research components of this paper include the following:
Classroom Expression Dataset (CED): This paper constructs a dataset tailored for the analysis of student facial expressions in classroom settings. Using video recordings from 30 real-world university classrooms, the dataset comprises 12,174 images spanning five categories: resistance, confusion, understanding, fatigue, and neutrality. Various data augmentation methods are employed to enhance the dataset’s diversity.
Deep Learning Expression Recognition Algorithm: The paper proposes a Multi-Attention Fusion Network for Expression Recognition (MAF-ER), integrating spatial attention, channel attention, and self-attention mechanisms. The network consists of four key components: a feature extraction network, channel attention mechanism, spatial attention mechanism, and self-attention mechanism. The feature extraction network captures facial expression features, while the attention mechanisms enable the neural network to focus on significant facial expression details. The self-attention mechanism reduces ambiguity from uncertain samples, improving the model’s representational capacity.
Application to Intelligent Classroom Evaluation: This study serves as an effective tool for classroom emotion recognition, enhancing the educational experience for students and providing teachers with new insights into student observation and analysis, thus advancing classroom instruction toward the era of smart education.
3.2. Classroom Expression CED Dataset
With the advancement of expression recognition technology, scholars have increasingly recognized the importance of high-quality expression data for developing effective neural network models and analyzing learning conditions. Currently, researchers both domestically and internationally have established various student expression datasets, though these datasets differ in scale and construction methods. Student expression datasets can be classified into three types: the first type is based on the six basic emotions proposed by Ekman, as shown in
Table 2; the second type is built using the facial action coding system; the third type is established according to specific research needs, analyzing the requirements to create an expression dataset suitable for the study at hand.
To facilitate research and applications of student expression recognition, this paper established a dataset in a classroom environment (CED). The CED dataset contains a large collection of facial expression images. Based on a literature review, this paper identified the expression categories to be collected, as shown in
Table 3. The specific steps are as follows:
- (1)
Data Collection: Camera equipment was used to capture pictures and videos of student expressions in the classroom environment, collecting a variety of expressions such as resistance, confusion, fatigue, and more.
- (2)
Data Cleaning: The collected images or videos were screened and edited to ensure consistency and usability in image quality.
- (3)
Data Labeling: Each image was labeled to indicate the facial expression category corresponding to the face in the image.
- (4)
Dataset Partitioning: The dataset was divided into training, validation, and test sets for model training, evaluation, and parameter tuning.
- (5)
Data Cleaning: During dataset creation, checks were conducted for missing values, outliers, duplicate values, and other irregularities, and appropriate cleaning procedures were applied.
- (6)
Exporting the Dataset: The dataset was exported in jpg format.
Table 3.
Classroom emotion classification.
Table 3.
Classroom emotion classification.
| Label | Mood | Expression Characteristics |
|---|
| 0 | Resistance | Furrowed brows, lowered eyebrows |
| 1 | Confusion | Wrinkled eyebrows, slightly tilted head, corners of mouth pulled down |
| 2 | Understanding | Prominent cheekbones, raised upper lip |
| 3 | Tiredness | Open mouth, protruding lips, eyes closed |
| 4 | Neutral | Relaxed expression, no obvious changes |
To advance research on student classroom expression recognition and address the issues of inconsistent quality in current student expression datasets and the challenge of achieving standardized category divisions, this paper recorded 30 real-world classroom videos from colleges to construct a dataset. By reviewing and comparing literature in related fields, analyzing college classroom environments, and consulting experts, this study categorizes and organizes existing student classroom expressions. The classification of the dataset is outlined in
Table 3. Some examples of facial expressions in the dataset are shown in
Figure 4. Through statistical analysis, expression categories that frequently occur in the classroom and positively influence classroom evaluation were identified. Ultimately, a student classroom expression dataset was constructed, containing five categories—resistance, confusion, understanding, fatigue, and neutrality—comprising a total of 12,174 images.
3.3. Construction of Face Data Enhancement Model Based on Generative Adversarial Network
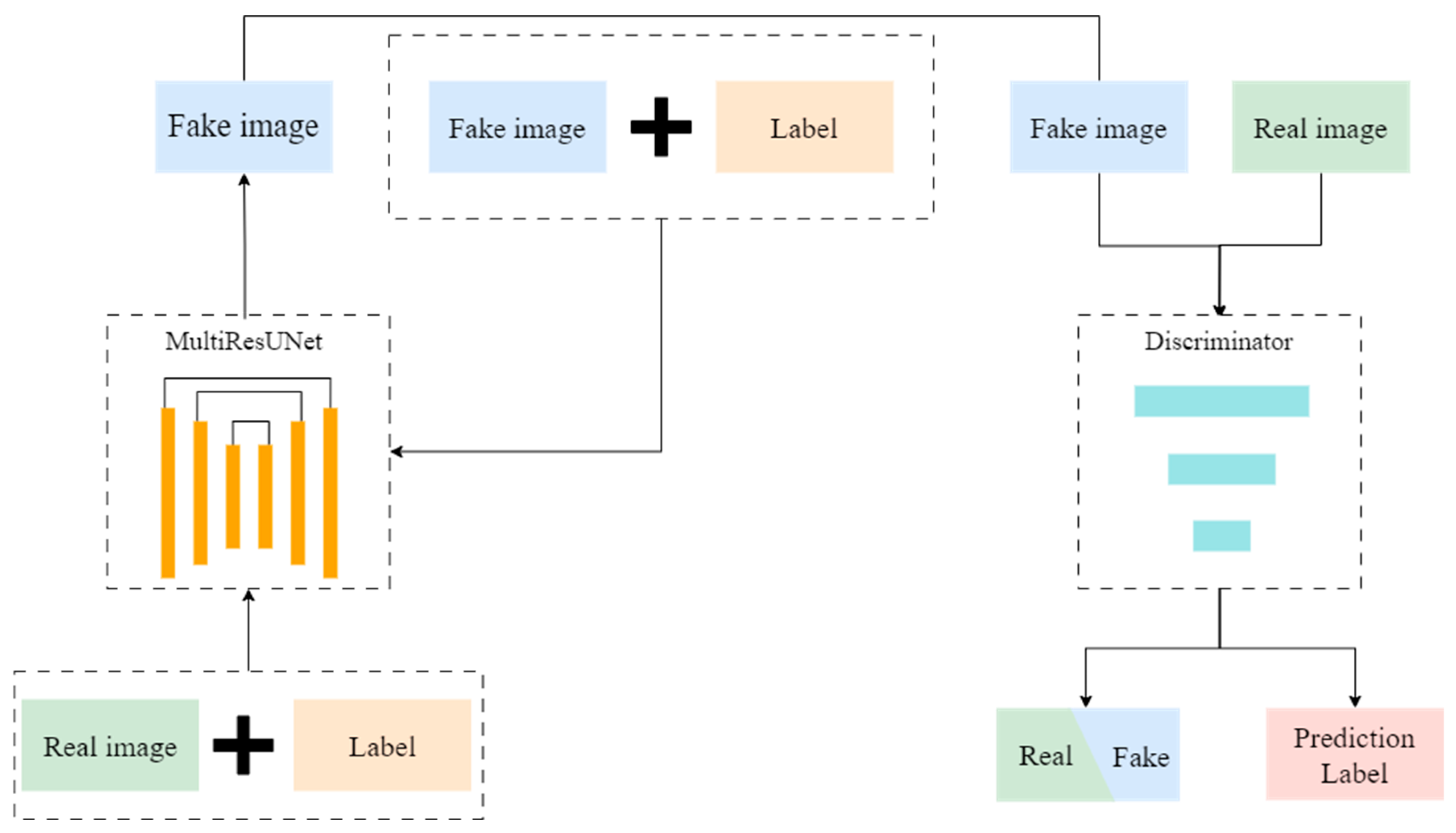
To address the issues of insufficient data volume and uneven data types in current datasets, this paper proposes a data augmentation method based on Generative Adversarial Networks (GANs). First, the highly efficient StarGAN network is selected as the base model. Second, the MultiResUNet model is introduced as the network generator, allowing the network to extract edge features more accurately. Finally, the reconstruction loss function is improved to help the network distinguish between significant defects in key areas and minor displacements in images [
27].
StarGAN is an image conversion model based on GANs, originally designed for multi-domain image conversion tasks. Its primary goal is to enable style conversion across multiple domains, rather than just between two. StarGAN’s architecture allows the model to handle multiple image conversion tasks simultaneously, without the need to train separate networks for each task. It can learn mappings between multiple domains using a single generator.
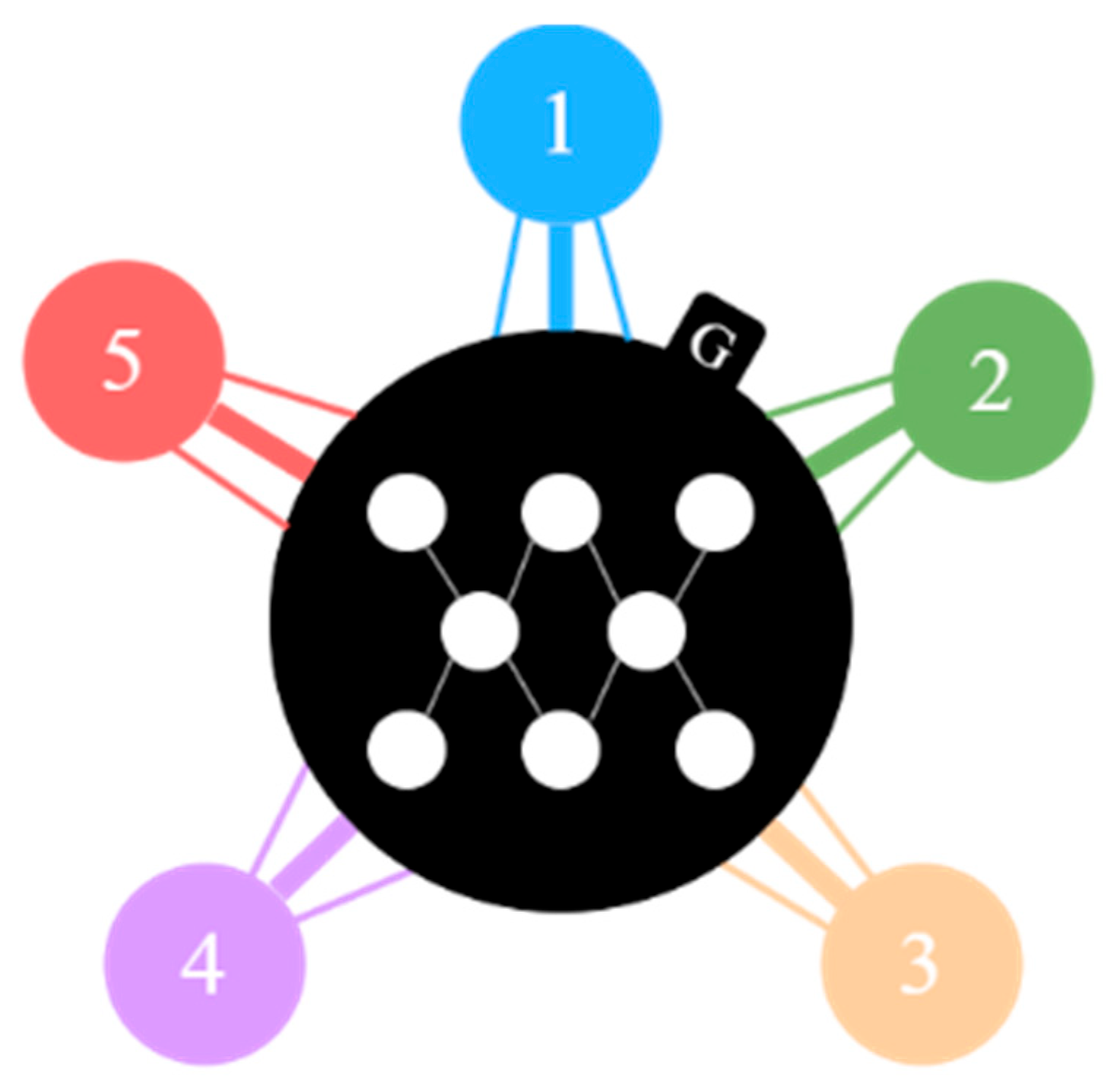
Figure 5 illustrates a star topology connecting multiple domains. The generator G achieves the conversion of multi-domain image generation by sharing network parameters. Five circles of different colors (marked 1 to 5) represent different image domains, such as categories of different expressions. Each circle is connected to the generator in the center by a line.
The StarGAN model employs a mask vector method to effectively manage all available domain labels within the network. In contrast to other models, StarGAN not only inputs the image into the generator G but also incorporates the label information corresponding to the target domain. This dual input allows for a more precise transformation of the input image across various styles. Furthermore, the model introduces a reconstruction loss function, specifically the L1 norm, which facilitates the reconstruction of the original image. This ensures that only the regions differing across domains are altered, thereby preserving the original feature information. In this architecture, the discriminator D provides two outputs: It distinguishes between real and generated images while simultaneously classifying the images into their respective domains.
The generator of StarGAN receives the input image and the target domain label and generates a new image that matches the target domain. The architecture is shown in
Table 4.
The main function of StarGAN’s discriminator is to determine whether the generated image is real and evaluate its matching degree with the target domain. The architecture is shown in
Table 5.
The MultiResUNetV model was introduced by Ibtehaz and Rahman [
28] as an enhancement of the U-Net architecture. This model replaces the corresponding modules with three 3 × 3 convolutional layers and incorporates an additional 1 × 1 convolutional layer within the network. By integrating concepts of multi-scale feature extraction and residual connections, MultiResUNetV significantly enhances the accuracy of image segmentation, particularly for complex or small structures. Compared to the standard U-Net, MultiResUNetV achieves superior feature representation capabilities through multi-resolution feature extraction and feature fusion. The structure of the residual path is illustrated in
Figure 6 below.
The original loss function is cumbersome to solve and may yield multiple optimal solutions. During this process, the subtle differences between the original image and the generated image result in relatively small, squared values. Consequently, the L2 loss function is preferable to the original loss function in terms of gradient computation and convergence speed. The formula for the L2 loss function is as follows:
The structure of MultiResUNet is illustrated in
Figure 7, where the left side represents the compression path, and the right side represents the expansion path. As shown in the figure, the compression path consists of four MultiRes Blocks, each utilizing three 3 × 3 convolution kernels instead of the traditional 7 × 7 convolution kernels used in U-Net, along with a maximum pooling operation. Notably, the last MultiRes Block does not perform a pooling operation; instead, its output is passed directly to the expansion path. The pooling operation serves to extract the most significant information from the feature map, reducing its size to half of the original dimensions. This not only decreases the number of parameters in the network but also mitigates the consumption of computational resources.
In the expansion path, the network performs additional convolution operations prior to fusing with the features from the compression path. Unlike U-Net’s skip connections, MultiResUNet employs residual paths, enabling the network to effectively integrate the low-level information from shallow convolutional layers with the high-level semantic information from deep convolutional layers, thereby reducing the discrepancies between them. Additionally, the encoder and decoder exhibit variations in the number of feature maps, the number of convolutional blocks, and the sizes of the convolution kernels. All convolutional layers, except for the output layer, which utilizes the Sigmoid activation function, employ the ReLU activation function along with batch normalization.
Figure 8 presents the complete architecture of the network model.
3.4. Multi-Attention Fusion Network for Expression Recognition
The core idea of this system is to integrate the channel attention mechanism, spatial attention mechanism, and self-attention mechanism based on the ResNet-34 residual network to enhance the accuracy of expression recognition. These three attention mechanisms work collaboratively to improve the network’s ability to extract and recognize expression features, enabling the model to accurately identify students’ expression states even in a complex classroom environment.
3.4.1. Feature Extraction Network
In a classroom setting with a large number of individuals, the complex background and dense faces can hinder the neural network’s ability to extract facial expression features, which may adversely affect the accuracy of expression recognition. To enhance the algorithm’s robustness in such interference-prone environments, this study selects the ResNet-34 network as the foundational architecture and designs a facial expression feature extraction network that integrates both channel attention and spatial attention mechanisms, as illustrated in
Figure 9.
The network comprises 33 convolutional layers and 3 fully connected layers, organized into 6 modules, as shown in
Figure 9. Initially, the channel attention and spatial attention mechanisms are introduced after the fifth module to suppress background noise and irrelevant features in both the channel and spatial dimensions. This reduces interference and enables the network to focus more effectively on extracting pertinent feature information. Subsequently, in the final module, an average pooling layer is employed to downsample the features, further strengthening the relationships among relevant channels, filtering out extraneous information, and extracting facial expression features.
Finally, expression classification is accomplished by incorporating a Softmax regression function into the last layer of the neural network. During network output, the model predicts the probabilities of different categories for each sample, selecting the category with the highest probability as the final classification result.
3.4.2. MAF-ER Algorithm Structure
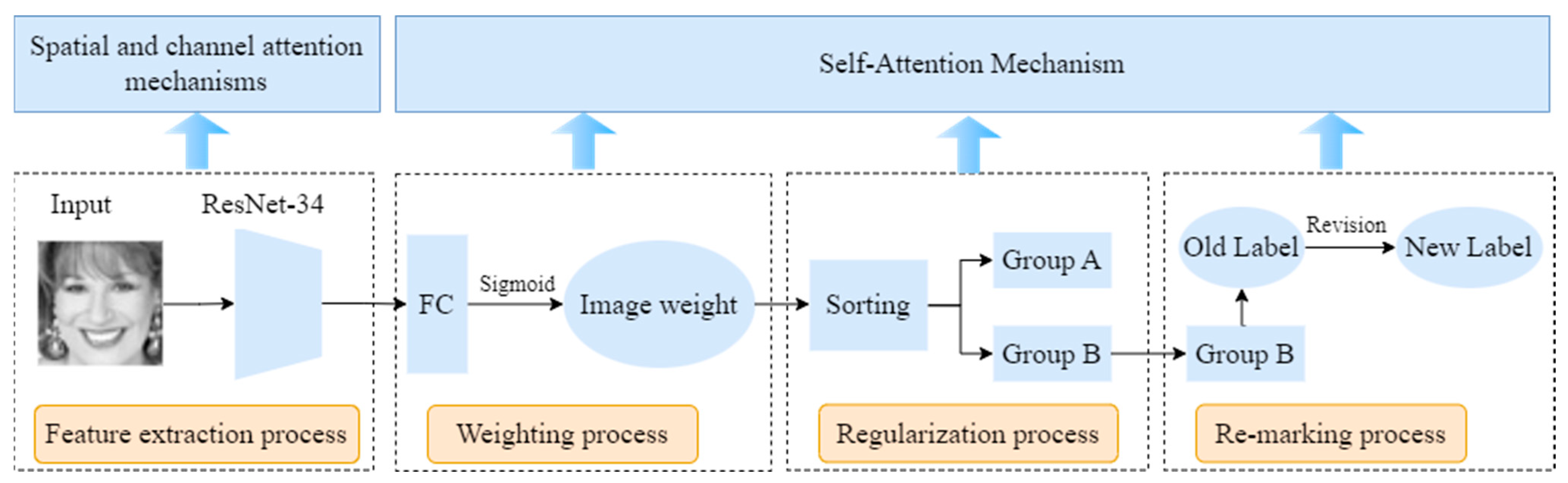
The network model comprises four primary components: the feature extraction network, the channel attention mechanism, the spatial attention mechanism, and the self-attention mechanism. The feature extraction network is responsible for extracting facial features, while the combination of channel and spatial attention mechanisms allows the network to focus on salient facial features. The self-attention mechanism helps suppress uncertain samples caused by factors such as lighting, occlusion, and variations in body posture, thereby enhancing the model’s expressive capability.
The MAF-ER algorithm process can be summarized in the following steps:
Feature Extraction: Facial images are processed through a ResNet-34 network that integrates channel and spatial attention mechanisms for feature extraction. This network effectively abstracts important information from the images, providing valuable facial expression features.
Self-Attention Mechanism: This mechanism consists of three steps to further optimize the feature extraction results:
Weighting Process: The extracted expression features are assigned weights to emphasize key characteristics, enhancing the model’s expressive power.
Regularization Process: Features are sorted based on their weights, categorizing them into high and low importance groups. This enables the model to focus on crucial features while reducing noise interference, thereby improving robustness and generalization capabilities.
Relabeling Process: Uncertain samples in the low importance group are relabeled to identify more definitive labels, further improving the model’s recognition accuracy and stability.
By employing these steps, the MAF-ER algorithm can effectively address expression recognition tasks under complex conditions such as varying lighting and occlusion, thereby enhancing the network’s accuracy, robustness, and reliability. As illustrated in
Figure 10, the facial image is first input into the ResNet-34 network, which integrates channel and spatial attention mechanisms for the efficient extraction of key information. Subsequently, the self-attention mechanism optimizes the feature processing through the weighting, regularization, and relabeling processes. During the weighting process, emphasis is placed on reinforcing key features; in the regularization process, feature weights are sorted to differentiate importance; and in the relabeling process, uncertain samples are reassessed to further improve recognition accuracy and the stability of the model.
4. Experiment and Analysis
In this section, we first test the expression recognition performance of the proposed model and compare it with other learning algorithms.
4.1. Experimental Design and Analysis of MAF-ER Algorithm
- A.
Experimental Setup
Experimental environment: The experiment was conducted on a Linux system, using two NVIDIA GeForce GTX 1080 Ti graphics cards (NVIDIA Corporation, Santa Clara, CA, USA), and the framework was PyTorch 1.12.1.
Experimental parameters: The cross-entropy loss function was used, the optimizer was AdaBound, the initial learning rate was 0.01, and exponential decay was used. The parameter δ1 between the high and low importance groups was set to 0.15 or a learnable parameter, and the relabeling parameter δ2 was initially 0.2. The dataset was expanded using data augmentation, and the image size was adjusted to 128 × 128. The dataset was divided into a test set and a validation set in a ratio of 7:3 and trained for 70 epochs.
- B.
Algorithm Analysis
The confusion matrix is used to evaluate the algorithm, showing the classification performance of the model on different categories and analyzing its performance through accuracy and error rate:
Among them, True Positive (TP) means that the true category of the sample is positive, and the result of model recognition is also positive; True Negative (TN): the true category of the sample is negative, and the model predicts it as a negative.
Among them, False Positive (FP): the true category of the sample is a negative example, but the model predicts it as a positive example; False Negative (FN): the true category of the sample is a positive example, but the model predicts it as a negative example.
As illustrated in
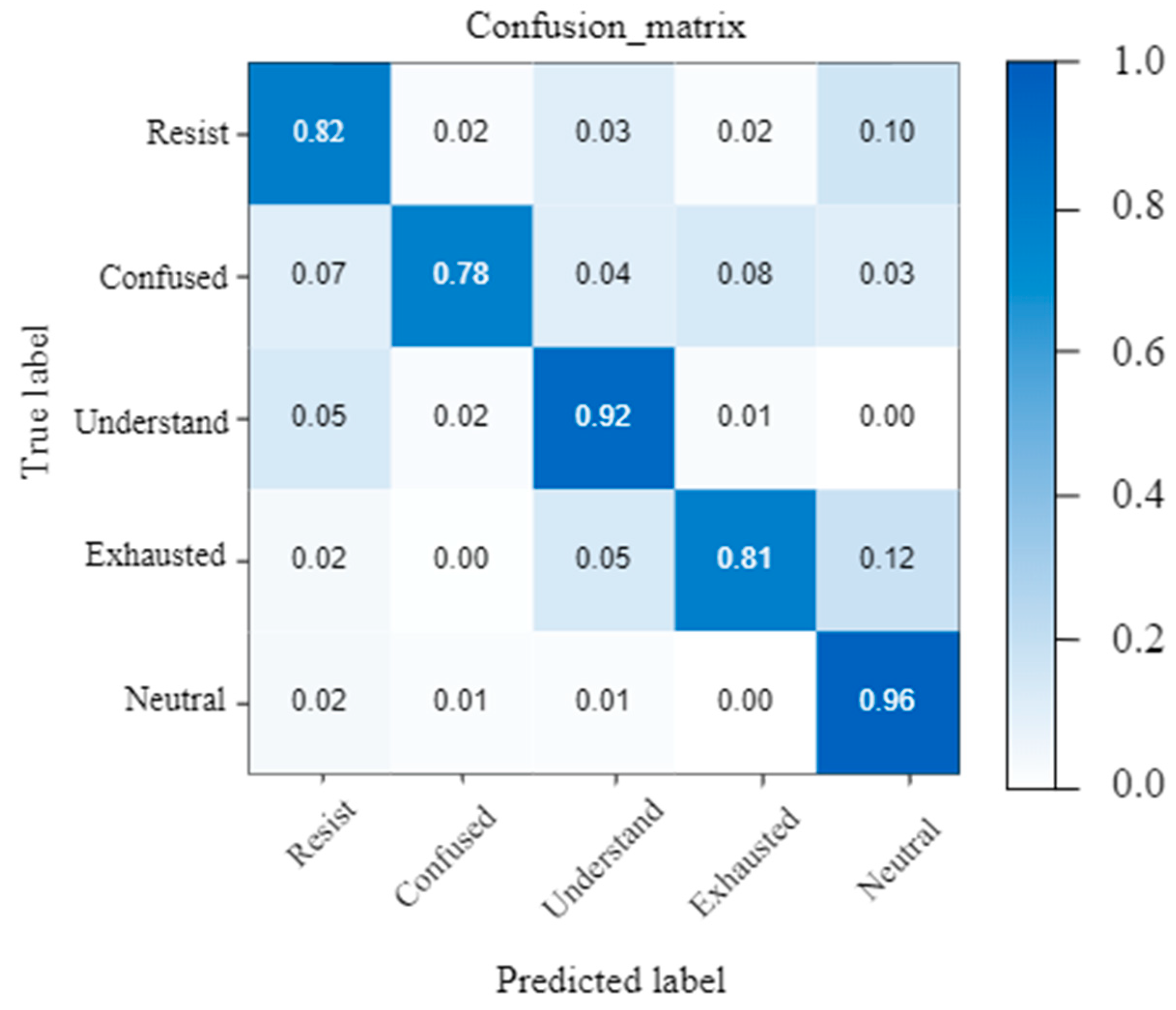
Figure 11 and
Figure 12, the proposed algorithm has led to improvements in the accuracy of each type of expression. The figures demonstrate a noticeable reduction in misclassification phenomena. For instance, the misclassification rate for the “Resist” class has decreased to 10% compared to 11% for the IXception algorithm, while the accuracy of the “Neutral” class has increased to 96%. This indicates that the algorithm has effectively reduced misclassification across most categories. Overall, the accuracy of the MAF-ER algorithm surpasses that of the IXception algorithm in most categories [
29]. Notably, MAF-ER excels in minimizing misclassification and enhancing the model’s ability to recognize complex features.
- C.
Algorithm Comparison
This section experiments with the proposed algorithm on the CED dataset and compares it with some widely used methods. The experimental results are shown in
Table 6. From
Table 6, it can be concluded that, through the comparison of various indicators, the MAF-ER algorithm performs well in precision, MAPE, F1-Score, and Recall and is better than the other comparison algorithms (IXception, LDL-ALSG, APM, and DLP-CNN). This shows that the MAF-ER algorithm has high accuracy and stability in the classroom expression recognition task and can more effectively identify the students’ expression state.
4.2. Expression Recognition Effect Display
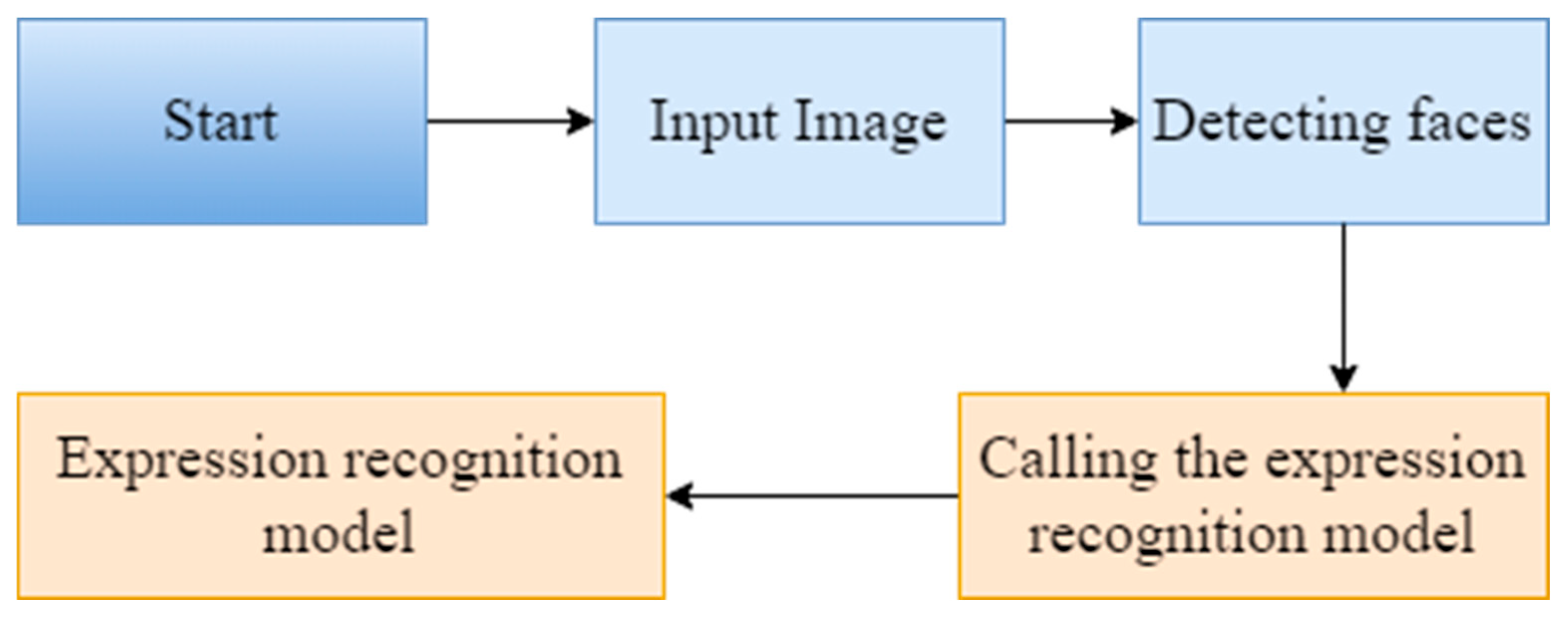
The expression recognition process in this paper can be divided into the following steps, the expression recognition workflow is shown in
Figure 13:
- (1)
Image acquisition. Perform face recognition on the input image, select the image, and perform expression recognition on the detected face.
- (2)
Face selection. According to the face detected in step (1), the O-Net network layer in the expression recognition network algorithm model is used to select the face coordinates, save the obtained coordinate data value, and pass it as a parameter to the next step.
- (3)
Call the model. The system calls the facial expression recognition model, selects the face coordinates detected in step (2), detects the face through the model, and recognizes the facial expression.
- (4)
Recognition result. The actual expression detected in step (3) is presented in the form of a label on the box of the selected face.
Figure 13.
Expression recognition workflow.
Figure 13.
Expression recognition workflow.
4.2.1. Expression Recognition Results
This section uses the expression recognition network algorithm model that integrates multiple attention mechanisms as the initial recognition module. First, face recognition is performed on the input data, and the detected face is cropped into an image of size 48 × 48. Then, the expression recognition model is called to complete the recognition of the expression.
When this system is used in actual classrooms, it automatically identifies students’ facial expressions and generates emotional feedback reports. For example, in a math class, when the system detects that students are becoming more confused, the teacher can re-stimulate students’ interest through examples, questions, or interactive exercises. In addition, the system can identify students’ long-term performance and help teachers provide personalized coaching and attention. Data-driven teaching adjustments can effectively improve students’ learning experience and classroom participation, thereby optimizing the overall teaching quality. The recognition results are shown in
Figure 14.
For a more intuitive description,
Table 7 describes the confidence of expression recognition using
Figure 14 as an example. The numbers in the first column of the table are sorted from front to back and from left to right according to the position of the students in the picture. This table only uses the four students in the front row of
Figure 14 as an example.
As shown in
Table 7, the MAF-ER algorithm successfully performs the task of student expression recognition. In the classroom setting, the majority of detected expressions are categorized as Neutral, indicating that most students maintain a relatively serious demeanor during class.
4.2.2. Experimental Analysis
To verify the effect of the MAF-ER algorithm on the CDE dataset, similar to
Section 4.1, the confusion matrix is also used to evaluate the model accuracy of the algorithm. The confusion matrix results are shown in
Figure 15.
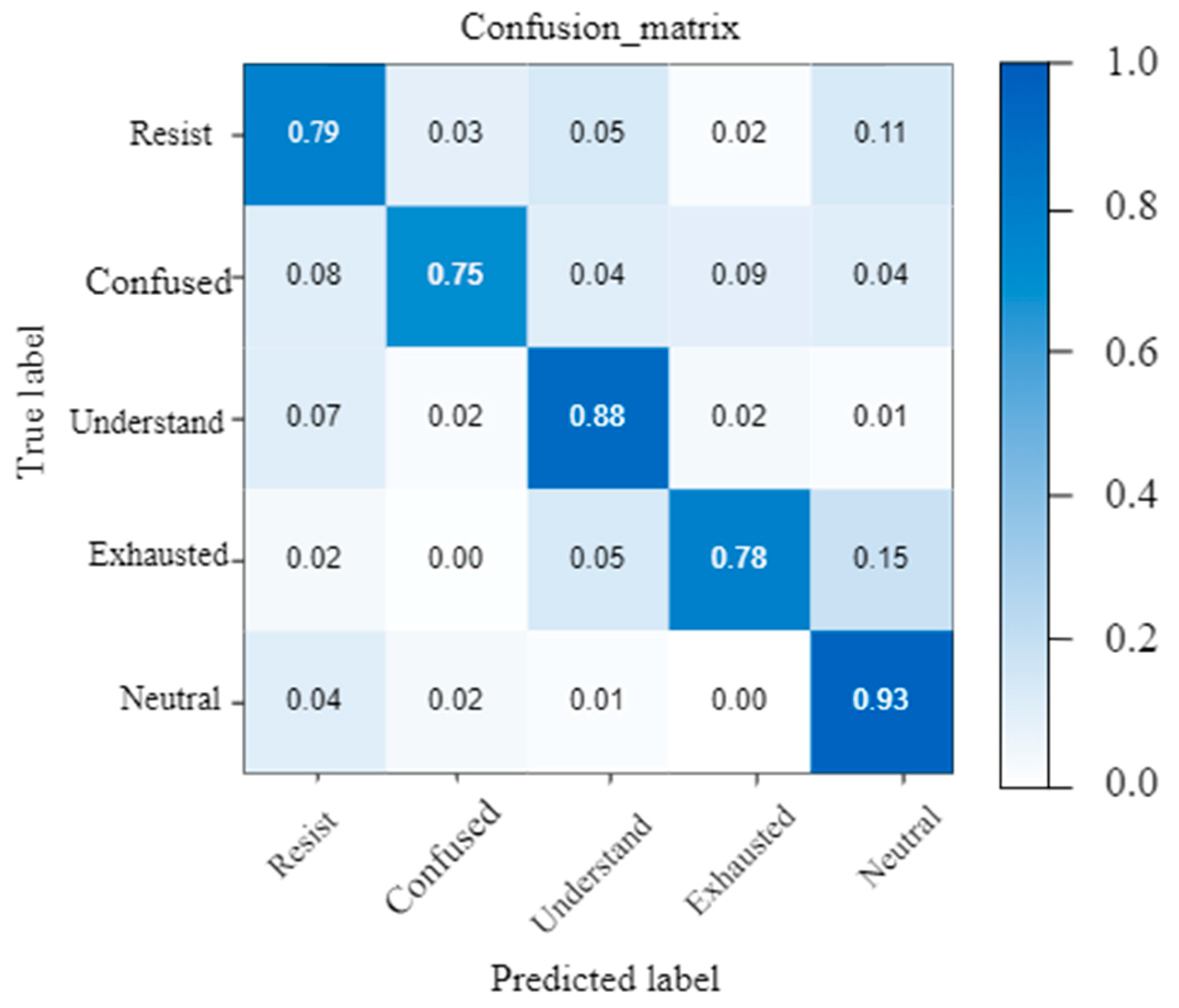
Figure 15 shows the confusion matrix of the CDE dataset. The vertical axis represents the true label, the horizontal axis represents the prediction result of the algorithm, and the diagonal of the matrix represents the probability of the model correctly predicting each type of label. Since most students are serious during class, the detected expression categories are mainly concentrated in Neutral and Understand. However, in some cases, students may not listen carefully, so the algorithm can also effectively classify some expression categories such as Confused and Exhausted.
To further assess the effectiveness of each MAF-ER module, an ablation experiment was conducted using the CED dataset. The same training procedure was repeated five times to record the results and calculate the average, as detailed in
Table 8. The recording steps are as follows:
- (1)
The channel attention mechanism unit was added to the baseline network, denoted as CA;
- (2)
The spatial attention mechanism unit was added to the baseline network, denoted as SA;
- (3)
The self-attention mechanism unit was added to the baseline network, denoted as SFA;
- (4)
Both the channel attention mechanism and the spatial attention mechanism were employed in the baseline network, denoted as CSA;
- (5)
The complete multi-attention mechanism, as proposed in this paper, was applied to the baseline network, denoted as MLA.
Table 8.
Ablation experiments of MAF-ER on the CED dataset.
Table 8.
Ablation experiments of MAF-ER on the CED dataset.
| Modules | Accuracy |
|---|
| CA | 81.37% |
| SA | 82.06% |
| SFA | 83.64% |
| CSA | 84.69% |
| MLA | 88.34% |
It can be concluded from
Table 8 that the MLA (multi-level attention) model achieved the highest accuracy of 88.34%, indicating that the multi-level attention mechanism can maximize the capture and utilization of important features in the image and significantly improve the accuracy of expression recognition.
5. Conclusions
The classroom is the main place for school education, so it has always been the focus of educational research. Teachers can grasp the emotional state of students in classroom teaching and adjust teaching methods in time. This standardized feedback mechanism can effectively improve the state that is difficult to achieve in time in traditional teaching. Understanding the shortcomings of students’ emotions can increase the interactivity and attention in the classroom. It has shown significant advantages in improving students’ attention, enhancing classroom participation and personalized teaching support, thereby promoting the overall improvement in teaching quality. This paper addresses the task of recognizing students’ classroom expressions and presents the following contributions to tackle the issue of sample uncertainty in this domain:
- (1)
Construction of a Student Classroom Expression Dataset: This paper constructs a dataset of student classroom expressions containing five types of emotions: resistance, confusion, understanding, affection, and neutrality. By recording 30 real classroom videos and going through multiple steps such as data collection, cleaning, and annotation, we finally obtained a dataset containing 12,174 images.
- (2)
Development of a Face Data Enhancement Model Based on Generative Adversarial Networks: In order to solve the problems of insufficient samples and category imbalance, this paper proposes a face data enhancement method based on the StarGAN network and further improves the quality and accuracy of image generation by introducing the MultiResUNet model and reconstructing the damage function.
- (3)
Multi-Attention Fusion Network Algorithm (MAF-ER): This paper proposes an expression recognition algorithm MAF-ER that combines spatial, channel, and self-attention mechanisms. By combining the attention mechanism, it focuses on a variety of background noises and related features, improves the accuracy of facial expression feature extraction, and solves the problem of inaccurate labeling caused by sample uncertainty.
With the continuous advancement of recognition technology and deep learning algorithms, classroom expression recognition systems will become more accurate and efficient. This technology can not only integrate multimodal data such as expression, voice, and action but also provide more comprehensive feedback teaching, further supporting the realization of smart classrooms and personalized education.
However, in the actual application process, we must face up to the ethical challenges brought by this technology. First, students’ emotional data involves personal privacy, and data protection regulations must be strictly observed to ensure the security and privacy of information. There are differences in data protection and privacy regulations, so the design and implementation of the system must strictly comply with local laws and ethical norms. In addition, the application of emotion recognition systems needs to prevent the erroneous consequences caused by mislabeling, especially in terms of the accuracy and fairness of emotion recognition. Therefore, future research should further improve the algorithm model to enhance its robustness and generalization ability.
In the future, classroom emotion recognition technology has the potential to be further expanded to a wider range of application scenarios, such as student behavior analysis, automatic adjustment of teaching content, etc., to promote educational transformation and data-driven changes. In the process of development, we must continue to pay attention to the ethical impact of technology implementation and ensure respect for students’ privacy and basic human rights. Educational institutions and technology developers should jointly formulate clear ethical standards and usage specifications and strengthen training for teachers and related personnel so that they can correctly understand and use emotion recognition technology. At the same time, an effective supervision mechanism should be established to regularly evaluate the effects and impacts of technology applications, promptly identify and correct possible problems, and maintain the fairness and humanity of education. Only under the premise of fully considering ethical and moral factors can classroom emotion recognition technology truly play its positive role and contribute to the development of education.
Author Contributions
Y.G.: Responsible for research design, dataset construction, algorithm development, and paper writing. Proposed a network algorithm based on multi-attention mechanisms and led the implementation. L.Z.: Responsible for system development, experimental implementation, data preprocessing, and model training. Participated in experimental tuning and assisted in revising the paper. J.H.: Contributed to research planning and discussions, supported algorithm optimization and experimental verification, assisted in paper editing and reviewing, and provided guidance on the overall project progress. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Research on the Integration of Party Building Teaching and Research, Learning and Work in Business Major Virtual Teaching and Research Room (No: JG24DB085).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Due to privacy restrictions, the data is not yet public.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Al Darayseh, A. Acceptance of artificial intelligence in teaching science: Science teachers’ perspective. Comput. Educ. Artif. Intell. 2023, 4, 100132. [Google Scholar] [CrossRef]
- Fiok, K.; Farahani, F.V.; Karwowski, W.; Ahram, T. Explainable artificial intelligence for education and training. J. Def. Model. Simul. 2022, 19, 133–144. [Google Scholar] [CrossRef]
- Wei, Q.; Sun, B.; He, J.; Yu, L. BNU-LSVED 2.0: Spontaneous multimodal student affect database with multi-dimensional labels. Signal Process. Image Commun. 2017, 59, 168–181. [Google Scholar] [CrossRef]
- Ramón, Z.C.; Lucia BE, M.; Daniel, L.H.; Mario, R.-F.J. Creation of a Facial Expression Corpus from EEG Signals for Learning Centered Emotions. In Proceedings of the 2017 IEEE 17th International Conference on Advanced Learning Technologies (ICALT), Timisoara, Romania, 3–7 July 2017; pp. 387–390. [Google Scholar]
- Bian, C.; Zhang, Y.; Yang, F.; Bi, W.; Lu, W. Spontaneous facial expression database for academic emotion inference in online learning. IET Comput. Vis. 2019, 13, 329–337. [Google Scholar] [CrossRef]
- Lin, S.S.J.; Chen, W.; Lin, C.H.; Wu, B.F. Building a Chinese Facial Expression Database for Automatically Detecting Academic Emotions to Support Instruction in Blended and Digital Learning Environments. In Innovative Technologies and Learning: Second International Conference, ICITL 2019, Tromsø, Norway, 2–5 December 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 155–162. [Google Scholar]
- Ashwin, T.S.; Guddeti, R. Affective database for e-learning and classroom environments using Indian students’ faces, hand gestures and body postures. Future Gener. Comput. Syst. 2020, 108, 334–348. [Google Scholar]
- Xu, Z.; Liu, Z.; Kong, X.; Zhao, T. Design and implementation of learning expression database for deep learning. Mod. Educ. Technol. 2021, 37, 112–118. [Google Scholar]
- Lyu, L.; Zhang, Y.; Chi, M.-Y.; Yang, F.; Zhang, S.-G.; Liu, P.; Lu, W.-G. Spontaneous facial expression database of learners’ academic emotions in online learning with hand occlusion. Comput. Electr. Eng. 2022, 97, 107667. [Google Scholar] [CrossRef]
- Lian, Z.; Li, Y.; Tao, J.H.; Huang, J.; Niu, M.Y. Expression analysis based on face regions in real-world conditions. Int. J. Autom. Comput. 2020, 17, 96–107. [Google Scholar] [CrossRef]
- Barsoum, E.; Zhang, C.; Ferrer, C.C.; Zhang, Z. Training deep networks for facial expression recognition with crowd-sourced label distribution. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 279–283. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Cai, J.; Meng, Z.; Khan, A.S.; O’Reilly, J.; Tong, Y. Island loss for learning discriminative features in facial expression recognition. In Proceedings of the 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 302–309. [Google Scholar]
- Zhang, Q.; Dai, R.; Zhu, X. Geometric feature extraction of facial expression based on chain code. Comput. Eng. 2012, 38, 156–159. [Google Scholar]
- Fabian Benitez-Quiroz, C.; Srinivasan, R.; Martinez, A.M. EmotioNet: An accurate, real-time algorithm for the automatic annotation of a million facial expressions in the wild. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5562–5570. [Google Scholar]
- Zheng, H. Micro-expression recognition based on 2D gabor filter and sparserepresentation. J. Phys. Conf. Ser. 2017, 787, 012013. [Google Scholar] [CrossRef]
- Mahmood, M.; Jalal, A.; Evans, H.A. Facial expression recognition in image sequences using 1D transform and gabor wavelet transform. In Proceedings of the 2018 International Conference on Applied and Engineering Mathematics (ICAEM), Taxila, Pakistan, 4–5 September 2018; pp. 1–6. [Google Scholar]
- Ramos, A.L.A.; Dadiz, B.G.; Santos, A.B.G. Classifying emotion based on facial expression analysis using Gabor filter: A basis for adaptive effective teaching strategy. In Computational Science and Technology: 6th ICCST 2019, Kota Kinabalu, Malaysia, 29–30 August 2019; Springer: Singapore, 2020; pp. 469–479. [Google Scholar]
- Lopes, A.T.; De Aguiar, E.; De Souza, A.F.; Oliveira-Santos, T. Facial expression recognition with convolutional neural networks: Coping with few data and the training sample order. Pattern Recognit. 2017, 61, 610–628. [Google Scholar] [CrossRef]
- Liu, P.; Han, S.; Meng, Z.; Tong, Y. Facial expression recognition via a boosted deep belief network. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1805–1812. [Google Scholar]
- Hariri, W.; Tabia, H.; Farah, N.; Declercq, D. 3D facial expression recognition using kernel methods on Riemannian manifold. Eng. Appl. Artif. Intell. 2017, 64, 25–32. [Google Scholar] [CrossRef]
- Farkhod, A.; Abdusalomov, A.B.; Mukhiddinov, M.; Cho, Y.-I. Development of real-time landmark-based emotion recognition CNN for masked faces. Sensors 2022, 22, 8704. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2, 27. [Google Scholar] [CrossRef]
- Kang, T. Research on Face Detection and Expression Recognition and Its Application in Classroom Teaching Evaluation. Master’s Thesis, Chongqing Normal University, Chongqing, China, 2019. [Google Scholar]
- Whitehill, J.; Serpell, Z.; Lin, Y.-C.; Foster, A.; Movellan, J.R. The faces of engagement: Automatic recognition of student engagement from facial expressions. IEEE Trans. Affect. Comput. 2014, 5, 86–98. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, G.; Meng, X.; Dang, T.; Kong, X. Learner emotion recognition and application based on deep learning. J. Audio-Vis. Educ. Res. 2019, 40, 87–94. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef] [PubMed]
- Wen, T. Research on Classroom Expression Recognition Based on Deep Learning. Master’s Thesis, Hebei Normal University, Shijiazhuang, China, 2023; pp. 523–528. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}