1. Introduction
Monitoring rotating machinery is a critical task in many industries, as it directly impacts operational safety and productivity. The primary objectives are to ensure operator safety and prevent unexpected production shutdowns, which can lead to significant financial losses. Reliability studies on industrial systems have shown that gearboxes are a critical component due to their high failure rates and the severe damage they can cause [
1]. Gears can be affected by over 20 types of faults, as classified by ISO 10825 [
2], which fall into six main categories: surface fatigue, surface deterioration, scuffing, deformation, cracking, and tooth breakage [
3]. The first four faults are considered surface-related wear issues. They can be caused by various factors, such as poor lubrication, contaminated lubricants, or misaligned gear mounting, which accelerates surface degradation through direct contact or abrasive wear. Repeated shocks during startup and shutdown can also lead to surface fatigue and permanent deformation. These faults can be mitigated by adhering to proper lubricant change intervals, selecting the right lubricant, using alignment measurement tools, and installing flexible couplings to reduce gear surface impacts. Cracking and tooth breakage are sudden, catastrophic failures that can result from the same factors, along with advanced corrosion (which can initiate cracks) and poor design that fails to account for stress concentration points. Preventive measures include ultrasonic inspections and preliminary stress concentration analysis to minimize their effects [
3,
4]. To detect these faults, robust and effective strategies for fault detection and diagnosis are essential [
5]. There are two main approaches to fault detection and diagnosis: model-based and data-driven. The model-based approach involves creating mathematical models of the physical phenomena involved in machinery operation and solving these models to predict faults. In contrast, the data-driven approach focuses on collecting and analyzing operational data to identify signs of degradation or the presence of faults [
6]. This analysis typically includes feature extraction from time-domain signals, where statistical indicators such as root mean square (RMS), skewness, and kurtosis are calculated. Advanced algorithms are commonly employed to select the most discriminative features, with popular approaches including principal component analysis (PCA) and Fisher’s criterion [
7]. While Fisher’s method can be limited when handling highly complex datasets, it offers the advantage of supervised separation, making it particularly well suited for fault diagnosis applications compared to PCA. Fisher focuses on selecting features by maximizing the inter-class distance and minimizing the intra-class distance, whereas PCA constructs new features by combining the original ones based on the direction of maximum variance. When working with statistical indicators, it is generally preferable to retain the original features to ensure better interpretability [
8].
Recently, several studies have adopted the Fisher score for discriminative feature selection to enhance inter-class separation [
9]. Sun et al. [
10] proposed a fault diagnosis method for railway point machines based on vibration signals. They combined feature extraction using variational mode decomposition and dispersion entropy with a two-stage feature selection method involving Fisher’s criterion and ReliefF. This approach achieved effective class discrimination with high accuracy. Kumar et al. [
11] developed an efficient method for diagnosing bearing defects in rotating machines using vibration signal analysis. Their Automated Fault Investigation approach combines Fisher score and genetic algorithm for feature selection with a hyperparameter-tuned Support Vector Machine classifier. This method achieves high classification accuracy for defects in rolling element bearings, including inner race, outer race, and combined faults. The study demonstrates that feature selection significantly enhances model performance while reducing computational time. Ardali et al. [
12] demonstrated the relevance of the Fisher discriminant ratio (FDR) in their study by comparing it with other feature selection methods. The FDR was used to assess the effectiveness of the feature subsets selected by the genetic algorithm and eXtreme Gradient Boosting (XGBoost). The results showed that FDR provided effective class discrimination, enhancing the performance of the fault diagnosis model. This method proved particularly useful in improving the accuracy of fault detection and diagnosis in chemical processes by optimizing the separation between different fault classes. Liu et al. [
13] addressed the challenges of unobserved faults in data-based semi-supervised industrial fault classification by proposing a robust semi-supervised Fisher discriminant analysis model. To tackle this, a sample recognition technique was developed to preprocess training samples and identify unobserved fault samples. Additionally, a regularized between-class was constructed to fully utilize both supervised and unsupervised information, enhancing classification accuracy. The proposed model was shown to be effective in experiments on the Tennessee Eastman process and a real industrial air separation unit, demonstrating its superiority in addressing both offline and online fault classification challenges.
The feature selection step is always followed by classification to ensure fault detection and diagnosis. Given the nature of the data, which consist of a feature vector, an efficient machine learning approach is required. The Adaptive Neuro-Fuzzy Inference System (ANFIS) combines fuzzy logic and neural networks, specifically designed to learn from nonlinear and complex data. Zemali et al. [
14] proposed a method integrating ANFIS models and Kalman observers to detect and isolate faults in wind turbines. This approach enables early and precise fault identification, improving wind turbine availability despite varying environmental conditions. Akbari et al. [
15] demonstrated the effectiveness of the ANFIS for fault detection, classification, and location, emphasizing its independence from wave propagation characteristics. The study optimized the ANFIS model using Harris hawks optimization and cuckoo search algorithms, comparing their performance with traditional training methods. Principal component analysis and discrete wavelet transform were employed to extract relevant features for training and testing the ANFIS model. The results showed that the optimized ANFIS achieved superior fault classification and location accuracy, outperforming traditional traveling wave models. Kanwal et al. [
16] compared ANFIS with other fault detection and localization methods for transmission lines, demonstrating that ANFIS outperformed traditional techniques like traveling wave and impedance-based methods. Using the IEEE 9-bus system for simulations, ANFIS models achieved superior accuracy in fault classification, detection, and localization. The ANFIS-based model had lower error rates compared to backpropagation, self-organizing maps, and the hybrid discrete wavelet–ANFIS model, making it a promising choice for real-time protection systems in power networks. Perez et al. [
17] proposed a robust fault diagnosis methodology for wind turbines based on zonotopic state estimators using Takagi–Sugeno models. The approach utilizes a Multiple Output ANFIS, which allows for multi-output architecture, reducing training time, uncertainties, and model complexity. This method improves fault detection by adjusting the parameters of the zonotopic estimator to account for modeling uncertainties. The approach was validated using a certified wind turbine case study, contributing to enhanced safety and operability of wind turbines through improved diagnostic systems.
The mentioned studies have relied on experimental datasets to validate the proposed methodologies. However, these datasets may contain acquisition noise and interference from other faults, which could compromise the accuracy and reliability of the methodologies. Furthermore, while this approach is specifically designed for fault classification and signature identification, it must first demonstrate its effectiveness in these tasks before being applied to experimental data, as demonstrated by [
18] for the diagnosis of tooth root cracks. In our study, we tested the methodology on multiple faults to ensure robustness in such environments, which is crucial for the successful deployment of these methods in real-world applications.
The framework presented in this paper introduces an intelligent methodology for gearbox fault detection and diagnosis. The contributions presented in this work are as follows:
A six-degree-of-freedom (6-DOF) multi-body dynamic model was developed to represent the transmission system and various fault conditions.
Features were extracted from time-domain signal analysis, with feature selection performed based on Fisher’s criterion.
Fault classification was carried out using an Adaptive Neuro-Fuzzy Inference System (ANFIS) to facilitate automation and real-time application.
The proposed diagnostic methodology was experimentally validated to demonstrate its reliability and effectiveness.
The paper is organized into five sections.
Section 1 introduces the problem and provides the state of the art in recent frameworks.
Section 2 covers the energetic modeling of gear transmission in both healthy and faulty states.
Section 3 presents time meshing stiffness as well as the vibrational response of the previous cases.
Section 4 discusses the methodology for feature extraction, selection, and learning.
Section 5 concludes the paper and offers perspectives.
2. Gear Mesh Stiffness Modeling
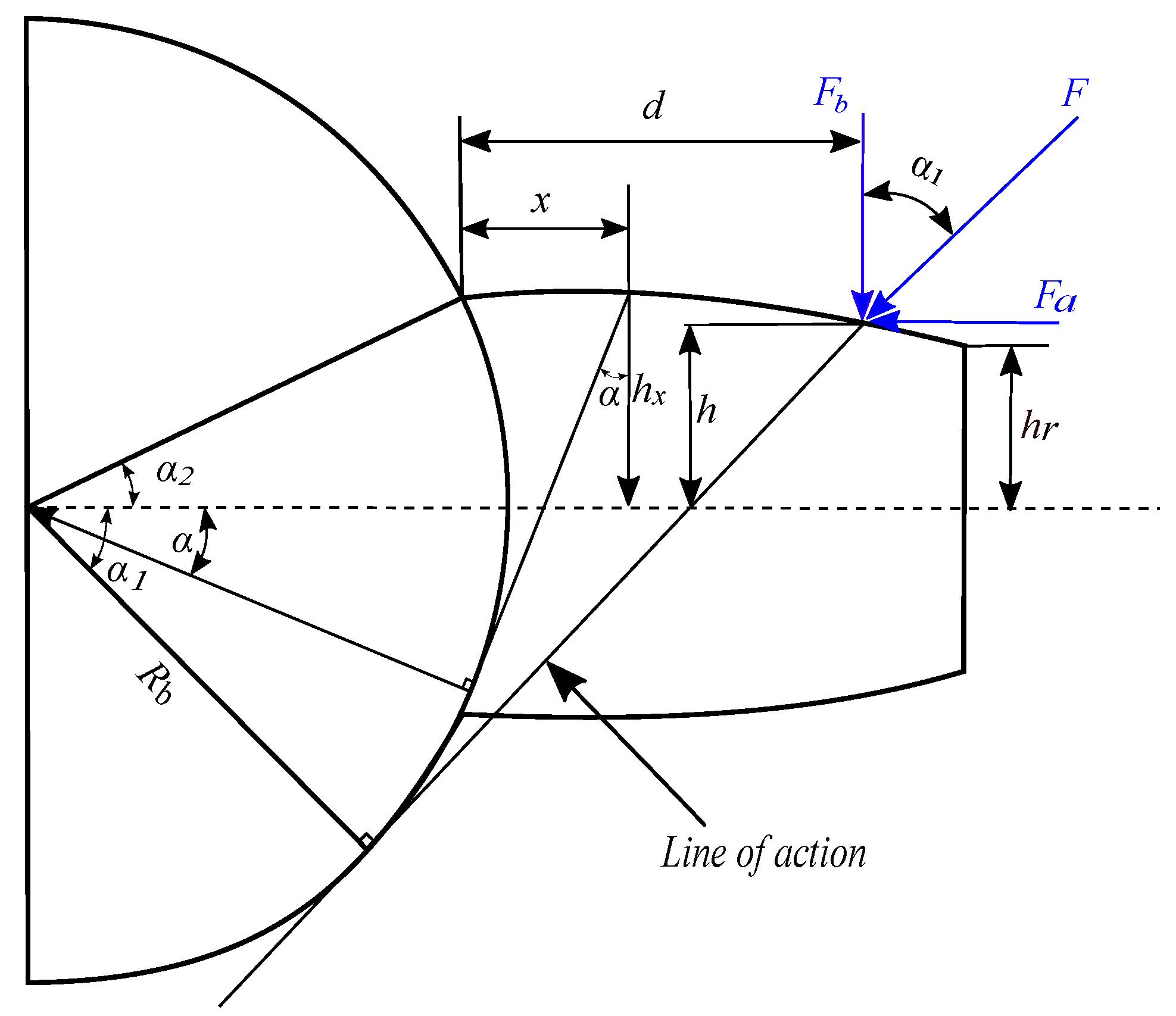
The energetic modeling of gear transmission is based on calculating the energy stored in the tooth during contact between the gears. The different geometric parameters used are illustrated in
Figure 1.
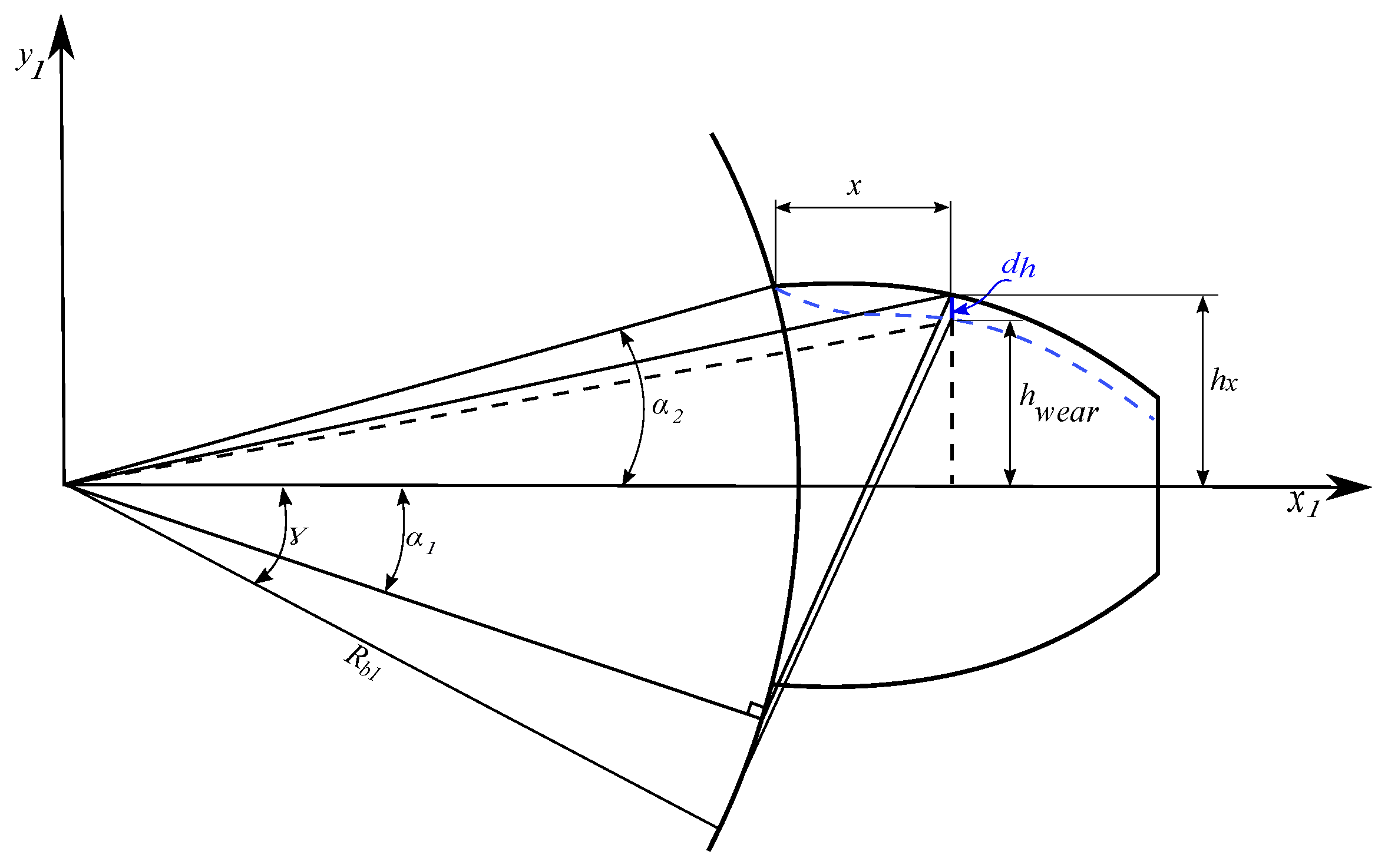
Figure 1 shows a gear with base radius
featuring a single tooth to illustrate the key parameters, where the contact force
F between mating teeth is inclined at angle
from the vertical line along the line of action, resolving into orthogonal components
and
along the
x and
y axes, respectively. The contact point is located at height
d from the tooth root and distance
h from the tooth centerline, while each point along the tooth profile is characterized by angle
(where
specifically denotes the root angle), height
x ranging from zero to the full tooth height, and radial distance
with
at the tooth tip [
20].
The energies considered in this model are Hertzian, bending, axial compressive, and shear energy. From these energies, the transmission rigidities
,
,
, and
are derived and formulated as follows [
19].
where
E,
L, and
denote Young’s modulus, tooth width, and Poisson’s ratio, respectively.
The expression for the effective total rigidity
of a single pair of teeth is formulated as in Equation (
5), where indices 1 and 2 represent the pinion and the gear, respectively.
For the engagement duration of two pairs of teeth, the effective total rigidity of engagement is the sum of the rigidities of the two pairs, as given by Equation (
6).
where
corresponds to the first pair of teeth in contact when there are two pairs engaged, and
corresponds to the second pair. Equations (
1)–(
6) are reproduced from [
19,
20].
For the modeling of the following faults, it is assumed that the defect affects the pinion teeth with a base circle radius denoted as .
2.1. Broken Tooth Fault Modeling
The deterioration of a tooth, as illustrated in
Figure 2, shows the meshing of two gears with a missing tooth represented by dotted lines. This reduces the rigidity of the gear system because a broken tooth can no longer engage properly with its counterpart. Typically, two pairs of teeth are in contact simultaneously; however, with a broken tooth, only one pair will be in contact during the same period. This halves the total rigidity of the gear. Therefore, the new formulation for the total rigidity noted
is reproduced from [
20] as follows.
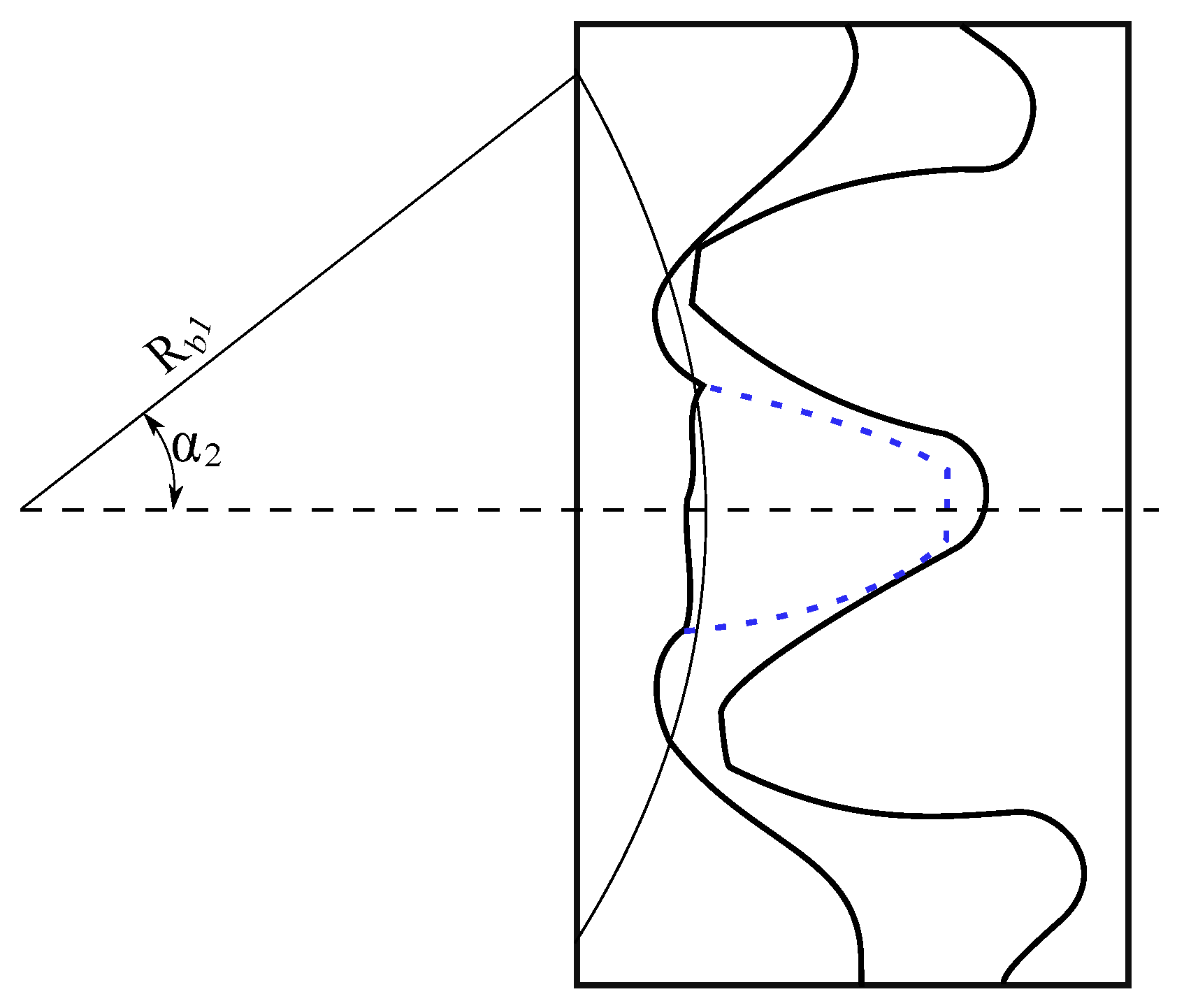
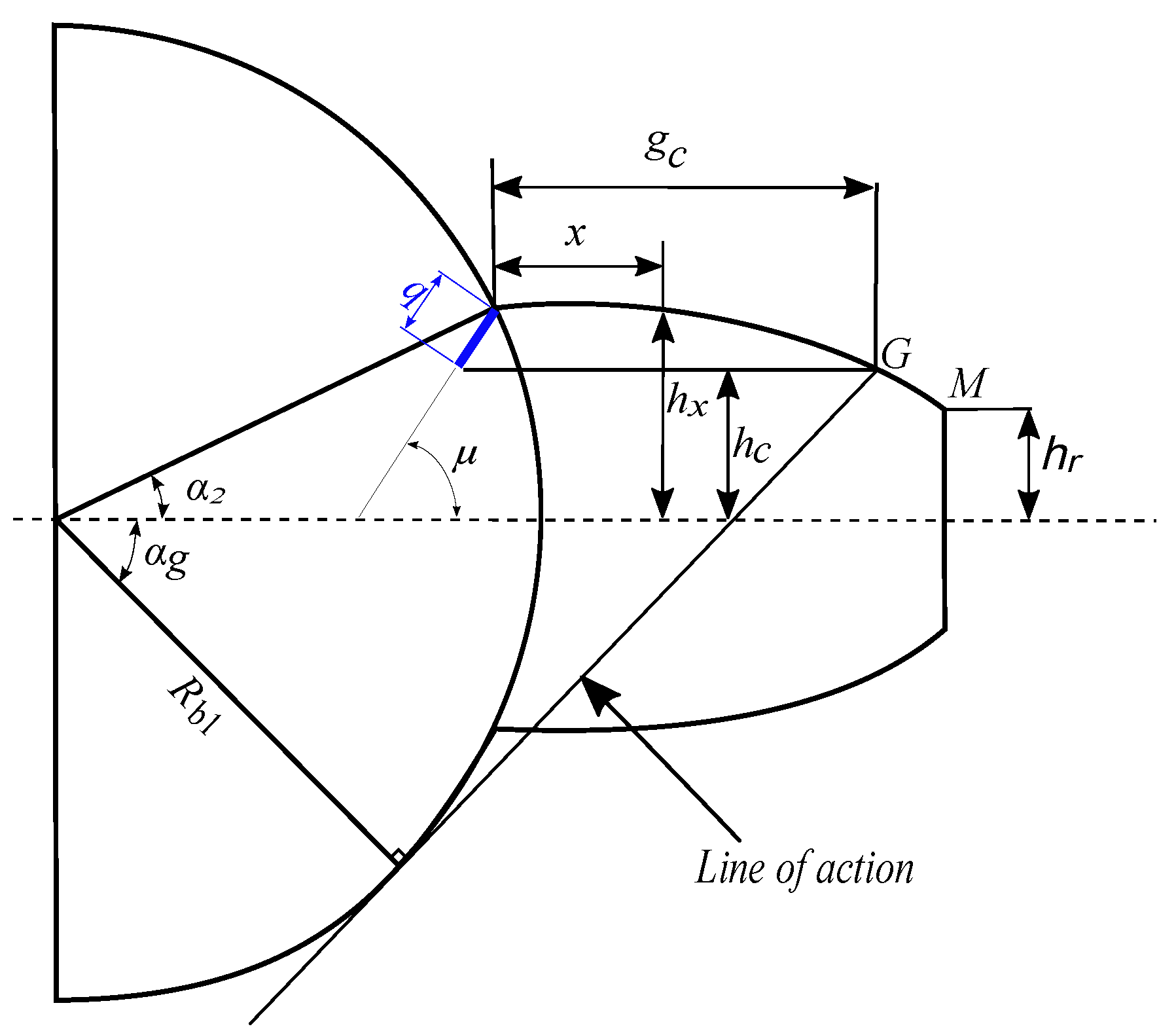
2.2. Crack Tooth Fault Modeling
The gear tooth crack illustrated in
Figure 3 typically starts at the point of greatest stress and develops at the tooth root. Furthermore, the crack follows a straight path with an intersection angle
between the crack and the central line of the tooth fixed at a constant value of 45° [
20].
The crack tip with length
q is located at point
G positioned at coordinates (
,
) along the
x and
y axes, with an orientation angle
. This crack induces a change in the moment of inertia
and the effective cross-sectional area
at a distance
x from the tooth root. These two parameters are reproduced from [
19] and formulated as follows.
Before the crack (
): the moment of inertia is calculated using a height increased by the vertical position of the crack
. After the crack (
): the crack divides the height, and only
is considered.
Before the crack (): the effective cross-sectional area is larger because it includes the portion up to the crack position. After the crack (): the area is reduced and depends only on .
The expressions of distances
and
are formulated as in Equations (
10) and (
11), reproduced from [
20].
The equations are incorporated into the energy expressions, and the rigidity equations reproduced from [
19] are presented as follows.
where
and
are calculated as in the healthy state, formulated in Equations (
1) and (
3), respectively.
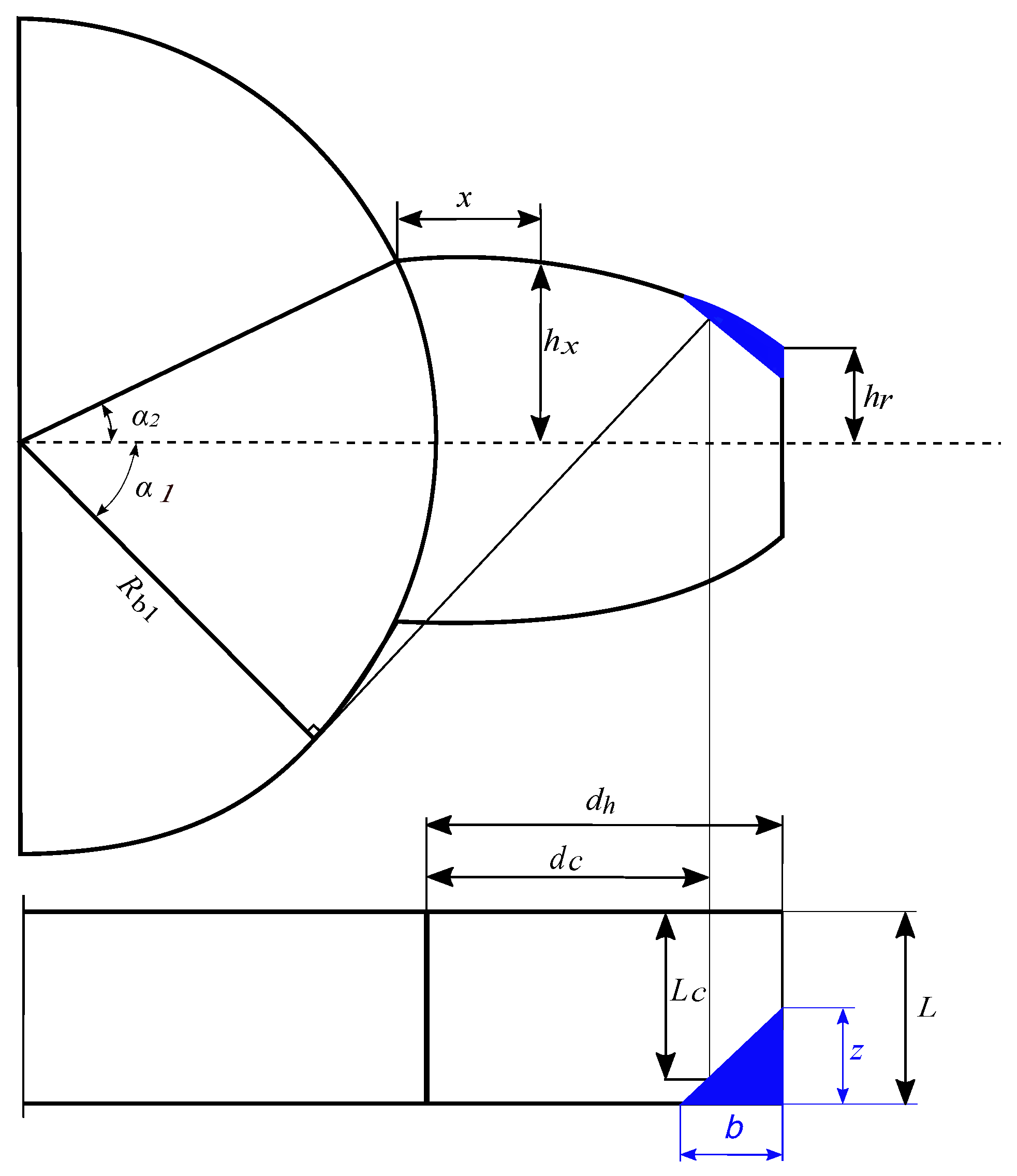
2.3. Chipped Tooth Fault Modeling
Chipped tooth fault is a type of fault where a portion of the material detaches near the end of the tooth. In this study, assuming that the fracture occurs along the width of the tooth, meaning that the variation occurs in two directions. For this purpose, the fracture surface is represented by a triangle with dimensions
b and
z (see
Figure 4). Assuming that the fracture is very thin compared to the tooth thickness, changes in the tooth thickness due to this chipping can be neglected when evaluating bending, shear, and axial compressive stiffnesses. As a result of integrating the calculations for these three stiffnesses, the variations caused by the failure can be disregarded, allowing these stiffnesses to be considered similar to those of a perfect tooth [
21].
The chipped portion of the tooth is characterized by height measurement
along its vertical profile, with reference to
, which represents the full height of the intact tooth structure. However, the Hertzian contact stiffness remains constant for a perfect tooth but varies proportionally in the case of a chipped tooth, due to changes in the width of the effective working surface along the tooth curve. The Hertzian contact stiffness for a chipped tooth noted
is reproduced from [
21] and calculated as follows.
where
represents the effective width of the broken tooth, which decreases where it is chipped and remains equal to the ideal length
L when undamaged. This expression can be written as follows.
where
is the height of the tooth and
is the contact height as shown in
Figure 4. The total rigidity of the pinion in the case of a chipped tooth fault can be expressed as follows.
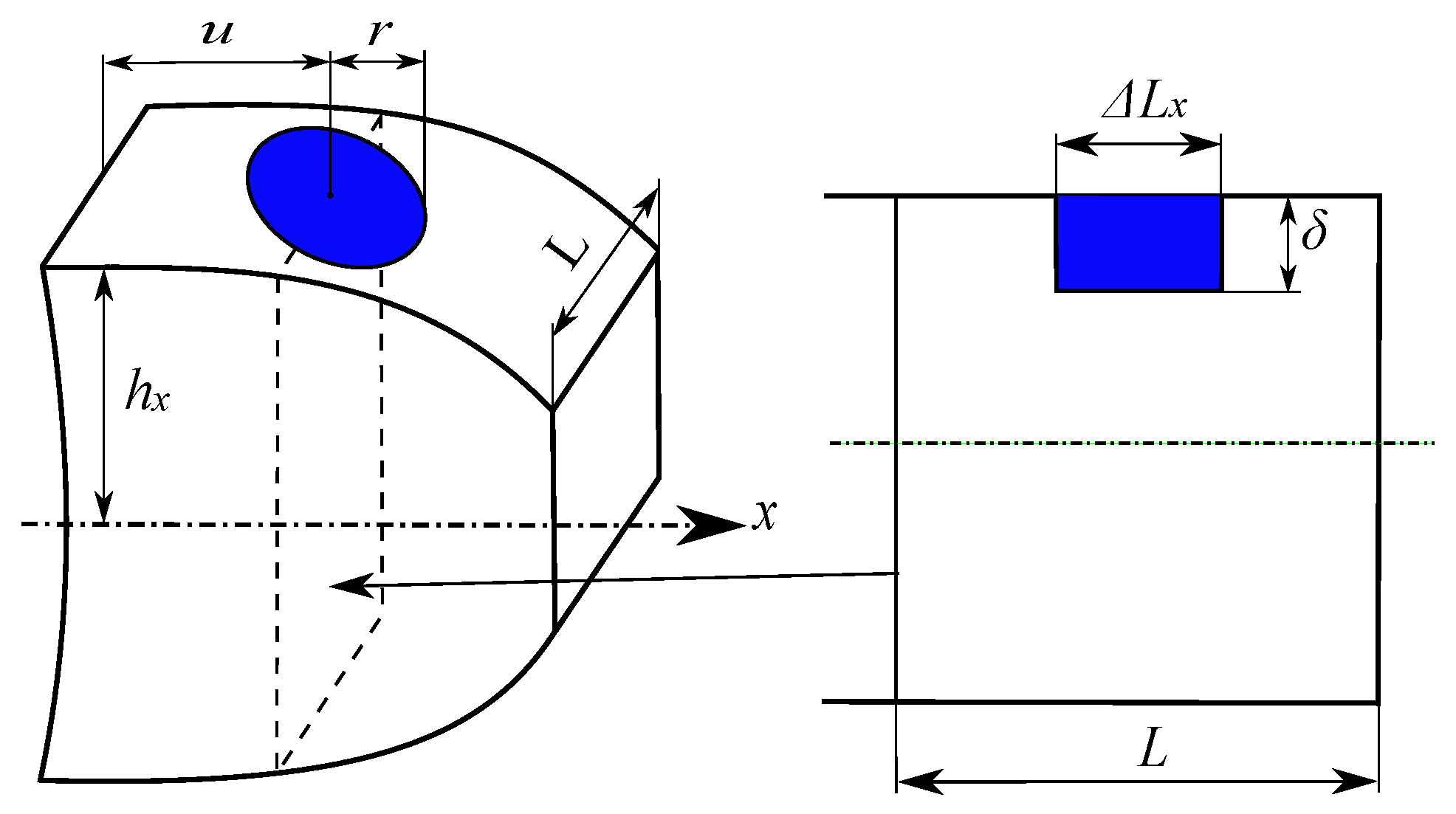
2.4. Pitting Tooth Fault Modeling
Consider the case of pitting illustrated in
Figure 5, in the form of standardized holes with a radius
r and a depth
, positioned at a height
u from the tooth root.
Adjust the expressions for the second moment of area
and the cross-sectional area
, and contact width
. It is necessary to introduce
,
, and
to represent the variation in these parameters with the distance
x along the line of action. The specific expressions for a tooth with a single pit are given in [
22].
The modified expressions for the moment of inertia
, cross-sectional area
, and width
as a function of
x such that
where
,
, and
represent the nominal (undamaged) properties of the section. These equations mathematically capture how a circular defect of radius
r centered at position
u affects the geometric properties of the structural element along its length. The variation is localized to the interval
, outside of which the properties remain unchanged from their nominal values. The parameter
represents the depth of the defect, and
denotes the distance from the centroidal axis to the extreme fiber at position
x.
By incorporating the expressions into the energy equations, the new formulations for the rigidities are as follows.
Equations (
22)–(
25) are reproduced from [
22] and adapted to the type of teeth studied.
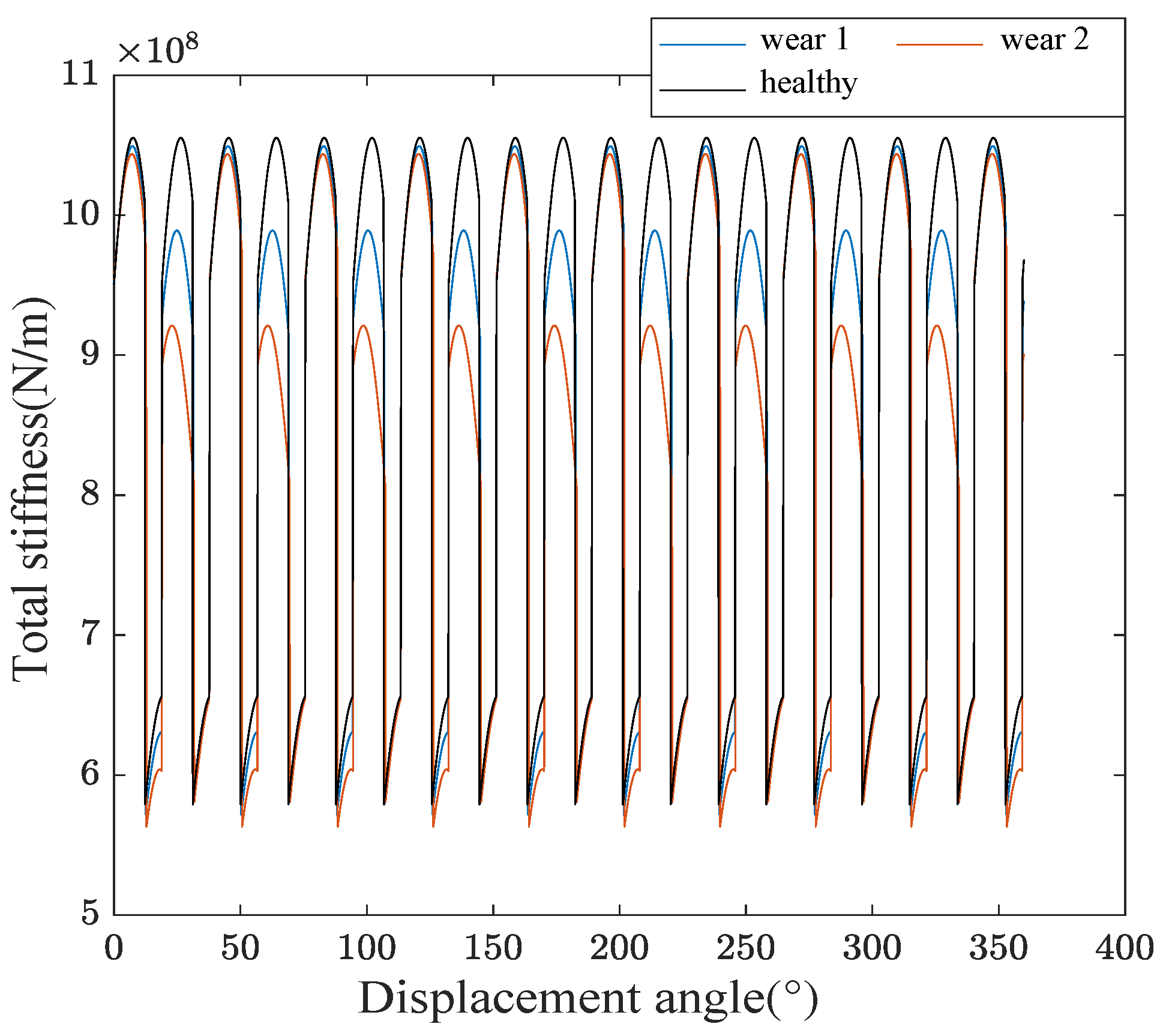
2.5. Wear Teeth Fault Modeling
As illustrated in
Figure 6, wear is a common fault in gears, where material is removed from the tooth surface, resulting in profile changes at the contact point, notably a reduction in the tooth thickness represented by
. According to Wang et al. [
23], the reduction is considered uniform on both sides of the tooth and constant along its height.
The new formulation for the tooth profile height
is used in the following equations.
This fault also influences the angle of force application along the line of action, causing the angle
to change to angle
. This angle is determined by the following expression.
The expressions for bending, compressive, and shear rigidities are modified, while the Hertzian contact stiffness
remains unchanged.
with
The equations governing tooth wear are taken from [
23] with adaptations to the type of teeth studied.
4. Proposed Diagnosis Methodology
4.1. Feature Extraction and Selection
After the signal preparation, the feature extraction for each signal is initiated. For this, statistical indicators in the time domain are calculated for each segment of the signal for each class. These indicators include: mean (), standard deviation (), skewness (), root mean square (), kurtosis (), crest factor (), entropy value (), shape factor (), operator energy (), fluctuation factor (), impulsiveness factor (), and the two factors and .
To enhance class separability, the determination of discriminant features is performed to maximize inter-class variance (dispersion between classes) relative to intra-class variance (dispersion within a class) [
8]. For
M classes and a given feature
, the Fisher criterion
is expressed as
where
: Mean value of feature for class i.
: Variance of feature for class i.
N: Number of samples in class i.
In the numerator: represents the squared distance between the means of classes i and j. A larger distance indicates that the classes are better separated.
In the denominator: reflects the dispersion or variability within the two classes. If the variances are large, it makes separation more difficult.
Although this criterion allows for ranking the extracted features according to their discriminative power, the optimal number of features to retain must be determined empirically through validation with a decision rule. The normalized contribution of each feature
can be calculated using Equation (
49).
4.2. Fault Detection
According to the Fisher criterion, the three most relevant indicators for detection are RMS, CF, and . Although the criterion allows for ranking the calculated indicators in descending order of importance, these three indicators are used to form the dataset. For each class, 80% is randomly selected for training and 20% for test.
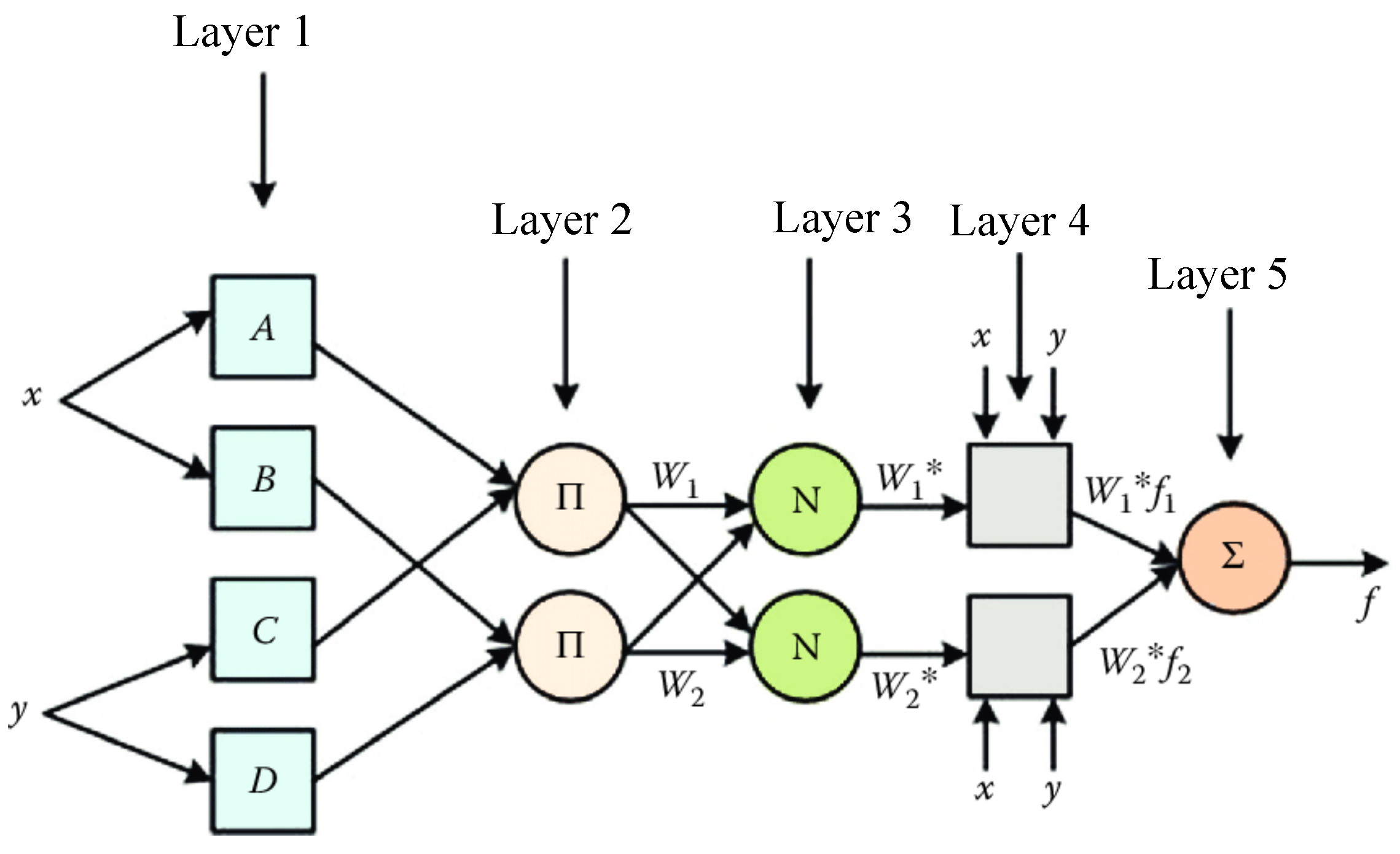
ANFIS (Adaptive Neuro-Fuzzy Inference System) is a sophisticated hybrid intelligent framework that synergistically combines neural network learning capabilities with fuzzy logic reasoning, as illustrated in
Figure 15. The architecture comprises five functionally distinct layers that work in tandem to process information: the initial Fuzzification Layer transforms crisp inputs into linguistic variables through membership functions; the subsequent Inference Layer applies fuzzy IF–THEN rules to generate appropriate weighting factors; the Normalization Layer scales these weights proportionally; then, the Aggregation Layer combines the normalized outputs; and finally, the Defuzzification Layer converts the fuzzy conclusions into actionable numerical outputs. This multilayered structure employs adaptive network parameters including connection weights (
,
), normalization operators (
N), and a series of intermediate computational nodes (
,
,
through
) that collectively enable the system to learn complex input–output relationships while maintaining interpretability through fuzzy rules [
25]. The unique integration of gradient-based learning from neural networks with the approximate reasoning of fuzzy systems allows ANFIS to effectively model highly nonlinear, uncertain processes across various domains, from industrial control to predictive analytics, while offering advantages in both accuracy and transparency compared to conventional approaches. The system’s adaptive nature permits continuous refinement of membership functions and rule bases through exposure to training data, making it particularly suitable for applications requiring both learning capacity and human-understandable decision logic [
16].
The dataset is prepared as follows: The first three columns represent the inputs (selected indicators), and the last column represents the desired output for our ANFIS model. After generating the dataset, create the initial FIS system with two membership functions and begin the learning phase by selecting the appropriate training options, as follows:
Learning method: Hybrid method using least squares and gradient back-propagation.
Error tolerance: 0 (used as a learning stopping criterion, related to the size of the error).
Number of iterations: Set to 200 to achieve error stabilization.
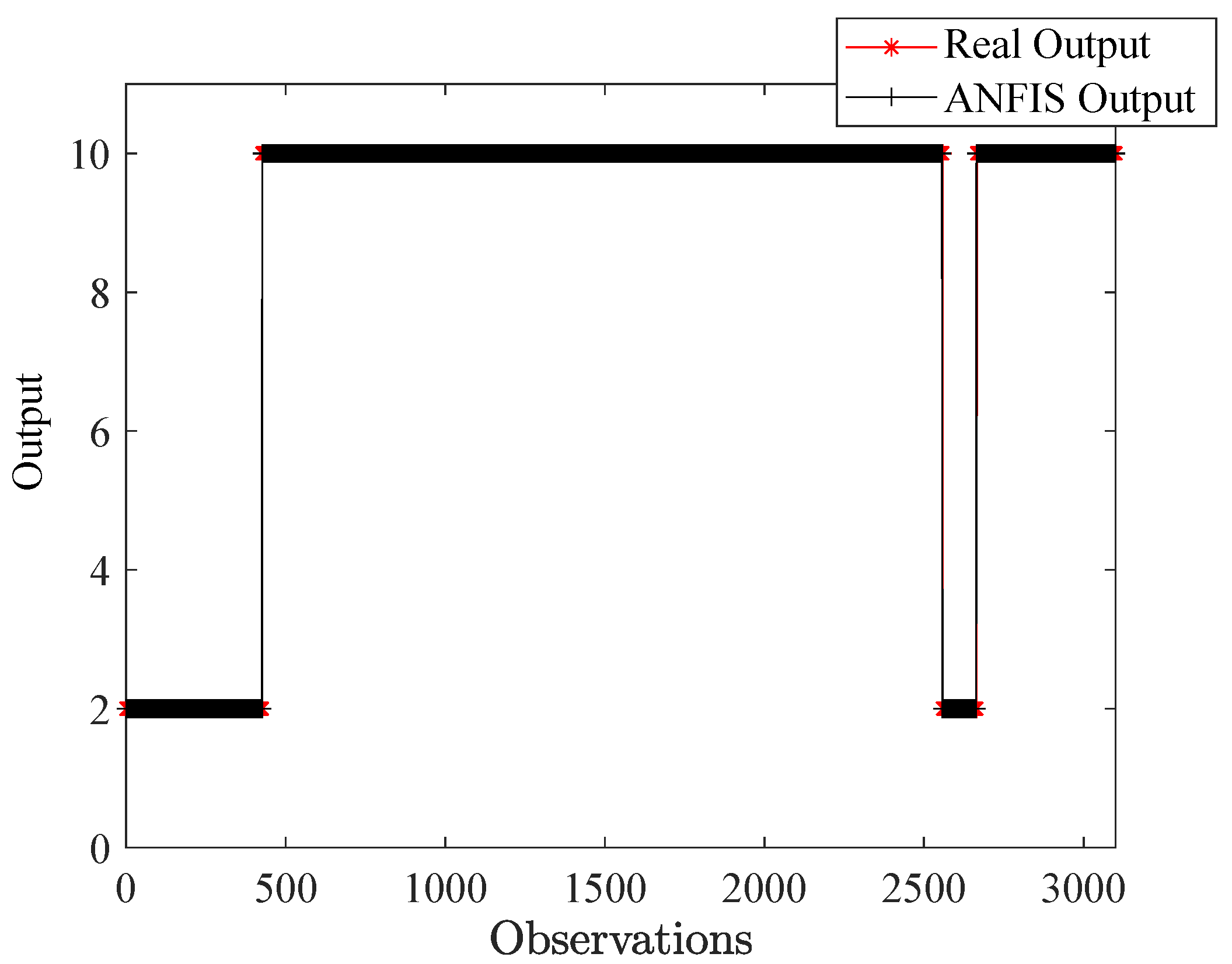
After training and testing, the detection result is 100%, as illustrated in
Figure 16.
Figure 16 shows the prediction versus the observations. The observations include all the training data (2556 samples: 426 samples for the healthy state and the rest for the five fault classes) and the testing data (642 samples: 107 samples for the healthy state and the rest for the five fault classes). The outputs are limited to two classes only (2 for the healthy state and 10 for the faulty state, where different faults are mixed). The figure demonstrates a perfect classification of the entire dataset, reflecting the effectiveness of Fisher’s criterion for selecting the most discriminative features, as well as the suitability of the ANFIS machine learning network for this detection task.
4.3. Fault Diagnostic
Based on the Fisher criterion, which evaluates the relevance of indicators in the fault diagnosis phase of the gearbox, certain indicators stand out for their ability to effectively discriminate between different faults. These key indicators provide essential information for accurately identifying and classifying gearbox faults. The three indicators selected for diagnosis are the impulse factor (
), the mean value (
), and the operator energy (
). Using the three indicators to train the ANFIS model results in a dataset with 533 samples for each fault. Divide each class into 80% for training and 20% for test. The other parameters of the ANFIS model are the same as those used for detection. The diagnostic result is 100%, as illustrated in the confusion matrix in
Figure 17.
The diagonal elements of the confusion matrix represent correct classifications, while the off-diagonal elements reflect misclassifications between classes. As shown in the confusion matrix in
Figure 17, all off-diagonal elements are zero, and the diagonal elements contain the exact number of correctly classified samples, which is 107 for each class. This reflects the high quality of the classification achieved, with an accuracy of 100%. Such a result highlights the effectiveness of combining the Fisher criterion for feature selection with ANFIS for classification.
4.4. Experimental Validation of the Proposed Approach
In this step, the diagnostic approach presented in the previous two sections was validated experimentally. This was accomplished using a dataset created by Fedala et al. [
27].
The gearbox test bench, illustrated in
Figure 18, consists of a direct current (DC) motor controlled by a speed regulator. This motor, which can reach a speed of 3600 RPM, is connected to the gearbox via a flexible coupling, with an encoder installed at both the input and output shafts. At the output, the gearbox is linked to a brake through another flexible coupling, allowing for load control. The gearbox comprises a single-stage spur gear system with a 25/56 tooth ratio.
To assess the effectiveness of the proposed method, six gears with different faults were considered during the experiment. The first gear is in Good state (G), while the others have various faults: a Root Crack (RC), a Chipped Tooth in Length (CTL), a Chipped Tooth in Width (CTW), a Missing Tooth (MT), and General Surface Wear (GSW), as shown in
Figure 19.
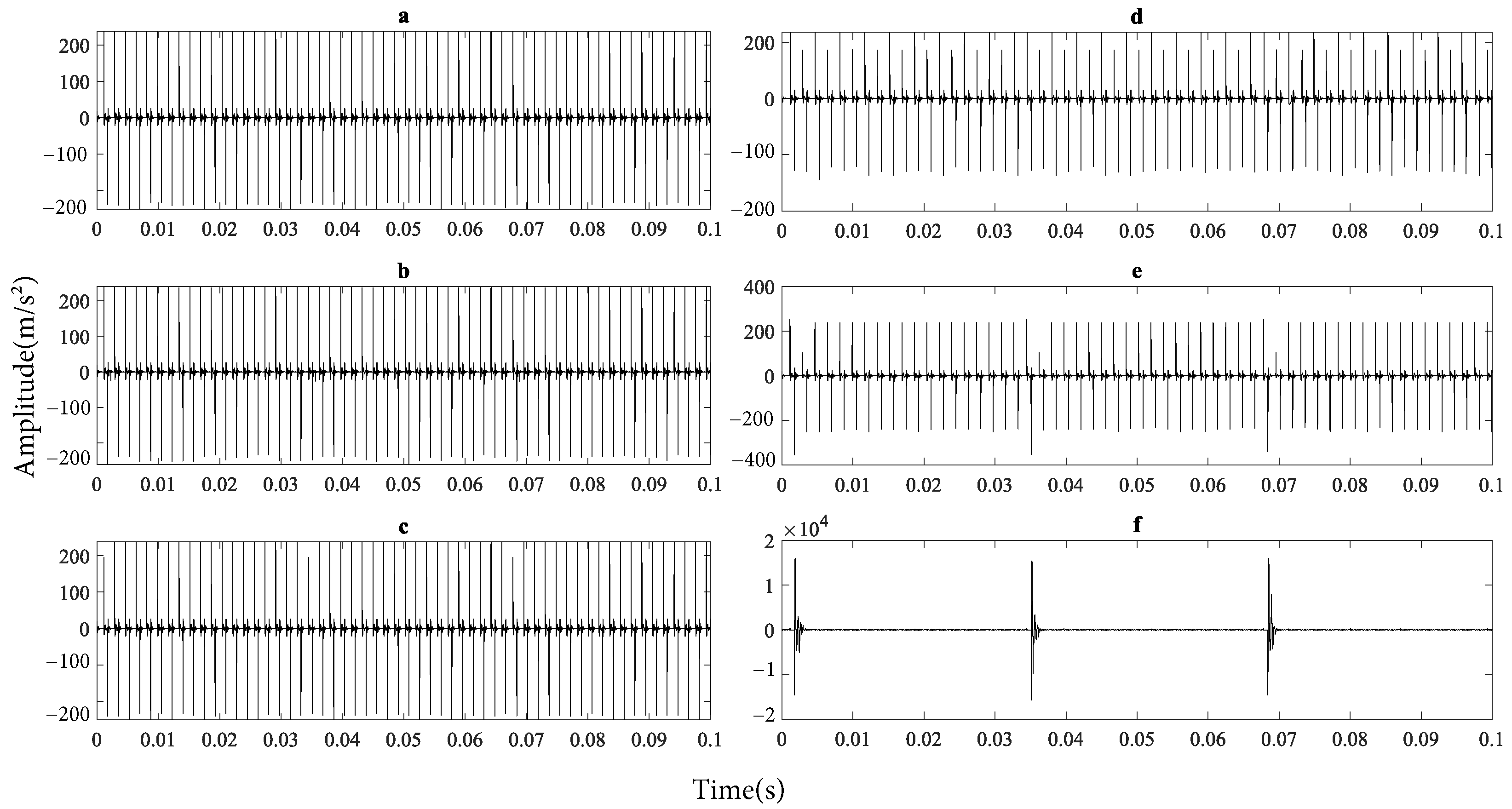
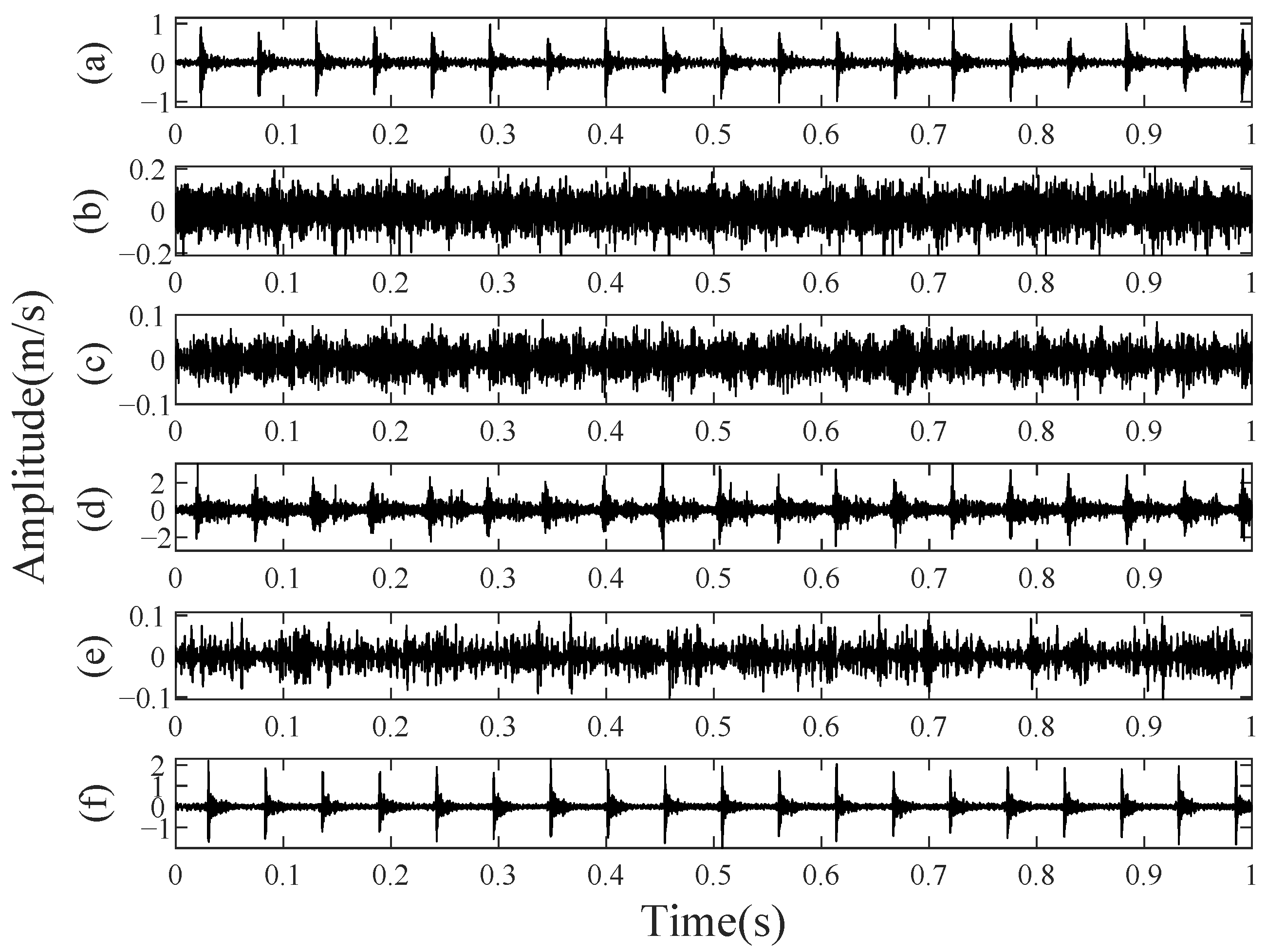
The accelerometer sampling frequency was set to 125 kHz with a 27 kHz filter cutoff frequency, using a 30 s acquisition duration. The diagnostic validation approach was implemented at an operating speed of 1200 RPM and a torque of 11 Nm, yielding the vibrational signals shown in
Figure 20.
When comparing the experimental signals in
Figure 20 with those obtained from the model in
Figure 14, the two classes exhibiting impulsive characteristics are missing tooth and chipped tooth. These two faults increase dynamic transmission error, resulting in more significant tooth impact [
28]. The other faults have a less significant impact, making their signatures comparable to noise levels.
Each measurement was subdivided into 120 segments of 0.25 s. The dataset is divided into 80% for training and 20% for testing to perform training with the ANFIS model. The selection of the most relevant indicators according to the Fisher criterion identified the following three indicators: standard deviation (), kurtosis (), and root mean square ().
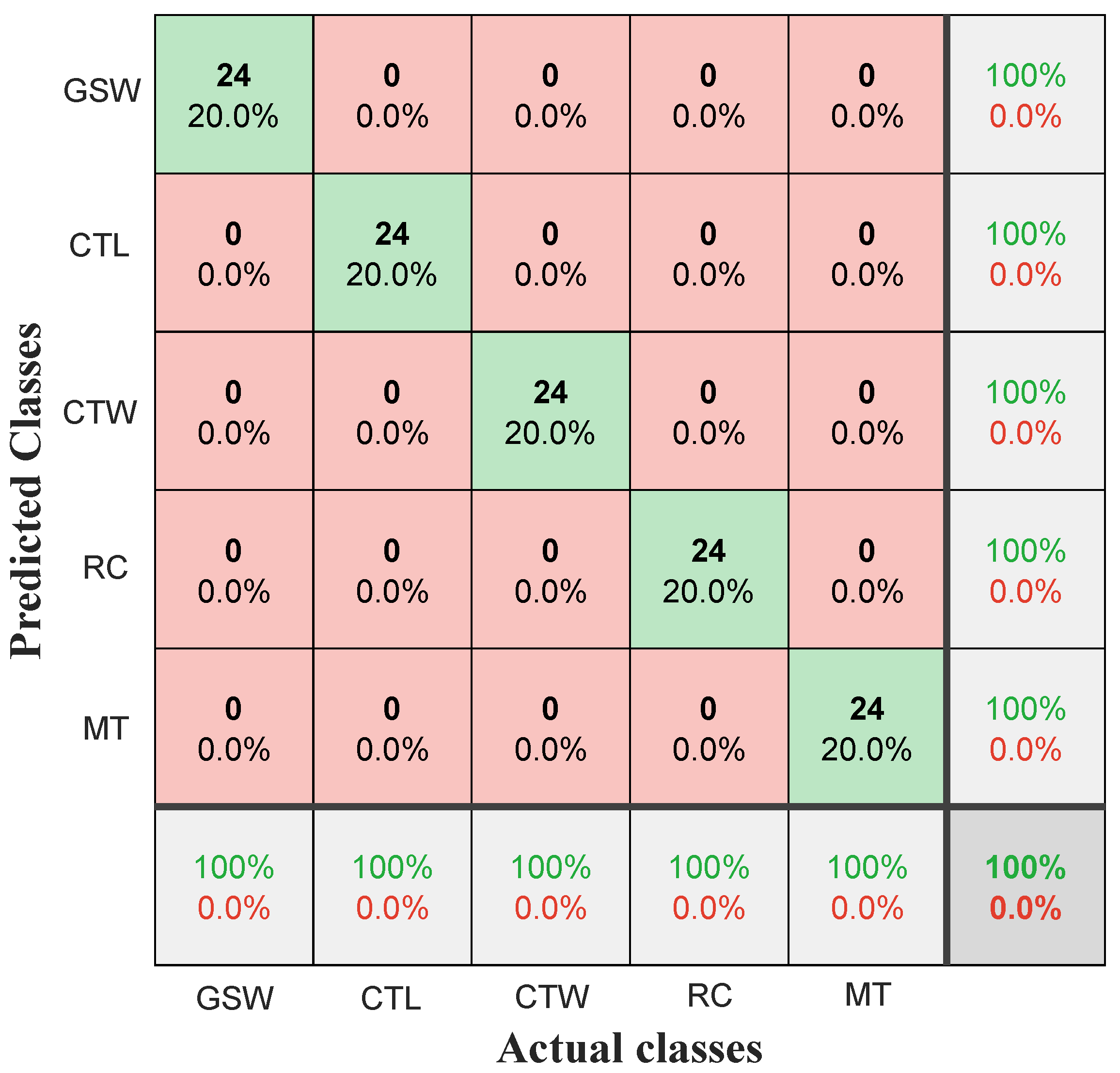
The classification accuracy rate is 100%. The confusion matrix in
Figure 21 presents the test results for each class.
The confusion matrix shown in
Figure 21 was obtained by applying the proposed methodology to the experimental data. As illustrated, the off-diagonal (red cells) elements are all zero, while the diagonal elements (green cells) display a perfect classification rate of 24/24 samples for each class (displayed in bold). These results demonstrate the effectiveness of the approach, which combines Fisher’s criterion for feature selection and ANFIS for classification. The methodology not only accurately distinguishes between different fault categories but also assesses their severity, thereby facilitating the diagnosis of emerging faults.
The ANFIS learning results were compared with well-known machine learning approaches, including Support Vector Machines (SVM), k-Nearest Neighbors (k-NN), and Random Forest (RF). These methods are widely used, particularly in fault diagnosis applications [
29]. The classification accuracy reached 96.67% for SVM and 100% for both k-NN and Random Forest. Compared to the identical 100% accuracy achieved by ANFIS, these results highlight the effectiveness of the Fisher criterion feature selection technique, which enables robust learning across different network architectures.
Another comparison with a recent framework was conducted using the same dataset [
30], where vibration signals were processed through the following methodology: First, the signal is decomposed using Maximal Overlap Discrete Wavelet Packet Transform. Next, the autocorrelation of the squared envelope is computed, followed by kurtosis calculation for each autocorrelation. The features extracted through this process are then used to train a Radial Basis Function Neural Network, achieving 100% fault detection and diagnosis accuracy—identical to the results obtained in our paper using time-domain signal analysis with ANFIS learning.
5. Conclusions
This paper investigates the potential of artificial intelligence techniques for fault detection and diagnosis in gearboxes, with a focus on modeling vibrational responses and leveraging machine learning. The main objective was to demonstrate how these innovative methods can enhance the predictive maintenance of gearboxes, thereby increasing their reliability and extending their operational lifespan. By modeling gear tooth rigidity, this study analyzed the impact of gear faults on the vibration response of the system. The findings revealed that a reduction in rigidity due to faults can significantly affect the performance of rotating systems, underscoring the importance of accurate fault diagnosis. To develop reliable fault detection and classification models, machine learning algorithms were applied to the vibration data collected during experiments. Feature selection based on the Fisher criterion was employed to identify the most discriminate features, enhancing the models’ ability to distinguish between healthy and faulty states effectively. This step was crucial in improving the performance and accuracy of the fault diagnosis models. Among the machine learning techniques used, fuzzy logic methods and ANFIS (Adaptive Neuro-Fuzzy Inference System) proved particularly effective in the learning process. These techniques delivered strong results in fault classification, showing high accuracy when tested on independent data. Trained on a comprehensive dataset of vibration signatures, the models outperformed traditional expert-based rule methods in both fault detection and classification tasks. In summary, the integration of feature selection based on the Fisher criterion, along with advanced machine learning techniques, demonstrated a significant advancement in gearbox fault diagnosis. This approach not only strengthens predictive maintenance strategies but also improves the overall performance and reliability of gearboxes. The use of modeling allows for the anticipation and reduction of relevant features prior to training with a suitable network, enabling the precise specification of the hardware required for deploying the proposed solution. Finally, a comparative analysis with other machine learning methods and a benchmark against a state-of-the-art framework confirmed the effectiveness of the ANFIS model for fault diagnosis.
One of the most interesting directions would be to extend our approach to prognostics, which involves monitoring the progression of fault severity and estimating the remaining useful life of each faulty component. This extension would not only detect existing faults but also predict their progression and plan maintenance interventions in a more proactive and optimized manner.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}