Abstract
Accurate detection of pressure-relief boreholes is crucial for evaluating drilling quality and monitoring safety in coal mine roadways. Nevertheless, the highly challenging underground environment—characterized by insufficient lighting, severe dust and water mist disturbances, and frequent occlusions—poses substantial difficulties for current object detection approaches, particularly in identifying small-scale and low-visibility targets. To effectively tackle these issues, a lightweight and robust detection framework, referred to as YOLO-DFBL, is developed using the YOLOv11n architecture. The proposed approach incorporates a DualConv-based lightweight convolution module to optimize the efficiency of feature extraction, a Frequency Spectrum Dynamic Aggregation (FSDA) module for noise-robust enhancement, and a Biformer (Bi-level Routing Transformer)-based routing attention mechanism for improved long-range dependency modeling. In addition, a Lightweight Shared Convolution Head (LSCH) is incorporated to effectively decrease the overall model complexity. Experimental results on a real coal mine roadway dataset demonstrate that YOLO-DFBL achieves an mAP@50:95 of 78.9%, with a compact model size of 1.94 M parameters, a computational complexity of 4.7 GFLOPs, and an inference speed of 157.3 FPS, demonstrating superior accuracy–efficiency trade-offs compared with representative lightweight YOLO variants and classical detectors. Field experiments under challenging low-illumination and occlusion environments confirm the robustness of the proposed approach in real mining scenarios. The developed method enables reliable visual perception for underground drilling equipment and facilitates safer and more intelligent operations in coal mine engineering.
1. Introduction
Pressure-relief boreholes are critical engineering structures in coal mine roadways, serving key roles in mitigating rockbursts, regulating stress, and controlling roadway stability [1,2]. Accurate detection of these boreholes is fundamental for evaluating drilling quality, assessing the effectiveness of pressure relief, and ensuring underground operational safety [3]. In practical applications, borehole inspection predominantly relies on vision-based sensing systems mounted on drilling or inspection equipment [4]. Nevertheless, the harsh underground environment poses significant challenges to the reliability of detection.
Coal mine roadways are characterized by low and uneven illumination, heavy dust interference, complex background textures, and frequent occlusion [5]. Under such conditions, pressure-relief boreholes typically appear as small-scale targets with low contrast and weak edge features, making them hard to discriminate against the surrounding coal–rock background. These factors often result in missed detections, false alarms, and unstable confidence, limiting the effectiveness of existing visual detection methods in underground applications.
Although deep learning–based object detectors generally perform well under standard conditions, their performance degrades significantly in complex imaging environments. Most mainstream detectors rely on salient texture and edge cues, which become unreliable under low illumination, high noise, and strong background interference [6]. Moreover, small targets are easily suppressed during multi-scale feature propagation, while conventional convolutional structures and attention mechanisms exhibit limited capability in modeling discriminative features and long-range dependencies for low-contrast objects in cluttered scenes [7,8,9,10]. Further enhancing detection accuracy by increasing network depth inevitably results in substantial computational overhead, which limits real-time deployment on resource-constrained underground platforms [11,12].
These limitations are particularly pronounced in coal mine roadways, where dust, poor lighting, and highly similar background textures further obscure the visual characteristics of pressure-relief boreholes. Meanwhile, underground detection systems are subject to strict constraints on computational resources and energy consumption. Existing studies indicate that even lightweight models still suffer from insufficient robustness when handling small-target detection under complex underground conditions [13,14].
In summary, existing object detection methods remain insufficient for pressure-relief borehole detection in underground coal mine roadways. Their performance degradation mainly stems from three aspects: (i) strong dependence on spatial-domain texture and edge cues, which become unreliable under low illumination, dust, and water mist interference; (ii) limited capability to robustly represent small, low-contrast, and partially occluded targets within cluttered coal–rock backgrounds; and (iii) the need to balance accuracy with computational demand, which hinders real-time implementation on underground platforms with limited resources. These limitations highlight the necessity of developing a detection framework that jointly enhances robustness, small-target perception, and lightweight deployment capability.
Therefore, a detection method that simultaneously achieves robustness and lightweight deployment for coal mine roadways is urgently needed. To this end, this paper presents YOLO-DFBL, a compact and reliable visual detection architecture for pressure-relief boreholes in coal mine roadways. Built upon the YOLOv11n architecture, the proposed method enhances feature representation and noise robustness without incurring excessive computational overhead, enabling accurate and efficient deployment in challenging underground environments. The key achievements of the present research are highlighted below:
- (1)
- To minimize parameter redundancy and computational load, a lightweight DualConv convolutional structure is adopted in the backbone, thereby enhancing multi-scale feature representation for pressure-relief boreholes in complex underground environments.
- (2)
- The FSDA module combined with a Biformer is incorporated into the feature extraction and fusion stages, significantly improving robustness against noise interference, illumination variation, and background clutter, while strengthening long-range dependency modeling and small-target perception.
- (3)
- The LSCH is designed to further compress the model size through parameter sharing, while preserving multi-scale detection capability, which enhances detection efficiency and supports efficient real-time use on computationally limited underground hardware.
2. Related Works
To clarify the technical background and research positioning of the proposed YOLO-DFBL framework, this section reviews related studies from three aspects: the evolution of deep learning–driven object detection, detection applications in coal mine roadway environments, and model optimization strategies for complex scenarios.
2.1. Developments in Deep Learning–Based Object Detection
The swift advancement of deep learning has led object detection methods to move beyond traditional, manually designed feature-based approaches to deep neural network–driven frameworks. Representative early two-stage detection methods such as R-CNN [15], Fast R-CNN [16], and Faster R-CNN [17], which achieve high detection accuracy through region proposal mechanisms but suffer from limited inference speed, restricting their real-time applicability. Compared with two-stage methods, prominent one-stage detection frameworks include SSD [18], RetinaNet [19], and YOLO [20], which formulate object detection as a unified regression formulation, considerably improving inference efficiency while maintaining competitive accuracy.
The YOLO architectures have evolved by optimizing backbone networks, strategies for merging intermediate feature maps, and the organization of detection heads. Since the introduction of the end-to-end regression framework in YOLO [21], YOLO9000 further improved detection performance through multi-scale training and refined bounding box prediction [22]. Subsequently, YOLOv7 achieved superior performance across a wide speed range by incorporating efficient training strategies and structural optimizations [23]. The latest versions, YOLOv8 and YOLOv11, further enhance modular design, lightweight deployment, and multi-scale feature representation, demonstrating improved adaptability in small-object detection tasks [24].
2.2. Object Detection Applications in Coal Mine Roadway Environments
Coal mine roadways are characterized by low and uneven illumination, severe dust interference, complex background textures, and frequent occlusions, placing stringent demands on algorithm stability and inference efficiency. Advances in deep learning have enabled the deployment of object detection techniques in underground tasks, including personnel identification, safety equipment inspection, and conveyor belt monitoring. Yang et al. [25] enhanced foreign-object detection and tracking in coal mines by introducing the COTN module and occlusion-aware attention mechanisms. Wang et al. [26] introduced a lightweight YOLOv11-based model (ECL-Tear), achieving a favorable balance between detection accuracy and inference efficiency with an extremely compact model size. Jin et al. [27] improved underground personnel detection by integrating dynamic convolution and enhanced up-sampling structures, achieving higher accuracy with reduced parameter counts.
Despite these advances, existing studies predominantly focus on large-scale targets or objects with prominent edge features. Systematic investigations on small-scale and low-contrast structures, such as pressure-relief boreholes, remain limited. Boreholes typically appear as small, weak-textured, and partially occluded targets, leading to frequent detection failures and degraded localization precision. Moreover, the constrained computational capability and energy consumption in underground equipment hinder the deployment of deep models with excessive complexity. Therefore, developing detection methods that balance lightweight design and high accuracy remains a critical challenge in underground visual perception.
2.3. Optimization Approaches for Object Detection Under Complex Conditions
In complex settings, addressing both the accurate detection of small objects and the need for real-time processing has motivated numerous strategies emphasizing backbone architecture, feature modeling, and enhanced robustness. At the architectural level, lightweight convolutional networks such as MobileNet [28] and ShuffleNet [29] employ depthwise separable convolutional operations and efficient channel-wise processing to substantially lower computational cost. Dynamic convolution methods, including CondConv [30] and KWConv [31], adapt convolution kernels according to input features, enhancing representation flexibility. The DualConv structure further improves multi-scale feature extraction while maintaining a lightweight design [32].
In terms of feature modeling, attention mechanisms have been widely adopted to enhance discriminative capability. Channel- and spatial-attention modules, such as SE [33] and CBAM [34], guide networks to focus on salient regions. Routing-based attention mechanisms, such as Biformer [35], exhibit superior performance in modeling long-range dependencies and small-object perception, making them well suited for detection in cluttered scenes. In addition, frequency-domain modeling techniques have been increasingly incorporated into detection networks. The FSDA module [36], for instance, enhances robustness against noise, blur, and illumination variations through dynamic frequency spectrum aggregation, which is particularly effective for multi-source interference commonly encountered in coal mine roadway imagery.
Overall, existing research contributes fundamental principles and methodological insights for robust target identification in intricate and dynamic environments. However, achieving high-precision, lightweight, and robust detection of small, low-contrast targets in coal mine roadways remains an open and challenging problem.
3. Methods
3.1. YOLO-DFBL
In this work, the detection of pressure-relief boreholes under challenging coal mine roadway conditions is addressed with a focus on both accuracy and deployability. YOLOv11n is chosen as the baseline because of its favorable balance between model compactness and computational efficiency, strong multi-scale feature representation, and high inference efficiency, making it particularly suitable for small, low-contrast, and partially occluded targets such as pressure-relief boreholes. Moreover, its modular architecture allows the integration of additional enhancement modules without extensive structural modification. Building upon YOLOv11n, the proposed YOLO-DFBL model introduces several key improvements. Firstly, the limited information transmission efficiency and performance bottlenecks of traditional convolutional operations motivate the integration of an efficient convolutional structure, termed DualConv, into the backbone network, enabling enhanced multi-scale feature extraction with reduced parameter redundancy for lightweight deep neural networks. By replacing the original standard convolutional modules, this modification achieves structural lightweight without sacrificing detection accuracy. Second, multi-stage feature refinement is achieved by coupling FSDA with C3K2 across the backbone and neck, thereby improving feature stability when exposed to severe environmental interference. Additionally, to strengthen the ability of the C2PSA module in modeling long-range dependencies and complex semantic interactions, a Biformer is introduced to replace the conventional self-attention module. This substitution enables the model to dynamically route informative tokens across multiple feature layers, thereby significantly improving its performance in detecting small and low-texture targets under challenging coal mine tunnel conditions. Finally, an LSCH is integrated into the Head architecture to further streamline the model structure while maintaining detection accuracy, thereby improving overall detection efficiency. Figure 1 presents the overall network structure of the proposed YOLO-DFBL model.
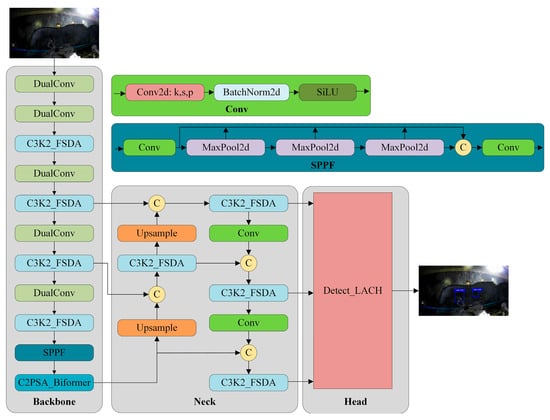
Figure 1.
YOLO-DFBL structure diagram.
3.2. DualConv
YOLOv11 strikes a practical compromise between detection performance and inference cost, its backbone network still contains many conventional convolutional layers, leading to considerable memory consumption and computational overhead. These limitations further constrain inference efficiency and hinder real-time deployment in complex subterranean coal mine settings, particularly for roadway pressure-relief hole detection tasks performed by anti-impact drilling robots. To overcome this limitation, a compact convolutional module named DualConv is incorporated to substitute the CBS convolution in the backbone network, as shown in Figure 2. Standard convolution, depthwise separable convolution, group convolution, and heterogeneous convolution are illustrated in Figure 2a–d, respectively. Based on these designs, the proposed DualConv module is illustrated in Figure 2e. DualConv module is a lightweight dual-branch convolution designed to enhance feature extraction while reducing computational cost. The module adopts a dual-branch architecture, where one branch employs group convolution to independently process channel groups, thereby reducing parameter count and computational cost. Heterogeneous Convolution branch, which applies convolution kernels of different shapes to capture multi-scale features. The DualConv module comprises two parallel convolutional branches: one employs a standard 3 × 3 convolution to extract local spatial features, while the other adopts a depthwise convolution to capture channel-wise features. The outputs of the two branches are merged and linearly integrated to enhance feature representation while minimizing redundant computation, thus enhancing the compact design of the network. The operation is formulated as Equation (1).
where and denote the standard convolution kernel and the depthwise convolution kernel, respectively, the channel-wise feature fusion is performed by the operator , the nonlinearity is introduced through the activation function , and correspond to the input and output feature representations, respectively.
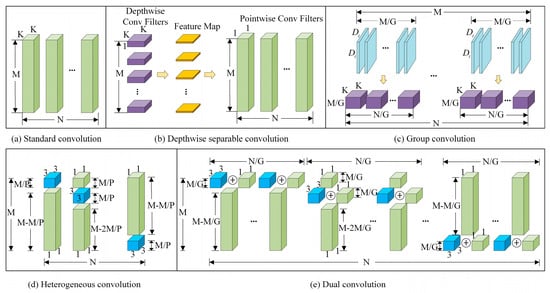
Figure 2.
Schematic comparison of convolutional filter structures, including (a) standard convolution, (b) depthwise separable convolution, (c) group convolution, (d) heterogeneous convolution, and (e) dual convolution. denotes the channel dimension of the input feature map, represents the number of convolution kernels corresponding to the output channels, indicates the spatial resolution (height × width) of the input feature map, is the convolutional kernel size, is the number of groups in group convolution and dual convolution, and is the ratio of convolutional kernels in heterogeneous convolution. Note that the heterogeneous filters are arranged in a shifted manner.
DualConv is deployed in the backbone network, where low-level and mid-level visual features are extracted. Introducing DualConv at this stage enables more effective multi-scale feature modeling and alleviates parameter redundancy, which is crucial for retaining fine-grained information of small pressure-relief boreholes under strict computational constraints.
3.3. C3K2_FSDA
Although the lightweight DualConv structure reduces network parameters and improves computational efficiency to some extent, factors such as sensor noise, illumination variation, and dust interference in complex coal–rock roadway environments still cause the degradation of high-frequency features during feature extraction, which impacts detection performance. To improve noise resistance, the FSDA module is integrated into the C3K2 block of the YOLOv11 architecture, as illustrated in Figure 3a. From an imaging perspective, dust and water mist introduce random scattering and local intensity fluctuations, which are mainly reflected as high-frequency noise components in the frequency domain. Meanwhile, low-illumination conditions suppress informative frequency bands and weaken discriminative texture representations. Conventional spatial-domain convolutions are sensitive to such disturbances and may amplify noise during feature extraction. By performing adaptive frequency-domain aggregation, the FSDA module suppresses noise-dominated components while enhancing informative frequencies, thereby improving robustness under dust, mist, and low-light conditions. Mathematically, it can be expressed as:
where and denote the forward and inverse Fourier transform operators, respectively, and represents a dynamic weighting factor that dynamically modifies the influence of each frequency component. and denote the input feature map in the spatial domain and the weighted reconstructed output feature map, respectively.
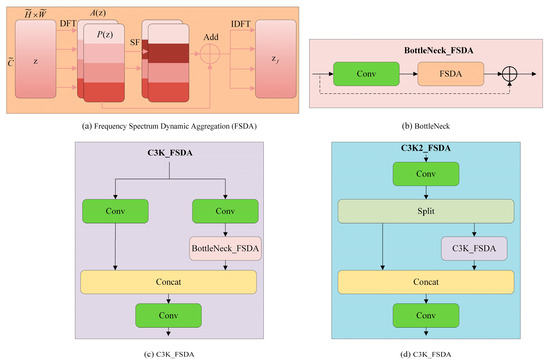
Figure 3.
Detailed structure of the C3K2_FSDA module. In subfigure (a), z denotes the input feature map, represents its DFT, SF indicates the spectral feature, A(z) is the enhancement coefficient generated from SF, and IDFT denotes the inverse DFT mapping the enhanced feature back to the spatial domain, (b) FSDA-enhanced Bottleneck structure, (c) C3K_FSDA module with frequency-domain adaptive filtering and (d) C3K2_FSDA module with dual-branch feature fusion.
Figure 3b illustrates that the second convolution layer (cv2) in the Bottleneck structure is reconfigured by embedding an FSDA-based feature extraction unit. This module processes features in the frequency domain through FFT/IFFT and recalibrates channel weights using an SE layer, while preserving the original residual connection and the first convolution layer (cv1) to ensure feature continuity. The C3K_FSDA module, shown in Figure 3c, incorporates a frequency-domain adaptive filtering mechanism during feature extraction, which strengthens the network’s resistance to high-frequency noise and improves the representation of fine spatial features. The C3K2_FSDA module, illustrated in Figure 3d, employs a dual-branch structure to achieve more comprehensive feature integration. Initially, the input passes through the FSDA module before being split into two independent branches. In the dual-branch design, one path retains the original feature representation, whereas the other employs the C3K_FSDA module to facilitate hierarchical feature refinement. Finally, another FSDA module is employed to concatenate and fuse the outputs from both branches. By jointly modeling spatial structures and frequency components, the proposed design enhances feature robustness and suppresses noise interference. Consequently, it provides a more stable feature foundation for roadway pressure-relief hole detection in underground coal-mine environments. Consider a feature map , where and denote the spatial resolution and represents the channel dimension.
Within the dual-path design, one pathway directly propagates the input features, functioning as an unaltered information stream.
In the alternative path, feature transformation follows the formulation in Equation (4).
The final feature representation is obtained by fusing the two paths, as formulated in Equation (5).
The FSDA module is introduced in both the backbone and neck to suppress noise and illumination-induced distortions at different semantic levels. In the backbone, FSDA enhances the robustness of early feature extraction against dust and low-light interference, while in the neck it stabilizes feature fusion across scales, preventing noise amplification during multi-level aggregation.
3.4. C2PSA_Biformer
The C2PSA module enhances contextual perception; however, it imposes a high computational burden and exhibits limited adaptability to variations in spatial scale and long-range dependencies. In complex coal mine environments with small targets and cluttered backgrounds, these issues reduce detection accuracy. To overcome them, the original attention layer is substituted with a Biformer, forming the C2PSA_Biformer module. This design enhances global context modeling and feature robustness under noise and occlusion. Biformer adopts a bi-level routing–based attention design, referred to as BRA, to capture both global dependencies and local contextual correlations [35]. As shown in Figure 4, x is forwarded along two parallel paths for subsequent processing. Within the dual-path routing scheme, one path maintains local spatial structure and positional cues through static routing, whereas the other employs dynamic routing to capture long-range dependencies based on query–key similarity. This dual-branch design balances local precision and global perception, facilitating information interaction across receptive fields. Given the input , the resulting feature representation produced by Biformer is formulated in Equation (6).
where , and represent the query, key, and value matrices, respectively, and preserves local detail information. The bi-level routing structure adaptively aggregates attention weights across spatial and semantic dimensions, allowing the model to attend to salient regions while reducing background interference.
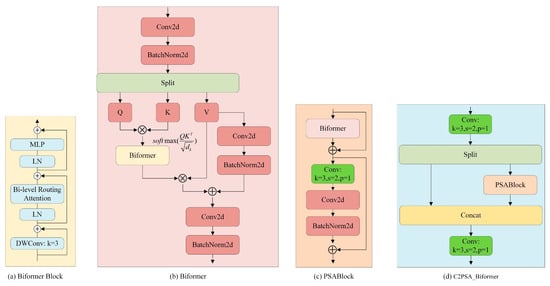
Figure 4.
Detailed description of the C2PSA_Biformer module.
The C2PSA_Biformer module improves multi-scale feature representation, enabling robust detection of small, low-contrast, and partially occluded targets. It is especially effective for pressure relief hole detection in coal mine roadways under low visibility and complex backgrounds. Its lightweight design maintains controllable computational cost, ensuring high accuracy without compromising real-time performance.
It should be noted that incorporating the C2PSA-Biformer module inherently increases computational complexity and may lead to a reduction in inference speed due to the introduction of bi-level routing attention and global dependency modeling. This design reflects a deliberate accuracy–efficiency trade-off at the architectural level. Accordingly, C2PSA-Biformer is not intended to serve as a default lightweight component, but rather as an accuracy-oriented enhancement aimed at improving high-IoU localization stability and detection robustness. In safety-critical underground coal mine environments, where pressure-relief boreholes are extremely small and frequently affected by low illumination and occlusion, reliable detection and precise localization are prioritized over strict real-time efficiency constraints.
The C2PSA-Biformer module is embedded in the neck rather than the backbone to model long-range dependencies across multi-scale semantic features. At this stage, high-level representations are sufficiently abstracted, allowing the routing attention mechanism to effectively enhance global context modeling and small-target perception without introducing excessive computational overhead.
3.5. LSCH
To decrease the model size while maintaining detection accuracy, this study introduces a lightweight redesign of the YOLOv11n Detect module. The original Detect head employs three independent and structurally identical convolutional branches for the P3, P4, and P5 scales, resulting in redundant parameters and a non-negligible proportion of the overall model complexity. To tackle this problem, we propose a “shared convolution with independent BatchNorm” detection head that effectively eliminates redundancy while maintaining multi-scale feature representation, as depicted in Figure 5.

Figure 5.
Architecture of the LSCH module. Three input feature maps are sequentially transformed through a 3 × 3 depthwise convolution, a 1 × 1 convolution, and an additional 3 × 3 depthwise convolution. The outputs share a 3 × 3 convolution, with independent batch normalization per scale. Features are decoupled into regression (Conv2d-Reg, k = 1) and classification (Conv2d-Cls, k = 1) pathways. A scale layer adjusts the regression output to match the target detection scale.
In multi-scale detection, feature representations of objects at different levels should remain consistent across scales. However, YOLOv11n employs separate detection heads for each feature level, resulting in suboptimal parameter efficiency. To reduce model complexity, this work adopts a shared-convolution strategy inspired by RetinaNet, substantially decreasing the number of parameters. A scale-adjustment layer is further introduced to account for differences in object sizes across feature levels. Additionally, statistical discrepancies among scales necessitate appropriate normalization. Directly applying BN within a shared head leads to biased running statistics, whereas Group Normalization (GN) increases inference cost. Following the design principles of Neural Architecture Search Feature Pyramid Network (NASFPN), we employ shared convolutions with independently computed BN for each scale, striking a balance between effectiveness and efficiency.
In Figure 5, three feature maps are extracted from the neck outputs. Each feature map is processed through a lightweight convolutional sequence, where a 3 × 3 depthwise separable convolution is employed for computational efficiency, a 1 × 1 convolution maintains feature information, and a subsequent 3 × 3 depthwise convolution further refines the representation. The resulting three-scale features then share the weights of a 3 × 3 convolution. After passing through independent batch normalization layers for each scale, the features are fed into shared regression (Reg) and classification (Cls) convolutional branches. Specifically, the regression and classification heads adopt Conv2d layers with kernel size k = 1. The output of the regression branch is further transformed by a scale layer, which consists of a DWConv (k = 3) followed by a pointwise Conv (k = 1), to adaptively rescale the feature map (e.g., 160 × 160 × 64) to the corresponding detection scale.
4. Experiments and Results
4.1. Datasets Construction and Characteristics
The dataset was collected from real coal mine roadway environments during on-site drilling and inspection operations, capturing challenging visual conditions including low and uneven illumination, dust and water mist interference, complex backgrounds, and partial occlusion.
It consists of 1980 images, each containing 1–3 pressure-relief boreholes (average 1.6, standard deviation 0.5). Based on dominant interference types, the dataset is divided into four scenarios: normal illumination (27.4%), low illumination (24.5%), dust and water mist (25.4%), and occlusion-dominated scenes (22.7%) (Figure 6). Approximately 48% of boreholes are partially occluded, and 35% exhibit weak or blurred contours, providing sufficient variability for robust evaluation.

Figure 6.
Representative samples of the dataset under different scenarios. The pressure-relief boreholes are annotated with bounding boxes to indicate the detection targets: (a) Normal illumination scenario, (b) Low-illumination scenario, (c) Dust- and water-mist–interference scenario, (d) Occlusion scenario.
All images were manually annotated with bounding boxes following a unified protocol. For partially occluded boreholes, bounding boxes cover the maximum visible area. Severely ambiguous or blurred regions were excluded. An independent review by two experienced researchers yielded inter-annotator agreement exceeding 95%, ensuring label reliability.
To improve data diversity and mitigate overfitting, a set of physically consistent data augmentation strategies was adopted, encompassing random rotations, vertical flips, contrast enhancement, illumination variation, and noise injection. Following data augmentation, the final dataset contained 5000 images with approximately 8100 annotated borehole instances. The dataset was divided into training, validation, and test subsets in a 7:2:1 ratio, ensuring proportional representation across all scenarios.
4.2. Experimental Setup and Evaluation Metrics
Experiments were carried out in PyCharm 2021 Professional Edition using Python 3.10. All evaluations were conducted on a Windows 11 system equipped with an Intel® Core™ i5-13600KF processor (3.5 GHz), 32 GB of RAM, and an NVIDIA GeForce RTX 4070 Ti GPU (12 GB) running under CUDA 12.7. All input images were resized to 640 × 640 pixels, and the dataset was partitioned into training, validation, and test sets with 3500, 1000, and 500 images, respectively. The optimizer used was Stochastic Gradient Descent (SGD) with an initial momentum of 0.937, a batch size of 16, a learning rate of 0.01, and 200 training epochs, including 3 warm-up epochs. These hyperparameters were chosen based on preliminary experiments and prior works on lightweight YOLO networks [32], balancing convergence speed, training stability, and detection accuracy for small, low-contrast targets.
To evaluate the effectiveness of pressure-relief hole detection in coal mine roadways, this study adopts several standard performance metrics, including Precision (P), Recall (R), mean Average Precision (mAP), GFLOPs, the number of parameters, and Frames Per Second (FPS). P, R, and mAP are used to assess the detection accuracy of the model. Here, mAP50 is the mAP computed at an IoU threshold of 0.5, while mAP@50:95 represents the average mAP across IoU thresholds ranging from 0.5 to 0.95. Since mAP@50:95 evaluates performance across multiple thresholds, it imposes stricter requirements and provides a more comprehensive assessment of the model’s detection capability. The specific formulas are presented as follows.
where true positives () stand for correctly detected instances, false positives () represent incorrect detections, and false negatives () indicate missed detections. N denotes the number of classes in the detection task.
In this study, following the COCO evaluation protocol, mAP refers specifically to mAP@50:95, which calculates the average precision across IoU thresholds from 0.5 to 0.95 in increments of 0.05. This metric offers a more rigorous assessment of both localization accuracy and detection robustness. P and R are implicitly reflected in the computation of AP and mAP, and therefore are not reported separately in the experimental tables. Accordingly, mAP@50:95 is reported in all quantitative comparisons, while mAP at a single IoU threshold (e.g., IoU = 0.5) is not separately listed.
GFLOPs indicate the model’s computation load, while its number of parameters represents the model size. FPS assesses detection speed.
4.3. Ablation
To assess the YOLOV-DFBL network, the coal-mine pressure-relief hole dataset was used for ablation experiments. YOLOv11n served as the baseline model, and four improvement strategies—DualConv, C3K2_FSDA, C2PSA_Biformer, and LSCH—were introduced progressively. This stepwise evaluation highlights the individual contribution and effectiveness of each module within the proposed architecture.
Table 1 summarizes the experimental results. The proposed model achieves a 24.8% reduction in parameters and a 25.4% decrease in GFLOPs, while enhancing mAP@50:95 by 0.5% and boosting FPS by 22.7%. Notably, although the C2PSA_Biformer module introduces additional parameters and computational cost, it enhances feature extraction and representation in complex coal mine roadway environments, thereby improving detection accuracy under occlusion conditions. The C3K2_FSDA module, despite its higher computational overhead compared with the baseline, brings only a small increase in parameter size while significantly improving detection robustness and accuracy under demanding conditions such as dust, illumination variations, and noise interference. The DualConv and LSCH modules substantially reduce both computational cost and model size with only minimal degradation in detection accuracy. Therefore, the YOLO-DFBL model is not only more lightweight but also exhibits superior detection performance for pressure-relief holes in coal mine roadways.

Table 1.
Ablation test results.
4.4. Comparative Experiment and Result Analysis
4.4.1. Comparative Experiment of DualConv Convolution
DualConv is a compact convolutional network designed to greatly reduce the computational cost of the YOLOv11n baseline while preserving comparable detection accuracy. To evaluate the effectiveness of DualConv in enhancing feature extraction efficiency, the Conv modules in the backbone were replaced with DualConv, forming a variant referred to as YOLOv11-D. Under the same baseline configuration, Depthwise Convolution (DWConv) [37] and Ghost Convolution (GhostConv) [38] were also introduced at the corresponding backbone locations for comparative experiments.
According to the comparative results in Table 2, DualConv achieves an effective balance between detection accuracy and computational efficiency. Although its mAP@50:95 registers a slightly smaller value compared to the baseline network, it remains significantly higher than DWConv and comparable to GhostConv. Meanwhile, DualConv keeps a small number of parameters and minimal computational overhead, achieving accuracy close to GhostConv while delivering a much higher inference speed than both YOLOv11n and GhostConv, with only a slight decrease relative to the highly simplified DWConv. Overall, DualConv achieves a better balance between network compactness and detection accuracy, with the YOLOv11-D model demonstrating the best comprehensive performance among all tested configurations.
Table 2.
Comparison of different convolution modules.
4.4.2. Comparative Experiment on the Improved C3K2 Module
This paper presents an enhanced C3K2 structure built upon the YOLO-D model to further improve noise suppression in pressure-relief hole detection in coal mine roadways. To examine the impact of the FSDA module relative to the original C3K2 design, three variant configurations were constructed for comparison. All variants preserve the overall C3K2 architecture while introducing different Simple Attention Module (SimAM) [39] or a frequency-domain reinforced feed-forward network (FRFN) [40]—within the feature interaction unit to ensure fair evaluation. The compared modules include the baseline C3K2, C3K2_SimAM, and C3K2_FRFN components.
Based on the comparative results of the four C3K2 variants (Table 3), the proposed C3K2_FSDA module achieves the best balance between detection performance and computational cost. Although its parameter count and FLOPs are slightly higher than the baseline C3K2, C3K2_FSDA achieves the highest mAP@50:95 (79.9%), exceeding all comparison modules. Compared with C3K2_FRFN and C3K2_SimAM, C3K2_FSDA provides a clear accuracy gain while maintaining a competitive inference speed. These results indicate that the FSDA-enhanced C3K2 structure effectively improves feature representation without imposing excessive computational burden, thereby offering superior overall performance and leading to the development of the YOLO-DF model.
Table 3.
Comparative results of different C3K2 structures.
4.4.3. Comparative Experiment on the C2PSA Module
The roadway environment in coal mines is characterized by insufficient illumination, dust interference, and severe occlusion, which often leads to incomplete relief-hole contour information and consequently degrades detection accuracy. To improve the model’s ability to extract features in difficult scenarios, a more powerful local–global feature interaction mechanism is incorporated into the existing network. In this study, the Biformer module is integrated into the C2PSA structure of the YOLO-DF network to form C2PSA_Biformer, thus enhancing feature representation in the backbone and neck modules. The resulting network is named YOLO-DFB. To verify its effectiveness, comparative experiments are conducted by replacing the C2PSA module at the same structural position with Deformable Large Kernel Attention (DLKA) [41], Large Selective Kernel Attention (LSKA) [42], and the original C2PSA module, without altering the main network structure of the baseline model.
Results from Table 4 indicate that the C2PSA_Biformer module attains superior detection performance across all evaluated variants. Even though its computational burden (10.2 GFLOPs) is marginally greater than that of the other enhanced modules, its mAP@50:95 reaches 81.7%, representing a clear improvement over the baseline YOLO-DF, C2PSA_DLKA, and C2PSA_LSKA models. In contrast, the accuracies of C2PSA_DLKA and C2PSA_LSKA are only 77.3% and 77.9%, respectively, showing a substantial gap from C2PSA_Biformer. Additionally, C2PSA_Biformer maintains nearly the same parameter count (2.32 M) while significantly enhancing feature representation, indicating that its dual-branch dynamic interaction mechanism more effectively captures both local and global information under complex roadway conditions. Despite a slight reduction in FPS, the accuracy gains substantially outweigh the speed loss, demonstrating superior overall detection performance.
Table 4.
Evaluation results among various C2PSA variants.
Although the overall improvement in mAP@50:95 introduced by the C2PSA-Biformer module appears modest, this metric places greater emphasis on localization accuracy at higher IoU thresholds. For pressure-relief borehole detection, which involves extremely small targets under low illumination and frequent occlusion, improvements at high IoU levels correspond to more stable and reliable localization rather than coarse detection. Moreover, the advantages of C2PSA-Biformer are more evident in challenging scenarios such as occlusion and low-visibility conditions, which are not fully captured by a single global mAP value.
4.4.4. Comparison with Other Methods
To thoroughly assess the effectiveness of the proposed YOLO-DFBL model, a comparative study was carried out with several representative object detection frameworks, including SSD, Faster R-CNN, RetinaNet, CenterNet [43], YOLOv5n, YOLOv8n, YOLOv10n, and YOLOv11n. As shown in Table 5, two lightweight one-stage detectors—YOLOv5n and YOLOv8n—achieve relatively high detection accuracy (71.3% and 75.6% mAP@50:95) with moderate computational costs. YOLOv10n and YOLOv11n further improve accuracy to 76.1% and 78.5% mAP@50:95 while maintaining low parameter counts and favorable inference speeds. In contrast, classical detectors such as SSD, Faster R-CNN, RetinaNet, and CenterNet exhibit significantly larger model sizes (25–136 M parameters) and higher computational burdens (31.5–386.1 GFLOPs), resulting in substantially lower inference speeds (10.9–46.8 FPS). Despite their increased complexity, their detection accuracy remains inferior to that of the latest lightweight YOLO series. The proposed YOLO-DFBL achieves a mAP@50:95 of 78.9%, using just 1.94 M model parameters and 4.7 GFLOPs, representing the most compact model among all compared methods. Moreover, it attains the highest inference speed of 157.3 FPS. This indicates that the introduced dual-branch feature boosting and lightweight decoupled head design significantly enhances both efficiency and representational capability. Overall, YOLO-DFBL delivers the optimal balance between accuracy, model compactness, and real-time performance, demonstrating clear superiority over existing lightweight and classical detectors.
Table 5.
Comparative experiment of different method.
Although only mAP@50:95 values are reported in Table 5, P and R are implicitly reflected in the AP computation. Models with higher mAP@50:95, such as YOLO-DFBL (78.9%), are expected to have both higher Precision and Recall compared with baseline models (YOLOv11n, 78.5%) and lightweight variants (YOLOv8n, 75.6%). In particular, under low-illumination and occlusion scenarios, YOLO-DFBL maintains more consistent detection performance, which implies reduced false positives and missed detections relative to other models. These results show the effectiveness of the DualConv module, FSDA, Biformer, and LSCH modules in enhancing both Precision and Recall under challenging underground conditions.
4.5. Performance Evaluation and Discussion
4.5.1. Overall Detection Performance Comparison
After completing systematic comparative experiments on the benchmark dataset, field detection experiments were further conducted for assessing the real-world applicability and reliability of the proposed model under actual coal mine roadway conditions. Images collected under three representative environments—normal illumination, low illumination, and occlusion interference—were selected for comparative analysis. Each environment contained three typical scenarios, and the detection confidence of YOLOv8n, YOLOv10n, YOLOv11n, and the proposed YOLO-DFBL was comprehensively compared, as shown in Figure 7.

Figure 7.
Qualitative comparison of pressure-relief borehole detection results under different roadway conditions. (a–c) normal illumination, (d–f) low il-lumination and (g–i) occlusion interference.
Under normal illumination, the borehole features are clear, and the target distribution is relatively simple. All four models achieve detection confidences above 0.5 and accurately identify all targets, with no significant performance differences observed.
Under low-illumination conditions, the brightness and color contrast between the boreholes and the background are significantly reduced, leading to performance degradation across all models. YOLOv8n and YOLOv10n exhibit generally low and unstable confidence levels (as low as 0.28–0.41), accompanied by missed detections. YOLOv11n shows moderate improvement, reaching confidence levels of 0.56–0.61 in some scenarios, but still suffers from low confidence and false detections. In contrast, YOLO-DFBL maintains higher and more stable confidence values in the range of 0.67–0.81, indicating that the FSDA module effectively suppresses noise and enhances discriminative features under insufficient lighting.
In occlusion-interference environments, where borehole features are partially obscured by dust, water mist, and structural elements, detection becomes significantly more challenging. YOLOv8n and YOLOv10n exhibit generally low confidence levels (predominantly below 0.45) and are prone to frequent false positives and missed detections, whereas YOLOv11n shows substantial confidence variability. In contrast, YOLO-DFBL consistently achieves confidence scores exceeding 0.81 across all occlusion scenarios, demonstrating superior detection stability and reliability. This performance advantage can be attributed to the Biformer dual-layer routing attention mechanism, which enhances global context modeling, and the FSDA module, which effectively suppresses noise and background interference.
Overall, the proposed YOLO-DFBL demonstrates higher detection confidence and stronger environmental adaptability than the compared models in complex coal mine roadway conditions, confirming its robustness and practical potential for pressure-relief borehole detection. Although a higher-accuracy variant (YOLO-DFB) can be obtained by further strengthening contextual modeling, it inevitably introduces additional computational overhead and reduces inference speed. Considering the strict real-time and resource constraints of underground deployment, YOLO-DFBL is selected as the final recommended model, because it achieves a better balance between detection performance and inference speed.
4.5.2. Detection Performance Under Different Roadway Scenarios
To complement the qualitative field results shown in Figure 7, quantitative detection performance was further analyzed under three representative coal mine roadway scenarios, namely normal illumination, low illumination, and occlusion interference. For each scenario, a set of field images was manually annotated, and scenario-level detection performance was evaluated by aggregating all annotated pressure-relief boreholes. The performance of YOLOv8n, YOLOv10n, YOLOv11n, and the proposed YOLO-DFBL was assessed using Recall at an IoU threshold of 0.5.
As summarized in Table 6, all compared models achieve relatively high Recall under normal illumination conditions, indicating reliable detection when visual features are clear and unobstructed. Under low-illumination conditions, the Recall of YOLOv8n and YOLOv10n decreases substantially, reflecting an increased number of missed detections caused by reduced contrast and weakened texture information. YOLOv11n exhibits moderate improvement, whereas YOLO-DFBL achieves the highest Recall, demonstrating superior robustness under insufficient lighting.
Table 6.
Quantitative detection performance under different roadway scenarios (Recall @ IoU = 0.5).
In occlusion-interference scenarios, detection performance degrades further for the baseline models due to partial obstruction of borehole features. In contrast, YOLO-DFBL consistently maintains higher Recall, indicating improved detection completeness under occluded conditions. Overall, the quantitative results across different roadway scenarios are consistent with the qualitative observations in Figure 7, validating the reliability and real-world applicability of the developed method in challenging underground scenarios.
5. Conclusions
This work introduces YOLO-DFBL, a lightweight and robust visual detection framework for pressure-relief boreholes in coal mine roadways. By systematically addressing the challenges posed by small target size, low contrast, noise interference, and strict computational constraints, the developed approach strikes an effective balance among detection accuracy, reliability, and computational efficiency. Through the introduction of the DualConv lightweight convolutional structure, the FSDA frequency-domain enhancement module, the Biformer-based attention mechanism, and a shared conv detection head, YOLO-DFBL significantly improves feature representation while enhancing noise robustness and concurrently decreasing model complexity. Extensive ablation experiments provide quantitative evidence of the separate and joint effects of each module. Comparisons with typical two-stage and one-stage detectors further demonstrate that YOLO-DFBL attains better overall performance regarding accuracy, model size, computational load, and inference time. Moreover, field experiments conducted under normal illumination, low-light conditions, and occlusion-interference scenarios verify the robustness and practical effectiveness of the proposed method in real coal mine roadway environments. The findings demonstrate the promising capability of YOLO-DFBL for real-time underground deployment on resource-constrained inspection and drilling equipment.
Despite its advantages, YOLO-DFBL incurs higher computational cost due to the C2PSA_Biformer module and may experience reduced performance under extreme visual conditions or unseen interference types. Moreover, it focuses solely on pressure-relief hole detection and does not yet support other tasks such as borehole quality assessment or drilling status recognition. In future research, we aim to expand the proposed framework to multi-task underground perception, such as joint borehole quality assessment and drilling status recognition, while further optimizing for embedded and edge-computing platforms to support large-scale industrial applications.
Author Contributions
Conceptualization, X.A. and Z.W.; methodology, X.A.; software, D.W. and F.L.; validation, X.A. and Z.W.; investigation, J.G.; data curation, C.Z. and G.X.; writing—original draft preparation, X.A.; writing—review and editing, D.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Key Research and Development Program of China under Grant 2020YFB1314200, and in part by the National Natural Science Foundation of China under Grant 52204179.
Data Availability Statement
The data that has been used is confidential.
Conflicts of Interest
The authors confirm that there are no competing interests.
References
- Chen, M.; Si, L.; Dai, J.; Liu, Y.; Wang, Z.; Wei, D.; Li, X. A Variable Structure Robust Control Strategy for Automatic Drilling Tools Loading and Unloading System. Control Eng. Pract. 2025, 161, 106340. [Google Scholar] [CrossRef]
- Zou, X.; Luo, L.; Wang, Z.; Tao, P.; Wu, H.; Pan, J. Refined Sticking Monitoring of Drilling Tool for Drilling Rig in Underground Coal Mine: From Mechanism Analysis to Data Mining. Mech. Syst. Signal Process. 2025, 228, 112467. [Google Scholar] [CrossRef]
- Si, L.; Liu, Y.; Wang, Z.; Gu, J.; Wei, D.; Liu, Y. Electromagnetic Signal Analysis and Recognition of Coal and Rock Properties during the Borehole Pressure Relief Process: Simulation and Experiment. Measurement 2025, 242, 116141. [Google Scholar] [CrossRef]
- Wei, D.; Wang, P.; Wang, Z.; Si, L.; Zou, X.; Gu, J.; Dai, J.; Long, C. Adaptive Image Enhancement Method for Coal-Mine Underground Image Based on No-Reference Quality Evaluation. IEEE Trans. Instrum. Meas. 2024, 73, 5036417. [Google Scholar] [CrossRef]
- Li, F.; Wang, Z.; Wei, D.; Li, X.; Si, L.; Gu, J.; Dai, J. A High-Precision and Efficient Method for Coal–Rock Characteristic Identification Utilizing Coal Wall Temperature Field. Eng. Appl. Artif. Intell. 2026, 163, 112888. [Google Scholar] [CrossRef]
- Liu, H.; Jin, F.; Zeng, H.; Pu, H.; Fan, B. Image Enhancement Guided Object Detection in Visually Degraded Scenes. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 14164–14177. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Dhanalakshmi, R.; Rajesh, R.; Sendhil, R. A Spatial Features and Weight Adjusted Loss Infused Tiny YOLO for Shadow Detection. Signal Process. Image Commun. 2026, 140, 117408. [Google Scholar] [CrossRef]
- Chen, Y.; Yuan, X.; Wang, J.; Wu, R.; Li, X.; Hou, Q.; Cheng, M.-M. YOLO-MS: Rethinking Multi-Scale Representation Learning for Real-Time Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 4240–4252. [Google Scholar] [CrossRef]
- Li, L.; Yao, X.; Wang, X.; Hong, D.; Cheng, G.; Han, J. Robust Few-Shot Aerial Image Object Detection via Unbiased Proposals Filtration. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5617011. [Google Scholar] [CrossRef]
- Liu, G.; Wu, W. Search and Recovery Network for Camouflaged Object Detection. Image Vis. Comput. 2024, 151, 105247. [Google Scholar] [CrossRef]
- Kaleem, Z. Lightweight and Computationally Efficient YOLO for Rogue UAV Detection in Complex Backgrounds. IEEE Trans. Aerosp. Electron. Syst. 2025, 61, 5362–5366. [Google Scholar] [CrossRef]
- Hu, R.; Lin, H.; Lu, Z.; Xia, J. Despeckling Representation for Data-Efficient SAR Ship Detection. IEEE Geosci. Remote Sens. Lett. 2025, 22, 4002005. [Google Scholar] [CrossRef]
- Wu, J.; Zheng, R.; Jiang, J.; Tian, Z.; Chen, W.; Wang, Z.; Yu, F.R.; Leung, V.C.M. A Lightweight Small Object Detection Method Based on Multilayer Coordination Federated Intelligence for Coal Mine IoVT. IEEE Internet Things J. 2024, 11, 20072–20087. [Google Scholar] [CrossRef]
- Mu, H.; Liu, J.; Guan, Y.; Chen, W.; Xu, T.; Wang, Z. Slim-YOLO-PR_KD: An Efficient Pose-Varied Object Detection Method for Underground Coal Mine. J. Real-Time Image Process. 2024, 21, 160. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Xu, D. Learning Rotation-Invariant and Fisher Discriminative Convolutional Neural Networks for Object Detection. IEEE Trans. Image Process. 2019, 28, 265–278. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Fang, F.; Li, L.; Zhu, H.; Lim, J.-H. Combining Faster R-CNN and Model-Driven Clustering for Elongated Object Detection. IEEE Trans. Image Process. 2020, 29, 2052–2065. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Wang, C.; Zeng, Z. WS-SSD: Achieving Faster 3D Object Detection for Autonomous Driving via Weighted Point Cloud Sampling. Expert Syst. Appl. 2024, 249, 123805. [Google Scholar] [CrossRef]
- Kim, Y.; Shin, J. Efficient and Robust Object Detection Against Multi-Type Corruption Using Complete Edge Based on Lightweight Parameter Isolation. IEEE Trans. Intell. Veh. 2024, 9, 3181–3194. [Google Scholar] [CrossRef]
- Wang, D.; Tan, J.; Wang, H.; Kong, L.; Zhang, C.; Pan, D.; Li, T.; Liu, J. SDS-YOLO: An Improved Vibratory Position Detection Algorithm Based on YOLOv11. Measurement 2025, 244, 116518. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Sankar, S.; Bartoli, A. Model-Based Active Learning to Detect an Isometric Deformable Object in the Wild with a Deep Architecture. Comput. Vis. Image Underst. 2018, 171, 69–82. [Google Scholar] [CrossRef]
- Shi, B.; Hou, C.; Xia, X.; Hu, Y.; Yang, H. Improved Young Fruiting Apples Target Recognition Method Based on YOLOv7 Model. Neurocomputing 2025, 623, 129186. [Google Scholar] [CrossRef]
- Wang, J.; Liu, J.; Wang, K.; Pan, Z.; Wang, Z.; Chen, C.; Yao, Y.; Li, T. YOLO-ROSP: A Deep Learning Method for Skiers’ Status Object Detection in UAV Perspective Based on Improved YOLOv11. Measurement 2026, 259, 119614. [Google Scholar] [CrossRef]
- Yang, D.; Miao, C.; Liu, Y.; Wang, Y.; Zheng, Y. Improved Foreign Object Tracking Algorithm in Coal for Belt Conveyor Gangue Selection Robot with YOLOv7 and DeepSORT. Measurement 2024, 228, 114180. [Google Scholar] [CrossRef]
- Wang, X.; Wan, S.; Li, Z.; Chen, X.; Zhang, B.; Wang, Y. ECL-Tear: Lightweight Detection Method for Multiple Types of Belt Tears. Measurement 2025, 251, 117269. [Google Scholar] [CrossRef]
- Jin, H.; Ren, S.; Li, S.; Liu, W. Research on Mine Personnel Target Detection Method Based on Improved YOLOv8. Measurement 2025, 245, 116624. [Google Scholar] [CrossRef]
- Wang, B.; Yu, L.; Zhang, B. AL-MobileNet: A Novel Model for 2D Gesture Recognition in Intelligent Cockpit Based on Multi-Modal Data. Artif. Intell. Rev. 2024, 57, 282. [Google Scholar] [CrossRef]
- Chuang, X.; Qiang, C.; Yinyan, S.; Xiaochan, W.; Xiaolei, Z.; Yao, W.; Yiran, W. Improved Lightweight YOLOv5n-Based Network for Bruise Detection and Length Classification of Asparagus. Comput. Electron. Agric. 2025, 233, 110194. [Google Scholar] [CrossRef]
- He, L.; Chen, R.; Liu, X.; Cao, X.; Zhu, S.; Wang, Y. PACformer: A Multi-Stage Heterogeneous Convolutional-Vision Transformer for Sparse-View Photoacoustic Tomography Restoration. IEEE Trans. Comput. Imaging 2025, 11, 377–388. [Google Scholar] [CrossRef]
- Qi, H.; Meng, X.; Du, Z. YOLO-DLA: A YOLO-Based Unified Framework for Multi-Scale Document Layout Analysis. Expert Syst. Appl. 2026, 299, 129981. [Google Scholar] [CrossRef]
- Zhang, K.; Wang, Q.; Zou, G.; Yang, J.; Song, T.; Liu, Y.; Liu, D. An Efficient Anchor-Free Model for Ore Particle Size Detection. Eng. Appl. Artif. Intell. 2025, 162, 112304. [Google Scholar] [CrossRef]
- Zhao, P.; Li, Z.; You, Z.; Chen, Z.; Huang, T.; Guo, K.; Li, D. SE-U-Lite: Milling Tool Wear Segmentation Based on Lightweight U-Net Model with Squeeze-and-Excitation Module. IEEE Trans. Instrum. Meas. 2024, 73, 5018408. [Google Scholar] [CrossRef]
- Mei, Z.; Xu, H.; Yan, L.; Wang, K. IALF-YOLO: Insulator Defect Detection Method Combining Improved Attention Mechanism and Lightweight Feature Fusion Network. Measurement 2025, 253, 117701. [Google Scholar] [CrossRef]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R. BiFormer: Vision Transformer with Bi-Level Routing Attention. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 10323–10333. [Google Scholar]
- Cong, X.; Gui, J.; Zhang, J.; Hou, J.; Shen, H. A Semi-Supervised Nighttime Dehazing Baseline with Spatial-Frequency Aware and Realistic Brightness Constraint. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 2631–2640. [Google Scholar]
- Park, M.; Hwang, S.; Cho, H. BiRD: Bi-Directional Input Reuse Dataflow for Enhancing Depthwise Convolution Performance on Systolic Arrays. IEEE Trans. Comput. 2024, 73, 2708–2721. [Google Scholar] [CrossRef]
- Li, Z.; Xiao, L.; Shen, M.; Tang, X. A Lightweight YOLOv8-Based Model with Squeeze-and-Excitation Version 2 for Crack Detection of Pipelines. Appl. Soft Comput. 2025, 177, 113260. [Google Scholar] [CrossRef]
- Zhang, J.; Tan, J.; Ma, C.; Wu, P.; Gou, Y.; Niu, Q.; Xia, W.; Huo, G.; An, T. Identification of Green Pepper (Zanthoxylum armatum) Impurities Based on Visual Attention Mechanism Fused Algorithm. J. Food Compos. Anal. 2025, 142, 107445. [Google Scholar] [CrossRef]
- Zhou, S.; Chen, D.; Pan, J.; Shi, J.; Yang, J. Adapt or Perish: Adaptive Sparse Transformer with Attentive Feature Refinement for Image Restoration. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Seattle, WA, USA, 16–22 June 2024; IEEE Computer Soc: Seattle, WA, USA, 2024; pp. 2952–2963. [Google Scholar]
- Azad, R.; Niggemeier, L.; Huettemann, M.; Kazerouni, A.; Aghdam, E.K.; Velichko, Y.; Bagci, U.; Merhof, D. Beyond Self-Attention: Deformable Large Kernel Attention for Medical Image Segmentation. In Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision, WACV, Waikoloa, HI, USA, 3–8 January 2024; IEEE Computer Soc: Waikoloa, HI, USA, 2024; pp. 1276–1286. [Google Scholar]
- Lau, K.W.; Po, L.-M.; Rehman, Y.A.U. Large Separable Kernel Attention: Rethinking the Large Kernel Attention Design in CNN. Expert Syst. Appl. 2024, 236, 121352. [Google Scholar] [CrossRef]
- Thai, H.-T.; Le, K.-H.; Nguyen, N.L.-T. EF-CenterNet: An Efficient Anchor-Free Model for UAV-Based Banana Leaf Disease Detection. Comput. Electron. Agric. 2025, 231, 109927. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.