

Displacement Prediction of Channel Slope Based on EEMD-IESSA-LSSVM Combined Algorithm

Abstract
:1. Introduction
2. Combined Predictive Models
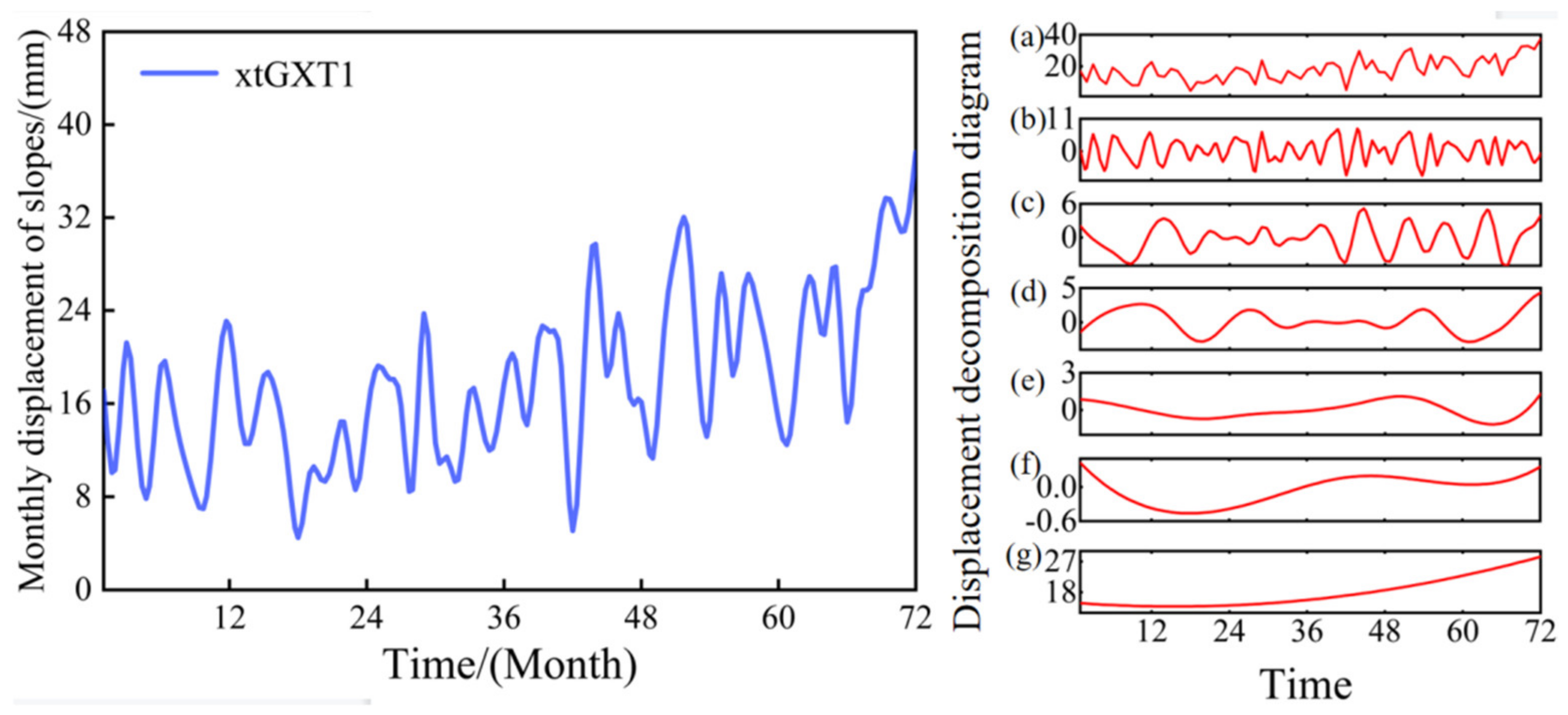
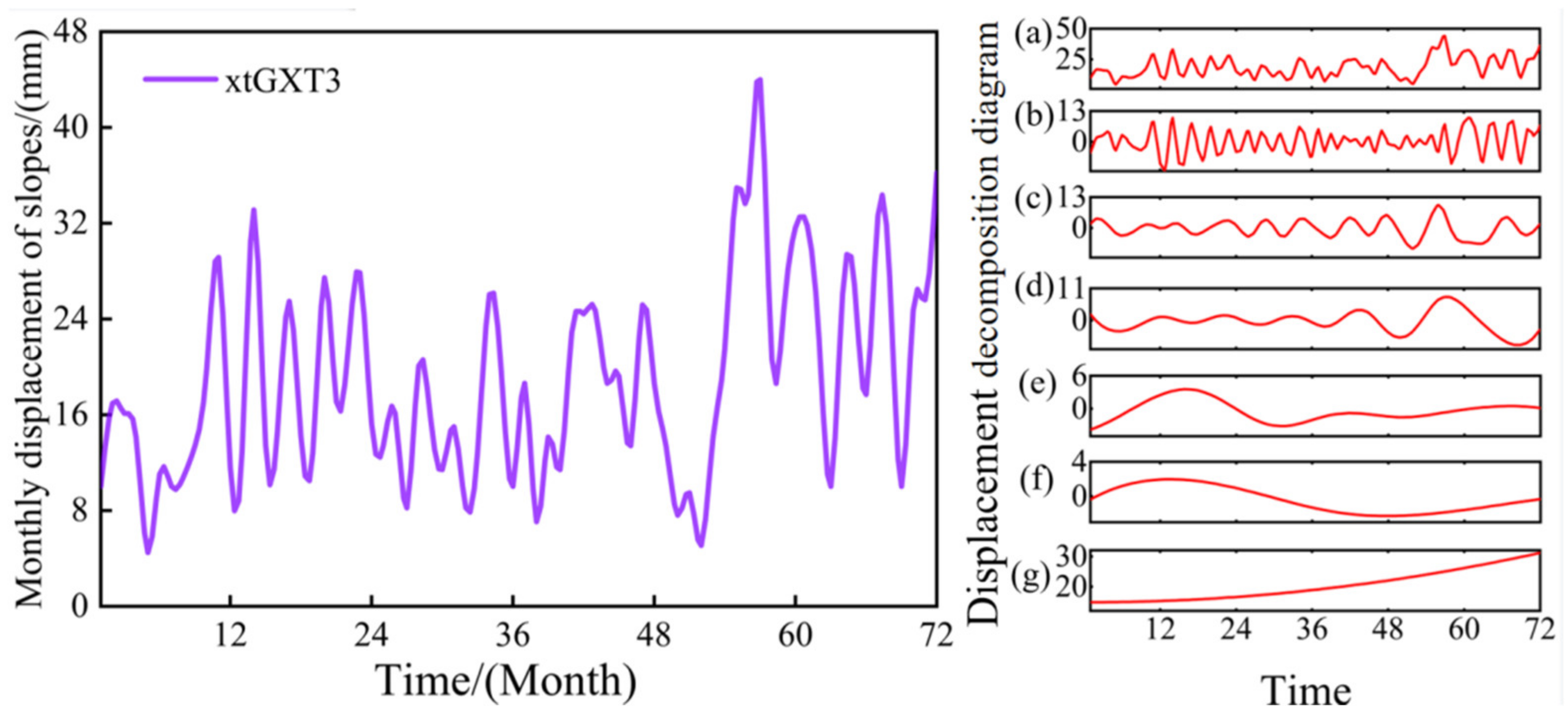
2.1. Empirical Modal Decomposition
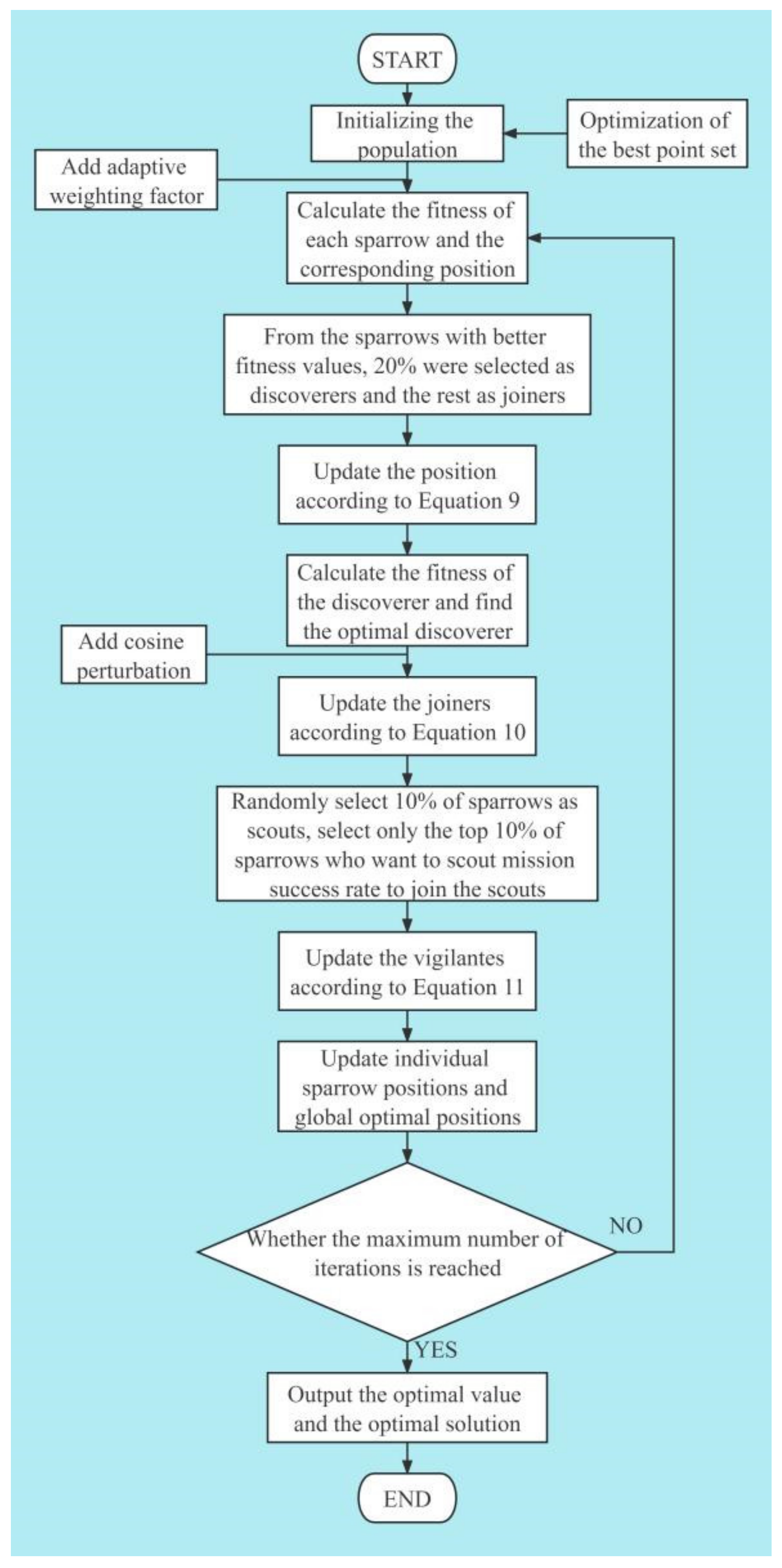
2.2. Sparrow Search Algorithm
2.3. Good Point Set Optimization
2.4. Irrational Escape Strategy Sparrow Search Algorithm
2.5. Least-Squares Support Vector Machine
2.6. Other Algorithms
2.6.1. Gray Wolf Algorithm
2.6.2. Particle Swarm Optimization Algorithm
2.6.3. Chaotic Sparrow Search Optimization Algorithm
3. Algorithm Validation
3.1. Pick Functions
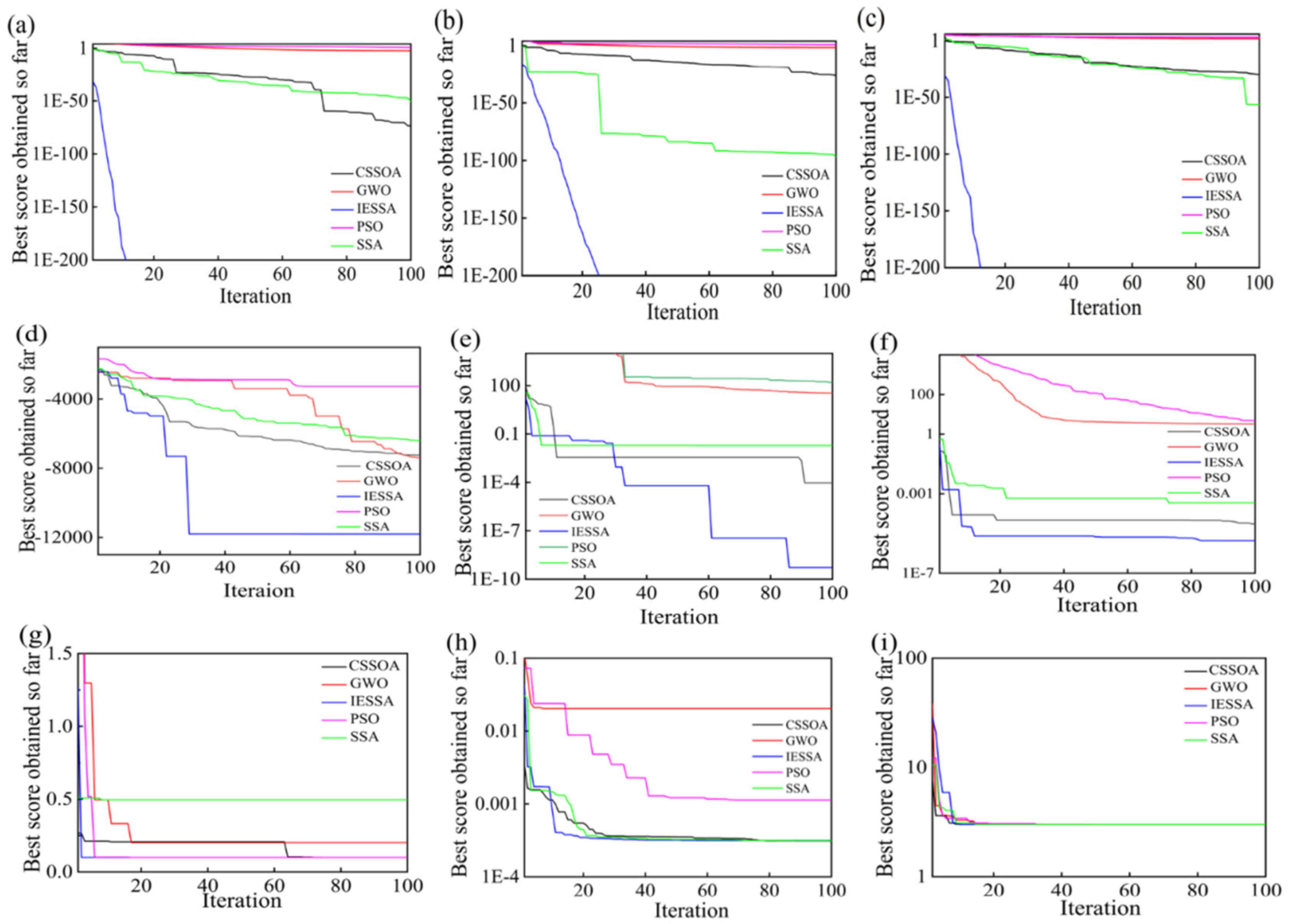
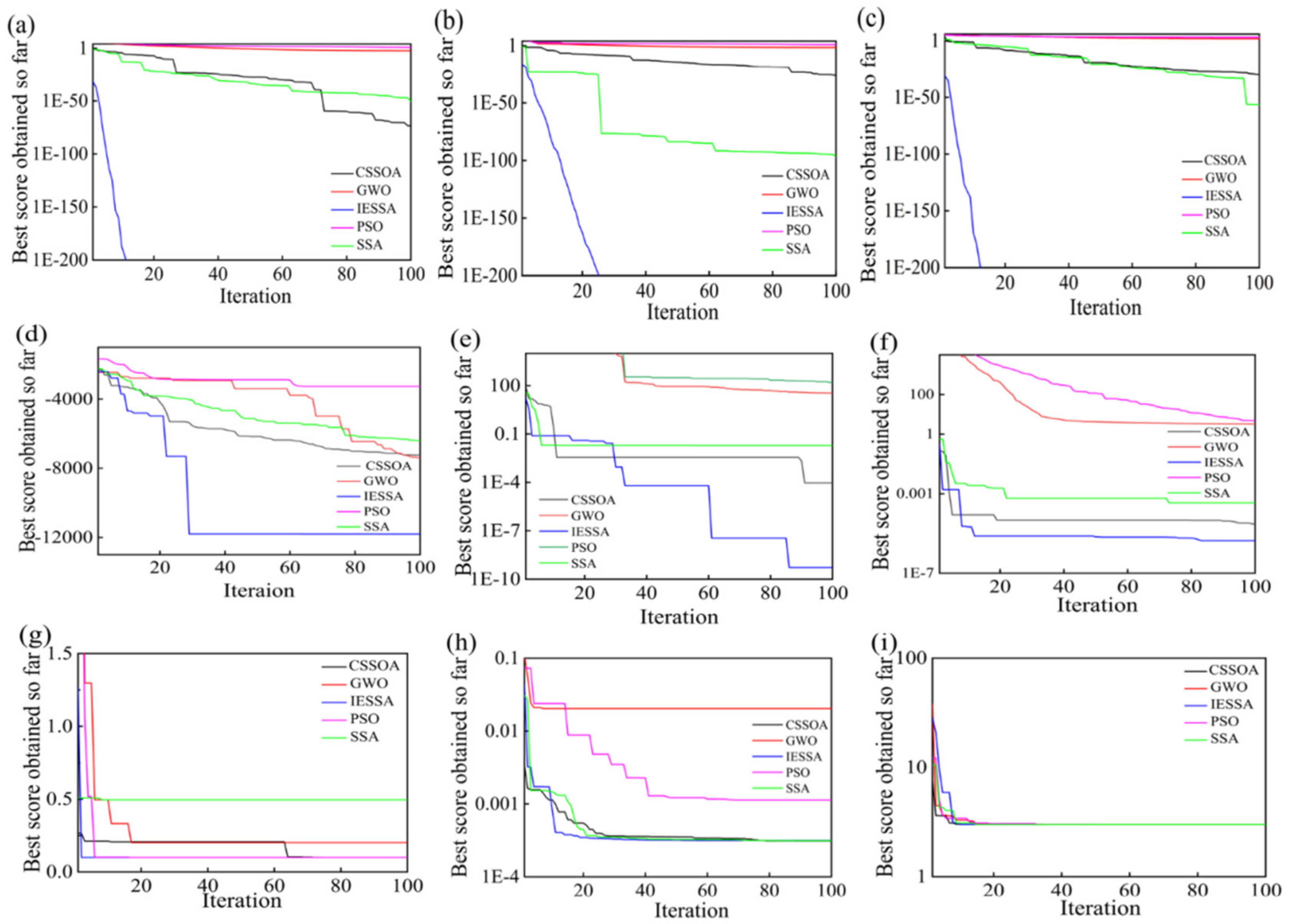
3.2. Analysis of Results
3.2.1. High-Dimensional Unimodal Test Function
3.2.2. High-Dimensional Polymodal Test Function
3.2.3. Low-Dimensional Multipeak Function
4. Engineering Example Application
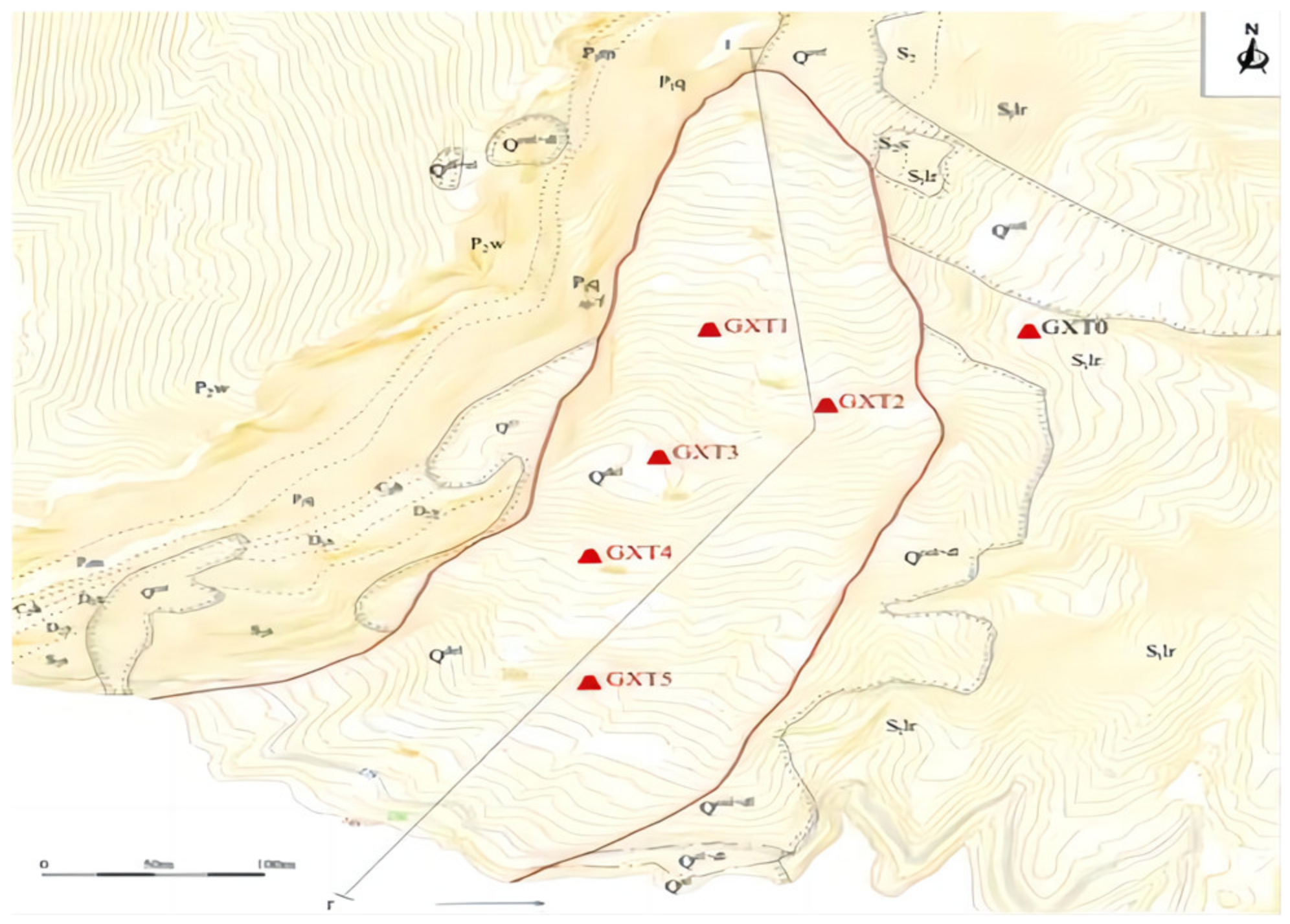
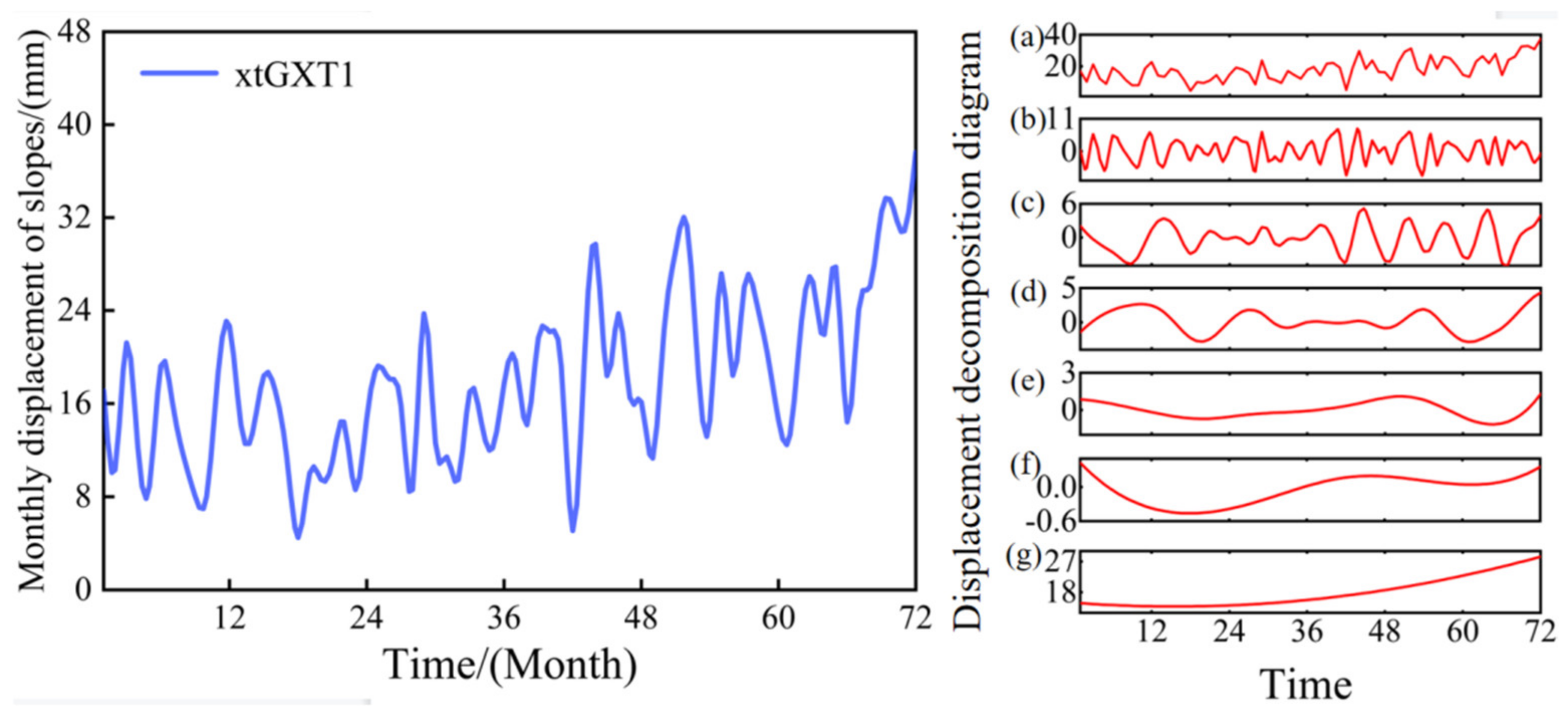
4.1. Hydrogeological Conditions of Xin Tan Landslide
4.2. External Factors Affecting Slope Displacement
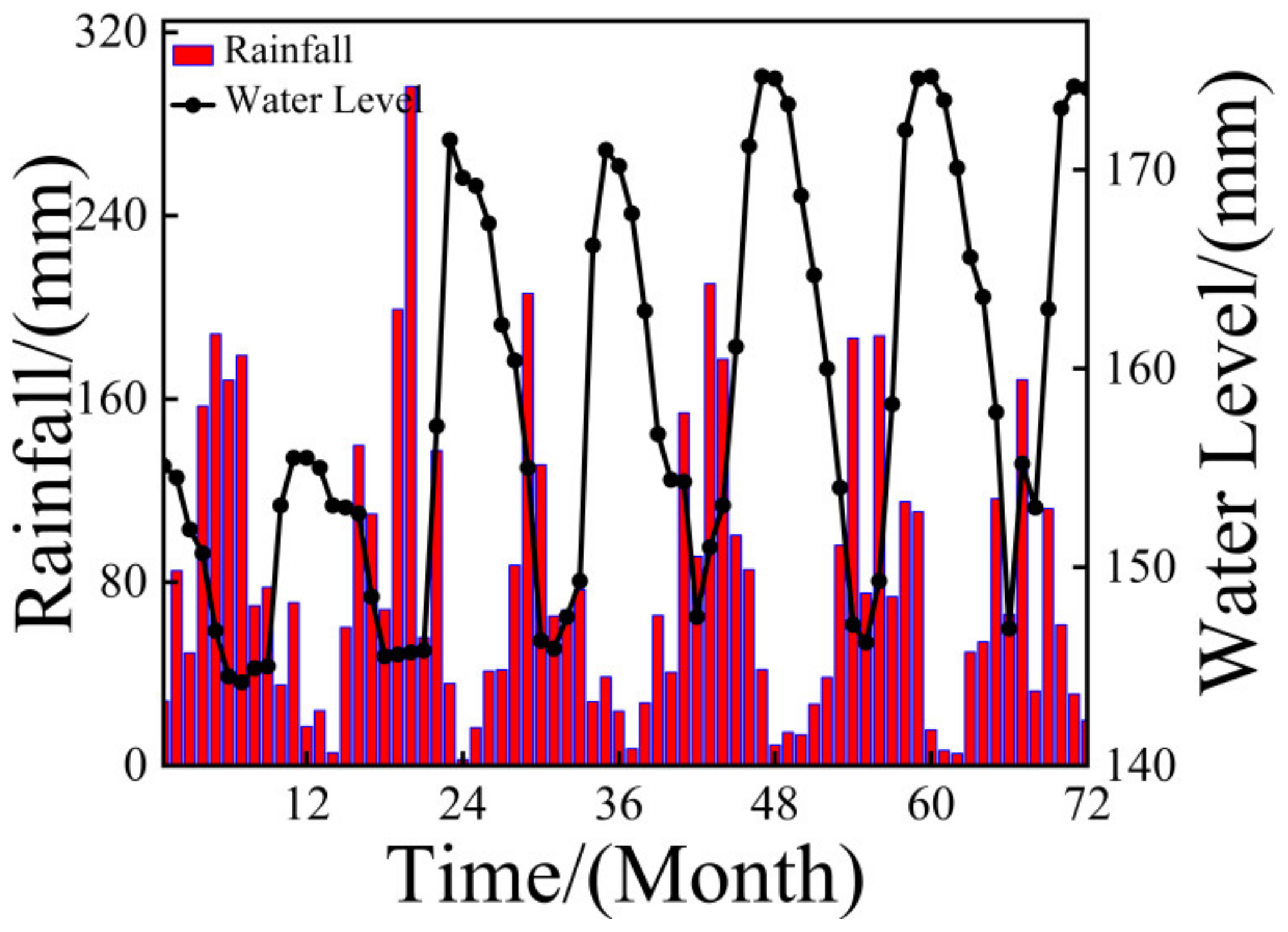
4.2.1. The Effect of Rainfall on Landslides
4.2.2. The Effect of Water Level on Landslide
4.3. Least Squares Support Vector Machine Test
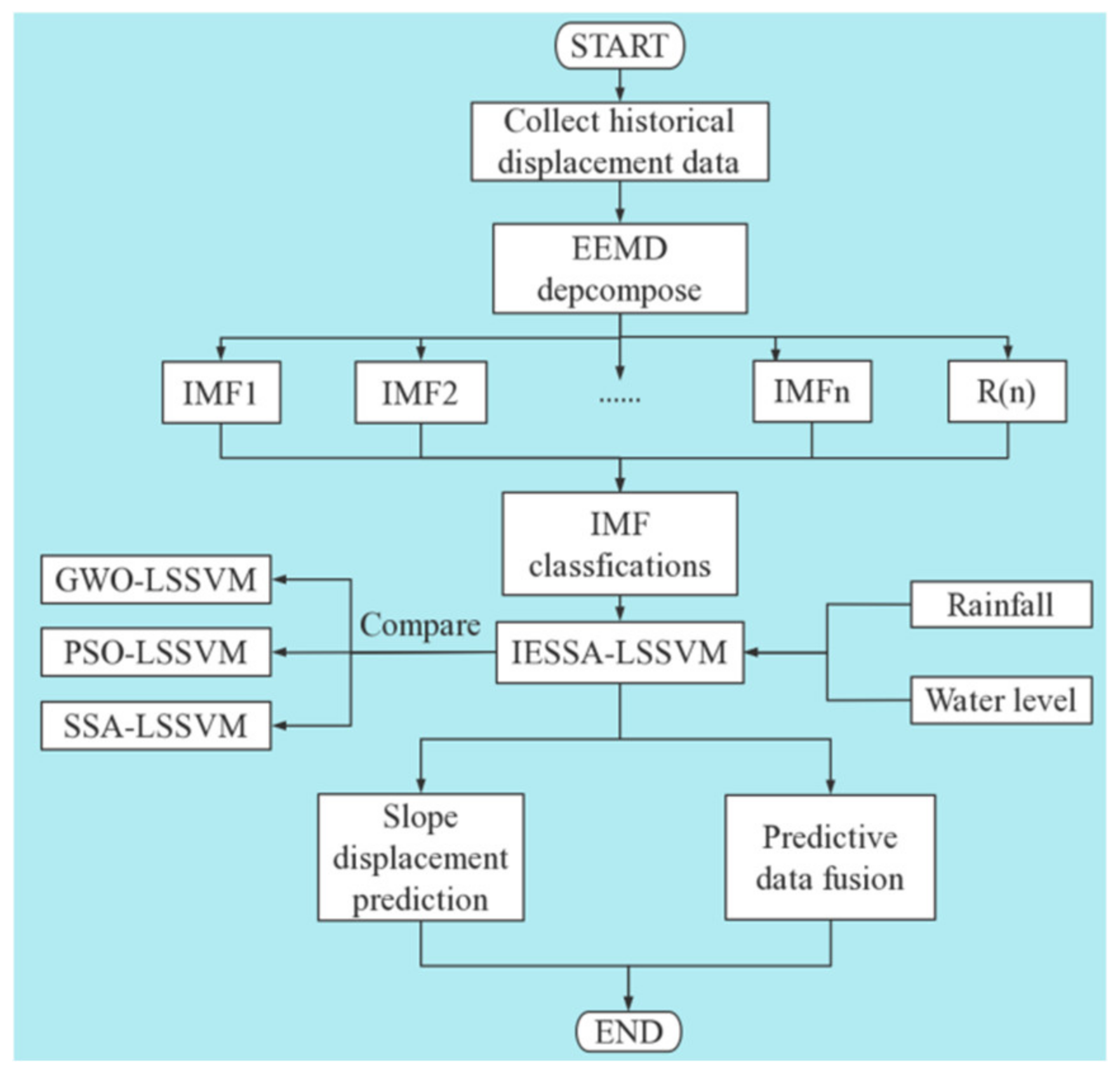
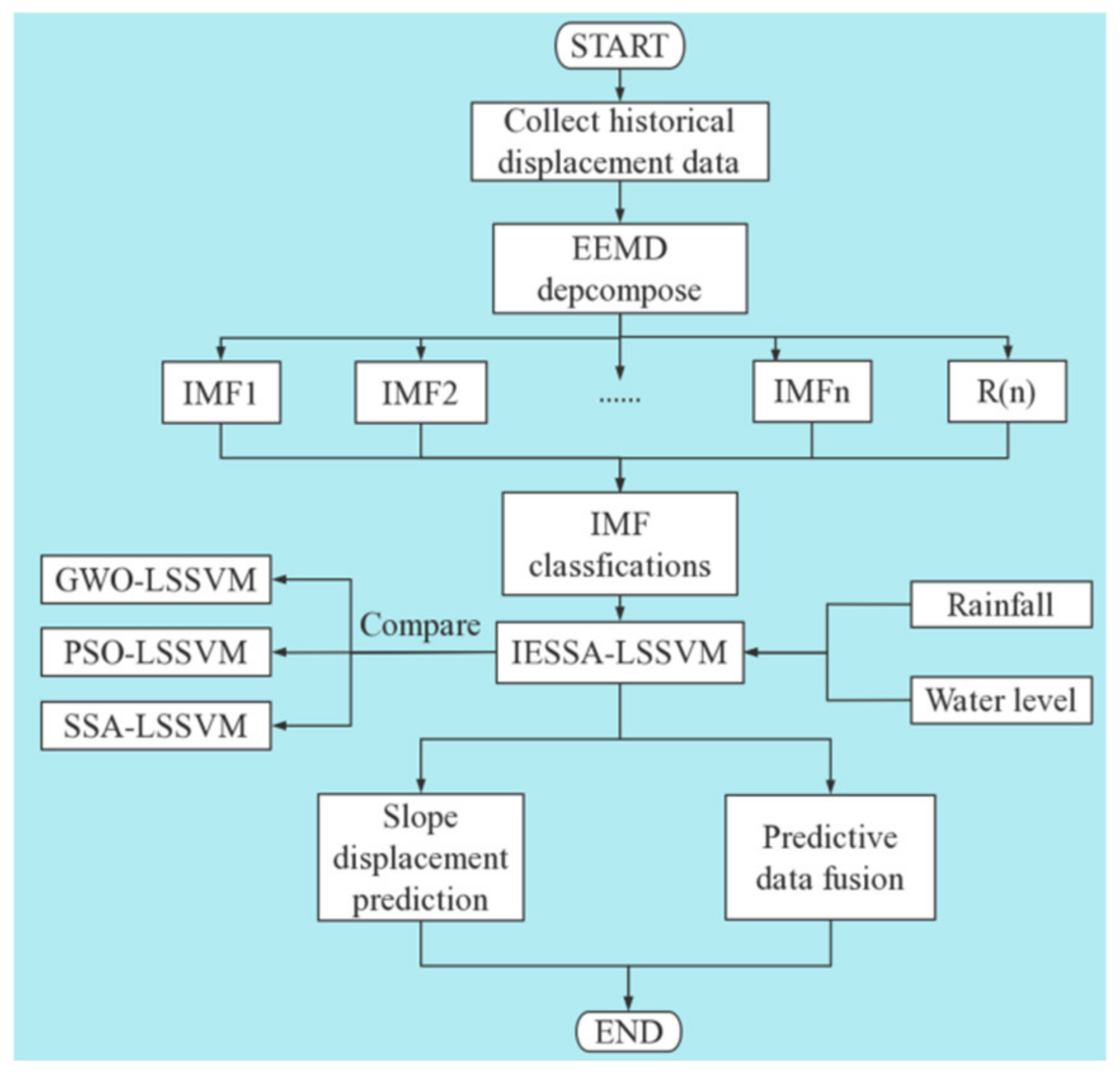
4.4. Technology Roadmap

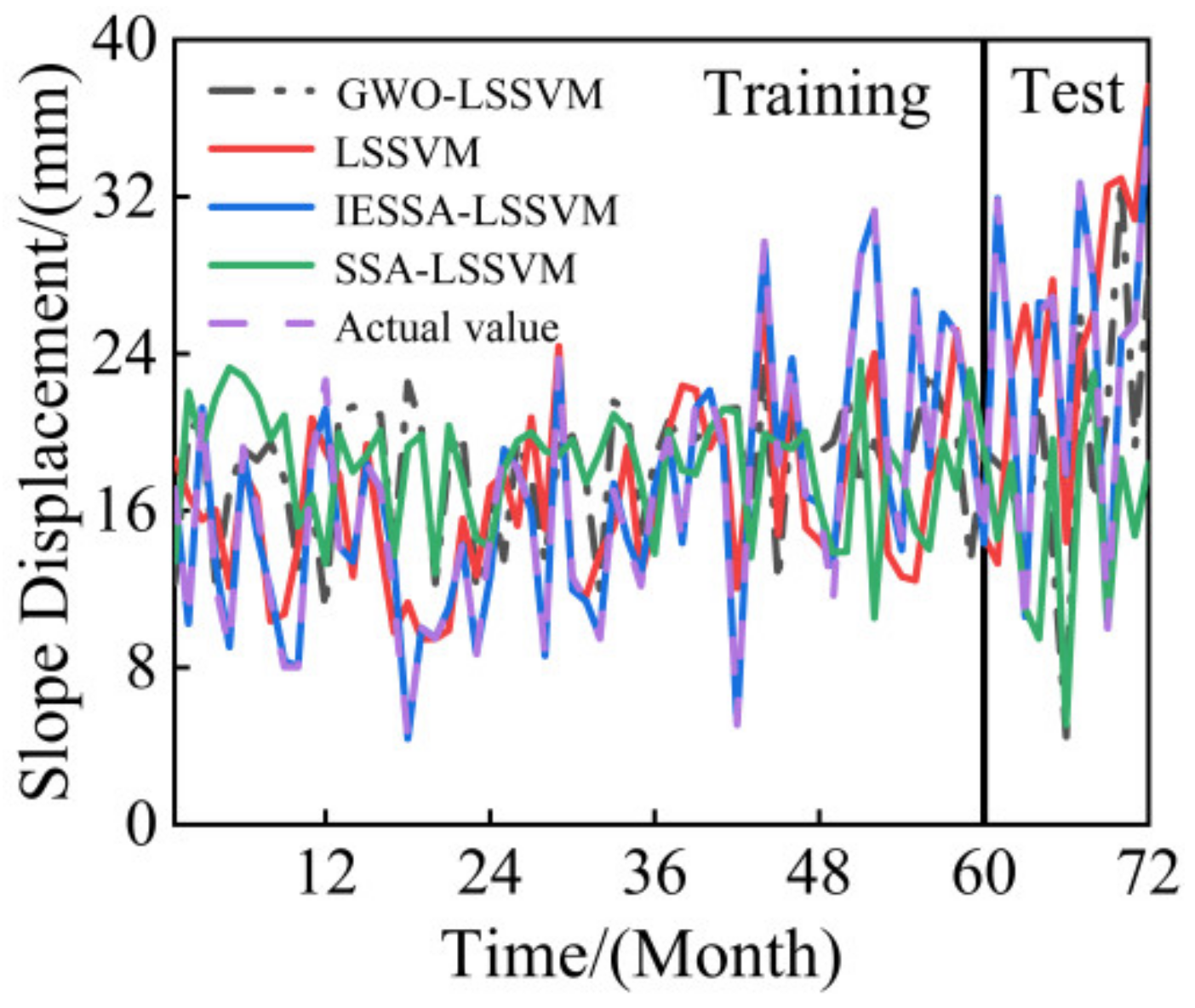
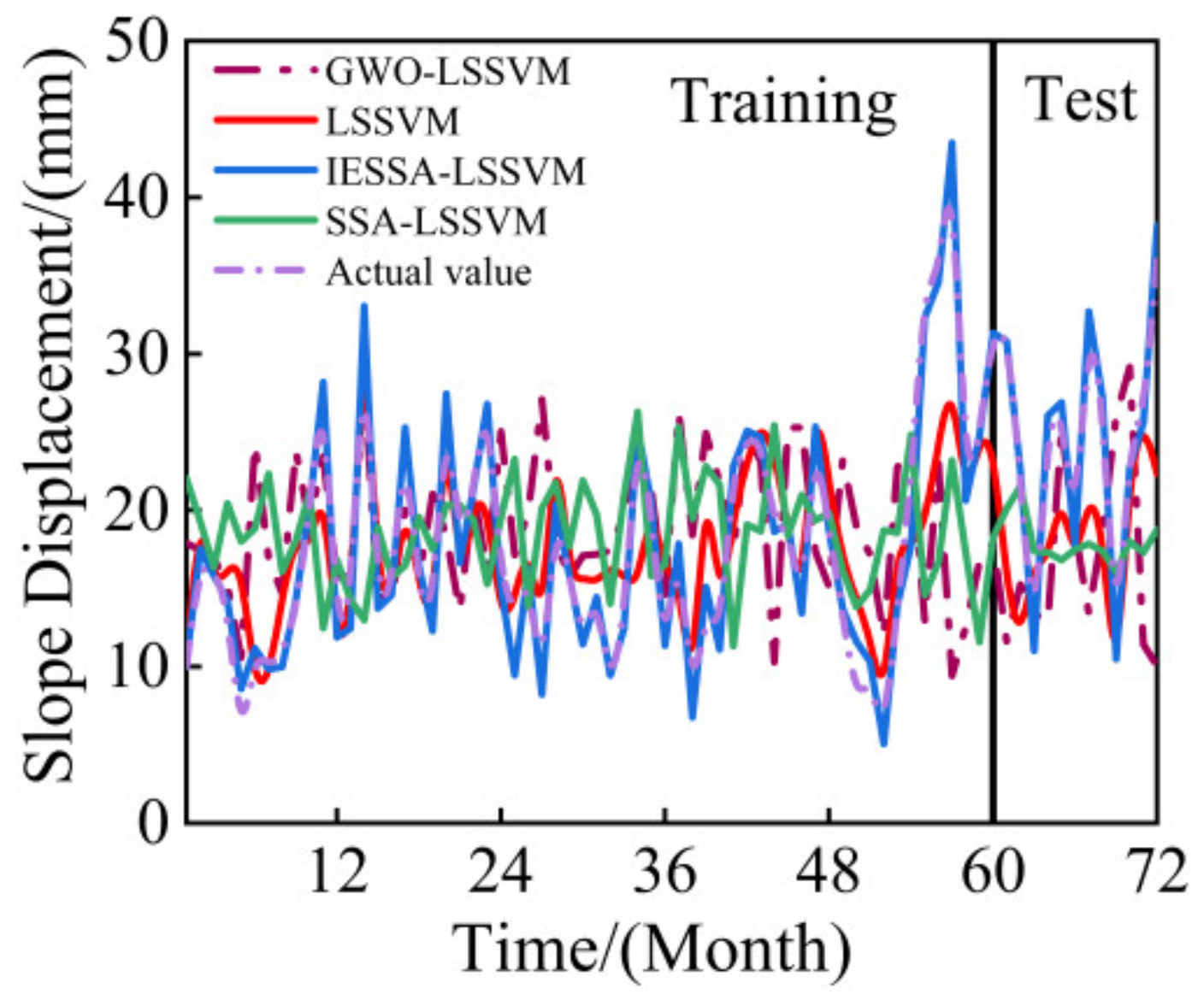
4.5. Analysis of the Predicted Results
4.6. Algorithmic Sorting
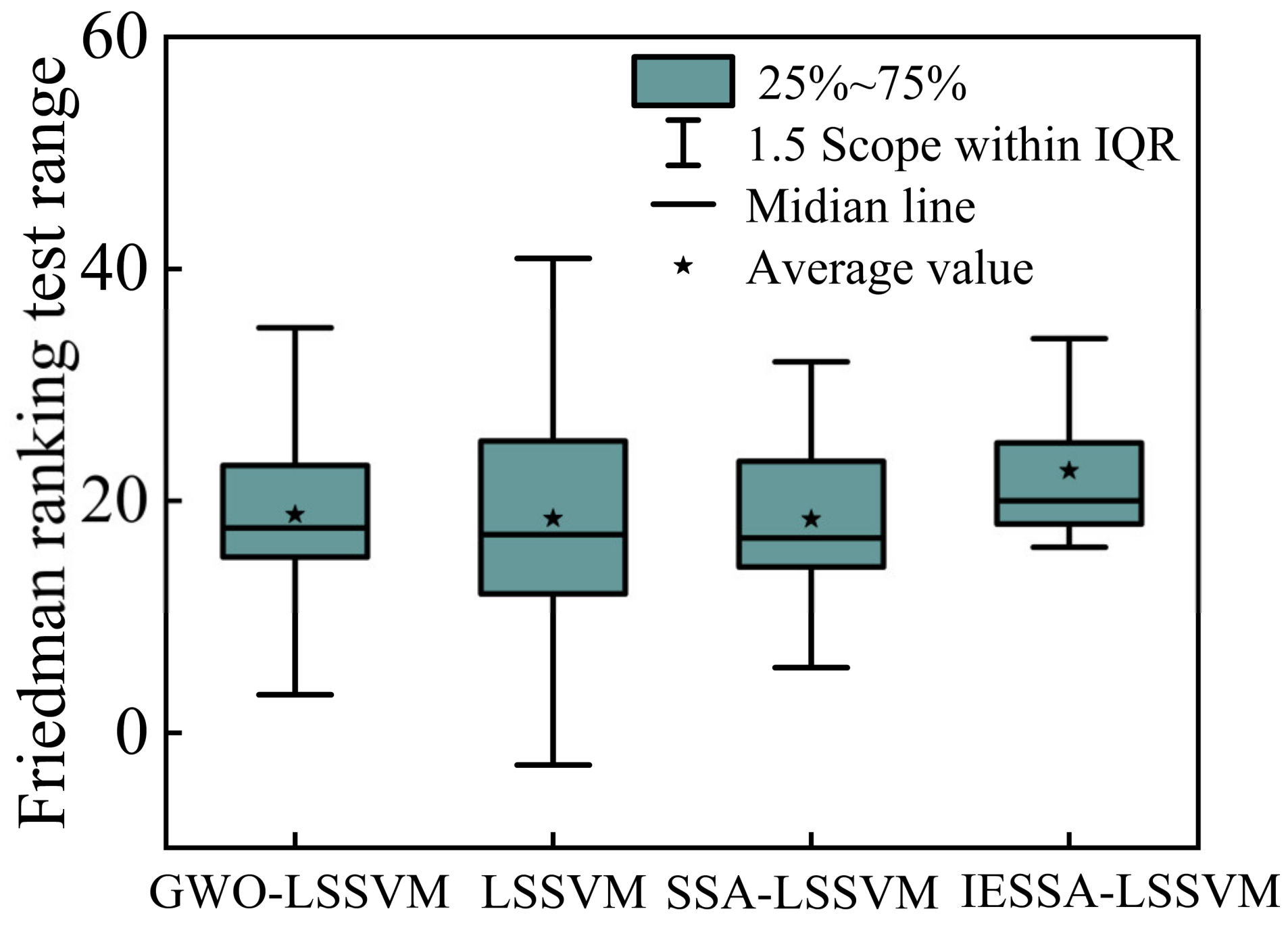
4.6.1. Friedman Ranking Test
4.6.2. Nemenyi Test
5. Discussion
6. Conclusions
- (1)
- In function verification, the IESSA algorithm performs well in 30 tests of nine benchmark functions, with eight best means and seven smallest standard deviations compared to GWO, SSA, PSO, and CSSOA. In three low-dimensional functions, it has the two best means and the two smallest variances. The root mean square error is the smallest, and the fit is closer to one, indicating that the IESSA algorithm has high accuracy and stability;
- (2)
- In contrast, the SSA, GWO, PSO, and CSSOA algorithms are prone to fall into local optimal solutions during the iterative process of function verification, making it difficult to perform a global search. The IESSA algorithm proposed in this paper can jump out of the local optimal solution. The iterative adaptation change curve shows that the convergence speed of the IESSA algorithm is much better than the other four algorithms, thus improving the efficiency of function computation;
- (3)
- In terms of engineering examples, this paper selects five years of rainfall, water level, and slope displacement data of two new beach slopes—xtGXT1 and xtGXT3—and applies the IESSA algorithm to obtain the slope displacement prediction. The comparison curves show that the IESSA algorithm outperforms the other four algorithms in terms of prediction accuracy. Its root mean square error is the smallest, and the fit is closer to one, indicating the feasibility and accuracy of the IESSA algorithm in engineering examples;
- (4)
- Considering factors such as convergence accuracy and speed, a comprehensive ranking of the four algorithms has been formulated and presented in the accompanying table. In the Friedman ranking test, the IESSA-LSSVM algorithm showcased distinctiveness from the remaining algorithms, with a figure exceeding 20 and a standard deviation of 3.18, which was the smallest. In the Nemenyi test, where pairwise comparisons were conducted, the significance of IESSA-LSSVM became even more pronounced. When incorporating convergence speed and accuracy into the assessment, the algorithms can be ranked in the following order: IESSA-LSSVM > GWO-LSSVM > SSA-LSSVM > LSSVM.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, X.; Liu, B. A Hybrid Time Series Model for Predicting the Displacement of High Slope in the Loess Plateau Region. Sustainability 2023, 15, 5423. [Google Scholar] [CrossRef]
- Huang, F.; Huang, J.; Jiang, S.; Zhou, C. Landslide displacement prediction based on multivariate chaotic model and extreme learning machine. Eng. Geol. 2017, 218, 173–186. [Google Scholar] [CrossRef]
- Xu, S.; Niu, R. Displacement prediction of Baijiabao landslide based on empirical mode decomposition and long short-term memory neural network in Three Gorges area, China. Comput. Geosci. 2018, 111, 87–96. [Google Scholar] [CrossRef]
- Wen, T.; Tang, H.; Wang, Y.; Lin, C.; Xiong, C. Landslide displacement prediction using the GA-LSSVM model and time series analysis: A case study of Three Gorges Reservoir, China. Nat. Hazards Earth Syst. Sci. 2017, 7, 2181–2198. [Google Scholar] [CrossRef]
- Cai, Z.; Xu, W.; Meng, Y.; Shi, C.; Wang, R. Prediction of landslide displacement based on GA-LSSVM with multiple factors. Bull. Eng. Geol. Environ. 2016, 75, 637–646. [Google Scholar] [CrossRef]
- Herrera, G.; Fernández-Merodo, J.; Mulas, J.; Pastor, M.; Luzi, G.; Monserrat, O. A landslide forecasting model using ground based SAR data: The Portalet case study. Eng. Geol. 2009, 105, 220–230. [Google Scholar] [CrossRef]
- Huang, F.; Yin, K.; Zhang, G.; Gui, L.; Yang, B.; Liu, L. Landslide displacement prediction using discrete wavelet transform and extreme learning machine based on chaos theory. Environ. Earth Sci. 2016, 75, 1376. [Google Scholar] [CrossRef]
- Cao, Y.; Yin, K.; Alexander, D.E.; Zhou, C. Using an extreme learning machine to predict the displacement of step-like landslides in relation to controlling factors. Landslides 2016, 13, 725–736. [Google Scholar] [CrossRef]
- Miao, F.; Wu, Y.; Xie, Y.; Li, Y. Prediction of landslide displacement with step-like behavior based on multialgorithm optimization and a support vector regression model. Landslides 2018, 15, 475–488. [Google Scholar] [CrossRef]
- Zhou, C.; Yin, K.; Cao, Y.; Ahmed, B. Application of time series analysis and PSO–SVM model in predicting the Bazimen landslide in the Three Gorges Reservoir, China. Eng. Geol. 2016, 204, 108–120. [Google Scholar] [CrossRef]
- Xing, Y.; Yue, J.; Chen, C.; Qin, Y.; Hu, J. A hybrid prediction model of landslide displacement with risk-averse adaptation. Comput. Geosci. 2020, 141, 104527. [Google Scholar] [CrossRef]
- Morshed-Bozorgdel, A.; Kadkhodazadeh, M.; Valikhan Anaraki, M.; Farzin, S. A Novel Framework Based on the Stacking Ensemble Machine Learning (SEML) Method: Application in Wind Speed Modeling. Atmosphere 2022, 13, 758. [Google Scholar] [CrossRef]
- Farzin, S.; Valikhan Anaraki, M. Modeling and predicting suspended sediment load under climate change conditions: A new hybridization strategy. J. Water Clim. Change 2021, 12, 2422–2443. [Google Scholar] [CrossRef]
- Tiwari, L.B.; Burman, A.; Samui, P. Modelling soil compaction parameters using a hybrid soft computing technique of LSSVM and symbiotic organisms search. Innov. Infrastruct. Solut. 2023, 8, 2. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, K.; Bao, R.; Liu, X.-H.; Qi, F.-F. Intelligent prediction of landslide displacements based on optimized empirical mode decomposition and K-Mean clustering. Rock Soil Mech. 2021, 42, 211–223. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control. Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Hua, L.G.; Wang, Y. Applications of Number Theory to Approximate Analysis; Science Press: Beijing, China, 1978. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Suykens, J.A.K.; Vandewalle, J. Least Squares Support Vector Machine Classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Wu, Y. Deformation Monitoring Data of Xin Tan Landslide in Zigui County, Three Gorges Reservoir Area, Yangtze River, 2007–2012; National Glacial Permafrost Desert Science Data Center: Lanzhou, China, 2016. [Google Scholar]
- Sharma, S.K.; Gajbhiye, S.; Tignath, S. Application of principal component analysis in grouping geomorphic parameters of a watershed for hydrological modeling. Appl. Water. Sci. 2015, 5, 89–96. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, W. A SAS macro for testing differences among three or more independent groups using Kruskal-Wallis and Nemenyi tests. J. Huazhong Univ. Sci. Technol. [Med. Sci.] 2012, 32, 130–134. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title | Function | Dim | Initial Range | |
|---|---|---|---|---|
| Unimodal test function | 30 | [−100, 100] | 0 | |
| 30 | [−10, 10] | 0 | ||
| 30 | [−100, 100] | 0 | ||
| Multimodal test function | 30 | [−500, 500] | −418.9829 × 5 | |
| 30 | [−5.12, 5.12] | 0 | ||
| 30 | [−600, 600] | 0 | ||
| Fixed- dimension test functions | 2 | [−65, 65] | 0.998 | |
| 4 | [−5, 5] | 0.00038 | ||
| 3 | [1, 3] | −3.75 |
| SSA | GWO | PSO | CSSOA | IESSA | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Ave | Std | Ave | Std | Ave | Std | Ave | Std | Ave | Std | |
| F1 | 2.6 × 10−46 | 1.4 × 10−45 | 0.015 | 0.015 | 5.80 | 2.96 | 1.6 × 10−42 | 8 × 10−42 | 0.0 | 0.0 |
| F2 | 2.1 × 10−22 | 9.4 × 10−22 | 0.023 | 0.008 | 6.92 | 1.68 | 3.7 × 10−18 | 2.1 × 10−17 | 0.0 | 0.0 |
| F3 | 5.6 × 10−26 | 3.1 × 10−25 | 267.69 | 178.5 | 1381.6 | 543.8 | 7.5 × 10−31 | 3.6 × 10−30 | 0.0 | 0.0 |
| F4 | 2.5 × 10−21 | 1.2 × 10−20 | 1.467 | 0.479 | 5.2355 | 1.649 | 1.6 × 10−20 | 5.1 × 10−20 | 0.0 | 0.0 |
| F5 | 0.003 | 0.006 | 30.75 | 3.50 | 1917.9 | 1302.8 | 0.005 | 0.013 | 9.6 × 10−6 | 1.5 × 10−5 |
| F6 | 0.0 | 0.0 | 0.081 | 0.061 | 20.36 | 4.05 | 0.0 | 0.0 | 0.0 | 0.0 |
| F7 | 9.21 | 4.949 | 5.282 | 3.976 | 3.494 | 2.751 | 7.949 | 5.274 | 6.324 | 5.783 |
| F8 | 3.2 × 10−3 | 1.6 × 10−4 | 0.004 | 0.0075 | 9.6 × 10−4 | 1.6 × 10−4 | 0.0003 | 6.2 × 10−5 | 3.1 × 10−4 | 3.0 × 10−5 |
| F9 | 10.2 | 12.14 | 3.0007 | 6.9 × 10−4 | 3 | 3.1 × 10−13 | 3 | 3.4 × 10−10 | 3 | 8.0 × 10−9 |
| Model Name | xtGXT1 Side Slope | |||
|---|---|---|---|---|
| RMSE | MAE% | R2 | MAPE% | |
| LSSVM | 7.4596 | 7.2644 | 0.46289 | 0.64336 |
| SSA-LSSVM | 6.9357 | 4.1177 | 0.50761 | 0.29981 |
| GWO-LSSVM | 3.496 | 3.549 | 0.5636 | 0.23704 |
| IESSA-LSSVM | 0.60002 | 0.33189 | 0.98998 | 0.023009 |
| Model Name | xtGXT3 Side Slope | |||
|---|---|---|---|---|
| RMSE | MAE% | R2 | MAPE% | |
| LSSVM | 6.698 | 6.1595 | 0.44741 | 0.35308 |
| SSA-LSSVM | 4.0392 | 4.4196 | 0.6324 | 0.26576 |
| GWO-LSSVM | 6.0246 | 5.2036 | 0.56495 | 0.30247 |
| IESSA-LSSVM | 1.2137 | 0.67279 | 0.97714 | 0.058192 |
| Variable Name | Median | Standard Deviation | P | Cohen’s f-Value |
|---|---|---|---|---|
| LSSVM | 16.791 | 6.495 | 0.043 | 0.13 |
| SSA-LSSVM | 17.089 | 5.16 | ||
| GWO-LSSVM | 17.763 | 4.858 | ||
| IESSA-LSSVM | 20.046 | 3.186 |
| Comparison Group | A and B | A and C | A and D | B and C | B and D | C and D |
|---|---|---|---|---|---|---|
| 6.712 | 5.340 | 7.984 | 1.528 | 9.403 | 9.518 | |
| P | 0.081 | 0.149 | 0.02 | 0.676 | 0.04 | 0.042 |
| Algorithm Name | Rankings |
|---|---|
| LSSVM | 4 |
| GWO-LSSVM | 2 |
| SSA-LSSVM | 3 |
| IESSA-LSSVM | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, H.; Song, G.; Li, Y. Displacement Prediction of Channel Slope Based on EEMD-IESSA-LSSVM Combined Algorithm. Appl. Sci. 2023, 13, 9582. https://doi.org/10.3390/app13179582
Yao H, Song G, Li Y. Displacement Prediction of Channel Slope Based on EEMD-IESSA-LSSVM Combined Algorithm. Applied Sciences. 2023; 13(17):9582. https://doi.org/10.3390/app13179582
Chicago/Turabian StyleYao, Hongyun, Guanlin Song, and Yibo Li. 2023. "Displacement Prediction of Channel Slope Based on EEMD-IESSA-LSSVM Combined Algorithm" Applied Sciences 13, no. 17: 9582. https://doi.org/10.3390/app13179582
APA StyleYao, H., Song, G., & Li, Y. (2023). Displacement Prediction of Channel Slope Based on EEMD-IESSA-LSSVM Combined Algorithm. Applied Sciences, 13(17), 9582. https://doi.org/10.3390/app13179582