Abstract
With the rapid economic development, manufacturing enterprises are increasingly using an efficient workshop production scheduling system in an attempt to enhance their competitive position. The classical workshop production scheduling problem is far from the actual production situation, so it is difficult to apply it to production practice. In recent years, the research on machine scheduling has become a hot topic in the fields of manufacturing systems. This paper considers the batch processing machine (BPM) scheduling problem for scheduling independent jobs with arbitrary sizes. A novel fast parallel batch scheduling algorithm is put forward to minimize the makespan in this paper. Each of the machines with different capacities can only handle jobs with sizes less than the capacity of the machine. Multiple jobs can be processed as a batch simultaneously on one machine only if their total size does not exceed the machine capacity. The processing time of a batch is determined by the longest of all the jobs processed in the batch. A novel and fast 4.5-approximation algorithm is developed for the above scheduling problem. For the special case of all the jobs having the same processing times, a simple and fast 2-approximation algorithm is achieved. The experimental results show that fast algorithms further improve the competitive ratio. Compared to the optimal solutions generated by CPLEX, fast algorithms are capable of generating a feasible solution within a very short time. Fast algorithms have less computational costs.
1. Introduction
How to reduce the production cycle and improve the utilization rate of resources is an important problem under the constraints of workshop production, such as delivery time, technical requirements and resource status, etc. Most enterprises adopt workshop scheduling technology to solve this problem. An effective scheduling optimization method can take advantage of many production resources in the workshop. The research and application of a workshop scheduling optimization method has become one of the basic contents of advanced manufacturing technology [1,2,3].
Batch processing machines (BPMs) are widely applied in many enterprises, for example, steel casting, chemical and mineral processing, and so on [4,5,6]. BPMs scheduling problem is a hot topic in workshop scheduling problem. In the traditional scheduling problem, each machine can only process, at most, one job at a time [7]. However, BPMs can process a number of jobs simultaneously as a batch and all jobs in a batch have the same processing time [8]. The processing time of one batch is equal to the maximum processing time of all the jobs processed by the batch [9].
In this paper, we analyze the parallel batch processing machine scheduling problem where the jobs have arbitrary size and the machines have different capacities. We give a set of jobs and a set of parallel batch machines , and we let all the jobs be released simultaneously (release time of job is 0). Let and denote the processing time and the size of job (), respectively, where and . Machine () has a finite capacity . Without loss of generality, we assume and for each job in order to ensure job can be processed by at least one machine. However, there might be for some and . Machine () can handle multiple jobs at the same time, but the total size of these jobs cannot exceed . The longest processing time of all jobs in a batch determines the processing time of a batch. The purpose of this problem is to allot each job to a batch and to schedule the batch on the machine to minimize the maximum completion time of the schedule, , where represents the completion time of job in the schedule [10,11]. Using the notations proposed in [12,13], this problem can be denoted as .
The notations used in this paper are summarized in Table 1.

Table 1.
Notations.
Before we move on, let us introduce some useful notations and terminologies. Let , and ; when , was used, but it was meaningless, so we set . It is possible that for some . We have . Let denote the index of a machine with the minimum capacity that can process the job , and then can be assigned to each machine in where . are called the golden machines for job , is the golden machines set, is called the golden job for , and all of the jobs that can be processed by are called the golden jobs set for . In a scheduling process, the running time of the machine is equal to the total processing time of batches scheduled on this machine.
The structure of the paper is as follows. Section 2 reviews the previous research in related areas. Section 3 gives the definition of the research problem. In Section 4, a novel fast 4.5-approximation algorithm is proposed for problem . In Section 5, a fast 2-approximation algorithm is proposed for problem . Section 6 designs several computational experiments to show the effectiveness of fast algorithms. Finally, conclusions are given in Section 7.
2. Literature Review
Since the 1980s, scholars have studied the job scheduling problem of parallel batch machines extensively [1]. In this section, we review the results of research dealing with different job sizes and minimization of the maximum completion time [14,15,16,17,18,19,20].
In the one-machine case of problem , we denote . Uzsoy [21] proved that is a strong NP-hard (non-deterministic polynomial) problem, and presented four heuristics. Zhang et al. [22] also proposed a 1.75-approximation algorithm for . Dupont and Flipo presented a branch and bound method for . Dosa et al. [23] presented a 1.7-approximation algorithm for . Li et al. [24] presented a -approximation algorithm for (the more general case where jobs have different release times), where is a number greater than 0 and is arbitrarily small.
The special case of is where all () is represented as . Chang et al. [25] studied and provided an algorithm that is based on the simulated annealing approach.
Dosa et al. [23] demonstrated that although the processing time for all jobs is the same (unless P = NP), cannot be approximated to a ratio less than 2. Dosa et al. presented a -approximation algorithm. Cheng et al. [26] presented a 8/3-approximation algorithm for with running time . Chung et al. [27] developed a mixed integer programming model and some heuristic algorithms for (the problem where jobs have different release times). A 2-approximation algorithm for (the special case of where all jobs have the same processing times) was given by Ozturk et al. [28]. Li [29] obtained a -approximation algorithm for .
More recently, several research groups have focused on the scheduling problems on parallel batch machines with different capacities and applications in many fields [30,31,32,33,34,35,36,37,38,39,40,41]. The special case of , where all (i.e., all jobs can be assigned to any machine), is denoted as . Costa et al. [30] studied and developed a genetic algorithm for it. Wang and Chou [31] proposed a metaheuristic for (the problem where jobs have different release times). Damodaran et al. [32] proposed a PSO method for . Jia et al. [33] presented a heuristic and a metaheuristic for . Wang and Leung [34] analyzed the problem where each job has its own unit processing time. They designed a 2-approximation algorithm for the problem. They also obtained an algorithm with asymptotic approximation ratio 3/2. Li [35] proposed a fast 5-approximation algorithm and a -approximation algorithm for , but the presented -approximation algorithm has high time complexity when is small. Jia et al. [36] presented several heuristics for (the problem where jobs have different release times) and evaluated the validity of the heuristics by computational experiments. Other methods have also been proposed in the literature [42,43,44,45,46,47,48,49,50,51,52,53].
In this paper, a novel fast 4.5-approximation algorithm was developed for problem , and we evaluate the algorithm performance via computational experiments. We also provide a simple and fast 2-approximation algorithm for the case that all jobs have the same processing time, (), improving upon and generalizing the results in [54,55,56,57]. The approximation ratio of the 2-approximation algorithm in this paper is equal to the presented algorithm in [26], but is now simpler to understand and easier to implement.
3. Mathematic Formulation of the Problem
In this section, we present the problem under consideration as a mixed integer linear programming (MILP) model. First, the problem parameters and decision variables are given, and then the model is provided. Table 2 shows the problem indices.
Table 2.
Indices.
Table 3 shows the problem decision variables.
Table 3.
Decision variables.
The research problem can be denoted as . The mathematical formulation of the research problem is shown as follows:
which is subject to
The Objective Function (1) shows that our aim is to find a schedule to minimize the makespan . Constraint (2) is to make sure that each job is assigned exactly to one machine. Constraint (3) guarantees that all batches are feasible; in other words, the total size of all jobs assigned to the batch does not exceed the capacity of machine where the batch is scheduled. Constraint (4) indicates that the processing time of a batch is not less than the processing time of the jobs in the batch. Constraint (5) guarantees that the makespan of the schedule is not less than maximum load of all the machines. In Constraint (6), the 0–1 variable indicates whether the th job is assigned into the batch on machine or not .
4. 5-Approximation Algorithm for
We denote the optimal makespan of the problem as . The main focus of the research is to develop a fast scheduling model to get a minimized makespan as close to as possible.
To solve the problem , we used the MBLPT (modified longest processing time batch) rule [35], a modification of the BLPT (longest processing time batch) rule. For a given jobs set that can be assigned to machine , we apply the MBLPT rule, which sorts jobs to get . We build a batch on machine , and then the rule repeatedly pops the first job from and assigns it to until the sum of all the jobs assigned to just exceeds the capacity of . Batch is called the one-job-overfull batch. Once the one-job-overfull batch exists, a new batch should be built on the same machine, unless the machine runs out of maximum completion time (maximum completion time is in the initialization parameters of the algorithm). We repeat the above job assignment procedure until the job list is empty.
Let denote the set of batches generated using the MBLPT rule to and machine , and is the total number of batches scheduled on machine . Let and denote the longest processing time (the processing time of batch is equal to the longest processing time of jobs on it) and the shortest processing time of the jobs in batch , respectively, such that . The batches are one-job-overfull batches, while can be one-job-overfull or not. We have (). The Inequality (7) below (refer to [27]) is easy to prove.
By the Inequality (7), we have
Lemma 1.
We now propose the 4.5-approximation algorithm for . Similar frameworks have been used in [58,59,60,61,62]. In [58], Ou et al. developed a 4/3 approximation algorithm to solve classical scheduling problems with minimized maximum completion time on parallel machines with processing set constraints. In [59], Li proposed a 9/4-approximation algorithm for (the special case of where all ). The algorithm to be described extends the previous research by involving non-identical job sizes.
We first run the 5-approximation algorithm for . The algorithm generates a feasible schedule with a maximum completion time of in time. Let the minimum completion time . We have . We use the binary search method to find the makespan of a feasible solution in the range of the interval. Firstly, set , and then classify both the jobs and batches into long, short, and median. A job is long if , median if , or short if . Similarly, a batch is long if , median if , or short if . Certainly, long batches may contain median and short jobs, and median batches may contain short jobs. After classification, we use the following SCMF-LPTJF (smallest capacity machine first processed and longest processing time job first processed) procedure to search for a schedule with a makespan at most , which permits one-job-overfull batches. If our above operation fails, we will continue searching for the upper half of the interval and set ; otherwise, we will continue searching for the lower half of the interval, record , and set . The binary search method is then repeated in the new range of the interval until .
| Algorithm 1. SCMF-LPTJF (smallest capacity machine first processed and longest processing time job first processed) | |
| Input: , Output:—best found solution, —running time | |
| 1: | , // denote the jobs have been assigned to batch as |
| 2: | for do |
| 3: | Sort according to the rule that processing time of jobs is not increased, denote |
| 4: | end for |
| 5: | for do |
| 6: | |
| 7: | Apply the MBLPT rule to and , get |
| 8: | Sort according to the rule that processing time of batches is not increased, denote |
| 9: | Denote long batches set, median batches set, and short batched set as , , and |
| 10: | , , |
| 11: | for batch in do // classify batches into long, median and short. |
| 12: | if then |
| 13: | append to |
| 14: | else if then |
| 15: | append to |
| 16: | else |
| 17: | append to |
| 18: | end if |
| 19: | end for |
| 20: | if then |
| 21: | // the longest processing time batch in |
| 22: | schedule on ; remove from ; remove jobs assigned to from and add these jobs to |
| 23: | // is the processing time of batch |
| 24: | end if |
| 25: | for batch in do |
| 26: | if then |
| 27: | schedule on ; remove from ; remove jobs assigned to from and add these jobs to |
| 28: | // the processing time of batch |
| 29: | end if |
| 30: | end for |
| 31: | for batch in do |
| 32: | if then |
| 33: | schedule on ; remove from ; remove jobs assigned to from and add these jobs to |
| 34: | // the processing time of batch |
| 35: | end if |
| 36: | end for |
| 37: | Update // append the batches scheduled on to |
| 38: | end for |
| 39: | return , |
Lemma 2.
If, then the SCMF-LPTJF algorithm will generates an optimal schedule forwith one-job-overfull batches whose makespan is at most.
Proof.
Let be an optimal schedule whose makespan is . Let be the set of long jobs and median jobs. □
In , each machine can process up to three median batches or one long batch and one median batch. On the other hand, the SCMF-LPTJF program will allocate a long batch on the machine as much as possible. After it assigns a long batch on a machine, this machine still has enough time (at least time) to handle at least two median batches. Note that the SCMF-LPTJF procedure forms batches greedily. (It overfills each batch with the longest currently unassigned jobs.) Therefore, the SCMF-LPTJF procedure allocates more processing times for long jobs and median jobs on the machines with smaller capacities than does. Equivalently, we claim that is the lower limit of the overall processing time in a long working state, and the median job arranged on machines in , . Hence, if , then all long and median jobs will be allocated by SCMF-LPTJF.
Therefore, if there is , but there is still a job when executing to the end of the SCMF-LPTJF process, then job must be a short job. When job is assigned, all of machines have a load greater than . Let be the largest index such that machine has a load less than or equal to . If all of the machines have load greater than , then set . Therefore, all of machines have load greater than . There is room on the machine for scheduling any short job. Hence, by the rule of the SCMF-LPTJF procedure, no short job from can be assigned to machines .
By Lemma 1, for , we have
It follows that
In , all the short jobs in have to be processed on machines . In addition, we have also proved that the overall processing time of the planned long and median jobs on machines in as a lower bound. Therefore, the above inequality shows that cannot make all of the jobs done in the time, which is a contradiction.
The algorithm performs a binary search within the range . Finally, we will get a schedule with one-job-overfull batches (Figure 1a) whose makespan is at most . We can turn it into a viable scheduling solution (Figure 1b), where the maximum completion time is , as follows: for each one-job-overfull batch, move the last packed job into a new batch and calculate the new batch on the same machine. Since the iterative number could be , then the following theorems are obtained.
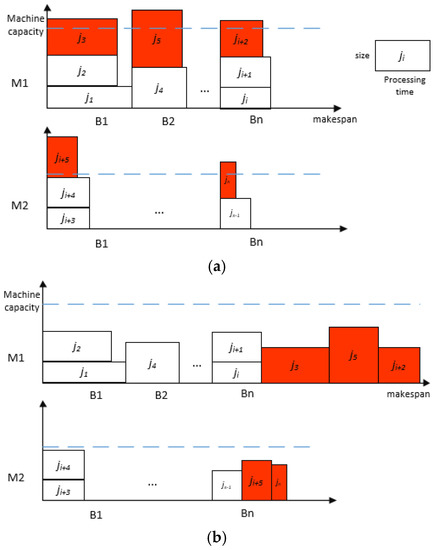
Figure 1.
Illustration of the 4.5-approximation algorithm. (a) The 4.5-approximation algorithm with one-job-overfull batches. (b) The 4.5-approximation algorithm with a feasible schedule.
Theorem 1.
There is a 4.5-approximation algorithm forthat runs intime, where.
In order to achieve a strongly polynomial time algorithm, we use a technique described to modify the above algorithm slightly. Therefore, the following theorems are obtained.
Theorem 2.
There is a-approximation algorithm forthat runs intime, wherecan be made arbitrarily small.
5. A 2-Approximation Algorithm for
In this section, we study , i.e., the problem of minimizing the makespan with equal processing times (), arbitrary job sizes (may exceed the processing power of certain batches), and non-identical machine capacities.
The 2-approximation algorithm is called LIM (largest index machine first consider). It groups the jobs in (this ordering is crucial), respectively, into batches greedily. During the run of the algorithm, represents the load on machine , i.e., the overall processing time of the batches on , . The algorithm dynamically maintains a variable , which represents the currently largest index such that . If there is no such index, then we can set . We can assign the next generated batch to machine .
| Algorithm 2. LIM (largest index machine first consider) | |
| Input: | |
| Output: —best found solution, —running time | |
| 1: | //the jobs have been assigned to any batch |
| 2: | for do |
| 3: | // the load on machine , equals to the overall processing time of the batches on , |
| 4: | end for |
| 5: | x=m |
| 6: | for do |
| 7: | if and then |
| 8: | |
| 9: | end if |
| 10: | create new batch , |
| 11: | for job in do |
| 12: | if then |
| 13: | assign job to batch |
| 14: | |
| 15: | remove job from and add it to |
| 16: | else |
| 17: | schedule to |
| 18: | |
| 19: | initiate |
| 20: | end if |
| 21: | end for |
| 22: | if is not empty and then |
| 23: | while and is not empty do |
| 24: | get first job from |
| 25: | assign job to |
| 26: | |
| 27: | remove job from and add it to |
| 28: | end while |
| 29: | schedule to |
| 30: | |
| 31: | end if |
| 32: | if then |
| 33: | if then |
| 34: | |
| 35: | else if then |
| 36: | |
| 37: | end if |
| 38: | end if |
| 39: | end for |
| 40: | for do |
| 41: | for batch in do |
| 42: | if then |
| 43: | create new batch |
| 44: | pop the last job from b and assign it to |
| 45: | schedule to |
| 46: | |
| 47: | end if |
| 48: | end for |
| 49: | Update // append the batches scheduled on to |
| 50: | end for |
| 51: | return ,. |
Theorem 3.
Algorithm LIM is a 2-approximation algorithm for.
Proof.
Let be the schedule with makespan generated by LIM after Step 2. In , all batches can be processed at the same time as they are assigned to a machine. During the running of the algorithm, the load on any machine is always less than or equal to the load on . Therefore, finishes last in . Let be the last batch assigned to . Let be the processing set of , which can be defined as the largest size processing set of the job in . In , let denote the start time of . We have: . □
Since we assigned to , at that moment must hold. Hence, machines are busy in the time interval . All the batches allocated to machines before are one-job-overfull batches. All jobs in these batches, together with the largest size job in , must be processed on machines in any feasible schedule. Hence, we get . So we can draw the conclusion that .
For a feasible schedule with makespan generated by LIM, we have .
6. Computational Experiments
6.1. Experimental Environment
For the performance evaluation of the 4.5-approximation and 2-approximation algorithms, all the instances are generated by a random algorithm, as in the papers [63,64,65,66,67,68]. In the process of the instances generation, five factors affecting the solution of the problem are determined: the number of jobs, the number of machines, the variation in job sizes, the variation in job processing time, and the variation in machine capacities [69,70,71,72,73,74,75].
The experiment is divided into two parts: (1) the 4.5-approximation algorithm is compared with the CPLEX result. (2) The 2-approximation algorithm is compared to CPLEX. The 4.5-approximation algorithm and 2-approximation algorithm were coded in C# and the CPLEX was programed by OPL (Optimization Programming Language), compiled, and run with the IBM ILOG CPLEX Optimization Studio 12.5.1.0 (Education Version). All the algorithms were run on the same machine (Win10, Intel (R) i7-4790, 16 GB).
First, we set the number of machines to two or four, and the capacity of each machine is represented by a uniform integer [10,40]. Then, random problem instances with number of jobs equals to 10, 20, 50, 100, 200, and 300 are generated, and each job processing time is generated by random sampling from a uniform distribution [1,10]. The factor settings of the experiment are summarized in Table 4.
Table 4.
Factors setting of the experiment.
We combine the parameters and randomly generate 50 instances for each combination (a test suite). Each test suite is denoted by a code. For instance, a test suite with 50 jobs and two machines is denoted by J3M1S1P1K1.
6.2. Comparison of 4.5-Approximation Algorithm and CPLEX
Here, a CPLEX algorithm is used to solve the MILP model given in Section 3, and we compare the CPLEX algorithm with the results of the 4.5-approximation algorithm. CPLEX always gives the optimal solution, but it cannot give the optimal solution for all instances even after operating several hours. Therefore, we set an upper execution time 1800s for CPLEX, and the best-known solution was compared. The job size and machine capacity distribution as shown in Figure 2.
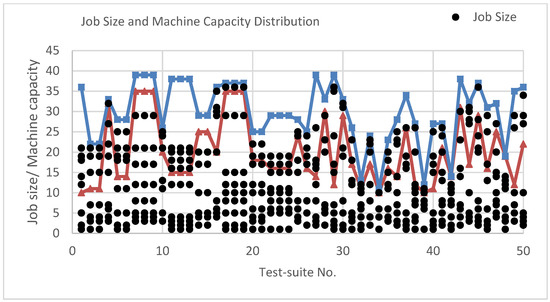
Figure 2.
Job size and machine capacity distribution.
Regarding the 4.5-approximation algorithm, and are initialized as follows:
Figure 3 shows the result of test suite J1M1S1P1K1.
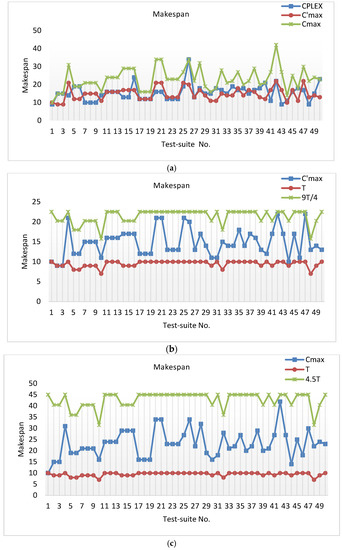
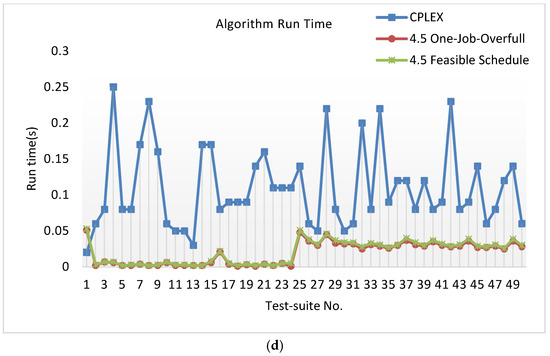
Figure 3.
Results of J1M1S1P1K1. (a) Comparison makespan of CPLEX and the 4.5-approximation algorithm with one-job-overfull batches and the 4.5-approximation algorithm with a feasible schedule. (b) Comparison makespan of the 4.5-approximation algorithm with one-job-overfull batches and . (c) Comparison makespan of the 4.5-approximation algorithm with a feasible schedule and 4.5T. (d) Comparison running time of CPLEX and the 4.5-approximation algorithm with one-job-overfull batches and the 4.5-approximation algorithm with a feasible schedule.
is the makespan of the 4.5-approximation algorithm with one-job-overfull batches and is the makespan of 4.5-approximation algorithm with a feasible schedule. Figure 3a shows the makespan of the 4.5-approximation algorithm with one-job-overfull batches and the algorithm with a feasible schedule. Figure 3b,c shows that the 4.5-approximation algorithm substantiates the feasibility of this research method:
Figure 3d shows that the run time of the 4.5-approximation algorithm is clearly better than CPLEX. Table 5 shows the results of all test suites. Though CPLEX is the best solver for linear programming problems, it cannot give an optimal solution for a long time, so we terminated CPLEX after running for 1800 s and used the best integer for comparison.
Table 5.
Simulation results of CPLEX and the 4.5-approximation algorithm with one-job-overfull batches and a feasible schedule.
The results illustrate that the 4.5 approximation algorithm is more effective than CPLEX in any scale test-suite. For the small-scale test-suite (10 jobs and two machines), the best solution obtained by the 4.5-approximation algorithm is closest to the CPLEX best solution. For the medium-scale and large-scale test-suites, the average result of the 4.5-approximation algorithm is no bigger than .
6.3. Comparison of 2-Approximation Algorithm (LIM) and CPLEX
For the problem , minimizing the makespan with equal running times, arbitrary job sizes (which may exceed the processing power of certain batches), and different machine capacities should be the solution. The running time of jobs was set to a default value of 8. Then, the and are denoted as
Table 6 show the experimental results given by the CPLEX and the LIM algorithm for all the test suites. Column SQL-AVG (the average value of SQL) reports the average makespan obtained using the LIM algorithm. Compared with the CPLEX makespan, the LIM algorithm can obtain the efficient solution in only little running time (Column Run Times).
Table 6.
Simulation results of CPLEX and the 2-approximation algorithm with one-job-overfull batches and a feasible schedule.
7. Conclusions and Future Works
The paper analyzed the parallel batch scheduling problem of minimizing the makespan, where arbitrary sizes of scheduling jobs are allowed and machines have different capacities. Each machine can only deal with jobs whose sizes do not exceed that machine’s capacity. We developed an efficient 4.5-approximation algorithm for this problem. The experimental results show that the algorithms can obtain a reasonable solution in a finite time. A 2-approximation algorithm is achieved under the particular circumstances of equivalent processing times. Computational experiments show that the fast algorithm can help to improve the efficiency of resource consumption and give researchers more choices to balance the quality of the solution and the running time in the parallel batch scheduling problem.
Several important related directions for this problem are worth researching in the future. First of all, how do we improve the fast algorithm to get closer to the optimal solution in shortest time? In addition, jobs with release times are more common BPM problems in the manufacturing industry. How to develop a fast scheduling algorithm for this problem is an import direction. Finally, BPM problems with different service levels can be considered as well.
Author Contributions
Methodology—Y.S. and B.Z., Data analysis—B.Z. and D.W., Writing—Original Draft Y.S., D.W. and K.L., Writing—Edit and Review, B.Z., Y.S., D.W., K.L. and J.X., Visualization—J.X., Funding acquisition—B.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the CERNET Innovation Project (NGII20190605), High Education Science and Technology Planning Program of Shandong Provincial Education Department under Grant (J18KA340, J18KA385), National Natural Science Foundation of China (61976125, 61772319, 61976124, 61771087, 51605068), A Project of Shandong Province Higher Educational Science and Technology Program (No.J16LN51), the Graduate science and technology innovation fund of Shandong Technology and Business University (2018yc038), Yantai Key Research and Development Program (2019XDHZ081).
Acknowledgments
We thank the anonymous referees for their constructive comments, which helped to improve this paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Marnix, K.; Van den Akker, M.; Han, H. Identifying and exploiting commonalities for the job-shop scheduling problem. Comput. Oper. Res. 2011, 38, 1556–1561. [Google Scholar]
- Xue, Y.; Xue, B.; Zhang, M. Self-adaptive particle swarm optimization for large-scale feature selection in classification. ACM Trans. Knowl. Discov. Data 2019, 13, 50. [Google Scholar] [CrossRef]
- Gahm, C.; Denz, F.; Dirr, M.; Tuma, A. Energy-efficient scheduling in manufacturing companies: A review and research framework. Eur. J. Oper. Res. 2015, 248, 744–757. [Google Scholar] [CrossRef]
- Deng, W.; Xu, J.; Zhao, H.M. An improved ant colony optimization algorithm based on hybrid strategies for scheduling problem. IEEE Access 2019, 7, 20281–20292. [Google Scholar] [CrossRef]
- Liao, C.J.; Liao, L.M. Improved MILP models for two-machine flowshop with batch processing machines. Math. Comput. Model. 2008, 48, 1254–1264. [Google Scholar] [CrossRef]
- Chang, P.Y. Heuristics to minimize makespan of parallel batch processing machines. Int. J. Adv. Manuf. Technol. 2008, 37, 1005–1013. [Google Scholar]
- Drozdowski, M. Classic scheduling theory. In Scheduling for Parallel Processing; Springer: London, UK, 2009; pp. 55–86. [Google Scholar]
- Deng, W.; Zhao, H.; Yang, X.; Xiong, J.; Sun, M.; Li, B. Study on an improved adaptive PSO algorithm for solving multi-objective gate assignment. Appl. Soft Comput. 2017, 59, 288–302. [Google Scholar] [CrossRef]
- Guo, S.K.; Liu, Y.Q.; Chen, R.; Sun, X.; Wang, X. Improved SMOTE algorithm to deal with imbalanced activity classes in smart homes. Neural Process. Lett. 2019, 50, 1503–1526. [Google Scholar] [CrossRef]
- Li, X.; Xie, Z.; Wu, J.; Li, T. Image encryption based on dynamic filtering and bit cuboid operations. Complexity 2019, 2019, 7485621. [Google Scholar] [CrossRef]
- Deng, W.; Zhao, H.M.; Zou, L.; Li, G.; Yang, X.; Wu, D. A novel collaborative optimization algorithm in solving complex optimization problems. Soft Comput. 2017, 21, 4387–4398. [Google Scholar] [CrossRef]
- Kim, S.; Kim, J.K. A method to construct task scheduling algorithms for heterogeneous multi-core systems. IEEE Access 2019, 7. [Google Scholar] [CrossRef]
- Leung, Y.T.; Li, C.L. Scheduling with processing set restrictions: A survey. Int. J. Prod. Econ. 2008, 116, 251–262. [Google Scholar] [CrossRef]
- Su, J.; Sheng, Z.; Leung, V.C.M.; Chen, Y. Energy efficient tag identification algorithms for RFID: Survey, motivation and new design. IEEE Wirel. Commun. 2019, 67, 118–124. [Google Scholar] [CrossRef]
- Luo, J.; Chen, H.; Heidari, A.A.; Xu, Y.; Zhang, Q.; Li, C. Multi-strategy boosted mutative whale-inspired optimization approaches. Appl. Math. Model. 2019, 73, 109–123. [Google Scholar] [CrossRef]
- Fu, H.; Wang, M.; Li, P.; Jiang, S.; Hu, W.; Guo, X.; Cao, M. Tracing knowledge development trajectories of the internet of things domain: A main path analysis. IEEE Trans. Ind. Inform. 2019, 15. [Google Scholar] [CrossRef]
- Su, J.; Sheng, Z.; Liu, A.X.; Han, Y.; Chen, Y. A group-based binary splitting algorithm for UHF RFID anti-collision systems. IEEE Trans. Commun. 2019. [Google Scholar] [CrossRef]
- Liu, Y.; Yi, X.; Chen, R.; Hai, Z.; Gu, J. Feature extraction based on information gain and sequential pattern for English question classification. IET Softw. 2018, 12, 520–526. [Google Scholar] [CrossRef]
- Yu, H.; Zhao, N.; Wang, P.; Chen, H.; Li, C. Chaos-enhanced synchronized bat optimizer. Appl. Math. Model. 2020, 77, 1201–1215. [Google Scholar] [CrossRef]
- Li, H.; Gao, G.; Chen, R.; Ge, X.; Guo, S.; Hao, L.Y. The influence ranking for testers in bug tracking systems. International. Int. J. Softw. Eng. Knowl. Eng. 2019, 29, 93–113. [Google Scholar] [CrossRef]
- Uzsoy, R. Scheduling a single batch processing machine with non-identical job sizes. Int. J. Prod. Res. 1994, 32, 1615–1635. [Google Scholar] [CrossRef]
- Zhang, G.; Cai, X.; Lee, C.Y.; Wong, C. Minimizing makespan on a single batch processing machine with nonidentical job sizes. Naval Res. Logist. 2001, 48, 226–240. [Google Scholar] [CrossRef]
- Dosa, G.; Tan, Z.; Tuza, Z.; Yan, Y.; Lányi, C.S. Improved bounds for batch scheduling with nonidentical job sizes. Naval Res. Logist. 2014, 61, 351–358. [Google Scholar] [CrossRef]
- Li, S.; Li, G.; Wang, X.; Liu, Q. Minimizing makespan on a single batching machine with release times and non-identical job sizes. Oper. Res. Lett. 2005, 33, 157–164. [Google Scholar] [CrossRef]
- Chang, P.Y.; Damodaran, P.; Melouk, S. Minimizing makespan on parallel batch processing machines. Int. J. Prod. Res. 2004, 42, 4211–4220. [Google Scholar] [CrossRef]
- Cheng, B.; Yang, S.; Hu, X.; Chen, B. Minimizing makespan and total completion time for parallel batch processing machines with non-identical job sizes. Appl. Math. Model. 2012, 36, 3161–3167. [Google Scholar] [CrossRef]
- Chung, S.; Tai, Y.; Pearn, W. Minimisingmakespan on parallel batch processing machines with non-identical ready time and arbitrary job sizes. Int. J. Prod. Res. 2009, 47, 5109–5128. [Google Scholar] [CrossRef]
- Ozturk, O.; Espinouse, M.L.; Mascolo, M.D.; Gouin, A. Makespanminimisation on parallel batch processing machines with non-identical job sizes and release dates. Int. J. Prod. Res. 2012, 50, 1–14. [Google Scholar] [CrossRef]
- Li, S. Makespan minimization on parallel batch processing machines with release times and job sizes. J. Softw. 2012, 7, 1203–1210. [Google Scholar] [CrossRef][Green Version]
- Costa, A.; Cappadonna, F.A.; Fichera, S. A novel genetic algorithm for the hybrid flow shop scheduling with parallel batching and eligibility constraints. Int. J. Adv. Manuf. Technol. 2014, 75, 833–847. [Google Scholar] [CrossRef]
- Wang, H.M.; Chou, F.D. Solving the parallel batch-processing machines with different release times, job sizes, and capacity limits by metaheuristics. Expert Syst. Appl. 2010, 37, 1510–1521. [Google Scholar] [CrossRef]
- Damodaran, P.; Diyadawagamage, D.A.; Ghrayeb, O.; Vélez-Gallego, M.C. A particle swarm optimization algorithm for minimizing makespan of nonidentical parallel batch processing machines. Int. J. Adv. Manuf. Technol. 2012, 58, 1131–1140. [Google Scholar] [CrossRef]
- Jia, Z.H.; Li, K.; Leung, J.Y.T. Effective heuristic for makespan minimization in parallel batch machines with non-identical capacities. Int. J. Prod. Econ. 2015, 169, 1–10. [Google Scholar] [CrossRef]
- Wang, J.Q.; Leung, J.Y.T. Scheduling jobs with equal-processing-time on parallel machines with non-identical capacities to minimize makespan. Int. J. Prod. Econ. 2014, 156, 325–331. [Google Scholar] [CrossRef]
- Li, S. Approximation algorithms for scheduling jobs with release times and arbitrary sizes on batch machines with non-identical capacities. Eur. J. Oper. Res. 2017, 263, 815–826. [Google Scholar] [CrossRef]
- He, Z.; Shao, H.D.; Zhang, X.Y.; Cheng, J.S.; Yang, Y. Improved deep transfer auto-encoder for fault diagnosis of gearbox under variable working conditions with small training samples. IEEE Access 2019, 7, 115368–115377. [Google Scholar] [CrossRef]
- Zhao, H.M.; Liu, H.D.; Xu, J.J.; Deng, W. Performance prediction using high-order differential mathematical morphology gradient spectrum entropy and extreme learning machine. IEEE Trans. Instrum. Meas. 2019. [Google Scholar] [CrossRef]
- Deng, X.; Feng, H.; Li, G.; Shi, B. A PTAS for semiconductor burn-in scheduling. J. Comb. Optim. 2005, 9, 5–17. [Google Scholar] [CrossRef]
- Liu, R.; Wang, H.; Yu, X.M. Shared-nearest-neighbor-based clustering by fast search and find of density peaks. Inf. Sci. 2018, 450, 200–226. [Google Scholar] [CrossRef]
- Hu, B.; Wang, H.; Yu, X.; Yuan, W.; He, T. Sparse network embedding for community detection and sign prediction in signed social networks. J. Ambient Intell. Humaniz. Comput. 2019, 10, 175–186. [Google Scholar] [CrossRef]
- Zhao, H.M.; Zheng, J.J.; Xu, J.J.; Deng, W. Fault diagnosis method based on principal component analysis and broad learning system. IEEE Access 2019, 7, 99263–99272. [Google Scholar] [CrossRef]
- Xu, Y.; Chen, H.; Heidari, A.A.; Luo, J.; Zhang, Q.; Zhao, X.; Li, C. An efficient chaotic mutative moth-flame-inspired optimizer for global optimization tasks. Expert Syst. Appl. 2019, 129, 135–155. [Google Scholar] [CrossRef]
- Su, J.; Sheng, Z.; Xie, L.; Li, G.; Liu, A.X. Fast splitting based tag identification algorithm for anti-collision in UHF RFID system. IEEE Trans. Commun. 2019, 67, 2527–2538. [Google Scholar] [CrossRef]
- Liu, W.; Li, H.; Zhu, H.; Xu, P. Properties of a steel slag-permeable asphalt mixture and the reaction of the steel slag-asphalt interface. Materials 2019, 12, 3603. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Du, Z.; Yang, Z.; Xu, Z. Dynamic parameters optimization of straddle-type monorail vehicles based multiobjective collaborative optimization algorithm. Veh. Syst. Dyn. 2019, 41, 1–21. [Google Scholar] [CrossRef]
- Li, T.; Shi, J.; Li, X.; Wu, J.; Pan, F. Image encryption based on pixel-level diffusion with dynamic filtering and dna-level permutation with 3D Latin cubes. Entropy 2019, 21, 319. [Google Scholar] [CrossRef]
- Wang, Z.; Pu, J.; Cao, L.; Tan, J. A parallel biological optimization algorithm to solve the unbalanced assignment problem based on DNA molecular computing. Int. J. Mol. Sci. 2015, 16, 25338–25352. [Google Scholar] [CrossRef]
- Kang, L.; Zhao, L.; Yao, S.; Duan, C. A new architecture of super-hydrophilic beta-SiAlON/graphene oxide ceramic membrane for enhanced anti-fouling and separation of water/oil emulsion. Ceram. Int. 2019, 45, 16717–16721. [Google Scholar] [CrossRef]
- Liu, Y.; Mu, Y.; Chen, K.; Li, Y.; Guo, J. Daily activity feature selection in smart homes based on pearson correlation coefficient. Neural Process. Lett. 2020. [Google Scholar] [CrossRef]
- Liu, G.; Liu, D.; Liu, J.; Gao, Y.; Wang, Y. Asymmetric temperature distribution during steady stage of flash sintering dense zirconia. J. Eur. Ceram. Soc. 2018, 38, 2893–2896. [Google Scholar] [CrossRef]
- Ren, Z.; Skjetne, R.; Jiang, Z.; Gao, Z.; Verma, A.S. Integrated GNSS/IMU hub motion estimator for offshore wind turbine blade installation. Mech. Syst. Signal Process. 2019, 123, 222–243. [Google Scholar] [CrossRef]
- Chen, H.; Jiao, S.; Heidari, A.A.; Wang, M.; Chen, X.; Zhao, X. An opposition-based sine cosine approach with local search for parameter estimation of photovoltaic models. Energy Convers. Manag. 2019, 195, 927–942. [Google Scholar] [CrossRef]
- Liu, D.; Cao, Y.; Liu, J.; Gao, Y.; Wang, Y. Effect of oxygen partial pressure on temperature for onset of flash sintering 3YSZ. J. Eur. Ceram. Soc. 2018, 38, 817–820. [Google Scholar] [CrossRef]
- Wang, H.; Song, Y.Q.; Wang, L.T.; Hu, X.H. Memory model for web ad effect based on multi-modal features. J. Assoc. Inf. Sci. Technol. 2019, 4, 1–14. [Google Scholar]
- Xu, Y.; Chen, H.; Luo, J.; Zhang, Q.; Jiao, S.; Zhang, X. Enhanced Moth-flame optimizer with mutation strategy for global optimization. Inf. Sci. 2019, 492, 181–203. [Google Scholar] [CrossRef]
- Chen, R.; Guo, S.K.; Wang, X.Z.; Zhang, T.L. Fusion of multi-RSMOTE with fuzzy integral to classify bug reports with an imbalanced distribution. IEEE Trans. Fuzzy Syst. 2019, 27. [Google Scholar] [CrossRef]
- Heidari, A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Ou, J.; Leung, J.Y.T.; Li, C.L. Scheduling parallel machines with inclusive processing set restrictions. Naval Res. Logist. 2008, 55, 328–338. [Google Scholar] [CrossRef]
- Li, S. Parallel batch scheduling with inclusive processing set restrictions and non-identical capacities to minimize makespan. Eur. J. Oper. Res. 2017, 260, 12–20. [Google Scholar] [CrossRef]
- Fu, H.; Manogaran, G.; Wu, K.; Cao, M.; Jiang, S.; Yang, A. Intelligent decision-making of online shopping behavior based on internet of things. Int. J. Inf. Manag. 2019, 50. [Google Scholar] [CrossRef]
- Li, T.; Hu, Z.; Jia, Y.; Wu, J.; Zhou, Y. Forecasting crude oil prices using ensemble empirical mode decomposition and sparse Bayesian learning. Energies 2018, 11, 1882. [Google Scholar] [CrossRef]
- Wang, Z.; Ren, X.; Ji, Z.; Huang, W.; Wu, T. A novel bio-heuristic computing algorithm to solve the capacitated vehicle routing problem based on Adleman–Lipton model. Biosystems 2019, 184, 103997. [Google Scholar] [CrossRef]
- Ham, A.; Fowler, J.W.; Cakici, E. Constraint programming approach for scheduling jobs with release times, non-identical sizes, and incompatible families on parallel batching machines. IEEE Trans. Semicond. Manuf. 2017, 30, 500–507. [Google Scholar] [CrossRef]
- Sun, F.R.; Yao, Y.D.; Li, G.Z.; Liu, W. Simulation of real gas mixture transport through aqueous nanopores during the depressurization process considering stress sensitivity. J. Pet. Sci. Eng. 2019, 178, 829–837. [Google Scholar] [CrossRef]
- Deng, W.; Xu, J.; Song, Y.; Zhao, H. An effective improved co-evolution ant colony optimization algorithm with multi-strategies and its application. Int. J. Bio-Inspired Comput. 2019. [Google Scholar]
- Wang, Z.; Ji, Z.; Wang, X.; Wu, T.; Huang, W. A new parallel DNA algorithm to solve the task scheduling problem based on inspired computational model. BioSystems 2017, 162, 59–65. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Shi, J.; Li, T. A novel image encryption approach based on a hyperchaotic system, pixel-level filtering with variable kernels, and DNA-level diffusion. Entropy 2020, 22, 5. [Google Scholar] [CrossRef]
- Peng, Y.; Lu, B.L. Discriminative extreme learning machine with supervised sparsity preserving for image classification. Neurocomputing 2017, 261, 242–252. [Google Scholar] [CrossRef]
- Xu, J.; Chen, R.; Deng, W.; Zhao, H. An infection graph model for reasoning of multiple faults in software. IEEE Access 2019, 7, 77116–77133. [Google Scholar] [CrossRef]
- Zhou, J.; Du, Z.; Yang, Z.; Xu, Z. Dynamics study of straddle-type monorail vehicle with single-axle bogies based full-scale rigid-flexible coupling dynamic model. IEEE Access 2019, 7, 2169–3536. [Google Scholar] [CrossRef]
- Shao, H.; Cheng, J.; Jiang, H.; Yang, Y.; Wu, Z. Enhanced deep gated recurrent unit and complex wavelet packet energy moment entropy for early fault prognosis of bearing. Knowl. Based Syst. 2019. [Google Scholar] [CrossRef]
- Li, T.; Yang, M.; Wu, J.; Jing, X. A novel image encryption algorithm based on a fractional-order hyperchaotic system and DNA computing. Complexity 2017, 2017, 9010251. [Google Scholar] [CrossRef]
- Zhao, H.; Zheng, J.; Deng, W.; Song, Y. Semi-supervised broad learning system based on manifold regularization and broad network. IEEE Trans. Circuits Syst. I Regul. Pap. 2019. [Google Scholar] [CrossRef]
- Li, T.; Zhou, Y.; Li, X.; Wu, J.; He, T. Forecasting daily crude oil prices using improved CEEMDAN and ridge regression-based predictors. Energies 2019, 12, 3603. [Google Scholar] [CrossRef]
- Liu, Y.Q.; Wang, X.X.; Zhai, Z.G.; Chen, R.; Zhang, B.; Jiang, Y. Timely daily activity recognition from headmost sensor events. ISA Trans. 2019, 94, 379–390. [Google Scholar] [CrossRef] [PubMed]




© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).