Author Contributions
Conceptualization, E.B. and K.H.R.; Methodology, E.B.; Formal analysis, E.B., V.-H.P. and K.H.R.; Investigation, E.B.; Data Curation, E.B.; Writing—original draft preparation, E.B.; Writing—review and editing, V.-H.P. and K.H.R.; Supervision, K.H.R.; Project administration, K.H.R.; Funding acquisition, K.H.R. All authors have read and agreed to the published version of the manuscript.
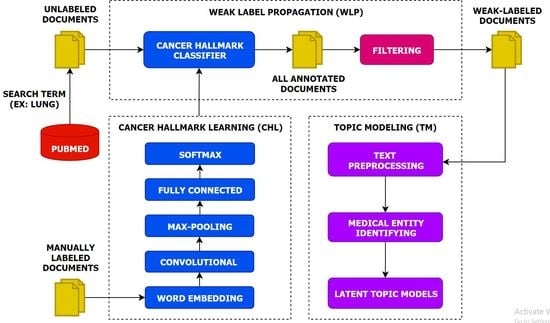
Figure 1.
The overview of the MTTA framework.
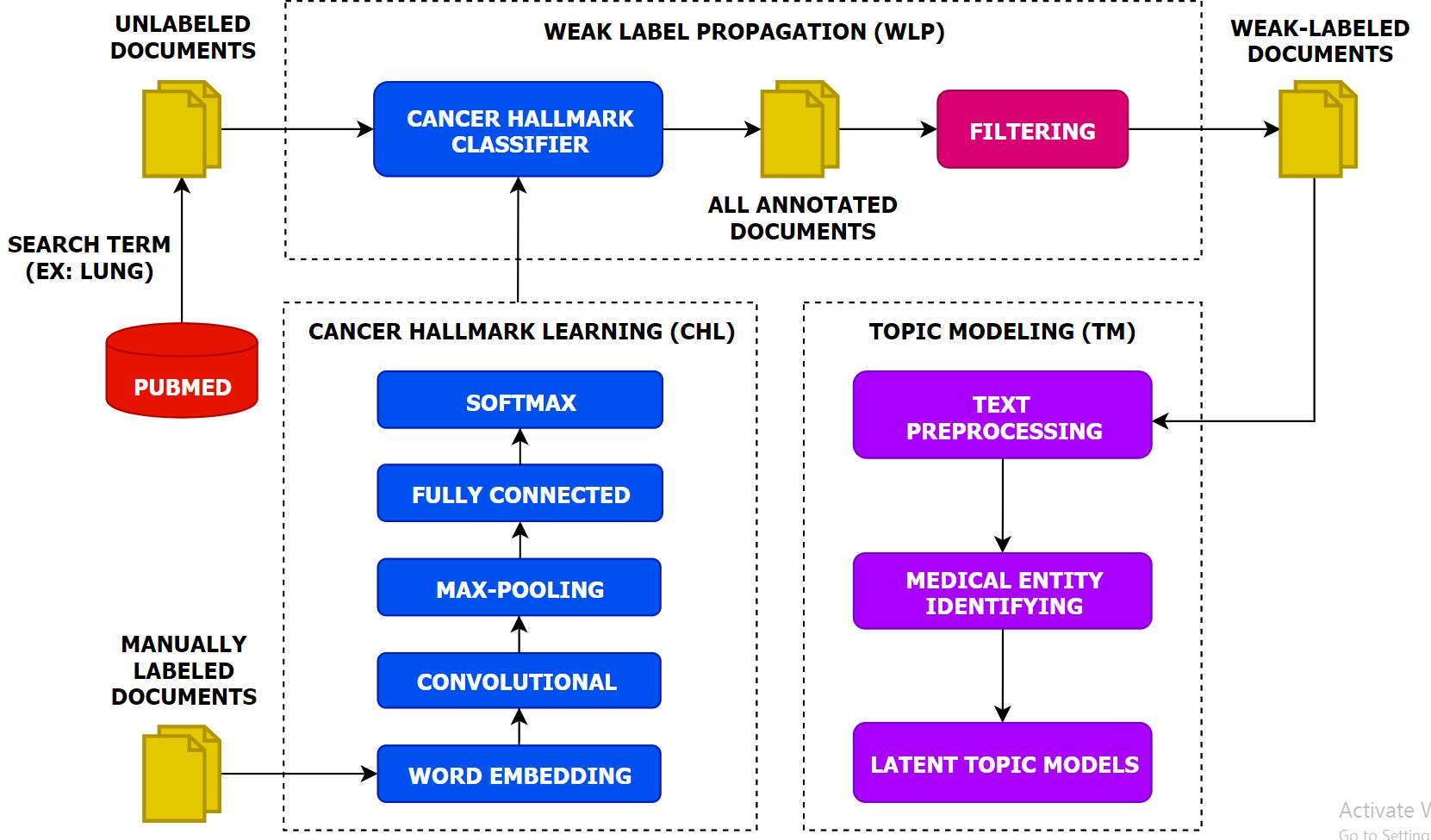
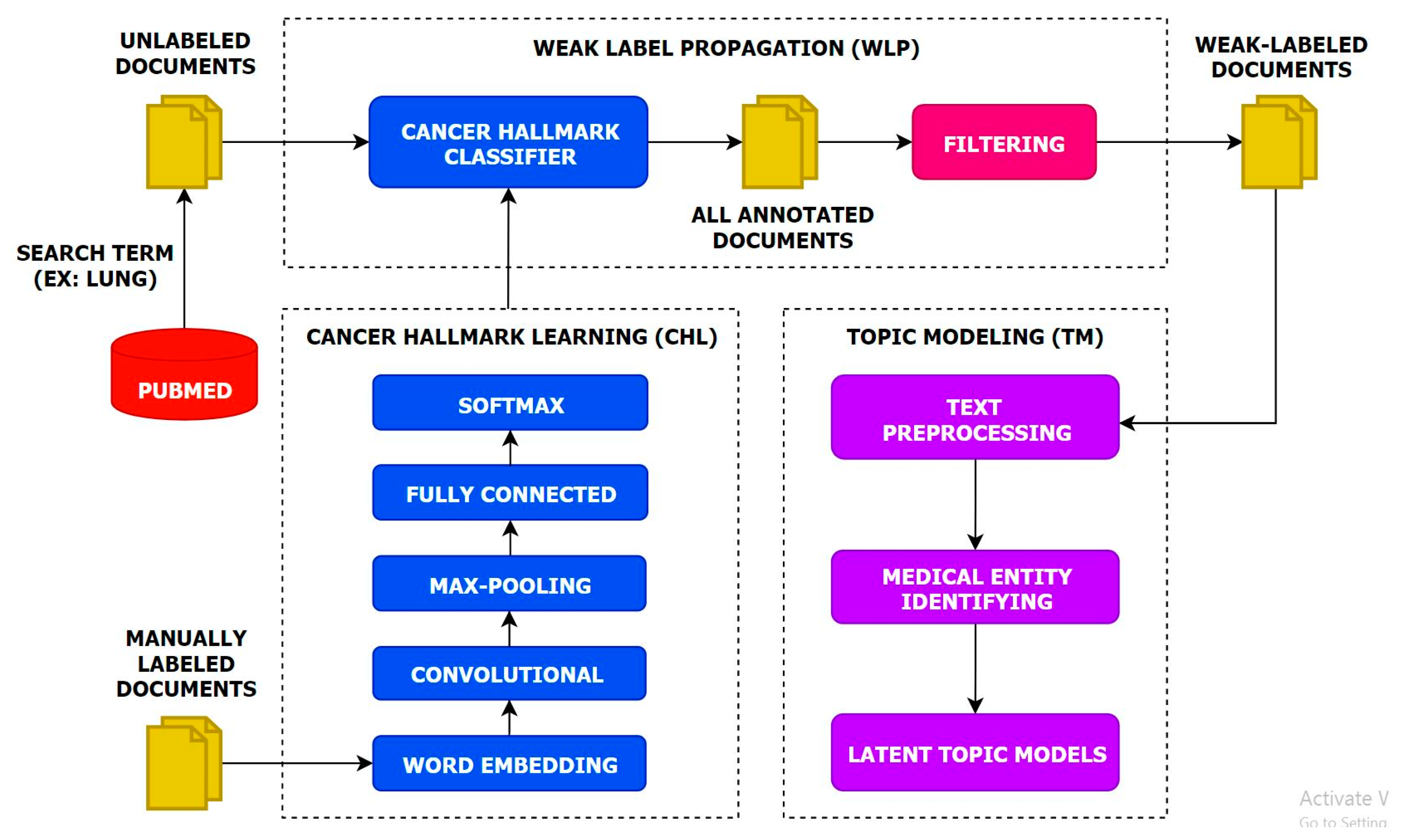
Figure 1.
The overview of the MTTA framework.
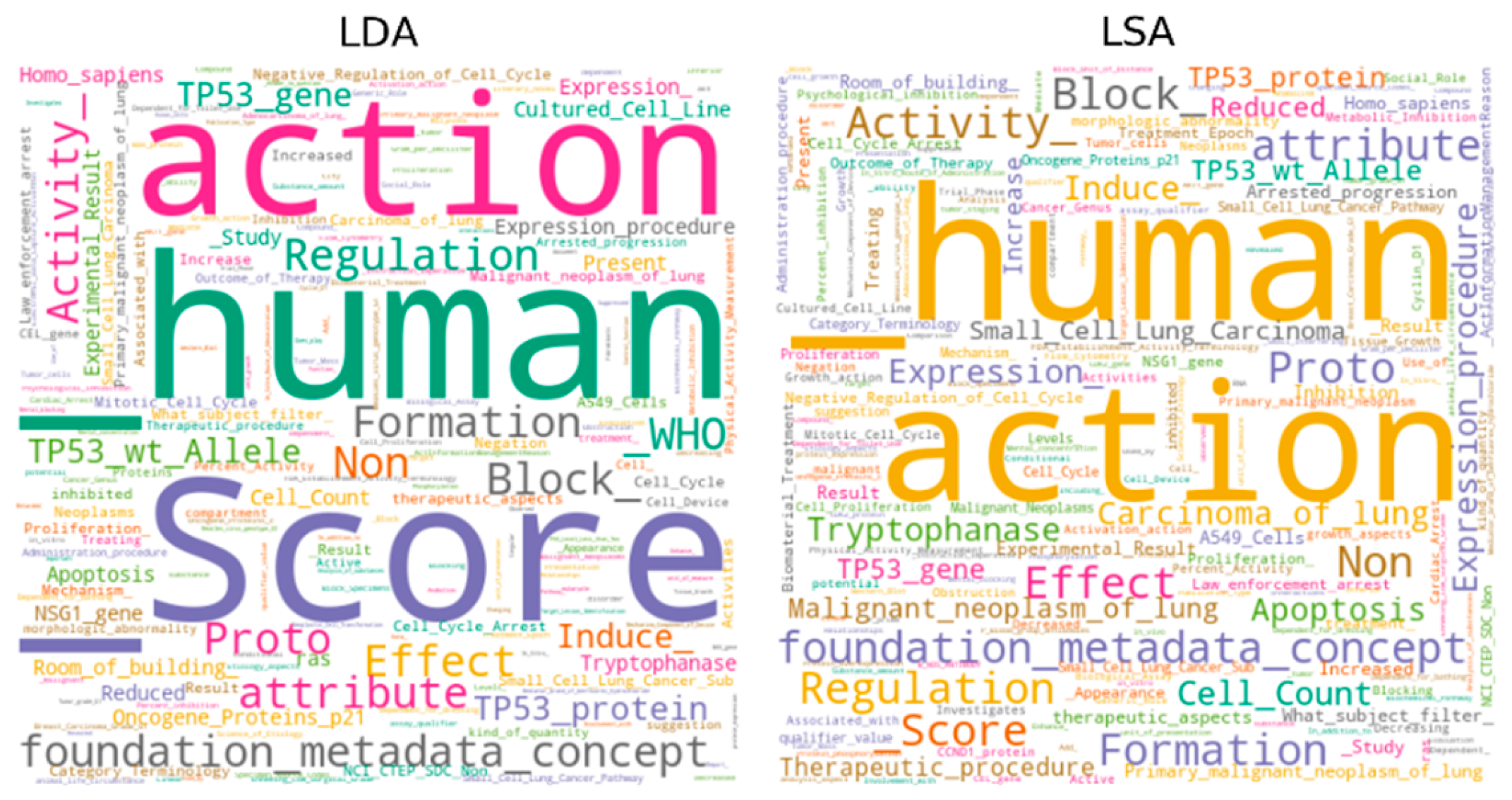
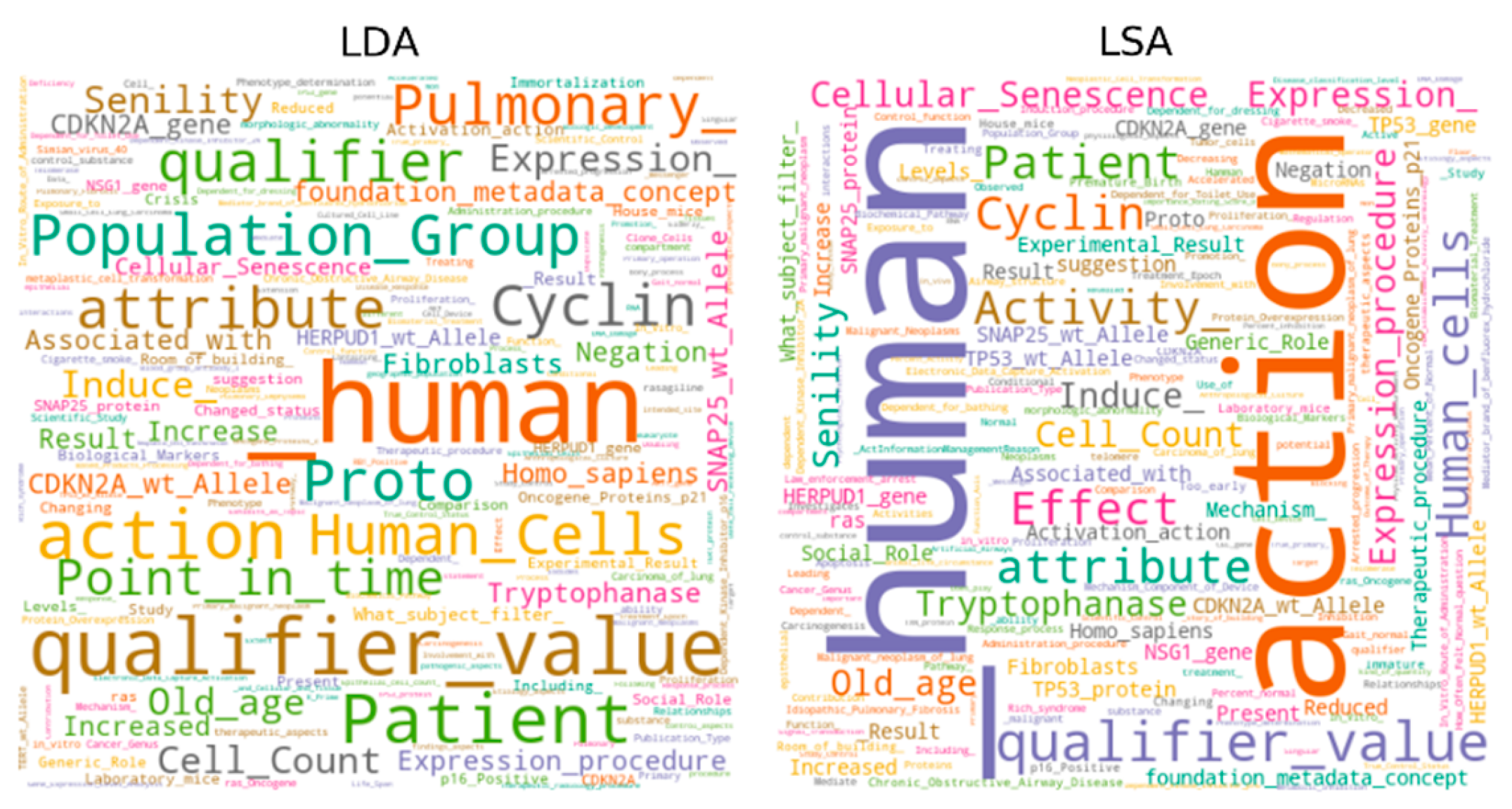
Figure 2.
Word cloud of the top-1 topics on the SPS hallmark.
Figure 2.
Word cloud of the top-1 topics on the SPS hallmark.
Figure 3.
Word cloud of the top-1 topics on the EGS hallmark.
Figure 3.
Word cloud of the top-1 topics on the EGS hallmark.
Figure 4.
Word cloud of the top-1 topics on the RCD hallmark.
Figure 4.
Word cloud of the top-1 topics on the RCD hallmark.
Figure 5.
Word cloud of the top-1 topics on the ERI hallmark.
Figure 5.
Word cloud of the top-1 topics on the ERI hallmark.
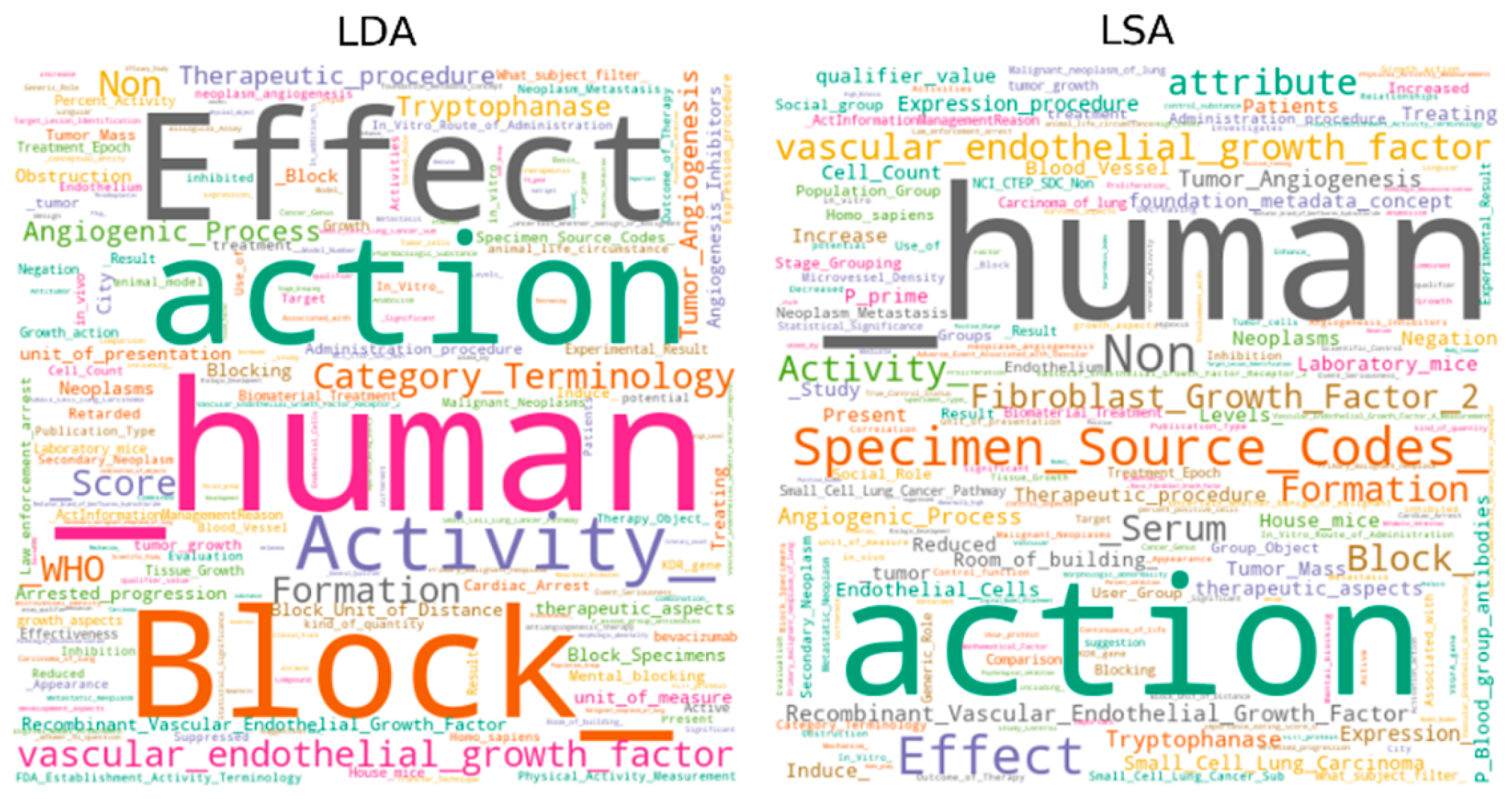
Figure 6.
Word cloud of the top-1 topics on the IA hallmark.
Figure 6.
Word cloud of the top-1 topics on the IA hallmark.
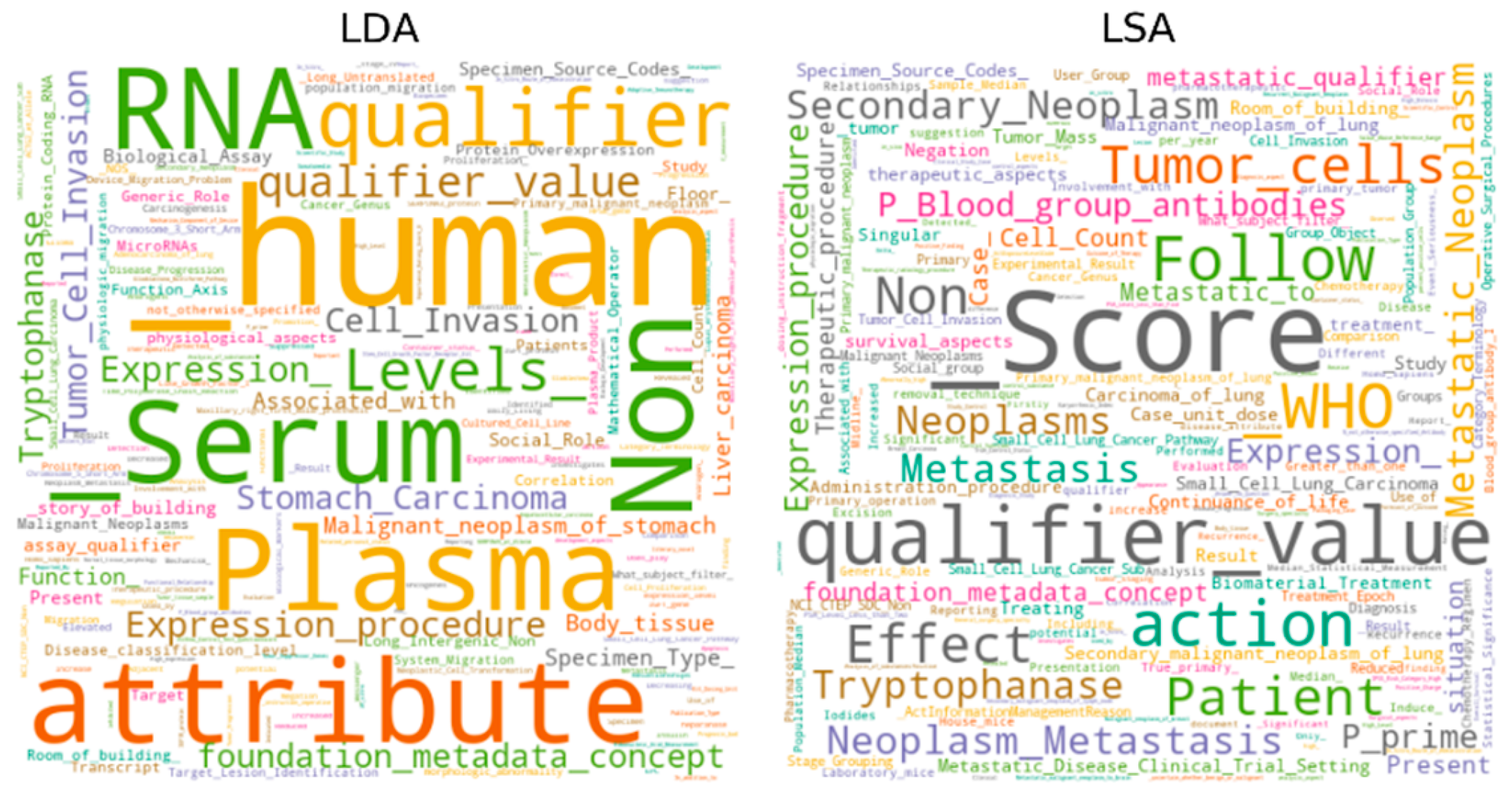
Figure 7.
Word cloud of the top-1 topics on the AIM hallmark.
Figure 7.
Word cloud of the top-1 topics on the AIM hallmark.
Figure 8.
Word cloud of the top-1 topics on the GIM hallmark.
Figure 8.
Word cloud of the top-1 topics on the GIM hallmark.
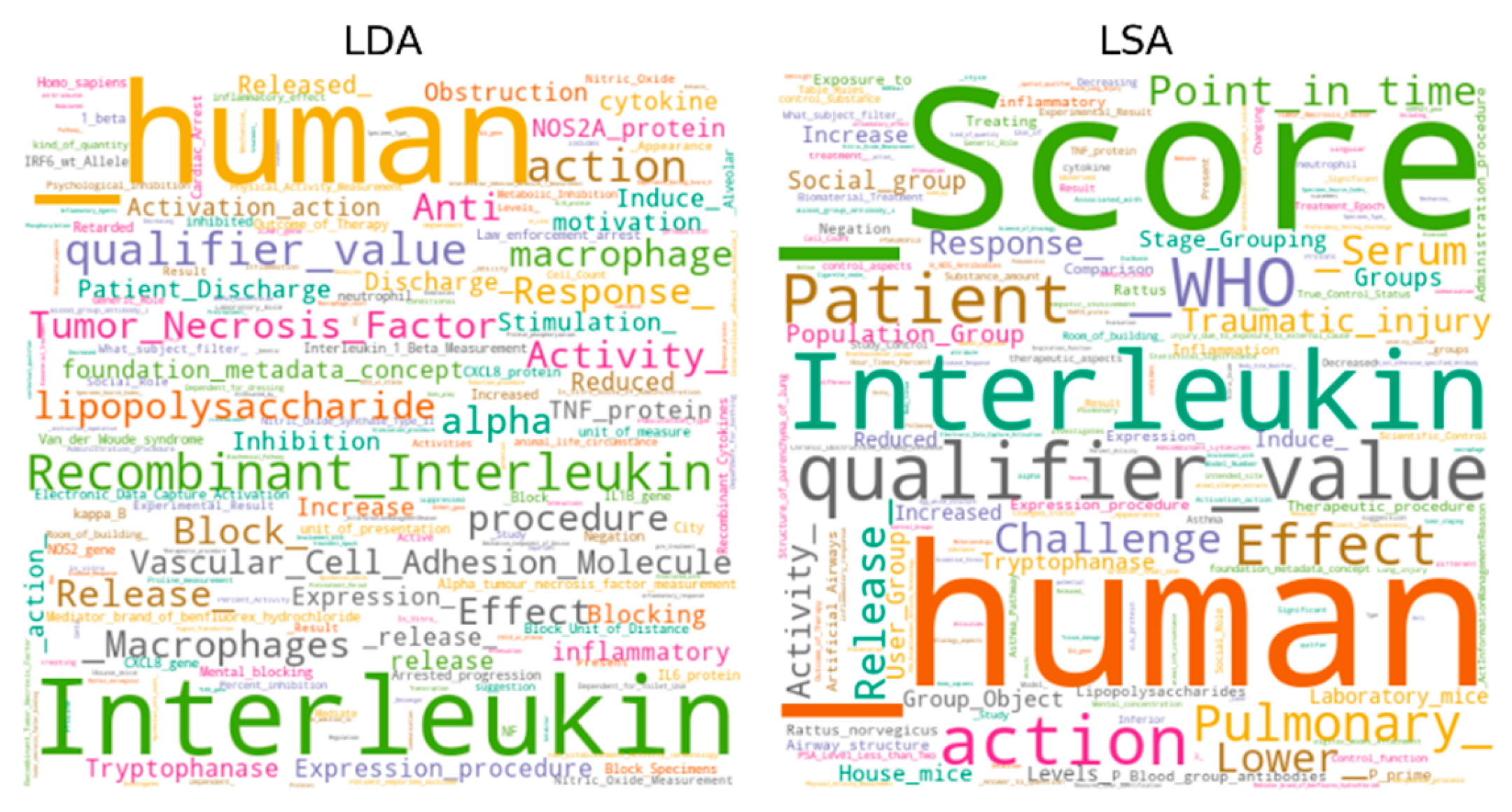
Figure 9.
Word cloud of the top-1 topics on the TPI hallmark.
Figure 9.
Word cloud of the top-1 topics on the TPI hallmark.
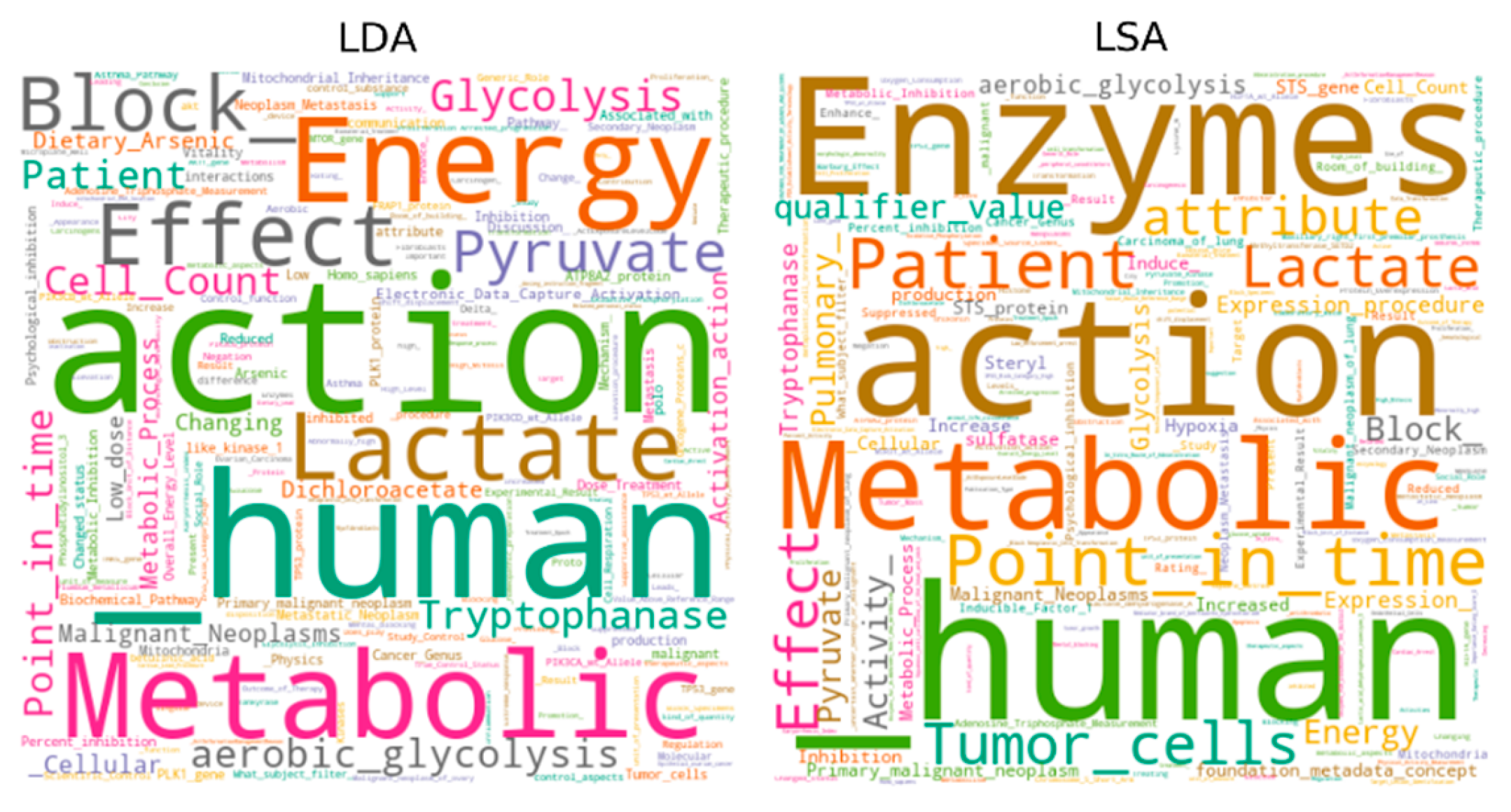
Figure 10.
Word cloud of the top-1 topics on the DCE hallmark.
Figure 10.
Word cloud of the top-1 topics on the DCE hallmark.
Figure 11.
Word cloud of the top-1 topics on the AID hallmark.
Figure 11.
Word cloud of the top-1 topics on the AID hallmark.
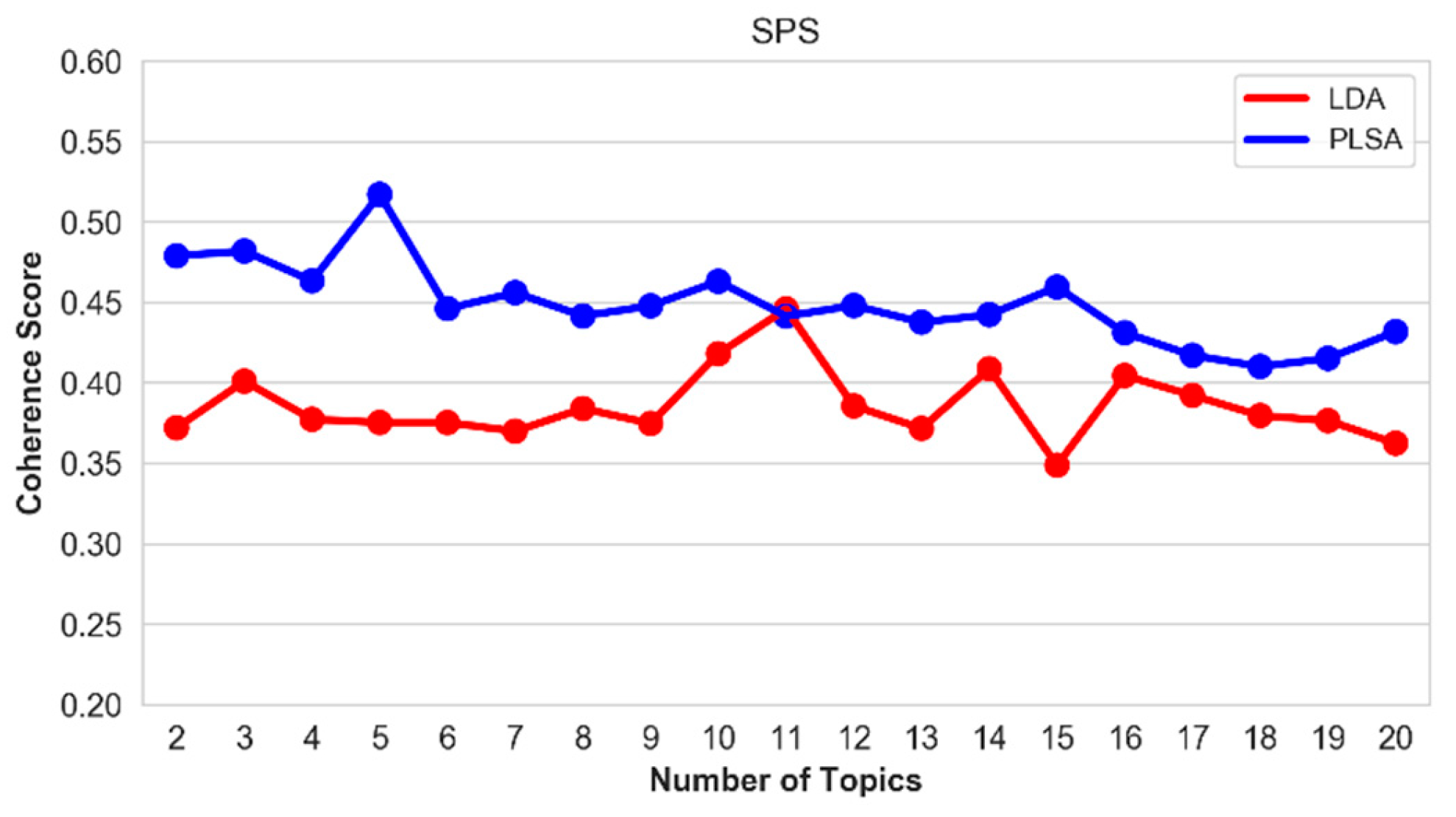
Figure 12.
Coherence score of the top-20 topics on the SPS hallmark.
Figure 12.
Coherence score of the top-20 topics on the SPS hallmark.
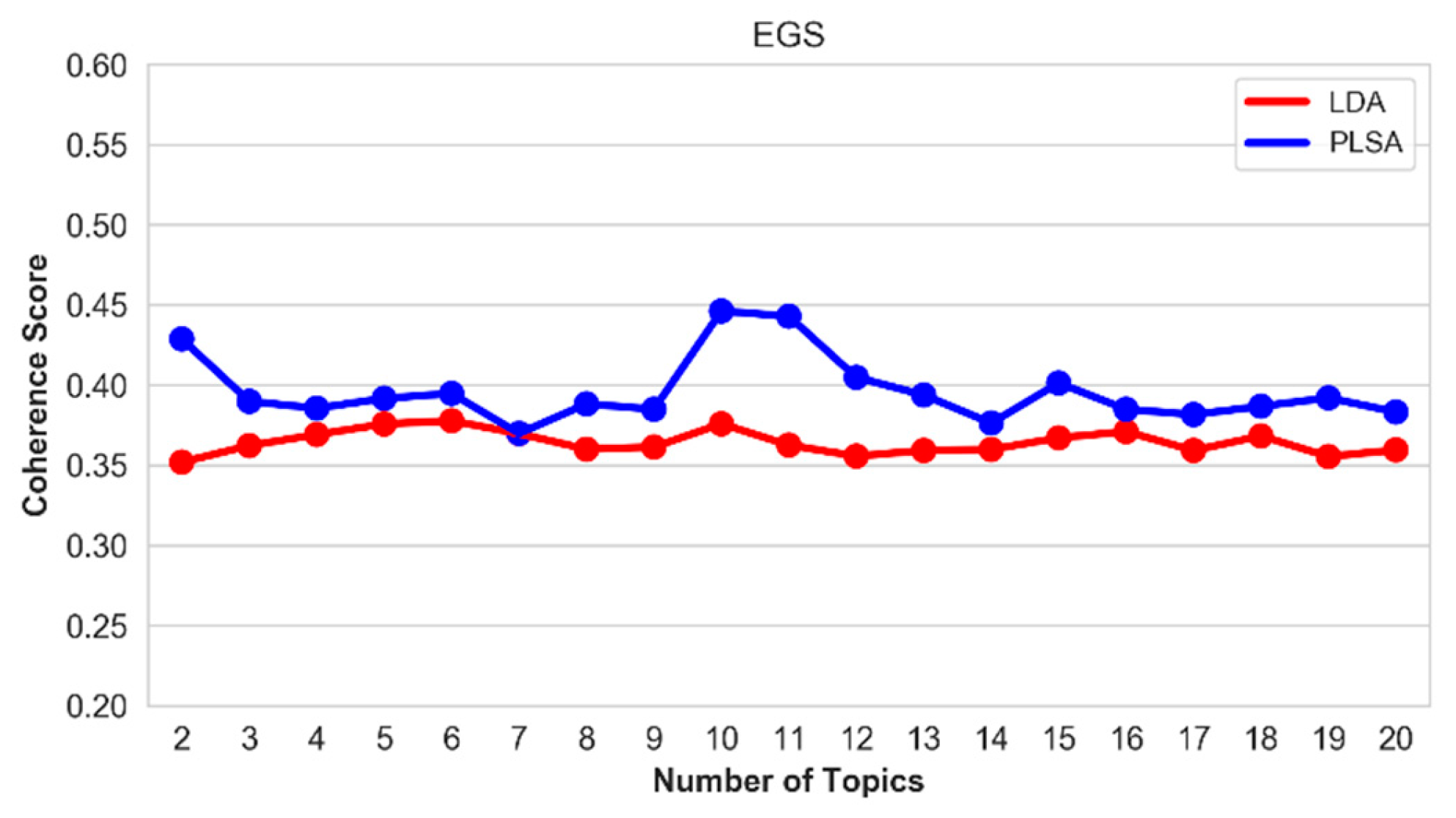
Figure 13.
Coherence score of the top-20 topics on the EGS hallmark.
Figure 13.
Coherence score of the top-20 topics on the EGS hallmark.
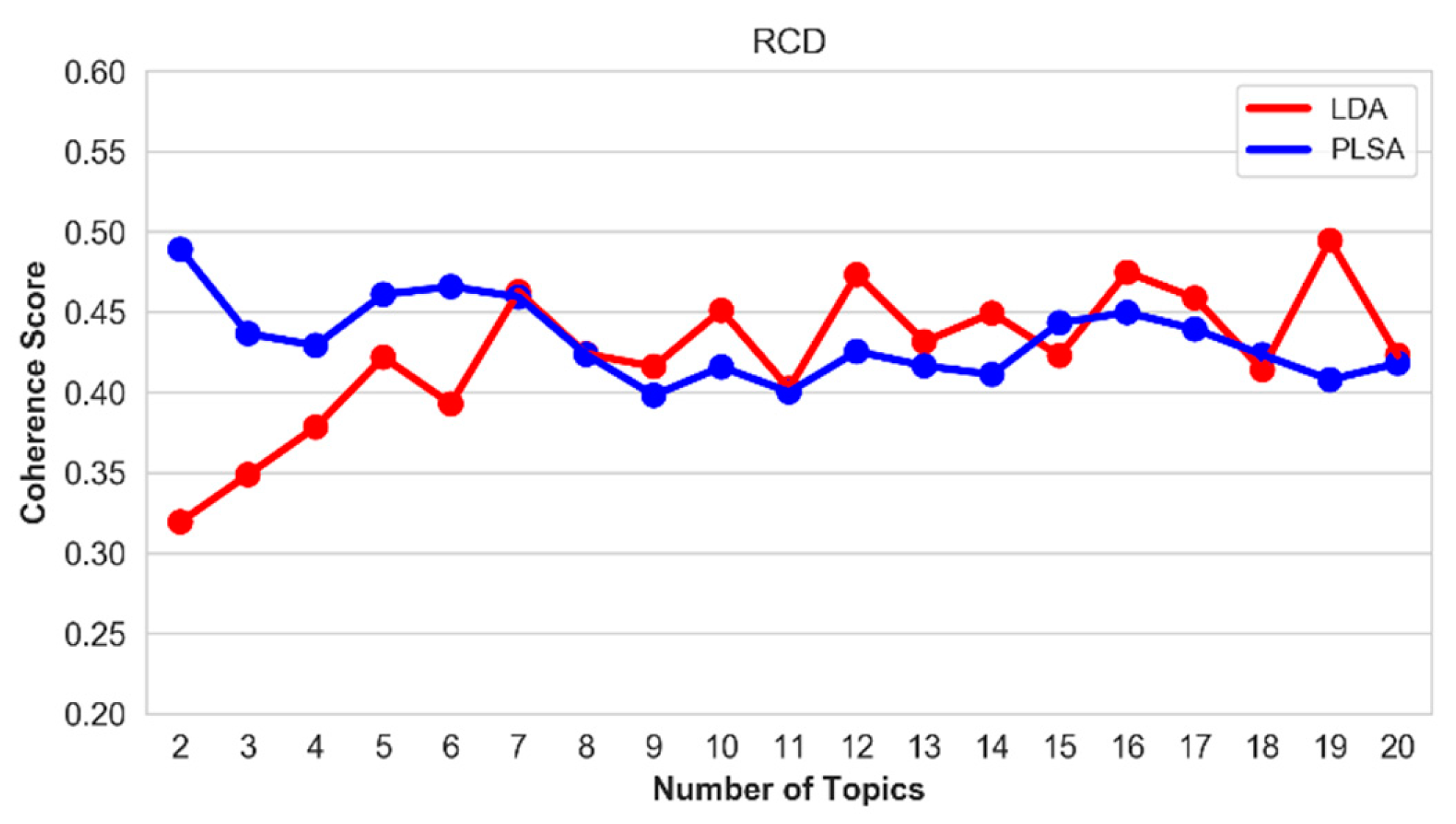
Figure 14.
Coherence score of the top-20 topics on the RCD hallmark.
Figure 14.
Coherence score of the top-20 topics on the RCD hallmark.
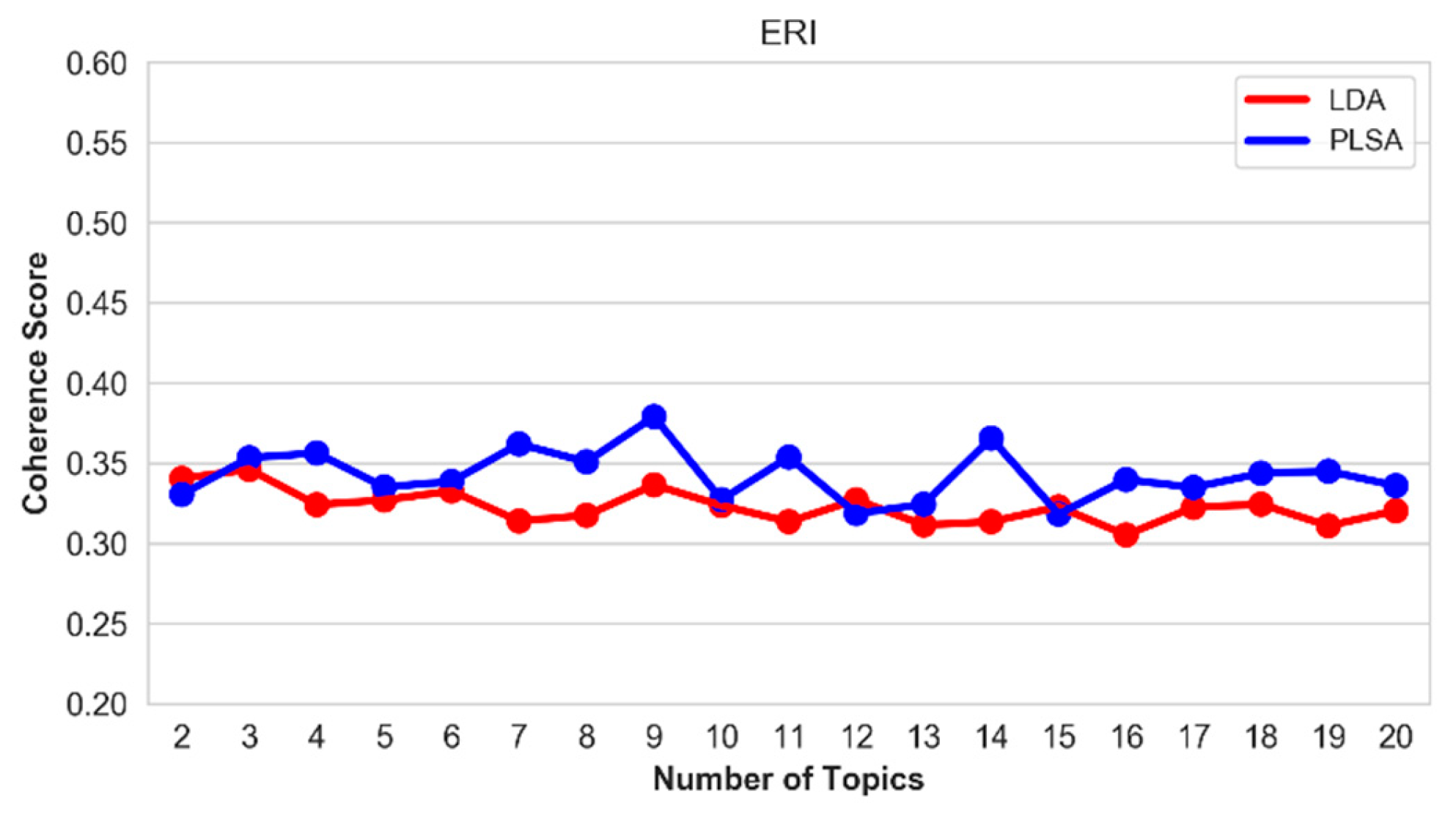
Figure 15.
Coherence score of the top-20 topics on the ERI hallmark.
Figure 15.
Coherence score of the top-20 topics on the ERI hallmark.
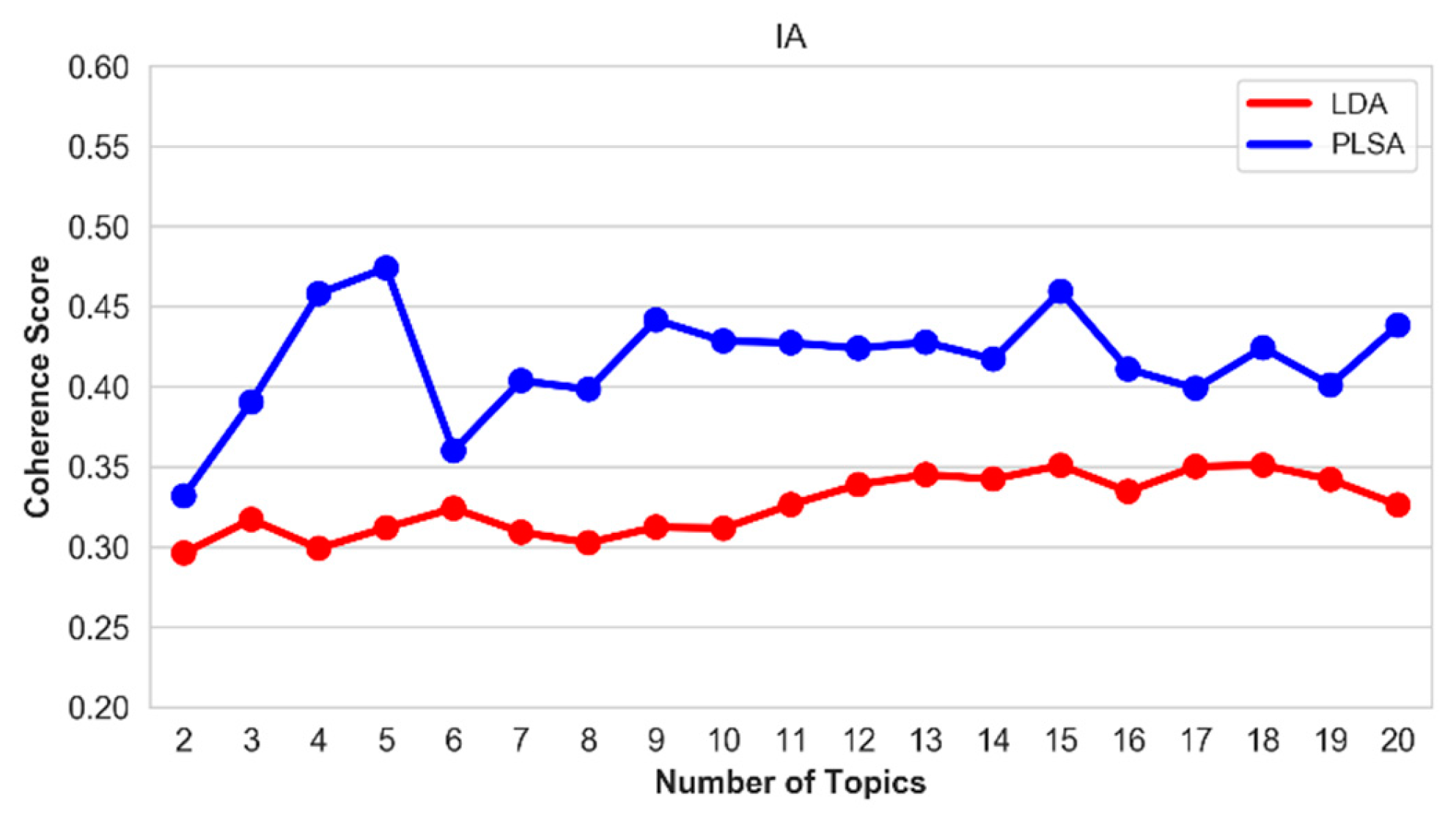
Figure 16.
Coherence score of the top-20 topics on the IA hallmark.
Figure 16.
Coherence score of the top-20 topics on the IA hallmark.
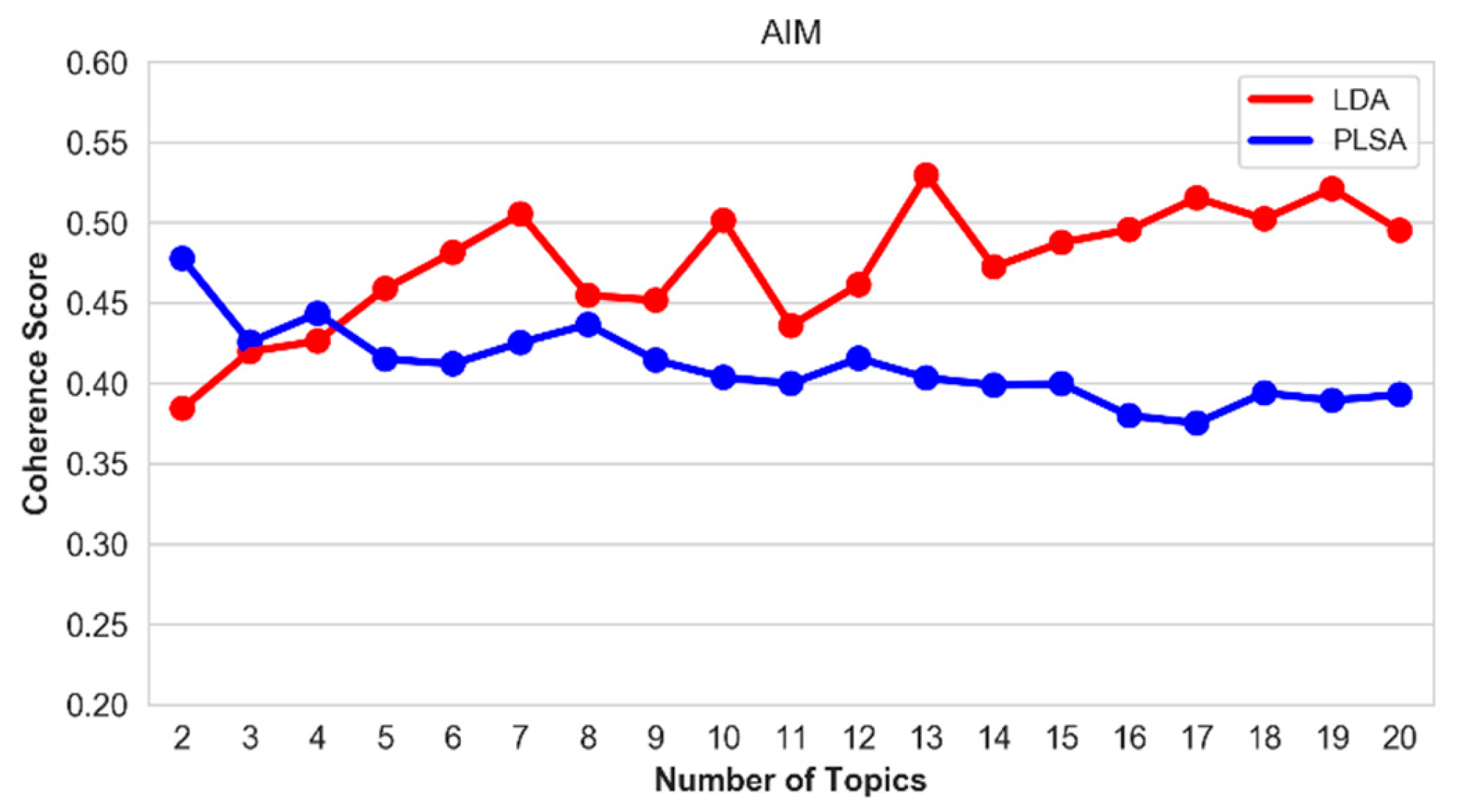
Figure 17.
Coherence score of the top-20 topics on the AIM hallmark.
Figure 17.
Coherence score of the top-20 topics on the AIM hallmark.
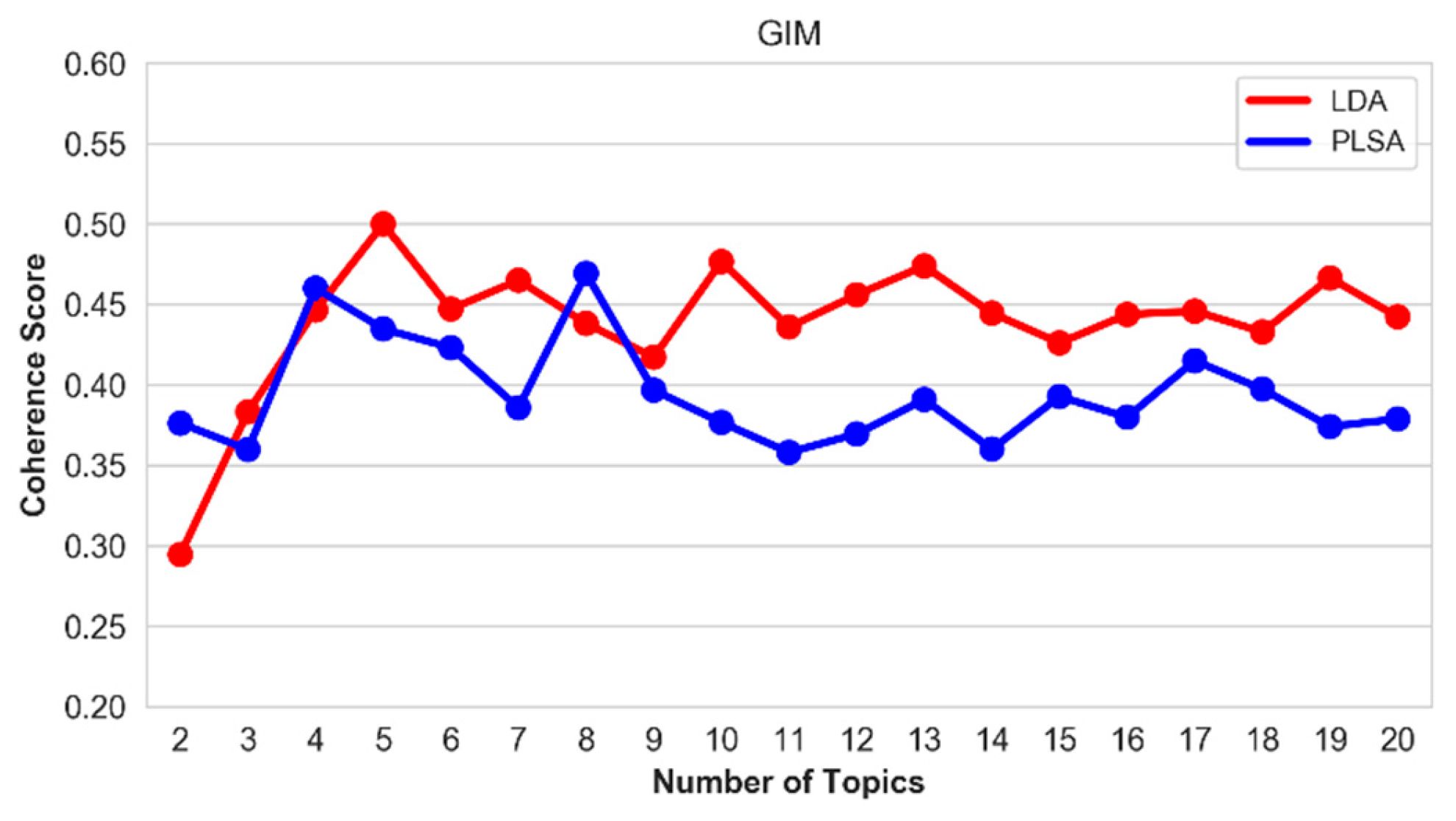
Figure 18.
Coherence score of the top-20 topics on the GIM hallmark.
Figure 18.
Coherence score of the top-20 topics on the GIM hallmark.
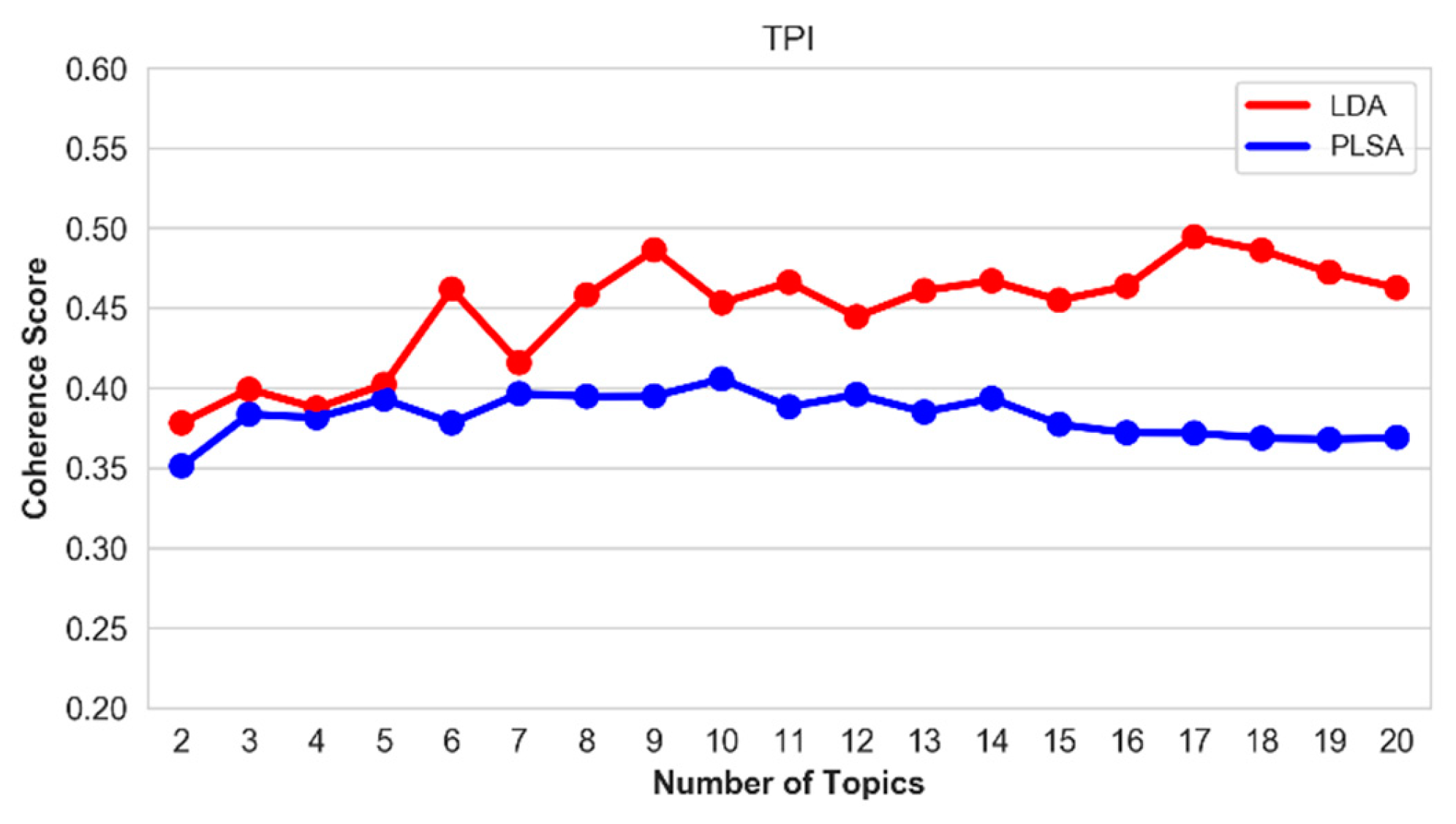
Figure 19.
Coherence score of the top-20 topics on the TPI hallmark.
Figure 19.
Coherence score of the top-20 topics on the TPI hallmark.
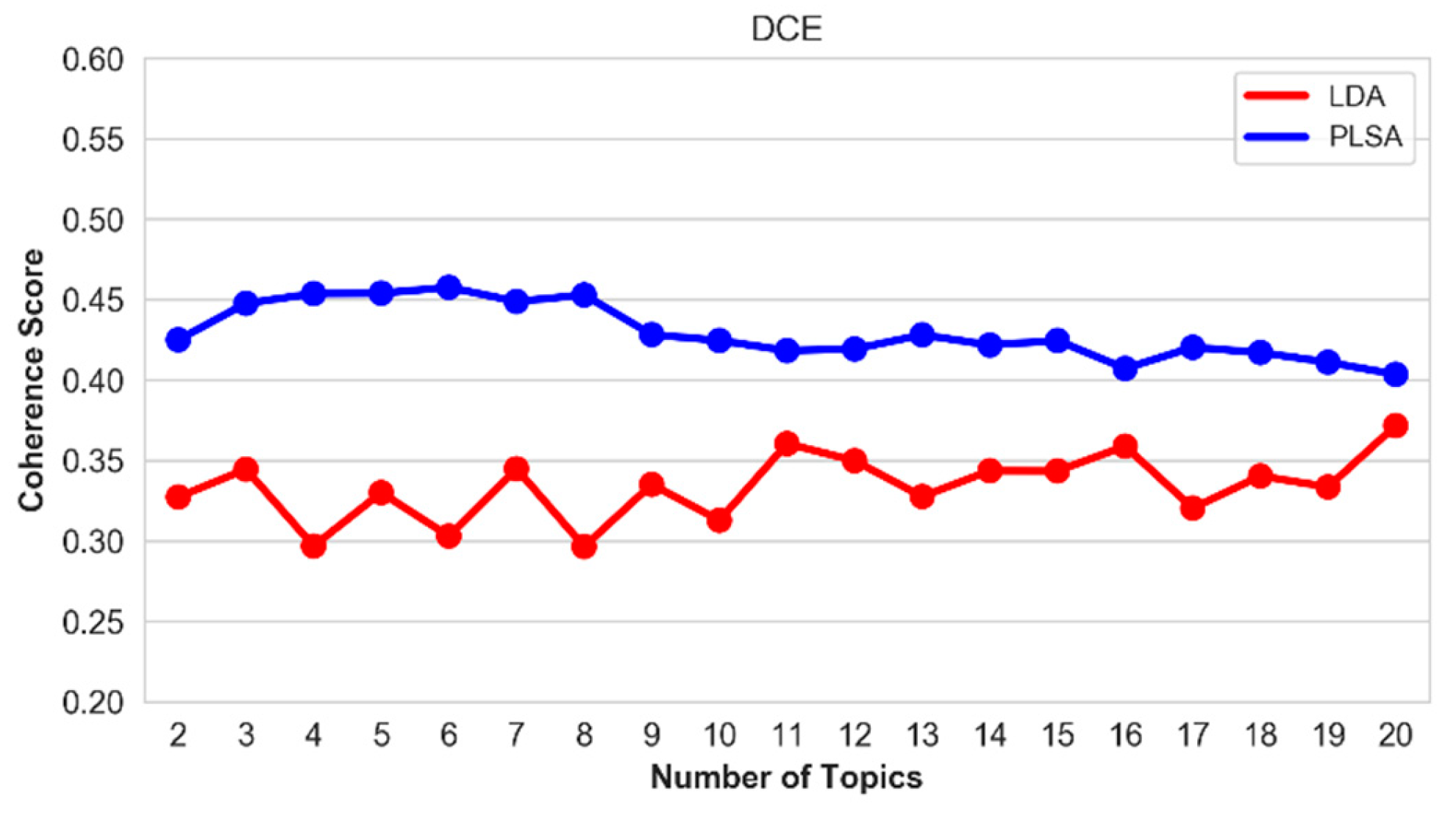
Figure 20.
Coherence score of the top-20 topics on the DCE hallmark.
Figure 20.
Coherence score of the top-20 topics on the DCE hallmark.
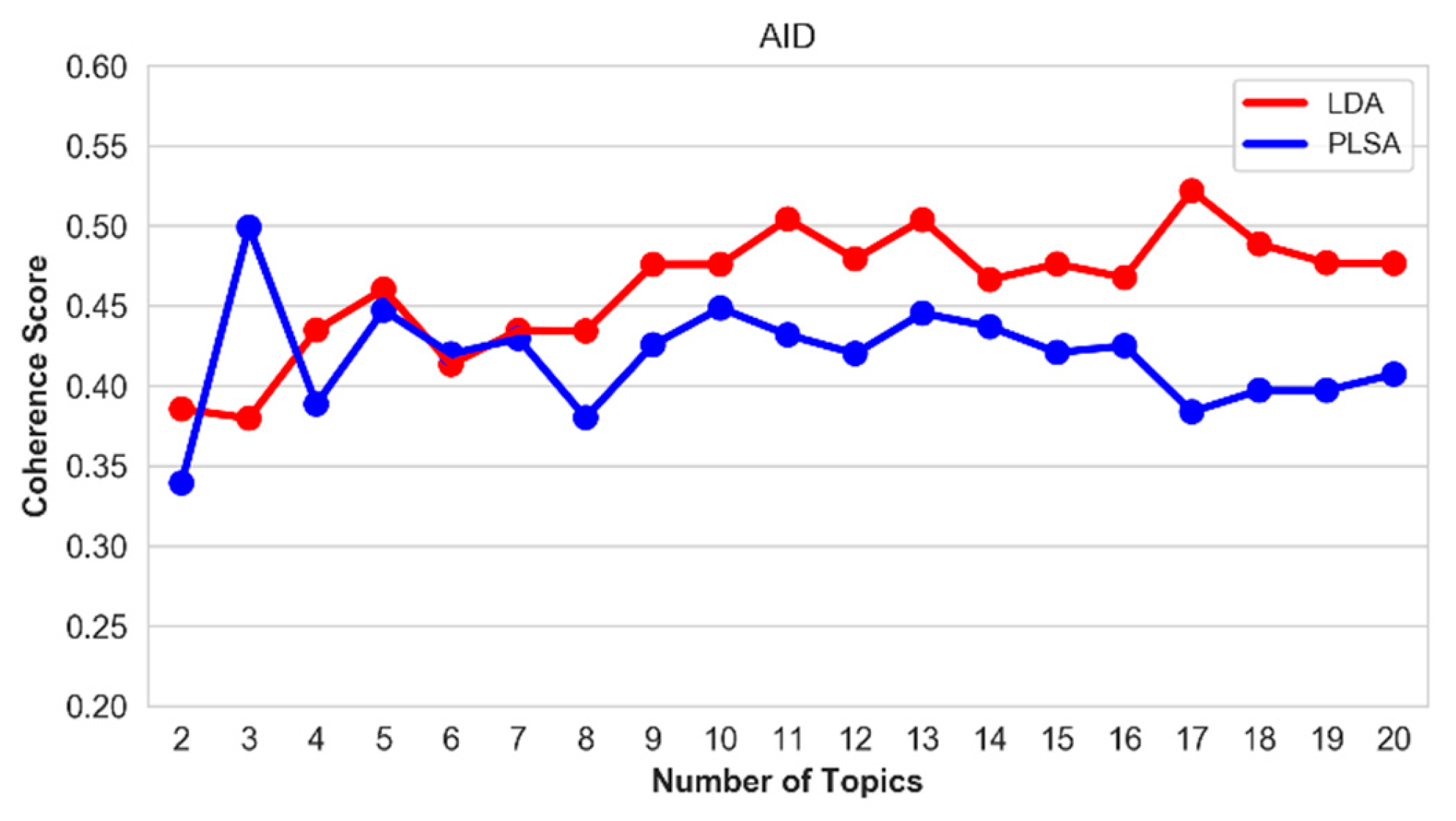
Figure 21.
Coherence score of the top-20 topics on the AID hallmark.
Figure 21.
Coherence score of the top-20 topics on the AID hallmark.
Table 1.
List of abbreviations.
Table 1.
List of abbreviations.
| Abbreviations | Definitions |
|---|
| Labeled documents |
| Number of labeled documents |
| Unlabeled documents |
| Number of unlabeled documents |
| Topics |
| Number of topics |
| Classification model |
| Vocabulary for labeled documents |
| Word vector |
| Weak labeled documents |
| Number of weak labeled documents |
| Class probability for each class (positive and negative) |
| Entities |
| Number of entities |
| Dirichlet prior (Topic distribution) |
| Dirichlet prior (Word distribution) |
| Multinomial distribution over Q topics |
| Multinomial distribution over entities |
Table 2.
Bag of words representation of documents.
Table 2.
Bag of words representation of documents.
| Entity (CUI or AA) | | | | | |
|---|
| low-folate (LF) | 1 | 2 | 8 | 0 | 7 |
| metastasis (C4255448) | 3 | 4 | 5 | 4 | 9 |
| neoplasm metastasis (C0027627) | 3 | 2 | 6 | 3 | 6 |
| decreased folic acid (C0239623) | 9 | 4 | 2 | 1 | 0 |
| tryptophanase (C0041260) | 2 | 1 | 0 | 1 | 3 |
Table 3.
Labeled datasets. Y: hallmarks and N: non-hallmarks.
Table 3.
Labeled datasets. Y: hallmarks and N: non-hallmarks.
| Hallmark | Train | Development | Test |
|---|
| Y | N | Y | N | Y | N |
|---|
| SPS | 328 | 975 | 43 | 140 | 91 | 275 |
| EGS | 172 | 1131 | 22 | 161 | 46 | 320 |
| RCD | 303 | 1000 | 42 | 141 | 84 | 282 |
| ERI | 81 | 1222 | 11 | 172 | 23 | 343 |
| IA | 99 | 1204 | 13 | 170 | 31 | 335 |
| AIM | 208 | 1095 | 29 | 154 | 54 | 312 |
| GIM | 227 | 1076 | 38 | 145 | 68 | 298 |
| TPI | 169 | 1134 | 24 | 159 | 47 | 319 |
| DCE | 74 | 1229 | 10 | 173 | 21 | 345 |
| AID | 77 | 1226 | 10 | 173 | 21 | 345 |
Table 4.
Hyperparameters.
Table 4.
Hyperparameters.
| Parameter | CNN | RNN |
|---|
| Learning rate | 0.001 | 0.001 |
| Batch size | 128 | 128 |
| Hidden dimension | 256 | - |
| Number of layers | 2 | - |
| Number of filters | - | 100 |
| Filter size | - | [3, 4, 5] |
| Early stopping patience | 20 | 20 |
| Dropout | 0.5 | 0.5 |
Table 5.
Supervised algorithms on the labeled dataset (macro F1-score).
Table 5.
Supervised algorithms on the labeled dataset (macro F1-score).
| Model | SPS | EGS | RCD | ERI | IA | AIM | GIM | TPI | DCE | AID |
|---|
| Baker et al. [20] | Best | 70.00 | 71.50 | 86.90 | 91.50 | 85.70 | 82.60 | 81.70 | 84.20 | 88.30 | 75.80 |
| CNN | Base | 73.49 | 82.22 | 92.93 | 92.98 | 88.60 | 88.45 | 86.93 | 87.43 | 94.36 | 84.42 |
| Tuned | 74.66 | 80.15 | 92.12 | 93.18 | 89.10 | 90.15 | 87.62 | 87.93 | 95.83 | 84.31 |
| RCNN | Base | 74.38 | 81.67 | 91.10 | 92.95 | 86.46 | 89.82 | 85.96 | 88.92 | 96.62 | 88.61 |
| Tuned | 75.13 | 79.77 | 91.32 | 92.82 | 87.41 | 89.57 | 86.05 | 88.70 | 95.52 | 88.55 |
| GRU | Base | 74.76 | 79.14 | 85.95 | 91.44 | 88.12 | 87.78 | 82.30 | 86.48 | 90.48 | 83.74 |
| Tuned | 76.65 | 74.03 | 87.86 | 90.57 | 88.28 | 87.38 | 83.31 | 86.78 | 93.52 | 81.31 |
| BiGRU | Base | 70.99 | 57.45 | 69.85 | 87.86 | 85.46 | 83.58 | 80.46 | 72.99 | 89.09 | 74.01 |
| Tuned | 71.16 | 58.73 | 70.61 | 85.87 | 85.39 | 82.69 | 81.05 | 71.03 | 90.40 | 70.37 |
| LSTM | Base | 76.47 | 72.42 | 82.94 | 86.32 | 86.48 | 86.30 | 82.22 | 82.08 | 91.05 | 78.83 |
| Tuned | 76.62 | 69.62 | 82.84 | 87.22 | 87.10 | 84.84 | 82.60 | 82.26 | 90.43 | 78.88 |
| BiLSTM | Base | 66.23 | 57.15 | 58.29 | 74.86 | 72.53 | 68.82 | 73.99 | 65.20 | 81.57 | 60.82 |
| Tuned | 65.33 | 56.75 | 56.36 | 73.44 | 72.61 | 69.73 | 73.00 | 64.00 | 80.90 | 62.40 |
Table 6.
Supervised algorithms on the labeled dataset (micro F1-score).
Table 6.
Supervised algorithms on the labeled dataset (micro F1-score).
| Model | SPS | EGS | RCD | ERI | IA | AIM | GIM | TPI | DCE | AID |
|---|
| CNN | Base | 81.99 | 92.31 | 95.08 | 98.13 | 96.68 | 94.06 | 91.68 | 94.96 | 98.64 | 96.92 |
| Tuned | 82.46 | 91.56 | 94.61 | 98.21 | 96.76 | 94.76 | 92.15 | 95.11 | 98.91 | 96.84 |
| RCNN | Base | 82.15 | 91.92 | 93.94 | 98.13 | 95.97 | 94.96 | 91.29 | 95.31 | 99.10 | 97.27 |
| Tuned | 82.46 | 91.37 | 94.06 | 98.09 | 96.36 | 95.00 | 91.17 | 95.27 | 98.87 | 97.35 |
| GRU | Base | 81.98 | 89.70 | 90.55 | 97.99 | 96.02 | 93.32 | 89.67 | 93.46 | 97.86 | 96.70 |
| Tuned | 82.99 | 89.64 | 91.68 | 97.83 | 95.93 | 93.13 | 90.25 | 93.57 | 98.52 | 96.62 |
| BiGRU | Base | 78.98 | 82.55 | 78.71 | 97.11 | 95.25 | 91.37 | 88.49 | 88.27 | 97.77 | 94.62 |
| Tuned | 79.51 | 82.61 | 78.60 | 96.84 | 95.44 | 90.82 | 89.18 | 87.17 | 97.69 | 93.98 |
| LSTM | Base | 82.97 | 87.94 | 88.19 | 96.95 | 95.58 | 92.61 | 89.48 | 91.13 | 98.05 | 95.88 |
| Tuned | 83.13 | 87.80 | 88.60 | 96.92 | 95.85 | 91.54 | 89.78 | 91.68 | 97.97 | 96.13 |
| BiLSTM | Base | 76.24 | 82.52 | 71.57 | 94.34 | 92.78 | 84.78 | 85.11 | 84.97 | 96.32 | 92.17 |
| Tuned | 75.63 | 80.19 | 70.96 | 94.10 | 93.00 | 85.60 | 84.95 | 83.88 | 96.43 | 92.64 |
Table 7.
The statistics of the weak-labeled documents (lung cancer).
Table 7.
The statistics of the weak-labeled documents (lung cancer).
| Hallmark | No. of Documents | No. of Entities | No. of Unique Entities |
|---|
| SPS | 4097 | 766,146 | 22,576 |
| EGS | 950 | 170,965 | 11,272 |
| RCD | 14,313 | 2,710,563 | 56,052 |
| ERI | 604 | 102,357 | 9531 |
| IA | 3009 | 582,378 | 22,362 |
| AIM | 48,953 | 7,698,235 | 80,444 |
| GIM | 7733 | 1,444,839 | 33,579 |
| TPI | 30,403 | 6,006,649 | 67,733 |
| DCE | 43 | 7701 | 2124 |
| AID | 13,098 | 2,094,029 | 40,055 |
Table 8.
The top-1 topic on the sustaining proliferative signaling (SPS) hallmark.
Table 8.
The top-1 topic on the sustaining proliferative signaling (SPS) hallmark.
| LDA | Patients; Epidermal Growth Factor Receptor Measurement; Epidermal Growth Factor Receptor; EGFR protein, human; Combined; Therapeutic procedure; Tryptophanase; Non-Small Cell Lung Carcinoma; EGFR gene; combination of objects. |
| PLSA | Epidermal Growth Factor Receptor Measurement; EGFR protein, human; Epidermal Growth Factor Receptor; EGFR gene; Non-Small Cell Lung Carcinoma; Patients; Tryptophanase; Therapeutic procedure; Non-Small Cell Lung Cancer Pathway; NCI CTEP SDC Non-Small Cell Lung Cancer Sub-Category Terminology. |
Table 9.
The top-1 topic on the evading growth suppressor (EGS) hallmark.
Table 9.
The top-1 topic on the evading growth suppressor (EGS) hallmark.
| LDA | Induce (action); Expression (foundation metadata concept); Expression procedure; Effect; Homo sapiens; Apoptosis; Tryptophanase; TP53 wt Allele; TP53 gene; Inhibition. |
| PLSA | Cell Count; Induce (action); Expression procedure; Expression (foundation metadata concept); Tryptophanase; Carcinoma of lung; Apoptosis; Malignant neoplasm of lung; Effect; TP53 gene. |
Table 10.
The top-1 topic on the resisting cell death (RCD) hallmark.
Table 10.
The top-1 topic on the resisting cell death (RCD) hallmark.
| LDA | Tryptophanase; Neoplasms; Treating; Therapeutic procedure; Patients; PSA Level Less than Two; 2+ Score, WHO; 2+ Score; therapeutic aspects; Administration procedure. |
| PLSA | Apoptosis; Induce (action); Tryptophanase; Cell Count; Expression procedure; Effect; Expression (foundation metadata concept); Therapeutic procedure; Treating; Increase. |
Table 11.
The top-1 topic on the enabling replicative immortality (ERI) hallmark.
Table 11.
The top-1 topic on the enabling replicative immortality (ERI) hallmark.
| LDA | Senility; Old age; Induce (action); Cellular Senescence; Tryptophanase; Fibroblasts; Cell Count; Homo sapiens; Associated with; Increase. |
| PLSA | Old age; Senility; Induce (action); Cellular Senescence; Tryptophanase; Cell Count; Expression procedure; Expression (foundation metadata concept); Fibroblasts; Homo sapiens. |
Table 12.
The top-1 topic on the inducing angiogenesis (IA) hallmark.
Table 12.
The top-1 topic on the inducing angiogenesis (IA) hallmark.
| LDA. | Vascular Endothelial Growth Factors; Recombinant Vascular Endothelial Growth Factor; Neoplasms; Tryptophanase; Angiogenic Process; Laboratory mice; Social group; Group Object; Tumor Mass; Population Group. |
| PLSA | Vascular Endothelial Growth Factors; Recombinant Vascular Endothelial Growth Factor; Tumor Angiogenesis; Angiogenic Process; Tryptophanase; Expression procedure; Expression (foundation metadata concept); Neoplasms; Patients; P prime. |
Table 13.
The top-1 topic on the activating invasion and metastasis (AIM) hallmark.
Table 13.
The top-1 topic on the activating invasion and metastasis (AIM) hallmark.
| LDA | Cell Count; Neoplasm Metastasis; Secondary Neoplasm; Tryptophanase; Metastatic to; Metastatic Neoplasm; metastatic qualifier; Metastatic Disease Clinical Trial Setting; Neoplasms; Metastasis. |
| PLSA | Patients; Neoplasm Metastasis; Secondary Neoplasm; Tryptophanase; Metastatic Neoplasm; Neoplasms; Metastasis; P Blood group antibodies; P prime; Expression procedure. |
Table 14.
The top-1 topic on the genome instability and mutation (GIM) hallmark.
Table 14.
The top-1 topic on the genome instability and mutation (GIM) hallmark.
| LDA | Mutation; Present; Tryptophanase; adduct; 1+ Score, WHO; 1+ Score; Greater than one; Carcinoma of lung; Mutation Abnormality; Malignant neoplasm of lung. |
| PLSA | Mutation; Patients; Tryptophanase; Mutation Abnormality; P Blood group antibodies; P prime; Induce (action); Exposure to; Present; EGFR protein, human. |
Table 15.
The top-1 topic on the tumor-promoting inflammation (TPI) hallmark.
Table 15.
The top-1 topic on the tumor-promoting inflammation (TPI) hallmark.
| LDA | Lipopolysaccharides; Tumor Necrosis Factor-alpha; Induce (action); TNF protein, human; Increase; Alpha tumor necrosis factor measurement; cytokine; Interleukin-1 beta; Protons; Hepatic Involvement. |
| PLSA | Population Group; Groups; Social group; User Group; Stage Grouping; Group Object; Tryptophanase; Induce (action); Increase; House mice. |
Table 16.
The top-1 topic on the deregulating cellular energetics (DCE) hallmark.
Table 16.
The top-1 topic on the deregulating cellular energetics (DCE) hallmark.
| LDA | Aerobic glycolysis; Inhibition; Tryptophanase; Glycolysis; Induce (action); Metabolic Process, Cellular; Glucose; Expression (foundation metadata concept); Increase; Mitochondria. |
| PLSA | Aerobic glycolysis; Glycolysis; Tryptophanase; Expression procedure; Expression (foundation metadata concept); Cell Count; Increase; production; Malignant Neoplasms; Induce (action). |
Table 17.
The top-1 topic on the avoiding immune destruction (AID) hallmark.
Table 17.
The top-1 topic on the avoiding immune destruction (AID) hallmark.
| LDA | Blood group antibody I; Iodides; Tryptophanase; Neoplasms; Tumor Mass; Specimen Source Codes—tumor; Neoplasm Metastasis; Induce (action); Vaccination; T-Lymphocyte. |
| PLSA | Tryptophanase; Patients; House mice; Laboratory mice; T-Lymphocyte; SNAP25 wt Allele; SNAP25 protein, human; HERPUD1 gene; HERPUD1 wt Allele; Negation. |


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}