Abstract
Error parameters are inevitable in systems. In formal verification, previous reasoning methods seldom considered the probability information of errors. In this article, errors are described as symmetric truncated normal intervals consisting of the intervals and symmetric truncated normal probability density. Furthermore, we also rigorously prove lemmas and a theorem to partially simplify the calculation process of truncated normal intervals and independently verify the formulas of variance and expectation of symmetric truncated interval given by some scholars. The mathematical derivation process or verification codes are provided for most of the key formulas in this article. Hence, we propose a new reasoning method that combines the probability information of errors with the previous statistical reasoning methods. Finally, an engineering example of the reasoning verification of train acceleration is provided. After simulating the large-scale cases, it is shown that the simulation results are consistent with the theoretical reasoning results. This method needs more calculation, while it is more effective in detecting non-error’s fault factors than other error reasoning methods.
1. Introduction
Formal verification technology has been widely used in industry [1,2]. The reasoning method is an essential step in theorem proving in formal verification. It requires strict mathematical deduction to ensure the correctness of the reasoning process [3]. In engineering, it is often combined with model-based verification methods [4] to complement each other [5,6,7]. Before verifying whether a system satisfies the safety properties, it is necessary to use certain logical semantics to precisely describe the system states and transition guards in mathematical language. In the past decades, numerous logical semantics have been proposed from binary logic [8] to polynomial algebraic logic [9] and semi-algebraic logic [10,11] for real numbers. Moreover, many achievements have emerged in the field of symbolic computation, which has been used as a mathematical deduction tool, such as Wu’s method [12], Gröbner basis method [13], and quantifier elimination method [14,15]. With the development of semantic and symbolic computation, reasoning verification for complex systems has become a reality. At present, several verification tools based on theorem proving have appeared for the verification of complex systems, such as KeYmaera [16] and ACL2 [17]. Polynomials-related reasoning methods based on the Gröbner basis have been widely applied in reasoning verification of polynomial and hybrid systems [18]. Nevertheless, a completely different Gröbner basis may be obtained when the polynomial coefficient changes slightly, which makes these methods invalid for the polynomials with uncertain coefficients. Wu’s method has been successfully applied in algebra proof, especially for proving geometry theorems (excluding inequality), but these methods based on Wu’s method are invalid for verifying semi-algebraic systems.
Most of the previous reasoning methods focused on systems with certain parameters. However, some uncertain coefficients, such as the error parameters, are unavoidable in systems. In most cases, we can determine the range of these error parameters in advance. For example, the measured values of the parameters do not exceed the measured allowable range of instruments. Most of the previous reasoning verification methods have failed to deal with polynomial systems with error parameters. For example, the Gröbner basis has been widely used in polynomial-based reasoning methods. However, the small fluctuation of parameters in polynomial systems may lead to significant changes in their Gröbner basis [19].
Several studies on reasoning methods have involved error parameters. In the previous studies, the authors proposed a reasoning method for linear error assertion [20,21], in which the relationship between precursor assertion and successor assertion can be derived based on analysis of whether vertexes of the precursor assertion are contained in the zero set of the successor assertion. A detailed method to obtain vertexes of the precursor assertion is provided in [21]. We also proposed a reasoning method to deal with the nonlinear error assertion [22], by assessing the implication relationship between polynomial error assertions by eliminating quantifiers problem in a specific semi-algebraic system. A limitation of the methods in [20,21,22] is that that they do not utilize the statistical information of the errors, which may result in lagging identification of potential non-error failure factors.
This paper proposes a new reasoning method to handle parameter imprecision by accommodating and inferencing with probabilistic information, which can be obtained by parameter estimation from samples. We adopt truncated normal distribution on intervals [23] to achieve richer representation of parameter errors than the current practice of using simple intervals in the reasoning process. The major contributions of this paper are highlighted as follows.
- We propose a novel reasoning method, which can make a conclusion about whether the system is likely to have potential risks caused by non-error factors when the system state is still inside the set. However, the previous method can give the assessment only when the system state is not inside the set. The method is more effective than other methods [20,21,22] for safety-critical systems if the time complexity of the specific problem is acceptable.
- Some lemmas (Lemmas 1, 2 and Theorem 1) and their proofs are provided, which partially simplify the calculations. These lemmas and theorem are beneficial to the methods, which are also based on symmetric truncated normal intervals in other fields.
- We provide an engineering example and the Maple codes to make our reasoning method easier to apply to the industrial field.
2. Preliminaries
2.1. Interval Random Errors
In this section, we introduce some of the mathematical concepts that have been established and are involved in our method (Definitions 1–3). We also prove Lemmas 1 and 2 and Theorem 1, which are the contributions of this study.
Definition 1.
The interval random error is a random variable in the interval,, andis the probability density function of, denoted by, or. Thus,must satisfy the normalization condition.
In engineering, the upper and lower bounds of are generally not infinite. When , can be obtained by replacing , and is an interval random error. The probability density function of is as follows:
As long as c is sufficiently large, will always hold. Therefore, the four operations of interval random errors discussed below only consider the case in which the lower bound of the interval random errors is not negative.
Let and be interval random errors in intervals and respectively, and the probability density functions of and are , , respectively. is the joint probability density of , and c is a constant real number. The probability density function is The four operations of random interval errors can be given as follows:
For addition:
When , are independent, we have .
For subtraction:
When , are independent, we have .
For multiplication:
When , are independent, we have .
For division:
When , are independent, we have .
2.2. Intervals with Symmetric Truncated Normal Density Function
Definition 2 is mainly due to the authors of reference [24], and it has been applied in industry [25]. The normalization of probability on interval was verified independently after Definition 2.
Definition 2.
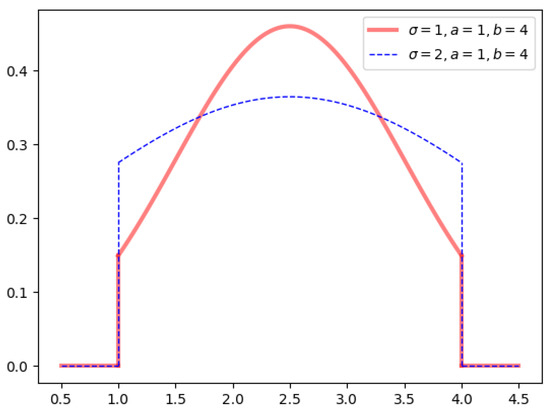
The symmetric truncated interval normal density function (short for truncated normal density) is as formula (6)
where, the function curve is symmetric about, that is,is the axis of symmetry as shown in Figure 1;respectively represent the upper and lower bounds of the interval;is the probability density function of the standard normal distribution;is the standard normal cumulative distribution function;is the parameter for the shape of the interval normal density. In Figure 1, the largercorresponds to a flatter function curve, which is similar to meaning in the normal probability density. The following verification in formula (7) shows that the formula “” holds, which must be satisfied according to Definition 1.
Figure 1.
Example of truncated normal density.
Figure 1 shows the truncated normal density curve for , and . Figure 2 shows the function curve of the normal density function when , and .
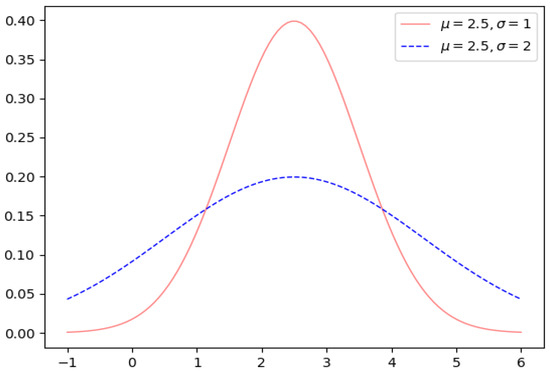
Figure 2.
Example of normal probability density function.
As shown in Figure 1, when and , which are different from the normal probability density function. Combining definitions 1 and 2, the definition of the interval normal interval can be given as follows:
Definition 3.
(Symmetric truncated normal interval, short for truncated normal interval) An interval random error X is a truncated normal interval, if X is in the range ,, and the probability densityof X has the form of formula (6). The truncated normal interval X can be denoted by,.
Obviously, taking as the midline, the errors variables appearing on the left and right sides of the midline are symmetrical. The normal truncation interval is used to represent uncertain parameters in the method introduced later in this paper.
Properties 1 and 2 (introduced in reference [26]) show how to calculate the expectation and variance of the truncated normal interval, respectively.
Property 1.
The expectation of truncated normal interval is:
Property 2.
The variance of truncated normal interval is:
The variance and expectation of the truncated normal interval were also independently verified by the following Maple2020 codes:
phi:= x -> exp(−1/2*x^2)/sqrt(2*Pi);
Phi:= x -> 1/2 + 1/2*erf(1/2*sqrt(2)*x);
f:= (x, a, b, sigma) -> phi((x − 1/2*a − 1/2*b)/sigma)/(sigma*(Phi((1/2*b − 1/2*a)/sigma) − Phi((1/2*a − 1/2*b)/sigma)));
E(X) = int(x*f(x, a, b, sigma), x = a .. b);
Var[1]:= X -> int(x^2*f(x, a, b, sigma), x = a .. b) − int(x*f(x, a, b, sigma), x = a .. b)^2;
Var[2]:= X -> sigma^2*(1 − ((1/2*b/sigma − 1/2*a/sigma)*phi(1/2*b/sigma − 1/2*a/sigma) − (1/2*a/sigma − 1/2*b/sigma)*phi(1/2*a/sigma − 1/2*b/sigma))/(Phi(1/2*b/sigma − 1/2*a/sigma) − Phi(1/2*a/sigma − 1/2*b/sigma)));
simplify(Var[1](X) − Var[2](X));
Lemma 1.
is a truncated normal interval, whichis introduced in Definition 2. whereis the positive real number. Then,must be a truncated normal interval with probability densityin.
Proof.
According to probability knowledge, formula (10) can be obtained.
In formula (10), and are the cumulative distribution functions of X and Y, respectively. After calculating the derivative of y in Equation (10), the probability density of Y can be obtained as follows:
In addition:
According to formula (6) and formula (11), we have:
That is, formula (13) is obtained:
Formula (13) conforms to the definition of “truncated normal density” introduced in Definition 2. Thus, we have:
In summary, according to the definitions of the truncated normal interval introduced in Definition 3, can be regarded as the truncated normal interval with . □
Lemma 2.
is a truncated normal interval, whichis introduced in Definition 2.is a real constant. Then,must be a truncated normal interval with probability densityin.
Proof.
According to probability knowledge, we have:
After calculating the derivation of formula (15) on y, we have
Because , we have .
In summary, can be treated as a truncated normal interval with and . □
Theorem 1.
is a truncated normal interval,are two real constants, and, andis also a truncated normal interval with the probability densityon the interval.
Proof.
According to Lemma 1, is a truncated normal interval with probability density on the interval, and from Lemma 2, is also a truncated normal interval on the interval with probability density . □
The parameter of the truncated normal interval is not the standard deviation of . can be regarded as a random variable generated by the normal random variable by truncating on [a, b]. As introduced in properties 1 and 2, the expectation of can be calculated by a and b, and the variance of is calculated by a, b, and . According to Theorem 1, the operations of truncated normal intervals introduced in Section 2.1, can be partially accelerated, especially for operations on truncated normal intervals. The following section introduces the reasoning methods based on truncated normal intervals.
3. Truncated Normal Interval-Based Reasoning Method
According to Definition 3, truncated normal intervals can be regarded as an extension of the interval by adding a truncated normal density to the interval. Hence, this makes the interval-based polynomial reasoning method (such as the methods from reference [20,21,22]) still valid for truncated normal intervals. In Section 3.2, we improved the reasoning methods [20,21] by adding the calculation of the truncated normal density into them. Before that, we introduce an implication relationship.
3.1. Reasoning Method between Polynomial Errors Assertions
3.1.1. Implication Relationship
In this section, we first introduce the polynomial error assertion, its zero set, Axiom 1, and the implication relationship, which were proposed by reference [22]. The implication relationship between assertions is the fundamental rule in the reasoning method based on theorem proving. The equivalence relationship can be attributed to assessing whether there are implication relationships with each other [27]. Hence, only the implication relationship is discussed below.
Definition 4 (Polynomial error assertion, PEA).
is a PEA ifandsatisfy (16) and (17), respectively.
Definition 5 (Real zero set of PEAs, short for zero set of PEAs).
is a PEA. The real zero set of, denoted by, satisfies (18).
In addition,satisfies Formula (19).
Apparently, the definition of the zero set of PEAs is self-consistent with that of classic polynomials. This is because when the upper and lower bounds of the interval are equal, the interval degenerates into a real number. For example, degenerates into a real number when . Here, the definition of the zero set of PEAs and that of the classical polynomial equations are identical.
Axiom 1.
implies(denoted as), whereandare polynomials or PEAs.
For polynomials, here is an example of Axiom 1. Let. . Now, we need to determine whether , which means whether implies . Simply put, if is true, then must be true. Indeed, must hold owing to .
For PEAs, is the set of all possible states of the system caused by the error parameters. In the polynomial-described system, the state of the system needs to satisfy specific polynomial equations, whose solutions define the safe area of the system in this state. For example, if the set indicates the safe area in a certain state of the system, we find that the variable value x of the system in this state is not included in , which means that the system is unsafe at the moment, and the fault should be eliminated immediately.
3.1.2. Problems of Previous Reasoning Methods
For error polynomial assertions, the previous reasoning methods [20,21,22] are all based on only characterizing errors as intervals, while ignoring the probability distribution information of the errors within the interval. In fact, the probability information of errors in the interval does exist and can be obtained from the statistics of the previous data. For example, in a large number of statistics on the measurement results of a certain physical quantity by a certain sensor, it can always be obtained that the measurement values closer to the true value will appear more frequently than the measurement values farther away. Ignoring the probability information of errors may lead to incomplete reasoning results, which affects the validity of the reasoning methods.
The set of all possible states caused by error parameters can be obtained. When designing the system, the impact of errors on the system should be fully considered. Thus, the system must have the ability to withstand the influence of errors. Hence, the system must allow the system states to appear at any position inside the set ; that is, set must be the subset of the designed state range of the system. Based on previous reasoning methods [20,21,22], if it is found that the state of the system () at a certain time is not in the set , that is, does not hold, then it indicates that there must be non-error factors (the non-error factors here and below are not the factors caused by similar uncertain parameters but the mechanical, electrical, and other factors that affect the performance of the system) affecting the system at this time, and the detection should be carried out immediately. In other words, only when we find that the system state is not in the set can we conclude that there must be the influence of non-error factors by previous reasoning methods. The following question is: Can it be concluded in advance that there is a great possibility of non-error factors in the system when the system state is still inside set ? Yes, but this requires more information about the error besides the interval. The focus of this study is to obtain such answers by combining statistical methods and reasoning methods.
3.2. Reasoning Method Based on Truncated Normal Interval
In this section, by introducing a truncated normal interval and combining the knowledge of probability and statistics, we generalize the methods in reference [20,21]. According to the quantile theory in statistics [28,29], the system state regions with a low probability in can be marked. If the system states often appear in the low probability area within a certain time period, then there is reason to believe that there are non-error factors affecting the system at this time. Although, at this time, the non-error factors can be withstood by the system; however, for safety-critical systems, it is necessary to eliminate potential mechanical or electrical problems early. The specific steps of the reasoning method are given below, which can be applied to the linear error assertion and the nonlinear problem in which the cross section (cross plane) of is a convex set, such as the example in Section 4.
In the following steps of the reasoning method, is the observation vector of the system state variables at time t: The error assertion that the system satisfies in a certain state is . Now, it is necessary to assess whether the system has non-error factors affecting the system at this time. The specific steps of the reasoning methods based on truncated normal intervals are given below.
Step 1: Calculate all the vertices of the set, , and generate inequalities that represent the area .
Step 2: Put any internal point p of set into the inequalities obtained in step 1 to obtain a specific inequality relationship.
Step 3: Put into the inequalities obtained in step (2). If cannot satisfy the inequalities, there must be non-error factors affecting the system. Here, fault detection is instantly required. If satisfies the inequalities, proceed to step (4).
Step 4: Calculate the probability distribution information of the area represented by set , and calculate the set ( is the subset of , where represents the area where the system state has a higher probability of occurrence when the system is running without potential failures). When , it is still very likely that there are non-error factors in the system, and it is still necessary to detect the system to avoid non-error factors beyond the acceptable range of the system.
In the next section, an example is provided regarding the application of the reasoning method to the two-body problem of decentralized power systems under train acceleration.
4. Verification of Two-Body Decentralized Power System during Train Acceleration
In Section 4.1, we present a case of the train acceleration state. In Section 4.2, we simulated the results obtained in Section 4.1, with a large number of random test cases.
4.1. Two-Body Problem of Train Acceleration
Assume that the train has two carriages (the 8-carriage and 16-carriage problems can be obtained recursively from the two-carriage problem). The two carriages have independent power outputs. When the train starts, the train moves from the acceleration state to the constant-speed state. The guard (guard: ) is the transition condition from acceleration to a constant state, as shown in Figure 3. and are the formulas that need to be satisfied in the acceleration state and the constant speed state, respectively. For example, in the acceleration state, if is not satisfied, the train power output system runs abnormally. Here, immediate detection is required.
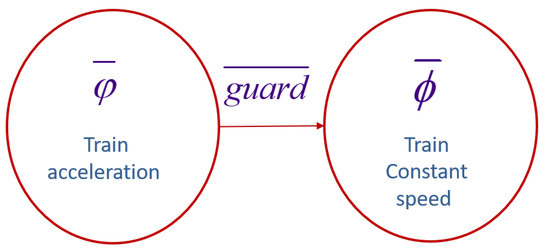
Figure 3.
Transition of train states.
When the train is accelerating and starting, the mass sum (including passengers) of carriage 1 and carriage 2 is a fixed value M. During a certain acceleration of the train, there is a random flow of passengers between the two carriages. However, the total mass of the two carriages was constant. However, for passengers to experience a comfortable train ride, a constant acceleration ( in this case) must be maintained during the acceleration state. The power control system of the train has a complex feedback mechanism that can maintain stable acceleration during acceleration. However, whether there are potential mechanical or electrical faults requires further verification and analysis.
After 200 s of acceleration with , the train speed reached . In the acceleration state with , some of the following parameters affect the power output: and represent the masses of two train cars (including passengers and their luggage), respectively; and represent the traction provided by carriage 1 and carriage 2, respectively, is the force of carriage 1 on carriage 2, is a parameter related to air density and pressure, represents acceleration (), and g is the gravity acceleration (). In a certain acceleration state, the sum of the masses of the two carriages is a fixed value of 110,000 kg. According to statistics of past passenger flow information and weather information during the same period, some of the above parameters can be regarded as truncated normal intervals, which were introduced in Section 2.2; that is, ; ; ; . According to the knowledge of mechanics, we can obtain Equation (20):
From the “step 1–step2” given in Section 3.2, the space area can be obtained shown in Figure 4 (The area surrounded by red lines, which short for red area as below).
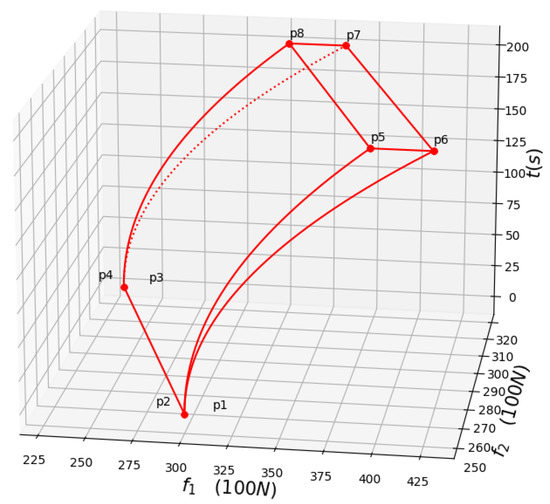
Figure 4.
Power distribution of the two bodies with the smoothly accelerating.
The vertexes of is shown in formula (21).
The possible power value at a certain time () is the inside enclosed area (including the boundary) by the black line shown in Figure 5, which is short for the black area as shown below. The black area (it is a quadrilateral, as shown in Figure 6) is actually the horizontal section of the red area at .
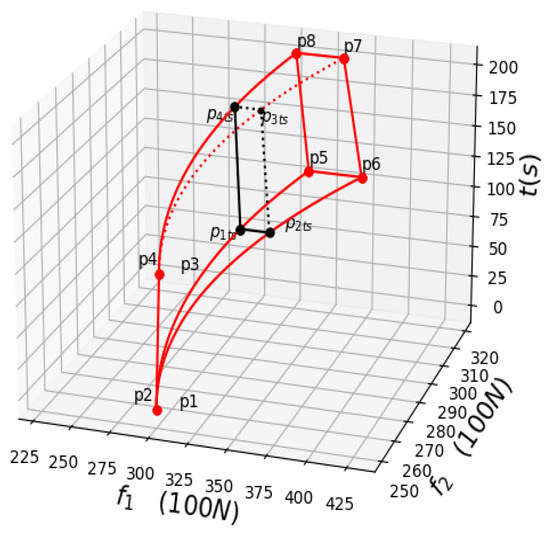
Figure 5.
Power distribution domain when t = ts (the interior surrounded by black lines).
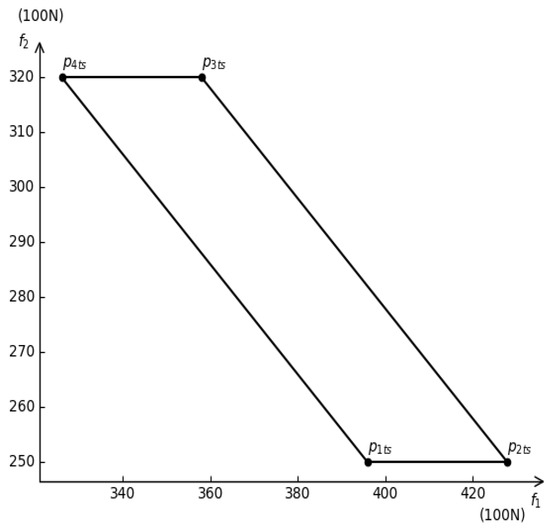
Figure 6.
Horizontal section of power distribution domain when t = ts.
According to the definitions of the truncated normal interval and the arithmetic rules in Section 2.1 and Section 2.2, the probability distribution information of can be obtained.
The values of are determined using the other variables (). First, the probability density of is calculated as . Let . According to Theorem 1, the probability density of can be obtained as From the second sub-formula () in formula (20), and combined with the arithmetic rules of the truncated normal interval introduced in Section 2.1, the probability density of can be obtained as formula (22):
After calculating Equation (22), (when ) can be obtained as formula (23):
The function appearing in formula (23) is .
In contrast, let be the sum of and , that is, . From the first sub-formula () in formula (20), when , the probability density of can be obtained as formula (24):
After calculating formula (24), (when ) can be obtained as Equation (25):
When or , ; When and , . is the Dirac δ function.
The codes of Maple2020 to obtain the results of Equations (23) and (25) are as follows:
phi:= x -> exp(−1/2*x^2)/sqrt(2*Pi);
Phi:= x -> 1/2 + 1/2*erf(1/2*sqrt(2)*x);
f:= (x, a, b, sigma) -> phi((x − 1/2*a − 1/2*b)/sigma)/(sigma*(Phi((1/2*b − 1/2*a)/sigma) − Phi((1/2*a − 1/2*b)/sigma)));
h(f[2], sigma[12], sigma[2]):= int(f(f[2] − f[12], 25,000, 30,000, 1/2*sigma[2])*f(f[12], 0, 2000, sigma[12]), f[12] = 0 .. 2000);
f(z, 6/25*t^2 + 55,000, 8/25*t^2 + 55,000, 4/25*t^2*sigma[Zeta]);
According to the analysis of historical data of train operations in the past, and can be obtained by parameter estimation methods. The following shows the division of when and quantile . The values of the upper and lower quantiles were calculated using the relevant integral equation. The lower quantile of is calculated using Equation (26).
The upper quantile of is calculated as formula (27).
The lower quantile of is calculated as formula (28).
In Equation (28), represents the root of equation . Similarly, the upper quantile of is calculated using Equation (29).
According to the numerical calculation from formulas (28) and (29), when t = 150(s), ; when t = 200(s), .
Figure 7 and Figure 8 show the division of by the quantiles (these quantiles are obtained by formulas (26)–(29)) when t = 150 s and t = 200 s, respectively.
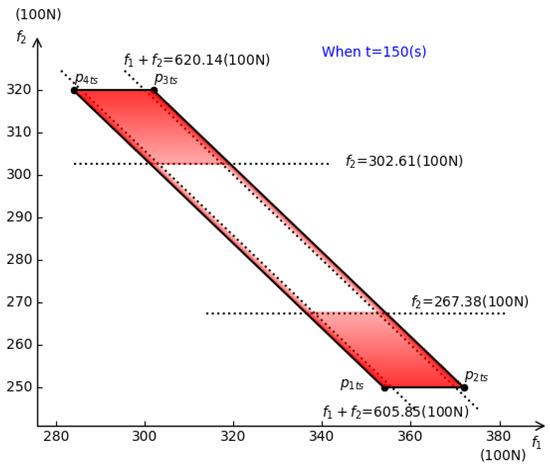
Figure 7.
Division of when t = 150.
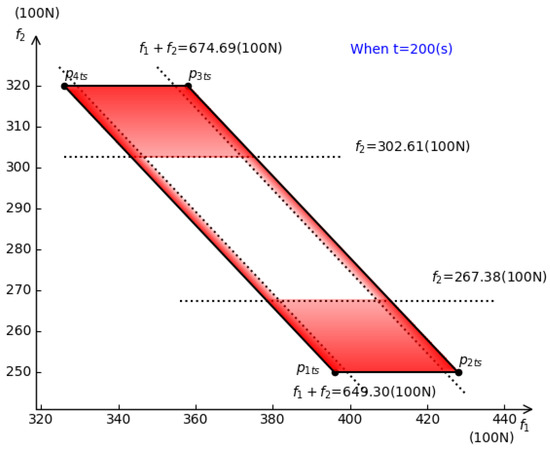
Figure 8.
Division of when t = 200.
Constant acceleration () ensures the stability of the train and the good riding experience of the passengers. During the acceleration of the train, the error parameters are uncertain, which leads to a real-time adjustment of the power output of the train. When the truncated normal intervals are given as ,, and , the red areas in Figure 7 and Figure 8 represent the areas with low probability of occurrence of train power output , and the red transparency (transparency is the concept of alpha blending about color) in the red area is proportional to the probability of . Hence, the higher the red transparency, the higher the probability of in the red areas of Figure 7 and Figure 8. In other words, during the acceleration of the train (t = [0,200]), if the values of and appear in the red area for a period of time, it is reasonable to believe that there are non-error factors in the power system at this time, and the system must be checked for safety in time to inspect whether there are mechanical or electrical faults. The parallelogram in Figure 8 (the area enclosed by ) is all possible areas of system power distribution caused by error parameters when t = 200. When designing the system, it is necessary to fully estimate the possible errors, and the power range must cover the area to ensure that the system has the ability to withstand the error parameters. As time passes, the mechanical equipment of the trains will inevitably wear out. Hence, it is necessary to detect factors that may cause system failure in time. This section discusses how to divide the area according to statistical knowledge. This is helpful for the safe operation of the system. Figure 9 shows the division of Figure 4, when and .
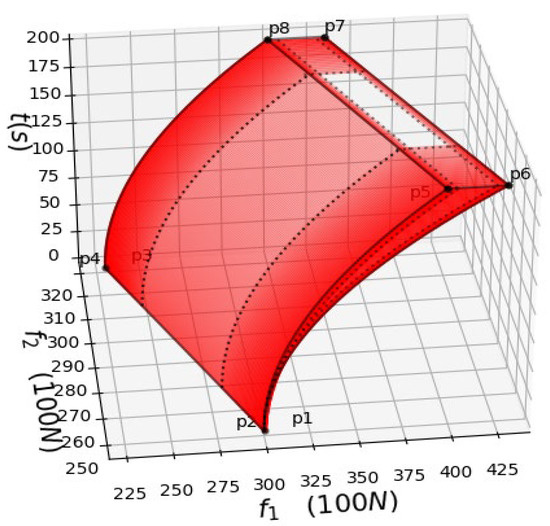
Figure 9.
Division of when t ∈ [0,200].
From (26)–(29), we obtain inequality(30) below, which represents the white area in Figure 9.
The red area in Figure 9 indicates a low occurrence probability of . It is unlikely that and will be in the red area for a long time, which means that there is a high possibility of non-error factors. Although the system can withstand it sometimes, early detection is still necessary for safety-critical systems.
4.2. Simulation and Test
The three truncated normal intervals in are, , and ,, and are the probability density functions. According to acceptance–rejection sampling, when , we can obtain n groups of test cases, denoted as . Taking into formula (20), the n solutions () can be obtained. We can then count the distributions of these solutions. Figure 10a,b show the distributions of f2 and in their truncated intervals, respectively, when n = 10,000; Figure 10c shows the distribution of that when t = 200.
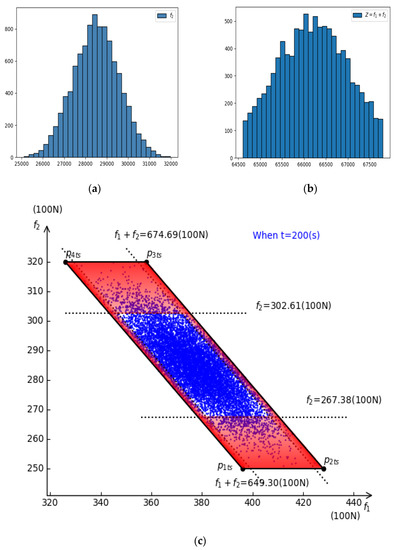
Figure 10.
(a) Distributions of f2 when n = 10,000 and t = 200; (b) The distributions of Z = f1 + f2 when n = 10,000 and t = 200; (c) The distributions of (i = 1, …, 10,000) when t = 200.
Algorithm 1 is given below for generating simulation cases and distribution values of and when t ranges from 1 to 200.
| Algorithm 1 used to generate simulation cases |
| 1: begin |
| 2: t = 1, ; 3: while (t <= 200) begin while |
| 4: Generate n cases ), according to acceptance –rejection sampling; 5: Take into formula (20), then calculate them and obtain ; |
| 6: ; end while |
| 7: end |
From the above algorithm, taking n = 100 for every discrete integer t value, , we can obtain Figure 11, where the power distributions of and are represented by the blue points.
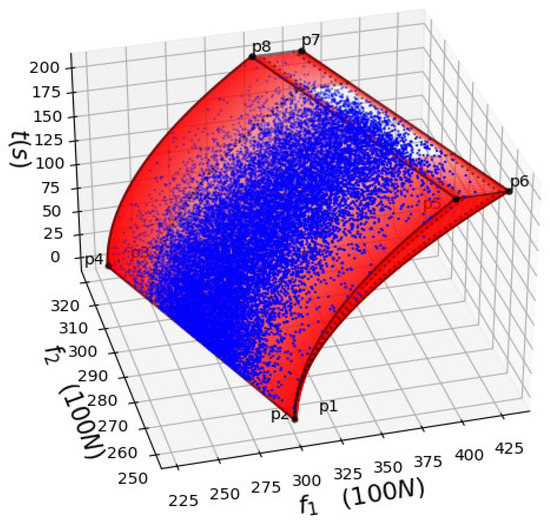
Figure 11.
Division of when t ∈ [0,200].
According to step 3 and step 4 of the reasoning method given in Section 3.2, we obtain the following: during the acceleration, if it is found that the power distribution of and are not within the area enclosed by “” in Figure 11, it means that there must be non-error factors affecting the power system, and fault detection should be carried out immediately; if the power distributions of and are inside the area “” in Figure 11, and if and continuously appear inside the red area of Figure 11, according to statistics, there is a high probability that non-error factors affect the system in the train power system at this time; fault detection is still required immediately.
From Figure 11, most of the distributions of and are inside the white area.
5. Discussion
Previous reasoning methods have mainly focused on systems with precise parameters. Most of these are invalid for systems with uncertain parameters because the Gröbner basis changes discontinuously with coefficients. The authors proposed some reasoning methods [20,21,22] for systems with uncertain parameters. Power distribution areas caused by error parameters can be obtained, and it can be used to determine whether the system has non-error fault factors (mechanical and electrical faults) by observing whether the system states are inside the area, but these methods ignore the probability information of the errors within the interval. The method proposed in this paper combines the probability information of errors with previous reasoning methods. Hence, not only can the power distribution areas be obtained, but also an area divided area by statistics, by which it can be earlier determined whether there are non-error fault factors compared with the methods [20,21,22]. Hence, the results obtained by this method are more complete than those of the methods [20,21]. Nevertheless, the method in this paper involves more calculations than the methods [20,21]. Finally, it is noteworthy while that this method increases the complexity of the calculation, it is necessary for safety-critical systems. Some scholars have studied based-fuzzy logic [30] reasoning rules [31], which have been applied in some aspects [32,33]. These are different from those of our method. Our method has a more obvious statistical significance. Table 1 shows the advantages and disadvantages of this method and other reasoning methods.

Table 1.
Advantages and disadvantages of this method and other methods.
6. Conclusions
Our main contributions are as follows: First, the errors were represented by symmetric truncated normal intervals, and the probability information of the errors was described by a truncated normal probability density function. Lemmas 1, 2 and Theorem 1 and their proofs are provided, which partially simplify the calculations between truncated normal intervals. Second, we combined symmetric truncated normal intervals with the previous reasoning methods and provided the steps of the reasoning method. The calculation of probability information is added to the reasoning method, which makes the reasoning method more effective and valuable than the method in [20,21,22] for safety-critical systems. Finally, a reasonable example of train acceleration was provided. Most of the points were inside the white area in Figure 11, which indicates that the theoretical calculation results (the white area comes from the reasoning method in this article) was consistent with the simulation results in this example.
Author Contributions
Conceptualization, P.W.; methodology, J.W. and J.L.; software, J.W.; formal analysis, P.W.; writing—original draft preparation, P.W.; writing—review and editing, Z.H.; funding acquisition, J.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (Grant no. 61772006), the Special Fund for Bagui Scholars of Guangxi (Grant no. 2017), and the Science and Technology Major Project of Guangxi (Grant no. AA 17204096), the key research and development project of Guangxi (Grant No. AB17129012).
Data Availability Statement
The data used to support the findings of this study are included within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Fisher, M.; Cardoso, R.C.; Collins, E.C.; Dadswell, C.; Dennis, L.A.; Dixon, C.; Farrell, M.; Ferrando, A.; Huang, X.; Jump, M.; et al. An Overview of Verification and Validation Challenges for Inspection Robots. Robotics 2021, 10, 67. [Google Scholar] [CrossRef]
- Sun, M.; Lu, Y.; Feng, Y.; Zhang, Q.; Liu, S. Modeling and Verifying the CKB Blockchain Consensus Protocol. Mathematics 2021, 9, 2954. [Google Scholar] [CrossRef]
- Wang, J.; Zhan, N.J.; Feng, X.Y.; Liu, Z.M. Overview of formal methods. J. Softw. 2019, 30, 33–61. [Google Scholar]
- Clarke, E.M.; Henzinger, T.A.; Veith, H.; Bloem, R. Handbook of Model Checking; Springer: Cham, Switzerland, 2018; Chapter 12; ISBN 9783030132330. [Google Scholar]
- Desai, A.; Dreossi, T.; Seshia, S.A. Combining Model Checking and Runtime Verification for Safe Robotics. In Runtime Verification, Proceedings of the International Conference on Runtime Verification, Seattle, WA, USA, 13–16 September 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 172–189. [Google Scholar] [CrossRef]
- Uribe, T.E. Combinations of model checking and theorem proving. In Proceedings of the International Workshop on Frontiers of Combining Systems, Nancy, France, 22–24 March 2000; pp. 151–170. [Google Scholar]
- Shankar, N. Combining theorem proving and model checking through symbolic analysis. Int. Conf. Concurr. Theory 2000, 1877, 1–16. [Google Scholar]
- Wu, J. Algebraic methods for mechanical theorem proving in many-valued logics. Chin. J. Comput. 1996, 10, 773–779. [Google Scholar]
- Fu, J.; Wu, J.; Tan, H. A deductive approach towards reasoning about algebraic transition systems. Math. Probl. Eng. 2015, 607013. [Google Scholar] [CrossRef]
- Platzer, A. Logical Analysis of Hybrid Systems: Proving Theorems for Complex Dynamics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2010; ISBN 9783642145087. [Google Scholar]
- Liu, J.; Zhan, N.; Zhao, H. Computing semi-algebraic invariants for polynomial dynamical systems. In Proceedings of the Ninth ACM International Conference on Embedded Software, Taipei, Taiwan, 9–14 October 2011; pp. 97–106. [Google Scholar]
- Elias, J. Automated Geometric Theorem Proving: Wu’s Method. Master’s Thesis, University of Montana, Missoula, MT, USA, 2006. [Google Scholar] [CrossRef]
- Buchberger, B. Gröbner bases: An algorithmic method in polynomial ideal theory. Multidimens. Syst. Theory 1995, 89–127. [Google Scholar] [CrossRef]
- Arnon, D.S.; Collins, G.E.; McCallum, S. Cylindrical algebraic decomposition. I. The basic algorithm. SIAM J. Comput. 1984, 13, 865–877. [Google Scholar] [CrossRef] [Green Version]
- Wang, D. Elimination Methods. Springer: Wien, Austria, 2001; ISBN 9783709162026. [Google Scholar]
- Fulton, N.; Mitsch, S.; Quesel, J.D.; Völp, M.; Platzer, A. KeYmaera X: An axiomatic tactical theorem prover for hybrid systems. In Proceedings of the Conference on Automated Deduction, Berlin, Germany, 1–7 August 2015; pp. 527–538. [Google Scholar] [CrossRef]
- Hunt, W.A.; Kaufmann, M.; Strother, M.J.; Slobodova, A. Industrial hardware and software verification with acl2. Philos. Trans. R. Soc. A 2017, 375, 20150399. [Google Scholar] [CrossRef] [PubMed]
- Chatterjee, K.; Zavadskas, E.K.; Tamošaitienė, J.; Adhikary, K.; Kar, S. A Hybrid MCDM Technique for Risk Management in Construction Projects. Symmetry 2018, 10, 46. [Google Scholar] [CrossRef] [Green Version]
- Kondratyev, A.; Stetter, H.J.; Winkler, S. Numerical computation of Gröbner bases. In Proceedings of the CASC2004 (Computer Algebra in Scientific Computing), Chişinău, Moldova, 11–15 September 2004; pp. 295–306. [Google Scholar]
- Wu, P.; Xiong, N.; Liu, J.; Huang, L.; Ju, Z.; Ji, Y.; Wu, J. Interval number-based safety reasoning method for verification of decentralized power systems in high-speed trains. Math. Probl. Eng. 2021, 6624528. [Google Scholar] [CrossRef]
- Wu, P.; Wu, J. Reasoning method based on linear error assertion. J. Comput. Appl. 2021, 41, 2199–2204. [Google Scholar] [CrossRef]
- Wu, P.; Xiong, N.; Xiong, J.; Wu, J. Reasoning method between polynomial error assertions. Information 2021, 12, 309. [Google Scholar] [CrossRef]
- Burkardt, J. The Truncated Normal Distribution. Available online: https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf. (accessed on 16 November 2021).
- Robert, C.P. Simulation of truncated normal variables. Stat. Comput. 1995, 5, 121–125. [Google Scholar] [CrossRef] [Green Version]
- Castillo, N.O.; Gallardo, D.I.; Bolfarine, H.; Gómez, H.W. Truncated Power-Normal Distribution with Application to Non-Negative Measurements. Entropy 2018, 20, 433. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barr, D.; Sherrill, E. Mean and variance of truncated normal distributions. Am. Stat. 1999, 53, 357–361. [Google Scholar]
- Shoenfield, J.R. Mathematical Logic; AK Peters/CRC Press: Natick, MA, USA, 2001; ISBN 1568811357. [Google Scholar]
- Csörgő, M. Quantile Processes with Statistical Applications; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1983; ISBN 0898711851. [Google Scholar]
- Volgushev, S.; Chao, S.-K.; Cheng, G. Distributed inference for quantile regression processes. Ann. Stat. 2019, 47, 1634–1662. [Google Scholar] [CrossRef] [Green Version]
- Belohlavek, R.; Dauben, J.W.; Klir, G.J. Fuzzy Logic and Mathematics: A Historical Perspective; Oxford University Press: Oxford, UK, 2017; ISBN 9780190200015. [Google Scholar]
- Nazari, S.; Fallah, M.; Kazemipoor, H.; Salehipour, A. A fuzzy inference-fuzzy analytic hierarchy process-based clinical decision support system for diagnosis of heart diseases. Expert Syst. Appl. 2018, 95, 261–271. [Google Scholar] [CrossRef]
- Mehrabi, M.; Pradhan, B.; Moayedi, H.; Alamri, A. Optimizing an Adaptive Neuro-Fuzzy Inference System for Spatial Prediction of Landslide Susceptibility Using Four State-of-the-art Metaheuristic Techniques. Sensors 2020, 20, 1723. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, H.; Liu, X.; Wang, X.; Liu, Y. A fuzzy inference and big data analysis algorithm for the prediction of forest fire based on rechargeable wireless sensor networks. Sustain. Comput. Infor. Syst. 2018, 18, 101–111. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).