Abstract
In soundscape studies, several models of perceived affective quality have been developed for specific indoor spaces to help characterize comfortable and satisfying environments. However, no model has been developed so far for dining spaces and the validity of existing models proposed for other indoor contexts, like residential buildings and offices, in dining spaces settings remains uncertain. Therefore, this sequential mixed-method study was conducted to establish a list of attributes that researchers may use to describe dining space soundscapes, which will help in developing an indoor soundscape model for dining spaces. A total of 505 potential attributes were identified and collected through multiple approaches including a Large Language Model-driven synthesis and a systematic review of literature related to dining space soundscapes. Subsequently, the original attributes were refined using qualitative analysis methods in several steps, resulting in a final set of 129 single-word attributes, clustered into 53 semantically coherent groups. This set of attributes will contribute to identifying the main perceptual dimensions of dining space soundscapes and constructing a principal components model through quantitative analyses, while the proposed methodology integrates an LLM-driven synthesis with iterative qualitative expert refinement and offers a more efficient and scalable alternative to conventional labor-intensive manual descriptor extraction for attribute collection, therefore supporting efficient and scalable attribute compilation.
1. Introduction
Traditional acoustic designs are usually intended to improve the acoustic environment and prevent any negative outcomes such as annoyance by reducing the noise exposure to users [1]. However, existing studies show that the background sound levels in many dining spaces are generally high, often exceeding 80 dBA [2,3,4]. Despite this, few strategies have been applied in practice to reduce noise levels in dining spaces [4]. Given the commercial nature of dining spaces and the pressures of profitability and market competition, their interiors are often influenced by both functional requirements and esthetic strategies [5]. For example, owners may prefer to install large windows facing the street to attract customers, adopt open kitchens to display the process of food preparation, or select hard, smooth floor and tabletop materials which are easy to maintain while can also create a clean and bright visual effect. However, although these measures enhance visual appeal of space and efficiency for operation, they often lead to worse overall acoustic environment. On the other hand, simply reducing noise levels does not always lead to lower annoyance or more positive perceptions [6,7,8]. This is because people’s evaluation of the acoustic environment is not determined solely by physical properties such as sound pressure levels, but is also influenced by multiple factors, including the meaning carried by sound sources and the characteristics and states of the listeners themselves [9]. Therefore, it is insufficient to improve users’ acoustic experience in dining spaces through traditional noise control strategies.
In this context, soundscape research provides an important theoretical framework for understanding people’s subjective experiences of sound in indoor environments. The ISO 12913-1 standard defines “soundscape” as “acoustic environment as perceived or experienced and/or understood by a person or people, in context” [10]. Consequently, as the target of building industry shift from creating “acceptable spaces” to designing buildings able to support task performance and enhance people’s health and well-being, the concept of soundscape has received growing attention in studies of indoor spaces [9,10,11].
Affective response models are key tools for quantifying soundscape perception therefore support soundscape design. Multiple models have been proposed to identify the core perceptual dimensions of soundscapes and evaluate people’s acoustic perceptions in various environments, including offices [12] and residential spaces [13]. The typical approach of developing such model is based on Semantic Differentials or Visual Analogue Scales, whereby participants are requested to rate sounds samples collected from different spaces according to a series of attribute rating scales. Principal Component Analysis is then applied to reduce the dimensionality of the attributes and extract the key perceptual dimensions that explain most of the variance in the data, forming the basis of the corresponding model.
Compared with outdoor environments, indoor environments are typically enclosed spaces, which lead to longer exposure times with fewer opportunities to select or move to preferred locations for users and exhibit reverberant sound fields as well as amplify sound sources both from outdoor and indoors, thereby increasing the overall complexity of the indoor acoustic environment. As a common type of indoor environment, the definition and scope of dining space is rarely mentioned in relevant studies, it is more often used as an alternative term for restaurants, canteens, cafés, etc. [14,15,16]. Bitner conceptualized restaurants as a type of servicescape which are ‘‘manmade, physical surroundings, as opposed to the natural or social environment”, characterized by “elaborate physical complexity” and “interpersonal services.” This “interpersonal” nature arises because both customers and employees engage in a series of actions through face-to-face interactions [17]. Although cafés and canteens may differ from restaurants in several aspects such as commercial nature or scale, they often share highly similar spatial functions in that they provide interpersonal services. Hence, dining spaces in this study are defined as indoor enclosed spaces with tables and chairs that provide on-site food and/or beverage service, enabling both eating and face-to-face communication.
Voices are one of the major sources of annoyance in restaurants [18]. When multiple conversations take place simultaneously in an enclosed space, people often raise their vocal level in order to be heard, which increases the background noise and creates a positive feedback loop of progressively increasing ambient noise, known as the Lombard effect [19]. Meanwhile, the cocktail party effects that listeners typically attend to one talker at a time, while the remaining voices are perceptually merge into the background usually occurs [20]. As the background sound level continues to rise, this effect becomes suppressed, and both individual conversations and background music that are not loud enough to be clearly heard and understood are perceptually merged into the background noise. As dining spaces are expected to support shared social experiences, they typically accommodate substantial amounts of conversation and often adopt open layouts with hard, easy-to-maintain surfaces [21]. Such design choices typically increase reverberation, which in turn reinforces the processes described above. In addition, the variety of sound sources and their stronger temporal variability make the acoustic environment of dining spaces more complex than that of many other indoor settings [22]. Meanwhile, social activities including conversation are cognitively demanding. Therefore, models developed for other indoor spaces may not contain the unique perceptual dimensions of dining spaces and directly applying such models may be inappropriate. So, it is necessary to develop a specific model for dining spaces to support soundscape assessment and acoustic environment design in such space.
The first step in developing such model is to collect a set of attributes that quantify participants’ subjective impressions of the acoustic environment. The selection of attributes is crucial for identifying perceptual dimensions, as Principal Component Analysis is limited to extracting dimensions from the attributes provided, if certain key aspects are missing from the original attribute set, the corresponding dimensions may not be identified [23]. Meanwhile, people are generally less skilled at describing sound than visual elements in daily communication, even though their receptive vocabulary tends to be larger than the vocabulary they actively use in speech or writing [24]. This results in a lack of descriptive terms for auditory experiences [7,25,26]. Therefore, to minimize the influence of verbal expression ability on the results, researchers usually provide participants with a predefined list of attributes during listening tests. Although these words may not be commonly used in daily communication, they are typically part of the participants’ passive vocabulary and are therefore likely to be understood and used appropriately [23].
As the attributes are natural language expressions used to describe soundscapes, a common approach to compiling such vocabularies is to extract them from public-generated texts. For example, Torresin et al. [13] adopted high-frequency descriptive terms identified by Tussyadiah and Zach [26] from more than 40,000 Airbnb user reviews and over 200,000 sentences describing residential experiences as attributes for their study. However, for space types that lack such corpus-based studies, compiling comparable vocabularies is challenging because it requires large-scale data processing and analysis. Therefore, it is practically meaningful to explore new tools that can support the extraction of public natural language expressions to generate and screen potential perceptual vocabulary.
Large language models (LLMs) are the most used generative artificial intelligence models, and the effectiveness of using commercial models in scientific research has been proved [27,28]. Since LLMs are trained on open-source textual content sourced including blogs, social media, product reviews, forum discussions, and news articles, they contain lots of knowledge about natural language expressions. Meanwhile, Andrea Pedrotti et al. [29] found that, for technical categories requiring encyclopedic or specialized knowledge, LLMs often generate more exemplars than humans, because producing such subordinate-category examples relies heavily on specialized knowledge that can be retrieved and recombined from text, and LLMs accumulate broader encyclopedic and domain-specific vocabulary coverage through their training corpora. Therefore, LLMs can extract potential attributes from the massive text which they were trained on within a relatively short period, while maintaining higher consistency and reproducibility, thereby compiling a broader and more diverse candidate vocabulary pool when combined with traditional soundscape research methods.
Therefore, this study has two aims. The first aim of this study is to create an initial list of attributes by collecting potential adjectives that can be used to describe dining spaces from multiple sources, and to process them through a multi-stage qualitative analysis. This yielded a grouped list of semantically similar attributes, providing a basis for quantitative analyses to identify key perceptual dimensions of dining space soundscapes and furthermore build a principal components model. Second, the study aims to propose and validate a scalable and reproducible methodological pathway for expanding attribute vocabulary coverage in highly specific contexts, so that it can be applied to other space types.
2. Methodology
The whole process involved four closely connected stages. A broad pool of candidate attribute vocabulary was collected in Stage 1 using two independent methods. In Stage 2, the resulting pool was refined through duplicate removal, where exact repeats were deleted and closely overlapping cognate forms were standardized to reduce redundant semantic content. In Stage 3, eligibility screening was conducted to remove attributes that were considered unsuitable for the study, based on group discussions. In Stage 4, the retained terms were further consolidated through semantic clustering of semantically similar attributes via in-person expert discussion, and the final set of attribute groups was generated for subsequent analyses.
2.1. Attribute Vocabulary Collection Stage
Potential attributes were collected at this stage from two sources. First, various attribute rating scales have been used to quantify individuals’ subjective perceptions of soundscapes in numerous studies on dining space soundscape evaluation, while descriptive terms have also been spontaneously elicited from participants during interviews or focus groups. Hence, the first set of attributes was extracted from existing acoustic and soundscape studies related to dining spaces from a literature review.
The second set of attributes was derived from the outputs of commercial LLMs. Four LLMs were selected as a pragmatic trade-off between coverage and reproducibility. Increasing the number of models is unlikely to substantially expand the vocabulary, while a single-model approach may be more vulnerable to model-specific lexical and cultural bias. Using four widely adopted commercial models developed in different countries enables cross-model triangulation while keeping the workflow transparent and auditable.
Since all LLM outputs were produced via the models’ commercial chat interfaces, decoding parameters (e.g., temperature, top-p, or random seeds) could not be explicitly set or retrieved by the user and therefore could not be fixed or systematically controlled. To reduce the potential influence of randomness, the following measures were applied: (i) exactly the same prompt was used across models; (ii) each run was conducted using newly registered accounts to avoid context accumulation; and (iii) the model name, version, generation date and time, and the full prompt were documented in the Supplementary Materials. Although commercial interfaces cannot guarantee byte-level reproducibility, the aim of this stage was to compile the broadest possible pool of candidate terms rather than to quantify generation uncertainty.
2.1.1. Literature Review
To systematically identify relevant studies on dining space acoustics and soundscape evaluation, studies were collected in two major academic databases, Web of Science and Scopus through advanced search. These databases were selected due to their comprehensive coverage of peer-reviewed journals across acoustics, architecture, and built environment research. The search strategy was designed to capture studies addressing both acoustic conditions and soundscape-related perceptual evaluations in dining spaces. The search was conducted using the following search expressions:
“Scopus: (TITLE-ABS-KEY (soundscape\*) OR TITLE-ABS-KEY (acoustic\*) OR TITLE-ABS-KEY (sound\*)) AND (TITLE-ABS-KEY (restaurant\*) OR TITLE-ABS-KEY (dining\*) OR TITLE-ABS-KEY (canteen\*))”
“Web of Science: (TS = (soundscape\*) OR TS = (acoustic\*) OR TS = (sound\*)) AND (TS = (restaurant\*) OR TS = (dining\*) OR TS = (canteen\*))”
Results from the two databases were merged after completing the searches, followed by a preliminary screening based on article titles to exclude studies unrelated to dining spaces or acoustics, as well as non-English publications. The full texts of the remaining papers were then obtained and carefully reviewed by the researcher.
During the full-text review, particular attention was given to the methods sections and interview-related content of the selected studies. Potential attributes used to describe soundscapes were extracted from two sources: (1) descriptive terms spontaneously used by participants during interviews or focus groups, and (2) pre-defined attributes included in semantic or attribute rating scales for dining space soundscape evaluation in previous studies. This process resulted in the generation of an independent list of candidate attributes. All extracted attribute terms were retained in their original forms for processing in later stages.
2.1.2. Large Language Models
Since different LLMs vary in training corpora, model architectures, and fine-tuning strategies, they may produce attribute lists with different semantic associations and linguistic styles from the same prompt provided. By using multiple different LLMs and aggregating their outputs can reduce the bias of a single model while increasing the diversity and range of attributes. Hence, 4 commercial LLMs were used in this study including ChatGPT-4.0 by OpenAI, Gemini 2.5 by Google, DeepSeek-V3, and Claude Sonnet 4 by Anthropic.
As LLMs differ from humans in perceptual and reasoning abilities fundamentally [30], they are essentially probabilistic models that predict the most likely next word based on statistical patterns from the massive corpora. In addition, most LLMs have limited access to the latest information or verify facts, so their output is mostly based on patterns in the training data rather than understanding or judgment [31]. When in the absence of sufficient relevant training data, LLMs only rely on indirect or weakly associated information to generate responses. These issues collectively lead to hallucinations and generate content that appears plausible but are inaccurate, unverifiable, or entirely fabricated, thereby affecting output quality [32]. Nearly all existing LLMs are affected by this problem, and reducing the influence of hallucinations remains a key research challenge in the field of natural language processing [33]. Nevertheless, carefully designing prompts that are complete, clear, and not overly open-ended can effectively mitigate this issue and ensure the model generates content which meets the intended expectations [33,34].
To minimize the risk of hallucination, the prompt was structured into five components including Instructions, Context, Examples, Input, and Output according to established practices and guidelines [35,36]. This could ensure the completeness and clarity of the prompts while avoiding overly open-ended generation requests and eventually producing semantically accurate and controllable results. The prompt used is as follows:
“You are a researcher studying the emotional or affective responses people have in indoor dining spaces. Please generate a concise list of around 100 single-word descriptive adjectives that naturally express people’s emotional reactions to the soundscape in such spaces.
Requirements: Focus only on emotional or affective descriptors (e.g., calm, stressful, cozy, overwhelming). Avoid technical acoustic terms or naming sound sources (e.g., “noise level”, “music”). Use natural language commonly and output the list as bullet points.”
Although LLM outputs were entirely based on pre-trained data and their model parameters do not change during user interactions, their generative behavior might still be influenced by prompt frequency or topic priming which led to bias and impacted the reproducibility and controllability of results. Each generation task was conducted using newly registered accounts to ensure a clean, context-free environment to minimize this risk. Given that LLMs are prone to performance degradation in multi-turn interactions [37], single-turn prompting technique was adopted, which means only one prompt was used for each model call, each model’s response was saved separately in an individual CSV file.
2.2. Duplicate Removal Stage
During the second stage, duplicate terms were removed from the initial attribute vocabulary obtained from literature extraction and generated by LLMs. As PCA reduces dimensionality by extracting key components that explain most of the variance in the data, meaning that attributes showing similar patterns of variation are clustered together and treated as a single dimension. Duplicate or highly synonymous terms can cause the covariance structure to be overly dominated by a narrow semantic domain, thereby inflating the explained variance of certain principal components because essentially the same attribute is counted multiple times. In addition, duplicate items increase the length of the experiment and add to the workload for both researchers and participants.
Meanwhile, some terms were standardized through cognate replacement. As cognates often show substantial semantic overlaps and may therefore affect the explained variance of PCA components in a similar way to duplicate items. Second, different grammatical forms tend to direct evaluation toward different targets: past participles are more likely to be interpreted as describing an individual’s state, whereas present participles are more likely to be used to describe an objectively existing entity or concept. Therefore, terms that primarily express an individual’s emotional state, rather than soundscape characteristics, were converted to semantically consistent cognate forms that are more suitable for describing the soundscape prior to further processing.
The procedure was implemented as follows: Exact duplicates in the Stage 1 attribute list were removed, retaining one instance per term in the first place. Next, terms that usually expressed an individual’s state, rather than describing the characteristics of an object, were replaced with cognate forms that differed in word form but conveyed highly similar meanings. This section focuses only on removing exact duplicates and addressing semantic overlaps introduced by cognates and does not involve a substantive evaluation of whether each term is appropriate for this study. the original word form is retained if no suitable cognate replacement is available. After this process, new duplicates introduced by the conversion were also removed, consolidated into a new candidate list for subsequent processing.
2.3. Eligibility Screening Stage
Unsuitable attributes were screened and deleted during Stage 3, which mainly contains two parts. First, attributes that were not aligned with the aim of the study were excluded. As the study focused on affective responses evoked by soundscapes rather than physical acoustic properties, technical terms describing physical characteristics of sound environment were removed first [6]. In addition, terms that were primarily associated with other sensory modalities (e.g., visual or olfactory) instead of describing soundscapes were also excluded. Second, to improve the clarity and comprehensibility of the attributes, terms that did not conform to common everyday English usage were removed. This included words with unclear meanings, words that are uncommon in daily English, and terms that were potentially ambiguous and could introduce confusion.
Decisions on whether to retain a given attribute were made through group discussions with two native English speakers with reference to definitions from the Collins English Dictionary. Both participants had no soundscape or acoustics research background and were selected to avoid introducing potential bias caused by academic background. All candidate terms were assigned to one of three categories: (1) removed due to unsuitable to the research background; (2) removed due to inappropriate language use; or (3) retained for subsequent steps. Attribute with multiple meanings was also retained if at least one common meaning could be used to describe dining space soundscapes. When disagreements arose, the discussion continued until consensus was reached. The decisions were recorded and annotated in an XLSX file for transparency and to facilitate subsequent processing, and the retained terms were then consolidated into a new candidate list for subsequent processing.
2.4. Semantically Similar Attributes Clustering Stage
A group discussion was conducted with an experienced team in soundscape re-search (the UCL IEDE Acoustics and Soundscape group) to cluster attributes with similar meanings or expressing similar concepts into the same group in this stage. This step is conceptually similar to deduplication: even when terms have different lexical forms, substantial semantic overlap may lead to effects comparable to exact duplicates, as such items essentially reflect the same perceptual dimension and thereby influence the explained variance of principal components. Therefore, semantically similar items were clustered and grouped accordingly, followed the principle that each term may be interpreted differently by respondents, and that overlapping meanings among similar terms help to more precisely define the underlying concept [23]. Therefore, although the terms within a given group share a core meaning, they may still differ subtly in emphasis, intensity, or affective connotation. The shared core meaning is used to support comparisons between groups, while the non-overlapping nuances are retained as modifiers that refine and specify the core meaning, rather than being treated as separate concepts or additional dimensions. In addition, because the core meaning of each group is difficult to fully capture with a short label without losing these nuances, no single group label was assigned to the attribute groups.
The discussions were held in person. In each round, one attribute was randomly presented for classification. The team first consulted dictionaries to clarify its meaning and then discussed whether it fitted into an existing group, based on the principles described above. If no suitable group was available, a new group was created. When disagreements arose, the discussion continued until consensus was reached. This process was repeated until all attributes had been grouped, and the results were consolidated into the final list of attribute groups. After the in-person consensus discussions, the authors conducted a brief post hoc consistency check by independently reviewing the final semantic group assignments and qualitatively verifying that each attribute aligned with the agreed group definition. This check was guided by the principle of ensuring within-group semantic coherence around a shared core meaning while preserving subtle, non-overlapping nuances as within-group modifiers rather than splitting them into additional concepts.
3. Results
Figure 1 summarizes the overall workflow of attribute collection and processing and reports the number of items retained and removed at each stage. As described in the previous section, potential attributes were first collected from two sources to form an initial candidate pool, which was then refined through deduplication, screening, and clustering.
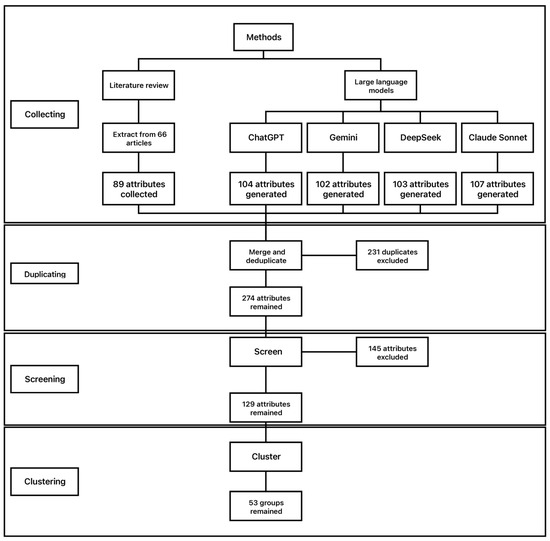
Figure 1.
Workflow for attribute collection and processing.
The initial literature search was completed on 10 July 2025. In total, 1151 records were retrieved at this stage, comprising 757 articles from Scopus and 394 from Web of Science. After merging the results and removing obviously irrelevant records through screening with the title and abstract, 79 studies judged to be related to dining spaces or acoustics were retained for further review, and the full texts of 66 of these papers were successfully obtained and examined in detail. From the included literature, a total of 89 single-word adjective terms were collected as the first component of the candidate attribute pool for describing dining soundscapes.
In parallel, approximately 100 single-word attributes were generated from each LLM as part of the LLM-based attribute generation procedure, resulting in a total of 416 attributes. Key metadata for the LLM generation, including the generation time, model version, and each model’s training data cutoff date, were recorded and stored alongside the generated outputs in dedicated XLSX files which can be accessed via the Supplementary Materials to ensure transparency and reproducibility, so that the provenance of each generated attribute could be traced during later processing and reporting. In addition, the attribute lists obtained from the two sources, as well as both the complete set of records retrieved in the literature search and the final set of included studies, were saved in separate XLSX files provided in Supplementary Materials.
In Stage 2, 197 exact duplicates of the 505 attributes collected in Stage 1 were first removed, reducing the pool to 308 unique terms. This step retained only one instance of repeated entries that appeared multiple times in the initial pool (e.g., calm and calm, agitated and agitated), to avoid counting the same semantic content multiple times. In addition, 44 terms were standardized via the conversion process to obtain semantically consistent word forms that are more suitable for describing soundscapes. Specifically, forms more likely to be interpreted as describing an individual’s state were converted to corresponding descriptive adjective forms when a close cognate was available (e.g., stressed → stressful, threatened → threatening). A second-round deduplication removed a further 34 terms introduced as new duplicates by the conversion process, resulted in a list of 274 single-word attributes.
In Stage 3, 145 unsuitable terms were excluded based on the criteria described in the Methodology, including 54 terms removed due to a mismatch with the research aim (e.g., loud and jarring) and 91 terms removed due to inappropriate language use (e.g., angry and heavy), left 129 attributes considered appropriate for describing dining space soundscapes. In Stage 4 these 129 attributes were consolidated into 53 attribute groups through in-person group discussions, resulting in the final grouped attribute list reported in Table 1. Detailed records of all intermediate steps, decisions, and outputs were documented and stored in an XLSX file provided in the Supplementary Materials.

Table 1.
Final list of the grouped attributes.
Table 1 contains 53 attribute groups covering 129 unique single-word attributes. The table is arranged alphabetically: columns are ordered by the initial letter of each group, and rows are ordered by the initial letter of the first attribute in each group. As noted above, no explicit group labels were assigned, so all attributes listed on the same line belong to the same group. In terms of group size, each group contains on average 2.43 attributes, with a range of 1–9. Most groups are small and contain less than two terms), which typically correspond to more specific meanings with fewer close alternatives, whereas a smaller number of groups contain more members, indicating a higher degree of synonym and semantic overlap within those domains.
4. Discussion
4.1. Provenance Analysis
The provenance of the 129 individual attributes from the final list was assessed by comparison with the lists obtained at the Collect stage which comprised 505 attributes in total, including 89 terms extracted from the literature review and 416 terms generated by LLMs. Cognate forms were treated as equivalent during provenance matching, as some attributes did not match the original word forms due to standardization in Stage 2. Thus, if any cognate form could be identified in the original source lists, the term was still attributed to the corresponding source. For example, as “relaxing” appears in the final list, “relaxing”, “relaxed”, and “relax” were treated as equivalent for provenance matching. Based on this rule, of the 129 attributes, 28 were shared by both sources, 16 were from the literature review only, and 85 were from the LLM outputs only. Based on this rule, among the 129 attributes, 16 came only from the literature review, 85 came only from the LLM outputs, and 28 came from both sources. Detailed records are provided in a dedicated XLSX file in the Supplementary Materials.
The results show that the attributes shared by both sources were commonly used ones across different spatial contexts (e.g., pleasant, annoying, calm, and tense). By contrast, attributes unique to the literature review were more closely aligned with the theoretical or scale-based language commonly used in soundscape research and often corresponded to more conceptual dimensions such as valence, arousal, or overall evaluation (e.g., arousing, positive, and good), which are typically used in standardized measurement contexts rather than in everyday language. Attributes unique to the LLM outputs were more numerous and often related to how the space feels and its ambience (e.g., oppressive, shrill, sophisticated, romantic). These attributes are less represented in the scale-driven language of prior soundscape studies, helping ensure list is not limited by an overly narrow, theory-coded vocabulary. Together, the two sources offer a list with broader coverage and greater diversity of attributes.
4.2. Overview of the Final Outcomes
Overall, these groups cover a wide range of semantic meanings, including both positive and negative affective outcomes as well as attributes describing arousal, activity, and ambience. The attributes in the smaller groups contain less than 2 attributes, usually have a more specific meaning and fewer close alternatives (e.g., groups starting with cacophonous, shrill, romantic). In contrast, the attributes of larger groups contain five or more attributes (e.g., groups starting with disquieting, bland, aggravating), usually have a highly overlapping in semantic domain and show high substitutability in actual language use. This also indicates that the semantic overlap among several attributes might be particularly high, further emphasizing the importance of the clustering step.
On the other hand, attribute groups referring to a clear affective outcome (e.g., groups starting with cheerful, aggravating and depressing) have the highest ratio among all categories. This suggests that people commonly evaluate dining space soundscapes according to overall affective responses and they are most accustomed to describing how the acoustic environment makes them feel. Meanwhile, the list also includes several groups reflecting arousal and energy level (e.g., groups starting with animated, electric, and arousing), indicating that whether a dining space soundscape makes people feel “lively,” supports intense social interaction, and helps create a more vibrant ambience, is also a key factor when evaluating.
In addition, the list also includes groups describing whether the sound environment is organized, stable, and clear (e.g., groups starting with controlled, hushed, and clear), as well as groups related to overstimulation, reduced controllability, or listening fatigue (e.g., groups start with disruptive, draining, strained, and deafening). This suggests that “clarity/controllability/orderliness” also functions as a relatively independent evaluative aspect that people use to judge whether the sound environment supports communication and provides a stable experience, or whether it instead leads to fatigue, a sense of oppression, or feeling out of control, as part of the overall evaluation of dining soundscape quality.
4.3. Comparison of Attribute Lists from Other Studies
A comparison of the attribute list developed for dining spaces in this study with existing frameworks for outdoor environments [38], residential buildings [13], and offices [39] reveals several shared features across the four contexts. Multiple attributes related to affective appraisal recur across studies, particularly words that describe emotional responses to the soundscape (e.g., pleasant, annoying, calm, relaxing). Meanwhile, attributes characterizing the level of activity and change in the sound environment also appear in multiple studies (e.g., lively, eventful, vibrant, dynamic). Taken together, these findings suggest that soundscape description typically focuses on two basic aspects: (1) how the acoustic environment makes people feel; and (2) how active and eventful the sound environment is over time. This cross-context consistency further indicates that these two aspects may constitute a relatively fundamental and transferable semantic scaffold for soundscape perception: regardless of spatial function, people often begin by organizing their overall impression of the acoustic environment in terms of “how good or bad it feels” and “how active or changeable it is”.
Nevertheless, clear differences remain in semantic emphasis and vocabulary coverage across space types. Compared with other contexts, the attribute set proposed for dining spaces includes more terms related to social interaction and interpersonal experience (e.g., friendly, welcoming, alienating, unfriendly) as well as terms that emphasize arousal and activation in response to the soundscape (e.g., arousing, energizing, and stimulating). The former suggests that dining soundscapes are not perceived merely as background noise, it directly affects the overall experience in the certain space, shapes how easily people can converse, how fluid interactions feel, and whether the shared atmosphere is experienced as comfortable. The latter focuses on whether the soundscape makes the space feel more energetic or stimulating, which is closely related to how lively the dining atmosphere is and how actively people interact. In other words, in dining settings, the acoustic environment is evaluated not only in terms of “comfort versus annoyance”, but also in terms of “whether it creates an atmosphere, has enough energy, and supports social activity” which appear less prominently in the attribute list for other spaces.
By contrast, in other indoor contexts, attributes for residential buildings [13] tend to place greater emphasis on controllability and privacy (e.g., intimate, sheltered, predictable, controllable, private). This difference is likely driven by different user expectations due to the various spatial functions that the space carries, as residential acoustic evaluation often reflects low-cognitive-demand activities including relaxing and watching TV under relatively long-term sound exposure, the core concerns involve predictability, recoverability, and the ability to regulate sound exposure, this makes themes such as control, shelter, and privacy particularly prominent. Dining spaces, however, usually involve shorter stays and are more strongly oriented toward social and consumer experience. Therefore, evaluations tend to focus more on whether the immediate ambience feels appropriate, whether communication is smooth, and whether the overall experience is enhanced or disrupted, placing greater emphasis on momentary affective responses and contextual ambience.
Meanwhile, attribute list for office setting [39] shows another distinctive emphasis, including terms related to attention and task support (e.g., demotivating, promoting concentration, inhibiting concentration) to assess whether the soundscape supports prolonged use and improves functional efficiency or behavioral performance. The evaluation of the quality of soundscape in office settings is often associated with sustained usability, low distraction, and stable cognitive performance, so vocabulary is more directly anchored in task demands and concentration management. By comparison, the attributes developed in this study for dining spaces place greater weight on immediate experience and perceived ambience, and are more readily linked to social comfort, emotional tension, or perceived activity level.
In addition, attribute list proposed for outdoor soundscape by Axelsson et al. [38] includes many terms that characterize place qualities and environmental identity. Examples include attributes related to naturalness versus artificiality (e.g., natural, artificial), spatial typology (e.g., urban, rural) and environmental “ambience” or “sensory quality” (e.g., full of atmosphere, refreshing, and pure). Such vocabulary tends to frame the acoustic environment as part of a location’s inherent character, expressing perceived naturalness, scene identity, and an overall esthetic impression. Although similar themes are partially reflected in the attributes developed in this study for dining space (e.g., classy, sophisticated, romantic, festive), unlike those for outdoor soundscape that place more emphasis on “sense of place” or environmental qualities, attributes developed for dining space soundscape still focus more on the overall dining ambience. Overall, these differentiated attribute clusters may reflect space-specific perceptual dimensions and evaluation mechanisms, which further underscores the need to develop models of perceived affective quality specifically for dining spaces.
4.4. Next Steps
Similarly to procedures used in other studies [13,38,39], the next step will be to use the attribute list developed in this study to design a questionnaire which will be employed as the core tool for further quantitative work. A controlled laboratory listening test will be conducted using representative stimuli of dining soundscape from binaural recordings while participants will rate each attribute. Principal component analysis (PCA) will be applied to identify the covariation structure among attributes according to the rating results, thereby summarizing multiple correlated attributes into a set of latent perceptual dimensions by extracting a small number of principal components that explain the largest proportion of variance. Subsequently, the semantic meaning of each dimension will be labeled based on the loading pattern of attributes on the corresponding principal component, thereby constructing a model of perceived affective quality for dining spaces and providing a structured framework for the collection of subjective evaluation data on dining space soundscapes. It is important to note that for the laboratory listening test the multisensory effects [40,41,42] should be considered, especially audio-visual interactions [43,44,45].
In addition, fellow scholars can systematically compare the attribute list developed in this study for dining space with attribute lists from more spaces which could help identify preferences and gaps in attribute selection across space types and further reveal how attribute varies with spatial functions and patterns of activities. Such comparisons can be conducted at both the lexical and semantic levels. Researchers can quantify overlap rates and identify unique terms that appear only in a specific space type while comparing how extensively each space type covers and emphasizes different themes, thereby providing more direct evidence for differences in the perceptual dimension across various spaces.
Moreover, validation across cultures and languages is an important next step. The current vocabulary was developed from English sources and generated through commercial LLM interfaces, so the attributes may reflect sound related experiences in a particular language and cultural context. Future work could replicate the same multistage procedure in other languages by combining locally relevant literature with public generated texts, followed by screening by native speakers and semantic clustering through expert discussion. This will help test whether the resulting perceptual dimensions remain stable across different languages and cultural contexts.
4.5. Limitations
Despite adopting a systematic research procedure, several methodological limitations should be acknowledged. First, the processing of attributes relied primarily on qualitative methods including semantic clustering and group discussions. As with most qualitative approaches, unavoidable subjectivity exists as the researchers’ academic background and disciplinary experience may influence the results to some extent. However, this risk was mitigated as far as possible through the adoption of a transparent procedure and the maintenance of a clear audit trail with key decisions documented in detail throughout the process [46].
In addition, although the experts have extensive experience in soundscape research, their understanding and categorization of terms may differ from that of everyday users in dining environments. Individual differences in cultural background, language comprehension, personal experience, and sensitivity to sound may cause variations in how attributes are perceived and interpreted. Therefore, the resulting attribute framework may not fully reflect the perceptions of ordinary diners. Future studies could involve quantitative methods including participant surveys to evaluate improve the clarity and generalizability of the attributes.
5. Conclusions
This study addresses a key gap in indoor soundscape research that the lack of a model of perceived affective quality specifically designed for dining spaces while existing models developed for other indoor spaces have uncertain applicability in this certain space. To fill this gap, potential attributes were first identified and compiled through multiple sources including systematic review of literature related to dining space soundscapes and generation by Large Language Models from numerous nature language text. These candidate attributes were then refined through a multi-step qualitative analysis, resulting in a final list organized into groups of semantically similar terms.
This processed attribute list provides a structured vocabulary for describing dining space soundscapes which can be used to collect subjective data in controlled listening tests and supports the identification of key perceptual dimensions of dining space soundscapes through principal component analysis, thereby establishing a measurement basis for subsequent quantitative research. Overall, this study offers the necessary conceptual and methodological prerequisites for specifically developing a principal component model of perceived affective quality to dining spaces and provides foundational tools and a research pathway for future soundscape research and design in dining space.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/buildings16051019/s1, File S1: A zipped folder containing all detailed worksheet files from the four stages of the attribute collection and processing procedure, with files named according to each stage.
Author Contributions
Conceptualization, H.Z., A.M., J.K. and F.A.; Methodology, H.Z., A.M., J.K. and F.A.; Validation, H.Z.; Formal analysis, H.Z.; Investigation, H.Z. and F.A.; Data curation, H.Z.; Writing—original draft, H.Z.; Writing—review and editing, H.Z., J.K. and F.A.; Visualization, H.Z.; Supervision, A.M., J.K. and F.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The original contributions presented in this study are included in the Supplementary Material. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
Author Andrew Mitchell was employed by the company Connected Places Catapult. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| LLM | Large language model |
| PCA | Principal component analysis |
References
- Torresin, S.; Aletta, F.; Babich, F.; Bourdeau, E.; Harvie-Clark, J.; Kang, J.; Lavia, L.; Radicchi, A.; Albatici, R. Acoustics for Supportive and Healthy Buildings: Emerging Themes on Indoor Soundscape Research. Sustainability 2020, 12, 6054. [Google Scholar] [CrossRef]
- Lebo, C.P.; Smith, M.F.; Mosher, E.R.; Jelonek, S.J.; Schwind, D.R.; Decker, K.E.; Krusemark, H.J.; Kurz, P.L. Restaurant noise, hearing loss, and hearing aids. West. J. Med. 1994, 161, 45–49. [Google Scholar] [PubMed]
- Borah, B.; Sarma, M.K. Acoustic Appetite: How Restaurant Soundscapes Shape Dining Experiences. Acta Univ. Bohem. Merid. 2024, 27, 17–33. [Google Scholar] [CrossRef]
- Rusnock, C.F.; Bush, P.M.C. An evaluation of restaurant noise levels and contributing factors. J. Occup. Environ. Hyg. 2012, 9, D108–D113. [Google Scholar] [CrossRef]
- Lindborg, P. Psychoacoustic, physical, and perceptual features of restaurants: A field survey in Singapore. Appl. Acoust. 2015, 92, 47–60. [Google Scholar] [CrossRef]
- Cain, R.; Jennings, P.; Poxon, J. The development and application of the emotional dimensions of a soundscape. Appl. Acoust. 2013, 74, 232–239. [Google Scholar] [CrossRef]
- Guastavino, C. The ideal urban soundscape: Investigating the sound quality of French cities. Acta Acust. United Acust. 2006, 92, 945–951. [Google Scholar]
- Yang, W.; Kang, J. Acoustic comfort evaluation in urban open public spaces. Appl. Acoust. 2005, 66, 211–229. [Google Scholar] [CrossRef]
- Torresin, S.; Albatici, R.; Aletta, F.; Babich, F.; Kang, J. Assessment methods and factors determining positive indoor soundscapes in residential buildings: A systematic review. Sustainability 2019, 11, 5290. [Google Scholar] [CrossRef]
- BS ISO 12913-1:2014; Acoustics—Soundscape—Part 1: Definition and Conceptual Framework. British Standards Institution: London, UK, 2014.
- Aletta, F.; Astolfi, A. Soundscapes of buildings and built environments. Build. Acoust. 2018, 25, 195–197. [Google Scholar] [CrossRef]
- West, B.; Ali-MacLachlan, I.; Deuchars, A. An in-situ investigation of office soundscape perceptual evaluation methodologies. Proc. Inst. Acoust. 2023, 45. [Google Scholar] [CrossRef]
- Torresin, S.; Albatici, R.; Aletta, F.; Babich, F.; Oberman, T.; Siboni, S.; Kang, J. Indoor soundscape assessment: A principal components model of acoustic perception in residential buildings. Build. Environ. 2020, 182, 107152. [Google Scholar] [CrossRef]
- Chen, X.; Kang, J. Acoustic comfort in large dining spaces. Appl. Acoust. 2017, 115, 166–172. [Google Scholar] [CrossRef]
- Kang, J.; Lok, W. Architectural acoustic environment, music and dining experience. In Proceedings of INTER-NOISE and NOISE-CON Congress and Conference Proceedings, Honolulu, HI, USA, 3-6 December 2006; Institute of Noise Control Engineering of the USA: Wakefield, MA, USA, 2006; Volume 5, pp. 3132–3141. [Google Scholar]
- Tarlao, C.; Fernandez, P.; Frissen, I.; Guastavino, C. Influence of sound level on diners’ perceptions and behavior in a montreal restaurant. Appl. Acoust. 2021, 174, 107772. [Google Scholar] [CrossRef]
- Bitner, M.J. Servicescapes: The Impact of Physical Surroundings on Customers and Employees. J. Mark. 1992, 56, 57–71. [Google Scholar] [CrossRef]
- Prewitt, M. Pipe down! Study blasts hazardous dining room noise. Nation’s Restaur. N. 2000, 34, 1. [Google Scholar]
- Webster, J.C.; Klumpp, R.G. Effects of Ambient Noise and Nearby Talkers on a Face-to-Face Communication Task. J. Acoust. Soc. Am. 1962, 34, 936–941. [Google Scholar] [CrossRef]
- Cherry, E.C. Some Experiments on the Recognition of Speech, with One and with Two Ears. J. Acoust. Soc. Am. 1953, 25, 975–979. [Google Scholar] [CrossRef]
- Roy, K.P. Satisfying Hunger, Thirst, and Acoustic Comfort in Restaurants, Diners, and Bars… Is This an Oxymoron? Acoust. Today 2019, 15, 20. [Google Scholar] [CrossRef]
- Lindborg, P. A taxonomy of sound sources in restaurants. Appl. Acoust. 2016, 110, 297–310. [Google Scholar] [CrossRef]
- Welch, D.; Shepherd, D.; Dirks, K.; Tan, M.Y.; Coad, G. Use of Creative Writing to Develop a Semantic Differential Tool for Assessing Soundscapes. Front. Psychol. 2019, 9, 2698. [Google Scholar] [CrossRef]
- Graves, M.F. The Vocabulary Book: Learning and Instruction, 2nd ed.; Teachers College Press: New York, NY, USA, 2016. [Google Scholar]
- Guastavino, C. Categorization of Environmental Sounds. Can. J. Exp. Psychol. 2007, 61, 54–63. [Google Scholar] [CrossRef]
- Tussyadiah, I.P.; Zach, F. Identifying salient attributes of peer-to-peer accommodation experience. J. Travel Tour. Mark. 2017, 34, 636–652. [Google Scholar] [CrossRef]
- Gultom, A.M.; Ashadi, A.; Fatnalaila, F.; Azizah, S.; Maftuhatu, D. The Use of Chat GPT for Academic Writing in Higher Education. Formosa J. Sustain. Res. 2024, 3, 1713–1730. [Google Scholar] [CrossRef]
- Lund, B.D.; Wang, T. Chatting about ChatGPT: How may AI and GPT impact academia and libraries? Libr. Hi Tech. News 2023, 40, 26–29. [Google Scholar] [CrossRef]
- Pedrotti, A.; Rambelli, G.; Villani, C.; Bolognesi, M. How Humans and LLMs Organize Conceptual Knowledge: Exploring Subordinate Categories in Italian. arXiv 2025, arXiv:2505.21301. [Google Scholar] [CrossRef]
- Demszky, D.; Yang, D.; Yeager, D.S.; Bryan, C.J.; Clapper, M.; Chandhok, S.; Eichstaedt, J.C.; Hecht, C.; Jamieson, J.; Johnson, M.; et al. Using large language models in psychology. Nat. Rev. Psychol. 2023, 2, 688–701. [Google Scholar] [CrossRef]
- Ramakrishnan, R. How LLMs Work: Top 10 Executive-Level Questions. MIT Sloan Manag. Rev. 2025, 66, 2–5. [Google Scholar]
- Huang, Y.; Feng, X.; Feng, X.; Qin, B. The Factual Inconsistency Problem in Abstractive Text Summarization: A Survey. arXiv 2021, arXiv:2104.14839. [Google Scholar] [CrossRef]
- He, J.; Shi, Y. Research on Categorical Recognition and Optimization of Hallucination Phenomenon in Large Language Models. Jisuanji Kexue Yu Tansuo 2025, 19, 1295–1301. (In Chinese) [Google Scholar] [CrossRef]
- Korzyński, P.; Mazurek, G.; Krzypkowska, P.; Kurasiński, A. Artificial intelligence prompt engineering as a new digital competence: Analysis of generative AI technologies such as ChatGPT. Entrepreneur. Bus. Econ. Rev. 2023, 11, 25–38. [Google Scholar] [CrossRef]
- Liu, P.; Qian, B.; Sun, Q.; Zhao, L. Prompt-WNQA: A prompt-based complex question answering for wireless network over knowledge graph. Comput. Netw. 2023, 236, 110014. [Google Scholar] [CrossRef]
- Zhang, Q.; Dong, J.; Chen, H.; Zha, D.; Yu, Z.; Huang, X. KnowGPT: Knowledge Graph based Prompting for Large Language Models. arXiv 2023, arXiv:2312.06185. [Google Scholar] [CrossRef]
- Li, S.S.; Balachandran, V.; Feng, S.; Ilgen, J.S.; Pierson, E.; Koh, P.W.; Tsvetkov, Y. MediQ: Question-Asking LLMs and a Benchmark for Reliable Interactive Clinical Reasoning. arXiv 2024, arXiv:2406.00922. [Google Scholar] [CrossRef]
- Axelsson, Ö.; Nilsson, M.E.; Berglund, B. A principal components model of soundscape perception. J. Acoust. Soc. Am. 2010, 128, 2836–2846. [Google Scholar] [CrossRef]
- West, B.; Deuchars, A.; Ali-MacLachlan, I. Office soundscape assessment: A model of acoustic environment perception in open-plan offices. J. Acoust. Soc. Am. 2024, 156, 2949–2959. [Google Scholar] [CrossRef]
- Zhang, R.; Ma, H.; Wang, C.; Zhang, Y.; Kang, J. Soundscape and its context: A framework based on a systematic review. J. Acoust. Soc. Am. 2025, 157, 441–446. [Google Scholar] [CrossRef]
- Ba, M.; Kang, J. Effect of a fragrant tree on the perception of traffic noise. Build. Environ. 2019, 156, 147–155. [Google Scholar] [CrossRef]
- Jin, Y.; Jin, H.; Kang, J. Effects of sound types and sound levels on subjective environmental evaluations in different seasons. Build. Environ. 2020, 183, 107215. [Google Scholar] [CrossRef]
- Ren, X.; Kang, J. Effects of the visual landscape factors of an ecological waterscape on acoustic comfort. Appl. Acoust. 2015, 96, 171–179. [Google Scholar] [CrossRef]
- Ren, X. Combined effects of dominant sounds, conversational speech and multisensory perception on visitors’ acoustic comfort in urban open spaces. Landsc. Urban Plan. 2023, 232, 104674. [Google Scholar] [CrossRef]
- Liu, C.; Kang, J.; Xie, H. Effect of sound on visual attention in large railway stations: A case study of St. Pancras railway station in London. Build. Environ. 2020, 185, 107177. [Google Scholar] [CrossRef]
- Thorne, S.E. Interpretive Description: Qualitative Research for Applied Practice, 3rd ed.; Routledge: New York, NY, USA, 2025; pp. 204–205. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.