Abstract
Object detection in remote sensing imagery is critical in environmental monitoring, urban planning, and land resource management. However, the task remains challenging due to significant scale variations, arbitrary object orientations, and complex background clutter. To address these issues, we propose a novel orientation module (SOAM Block) that jointly models object scale and directional features while exploiting geometric symmetry inherent in many remote sensing targets. The SOAM Block is constructed upon a lightweight and efficient Adaptive Multi-Scale (AMS) Module, which utilizes a symmetric arrangement of parallel depth-wise convolutional branches with varied kernel sizes to extract fine-grained multi-scale features without dilation, thereby preserving local context and enhancing scale adaptability. In addition, a Strip-based Context Attention (SCA) mechanism is introduced to model long-range spatial dependencies, leveraging horizontal and vertical 1D strip convolutions in a directionally symmetric fashion. This design captures spatial correlations between distant regions and reinforces semantic consistency in cluttered scenes. Importantly, this work is the first to explicitly analyze the coupling between object scale and orientation in remote sensing imagery. The proposed method addresses the limitations of fixed receptive fields in capturing symmetric directional cues of large-scale objects. Extensive experiments are conducted on two widely used benchmarks—DOTA and HRSC2016—both of which exhibit significant scale variations and orientation diversity. Results demonstrate that our approach achieves superior detection accuracy with fewer parameters and lower computational overhead compared to state-of-the-art methods. The proposed SOAM Block thus offers a robust, scalable, and symmetry-aware solution for high-precision object detection in complex aerial scenes.
1. Introduction
Object detection in remote sensing imagery is one of the core tasks in intelligent interpretation of remote sensing data, aiming to automatically identify and localize targets of interest from large-scale aerial or satellite images. This task has demonstrated broad application value in various fields, including environmental monitoring, geological disaster warning, innovative city development, intelligent transportation management, and land resource surveying []. In recent years, with the rapid advancement of deep learning techniques, particularly the breakthroughs achieved by convolutional neural networks (CNNs) in computer vision, deep learning-based methods for remote sensing object detection have attracted increasing attention from the research community.
Current deep learning-based object detection methods are generally divided into two-stage and one-stage approaches. Two-stage detectors (e.g., SCRDet [], RoI Transformer [], and ReDet []) first generate region proposals and then refine them through classification and bounding box regression. SCRDet enhances small and dense object detection via attention and feature fusion; RoI Transformer addresses rotation misalignment through rotated region transformation; ReDet further embeds rotation-equivariant structures to handle orientation variations. One-stage detectors (e.g., R3Det [], CFA [], and DAFNet []) directly predict object classes and locations from feature maps. R3Det introduces a refinement module to improve feature alignment; CFA employs shared weights and fusion to boost small object detection; DAFNet simplifies the pipeline by eliminating anchor boxes. These two categories offer a trade-off: two-stage methods often achieve higher accuracy, while one-stage methods provide faster inference.
However, object detection in remote sensing imagery remains challenging due to significant scale variation and complex background interference. To enhance robustness, various studies have explored data augmentation and multi-scale modeling strategies. For instance, the Rotation Equivariant Feature Image Pyramid Network (REFIPN) [] employs specialized convolutional filters to extract features in both scale and orientation domains, generating vector fields for directional estimation at each spatial location. Stitcher [] adopts a feedback-driven strategy to divide and reassemble image patches, enabling balanced training for detectors. Other methods focus on integrating multi-scale features. SE-Faster R-CNN [] incorporates a squeeze-and-excitation mechanism to enhance channel-wise representation for ship detection. Zhang et al. [] propose hierarchical feature fusion to address scale diversity and background clutter, while Liang et al. [] improve small object detection by fusing multi-scale features with spatial context modeling. FSoD-Net [] further advances full-scale integration to boost performance on small and densely packed targets. Despite these efforts, most existing approaches rely on fixed receptive field configurations and lack adaptive mechanisms to dynamically respond to varying object scales. This limits their ability to capture long-range contextual semantics, particularly for large-scale targets, thereby constraining detection performance (Figure 1).

Figure 1.
Illustration of challenges in remote sensing object detection. Left: When the target is large, the fixed receptive field may only cover internal local features (as highlighted by the yellow dashed box), resulting in insufficient orientation awareness. Right: Targets exhibit diverse orientations, which further complicates robust detection and localization.
(1) Coupling Between Scale and Orientation: In remote sensing object detection tasks, existing methods typically model scale variation and orientation variation independently, overlooking the intrinsic coupling between the two. As illustrated in Figure 1left, when object size becomes large, the limited receptive field of convolutional operations often leads to incomplete coverage of the object within a single feature region. As a result, local features may lack critical directional information, making it challenging to capture the object’s orientation and structural shape accurately. This phenomenon highlights the limitation of relying solely on local scale features, which impairs detection accuracy. The increase in object scale exacerbates the locality issue in feature extraction and indirectly weakens the model’s ability to perceive orientation. Some recent efforts attempt to mitigate this by aligning deep features with orientation priors. For instance, Han et al. [] propose feature alignment mechanisms to enhance orientation sensitivity, and AR2Det [] integrates rotation prediction into one-stage detection, improving detection precision under rotational variation. Moreover, saliency-aware frameworks [] further aid feature focus under large-scale variation. To effectively address the challenge, it is essential first to perform fine-grained scale modeling to ensure that local features possess sufficient global context. Subsequently, incorporating an orientation modeling mechanism allows the network to better capture directional attributes under varying scale conditions. This joint strategy can synergistically perceive and enhance scale and orientation, improving the detector’s adaptability and robustness in complex remote sensing scenes.
(2) Progressive Scale Variation: As illustrated in Figure 1right, objects of varying sizes (e.g., ships of different dimensions) exhibit a continuous and gradual change in scale within the same scene. This progressive variation poses a significant challenge for traditional object detection algorithms, which are typically designed with fixed-scale assumptions and struggle to detect targets across a wide range of sizes simultaneously. Many existing approaches adopt multi-level structures such as Feature Pyramid Networks (FPNs) to perform feature fusion across different resolutions to address scale variation. Although increasing the number of stacked layers can help cover a broader range of object scales, it inevitably leads to a substantial rise in computational complexity. In contrast, reducing the number of layers compromises the accuracy of the model’s detection. As a result, current methods often face difficulties in striking an optimal balance between detection performance and computational efficiency. Recent solutions such as LSKNet [] attempt to expand the spatial receptive field using large-kernel convolutions to enhance context modeling. However, this may lead to noisy responses for small targets. Dilated convolutions, although useful in expanding the receptive field, may miss fine-grained details, resulting in sparse feature maps. Meanwhile, methods like S2ANet [] and the HRSC2016-based baselines [] explore multi-directional context aggregation and anchor adaptation for improving scale-aware performance. Despite these developments, efficiently detecting objects under progressive scale variation remains a key challenge, especially when balancing fine detail preservation and global context understanding.
In summary, to address the challenges posed by progressive scale variations and complex contextual dependencies in remote sensing imagery, we propose a lightweight and efficient detection framework that centers around a novel module named the Scale-Oriented Aware Module (SOAM Block). This module integrates fine-grained multi-scale modeling with orientation-aware enhancement and contextual reasoning, enabling robust object detection in diverse remote sensing scenarios. Unlike traditional approaches that expand the receptive field through large-kernel or dilated convolutions, the SOAM Block adopts a parallel structure of depth-wise convolution kernels with varying sizes to extract scale-adaptive features across multiple receptive fields, without introducing dilation. These features are then fused adaptively along the channel dimension to preserve local detail and enhance intra-scale interactions. In addition, a Strip-based Context Attention (SCA) mechanism is incorporated into the SOAM block to strengthen long-range dependency modeling. By combining global average pooling with one-dimensional strip convolutions, SCA effectively captures spatial correlations between distant pixels and reinforces semantic consistency in complex scenes. To further improve geometric alignment between extracted features and target objects, AlignConv is introduced following SCA. By dynamically adjusting the sampling positions based on the offsets of anchor boxes, AlignConv enhances the spatial correspondence between features and object locations, mitigating misalignment issues commonly associated with standard convolutional grids. Our contributions are as follows:
(1) We investigate the intrinsic coupling between object scale and orientation in remote sensing imagery. As object size increases, conventional convolutional operations with fixed receptive fields tend to lose directional cues, which hinders accurate object localization. To address this limitation, the SOAM Block integrates AlignConv, which adaptively adjusts the spatial sampling positions based on the geometry of anchor boxes. This enables the convolutional kernels to better align with the orientation and structure of large-scale targets, preserving directional information that would otherwise be lost. By jointly encoding scale-adaptive features and orientation-aware representations, the SOAM Block provides a unified solution for robust scale–orientation modeling in remote sensing detection.
(2) Inspired by the parallel arrangement of multi-scale convolutional kernels, our method adopts the Adaptive Multi-Scale Module (AMS Module) [] as the backbone to address progressive scale variation in remote sensing targets. AMS MOdule leverages parallel depth-wise convolutional kernels of varying sizes, without dilation, to facilitate efficient multi-scale feature extraction while preserving local contextual information. This design mitigates the sparsity typically introduced by dilated convolutions, thereby improving the density and continuity of feature representations and enhancing the network’s ability to detect objects across diverse scales in complex scenes.
(3) A joint optimization strategy is established by incorporating the Strip-based Context Attention (SCA) mechanism into the multi-scale convolutional framework. By enhancing the interaction between scale-aware feature extraction and global context modeling, SCA facilitates the integration of local and long-range dependencies. This collaborative design significantly improves detection performance in remote sensing scenarios [].
(4) A lightweight design is adopted to reduce computational overhead while preserving representational capacity by integrating depth-wise separable convolutions with 1D strip convolutions. This combination enhances computational efficiency while maintaining effective feature representation, offering a more efficient alternative to conventional convolutional architectures [].
2. Related Works
2.1. Multi-Scale Object Model
Targets in remote sensing imagery often exhibit substantial scale variation, ranging from small vehicles to large buildings and bridges. This wide-scale distribution introduces significant challenges to detectors generalization []. To address this issue, extensive research has focused on designing robust and expressive feature extraction frameworks capable of adapting to multi-scale objects, thereby improving detection performance under varying scale conditions []. SCRDet introduces several improvements based on the Fast R-CNN framework to enhance the detection of small-scale objects. It employs a multi-level feature fusion strategy that integrates shallow and deep feature maps and a fine-grained anchor sampling mechanism to strengthen the perception of small objects. Additionally, a multi-dimensional attention module is designed to suppress background noise by capturing pixel-level features and applying selective channel weighting, thereby improving detection performance in densely populated regions. To address the instability in rotated bounding box regression, the method incorporates an IoU-based weighting factor into the smooth L1 loss, stabilizing the regression gradients across anchors with varying IoU and improving the robustness of the model to rotated targets [].
R3Det addresses the feature misalignment issue in existing detectors by introducing a coarse-to-fine framework for rotated object detection. A Feature Refinement Module (FRM) is designed to encode the locations of refined proposals through pixel-level interpolation, thereby aligning features and enhancing the accuracy of boundary representation. To further improve angle regression for rotated bounding boxes, an approximate SkewIoU loss is proposed, which resolves the non-differentiability problem of traditional skew IoU in gradient-based optimization [].
To address challenges posed by objects with extreme aspect ratios or significant angular deviations, LIIoU introduces an optimized strategy for object detection orientation. The method mitigates instability caused by angle periodicity during prediction by vectorizing angle representation using two-dimensional vectors. Additionally, to resolve the issue where angular errors hinder accurate IoU estimation for elongated targets, LIIoU proposes a truncated-region-based IoU computation. This approach reduces the sensitivity of overlap estimation to aspect ratio and angle deviations, thereby improving detection accuracy.
In addition, to address the instability in feature learning caused by loss discontinuities in regression-based Oriented Bounding Box (OBB) methods at certain angles, Mask OBB proposes a segmentation-based object representation. By predicting a binary segmentation mask for each object and generating the corresponding OBB from the mask, the detection task is reformulated as a pixel-level classification problem. This strategy avoids the ambiguity introduced by angular discontinuities, enhancing the stability and robustness of rotated object representation []. To further enhance the model’s capacity for rotation-aware representation, ReDet introduces a rotation-equivariant detection framework. Specifically, rotation-equivariant convolutional modules are incorporated into the backbone network to learn direction-sensitive features, thereby mitigating performance degradation caused by orientation variations. To achieve precise alignment of rotated features, ReDet proposes a Rotation-Invariant RoI Align (RiRoI Align) mechanism, which transforms candidate region features in the spatial domain and employs cyclic channel shifting and feature interpolation in the angular domain. Such a design facilitates efficient and accurate alignment of features for rotated object detection [].
2.2. Oriented Object Detection
In remote sensing imagery, targets are often densely distributed and embedded in complex backgrounds, making it difficult to achieve stable and accurate detection using only local features. Consequently, enhancing the model’s ability to capture contextual semantics has become a key focus for improving detection performance in remote sensing applications.
To address the geometric misalignment between anchors and objects, S2A-Net introduces a Feature Alignment Module (FAM), which employs an Anchor Refinement Network (ARN) to generate high-quality anchors and incorporates AlignConv to align spatial sampling positions adaptively. This improves the accuracy of feature representation in object regions. Additionally, a Rotation Detection Module (ODM) is proposed, which utilizes Active Rotating Filters (ARFs) to encode directional information and produce rotation-invariant features, thereby mitigating the directional sensitivity limitations of standard convolutions and significantly enhancing the detection and localization of rotated objects. Built upon the CenterNet framework, DRNet enhances the flexibility and precision of feature modeling by introducing the Feature Selection Module (FSM) and Dynamic Refinement Head (DRH). FSM adaptively adjusts the receptive field based on the geometry and orientation of targets, effectively mitigating the mismatch between receptive fields and object structures. Meanwhile, DRH dynamically generates parameters tailored to individual samples, enabling task-specific optimization for classification and regression, thereby improving the model’s adaptability to objects with significant orientation variations [].
To address the discontinuity in angle regression under boundary conditions in rotated object detection, the Dense Label Encoding method replaces regression-based angle modeling with a classification-based strategy []. Building upon Circular Smooth Labels (CSLs), this approach introduces Binary-Coded Labels (BCLs) to simplify multi-class representation. It applies Gray-Coded Labels (GCLs) to reduce abrupt transitions between adjacent angle classes. This design enhances the continuity and accuracy of angle prediction while maintaining detection performance and reducing model complexity and training costs.
Li et al. proposed an enhanced Feature Pyramid Network (AFP) to enhance contextual semantic representation. This network incorporates sub-inception modules to capture target features across varying scales and shapes, thereby enriching multi-level feature representations. A semantic segmentation-guided module was also introduced to integrate object masks and semantic priors into proposal generation and RoI pooling. This design strengthens the model’s ability to perceive object boundaries and improves detection accuracy [].
Recent YOLO-based methods have made substantial progress in rotation-aware ship detection for remote sensing imagery. For instance, Wan et al. [] proposed an improved YOLOv5 framework with a rotated bounding box regression mechanism tailored for densely arranged and arbitrarily oriented ships. Similarly, Bakirci et al. [] designed a rotation-adaptive head for YOLOv8 to enhance its detection capability on challenging maritime scenes. These approaches demonstrate the effectiveness of integrating orientation awareness into anchor-based detectors. Our proposed SOAM Block further extends this direction by explicitly modeling the coupling between object scale and orientation while maintaining computational efficiency.
3. Methodology
The proposed architecture adopts AMSNet as the backbone, where multiple separable convolutional kernels of different scales in depth are arranged parallel to extract fine-grained spatial features. These features are adaptively fused along the channel dimension to capture rich local contextual information. A Strip-based Context Attention (SCA) module is introduced to further enhance long-range dependency modeling. This module combines global average pooling with horizontal and vertical 1D strip convolutions to capture global semantic relationships, thereby improving contextual understanding. In addition, an Alignment Convolution (AlignConv) module is incorporated to refine spatial sampling positions based on anchor geometry. Unlike standard or deformable convolutions, AlignConv aligns features more accurately with the target’s orientation and shape, making it particularly effective for detecting rotated and elongated objects. Furthermore, a Feature Alignment Module (FAM) is constructed by integrating an anchor refinement network with AlignConv. During training, FAM dynamically optimizes anchor parameters and guides feature sampling to better align with object boundaries, enhancing the detector’s ability to handle densely packed and directionally varied targets, as shown in Figure 2.
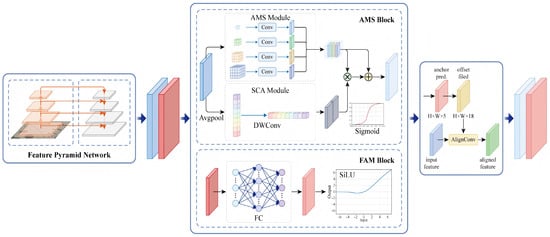
Figure 2.
The structure of the proposed SOAM block.
3.1. AMSNet
In remote sensing imagery, object scales vary widely: from small targets such as vehicles to large structures such as buildings and bridges. Conventional convolutional networks struggle to adapt to such variations due to their fixed receptive fields, limiting their ability to capture multi-scale features effectively. Two typical strategies are often used to address significant scale variation. One approach involves using large-kernel or dilated convolutions to expand the receptive field and capture features of larger objects. Although this improves the representation of large-scale targets, it substantially increases the computational cost. Moreover, the broad receptive scope of large kernels tends to introduce background noise, which may interfere with the extraction of the target feature and lead to the loss of edge details, ultimately compromising the accuracy of localization.
In addition, some approaches attempt to address scale variation by fusing multi-scale features through pyramid structures. These architectures typically perform feature fusion at fixed layers to capture information across scales. However, the predetermined fusion hierarchy limits the network’s flexibility to adaptively adjust the number and position of fused layers based on target size. As a result, the effectiveness of multi-scale feature integration is limited, reducing the model’s ability to fully exploit hierarchical representations and hindering the accurate detection of objects at varying scales.
This paper adopts the Adaptive Multi-Scale Kernel (AMS) architecture to address these challenges. Its core module constructs diverse feature representations through parallel depth-wise convolutions with varying kernel sizes, effectively capturing multi-scale information. These features are then adaptively fused using 1 × 1 convolutions, followed by a bidirectional fusion strategy integrating shallow and deep layers to jointly encode local details and global context. Unlike conventional pyramid-based structures with fixed fusion layers or methods that expand the receptive field using large or dilated convolutions—which often introduce sparse activations, detail loss, and increased computational cost—the AMS module enables efficient, fine-grained feature extraction across scales with minimal overhead. This design significantly enhances the model’s ability to represent objects of varying sizes in complex remote sensing scenes.
First, the module employs parallel depth-wise convolutions with varying spatial receptive fields to extract contextual features:
where represents the output feature map of layer of the network. indicates a convolution operation using a convolution kernel size of . denotes that the size of the convolution kernel is 3, 5, 7, and 9, respectively. Multi-scale local detail features are extracted by employing convolutional kernels of varying sizes. In our design, we adopt depth-wise convolutional kernels with sizes 3, 5, 7, 9. This choice aims to capture fine-to-coarse receptive fields in a progressive manner, effectively covering small to large objects. We also test other combinations, such as 1, 3, 5, 7 and 5, 7, 9, 11, but find that smaller kernels (e.g., 1) lack spatial context, while larger kernels (e.g., 11, 13) yield limited gains and lead to increased computational cost and overfitting. The selected set strikes a good balance between accuracy and efficiency. To better preserve the detailed information of the original feature map and effectively integrate the contextual cues captured by the parallel convolutions, a summation-based fusion strategy is adopted, where multi-scale features are aggregated with the input feature map. A subsequent 1 × 1 convolution is then applied to establish inter-channel dependencies and achieve efficient information integration. The process is described as follows:
Relying solely on scale-aware features is often insufficient in multi-scale object detection, as convolution operations may progressively lose critical detail information during feature extraction. The proposed fusion strategy enhances local detail preservation and broader scale representation to address this limitation. This approach improves the overall feature expressiveness while strengthening the model’s capacity for fine-grained target description. While AMSNet demonstrates promising multi-scale feature extraction capabilities, it still has some notable limitations. First, its depth-wise convolutions are limited to fixed kernel configurations, lacking direction-aware mechanisms, which restricts its effectiveness in handling oriented targets. Second, AMSNet primarily focuses on local multi-scale fusion but does not explicitly model long-range spatial dependencies, making it less robust in cluttered or context-rich scenes. The proposed SOAM Block addresses these challenges by integrating scale–orientation joint modeling and strip-based contextual attention, which significantly enhances the network’s ability to represent complex remote sensing objects.
3.2. Strip-Based Context Attention (SCA)
Building on the refined feature extraction strategy from the previous section, this work introduces global context into the feature representation to enhance the descriptiveness of the target. To this end, the Strip-based Context Attention (SCA) module is employed. By integrating global and local information, SCA adaptively reweights multi-scale features to suppress irrelevant background interference and emphasize critical target regions. The integration of global and local information through the SCA module improves the representation capacity and robustness of the model in complex scenes. The SCA module first captures global contextual features through global average pooling and convolution. Then, it utilizes depthwise separable strip convolutions in horizontal and vertical directions to model long-range dependencies.
where denotes the global average pooling operation applied to aggregate spatial information across each channel. denotes the intermediate feature embedding enriched with global contextual information, which is used for subsequent directional enhancement. denotes the feature map obtained by applying depth-wise horizontal strip convolution with kernel size to the global-pooled feature. denotes the feature map refined via depth-wise vertical strip convolution with kernel size , applied to the horizontally enhanced feature.
By applying a convolution, multi-scale features can be effectively integrated, enabling the model to capture long-range spatial dependencies better while preserving the integrity of global representations. Strip convolutions are introduced to expand the receptive field with minimal computational overhead. As the depth of the AMS blocks increases, the SCA module progressively enlarges the convolutional kernel size at each layer. This design improves the ability of the network to capture long-range spatial dependencies without increasing the number of parameters or computational complexity. Strip convolutions are introduced to effectively expand the receptive field while maintaining low computational cost. As the depth of the AMS blocks increases, the SCA module adaptively enlarges the kernel size at each layer. This progressive adjustment allows the receptive field to grow without additional computational burden or parameter overhead, enhancing the network’s ability to model long-range spatial dependencies. Finally, attention weights are generated using a sigmoid activation function and applied to the original feature map through element-wise multiplication and addition operations. Unlike standard convolutions, which capture local information within limited receptive fields, strip-based convolutions extend the receptive field along one spatial axis (horizontal or vertical), effectively modeling long-range dependencies in structured remote sensing scenes. Horizontal and vertical strips are particularly effective due to the strong directional patterns present in roads, rivers, building layouts, and ship alignments, enabling the network to capture context relationships across distant regions without incurring high computational costs.
Normalization is applied to smooth the attention weights, preventing enormous values from interfering with subsequent computations. The SCA module enhances critical information by multiplying element-wise and amplifying feature values in important regions or channels. In addition, element-wise addition preserves a proportion of the original features while enhancing key representations, which helps prevent overfitting and ensures that potentially useful but less salient information is not overlooked.
3.3. Alignment Convolution
To address the misalignment between convolutional sampling grids and object orientations in remote sensing imagery, we introduce an improved version of Alignment Convolution, termed Rotated Anchor-Guided Convolution (RAG-Conv). This module dynamically adjusts the sampling locations based on anchor box geometry, enabling better alignment between the receptive fields and rotated object regions.
Given an input feature map , the standard convolution samples features at regular grid locations , corresponding to a kernel. For a spatial location , the standard convolution is defined as
We define an anchor-aligned convolutional transformation to incorporate orientation awareness using predicted rotated anchor boxes at each location. We let each anchor box be represented by a tuple , denoting the center coordinates, width, height, and rotation angle, respectively. The RAG-Conv adjusts the sampling position as follows:
where k is the kernel size. s is the stride of the feature map. is the 2D rotation matrix.
The offset field is then derived by computing the difference between the anchor-guided sampling position and the standard grid:
Finally, the output feature at position q is computed by aggregating features from the adjusted sampling locations:
This formulation allows RAG-Conv to extract features spatially aligned with the orientation and scale of the target objects. Unlike Deformable Convolution, which learns offsets implicitly, our approach explicitly computes them based on anchor geometry, ensuring better interpretability and alignment fidelity in rotation-sensitive scenarios. Compared to Deformable Convolutions, which learn free-form sampling offsets without structural guidance, AlignConv explicitly leverages anchor geometry (e.g., center, aspect ratio, orientation) to determine sampling positions. This geometric prior restricts the flexibility of learned offsets, reducing the risk of overfitting, especially in cluttered or limited-data scenarios. Moreover, the sampling pattern of AlignConv is stable across similar targets, enhancing the consistency of feature extraction. Unlike deformable layers, AlignConv introduces no additional offset regression branch, resulting in lower parameter complexity and more stable gradient propagation. These characteristics collectively contribute to improved training stability and better generalization performance.
3.4. Feature Alignment Module (FAM)
The Feature Alignment Module (FAM) is designed to enhance spatial alignment between feature representations and object regions, particularly for targets that exhibit orientation and scale variations. As illustrated in Figure 2, FAM is composed of two key components: an Anchor Refinement Subnetwork (ARS) and an Alignment Convolutional Layer (ACL).
Traditional 2D convolution performs feature sampling over a fixed, grid-based structure on the feature map. Although Deformable Convolution (DeformConv) improves on this by learning spatial offsets to adjust sampling positions, its offset estimation is data-driven and often lacks explicit spatial priors. As a result, DeformConv may sample inaccurate regions, especially in cluttered or densely populated scenes.
In contrast, the proposed Alignment Convolution (AlignConv) employs a geometric prior derived from predicted anchor boxes to guide sampling. Instead of learning offset implicitly, AlignConv calculates sampling positions based on the spatial configuration of anchor boxes.
The ACL integrates AlignConv within a lightweight framework to realign features to object instances. Given an anchor regression map of size , where the six channels represent the relative offsets , these values are decoded into absolute anchor parameters , representing the object center, semi-axes, orientation angle, and confidence score. For each output location q, we define a regular sampling grid (e.g., a kernel , ). The anchor-aligned sampling position is computed as
where is the feature map stride, k denotes kernel size, and is the 2D rotation metric:
The offset for each sampling point is defined as
The final output at location q is obtained via
where denotes the convolution weight at sampling position and is the input feature map.
It should be noted that ACL samples 9 positions for each anchor, with horizontal and vertical offsets resulting in an offset field of 18 channels. Despite the additional offset computation, ACL maintains minimal latency, making it suitable for real-time detection scenarios.
3.5. Network Architecture
Local–Global Feature Fusion: The core design of the AMS Block integrates the AMS and SCA modules in parallel to efficiently combine local and global representations, thereby enhancing the overall feature expressiveness.
The first pathway performs element-wise multiplication between the outputs of the two modules to capture fine-grained interactions at the pixel level. Subsequently, the multiplication result is added element-wise to the original output of the AMS module. This operation enhances the representation of local features while preserving essential input information, effectively balancing global semantic context and regional detail.
A subsequent 1 × 1 convolution is applied to perform non-linear mapping and channel compression on the combined features. This operation reduces computational complexity while further enhancing the feature representation capability. The process is formulated as follows:
An additional pathway adopts a straightforward feedforward network (FFN) that processes the input and outputs the result . The module comprises AMS blocks that sequentially process the input , ultimately producing the output .
Multi-stage Feature Cascade Fusion: After completing the local–global feature integration, the resulting feature maps are concatenated along the channel dimension with features processed by the feedforward network (FFN). This concatenation is designed to integrate multi-level feature representations, enhancing the network’s ability to capture semantic information by fusing features from different hierarchical levels. Subsequently, a convolution operation is applied to the concatenated features to enhance the integration of local and global contextual information, resulting in the output feature map for this stage. The above process is defined as a stage. This design demonstrates strong multi-scale feature modeling capabilities, effectively capturing fine-grained target details and global contextual information, particularly in complex remote sensing scenarios. Each AMS block is composed of a AMS module and a SCA module. The formulation for each stage’s output is as follows:
The AMSNet architecture consists of multiple cascaded stages (typically four), which form a hierarchical network structure. This multi-stage design progressively accumulates and integrates multi-level features, resulting in final output feature maps with enhanced semantic richness and stronger representational capacity. Moreover, this progressive feature fusion strategy demonstrates significant advantages in addressing feature distribution imbalance, further enhancing the network’s generalization and robustness in visual tasks such as object detection and semantic segmentation.
4. Experiments
4.1. Datasets
To rigorously assess the effectiveness of the proposed method in diverse remote sensing scenarios, we conduct experiments on three widely recognized benchmark datasets: DOTA, HRSC2016, and UCAS-AOD. These datasets encompass a diverse range of remote sensing targets with significant variations in object scale, category, and orientation. They serve as standard benchmarks for evaluating the performance of algorithms in oriented object detection tasks.
DOTA [] is one of the most representative datasets for remote sensing object detection, characterized by its large scale, high resolution, diverse object categories, and arbitrary object orientations. It contains 2806 aerial images with resolutions ranging from 800 × 800 to 4000 × 4000 pixels, annotated with over 188,000 object instances spanning 15 categories, including Plane, Ship, Vehicle, Storage Tank, Baseball Diamond, and Bridge. Each object is labeled using rotated bounding boxes defined by four vertices, making the dataset particularly suitable for evaluating the robustness of detection algorithms concerning scale variation, directional diversity, and densely distributed targets.
HRSC2016 [] is a remote sensing dataset specifically curated for ship detection, and it is widely adopted to assess the performance of object detectors on elongated targets with significant orientation variations. It comprises 1061 images sourced from Google Earth and aerial photography, with spatial resolutions ranging from 2 m/pixel to 0.4 m/pixel. The dataset includes 20 categories of ship targets, divided into 436 images for training, 181 for validation, and 444 for testing. All objects are annotated using rotated bounding boxes, and the significant variations in aspect ratios among targets make the detection task particularly challenging.
UCAS-AOD [] is a small-scale remote sensing object detection dataset released by the University of Chinese Academy of Sciences. It focuses on two primary object categories: cars and planes. The dataset comprises 1510 images with a fixed resolution of 1280 × 659 pixels, capturing representative scenes such as urban roads, airports, and grasslands. Targets in UCAS-AOD exhibit considerable orientation variability and often appear in dense spatial distributions. All objects are annotated with rotated bounding boxes, enabling the evaluation of detection algorithms under sparse and dense conditions with arbitrary object orientations. Despite its compact size, UCAS-AOD demonstrates strong class separability and is widely adopted as a lightweight yet practical benchmark for oriented object detection research.
4.2. Experimental Evaluation Metrics
Regeading mAP, in object detection tasks, it is essential to note that multiple objects of different categories and positions may coexist within a single image. In object detection, multiple objects with varying categories and locations within a single image necessitate a comprehensive evaluation of classification accuracy and localization precision. The evaluation metrics traditionally employed in image classification are not directly applicable to object detection. Researchers have proposed the mean Average Precision (mAP) metric to address this issue. The mean Average Precision (mAP) metric is a unified measure for assessing detector performance in scenarios involving multiple classes and objects. The precision (P) and recall (R) are calculated using the following formulae:
In object detection evaluation, TP, FP, TN, and FN denote true positives, false positives, true negatives, and false negatives, respectively. Substantial precision and recall performance are expected for a high-performance detector. Therefore, a comprehensive assessment must consider both metrics. To this end, precision–recall (PR) curves are typically constructed for each category, and the area under each curve, called Average Precision (AP), is computed. The mean of the AP values across all categories yields the mean Average Precision (mAP), a standard metric for measuring overall detection performance. For datasets with categories, mAP is defined as follows:
4.3. Parameter Setting
In the experimental setup, AMSNet is adopted as the backbone network, and a Feature Pyramid Network (FPN) is integrated to enhance the extraction of multi-scale features, thereby improving semantic information modeling across varying object scales. During training, the AdamW optimizer is used, with a momentum of 0.9, a weight decay of 0.05, and an initial learning rate set to 1 × 10−4. A cosine annealing learning rate schedule and a learning rate warm-up mechanism are applied to improve training stability and convergence efficiency. The warm-up phase spans the first five epochs, during which the learning rate linearly increases from 1 × 10−6 to the initial value. Various data augmentation techniques are introduced during training, including random horizontal flipping and scale variation within a range of 0.8× to 1.2×. We employed standard data augmentation techniques, including random horizontal flipping and scale jittering. While rotation augmentation is commonly used in oriented object detection tasks, we did not apply it in our main experiments to maintain consistency with prior works and avoid introducing label ambiguity due to interpolation artifacts. In preliminary tests, we observed that rotation augmentation had a limited impact on performance improvement while increasing training instability. The model is trained for 100 epochs with a batch size of 16. To ensure reproducibility, we fixed the random seed to 42 for all training and evaluation experiments. Additionally, to account for variability due to stochastic factors such as parameter initialization and data shuffling, each experiment was repeated three times. Performance was periodically evaluated in the validation set, and the model that achieved the best validation accuracy was saved for subsequent testing. All experiments were conducted using the PyTorch 1.12 framework on a server equipped with an NVIDIA RTX A100 GPU (40 GB memory), running Ubuntu 20.04 with CUDA 11.3.
4.4. Ablation Experiment
We conducted comprehensive ablation studies on two remote sensing object detection datasets, HRSC2016 and UCAS-AOD, to evaluate the effectiveness of the proposed multi-scale convolutional structure (AMS module) and the Context Anchor Attention mechanism (SCA module). In addition, the experiments are designed to investigate the performance gains achieved through their joint integration. Table 1 presents the detection performance of AMSNet under different module configurations in both datasets. Without incorporating structural enhancements, the baseline model achieves only 90.70% and 88.50% mAP on the HRSC2016 and UCAS-AOD datasets, respectively. This performance limitation arises from the inability of conventional feature extraction networks to simultaneously capture fine-grained multi-scale details and long-range contextual dependencies, resulting in suboptimal target representation under complex background conditions. When the AMS module is integrated into the baseline model, the detection precision improves to 91.20% on the HRSC2016 dataset and 89.80% on the UCAS-AOD dataset. The observed performance improvement indicates that the parallel multi-scale depth-wise convolutional structure effectively captures fine-grained texture features across receptive fields, enhancing the model’s adaptability to scale variations. Furthermore, when only the SCA module is integrated, the detection performance improves to 91.60% on HRSC2016 and 90.09% on UCAS-AOD. These results indicate that modeling long-range contextual information in remote sensing imagery contributes to more accurate boundary localization and category discrimination, particularly under complex background conditions with substantial interference. When the AMS and SCA modules are integrated into the baseline model, the detection performance reaches 92.43% mAP on HRSC2016 and 91.86% mAP on UCAS-AOD, representing the highest overall accuracy achieved across all configurations. This performance gain underscores the complementary nature of the two modules: the AMS module enhances local multi-scale feature extraction through parallel depth-wise convolutions. In contrast, the SCA module captures long-range contextual dependencies via attention mechanisms. Their synergistic integration significantly improves the model’s precision and robustness in oriented object detection tasks, validating the structural efficacy and generalizability.

Table 1.
Ablation Results of Different Modules (%).
Table 2 compares two network configurations proposed in this study, tailored for lightweight and high-performance application scenarios, respectively. Both configurations adopt a four-stage stacked architecture, where multiple multi-scale convolutional modules are introduced at each stage to extract rich feature representations. The lightweight variant employs a smaller initial channel width of 32, progressively increasing to 64, 128, 256, and 512 at each stage. Consequently, the stacked modules per stage are 4, 14, 22, and 4. While maintaining strong representational capacity, this configuration achieves a compact model size of only 4.13 M parameters and 22.70 GFLOPs, offering high computational efficiency suitable for resource-constrained environments.
Table 2.
Network Architecture Configuration Comparison.
In contrast, the high-performance configuration sets the initial channel width to 64, with subsequent stages expanding to 128, 256, 512, and 1024 channels, and stacking 4, 12, 20, and 4 modules at each respective stage. Despite the elevated parameter count (13.69 M) and computational cost (70.20 G), this variant considerably improves the capability to represent network characteristics and detection precision. This configuration is especially well-suited for remote sensing applications in which accuracy is paramount. The comparison demonstrates that the proposed architecture offers strong scalability and adaptability in balancing the complexity of the model and the performance requirements.
Table 3 compares the performance of different backbone architectures on the DOTA dataset in terms of parameter size (M), computational complexity (FLOPs, G), detection accuracy (mAP, %), and inference speed (FPS). ResNet-50 achieves a respectable mAP of 75.87% and an inference speed of 21.8 FPS, but its high parameter count (23.3 M) and FLOPs (86.1 G) result in considerable computational overhead. LSKNet reduces the model size to 14.4 M and FLOPs to 52.3 G, slightly improving detection accuracy to 77.49% and maintaining competitive speed (20.7 FPS), offering a better balance between efficiency and accuracy. In comparison, our method achieves the highest accuracy of 78.85% with the smallest parameter size (14.1 M) and moderate FLOPs (71.2 G), highlighting the effectiveness of the proposed design. Although its inference speed (12.2 FPS) is relatively lower, the substantial gain in detection precision justifies the trade-off, especially in remote sensing applications where accuracy is critical. The performance improvements are attributed to the synergistic integration of the multi-scale convolutional kernel design and the context-aware modules, which enhance feature representation without increasing model depth or complexity. Although 12.2 FPS may not meet the strict definition of real-time in video-based applications, in the context of remote sensing deployments—where imagery is often captured at low frame rates (e.g., 1–2 FPS from UAV or satellite platforms)—this speed is sufficient for near real-time analysis. Moreover, inference speed can be further improved through model compression or hardware-level optimization (e.g., TensorRT deployment), making the proposed method practical for time-sensitive applications such as disaster response or maritime surveillance.
Table 3.
Performance Comparison of Different Backbones.
To validate the lightweight nature of the proposed AMS module, we conduct a comprehensive comparison with conventional backbones such as ResNet-50 and LSKNet in terms of parameter count, floating-point operations (FLOPs), mean Average Precision (mAP), and inference speed (FPS). As shown in Table 3, the AMS-based network achieves a favorable trade-off, reducing computational cost (13.7 M parameters, 48.3 G FLOPs) while maintaining superior detection accuracy (mAP of 78.85%) compared to ResNet-50 (23.3 M, 86.1G, mAP 75.87%) and LSKNet (14.4M, 52.3 G, mAP 77.49%). These results demonstrate that the AMS module significantly reduces inference latency while preserving strong feature representation capabilities.
4.5. Comparisons Results for Different Datasets
4.5.1. Evaluation on DOTA
The experimental results on the DOTA dataset, as presented in Table 4, indicate that the proposed AMSNet achieves superior performance compared to other oriented object detection methods. In particular, AMSNet achieves the highest detection accuracy in several representative categories, including Plane (91.36%), Building (87.61%), Bridge (68.51%), Storage Tank (79.86%), and Baseball Diamond (91.32%). Furthermore, the model yields the best overall detection performance, achieving a mean Average Precision (mAP) of 81.72%. It effectively handles multi-class, multi-scale, and multi-oriented targets in complex remote sensing scenes.
Table 4.
Detection results (%) of different methods on the DOTA dataset.
In addition to ours, LSKNet-T (mAP = 81.37%) and RVSA-ORCN (mAP = 81.01%) demonstrate strong competitiveness across several object categories. Their promising performance can be attributed to their architectural designs incorporating multi-scale receptive field modeling and rotation-invariant feature extraction mechanisms. For instance, LSKNet-T leverages large receptive fields and contextual information integration to improve adaptability to large-scale targets and complex backgrounds. However, LSKNet-T underperforms in categories such as Bridge (BR), Storage Tank (ST), and Sports Field (SP), particularly due to limitations in modeling long-range contextual dependencies. By contrast, ours integrates parallel multi-scale depth-wise convolution modules for capturing dense texture features and introduces a SCA mechanism to model long-range pixel-wise dependencies. This synergistic design improves the ability of the model to represent targets with large scales, complex structures, and cluttered backgrounds. Consequently, ours achieves superior overall detection performance, outperforming LSKNet-T by 0.35 percentage points in mAP and validating the effectiveness and generalization capability of the proposed approach in remote sensing object detection tasks. Although the overall mAP improvement over state-of-the-art backbones ranges from 0.3% to 1.0%, this gain is considered meaningful under the challenging conditions of the DOTA dataset, where achieving further performance improvements becomes increasingly difficult. Moreover, our method yields more notable gains in specific object categories with complex orientation or large scale (e.g., 2.1% AP improvement in plane and 1.6% in bridge). In addition to accuracy, the proposed model reduces parameter count and computational cost significantly, highlighting its potential for real-world deployment where both precision and efficiency are critical.
The following figure illustrates several representative detection results. As described in the image in the second row and second column, the ships exhibit substantial scale variation, are densely moored along the dock, and present diverse orientations. Notwithstanding the challenges above, our model can detect them with high precision. As illustrated in the image in the first row and third column, the dock targets are distinguished by their extreme aspect ratios and arbitrary orientations. The rotated bounding boxes generated by our model demonstrate high alignment with the target shapes, effectively enclosing the objects while minimizing background inclusion. The visualization is shown in Figure 3.

Figure 3.
Visualization of detection results on the DOTA dataset.
The findings underscore the necessity of designing feature extraction modules that integrate multi-scale modeling, directional sensitivity, and contextual awareness to address the challenges posed by large-scale variation, complex object orientations, and cluttered backgrounds in remote sensing imagery. The proposed module leverages parallel depth-wise convolutional kernels of varying sizes without dilation to capture dense texture representations across multiple receptive fields. Extracting dense texture representations across multiple receptive fields achieves enhanced sensitivity to scale variation and preservation of fine-grained local details.
The SCA mechanism is incorporated to improve global contextual modeling further, combining global average pooling and 1D strip convolutions to capture long-range semantic dependencies between spatial regions. An AlignConv operation is also introduced to address geometric misalignment between anchors and target objects. By adaptively adjusting sampling positions based on anchor geometry, AlignConv improves the spatial alignment between extracted features and oriented objects, thereby refining localization accuracy.
Together, these modules function synergistically to achieve scale adaptivity, orientation alignment, and global context modeling, significantly improving the network’s capacity for precise and robust oriented object detection in complex remote sensing scenes while maintaining computational efficiency.
4.5.2. Evaluation on HRSC2016
The detection results on the HRSC2016 dataset are presented in Table 5. As observed, our method achieves a mean Average Precision (mAP) of 92.43%, significantly outperforming existing mainstream methods and demonstrating superior detection performance. Compared to advanced models such as ReDet (90.46%), S2ANet (90.17%), and TIOE-Det (90.16%), AMSNet achieves an improvement of nearly two percentage points. These results validate the strong generalization capability of the proposed method in typical remote sensing scenarios characterized by substantial scale variation, diverse object orientations, and complex backgrounds.
Table 5.
Detection performance comparison on the HRSC2016 dataset.
Notably, most existing methods, such as R3Det, CSL, GWD, and DAL, are built upon ResNet-101 as the backbone and typically operate on input resolutions of 800 × 800 or smaller. Despite adopting the exact input resolution, AMSNet achieves superior detection performance. This improvement can be primarily attributed to the synergistic design of the proposed multi-scale convolutional structure and the SCA mechanism. Together, these components enhance the network’s sensitivity to scale variations and improve its ability to model long-range contextual dependencies, enabling more accurate recognition and localization of multi-oriented targets in complex remote sensing scenes.
The figure presents the visualized detection results on the HRSC2016 dataset. It can be observed that AMSNet maintains stable and accurate detection performance even under challenging conditions such as dense object distribution, varying orientations, and high similarity between target and background textures. These results demonstrate the robustness and adaptability of the proposed feature extraction strategy, highlighting its effectiveness for remote sensing object detection tasks. The visualization is shown in Figure 4.

Figure 4.
Visualization of detection results on the HRSC2016 dataset.
4.6. Evaluation on UCAS-AOD
The comparison of detection results on the UCAS-AOD dataset is summarized in Table 6. As shown, ours achieves a mAP of 91.86%, significantly outperforming all competing methods and demonstrating superior detection performance. Compared to high-performing detectors such as DAL (89.87%), CFC-Net (89.49%), and SLA (89.44%), our detector improves accuracy by nearly two percentage points. This result highlights the strong adaptability and robustness of the proposed architecture in handling remote sensing images characterized by large-scale variations and arbitrary object orientations. Most existing methods, such as R-YOLOv3, R-RetinaNet, and RoI Transformer, typically employ ResNet-50 or Darknet-53 as the backbone and use an input resolution 800 × 800. Under the same or even larger input settings (800 × 800), our method still achieves superior detection accuracy. This performance gain primarily stems from the deep integration of the proposed multi-scale convolutional architecture and the SCA mechanism. The former enhances the extraction of features across varying object scales, while the latter improves the modeling of global contextual information. Together, these components enable the network to accurately recognize and localize rotated objects even in complex backgrounds and densely cluttered scenes.
Table 6.
Comparison of detection accuracy (mAP, %) on the UCAS-AOD dataset.
5. Conclusions
This study presents a structural enhancement of the AMSNet architecture to improve multi-scale modeling and contextual awareness in remote sensing object detection. Specifically, a parallel multi-scale depthwise convolution module is introduced to capture fine-grained features effectively under progressive scale variations. In addition, a Strip-based Context Attention (SCA) mechanism is integrated to model long-range dependencies, improving the network’s robustness in complex backgrounds. To further enhance directional adaptability, the framework incorporates Alignment Convolution (AlignConv), guided by anchor box geometry, along with a Feature Alignment Module (FAM) to refine spatial alignment and localization accuracy. Extensive experiments conducted on DOTA, HRSC2016, and UCAS-AOD datasets demonstrate the superior performance and generalizability of the proposed approach in various remote sensing scenarios. Despite the effectiveness of SOAM Block in enhancing scale–orientation perception, several limitations remain. First, the performance may degrade in cases of extreme object size imbalance or severe occlusion, where feature misalignment still exists. Second, the kernel sizes in the AMS module are manually selected and may not generalize optimally across different datasets. Third, the current evaluation is limited to optical remote sensing images; future work will explore the generalizability of the method to other modalities such as SAR or multispectral imagery. These directions offer promising avenues for further improvement and broader applicability.
Author Contributions
Conceptualization, Y.C. and Y.Z.; Methodology, Y.C.; Software, Y.C.; Validation, Z.W., Z.X. and X.X.; Formal analysis, Z.W. and Z.X.; Investigation, X.X. and Y.Z.; Resources, Z.W., Z.X. and X.X.; Data curation, Z.W., Z.X. and X.X.; Writing—original draft preparation, Y.C., Z.W. and Z.X.; Writing—review and editing, Y.C.; Visualization, Z.W. and Z.X.; Supervision, Y.C.; Project administration, Y.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
No new data were created or analyzed in this study.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zhang, Z.; Li, G. UAV Imagery Real-Time Semantic Segmentation with Global–Local Information Attention. Sensors 2025, 25, 1786. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8231–8240. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning roi transformer for oriented object detection in aerial images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Xue, N.; Xia, G.S. ReDet: A Rotation-equivariant Detector for Aerial Object Detection. arXiv 2021, arXiv:2103.07733. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. arXiv 2019, arXiv:1908.05612. [Google Scholar] [CrossRef]
- Guo, Z.; Liu, C.; Zhang, X.; Jiao, J.; Ji, X.; Ye, Q. Beyond bounding-box: Convex-hull feature adaptation for oriented and densely packed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8792–8801. [Google Scholar]
- Xu, J.; He, X. DAF-Net: A Dual-Branch Feature Decomposition Fusion Network with Domain Adaptive for Infrared and Visible Image Fusion. arXiv 2024, arXiv:2409.11642. [Google Scholar]
- Shamsolmoali, P.; Zareapoor, M.; Chanussot, J.; Zhou, H.; Yang, J. Rotation equivariant feature image pyramid network for object detection in optical remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5608614. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, P.; Li, Z.; Li, Y.; Zhang, X.; Meng, G.; Xiang, S.; Sun, J.; Jia, J. Stitcher: Feedback-driven data provider for object detection. arXiv 2020, arXiv:2004.12432. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zhang, Y.; Yuan, Y.; Feng, Y.; Lu, X. Hierarchical and robust convolutional neural network for very high-resolution remote sensing object detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5535–5548. [Google Scholar] [CrossRef]
- Liang, X.; Zhang, J.; Zhuo, L.; Li, Y.; Tian, Q. Small object detection in unmanned aerial vehicle images using feature fusion and scaling-based single shot detector with spatial context analysis. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1758–1770. [Google Scholar] [CrossRef]
- Wang, G.; Zhuang, Y.; Chen, H.; Liu, X.; Zhang, T.; Li, L.; Dong, S.; Sang, Q. FSoD-Net: Full-scale object detection from optical remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5602918. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Li, J.; Xia, G.-S. Align deep features for oriented object detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5602511. [Google Scholar] [CrossRef]
- Yang, Y.; Tang, X.; Cheung, Y.M.; Zhang, X.; Liu, F.; Ma, J.; Jiao, L. AR2Det: An Accurate and Real-Time Rotational One-Stage Ship Detector in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5605414. [Google Scholar] [CrossRef]
- Ren, Z.; Tang, Y.; He, Z.; Tian, L.; Yang, Y.; Zhang, W. Ship Detection in High-Resolution Optical Remote Sensing Images Aided by Saliency Information. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5623616. [Google Scholar] [CrossRef]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.; Yang, J.; Li, X. Large Selective Kernel Network for Remote Sensing Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023. [Google Scholar]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A high resolution optical satellite image dataset for ship recognition and some new baselines. In Proceedings of the International Conference on Pattern Recognition Applications and Methods, Porto, Portugal, 24–26 February 2017; Volume 2, pp. 324–331. [Google Scholar]
- Cai, X.; Lai, Q.; Wang, Y.; Wang, W.; Sun, Z.; Yao, Y. Poly Kernel Inception Network for Remote Sensing Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Darabi, N.; Tayebati, S.; Ravi, S.; Tulabandhula, T.; Trivedi, A.R. Starnet: Sensor trustworthiness and anomaly recognition via approximated likelihood regret for robust edge autonomy. arXiv 2023, arXiv:2309.11006. [Google Scholar]
- Khan, S.D.; Basalamah, S. Multi-branch deep learning framework for land scene classification in satellite imagery. Remote Sens. 2023, 15, 3408. [Google Scholar] [CrossRef]
- Wang, X.; Kang, M.; Chen, Y.; Jiang, W.; Wang, M.; Weise, T.; Tan, M.; Xu, L.; Li, X.; Zou, L.; et al. Adaptive local cross-channel vector pooling attention module for semantic segmentation of remote sensing imagery. Remote Sens. 2023, 15, 1980. [Google Scholar] [CrossRef]
- Tao, H.; Duan, Q.; Lu, M.; Hu, Z. Learning discriminative feature representation with pixel-level supervision for forest smoke recognition. Pattern Recognit. 2023, 143, 109761. [Google Scholar] [CrossRef]
- Guo, N.; Jiang, M.; Gao, L.; Li, K.; Zheng, F.; Chen, X.; Wang, M. HFCC-Net: A dual-branch hybrid framework of CNN and CapsNet for land-use scene classification. Remote Sens. 2023, 15, 5044. [Google Scholar] [CrossRef]
- Ngo, B.H.; Chae, Y.J.; Park, J.H.; Kim, J.H.; Cho, S.I. Easy-to-hard structure for remote sensing scene classification in multitarget domain adaptation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4700215. [Google Scholar] [CrossRef]
- Zheng, X.; Gong, T.; Li, X.; Lu, X. Generalized scene classification from small-scale datasets with multitask learning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5609311. [Google Scholar] [CrossRef]
- Zeng, D.; Chen, S.; Chen, B.; Li, S. Improving remote sensing scene classification by integrating global-context and local-object features. Remote Sens. 2018, 10, 734. [Google Scholar] [CrossRef]
- Guo, F.; Li, Z.; Xin, Z.; Zhu, X.; Wang, L.; Zhang, J. Dual graph U-Nets for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8160–8170. [Google Scholar] [CrossRef]
- Bi, Q.; Qin, K.; Zhang, H.; Li, Z.; Xu, K. RADC-Net: A residual attention based convolution network for aerial scene classification. Neurocomputing 2020, 377, 345–359. [Google Scholar] [CrossRef]
- Huang, H.; Xu, K. Combing triple-part features of convolutional neural networks for scene classification in remote sensing. Remote Sens. 2019, 11, 1687. [Google Scholar] [CrossRef]
- Wan, D.; Lu, R.; Wang, S.; Shen, S.; Xu, T.; Lang, X. Yolo-hr: Improved yolov5 for object detection in high-resolution optical remote sensing images. Remote Sens. 2023, 15, 614. [Google Scholar] [CrossRef]
- Bakirci, M. Advanced ship detection and ocean monitoring with satellite imagery and deep learning for marine science applications. Reg. Stud. Mar. Sci. 2025, 81, 103975. [Google Scholar] [CrossRef]
- Xia, G.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.J.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef]
- Yang, Z.; Liu, S.; Li, Z.; Shi, Z.; Shen, C.; Shao, J. HRSC2016: A Benchmark for Ship Detection in Aerial Images. In Proceedings of the International Conference on Image and Graphics (ICIG); Springer: Berlin/Heidelberg, Germany, 2016; pp. 432–443. [Google Scholar]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).