Abstract
This paper proposes a variable selection method for a semiparametric varying coefficient spatial autoregressive panel model with fixed effects based on a penalized profile quasi-likelihood method, which can simultaneously select significant variables in parametric components and nonparametric components without estimating fixed effects. With an appropriate selection of the tuning parameters and some mild assumptions, the consistency of this procedure and the oracle property of the obtained estimators are established. Then, we conduct some Monte Carlo simulations to assess the finite sample performance of the proposed variable selection method, and finally, we analyze a real dataset for further illustration.
Keywords:
semiparametric varying coefficient; spatial autoregressive panel model; fixed effects; variable selection; profile quasi-likelihood MSC:
62G05; 62F12
1. Introduction
Recently, there has been a surge in focus on spatial panel data model research. These models not only account for the spatial interdependencies of economic phenomena but also allow investigators to manage the unobservable heterogeneity among geographical units [1,2,3,4,5]. The basic spatial panel model is specified as follows:
where represents the observations of an individual i in period t, denotes the spatial weight between an individual i and j, denotes the unobserved and time-invariant individual effect, denotes random disturbance, and denotes the unknown true parameter value. However, model (1) adopts a linear specification and conducting parametric statistical inference inherently requires a set of model assumptions, with linearity serving as one of the most practical options. Despite their robust theoretical foundations, linear models frequently fall short in practical applications. Furthermore, when a linear model is misspecified with respect to the data analysis process, it may result in significant modeling biases and misleading conclusions. Therefore, more flexible spatial panel models are required. Ai and Zhang [6] extended model (1) to a partially linear spatial panel model with fixed effects by adding an unknown function, and they proposed a sieve two-stage least squares regression to consistently estimate their model. Zhang and Sun [7] considered a partially specified dynamic spatial panel model, which takes into account past information of the dependent variable. Furthermore, a model known as the semiparametric varying coefficient spatial autoregressive (hereafter, SVCSAR) panel model, which strikes a balance between flexibility and interpretability, is being popularly studied; see [8,9] for more details. The model is specified as follows:
where represents the observations of an individual i in period t. is a vector of unknown functions. Model (2) is a general model that can be reduced to some existing panel models. For instance, if , this model is reduced to the varying coefficient panel model studied by [10,11,12,13]. If and , this model is reduced to a varying coefficient panel model [14]. If , this model generalizes the spatial autoregressive panel model [5]. Moreover, if , and , this model becomes the classical panel model. However, while model (2) can be reduced to various panel models, it also increases the risk of model misspecification in practical applications. Specifying the model form becomes an inevitable issue, which is equivalent to detecting the zero components of . In other words, a variable selection method for model (2) is required. Additionally, when the number of covariates in model (2) is large, selecting important variables is also a purpose of the variable selection method.
Variable selection constitutes a crucial aspect of contemporary statistical inference. Over the years, numerous variable selection techniques have emerged for parametric models. LASSO [15], SCAD [16], and ALASSO [17] are the most popular methods among them. Based on those methods, variable selection methods for nonparametric or semiparametric models have been established in recent years. Wang et al. [18] considered variable selection for varying coefficient models using the SCAD penalty. Li and Liang [19] utilized the SCAD penalty to identify significant variables within the parametric components of a semiparametric varying coefficient partially linear model. Wang et al. [20] and Zhao and Xue [21] presented a variable selection procedure by combining basis function approximations with SCAD penalty for semiparametric varying coefficient partially linear models. The proposed procedure simultaneously selects significant variables in parametric components and nonparametric components. Tian et al. [22] introduced a novel method for variable selection, which integrates basis function approximations with quadratic inference functions. This approach enables the simultaneous identification of significant variables in both parametric and nonparametric components. For further development of the variable selection methods for nonparametric or semiparametric models, see [23,24,25,26], among others. However, there are few studies on the variable selection of panel model (2), in which spatial components and nonparametric components are simultaneously included.
In this paper, we propose a variable selection procedure for model (2). In order to avoid incidental parameter problems [27] brought by unknown fixed effects, this variable selection procedure combines a profile quasi-likelihood method with the basis function approximation and SCAD penalty to achieve estimation and variable selection simultaneously. The proposed procedure can shrink the spatial, linear, and functional coefficients of irrelevant covariates automatically to achieve variable selection. Moreover, by selecting appropriate tuning parameters, we demonstrate the consistency of our variable selection method. The regression coefficient estimators exhibit the oracle property, which implies that the nonparametric component estimators converge optimally, while the parametric component estimators share the same asymptotic behavior as those derived from the true submodel. This suggests that our penalized estimators perform as effectively as if the true zero coefficients were known. Compared with Liu et al. [28] and Xie et al. [29], we consider panel data and varying coefficient components. In comparison, although Luo and Wu [30] took into account variable selection for the SVCSAR model, the model they analyzed was confined to cross-sectional data. Furthermore, they only selected parametric coefficients. However, our method enables the simultaneous selection of significant variables in both parametric and nonparametric components under panel data.
The rest of this paper is structured as follows. In Section 2, we introduce a variable selection process designed for the SVCSAR panel model with fixed effects. In Section 3, we establish the asymptotic properties of the resulting estimators. In Section 4, we detail the computational steps for obtaining these estimators and discuss the selection of tuning parameters. In Section 5, we conduct simulations to assess the performance of our method with finite samples. Additionally, in Section 6, we provide a real-data analysis to further demonstrate the application of our proposed methodology. Finally, in Section 7, we conclude the article with a concise discussion. All technical proofs supporting the asymptotic results are included in the Appendix A.
2. Penalized Profile Quasi-Likelihood Method
We first consider the SVCSAR panel model described in (2). Specifically, and are scalars, while is a vector and is a vector, respectively; is an unknown vector that reflects the linear effect of on , and it is assumed that only a subset of its elements are non-zero. Without loss of generality, we assume that the first s elements specifically are non-zero. is a vector of unknown functions. Similarly, we assume that the first d function is non-zero. is an i.i.d. disturbance with zero mean and finite unknown variance ; thus, are unknown components. Next, we show a penalized quasi-likelihood method that can skip the estimation of and shrink the remaining estimators.
Let with , where “⊗” demotes the Kronecker product symbol and denotes a T-dimensional identity matrix; with ; with ; with ; denotes the fixed effects vector; , where represents a T-dimensional vector with all 1. Then, the model (2) can be expressed in matrix form:
where . Thus, the unknown parametric component is , and the unknown nonparametric component is .
Let , , and for any and . Subsequently, we suggest optimizing the log-Gaussian quasi-likelihood, following the approach taken by [31,32], and the log-Gaussian quasi-likelihood of (3) is
where , , and . When maximizing Equation (4), we encounter two main challenges: (i) Directly estimating can lead to the incidental parameter problem [27], especially when becomes high-dimensional as N increases. (ii) Estimating is difficult due to its infinite dimensionality. To address these issues, we follow the approach in Tian et al. [32] and let
denote a vector comprising normalized B-spline basis functions of order l with internal knots. Subsequently, we approximate as a linear combination of , i.e., for . Consequently, mode (3) can be written as follows:
where , , and . The log-Gaussian quasi-likelihood of (5) is
To avoid the incidental parameter problem [27] caused by , we first concentrate out and obtain the profile quasi-likelihood. Let . For given , from (6), we derive
and substitute this into (6). Then,
where and .
Inspired by the concept of variable selection in semiparametric varying coefficient partially linear models [21], we introduce a penalized profile quasi-likelihood function defined as follows:
where , and is a SCAD penalty function [16] defined by
with and . Throughout this paper, we adopt the suggestion by Fan and Li [16] that the choice of performs well in a variety of situations. The tuning parameter can be different for all and . Note that , where . Then, the penalized profile quasi-likelihood function can be written as follows:
Let be the solution by maximizing (9). Then, is the penalized profile quasi-likelihood estimator (penalized profile QMLE) of , and the estimator of can be obtained by . Next, we study the asymptotic properties of the resulting penalized profile likelihood estimators. Without loss of generality, we assume that for , with the remaining being the non-zero components of . Similarly, we assume that for and that the constitute all the non-zero components of .
3. Asymptotic Results
Denote , . The following assumptions are necessary prior to establishing the asymptotic properties.
- C1
- T is finite and greater than 2, and N is large.
- C2
- The disturbances for and are independently and identically distributed with zero mean, and the finite variance is . Additionally, for some , exists.
- C3
- The entries of satisfy and , where as .
- C4
- The matrix is nonsingular for all in a compact parameter space . The sequences are uniformly bounded in either row or column sums for all . The true is in the interior of .
- C5
- The sequences of matrices and are uniformly bounded in both row and column sums.
- C6
- The elements of and are uniformly bounded for all n, and the limit exists and is nonsingular.
- C7
- There exists a constant , such that is positive and semidefinite for all n, where .
- C8
- The limits exist.
- C9
- Third derivatives exist for all in an open set that contains the parameter point . Furthermore, there exist functions , such that for all , where for .
- C10
- For , , where . The distribution of is absolutely continuous, and its density is bound away from zero and infinity on .
- C11
- Let denote the interior knots within the interval and , . Define . There exists a constant C, such that and .
- C12
- The knot number is assumed to satisfy .
- C13
- Let . Then, , as .
- C14
- , and hold.
Remark 1.
C1 excludes the scene where T approaches infinity. Essentially, this assumption implies a setting (large N, small T) aligning with many spatial data studies. Conversely, the scenarios in which only T increases indefinitely and where both N and T go to infinity closely resemble the scenario where only N goes to infinity. C2 is needed to apply the central limit theorem in Kelejian and Prucha [33]. C3–C5 are analogous to Assumption 2 in Lee [31], which focuses on the properties of the spatial weight matrix and is essential for the identifiability of ρ. Specifically, when satisfies for all i. C6–C9 are applied for asymptotic normality of the profile QMLE. C10–C12 facilitate achieving the optimal convergence rate for . He et al. [34] suggested that cubic B-splines are adequate for accurately approximating nonparametric functions, with the number of interior knots set to the integer part of . Meanwhile, C13 and C14 present assumptions about the penalty function, which are comparable to those utilized in [16,18,19].
Due to the projection matrix , a portion of the degrees of freedom is lost; therefore, the estimator derived from (9) is not a consistent estimator of . A correction is needed. Let and . Under the assumptions, the subsequent theorem establishes the consistency property of the penalized profile QMLE.
Theorem 1.
Suppose that Assumptions C1–C12 hold; then, we can have
where
Furthermore, under some conditions, we show that such consistent estimators must possess the sparsity property, which is stated as follows.
Theorem 2.
Suppose that Assumptions C1–C14 hold, and let and . If and as , then, with probability tending to 1, and must satisfy
- (i)
- (ii)
According to Remark 1 in Fan and Li [16], if as , then . Consequently, based on Theorems 1 and 2, it becomes evident that by selecting appropriate tuning parameters, our variable selection approach is consistent. Furthermore, the estimators of the nonparametric components attain the optimal convergence rate as if the subset of true zero coefficients were already known [35]. Subsequently, we will demonstrate that the estimators for the non-zero coefficients in the parametric components share the same asymptotic distribution as those derived from the correct submodel. Let , where the following result states the asymptotic normality of .
Theorem 3.
Suppose that Assumptions C1–C14 and the conditions in Theorem 2 hold, then
where are defined in the Appendix A.
4. Some Issues in Practice
In the practical situation, we have to choose the proper tuning parameters and provide an effective calculation algorithm. In this section, we discuss these practical issues.
4.1. Selection of Tuning Parameters
The tuning parameters ’s and ’s should be chosen. In practice, we suggest taking and , and the pair is derived by minimizing the following BIC-type criterion:
where is the derived for given , and is the number of non-zero elements of both and .
4.2. Computational Algorithm
Given that is not differentiable at the origin, the standard gradient method cannot be employed. Therefore, we have devised an iterative algorithm that relies on a local quadratic approximation of the penalty function , similar to the approach taken by Fan and Li [16]. Let
Then, a feasible algorithm is as follows:
- Step 1
- Initialize .
- Step 2
- Update .
- Step 3
- Iterate Step 2 until convergence, and denote the final estimators as the penalized profile quasi-likelihood estimators.
The initial value in Step 1 is obtained from the profile QMLE, i.e., .
5. Monte Carlo Simulations
In this section, we conduct Monte Carlo simulations to assess the finite sample performance of our proposed method. Following the methodology employed by Li and Liang in [19], we evaluate the estimator using the generalized mean square error (GMSE), which is defined as follows:
The performance of estimator is assessed using average square errors (ASE):
where are the grid points at which the function is evaluated. In our simulation, is used.
The spatial matrix is generated from the following procedure. (i) Calculate as the number of “groups” and as the average number of individuals in each group. (ii) Generate the “group” size and adjust so that it satisfies . (iii) Normalize the matrices with zero for diagonal elements and for other elements. (iv) Generate the final spatial matrix .
Data are generated from model (2), and we construct two examples to simulate different scenarios. Example 1 is a regular example that is primarily used to verify the asymptotic properties of penalized profile likelihood estimators. Various sample sizes, degrees of spatial dependence, distributions of disturbances, and variances in disturbances are considered. Example 2 focuses on examining the performance of the proposed method in cases where the sample size is large, and the dimensions of parametric and nonparametric components are high. Unlike Example 1, Example 2 includes covariates with AR structure and different functions. All simulation results are obtained based on 500 repetitions.
5.1. Example 1: Regular Scenario
Let , . To simulate different spatial degrees, we choose different . We take two distribution settings for : (i) and (ii) , with . To perform this simulation, we take the covariates and . The fixed effect is generated from . We use the cubic B-splines in all simulations and generate , respectively.
We compare the performance of the variable selection procedure based on the SCAD penalty (SCAD) proposed by this paper with that based on the adaptive LASSO (ALASSO) penalty [17]. Table 1 and Table 2 report the effects of variable selection under normal disturbance. The column labeled “C” indicates the average number of true zeros correctly set to zero, while the column labeled “I” shows the average number of true non-zeros incorrectly set to zero. The row labeled “Oracle” refers to the oracle estimators computed using the true model when the zero coefficients are known.

Table 1.
Variable selection under in Example 1 .
Table 2.
Variable selection under in Example 1 .
From Table 1 and Table 2, we can infer the following consequences. (i) As increases, the performance of all variable selection methods, both parametric and nonparametric, converges towards the oracle procedure in terms of model error and complexity. (ii) For the parametric component, SCAD-based variable selection outperforms ALASSO-based methods, while for the nonparametric component, the reverse is true. However, overall, the effects of variable selection based on these two penalty functions are satisfactory and comparable. (iii) When the true parameter , reducing the model to a non-spatial varying coefficient panel model, the proposed variable selection methods can accurately identify the true model.
Table A1 in Appendix B reports the effect of variable selection under t disturbance. We can see that the conclusions drawn from Table 1 and Table 2 also hold for Table A1. Comparing Table 1 and Table 2 and Table A1, the GMSE and ASE under t disturbance are slightly larger than those under normal disturbance, but this difference is so small that it can be ignored, which implies the robustness of the proposed variable selection procedure.
5.2. Example 2: High-Dimension Scenario
Let , , and . The covariates are generated from , where
To save space, we only considered the case where the disturbance term follows a normal distribution in this example. The remaining settings are identical to those in Example 1.
Table A2 in Appendix B presents the outcomes of Example 2. As depicted in Table A2, the proposed procedures demonstrate robust performance despite the substantial dimensions of both the parametric and nonparametric components.
6. A Real Example
In this section, we use China’s provincial carbon emission panel dataset to illustrate our proposed methods. The dataset contains 14 annual variables of 30 provinces in China from 2007 to 2019. The model used is an extension of the STRIPAT model of Dietz and Rosa [36], which is specified as
for . The corresponding variables are described in Table 3. Such a model aims to analyze the social factors that have an impact on carbon dioxide emissions, especially the affluence factor. The spatial weight matrix is specified by contiguity rules; that is, let
Table 3.
Description of related variables.
Then, adjust so that the diagonal elements of are 0 and the row sums are 1.
In previous studies, the affluence factor always had significantly positive effects on carbon dioxide emissions, and the effects were always set as a constant, see [37,38]. This phenomenon can be described by the following mechanism: among the three major industries, the secondary industry exhibits the highest dependence on energy consumption, followed by the tertiary industry. However, these two industries are also the pillar industries that drive economic development, implying a significant reliance on economic growth on energy consumption. Currently, fossil fuels constitute the primary energy source in the world, and their consumption leads to a substantial release of carbon dioxide. As indicated by existing research analyses, economic development contributes significantly to carbon emissions. It is well known that coal consumption among fossil fuels generates the most carbon dioxide, suggesting that the energy structure may directly influence the impact of economic development on carbon emissions. However, considering the significant variations in energy structures across and within different provinces, cities, and over different years, it may be unreasonable to measure this impact using a constant. Therefore, we wish to capture the potential heterogeneity of this impact using the coal consumption proportion (CCP), which is why we set the CCP as and six variables describing affluence as .
Table 4 reports the estimated coefficient parameters, and Figure 1 depicts the estimated coefficient functions. There is not much difference between the results for SCAD and ALASSO, so we focus on the SCAD results in the following analysis. The spatial coefficient is not shrunk to zero and is positive, which means that neighboring provinces exhibit a substantial spatial positive correlation. The constant coefficients , and are positive, and the mean values are estimated when EI, RDF, FIR, and FV change by 1% and CE changes by 0.35%, 0.087%, 0.245%, and 0.1%, respectively. is the only negative constant coefficient, which implies that as the public transportation passenger volume increases, carbon emissions tend to decrease. Public transportation is a low-carbon mode of transportation. The more people choose to travel by public transportation, the fewer people use private cars, leading to a reduction in carbon emissions. This provides the evidence for the negative coefficient . The remaining coefficients are estimated to be zero, which means that they are excluded through variable selection. In addition, most of the coefficient functions in Figure 1 show an upward trend, which means that as coal consumption proportion increases, the contribution of affluence factors to carbon emission increases. Meanwhile, two function coefficients are removed through variable selection. This is generally consistent with the previous analysis in this section.
Table 4.
Penalized estimators for the parametric components.
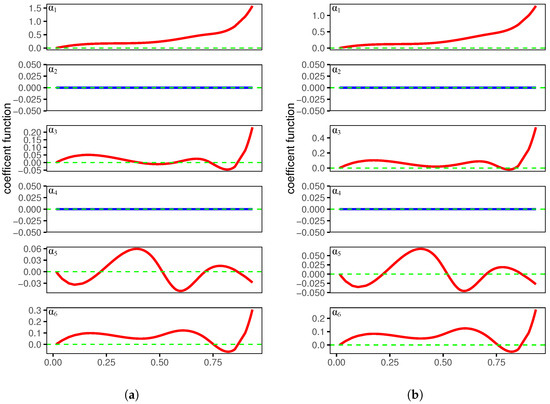
Figure 1.
The estimated varying coefficient functions based on SCAD and ALASSO. (a) Varying coefficient derived from SCAD; (b) varying coefficient derived from ALASSO.
7. Discussion and Conclusions
Within the context of SVCSAR panel models with fixed effects, we developed a variable selection process that utilizes basis function approximations alongside the profile quasi-likelihood method. This approach allows for the simultaneous selection of significant variables in both parametric and nonparametric components, as well as the estimation of unknown coefficients. By selecting appropriate tuning parameters, we demonstrated that this selection process is consistent, and the estimators of constant coefficients exhibit the oracle property. Simulation results highlight the effectiveness of our proposed method in selecting variables and estimating both constant and varying coefficients. In this study, we assume that the dimensions of covariates X and Z remain fixed. Additionally, we also presented simulations in Section 5 and obtained desired results when the dimensions p and q were large. However, it is worth noting that our variable selection process may not be applicable to scenarios involving ultra-high-dimensional covariates. As a potential area for future research, exploring variable selection techniques for SVCSAR panel models with ultra-high-dimensional covariates would be of great interest.
Author Contributions
Conceptualization, R.T. and M.X.; Methodology, R.T., M.X. and D.X.; Software, M.X.; Formal analysis, R.T. and M.X.; Writing—original draft, R.T., M.X. and D.X.; Supervision, R.T. All authors have read and agreed to the published version of the manuscript.
Funding
R.T.’s work is supported by the Zhejiang Provincial Philosophy and Social Sciences Planning Project (No. 24NDJC014YB). D.X.’s work is supported by the Zhejiang Provincial Natural Science Foundation of China (No. LY23A010013).
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Proof of Theorems
The following list summarizes some frequently used facts in the appendix.
Fact A1.
Let be symmetric matrices, with being positive semidefinite. Then, for , where denotes the i-th eigenvalue.
Fact A2.
Let and be matrices and uniformly bound in either row or column sums; then, the entries of their product are also uniformly bound.
Before proving the main theorems, we supplement several lemmas.
Lemma A1.
Let , supposing that Assumptions C1–C12 hold. Then,
for and .
Proof.
The proof is similar to that of Lemma 1 in Tian et al. [32]. □
Lemma A2.
Suppose that Assumptions C1–C4 hold, then
Proof.
The proof method is similar to that of Lemma 3 in Tian et al. [32]; therefore, will not be elaborated here. □
Lemma A3.
Suppose that Assumptions C1–C12 hold, then
Proof.
The first order partial derivatives of the profile likelihood function is
The variance of is
Therefore, . The variance of is
Thus, . Given the uniform boundedness of the elements of and are uniformly bound for all n, as stated in C6, it is evident that
□
Lemma A4.
Suppose that Assumptions C1–C12 hold, then
Proof.
Utilizing a similar argument as in Theorem 3.2 of Lee [31], Lemma A4 is proven. □
Proof of Theorem 1.
Let and . It is sufficient to show that, for any given , there exists a large constant C such that
Let ; then, with a simple calculation, we see that
It follows by Lemma A3 and the Cauchy inequality that
According to Lemma A4, a simple calculation yields
Hence, by choosing a sufficiently large C, dominates uniformly in . Furthermore, invoking C13 and , and by the standard argument of the Taylor expansion, we obtain that
Then, it is easy to show that is dominated by uniformly in . With the same argument, we can prove that is dominated by . Hence, by choosing a sufficiently large C, (A1) holds. This implies that a local maximizer exists such that . Then, . Let . Note that
and by invoking , a simple calculation yields
Together with
the proof is completed. □
Proof of Theorem 2.
We begin by proving part (i). Given , it follows easily that for large n. Then, according to Theorem 1, it suffices to show that for any satisfying and any satisfying , with some given small , as , the probability tends to 1 that
and
Thus, (A2) and (A3) imply that the maximizer of attains .
Using a similar argument to the proof of Theorem 1, we obtain that
where lies between and . From Lemmas A1 and A2 and assumption C9, we have
Then,
Since and , the sign of the derivation is completely determined by that of ; then, (A2) and (A3) hold.
By applying similar techniques to our analysis of part (i) in this theorem, we find that with probability tending to 1, . Then, using the fact that , the result of this theorem follows immediately from . □
Proof of Theorem 3.
Let , , , and . In order to obtain the asymptotic distribution, we first write the components of as follows:
where . By Lemma A1, for and , and the formula above is rewritten as follows:
Let and , for or . Then, using Lemma A2 we write the following:
where is the i-th diagonal element of and
To derive the asymptotic distribution of , we divide into four block matrices, which correspond to the second-order derivatives of the likelihood function with respect to , the cross-partial derivatives of and , and the second-order derivatives of . The matrices are as follows:
where
Let be the first upper-left submatrix of , be the first upper-left submatrix of , and be the first upper-left submatrix of . Using the same argument, we partition into four block matrices, that is
and obtain submatrices and . Let the notation of matrices without subscripts “n” represent the limiting version of the matrices. For example, . Let , and we assume that is non-singular.
According to Theorems 1 and 2, as , with probability tending to 1, achieves its maximal value at and ; then, and must satisfy the following:
Applying the Taylor expansion, we have
where
Applying the Taylor expansion to , we obtain that
Furthermore, Assumption C13 implies that , and note that as , then . Using similar arguments, we can prove that . Together with Lemma A4 and Equation (A9), a simple calculation yields the following:
By substitution, the term is eliminated, yielding
Furthermore, the central limit theorem for linear–quadratic forms [33] shows that
where the definition of the symbols in the covariance matrix is located in the context of (A8). Then, invoking (A10) and (A11), and using the Slutsky theorem, we have
□
Appendix B. Supplementary Simulation Results
Table A1.
Variable selection under in Example 1.
Table A1.
Variable selection under in Example 1.
| Method | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GMSE | C | I | ASE | C | I | GMSE | C | I | ASE | C | I | |||
| 0 | SCAD | 0.027 | 5.944 | 0 | 0.161 | 4.944 | 0 | 0.076 | 5.938 | 0 | 0.234 | 4.716 | 0 | |
| ALASSO | 0.032 | 5.748 | 0 | 0.160 | 4.960 | 0 | 0.086 | 5.630 | 0 | 0.211 | 4.914 | 0 | ||
| Oracle | 0.027 | 6.000 | 0 | 0.157 | 5.000 | 0 | 0.071 | 6.000 | 0 | 0.206 | 5.000 | 0 | ||
| 0.3 | SCAD | 0.032 | 4.846 | 0 | 0.160 | 4.962 | 0 | 0.084 | 4.798 | 0 | 0.237 | 4.734 | 0 | |
| ALASSO | 0.032 | 4.902 | 0 | 0.158 | 4.968 | 0 | 0.086 | 4.830 | 0 | 0.213 | 4.944 | 0 | ||
| Oracle | 0.029 | 5.000 | 0 | 0.157 | 5.000 | 0 | 0.074 | 5.000 | 0 | 0.207 | 5.000 | 0 | ||
| 0.7 | SCAD | 0.032 | 4.970 | 0 | 0.158 | 4.954 | 0 | 0.092 | 4.966 | 0 | 0.236 | 4.750 | 0 | |
| ALASSO | 0.036 | 4.904 | 0 | 0.158 | 4.960 | 0 | 0.102 | 4.798 | 0 | 0.218 | 4.918 | 0 | ||
| Oracle | 0.031 | 5.000 | 0 | 0.155 | 5.000 | 0 | 0.086 | 5.000 | 0 | 0.211 | 5.000 | 0 | ||
| 0 | SCAD | 0.021 | 5.972 | 0 | 0.140 | 4.918 | 0 | 0.052 | 5.966 | 0 | 0.188 | 4.712 | 0 | |
| ALASSO | 0.025 | 5.836 | 0 | 0.138 | 4.980 | 0 | 0.066 | 5.752 | 0 | 0.172 | 4.946 | 0 | ||
| Oracle | 0.022 | 6.000 | 0 | 0.137 | 5.000 | 0 | 0.051 | 6.000 | 0 | 0.170 | 5.000 | 0 | ||
| 0.3 | SCAD | 0.021 | 4.890 | 0 | 0.138 | 4.932 | 0 | 0.060 | 4.866 | 0 | 0.185 | 4.736 | 0 | |
| ALASSO | 0.023 | 4.944 | 0 | 0.135 | 4.998 | 0 | 0.069 | 4.896 | 0 | 0.170 | 4.982 | 0 | ||
| Oracle | 0.020 | 5.000 | 0 | 0.135 | 5.000 | 0 | 0.059 | 5.000 | 0 | 0.167 | 5.000 | 0 | ||
| 0.7 | SCAD | 0.025 | 4.994 | 0 | 0.139 | 4.922 | 0 | 0.063 | 4.966 | 0 | 0.183 | 4.762 | 0 | |
| ALASSO | 0.030 | 4.920 | 0 | 0.138 | 4.994 | 0 | 0.076 | 4.858 | 0 | 0.174 | 4.956 | 0 | ||
| Oracle | 0.025 | 5.000 | 0 | 0.136 | 5.000 | 0 | 0.060 | 5.000 | 0 | 0.167 | 5.000 | 0 | ||
| 0 | SCAD | 0.015 | 5.992 | 0 | 0.128 | 5.000 | 0 | 0.039 | 5.976 | 0 | 0.152 | 4.988 | 0 | |
| ALASSO | 0.018 | 5.832 | 0 | 0.129 | 4.996 | 0 | 0.053 | 5.812 | 0 | 0.153 | 4.992 | 0 | ||
| Oracle | 0.016 | 6.000 | 0 | 0.128 | 5.000 | 0 | 0.040 | 6.000 | 0 | 0.152 | 5.000 | 0 | ||
| 0.3 | SCAD | 0.020 | 4.932 | 0 | 0.129 | 5.000 | 0 | 0.038 | 4.894 | 0 | 0.151 | 4.998 | 0 | |
| ALASSO | 0.022 | 4.966 | 0 | 0.129 | 4.998 | 0 | 0.043 | 4.928 | 0 | 0.152 | 4.992 | 0 | ||
| Oracle | 0.020 | 5.000 | 0 | 0.129 | 5.000 | 0 | 0.036 | 5.000 | 0 | 0.151 | 5.000 | 0 | ||
| 0.7 | SCAD | 0.020 | 4.988 | 0 | 0.128 | 5.000 | 0 | 0.049 | 4.990 | 0 | 0.151 | 4.998 | 0 | |
| ALASSO | 0.024 | 4.954 | 0 | 0.129 | 4.998 | 0 | 0.060 | 4.926 | 0 | 0.154 | 4.996 | 0 | ||
| Oracle | 0.020 | 5.000 | 0 | 0.128 | 5.000 | 0 | 0.048 | 5.000 | 0 | 0.151 | 5.000 | 0 | ||
| 0 | SCAD | 0.014 | 6.000 | 0 | 0.118 | 4.994 | 0 | 0.028 | 5.998 | 0 | 0.139 | 4.888 | 0 | |
| ALASSO | 0.016 | 5.906 | 0 | 0.119 | 5.000 | 0 | 0.036 | 5.878 | 0 | 0.136 | 4.998 | 0 | ||
| Oracle | 0.014 | 6.000 | 0 | 0.118 | 5.000 | 0 | 0.030 | 6.000 | 0 | 0.135 | 5.000 | 0 | ||
| 0.3 | SCAD | 0.015 | 4.930 | 0 | 0.119 | 4.978 | 0 | 0.037 | 4.958 | 0 | 0.139 | 4.854 | 0 | |
| ALASSO | 0.017 | 4.934 | 0 | 0.120 | 4.984 | 0 | 0.043 | 4.938 | 0 | 0.135 | 5.000 | 0 | ||
| Oracle | 0.015 | 5.000 | 0 | 0.119 | 5.000 | 0 | 0.037 | 5.000 | 0 | 0.134 | 5.000 | 0 | ||
| 0.7 | SCAD | 0.015 | 4.998 | 0 | 0.119 | 4.998 | 0 | 0.030 | 4.990 | 0 | 0.136 | 4.920 | 0 | |
| ALASSO | 0.018 | 4.970 | 0 | 0.119 | 4.998 | 0 | 0.040 | 4.940 | 0 | 0.136 | 4.994 | 0 | ||
| Oracle | 0.016 | 5.000 | 0 | 0.119 | 5.000 | 0 | 0.031 | 5.000 | 0 | 0.134 | 5.000 | 0 | ||
Table A2.
Variable selection for in Example 2.
Table A2.
Variable selection for in Example 2.
| Method | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GMSE | C | I | ASE | C | I | GMSE | C | I | ASE | C | I | ||
| 0 | SCAD | 0.004 | 46.986 | 0 | 0.037 | 11.670 | 0 | 0.010 | 46.982 | 0 | 0.049 | 11.508 | 0 |
| ALASSO | 0.005 | 46.388 | 0 | 0.036 | 11.996 | 0 | 0.018 | 45.818 | 0 | 0.048 | 11.982 | 0 | |
| Oracle | 0.003 | 47.000 | 0 | 0.036 | 12.000 | 0 | 0.009 | 47.000 | 0 | 0.046 | 12.000 | 0 | |
| 0.3 | SCAD | 0.004 | 45.814 | 0 | 0.039 | 10.972 | 0 | 0.011 | 45.602 | 0 | 0.053 | 11.110 | 0 |
| ALASSO | 0.006 | 45.506 | 0 | 0.037 | 11.914 | 0 | 0.018 | 44.648 | 0 | 0.049 | 11.672 | 0 | |
| Oracle | 0.004 | 46.000 | 0 | 0.036 | 12.000 | 0 | 0.009 | 46.000 | 0 | 0.046 | 12.000 | 0 | |
| 0.7 | SCAD | 0.004 | 45.986 | 0 | 0.038 | 11.450 | 0 | 0.011 | 45.964 | 0 | 0.049 | 11.420 | 0 |
| ALASSO | 0.006 | 45.568 | 0 | 0.037 | 11.992 | 0 | 0.021 | 44.846 | 0 | 0.048 | 11.964 | 0 | |
| Oracle | 0.004 | 46.000 | 0 | 0.036 | 12.000 | 0 | 0.010 | 46.000 | 0 | 0.046 | 12.000 | 0 | |
References
- Anselin, L.; Hudak, S. Spatial econometrics in practice: A review of software options. Reg. Sci. Urban Econ. 1992, 22, 509–536. [Google Scholar] [CrossRef]
- Baltagi, B.H.; Heun Song, S.; Cheol Jung, B.; Koh, W. Testing for serial correlation, spatial autocorrelation and random effects using panel data. J. Econom. 2007, 140, 5–51. [Google Scholar] [CrossRef]
- Kapoor, M.; Kelejian, H.H.; Prucha, I.R. Panel data models with spatially correlated error components. J. Econom. 2007, 140, 97–130. [Google Scholar] [CrossRef]
- Baltagi, B.H.; Kao, C.; Liu, L. Asymptotic properties of estimators for the linear panel regression model with random individual effects and serially correlated errors: The case of stationary and non-stationary regressors and residuals. Econom. J. 2008, 11, 554–572. [Google Scholar] [CrossRef]
- Lee, L.F.; Yu, J. Estimation of spatial autoregressive panel data models with fixed effects. J. Econom. 2010, 154, 165–185. [Google Scholar] [CrossRef]
- Ai, C.; Zhang, Y. Estimation of partially specified spatial panel data models with fixed-effects. Econom. Rev. 2017, 36, 6–22. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, Y. Estimation of partially specified dynamic spatial panel data models with fixed-effects. Reg. Sci. Urban Econ. 2015, 51, 37–46. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Shen, D. Estimation of semi-parametric varying-coefficient spatial panel data models with random-effects. J. Stat. Plan. Inference 2015, 159, 64–80. [Google Scholar] [CrossRef]
- Feng, S.; Tong, T.; Chiu, S.N. Statistical Inference for Partially Linear Varying Coefficient Spatial Autoregressive Panel Data Model. Mathematics 2023, 11, 4606. [Google Scholar] [CrossRef]
- Hu, X. Estimation in a semi-varying coefficient model for panel data with fixed effects. J. Syst. Sci. Complex. 2014, 27, 594–604. [Google Scholar] [CrossRef]
- He, B.; Hong, X.; Fan, G. Empirical likelihood for semi-varying coefficient models for panel data with fixed effects. J. Korean Stat. Soc. 2016, 45, 395–408. [Google Scholar] [CrossRef]
- Feng, S.; He, W.; Li, F. Model detection and estimation for varying coefficient panel data models with fixed effects. Comput. Stat. Data Anal. 2020, 152, 107054. [Google Scholar] [CrossRef]
- Feng, S.; Li, G.; Peng, H.; Tong, T. Varying coefficient panel data model with interactive fixed effects. Stat. Sin. 2021, 31, 935–957. [Google Scholar] [CrossRef]
- Sun, Y.; Carroll, R.; Li, D. Semiparametric estimation of fixed-effects panel data varying coefficient models. Adv. Econom. 2009, 25, 101–129. [Google Scholar]
- Tibshirani, R. Regression Shrinkage and Selection Via the Lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Fan, J.; Li, R. Variable Selection via Nonconcave Penalized Likelihood and its Oracle Properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Zou, H. The Adaptive Lasso and Its Oracle Properties. J. Am. Stat. Assoc. 2006, 101, 1418–1429. [Google Scholar] [CrossRef]
- Wang, L.; Li, H.; Huang, J.Z. Variable Selection in Nonparametric Varying-Coefficient Models for Analysis of Repeated Measurements. J. Am. Stat. Assoc. 2008, 103, 1556–1569. [Google Scholar] [CrossRef]
- Li, R.; Liang, H. Variable selection in semiparametric regression modeling. Ann. Stat. 2008, 36, 261–286. [Google Scholar] [CrossRef]
- Wang, H.J.; Zhu, Z.; Zhou, J. Quantile regression in partially linear varying coefficient models. Ann. Stat. 2009, 37, 3841–3866. [Google Scholar] [CrossRef]
- Zhao, P.; Xue, L. Variable selection for semiparametric varying coefficient partially linear models. Stat. Probab. Lett. 2009, 79, 2148–2157. [Google Scholar] [CrossRef]
- Tian, R.; Xue, L.; Liu, C. Penalized quadratic inference functions for semiparametric varying coefficient partially linear models with longitudinal data. J. Multivar. Anal. 2014, 132, 94–110. [Google Scholar] [CrossRef]
- Tian, R.; Xue, L.; Hu, Y. Smooth-threshold GEE variable selection for varying coefficient partially linear models with longitudinal data. J. Korean Stat. Soc. 2015, 44, 419–431. [Google Scholar] [CrossRef]
- Li, R.; Mu, S.; Hao, R. Estimation and variable selection for partially linear additive models with measurement errors. Commun. Stat. Theory Methods 2021, 50, 1416–1445. [Google Scholar] [CrossRef]
- Ma, X.; Du, Y.; Wang, J. Model detection and variable selection for mode varying coefficient model. Stat. Methods Appl. 2022, 31, 321–341. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Z.; Tian, M.; Yu, K. Estimation and variable selection for generalized functional partially varying coefficient hybrid models. Stat. Pap. 2024, 65, 93–119. [Google Scholar] [CrossRef]
- Neyman, J.; Scott, E.L. Consistent Estimates Based on Partially Consistent Observations. Econometrica 1948, 16, 1–32. [Google Scholar] [CrossRef]
- Liu, X.; Chen, J.; Cheng, S. A penalized quasi-maximum likelihood method for variable selection in the spatial autoregressive model. Spat. Stat. 2018, 25, 86–104. [Google Scholar] [CrossRef]
- Xie, T.; Cao, R.; Du, J. Variable selection for spatial autoregressive models with a diverging number of parameters. Stat. Pap. 2020, 61, 1125–1145. [Google Scholar] [CrossRef]
- Luo, G.; Wu, M. Variable selection for semiparametric varying-coefficient spatial autoregressive models with a diverging number of parameters. Commun. Stat. Theory Methods 2021, 50, 2062–2079. [Google Scholar] [CrossRef]
- Lee, L.F. Asymptotic Distributions of Quasi-Maximum Likelihood Estimators for Spatial Autoregressive Models. Econometrica 2004, 72, 1899–1925. [Google Scholar] [CrossRef]
- Tian, R.; Xia, M.; Xu, D. Profile quasi-maximum likelihood estimation for semiparametric varying-coefficient spatial autoregressive panel models with fixed effects. Stat. Pap. 2024, 65, 5109–5143. [Google Scholar] [CrossRef]
- Kelejian, H.H.; Prucha, I.R. On the asymptotic distribution of the Moran I test statistic with applications. J. Econom. 2001, 104, 219–257. [Google Scholar] [CrossRef]
- He, X.; Fung, W.K.; Zhu, Z. Robust Estimation in Generalized Partial Linear Models for Clustered Data. J. Am. Stat. Assoc. 2005, 100, 1176–1184. [Google Scholar] [CrossRef]
- Stone, C.J. Optimal Global Rates of Convergence for Nonparametric Regression. Ann. Stat. 1982, 10, 1040–1053. [Google Scholar] [CrossRef]
- Dietz, T.; Rosa, E. Effects of population and affluence on CO2 emissions. Proc. Natl. Acad. Sci. USA 1997, 94, 175–179. [Google Scholar] [CrossRef]
- Wen, L.; Shao, H. Analysis of influencing factors of the carbon dioxide emissions in China’s commercial department based on the STIRPAT model and ridge regression. Environ. Sci. Pollut. Res. 2019, 26, 27138–27147. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Wang, W.; Wang, Y.; Qin, Y. Industrial structure, technological progress and CO2 emissions in China: Analysis based on the STIRPAT framework. Nat. Hazards 2017, 88, 1545–1564. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).