Abstract
In this paper, a three-parameter subspace conjugate gradient method is proposed for solving large-scale unconstrained optimization problems. By minimizing the quadratic approximate model of the objective function on a new special three-dimensional subspace, the embedded parameters are determined and the corresponding algorithm is obtained. The global convergence result of a given method for general nonlinear functions is established under mild assumptions. In numerical experiments, the proposed algorithm is compared with SMCG_NLS and SMCG_Conic, which shows that the given algorithm is robust and efficient.
1. Introduction
The conjugate gradient method is one of the most important methods used for solving large-scale unconstrained problems, because of its simple structure, lower computation, storage, fast convergence, etc. The general unconstrained optimization problem is as follows:
where is continuously differentiable. The function value of at is denoted as , and its gradient is expressed as . Let be the step size; we have the following iteration form for conjugate gradient method:
where is the search direction, which has the form of
where , referred to as the conjugate parameter. For different selections of , there are several well-known nonlinear conjugate gradient methods [1,2,3,4,5,6]:
where represents the Euclidean norm, and .
The step size can be obtained in different ways. Zhang and Hager [7] proposed an effective non-monotone Wolfe line search as follows:
The in the Formula (4) is the convex combination of . , and are updated by the following rule:
where .
For large-scaled optimization problems, some researchers have been looking for more efficient algorithms. In 1995, Yuan and Stoer [9] first proposed the method of embedding subspace technology into the conjugate gradient algorithm framework, namely the two-dimensional subspace minimization conjugate gradient method (SMCG for short). The search direction is calculated by minimizing the quadratic approximation model on the two-dimensional subspace , namely
where and are parameters, and . Analogously, the calculation of the search direction is directly extended to . By this way, we can avoid solving the sub-problem in the total space, which can reduce the computation and storage cost immensely.
Inspired by SMCG, some researchers began to investigate the algorithm of the conjugate gradient method combined with subspace technology. Dai et al. [10] focused on the analysis of the subspace minimization conjugate gradient method proposed by Yuan and Stoer [9] and integrated SMCG with Barzilai–Borwein [11], a new Barzilai–Borwein conjugate gradient method (BBCG for short) was proposed. In the subspace , Li et al. [12] discussed the case where the search direction was generated by minimizing the conic model when the non-quadratic state of the objective function was stronger. Wang et al. [13] changed the conic model of [12] into the tensor model. Zhao et al. [14] discussed the case of regularization model. Andrei [15] further expanded the search direction, developed it into a three-dimensional subspace , and proposed a new SMCG method (TTS). Inspired by Andrei, Yang et al. [16] carried out a similar study. They applied the subspace minimization technique to another special three-dimensional subspace , and obtained a new SMCG method (STT). On the same subspace, Li et al. [17] further studied Yang’s results, analyzed the more complex three parameters, and proposed a new subspace minimization conjugate gradient method (SMCG_NLS). Yao et al. [18] proposed a new three-dimensional subspace and obtained the TCGS method by using the modified secant equation.
According to [19], it can be seen that the key to embedding subspace technology into the conjugate gradient method is to construct an appropriate subspace, select an approximate model, and estimate the terms of the Hessian matrix. The subspace contains the gradient of the two iteration points. If the difference between the two gradient points is too large, the direction of the gradient change and its value will be affected. We consider making appropriate corrections to the gradient changes of the two iteration points, and then combine the current iteration point gradient with the previous search direction to form a new three-dimensional subspace, and whether this subspace is valuable for research. This paper is taking its as the breakthrough point for research.
In this paper, to avoid the situation in which the changes of the gradient dominate the subspace , inspired by [20], we construct a similar subspace in which , and then, by solving the optimal solution of an approximate model of the objective function in the given subspace to gain the corresponding parameters and algorithm. It can be shown that the obtained method is a global convergent and has nice numerical performance.
The rest of this paper is organized as follows: in Section 2, the search direction constructed on a new special three-dimensional subspace is presented, and the estimations of matrix-vector production are given. In Section 3, The proposed algorithm and its properties under two necessary assumptions are described in detail. In Section 4, we establish the global convergence of our proposed algorithm under mild conditions. In Section 5, we compare the proposed method numerically with algorithms SMCG_NLS [17] and SMCG_Conic [12]. Finally, in Section 6, we conclude this paper and highlight future work.
2. Search Direction and Step Size
The main content of this section is to introduce four search direction models and the selections of initial step sizes on the newly spanned three-dimensional subspace.
2.1. Direction Choice Model
Inspired by [20], in this paper, the gradient change is replaced by . Then, the search directions are constructed in the three-dimensional subspace .
From [10], we know that the approximate model used plays two roles: one is to approximate the original objective function in the subspace ; the other one is to make the search direction obtained by the approximate model descend, so that the original objective function declines along this direction. On our proposed subspace , we consider the approximate model of the objective function as
where is a symmetric positive definite approximation matrix of the Hessian matrix, satisfying .
Obviously, there are three dimensions in the subspace that we are considering.
Situation I:
dim() = 3.
When the dimension is 3, it is easy to know that are not collinear. The form of the search direction is of the following form
where and are undetermined parameters. Substituting (10) into (9) and simplifying, we have
where , , . Set
Thus, (11) can be summarized as
Under some mild conditions, we can prove that is positive definite, which will be discussed in Lemma 1. When is positive definite, by calculation and simplification, the only solution of (11) is
where
In order to avoid the matrix-vector multiplication, we need to estimate , and . Before estimating , we first estimate .
For , we get
Based on the analysis of [9], is desirable, which shows that can have the following estimation:
which also means that
In order for the experiment to have a better numerical effect, we amended as
where
Obviously, . Consider the following matrix,
From (13) and , it can be known that the sub-matrix (15) is positive definite, inspired by the BBCG method [11], for , we take
where
where , .
Now, we estimate . Since is positive definite, it is easy to know , therefore
According to (14), we know that .
In order to ensure that (18) holds, we estimate the parameter by taking
where , , and . Through the debugging of the algorithm, we find that the numerical experiment effect of using the adaptive value of (17) is better than that of with a fixed value, so also uses (17).
In summary, we find that when the following conditions are satisfied, the search direction is calculated by (10) and (12).
where are positive constants.
Now, let us prove that is positive definite.
Lemma 1.
Proof of Lemma 1.
Using mathematical induction, it is easy to know from (18); for therefore
So the proof is over. □
Situation II:
dim() = 2.
In this case, the form of the search direction is as follows:
where are undetermined parameters. Substituting (24) into (9), we get
where , if it satisfies
Then the unique solution of the problem (25) is
Obviously, under certain conditions, the HS direction can be regarded as a special case of Formula (24). Taking into account the finite termination of the HS method, in order to make our algorithm have good properties, when the following conditions hold,
where . We consider
In summary, for the case where the dimension of the subspace is 2; if only condition (22) is true, is calculated by (24). When inequalities (28) and (29) hold, is calculated from (30).
According to the above analysis, is calculated by (24) when only condition (22) is true for the case of the 2-subspace dimension. When conditions (28) and (29) hold, is calculated by (30).
Situation III:
dim() = 1.
2.2. Selection of Initial Step Size
Considering that the selections of initial step sizes will also have an impact on the algorithm, we choose the initial step size selection method of SMCG_NLS [17], which is also a subspace algorithm.
According to [21], we know that
which indicates how close the objective function is to the quadratic function on the line segment formed between the current iteration point and the previous iteration point. Based on [22], we know that the following condition indicates that the objective function is close to a quadratic function:
where .
Case I: when the search direction is calculated by Equations (10), or (24) or (30), the initial step size is .
Case II: when , the initial step size is
where .
3. The Obtained Algorithm and Descent Property
This section describes the obtained algorithm and its descending properties under two necessary assumptions in detail.
3.1. The Obtained Algorithm
The main content of this section is to introduce our proposed algorithm and give two necessary assumptions. Before introducing the algorithm, we first introduce the restart method we use to restart the proposed algorithm, and then describe the proposed algorithm in detail.
According to [23], set
If is close to 1, then the one-dimensional line search function is close to the quadratic function. Similar to [21], if in multiple consecutive iterations, , we restart the search direction along . In addition, we restart our algorithm if the number of consecutive uses of CG directions reaches the MaxRestart threshold.
Now, the details of the three-term subspace conjugate gradient method (TSCG for short) is given as follows:
| Algorithm 1: TSCG Alogrithm |
|
3.2. Descent Properties of Search Direction
In this subsection, we discuss the descent properties of the given algorithm, in which it will be proved that the proposed algorithm (TSCG) fulfills sufficient descent conditions in all cases. Now, we first introduce some common assumptions on the objective function.
Assumption 1.
The objective function is continuous differentiable and has a lower bound on .
Assumption 2.
The gradient function g is Lipschitz continuous on the bounded level set ; that is, there exists constant , such that
That is: .
Proof of Lemma 2.
We only need to discuss the situation of search direction in relation to .
Case I: if is generated by (24), the proof is similar to [22], so the proof process is omitted.
Case II: when is calculated by (10) and (12), we have
where is the binary quadratic function of variables and represented as x and y, and its simplified form is expressed as
From Lemma 1, it is easy to get , ; that is
Therefore, we have
Thus, that is the end of the proof. □
Lemma 3.
Assume that is generated by the algorithm TSCG. there exists a constant , such that
Proof of Lemma 3.
As for the four forms of the constituent directions, we discuss them separately.
Case I: if , let , then (36) holds.
Case II: when the search direction is binomial, namely, we first discuss the situation given by (30). When is determined by (30), combined with (28) and (29), for , we have
Case III: now, we discuss another case where the search direction is a binomial; that is, the situation where the search direction is generated by (24). Combining (22) and (27), obviously
In combination with the above formula and (35), it can be obtained
Case IV: when the search direction is trinomial; that is, is given by (10) and (12). Consider Lemma 2 and use (20), (21), and , we first prove that has an upper bound:
The in the root of the above second inequality is .
There is
Finally, according to Lemma 2, we have
In summary, the value of , satisfying (36), is
Then the proof is complete. □
Lemma 4.
If the search direction is calculated by TSCG, then there exists a constant , such that
Proof of Lemma 4.
Similar to Lemma 3, we discuss four cases of search directions, respectively.
Case I: if , let , then (37) is true.
Case III: if is calculated by (24) and (26), then, combining (22) and (27), and the Cauchy inequality, we deduce
Combining the above equation, (27), the Cauchy inequality, and the triangle inequality, we can get
Case IV: when the search direction is three; that is, the search direction is calculated by (10) and (12). Similar to Case III, let us first derive the lower bound of . According to (16), (18) and (20), we have
Let us write , and combine that with , we have , therefore
According to the above results, it can be further deduced
According to the four cases of the above analyses, the value of that satisfies (38) is
The proof is ended. □
4. Convergence Analysis
The global convergence of the algorithm for general functions is proven in this section.
Proof of Lemma 5.
We notice that , , and (39) holds immediately. □
Theorem 1.
Suppose Assumption 1 and Assumption 2 are satisfied, and sequence is generated by algorithm TSCG, then
Proof of Theorem 1.
Clearly
The above equation with is equivalent to
Suppose , for , for any , there exists , then
Combining with (44) and , then . This contradicts Assumption 1 that on has a lower bound. Therefore,
5. Numerical Results
In this section, we compare the numerical performance of the TSCG algorithm with SMCG_NLS [17] and SMCG_Conic [12] algorithms, both of which are subspace minimization algorithms, through numerical experiments to prove the effectiveness of the proposed TSCG algorithm. Performance profiles of Dolan and Moré [24] were used to test the performance of the method. Our test functions were derived from 67 functions in [25], as shown in Table 1. It was programmed and run on a Windows 10 PC with a 1.80-GHz CPU and 16.00 GB memory, 64-bit operating system. We set the termination criteria as: , or when the number of iterations of the program exceeded 200,000, and exited when one of them was true. The dimensions of the variables of the test function were 10,000 and 12,000 respectively.

Table 1.
The test problems.
The following shows the selection of parameters and some tags and numerical experiments. The initial step size of the first iteration in this paper uses the adaptive strategy of [26].
where represents the infinite norm.
The parameters of SMCG_NLS and SMCG_Conic algorithms are selected according to the values selected in the original paper. The parameters of the TSCG algorithm proposed by us are selected as follows.
The relevant tags of this article are as follows:
- Ni: the number of iterations.
- Nf: the number of function evaluations.
- Ng: the number of gradient evaluations.
- CPU: the running time of the algorithm (in seconds).
Now, we compare the algorithm TSCG in this paper with SMCG_NLS [17] and SMCG_Conic [12] in numerical diagrams. The performance comparison diagrams of Ni, Ng, Nf and CPU correspond to Figure 1, Figure 2, Figure 3 and Figure 4 respectively. According to Figure 1 and Figure 2, it is found that the robustness and stability of TSCG are significantly better than that of SMCG_NLS and SMCG_Conic in terms of the number of iterations and the total number of gradient calculations. Overall, SMCG_NLS has better robustness and stability than SMCG_Conic. From Figure 3, we know that both TSCG and SMCG_NLS are superior to SMCG_Conic, and TSCG begins to be better than SMCG_NLS when , even when factor , the total calculated by the function TSCG does not perform as well as SMCG_NLS. Figure 4 shows that TSCG and SMCG_NLS are better than SMCG_Conic in terms of the robustness and stability of running time. In general, TSCG is almost better than SMCG_NLS in terms of robustness and stability, only when factor , TSCG is inferior to SMCG_NLS.
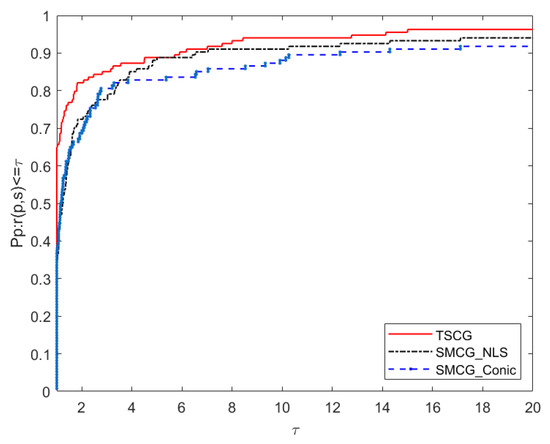
Figure 1.
Performance profiles of the number of iterations (Ni).
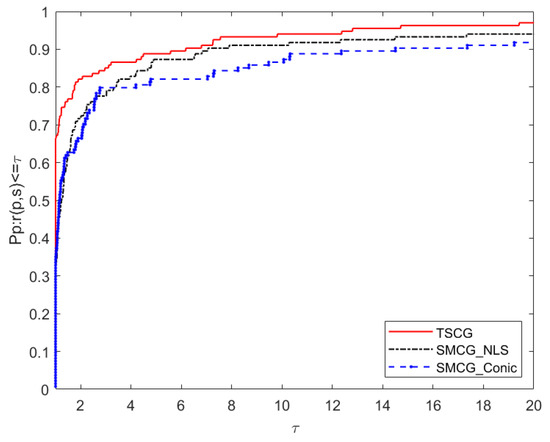
Figure 2.
Performance profiles of the gradient (Ng).
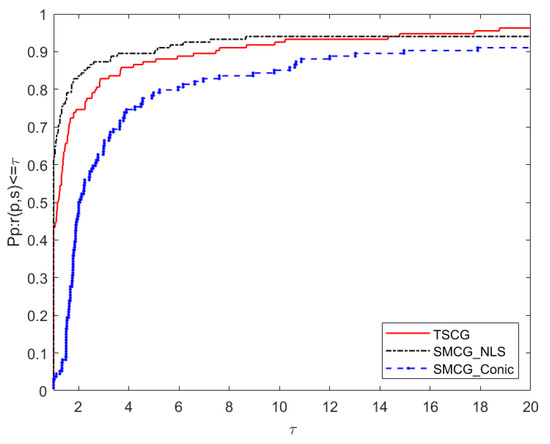
Figure 3.
Performance profiles of the function (Nf).
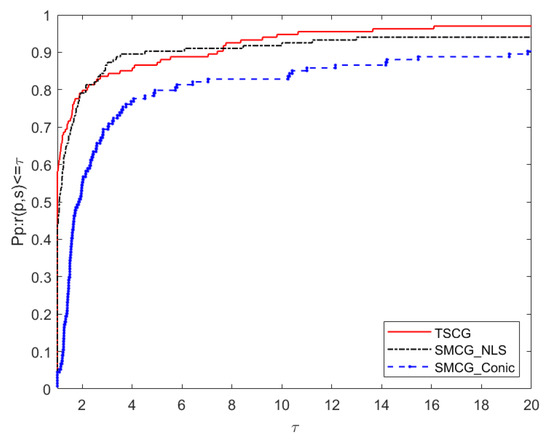
Figure 4.
Performance profiles of CPU time (CPU).
6. Conclusions and Prospect
In order to obtain a more efficient and robust conjugate gradient algorithm for solving the unconstrained optimization problem, by constructing a new three-dimensional subspace , and solving the sub-problem of a quadratic approximate model of the objective function in the given subspace, we obtained a new three-term conjugate gradient method (TSCG). The global convergence of the TSCG method for general functions is established under mild conditions. Numerical results show that TSCG has better performance than SMCG_NLS and SMCG_Conic, both of which are subspace algorithms, for a given test set.
As for the research of the subspace algorithm, the main content of our future work is to continue to study the estimation of terms, including Hessian matrix, to discuss whether it can be extended to the constrained optimization algorithm, and consider the application of the algorithm to image restoration, image segmentation, and path planning of engineering problems.
Author Contributions
Conceptualization, J.H. and S.Y.; methodology, J.Y.; software and validation, J.Y., G.W., visualization and formal analysis, J.Y.; writing—original draft preparation, J.Y.; supervision, S.Y.; funding acquisition, S.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Natural Science Foundation of China no. 71862003, Natural Science Foundation of Guangxi Province (CN) no. 2020GXNSFAA159014, the Program for the Innovative Team of Guangxi University of Finance and Economics, and the Special Funds for Local Science and Technology Development guided by the central government, grant number ZY20198003.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hestenes, M.R.; Stiefel, E. Methods of conjugate gradients for solving linear systems. J. Res. Natl. Bur. Stand. 1952, 49, 409–436. [Google Scholar] [CrossRef]
- Fletcher, R.; Reeves, C.M. Function minimization by conjugate gradients. Comput. J. 1964, 7, 149–154. [Google Scholar] [CrossRef] [Green Version]
- Polyak, B.T. The conjugate gradient method in extremal problems. JUssr Comput. Math. Math. Phys. 1969, 9, 94–112. [Google Scholar] [CrossRef]
- Liu, Y.; Storey, C. Efficient generalized conjugate gradient algorithms, part 1: Theory. J. Optim. Theory Appl. 1991, 69, 129–137. [Google Scholar] [CrossRef]
- Dai, Y.H.; Yuan, Y. A nonlinear conjugate gradient method with a strong global convergence property. Siam J. Optim. 1999, 10, 177–182. [Google Scholar] [CrossRef] [Green Version]
- Fletcher, R. Volume 1 Unconstrained Optimization. In Practical Methods of Optimization; Wiley-Interscience: New York, NY, USA, 1980; p. 120. [Google Scholar]
- Zhang, H.; Hager, W.W. A non-monotone line search technique and its application to unconstrained optimization. Soc. Ind. Appl. Math. J. Optim. 2004, 14, 1043–1056. [Google Scholar]
- Liu, H.; Liu, Z. An efficient Barzilai–Borwein conjugate gradient method for unconstrained optimization. J. Optim. Theory Appl. 2019, 180, 879–906. [Google Scholar] [CrossRef]
- Yuan, Y.X.; Stoer, J. A subspace study on conjugate gradient algorithms. ZAMM-J. Appl. Math. Mech. FüR Angew. Math. Und Mech. 1995, 75, 69–77. [Google Scholar] [CrossRef]
- Dai, Y.H.; Kou, C.X. A Barzilai–Borwein conjugate gradient method. Sci. China Math. 2016, 59, 1511–1524. [Google Scholar] [CrossRef]
- Barzilai, J.; Borwein, J.M. Two-Point Step Size Gradient Methods. IMA J. Numer. Anal. 1988, 8, 141–148. [Google Scholar] [CrossRef]
- Li, Y.; Liu, Z.; Hongwei, L. A subspace minimization conjugate gradient method based on conic model for unconstrained optimization. Comput. Appl. Math. 2019, 38, 16. [Google Scholar] [CrossRef]
- Wang, T.; Liu, Z.; Liu, H. A new subspace minimization conjugate gradient method based on tensor model for unconstrained optimization. Int. J. Comput. Math. 2019, 96, 1924–1942. [Google Scholar] [CrossRef]
- Zhao, T.; Liu, H.; Liu, Z. New subspace minimization conjugate gradient methods based on regularization model for unconstrained optimization. Numer. Algorithms 2020, 87, 1501–1534. [Google Scholar] [CrossRef]
- Andrei, N. An accelerated subspace minimization three-term conjugate gradient algorithm for unconstrained optimization. Numer. Algorithms 2014, 65, 859–874. [Google Scholar] [CrossRef]
- Yang, Y.; Chen, Y.; Lu, Y. A subspace conjugate gradient algorithm for large-scale unconstrained optimization. Numer. Algorithms 2017, 76, 813–828. [Google Scholar] [CrossRef]
- Li, M.; Liu, H.; Liu, Z. A new subspace minimization conjugate gradient method with non-monotone line search for unconstrained optimization. Numer. Algorithms 2018, 79, 195–219. [Google Scholar] [CrossRef]
- Yao, S.; Wu, Y.; Yang, J.; Xu, J. A Three-Term Gradient Descent Method with Subspace Techniques. Math. Probl. Eng. 2021, 2021, 8867309. [Google Scholar] [CrossRef]
- Yuan, Y. A review on subspace methods for nonlinear optimization. Proc. Int. Congr. Math. 2014, 807–827. [Google Scholar]
- Wei, Z.; Yao, S.; Liu, L. The convergence properties of some new conjugate gradient methods. Appl. Math. Comput. 2006, 183, 1341–1350. [Google Scholar] [CrossRef]
- Yuan, Y. A modified BFGS algorithm for unconstrained optimization. IMA J. Numer. Anal. 1991, 11, 325–332. [Google Scholar] [CrossRef]
- Dai, Y.; Yuan, J.; Yuan, Y.X. Modified two-point stepsize gradient methods for unconstrained optimization. Comput. Optim. Appl. 2002, 22, 103–109. [Google Scholar] [CrossRef]
- Dai, Y.H.; Kou, C.X. A nonlinear conjugate gradient algorithm with an optimal property and an improved Wolfe line search. Soc. Ind. Appl. Math. J. Optim. 2013, 23, 296–320. [Google Scholar] [CrossRef] [Green Version]
- Dolan, E.D.; Moré, J.J. Benchmarking optimization software with performance profiles. Math. Program. 2002, 91, 201–213. [Google Scholar] [CrossRef]
- Andrei, N. An unconstrained optimization test functions collection. Adv. Model. Optim. 2008, 10, 147–161. [Google Scholar]
- Hager, W.W.; Zhang, H. A new conjugate gradient method with guaranteed descent and an efficient line search. SIAM J. Optim. 2005, 16, 170–192. [Google Scholar] [CrossRef] [Green Version]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).