Abstract
Trajectory data contain numerous sensitive attributes. Unauthorized disclosure of precise user trajectory information generates persistent privacy and security concerns that significantly impact daily life. Most existing trajectory privacy protection schemes focus on geographic trajectories while neglecting the critical importance of semantic trajectories, resulting in ongoing privacy vulnerabilities. To address this limitation, we propose the Semantic Behavior Sequence-based Trajectory Privacy Protection method (SBS-TPP). Our approach integrates short-term and long-term behavioral patterns within a user behavior modeling layer to identify user preferences. A dual-model framework (geographic and semantic) generates noise-injected trajectories with maximized noise potential. This methodology applies symmetric noise addition to both geographic trajectory fragments and semantic trajectory segments, optimizing trajectory data utility while ensuring robust protection of sensitive information. The SBS-TPP framework operates in the following two phases: firstly, behavior modeling, which comprises interest extraction from behavioral trajectory sequences, and secondly, noise generation, which creates synthetic noise locations with maximal semantic expectation from original locations, yielding privacy-enhanced trajectories for publication. Experimental results demonstrate that our interest extraction model achieves 93.7% accuracy while maintaining 81.6% data utility under strict privacy guarantees. The proposed method significantly enhances data usability and enables effective recommendation services without compromising user privacy or security.
1. Introduction
Rapidly developing mobile Internet technology and smart mobile devices have driven Location-Based Social Networks(LBSNs) to stand out from the many mobile Internet services. LBSNs are an online social networking service based on a geographic information system seamlessly integrated with the Internet. In LBSNs, location servers collect users’ daily trajectory data through service requests, check-ins, passive tracking, and other methods. To enable comprehensive interest profiling and enhance service engagement, these servers extract and analyze behavioral patterns and preferences from daily user activities. User behavior patterns and preferences are the basis for discovering similar users and communities of similar users, and they are also favorable support for providing personalized services to users in LBSNs []. To obtain relevant service recommendations, users must transmit actual trajectory data to Location-Based Social Network (LBSN) servers for analysis. However, trajectory data inherently contains extensive multidimensional sensitive information. In January 2025, a cyberattack targeted the U.S.-based data broker Gravy Analytics, resulting in the theft of historical location data pertaining to millions of mobile users, including precise movement trajectories []. This breach not only exposed users’ personal privacy information, posing significant risks to their personal and financial security but also posed a substantial threat to social stability. Its exposure compromises not only movement privacy but also other private attributes, including home/workplace addresses, behavioral patterns, and consumption status [,,]. The primary privacy threat in LBSNs stems from data leakage through server breaches or untrustworthy server conduct [,]. Such disclosures may cause users to disengage entirely from LBSN platforms. Consequently, trajectory privacy protection constitutes a prerequisite for service quality enhancement. Traditional solutions include cryptographic approaches [] and anonymization techniques []. While cryptographic methods provide robust privacy safeguards, they restrict legitimate data access by trusted parties, impairing data fluidity and undermining inherent sharing characteristics. Critically, inaccessible data provides no practical utility. Anonymization-based protection necessitates trusted third-party servers to generalize and suppress trajectories. However, malicious actors may compromise even trusted third-party servers [], fundamentally subverting traditional privacy preservation mechanisms.
Differential privacy (DP) has emerged as the predominant privacy-preserving framework for private data protection, attracting extensive research attention [,]. DP enables noise-injected data analysis while resisting adversary inference attacks []. Unlike traditional anonymization techniques, it eliminates the need for trusted third-party providers. Notable trajectory privacy implementations include DP-Star (Zheng et al. []), applying the minimum description principle to generate representative noise points; N-gram (Chen et al. []), employing adaptive per-point noise addition; and DPT []. While DP-Star provides adequate privacy protection, its exclusive focus on geographical distance neglects semantic similarity, limiting recommendation system utility. The N-gram method’s disregard for geographical constraints generates trajectories excessively deviating from originals, degrading recommendation efficacy.
Consequently, existing methods remain suboptimal for privacy-preserving discovery of users with similar mobility patterns. To address this, our semantic behavior sequence-based trajectory privacy preservation method enables discovery of trajectory-similar users while ensuring privacy. The contributions of this chapter are as follows:
- We present a novel differential privacy approach for discovering similar trajectories. The method generates trajectory data with calibrated noise injection, ensuring maximal expected perturbation while maintaining consistency with published user trajectories. This framework enables accurate user recommendations while providing robust privacy assurance for trajectory information.
- The semantic behavior sequence-based region of interest (ROI) discovery method effectively identifies user-specific ROIs. During behavioral modeling, user behavioral interactions are chronologically sorted, with a differential threshold delineating short-term and long-term behavioral sequences. A Transformer encoder models short-term behavioral sequences to capture intra-sequence behavioral relationships, while integrated positional encoding represents spatial information.
- Following a comprehensive security analysis and feasibility assessment, it has been determined that the solution proposed in this chapter meets the requisite standards for differential privacy protection. Furthermore, the noise trajectory processed and released is highly usable, enabling the realization of similar user discovery based on the noise trajectory.
The organization of this article is as follows: Section 2 (Related Work) reviews semantic-based trajectory privacy protection research. Section 3 (Preliminary) presents preliminary knowledge and formal definitions. Section 4 details the core contribution through our proposed framework, including algorithm design and implementation. Section 5 (Experimental Results and Analysis) evaluates experimental results and analyzes performance. Section 6 (Summary of Future Work) concludes the current work and outlines future research directions.
2. Related Work
2.1. Synthetic Trajectory
Trajectory data comprises spatio-temporally correlated location sequences. Beyond enabling user-specific services, such data plays crucial roles in macroscopic domains like urban planning. Conventional trajectory privacy methods predominantly focus on geographical trajectories, as established in prior research. However, reliable simulation of user mobility behavior requires incorporating semantic characteristics. Attackers can readily identify implausible locations using road network data and trajectory plausibility analysis. Consequently, privacy protection approaches neglecting trajectory semantics remain fundamentally vulnerable to inference attacks.
Most existing trajectory privacy-preserving methods employ data synthesis techniques, commonly termed pseudo-trajectory generation. In Location-Based Social Networks (LBSNs) and trajectory data publication, such techniques conceal actual trajectories within synthetic counterparts to achieve privacy protection []. Traditional pseudo-trajectory generation predominantly relies on heuristic approaches. Lu et al. [] proposed a grid-based method that ensures regional privacy through location density and query range considerations. The limitations of the grid-based approach stem from the discretization of continuous space into discrete grids, where trajectory points are compelled to align with grid centers or intersections, thereby compromising the original geometric characteristics of the path. Additionally, grids retain only spatial coordinates, disregarding semantic locations. Consequently, this leads to difficulties in balancing privacy and utility, necessitating dynamic adjustment of grid granularity. Kato et al. [] introduced a stop-detection approach minimizing noise injection for plausible trajectories. The limitations of the stop-point detection method stem from its reliance on predefined time and distance thresholds, which introduce subjectivity and result in the omission of movement path information. An overemphasis on the protection of stop-points tends to overlook privacy risks associated with the movement process itself. Ref. [] developed road network-based pseudo-location generation for publishable trajectories. Suzuki et al. [] implemented point-of-interest sampling to reduce noise. To balance privacy and utility, Gramaglia et al. [] applied spatio-temporal similarity constraints. Liu et al. [] enhanced trajectory realism through temporal, spatial, and network degree constraints. Li et al. [] improved plausibility via POI estimation and road network topology. Critically, these methods neglect behavioral movement patterns and semantic coherence, rendering synthesized trajectories vulnerable to detection.
This paper proposes a semantic geo-trajectory similarity-controlled framework for pseudo-trajectory generation. Our approach regulates trajectory synthesis through dual-domain constraints—geographical and semantic—to significantly enhance trajectory plausibility.
2.2. Behavioral Sequence Modeling
Sequence feature modeling has gained significant traction in search advertising and recommendation systems, with substantial recent advances in both academic and industrial research. User behavioral sequences—comprising platform interactions like information posting and service queries—play a vital role in interest understanding and click-through rate (CTR) prediction enhancement []. Initial modeling approaches employed summation, averaging, and concatenation for behavior representation [], yet these capture limited interest information by overlooking behavioral significance, temporal relationships, and sequential dependencies. Recent work has substantially advanced user behavior modeling and interest representation. Recognizing that behavioral data alone inadequately captures interest diversity, the DIN model [,] utilizes attention mechanisms to weight historical behaviors, adaptively learning interest representations by emphasizing candidate-relevant actions. However, DIN neglects behavioral dependencies. Subsequent DIEN [,] introduces interest extraction and evolution layers, modeling sequences through gated recurrent units (GRUs) with attention-updated gates (AUGRU) to capture dynamic interest progression. For extended behavioral sequences, MIMN [,] maintains user-specific interest states via dedicated interest centers.
The DMIN model [] subsequently employs multi-head self-attention to derive enhanced representations of historical user items, followed by a multi-interest extraction layer to capture diverse user interests. Xu et al. [] introduced the Core Interest Network (CIN), utilizing hierarchical GRUs to identify fundamental interests within extensive behavioral sequences. While users’ long-term preferences invariably influence current decisions, existing approaches like Li et al. [] merely concatenate long-term preferences with current sessions. This simplification proves inadequate given mobile users’ sophisticated service requirements and complex behavioral dynamics. Crucially, the correlation between long-term preferences and short-term sessions remains non-trivial, rendering simple concatenation or aggregation insufficient for effective representation fusion. Table 1 provides a comparative illustration of the models discussed in this section.

Table 1.
Comparative analysis of system models.
3. Preliminary
This section systematically defines core concepts used throughout our study and outlines the proposed methodology, including the system model, attack model, and design principles.
3.1. Related Definitions
Differential privacy operates under a foundational premise: the addition or removal of any individual record in a relational database should not substantially influence query outcomes. While real-world record modification inevitably alters query results, differential privacy formalizes this concept through a privacy budget . This tolerance parameter quantifies the maximum permissible discrepancy between original and perturbed query outputs. The privacy guarantee strength is inversely proportional to —smaller values enforce stricter privacy protection by constraining result divergence.
Consider two databases D and D’ differing by exactly one record, referred to as adjacent databases. A randomized algorithm satisfies differential privacy when noise is introduced to the query function . Differential Privacy is formally defined as follows:
Definition 1
(-DP). For any adjacent datasets D and differing by exactly one record, a randomized algorithm satisfies ϵ-differential privacy if for all possible outputs :
Differential privacy implementation employs distinct mechanisms for query result protection. The Laplace and exponential mechanisms represent two primary approaches: the former typically secures numerical query outputs, while the latter safeguards non-numerical results. Prior to detailing these mechanisms, we formally define sensitivity as the maximum possible change in query outcomes when adding or removing any single database record.
Definition 2
(Sensitivity). For any query function , the sensitivity is defined as
where denotes the one-parameter distance.
Definition 3
(Laplace mechanism). Given a dataset D and query function with sensitivity , the randomized algorithm satisfies ϵ-DP if
where obeys the Laplace distribution . The probability density function of Laplace is centrally symmetric.
Definition 4
(Geographic trajectory data). Geographic trajectory data represents a chronologically ordered sequence of location points, typically formalized as
where represents the n-th position of user , and
Definition 5
(Semantic trajectory data). Semantic trajectories derived from region of interest (ROI) descriptions form sequential structures defined as
where denotes the semantic trajectory of user , and represents the semantic description of the stay area.
Definition 6
(Area of interest). Suppose that given is the trajectory sequence of a user . If there exists
Then the region formed by the position points satisfying Equation (6) from to and the moving position of is called the region of interest of the user , where and are set distance thresholds and time thresholds, and is the distance between two location points.
Definition 7
(Location Distance). The location data of user and are and respectively, where and denote the longitude and latitude of user at point p respectively, and the distance between the two locations can be calculated as
Definition 8
(Feature location). For a point-of-interest category a, define as the set comprising all locations of category a within a geographical region, where denotes the i-th location point (). The characteristic location for category a in the stay region is
3.2. Definition of Attack
The system model incorporates secure communication protocols [] to ensure encrypted data transmission between entities. Received data is protected through anonymization mechanisms []. While LBSNs perform recommendations per established protocols, they may attempt to infer actual trajectories using interest-driven analysis to gain additional user insights—potentially enhancing proactive engagement and platform longevity. Mobile users are assumed to act as trusted data holders and providers, as voluntary privacy compromise is implausible.
Furthermore, users increasingly recognize data security importance over time. Consequently, all system participants are treated as both data custodians and co-protectors of private information. Service providers—entities collecting data for commercial interests—constitute untrusted actors due to potential intentional or inadvertent data disclosure. Within our framework, these providers solely perform historical trend analysis and supply regional public data, bearing no responsibility for subsequent privacy breaches. Thus, service providers pose no credible privacy threat. To safeguard private trajectory data, each user generates pseudo-trajectories through noise injection prior to release. Consequently, neither service providers nor LBSN servers access actual trajectory data, ensuring comprehensive trajectory privacy protection.
4. A Semantic Behavior-Based Approach to Trajectory Protection
Most existing trajectory privacy methods protect entire trajectories, often introducing excessive noise that degrades data utility. These geographic-only approaches disregard semantic similarity, consequently failing to deliver usable recommendations for users with similar mobility patterns. Our scheme innovatively safeguards only regions of interest (ROIs) within trajectories while publishing non-sensitive mobile regions directly. Subjectively, transient mobility points warrant no privacy budget expenditure. Users selectively designate protection-worthy locations, with historically derived interest stay regions identified as safe zones. Within such regions, users may generate query proxies by selecting pseudo-locations that satisfy minimum privacy distance constraints while maximizing geo-semantic similarity to actual positions. Strategic injection of erroneous locations between successive ROIs ensures trajectory confidentiality. Crucially, published pseudo-trajectories preserve directional mobility patterns, maintaining data utility for daily applications while guaranteeing privacy.
4.1. Interest Region Segmentation Based on Semantic Behavior Extraction
To address privacy budget allocation in trajectory data, regions must be partitioned into interest and non-interest categories based on user historical data analysis. Regions of interest play a more critical role in privacy budget allocation, while non-interest regions can be output directly. This partitioning strategy effectively controls budget distribution, preventing excessive noise introduction that reduces data availability. Based on these considerations, this paper proposes a behavior sequence-based region-of-interest prediction model, designated MA. The MA model represents an algorithm for detecting regions of interest based on semantic behavior, which analyzes the regions of interest in users’ long-term or short-term behavioral trajectories by examining their historical trajectory information. Its primary components include an embedding layer, behavior modeling, interest extraction, and an output layer. The embedding layer is responsible for transforming user features into a format directly inputtable into a DNN. The long-term behavior modeling layer aims to extract motion-related behaviors, thereby mitigating the impact of irrelevant behaviors or noise data on trajectory feature extraction. The interest extraction layer focuses on identifying high-weight interests within both long-term and short-term contexts. Finally, the output layer is designed to produce the regions of interest. In this paper, the primary focus is on processing the regions of interest within user trajectories to generate pseudo-trajectories. The comprehensive framework of the model, illustrated in Figure 1, comprises four principal components: the embedding layer, the behavior modeling layer, the multi-interest extraction layer, and the output layer. Within the user behavior sequence modeling component, user interaction items are categorized as short-term and long-term behavioral sequences. The Transformer encoder and LSTM are employed to model the short-term and long-term sequences, respectively, capturing behavioral relationships within each sequence. In the multi-interest extraction layer, an attention capsule network identifies regions of interest from the integrated behavioral sequences. Accurate identification of regions of interest enhances overall trajectory privacy protection levels and enables rational noise allocation.
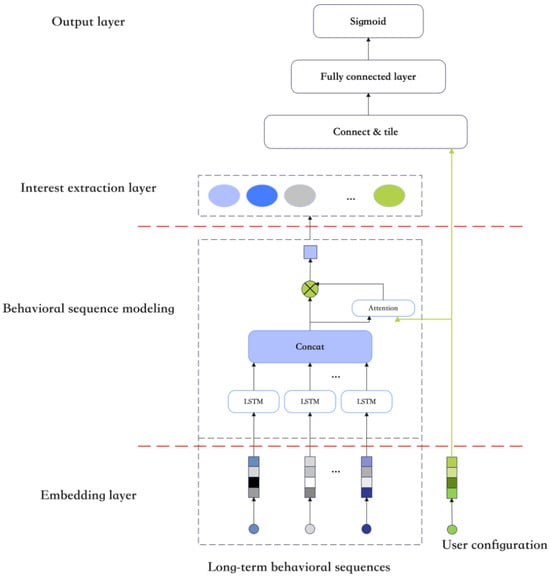
Figure 1.
Structure diagram of MA model.
Unlike traditional neurons operating with scalar values, capsules process and output vectors. The vector norm (length) represents the probability of an entity’s presence, analogous to the scalar output of a neuron, while the vector orientation encodes its instantiation parameters, such as pose or deformation attributes. The dynamic routing mechanism replaces max-pooling operations traditionally used in Convolutional Neural Networks (CNNs) for feature selection and spatial invariance between capsule layers.
4.1.1. Embedded Layer
If input user feature item cannot be directly input into the DNN, it will be transformed into a dense vector by the embedding layer, and the embedding vector is expressed as Equation (9)
where represents the input embedding for feature q of item i with embedding size , denotes the transformation matrix for feature q, and is a unique heat vector.
Similarly, a user profile can characterize user u through various feature dimensions, such as age and gender. The profile information of user u is represented as a dense vector ,
where f is the feature set of the profile and is the embedding of the feature f.
4.1.2. Long-Term Behavioral Sequence Modeling
In the field of user long-term behavior sequence modeling, the initial step involves the presentation of a long-term behavior sequence, designated as , exhibited by a specific user, designated as u. To effectively model the global temporal dependencies inherent in long-sequence data, the Long Short-Term Memory (LSTM) unit is employed. This recurrent unit, utilized for session-based recommendations, features three inputs: the current network input, the previous LSTM output, and the previous unit state. The LSTM produces two outputs: the current LSTM output and the current unit state. The LSTM unit’s update mechanism is governed by Equations (11)–(15).
The forget gate determines the proportion of the previous cell state that is preserved to the current state . This is computed using the following equation:
where and denote the weight matrix and bias term, respectively, for the forget gate.
The input gate determines the proportion of the current network input that is retained in the cell state , defined as follows:
where and denote the weight matrix and bias term, respectively, for the input gate.
The cell state is computed as follows:
Through the forget gate’s regulation, the network retains long-range temporal dependencies, while the input gate mitigates the incorporation of irrelevant immediate inputs. The output gate governs the influence of long-term memory on the current output as follows:
The final LSTM output , governed jointly by the output gate and cell state, is computed as follows:
The LSTM encodes user u’s long-term interaction sequence at timestep t into a hidden output vector , termed the sequential preference representation, while constitutes the unit state vector containing historical information. The LSTM outputs are summarized as .
Since irrelevant behaviors affect the representation of in the sequence in one way or another, attention units are used here to reduce the impact of those irrelevant behaviors. the long-term behavioral representation at moment t is
4.1.3. Interest Extraction Layer
Within the interest extraction layer, we aggregate long- and short-term behavioral sequences into a capsule set representing user interests. Each capsule comprises neurons whose activity vectors instantiate parameters of a specific interest type for a given user. The activity vector’s magnitude indicates interest existence probability, while its orientation encodes properties characterizing an interest class. This layer learns to represent interest attributes and detect interest presence. Distinct capsules capture different aspects of user interests, with related capsules evaluating interests in particular semantic categories. Dynamic routing—a parallel attention mechanism—enables capsules to selectively attend to relevant lower-level interest capsules. This algorithm produces high-level capsules representing user interests.
Assuming a two-layer capsule network architecture with low-level capsules and high-level capsules , dynamic routing iteratively derives high-level capsule values from low-level capsules. Each iteration processes low-level capsule vectors , and high-level capsule vectors , . The routing logic is computed as follows:
In Equation (18), denotes the learnable bilinear mapping matrix, with m and n representing the number of low-level and high-level capsules, respectively. The candidate vector for high-level capsules is given by the weighted sum of low-level capsules:
where represents the connection weight between low-level and high-level capsules, computed as the coupling coefficient through iterative dynamic routing. This coefficient is obtained by applying the softmax function:
Finally, a nonlinear squash function is utilized to obtain the advanced capsule:
In Equation (21), squash is a nonlinear activation function, the first term of the function is a value greater than 0 and less than 1, and the number in the denominator represents the degree of squeezing of the function. And when is less than the degree of extrusion, the first term will be less than 0.5, indicating that the capsule represents a small chance of the existence of the feature; when is greater than the degree of extrusion, the first term will be greater than 0.5, indicating that the capsule represents a large chance of the existence of the feature. In this way the important parts of z can be enlarged and the unimportant parts of z can be reduced. The second term serves to unitize z, i.e., compress it to .
In particular, given a target item representation and a sequence context vector o, is first sequentially flattened to , and then the attention score is obtained as the attention weight of the lower-level capsule by a linear transformation:
is used to maximize the weight of capsules from essential items and minimize the weight of irrelevant capsules, maximizing the difference between essential and irrelevant capsules. This attentional weight is multiplied when computing the input for the advanced capsule . This process serves to model higher-order interactions between the target item representation and the user’s historical behavior. At this point, we will have completed the discovery and segmentation of regions of interest based on semantic behavioral sequences, followed by the allocation of privacy budgets and related protection methods based on the corresponding regions of interest.
4.2. Region of Interest Privacy Proxy Location and Pseudo-Trajectory Generation Method
This analysis enables identification of the user’s semantic region of interest and generation of a privacy proxy location for that region. As the term implies, the privacy proxy location represents the region’s most characteristic location data. First, semantic weights for each point-of-interest category are computed based on regional semantic features. Within stay region , let n denote the total semantic point-of-interest categories, with representing their total count. Similarly, let a denote the count of locations in category *a* within the region. For the entire trajectory containing stay regions, indicates the count of regions containing category a. The semantic weight for category a is then given by
Our mechanism’s privacy budget is determined by the assigned semantic weights of the region of interest. We construct a noisy trajectory dataset using differential privacy (DP). This paper proposes a minimal-noise semantic approach for pseudo-trajectory generation. To ensure trajectory utility, the mechanism produces highly similar semantic proxy locations. Consecutive privacy proxies generate pseudo-trajectories with spatio-semantic similarity to original trajectories.
Semantic trajectory generation utilizes the user’s historical trajectory data and accessible point-of-interest (POI) datasets near their current location. This transforms geographic trajectories into semantic trajectories as defined by
A semantic location may correspond to multiple geographic stay regions. Consequently, proxy locations are generated exclusively within corresponding stay regions. To enhance trajectory privacy, we select the proxy location exhibiting maximal semantic dissimilarity from the actual location within the region’s candidate set. This proxy substitutes the actual location. First, feature locations for points of interest (POIs) within the stay region are calculated (Equation (8)), requiring POI location data and count statistics. Second, we compute fuzzy probabilities representing the user’s actual position relative to POI feature locations. Using these probabilities, the semantic expectation is derived to generate the publishable proxy location. We assume the POI feature location set within the stay area is precomputed.
where denotes stay region i and represents the feature location of each point of interest. The probability that user ’s actual location is blurred to any feature location in the set is given by
Finally, obtaining the user’s true location can be fuzzy to the semantic expectation of these feature locations, which can be computed as
where denotes the semantic expectation between the actual location and each POI feature location in stay region . To ensure output locations satisfy privacy preservation requirements while safeguarding against differential query attacks that could reveal generated proxy locations, our mechanism injects Laplace noise into the POI feature location set.
Based on this framework, we assign distance scores to both actual locations and POI feature locations. The noise score is then computed as follows:
In Equation (28), denotes the noise score between actual location and feature location for all POI categories within the region. To preserve trajectory privacy, the feature location with minimal noise score in each stay area is selected as the publishable location . This proxy inherits the semantic description of the original location. Finally, proxy locations from interest areas and transit points from non-interest areas form publishable pseudo-trajectories, while proxies from stay areas constitute the user’s semantic trajectory data.
As shown in Figure 2, we generate a proxy geographic trajectory map. In Figure 2, the red markers denote the actual location information of users within the interest area, whereas the green markers represent the pseudo-location information generated with the same POI search queries. The red connecting lines indicate the true trajectories of users, while the green connecting lines signify the pseudo-trajectories. The core operation selects the nearest POI feature as both publishable location and semantic representation. To protect location/trajectory privacy, we inject Laplace noise into location distances according to semantic expectations, thereby transforming the selection criterion to the feature location with minimal original location noise score. This mitigates adversarial inference of actual locations from proxies.
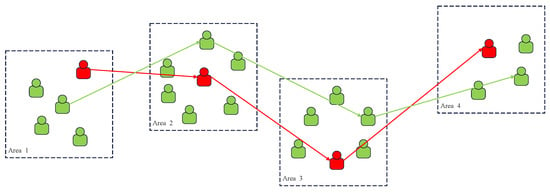
Figure 2.
Schematic diagram of pseudo-trajectory generation.
In Algorithm 1, denotes the original trajectory data, corresponds to the set of user ’s areas of interest, represents the set of POI data within each area of interest, is the privacy protection budget, denotes the proxy locations for all areas of stay, and represents the set of all moving points on the user’s trajectory outside the user’s areas of stay.
| Algorithm 1: SBS-TPP |
 |
We prove that the proposed algorithm SBS-TPP satisfies the definition of differential privacy. Assume the user’s true location , the feature location set , and the fuzzy semantic expectation set for feature locations within the interest area are given. For any feature location deleted from , yielding the modified set , the semantic expectation set represents locations proximal to . With query sensitivity , the semantic expectation query indicates that may be interpreted as a fuzzy point within . Specifically, this query expresses the expectation for to be interpreted as a fuzzy point within any feature location .
Then, our proposed trajectory privacy-preserving method satisfies -difference privacy.
5. Experimental Results and Analysis
This section evaluates the performance of SBS-TPP. All algorithms were implemented in Python 3.12.8. Experiments were conducted on a MacOS Catalina system with a 2.9 GHz processor and 16 GB of RAM.
5.1. Dataset
The data presented in this section are empirically derived. The analysis utilizes the Geolife dataset [,,] and the Beijing taxi trajectory dataset T-Drive []. The Geolife dataset was collected by Microsoft Research Asia over approximately five years (April 2007 to August 2012). This timestamped dataset contains longitude, latitude, and altitude records. Trajectories are distributed primarily across Beijing, with additional data points in Europe and the United States, totaling 17,621 locations.
The T-Drive dataset was also provided by Microsoft Research Asia. It comprises trajectories from 10,357 Beijing taxis, with each record containing taxi ID, timestamp, longitude, and latitude. The dataset encompasses approximately 15 million trajectories covering 9 million kilometers total distance. In this chapter, T-Drive serves as the historical trajectory dataset. User stay regions (areas of interest) were analyzed and mined using Geolife as the user dataset. Additionally, a publicly available Beijing POI dataset was incorporated, containing latitude/longitude coordinates and semantic descriptions for points of interest.
5.2. Impact Assessment
This paper conducts two experimental studies on real-world datasets to demonstrate the effectiveness of the proposed model in user behavior modeling. Subsequent sections detail the privacy-preserving algorithm’s efficacy. The first experiment compares the proposed model against three model categories: shallow models with feature interactions, deep learning models, and user behavior sequence-based models. The second experiment evaluates the necessity and performance contribution of each module in the proposed model. Comparative methods include the following:
DIN []: An early user behavior modeling approach that employs a local activation unit to derive task-specific representations from users’ historical behaviors.
SDM []: Integrates short-term session data with long-term behavior records to capture dynamic preference representations, incorporating long-term preferences through a gated fusion module.
DMIN []: Utilizes multi-head self-attention in a behavioral refinement layer to enhance historical item representations, followed by a multi-interest extraction layer.
ACN []: Employs Transformer architecture for feature interaction and capsule networks for clustering diverse user interests derived from behaviors.
We evaluate all methods using AUC (Area Under the Curve) and Logloss (Logarithmic Loss). AUC measures binary classification ranking capability, while Logloss quantifies the model’s cross-entropy loss, reflecting overall data likelihood. All four baseline models are dedicated to mining user interests to achieve more accurate partitioning of interest areas. The DIN model employs an attention mechanism to assign varying weights to historical behaviors but overlooks the temporal relationships among these behaviors. The SDM model integrates LSTM, attention mechanisms, and gate control modules, combining long-term and short-term interests and modeling multiple user interests through multi-head attention mechanisms. The ACN model employs multi-head self-attention mechanisms for feature extraction and utilizes a capsule network to cluster different interests within the user’s behavioral history. Among the four baseline models, the ACN model excels in learning the correlations between user behaviors, outperforming the other three baseline models in performance.It is particularly important to note that the AUC (Area Under the ROC Curve) metric measures the probability that the predicted score for a randomly chosen positive instance exceeds that for a randomly chosen negative instance. AUC is widely adopted as an evaluation criterion for classification problems, where a higher AUC value indicates superior model performance. Logloss (Logarithmic Loss) quantifies the discrepancy between the true labels and the predicted probabilities. The labels for the prediction task are typically binary, denoted as [0, 1], representing the negative class and positive class, respectively. When a sigmoid activation function is applied in the model’s output layer to produce probabilities, the Logloss can be computed using Equation (30). A higher Logloss value signifies a greater deviation between predictions and true labels, whereas a lower Logloss value corresponds to higher prediction accuracy. The objective function for model training is the Logloss function, which can be computed as follows.
where N represents the total number of training samples, denotes the true position of the i sample, and signifies the predicted position. Results are presented in Table 2.
Table 2.
Performance comparison of various ROI extraction models.
Compared to the four baseline model, the proposed MA model demonstrates superior performance across all datasets for both metrics. MA achieves AUC, DMIN, SDM, and DIN improvements of 1.23%, 0.88%, 1.68%, and 4.33% (Geolife), respectively, and Logloss reductions of 0.12%, 1.3%, 5.35%, and 5.04% (Geolife), respectively. MA achieves AUC, DMIN, SDM, and DIN improvements of 0.4%, 1.82%, 0.27%, and 0.28% (T-drive), respectively, and Logloss reductions of 0.19%, 2.47%, 3.91%, and 3.34% (T-drive), respectively. These results demonstrate MA’s effectiveness. We validated each module’s contribution through ablation studies by systematically removing components and evaluating performance impact. Removing behavior sequence modeling entails feeding embedded outputs directly into the capsule network, bypassing sequential behavior modeling. Removing long-term behavior modeling eliminates the LSTM module and omits modeling of long-term behavioral sequences. Table 2 presents ablation results on the three datasets.
As shown in Table 3, the proposed model achieves optimal performance under identical conditions. Removing any module significantly degrades overall performance. Ablation of behavior sequence modeling particularly impacts results, as user interest preferences are embedded in sequential behavior patterns; disregarding this information reduces prediction accuracy. Although long-term behaviors exhibit relative stability, their removal still affects performance. Capturing regions of interest is essential for objectively analyzing historical behaviors. These experiments validate the necessity of each module.
Table 3.
Performance comparison of different components.
Having established that the proposed scheme satisfies differential privacy, we next evaluate its impact on privacy protection and data utility. Following established experimental practice, precision (P), recall (R), and F-value (F) are employed to comprehensively assess algorithm performance. The metrics are computed as follows:
where and denote the counts of similar users detected using real trajectory data and noisy trajectory data, respectively, and represents the corresponding count magnitude.
In practical applications, the quality of published pseudo-trajectory data determines whether it can meet the demands of daily life queries and trajectory mining applications. Therefore, this paper introduces relative error () as a usability evaluation metric to assess the efficacy of a query function Q on pseudo-trajectories versus original trajectories. The RE mechanism utilizes randomly generated spatial query statements to simulate real-world application scenarios, thereby evaluating the accuracy of the data. The RE is calculated as follows:
To evaluate trajectory data usability preservation, we employ relative error (RE) as a metric to compare the performance of our proposed SBS-TPP method against established trajectory privacy protection methods N-gram [] and [] in terms of data utility.
Figure 3 illustrates the availability of the noisy trajectory. It can be observed that RE demonstrates a declining trend in conjunction with an alteration in trajectory length. Additionally, the availability of processed trajectory data exhibits an upward trajectory with an increased privacy budget. As the trajectory interception length diminishes, the discrepancy between the noisy and original trajectories intensifies. This phenomenon illustrates that when the number of location points is significantly reduced, data availability is significantly diminished due to the elevated level of added noise, which results in a considerable bias in the noisy trajectory.
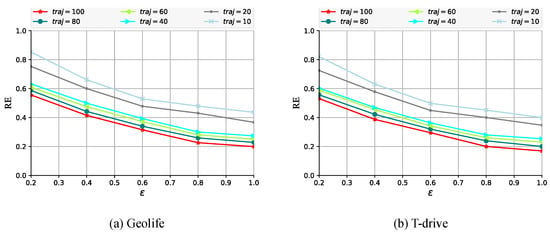
Figure 3.
Impact of trajectory length on privacy utility across two datasets.
This paper conducts a comparative analysis of the proposed semantic-based trajectory privacy-preserving method with existing methods and N-gram wherein the latter two employ distinct privacy-preserving budgets. Experimental results (Figure 4 and Figure 5) demonstrate that under identical privacy budgets, our method achieves significantly superior performance compared to and N-gram. Furthermore, increasing the privacy budget enhances the effectiveness of all three algorithms, as this scenario necessitates minimal noise injection to ensure adequate trajectory protection. Crucially, our method outperforms existing approaches because and N-gram fail to incorporate location semantic information. This omission necessitates excessive noise addition, causing substantial trajectory deviation from the original path and resulting in pronounced distortion between sanitized and original trajectories.
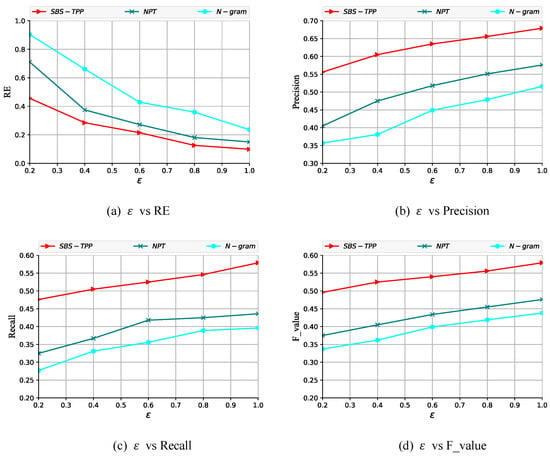
Figure 4.
Evaluation of SBS-TPP methods on Geolife.
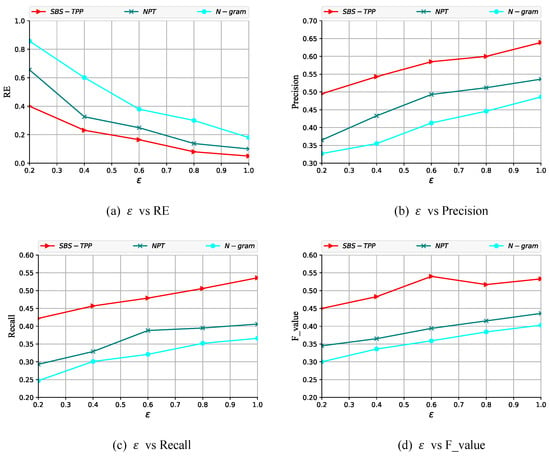
Figure 5.
Evaluation of SBS-TPP methods on T-drive.
6. Summary of Future Work
This paper introduces a trajectory privacy protection method based on semantic behavioral sequences. The approach comprises two phases: user interest region detection and trajectory privacy protection based on identified interest regions. During user behavior pattern modeling, interest regions are identified and segmented with over 90% accuracy. In the privacy protection phase, trajectories with maximum noise expectation are generated from original trajectories, yielding protected data that remains usable in >80% of cases. Critically, the proposed method enhances data accessibility while simultaneously guaranteeing user privacy.
Future work will deepen understanding of user trajectory data protection and its application potential, contributing to adaptive trajectory privacy protection technology. In practical scenarios, users exhibit divergent requirements for privacy protection versus data utility—requirements that may vary even for individual users across different service types. Consequently, we will investigate customizable trajectory privacy protection schemes where users dynamically adjust privacy and utility trade-offs. Therefore, in the future, we will undertake further optimization in practical applications, ensuring that the computational efficiency of our algorithms aligns with the query speed requirements of users. Building upon this foundation, we will continue to refine the research on privacy-preserving personalized recommendation methods, enabling the privacy protection approach to tailor individualized privacy protection schemes based on the specific needs of users in various scenarios.
Author Contributions
Conceptualization, J.X. and W.Z.; methodology, J.X. and W.Z.; coding, Z.X.; validation, J.X. and W.Z.; investigation, Z.X.; writing—original draft preparation, J.X. and W.Z.; writing—review and editing, J.X., W.Z., and L.Z.; visualization, Z.X. and H.T.; supervision, L.Z.; project administration, J.X. and W.Z.; funding acquisition, Z.X. and H.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Science and Technology Plan Project of Changzhou (CJ20210155, CJ20220151).
Data Availability Statement
The data presented in this study are openly available in https://www.microsoft.com/en-us/download/details.aspx?id=52367 (accessed on 4 August 2025).
Acknowledgments
Thanks to the anonymous reviewers and editor from the journal.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Sun, W.; Zhao, K.; Liang, G.; Liang, Z.; Jiang, L. UdpTrace: Utility-enhanced differential privacy scheme for trajectory data publishing. Neurocomputing 2025, 649, 130785. [Google Scholar] [CrossRef]
- Cong, X.; Zhu, H.; Cui, W.; Zhao, G.; Yu, Z. Critical Observability of Stochastic Discrete Event Systems Under Intermittent Loss of Observations. Mathematics 2025, 13, 1426. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, G.; Bhuiyan, M.Z.A.; Liu, Q. A dual privacy preserving scheme in continuous location-based services. IEEE Internet Things J. 2018, 5, 4191–4200. [Google Scholar] [CrossRef]
- Peng, T.; Liu, Q.; Wang, G.; Xiang, Y.; Chen, S. Multidimensional privacy preservation in location-based services. Future Gener. Comput. Syst. 2019, 93, 312–326. [Google Scholar] [CrossRef]
- Zhu, L.; Lei, T.; Mu, J.; Mu, J.; Cai, Z.; Zhang, J. Differential Privacy-Based Spatial-Temporal Trajectory Clustering Scheme for LBSNs. Electronics 2023, 12, 3767. [Google Scholar] [CrossRef]
- Bhattacharya, M.; Roy, S.; Mistry, K.; Shum, H.P.; Chattopadhyay, S. A privacy-preserving efficient location-sharing scheme for mobile online social network applications. IEEE Access 2020, 8, 221330–221351. [Google Scholar] [CrossRef]
- Wang, J.; Lu, Z.; Fu, M.; Wang, J.; Lu, K.; Jukan, A. Decode-and-Compare: An Efficient Verification Scheme for Coded Distributed Edge Computing. IEEE Trans. Cloud Comput. 2023, 11, 2784–2802. [Google Scholar] [CrossRef]
- Xiao, Z.; Yang, J.J.; Huang, M.; Ponnambalam, L.; Fu, X.; Goh, R.S.M. QLDS: A novel design scheme for trajectory privacy protection with utility guarantee in participatory sensing. IEEE Trans. Mob. Comput. 2017, 17, 1397–1410. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, W.; Wu, J.; Kou, Q.; Song, Z.; Ngai, E.C.H. Privacy-preserving social tie discovery based on cloaked human trajectories. IEEE Trans. Veh. Technol. 2016, 66, 1619–1630. [Google Scholar] [CrossRef]
- Wang, G.; Wang, B.; Wang, T.; Nika, A.; Zheng, H.; Zhao, B.Y. Defending against sybil devices in crowdsourced mapping services. In Proceedings of the 14th Annual International Conference on Mobile Systems, Applications, and Services, Singapore, 26–30 June 2016; pp. 179–191. [Google Scholar]
- Li, S.; Tian, H.; Shen, H.; Sang, Y. Privacy-preserving trajectory data publishing by dynamic anonymization with bounded distortion. ISPRS Int. J. Geo-Inf. 2021, 10, 78. [Google Scholar] [CrossRef]
- Zhang, W.; Yin, G.; Xie, B. SUDM-SP: A method for discovering trajectory similar users based on semantic privacy. High-Confid. Comput. 2023, 3, 100146. [Google Scholar] [CrossRef]
- Terrovitis, M.; Poulis, G.; Mamoulis, N.; Skiadopoulos, S. Local suppression and splitting techniques for privacy preserving publication of trajectories. IEEE Trans. Knowl. Data Eng. 2017, 29, 1466–1479. [Google Scholar] [CrossRef]
- Zheng, Y.; Xie, X.; Ma, W.Y. GeoLife: A collaborative social networking service among user, location and trajectory. IEEE Data Eng. Bull. 2010, 33, 32–39. [Google Scholar]
- Chen, R.; Acs, G.; Castelluccia, C. Differentially private sequential data publication via variable-length n-grams. In Proceedings of the 2012 ACM Conference on Computer and Communications Security, Raleigh, NC, USA, 16–18 October 2012; pp. 638–649. [Google Scholar]
- He, X.; Cormode, G.; Machanavajjhala, A.; Procopiuc, C.; Srivastava, D. DPT: Differentially private trajectory synthesis using hierarchical reference systems. Proc. VLDB Endow. 2015, 8, 1154–1165. [Google Scholar] [CrossRef]
- Zhang, W.; Yin, G.; Dong, Y.; Chen, F.; Zia, Q. DPTP-LICD: A differential privacy trajectory protection method based on latent interest community detection. High-Confid. Comput. 2023, 3, 100134. [Google Scholar] [CrossRef]
- Lu, H.; Jensen, C.S.; Yiu, M.L. Pad: Privacy-area aware, dummy-based location privacy in mobile services. In Proceedings of the Seventh ACM International Workshop on Data Engineering for Wireless and Mobile Access, Vancouver, BC, Canada, 13 June 2008; pp. 16–23. [Google Scholar]
- Kato, R.; Iwata, M.; Hara, T.; Suzuki, A.; Xie, X.; Arase, Y.; Nishio, S. A dummy-based anonymization method based on user trajectory with pauses. In Proceedings of the 20th International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 6–9 November 2012; pp. 249–258. [Google Scholar]
- Chow, R.; Golle, P. Faking contextual data for fun, profit, and privacy. In Proceedings of the 8th ACM Workshop on Privacy in the Electronic Society, Chicago, IL, USA, 9 November 2009; pp. 105–108. [Google Scholar]
- Suzuki, A.; Iwata, M.; Arase, Y.; Hara, T.; Xie, X.; Nishio, S. A user location anonymization method for location based services in a real environment. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 398–401. [Google Scholar]
- Gramaglia, M.; Fiore, M. Hiding mobile traffic fingerprints with glove. In Proceedings of the 11th ACM Conference on Emerging Networking Experiments and Technologies, Heidelberg, Germany, 1–4 December 2015; pp. 1–13. [Google Scholar]
- Liu, H.; Li, X.; Li, H.; Ma, J.; Ma, X. Spatiotemporal correlation-aware dummy-based privacy protection scheme for location-based services. In Proceedings of the IEEE INFOCOM 2017-IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017; pp. 1–9. [Google Scholar]
- Li, Y.; Li, S. A real-time location privacy protection method based on space transformation. In Proceedings of the 2018 14th International Conference on Computational Intelligence and Security (CIS), Hangzhou, China, 16–19 November 2018; pp. 291–295. [Google Scholar]
- Qin, J.; Zhang, W.; Wu, X.; Jin, J.; Fang, Y.; Yu, Y. User behavior retrieval for click-through rate prediction. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, China, 25–30 July 2020; pp. 2347–2356. [Google Scholar]
- Zhu, M.; Shu, Q.; Shen, S.; Feng, L.; Wu, J.; Huang, Z. Live streaming recommendation based on multiple types of repeated behaviors. Expert Syst. Appl. 2025, 288, 128217. [Google Scholar] [CrossRef]
- Zhou, G.; Zhu, X.; Song, C.; Fan, Y.; Zhu, H.; Ma, X.; Yan, Y.; Jin, J.; Li, H.; Gai, K. Deep interest network for click-through rate prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1059–1068. [Google Scholar]
- An, Z.; Si, G.; Tian, P.; Li, J.; Liang, X.; Zhou, F.; Wang, X. Research on Earthquake Data Prediction Method Based on DIN-MLP Algorithm. Electronics 2023, 12, 3519. [Google Scholar] [CrossRef]
- Zhou, G.; Mou, N.; Fan, Y.; Pi, Q.; Bian, W.; Zhou, C.; Zhu, X.; Gai, K. Deep interest evolution network for click-through rate prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 5941–5948. [Google Scholar]
- Yu, M.; Liu, T.; Yin, J. Deep Filter Context Network for Click-Through Rate Prediction. J. Theor. Appl. Electron. Commer. Res. 2023, 18, 1446–1462. [Google Scholar] [CrossRef]
- Pi, Q.; Bian, W.; Zhou, G.; Zhu, X.; Gai, K. Practice on long sequential user behavior modeling for click-through rate prediction. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2671–2679. [Google Scholar]
- Dong, G.; Yang, X.; Fang, Y.; Tentzeris, M.M. Filtering Push-Pull Power Amplifier Based on Multifunctional Impedance Matching Network. IEEE Microw. Wirel. Components Lett. 2022, 32, 422–425. [Google Scholar] [CrossRef]
- Xiao, Z.; Yang, L.; Jiang, W.; Wei, Y.; Hu, Y.; Wang, H. Deep multi-interest network for click-through rate prediction. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual Event, Ireland, 19–23 October 2020; pp. 2265–2268. [Google Scholar]
- Xu, E.; Yu, Z.; Guo, B.; Cui, H. Core interest network for click-through rate prediction. ACM Trans. Knowl. Discov. Data (TKDD) 2021, 15, 1–16. [Google Scholar] [CrossRef]
- Li, Z.; Zhao, H.; Liu, Q.; Huang, Z.; Mei, T.; Chen, E. Learning from history and present: Next-item recommendation via discriminatively exploiting user behaviors. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1734–1743. [Google Scholar]
- Alrawais, A.; Alhothaily, A.; Cheng, X.; Hu, C.; Yu, J. SecureGuard: A certificate validation system in public key infrastructure. IEEE Trans. Veh. Technol. 2018, 67, 5399–5408. [Google Scholar] [CrossRef]
- Xu, J.; Xue, K.; Yang, Q.; Hong, P. PSAP: Pseudonym-based secure authentication protocol for NFC applications. IEEE Trans. Consum. Electron. 2018, 64, 83–91. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhang, L.; Xie, X.; Ma, W.Y. Mining interesting locations and travel sequences from GPS trajectories. In Proceedings of the 18th International Conference on World Wide Web, Madrid, Spain, 20–24 April 2009; pp. 791–800. [Google Scholar]
- Zheng, Y.; Li, Q.; Chen, Y.; Xie, X.; Ma, W.Y. Understanding mobility based on GPS data. In Proceedings of the 10th International Conference on Ubiquitous Computing, Seoul, Republic of Korea, 21–24 September 2008; pp. 312–321. [Google Scholar]
- Yuan, J.; Zheng, Y.; Xie, X. Discovering regions of different functions in a city using human mobility and POIs. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 186–194. [Google Scholar]
- Lv, F.; Jin, T.; Yu, C.; Sun, F.; Lin, Q.; Yang, K.; Ng, W. SDM: Sequential deep matching model for online large-scale recommender system. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2635–2643. [Google Scholar]
- Li, D.; Hu, B.; Chen, Q.; Wang, X.; Qi, Q.; Wang, L.; Liu, H. Attentive capsule network for click-through rate and conversion rate prediction in online advertising. Knowl.-Based Syst. 2021, 211, 106522. [Google Scholar] [CrossRef]
- Chen, R.; Fung, B.C.; Desai, B.C.; Sossou, N.M. Differentially private transit data publication: A case study on the montreal transportation system. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 213–221. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).