Abstract
In this paper, we present an extension of the truncated positive normal (TPN) distribution to model positive data with a high kurtosis. The new model is defined as the quotient between two random variables: the TPN distribution (numerator) and the power of a standard uniform distribution (denominator). The resulting model has greater kurtosis than the TPN distribution. We studied some properties of the distribution, such as moments, asymmetry, and kurtosis. Parameter estimation is based on the moments method, and maximum likelihood estimation uses the expectation-maximization algorithm. We performed some simulation studies to assess the recovery parameters and illustrate the model with a real data application related to body weight. The computational implementation of this work was included in the tpn package of the R software.
1. Introduction
The modeling of non-negative data has grown exponentially, since many datasets have this characteristic. Distributions with support in the positive line are used widely in the engineering and reliability fields related to failure time (also known as lifetime data). The half-normal distribution (HN) is a very well-known model for non-negative data, discussed extensively in the literature. For instance, Rafiqullah et al. [1] used the HN model to analyze survival data related to breast cancer in Hispanic black and non-Hispanic black women. Bosch-Badia et al. [2] studied the applicability of the HN distribution to risk analysis traditionally performed using risk matrices. Tsizhmovska et al. [3] analyzed the length of sentences where one of their distributions was the HN.
Olmos et al. [4] generated an extension of the HN distribution, obtaining a distribution that captures atypical data, but with little flexibility, called the slashed half-normal distribution (SHN). Cooray and Ananda [5] generalized the HN distribution, obtaining a new flexible model, which they denominated the generalized half-normal (GHN) distribution, which includes the HN model as a particular case. Despite the flexibility offered, a major difficulty appears, commonly related to limitations on the use of atypical data. To solve the obstacle, Olmos et al. [6] proposed an extension of the GHN model, named the slashed generalized half-normal (SGHN) distribution. The main aim of the authors was to generate a model with a higher kurtosis that allows better modeling of positive data in the presence of outliers. Other authors have worked on a similar idea, e.g., Iriarte et al. [7], Reyes et al. [8], Olmos et al. [9], Segovia et al. [10], and Astorga et al. [11].
Gómez et al. [12] truncated the normal distribution, conditioning it to positive values, i.e., if X has a normal distribution, the authors studied (see Jonhson et al. [13]), creating a distribution that they named the truncated positive normal distribution (TPN). A random variable (rv) Z follows a TPN distribution, denoted by , if its probability density function (pdf) is given by:
where denotes the pdf of the standard normal model, is a scale parameter, and is a shape parameter.
On the other hand, the slash distribution is defined stochastically as the quotient between two independent rv, let us say Z and U, as follows:
where and are independent and is a shape parameter.
Olmos et al. [6] used this idea to propose an extension to the half-normal generalized model of Cooray and Ananda [1], called the slashed generalized half-normal distribution (SGHN). The density function of this rv is as follows:
where and is the cumulative distribution function (cdf) of the gamma distribution with shape parameter a and rate parameter one. We denote .
The objective of this paper is to propose an extension of the model proposed by Gómez et al. [12] using the “slash” procedure, utilizing a TPN rv in the numerator. Thus, the new model, which we call the slash truncated positive normal (STPN), will become a direct competitor model for SGHN, since it creates heavier tails and, moreover, allows the fitting of atypical data.
The paper is organized as follows. Section 2 presents the pdf of the STPN distribution and some properties such as moments, the hazard function, and the kurtosis coefficient. Section 3 studies the inference for the proposed model. In particular, we discuss the moments estimator and the expectation-maximization (EM) [14] algorithm to find the maximum likelihood estimator. In addition, we offer the observed Fisher information using Louis’ method [15]. Section 4 shows a simulation study to assess the recovery parameters. Section 5 conducts a real data application, where the STPN is compared with other proposals in the literature. Finally, Section 6 presents the conclusions of the manuscript.
2. The Slash Truncation Positive Normal Model
In this section, we describe the stochastic representation of the STPN model, its pdf, and some basic properties of the model.
2.1. Stochastic Representation and Particular Cases
Definition 1.
An rv Y has an STPN distribution with parameters σ, λ, and q if it can be represented as the ratio:
where and are independent rvs, , , and . We denote it as
By construction, the following models are particular cases for the STPN distribution:
- STPN TPN;
- STPN SHN;
- STPN HN.
Figure 1 summarizes the relationships among the STPN and its particular cases.
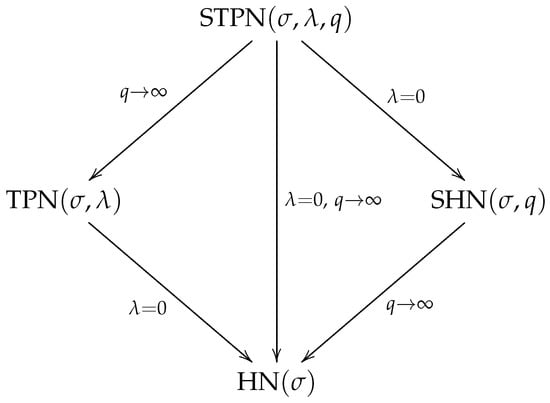
Figure 1.
Particular cases for the STPN distribution.
2.2. Density Function
Proposition 1.
Let . Then, the pdf of Y is given by:
where is a scale parameter, is a shape parameter, and is a parameter related to the kurtosis of the distribution.
Proof.
Using the representation in (4) and computing the Jacobian of the transformation for and , we obtain:
Therefore,
Marginalizing with respect to variable W, we obtain the density function corresponding to the rv Y, that is,
An alternative way to obtain this pdf is by substituting , obtaining:
With in the last expression, we obtain:
□
2.3. Some Properties
In this section, we study some basic properties of the STPN distribution.
Proposition 2.
Let . Then, the cdf of Y is given by:
Proof.
It is immediate from the definition. □
Proposition 3.
Let . Then, the hazard function is given by:
Figure 2 shows the pdf, cdf, and hazard function for the STPN model with different combinations of parameters.
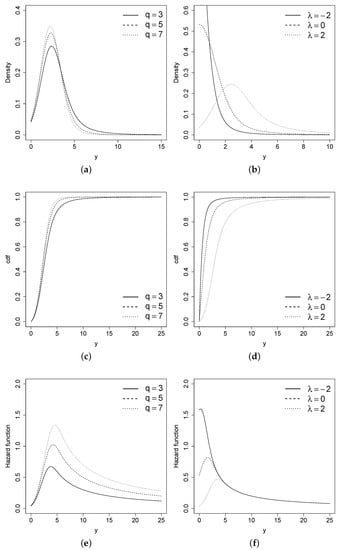
Figure 2.
pdf, cdf, and hazard function for the STPN model with different combinations of q and the STPN model with different combinations of . (a) pdf of STPN. (b) pdf of STPN. (c) cdf of STPN. (d) cdf of STPN. (e) hazard function of STPN. (f) hazard function of STPN.
Proposition 4.
Let . If , then Y strongly converges to the rv .
Proof.
Let . Then, Y can be written as , where and . First, we studied the convergence in the probability of . It is clear that , then , so that . If , then . Therefore,
where denotes convergence in probability. Then, applying Slutsky’s theorem [16] to , we have:
where denotes convergence in the distribution. In other words, for greater q values, Y strongly converges to the distribution.
□
Proposition 5.
If and , then
Proof.
The marginal distribution of Y can be computed as:
With the transformation , we obtain Equation (5). □
Remark 1.
Proposition 4 implies that for , the pdf of the STPN distribution converges to the pdf of the TPN model. Proposition 5 shows that the STPN distribution can also be seen as a scale mixture of the TPN model. This property is very important for obtaining random values from this model and for the application of an EM-type algorithm to estimate the parameters of the model.
2.4. Moments
The following proposition provides the moments of the STPN distribution.
Proposition 6.
Let . Therefore, for and , the r-th moment of Y is given by:
where .
Proof.
Using the stochastic representation given in Equation (4), we have that:
where , , and are the moments of the TPN model. □
Corollary 1.
If , then its first four moments are determined as follows:
Proof.
It is immediate from Proposition 6. □
Corollary 2.
Let , then the asymmetry coefficient and the kurtosis coefficient are:
where and .
Proof.
By the definition of the asymmetry and kurtosis coefficients, we have:
Replacing , and obtained in Corollary 1, we have the result. □
Remark 2.

Proposition 6 shows that the moments of the distribution depend essentially on the moments of the distribution. Equations (6) and (8) show the effect of parameter q on the model; a lower value of q produces greater variance and kurtosis. Table 1 shows some values of the kurtosis coefficient of the distribution for different values of λ and q.
Table 1.
Some values for the kurtosis coefficients of the STPN distribution for different values of and q.
Figure 3 shows the mean, standard deviation, asymmetry coefficient, and kurtosis coefficient for the STPN in terms of and q.
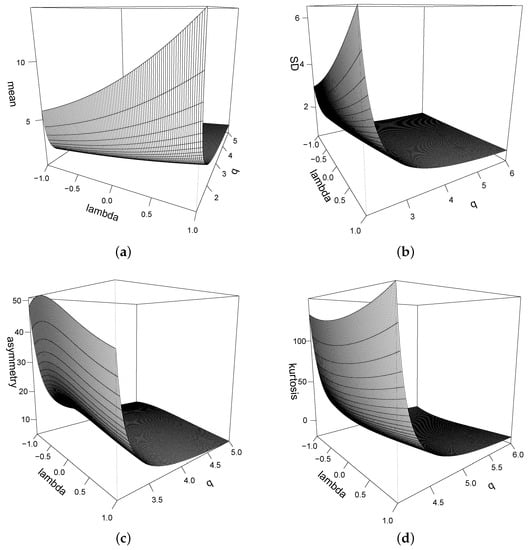
Figure 3.
(a) Mean; (b) standard deviation; (c) asymmetry coefficient; (d) kurtosis coefficient for the STPN() model.
3. Inference
In this Section, we discuss a classical approach for the inference for the STPN distribution. In particular, we discuss the moments estimators and maximum likelihood (ML) estimation based on the EM algorithm.
3.1. Moments Estimators
The moments estimators result from the solution of the equation , for , where denotes the j-th sample moment. Solving , we have that:
Replacing this, we have the following nonlinear equations
These equations can be solved using different software. For instance, in R [17], we can use the nleqslv function to obtain the moments estimators and . The moments estimator is obtained by substitution in Equation (9).
3.2. Maximum Likelihood Estimation
Given , a random sample from the STPN distribution, the log-likelihood function for is given by:
where:
Deriving in relation to the components of , we obtain the following ML equations:
where , , and . For , we define:
With those notations, the ML equations can also be written as:
Taking , , , and , the equations are equivalent to:
The ML estimators can be obtained directly using numerical procedures. However, to increase the robustness of the procedure for obtaining those estimators, we also discuss an EM-type algorithm for estimation in the model.
3.3. EM Algorithm
The EM algorithm is a well-known tool for ML estimation in the presence of nonobserved (latent) data. For this particular problem, the algorithm takes advantage of the stochastic representation of the STPN model in Equation (4). Let . The representation of the model can be seen as , where Beta.
In this context, the STPN distribution can also be written using the following hierarchical representation:
In our context, and represent the observed and nonobserved data, respectively. The complete data are given by . We also denote as the complete log-likelihood function, which up to a constant is given by:
Note that ; the expected value of provided the observed data is given by:
where , , and . In our context, , and do not have a closed form; they therefore need to be computed numerically. In short, the k-th step of the EM algorithm is detailed as follows:
- E-step: For , the value for the vector of parameters at the k-step, compute , , and , for ;
- CM-Step I: Given and , update as follows:
- CM-Step II: Given and , update since the solution is obtained from the nonlinear equation.
- CM-Step III: Given , update q as follows:
The E-, CM-I, CM-II, and CM-III steps are repeated until an ad hoc criterion is satisfied. For instance, we considered , for a fixed . In other words, the difference in the observed log-likelihood for successive steps is lower than a determined value. The initial values for the algorithm can be obtained, for instance, using the , , and , moments estimators.
3.4. Observed Fisher Information Matrix
The variance of the estimators can be estimated based on the observed Fisher information matrix, say . In particular, we have that:
where denotes the standard trivariate normal distribution. The computation of is not trivial, because it involves the derivation of functions that depend on integrals. Taking advantage of the complete log-likelihood function, can also be approximated by Louis’ method [14] as follows:
The details of the components of are provided in the Appendix A.
3.5. Computational Aspects
The EM algorithm and Louis’ method to obtain the ML estimators and their standard errors for the STPN distribution are included in the tpn package [18] from R [17]. The following function can be used to obtain these results:
where y is the response variable, sigma0, lambda0, q0 are the initial values for the algorithm (they are not defined by default), prec is the precision for the parameters, and max.iter is the maximum number of iterations to be applied for the algorithm. The tpn package also includes the functions dstpn, pstpn, and rstpn, which compute the pdf, cdf, and generation for the STPN distribution.
est.stpn(y, sigma0=NULL, lambda0=NULL, q0=NULL, prec = 0.001, max.iter = 1000)
4. Simulation
In this section, we study the performance of the ML estimators using the EM algorithm for the STPN distribution under different scenarios. We considered two values for : 2 and 10; three values for : −1, 1, and 3; two values for q: and 3; and four sample sizes: 50, 100, 200, and 500. For each combination of and n (totaling 48 combinations), we drew 1000 replicates, and we used the tpn package to estimate the parameters based on the EM algorithm and estimated the standard deviations based on Louis’ method to estimate the observed Fisher information matrix. Table 2 summarizes the mean of the estimated bias for the 1000 replicates (bias), the mean of the standard errors (SEs), the root of the estimated mean-squared error (RMSE), and the estimated coverage probability based on the asymptotic distribution for the ML estimator using a 95% confidence level (CP). Note that the bias and the RMSE terms are reduced when the sample size is increased, suggesting that the estimators are consistent even in finite samples. The SE and RMSE terms are closer when the sample size is increased, suggesting that the standard errors are also consistently estimated. Finally, the CP terms converges to the nominal value when the sample size is increased, suggesting that the asymptotic distribution of the ML estimators also works well in finite samples.
Table 2.
Recovery parameters for the STPN distribution based on 1000 replicates for different combinations of parameters and sample size.
5. Application
In this section, we present a real data application in order to illustrate the performance of the STPN model in comparison with other proposals in the literature. For this, a comparison was conducted utilizing the TPN distribution and the model proposed by Gómez et al. [19], which is a generalization of a TPN model, denominated the generalized TPN (GTPN). The density function of the GPTN model is given by:
with , , and .
A real dataset of body fat was considered, which measured weight and various body circumferences (see http://lib.stat.cmu.edu/datasets/bodyfat (accessed on 8 October 2021)); for examination purposes, the weight variable (measured in pounds (lbs)) was chosen to conduct the application. When calculating basic statistics (Table 3 shows basic statistics), high kurtosis can be observed for the variable, suggesting the use of a distribution with heavy tails as the STPN.
Table 3.
Descriptive statistics for the dataset.
Table 4 shows the estimated parameters for the three models considered. Based on the AIC [20] and BIC [21], the STPN model provides a better fit. In addition, Figure 4 shows the histogram for the data and the estimated pdf for all the models, where a better performance of the STPN model is shown. In order to check the better fit of the STPN model in comparison with the rest of the models, we also computed the quantile residuals (QRs). If the model is appropriate for the data, the QRs should be a sample from the standard normal model. This assumption can be validated with traditional normality tests such as the Anderson–Darling (AD), Cramér–von Mises (CVM), and Shapiro–Wilkes (SW) tests. Figure 5 suggests that the STPN model provides a better fit for this dataset.
Table 4.
Estimated parameters and their standard errors (in parentheses) for the STPN, TPN, and GTPN models for the dataset. The AIC and BIC are also presented.
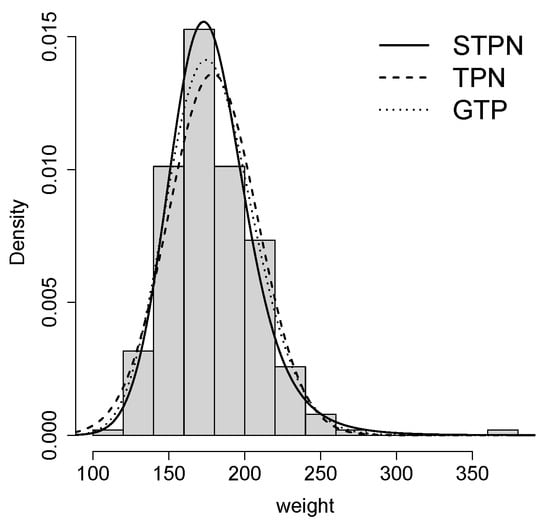
Figure 4.
Fit of the distributions for the dataset.

Figure 5.
QRs for the fitted models in the dataset. The p-values for the AD, CVM, and SW normality tests are also presented to check if the QRs came from the standard normal distribution. (a) qq-plot STPN. (b) qq-plot TPN. (c) qq-plot GTPN.
6. Conclusions
This study presents a new distribution with positive support denominated the slash truncation positive normal. This distribution serves as a more general model compared to the TPN model, pursuing the increase of kurtosis in order to improve the modeling of positive databases with high kurtosis. The basic properties of the model were analyzed, and a simulation study was conducted implementing the EM algorithm. Finally, an application with real data was performed proving that the new model performs better than competing models.
Author Contributions
Conceptualization, H.J.G. and D.I.G.; Data curation, H.J.G.; Formal analysis, D.I.G. and K.I.S.; Investigation, K.I.S.; Methodology, H.J.G., D.I.G. and K.I.S.; Software, H.J.G. and D.I.G.; Supervision, D.I.G. All authors have read and agreed to the published version of the manuscript.
Funding
The research of Hector J. Gómez was supported by Proyecto de Investigación de Facultad de Ingeniería, Universidad Católica de Temuco, UCT-FDI032020.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used in Section 5 were duly referenced.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
In this Appendix, we explain the terms involved in the observed Fisher information matrix presented in Section 3.4. Let , , , , , , , and .
We also define , , and .
The elements of are , and .
The elements of are:
Finally, the elements of are given by:
Appendix B
In this section, we present the codes in R used to estimate the parameters for the STPN model in the real data application presented in Section 5.
require(tpn)
y<-c(154.25, 173.25, 154.00, 184.75, 184.25, 210.25, 181.00, 176.00, 191.00, 198.25,
186.25, 216.00, 180.50, 205.25, 187.75, 162.75, 195.75, 209.25, 183.75, 211.75,
179.00, 200.50, 140.25, 148.75, 151.25, 159.25, 131.50, 148.00, 133.25, 160.75,
182.00, 160.25, 168.00, 218.50, 247.25, 191.75, 202.25, 196.75, 363.15, 203.00,
262.75, 205.00, 217.00, 212.00, 125.25, 164.25, 133.50, 148.50, 135.75, 127.50,
158.25, 139.25, 137.25, 152.75, 136.25, 198.00, 181.50, 201.25, 202.50, 179.75,
216.00, 178.75, 193.25, 178.00, 205.50, 183.50, 151.50, 154.75, 155.25, 156.75,
167.50, 146.75, 160.75, 125.00, 143.00, 148.25, 162.50, 177.75, 161.25, 171.25,
163.75, 150.25, 190.25, 170.75, 168.00, 167.00, 157.75, 160.00, 176.75, 176.00,
177.00, 179.75, 165.25, 192.50, 184.25, 224.50, 188.75, 162.50, 156.50, 197.00,
198.50, 173.75, 172.75, 196.75, 177.00, 165.50, 200.25, 203.25, 194.00, 168.50,
170.75, 183.25, 178.25, 163.00, 175.25, 158.00, 177.25, 179.00, 191.00, 187.50,
206.50, 185.25, 160.25, 151.50, 161.00, 167.00, 177.50, 152.25, 192.25, 165.25,
171.75, 171.25, 197.00, 157.00, 168.25, 186.00, 166.75, 187.75, 168.25, 212.75,
176.75, 173.25, 167.00, 159.75, 188.15, 156.00, 208.50, 206.50, 143.75, 223.00,
152.25, 241.75, 146.00, 156.75, 200.25, 171.50, 205.75, 182.50, 136.50, 177.25,
151.25, 196.00, 184.25, 140.00, 218.75, 217.00, 166.25, 224.75, 228.25, 172.75,
152.25, 125.75, 177.25, 176.25, 226.75, 145.25, 151.00, 241.25, 187.25, 234.75,
219.25, 118.50, 145.75, 159.25, 170.50, 167.50, 232.75, 210.50, 202.25, 185.00,
153.00, 244.25, 193.50, 224.75, 162.75, 180.00, 156.25, 168.00, 167.25, 170.75,
178.25, 150.00, 200.50, 184.00, 223.00, 208.75, 166.00, 195.00, 160.50, 159.75,
140.50, 216.25, 168.25, 194.75, 172.75, 219.00, 149.25, 154.50, 199.25, 154.50,
153.25, 230.00, 161.75, 142.25, 179.75, 126.50, 169.50, 198.50, 174.50, 167.75,
147.75, 182.25, 175.50, 161.75, 157.75, 168.75, 191.50, 219.15, 155.25, 189.75,
127.50, 224.50, 234.25, 227.75, 199.50, 155.50, 215.50, 134.25, 201.00, 186.75,
190.75, 207.50)
est.stpn(y)
References
- Rafiqullah, H.M.; Saxena, A.; Vera, V.; Abdool-Ghany, F.; Gabbidon, K.; Perea, N.; Shauna-Jeanne Stewart, T.; Ramamoorthy, V. Black Hispanic and Black Non-Hispanic Breast Cancer Survival Data Analysis with Half-normal Model Application. Asian Pac. J. Cancer Prev. 2014, 15, 9453–9458. [Google Scholar]
- Bosch-Badia, M.T.; Montllor-Serrats, J.; Tarrazon-Rodon, M.A. Risk Analysis through the Half-Normal Distribution. Mathematics 2020, 8, 2080. [Google Scholar] [CrossRef]
- Tsizhmovska, N.L.; Martyushev, L.M. Principle of Least Effort and Sentence Length in Public Speaking. Entropy 2021, 23, 1023. [Google Scholar] [CrossRef] [PubMed]
- Olmos, N.M.; Varela, H.; Gómez, H.W.; Bolfarine, H. An extension of the half-normal distribution. Stat. Pap. 2012, 53, 875–886. [Google Scholar] [CrossRef]
- Cooray, K.; Ananda, M.M.A. A generalization of the half-normal distribution with applications to lifetime data. Comm. Stat. Theory Methods 2007, 36, 1323–2157. [Google Scholar] [CrossRef]
- Olmos, N.M.; Varela, H.; Gómez, H.W.; Bolfarine, H. An extension of the generalized half-normal distribution. Stat. Pap. 2014, 55, 967–981. [Google Scholar] [CrossRef]
- Iriarte, Y.; Gómez, H.W.; Varela, H.; Bolfarien, H. Slashed Rayleigd distribution. Rev. Colomb. Estad. 2015, 38, 31–44. [Google Scholar] [CrossRef]
- Reyes, J.; Barranco-Chamorro, I.; Gallardo, D.I.; Gómez, H.W. Generalized modified slash Birnbaum-Saunders distribution. Symmetry 2018, 10, 724. [Google Scholar] [CrossRef] [Green Version]
- Olmos, N.M.; Osvaldo, V.; Gómez, Y.M.; Iriarte, Y.A. Confluent hypergeometric slashed-Rayleigh distribution: Properties, estimation and applications. J. Comput. Appl. Math. 2020, 328, 112548. [Google Scholar] [CrossRef]
- Segovia, F.A.; Gómez, Y.M.; Venegas, O.; Gómez, H.W. A Power Maxwell Distribution with Heavy Tails and Applications. Mathematics 2020, 8, 1116. [Google Scholar] [CrossRef]
- Astorga, J.M.; Reyes, J.; Santoro, K.I.; Venegas, O.; Gómez, H.W. A Reliability Model Based on the Incomplete Generalized Integro-Exponential Function. Mathematics 2020, 8, 1537. [Google Scholar] [CrossRef]
- Gómez, H.J.; Olmos, N.M.; Varela, H.; Bolfarine, H. Inference for a truncated positive normal distribution. Appl. Math. J. Chin. Univ. 2018, 33, 163–176. [Google Scholar] [CrossRef]
- Jonhson, N.L.; Kotz, S.; Balakrishnan, N. Continuos Univariate Distribution, 2nd ed.; Wiley: New York, NY, USA, 1995; Volume 2. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data via the EM Algorithm. J. R. Stat. Soc. Ser. B 1977, 39, 1–38. [Google Scholar]
- Louis, T.A. Finding the observed information matrix when using the EM algorithm. J. R. Stat. Soc. Ser. B Methodol. 1982, 44, 226–233. [Google Scholar]
- Casella, G.; Berger, R.L. Statistical Inference; Duxbury: Pacific Grove, CA, USA, 2002. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021; Available online: https://www.R-project.org/ (accessed on 8 October 2021).
- Gallardo, D.I.; Gómez, H.J. tpn: Truncated Positive Normal Model and Extensions. R Package Version 1.0. 2021. Available online: https://cran.r-project.org/web/packages/tpn/index.html (accessed on 8 October 2021).
- Gómez, H.J.; Gallardo, D.I.; Osvaldo, V. Generalized truncation positive normal distribution. Symmetry 2019, 11, 1361. [Google Scholar] [CrossRef] [Green Version]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Auto Contr. 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).