1. Introduction
Nowadays, networks are inextricably interwoven with human social activities, which simultaneously presents unprecedented challenges to the future development of networks. Satellite–terrestrial networks (STNs), namely the global heterogeneous networks based on terrestrial networks and extended on space networks, use internet technologies to realize the connectivity among internet networks, mobile networks, and space networks, which have become a significant developing direction of future networks.
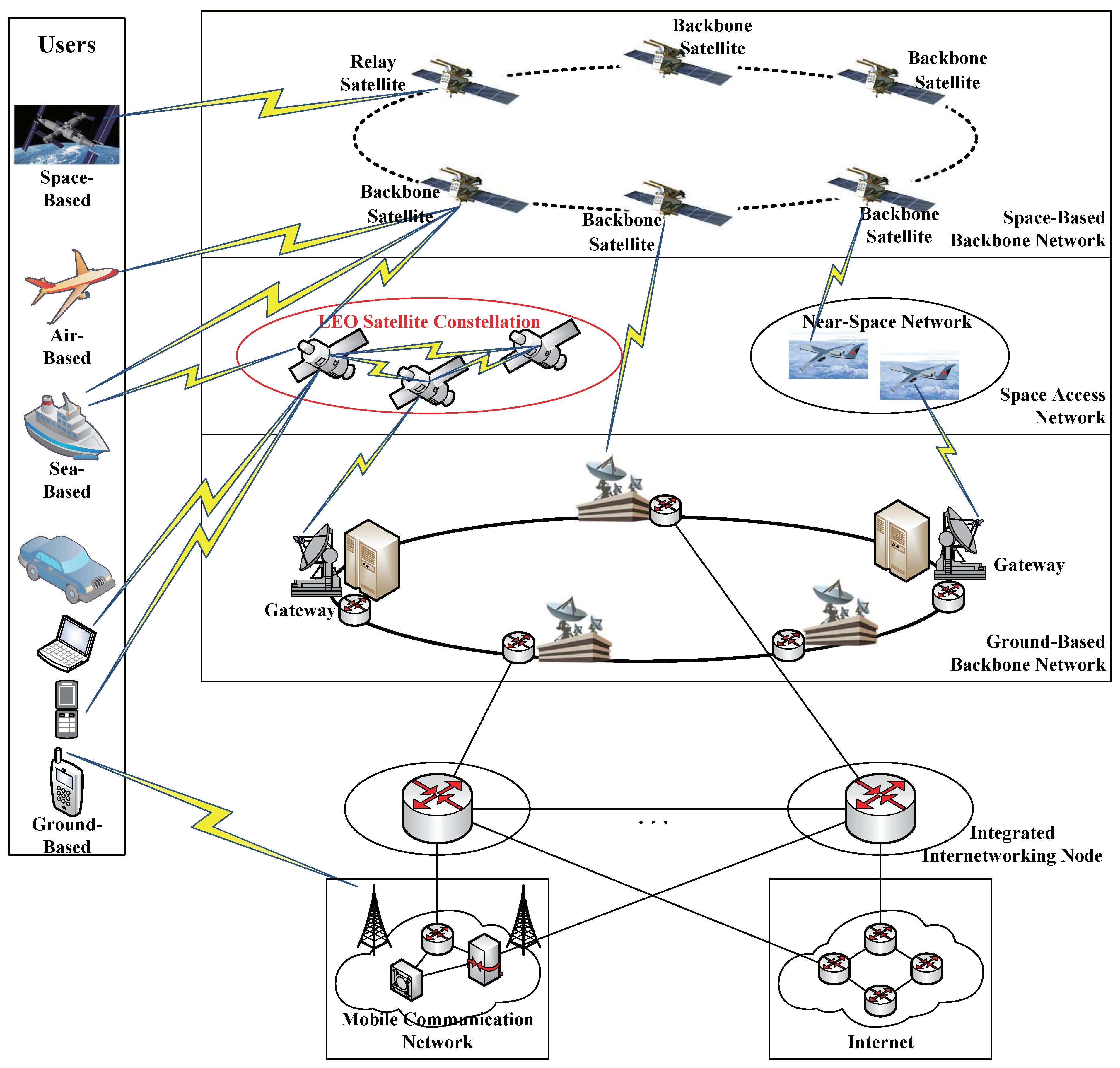
Recent technological advances (including improvements in single-satellite performance and reductions in launching and manufacturing costs) make it possible to the deployment of low Earth orbit (LEO) satellite constellation systems, which can offer high-speed and huge-capacity communications between satellites and the ground, and thus STNs have attracted much attention in the sixth generation (6G) mobile communication technology. In terms of the structure of STNs, as illustrated in
Figure 1, LEO satellite constellations play a crucial role. Unlike traditional geostationary Earth orbit (GEO) satellites, LEO satellites have the advantage of low latency, and mega-constellation systems of LEO satellites provide an effective way to realize global continuous coverage. Therefore, LEO satellite constellations are considered a promising solution for space backbone networks, capable of providing phone high-bandwidth, low-latency, and wide-ranging internet service access to users across the globe, and satellite internet is increasingly becoming an important information infrastructure.
There are three active global LEO satellite initiatives that have stood out in recent years: Starlink by SpaceX, Project Kuiper by Amazon, and OneWeb backed by the government of the United Kingdom and Bharti Enterprises, which are licensed by the Federal Communications Commission (FCC) to launch 4408 [
1], 3236 [
2], and 716 [
3] satellites in the initial phases, respectively. Generally, each satellite node in space networks has the capability of signal and data processing, and data interchange is implemented via inter-satellite links (ISLs). In the initial deployments of these constellations, it is not specified whether they plan to use ISLs, and their total throughputs without ISLs are all over 1 Tbps [
4]. Since optical ISLs allow satellite constellations to serve users globally, even when a terrestrial gateway is not within the line-of-sight (LoS) of the satellite, optical ISLs are planned to be used to improve constellation system throughput in the future [
3].
Like terrestrial networks, satellite networks rely on certain routing protocols to achieve data forwarding. Routing protocols are responsible for creating routing tables, describing the network topology structure, and performing routing and packet forwarding. Thus, satellite routing protocols play a crucial role in satellite network communications. Currently, Internet Protocol (IP) is the mainstream scheme for satellite networks to connect the global Internet. Specifically, satellites can perform dynamic IP routing via configuring interior/exterior gateway protocols at the terrestrial terminal, or serve as IP routing nodes in the constellation system to access the Internet [
5]. However, due to the low computing power and limited memory resources on satellites, inter-satellite networks differ greatly from terrestrial networks, and how to realize IP packet routing and forwarding with high speed has become a key issue in designing LEO satellite routers.
IP route lookup, also known as IP address lookup or IP lookup, is a core technology in IP routers, and its algorithm performance will directly affect the system performance of routers. Since Classless Inter-Domain Routing (CIDR) was proposed by the Internet Engineering Task Force (IETF) in 1993 [
6], which allows arbitrary prefix lengths and also introduces the longest prefix matching (LPM) problem, IP route lookup has attracted a great deal of attention from both academia and industry.
Various IP lookup mechanisms have been proposed, from ternary content addressable memory (TCAM)-based schemes [
7,
8] to algorithms based on hash [
9,
10], trie [
11,
12,
13], and Bloom filter [
14,
15]. However, the above algorithms are mainly intended for terrestrial networks, some could not be applied in demanding inter-satellite networks directly; for instance, the traditional TCAM possesses the characteristics of a high cost and large power consumption, and the hashing algorithm inevitably has hash collisions. In modern embedded systems, since the time of arithmetic logical operations is negligible for memory access latency [
16] and on-chip memory access is much faster than off-chip memory access [
17], the number of off-chip memory accesses is a major determinant of IP lookup algorithm performance. We are interested in both trie-based and Bloom filter-based schemes, the former provides a compact data structure and the latter can effectively reduce off-chip memory accesses, which makes them attractive for satellite routers.
Due to its high performance and flexibility, the field programmable gate array (FPGA) is generally recognized as suitable for space applications [
18,
19,
20]. Current high-end FPGAs are equipped with a large number of logical units and static random-access memory (SRAM), which allow them to provide hardware acceleration for complex tasks, thereby achieving a higher processing throughput. At the same time, with the capability of being reconfigured, to some extent, FPGAs can mitigate the impact of single-event upsets (SEUs) that are caused by space radiation. In addition, the application-specific integrated circuit (ASIC) is superior to FPGA in terms of power consumption and processing speed; however, the ASIC chip is fixed, i.e., not reconfigurable, limiting its application in the space environment. Therefore, it is apparent that FPGAs offer a significant advantage in supporting remote upgrades and repairs in space missions since they are more flexible.
In this paper, we propose a new filter structure called the cuckoo Bloom hybrid filter (CBHF), which is a hybrid of the Bloom filter and cuckoo filter for accelerating trie-based IP route lookup. A CBHF-based satellite IP route lookup architecture is also developed. The CBHF can achieve only one off-chip memory access for an IP route lookup, which is a valuable feature saving compute and storage resources on satellites. We prototype our design using Verilog hardware description language (HDL) with an FPGA and one single dynamic random-access memory (DRAM), and the proposed architecture is evaluated in two parts. The performance of the CBHF structure has been evaluated in terms of false positive probability, on-chip memory requirement, and average time per lookup; the performance of the lookup architecture has been evaluated in terms of on-chip block random-access memory (BRAM) overhead, resource utilization, and system throughput.
The remainder of this paper is organized as follows.
Section 2 introduces the Bloom filter and cuckoo filter, and reviews previously proposed IP lookup algorithms based on the above filters.
Section 3 describes the proposed satellite IP lookup algorithm using the CBHF and presents the theoretical performance analysis of our proposed filter.
Section 4 illustrates the prototype hardware architecture implemented on FPGA. The optimization and evaluation of the CBHF structure are shown in
Section 5. The hardware implementation result of our proposed satellite IP route lookup architecture is detailed in
Section 6. The performance analysis is discussed in
Section 7. Finally,
Section 8 gives some conclusions.
2. Related Works
The most popular data structure to perform approximate set membership testing is the Bloom filter, but a recently proposed cuckoo filter has also received significant attention from researchers. In this section, we briefly explain the Bloom filter and cuckoo filter, then discuss the existing IP lookup algorithms utilizing the Bloom filter or cuckoo filter.
2.1. Bloom Filter
The Bloom filter is a multi-bit data structure that represents a set of elements succinctly and efficiently, and thus can support membership queries. It was proposed by Burton H. Bloom in 1970 [
21], and is widely used in packet classification [
22], web caching [
23], and network security [
24].
Essentially, the Bloom filter is an array of m bits with an initial value of zero for each bit, on which a set of k different hash functions are used to insert or check elements. When programming the filter, or inserting the element x, the bit positions in the array corresponding to the k hash indexes are set to ‘1’. Instead, given a query for the element y, we check the corresponding k bits at positions generated from the same hash functions. If and only if all of them are ‘1’, the filter returns a positive and we can conjecture that the element y would be a member of the set.
The standard Bloom filter structure is shown in
Figure 2, on which we have inserted elements
x and
y, then query the membership of elements
x,
y,
, and
(
and
have not been inserted in the filter). Obviously, the query results for
x,
y,
, and
are positive, positive, negative, and positive, respectively.
The most recognized advantage of the Bloom filter is that there are no results of false negatives, i.e., the membership query results will always return positives for inserted elements. However, the Bloom filter still produces false positive results with a certain probability. Considering a query in
Figure 2 for the element
that has not been inserted, a false positive is returned since all the bits at positions
,
, and
are set to ‘1’, which is caused by the insertion of other elements.
Now, let us derive the false positive probability of the Bloom filter step by step. Supposing that generated hash indexes are uniformly distributed, the probability that a random bit in an array of
m bits is set to ‘1’ by a single hash function is clearly
. After inserting
n elements, the probability that a certain bit is not set to ‘1’ is expressed as
where
k is the number of hash functions. Hence, the false positive probability of the Bloom filter is calculated as
if the size of the filter (i.e.,
m) is large enough, Equation (
2) can be further simplified as follows.
As shown, the false positive probability can be reduced by adjusting the size of the Bloom filter and the number of hash functions, but it cannot be completely eliminated. For a given ratio of
, in order to minimize
, we obtain the optimal value of
k:
and, thus, the false positive probability in the optimal case is stated as
There is another major limitation of the Bloom filter: it does not support the deletion of elements. Since a particular bit position may have been set to ‘1’ by more than one element, clearing the bit (i.e., setting it to ‘0’) when deleting a single element cannot guarantee that the Bloom filter is free from false negatives. Therefore, the element cannot be removed.
2.2. Cuckoo Filter
The cuckoo filter [
25] proposed recently is considered an alternative to the Bloom filter that supports deletion operations and offers a lower false positive probability, for instance in networking applications such as IP packet forwarding [
26], message authentication [
27], and traffic monitoring [
28]. It is a compact data structure using the probability-based cuckoo hashing algorithm [
29], which maintains two dynamic hash tables to address hash collisions when inserting new keys.
Instead of a bit in the Bloom filter, a partial key is used in the cuckoo filter to perform approximate set membership testing. In more detail, a multi-bit fingerprint is generated from a hash function ; for example, is stored in the filter when inserting the element x. The cuckoo filter comprises an array of m buckets, each of which is formed by b cells, and each cell can store the fingerprint of an element. The fingerprint for an element x (i.e., ) can be stored in two buckets at the positions given by two hash functions and , respectively.
In the original cuckoo filter paper [
25], the authors suggest
, to achieve the best or close-to-best space efficiency for the false positive probability. In addition, the authors cleverly set the following relationship (for an element
x):
the exclusive-OR operation in Equation (
6) ensures an important property:
namely,
can also be calculated from
and
, no matter if element
x is stored at
or
, which is important in programming. A cuckoo filter on which several elements are inserted is illustrated in
Figure 3.
In order to insert an element x, select an empty cell in the buckets or and then store the fingerprint , if any. If two buckets are full, randomly remove an element from one cell in these buckets and store in that cell. The element ejected will be inserted into its alternate bucket, which can be found by doing the exclusive-OR of its original address information (i.e., or ) and the hash function of its fingerprint. The above procedure will be iterated until a free cell is found, and the element cannot be inserted in the filter if there are no empty buckets or cells available. The inserting process is more complex than that of the Bloom filter, especially in the case of the cuckoo filter with high occupancy, an insertion may lead to hundreds of element translocations, which is one of the drawbacks of the cuckoo filter.
When checking the membership of an element
y,
,
, and
are computed, and then it is checked if
is stored in any cell of those buckets given by
and
. Therefore, the results will always return positives for the elements that have been inserted in the filter. However, like the Bloom filter, there are also false positives when the element
y not stored in the filter has the same fingerprint as an element
x stored in the buckets
or
(i.e.,
). Specifically, let us consider the worst case in which the cuckoo filter is full, the probability that
matches the
f-bit fingerprint in a cell is at most
. Therefore, the upper bound of the false positive probability can be expressed as
where
b is the number of cells. As the authors state in ref. [
25], Equation (
8) can give a reasonably accurate estimate when the hash table is 95% full. For a cuckoo filter on which
n elements are inserted, the load factor
(
) or the occupancy is defined as
where
m is the total number of buckets or the size of the filter. In addition, the authors also compare the Bloom filter and cuckoo filter with large values of
, showing that the latter can provide a lower false positive probability when
f is more than 8.
The salient advantage of the cuckoo filter is that multi-bit fingerprints used support deletion. Unlike its complex inserting procedure, the fingerprint-based structure makes the deleting process much simpler. To remove an element x, both candidate buckets and are accessed, and then the matching fingerprint is removed from a cell in one bucket. It is noteworthy that there might be more than one matching fingerprint in two buckets, and only one copy of that is removed during the deletion since another element stored in the filter could share the same bucket and fingerprint as that of the element x.
2.3. IP Lookup Algorithms Based on Bloom or Cuckoo Filter
As mentioned above, both the Bloom filter and cuckoo filter have no false negatives but do have false positives, which would typically only cause unnecessary access to the set. Therefore, the filter structures are commonly used in this scenario, in which multiple direct accesses (e.g., external memory) are quite costly for the search of an element. Only if the membership of the element has been confirmed will the external memory be accessed. In particular, the filter structures can effectively improve longest prefix matching (LPM) for IP packet forwarding, which is also the focus studied in this paper.
Dharmapurikar et al. first introduced the Bloom filter into the LPM algorithms for IP route lookup [
14]. In their scheme,
W distinct Bloom filters associated with IP address prefix sets of each length are maintained on-chip, where
W is the number of different prefix sets, thus called the parallel Bloom filter (PBF) architecture. When performing IP lookups, first input each IP address into all of the Bloom filters based on the length in parallel, in order to perform membership queries, then detect off-chip forwarding tables in order of a priority of length according to the positive results of the filters and, finally, determine the next-hop information (NHI) of IP packet forwarding.
Byun et al. developed a vectored-Bloom filter (VBF) structure for IP route lookup [
15]. The VBF structure stores output ports on-chip and can be implemented parallel in the lookup architecture. Since the off-chip hash table (i.e., NHI table) is rarely accessed, the memory efficiency is increased, which improves the search performance.
Kwon et al. proposed a new filter structure called the length-aware cuckoo filter (LACF) in ref. [
26], which realizes faster IP lookup with limited memory requirements. The basic idea of the LACF is to use different numbers of hash functions to insert and query routing entries based on the prefix length popularity. Due to the double insertion mechanism for the prefixes of less popular lengths, the LACF has a lower false positive probability.
Based on the above discussion, the properties of the Bloom filter and cuckoo filter are summarized in
Table 1.
3. Satellite IP Route Lookup Using Cuckoo Bloom Hybrid Filter
In our previous work [
30], we proposed the cuckoo Bloom hybrid filter (CBHF) structure, which can be used to accelerate a trie-based IP lookup algorithm called Tree Bitmap (TBM) [
11]. The CBHF comprises three Bloom filters and a cuckoo filter based on the prefix partitioning scheme in the TBM. Specifically, a cuckoo filter for the subtries that belong to the popular level is maintained to reduce the false positive probability, while the subtries of each unpopular level are inserted in a Bloom filter. All of the filters are configured on-chip, and the proposed lookup architecture completes IP lookups by performing the TBM algorithm to access the off-chip next-hop information (NHI) table according to the query results of the CBHF. The above lookup architecture is shown in
Figure 4.
Like most filter-based IP lookup schemes, the motivation of the proposed CBHF structure is to achieve only one off-chip memory access for a single lookup, without unnecessary access due to longest prefix matching (LPM). In addition, the proposed CBHF-based lookup architecture can provide higher memory efficiency since we utilize a trie data structure or, precisely, multibit-trie in IP lookups.
However, the TBM algorithm also has drawbacks. One of them is that a pair of bitmaps (i.e., the internal and external bitmaps) with a pointer used for each subtrie may require a considerable memory overhead, which is unpalatable in satellite IP route lookup. And the presence of pointers in the TBM also complicates the lookup operation. Hence, we must propose a new algorithm suitable for satellite IP route lookup.
In Reference [
31], we introduced a new IP lookup algorithm called Prefix-Route Trie (PR-Trie). This scheme considers a special coding concept for a hybrid of prefixes and routes, which we call Overlapping Hybrid Trie (OHT). It is important that using the OHT, the LPM process is converted into specific logic calculation instead of the pointer operation, and thus significantly reduces the lookup complexity. In addition, memory optimization for prefix partitioning is also considered in PR-Trie. However, the proposed PR-Trie architecture is implemented in parallel, and a discrete memory module is employed for each level while consuming a large amount of compute resources. Therefore, we consider introducing the CBHF into the PR-Trie algorithm to realize faster serial lookup based on the level priority, which can be more applicable in satellite IP route lookup.
In this paper, we detail the serial version of PR-Trie architecture with a CBHF, and thus
Section 4 is a completely new section. In our previous work [
30], we briefly describe the parameter configuration of CBHF for typical routing tables in terrestrial networks, but the dynamic changes in these parameters are not evaluated, which has been largely supplemented in
Section 5. In addition, we implement the proposed lookup architecture on FPGA, and the prototype system has been evaluated through comprehensive simulation and hardware implementation. Therefore,
Section 6 is also a completely new section.
3.1. CBHF Algorithms
As described in
Section 2.1, a property of the Bloom filter is that it does not support the deletion of elements stored in the filter. Since online routing update occurs frequently in networks, and to provide the consistency of allowing deleting in the CBHF, we adopt the counting Bloom filter proposed in ref. [
32]. The basic idea of the counting Bloom filter is to associate a counter with each bit of the standard Bloom filter; whenever an element is inserted into or removed from the filter, the counters corresponding to the bit positions are incremented or decremented accordingly. We will detail this further in
Section 5, and here we only focus on the CBHF algorithms.
In the following, we denote the Bloom filter as “BF”, and the cuckoo filter as “CF”, and all the algorithms are detailed in
Appendix A. Algorithm A1 shows the pseudocode of the inserting procedure in the CBHF. For an element
x, it will be inserted into the specific filter according to the level ascription. If the element
x belongs to an unpopular level, it will be inserted into a Bloom filter. Otherwise,
x will be inserted into a cuckoo filter.
Similarly, Algorithms A2 and A3 describe the pseudocode of the querying and deleting process, respectively. Some content about the Bloom filter and cuckoo filter algorithms can be referred to in
Section 2.
3.2. Satellite IP Route Lookup Using CBHF
As mentioned earlier, the proposed satellite IP lookup scheme is based on the PR-Trie architecture. Now, let us briefly review the PR-Trie algorithm, Algorithm A4 (see
Appendix A), which describes the core idea of PR-Trie.
Like the TBM algorithm, PR-Trie also uses a multibit-trie-based data structure called Bitmap. However, the most significant feature of PR-Trie is that IP lookups can be realized by calculating both Prefix Trie and Route Trie, where Prefix Trie (P-Trie) and Route Trie (R-Trie) denote the data structures of routing tables and input IP addresses, respectively. Therefore, the perfect lookup complexity of can be theoretically achieved.
In the original PR-Trie paper [
31], we recommend the parallel version of PR-Trie that can achieve the fastest lookup and update speeds. Unfortunately, it may be impractical to employ a lot of computing and memory resources in satellite IP route lookup. Now, let us consider the serial version of PR-Trie architecture. Generally, this shared memory-based lookup mostly adopts priority search, in which a secondary priority phase will be accessed if there is no match in the high-priority phase. Hence, unnecessary search phases lead to an increase in lookup time, lowering lookup algorithm performance.
To ensure only one off-chip memory access, or reduce unnecessary search phases, for a single IP lookup, the CBHF structure is introduced. Each potential subtrie corresponding to a given input address is probed using the CBHF at the pre-lookup phase, and then a level-priority-based PR-Trie lookup is performed according to probe results. Note that since not all subtries have a real root (i.e., a root node with prefix information), the mere existence of a subtrie does not ensure that there is at least a match. Therefore, we maintain an on-chip imaginary root table that stores the LPM information for every imaginary root (i.e., a root node without prefix information).
Algorithm A5 (see
Appendix A) shows the pseudocode of the satellite IP route lookup procedure using the CBHF. For an input IP address, if there is a matching prefix in the subtrie (i.e., the OHT bitmap
), look up the off-chip NHI table; if there is no match in the subtrie (i.e., the OHT bitmap
), the imaginary root table will be accessed.
3.3. Theoretical Performance Analysis on CBHF
In this section, we discuss the theoretical performance of the proposed CBHF, including the false positive probability, the average number of subtrie accesses, and the lookup time. According to the IPv4 prefix partitioning scheme recommended in Reference [
31] (i.e., Level 1 contains prefixes in /1 to /8; Level 2 contains prefixes in /9 to /16; Level 3 contains prefixes in /17 to /24; Level 4 contains prefixes in /25 to /32), Level 3 and Level 4, containing the most potential subtries (
and
, respectively), are set to the popular levels in the CBHF, and the rest of levels are set to unpopular. Therefore, the CBHF in PR-Trie comprises two Bloom filters and two cuckoo filters.
In
Section 2, certain formulas of the false positive probability of the Bloom filter and cuckoo filter are obtained. Note that Equation (
8) applies only to an almost full hash table. Now, let us consider a more general case where hash addresses are uniformly distributed, the false positive probability of the cuckoo filter can be expressed as
where all variables are referred to in
Section 2 (the same applies below). Thus, the false positive probability of the proposed CBHF (seen as a whole, and the subscript
i represents the level) is calculated as
where we assume that Bloom filters are always in the optimal case, and this is clearly desirable due to the dynamic reconfiguration of FPGA.
The number of subtrie accesses required to compute the correct LPM for an input IP address is determined by the number of matching filters. For an IP address
x matching a subtrie in Level
l, we will first inspect the levels of high priority if there are false positives in the levels of priority greater than Level
l. Therefore, the average number of additional subtrie accesses required for the input IP address
x is
considering the worst case in which
(i.e.,
x matches a default prefix) and all the filters produce false positives and, thus, the average number of total subtrie accesses per lookup can be upper bounded as
Note that Equation (
13) gives the average number of subtrie accesses due to the false positives, and for the worst case mentioned above, the number of required subtrie accesses obviously is
(the default prefix constitutes one access here).
However, the average number of subtrie accesses is generally lower than the estimated value using Equation (
13) in practical implementation, because of the relative priority of filters. In more detail, for a lookup that has been hit by the level of high priority, whether there are any false positives in the filters of lower priority makes no difference to the query results. For this reason, we define a weighting factor
, which is stated as
Hence, the average number of subtrie accesses per lookup can be further refined as
In real systems, the speed for a single lookup is determined by the total time of a direct hit and additional subtrie accesses. Thus, the lookup time of our proposed architecture can be calculated as
where
and
denote the time of a direct hit and additional subtrie accesses, respectively. The lookup time is a key indicator in satellite IP route lookup, which will be further evaluated in
Section 6.
4. Hardware Architecture
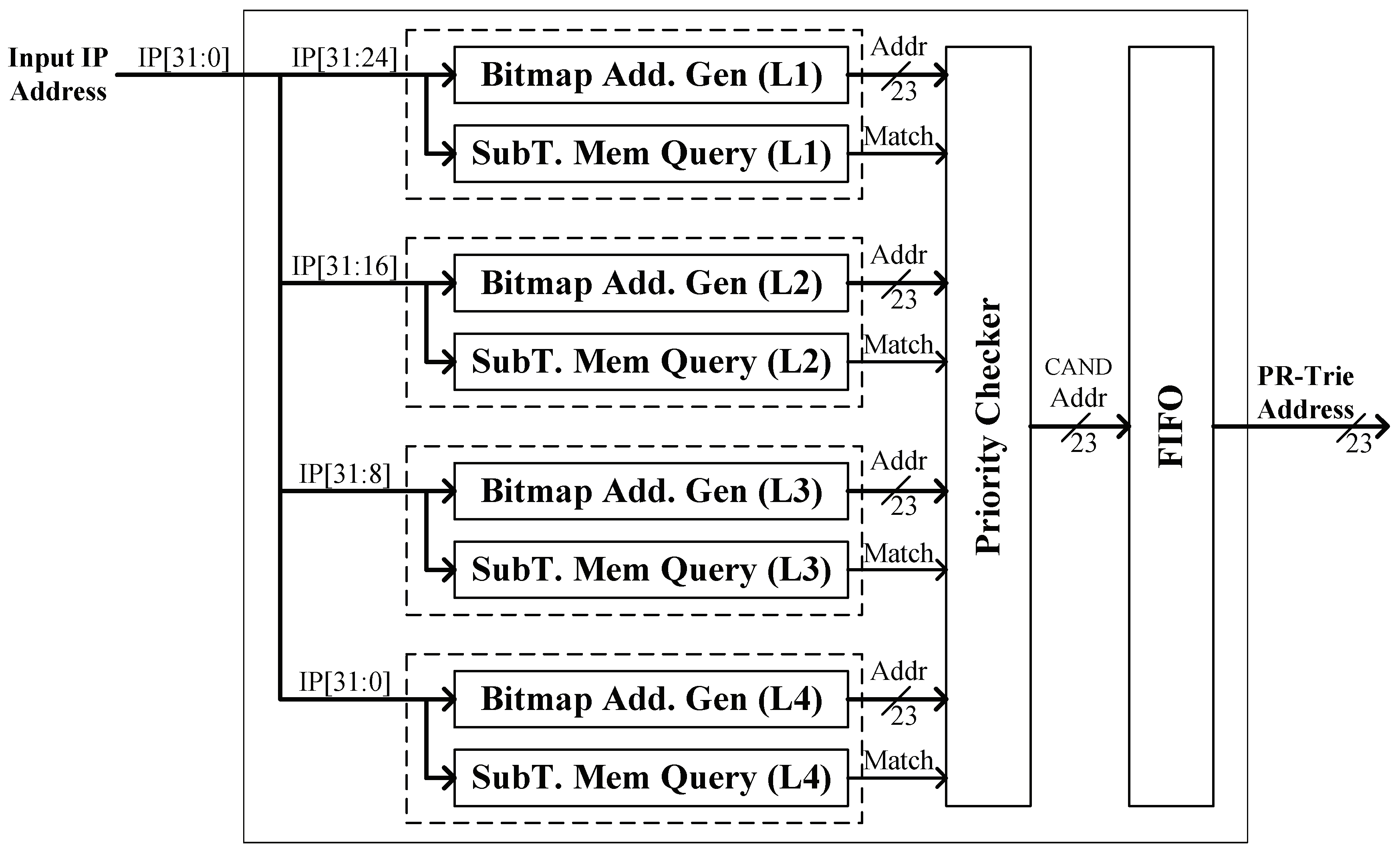
In this section, we describe the detailed architecture of our prototype hardware design.
Figure 5 shows the block diagram of our proposed satellite IP route lookup engine. In the lookup engine, there are four main modules: CBHF, Bitmap Lookup, PR-Trie Lookup, and NHI Lookup. As shown, the input IP address is first fed into the CBHF module, and then the CBHF module checks for the existence of subtries for the input IP address in the four levels. We assume that the matching subtrie of the highest priority is designated as a PR-Trie, the CBHF module will output the PR-Trie address, and forward it to the Bitmap Lookup module to query on-chip memory, where the P-Trie and R-Trie bitmaps are stored. The PR-Trie Lookup module reads the P-Trie and R-Trie data from the preceding module, computing the OHT bitmap according to the PR-Trie algorithm, and generating the addresses of the target next-hop information (NHI) and imaginary root information, which are, respectively, stored in two first-in-first-out (FIFO) buffers for pipelining to accelerate the processing speed. Finally, the NHI Lookup module obtains output port data using the above addresses, then picks out the correct NHI based on Algorithm A5.
4.1. Hardware Architecture of CBHF Module
At the pre-lookup phase, the IP address is input into the CBHF module, and the subtrie matching queries of variable length are performed in parallel. The CBHF module checks if there are existent subtries of different levels for the input IP address. As mentioned previously, the binary trie in the PR-Trie architecture is divided into four levels for IPv4 lookups, which are also adopted in the proposed satellite IP route lookup.
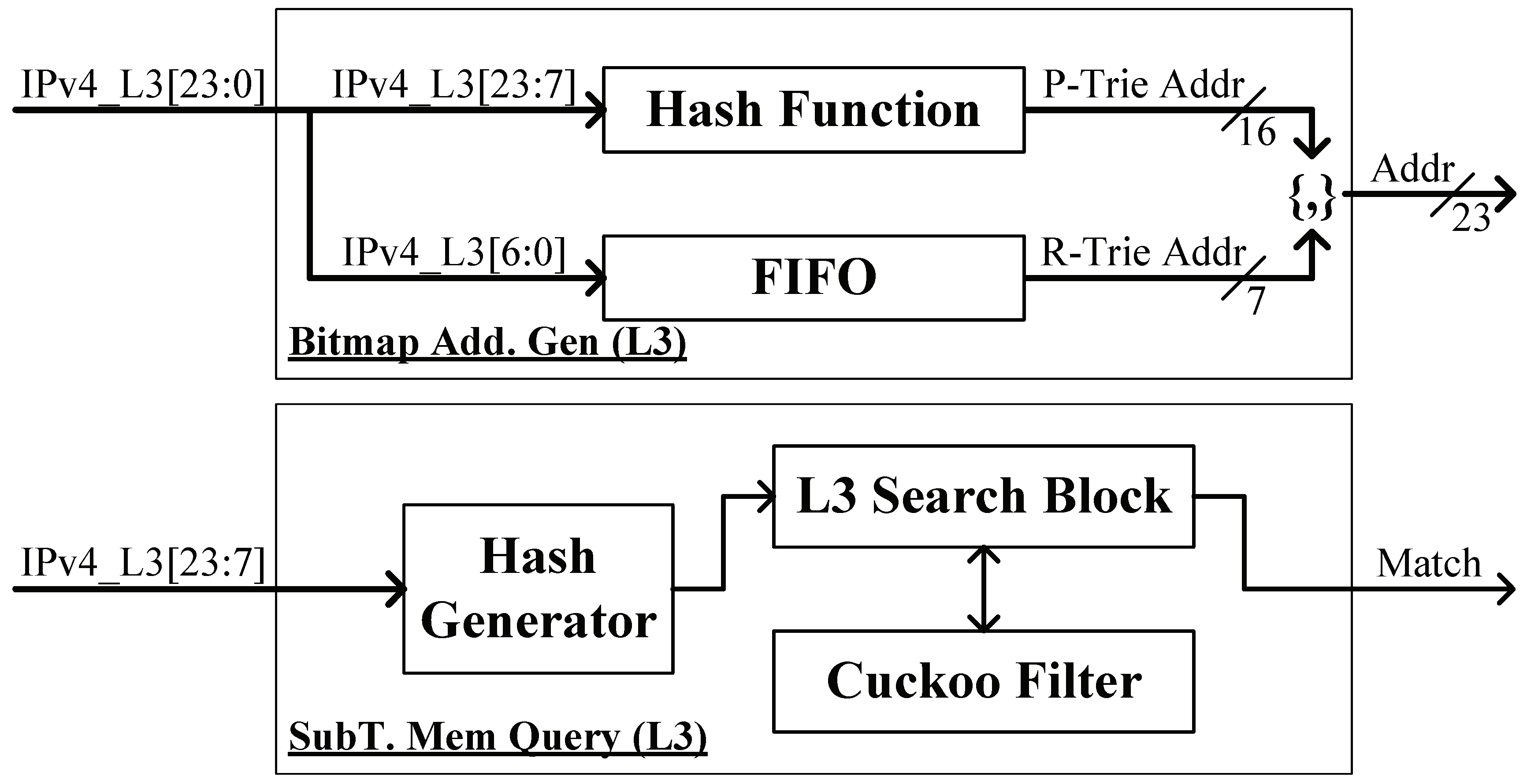
Figure 6 shows the parallel architecture of the CBHF module. Each level has an individual Bitmap Address Generator and an individual Subtrie Membership Query. Bits [31:24], bits [31:16], bits [31:8], and bits [31:0] of the input IP address are used as the input for the Level 1 submodule, Level 2 submodule, Level 3 submodule, and Level 4 submodule, respectively. Note that these submodules are basically the same in structure and operation, except that cuckoo filters are used in Level 3 and Level 4 submodules and the rest submodules use Bloom filters. Therefore, we take the Level 3 submodule as an example, which is shown in
Figure 7.
In the Level 3 submodule, the most significant 17 bits of the input (i.e., IPv4_L3 [23:7]) are used to calculate the P-Trie bitmap address in the Bitmap Address Generator and perform the membership query in the Subtrie Membership Query. The least significant 7 bits of the input (i.e., IPv4_L3 [6:0]) used as the R-Trie address indexing the R-Trie bitmap are stored in a FIFO buffer until the P-Trie address hashing procedure is completed, then concatenate the above two addresses to generate a candidate PR-Trie address.
For subtrie membership queries in each level, if a subtrie corresponding to the input IP address is found, or to be more precise, the filter of this level returns a positive, the candidate PR-Trie address will be input into the priority checker module. The priority checker module inspects the candidate PR-Trie address set based on the longest prefix matching (LPM) principle, and these candidate addresses will be stored in a FIFO buffer in priority order. Once the correct PR-Trie address is accessed next (in Bitmap Lookup), the FIFO buffer is cleared at the same time.
4.2. Hardware Architecture of Bitmap Lookup Module
The Bitmap Lookup module is used for the P-Trie and R-Trie bitmap lookup. Both bitmaps are stored in on-chip memory. The composite PR-Trie address is divided here, and the P-Trie address is used to query the hash table, while the R-Trie address is for the linear table. Then, the P-Trie data (including bitmap and current hash address) and the R-Trie bitmap are output to the PR-Trie Lookup module.
4.3. Hardware Architecture of PR-Trie and NHI Lookup Modules
The PR-Trie Lookup module resolves the P-Trie data, as shown in
Figure 8, and the P-Trie and R-Trie bitmaps are used to compute the OHT bitmap, to obtain the offset. The P-Trie address is involved in calculating the NHI base address and potential on-chip imaginary root address, then the off-chip NHI address generated by the base address plus the offset is obtained.
In the NHI Lookup module, as shown in
Figure 9, the DDR3 interface employs a DDR3 memory controller generated by the Xilinx Memory Interface Generator (MIG). The NHI address is applied to query the off-chip memory, while the imaginary root address is used to query the on-chip imaginary root table and its result will be stored in a FIFO buffer until the off-chip NHI searching is completed. Then, the off-chip output port bitmap is selected as the correct NHI if it is not zero (i.e., 16’b0), otherwise, the on-chip output port bitmap from the imaginary root table will be picked out.
5. Optimization and Evaluation on CBHF
As mentioned in
Section 3.1, the counting Bloom filter is adopted in the CBHF structure, to support subtrie deletions. The basic update operation of the original PR-Trie has been provided in Reference [
31], and in this paper, updates in the imaginary root table of the proposed architecture are quite easy, since there are not many imaginary roots in real-life routing tables (in quantity) and the update procedure is not necessarily performed in real-time (in terms of speed).
In this section, we detail the counting Bloom filter structure, including the size configuration of its counters. The behavioral simulation of the CBHF structure is implemented in C++ language. Predicting the size of a satellite routing table is challenging, as vendors are resistant to allowing access and the rapid growth of global subscribers can be continued. Therefore, we refer to the current routing tables of backbone routers in terrestrial networks, which are downloaded from the Route Views project of the University of Oregon [
33]. We create three routing prefix sets: 1 k (contains 1078 prefixes), 5 k (contains 5096 prefixes), and 25 k (contains 25,707 prefixes), which are used to evaluate the performance of filters in the CBHF. Since the number of current satellite internet users is still tiny compared to the number of wired cable or fiber subscribers, we use the above sets with a small number of prefixes instead of the present large-scale IPv4 backbone routing tables (containing nearly 1 M prefixes) in this paper.
5.1. Counting Bloom Filter Structure
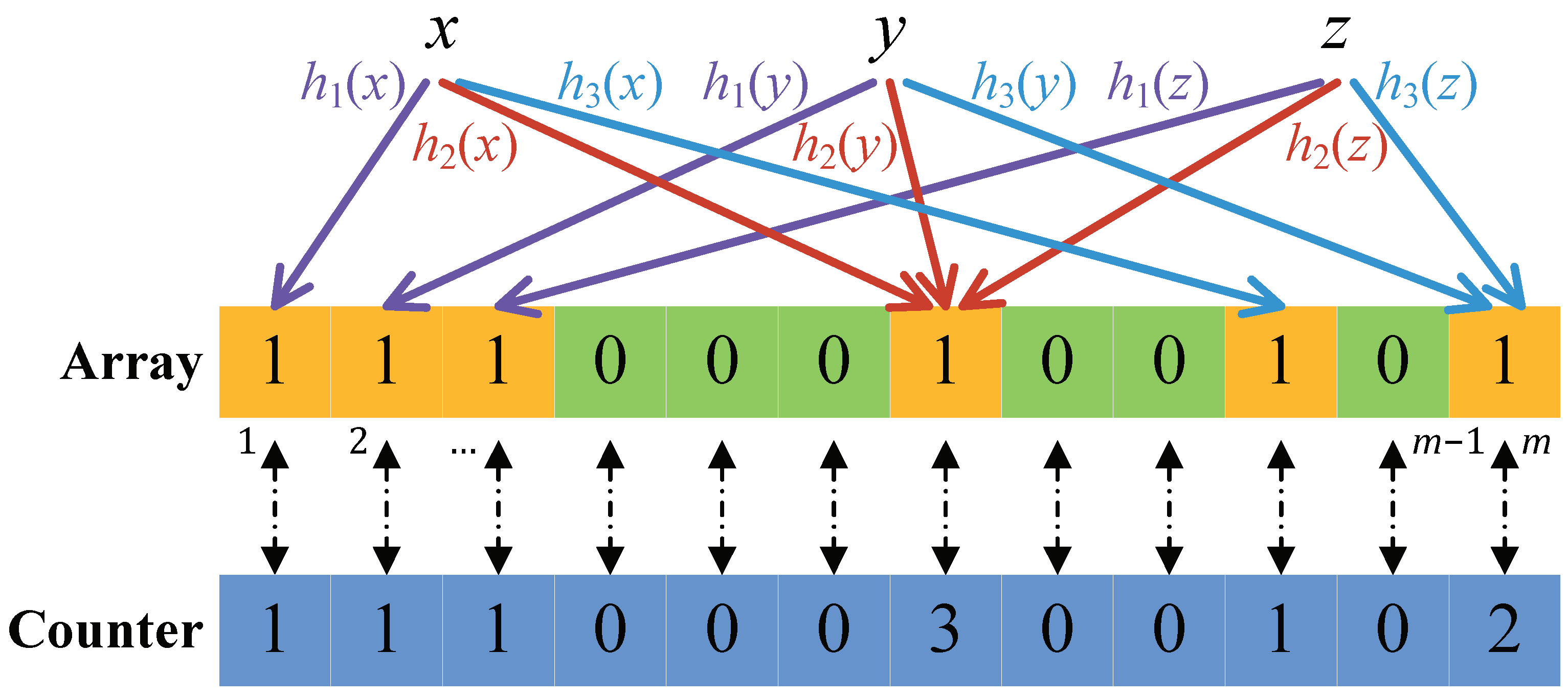
Figure 10 shows the counting Bloom filter structure with several elements inserted in the filter. For each local counter in the filter, it is initially set to ‘0’. When an element
x is inserted or deleted, the counters
are incremented or decremented, respectively.
The bit at the position is set to ‘1’ whenever the counter changes from 0 to 1. Conversely, the bit at position is set to ‘0’ whenever the counter changes from 1 to 0. Hence, the counting Bloom filter always correctly reflects the current set. Note that counters in the counting Bloom filter structure are only used for insertions and removals, but not for lookups. Therefore, the counting Bloom filter has the same false positive probability as the standard Bloom filter.
In addition, the memory allocation of the counters is also important, namely, how largely each counter can become. In our previous paper [
30], we have already obtained some conclusions about the probability that the counting value overflows:
where
c and
m denote the counting value and the bit array size, respectively. These theoretical probabilities will help us construct the filters in the CBHF.
5.2. Performance Evaluation
Since the satellite IP route lookup architecture is implemented on FPGA, the CBHF structure can be easily modified. In other words, it allows upgrading the configuration of filters in space missions. Hence, the performance of filters is affected by the routing table the satellite IP router maintains.
Figure 11 shows the data of the prefix length distribution in each routing prefix set for testing.
First, we extract subtries to generate the PR-Trie data structure for each routing prefix set. The number of subtries in each level and the total subtries in each set are shown in
Table 2. It is shown that there are many more subtries that need to be maintained in Level 3 than other levels, which is consistent with the filter strategies that we have assumed previously. Note that there are a few subtries in Level 4, but it is desirable to use the cuckoo filter, since it has a higher space efficiency. In more detail, considering the case in which there are many potential subtries (in lookup), but few stored in the filter, we should maintain a large enough array but few elements have been inserted if using the Bloom filter.
Table 3 reports the detailed configuration of the CBHF structure. As shown, for the Bloom filters of Level 1, there are at most two elements due to the one-bit subtrie index (i.e., IP [31]), which makes these filters safely work without the counters, and thus the width is
(array + counter). For the cuckoo filters of Level 3 and Level 4, the number of hash functions (
N) is always
(
), and the widths are
and
(cell × fingerprint) accordingly. In addition, all the hash indexes in the system are generated by the family of cyclic redundancy check (CRC) functions, including the CRC-12, CRC-16, CRC-32, CRC-48, CRC-64, etc., which can be easily implemented with a shift register and some exclusive-OR gates on FPGA. The total memory requirement for a CBHF is shown as well.
According to Equations (
2) and (
10), we can obtain the theoretical false positive probability of each filter in the CBHF. Furthermore, we compute the false positive probability of the CBHF using Equation (
11).
Table 4 shows the above false positive probability according to the configuration of the CBHF. In addition, a simulation is run for each system configuration, where we perform lookups of all the remaining elements (which have not been inserted) for Level 1 and Level 2, and 100 k lookups for different random elements that have not been inserted in Level 3 and Level 4. The results are also summarized in
Table 4.
Note that, in fact, the results for Level 1 are free from false positives, thus we recalculate the theoretical false positive probability of the CBHF. The results show that each filter in the CBHF remains a stable false positive probability through dynamic reconfiguration, which adopts the conventions that the Bloom filter will be reconstructed when its occupancy exceeds 60%, and the occupancy is 90% for the cuckoo filter. In theory, the CBHF structure can achieve an accuracy rate of almost 95% with less storage space. And, our simulation results show that higher accuracy rates can be reached in practical configurations.
6. Hardware Implementation
In this section, we describe the hardware implementation results of our proposed lookup architecture in detail. The proposed satellite IP route lookup engine is implemented in Verilog HDL on a Xilinx Virtex-7 XC7VX690T FPGA chip, and the development environment is Vivado 2019.2. Our prototype design is downloaded on the FPGA development board, which is equipped with two 4 GB DDR3 synchronous DRAMs (SDRAMs). We use a single DDR3 memory for next-hop information (NHI) storage.
Table 5 shows the on-chip memory requirement in the hardware implementation. There are two types of on-chip BRAMs: 18 k-bit blocks and 36 k-bit blocks, which are automatically allocated for each module. Note that the memory of each module is allocated in standard blocks, thus the practical memory requirement of filter structure in the CBHF is greater than that in
Table 3. The on-chip memory requirement for other modules is shown as well. The value of total BRAMs is the capacity of memory required in KByte, and the utilization rate of total BRAMs is based on the amount of available block memory, which is 52,920 Kbits on an XC7VX690T chip.
The resource utilization is listed in
Table 6. It is shown that the utilization of BRAM increases considerably as the size growth of the routing prefix sets increases, while the utilization of LUT and FF is almost invariant. In addition, the utilization of IO and BUFG is constant, since their numbers do not depend on the sizes of the routing prefix sets.
In order to enhance system reliability, triple modular redundancy (TMR) is widely adopted in satellite applications, which requires two extra duplicate systems to guarantee correct operations. Since each individual resource utilization of our prototype design is less than 1/3, the basic requirement of a TMR system can be met.
The whole design is operating at 200 MHz. In this case, the worst negative slack (WNS) and the total on-chip power are presented in the Vivado 2019.2 development tool, which is reported in
Table 7.
7. Results and Analysis
We implemented a testbench in Verilog HDL to check system timing.
Table 8 shows the time consumption of the system in all cases. Since the two subtries always exist (in real-life routing tables) in Level 1, where the total number of potential subtries is
, and Level 1 has no false positives, the special case of the default prefix matching is not shown. In the following, we denote the subsystem before two FIFO buffers (including the CBHF, Bitmap Lookup, and PR-Trie Lookup modules) as “Phase 1”, and the following subsystem as “Phase 2”, which can be seen in
Figure 5.
As shown in
Table 8, for the worst case, in which there is a false positive in each filter except Level 1, the number of subtrie accesses is 4, and the time consumption in Phase 1 is 14 clock cycles (clks). Similarly, in other cases, the results are also obtained. Since there is a pipelining design between two phases, the lookup time of the system (
) is the maximum in two phases. Hence, the theoretical throughput (
X) can be calculated as follows:
The meanings and values of notations used in Equation (
20) are shown in
Table 9. In addition, using Equation (
16), we also obtain the average system throughput for each testing routing prefix set, which is shown in
Table 10.
In order to evaluate the system throughput more objectively, we constructed the relevant hash tables and linear tables for each routing prefix set (in conditions of different system configurations) offline. Then, we randomly tested 100 k IP addresses for each routing prefix set.
Table 11 reports their average time per lookup and their system throughput.
The results show that the average lookup time of our proposed satellite IP route lookup architecture remains steady in different configurations, and its single-port throughput can reach at least 13.44 Gbps, which can match the current mainstream inter-satellite links (ISLs) of 10 Gbps. To improve throughput, generally, we adopt the system of multiple lookup engines. Note that the resource utilization is still able to guarantee the standard requirement of TMR, even if we have three lookup engines on an XC7VX690T chip. Thus, the expected performance can be improved by three times, equivalent to a throughput beyond 40 Gbps. Since the scale of routing prefix sets used in our simulation is much larger than current satellite routing tables, our proposed architecture can provide considerable throughput in practical satellite applications.








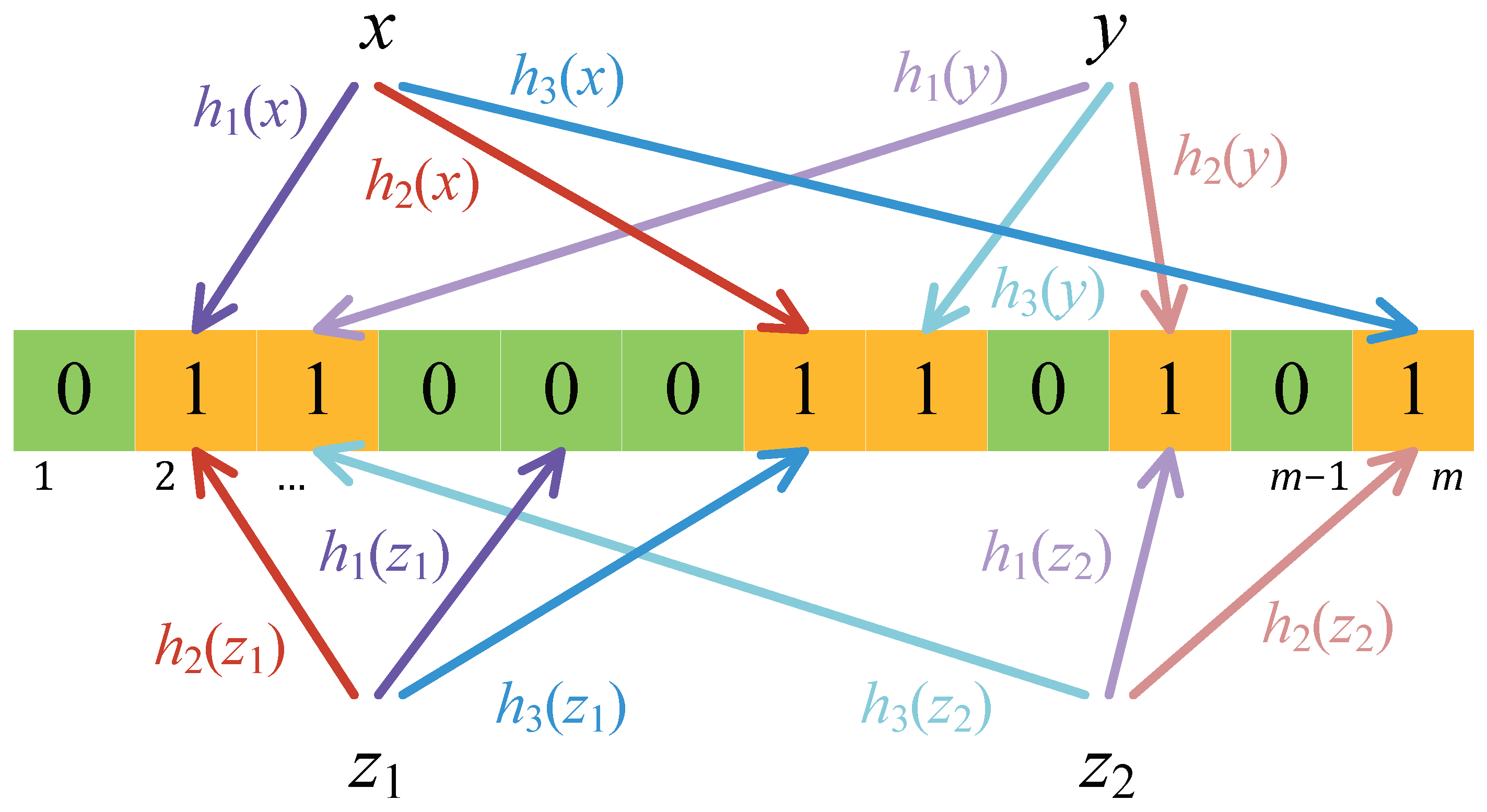







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}