Abstract
Canola meal (CM), the protein-rich by-product of canola oil extraction, has shown promise as an alternative feedstuff and protein supplement in poultry diets, yet its use has been limited due to the abundance of plant cell wall fibre, specifically non-starch polysaccharides (NSP) and lignin. The addition of exogenous enzymes to promote the digestion of CM NSP in chickens has potential to increase the metabolizable energy of CM. We isolated chicken cecal bacteria from a continuous-flow mini-bioreactor system and selected for those with the ability to metabolize CM NSP. Of 100 isolates identified, Bacteroides spp. and Enterococcus spp. were the most common species with these capabilities. To identify enzymes specifically for the digestion of CM NSP, we used a combination of glycomics techniques, including enzyme-linked immunosorbent assay characterization of the plant cell wall fractions, glycosidic linkage analysis (methylation-GC-MS analysis) of CM NSP and their fractions, bacterial growth profiles using minimal media supplemented with CM NSP, and the sequencing and de novo annotation of bacterial genomes of high-efficiency CM NSP utilizing bacteria. The SACCHARIS pipeline was used to select plant cell wall active enzymes for recombinant production and characterization. This approach represents a multidisciplinary innovation platform to bioprospect endogenous CAZymes from the intestinal microbiota of herbivorous and omnivorous animals which is adaptable to a variety of applications and dietary polysaccharides.
1. Introduction
Canola meal (CM) is the protein rich by-product generated by oil extraction from the seeds of several registered rapeseed (Brassica napus L.) canola cultivars specifically developed by Canadian plant breeders for the production of high-quality oil [1]. Recently, CM has emerged as a staple for dairy cattle production [2] and has also shown promise as an alternative feed for monogastric species, such as swine [3] and poultry [4,5,6]. Historically, the use of CM in poultry diets has been limited due to its correlation with weaker performance outcomes when compared to other protein sources, such as soybean meal (SBM), despite containing similar levels of protein (37% CM: 46% SBM) [7,8]. This outcome has been attributed to the higher abundance of plant cell wall-derived non-starch polysaccharides (NSP) (32% CM: 22% SBM) and lignin (10% CM: 3% SBM) in CM [8,9,10]. The use of enzymes in CM feed mixes at higher inclusion rates has been pursued in an attempt to increase the digestibility of CM by monogastrics with limited success [8,11,12].
The chicken intestinal microbiome, while not as efficient as that of the cattle rumen at carbohydrate metabolism, is replete with bacterial species well known for their ability to deconstruct plant cell walls and liberate metabolizable carbohydrates. Indeed, Bacteroidetes and Firmicutes dominate the phylotypes of both the chicken cecal [13] and gastrointestinal [14] microbiomes. Previous work reported that the carbohydrate active enzyme (CAZyme) content within the chicken cecal microbiome is enriched in select families of core enzymes (e.g., GH5 cellulase; GH10 xylanases) and devoid of others that possess complementary activities (e.g., GH6, GH7, GH45, and GH48 cellulases; GH11 xylanase; and GH12 xyloglucanase). This suggests that the chicken intestinal microbiome is tuned towards the digestion of specific dietary polysaccharides (e.g., starch), and that the metabolism of more complex substrates may be less efficient. Thus, introducing enzymes from other biological sources, such as the digestive organs of ruminants or other herbivorous species, or enriching the abundance of limiting enzyme activities found within the chicken microbiota may have utility for improving the digestion of alternative feedstuffs, such as CM.
Enzyme feed additives are attractive means to improve the digestibility of feedstuffs. Historically, they have focused mainly on corn and soybean meal (SBM) as the two dominant feed ingredients for monogastric animals. Treatment of SBM with proteases can inactivate anti-nutritional factors and increase nutrient accessibility [15]. High-starch diets can be more readily digested by poultry when supplemented with α-amylase, leading to increased weight gain [16]. Despite these reports, enzyme additives can have mixed results in poultry; the inclusion of β-glucanases in the diet has shown no improvement in growth performance of barley-fed chickens, despite targeting β-glucans dominant in barley cell walls [17]. Furthermore, non-specific enzymatic cocktails of proteases, amylases, and xylanases, while successful for barley- and wheat-based diets [18], have shown limited improvements to animal performance when used in conjunction with corn and SBM diets [19,20,21,22]. Specifically, the addition of exogenous enzymes has been shown to assist in the digestion of CM NSP, such as pectins and arabinoxylans [10,23], often using multi-enzyme mixtures [11]. CM NSP are more recalcitrant to digestion than those of SBM and corn [8] and thus these fibers represent a novel target substrates for enzyme assisted digestion of CM cell walls.
Very little research has been conducted to optimize the performance of enzymes for unique feed ingredients or within the digestive system of individual livestock species. To address these limitations, we have deployed an enzyme discovery innovation platform (Supplemental Figure S1) that incorporates high-resolution characterization of complex substrates, isolation of chicken-associated bacteria using selective metabolism, and bioinformatic and biochemical approaches to mine bacterial genomes for candidate enzymes. For this study, the glycomes of cold-pressed (expelled) and pre-press solvent-extracted CM were characterized using two-different glycomic approaches. A preparative method for extraction of CM NSP was optimized to purify sufficient material to ascertain the impact of the NSP and CM on the broiler cecal bacterial community using a continuous-flow mini-bioreactor system, and to use the system to enrich for bacteria with CAZymes of interest. The genomes of six isolates were mined for CAZymes that are proficient in the hydrolysis of CM polysaccharides. Two enzymes with the potential to alleviate poor performance outcomes associated with CM digestion were recombinantly produced and characterized for their ability to digest intact and substrates identified within CM NSP. This study represents a proof of concept for a CAZyme discovery platform that can be tailored to mine the genomes of intestinal bacteria for enzymes active on structurally diverse plant cell wall material.
2. Materials and Methods
2.1. Extraction of NSP from CM
Large-scale NSP extraction was adapted from previous cell wall extraction methods specialized for oil-rich plant matter [24], in order to obtain sufficient quantities of NSP required for the isolation and selective growth of bacterial samples. Raw cold-pressed (Hartland Hutterite Colony, Badshaw, AB, Canada) or pre-press solvent-extracted (Matt A. Oryschak, University of Alberta, Edmonton, AB, Canada) CM was ball-milled to a fine powder, and 500 g was weighed and washed in 2.5 L of 100% hexanes to remove residual lipid contaminants for 2 h with robust stirring, three times. CM residues were then washed three times (once for 16 h, twice more for 2 h each) with 2.5 L of 100% ethyl acetate to remove residual hexane and other small molecule impurities. Ethyl acetate insoluble residues were extracted by the addition of 2.5 L of 80% (v/v) ethanol three times for 16 h each. Alcohol insoluble residues (AIRs) were washed for 20 min three times each in 2.5 L of 100% acetone, followed by triplicate washes in 100% methanol. The residue was vacuum-dried for approximately 3 days (or until dryness) at room temperature, and then ball-milled to a fine powder.
Destarching via enzymatic treatments was performed to obtain non-starch polysaccharides (NSP); 100 g of ball-milled CM AIR was weighed and suspended in 0.3 L of 100% DMSO and stirred gently at 80 °C for 1 h. Another 0.3 L of 100% DMSO was added and the mixture was stirred gently at 100 °C for a further 5 min. The solution temperature was lowered to 70 °C, and 0.9 L of amylase solution (90,000 U mL−1 thermostable Bacillus licheniformis α-amylase (Megazyme) in 100 mM sodium acetate pH 5.0, 5 mM CaCl2) was added with gentle stirring for 16 h. The temperature was then adjusted to 50 °C, and 0.6 L of 200 mM sodium acetate buffer pH 4.5 was added followed by an additional 0.6 L of 3 mg mL−1 Aspergillus niger amyloglucosidase (Megazyme) in 200 mM sodium acetate pH 4.5. The solution was stirred gently at 50 °C for 2 h. The resulting destarched residue suspension was then dialyzed (MWCO 3500 Da) extensively against deionized water. Samples were then removed from dialysis tubing, and water-insoluble CM NSP residues were separated, lyophilized to dryness, and ball-milled to a fine powder prior to subsequent use. Cold-pressed CM was used for the artificial intestine and broiler experiments, and all bacterial isolates were obtained from cold-pressed CM.
2.2. Antibody-Based Polysaccharide Characterization
Two monoclonal antibody-based screens were used to characterize the plant cell wall glycans of CM. The first enzyme-linked immunosorbent assay (ELISA) screen contains 155 plant cell wall glycan-directed monoclonal antibodies (mAbs) targeting a broad spectrum of epitopes [25,26]. Briefly, CM AIRs were sequentially extracted from CM whole cell wall using 50 mM ammonium oxalate, 50 mM sodium carbonate (with 0.5% (w/v) NaBH4), 1 M KOH (with 1% (w/v) NaBH4), 4 M KOH (with 1% (w/v) NaBH4), sodium chlorite (acidified by glacial acetic acid), and 4 M KOH (with 1% (w/v) NaBH4) resulting in AO, SC, 1 M KOH, 4 M KOH, CH, and 4 M KOHPC extracts, respectively [26]. Background signals resulting from wells carrying no antigen were subtracted from all readings, and the OD output of the ELISAs were plotted as heat maps. The glycome profiles are organized based on current information about the epitopes recognized by the mAbs [25,27,28,29,30,31]; antibodies that recognize similar epitopes are grouped together. The second, Micro Array Polymer Profiling (MAPP) screen probed differentially fractionated CM with 10 mAbs with well-established glycan epitope binding profiles [32]. CM cell wall glycans were sequentially extracted using 50 mM diamino-cyclo-hexane-tetra-acetic acid (CDTA) pH 7.5, 4 M NaOH (with 1% (w/v) NaBH4), and cellulase enzyme (CDTA, NaOH, and cellulase fractions respectively). These fractions were robotically printed (Arrayjet, Roslin, Scotland) onto 0.45 µM nitrocellulose membrane in 4 dilutions, creating microarrays, which were probed with mAbs as previously described [32]. Background signals from control arrays that were probed with secondary but not primary mAbs was subtracted from, and signals are reported as means of triplicates.
2.3. Polysaccharide Linkage Analyses
Cell wall of each CM sample was prepared as de-starched AIRs according to the previous report [24], with slight modifications; the de-starched sample remained in tubing after extensive dialysis against deionized water was centrifuged and the resulting precipitate was collected, lyophilized, and ball-milled.
Starting material (~0.3 mL mg−1) was subjected to sequential fractionation with the following solutions: 50 mM EDTA (pH 6.5), 50 mM Na2CO3 containing 25 mM sodium borodeuteride (NaBD4, 99 atom % D, Alfa Aesar), and 4 M KOH containing 25 mM NaBD4 for 24 h each at room temperature with gentle magnetic stirring, which was modified based on the literature [33]. After each extraction, the soluble fraction was collected by differential centrifugation followed by neutralization. The residue was washed with deionized water three times with centrifugation in between, and all washes were pooled into the corresponding soluble fraction. The EDTA and Na2CO3 extracts were pooled. Final fractions were dialyzed extensively against deionized water and lyophilized.
Alternatively, before fractionation the cell wall was pre-treated with 0.25 M NaBD4 solution (0.2 mL mg−1 of starting material) at 4 °C for 24 h [34], followed by neutralization by slow dropwise addition of 10% (v/v) acetic acid over ice and centrifugation (3000× g, 30 min). The resulting supernatant was pooled with three water washes of the pellet with centrifugation between washes, and the pooled solution was further incorporated into the EDTA and Na2CO3 fraction isolated from the washed pellet that was sequentially fractionated using the same method as described above.
Linkage analyses of the two cell walls (cold-pressed and solvent-extracted) and their fractions were performed by carboxyl reduction of uronic acids to their corresponding 6,6-dideuterio neutral sugars [35] followed by GC-MS analysis of partially methylated alditol acetate derivatives according to the published protocol [36], except that sample solution (1 μL) was splitless-injected to an Agilent 7890A-5977B GC-MS system (Agilent Technologies) installed with a Supelco SP-2380 column (30 m × 0.25 mm × 0.20 μm, Sigma-Aldrich) with a constant helium flow of 0.8 mL min−1 and with optimized oven temperature programmed to start at 55 °C (hold 1 min) followed by increasing at 30 °C min−1 to 135 °C, 3 °C min−1 to 180 °C (hold 20 min), 1.5 °C min−1 to 200 °C, and 3 °C min−1 to 255 °C (hold 3 min). Four separate experiments were conducted to each unfractionated cell wall, and three to each fraction.
2.4. Cecal Digesta Collection and Establishment of Bacterial Communties in Continuous-Flow Mini-Bioreactors
Digesta were harvested within 30 min of death from the ceca of three healthy ca. six-month-old mature male broiler breeders obtained from a local producer (i.e., humanely culled by the producer according to industry standards and transported to the Lethbridge Research and Development Centre immediately after euthanization). Ceca were removed and digesta were harvested in an anaerobic chamber containing a 85:5:10% N2:H2:CO2% atmosphere (referred to as the nitrogen atmosphere hereafter). Harvested cecal digesta were thoroughly mixed, and a subsample of the digesta was used for the direct isolation of bacteria. Subsamples of digesta were also used to establish a broiler cecal bacterial community in continuous-flow mini-bioreactors.
For cecal communities established in bioreactors, digesta were suspended in reduced BRM [37], and were added to individual bioreactor vessels at a final concentrate of 25% w/v. The mini-bioreactor array consisted of a multi-vessel continuous-flow system [37] that was situated in a Thermo Forma 1025 anaerobic chamber (Thermo Fisher Scientific Inc., Waltham, MA, USA) with a nitrogen atmosphere. Two 24-channel peristaltic pumps (205U, Watson Marlow, Concord, ON, Canada) with low flow capabilities provided nutrient exchange to individual vessels. Each vessel had an inflow and outflow tube, and peristaltic pumps were set for an intake rate of 2 RPM (3.76 mL/h) and an outtake rate of 4 RPM (7.52 mL/h). Cold-extracted CM (5.0%) or NSP extracted from CM (0.9%) was added to the BRM-digesta mixture in the vessels. A control treatment (CON) consisted of the BRM medium with cecal digesta not supplemented with either NSP or CM. Flow to/from the bioreactor vessels was commenced after 24 h after the addition of the cecal digesta; inflow BRM was maintained in individual 1 L media bottles, and the medium was replaced daily. The volume of each vessel was maintained at 60 mL, with four replicate vessels per treatment. A micro stir bar (10 mm × 1.5 mm) was placed in each vessel, and vessels were placed on a multi-position stir plate (Variomag® POLY 15, Thermo Fisher Scientific Inc., Waltham, MA, USA) set at 200 rpm to ensure consistent mixing of the vessel contents. The ambient temperature was maintained at 37 °C with top-mounted heaters. The temperature was verified using digital thermometers positioned throughout the chamber. Moisture, oxygen, and sulfurous gases were minimized within the chamber using desiccant, palladium, and charcoal catalysts, and were replaced as needed (depending on moisture). Each vessel was fitted with sampling port, and samples were removed via a rubber septum using a sterile needle fitted to a 5 mL syringe.
Subsamples were collected from individual bioreactor vessels at day 0, 1, 2, 3, 4, 6, 8, and 10 using a 22G 7.6 cm hypodermic needle (Air-Tite Products Co., Inc., Virginia Beach, VA, USA) fitted to a 5 mL syringe. To collect the sample, the sterile needle was inserted through the septum of the sampling port of the vessel.
2.5. Temporal Characterization of Bacterial Communities in Mini-Bioreactor Vessels
On all eight sample days, 1 mL of the contents from each vessel was placed into individual sterile 2 mL screw-capped tubes, tubes were centrifuged (13,200× g for 10 min), the supernatants were transferred to new screw-capped tubes, and both samples were flash frozen in liquid nitrogen. Samples were stored at −80 °C until processed. The frozen pellet was re-suspended in 200 µL of lysis buffer containing 10 mg mL−1 lysozyme, and DNA was extracted from using the DNeasy Blood and Tissue kit (Gram Positive protocol; Qiagen Inc., Hilden, Germany). DNA from the four replicate bioreactors per treatment was pooled by volume for Illumina sequencing. Extracted DNA was quantified using a Qubit 4 fluorometer (Thermo Fisher Scientific Inc., Waltham, MA, USA), and PCR was amplified for 16S rRNA gene metagenomics analyses using the protocol developed by Kozich et al. [38], which targets the V4 region of the 16S rRNA gene with a dual-indexing strategy. The PCR mastermix included 12.5 µL of Paq5000 Hi Fidelity Taq Master Mix (Agilent Technologies, Mississauga, ON, Canada), 1 µL of 10 µM of forward primer (V4-Read 1 Primer TATGGTAATTGTGTGCCAGCMGCCGCGGTAA), 1 µL of 10 µM of reverse primer (V4-Read 2 Primer AGTCAGTCAGCCGGACTACHVGGGTWTCTAAT) (Integrated DNA Technologies, Coralville, IA, USA), 8.5 µL of Nuclease free water (Qiagen Inc., Hilden, Germany), and 2 µL of genomic DNA template (30–50 ng). Reactions were amplified on a thermocycler (Mastercycler Pro S; Eppendorf, Mississauga, ON, Canada) using the following conditions: 95 °C for 2 min; 25 cycles of 95 °C for 20 s, 55 °C for 15 s, and 72 °C for 2 min; and a final elongation cycle at 72 °C for 10 min. Amplicons were purified with AMPure XP beads (Beckman Coulter Diagnostics, Brea, CA, USA), and checked for quality and size with a Bioanalyzer 2100 (Agilent Technologies, Mississauga, ON, Canada). Quantification of the amplicons was done using a Qubit 4. Samples were normalized to 4 nM, pooled, denatured with NaOH, and further diluted with HT1 (Illumina, San Diego, CA, USA) to produce a 4 pM library for analysis using a MiSeq System (Illumina, San Diego, CA, USA). Twenty percent PhiX control DNA was added to the library as a sequencing control. The library was loaded using a MiSeq Reagent Kit v2 500-cycle, and run on an Illumina MiSeq platform (Illumina, San Diego, CA, USA). The Q30 score for the output data was 89%. QIIME2 [39] was used to process and classify bacterial reads. Raw reads were de-noised with DADA2 [40], and representative sequences and amplicon sequence variants (ASVs) were generated. Samples with a read depth of less than 22,000 were removed from the analyses. A phylogenetic tree of ASV sequences was generated, and the taxonomy of each ASV was identified by using a machine learning classifier pre-trained with the reference SILVA 132 database (lva-132-99-515-806-nb-classifier.qza). Evenness (i.e., Pielou’s evenness index) and α-diversity (i.e., Shannon’s index) were calculated. In addition, β-diversity was determined using unweighted UniFrac, weighted UniFrac, Bray-Curtis, and Jaccard distance/dissimilarity.
2.6. Selective Isolation of Intestinal Bacteria
Reduced samples from the vessels on days 3 and 10 were immediately transferred to an anaerobic chamber (Coy Lab Products) with a nitrogen atmosphere. Samples were diluted serially (100–106) in sterile, anaerobic 1X phosphate-buffered saline (PBS); 100 µL of each serial dilution was plated onto nutrient restricted media to select for microorganisms that could metabolise CM and CM NSP: Agar (1.5%) plates supplemented with minimalized medium (MM) and CM AIR (5%) or CM NSP (1%) as a sole carbohydrate source. The MM was adapted from [41]; a 1X MM solution contained the following: 0.23 g L−1 K2HPO4, 0.23 g L−1 KH2PO4, 0.23 g L−1 (NH4)2SO4, 0.46 g L−1 NaCl, 0.09 g L−1 MgSO4·7H2O, 40 mg L−1 CaCl2·2H2O, 2 g L−1 tryptone, 1 mg L−1 hemin, 4 g L−1 Na2CO3, and 0.5 g L−1 cysteine-HCl. Colonies were selected after 4 days of growth and re-streaked twice to obtain single colonies, numbered consecutively from 1 to 332, on agar (1.5%) plates containing Columbia medium supplemented with 1 mg L−1 hemin.
2.7. Identification of Bacterial Isolates
Liquid cultures were grown of all selected CM NSP-degrading single colony bacterial isolates in Columbia medium (Difco) supplemented with 1 mg L−1 hemin at 37 °C in an anaerobic chamber (Coy Lab Products, Grass Lake, MI, USA) in a nitrogen atmosphere. Bacterial cells were harvested by centrifugation at 8000× g for 10 min. Genomic DNA samples were extracted using a 96-well Bacteria Genomic DNA Miniprep Kit (BioBasic Inc., Markham, ON, Canada) and sent for 16S rDNA sequencing (Eurofins Genomics, Toronto, ON, Canada) using degenerate 27F and 1492R primers [42,43] to identify bacterial species.
2.8. Evaluation of Growth Profiency of Isolates on CM NSP
Growth proficiency of Bacteroides isolates was evaluated at 37 °C in an anaerobic chamber (Coy Lab Products, Grass Lake, MI, USA) in an atmosphere consisting of 85% N2, 10% CO2, and 5% H2. Canola meal NSP-utilizing numbered isolates (CMU#) corresponding to Bacteroides spp., CMU13, CMU19, CMU33, CMU36, CMU103, CMU108, CMU128, were cultured overnight in Columbia medium (supplemented with 1 mg L−1 hemin). Isolates were then subcultured overnight at 37 °C into MM supplemented with D-glucose (0.5%) to adapt to nutrient restricted media. Liquid culture growths were inoculated from overnight cultures and performed in triplicate, in MM supplemented with CM NSP (1%) or D-glucose (0.5%) as a control. NSP were insoluble which prevented us from using an anaerobic multiplexed robotic plate reader. Thus, growth profiles were assessed by OD600 nm using manual time point readings at 0, 5, and 24 h, with gentle manual agitation after each time point to promote NSP accessibility and bacterial growth.
2.9. Whole Genome Sequencing and CAZyme Identification
Six Bacteroides isolates, two from each species, were selected for whole genome sequencing using Illumina HiSeq4000 PE150 (Bacteroides thetaiotaomicron (theta) CMU13 and CMU108, Bacteroides ovatus CMU19 and CMU33, and Bacteroides fragilis CM103) or Illumina NovaSeq 6000 S4 PE150 (Bacteroides fragilis CMU36) (Genome Québec, Montréal, QC, Canada). Contigs were assembled de novo using the SPAdes assembler [44], and sequencing quality was assessed using QUAST [45]. Genomes were submitted to NCBI GenBank, with contigs smaller than 200 bp deleted prior to submission, and accession numbers/BioSample IDs are as follows: CMU13 (SAMN15915567), CMU108 (SAMN15915568), CMU19 (SAMN15915569), CMU33 (SAMN15915570), CMU36 (SAMN15915571), and CMU103 (SAMN15915572). Genomes were analyzed by Prokka [46] to annotate putative proteins.
2.10. CAZyme Phylogenetic Analyses and Target Selection
Prokka results were analyzed locally by dbCAN [47] to determine total CAZyme content (CAZome) for all isolated bacterial species. CAZyme families were chosen based on polysaccharide composition as determined by the glycomics analyses; predicted CAZyme genes from GH28, GH43, GH78, and CE6 families, active on rhamnogalacturonan-I (RG-I) backbone, arabinoxylan (AX), arabinan (AB), and homogalacturonan (HG), were selected from CMU13 and CMU19 isolates analyzed by SACCHARIS [48] to determine phylogenetic relatedness to biochemically characterized sequences. Sequences and accession numbers for characterized proteins were extracted from the CAZy database [49], and all protein sequences were aligned using MUSCLE [50]. ProtTest [51] was used for best-fit model selection using the MUSCLE sequence alignment, and FastTree [52] was used to generate the trees. Phylogenetic trees were annotated using iTOL [53]. Target enzymes were chosen based on distally related sequences, represented by novel clades within the phylogenetic trees. Domain boundaries were manually curated via predictions by dbCAN [54] and InterProScan [55].
2.11. Target CAZyme Gene Synthesis and Expression in E. coli
Selected gene targets (with GenBank-assigned locus tags in parentheses): N872 (IAG16_04270), N1089 (IAG16_05330), N2073 (IAG16_10110), N2589 (IAG16_12615), N3394 (IAG16_16585), K696 (IAG19_03410), K2605 (IAG19_12770), and K3550 (IAG19_17440) were codon optimized for expression within E. coli and gene synthesized as full-length constructs without their native signal peptide but including flanking NdeI and XhoI restriction sites at the 5′ and 3′, respectively (BioBasic Inc.). Genes were ordered synthesized in the pET24b vector for C-terminal His6-tag protein expression. Each protein construct vector was transformed into E. coli BL21 (DE3) Star cells (Thermo Fisher). Cells were grown in LB Miller broth containing 50 µg mL−1 kanamycin at 37 °C to an OD600 nm of 0.6, when protein expression was then induced by the addition of IPTG to a final concentration of 1 mM. The cell culture was incubated at 18 °C for 16 h prior to being harvested by centrifugation at 6500× g for 20 min at 4 °C. Cell pellets were stored at −20 °C until needed.
2.12. Recombinant Gene Expression and Purification
The cell pellet from 1 L of bacterial culture was thawed and resuspended in 50 mL of lysis buffer (20 mM Tris pH 8.0, 500 mM NaCl, 0.1 mg mL−1 lysozyme). Cells were homogenized by sonication for 2 min of 1 s intervals of medium intensity sonic pulses at a power setting of 4.5 (Heat Systems Ultrasonics Model W-225 and probe). Cellular debris was removed by centrifugation at 17,500× g for 45 min at 4 °C and passed through a 0.45 µm filter. The filtrate was loaded onto Ni-NTA resin and purified by immobilized metal affinity chromatography, whereby recombinant protein was eluted by an increasing gradient 0–500 mM imidazole in 20 mM Tris pH 8.0 and 500 mM NaCl. Protein was concentrated by centrifugation with 10 kDa (K2605) or 30 kDa (N1089) cutoff Amicon Ultra centrifugal concentrators (Millipore Sigma). His6-tagged protein was further purified using a HiLoad 16/60 Superdex 200 prep-grade size exclusion column (GE Healthcare, Chicago, IL, USA) in 20 mM Tris pH 7.5, 500 mM NaCl, 2% glycerol. Pure protein fractions were pooled and concentrated. Protein purification was monitored throughout by SDS-PAGE. All recombinant proteins were used freshly prepared for downstream enzyme activity assays.
2.13. pNP-Sugar Colourimetric Activity Assay
Enzyme activities were assayed against several p-nitrophenol (pNP)-sugar conjugate substrates: pNP-α-D-Manp, pNP-α-L-Araf, pNP-α-L-Arap, pNP-β-D-Xylp, pNP-β-D-Galp, pNP-β-D-Glcp, and pNP-acetate. Reactions contained 1 µM enzyme in 50 mM Tris pH 8.0 and were initiated via the addition of a final concentration of 1 mM pNP-sugar conjugate. Assays were carried out in triplicate in 96-well microtitre plates. Product release was measured by monitoring at OD405 nm (BioTek Instruments) every 1 min for 30 min. Final product concentration was calculated using a calibration curve for the hydrolysis product pNP. The final concentration of DMSO in each reaction did not exceed 2%. Background hydrolysis rates were measured and subtracted from reaction rates.
2.14. Thin Layer Chromatography (TLC)
Purified CAZymes were screened for activity on CM AIR and extracted CM NSP. Additionally, commercial sources of polysaccharides and synthetic substrates consistent with substrates identified within CM were tested, including: Potato RG-I (Megazyme), citrus PGA (Megazyme), wheat arabinoxylan (Megazyme), galacturonic acid ladder of mono, di, and triose forms (GalA1,2,3) (Megazyme), 32-α-L-arabinofuranosyl-xylobiose (A3X) (Megazyme), 23,33-di-α-l-arabinofuranosyl-xylotriose (A2,3XX) (Megazyme). Reactions contained 1 µM enzyme and 5 mg mL−1 substrate in 20 mM Tris pH 8.0 and incubated overnight at 37 °C with mild shaking to maximize accessibility of insoluble substrates (i.e., CM AIR and CM NSP). After incubation, the samples were heat treated at 100 °C for 10 min to denature the enzyme and terminate the reaction. Samples were then shortly centrifuged at 8000× g to pellet denatured protein and undigested insoluble substrate particles from the product. Digested samples were spotted (total 6 µL; spotted 3 times with 2 µL each) onto TLC plates (TLC Silica Gel 60; EMD Millipore). The samples were dried between multiple rounds of spotting. Appropriate monosaccharide standards were included as controls (6 µL of 1 mM concentration); D-galactose (D-Gal), L-arabinose (L-Ara), D-xylose (D-Xyl), D-rhamnose (D-Rha), D-glucose (D-Glc), and D-mannose (D-Man). The samples were resolved using a mobile phase of 2:1:1 butanol:acetic acid:H2O, and dried prior to visualization with an orcinol solution (70:3, acetic acid:sulfuric acid with 1% orcinol) and heating at 100 °C for 3–5 min.
3. Results
3.1. Whole Plant Cell Wall Characterization via Antibody-Based Glycome Profiling
While the monosaccharide composition of CM has been elucidated [8], defined polysaccharide content and linkages within CM NSP remained largely unknown [56]. Enzyme discovery for targeted biomass deconstruction is quite difficult without knowledge of the structure of CM NSP. However, determination of polysaccharide composition in cell wall rich samples such as CM is challenging because of the sheer complexity of structures present and the variety of molecular associations between them. Biochemical approaches enable monosaccharides and glycosidic linkages to be quantified, but these cannot always be assigned with confidence to particular polysaccharides because of the polymer deconstruction that is required for analysis. In contrast, although mAb based techniques such as ELISAs and MAPP are only semi-quantitative, they are based on the extraction of largely intact polysaccharides. Moreover, the glycan epitopes recognized by mAbs typically encompass several linked monosaccharides, and can be highly specific for a particular polysaccharide. Thus, ELISAs and MAPP provide useful information about polysaccharides per se, and changes to those polysaccharides due to enzyme processing.
CM plant cell wall fractions were extracted and analyzed for their glycome profiles using 155 plant cell wall glycan-directed mAbs [25,26] (Figure 1A). These results determined that CM contains all major groups of non-cellulosic polysaccharides typically found in higher plant cell walls, including xyloglucans, xylans, rhamnogalacturonans (RG), and galactans. Mannans were notably absent from the CM, and arabinogalactans were also not as abundant as seen in some other plant cell wall preparations (Figure 1A). Additionally, MAPP was used to screen a targeted panel of glycan-directed mAbs (Figure 1B), presenting results consistent with the broad-panel mAbs; CM AIR and NSP contain glycans consistent with those found in pectins (including RG-I and -II), xyloglucan, and xylan (Figure 1C).
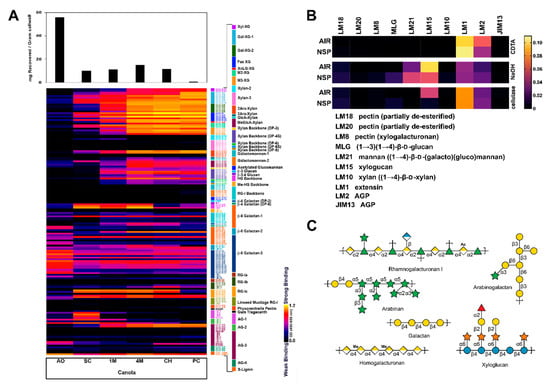
Figure 1.
Cell wall glycome profiling of canola meal. Canola meal (CM) plant cell wall extracts were analyzed through an enzyme-linked immunosorbent assay (ELISA)-based screen against a collection of (A) 155 plant cell wall or (B) 10 glycosidic linkage-specific glycan-directed monoclonal antibodies (mAbs) analysed through MicroArray Polymer Profiling (MAPP). (A) Each column represents the different fractions from polysaccharide extractions of the CM plant cell wall: Ammonium oxalate (AO); sodium carbonate (SC); 1 M KOH (1M); 4 M KOH (4M); chlorite (CH); post-chlorite (PC). The colour of each element in the map reflects the strength of the ELISA signal (black = no binding, yellow = strong binding). The antibodies are grouped according to the epitopes that they recognize (bar at the right of the profiles). Each row reflects the binding pattern of a single mAB against the series of CM extracts. The bar graphs above the glycome profiles show the amounts of carbohydrate present in each extract. (B) Each column represents the binding pattern of a mAb, as indicated. Each row reflects the different fractions of polysaccharide extractions by CDTA, NaOH, or cellulase treatment for CM alcohol insoluble residue (AIR) or non-starch polysaccharide (NSP). (C) Based on the results from the ELISA-based polysaccharide composition screens, schematics were drawn for the dominant polysaccharides found in CM. Monosaccharide symbols follow the SNFG (Symbol Nomenclature for Glycans) system [57].
3.2. Linkage Analyses of CM NSP
The linkage analyses of cell walls of cold-pressed and solvent-extracted canola meal were conducted for the first time. Sequential fractionation by extractants with increasing strength was conducted to the cell walls with and without the pre-treatment of NaBD4. The reducing agent NaBH4 acts on the reducing ends of polysaccharides and on the carboxyl groups resulting from alkaline cleavage of the esters of uronic acids (e.g., the methyl ester of galacturonic acids in pectins and ester link of the glucuronic acids of the hemicellulose glucuronoxylan) to prevent oxidative degradation during alkaline extraction [58,59,60]. NaBD4, a deuterated form of NaBH4, was used here for the analytical purpose of deuterium labelling changes that can be tracked by GC-MS analysis [35]. As expected, a much higher yield of the EDTA and Na2CO3 extract (32.1% versus 16.4%) and a much lower yield of the 4 M KOH fraction (29.0% versus 48.4%) was found in the NaBD4 pretreated cold-pressed sample than the untreated one, while slight difference in the insoluble residue yield (38.9% versus 35.2%) between the two was observed (Supplemental Figure S2), indicating that NaBD4 treatment greatly increased the extractability of polysaccharides from the cell wall and enabled the release of more polysaccharides by the relatively weaker extractants EDTA and Na2CO3. Similar trends were observed in the solvent-extracted CM fractions.
The cell walls and their fractions were subjected to carboxyl reduction-methylation-GC-MS analysis for the composition of linkages from uronic acids and neutral sugars [36]. Results showed that 4-Glcp and 4-GalAp were the two most abundant linkages in the whole cell wall (Figure 2, Supplemental Figure S3, Supplemental Tables S1 and S2) indicating higher abundance of cellulose and pectins than hemicelluloses in the sample. The 4-GalAp from pectins and 4-Glcp from cellulose were found dominant in the pooled EDTA + Na2CO3 fraction and the alkali insoluble residue, respectively, and high amounts of linkages (e.g., 4-Xylp) typical for hemicelluloses were observed in the 4 M KOH fraction, which was in agreement with the previous reports on the fractionation of higher plant cell wall [33,61].
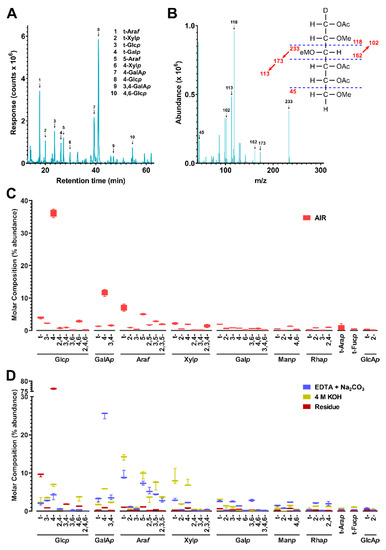
Figure 2.
Cell wall linkage composition of cold-pressed canola meal. (A) Total ion current (TIC) chromatogram of cold-pressed canola meal (CM) non-starch polysaccharides (NSP) analyzed by PMAA gas chromatography-mass spectrometry (GC-MS). (B) Mass spectrum of example PMAA from 4-Glcp (β-1,4-linked glucopyranose). Peaks in TIC chromatogram (A) were assigned to linkages based on their MS fragmentation patterns and retention times by referring to those of standards. (C,D) Calculated relative composition of linkages (molar%) from peaks shown in (A) for (C) CM alcohol insoluble residue (AIR) and (D) fractionated extracts of EDTA + Na2CO3, 4 M KOH, or residue A pre-treatment of NaBD4 was conducted to the cell wall before its sequential fractionation in order to increase the extricability of polysaccharides. Four separate experiments were conducted to cell wall and three to each fraction. Values are averages from the separate experiments, presented as bar and whiskers with error bars representing the standard deviation from the mean.
Based on the linkage data (Supplemental Tables S1 and S2), the relative composition of polysaccharides were estimated by assigning glycosidic linkages to polysaccharides (Table 1) and summing up the compositions of assigned linkages for corresponding polysaccharides following the published protocol [36], with the modifications that t-Fucp was additionally assigned to arabinogalactan-II (AG-II) according to the recent reports [62,63] and extensin was grouped with AG-II based on the finding of the presence of extensin in the cell wall by the monoclonal antibody assay (Figure 1B) and the consideration that AG-II structure contains all the glycosidic linkage types of extensin glycoprotein [63]; 3-Glcp was assigned to callose instead of the mixed-linkage (1,3;1,4)-β-D-glucans that dicotyledonous plants lack [36]. Results showed the cell wall was rich in cellulose, pectins (homogalacturonan (HG), RG-I), arabinan (AB), and xyloglucan (XG) (Figure 3, Supplemental Figure S4). It is well accepted that linear 5-linked AB are most prevalent in the side chains of RG-I [64,65,66], although they can also be found as part of arabinogalactan glycoproteins (AGPs). Considerable amounts of AG-I and AG-II structures were also found in the cell wall, which could be present as side chain structures of RG-I [64,65,66] or attached to AGPs. The possible crossing-linking between AB, AG-I and AG-II in the cell wall was supported by the observation of co-extraction and enrichment of them with the HG and RG-I in the pectin-rich EDTA and Na2CO3 fraction; however, direct evidence needs to be found in future studies in order to confirm the existence of such structures in the canola meal sample. XG were the most abundant hemicellulose in the canola meal cell wall, followed by heteroxylan (HX) and heteromannan (HM) in decreasing abundance (Figure 3). It was apparent that both the XG and HX were enriched in the strong alkali soluble fraction, which was in good agreement with previous reports [33,61], indicating both XG and HX were intensively cross-linked to the cell wall matrix and therefore strong extractants are needed to break the bonding and release them.

Table 1.
Polysaccharide linkage assignments.
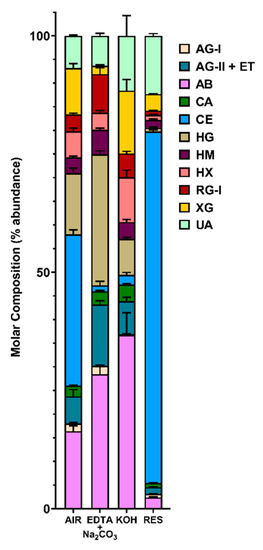
Figure 3.
Estimated polysaccharide composition of cold-pressed canola meal cell wall (de-starched AIR) and its three fractions (EDTA + Na2CO3, 4 M KOH, Residue). The composition of polysaccharides was estimated based on linkage composition data (Figure 2 and Supplemental Table S1) by assigning the linkages of uronic acids and neutral sugars to polysaccharides (Table 1; as in [36]). A pre-treatment of NaBD4 was conducted to the cell wall before its sequential fractionation in order to increase the extricability of polysaccharides. Four separate experiments conducted to cell wall and three to each fraction. Stacked bar plots are shown, with a mean value from the separate experiments represented as a horizontal bar and bars depicting the standard deviation from the mean. The polysaccharides were assigned as in Table 1: Arabinan (AB), type I arabinogalactan (AG-I), type II arabinogalactan (AG-II) and extensin (ET), heteroxylan (HX), xyloglucan (XG), callose (CA), cellulose (CE), rhamnogalacturonan I (RG-I), homogalacturonan (HG), heteromannan (HM), and unassigned linkages (UA).
3.3. Temporal Characterization of Broiler Cecal Bacterial Communities in Mini-Bioreactors
There was no difference in α-diversity (p ≥ 0.298) or evenness (p ≥ 0.418) of communities within the mini-bioreactor vessels among the CM, NSP, and control treatments over time. However, a reduction in α-diversity was observed within the first 24 h for all treatments; Shannon’s Index values ranged from 6.7 to 6.9 at day 0, and from 4.2 to 4.6 at day 1. From day 1 onward, bacterial diversity was stable (p ≥ 0.083), ranging from 3.3 to 4.9 over the remaining nine days of the experiment. Despite the loss of diversity, bacteria in the phyla Firmicutes and Bacteroidetes were retained, although selection for some taxa occurred over time independent of treatment (Supplemental Figure S5). In this regard, bacteria in the families Bacteroidaceae and Fusobacteriaceae increased over time. The β-diversity (i.e., structure) of bacterial communities was not altered by NSP relative to the control treatment (p ≥ 0.441). In contrast, the structure of communities was altered for the CM treatment as determined by unweighted UniFrac (p = 0.045) and Jaccard (p = 0.055) (Figure 4). However, no or modest quantitative differences in β-diversity were observed among the CM and CON treatments as determined by weighted UniFrac (p = 0.237) and Bray-Curtis (p = 0.067). The observed impact on β-diversity for the CM treatment was attributed in part to selection for bacteria within the Veillonellaceae family (Supplemental Figure S5).
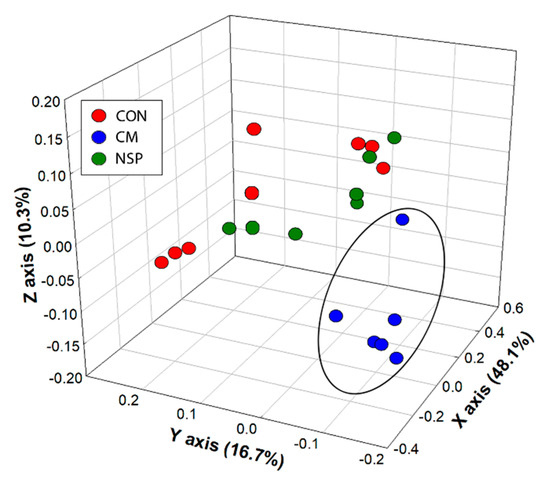
Figure 4.
Unweighted UniFrac principal coordinate analysis of cecal communities within mini-bioreactor vessels containing the basal medium (CON), the basal medium with cold press extracted canola meal (CM), and the basal medium with non-starch polysaccharides extracted from canola meal (NSP). Replicate vessels were combined for Illumina characterization of bacterial communities. The ellipsoid illustrates clustering of bacterial communities for the CM treatment, relative to communities for the NSP and CON treatments.
3.4. Enrichment and Isolation of CM NSP-Degrading Bacterial Species
Bacteria were isolated directly from cecal digesta or from the bioreactors (days 3 and 10); 332 isolates able to grow on an agar medium supplemented with MM and CM or CM NSP as a carbohydrate source were recovered. Of the 332 isolates, 325 were culturable in liquid rich media. We identified 100 intestinal bacterial isolates with the ability to degrade and metabolize CM NSP via growth on CM NSP-supplemented agar plates, and subsequent species identification was performed via 16S rDNA sequencing using degenerate 27F and 1492R primers [42,43] (Figure 5A). Enterococcus spp., and Bacteroides spp. were the most predominant bacteria able to utilize CM NSP.
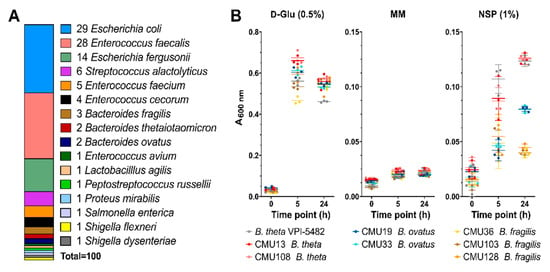
Figure 5.
Identification and characterization of bacterial CM NSP degraders. (A) 16S rDNA sequencing was performed to identify the 100 bacterial species obtained from isolation plating bioreactor samples on CM NSP. Of those bacterial samples, Bacteroides isolate growth was assayed (B) in liquid minimal media containing 0.5% D-Glu (positive control), no carbohydrate (MM) (negative control), or 1% CM NSP. Background data was subtracted for media containing no bacterial culture inoculate. Error bars represent the SEM from triplicate data. Liquid culture bacterial isolates are coloured as indicated.
3.5. Growth Metrics of “High-Efficiency” CM Degraders
Based on the bioreactor community analyses, growth in liquid culture for the Bacteroides isolates were evaluated to identify “high-efficiency” utilizers (Figure 5B). Of the seven isolates, two B. theta CM NSP-utilizing isolates (CMU13 and CMU108) and two B. ovatus isolates (CMU19 and CMU33) were capable of moderate growth in CM NSP after 24 h (termed high-efficiency utilizers for our purposes), whereas three B. fragilis isolates (CMU36, CMU103, and CMU128) grew to low density.
3.6. Total CAZyme Content of Bacteroides CM-Degrading Isolates
Many members of Bacteroidetes are polysaccharide generalists that consume diverse cell wall polysaccharides. Therefore, the six top performing B. theta and B. ovatus isolates were selected for genome sequencing and prospecting (Table 2). Functional annotation of assembled contigs and putative protein identification was done using Prokka [46].
Table 2.
Whole genome sequencing SPAdes assembly statistics.
Prokka results were analyzed by dbCAN [54] to annotate predicted CAZomes for all seven isolated bacterial species (Table 3 and Table 4, and Supplemental Table S3). Significantly, B. theta and B. ovatus high-efficiency utilizers contain 2X and 2.1X, respectively, the total CAZyme content as the B. fragilis isolates, which predominantly results from the number of glycoside hydrolase family members. When comparing CM-metabolizing isolates to environmental “wild-type” strains such as B. theta VPI-5482 and B. ovatus ATCC8483, CM isolates contain markedly higher numbers of CAZyme genes in many families relevant to debranching and degrading plant cell wall polysaccharides and their associated downstream oligosaccharide products (Table 3 and Table 4, highlighted). Many of the enzymes identified, including those of GH28, GH43, GH78, and CE6 families, are especially relevant in the context of the ELISA- and MAPP-based screening results and the polysaccharides identified in CM. As these predictions are based upon genome sequence, future transcriptomic studies would be useful to quantify expression of genes under CM NSP conditions.
Table 3.
CAZome of bacterial isolates for the major glycoside hydrolase (GH) families involved in degradation of plant cell walls.
Table 4.
CAZome of bacterial isolates for the major carbohydrate esterase (CE) and polysaccharide lyase (PL) families involved in degradation of plant cell walls.
3.7. Target Selection for CAZymes with Potential Enzymatic Activity on CM NSP
Based on polysaccharide linkage analyses, genes from CAZyme families of interest were selected from the genomes of high growers and analyzed using our in-house pipeline SACCHARIS [48]. Gene sequences from bacterial isolates CMU13 (B. theta) and CMU19 (B. ovatus) for GH28 (pectins), GH43 (arabinoxylans), GH78 (RG-I/II), and CE6 (xylans) enzymes were embedded into phylogenetic trees comprised of characterized enzyme sequences (Figure 6). From these trees, we can predict enzymatic function with higher accuracy. Overall, the majority of GH43 enzymes were found to be highly related both to each other, when comparing those from isolate CMU13 to isolate CMU19, as well as to other characterized enzymes; few isolate gene sequences are in novel clades, with two most distantly related groupings identified (Figure 6). GH28, GH78, and CE6 family members have individual outliers, signifying targets that may possess unique enzyme specificities. A total of 8 CAZyme sequences from either CMU13 or CMU19 were chosen from GH28 (N2073, K2605), GH43 (N1089, K696), GH78 (N872, N3394, K3550), and CE6 (N2589) families based on these criteria (Figure 6).
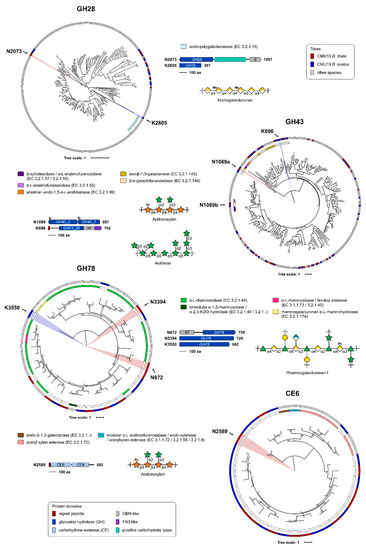
Figure 6.
Prediction of enzyme activities and target selection by phylogenetic analyses. Genomes from isolates CM13 (B. theta) (red) and CM19 (B. ovatus) (blue) were annotated by Prokka [46]. Putative protein sequences were annotated by dbCAN [54] and used as query sequence inputs for SACCHARIS [48] and embedded into phylogenetic trees of characterized GH28, GH43, GH78, and CE6 enzymes. EC number and CAZy database annotated functions are colour-coded as indicated. Target enzymes were chosen based on distally related sequences, represented by novel clades within the phylogenetic trees. Domain boundaries are based on manual curation of predictions by dbCAN [54] and InterProScan [55], with all schematics to scale and colour-coded. The polypeptide length for the open reading frame of each target is shown. Schematics of potential plant cell wall substrates for selected target CAZymes, as identified by EC number, are shown.
The selected targets were further analyzed by InterProScan [55] to identify any accessory modules of interest (Figure 6). Five of the eight enzymes selected were determined to be multimodular. Of note, the CMU13 GH28 CAZyme N2073 contains a putative carbohydrate lyase domain that was not identified by dbCAN; and CMU13 N1089 contains two tandem GH43 subfamily 2 domains, only one of which is divergent from other GH43 family members in the phylogenetic tree.
3.8. Characterization of Novel CM-Targeted CAZymes
Full-length constructs of the selected enzyme targets were cloned for recombinant expression in E. coli, and evaluated by small-scale expression tests to determine expression conditions that result in large amounts of soluble protein. Of the eight enzyme targets selected, two full-length enzymes were found to produce soluble recombinant protein: CMU13 N1089, with two tandem GH43 domains; and CMU19 K2605, one GH28 CAZyme.
In order to screen CAZymes for function, colourimetric pNP assays were used. When pNP-sugar conjugate substrates are cleaved by enzymes with the required activity, the products can be detected and quantified spectrophotometrically. The GH43 family enzyme N1089 can function as both an arabinofuranosidase and xylosidase, consistent with other GH43 enzymatic activities (Figure 7A), whereas the GH28 enzyme K2605 demonstrated faint activity on pNP-galactose (data not shown), with no detectable activity on other pNP-sugar substrates.
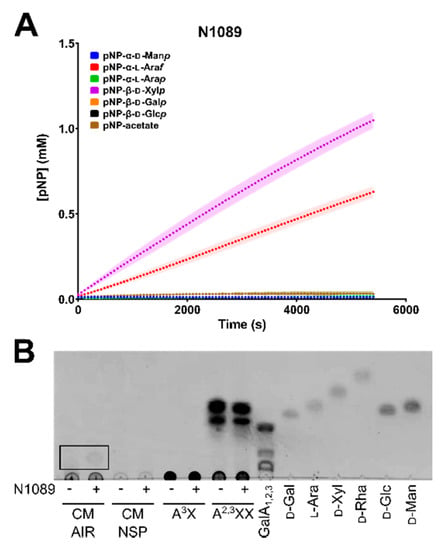
Figure 7.
Enzymatic assays for CAZyme activity characterization. Full-length soluble enzymes (A) N1089 was incubated with pNP-conjugated substrates, and monitored spectrophotometrically at OD405 nm over a period of 90 min. A standard curve was generated of OD405 nm vs concentration of pNP in order to calculate final product formed by enzyme addition. Plotted points represent an average of three technical replicates, with the standard deviation from the mean shown as a shadow. (B) Thin-layer chromatography (TLC) of commercial and synthetic polysaccharides incubated without (−) and with (+) N1089 enzyme. Polysaccharide substrates consisted of: canola meal (CM) alcohol insoluble residue (AIR), CM non-starch polysaccharide (NSP), 32-α-L-arabinofuranosyl-xylobiose (A3X), 23,33-di-α-L-arabinofuranosyl-xylotriose (A2,3XX), or a galacturonic acid ladder of mono, di, and triose forms (GalA1,2,3). Monosaccharide standards were included as controls; D-galactose (D-Gal), L-arabinose (L-Ara), D-xylose (D-Xyl), D-rhamnose (D-Rha), D-glucose (D-Glc), and D-mannose (D-Man). TLC solvent was composed of 2:1:1 butanol:acetic acid:H2O and plates were stained with 1% orcinol.
pNP-conjugate substrates provide an initial activity-based screen for enzymatic function, however these small-molecules do not reflect the complexity within native polysaccharide substrates. Thus, purified N1089 and K2605 were screened for activity on CM AIR and extracted CM NSP. Additionally, numerous commercial sources of polysaccharides and synthetic substrates were tested against general activities. The GH43 enzyme N0189 was found to be active on CM AIR, as smaller products consistent with oligosaccharide production can be seen by TLC (Figure 7B). A similar cleavage product cannot be seen on CM NSP, likely due to the highly insoluble nature of the NSP substrate. No other oligo/polysaccharide-based substrates tested were shown to be cleaved by either N1089 or K2605, including: RG-I, polygalacturonic acid (PGA), wheat arabinoxylan, 23-α-L-arabinofuranosyl-xylotriose (A2XX), arabinobiose (Ara2), arabinotriose (Ara3) (data not shown).
4. Discussion
Previous research and development of commercial enzyme products has shown that the addition of exogenous enzymes to animal feed can improve the digestion of NSP [67,68,69]; however, these approaches did not optimize the enzymes for unique structural features within the cell walls of feed or to function within the intestine of animals. NSP content (cellulose and non-cellulosic) varies greatly between common feeds in poultry diets [70]. Cereal grains such as corn, wheat, and barley are rich in arabinoxylans and β-glucans, whereas the protein-rich dietary components, soybean and canola meals, are also rich in xyloglucans, galactans, and pectic polysaccharides, in addition to the xylans. Here, we have used an enzyme discovery platform to identify enzymes within the genomes of cecal bacteria isolated from chickens. Importantly, tailored enzyme discovery required the development of a comprehensive analytic pipeline to fully characterize the structure of the substrate and to select for relevant enzyme activities. Accordingly, we conducted the first in depth glycomic analysis of CM and CM NSP cell walls through a holistic strategy involving glycome profiling and glycosidic linkage analyses.
Canola is the registered name for the rapeseeds of several cultivars of Brassica napus species, and CM is superior to its predecessor rapeseed meal (RSM) in nutritional values [1]. Previously, CMs from different varieties and lines were found to contain 8–10% sucrose, 2–3% oligosaccharides, 20–22% NSP, and 5–8% lignin and polyphenols. It was reported that CM was rich in cellulose, hemicelluloses, and pectins based on neutral sugar analysis using GC and total uronic acid colorimetric assay [56]. There have been very few reports on the structural characterization of cell wall polysaccharides of either RSM or the closest genetic relative to canola meal, Brassica campestris [71]. Oil-free de-hulled RSM contains arabinogalactan (1%), arabinan (2%), pectin (14.5%), cellulosic residue (7%), and small amounts of xylans [72]. The de-fatted seed meal of B. campestris is rich in AB, RG-I, AGPs, XGs, and xylans [73]. Both RSM and B. campestris seed meals have similar compositions with respect to pectins, AG, AB, glucuronoxylans, and XG with minor differences in some of the detailed structural features of AB and XG [71]. Linkage analysis was used in the previous studies, but uronic acids were not treated by carboxyl reduction before methylation analysis, resulting in the detection of only neutral sugar linkages. Notably, pectins were observed in several sequential extracts even in the final residue after alkaline extraction indicating a rigid matrix of the seed meals, suggesting that pre-treatments are needed to loosen the cell wall structure for increased digestibility by monogastric animals [71], further supported by an in vivo study [74].
We are not aware of any structural studies of the cell wall composition of CM beyond its monosaccharide composition and inferred polysaccharide content [56]. The first step of conventional monosaccharide composition analysis is acid hydrolysis or methanolysis of polysaccharides to their constituent monosaccharides, and it is widely accepted that this initial hydrolysis can yield an incomplete release of monosaccharides from some cell wall polysaccharides (e.g., the release of glucose from insoluble crystalline cellulose or galacturonic acids from pectins) and degradation of released monosaccharides [75,76]. Unlike direct hydrolysis of underivatized samples, per-methylated polysaccharides can be completely hydrolyzed by relatively mild acid such as 2 M TFA without signs of degradation [36,77]. In the current study, uronic acids in the CM cell walls were carboxyl-reduced to neutral sugars with deuterium labelling, followed by methylation-GC-MS analysis of the carboxyl reduced samples, which enabled not only complete hydrolysis of the insoluble pectin-rich cell walls to monosaccharides, but also the determination of linkage patterns of the released monosaccharides. Based on the linkage composition data, estimation of polysaccharide composition was performed following a published protocol [36]. Glycosidic linkage analysis determined that CM NSP are rich in pectins (RG-I, AB, galactans, HG, and arabinogalactans), XG, and AX (Figure 3). In addition to linkage analysis, the CM cell walls were comprehensively characterized using two glycome profiling methods, one based on ELISAs using a large and diverse collection of mAbs, the other based on spotted arrays, using a smaller set of mAbs. The ELISA-based glycome profiling showed the presence of non-cellulosic polysaccharides typical of higher plant cell wall preparations (xyloglucans, xylans, pectins, galactans and arabinogalactans), although mannan epitopes were largely absent, and arabinogalactan epitopes appear underrepresented compared with other plant cell walls (Figure 1A). The array-based glycome profiling also revealed the prominent presence of xyloglucans and arabinogalactans, with a lesser amount of a galactoglucomannan epitope (Figure 1B). However, the spotted array did not detect appreciable levels of HG, in contrast to the ELISA-based results, where HG epitopes were easily detected. Interestingly, destarching appears to modify CM cell walls, as evidenced by lower detection of xyloglucan (LM15) and AGP (LM2) epitopes, and slightly higher detection of the mannan epitope recognized by LM21 (Figure 1B). Amylase has been previously shown to extract NSP [78]. Both glycome profiling methods reveal the polymeric complexity of NSP prepared from CM, illustrating a highly diverse set of epitope structures within each of several polysaccharide classes. In addition, the glycome profiling revealed that xylans and xyloglucans, as well as some RG-I and AGP epitopes are quite tightly bound to the cell wall matrix and require quite harsh conditions to release them from the wall. Homogalacturonans appear to be less tightly integrated into the CM walls, since the majority of these epitopes are released prior to the chlorite step in the wall extraction sequence.
High-resolution methods glycome profiling and glycosidic linkage analyses used herein have now revealed the true complexity of NSP within CM (Figure 1), and the digestion of these complex dietary fibres is likely to require the addition of appropriate enzymatic activities for their digestion. Some candidate types of enzymes are suggested by the data presented here. Bi-functional enzymes offer a more comprehensive breakdown strategy encoded within a single polypeptide, where the presence of multiple CAZyme domains of complementary specificities could work to more efficiently digest complex polysaccharides [79] (i.e., the two tandem GH43 domains of N1089). In addition, carbohydrate-binding modules were found as part of a number of the selected CAZyme targets, which may help increase the concentration and/or targeting of these enzymes to their substrates [80]. Additionally, polysaccharide linkages within the insoluble NSP may be inaccessible to the target enzymes and/or CM isolates under the designed assay and growth conditions used here. While bacterial CM isolates were able to utilize CM NSP as a sole carbohydrate source, these cultures reached relatively low density when compared to growth on glucose (Figure 5B) or to that of wild-type B. theta VPI-5482 on complex polysaccharides, such as pectins [81]. A comprehensive approach involving the use of an enzymatic cocktail with multiple complementary activities may be required to more effectively digest CM NSP for use as livestock feed stocks.
Novel enzymatic activities may also be required for efficient breakdown of CM, tailored to specific linkages found in NSP (Figure 6). With this in mind, two enzymes from CM-utilizing Bacteroides isolates, N1089 and K2605, were selected and screened for enzymatic activity. N1089 was discovered to be an arabinofuranosidase and xylosidase, both activities directly relevant to the degradation of arabinosyl- and xylosyl-containing polysaccharides or sidechains found in CM NSP (Figure 1, Figure 2 and Figure 3). Additionally, we were able to successfully demonstrate activity of N1089 on CM AIR. As the genetic construct assayed with the pNP-substrate screen is a full-length enzyme, it is possible that the dual arabinofuranosidase/xylosidase activity seen is the result of one domain of N1089 functioning as an arabinofuranosidase, while the other may possess xylosidase activity. Indeed, the C-terminal module (“b”) of N1089 was found to cluster with α-L-arabinofuranosidases active on arabinan (Figure 6), suggesting that the N-terminal module (“a”) may be responsible for cleaving xylan backbone linkages common to CM plant cell walls (Figure 1 and Figure 3). K2605 was identified by dbCAN as a GH28 and clustered with numerous other endo-polygalacturonases (Figure 6). It is thus likely that the K2605 enzyme is a polygalacturonase, but may accommodate a pNP-galactose substrate in the -1 subsite. Unfortunately, the pNP-α-galacturonide substrate is not commercially available which prevents screening K2605 against this synthetic substrate. Regardless, the galactosidase/galacturonase activity of K2605 may assist with dismantling the homogalacturonan found in CM NSP (Figure 1 and Figure 3). These two enzymes presented here may represent valuable targets for further product development, perhaps as part of a combinatorial strategy to dismantle the complex multitude of polysaccharides present in CM.
Surprisingly, species not commonly associated with complex carbohydrate utilization were also isolated from CM-NSP medium, including Enterococcus faecalis, E. faecium, E. cecorum, and E. avium (Figure 5). In all likelihood these microorganisms do not possess the enzymatic machinery required to utilize CM NSPs. Inspection of their genomes revealed that E. faecium and E. avium possess one GH43 and one GH78 enzyme, while the genomes of E. cecorum and E. faecalis do not [49]. The genome of E. faecium does encode two GH28 enzymes; however, whether these enzymes are secreted and active on CM NSPs is not known. As isolations were performed on rich media after initial minimal media selections, it is possible that these species were able to grow on contaminating monosaccharides in the media or on products generated by neighbouring colonies from Bacteroides sp. Importantly, two of the enzymes identified in this study were found to possess N-terminal signal peptides, suggesting that at least some CM NSP-relevant enzymes may be secreted for extracellular function (Figure 6).
5. Conclusions
The discovery of enzymes that improve the digestion of feed by livestock has been difficult to achieve in the past. The majority of commercially available enzyme additives have been repurposed for applications in biofuel production [82,83]; thus, they have not been optimized for dietary substrates or to function within the intestine of animals. To address both of these limitations, we have developed an enzyme discovery platform that combines glycomic characterization of complex substrates to inform enzyme selection, selective isolation of bacteria that colonize the cecum of the host species, in silico identification of enzymes from sequenced genomes, and biochemical characterization of recombinantly produced target enzymes. In this study, two promising enzymes, N1089 and K2605, were identified from chicken-associated Bacteroides spp. that are active on CM polysaccharides. This enzyme discovery platform may provide a new route for informed biocatalyst development that can be adapted to a variety of other plant sources, host species, and industrial applications.
Supplementary Materials
The following are available online at https://www.mdpi.com/2076-2607/8/12/1888/s1, Figure S1: Enzyme discovery platform for the tailored degradation of non-starch dietary polysaccharides, Figure S2: Fractionated yield of cold-pressed and solvent-extracted canola meal (CM) plant cell wall extractions for glycomic linkage analyses, Figure S3: Cell wall linkage composition of solvent-extracted canola meal, Figure S4: Estimated polysaccharide composition of solvent-extracted canola meal, Figure S5: Temporal relative abundance of primary bacterial families in CON, NSP, and CM treatment bio-reactor vessels, Table S1: Linkage composition of cold-pressed canola meal whole cell wall (AIR) and fractions, Table S2: Linkage composition of solvent-extracted canola meal whole cell wall (AIR) and fractions, Table S3: CAZome of bacterial isolates for the GH5 and GH43 subfamilies.
Author Contributions
Conceptualization, D.W.A. and G.D.I.; methodology, K.E.L., P.E.M., X.X., M.L.K., D.R.J. and S.V.; software, K.E.L.; validation, K.E.L.; formal analysis, K.E.L., D.W.A., G.D.I., M.G.H., C.Y.T.-J., and W.G.T.W.; investigation, K.E.L., G.D.I. and D.W.A.; resources, D.W.A. and G.D.I.; data curation, K.E.L. and G.D.I.; writing—original draft preparation, K.E.L. and X.X.; writing—review and editing, D.W.A., G.D.I., B.A.S., M.G.H., and W.G.T.W.; visualization, K.E.L., G.D.I., and M.G.H.; supervision, D.W.A. and G.D.I.; project administration, D.W.A., G.D.I., and K.E.L.; funding acquisition, D.W.A., G.D.I., and B.A.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Alberta Agriculture and Forestry, grant number RDP-040841. P.E.M. was supported by a Canada Graduate Scholarship from the Natural Sciences and Engineering Research Council (NSERC), a President’s Doctoral Prize of Distinction from the University of Alberta, and Alberta Agriculture and Forestry (proposal #2016E002). The generation of the CCRC series of plant glycan-directed monoclonal antibodies used in this work was supported by grants from the US National Science Foundation Plant Genome Program (DBI-0421683 and IOS-0923992). Glycome profiling of canola meal samples was supported by the Center for Bioenergy Innovation (Oak Ridge National Laboratory), US Department of Energy (DOE) Bioenergy Research Center supported by the Office of Biological and Environmental Research in the DOE Office of Science.
Acknowledgments
We wish to thank Adam Smith, Carolyn Amundsen, Jenny Gusse, Kathaleen House, and Tara Shelton for technical assistance. Thanks are extended to a broiler breeder producer in southwestern Alberta who provided the euthanized birds used in the study.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bell, J.M. Factors affecting the nutritional value of canola meal: A review. Can. J. Anim. Sci. 1993, 73, 689–697. [Google Scholar] [CrossRef]
- Mulrooney, C.N.; Schingoethe, D.J.; Kalscheur, K.F.; Hippen, A.R. Canola meal replacing distillers grains with solubles for lactating dairy cows. J. Dairy Sci. 2009, 92, 5669–5676. [Google Scholar] [CrossRef] [PubMed]
- Seneviratne, R.W.; Young, M.G.; Beltranena, E.; Goonewardene, L.A.; Newkirk, R.W.; Zijlstra, R.T. The nutritional value of expeller-pressed canola meal for grower-finisher pigs. J. Anim. Sci. 2010, 88, 2073–2083. [Google Scholar] [CrossRef] [PubMed]
- Gopinger, E.; Xavier, E.G.; Lemes, J.S.; Moraes, P.O.; Elias, M.C.; Roll, V.F. Carcass yield and meat quality in broilers fed with canola meal. Br. Poult. Sci. 2014, 55, 817–823. [Google Scholar] [CrossRef]
- Kocher, A.; Choct, M.; Morrisroe, L.; Broz, J. Effects of enzyme supplementation on the replacement value of canola meal for soybean meal in broiler diets. Aust. J. Agric. Res. 2001, 52, 447–452. [Google Scholar] [CrossRef]
- Leeson, S.; Atteh, J.O.; Summers, J.D. The replacement value of canola meal for soybean meal in poultry diets. Can. J. Anim. Sci. 1987, 67, 151–158. [Google Scholar] [CrossRef]
- Batal, A.; Dale, N. Ingredient Analysis Table: 2016 edition. Available online: https://www.feedstuffs.com/story-feedstuffs-reference-issue-2016-46-70391 (accessed on 5 November 2020).
- Khajali, F.; Slominski, B.A. Factors that affect the nutritive value of canola meal for poultry. Poult. Sci. 2012, 91, 2564–2575. [Google Scholar] [CrossRef]
- Slominski, B.A.; Campbell, L.D.; Guenter, W. Oligosaccharides in canola meal and their effect on nonstarch polysaccharide digestibility and true metabolizable energy in poultry. Poult. Sci. 1994, 73, 156–162. [Google Scholar] [CrossRef]
- Knudsen, K.E. Fiber and nonstarch polysaccharide content and variation in common crops used in broiler diets. Poult. Sci. 2014, 93, 2380–2393. [Google Scholar] [CrossRef]
- Meng, X.; Slominski, B.A. Nutritive values of corn, soybean meal, canola meal, and peas for broiler chickens as affected by a multicarbohydrase preparation of cell wall degrading enzymes. Poult. Sci. 2005, 84, 1242–1251. [Google Scholar] [CrossRef]
- Simbaya, J.; Slominski, B.A.; Guenter, W.; Morgan, A.; Campbell, L.D. The effects of protease and carbohydrase supplementation on the nutritive value of canola meal for poultry: In vitro and in vivo studies. Anim. Feed Sci. Technol. 1996, 61, 219–234. [Google Scholar] [CrossRef]
- Sergeant, M.J.; Constantinidou, C.; Cogan, T.A.; Bedford, M.R.; Penn, C.W.; Pallen, M.J. Extensive microbial and functional diversity within the chicken cecal microbiome. PLoS ONE 2014, 9, e91941. [Google Scholar] [CrossRef] [PubMed]
- Oakley, B.B.; Lillehoj, H.S.; Kogut, M.H.; Kim, W.K.; Maurer, J.J.; Pedroso, A.; Lee, M.D.; Collett, S.R.; Johnson, T.J.; Cox, N.A. The chicken gastrointestinal microbiome. Fems Microbiol. Lett. 2014, 360, 100–112. [Google Scholar] [CrossRef] [PubMed]
- Ghazi, S.; Rooke, J.A.; Galbraith, H.; Bedford, M.R. The potential for the improvement of the nutritive value of soya-bean meal by different proteases in broiler chicks and broiler cockerels. Br. Poult. Sci. 2002, 43, 70–77. [Google Scholar] [CrossRef] [PubMed]
- Gracia, M.I.; Aranibar, M.J.; Lazaro, R.; Medel, P.; Mateos, G.G. Alpha-amylase supplementation of broiler diets based on corn. Poult. Sci. 2003, 82, 436–442. [Google Scholar] [CrossRef]
- Yu, B.; Sun, Y.-M.; Chiou, P.W.-S. Effects of glucanase inclusion in a de-hulled barley diet on the growth performance and nutrient digestion of broiler chickens. Anim. Feed Sci. Technol. 2002, 102, 35–52. [Google Scholar] [CrossRef]
- Vranjes, M.V.; Wenk, C. Influence of dietary enzyme complex on the performance of broilers fed on diets with and without antibiotic supplementation. Br. Poult. Sci. 1995, 36, 265–275. [Google Scholar] [CrossRef]
- Cowieson, A.J.; Bedford, M.R.; Ravindran, V. Interactions between xylanase and glucanase in maize-soy-based diets for broilers. Br. Poult. Sci. 2010, 51, 246–257. [Google Scholar] [CrossRef]
- Yu, B.; Wu, S.T.; Liu, C.C.; Gauthier, R.; Chiou, P.W.S. Effects of enzyme inclusion in a maize–soybean diet on broiler performance. Anim. Feed Sci. Technol. 2007, 134, 283–294. [Google Scholar] [CrossRef]
- West, M.L.; Corzo, A.; Dozier, W.A.; Blair, M.E.; Kidd, M.T. Assessment of dietary rovabio excel in practical united states broiler diets. J. Appl. Poult. Res. 2007, 16, 313–321. [Google Scholar] [CrossRef]
- Cowieson, A.J.; Singh, D.N.; Adeola, O. Prediction of ingredient quality and the effect of a combination of xylanase, amylase, protease and phytase in the diets of broiler chicks. 1. Growth performance and digestible nutrient intake. Br. Poult. Sci. 2006, 47, 477–489. [Google Scholar] [CrossRef] [PubMed]
- Cheng, G.; Hao, H.; Xie, S.; Wang, X.; Dai, M.; Huang, L.; Yuan, Z. Antibiotic alternatives: The substitution of antibiotics in animal husbandry? Front. Microbiol. 2014, 5, 217. [Google Scholar] [CrossRef] [PubMed]
- Wood, J.A.; Tan, H.T.; Collins, H.M.; Yap, K.; Khor, S.F.; Lim, W.L.; Xing, X.; Bulone, V.; Burton, R.A.; Fincher, G.B.; et al. Genetic and environmental factors contribute to variation in cell wall composition in mature desi chickpea (Cicer arietinum l.) cotyledons. PlantCell Environ. 2018, 41, 2195–2208. [Google Scholar]
- Pattathil, S.; Avci, U.; Baldwin, D.; Swennes, A.G.; McGill, J.A.; Popper, Z.; Bootten, T.; Albert, A.; Davis, R.H.; Chennareddy, C.; et al. A comprehensive toolkit of plant cell wall glycan-directed monoclonal antibodies. Plant. Physiol. 2010, 153, 514–525. [Google Scholar] [CrossRef] [PubMed]
- Pattathil, S.; Avci, U.; Miller, J.S.; Hahn, M.G. Immunological Approaches to Plant Cell Wall and Biomass Characterization: Glycome Profiling; Humana Press: Totowa, NJ, USA, 2012; pp. 61–72. [Google Scholar]
- Puhlmann, J.; Bucheli, E.; Swain, M.J.; Dunning, N.; Albersheim, P.; Darvill, A.G.; Hahn, M.G. Generation of monoclonal antibodies against plant cell-wall polysaccharides (i. Characterization of a monoclonal antibody to a terminal [alpha]-(1->2)-linked fucosyl-containing epitope. Plant Physiol. 1994, 104, 699–710. [Google Scholar] [CrossRef] [PubMed]
- Steffan, W.; Kovácč, P.; Albersheim, P.; Darvill, A.G.; Hahn, M.G. Characterization of a monoclonal antibody that recognizes an arabinosylated (1 → 6)-β-d-galactan epitope in plant complex carbohydrates. Carbohydr. Res. 1995, 275, 295–307. [Google Scholar] [CrossRef]
- Ruprecht, C.; Bartetzko, M.P.; Senf, D.; Dallabernadina, P.; Boos, I.; Andersen, M.C.F.; Kotake, T.; Knox, J.P.; Hahn, M.G.; Clausen, M.H.; et al. A synthetic glycan microarray enables epitope mapping of plant cell wall glycan-directed antibodies. Plant Physiol. 2017, 175, 1094–1104. [Google Scholar] [CrossRef]
- Schmidt, D.; Schuhmacher, F.; Geissner, A.; Seeberger, P.H.; Pfrengle, F. Automated synthesis of arabinoxylan-oligosaccharides enables characterization of antibodies that recognize plant cell wall glycans. Chem. Eur. J. 2015, 21, 5709–5713. [Google Scholar] [CrossRef]
- Dallabernardina, P.; Ruprecht, C.; Smith, P.J.; Hahn, M.G.; Urbanowicz, B.R.; Pfrengle, F. Automated glycan assembly of galactosylated xyloglucan oligosaccharides and their recognition by plant cell wall glycan-directed antibodies. Org. Biomol. Chem. 2017, 15, 9996–10000. [Google Scholar] [CrossRef]
- Moller, I.; Sorensen, I.; Bernal, A.J.; Blaukopf, C.; Lee, K.; Obro, J.; Pettolino, F.; Roberts, A.; Mikkelsen, J.D.; Knox, J.P.; et al. High-throughput mapping of cell-wall polymers within and between plants using novel microarrays. Plant. J. 2007, 50, 1118–1128. [Google Scholar] [CrossRef]
- Hsieh, Y.S.Y.; Chien, C.; Liao, S.K.S.; Liao, S.F.; Hung, W.T.; Yang, W.B.; Lin, C.C.; Cheng, T.J.R.; Chang, C.C.; Fang, J.M.; et al. Structure and bioactivity of the polysaccharides in medicinal plant dendrobium huoshanense. Bioorganic Med. Chem. 2008, 16, 6054–6068. [Google Scholar] [CrossRef] [PubMed]
- Bacic, A.; Moody, S.F.; Clarke, A.E. Structural analysis of secreted root slime from maize (zea mays l.). Plant. Physiol. 1986, 80, 771–777. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.B.; Carpita, N.C. Changes in esterification of the uronic acid groups of cell wall polysaccharides during elongation of maize coleoptiles. Plant. Physiol. 1992, 98, 646–653. [Google Scholar] [CrossRef] [PubMed]
- Pettolino, F.A.; Walsh, C.; Fincher, G.B.; Bacic, A. Determining the polysaccharide composition of plant cell walls. Nat. Protoc. 2012, 7, 1590–1607. [Google Scholar] [CrossRef] [PubMed]
- Auchtung, J.M.; Robinson, C.D.; Farrell, K.; Britton, R.A. Minibioreactor arrays (mbras) as a tool for studying c. Difficile physiology in the presence of a complex community. In Clostridium Difficile: Methods and Protocols, Methods in Molecular Biology; Roberts, A.P., Mullany, P., Eds.; Springer Science+Business Media: New York, NY, USA, 2016; Volume 1476. [Google Scholar]
- Kozich, J.J.; Westcott, S.L.; Baxter, N.T.; Highlander, S.K.; Schloss, P.D. Development of a dual-index sequencing strategy and curation pipeline for analyzing amplicon sequence data on the miseq illumina sequencing platform. Appl. Env. Microbiol. 2013, 79, 5112–5120. [Google Scholar] [CrossRef]
- Bolyen, E.; Rideout, J.R.; Dillon, M.R.; Bokulich, N.A.; Abnet, C.C.; Al-Ghalith, G.A.; Alexander, H.; Alm, E.J.; Arumugam, M.; Asnicar, F.; et al. Reproducible, interactive, scalable and extensible microbiome data science using qiime 2. Nat. Biotechnol. 2019, 37, 852–857. [Google Scholar] [CrossRef]
- Callahan, B.J.; McMurdie, P.J.; Rosen, M.J.; Han, A.W.; Johnson, A.J.; Holmes, S.P. Dada2: High-resolution sample inference from illumina amplicon data. Nat. Methods 2016, 13, 581–583. [Google Scholar] [CrossRef]
- Deplancke, B.; Vidal, O.; Ganessunker, D.; Donovan, S.M.; Mackie, R.I.; Gaskins, H.R. Selective growth of mucolytic bacteria including clostridium perfringens in a neonatal piglet model of total parenteral nutrition. Am. J. Clin. Nutr. 2002, 76, 1117–1125. [Google Scholar] [CrossRef]
- Frank, J.A.; Reich, C.I.; Sharma, S.; Weisbaum, J.S.; Wilson, B.A.; Olsen, G.J. Critical evaluation of two primers commonly used for amplification of bacterial 16s rrna genes. Appl. Env. Microbiol. 2008, 74, 2461–2470. [Google Scholar] [CrossRef]
- Lane, D.J. 16s/23s rrna sequencing. In Nucleic Acid Techniques in Bacterial Systematics; Stackebrandt, E., Goodfellow, M., Eds.; John Wiley and Sons: New York, NY, USA, 1991; pp. 115–175. [Google Scholar]
- Bankevich, A.; Nurk, S.; Antipov, D.; Gurevich, A.A.; Dvorkin, M.; Kulikov, A.S.; Lesin, V.M.; Nikolenko, S.I.; Pham, S.; Prjibelski, A.D.; et al. Spades: A new genome assembly algorithm and its applications to single-cell sequencing. J. Comput. Biol. 2012, 19, 455–477. [Google Scholar] [CrossRef]
- Gurevich, A.; Saveliev, V.; Vyahhi, N.; Tesler, G. Quast: Quality assessment tool for genome assemblies. Bioinformatics 2013, 29, 1072–1075. [Google Scholar] [CrossRef] [PubMed]
- Seemann, T. Prokka: Rapid prokaryotic genome annotation. Bioinformatics 2014, 30, 2068–2069. [Google Scholar] [CrossRef] [PubMed]
- Yin, Y.; Mao, X.; Yang, J.; Chen, X.; Mao, F.; Xu, Y. Dbcan: A web resource for automated carbohydrate-active enzyme annotation. Nucleic Acids Res. 2012, 40, W445–W451. [Google Scholar] [CrossRef] [PubMed]
- Jones, D.R.; Thomas, D.; Alger, N.; Ghavidel, A.; Inglis, G.D.; Abbott, D.W. Saccharis: An automated pipeline to streamline discovery of carbohydrate active enzyme activities within polyspecific families and de novo sequence datasets. Biotechnol. Biofuels 2018, 11, 27. [Google Scholar] [CrossRef]
- Lombard, V.; Golaconda Ramulu, H.; Drula, E.; Coutinho, P.M.; Henrissat, B. The carbohydrate-active enzymes database (cazy) in 2013. Nucleic Acids Res. 2014, 42, D490–D495. [Google Scholar] [CrossRef]
- Edgar, R.C. Muscle: Multiple sequence alignment with high accuracy and high throughput. Nucleic Acids Res. 2004, 32, 1792–1797. [Google Scholar] [CrossRef]
- Darriba, D.; Taboada, G.L.; Doallo, R.; Posada, D. Prottest 3: Fast selection of best-fit models of protein evolution. Bioinformatics 2011, 27, 1164–1165. [Google Scholar] [CrossRef]
- Price, M.N.; Dehal, P.S.; Arkin, A.P. Fasttree 2—Approximately maximum-likelihood trees for large alignments. PLoS ONE 2010, 5, e9490. [Google Scholar] [CrossRef]
- Letunic, I.; Bork, P. Interactive tree of life (itol) v4: Recent updates and new developments. Nucleic Acids Res. 2019, 47, W256–W259. [Google Scholar] [CrossRef]
- Zhang, H.; Yohe, T.; Huang, L.; Entwistle, S.; Wu, P.; Yang, Z.; Busk, P.K.; Xu, Y.; Yin, Y. Dbcan2: A meta server for automated carbohydrate-active enzyme annotation. Nucleic Acids Res. 2018, 46, W95–W101. [Google Scholar] [CrossRef]
- Jones, P.; Binns, D.; Chang, H.Y.; Fraser, M.; Li, W.; McAnulla, C.; McWilliam, H.; Maslen, J.; Mitchell, A.; Nuka, G.; et al. Interproscan 5: Genome-scale protein function classification. Bioinformatics 2014, 30, 1236–1240. [Google Scholar] [CrossRef] [PubMed]
- Slominski, B.A.; Campbell, L.D. Non-starch polysaccharides of canola meal: Quantification, digestibility in poultry and potential benefit of dietary enzyme supplementation. J. Sci. Food Agric. 1990, 53, 175–184. [Google Scholar] [CrossRef]
- Varki, A.; Cummings, R.D.; Aebi, M.; Packer, N.H.; Seeberger, P.H.; Esko, J.D.; Stanley, P.; Hart, G.; Darvill, A.; Kinoshita, T.; et al. Symbol nomenclature for graphical representations of glycans. Glycobiology 2015, 25, 1323–1324. [Google Scholar] [CrossRef] [PubMed]
- Whistler, R.L.; BeMiller, J.N. Alkaline degradation of polysaccharides. In Advances in Carbohydrate Chemistry; Wolfrom, M.L., Ed.; Academic Press: Cambridge, MA, USA, 1958; Volume 13, pp. 289–329. [Google Scholar]
- Imamura, T.; Watanabe, T.; Kuwahara, M.; Koshijima, T. Ester linkages between lignin and glucuronic acid in lignin-carbohydrate complexes from fagus crenata. Phytochemistry 1994, 37, 1165–1173. [Google Scholar] [CrossRef]
- Renard, C.M.G.C.; Thibault, J.F. Pectins in mild alkaline conditions: Β-elimination and kinetics of demethylation. In Progress in Biotechnology; Visser, J., Voragen, A.G.J., Eds.; Elsevier: Amsterdam, The Netherlands, 1996; Volume 14, pp. 603–608. [Google Scholar]
- Li, J.; Wang, D.; Xing, X.; Cheng, T.J.R.; Liang, P.H.; Bulone, V.; Park, J.H.; Hsieh, Y.S.Y. Structural analysis and biological activity of cell wall polysaccharides extracted from panax ginseng marc. Int. J. Biol. Macromol. 2019, 135, 29–37. [Google Scholar] [CrossRef]
- Cartmell, A.; Muñoz-Muñoz, J.; Briggs, J.A.; Ndeh, D.A.; Lowe, E.C.; Baslé, A.; Terrapon, N.; Stott, K.; Heunis, T.; Gray, J.; et al. A surface endogalactanase in bacteroides thetaiotaomicron confers keystone status for arabinogalactan degradation. Nat. Microbiol. 2018, 3, 1314–1326. [Google Scholar] [CrossRef]
- Showalter, A.M.; Basu, D. Extensin and arabinogalactan-protein biosynthesis: Glycosyltransferases, research challenges, and biosensors. Front. Plant. Sci. 2016, 7, 814. [Google Scholar] [CrossRef]
- Albersheim, P.; Darvill, A.G.; O’Neill, M.A.; Schols, H.A.; Voragen, A.G.J. An hypothesis: The same six polysaccharides are components of the primary cell walls of all higher plants. In Progress in Biotechnology; Visser, J., Voragen, A.G.J., Eds.; Elsevier: Amsterdam, The Netherlands, 1996; Volume 14, pp. 47–55. [Google Scholar]
- Gawkowska, D.; Cybulska, J.; Zdunek, A. Structure-related gelling of pectins and linking with other natural compounds: A review. Polymers 2018, 10, 762. [Google Scholar] [CrossRef]
- Moore, J.P.; Farrant, J.M.; Driouich, A. A role for pectin-associated arabinans in maintaining the flexibility of the plant cell wall during water deficit stress. Plant. Signal. Behav. 2008, 3, 102–104. [Google Scholar] [CrossRef]
- Alagawany, M.; Elnesr, S.S.; Farag, M.R. The role of exogenous enzymes in promoting growth and improving nutrient digestibility in poultry. Iran. J. Vet. Res. 2018, 19, 157–164. [Google Scholar]
- Beauchemin, K.A.; Colombatto, D.; Morgavi, D.P.; Yang, W.Z. Use of exogenous fibrolytic enzymes to improve feed utilization by ruminants12. J. Anim. Sci. 2003, 81, E37–E47. [Google Scholar]
- Bedford, M.R.; Cowieson, A.J. Exogenous enzymes and their effects on intestinal microbiology. Anim. Feed Sci. Technol. 2012, 173, 76–85. [Google Scholar] [CrossRef]
- Slominski, B.A. Recent advances in research on enzymes for poultry diets. Poult. Sci. 2011, 90, 2013–2023. [Google Scholar] [CrossRef] [PubMed]
- Pustjens, A.M.; Schols, H.A.; Kabel, M.A.; Gruppen, H. Characterisation of cell wall polysaccharides from rapeseed (brassica napus) meal. Carbohydr. Polym. 2013, 98, 1650–1656. [Google Scholar] [CrossRef]
- Siddiqui, I.R.; Wood, P.J. Carbohydrates of rapeseed: A review. J. Sci. Food Agric. 1977, 28, 530–538. [Google Scholar] [CrossRef]
- Ghosh, P.; Ghosal, P.; Thakur, S.; Lerouge, P.; Loutelier-Bourhis, C.; Driouich, A.; Ray, B. Cell wall polysaccharides of brassica campestris seed cake: Isolation and structural features. Carbohydr. Polym. 2004, 57, 7–13. [Google Scholar] [CrossRef]
- Pustjens, A.M.; de Vries, S.; Bakuwel, M.; Gruppen, H.; Gerrits, W.J.J.; Kabel, M.A. Unfermented recalcitrant polysaccharide structures from rapeseed (brassica napus) meal in pigs. Ind. Crop. Prod. 2014, 58, 271–279. [Google Scholar] [CrossRef]
- Willför, S.; Pranovich, A.; Tamminen, T.; Puls, J.; Laine, C.; Suurnäkki, A.; Saake, B.; Uotila, K.; Simolin, H.; Hemming, J.; et al. Carbohydrate analysis of plant materials with uronic acid-containing polysaccharides–a comparison between different hydrolysis and subsequent chromatographic analytical techniques. Ind. Crop. Prod. 2009, 29, 571–580. [Google Scholar] [CrossRef]
- Garna, H.; Mabon, N.; Nott, K.; Wathelet, B.; Paquot, M. Kinetic of the hydrolysis of pectin galacturonic acid chains and quantification by ionic chromatography. Food Chem. 2006, 96, 477–484. [Google Scholar] [CrossRef]
- Black, I.; Heiss, C.; Azadi, P. Comprehensive monosaccharide composition analysis of insoluble polysaccharides by permethylation to produce methyl alditol derivatives for gas chromatography/mass spectrometry. Anal. Chem. 2019, 91, 13787–13793. [Google Scholar] [CrossRef] [PubMed]
- Zabotina, O.A.; Avci, U.; Cavalier, D.; Pattathil, S.; Chou, Y.-H.; Eberhard, S.; Danhof, L.; Keegstra, K.; Hahn, M.G. Mutations in multiple xxt genes of arabidopsis reveal the complexity of xyloglucan biosynthesis. Plant Physiol. 2012, 159, 1367–1384. [Google Scholar] [CrossRef] [PubMed]
- Naas, A.E.; Pope, P.B. A mechanistic overview of ruminal fibre digestion. Peerj Prepr. 2019. [Google Scholar] [CrossRef]
- Boraston, A.B.; Bolam, D.N.; Gilbert, H.J.; Davies, G.J. Carbohydrate-binding modules: Fine-tuning polysaccharide recognition. Biochem. J. 2004, 382, 769–781. [Google Scholar] [CrossRef] [PubMed]
- Luis, A.S.; Briggs, J.; Zhang, X.; Farnell, B.; Ndeh, D.; Labourel, A.; Basle, A.; Cartmell, A.; Terrapon, N.; Stott, K.; et al. Dietary pectic glycans are degraded by coordinated enzyme pathways in human colonic bacteroides. Nat. Microbiol. 2018, 3, 210–219. [Google Scholar] [CrossRef]
- Bhat, M.; Hazlewood, G. Enzymology and other characteristics of cellulases and xylanases. Enzym. Farm. Anim. Nutr. 2001, 7, 11–13. [Google Scholar]
- Direct-Ted Microbial, Enzyme & Forage Additive Compendium. Available online: http://www.microbialcompendium.com (accessed on 12 August 2020).
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the “Her Majesty the Queen in Right of Canada” for possible open access publication under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).