
A Class of Three-Dimensional Subspace Conjugate Gradient Algorithms for Unconstrained Optimization

Abstract
:1. Introduction
2. Search Direction and Step Size
2.1. Direction Choice Model
2.2. Selection of Initial Step Size
3. The Obtained Algorithm and Descent Property
3.1. The Obtained Algorithm
| Algorithm 1: TSCG Alogrithm |
|
3.2. Descent Properties of Search Direction
4. Convergence Analysis
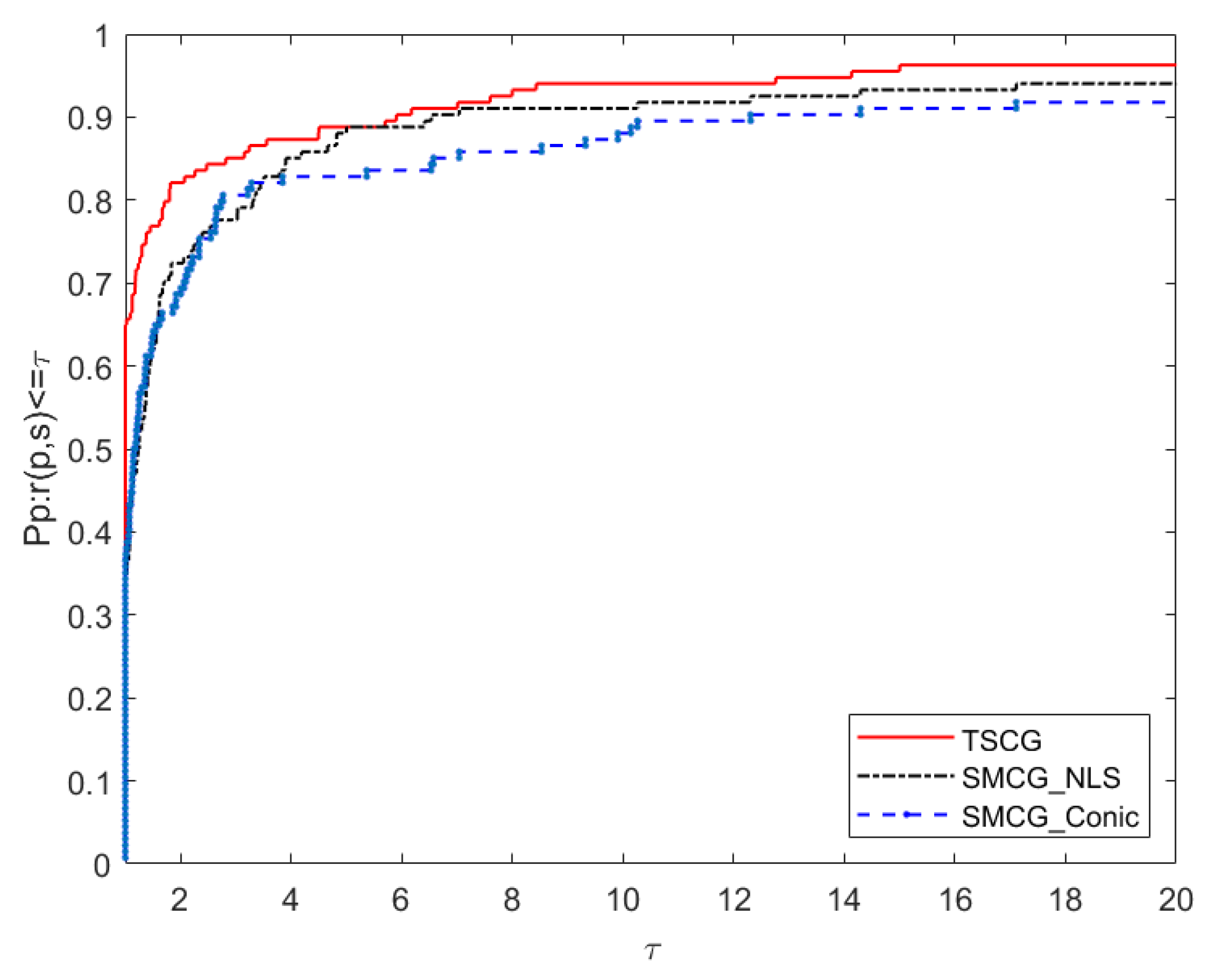
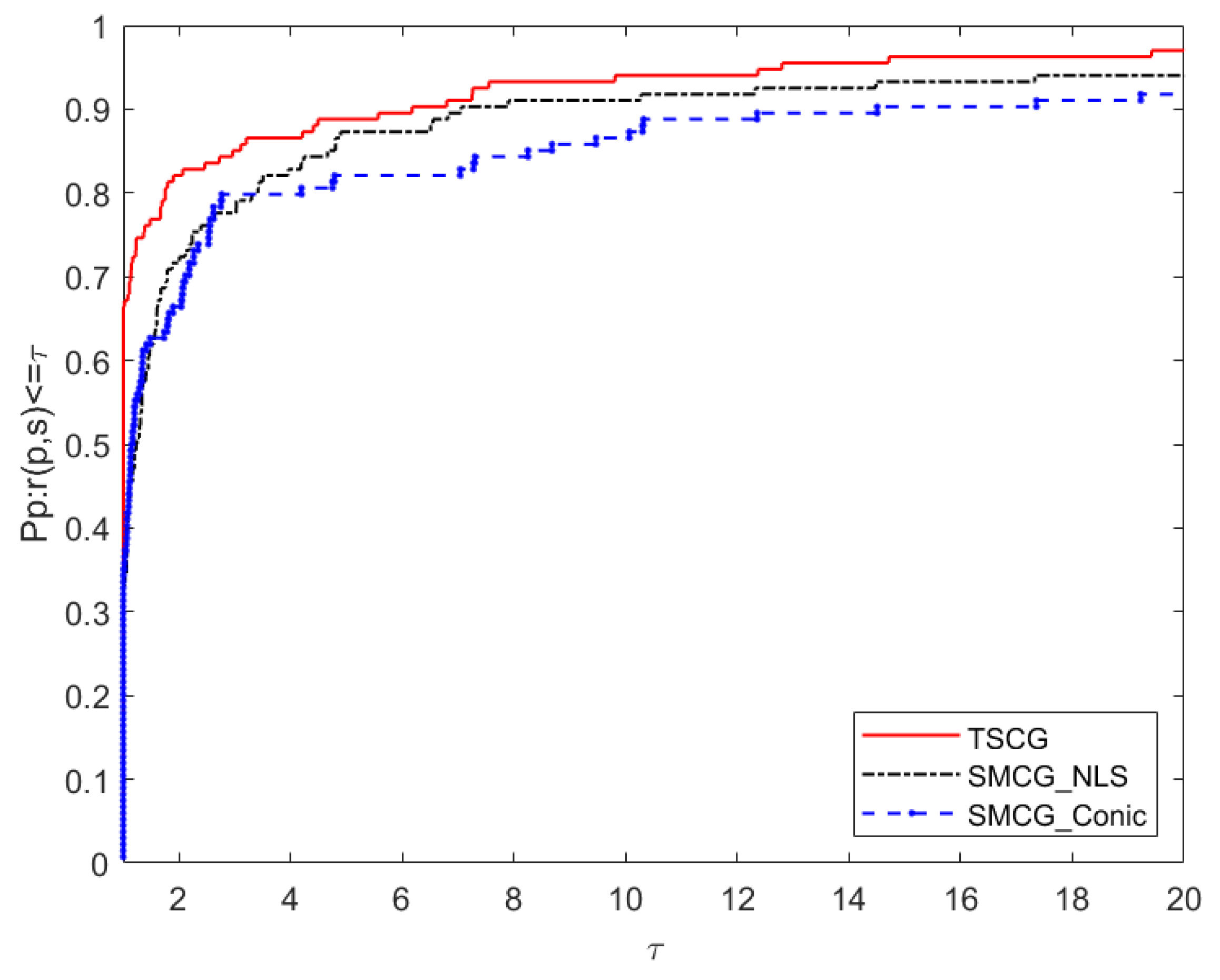
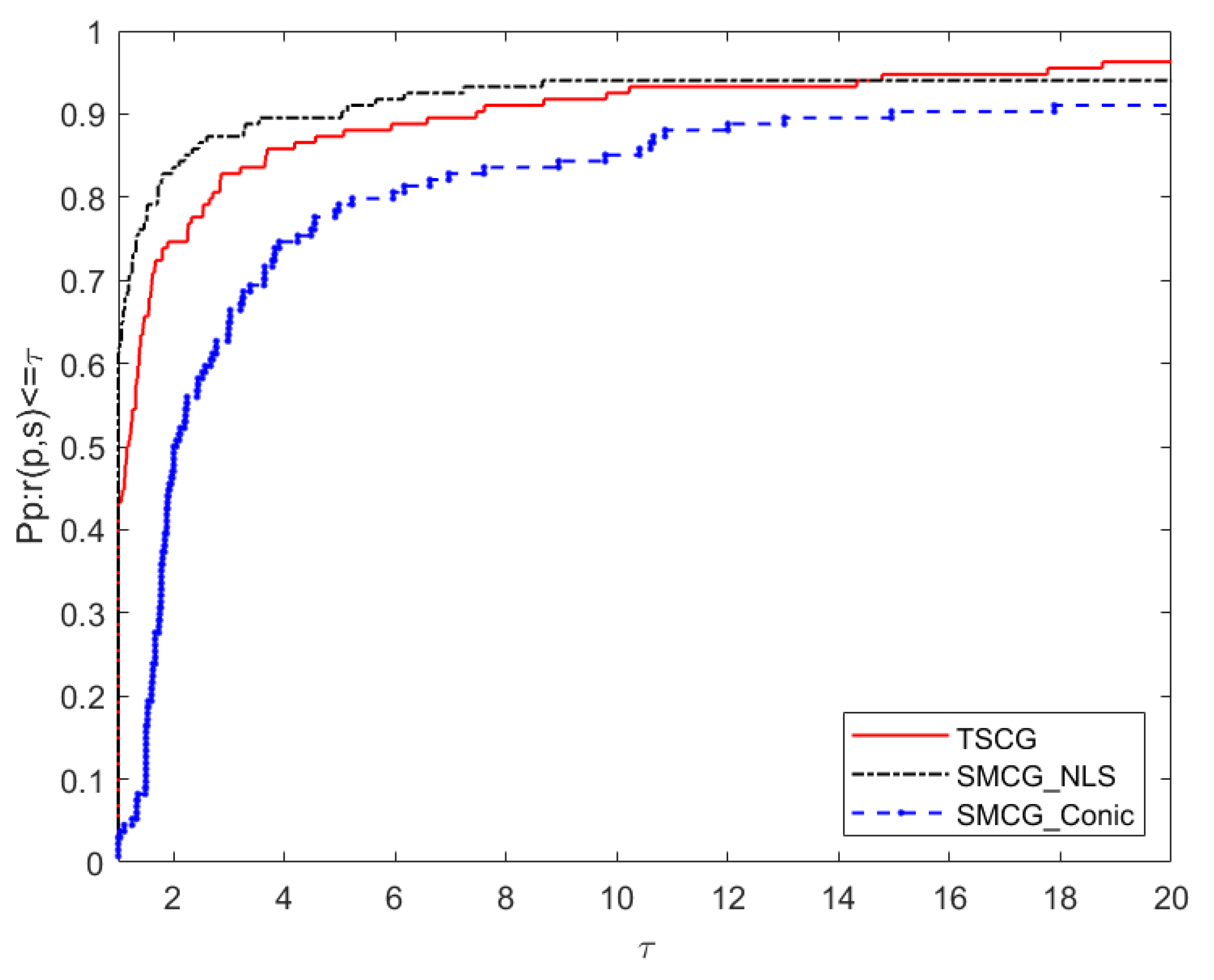
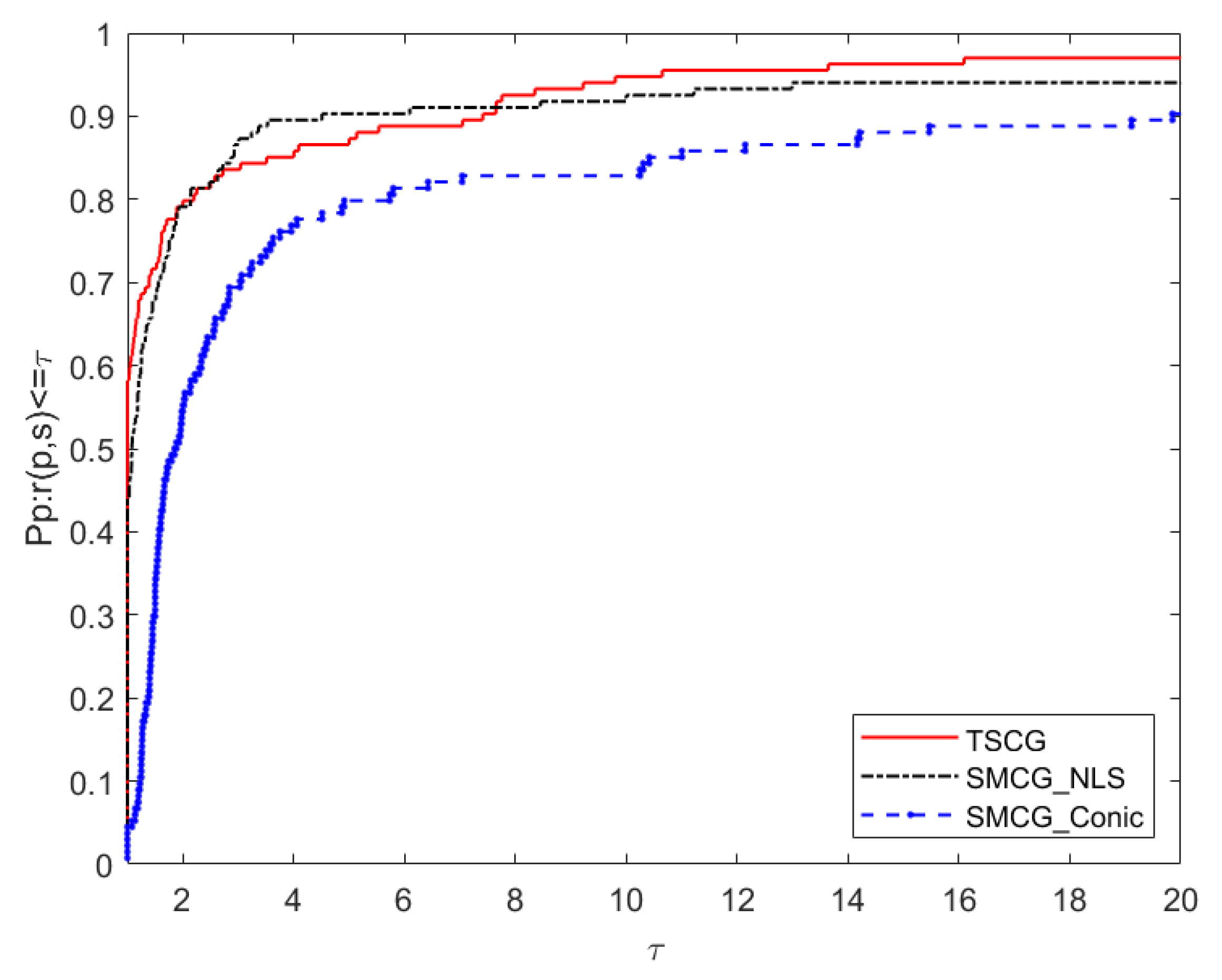
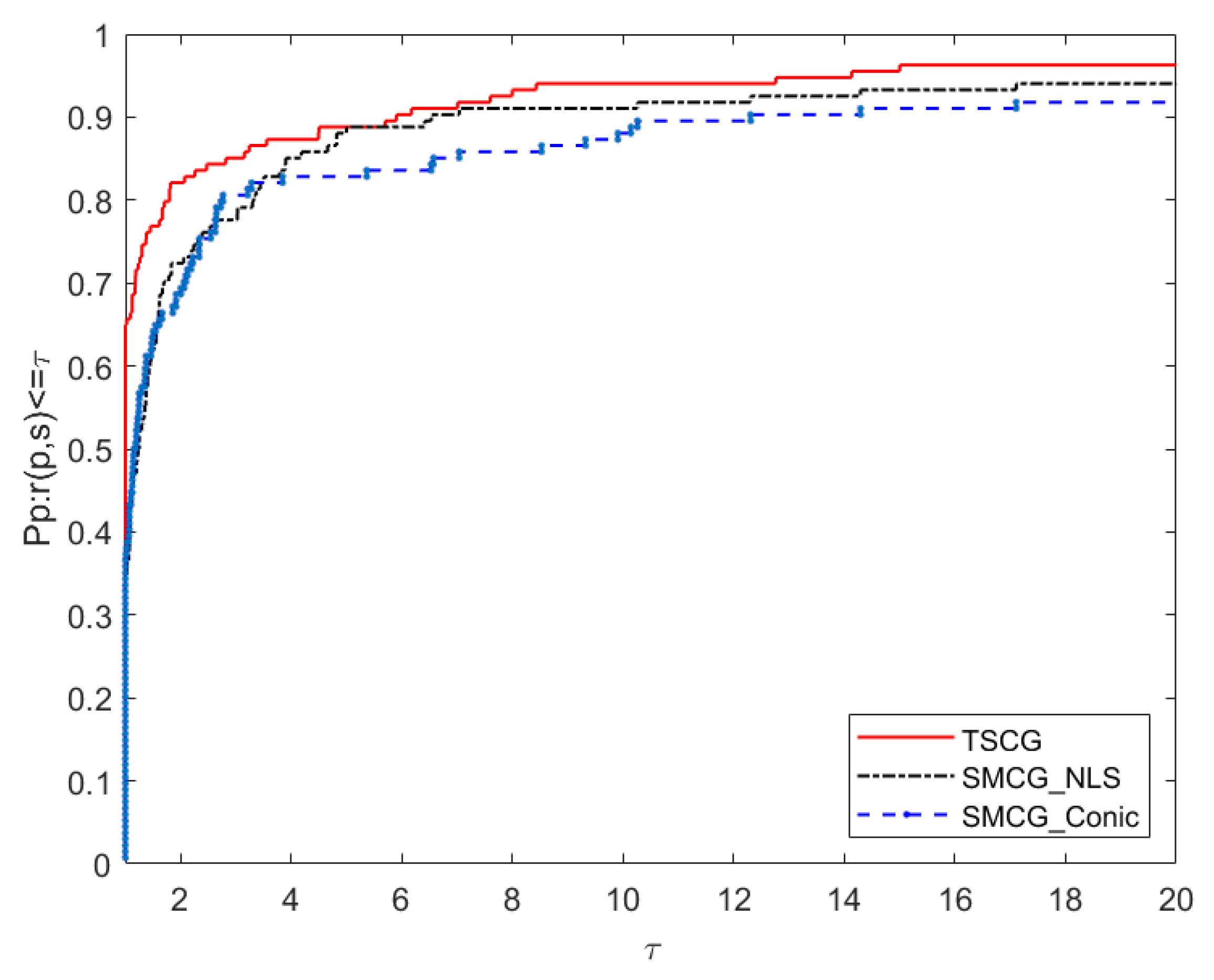
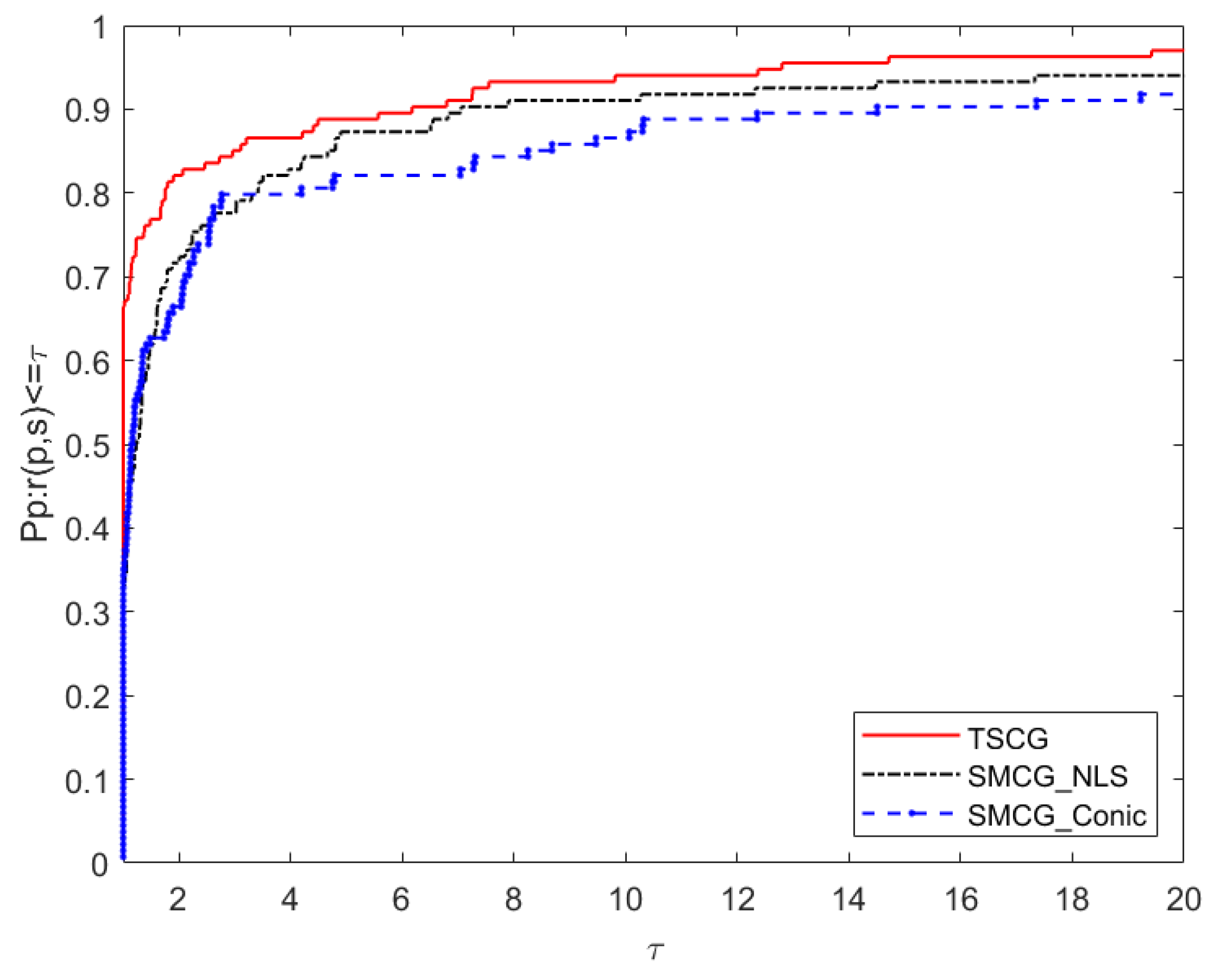
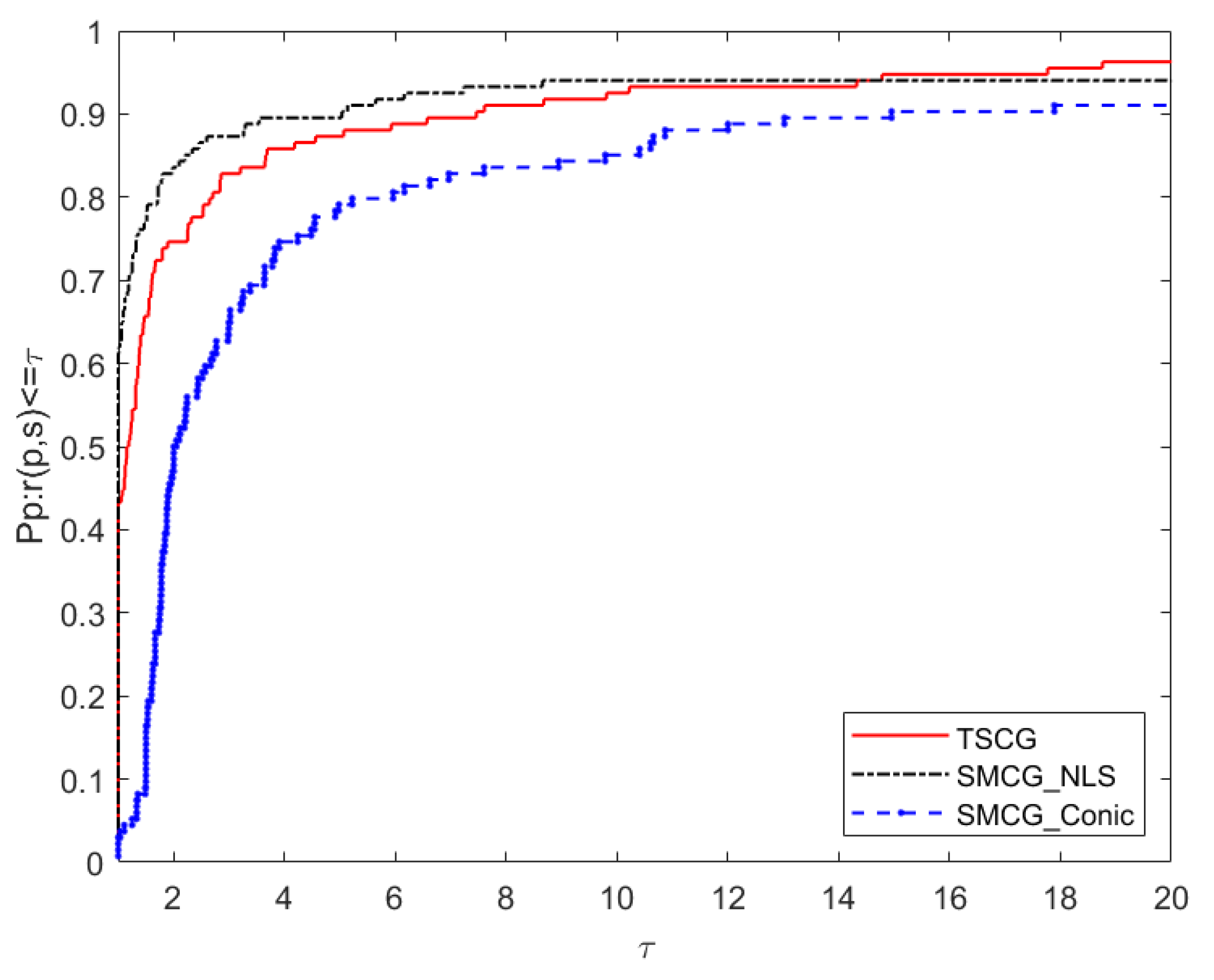
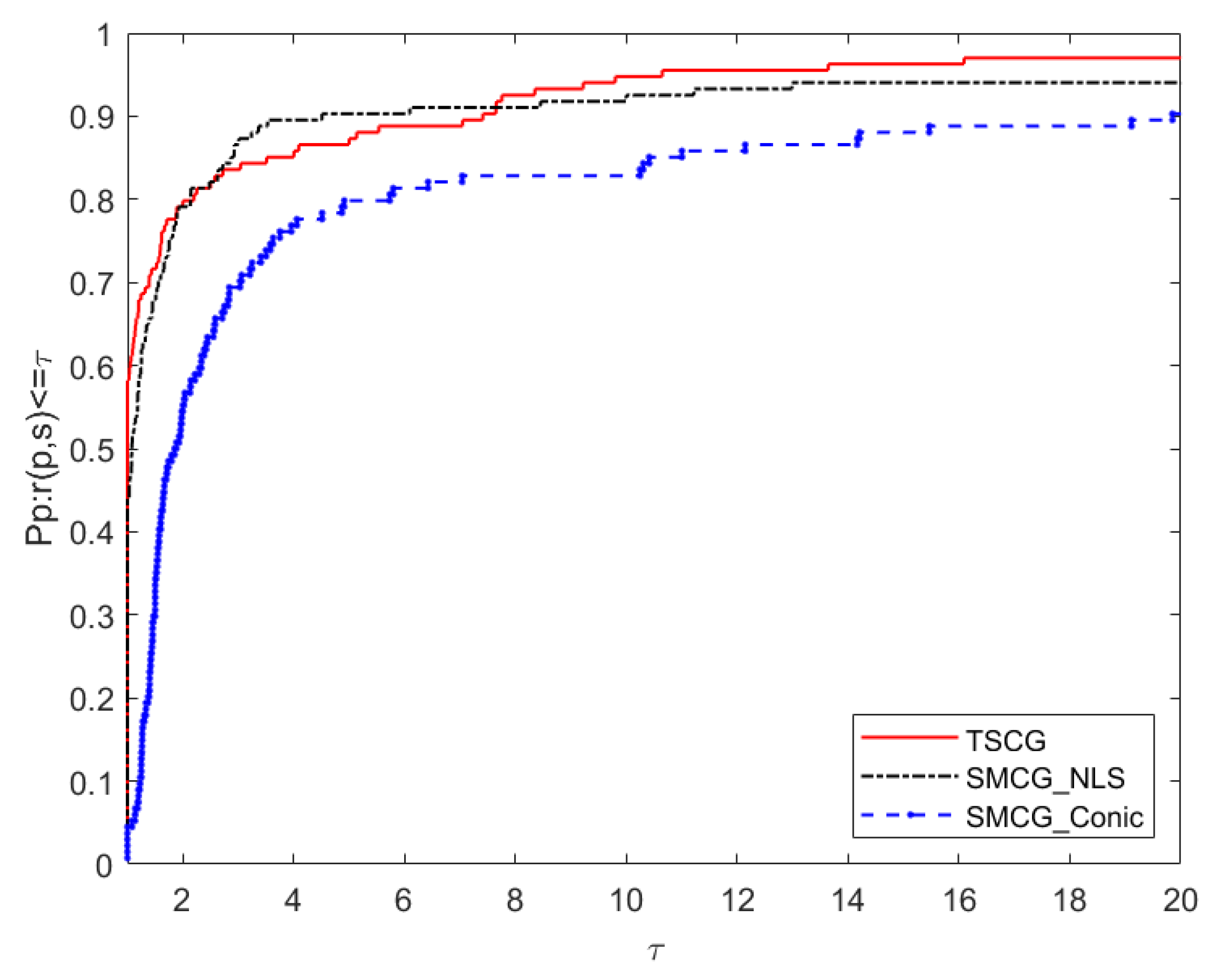
5. Numerical Results
- Ni: the number of iterations.
- Nf: the number of function evaluations.
- Ng: the number of gradient evaluations.
- CPU: the running time of the algorithm (in seconds).
6. Conclusions and Prospect
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hestenes, M.R.; Stiefel, E. Methods of conjugate gradients for solving linear systems. J. Res. Natl. Bur. Stand. 1952, 49, 409–436. [Google Scholar] [CrossRef]
- Fletcher, R.; Reeves, C.M. Function minimization by conjugate gradients. Comput. J. 1964, 7, 149–154. [Google Scholar] [CrossRef] [Green Version]
- Polyak, B.T. The conjugate gradient method in extremal problems. JUssr Comput. Math. Math. Phys. 1969, 9, 94–112. [Google Scholar] [CrossRef]
- Liu, Y.; Storey, C. Efficient generalized conjugate gradient algorithms, part 1: Theory. J. Optim. Theory Appl. 1991, 69, 129–137. [Google Scholar] [CrossRef]
- Dai, Y.H.; Yuan, Y. A nonlinear conjugate gradient method with a strong global convergence property. Siam J. Optim. 1999, 10, 177–182. [Google Scholar] [CrossRef] [Green Version]
- Fletcher, R. Volume 1 Unconstrained Optimization. In Practical Methods of Optimization; Wiley-Interscience: New York, NY, USA, 1980; p. 120. [Google Scholar]
- Zhang, H.; Hager, W.W. A non-monotone line search technique and its application to unconstrained optimization. Soc. Ind. Appl. Math. J. Optim. 2004, 14, 1043–1056. [Google Scholar]
- Liu, H.; Liu, Z. An efficient Barzilai–Borwein conjugate gradient method for unconstrained optimization. J. Optim. Theory Appl. 2019, 180, 879–906. [Google Scholar] [CrossRef]
- Yuan, Y.X.; Stoer, J. A subspace study on conjugate gradient algorithms. ZAMM-J. Appl. Math. Mech. FüR Angew. Math. Und Mech. 1995, 75, 69–77. [Google Scholar] [CrossRef]
- Dai, Y.H.; Kou, C.X. A Barzilai–Borwein conjugate gradient method. Sci. China Math. 2016, 59, 1511–1524. [Google Scholar] [CrossRef]
- Barzilai, J.; Borwein, J.M. Two-Point Step Size Gradient Methods. IMA J. Numer. Anal. 1988, 8, 141–148. [Google Scholar] [CrossRef]
- Li, Y.; Liu, Z.; Hongwei, L. A subspace minimization conjugate gradient method based on conic model for unconstrained optimization. Comput. Appl. Math. 2019, 38, 16. [Google Scholar] [CrossRef]
- Wang, T.; Liu, Z.; Liu, H. A new subspace minimization conjugate gradient method based on tensor model for unconstrained optimization. Int. J. Comput. Math. 2019, 96, 1924–1942. [Google Scholar] [CrossRef]
- Zhao, T.; Liu, H.; Liu, Z. New subspace minimization conjugate gradient methods based on regularization model for unconstrained optimization. Numer. Algorithms 2020, 87, 1501–1534. [Google Scholar] [CrossRef]
- Andrei, N. An accelerated subspace minimization three-term conjugate gradient algorithm for unconstrained optimization. Numer. Algorithms 2014, 65, 859–874. [Google Scholar] [CrossRef]
- Yang, Y.; Chen, Y.; Lu, Y. A subspace conjugate gradient algorithm for large-scale unconstrained optimization. Numer. Algorithms 2017, 76, 813–828. [Google Scholar] [CrossRef]
- Li, M.; Liu, H.; Liu, Z. A new subspace minimization conjugate gradient method with non-monotone line search for unconstrained optimization. Numer. Algorithms 2018, 79, 195–219. [Google Scholar] [CrossRef]
- Yao, S.; Wu, Y.; Yang, J.; Xu, J. A Three-Term Gradient Descent Method with Subspace Techniques. Math. Probl. Eng. 2021, 2021, 8867309. [Google Scholar] [CrossRef]
- Yuan, Y. A review on subspace methods for nonlinear optimization. Proc. Int. Congr. Math. 2014, 807–827. [Google Scholar]
- Wei, Z.; Yao, S.; Liu, L. The convergence properties of some new conjugate gradient methods. Appl. Math. Comput. 2006, 183, 1341–1350. [Google Scholar] [CrossRef]
- Yuan, Y. A modified BFGS algorithm for unconstrained optimization. IMA J. Numer. Anal. 1991, 11, 325–332. [Google Scholar] [CrossRef]
- Dai, Y.; Yuan, J.; Yuan, Y.X. Modified two-point stepsize gradient methods for unconstrained optimization. Comput. Optim. Appl. 2002, 22, 103–109. [Google Scholar] [CrossRef]
- Dai, Y.H.; Kou, C.X. A nonlinear conjugate gradient algorithm with an optimal property and an improved Wolfe line search. Soc. Ind. Appl. Math. J. Optim. 2013, 23, 296–320. [Google Scholar] [CrossRef] [Green Version]
- Dolan, E.D.; Moré, J.J. Benchmarking optimization software with performance profiles. Math. Program. 2002, 91, 201–213. [Google Scholar] [CrossRef]
- Andrei, N. An unconstrained optimization test functions collection. Adv. Model. Optim. 2008, 10, 147–161. [Google Scholar]
- Hager, W.W.; Zhang, H. A new conjugate gradient method with guaranteed descent and an efficient line search. SIAM J. Optim. 2005, 16, 170–192. [Google Scholar] [CrossRef] [Green Version]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Test Problems | No. | Test Problems |
|---|---|---|---|
| 1 | Extended Freudenstein & Roth function | 35 | NONDIA function (CUTE) |
| 2 | Extended Trigonometric function | 36 | DQDRTIC function (CUTE) |
| 3 | Extended Rosenbrock function | 37 | EG2 function (CUTE) |
| 4 | Generalized Rosenbrock function | 38 | DIXMAANA - DIXMAANL functions |
| 5 | Extended White & Holst function | 39 | Partial Perturbed Quadratic function |
| 6 | Extended Beale function | 40 | Broyden Tridiagonal function |
| 7 | Extended Penalty function | 41 | Almost Perturbed Quadratic function |
| 8 | Perturbed Quadratic function | 42 | Perturbed Tridiagonal Quadratic function |
| 9 | Diagonal 1 function | 43 | Staircase 1 function |
| 10 | Diagonal 3 function | 44 | Staircase 2 function |
| 11 | Extended Tridiagonal 1 function | 45 | LIARWHD function (CUTE) |
| 12 | Full Hessian FH3 function | 46 | POWER function (CUTE) |
| 13 | Generalized Tridiagonal 2 function | 47 | ENGVAL1 function (CUTE) |
| 14 | Diagonal 5 function | 48 | CRAGGLVY function (CUTE) |
| 15 | Extended Himmelblau function | 49 | EDENSCH function (CUTE) |
| 16 | Generalized White & Holst function | 50 | CUBE function (CUTE) |
| 17 | Extended PSC1 function | 51 | BDEXP function (CUTE) |
| 18 | Extended Powell function | 52 | NONSCOMP function (CUTE) |
| 19 | Full Hessian FH2 function | 53 | VARDIM function (CUTE) |
| 20 | Extended Maratos function | 54 | SINQUAD function (CUTE) |
| 21 | Extended Cliff function | 55 | Extended DENSCHNB function (CUTE) |
| 22 | Perturbed quadratic diagonal function 2 | 56 | Extended DENSCHNF function (CUTE) |
| 23 | Extended Wood function | 57 | LIARWHD function (CUTE) |
| 24 | Extended Hiebert function | 58 | COSINE function (CUTE) |
| 25 | Quadratic QF1 function | 59 | SINE function:83 |
| 26 | Extended quadratic penalty QP1 function | 60 | Generalized Quartic function |
| 27 | Extended quadratic penalty QP2 function | 61 | Diagonal 7 function |
| 28 | Quadratic QF2 function | 62 | Diagonal 8 function |
| 29 | Extended quadratic exponential EP1 function | 63 | Extended TET function:(Three exponential terms) |
| 30 | Extended Tridiagonal 2 function | 64 | SINCOS function |
| 31 | FLETCHCR function (CUTE) | 65 | Diagonal 9 function |
| 32 | TRIDIA function (CUTE) | 66 | HIMMELBG function (CUTE) |
| 33 | ARGLINB function (CUTE) | 67 | HIMMELH function (CUTE) |
| 34 | ARWHEAD function (CUTE) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huo, J.; Yang, J.; Wang, G.; Yao, S. A Class of Three-Dimensional Subspace Conjugate Gradient Algorithms for Unconstrained Optimization. Symmetry 2022, 14, 80. https://doi.org/10.3390/sym14010080
Huo J, Yang J, Wang G, Yao S. A Class of Three-Dimensional Subspace Conjugate Gradient Algorithms for Unconstrained Optimization. Symmetry. 2022; 14(1):80. https://doi.org/10.3390/sym14010080
Chicago/Turabian StyleHuo, Jun, Jielan Yang, Guoxin Wang, and Shengwei Yao. 2022. "A Class of Three-Dimensional Subspace Conjugate Gradient Algorithms for Unconstrained Optimization" Symmetry 14, no. 1: 80. https://doi.org/10.3390/sym14010080
APA StyleHuo, J., Yang, J., Wang, G., & Yao, S. (2022). A Class of Three-Dimensional Subspace Conjugate Gradient Algorithms for Unconstrained Optimization. Symmetry, 14(1), 80. https://doi.org/10.3390/sym14010080