Combination of Discrete Element Method and Artificial Neural Network for Predicting Porosity of Gravel-Bed River



Abstract
1. Introduction
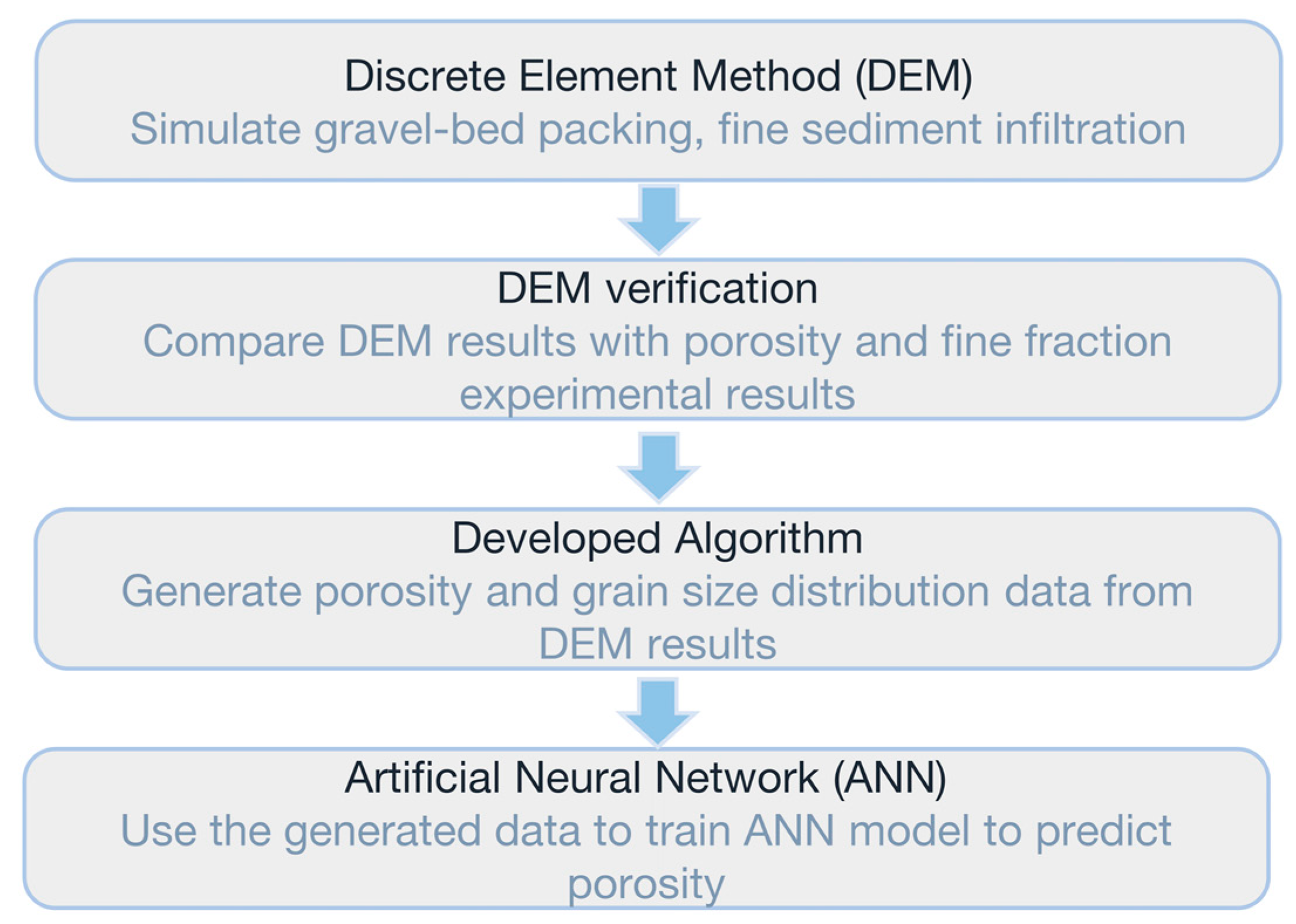
2. Methodology
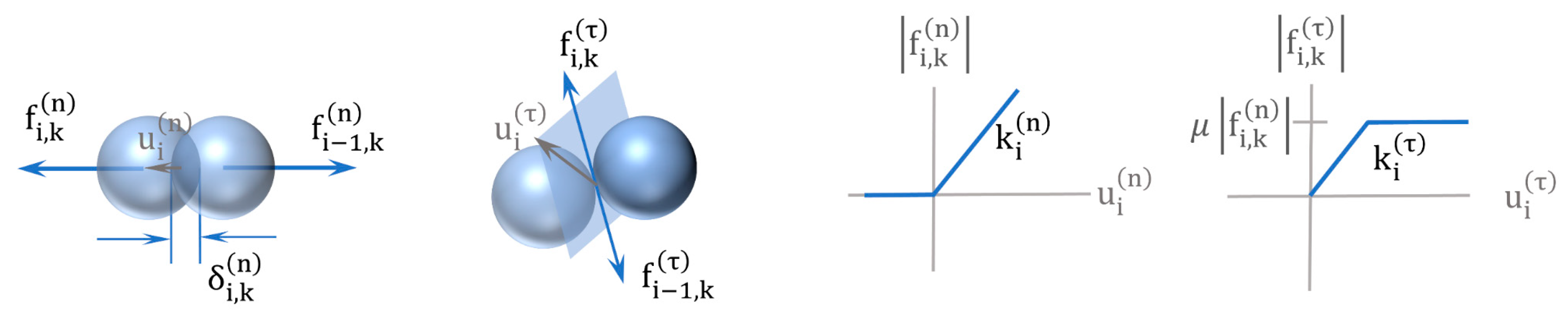
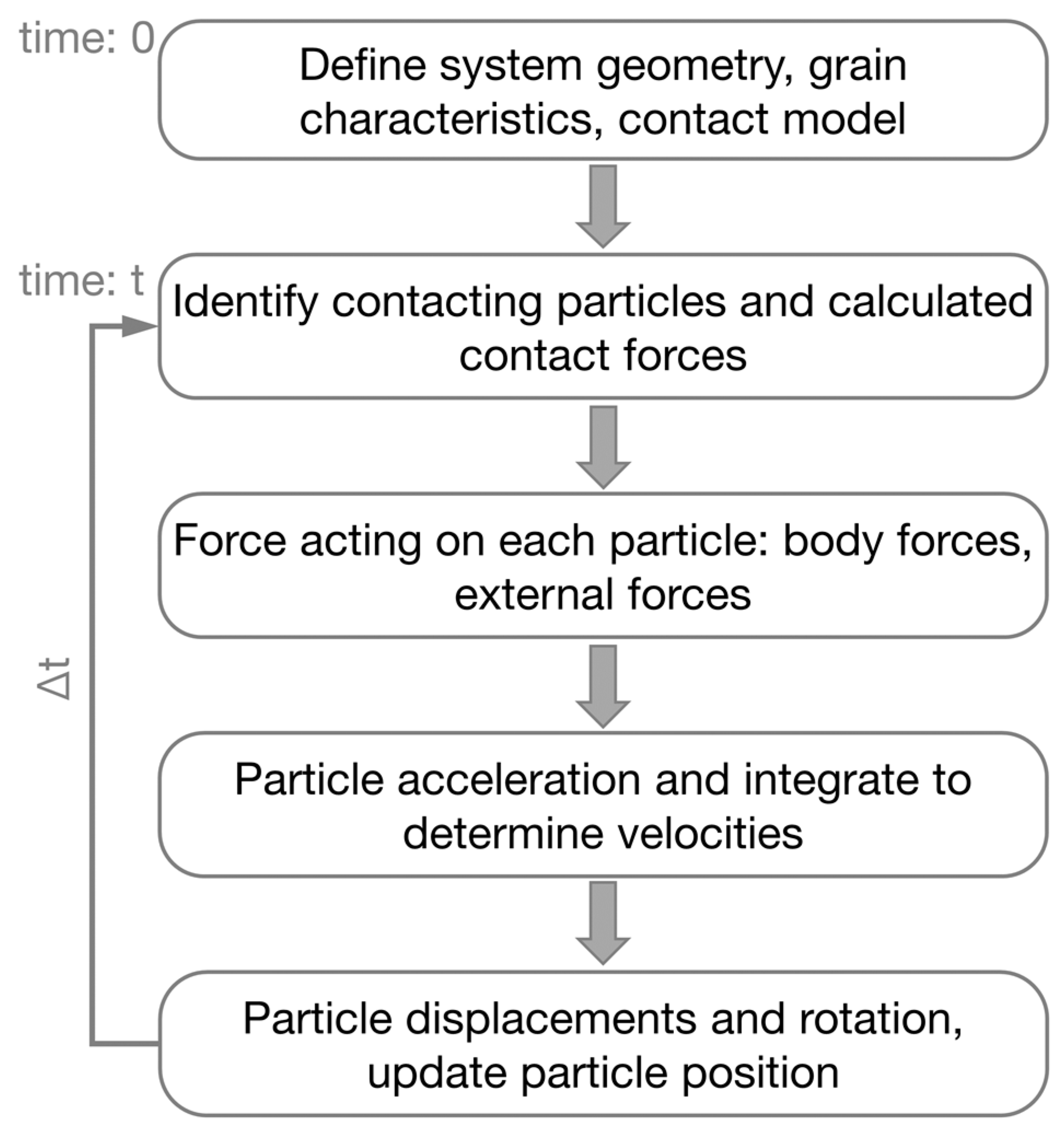
2.1. Discrete Element Method (DEM)
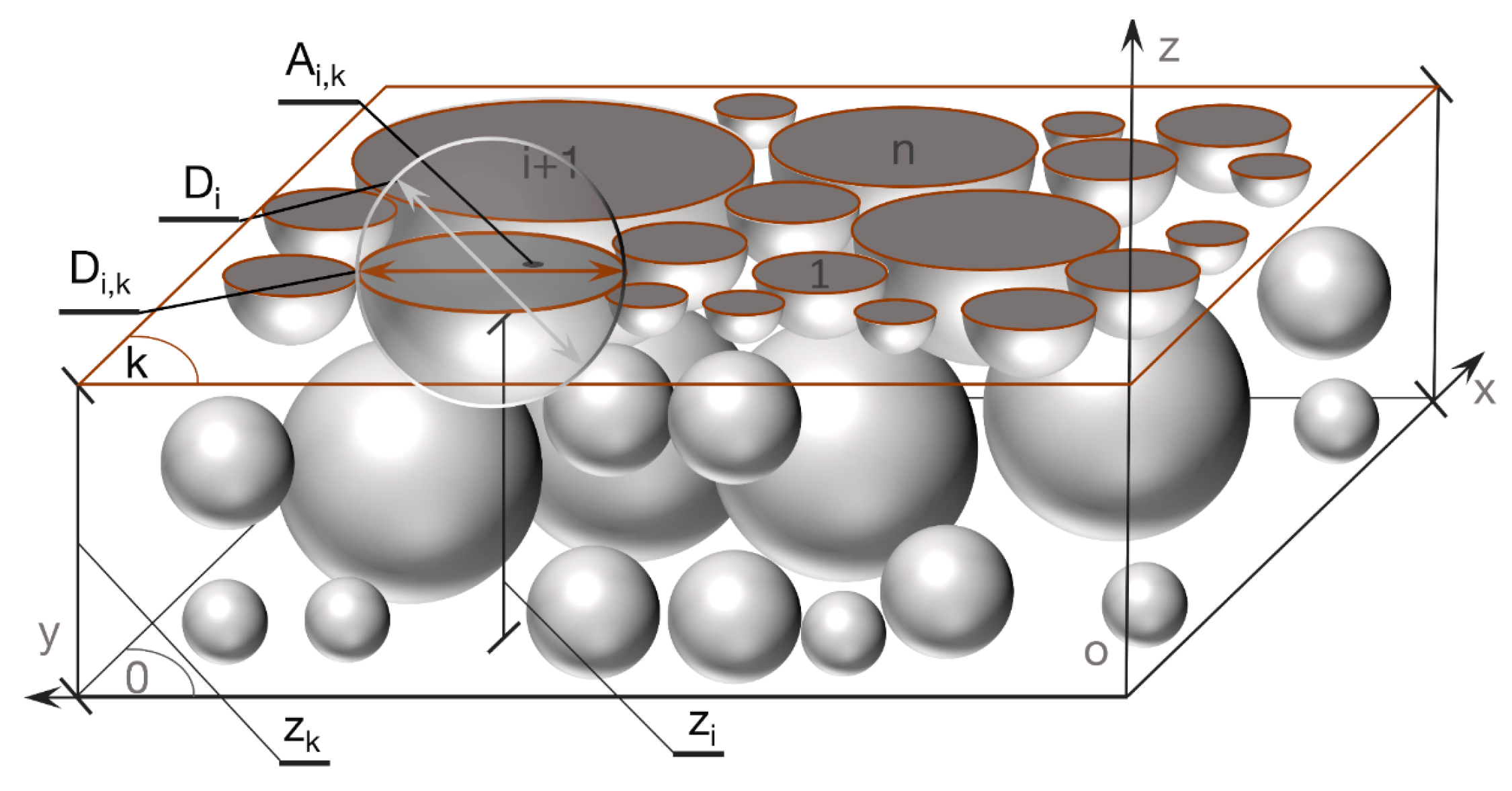
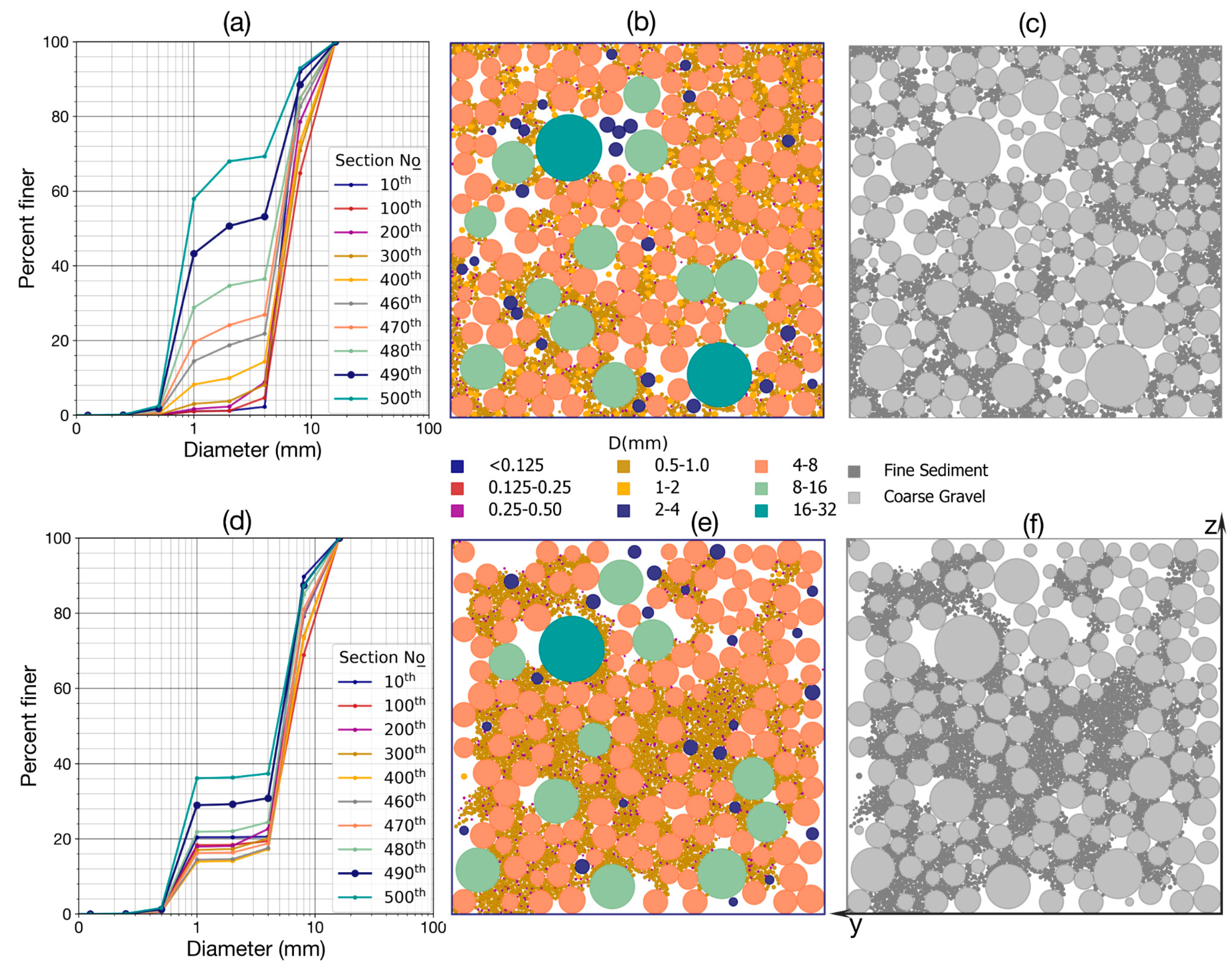
2.2. Algorithms for Calculating Grain Size Distribution and Porosity of a Cross Section from DEM Results
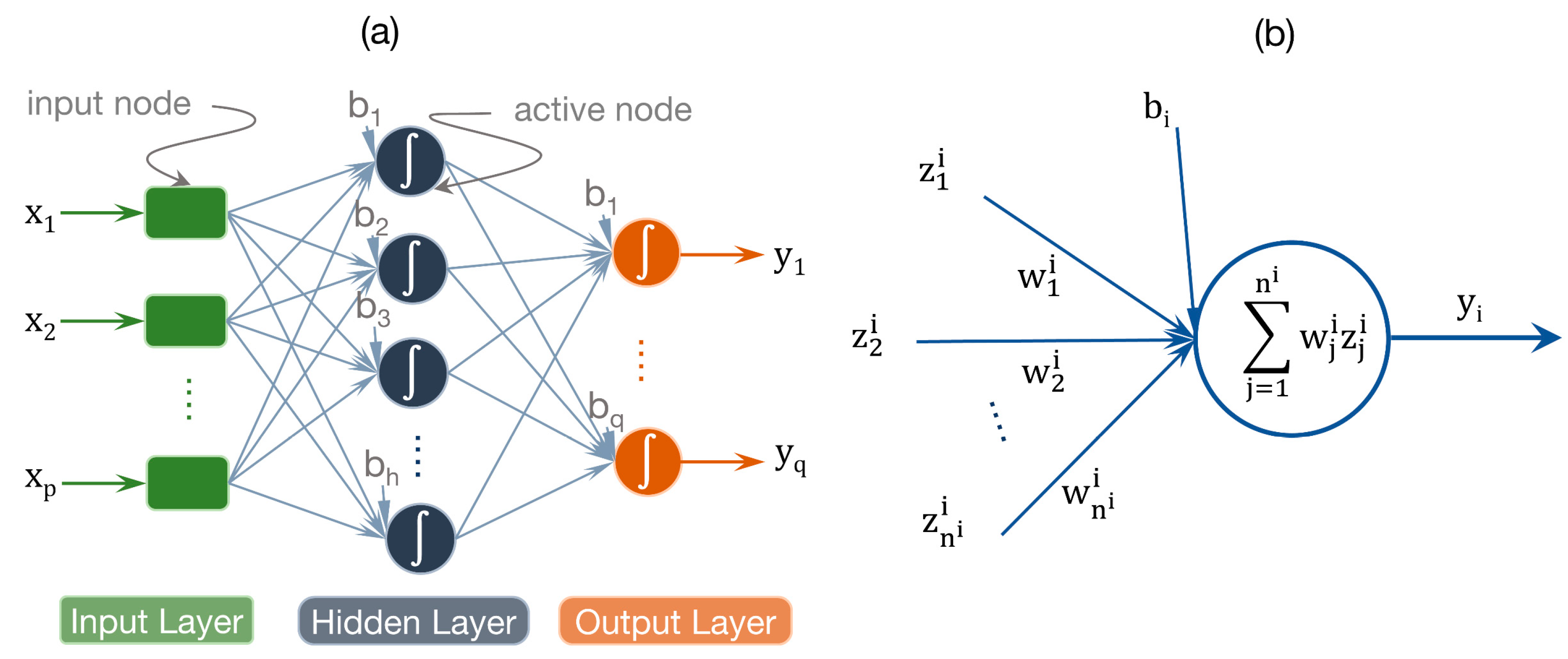
2.3. Feed Forward Neural Network (FNN)
2.4. Evaluation of the Model Performance
3. Results and Discussions
3.1. Input Parameters for DEM
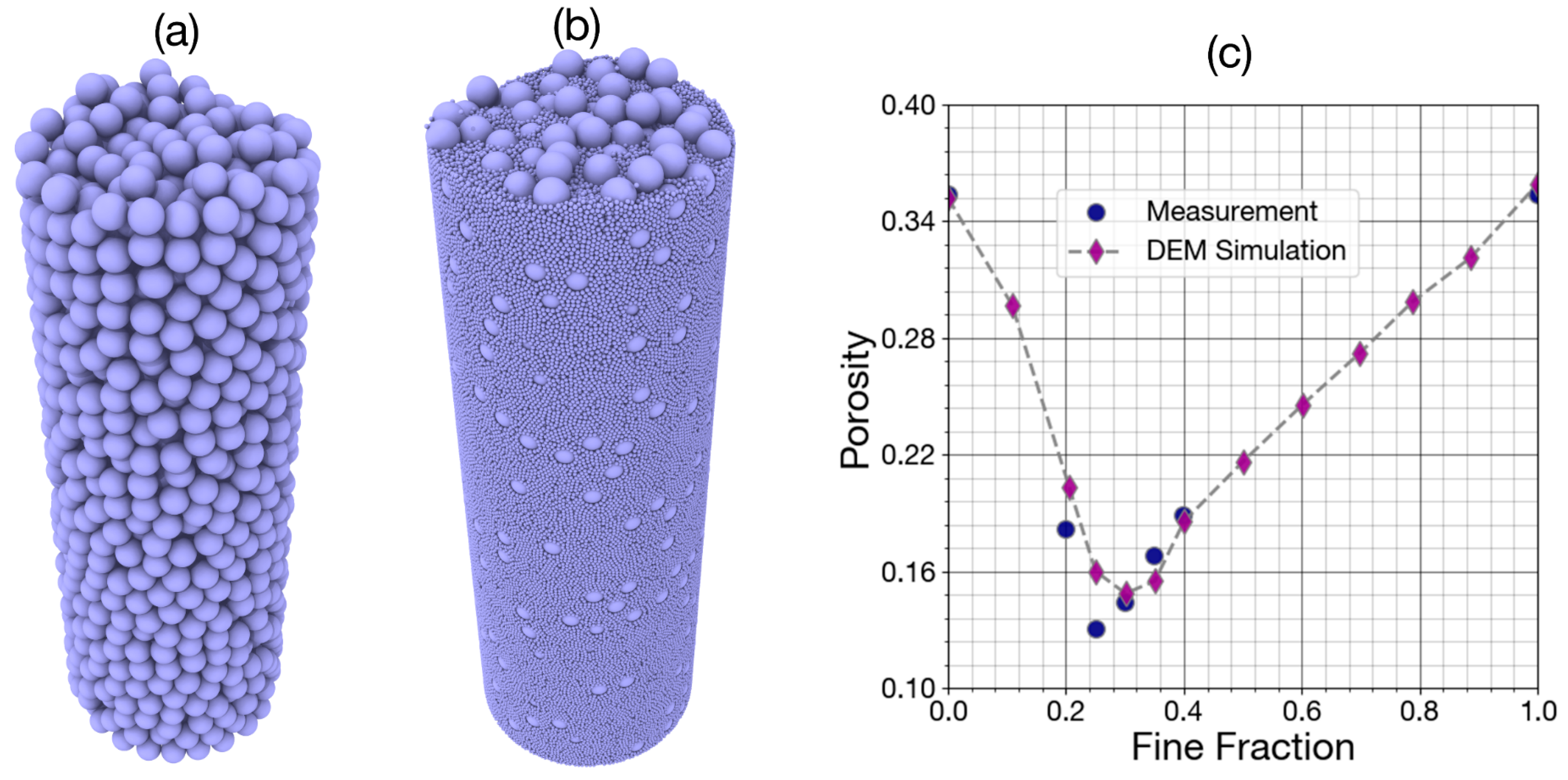
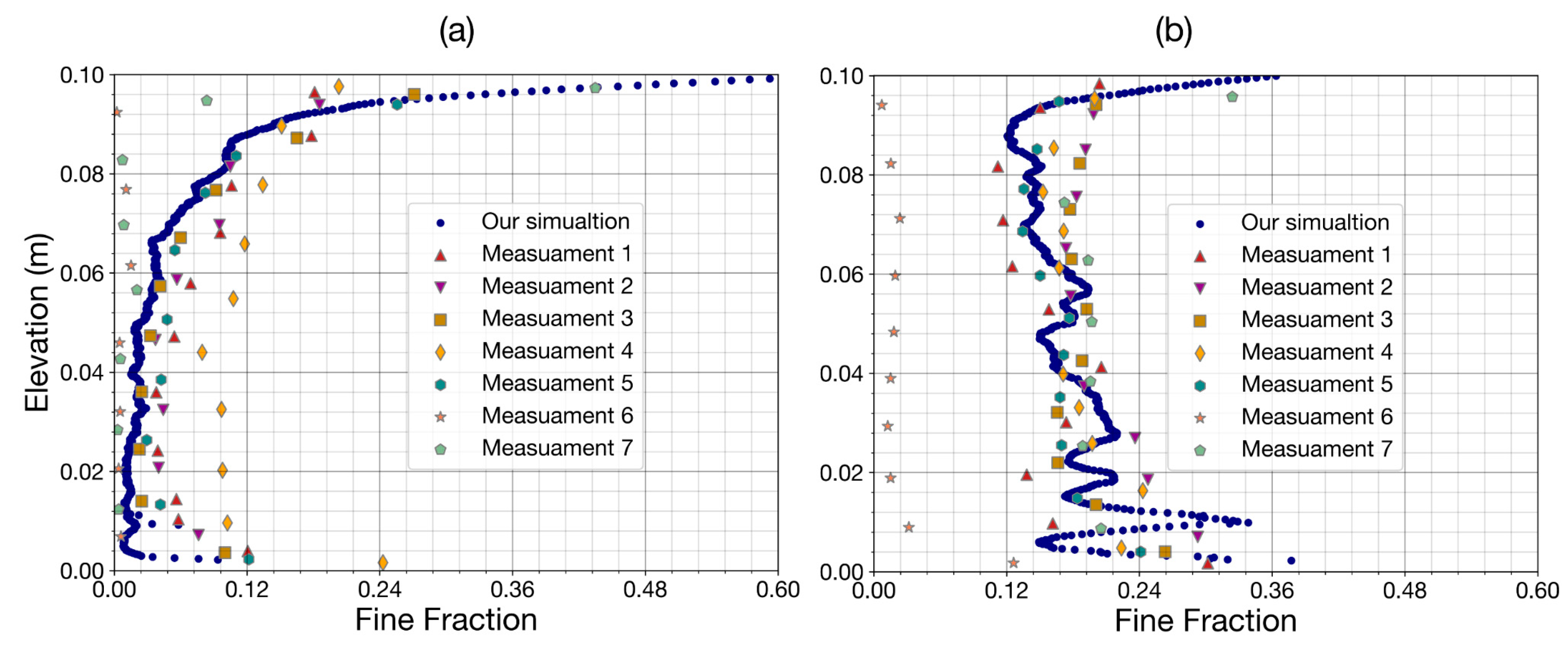
3.2. DEM Verification for Porosity
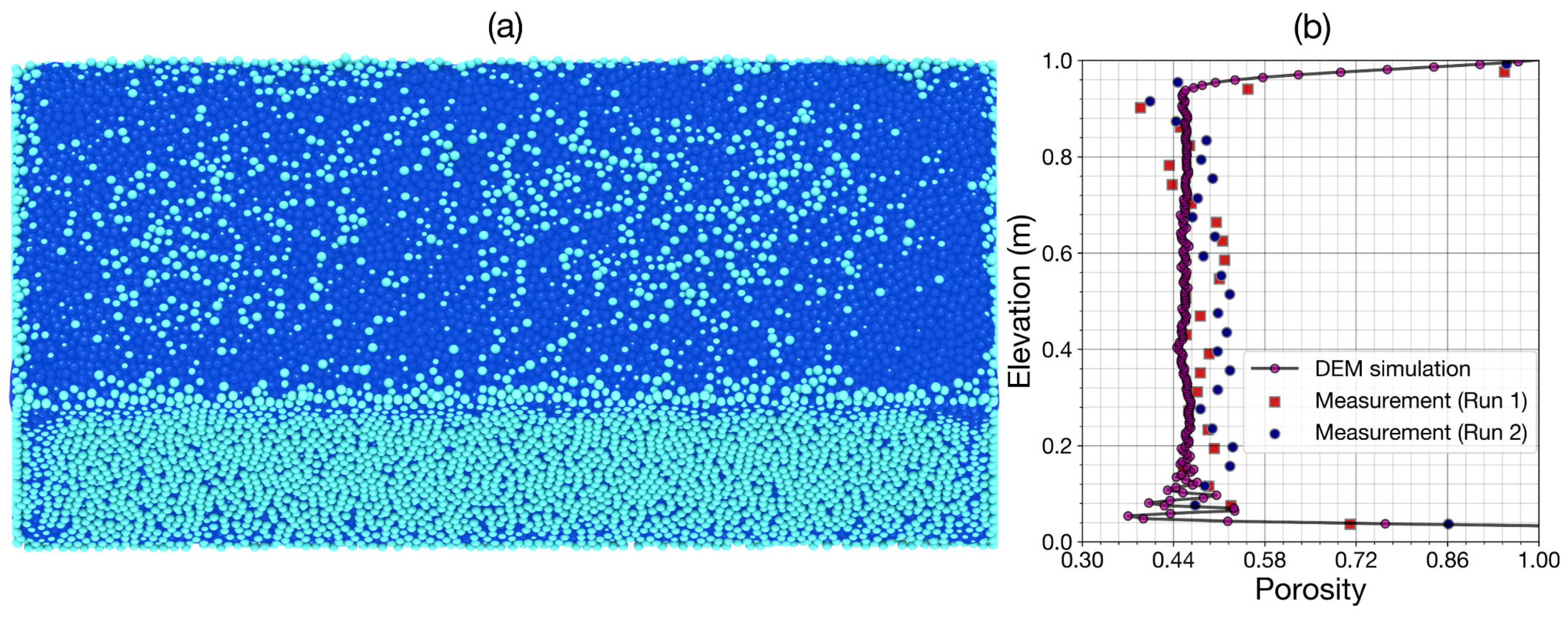
3.3. DEM Verification for Infiltration
3.4. Input Data for FNN
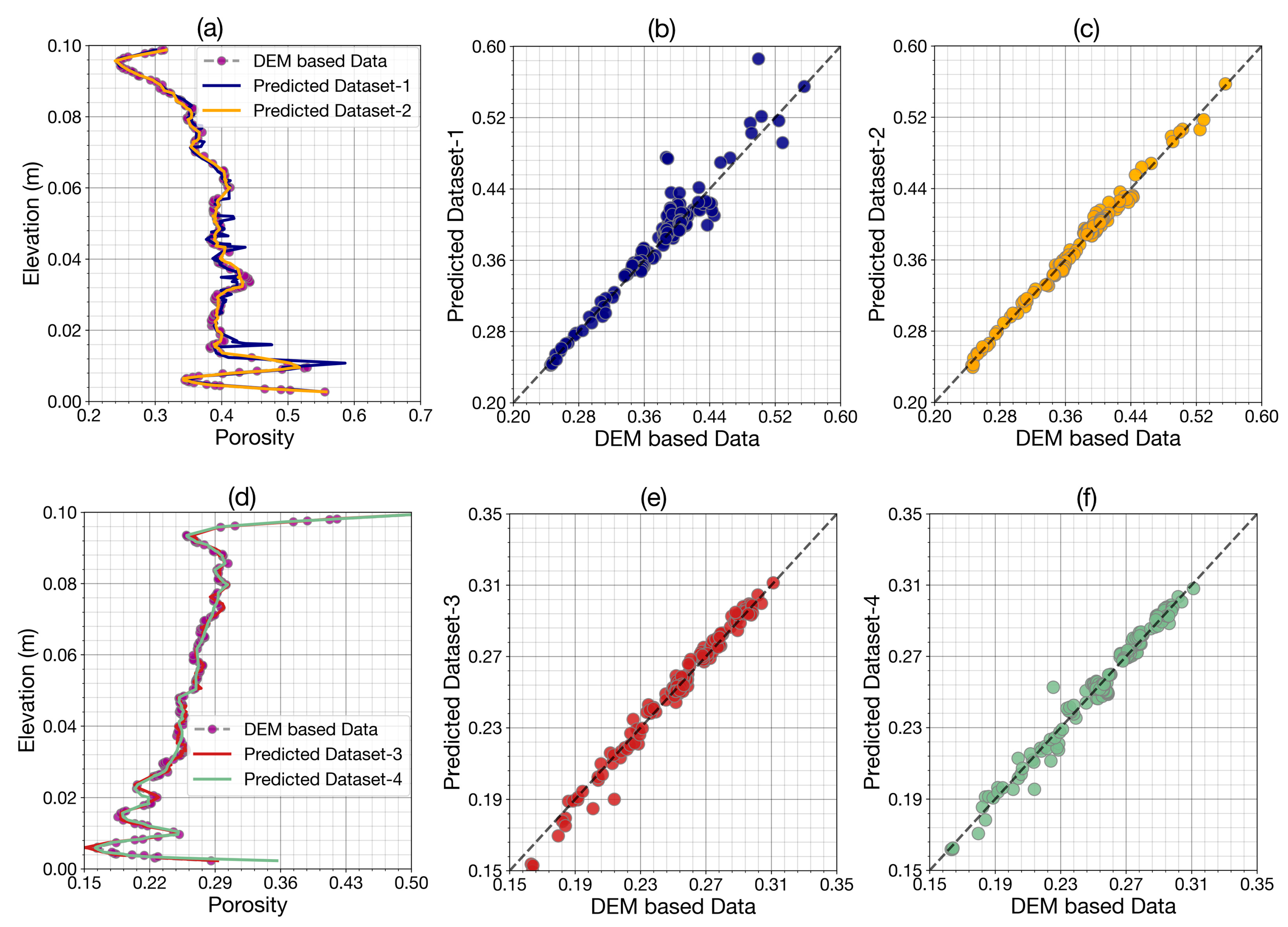
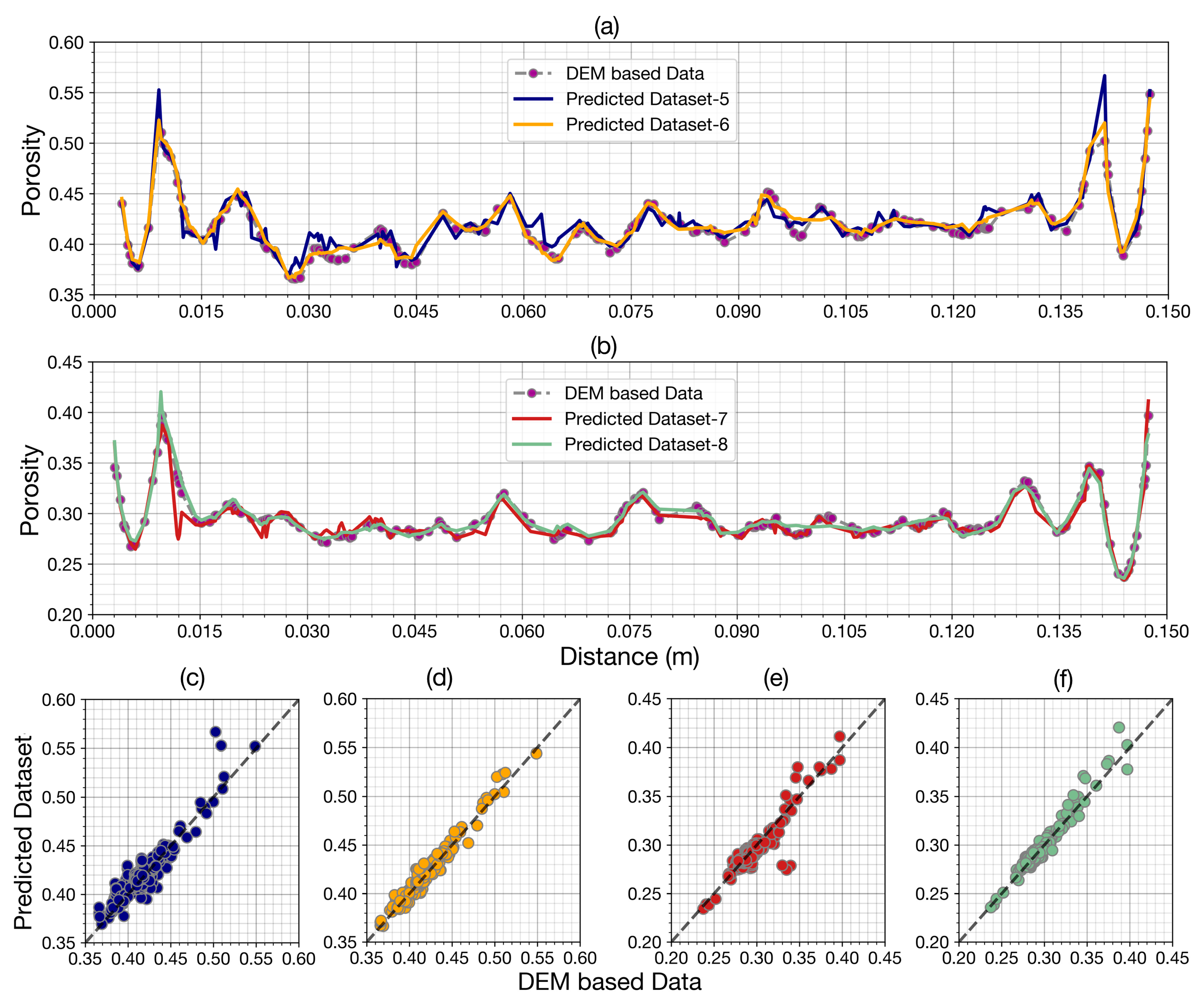
3.5. Porosity Prediction Based on FNN Model
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Frings, R.M.; Kleinhans, M.G.; Vollmer, S. Discriminating between pore-filling load and bed-structure load: A new porosity-based method, exemplified for the river Rhine. Sedimentology 2008, 55, 1571–1593. [Google Scholar] [CrossRef]
- Nunez-Gonzalez, F.; Martin-Vide, J.P.; Kleinhans, M.G. Porosity and size gradation of saturated gravel with percolated fines. Sedimentology 2016, 63, 1209–1232. [Google Scholar] [CrossRef]
- Gayraud, S.; Philippe, M. Influence of Bed-Sediment Features on the Interstitial Habitat Available for Macroinvertebrates in 15 French Streams. Int. Rev. Hydrobiol. 2003, 88, 77–93. [Google Scholar] [CrossRef]
- Verstraeten, G.; Poesen, J. Variability of dry sediment bulk density between and within retention ponds and its impact on the calculation of sediment yields. Earth Surf. Process. Landf. 2001, 26, 375–394. [Google Scholar] [CrossRef]
- Wilcock, P.R. Two-fraction model of initial sediment motion in gravel-bed rivers. Science 1998, 280, 410–412. [Google Scholar] [CrossRef] [PubMed]
- Driscoll, F.G. Groundwater and Wells, 2nd ed.; Johnson Filtration Systems Inc.: Saint Paul, MN, USA, 1986. [Google Scholar]
- Bui, V.H.; Bui, M.D.; Rutschmann, P. Advanced Numerical Modeling of Sediment Transport in Gravel-Bed Rivers. Water 2019, 11, 550. [Google Scholar] [CrossRef]
- Doherty, J. Calibration and Uncertainty Analysis for Complex Environmental Models; Watermark Numerical Computing: Brisbane, Queensland, Australia, 2015. [Google Scholar]
- Wu, W.; Wang, S.S. Formulas for sediment porosity and settling velocity. J. Hydraul. Eng. 2006, 132, 858–862. [Google Scholar] [CrossRef]
- Wooster, J.K.; Dusterhoff, S.R.; Cui, Y.T.; Sklar, L.S.; Dietrich, W.E.; Malko, M. Sediment supply and relative size distribution effects on fine sediment infiltration into immobile gravels. Water Resour. Res. 2008, 44. [Google Scholar] [CrossRef]
- Peronius, N.; Sweeting, T.J. On the correlation of minimum porosity with particle size distribution. Powder Technol. 1985, 42, 113–121. [Google Scholar] [CrossRef]
- Carling, R.C.; Templeton, D. The effect of carbachol and isoprenaline on cell division in the exocrine pancreas of the rat. Q. J. Exp. Physiol. 1982, 67, 577–585. [Google Scholar] [CrossRef]
- Komura, S. Discussion of “Sediment transportation mechanics: Introduction and properties of sediment”. J. Hydraul. Div. 1963, 89, 263–266. [Google Scholar]
- Frings, R.M.; Schuttrumpf, H.; Vollmer, S. Verification of porosity predictors for fluvial sand-gravel deposits. Water Resour. Res. 2011, 47. [Google Scholar] [CrossRef]
- Ouchiyama, N.; Tanaka, T. Porosity estimation for random packings of spherical particles. Ind. Eng. Chem. Fundam. 1984, 23, 490–493. [Google Scholar] [CrossRef]
- Yu, A.B.; Standish, N. Estimation of the Porosity of Particle Mixtures by a Linear-Mixture Packing Model. Ind. Eng. Chem. Res. 1991, 30, 1372–1385. [Google Scholar] [CrossRef]
- Yu, A.B.; Standish, N. Limitation of Proposed Mathematical-Models for the Porosity Estimation of Nonspherical Particle Mixtures. Ind. Eng. Chem. Res. 1993, 32, 2179–2182. [Google Scholar] [CrossRef]
- Suzuki, M.; Oshima, T. Estimation of the co-ordination number in a multi-component mixture of spheres. Powder Technol. 1983, 35, 159–166. [Google Scholar] [CrossRef]
- Nolan, G.; Kavanagh, P.E. Computer simulation of random packings of spheres with log-normaldistributions. Powder Technol. 1993, 76, 309–316. [Google Scholar] [CrossRef]
- Desmond, K.W.; Weeks, E.R. Influence of particle size distribution on random close packing of spheres. Phys. Rev. E 2014, 90, 022204. [Google Scholar] [CrossRef]
- Saljooghi, B.S.; Hezarkhani, A. Comparison of WAVENET and ANN for predicting the porosity obtained from well log data. J. Pet. Sci. Eng. 2014, 123, 172–182. [Google Scholar] [CrossRef]
- Bui, M.D.; Kaveh, K.; Rutschmann, P. Integrating Artificial Neural Networks into Hydromorphological Model for Fluvial Channels. In Proceedings of the 36th IAHR World Congress, Hague, The Netherlands, 28 June–3 July 2015; pp. 1673–1680. [Google Scholar]
- Link, C.A.; Himmer, P.A. Oil reservoir porosity prediction using a neural network ensemble approach. In Geophysical Applications of Artificial Neural Networks and Fuzzy Logic; Springer: Berlin/Heidelberg, Germany, 2003; pp. 197–213. [Google Scholar]
- Bagheripour, P.; Asoodeh, M. Fuzzy ruling between core porosity and petrophysical logs: Subtractive clustering vs. genetic algorithm-pattern search. J. Appl. Geophys. 2013, 99, 35–41. [Google Scholar] [CrossRef]
- Kraipeerapun, P.; Fung, C.C.; Nakkrasae, S. Porosity prediction using bagging of complementary neural networks. In Proceedings of the International Symposium on Neural Networks; Springer: Berlin/Heidelberg, Germany, 2009; pp. 175–184. [Google Scholar]
- Toro-Escobar, C.M.; Parker, G.; Paola, C. Transfer function for the deposition of poorly sorted gravel in response to streambed aggradation. J. Hydraul. Res. 1996, 34, 35–53. [Google Scholar] [CrossRef]
- Cundall, P.A.; Strack, O.D. A discrete numerical model for granular assemblies. Geotechnique 1979, 29, 47–65. [Google Scholar] [CrossRef]
- Johnson, K.L. Contact Mechanics; Cambridge University Press: Cambridge, UK, 1985. [Google Scholar]
- Fleischmann, J.; Serban, R.; Negrut, D.; Jayakumar, P. On the Importance of Displacement History in Soft-Body Contact Models. J. Comput. Nonlinear Dyn. 2016, 11, 044502. [Google Scholar] [CrossRef]
- Landau, L.; Lifshitz, E. Theory of Elasticity, 3rd ed.; Pergamon Press: Oxford, UK, 1986. [Google Scholar]
- Mindlin, R. Compliance of elastic bodies in contact. J. Appl. Mech. Trans. ASME 1949, 16, 259–268. [Google Scholar]
- Zell, A. Simulation Neuronaler Netze; Addison-Wesley: Bonn, Germany, 1994; Volume 1. [Google Scholar]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice Hall: Upper Saddle River, NJ, USA, 1999. [Google Scholar]
- Bhattacharya, B.; Price, R.; Solomatine, D.P. Machine learning approach to modeling sediment transport. J. Hydraul. Eng. 2007, 133, 440–450. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Jangid, M.; Srivastava, S. Handwritten Devanagari Character Recognition Using Layer-Wise Training of Deep Convolutional Neural Networks and Adaptive Gradient Methods. J. Imaging 2018, 4, 41. [Google Scholar] [CrossRef]
- He, Z.; Zhang, X.; Cao, Y.; Liu, Z.; Zhang, B.; Wang, X. LiteNet: Lightweight neural network for detecting arrhythmias at resource-constrained mobile devices. Sensors 2018, 18, 1229. [Google Scholar] [CrossRef]
- Bui, M.D.; Kaveh, K.; Penz, P.; Rutschmann, P. Contraction scour estimation using data-driven methods. J. Appl. Water Eng. Res. 2015, 3, 143–156. [Google Scholar] [CrossRef]
- Heaton, J. Introduction to Neural Networks with Java; Heaton Research, Inc.: St. Louis, MO, USA, 2008. [Google Scholar]
- McGeary, R.K. Mechanical packing of spherical particles. J. Am. Ceram. Soc. 1961, 44, 513–522. [Google Scholar] [CrossRef]
- Navaratnam, C.U.; Aberle, J.; Daxnerová, J. An Experimental Investigation on Porosity in Gravel Beds. In Free Surface Flows and Transport Processes; Springer: Cham, Switzerland, 2018; pp. 323–334. [Google Scholar]
- Gibson, S.; Abraham, D.; Heath, R.; Schoellhamer, D. Vertical gradational variability of fines deposited in a gravel framework. Sedimentology 2009, 56, 661–676. [Google Scholar] [CrossRef]
- Gibson, S.; Abraham, D.; Heath, R.; Schoellhamer, D. Bridging Process Threshold for Sediment Infiltrating into a Coarse Substrate. J. Geotech. Geoenviron. Eng. 2010, 136, 402–406. [Google Scholar] [CrossRef]
- Holdich, R.G. Fundamentals of Particle Technology; Midland Information Technology and Publishing: Nottingham, UK, 2002. [Google Scholar]
- Valdes, J.R.; Santamarina, J.C. Clogging: Bridge formation and vibration-based destabilization. Can. Geotech. J. 2008, 45, 177–184. [Google Scholar] [CrossRef]
- Leonardson, R. Exchange of Fine Sediments with Gravel Riverbeds. Ph.D. Thesis, University of California, Berkeley, CA, USA, 2010. [Google Scholar]
- Seal, R.; Parker, G.; Paola, C.; Mullenbach, B. Laboratory experiments on downstream fining of gravel, narrow channel runs 1 through 3: Supplemental methods and data. In External Memo M-239; St. Anthony Falls Hydraulic Lab, University of Minnesota: Minneapolis, MN, USA, 1995. [Google Scholar]
- Ridgway, K.; Tarbuck, K. Voidage fluctuations in randomly-packed beds of spheres adjacent to a containing wall. Chem. Eng. Sci. 1968, 23, 1147–1155. [Google Scholar] [CrossRef]
- Sulaiman, M.; Tsutsumi, D.; Fujita, M. Porosity of sediment mixtures with different type of grain size distribution. Annu. J. Hydraul. Eng. 2007, 51, 133–138. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Density of Sphere (kg/m3) | Density of Water (kg/m3) | Young’s Modulus (Pa) | Poisson Ratio | Friction between Grains | Coefficient of Restitution |
|---|---|---|---|---|---|
| 2350 | 1000 | 5.0 × 106 | 0.45 | 0.35 | 0.40 |
| Statistical Indicators | Case-1 | Case-2 | |
|---|---|---|---|
| Run 1 | Run 2 | ||
| R | 0.9857 | 0.957526 | 0.908266 |
| RMSE | 0.0165 | 0.048585 | 0.059763 |
| MAE | 0.0125 | 0.036198 | 0.05138 |
| Process | Pair Time | Neigh Time | Comm Time | Outpt Time | Other Time |
|---|---|---|---|---|---|
| Case-3 (Bridging) | |||||
| Insert | 14,607.7 | 16,269.9 | 19.4313 | 8.31424 | 2593.69 |
| Settle | 8319.46 | 2372.5 | 5.84765 | 4.09249 | 1035.83 |
| Case-4 (Percolation) | |||||
| Insert | 24,954.6 | 43,270.4 | 42.0592 | 8.5656 | 5287.41 |
| Settle | 14,112.2 | 12,281.2 | 11.608 | 3.28125 | 2083.9 |
| Statistical Indicators | Case-3 (Bridging) | Case-4 (Percolation) |
|---|---|---|
| R | 0.969191 | 0.940474 |
| RMSE | 0.128067 | 0.261443 |
| MAE | 0.066765 | 0.121255 |
| Statistical Indicators | Bridging | Percolation | ||
|---|---|---|---|---|
| Dataset-1 | Dataset-2 | Dataset-3 | Dataset-4 | |
| R | 0.965968 | 0.989206 | 0.990841 | 0.994024 |
| RMSE | 0.015736 | 0.008786 | 0.007807 | 0.005753 |
| MAE | 0.009580 | 0.006548 | 0.004898 | 0.003155 |
| Statistical Indicators | Bridging | Percolation | ||
|---|---|---|---|---|
| Dataset-5 | Dataset-6 | Dataset-7 | Dataset-8 | |
| R | 0.9298 | 0.9786 | 0.9236 | 0.9748 |
| RMSE | 0.0113 | 0.0063 | 0.0097 | 0.0060 |
| MAE | 0.0080 | 0.0050 | 0.0056 | 0.0041 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bui, V.H.; Bui, M.D.; Rutschmann, P. Combination of Discrete Element Method and Artificial Neural Network for Predicting Porosity of Gravel-Bed River. Water 2019, 11, 1461. https://doi.org/10.3390/w11071461
Bui VH, Bui MD, Rutschmann P. Combination of Discrete Element Method and Artificial Neural Network for Predicting Porosity of Gravel-Bed River. Water. 2019; 11(7):1461. https://doi.org/10.3390/w11071461
Chicago/Turabian StyleBui, Van Hieu, Minh Duc Bui, and Peter Rutschmann. 2019. "Combination of Discrete Element Method and Artificial Neural Network for Predicting Porosity of Gravel-Bed River" Water 11, no. 7: 1461. https://doi.org/10.3390/w11071461
APA StyleBui, V. H., Bui, M. D., & Rutschmann, P. (2019). Combination of Discrete Element Method and Artificial Neural Network for Predicting Porosity of Gravel-Bed River. Water, 11(7), 1461. https://doi.org/10.3390/w11071461