Abstract
Extracting structured threat intelligence from unstructured cybersecurity texts requires accurate identification of entities together with their underlying semantic relations. However, threat reports often exhibit intricate sentence structures, long-range contextual dependencies, and tightly coupled entity–relation patterns, which pose substantial challenges for existing extraction approaches. To address these challenges, this study investigates joint entity–relation extraction from the perspective of semantic dependency modeling and develops HDIM-JER, a unified framework that captures structured interactions among heterogeneous linguistic features. HDIM-JER integrates character-level cues, contextual representations, and higher-order semantic dependency evidence to enhance structural awareness during joint inference, where different second-order dependency configurations provide an interpretable perspective on structurally symmetric and hierarchically asymmetric interaction patterns among entity–relation instances. By incorporating multi-level dependency interactions, HDIM-JER effectively alleviates error propagation associated with pipeline-based architectures and improves the modeling of complex relational dependencies. Extensive experiments on a threat intelligence corpus and a public benchmark dataset demonstrate consistent performance improvements over representative state-of-the-art methods in both entity recognition and relation extraction, confirming the effectiveness of higher-order semantic dependency interaction modeling for threat intelligence analysis.
1. Introduction
Cyber threat intelligence extraction aims to convert unstructured cybersecurity reports into structured representations that support automated analysis, threat correlation, and decision-making. With the rapid growth in both the volume and complexity of cyberattacks, threat intelligence texts increasingly describe multiple entities and their interactions within a single context. These interactions often span long textual distances. As a result, accurate identification of entities and inference of their semantic relations have become critical requirements for downstream applications such as knowledge graph construction, intrusion analysis, and situational awareness.
A key challenge in threat intelligence extraction lies in the complex structural characteristics of cybersecurity narratives. Such texts frequently contain implicit semantic associations, heterogeneous linguistic patterns, and entangled relational dependencies that extend beyond local contexts. These properties make it difficult for conventional extraction models to fully capture interactions among entities and relations, especially when relational cues are distributed across distant segments of text.
Compared with general-domain texts, threat intelligence reports typically contain a high density of heterogeneous entities. Their relations are often expressed implicitly through descriptive narratives rather than explicit lexical triggers. As a result, multiple entities and relations are tightly coupled within the same context, and relational semantics frequently depend on indirect and long-range dependencies. Under these conditions, sequential pipeline-based extraction methods become particularly brittle. Errors in entity recognition can easily propagate and invalidate relation interpretation, especially in the presence of strong type constraints and asymmetric entity roles that are common in threat intelligence scenarios.
Although significant progress has been made in entity–relation extraction, existing approaches remain limited when applied to threat intelligence texts. Many methods adopt sequential processing strategies that decouple entity recognition from relation classification. This design is problematic in threat intelligence scenarios due to densely coupled entities and strong asymmetric constraints between entity types and relation semantics. Moreover, most existing models rely primarily on first-order syntactic or surface-level dependency information. This reliance limits their ability to represent higher-order relational patterns, such as sibling, co-parent, and hierarchical dependencies, which commonly arise in complex cyber threat descriptions. In addition, effectively integrating heterogeneous features, including character-level signals, contextual representations, and structural dependency information, remains a persistent challenge. This challenge is further amplified by long-distance dependencies and domain-specific language variations.
Motivated by these observations, this study investigates joint entity–relation extraction from the perspective of semantic dependency modeling. We examine how higher-order semantic dependencies and structured interactions among heterogeneous features can be incorporated into a unified framework to improve relational reasoning in threat intelligence texts. By explicitly modeling both local and higher-order dependency evidence, the proposed HDIM-JER framework enhances structural awareness during joint inference and alleviates limitations associated with pipeline-based extraction strategies.
Although higher-order and structured dependency modeling has been explored in prior work, HDIM-JER differs fundamentally in how such dependencies are integrated into joint entity–relation extraction. Specifically, second-order semantic dependencies, including sibling, co-parent, and grandparent configurations, are not treated as auxiliary features or post-processing constraints. Instead, they are explicitly modeled as latent interaction variables within a CRF-style inference framework and are iteratively refined through mean-field updates. Moreover, semantic dependency inference in HDIM-JER functions as an intermediate structural reasoning layer that jointly influences entity recognition and relation classification, rather than targeting dependency parsing or relation prediction in isolation. Through a unified bilinear–trilinear interaction mechanism, first-order and second-order dependencies are integrated into a joint inference process. This design reflects structurally symmetric and hierarchically asymmetric interaction patterns among entity–relation instances and distinguishes HDIM-JER from existing dependency-based approaches. In this work, structural symmetry and hierarchical asymmetry are used as interpretative perspectives for understanding second-order semantic dependency interactions, rather than as explicit optimization objectives or quantitative metrics.
The main contributions of this work can be summarized as follows:
- We present a unified joint modeling frameworkfor threat intelligence extraction that performs entity recognition and relation classification simultaneously, thereby reducing error propagation and improving semantic consistency.
- We develop a higher-order semantic dependency modeling strategy that incorporates second-order dependency structures to capture complex contextual interactions beyond first-order relations. These higher-order dependencies provide an interpretable perspective in which different interaction configurations can be viewed as reflecting structural symmetry and hierarchical asymmetry among entity–relation patterns.
- We propose a structured interaction mechanism that integrates character-level cues, contextual representations, and dependency-based structural information within a joint inference process, enabling effective modeling of long-distance and domain-specific entity–relation interactions.
- We conduct comprehensive experiments on a threat intelligence corpus and the public SciERC benchmark, including comparative evaluations and ablation analyses, to demonstrate the effectiveness and generalization ability of the proposed HDIM-JER framework.
2. Related Work
2.1. Generic Entity–Relation Extraction Models
Entity–relation extraction aims to identify semantic relations expressed between entity mentions in text [1]. A common formulation is to extract relational triples such as “(head entity, relation, tail entity)” from unstructured sentences. These structured outputs support downstream applications including knowledge graph construction, question answering, and automatic summarization [2]. In threat intelligence texts, joint entity–relation extraction focuses on directly identifying entities and their relations without separating the process into independent stages. From a modeling perspective, existing studies are commonly categorized into two paradigms: pipeline-based systems and jointly learned systems.
In pipeline-based settings, entity recognition is performed first, followed by relation prediction for candidate entity pairs using rules or supervised classifiers. Early neural approaches for relation classification employed convolutional architectures that combine word representations with positional features to capture relation-indicative patterns [3]. Subsequent studies enhanced these CNN-based models by introducing multi-level attention mechanisms to improve relation-specific representations [4]. To better incorporate structural information, graph neural models with dynamically generated parameters were later proposed to adapt to diverse sentence structures [5]. Despite their modular design, pipeline-based methods are prone to cascading errors. Incorrect entity predictions directly affect downstream relation decisions, especially when relations depend on long contexts or when multiple entities appear within a single sentence.
Joint learning-based approaches aim to mitigate these limitations by optimizing entity and relation predictions within a unified framework [6]. By jointly modeling entity boundaries and relational semantics, these methods can capture mutual constraints between the two subtasks and often achieve better performance in complex scenarios [7]. Most joint models are trained end-to-end and treat entity and relation extraction as a single optimization objective [8]. Representative approaches include set prediction frameworks that generate unordered relational sets and handle overlapping or nested structures effectively [9], heterogeneous graph neural networks that iteratively fuse different types of information [10], attention-based architectures that combine convolutional and recurrent components to learn rich semantic representations [11], and span-based joint frameworks that enumerate candidate spans to improve extraction while reducing pipeline error propagation [12]. More recently, retrieval-based relation extraction with in-context learning has been explored to better handle overlapping relations, where symmetry and asymmetry are discussed as interpretative perspectives on relational structures [13]. Related iterative and structure-preserving modeling ideas have also been explored beyond NLP. For example, Zhuang et al. [14] propose a frequency-domain iterative clustering framework for boundary-preserving segmentation.
2.2. Domain-Specific Entity–Relation Extraction for Threat Intelligence
Compared with general-domain settings, entity–relation extraction for threat intelligence has received relatively less attention, and most existing studies rely on pipeline-style processing. One representative line combines pretrained language models, such as BERT, with graph neural networks in a pipeline to extract entities and relations from multi-source threat intelligence data. This design enables semantic understanding and knowledge fusion from unstructured texts [15]. Another direction focuses on extracting entity pairs from cybersecurity texts, learning entity representations using methods such as Word2Vec, and applying feed-forward networks for relation classification [16]. In addition, graph attention networks have been used to construct unified graph representations across security databases and to predict relations between entities in a shared semantic space [17].
To better address domain-specific characteristics, several studies incorporate additional linguistic or structural signals. Bootstrapping methods combined with semantic role labeling have been proposed to strengthen the modeling of semantic structures in threat intelligence texts [18]. Deep learning approaches have also been applied to extract attack behavior entities from threat reports and to support threat attribution through knowledge graph construction [19]. Furthermore, pipeline-based extraction frameworks aligned with cybersecurity ontologies define standardized terminologies, relations, and metadata attributes tailored to threat intelligence scenarios [20].
Beyond these approaches, dependency-informed modeling has been explored for relation extraction in cybersecurity texts. Part-of-speech features and syntactic dependency trees have been leveraged to support threat intelligence relation extraction [21]. A BiLSTM–CRF architecture has also been used for entity extraction, followed by relation classification with graph attention mechanisms [22]. Another line of work obtains contextual representations using BERT and fuses them with syntactic dependency features through graph convolution to improve relation extraction [23]. Related research further investigates unsupervised multimodal entity alignment through dual-space embeddings, which offers an interpretable perspective on symmetric interaction patterns in representation learning for knowledge graph construction tasks [24].
Nevertheless, most of the above studies still adopt pipeline extraction strategies that separate entity identification from relation prediction. This separation makes it difficult to fully capture the intrinsic interplay between entities and relations. In particular, entity type constraints can influence relation categories, while relational semantics can provide corrective signals for entity boundary decisions. Ignoring such interactions may limit the overall effectiveness of threat intelligence entity–relation extraction systems.
2.3. Comparison and Experimental Settings of Related Studies
Although HDIM-JER is related to prior work on joint entity–relation extraction and cyber threat intelligence analysis, it differs from several closely related studies in problem setting, modeling focus, inference strategy, and experimental design.
Ref. [6] provides a systematic survey of existing joint entity–relation extraction methods from a methodological perspective. In contrast, HDIM-JER proposes a concrete unified framework tailored to threat intelligence texts, where semantic dependency modeling is introduced as a core interaction mechanism rather than treated as auxiliary analysis. Ref. [10] presents a heterogeneous graph neural network that refines entity and relation representations through iterative graph-based message passing. While both approaches aim to enhance feature interaction, HDIM-JER differs in that it centers on explicit semantic dependency structures and models both first-order and second-order dependencies, including sibling, co-parent, and grandparent configurations. These dependencies are further integrated into a CRF-style joint inference framework defined over candidate dependency edges, enabling iterative mean-field refinement and global structural consistency instead of relying solely on representation-level fusion.
Ref. [15] focuses on automated open-source cyber threat intelligence collection and knowledge graph construction, and typically adopts pipeline-based or cross-document extraction settings. These settings differ from the sentence-level joint entity–relation extraction task considered in this work, where multiple entities and relations are densely coupled within a single context. HDIM-JER is specifically designed to handle this coupling by performing joint inference and reducing error propagation between entity recognition and relation classification. Ref. [23] improves cybersecurity relation extraction by fusing contextual representations with syntactic dependency features through graph convolution. Although effective for incorporating syntactic cues, this approach treats dependency information as external features and focuses mainly on relation prediction. In contrast, HDIM-JER emphasizes higher-order semantic dependency interaction modeling and incorporates dependency inference as an intermediate structural reasoning layer that jointly influences both entity boundary decisions and relation interpretation.
Overall, although a wide range of generic and domain-specific entity–relation extraction methods has been discussed, these studies are often evaluated on different datasets with distinct task definitions, annotation schemes, and experimental settings. Generic joint extraction models are typically assessed on benchmarks such as ACE2005, NYT, or WebNLG, which differ substantially from threat intelligence texts in entity types, relation semantics, and linguistic characteristics. Domain-specific studies for cyber threat intelligence often rely on pipeline-based or cross-document extraction and focus on knowledge graph construction rather than sentence-level joint entity–relation extraction. As a result, direct experimental comparison under identical conditions is not technically feasible or methodologically appropriate. Within this context, HDIM-JER is distinguished by explicitly modeling semantic dependency structures for threat intelligence texts, incorporating second-order dependency configurations to capture higher-order interactions, and enforcing structured consistency through a CRF-style iterative joint inference mechanism. Accordingly, we compare HDIM-JER with representative joint extraction models under consistent experimental settings and additionally evaluate it on the publicly available SciERC benchmark to provide a fair and reproducible assessment of generalization performance.
3. Methods
Figure 1 provides an overview of HDIM-JER, a joint entity–relation extraction framework for threat intelligence analysis based on semantic dependency modeling. The framework consists of several interconnected components, including linguistic feature embedding, sequence encoding, semantic dependency representation, and structured interaction-based joint prediction. These components are designed to model entity recognition and relation extraction in parallel and to capture their intrinsic dependencies.
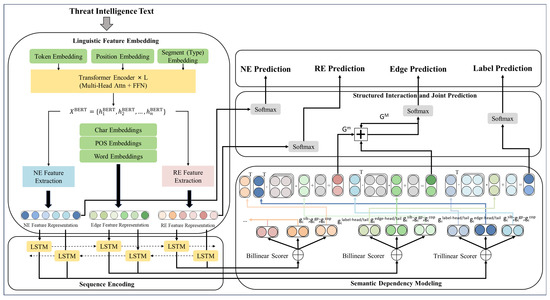
Figure 1.
Overall architecture of HDIM-JER: joint entity and relation extraction with higher-order dependency interactions and iterative inference. Different colors are used to distinguish different representations and components, arrows indicate information flow, and ellipses represent repeated structural components for multiple tokens or dependency edges.
At the input stage, threat intelligence texts are encoded using a pretrained BERT model. Character-level, part-of-speech, and word-level embeddings are incorporated to enrich lexical representations. Task-specific feature extractors then generate representations for entity (NE), edge, and relation (RE) modeling, which are processed by a bidirectional BiLSTM encoder to capture contextual and long-range dependencies. Based on these encoded features, semantic dependency representations are constructed using bilinear and trilinear scorers to model both first-order and higher-order dependency structures. Finally, heterogeneous representations are integrated through structured interactions, and joint prediction of entity labels, dependency edges, and relation types is performed using softmax classifiers.
The architecture in Figure 1 is designed to jointly handle dense entity–relation coupling, implicit relational semantics, and higher-order structural interactions in threat intelligence texts. Multi-source linguistic embeddings provide robust lexical and contextual representations under domain-specific noise, while task-specific projections separate entity boundary features from relation interaction features. Bilinear and trilinear dependency scoring functions are used to model first-order and higher-order semantic dependencies, enabling structured interactions beyond independent pairwise predictions. The CRF-style inference layer then integrates local evidence and higher-order dependency information through iterative refinement to enforce global structural consistency during joint prediction. In addition, the BiLSTM encoder acts as a lightweight task-adaptive sequential module that complements pretrained contextual representations and supports subsequent structured dependency scoring.
To improve the readability of the mathematical formulation, the main symbols and variables used in the model are summarized in Table 1. This table serves as a unified reference for dependency variables, scoring functions, and inference-related terms in higher-order semantic dependency modeling and joint entity–relation extraction.

Table 1.
Notation and symbol definitions used in the HDIM-JER framework.
3.1. Linguistic Feature Embedding
Given an input sentence of length n, denoted as , where represents the i-th token, the model constructs token-level representations by integrating multiple sources of linguistic information. Character-level representations are first obtained using a convolutional neural network (CNN), which is effective in capturing subword patterns and morphological variations frequently observed in cybersecurity terminology. In parallel, contextualized semantic representations are generated using a BERT model pretrained on cybersecurity-related corpora, providing rich bidirectional contextual information for each token.
Based on the contextual embeddings, task-oriented representations for entity and relation modeling are derived through separate multilayer perceptrons (MLPs). Specifically, two independent MLPs are employed to project into feature spaces tailored for entity-related and relation-related modeling, respectively. The resulting entity feature representation and relation feature representation are defined as follows:
The features and are trained under the BMES (Begin–Middle–End–Single) tagging scheme, enabling the model to encode boundary-aware patterns that are essential for accurate entity span identification. To facilitate subsequent relational reasoning, is further augmented with role indicators Hand T, which explicitly distinguish head and tail entities and provide additional cues for interaction modeling.
Beyond task-specific representations, the model also incorporates randomly initialized word-level embeddings and part-of-speech embeddings to introduce complementary lexical and syntactic information. All available feature representations are then combined to form a unified embedding for each token through vector concatenation:
where “;” denotes the concatenation operation. By integrating character-level, lexical, syntactic, contextual, and task-specific features, this embedding formulation provides a rich and informative representation that serves as the foundation for subsequent sequence encoding and semantic dependency modeling.
3.2. Sequence Encoding
To capture contextual dependencies within threat intelligence texts, the unified token representations are further processed by a bidirectional long short-term memory (BiLSTM) encoder. By modeling sequential information in both forward and backward directions, the BiLSTM is able to incorporate contextual cues from surrounding tokens, which is crucial for representing long-range interactions and complex contextual patterns commonly observed in cybersecurity narratives.
For each token position i at layer l, the BiLSTM computes a pair of hidden states, namely the forward hidden state and the backward hidden state , corresponding to information propagated from the left and right contexts, respectively. The forward and backward transitions are defined as follows:
The two directional hidden states provide complementary contextual information, which is combined to form the final sequence representation for each token. Specifically, the forward and backward hidden states are concatenated to obtain the context-aware token representation:
where denotes vector concatenation. Through bidirectional sequence encoding, the resulting representations capture both local and long-distance contextual dependencies, thereby providing informative inputs for subsequent semantic dependency modeling and structured interaction during joint entity–relation extraction.
3.3. Semantic Dependency Modeling
To model semantic dependency relations in threat intelligence texts, the contextualized token representations are projected into role-specific embeddings using multilayer perceptrons (MLPs). These embeddings encode different roles involved in dependency construction and are used to score directed semantic dependency relations in a dependency graph.
For each token , separate head and tail representations are learned for dependency edge existence and dependency label prediction. The head role represents a governing token, while the tail role represents a dependent token in a directed dependency relation. The corresponding role-aware embeddings are defined as follows:
These role-specific representations encode directional information that is essential for dependency modeling. To score first-order dependency relations, a bilinear scoring function is employed to capture interactions between head and tail representations:
where W and b denote learnable parameters. Based on this formulation, the scores for first-order dependency edges and dependency labels between tokens and are computed as
where and , d denotes the embedding dimension, and c represents the number of dependency labels.
While first-order dependency modeling captures local relational semantics, it is often insufficient for representing the nested and long-range dependency patterns commonly present in threat intelligence texts. To enhance structural expressiveness, second-order semantic dependency structures are further introduced, including sibling, co-parent, and grandparent configurations, which model interactions among triplets of tokens.
For second-order dependency modeling, additional role-specific embeddings are derived as follows:
To compute scores for second-order dependency structures, a trilinear scoring function is adopted to model three-way interactions among token representations:
where W denotes learnable parameters that are distinct from those used in bilinear scoring. In the following formulations, the superscripts head, tail, and head_tail are used as shorthand to indicate the corresponding role-specific embeddings defined for sibling, co-parent, and grandparent structures.
Accordingly, the scores for sibling, co-parent, and grandparent dependency configurations are computed as
Here, indices i, j, and k denote tokens involved in a second-order dependency structure. Token i represents the shared head, while j and k denote dependent tokens in sibling, co-parent, or grandparent configurations. These second-order dependency representations allow the model to capture higher-order semantic interactions beyond first-order dependencies and improve structural modeling for entity and relation extraction in threat intelligence texts.
3.4. Structured Interaction and Joint Prediction
Joint prediction of entities and relations is achieved by integrating first-order and second-order dependency information through a structured interaction mechanism. For dependency edge existence prediction, the edge scores are transformed using a Softmax function to estimate the probability of each directed edge in the semantic dependency graph. To formalize this process, we introduce a binary random variable , where indicates the presence of an edge and otherwise. Based on this definition, the unary potential function in the conditional random field (CRF) formulation is defined as follows:
To incorporate higher-order structural interactions, second-order semantic dependency types—including sibling, co-parent, and grandparent relations—are modeled through pairwise potential functions that capture interactions between pairs of dependency edges. The corresponding binary potential is defined as
where denotes the score of a specific second-order dependency type , and and denote two dependency edges that participate in the same higher-order configuration.
In this formulation, the CRF is defined over candidate directed dependency edges rather than over tokens. Each binary variable represents a potential dependency edge from token i to token j and corresponds to a node in the CRF graph. Unary potentials are defined independently for each node to capture first-order edge evidence. Binary potentials are introduced only between pairs of nodes that form sibling, co-parent, or grandparent configurations, thereby modeling higher-order structural interactions. Figure 2 illustrates the resulting CRF graph structure.
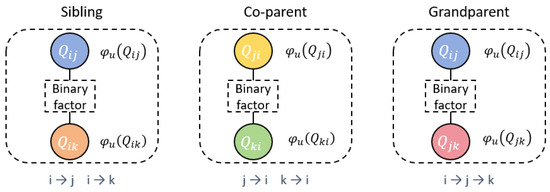
Figure 2.
Illustration of the CRF graph structure used in HDIM-JER. Each node corresponds to a candidate directed dependency edge and is associated with a unary potential . Binary potentials are introduced only between pairs of nodes forming sibling, co-parent, or grandparent dependency configurations. Different colors are used to visually distinguish nodes, and solid lines represent potential interactions between variables.
Exact inference over the resulting CRF graph is intractable due to the large number of interacting variables. To address this issue, we adopt a mean-field variational inference approach to approximate the marginal posterior distributions. Let denote the approximate posterior probability of variable at iteration m. During inference, interactions among related dependency edges are aggregated through an auxiliary message term , which is updated iteratively as follows:
where m indicates the iteration index. Expanding this formulation for different second-order dependency configurations yields the following update rule:
The posterior distribution is initialized as , and subsequent updates are computed as
Accordingly, the unary potential is normalized to initialize . After M mean-field iterations, the final approximate posterior distribution is obtained for each candidate dependency edge. Equation (30) plays a central role in the proposed framework by integrating first-order edge evidence with higher-order semantic dependency interactions during joint inference. In this formulation, the posterior probability of an edge depends on both its local edge score and the aggregated message term , which summarizes second-order influences from sibling, co-parent, and grandparent configurations. Through iterative updates, higher-order structural information is propagated to refine local dependency predictions and enforce global structural consistency across entity–relation interactions.
Through this structured interaction and iterative inference process, the model jointly integrates local edge evidence and higher-order dependency information. By refining posterior probabilities via message passing, the framework enforces global consistency among dependency predictions and improves the accuracy and robustness of entity–relation extraction in complex threat intelligence texts.
3.5. Loss Function
During training, the model is optimized with respect to a gold semantic dependency graph for each input sentence. Based on the predicted posterior distributions, learning signals are derived for multiple prediction objectives, including dependency edge existence, dependency labels, entity types, and relation types. Cross-entropy loss is adopted for each component to guide parameter estimation.
For each directed dependency edge , the model estimates the probability that an edge exists between the two tokens. This probability is given by the final mean-field posterior distribution:
Using this estimate, the loss for edge existence prediction is defined as
For dependency edges that are present in the gold graph, the model further predicts their corresponding dependency labels. The conditional probability distribution over edge labels is computed using the label score matrix:
Accordingly, the loss for dependency label prediction is formulated as
In addition to dependency modeling, the framework also performs entity type classification. For an entity instance e, the probability of assigning entity type is defined as
The corresponding loss for entity classification is given by
Similarly, for relation classification, the probability of assigning relation type q to a relation instance r is computed as
and the corresponding relation classification loss is defined as
Here, denotes the set of all learnable parameters, and is an indicator function that ensures the dependency label loss is activated only for edges that exist in the gold semantic dependency graph.
To jointly optimize all prediction objectives, a multi-task learning strategy is adopted by combining the individual loss terms into a unified training objective. A hyperparameter is introduced to balance the contributions of entity and relation classification relative to dependency prediction. The overall loss function is defined as
In practice, we do not observe notable training instability when jointly optimizing the four objectives in Equation (39). This is because the objectives are structurally coupled through shared representations and semantic dependency inference, rather than being optimized as independent tasks. With appropriate learning rate settings and the balancing parameter , the training process remains stable across all experiments.
Although entity and relation classification losses are weighted by a shared hyperparameter , the coupling between the two tasks is not limited to loss-level aggregation. Entity and relation representations are jointly influenced by the inferred semantic dependency structures, which are optimized through and and serve as a shared structural context during decoding. As a result, dependency prediction acts as an explicit interaction bridge between entity recognition and relation classification, enabling joint learning beyond simple multi-task loss weighting. This joint optimization objective encourages consistent learning across dependency structure prediction, entity recognition, and relation classification, thereby reinforcing the coherence of structured representations learned for threat intelligence extraction. The balancing parameter is selected empirically based on validation set performance. We tune within a small range and observe that the model performance is relatively insensitive to moderate variations. In all experiments, is fixed to a constant value to ensure consistent training and fair comparison across models.
Model parameters are optimized using the Adam optimizer with weight decay. Following common practice for pretrained language models, different learning rates are applied to different parameter groups: the pretrained BERT encoder is fine-tuned with a smaller learning rate, while task-specific components such as the BiLSTM encoder, semantic dependency scoring modules, and classification layers are trained with a larger learning rate. All parameters are updated jointly in an end-to-end manner during training.
4. Experiment
4.1. Datasets
To facilitate threat intelligence entity–relation extraction, a domain-specific dataset was constructed to cover diverse threat-related entities and their complex semantic associations. The data were collected from multiple authoritative sources, including the National Vulnerability Database, the Qi An Xin Threat Intelligence Center, and the 360 Threat Intelligence Center, and consist primarily of unstructured cybersecurity reports and threat descriptions. Based on these sources, five entity types and seven relation types were defined to reflect common threat intelligence scenarios. The entity categories include Attacker, Tool, Attack Method, Industry, and Country/Region. Owing to security considerations and commercial usage restrictions associated with redistributing curated threat intelligence resources, the constructed dataset is not publicly available. Detailed definitions and examples of the entity and relation categories are summarized in Table 2 and Table 3, respectively.
Table 2.
Entity types and examples in the threat intelligence entity–relation extraction dataset.
Table 3.
Overview of relation types in the threat intelligence entity–relation extraction dataset.
Raw documents were collected from the above sources and segmented into sentences using standard sentence splitting rules. To focus on threat-relevant content, only sentences containing at least one security-related entity mention were retained. Entity and relation annotation was performed following a predefined guideline tailored to threat intelligence analysis: entities were annotated at the mention level according to the five predefined types, and relations were labeled only when both participating entities were explicitly mentioned or could be reliably inferred within the same sentence. The annotation process was conducted by annotators with a cybersecurity background, with ambiguous cases resolved through discussion to ensure consistency. As a result, the dataset exhibits a sparse and heterogeneous distribution of threat intelligence facts, with an average of 2.6 entity mentions and 1.4 annotated relations per sentence.
The dataset was randomly partitioned into training, validation, and test sets following an 8:1:1 split. After data cleaning and filtering, a total of 9158 sentences were retained for experimental evaluation, and the statistics of each subset are reported in Table 4. Following common practice in joint entity–relation extraction, this random split is adopted to enable fair comparison with existing methods. We acknowledge that threat intelligence reports may share recurring templates or phrasing patterns across sources and time periods, which could potentially introduce information leakage under random splitting. However, the primary goal of this work is to evaluate the relative effectiveness of different modeling strategies under a unified experimental setting. Moreover, the consistent performance gains observed across both the threat intelligence dataset and the publicly available SciERC benchmark suggest that the improvements in HDIM-JER are not solely attributable to dataset-specific template memorization. In addition to the threat intelligence dataset, we further evaluate HDIM-JER on the publicly available SciERC dataset [25], which consists of 500 scientific abstracts from the AI domain and is widely used to assess joint entity–relation extraction performance.
Table 4.
Data split of the threat intelligence ER dataset.
4.2. Evaluation Metrics
To quantitatively assess the performance of entity–relation extraction, Precision, Recall, and F1-score are adopted as evaluation metrics. Precision measures the proportion of correct predictions among all instances identified by the model, reflecting the accuracy of extracted entities or relations. Recall evaluates the model’s ability to identify all relevant instances present in the dataset, indicating the completeness of extraction results. The F1-score provides a balanced evaluation by jointly considering both Precision and Recall.
The definitions of these evaluation metrics are given as follows:
In these formulas, represents the number of true positive instances correctly predicted by the model, denotes the number of false positive instances incorrectly identified as valid predictions, and indicates the number of false negative instances that are missed during extraction.
4.3. Experimental Setup
To ensure a fair and reproducible evaluation of the proposed threat intelligence entity–relation extraction model, all experiments were conducted under a controlled computing environment. The hardware configuration includes a Windows 11 64-bit operating system, an NVIDIA GeForce RTX 4060 GPU, an Intel Core i9-14900HX 2.20 GHz CPU, and 32 GB of RAM. The software environment consists of Python 3.8.0 as the primary development language and PyTorch 2.0.0 as the deep learning framework. These configurations ensure that the model can efficiently process large-scale threat intelligence corpora and benefit from GPU-accelerated training. The detailed environment settings are summarized in Table 5.
Table 5.
Implementation details and experimental setup.
In addition to the computing environment, the model employs a set of well-defined hyperparameters that govern the behavior of different components, such as the BiLSTM encoder, character-level feature extractor, unary and binary potential functions of the semantic dependency network, and the optimization strategy. These hyperparameters were empirically selected through preliminary experiments to balance computational efficiency, training stability, and overall extraction performance. Although the reported learning rate is 0.01, this value is applied only to task-specific components such as the BiLSTM encoder, dependency scoring modules, and classification layers, while the pretrained BERT encoder is fine-tuned using a substantially smaller learning rate following common practice to ensure stable optimization and prevent training divergence. All hyperparameters used in our experiments are listed in Table 6.
Table 6.
Hyperparameter settings for HDIM-JER.
In addition to accuracy-based evaluation, we report system-level computational cost to assess the practical efficiency of the proposed framework. Table 7 summarizes the training time, inference latency, throughput, and peak GPU memory usage of HDIM-JER measured on our experimental hardware under a fixed inference setting.
Table 7.
System-level computational cost of HDIM-JER on RTX 4060 (max_len = 100, ).
4.4. Comparative Experiments
Comparative experiments are conducted on both the constructed threat intelligence entity–relation extraction dataset and the SciERC dataset to evaluate the performance of HDIM-JER under different extraction scenarios. Eight representative entity–relation extraction models are selected as baselines, including SpERT, UniRel, OneRel, CasRel, TPLinker, UIE, PGRC, and NER4CTI. These baselines cover diverse modeling paradigms, such as span-based extraction, cascade architectures, unified generation frameworks, and graph-based approaches, enabling a comprehensive comparison with HDIM-JER. Although several domain-specific studies discussed in Section 2.2 (e.g., [15,16]) are closely related at the application level, they are not included as baselines because they adopt pipeline-based or cross-document extraction settings and do not perform sentence-level joint entity–relation extraction, making direct comparison infeasible under our experimental protocol.
- SpERT [26]: A span-based joint entity–relation extraction model built on BERT. It follows an end-to-end framework but requires relatively high computational cost and training time.
- OneRel [27]: A unified one-stage framework designed for efficient end-to-end relation extraction. It is suitable for tasks with a limited number of relation types.
- UniRel [28]: A generation-based framework that formulates entity–relation extraction as a unified generation task, simplifying traditional pipeline designs. Its performance typically benefits from large-scale training data.
- PGRC [29]: A graph-based approach that constructs entity graphs and applies graph convolution to jointly model entities and relations.
- CasRel [30]: A cascade-style end-to-end model that handles overlapping relations effectively, but may degrade when the number of relation types is large.
- TPLinker [31]: A span–span linking framework that models relations through token-pair interactions and supports end-to-end extraction.
- UIE [32]: A unified text-to-structure generation framework that supports multiple information extraction tasks within a single architecture.
- NER4CTI [33]: A domain-specific model that integrates cybersecurity knowledge with deep learning through multi-task learning and enhanced semantic features.
The experimental results on both datasets are summarized in Table 8, where Precision (P), Recall (R), and F1-score (F1) are used as evaluation metrics.
Table 8.
Comparison results on the threat intelligence and SciERC datasets.
As shown in Table 8, HDIM-JER achieves the best overall performance on both the threat intelligence dataset and the SciERC dataset across all evaluation metrics. On the threat intelligence dataset, HDIM-JER obtains an F1-score of 88.7%, outperforming the strongest baseline, NER4CTI, by 1.8 percentage points. Similar gains are observed on the SciERC dataset, where HDIM-JER improves the F1-score by 1.6 points over the best competing method.
A closer comparison with individual baselines further highlights the advantages of HDIM-JER. Compared with SpERT, HDIM-JER achieves clear improvements in precision, recall, and F1-score, indicating stronger capability in modeling complex semantic dependencies. Although OneRel adopts a one-stage extraction strategy, it shows noticeable performance gaps, suggesting limitations in capturing intricate interaction patterns in threat intelligence texts. UniRel and PGRC also yield lower scores across all metrics, indicating that their modeling strategies are less effective for representing higher-order semantic dependencies.
CasRel and TPLinker demonstrate competitive performance among the baselines; however, both remain inferior to HDIM-JER, underscoring the benefits of explicitly modeling semantic dependency structures. UIE and NER4CTI achieve relatively strong results, particularly on the threat intelligence dataset, yet HDIM-JER consistently outperforms them. This observation suggests that incorporating second-order semantic dependencies provides additional gains in extracting deep semantic relations.
Overall, the superior performance of HDIM-JER can be attributed to its ability to address key limitations of existing entity–relation extraction approaches under the same experimental settings. Many baseline methods rely on pipeline-based, cascade-based, or weakly coupled designs, which are prone to error propagation when entity recognition and relation classification are performed sequentially or with limited interaction. In contrast, HDIM-JER performs structured joint inference, allowing entity boundaries and relation semantics to mutually constrain each other through semantic dependency structures.
Moreover, unlike span-based or token-pair linking methods that depend on flat enumeration and largely independent predictions, as well as graph-based or feature-fusion approaches that primarily enhance representations, HDIM-JER explicitly constructs semantic dependency graphs and models higher-order dependency configurations. By enforcing global consistency through a CRF-style inference process with iterative refinement, the framework introduces stronger structural inductive bias and achieves more robust predictions across both datasets.
4.5. Statistical Validation and Significance Analysis
To further assess the statistical robustness of the reported performance improvements, we conduct multiple runs with different random seeds for HDIM-JER and the baseline NER4CTI on the threat intelligence dataset. Table 9 reports the mean and standard deviation of F1 scores across runs, together with 95% confidence intervals and a significance test. Results are averaged over three runs with different random seeds.
Table 9.
Statistical validation of HDIM-JER and NER4CTI on the threat intelligence dataset. Results are reported as mean ± standard deviation over multiple runs, together with 95% confidence intervals (CIs).
4.6. Ablation Study
To analyze the contribution of second-order semantic dependency structures within HDIM-JER, ablation experiments were conducted on both the threat intelligence dataset and the SciERC dataset. In each ablation setting, one specific type of second-order semantic dependency was removed while keeping the remaining components unchanged, and the resulting performance variations were evaluated on the corresponding test sets. The ablation configurations include the following variants:
- -siblings: Sibling dependencies are removed such that no cross-layer structural relations between sibling entities are introduced.
- -grandparents: Grandparent relations are removed such that no multi-level dependencies between parent and child entities are introduced.
- -co-parents: Co-parent dependencies are removed such that no horizontal relations between entities sharing the same parent entity are included.
- -semantic dependency layer: The entire second-order semantic dependency representation layer is removed so that no second-order structured features are introduced into the threat intelligence extraction task.
The experimental results on both the threat intelligence dataset and the SciERC dataset are reported in Table 10.
Table 10.
Ablation study results on two datasets.
The results indicate that removing second-order semantic dependency structures leads to consistent performance degradation across both datasets. Among all ablation settings, removing the complete semantic dependency layer causes the most pronounced decline in performance, highlighting the importance of higher-order structural information in modeling complex entity–relation interactions. When individual dependency types are excluded, noticeable reductions in extraction performance are also observed. In particular, removing co-parent and grandparent dependencies results in larger performance drops compared with sibling dependencies, suggesting that these structures play a more substantial role in capturing long-range and hierarchical semantic relations.
A similar pattern is observed on both datasets. For both the threat intelligence dataset and the SciERC dataset, the absence of the semantic dependency layer consistently leads to a marked decrease in overall extraction quality, while the removal of specific second-order dependency types produces varying degrees of degradation. These observations indicate that second-order semantic dependency modeling contributes complementary structural cues that are not captured by first-order dependencies alone.
To further examine how different second-order semantic dependencies influence extraction errors, an error-type analysis was performed on the SciERC dataset. Three representative error categories were considered: Category Error, where both head and tail entities are correctly identified but the predicted relation type is incorrect; Head Error, where the head entity is incorrectly recognized while the tail entity is correctly identified; and Tail Error, where the tail entity is incorrectly recognized while the head entity is correctly identified.
As illustrated in Figure 3, sibling dependency modeling contributes to reducing head entity recognition errors by providing additional contextual constraints among semantically related entities. This effect is particularly beneficial in cases involving coordination structures or implicit coreference, where multiple entity mentions share similar semantic roles. Grandparent dependencies exhibit a stronger influence on tail entity recognition, especially in hierarchical or nested entity structures, where entity boundaries and long-range dependencies are more difficult to resolve. In such cases, removing grandparent dependencies leads to notable declines in prediction accuracy, indicating their importance for capturing hierarchical semantic cues.
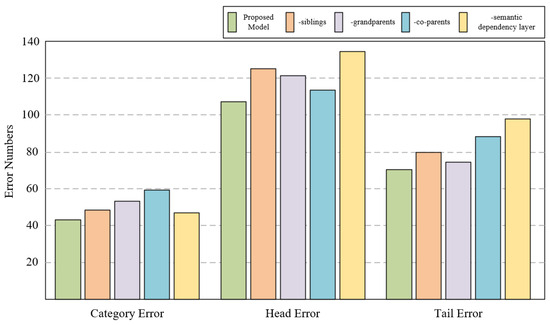
Figure 3.
Impact of second-order semantic dependencies on error types in the SciERC test set.
Beyond label-level error categorization, we observe that several linguistically driven failure patterns remain challenging. These include long-range coreference chains involving aliases or abbreviated entity mentions, nested or overlapping entities frequently found in scientific and technical texts, and relations that are implicitly expressed without explicit lexical triggers. While higher-order dependency modeling improves structural consistency in many of these scenarios, such linguistic phenomena continue to pose challenges for joint entity–relation extraction.
Overall, the ablation and error analysis results demonstrate that incorporating second-order semantic dependency structures enhances the model’s ability to handle complex relational patterns. By explicitly modeling higher-order interactions, HDIM-JER achieves improved robustness and generalization performance in scenarios involving overlapping, hierarchical, and long-distance semantic dependencies, while also highlighting remaining limitations associated with linguistically implicit structures.
4.7. Effect of Iteration Depth in Multi-Feature Interaction Experiment
To investigate the impact of iteration depth in the multi-feature interaction network, experiments were conducted on both the threat intelligence dataset and the SciERC dataset by varying the number of inference iterations M. The corresponding results are presented in Figure 4. As the iteration number increases, the extraction performance exhibits noticeable fluctuations and achieves its highest values when . Based on this observation, is selected as the default iteration setting for HDIM-JER in subsequent experiments.
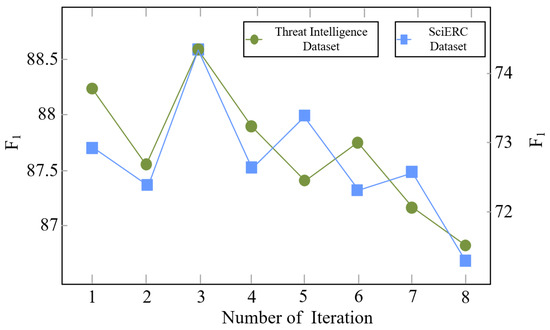
Figure 4.
Impact of inference iterations on F1 performance for the threat intelligence and SciERC datasets. F1 scores are shown on both the left and right y-axes, with an auxiliary scale provided to facilitate visual comparison.
We adopt a fixed number of inference iterations rather than a convergence-based termination criterion. In neural structured inference frameworks, mean-field inference is commonly unrolled as a fixed-depth computation graph to ensure stable optimization, consistent training and inference behavior, and controllable computational cost. In contrast, convergence-based termination would require additional stopping criteria and threshold tuning, and may introduce sample-dependent inference depth, which complicates batch-level optimization and training stability. Our empirical results further indicate that effective higher-order dependency propagation is achieved within a small number of iterations, making fixed iteration depth a practical and sufficient design choice in our setting.
When the number of iterations exceeds this value, the overall performance gradually declines on both datasets. This phenomenon suggests that excessive higher-order message passing may amplify early prediction errors rather than correct them. In particular, repeated message propagation tends to over-smooth feature representations, reducing the discriminability between entity and relation features and reinforcing erroneous dependency signals. As a result, the model becomes more prone to overfitting the training data, which negatively affects its generalization capability and leads to degraded extraction performance on unseen samples.
These results indicate that an appropriate balance between structural information propagation and feature preservation is critical for effective multi-feature interaction modeling. A moderate iteration depth enables the model to integrate higher-order dependency information while explicitly controlling error propagation, thereby achieving more robust and stable entity–relation extraction performance across different datasets.
5. Conclusions
This work studies threat intelligence entity–relation extraction from the perspective of semantic dependency interaction and proposes HDIM-JER, a unified framework for modeling complex and implicit relational structures in cybersecurity texts. By integrating first-order and second-order semantic dependencies into a joint inference process, HDIM-JER strengthens the interaction between entity recognition and relation extraction and reduces error propagation commonly observed in pipeline-based approaches. Experimental results on a self-constructed threat intelligence dataset and the public SciERC benchmark demonstrate consistent performance improvements over strong baselines. Although the absolute gains are moderate, joint entity–relation extraction has reached a relatively mature stage, where stable improvements of 1–2 F1 points are considered meaningful. This is especially the case when such gains are achieved with bounded and configurable inference complexity suitable for offline or near-real-time threat intelligence analysis. Future work will explore discourse-level reasoning, cross-domain adaptation, and multimodal extensions to further improve practical entity–relation extraction for cyber threat intelligence applications.
5.1. Complexity Analysis
Although HDIM-JER adopts a BERT–BiLSTM backbone for contextual representation learning, its overall computational cost is still dominated by the pretrained BERT encoder, which is common to most state-of-the-art joint extraction models. The additional overhead introduced by HDIM-JER mainly arises from semantic dependency scoring and structured inference.
Specifically, first-order and second-order semantic dependency scores are computed using bilinear and trilinear interactions over token representations, resulting in a time complexity of , where n denotes the sentence length and d is the hidden dimension. Higher-order dependency modeling is restricted to local configurations, such as sibling, co-parent, and grandparent relations, thereby avoiding cubic complexity. The CRF-style inference is carried out with a small and fixed number of mean-field iterations, introducing an additional cost of , where . Consequently, the overall time and space complexity of HDIM-JER remains quadratic in the sentence length and is comparable to existing BERT-based joint extraction frameworks. In terms of memory usage, HDIM-JER primarily maintains token-level representations and pairwise dependency scores, leading to a quadratic memory footprint with respect to sentence length.
From a practical perspective, HDIM-JER is suitable for real-world threat intelligence applications, where extraction is typically performed at the sentence or document level under near-real-time or batch processing settings. The structured inference component introduces only moderate overhead while yielding clear gains in extraction accuracy, making the framework practical for deployment in cyber threat intelligence analysis pipelines.
5.2. Limitations and Future Work
Several limitations and future directions remain in this work. First, the threat intelligence dataset is evaluated using a random train–validation–test split. Although this setting follows common practice, it may underestimate generalization challenges in realistic deployment scenarios with temporal or source-level correlations. More rigorous source-aware and time-aware evaluation protocols will therefore be explored in future work. Second, while the dataset is collected from specific platforms, HDIM-JER is not designed around source-specific templates or lexical heuristics. Instead, it focuses on modeling semantic dependency structures and higher-order interaction patterns that reflect general linguistic regularities. In addition, the dataset aggregates reports from multiple threat intelligence sources with diverse writing styles, which helps mitigate single-source bias. The consistent performance gains observed on the public SciERC benchmark further support the transferability of the proposed framework.
From a modeling perspective, several linguistically complex phenomena remain challenging for the current framework. These include long-range coreference, nested entities, and implicitly expressed relations, which are not explicitly modeled. Incorporating discourse-level representations is a promising direction for future extensions. Moreover, although HDIM-JER couples entity recognition and relation extraction through semantic dependency inference, the decoding process remains task-specific. Exploring shared or partially shared decoding mechanisms may further improve decoding-level consistency. Finally, the structured inference component introduces moderate computational and memory overhead. While this overhead is acceptable for sentence- or document-level processing in offline or near-real-time threat intelligence analysis, further optimization will be necessary to support large-scale or real-time deployment.
Author Contributions
Conceptualization, S.Z. and W.M.; methodology, S.Z., J.Y. and C.D.; software, S.Z., C.D. and L.M.; validation, S.Z., J.Y. and X.G.; formal analysis, S.Z., C.D. and L.M.; investigation, J.Y., C.D. and L.W.; resources, W.M. and X.L.; data curation, S.Z., J.Y. and C.D.; writing—original draft preparation, S.Z.; writing—review and editing, S.Z., W.M., L.M. and N.L.; visualization, X.G. and L.W.; supervision, L.M. and X.L.; project administration, L.M. and X.L.; funding acquisition, J.Y. and X.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the 2024 Annual Open Competition Mechanism for Science and Technology R&D Program of China Railway Group Limited (Academy 2025-Major-01); the National Key R&D Program of China under Grant 2022YFF0604502; and the Young Elite Scientists Sponsorship Program of the Beijing High Innovation Plan.
Data Availability Statement
The threat intelligence dataset used in this study was constructed by collecting, curating, and annotating threat intelligence texts from multiple platforms. Due to potential security risks related to the redistribution of aggregated and value-added threat intelligence data, as well as commercial usage restrictions, this dataset is not publicly available. In addition, experiments were conducted on the publicly available SciERC dataset, a scientific information extraction corpus introduced by Luan et al., which can be accessed through the corresponding ACL Anthology release. No new datasets were generated or analyzed during this study.
Conflicts of Interest
Author Jing Yin was employed by Intelligence Center, China Railway Academy Group Co., Ltd., Chengdu 611731, China and author Liang Wang was employed by Shaanxi Aerospace Technology Application Research Institute Co., Ltd., Xi’an, China. The funder was not involved in the study design, collection, analysis, interpretation of data, the writing of this article, or the decision to submit it for publication. The remaining authors declare no conflict of interest.
References
- Zhang, Y.; Liu, S.; Liu, Y.; Ren, L.; Xin, Y. Joint Extraction of Entities and Relations Based on Deep Learning: A Survey. Acta Electron. Sin. 2023, 51, 1093–1116. [Google Scholar]
- Zhang, X.; Liu, L.; Wang, H.; Liu, J. Survey of Entity Relationship Extraction Methods in Knowledge Graphs. J. Comput. Sci. Explor. 2024, 18, 574–596. [Google Scholar]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation Classification via Convolutional Deep Neural Network. In Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers; Dublin City University and Association for Computational Linguistics: Dublin, Ireland, 2014; pp. 2335–2344. [Google Scholar]
- Wang, L.; Cao, Z.; De Melo, G.; Liu, Z. Relation Classification via Multi-Level Attention CNNs. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 1298–1307. [Google Scholar]
- Zhu, H.; Lin, Y.; Liu, Z.; Fu, X.; Chen, M.; Sun, M. Graph Neural Networks with Generated Parameters for Relation Extraction. arXiv 2019, arXiv:1902.00756. [Google Scholar] [CrossRef]
- Ding, R. Research on Joint Entity-Relation Extraction Methods. Master’s Thesis, Chongqing University of Technology, Chongqing, China, 2024. [Google Scholar]
- Zhang, S.; Wang, X.; Chen, Z.; Wang, L.; Xu, D.; Jia, Y. Survey of Supervised Joint Entity Relation Extraction Methods. J. Front. Comput. Sci. Technol. 2022, 16, 713–733. [Google Scholar]
- Li, D.; Zhang, Y.; Li, D.; Lin, Q. Review of Entity Relationship Extraction Methods. J. Comput. Res. Dev. 2020, 57, 1424–1448. [Google Scholar]
- Sui, D.; Zeng, X.; Chen, Y.; Xu, R.; Xu, P. Joint Entity and Relation Extraction with Set Prediction Networks. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 12784–12795. [Google Scholar] [CrossRef] [PubMed]
- Zhao, K.; Xu, H.; Cheng, Y.; Li, X.; Gao, K. Representation Iterative Fusion Based on Heterogeneous Graph Neural Network for Joint Entity and Relation Extraction. Knowl.-Based Syst. 2021, 219, 106888. [Google Scholar] [CrossRef]
- Geng, Z.; Zhang, Y.; Han, Y. Joint Entity and Relation Extraction Model Based on Rich Semantics. Neurocomputing 2021, 429, 132–140. [Google Scholar] [CrossRef]
- Ji, B.; Li, S.; Xu, H.; Yu, J.; Ma, J.; Liu, H.; Yang, J. Span-Based Joint Entity and Relation Extraction Augmented with Sequence Tagging Mechanism. Sci. China Inf. Sci. 2024, 67, 152105. [Google Scholar] [CrossRef]
- Tang, M.; Zhang, L.; Yu, Z.; Shi, X.; Liu, X. Symmetry- and Asymmetry-Aware Dual-Path Retrieval and In-Context Learning-Based LLM for Equipment Relation Extraction. Symmetry 2025, 17, 1647. [Google Scholar] [CrossRef]
- Zhuang, J.; Wang, K.; Yuan, Z.; Yan, Y. Frequency Domain Iterative Clustering for Boundary-Preserving Superpixel Segmentation. Appl. Soft Comput. 2026, 191, 114717. [Google Scholar] [CrossRef]
- Gao, P.; Liu, X.; Choi, E.; Ma, S.; Yang, X.; Song, D. ThreatKG: A Threat Knowledge Graph for Automated Open-Source Cyber Threat Intelligence Gathering and Management. arXiv 2022, arXiv:2212.10388. [Google Scholar]
- Pingle, A.; Piplai, A.; Mittal, S.; Joshi, A.; Holt, J.; Zak, R. RelexT: Relation Extraction Using Deep Learning Approaches for Cybersecurity Knowledge Graph Improvement. In ASONAM ’19: Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining; Association for Computing Machinery: New York, NY, USA, 2019; pp. 879–886. [Google Scholar]
- Yuan, L.; Bai, Y.; Xing, Z.; Tian, L.; Wang, H. Predicting Entity Relations across Different Security Databases by Using Graph Attention Network. In 2021 IEEE 45th Annual Computers, Software, and Applications Conference (COMPSAC); IEEE: Piscataway, NJ, USA, 2021; pp. 834–843. [Google Scholar]
- Cheng, S.; Li, Z.; Wei, T. Threat Intelligence Entity Relation Extraction Method Integrating Bootstrapping and Semantic Role Labeling. Comput. Appl. 2023, 43, 1445–1453. [Google Scholar]
- Satvat, K.; Gjomemo, R.; Venkatakrishnan, V. Extractor: Extracting Attack Behavior from Threat Reports. In 2021 IEEE European Symposium on Security and Privacy (EuroS&P); IEEE: Piscataway, NJ, USA, 2021; pp. 598–615. [Google Scholar]
- Kurniawan, K.; Kiesling, E.; Winkler, D.; Ekelhart, A. The ICS-SEC KG: An Integrated Cybersecurity Resource for Industrial Control Systems. In The Semantic Web—ISWC 2024; Springer Nature: Cham, Switzerland, 2024; pp. 153–170. [Google Scholar]
- Jones, C.; Bridges, R.; Huffer, K.; Goodall, J.R. Towards a Relation Extraction Framework for Cyber-Security Concepts. In CISR ’15: Proceedings of the 10th Annual Cyber and Information Security Research Conference; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1–4. [Google Scholar]
- Gasmi, H.; Laval, J.; Bouras, A. Information Extraction of Cybersecurity Concepts: An LSTM Approach. Appl. Sci. 2019, 9, 3945. [Google Scholar] [CrossRef]
- Wang, X.; Xiong, M.; He, F.; Li, Y. FSSRE: Fusing Semantic Feature and Syntactic Dependencies for Threat Intelligence Relation Extraction. In SEKE 2021; KSI Research Inc.: Pittsburgh, PA, USA, 2021; pp. 79–85. [Google Scholar]
- Zhu, S.; Tai, Q.; Wang, J.; Tang, M.; Wang, L.; Li, N.; Hou, S.; Liu, X. UMEAD: Unsupervised Multimodal Entity Alignment for Equipment Knowledge Graphs via Dual-Space Embedding. Symmetry 2025, 17, 1869. [Google Scholar] [CrossRef]
- Luan, Y.; He, L.; Ostendorf, M.; Hajishirzi, H. Multi-Task Identification of Entities, Relations, and Coreference for Scientific Knowledge Graph Construction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 3219–3232. [Google Scholar]
- Santosh, T.; Chakraborty, P.; Dutta, S.; Sanyal, D.K.; Das, P.P. Joint Entity and Relation Extraction from Scientific Documents: Role of Linguistic Information and Entity Types. In Proceedings of the 2nd Workshop on Extraction and Evaluation of Knowledge Entities from Scientific Documents (EEKE 2021) Co-Located with JCDL 2021, Virtual, 30 September 2021; pp. 15–19. [Google Scholar]
- Shang, Y.; Huang, H.; Mao, X. OneRel: Joint Entity and Relation Extraction with One Module in One Step. In Proceedings of the AAAI 2022, Virtual, 22 February–1 March 2022; pp. 11285–11293. [Google Scholar]
- Tang, W.; Xu, B.; Zhao, Y.; Mao, Z.; Liu, Y.; Liao, Y.; Xie, H. UniRel: Unified Representation and Interaction for Joint Relational Triple Extraction. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 7087–7099. [Google Scholar]
- Zheng, H.; Wen, R.; Chen, X.; Yang, Y.; Zhang, Y.; Zhang, Z.; Zhang, N.; Qin, B.; Xu, M.; Zheng, Y.; et al. PRGC: Potential Relation and Global Correspondence Based Joint Relational Triple Extraction. arXiv 2021, arXiv:2106.09895. [Google Scholar] [CrossRef]
- Wei, Z.; Su, J.; Wang, Y.; Tian, Y.; Chang, Y. A Novel Cascade Binary Tagging Framework for Relational Triple Extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 1476–1488. [Google Scholar]
- Wang, Y.; Yu, B.; Zhang, Y.; Liu, T.; Zhu, H.; Sun, L. TPLinker: Single-Stage Joint Extraction of Entities and Relations Through Token Pair Linking. In Proceedings of the 28th International Conference on Computational Linguistics; International Committee on Computational Linguistics: New York, NY, USA, 2020; pp. 1572–1582. [Google Scholar]
- Lu, Y.; Liu, Q.; Dai, D.; Xiao, X.; Lin, H.; Han, X.; Sun, L.; Wu, H. Unified Structure Generation for Universal Information Extraction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 5755–5772. [Google Scholar]
- Wang, G.; Liu, P.; Huang, J.; Bin, H.; Wang, X.; Zhu, H. KnowCTI: Knowledge-based Cyber Threat Intelligence Entity and Relation Extraction. Comput. Secur. 2024, 141, 103824. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.