Abstract
Maximizing the expected value of a concave and strictly increasing utility function defines a fundamental class of discrete optimization problems. Among them, coverage decision problems with diminishing marginal returns under uncertainty, typically modeled via a set-union operator, have been extensively studied. In the classical framework, an item becomes active once it is covered by at least one chosen meta-item. Motivated by increasing robustness requirements in applications such as automated systems, social networks, and emergency response planning, we extend this setting by introducing threshold-based activation. The resulting generalized problem can be formulated as a mixed-integer nonlinear programming problem, for which we further propose three exact algorithms. The first two methods linearize the utility function using submodular cuts (SC) and outer-approximation (OA) techniques, respectively, resulting in formulations that can be solved exactly by off-the-shelf mixed-integer linear programming solvers. The third method builds upon the OA framework and further employs Benders decomposition (BD) to project out the item-related variables, which enables superior performance on ultra-large-scale instances. Extensive computational experiments show that, compared with the SC and BD methods, the OA method exhibits a substantial speed advantage on instances with a size of around 40,000, which can be solved within 100 s. In contrast, for ultra-large-scale instances with more than 100,000 items, the BD method demonstrates superior computational efficiency. These results provide practical guidance for algorithmic strategy selection and further demonstrate the computational tractability of this broader class of utility maximization problems under threshold-based activation.
Keywords:
diminishing marginal utility; utility function; submodular cuts; outer-approximation; benders decomposition; mixed-integer programming; branch-and-cut algorithms MSC:
90C27; 90C46; 90C10
1. Introduction
The problem of maximizing the expected value of a concave, strictly increasing, and differentiable utility function f applied to the aggregate value of a selected item set has been extensively studied in the literature [1,2,3]. Such utility functions naturally capture diminishing marginal returns while preserving monotonicity, reflecting the intuitive principle that additional resources always increase utility but at a decreasing rate [4]. A commonly adopted specification is , where controls the degree of concavity and thus the level of risk aversion. To formalize this class of problems, a finite ground set of items J is given, and uncertainty is modeled through a finite set of scenarios K, where each scenario is associated with a value vector . Let denote the family of all feasible selections. The objective is to select a subset that maximizes the expected utility:
Here, denotes the probability of scenario k and is a scenario-dependent constant. This class of problems has found wide applicability across multiple domains, including expected utility theory [4], facility location [5], and combinatorial auctions [6].
More recently, Coniglio et al. [7] generalized this framework by replacing the additive structure with a set-union operator. In the resulting model, a set of meta-items I is introduced, where each meta-item covers a subset of the ground set. Let denote the family of all feasible selections of meta-items. The decision problem is to select a subset of meta-items so as to maximize the utility, which is evaluated on the activated items, defined as the union of the item covered by the selected meta-items, namely, :
This set-union-based framework admits a natural interpretation in influence maximization problems in social networks [8]. In this context, the ground set J represents the set of users in the network, while set I corresponds to candidate seed users. A selected seed user i activates a subset of users that can be influenced by i. Accordingly, for a selected seed user set , the resulting activated user set is given by . The expected activation utility can then be expressed as , where denotes the probability of scenario k, represents the weight or utility of user j in scenario k, and f is the utility function. This formulation reveals that influence maximization can be viewed as a stochastic set-covering problem, in which the set-union operator captures the cumulative coverage of activated users and naturally induces a submodular objective function. Additionally, this modeling framework also arises in marketing problems [9] and stochastic competitive facility location [10].
In this paper, we further generalize this problem by introducing activation thresholds for items in the ground set, whereby an item is activated only when it is covered by many sufficiently selected meta-items. Specifically, for each item , let denote its activation threshold. Given a selected subset , item j is activated if and only if , where is the set of meta-items that cover item j. Accordingly, the item set activated by T is defined as , and the corresponding decision problem can be formulated as
Under this generalized activation rule, the activated set is no longer determined by a simple set union, but instead by these threshold-based activation constraints. When for all , the proposed model reduces to the classical set-union formulation studied in Coniglio et al. [7], demonstrating that our framework strictly generalizes existing models. When the utility function is linear, model (3) reduces to the Maximal Availability Location Problem (MALP) [11,12], which has been extensively studied in the facility location literature. A closely related formulation is the (PSMCP) [13,14], in which activation thresholds are similarly imposed on items, and the objective is to select the minimum number of sets such that the total covered utility exceeds a prescribed target level. Variants of MALP and PSMCP have been widely investigated in the combinatorial optimization literature [15,16,17,18,19,20]. However, the linear utility structure adopted in these formulations limits their ability to capture diminishing marginal returns and heterogeneous valuation effects that frequently arise in practice. For example, in social network applications, the value of activating a user may depend on multiple dimensions, such as purchasing power, influence, and engagement intensity, which cannot be adequately represented by a simple linear aggregation [21,22,23]. By incorporating a concave utility function into the objective, our framework can be viewed as a generalization of both MALP and PSMCP. It enables a richer representation of nonlinear benefit structures under budget constraints, whose practical implications are discussed in greater detail below.
More broadly, a wide range of real-world applications can be naturally modeled within this threshold-based activation framework. A prominent example arises in cumulative activation processes in social networks [24]. Most existing studies on influence maximization focus on one-shot propagation mechanisms in which influence is propagated from seed users only once according to a probabilistic diffusion model. However, in many practical settings, a single exposure is often insufficient to trigger adoption. Instead, influence accumulates over multiple rounds of information dissemination until a user’s internal adoption threshold is reached. Moreover, users exhibit heterogeneous susceptibility to influence: some may be easily activated after a few exposures, while others require repeated reinforcement. Such multi-round propagation mechanisms more accurately capture the cumulative nature of influence diffusion in real social networks. For instance, an empirical study on Twitter by Romero et al. [25] shows that the probability of adopting a hashtag increases significantly with the number of exposures, typically reaching its peak after two to four exposures rather than after the first one. Within our threshold-based activation framework, represents the set of seed users that can influence user j. Given a set of selected seed users , a user becomes activated only if the number of seed users in T influencing j reaches or exceeds its activation threshold , i.e., .
Another important application arises in stochastic facility location problems, which involve a set of customers J and a set of potential facility locations I. The objective is to select a subset of facilities to maximize the expected satisfied demand under multicover constraints, which naturally arise in settings where reliable coverage requires redundancy [11,12,26]. In practice, reliability considerations often require each demand point to be covered by at least two facilities to ensure service continuity under single-facility failure scenarios, such as disruptions caused by adverse weather or operational breakdowns [27]. Multicover requirements can be modeled by introducing activation thresholds for each customer , such that customer j belongs to the activated set only if at least selected facilities cover it. In the stochastic setting, the expected utility of a facility selection T can be expressed as , where K denotes a set of possible demand scenarios (e.g., weekdays and holidays exhibiting different traffic patterns for wireless towers), represents the demand of customer j in scenario k, and is the probability of scenario k.
A third class of applications arises in marketing problems, where firms aim to select a subset of products or advertising channels to maximize the number of consumers who form brand awareness. In typical marketing settings, customer loyalty or sustained engagement is often not established by exposure to a single product or advertisement alone. Instead, effective engagement commonly requires repeated or simultaneous exposure to multiple marketing stimuli from the same brand, reflecting a cumulative persuasion effect [28,29]. Empirical evidence in advertising practice suggests that approximately three exposures within a purchase cycle constitute a baseline level for achieving persuasive impact [30]. This phenomenon can be naturally modeled through a threshold-based mechanism, in which a consumer segment j becomes effectively engaged only when the number of attractive products or advertisements associated with the same brand exceeds a segment-specific threshold . In media planning settings, a closely related concept is effective frequency, which refers to the minimum number of advertising exposures required for a consumer j to be effectively influenced, thus naturally corresponding to the threshold . Early studies suggest that repeated advertising exposure is necessary for effectiveness, with Naples identifying three exposures within a purchase cycle as a baseline level of effective frequency [30]. Ostrow proposes that this effective frequency threshold should be adjusted according to target audiences and market conditions [31]. More recent empirical evidence indicates that, particularly in local markets with limited budgets, planners tend to prioritize frequency over reach while still relying on the effective frequency principle adapted to market-specific conditions [32].
By introducing binary decision variables, Problem (1) can be formulated as a mixed-integer nonlinear programming (MINLP) problem, which is described in detail in the next section. Since in Problem (1) all coefficients and are nonnegative and the utility function f is concave and nondecreasing, this problem can be naturally viewed as a submodular function maximization problem, which is known to be NP-hard [33]. A standard method to address such problems is to linearize the submodular function via submodular cuts [34], so that Problem (1) can be reformulated as a mixed-integer linear programming (MILP) for exact solution. Building on this formulation, Ahmed and Atamtürk [1] conducted a polyhedral analysis of this class of MILPs and applied lifting techniques to significantly strengthen the standard submodular formulation. Subsequently, Yu and Ahmed [2] further investigated the variant of the problem with a single knapsack constraint. Shi et al. [35] extended the results of Ahmed and Atamtürk [1] and studied the case involving multiple disjoint cardinality constraints. For Problem (2), Coniglio et al. [7] employed outer-approximation, Benders decomposition, and submodular cuts methods to linearize both the submodular objective function and the set-union operator, and provided a comparative evaluation of the resulting formulations. Subsequently, Lamontagne et al. [36] studied a dynamic (multi-period) variant of this problem and developed an exact solution method using Benders decomposition. Despite the wide range of practical applications and the growing demand for Problem (3), effective exact solution methods for these generalized models remain largely underdeveloped.
To address this gap, this paper studies Problem (3) and develops exact solution algorithms, with particular emphasis on instances in which the number of items exceeds the number of meta-items. The main contributions of this work are summarized as follows:
- We generalize the framework of Problem (2) by relaxing the single-coverage assumption, allowing an item to be considered activated only when it is simultaneously covered by a prescribed threshold. The resulting formulation broadens the applicability of the framework to settings such as social influence propagation, stochastic facility location, marketing and media planning.
- Three exact algorithms are proposed. The first algorithm is based on direct linearization by submodular cut (SC) method. The second algorithm relies on a single hypograph formulation using outer approximation (OA) method. Building on the OA framework, a third algorithm further incorporates Benders decomposition (BD) method to project out item-related variables, thereby substantially enhancing scalability on very large-scale instances. These methods offer practical solution choices for real-world applications.
- Extensive numerical experiments were conducted to evaluate the performance of the three methods. The results indicate that the OA method can solve instances with a size of up to 40,000 within 100 s, achieving solution times that are approximately 2–5 times faster than those of the BD method. In contrast, for very large-scale instances with more than 100,000 items, the BD method exhibits superior performance and outperforms the OA method. Overall, the SC method generally performs worse than the other two methods.
The remainder of this paper is organized as follows. Section 2 formally presents a MINLP formulation. Section 3 develops three exact solution methods for the proposed problem. Section 4 describes in detail the branch-and-cut implementation framework, including the separation strategies and pseudocode for each method. Section 5 reports extensive computational experiments, compares the performance of the three methods, and provides a detailed analysis of the numerical results. Section 6 summarizes the main contributions and findings of this paper and discusses directions for future research.
2. Problem Formulation
In this section, we formally present the mathematical formulation of the problem. Let the binary vector indicate whether each item is activated. Specifically, for each , if , and otherwise. Problem (1) can then be equivalently written as
where denotes the feasible region of decision vector . The objective function (4a) maximizes the expected utility across all scenarios, where the utility in each scenario is evaluated based on the total value of the activated items.
Furthermore, we introduce a binary decision variable to indicate whether meta-item is selected. An item becomes activated (i.e., ) if and only if at least one meta-item in set is selected. This covering condition is encoded by the constraints
Building on this structure, Problem (2) can be formulated as the following MINLP:
where denotes the feasible region of decision vector , such as those induced by budget constraints , with , or by cardinality constraints , with .
In the presence of activation thresholds for items, an item becomes activated (i.e., ) if and only if at least meta-items in set are selected. This relationship can be enforced by the following constraints:
Under this setting, Problem (3) can be equivalently reformulated as
Due to the strict monotonicity of f and the nonnegativity of , even if constraint (7b) is ignored, there exists an optimal solution in which whenever at least meta-items in are selected. Consequently, constraints (7b) are automatically satisfied and can be omitted from the model. Hence, Problem (3) is equivalent to
3. Methodology
This section presents three exact solution algorithms for Problem (8). We first describe, in Section 3.1, a SC method that exploits the submodularity of the objective function to derive a MILP reformulation solvable by off-the-shelf solvers. Next, in Section 3.2, we leverage the concavity of the utility function and develop an alternative linearization based on an OA scheme. Finally, in Section 3.3, we further incorporate a BD method to project out the variables , which enables the efficient solution of very large-scale instances.
3.1. Submodular-Cut-Based Exact Formulation
We first briefly review some useful theoretical results on SC method. Based on these results, Problem (8) is reformulated using SC method. Specifically, the nonlinear utility function is linearized, yielding a MILP formulation that can be solved by solvers.
3.1.1. Brief Review of SC Method
Let denote a finite non-empty ground set, and let be the collection of all the subsets of N. We briefly review the fundamental theory related to submodular functions as follows.
Definition 1.
For any subset and any item , we define the marginal return of adding i to S asA set function is submodular on N if
Proposition 1
([33]). The set function is submodular if and only if for all and .
Proposition 2
([33]). If h is submodular, then
Proposition 3
([37]). Given a submodular function h, denote . The following three sets are equivalent:
3.1.2. Submodular Cut Formulation for Problem (8)
Problem (8) is equivalent to
where is a submodular function [1]. It follows from Propositions 2 and 3 that Problem (13) is equivalent to
Problem (14) is a MILP and can be solved using MILP solvers based on the branch-and-bound framework. However, constraints (14a) and (14b) are exponential in number, rendering a formulation that explicitly includes all such constraints impractical. In fact, only a subset of the SCs is required to characterize an optimal solution. Therefore, we adopt the well-established branch-and-cut (B&C) framework [38,39], which solves the problem by iteratively refining a relaxed formulation that initially contains only a subset of the inequalities. Within the B&C algorithm, constraints (14a) and (14b) are treated as lazy constraints: they are not included in full at the outset; instead, only a small subset of these constraints is enforced initially, and additional violated constraints are generated and added dynamically when a candidate solution is encountered during the solution process.
At each iteration of the B&C algorithm, given a candidate solution , the separation problem aims to either identify a violated inequality from (14a) or (14b) or certify that no such violated inequality exists, in which case this candidate solution is feasible for the original problem. In the case of SC method, the separation procedure is straightforward: the inequality corresponding to the set is violated if and only if constraint (13b) is violated.
In the B&C framework, constraints (14a) and (14b) can also be added as cutting planes. The purpose of these cutting planes is to cut off a given linear programming (LP) relaxation in order to strengthen the lower bound of the problem. In this case, for the separation problem, an integer solution is first obtained by rounding the fractional solution to the nearest integer. Based on this rounded integer solution, the corresponding SCs are generated, and those SCs that are violated by the LP relaxation are added to the model.
Remark 1.
Problem (8) can also be equivalently reformulated as
Here, , where . However, (15b) cannot be linearized using SC method because the corresponding set function does not possess the submodularity property.
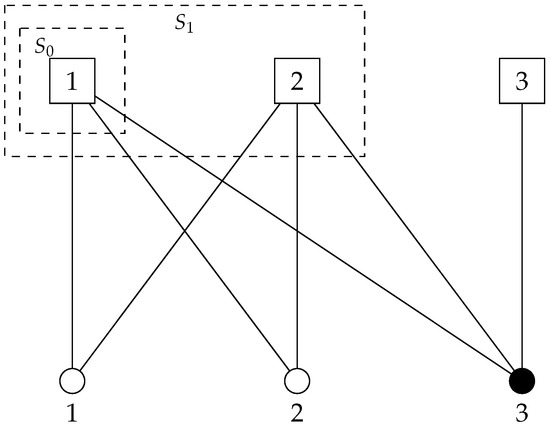
We illustrate this phenomenon through a simple example. Suppose that there are three meta-items (represented by squares) and three items (represented by circles), as shown in Figure 1. The white items require coverage from one meta-item, whereas the black items require coverage from three meta-items. Meta-items 1 and 2 are capable of covering items 1, 2, and 3, while meta-item 3 can only cover item 3. Moreover, let . Under scenario k, let for all and . Consider the sets and . Define
which denotes the set of items that are activated when the selected meta-item set is S. Then we have
Consequently,
It follows that
This example demonstrates that violates the diminishing returns property and is therefore not submodular.
Figure 1.
Illustration of non-submodularity. Squares represent meta-items, circles represent items, and dashed boxes indicate activated sets.
Let denote the set of items covered by meta-item i. The following proposition characterizes the loss of submodularity. Without loss of generality, we assume that , , and . Under these assumptions, for any selected set of meta-items S, we have .
Proposition 4.
Let be an item with activation threshold . Suppose there exist meta-items such that, for any distinct meta-items , . Then the set function is not submodular.
Proof.
Proposition 4 indicates that once the activation threshold satisfies , submodularity may fail to hold even under very simple structures. A precise characterization of the conditions under which submodularity is preserved (or violated) under threshold-based activation remains an open question and is deferred to future work.Let and , so that . Assume that , that is, a single meta-item activates s items. Under the threshold activation rule, item j is not activated by because it is covered only once, which is strictly less than . Hence, we have
On the other hand, in A, the item j is covered by exactly meta-items (namely ). After adding meta-item , item j becomes covered by meta-items and is therefore activated, yielding a greater marginal gain:
Therefore,
which violates the diminishing marginal returns property of submodular functions. □
3.2. Outer-Approximation-Based Exact Formulation
In this section, we exploit the concavity of the utility function and apply an OA method to obtain a linear reformulation. The following proposition provides a formal description of how a concave function can be linearized via the OA method.
Proposition 5.
Given a concave function , the following two sets are equivalent:
where is the gradient of f at point .
Proof.
Since f is concave and differentiable, for any in the domain, we have
This implies that
- If (i.e., ), then for any , . Hence, for all .
- Conversely, if , then by taking , , which implies that .
Therefore, equals the intersection of all hyperplanes defined by the supporting hyperplanes at each point . □
To apply the OA method, we first reformulate Problem (8) as follows:
It follows from Proposition 5 that Problem (16) admits an equivalent linear description given by
Remark 2.
An alternative way to linearize the utility function via OA is to reformulate Problem (8) equivalently as
Here, , and its gradient is given by
Applying standard OA theory, the nonlinear constraint can be equivalently replaced by its supporting hyperplanes, yielding the following MILP formulation:
where
Given its inferior numerical performance compared to the former formulation, the OA method adopted in this paper consistently employs the Formulation (17), which is defined by introducing the auxiliary variables . Similar to the SC method, the number of constraints in (17b) is prohibitively large, whereas the associated separation problem remains simple. Specifically, constraints (16a) are satisfied at a candidate solution (or, for LP relaxation, ) if and only if the inequalities in (17b) associated with (or, for LP relaxation, ) are satisfied.
3.3. Benders-Decomposition-Based Exact Formulation
In this section, to cope with problem instances involving a large number of items, we further explore a BD method in which the variable is projected out. In the Benders framework, the original problem is decomposed into a master problem defined over the remaining variables and a subproblem that evaluates the feasibility and optimality of a given master solution. The subproblem is typically required to be a LP in order to admit a well-defined dual and enable the generation of Benders cuts. This requires a suitable reformulation of constraints (7a) that allows to be relaxed to a continuous variable:
Proposition 6
([12]). Let . The following two sets are equivalent:
For each scenario , define the following auxiliary optimization problem:
where was defined in Proposition 6. Since and for all and , the vector can be further relaxed to . Consequently, the auxiliary problem can be equivalently written as
By Proposition 6, Problem (17) admits the following equivalent reformulation:
Eliminate by BD, and (22) is equivalent to
where (23b) denotes the Benders feasibility inequalities and (23c) denotes the Benders optimality inequalities, corresponding to extreme rays and extreme points , respectively, of the polyhedron P associated with the dual LP of the Benders subproblem.
In what follows, we focus on a single scenario and further examine the explicit forms of constraints (23c) and (23b). Given a fixed , the corresponding Benders subproblem can be formulated as
The dual of Problem (24) can be written as
where and . The dual variables and correspond to the constraints and , respectively, for each and .
Since the Benders subproblem (24) is always feasible, no Benders feasibility cuts are required. Regarding the Benders optimality cuts, strong duality for LP implies that Problem (24) and its dual (25) attain the same optimal objective value. Then, for any extreme point of the dual feasible region P, the associated Benders optimality inequality can be written as
Therefore, Problem (23) can be written explicitly as follows:
In the B&C framework, the relaxation that includes only a subset of the Benders optimality cuts (27b) is commonly referred to as the Benders master problem. Given a candidate solution or the LP relaxation to the Benders master problem, the separation of Benders optimality cuts is carried out by solving the dual Benders subproblem (25), which may yield a Benders optimality cut violated by the current solution. Problem (25) can be decomposed into subproblems, each associated with a facility , and involving only the variables and for all . Each subproblem takes the following form:
which is a standard LP with a single constraint. Let . Then, the optimal solution can be explicitly given as follows:
If
the corresponding Benders optimality cut is violated and is therefore added to the master problem. Otherwise, the current solution is optimal for the original Problem (23), and the algorithm terminates. For a more detailed description of the B&C approach for Benders cuts, also known as the branch-and-Benders-cut approach, we refer the reader to Fischetti et al. [40], Cordeau et al. [41], Güney et al. [42].
4. Branch-and-Cut Strategy
This section presents three exact solution strategies for solving Problem (8). Due to the exponential number of constraints induced by the linearization of the utility function and the projection of variable , rather than solving the full formulation with all constraints included from the outset, all three methods adopt a row-generation approach embedded within a branch-and-bound framework [43,44]. Specifically, for the SC method, all submodular inequalities (14a) and (14b) are enforced as lazy constraints. For each candidate solution or LP relaxation, the potentially violated submodular cuts are separated for each scenario following the procedure described in Section 3.1.2. Algorithm 1 presents the pseudocode for the generation of submodular cuts. For the OA method, all linearization (tangent) inequalities (17b) are also treated as lazy constraints. Algorithm 2 outlines the procedure for generating the tangent inequalities in the OA method. For the BD method, the Benders optimality cut is generated according to (29), where the key step lies in identifying the set . By definition, consists of the elements in with the smallest relaxed values. Hence, can be determined via a sorting procedure with time complexity . For each item , it follows from (29) that the dual variables corresponding to all are equal to zero. Consequently, the Benders optimality cuts (27b) admits the following simplified form:
If , then ; if , then . In the boundary case , choosing either or yields the same objective value for the dual subproblem (25) but results in different Benders optimality cuts. Following the strategy proposed in [12], we set if , and otherwise. Algorithm 3 details the complete procedure for generating Benders optimality cuts.
| Algorithm 1 Cutting plane generation framework for SC method |
| Require: The MILP model (13), and the candidate solution or the LP relaxation Ensure: Potentially violated SCs of the form 1: for do 2: Initialize the submodular inequalities with for all and ; 3: for do 4: if then 5: Set ; 6: Set ; 7: else 8: Set ; 9: end if 10: end for 11: end for |
| Algorithm 2 Cutting plane generation framework for OA method |
| Require: The MILP model (17), and the candidate solution or the LP relaxation Ensure: Potentially violated OA inequalities of the form violated by 1: for do 2: Initialize the OA inequalities with and ; 3: Set 4: Set 5: end for |
| Algorithm 3 Cutting plane generation framework for BD method |
| Require: The MILP model (27), and the candidate solution or the LP relaxation Ensure: The benders inequalities violated by 1: for do 2: Initialize the benders inequalities with and . 3: for do 4: Sort such that ; 5: Compute ; 6: if then 7: for do 8: Set ; 9: end for 11: else if then 11: Set ; 12: else 13: // 14: if then 15: Set ; 16: else 17: Set ; 18: end if 19: end if 20: end for 21: end for |
5. Computational Experiments
In this section, we present comprehensive computational experiments to evaluate the effectiveness of the three proposed methods for Problem (8). The experiments were conducted within the branch-and-bound framework of IBM CPLEX 20.1.0 [45], and all algorithms were implemented in C++17. The source code is publicly available at https://github.com/lostedsailor/januaryoa, accessed on 16 January 2026. We utilized CPLEX’s callback functions to add lazy constraints and user cuts. The relative gap tolerance of CPLEX was set to , and each test run was executed in single-threaded mode with a time limit of 3600 s. The other CPLEX parameters were kept at their default values. The experiments were performed on a cluster of 2.30 GHz Intel(R) Xeon(R) Gold 6140 CPU processors and 180 GB RAM, running Linux in 64-bit.
Our instance generation procedure is consistent with the commonly used settings in Coniglio et al. [7] and Li et al. [12]. The problem scenario considered in the experiments is motivated by facility covering location problems [41,46]. In all test instances, we consider a geographical region represented by a square grid. Both meta-items (interpreted as facilities) and items (interpreted as demand points) are independently and uniformly distributed over this two-dimensional area. Each meta-item is associated with a circular coverage region of a prescribed radius R. An item is deemed to be covered by meta-item i if the Euclidean distance between i and j does not exceed the coverage radius. Throughout the experiments, we employ the widely used concave utility function and impose a cardinality (budget) constraint on meta-items, namely, . For each item , the activation threshold is randomly selected as an integer from the interval . For all scenarios , the scenario-dependent constant is set to zero and the scenario probabilities are taken to be uniform, i.e., . For each scenario–item pair , the value parameter is independently drawn from a uniform distribution on the interval . Moreover, to ensure numerical stability of the exponential utility function, all values are rescaled by a factor of . To provide a comprehensive assessment of the solution performance of all methods, the number of scenarios is set to . In addition, the coverage radius of meta-items is selected from , the number of meta-items is fixed at , and the budget is fixed at . For each parameter setting, ten instances are generated with identical characteristics, except for the random seeds used in data generation. In the remainder of this section, we systematically assess the three proposed methods through extensive numerical experiments. It is worth noting that the BD method is developed on the basis of the OA method, and the numerical results indicate that the SC method performs significantly worse than both the OA and BD methods. Therefore, in Section 5.1, we restrict the comparison to the OA and SC methods. In Section 5.2, we further compare the OA method with the BD method.
5.1. Comparison of the SC and OA Methods
This subsection examines the numerical performance of the SC method and the OA method. The number of items varies over {1000, 5000, 10,000}. Table 1 reports the performance comparison results. Each row reports the average computational time over 30 instances, consisting of three coverage radius settings with 10 random seeds each. Each group of three rows corresponds to a fixed number of meta-items , with the number of items increasing across rows within each group. The three groups are ordered by increasing values of . For each formulation, we also report the number of instances in each group that are solved to proven optimality, indicated in the column “# opt”. All average CPU times are computed under a time limit of 3600 s. For instances that are not solved within the prescribed time limit, the computational time is recorded as 3600 s. As shown in the table, over the entire range of parameter settings considered in the experiments, the OA method proves optimality for all 270 instances within the prescribed time limit, whereas the SC method fails to solve 35 instances within the time limit, resulting in a solution rate of 87.0%. In terms of computational time, the OA method solves all instances within 10 s on average, except for the case with and , where the average solution time is 10.08 s. In contrast, the SC method exhibits average solution times exceeding 10 s across all settings, and instances with require more than 2000 s on average. Overall, these results indicate that the OA method substantially outperforms the SC method. For both methods, the solution time grows nonlinearly with the number of items. For example, for the SC method with , increasing from 1000 to 5000 raises the average solution time from 14.84 s to 326.68 s, corresponding to an average growth rate of . When further increases from 5000 to 10,000, treating timeouts as 3600 s, the average solution time increases to at least 2393.28 s, yielding a substantially higher growth rate of 0.41. This nonlinear dependence is already evident from the results reported in the table. In addition, despite a few isolated exceptions, the overall computational difficulty tends to increase with the number of scenarios.

Table 1.
Performance comparison of SC and OA methods.
5.2. Comparison of the OA and BD Methods
In this section, we compare the OA and the BD methods. Table 2 and Table 3 summarize the numerical results using the same notation as in the previous tables. To provide a more in-depth comparison of the two methods, the number of items is varied over for large-scale instances and over for ultra-large-scale instances. All other parameter settings, including the number of scenarios , the coverage radius R, the budget B, and the number of meta-items , are kept identical to those in Table 1.
Table 2.
Performance comparison of OA and BD methods.
Table 3.
Performance comparison of OA and BD methods on ultra-large-scale instances.
Table 2 compares the performance of the OA method and the BD method on large-scale instances. Both methods are able to obtain optimal solutions within the prescribed time limit. However, the OA method demonstrates a clear advantage. Specifically, the OA method achieves an average solution time of 38.94 s, with all instances solved within 100 s, whereas the BD method requires 100.89 s on average. In particular, for the case with and , the BD method takes 173.29 s on average to solve the 30 instances. For the BD method, when the number of scenarios is fixed at , the computational difficulty exhibits a positive correlation with the number of items; as the number of scenarios increases, this correlation becomes less evident. In contrast, the OA method shows more stable performance, with solution times increasing steadily as the number of items grows. For example, when , increasing the number of items from 20,000 to 30,000 raises the average solution time from 16.78 s to 23.69 s, and a further increase to 40,000 items leads to an average solution time of 67.80 s.
A further comparison between the OA method and the BD method on ultra-large instances is reported in Table 3. At this scale, the BD method successfully solves all 270 instances, whereas the OA method fails to solve 11 instances, achieving a solution rate of 95.9%. The BD method exhibits superior performance, with an average solution time of 361.63 s, whereas the OA method requires 812.41 s on average; in particular, for the case with and , the average solution time of the OA method reaches 1541.30 s. It can be observed that, for ultra-large instances, the computational difficulty of both methods is positively correlated with the number of items across different scenario settings. For example, when , increasing the number of items from 100,000 to 150,000 raises the average solution time of the BD method from 346.74 s to 414.60 s; a further increase to 200,000 items leads to an average solution time of 639.22 s.
5.3. Discussion
We have provided a comprehensive comparison of the three proposed methods. The numerical experiments indicate that, overall, the SC method performs the worst, with solution times that are substantially longer than those of the OA and BD methods. In contrast, both the OA and BD methods are able to obtain optimal solutions under the considered parameter settings within the one-hour time limit. Interestingly, the OA and BD methods exhibit complementary strengths across different problem scales. When the number of items lies in , the OA method demonstrates superior performance. This can be attributed to the fact that, for relatively large-scale instances, the OA method incorporates all covering constraints between items and meta-items (7a) from the outset, providing richer structural information to the model and thereby enabling faster convergence. In contrast, the BD method relies on the dynamic generation of Benders optimality cuts, meaning that relationships between items and meta-items are introduced progressively during the solution process. Consequently, more iterations may be required to accumulate sufficient structural information for convergence, even though each individual iteration can be computationally cheaper. Moreover, the associated separation problems incur additional computational overhead, leading to slower convergence for smaller-scale instances. As the problem size further increases to items, the BD method begins to exhibit a clear advantage. At this scale, the large number of covering constraints (7a) significantly increases the size of the master problem in the OA formulation. In particular, incorporating all covering constraints from the outset leads to substantial growth in the constraint matrix and memory footprint. As a result, each LP re-optimization within the branch-and-bound process becomes increasingly expensive, and the computational time is dominated by repeated factorization and basis updates of large-scale linear systems, even though the total number of branch-and-bound iterations may be smaller than that of the BD method. By contrast, the BD method keeps the master problem compact and introduces covering constraints only when they are violated. This selective constraint generation strategy effectively controls both the memory usage and the per-iteration LP solution time. Although the separation procedures incur additional CPU overhead, this cost grows more moderately compared to the rapid increase in LP solution time experienced by the OA formulation. Consequently, BD method scales more efficiently for ultra-large instances and outperforms OA beyond the crossover point.
Remark 3.
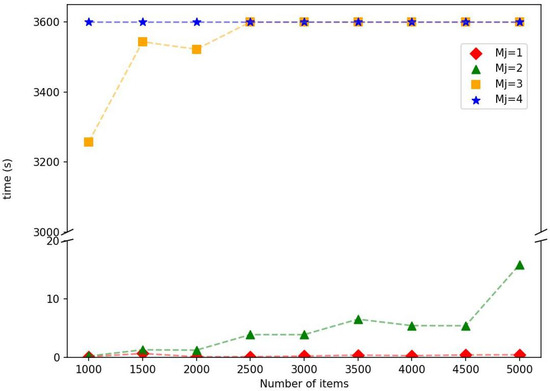
The computational complexity of multi-cover-type problems typically increases with the coverage thresholds. To isolate and explicitly examine this effect, we conduct additional experiments in which the activation thresholds are no longer generated randomly. Instead, all items are assigned a common threshold value . The remaining parameters are fixed as , , and all instances are solved using the OA method. Figure 2 reports the solution times under varying numbers of items and different common threshold values. Each point in the figure represents the average solution time over ten randomly generated instances. As expected, the computational effort increases with the number of items. More importantly, a substantial escalation in solution time is observed as the common threshold increases. When or 2, all instances are solved within 20 s. For , the solution time increases significantly, requiring more than 3000 s. When , none of the instances can be solved to optimality within the prescribed time limit. These findings indicate that the activation threshold is a key factor influencing the intrinsic computational difficulty of the problem.
Figure 2.
Solution times for different numbers of items and threshold values .
6. Conclusions
This paper studies a class of optimization problems that maximize the expected value of a concave, strictly increasing utility function with explicit incorporation of activation thresholds, thereby addressing the growing demand for reliability in real-world applications. We formulate generalized models for this problem class, which lead to MINLP. To address the resulting nonlinearity, we employ SC and OA techniques to linearize the utility function, thereby reformulating the original model into two MILPs solvable by off-the-shelf solvers. Motivated by the superior performance of the OA method, we further develop a BD method that projects out item-related variables and dynamically generates the associated large-scale coupling constraints. This decomposition strategy significantly enhances the scalability of the proposed model and enables the efficient solution of ultra-large-scale instances. The numerical results indicate that the OA and BD methods possess complementary advantages across different problem scales. In particular, the OA method performs more efficiently for instances with the number of items in , whereas the BD method shows superior performance on larger instances with items. By contrast, the SC method consistently yields inferior computational performance compared with the other two methods.
This study also suggests several promising directions for future research. From an application-oriented perspective, the proposed modeling framework and solution methods can be leveraged to enhance robustness in a variety of practical settings, including autonomous driving, social network analysis, and emergency response planning. The numerical findings further provide practical guidance for algorithm selection: the OA formulation is generally preferable for moderate-scale instances, whereas the BD approach offers superior scalability for ultra-large problems, enabling practitioners to select solution strategies according to dataset size and operational requirements. From a methodological standpoint, future work may focus on designing more advanced preprocessing techniques to reduce problem size and accelerate solution times. Although the SC method exhibits relatively weak performance in its current form, its effectiveness may be improved by strengthening the associated inequalities through lifting strategies. For structurally related problems without activation thresholds, several preprocessing techniques [47] as well as strengthened submodular cut formulations [1] have been studied in the literature. Extending these ideas to the more general setting considered in this paper remains a worthwhile direction for future research. Furthermore, developing parallel implementations of the proposed algorithms represents another important direction, with the potential to significantly improve scalability and facilitate the efficient solution of large-scale problems involving a greater number of scenarios.
Author Contributions
Conceptualization, G.L.; methodology, G.L., Y.L., S.C., M.S. and W.Z.; software, G.L. and Y.L.; validation, G.L. and Y.L.; formal analysis, G.L., Y.L. and S.C.; investigation, G.L. and Y.L.; resources, G.L. and M.S.; data curation, Y.L.; writing—original draft preparation, G.L. and Y.L.; writing—review and editing, G.L., Y.L. and S.C.; visualization, G.L., S.C. and M.S.; supervision, S.C.; project administration, S.C.; funding acquisition, M.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key Research and Development Program of China (Grant No. 2023YFE0108600).
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Acknowledgments
The computations were carried out on the high-performance computers of the State Key Laboratory of Scientific and Engineering Computing, Chinese Academy of Sciences.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| SC | submodular cuts |
| OA | outer-approximation |
| BD | Benders decomposition |
| MINLP | mixed-integer nonlinear programming |
| B&C | branch-and-cut |
| MILP | mixed-integer linear programming |
| MALP | maximal availability location problem |
| PSMCP | partial set multi-cover problem |
| LP | linear programming |
| NP | nondeterministic polynomial-time |
| IBM | International Business Machines |
| CPLEX | (IBM) ILOG CPLEX Optimizer |
| CPU | central processing unit |
| RAM | random-access memory |
| GB | gigabyte |
References
- Ahmed, S.; Atamtürk, A. Maximizing a class of submodular utility functions. Math. Program. 2011, 128, 149–169. [Google Scholar] [CrossRef]
- Yu, J.; Ahmed, S. Maximizing a class of submodular utility functions with constraints. Math. Program. 2017, 162, 145–164. [Google Scholar] [CrossRef]
- Yu, J.; Ahmed, S. Maximizing expected utility over a knapsack constraint. Oper. Res. Lett. 2016, 44, 180–185. [Google Scholar] [CrossRef]
- Corner, J.L.; Corner, P.D. Characteristics of decisions in decision analysis practice. J. Oper. Res. Soc. 1995, 46, 304–314. [Google Scholar] [CrossRef]
- Aboolian, R.; Berman, O.; Krass, D. Competitive facility location model with concave demand. Eur. J. Oper. Res. 2007, 181, 598–619. [Google Scholar] [CrossRef]
- Feige, U. On maximizing welfare when utility functions are subadditive. In Proceedings of the 38th Annual ACM Symposium on Theory of Computing, Seattle, WA, USA, 21–23 May 2006; pp. 41–50. [Google Scholar]
- Coniglio, S.; Furini, F.; Ljubić, I. Submodular maximization of concave utility functions composed with a set-union operator with applications to maximal covering location problems. Math. Program. 2022, 196, 9–56. [Google Scholar] [CrossRef]
- Kempe, D.; Kleinberg, J.; Tardos, É. Maximizing the spread of influence through a social network. In Proceedings of the 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–27 August 2003; pp. 137–146. [Google Scholar]
- Lehmann, B.; Lehmann, D.; Nisan, N. Combinatorial auctions with decreasing marginal utilities. In Proceedings of the 3rd ACM Conference on Electronic Commerce, Tampa, FL, USA, 14–17 October 2001; pp. 18–28. [Google Scholar]
- Ljubić, I.; Moreno, E. Outer approximation and submodular cuts for maximum capture facility location problems with random utilities. Eur. J. Oper. Res. 2018, 266, 46–56. [Google Scholar] [CrossRef]
- ReVelle, C.; Hogan, K. The maximum availability location problem. Transp. Sci. 1989, 23, 192–200. [Google Scholar] [CrossRef]
- Li, G.; Li, Y.; Zhang, W.; Chen, S. Benders decomposition approach for generalized maximal covering and partial set covering location problems. Symmetry 2025, 17, 1417. [Google Scholar] [CrossRef]
- Shi, Y.; Ran, Y.; Zhang, Z.; Willson, J.; Tong, G.; Du, D.Z. Approximation algorithm for the partial set multi-cover problem. J. Glob. Optim. 2019, 75, 1133–1146. [Google Scholar] [CrossRef]
- Ran, Y.; Shi, Y.; Tang, C.; Zhang, Z. A primal-dual algorithm for the minimum partial set multi-cover problem. J. Comb. Optim. 2020, 39, 725–746. [Google Scholar] [CrossRef]
- Revelle, C.; Hogan, K. The maximum reliability location problem and α-reliable p-center problem: Derivatives of the probabilistic location set covering problem. Ann. Oper. Res. 1989, 18, 155–173. [Google Scholar]
- ReVelle, C.; Hogan, K. A reliability-constrained siting model with local estimates of busy fractions. Environ. Plan. B Plan. Des. 1988, 15, 143–152. [Google Scholar] [CrossRef]
- Marianov, V.; ReVelle, C. The queueing maximal availability location problem: A model for the siting of emergency vehicles. Eur. J. Oper. Res. 1996, 93, 110–120. [Google Scholar] [CrossRef]
- Wang, W.; Wu, S.; Wang, S.; Zhen, L.; Qu, X. Emergency facility location problems in logistics: Status and perspectives. Transp. Res. Part E Logist. Transp. Rev. 2021, 154, 102465. [Google Scholar] [CrossRef]
- Berman, O.; Drezner, Z.; Krass, D. Discrete cooperative covering problems. J. Oper. Res. Soc. 2011, 62, 2002–2012. [Google Scholar] [CrossRef]
- Curtin, K.M.; Hayslett-McCall, K.; Qiu, F. Determining optimal police patrol areas with maximal covering and backup covering location models. Netw. Spat. Econ. 2010, 10, 125–145. [Google Scholar] [CrossRef]
- Reichlin, C.R.A. Non-Concave Utility Maximization:: Optimal Investment, Stability and Applications. Ph.D. Thesis, ETH Zurich, Zürich, Switzerland, 2012. [Google Scholar]
- Rahmattalabi, A.; Jabbari, S.; Lakkaraju, H.; Vayanos, P.; Izenberg, M.; Brown, R.; Rice, E.; Tambe, M. Fair influence maximization: A welfare optimization approach. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 11630–11638. [Google Scholar]
- Wang, Z.; Zhao, J.; Sun, C.; Rui, X.; Yu, P.S. A general concave fairness framework for influence maximization based on poverty reward. ACM Trans. Knowl. Discov. Data 2024, 19, 1–23. [Google Scholar] [CrossRef]
- Shan, X.; Chen, W.; Li, Q.; Sun, X.; Zhang, J. Cumulative activation in social networks. Sci. China Inf. Sci. 2019, 62, 52103. [Google Scholar] [CrossRef]
- Romero, D.M.; Meeder, B.; Kleinberg, J. Differences in the mechanics of information diffusion across topics: Idioms, political hashtags, and complex contagion on twitter. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 695–704. [Google Scholar]
- Church, R.L.; Gerrard, R.A. The multi-level location set covering model. Geogr. Anal. 2003, 35, 277–289. [Google Scholar] [CrossRef]
- Snyder, L.V.; Daskin, M.S. Reliability models for facility location: The expected failure cost case. Transp. Sci. 2005, 39, 400–416. [Google Scholar] [CrossRef]
- Hauser, J.R.; Wernerfelt, B. An evaluation cost model of consideration sets. J. Consum. Res. 1990, 16, 393–408. [Google Scholar] [CrossRef]
- Messinger, P.R.; Narasimhan, C. A model of retail formats based on consumers’ economizing on shopping time. Mark. Sci. 1997, 16, 1–23. [Google Scholar] [CrossRef]
- Naples, M.J. Effective frequency: Then and now. J. Advert. Res. 1997, 37, 7–12. [Google Scholar] [CrossRef]
- Ostrow, J.W. Setting effective frequency levels. In Proceedings of the Effective Frequency: The State of the Art; Advertising Research Foundation, Key Issues Workshop: New York, NY, USA, 1982; pp. 89–102. [Google Scholar]
- Makienko, I. Effective frequency estimates in local media planning practice. J. Target. Meas. Anal. Mark. 2012, 20, 57–65. [Google Scholar] [CrossRef]
- Nemhauser, G.L.; Wolsey, L.A.; Fisher, M.L. An analysis of approximations for maximizing submodular set functions—I. Math. Program. 1978, 14, 265–294. [Google Scholar] [CrossRef]
- Wolsey, L.A.; Nemhauser, G.L. Integer and Combinatorial Optimization; John Wiley & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
- Shi, X.; Prokopyev, O.A.; Zeng, B. Sequence independent lifting for a set of submodular maximization problems. Math. Program. 2022, 196, 69–114. [Google Scholar] [CrossRef]
- Lamontagne, S.; Carvalho, M.; Atallah, R. Accelerated Benders decomposition and local branching for dynamic maximum covering location problems. Comput. Oper. Res. 2024, 167, 106673. [Google Scholar] [CrossRef]
- Nemhauser, G.; Wolsey, L. Matroid and Submodular Function Optimization. In Integer and Combinatorial Optimization; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 1988; Chapter 3; pp. 659–719. [Google Scholar]
- Padberg, M.; Rinaldi, G. A branch-and-cut algorithm for the resolution of large-scale symmetric traveling salesman problems. SIAM Rev. 1991, 33, 60–100. [Google Scholar] [CrossRef]
- Wolsey, L.A. Integer Programming; John Wiley & Sons: Hoboken, NJ, USA, 2020. [Google Scholar]
- Fischetti, M.; Ljubić, I.; Sinnl, M. Benders decomposition without separability: A computational study for capacitated facility location problems. Eur. J. Oper. Res. 2016, 253, 557–569. [Google Scholar] [CrossRef]
- Cordeau, J.F.; Furini, F.; Ljubić, I. Benders decomposition for very large scale partial set covering and maximal covering location problems. Eur. J. Oper. Res. 2019, 275, 882–896. [Google Scholar] [CrossRef]
- Güney, E.; Leitner, M.; Ruthmair, M.; Sinnl, M. Large-scale influence maximization via maximal covering location. Eur. J. Oper. Res. 2021, 289, 144–164. [Google Scholar] [CrossRef]
- Di Summa, M.; Grosso, A.; Locatelli, M. Branch and cut algorithms for detecting critical nodes in undirected graphs. Comput. Optim. Appl. 2012, 53, 649–680. [Google Scholar] [CrossRef]
- Pavlikov, K. Improved formulations for minimum connectivity network interdiction problems. Comput. Oper. Res. 2018, 97, 48–57. [Google Scholar] [CrossRef]
- CPLEX. User’s Manual for CPLEX; IBM: Armonk, NY, USA, 2022; Available online: https://www.ibm.com/docs/en/icos/20.1.0?topic=cplex-users-manual (accessed on 16 January 2026).
- ReVelle, C.; Scholssberg, M.; Williams, J. Solving the maximal covering location problem with heuristic concentration. Comput. Oper. Res. 2008, 35, 427–435. [Google Scholar] [CrossRef]
- Chen, S.J.; Chen, W.K.; Dai, Y.H.; Yuan, J.H.; Zhang, H.S. Efficient presolving methods for the influence maximization problem. Networks 2023, 82, 229–253. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.