
GraphAT Net: A Deep Learning Approach Combining TrajGRU and Graph Attention for Accurate Cumulonimbus Distribution Prediction

 ,
,  , ,
, ,
Abstract
:1. Introduction
- In this study, a novel method for predicting the distribution of cumulonimbus clouds. The proposed method achieves accurate predictions on both the moving MNIST dataset and real-world radar echo data.
- The proposed method combines multiple refinements, including graph convolution, recurrent neural networks, convolutional neural networks, and attention mechanisms. We also adopt a hybrid loss function that includes mean square error (MSE) and difference structure similarity index measure (SSIM).
- We evaluate the model’s effectiveness using a time-space series prediction dataset based on radar echo data of cumulonimbus clouds. This dataset enables the rigorous evaluation of the model’s performance in predicting complex phenomena.
2. Related Works
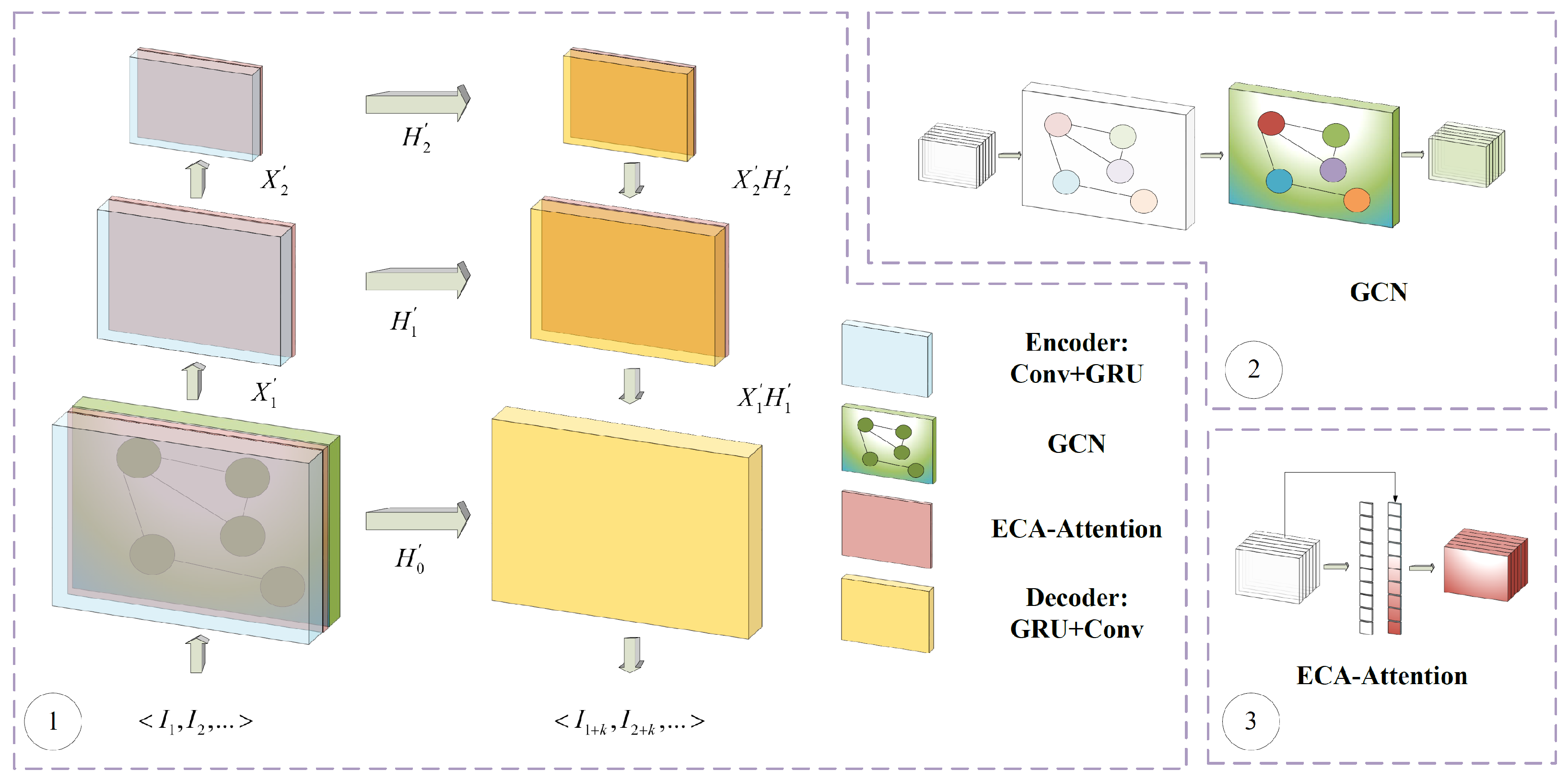
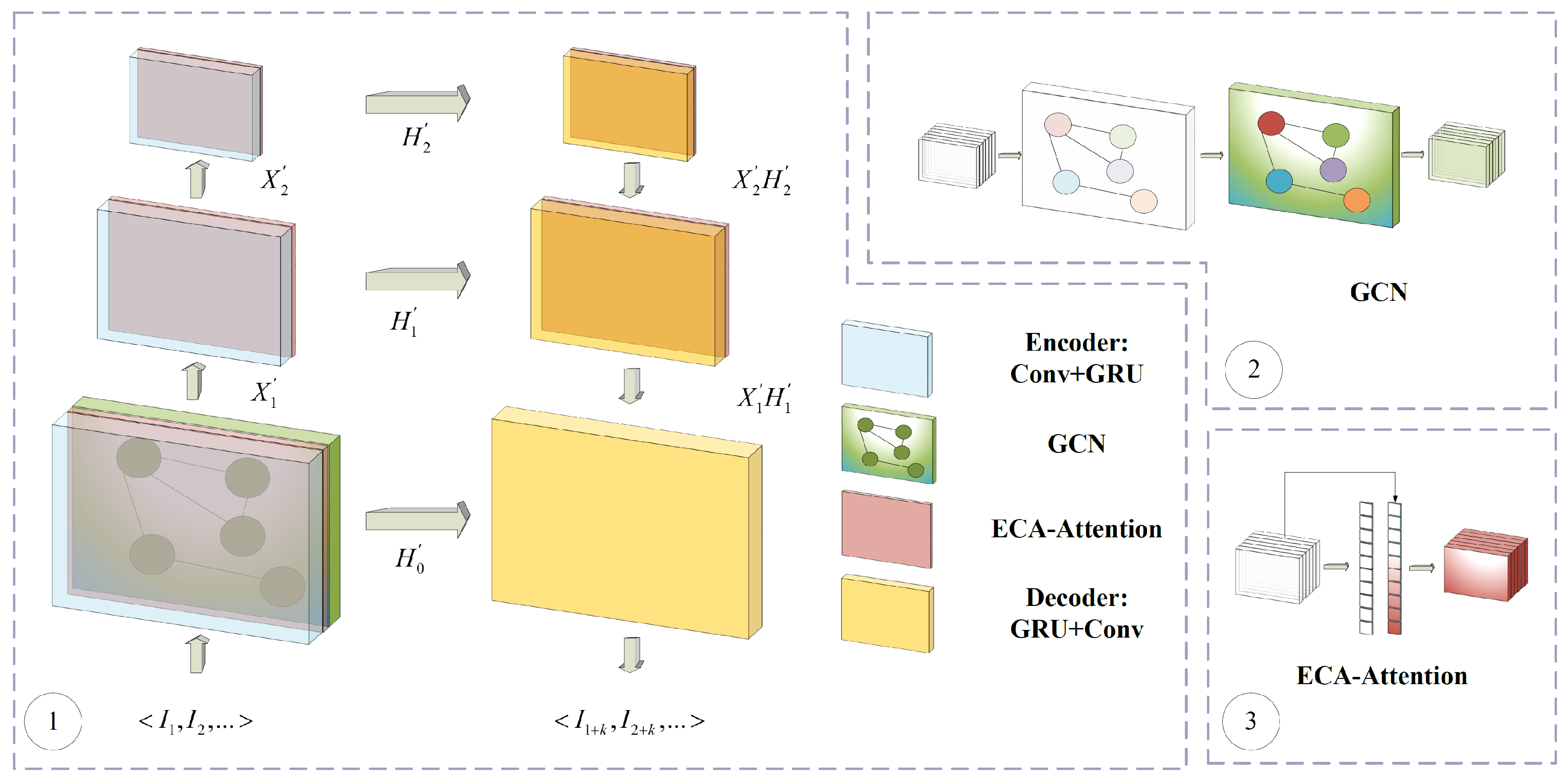
3. Methods
3.1. Trajectory GRU Structure
3.2. GCN Structure
3.3. ECA Attention Structure
4. Experiment Settings
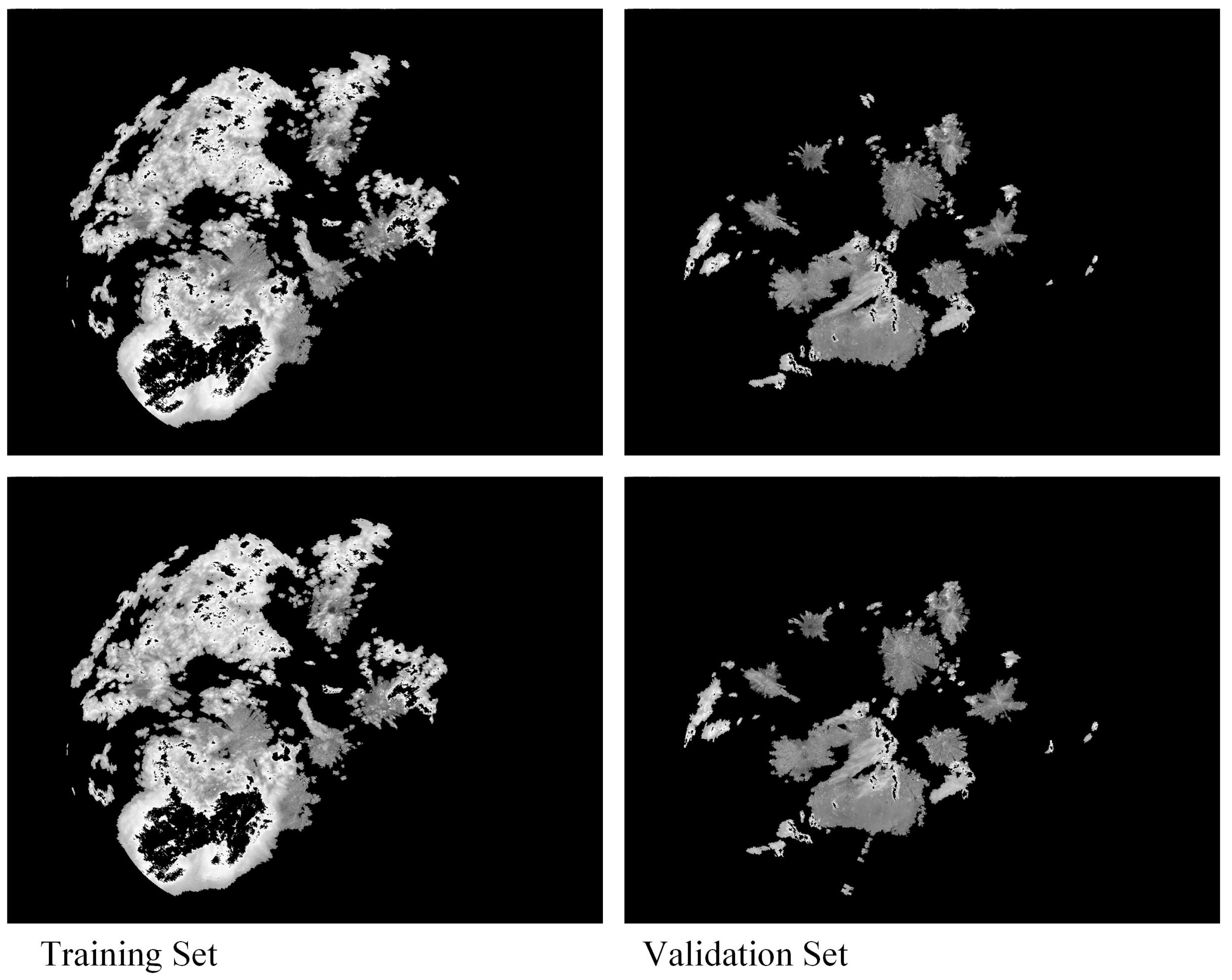
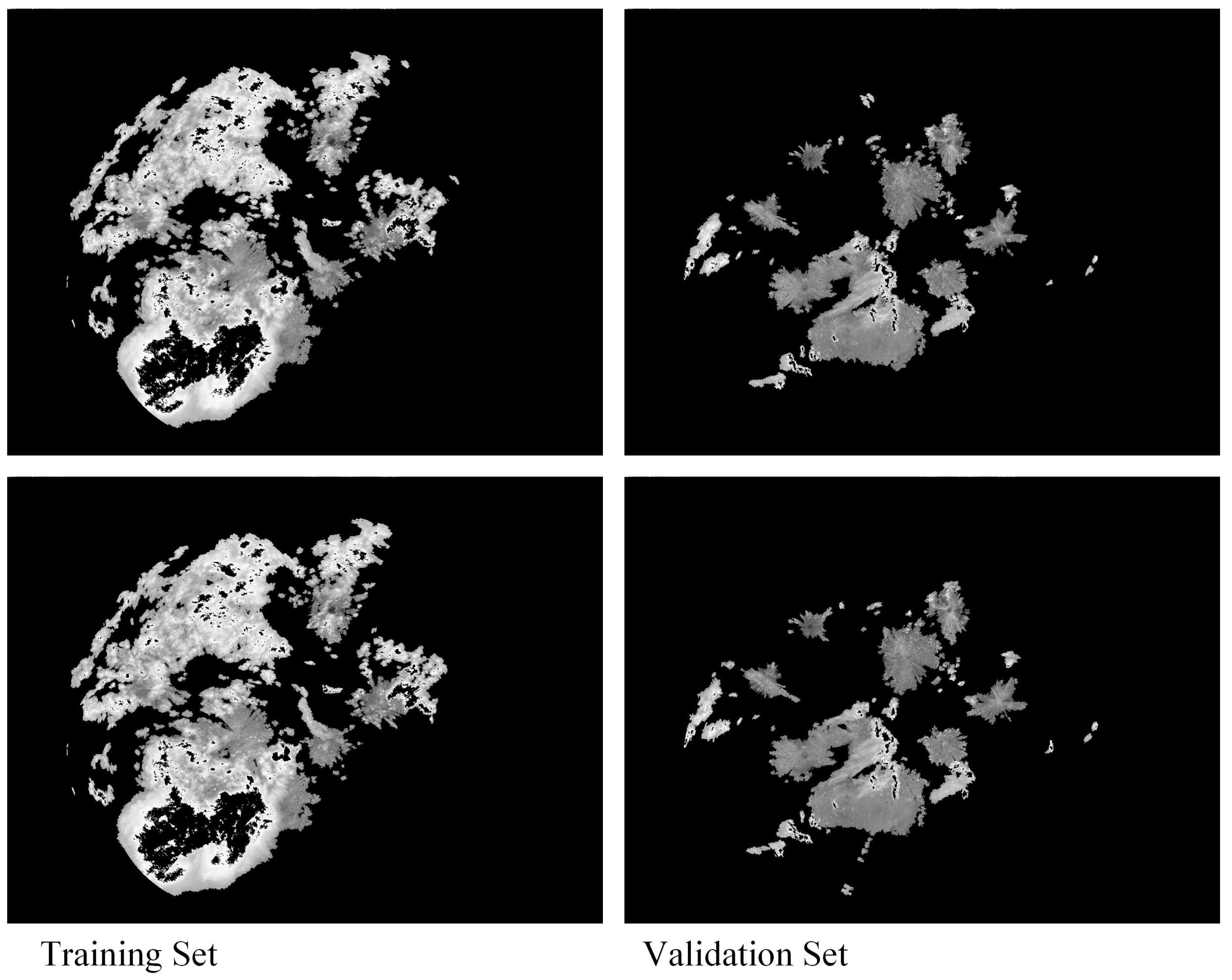
4.1. Dataset Information
4.2. Evaluation Metrics
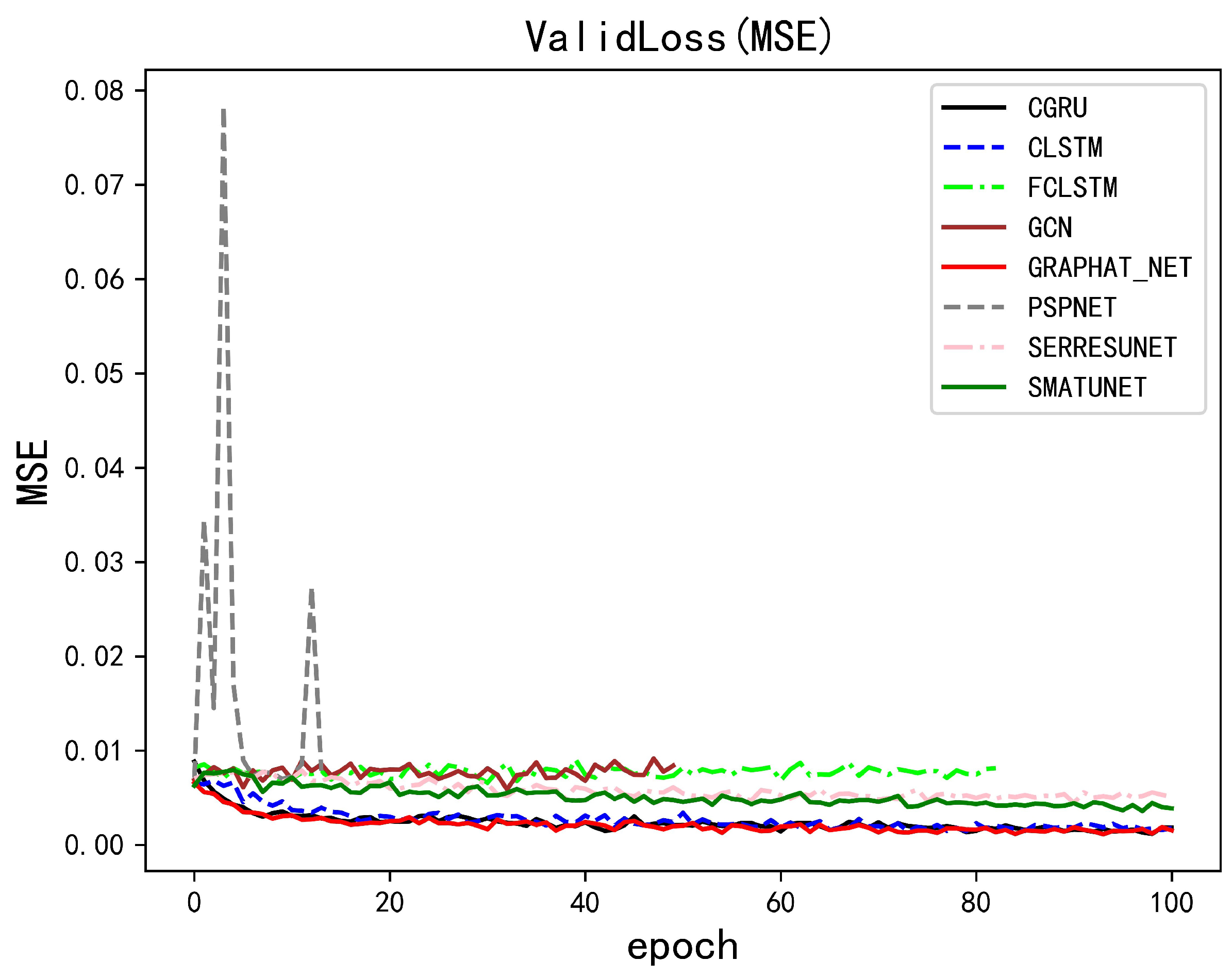
4.3. Training Details
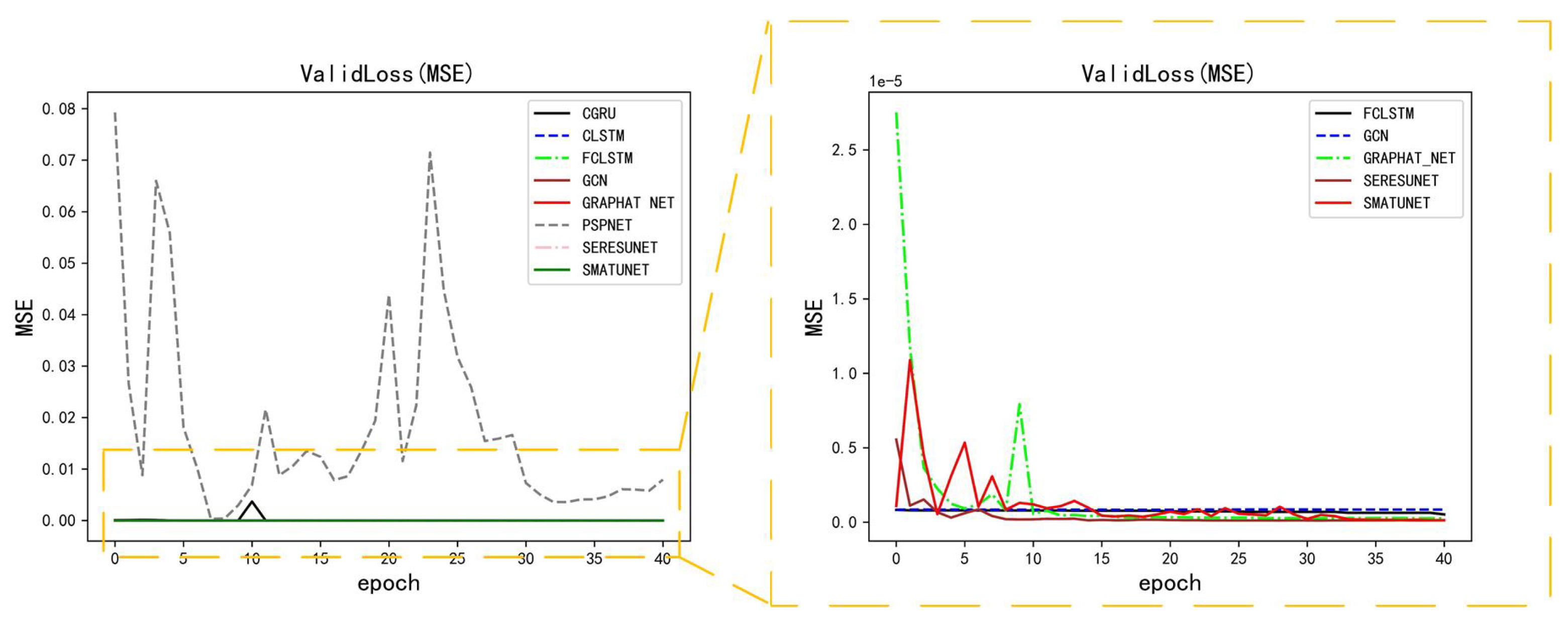
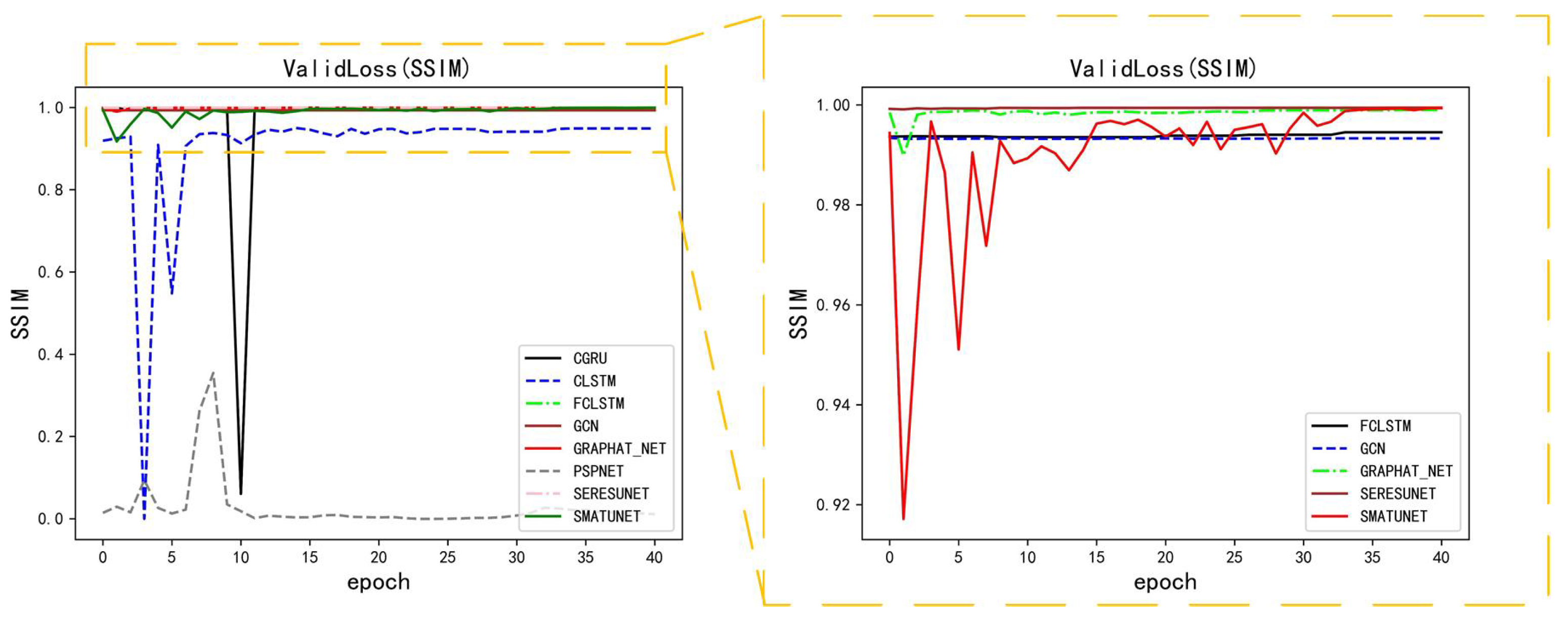
5. Performance
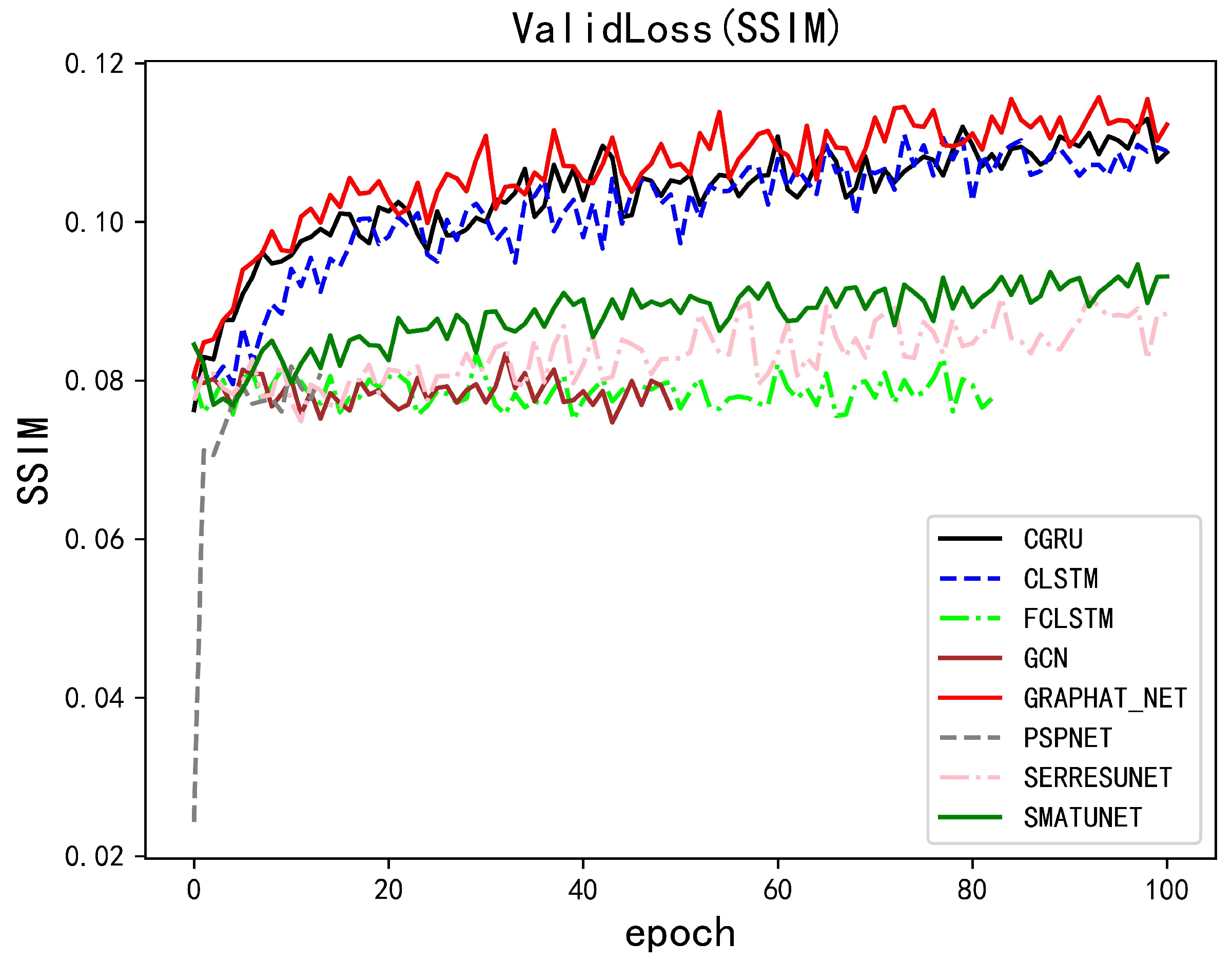
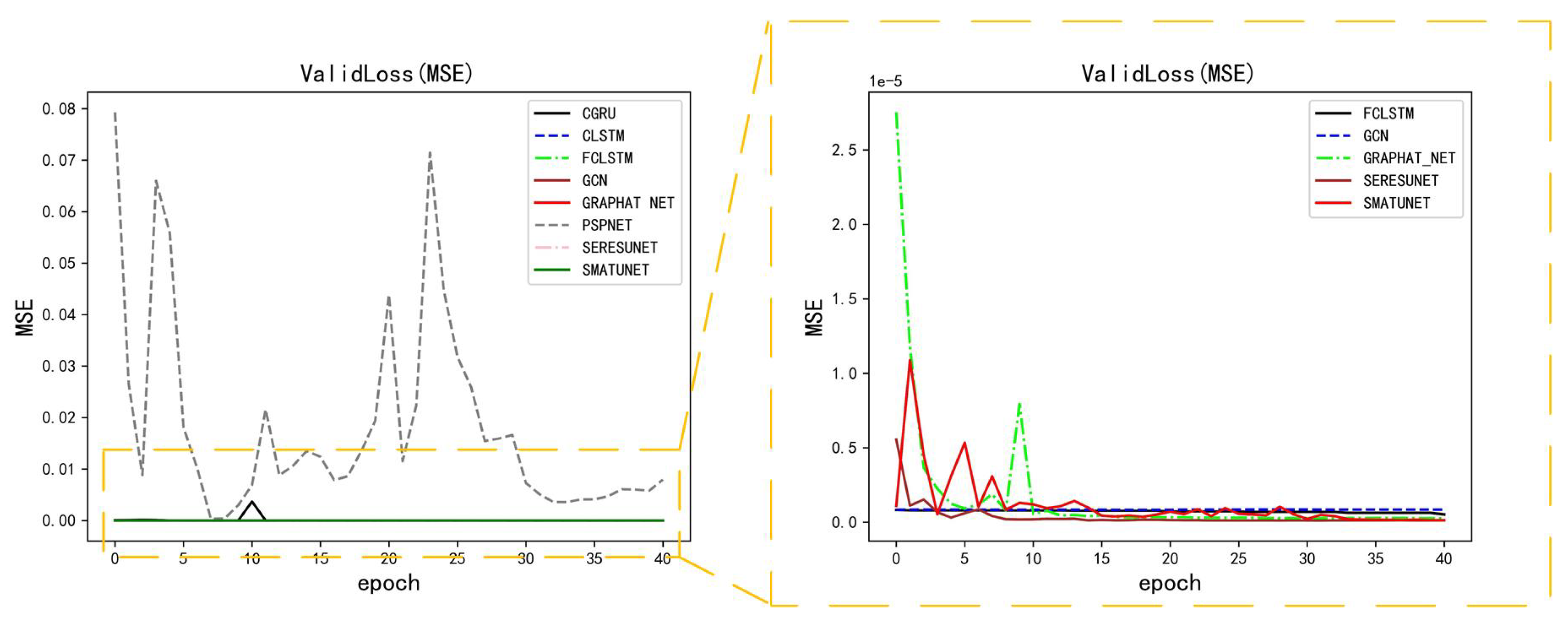
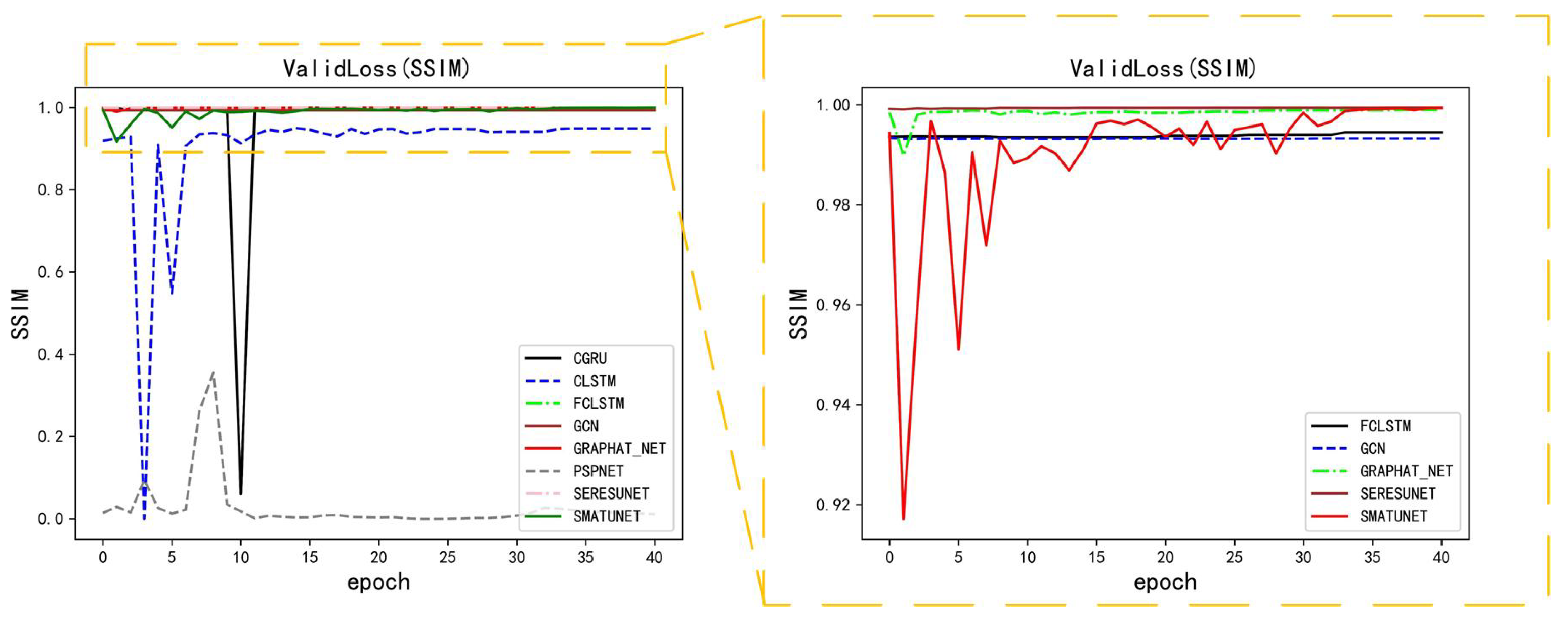
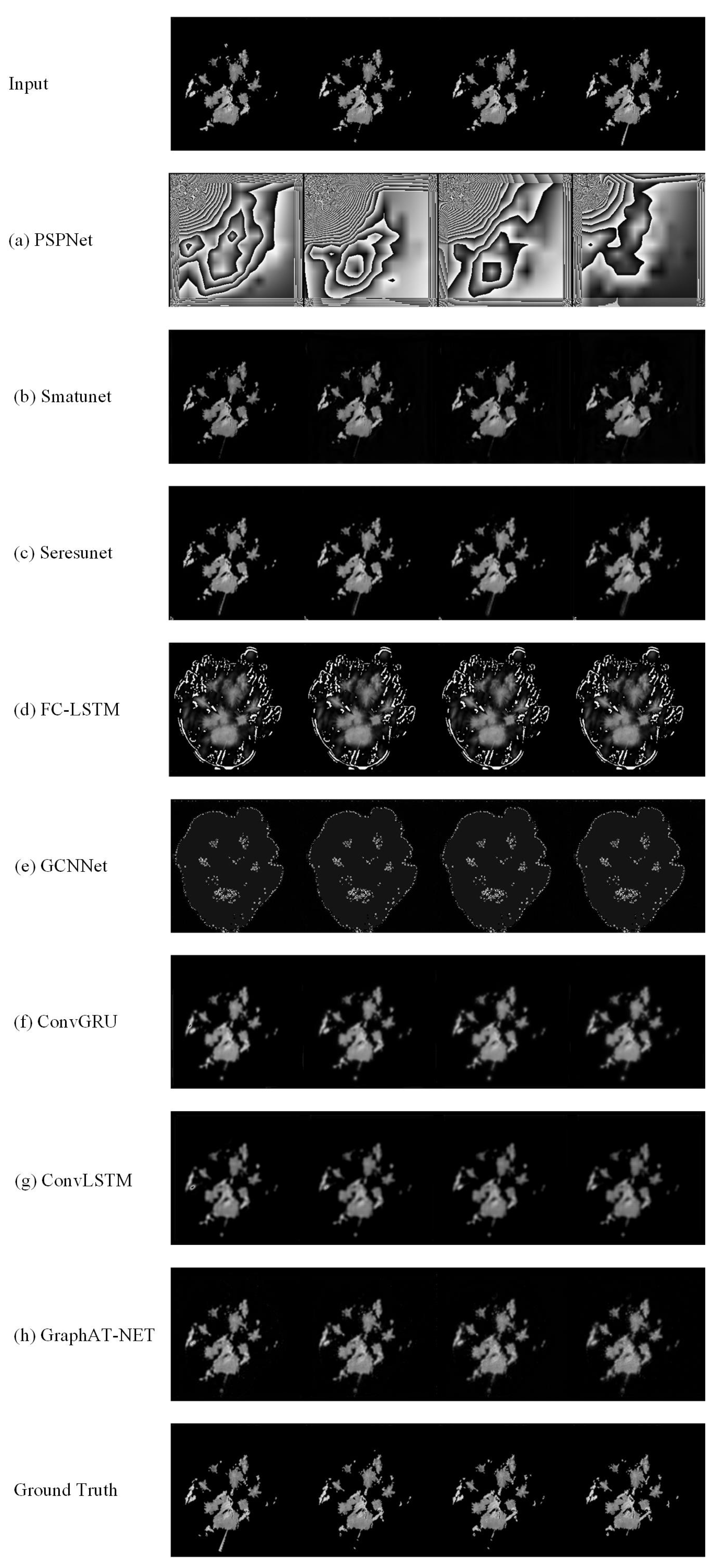
5.1. Performance of Methods on Moving-MNIST Dataset
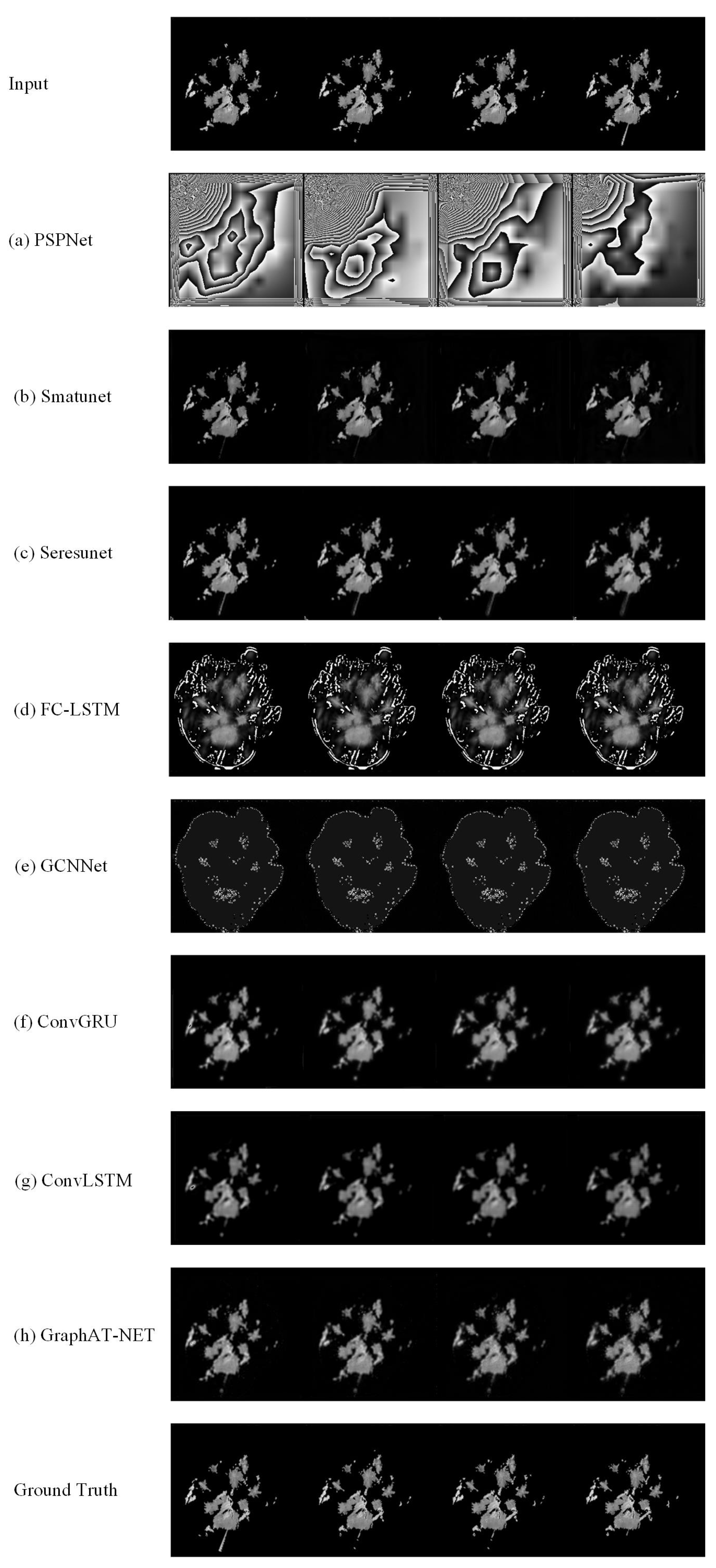
5.2. Performance of Methods on GCAPPI Dataset
6. Ablation Study
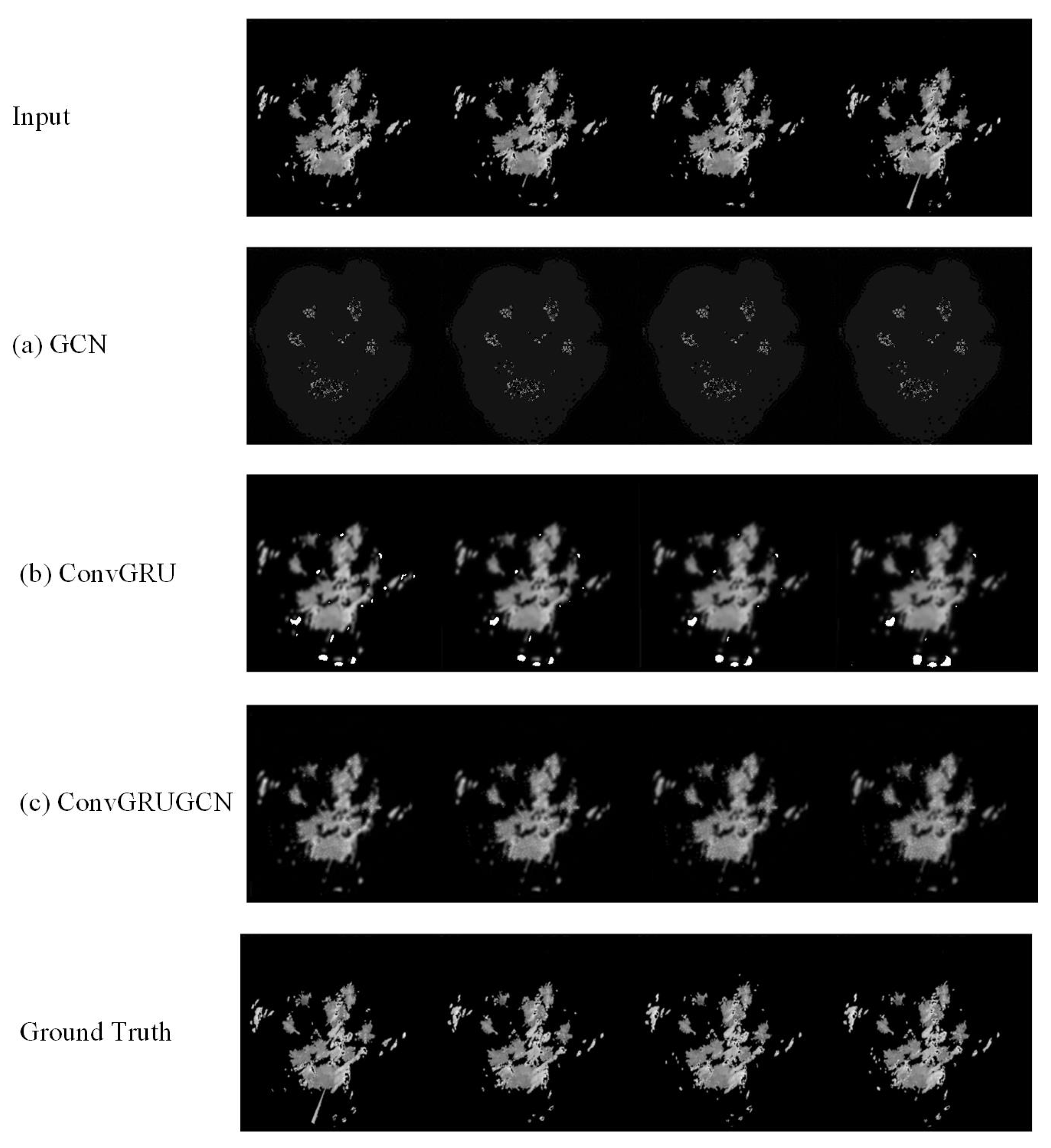
6.1. Effectiveness of GCN
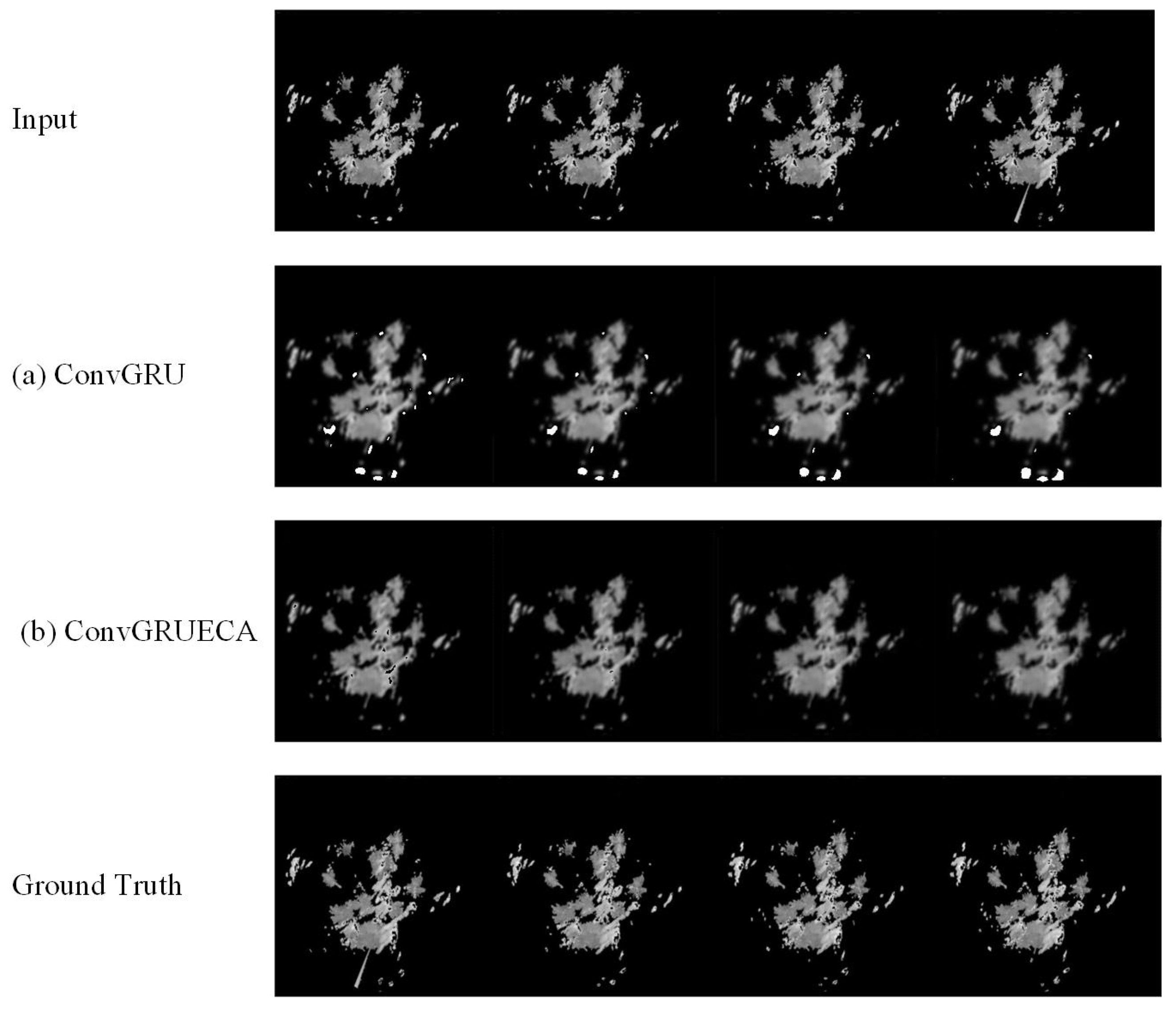
6.2. Effectiveness of ECA
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Collier, C.G. Developments in radar and remote-sensing methods for measuring and forecasting rainfall. Philos. Trans. R. Soc. A 2002, 360, 1345–1361. [Google Scholar] [CrossRef]
- DALEZIOS, N.R. Digital processing of weather radar signals for rainfall estimation. Int. J. Remote Sens. 1990, 11, 1561–1569. [Google Scholar] [CrossRef]
- Michaelides, S.; Levizzani, V.; Anagnostou, E.; Bauer, P.; Kasparis, T.; Lane, J. Precipitation: Measurement, remote sensing, climatology and modeling. Atmos. Res. 2009, 94, 512–533. [Google Scholar] [CrossRef]
- Ghaemi, E.; Kavianpour, M.; Moazami, S.; Hong, Y.; Ayat, H. Uncertainty analysis of radar rainfall estimates over two different climates in Iran. Int. J. Remote Sens. 2017, 38, 5106–5126. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.; Wong, W.; Woo, W. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Peng, W.; Alan, S.; Lao, S.; Edel, O.; Yunxiang, L.; Noel, O. Short-term rainfall nowcasting: Using rainfall radar imaging. In Proceedings of the Eurographics Ireland 2009: The 9th Irish Workshop on Computer Graphics, Dublin, Ireland, 11 December 2009. [Google Scholar]
- Scarchilli, G.; Gorgucci, V.; Chandrasekar, V.; Dobaie, A. Self-consistency of polarization diversity measurement of rainfall. IEEE Trans. Geosci. Remote Sens. 1996, 34, 22–26. [Google Scholar] [CrossRef]
- Suhartono; Faulina, R.; Lusia, D.A.; Otok, B.W.; Sutikno; Kuswanto, H. Ensemble method based on ANFIS-ARIMA for rainfall prediction. In Proceedings of the 2012 International Conference on Statistics in Science, Business and Engineering (ICSSBE), Langkawi, Malaysia, 10–12 September 2012; pp. 1–4. [Google Scholar] [CrossRef]
- Tang, L.; Hossain, F. Understanding the Dynamics of Transfer of Satellite Rainfall Error Metrics From Gauged to Ungauged Satellite Gridboxes Using Interpolation Methods. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 844–856. [Google Scholar] [CrossRef]
- Horn, B.K.P.; Schunck, B.G. Determining Optical Flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Song, K.; Yu, X.; Gu, Z.; Zhang, W.; Yang, G.; Wang, Q.; Xu, C.; Liu, J.; Liu, W.; Shi, C.; et al. Deep Learning Prediction of Incoming Rainfalls: An Operational Service for the City of Beijing China. In Proceedings of the 2019 International Conference on Data Mining Workshops, ICDM Workshops 2019, Beijing, China, 8–11 November 2019; pp. 180–185. [Google Scholar]
- Sønderby, C.K.; Espeholt, L.; Heek, J.; Dehghani, M.; Oliver, A.; Salimans, T.; Agrawal, S.; Hickey, J.; Kalchbrenner, N. MetNet: A Neural Weather Model for Precipitation Forecasting. arXiv 2020, arXiv:2003.12140. [Google Scholar]
- Shi, X.; Gao, Z.; Lausen, L.; Wang, H.; Yeung, D.; Wong, W.; Woo, W. Deep Learning for Precipitation Nowcasting: A Benchmark and A New Model. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5617–5627. [Google Scholar]
- Wang, D.; Zhang, C.; Han, M. FIAD net: A Fast SAR ship detection network based on feature integration attention and self-supervised learning. Int. J. Remote Sens. 2022, 43, 1485–1513. [Google Scholar] [CrossRef]
- Srivastava, N.; Mansimov, E.; Salakhutdinov, R. Unsupervised Learning of Video Representations using LSTMs. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6–11 July 2015; Volume 37, pp. 843–852. [Google Scholar]
- Trebing, K.; Stanczyk, T.; Mehrkanoon, S. SmaAt-UNet: Precipitation nowcasting using a small attention-UNet architecture. Pattern Recognit. Lett. 2021, 145, 178–186. [Google Scholar] [CrossRef]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernocký, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the INTERSPEECH 2010, 11th Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010; pp. 1045–1048. [Google Scholar]
- Souto, Y.M.; Porto, F.; de Carvalho Moura, A.M.; Bezerra, E. A Spatiotemporal Ensemble Approach to Rainfall Forecasting. In Proceedings of the 2018 International Joint Conference on Neural Networks, IJCNN 2018, Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Kim, Y.; Hong, S. Very Short-term Prediction of Weather Radar-Based Rainfall Distribution and Intensity Over the Korean Peninsula Using Convolutional Long Short-Term Memory Network. Asia-Pac. J. Atmos. Sci. 2022, 58, 489–506. [Google Scholar] [CrossRef]
- Fang, W.; Pang, L.; Yi, W.N.; Sheng, V.S. AttEF: Convolutional LSTM Encoder-Forecaster with Attention Module for Precipitation Nowcasting. Intell. Autom. Soft Comput. 2021, 30, 453–466. [Google Scholar] [CrossRef]
- Chung, J.; Gülçehre, Ç.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Tian, L.; Li, X.; Ye, Y.; Xie, P.; Li, Y. A Generative Adversarial Gated Recurrent Unit Model for Precipitation Nowcasting. IEEE Geosci. Remote Sens. Lett. 2020, 17, 601–605. [Google Scholar] [CrossRef]
- Xie, P.; Li, X.; Ji, X.; Chen, X.; Chen, Y.; Liu, J.; Ye, Y. An Energy-Based Generative Adversarial Forecaster for Radar Echo Map Extrapolation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Yu, T.; Kuang, Q.; Yang, R. ATMConvGRU for Weather Forecasting. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- He, W.; Xiong, T.S.; Wang, H.; He, J.X.; Ren, X.Y.; Yan, Y.L.; Tan, L.Y. Radar Echo Spatiotemporal Sequence Prediction Using an Improved ConvGRU Deep Learning Model. Atmosphere 2022, 13, 88. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Wu, Y.; Tang, Y.; Yang, X.; Zhang, W.; Zhang, G. Graph Convolutional Regression Networks for Quantitative Precipitation Estimation. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1124–1128. [Google Scholar] [CrossRef]
- Markner-Jäger, B. Meteorology and Climatology. In Technical English for Geosciences; Springer: Berlin/Heidelberg, Germany, 2008; pp. 156–158. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Han, F.; Wo, W. Design and Implementation of SWAN2.0 Platform. J. Appl. Meteorol. Sci. 2016, 29, 25–34. [Google Scholar]
- Wu, T.; Wan, Y.; Wo, W.; Leng, L. Design and Application of Radar Reflectivity Quality Control Algorithm in SWAN. Meterol. Sci. Technol. 2013, 41, 809. [Google Scholar]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | MSE | SSIM | Vali Loss |
|---|---|---|---|
| GCNNet | |||
| PSPNet | |||
| FC-LSTM | |||
| Seresunet | |||
| Smatunet | |||
| ConvLSTM | |||
| ConvGRU | |||
| GraphAT-Net |
| Methods | MSE | SSIM | Vali Loss |
|---|---|---|---|
| PSPNet | |||
| Smatunet | |||
| Seresunet | |||
| FC-LSTM | |||
| GCNNet | |||
| ConvGRU | |||
| ConvLSTM | |||
| GraphAT-Net |
| Methods | MSE | SSIM | Vali Loss |
|---|---|---|---|
| GCNNet | |||
| ConvGRU | |||
| ConvGRU + GCN | |||
| GraphAT-Net |
| Methods | MSE | SSIM | Vali Loss |
|---|---|---|---|
| ConvGRU | |||
| ConvGRU + ECA | |||
| GraphAT-Net |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, T.; Liew, S.-Y.; Ng, H.-F.; Qin, D.; Lee, H.C.; Zhao, H.; Wang, D. GraphAT Net: A Deep Learning Approach Combining TrajGRU and Graph Attention for Accurate Cumulonimbus Distribution Prediction. Atmosphere 2023, 14, 1506. https://doi.org/10.3390/atmos14101506
Zhang T, Liew S-Y, Ng H-F, Qin D, Lee HC, Zhao H, Wang D. GraphAT Net: A Deep Learning Approach Combining TrajGRU and Graph Attention for Accurate Cumulonimbus Distribution Prediction. Atmosphere. 2023; 14(10):1506. https://doi.org/10.3390/atmos14101506
Chicago/Turabian StyleZhang, Ting, Soung-Yue Liew, Hui-Fuang Ng, Donghong Qin, How Chinh Lee, Huasheng Zhao, and Deyi Wang. 2023. "GraphAT Net: A Deep Learning Approach Combining TrajGRU and Graph Attention for Accurate Cumulonimbus Distribution Prediction" Atmosphere 14, no. 10: 1506. https://doi.org/10.3390/atmos14101506
APA StyleZhang, T., Liew, S.-Y., Ng, H.-F., Qin, D., Lee, H. C., Zhao, H., & Wang, D. (2023). GraphAT Net: A Deep Learning Approach Combining TrajGRU and Graph Attention for Accurate Cumulonimbus Distribution Prediction. Atmosphere, 14(10), 1506. https://doi.org/10.3390/atmos14101506