Abstract
Effective prediction of protein tertiary structure from sequence is an important and challenging problem in computational structural biology. Ab initio protein structure prediction is based on amino acid sequence alone, thus, it has a wide application area. With the ab initio method, a large number of candidate protein structures called decoy set can be predicted, however, it is a difficult problem to select a good near-native structure from the predicted decoy set. In this work we propose a new method for selecting the near-native structure from the decoy set based on both contact map overlap (CMO) and graphlets. By generalizing graphlets to ordered graphs, and using a dynamic programming to select the optimal alignment with an introduced gap penalty, a GR_score is defined for calculating the similarity between the three-dimensional (3D) decoy structures. The proposed method was applied to all 54 single-domain targets in CASP11 and all 43 targets in CASP10, and ensemble clustering was used to cluster the protein decoy structures based on the computed CR_scores. The most popular centroid structure was selected as the near-native structure. The experiments showed that compared to the SPICKER method, which is used in I-TASSER, the proposed method can usually select better near-native structures in terms of the similarity between the selected structure and the true native structure.
1. Introduction
The human genome project was first proposed by American scientists in 1985 and officially launched in 1990 [1]. Its purpose is to determine the nucleotide sequence consisting of three billion base pairs contained in a human chromosome, thereby mapping the human genome and identifying the genes and their sequences to decipher humans. With the completion of the program, the gene sequence can be obtained by measuring the obtained map, and the sequence of the corresponding protein can also be inferred using the genetic central dogma [2]. Since the function of genes can be studied via the study of the corresponding proteins produced through gene expression, the use of bioinformatics to discover the function of a protein product of a gene becomes more and more significant. In fact, determining protein functions from genomic sequences is a central goal of bioinformatics [3]. Since the function of proteins is determined by its tertiary structure, the prediction of tertiary structure based on protein sequences is a very important problem.
It is known that the number of known protein structures increases exponentially. By the end of the decade, the PDB [4] database size will be more than 150,000 structures at the current rate. However, the newly published UniProtKB/TrEMBL [5] protein database in Jan, 2019 contains 139,694,261 sequence entries. Hence, only a very small part of them have experimentally solved structures. Therefore, protein tertiary structure prediction becomes an important and challenging problem in computational structural biology.
Although many protein tertiary structure prediction methods have been proposed, there is no consensus on which one is the best [6,7]. There are usually three kind of structure prediction methods: homology modeling, threading or fold recognition, and ab initio modeling [8]. Both homology modeling and threading require known protein structures as templates, thus, they are difficult to be successfully applied in the absence of template structures. In contrast, ab initio modeling does not require a known structure: it directly predicts its spatial structure from the protein sequence. Different from these methods, which directly predict the tertiary structures, there are also methods to predict contact maps of the proteins from sequence information [9,10]. Contact maps can be predicted by finding correlated pairs of amino acids in multiple sequence alignments, or using neural network approaches. The predicted contact maps can then be used to help the tertiary structure prediction of the proteins. To help the development of high-quality protein tertiary structure prediction methods, a worldwide experiment called Critical Assessment of Protein Structure Prediction (CASP) has been held every two years since 1994 [11]. The goal of the CASP is to evaluate existing protein structure prediction methods or detect their flaws. CASP provides research groups with an opportunity to objectively test their structure prediction methods and delivers an independent assessment of the state of the art in protein structure modeling to the research community and software users. The decoy sets, generated by I-TASSER, of single-domain targets in the CASP11 [12] and CASP10 [13] were used in our experiments. These decoy sets can be downloaded from the Zhang Lab website [14].
One of the challenges in designing the ab initio structure prediction method is to select the best near-native model from a large number of predicted decoy structures. Using clustering methods based on structure similarity score have been shown to be superior to using energy function in selecting the near-native structures [15]. To use the clustering methods, a key problem is the computation of the protein structure similarity.
Many tools for comparing protein structures and computing structure similarity have been developed. One type of the comparison methods is based on the model superposition, which can be further divided into two categories: the rigid-body approaches and flexible alignment approaches. The rigid-body approaches consider the proteins as rigid objects and aim to find alignments that have the maximum number of mapped residues and the minimum deviations between the mapped structures. The rigid-body approaches mainly differ in how they combine these two objectives [16]. The final score is often expressed in terms of root mean square deviation (RMSD). Combinatorial extension (CE) [17] is a typical example of rigid structure comparison method. It aligns protein structures by chaining the consecutive aligned fragment pairs (AFPs) without twists. These AFPs are combined to evaluate the protein similarity. Global distance test (GDT) [18], also written as GDT-TS (GDT total score), is one of the scores developed to overcome shortcomings of RMSD. The GDT-TS measures the structure similarity by quantifying the number of corresponding atoms in the model that can be superposed within a set of predefined tolerance thresholds to the reference structure. Unlike RMSD, GDT-TS is more robust against small fragments movements, benefited from using several superposition thresholds. The GDT-TS is now a major assessment criterion in CASP. The template modeling score (TM-score) [19] is a variation of the Levitt-Gerstein (LG) score to assess the quality of protein structure templates and predicted full-length models. All the residues of the modeled proteins are evaluated by a protein size dependent scale, rather than using a specific distance cutoff and focusing only on the fractions of structures as in the GDT-TS. TM-score is more sensitive to the correctness of global topology than the local structural errors, while the RMSD measure is sensitive to local small disorientations which may result in a big overall RMSD change even though the core region of the model may be correct. Because proteins are flexible molecules and can undergo large conformational changes that are not captured by the rigid-body approaches, flexible alignment methods have also been developed. Flexible alignment methods overcome the limitations of the rigid body approaches by either allowing twists between rigidly aligned fragments or by only maximizing local similarities (in terms of Euclidean distance) [20]. One of the typical flexible alignment methods is FATCAT (flexible structure alignment by chaining aligned fragment pairs with twists) [20]. FATCAT is an improvement based on CE. It first identifies the local AFPs and then produces an optimal combination of these AFPs using dynamic programming, where twists and gap penalty are used to allow flexible alignments.
Another type of the protein structure comparison methods is not based on the model superposition. One of the methods is Contact Area Difference (CAD) [21], which evaluates the structure similarities based on contacts. It computes the structure similarity by measuring the differences between the physical contacts of a model and a reference structure, without supposition of the two models. The local Distance Difference Test (lDDT) [22] is another superposition free score that evaluates local distance differences of all atoms in a model, including validation of stereochemical plausibility. The reference can be a single structure, or an ensemble of equivalent structures. It is computed over all pairs of atoms in the reference structure at a distance closer than a predefined threshold, and not belonging to the same residue.
There are also methods developed specially for evaluating predicted decoys using both energy functions and the structure information. The random forest-based model quality assessment (RFMQA) [23] predicts a relative score of a decoy model by using its secondary structure, solvent accessibility and knowledge-based potential energy terms. The support-vector-machine-based single-model quality assessment (SVMQA) [24] is trained to predict TM-score and GDT_TS score based on both statistical potential energy terms and structure consistency features.
In this article, a new protein structure similarity score, called the GR_score, was defined based on maximum Contact Map Overlap (CMO) [25] which is a superposition free protein structure alignment method defined by Godzik and Skolnick, and the ordered graphlet degree [26] which is a new systematic measure of a network’s local structure similarity. The superposition free structure alignment methods based on contact maps may capture both the local structure similarities from contact maps and the global structure similarities using dynamic programming. Using the ordered graphlet degree can further improve the measuring of the local structure similarities by comparing the local topology structures. Thus, the proposed GR_score can help in measuring the decoy structure similarities, and in selecting the near-native models from a large number of predicted decoy models in ab initio structure prediction.
2. Materials and Methods
2.1. Maximum Contact Map Overlap (CMO)
A contact map is an ordered graph, , where nodes V and edges E are defined as follows. Each node in V represents an amino acid of a protein. It leads to a strict total ordering of the nodes: for two different nodes and , either if is before in the protein sequence or otherwise. The two nodes and are connected by an edge , if and only if the Euclidean distance between the Cα atoms of the corresponding amino acids is less than a given threshold ɛ. This is presented in Figure 1 [27].
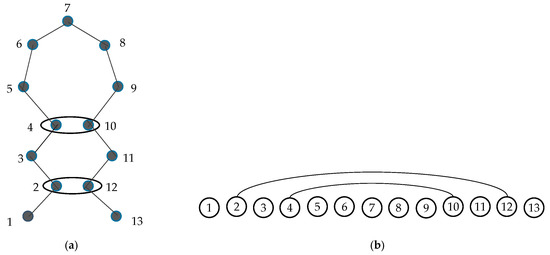
Figure 1.
(a) Schematic diagram of a protein backbone. Amino acid 2 is in contact with 12 and 4 is in contact with 10 (the distance between two nodes is less than ɛ). (b) The corresponding contact map graph, where two edges connect node 2 with 12 and 4 with 10 [27].
2.2. Graphlets and Graphlet Degrees
Graphlets are small, connected, non-isomorphic and induced subgraphs of a larger graph having nodes [27]. Some nodes are identical to each other topologically within each graphlet, which is considered to belong to the same automorphism orbit to represent that a graphlet can touch a node in by different ways topologically. The concepts used to summarize the graphlets degree are: the graphlet degree of node , represented by , is the number of times a graphlet touches node at orbit . In the graph degree distribution protocol, the degree distribution is extended to 73 graph degree distributions by using all 2-5 nodes and their corresponding 73 automorphism orbits (the first of the 73 graph degree distributions is the degree distribution) [28]. The ordered graphlet degree of node , represented by , is the number of times an ordered graphlet touches the node at orbit . To reduce the calculation times, the five 2-node and 3-node ordered graphlets have been chosen to define 14 orbits (see Figure 2) [27]. Therefore, a 14-dimensional vector () could describe each node of a contact map. For a given contact map , there would be a limitation of the degree of a node by the number of residues that can fit in a sphere with radius ɛ. In fact, a linear worst time complexity could be led by using a distance threshold ɛ of 7.5 Å.
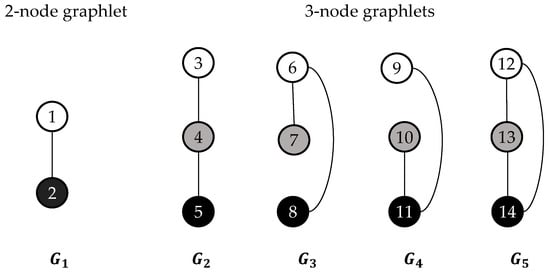
Figure 2.
The five 2-node and 3-node ordered graphlets and the corresponding 14 automorphism orbits. The ordering of the graphlet nodes in each graphlet } is represented by their colors: white nodes <gray nodes<black nodes [27].
2.3. TM-Score
The TM-score [19] is intended as a more accurate measure of the protein structure similarity than RMSD and GDT-TS. It gives the residue pairs at smaller distance higher weights than those at larger distances and normalized by the length of the target proteins, thus, it can represent the global structure similarities better than RMSD or GDT-TS measures. The TM-score is between 0 and 1, where 1 indicates a perfect match between two structures. Generally, scores below 0.2 correspond to randomly chosen unrelated proteins. The score of the structures roughly having the same fold is higher than 0.5.
2.4. SPICKER
SPICKER is an iterative clustering method to identify near-native protein folds developed by Zhang and Jeffery [29]. The procedure of selecting protein structure by this clustering method is as follows. First, a self-adjusting cutoff between 7.5 to 12 Å is found in an iterative way to make sure that the largest cluster contains less than 70% and more than 15% of total decoys. Second, another iterated approach is applied to identify the cluster with the most neighbors under the cutoff excluding the members of cluster found in the previous iterations. Finally, an averaging model, called final model, is built from all the decoy members of the cluster in the current iteration.
2.5. Ensemble Clustering
Using the ensemble clustering method as introduced in [30] can avoid local optimality. The most popular centroid structure identified in the ensemble clustering is selected as the near-native structure in the proposed method. The method includes two steps: constructing a distance matrix for the decoy set using a similarity score, and finding the most possible largest cluster centroid using an ensemble k-medoids. A confidence score as described in [30] is used to select the cluster centroid with the maximum score as the near-native structure.
2.6. GR_score
2.6.1. Ordered Graphlet Degree Similarity.
Only Cα atoms were used in the structure comparison in the proposed method. For two proteins A and B, and are the different Cα atoms of the two proteins. Based on graphlet degrees, between two nodes and , the order graphlet degree similarity is defined as follows [27]:
the range of the similarity score is from 0 to 1. The two nodes having similar local topologies will have a high similarity score.
2.6.2. Structure Alignment Algorithm.
The alignment between two structures having, respectively, and nodes was computed using the Needleman-Wunsch dynamic programming algorithm [31] as in the original CMO, where the score of mapping two nodes is their ordered graphlet degree similarity defined in (1). It corresponds to the following dynamic programming procedure:
where the gap penalty is defined as follows:
where is a constant parameter that will be discussed in Section 3.2.
2.6.3. Definition of the GR_score.
The dynamic programming algorithm introduced in the above section produces the matrix, where and . Thus, the final similarity score of the two proteins is defined as follows:
The range of the similarity score is also from 0 to 1. The closer the value of the GR_score is to 1, the higher the similarity of the two structures; the closer the value of the GR_score is to 0, the lower the structural similarity of the two proteins.
2.7. Constructing the Distance Matrix
To get the distance matrix for the clustering method, a similarity matrix for the decoys needed to be constructed, and then we can get the distance matrix by defining . The distance matrix is a symmetric matrix whose diagonal elements are all 0. The element in row and column represents the dissimilarity between two decoys and .
2.8. Select the Near-native Structure using Ensemble Clustering
K-medoids was ran m = 500 times, which was enough to ensure statistical stability, with random initialization. The times a decoy became the centroid of the largest cluster was counted. It was found that a reasonable value for parameter k used in k-medoids was five. Finally, to consider both the size and the internal similarity of a cluster in selecting the near-native structure, a confidence score as defined in [30] was used. The centroid with the maximum confidence score within the cluster centroids whose count was more than 70% of the maximum count was selected as the near-native structure, where the count was the times a decoy became the centroid of the largest cluster.
3. Results and Discussion
3.1. Dataset
Up to 54 decoys sets (from CASP11) [12] and 43 decoys sets (from CASP10) [13], which are single-domain targets and have experimental native structures, were downloaded from Zhang Lab website [14]. These decoy sets contain structurally non-redundant set of protein structures from the raw decoy sets. The native structure, the generated model by SPICKER used in I-TASSER [32] sever, and the best TM-score for the target in the decoy set were also downloaded from the Zhang Lab website [14] (Supplementary materials).
3.2. Parameter Selection
In the dynamic programming, to select a good parameter , four values of , 0.2, 0.5, 1, and 2, were compared. For each decoy set, the similarity matrix was obtained by using the proposed GR_score in Section 2.6.3 using each value. Then, the most popular centroid structure was selected as the near-native structure by the proposed method. The near-native structures selected by the proposed method and the corresponding native structures were compared using the TM-score.
In the experiments, 54 targets from CASP11 were used. For each target, four different TM-scores were produced from four values, and the value that produced the highest TM-score was recorded. Finally, for each value, the number of the targets for which the highest TM-scores were produced using the value was counted. The numbers of the targets with the highest TM-scores for four values are shown in Figure 3.
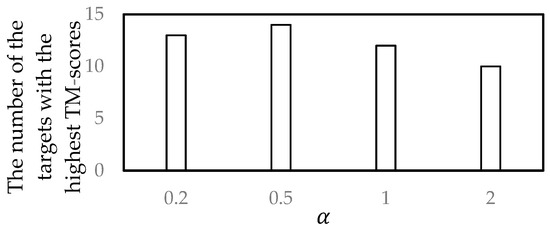
Figure 3.
Parameter selection.
It can be seen from Figure 3 that when , the selected near-native structures were more similar to the corresponding native structure, compared to the other values. Thus, the parameter was set to 0.5 in the proposed method.
3.3. Experimental Results
3.3.1. The Experimental Results for Datasets from CASP10.
For the proposed method, the GR_score was used to calculate the similarity matrix of the 43 decoy sets from CASP10. Then, the ensemble clustering was used to select the near native structures for each target. The near-native structure selected by the proposed method and the near-native structure generated by the SPICKER method used in I-TASSER sever were compared. The TM-sore and the GR_score between the selected near-native structures and the native structure were computed. The results are shown in the scatter plots in Figure 4, in which each target protein is represented as one point. The x-axis represents the GR_score or TM-score produced by the proposed method, and the y-axis represents the scores produced by the SPICKER method for the same target. The blue diagonal line in Figure 4 represents y=x. The same score does not necessarily mean the same model.
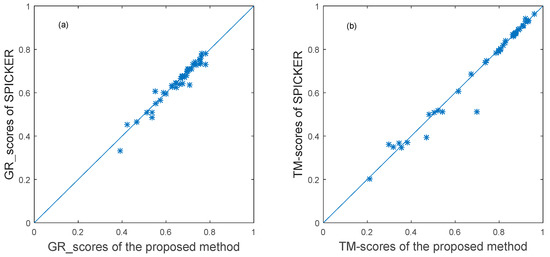
Figure 4.
The plot of GR_scores and TM-scores produced by two methods for datasets from CASP10.
The details of the comparison can also be found in Table 1, in which the first column is the ID of the target protein, the second column and the third column are the GR_scores of the selected near-native models by the proposed method and the SPICKER method, the fourth column and the fifth column are the TM-scores of the selected near-native model by the proposed method and the SPICKER method. All the scores were computed between the selected near-native model and the corresponding native structure.

Table 1.
The Comparison of GR_scores and TM-scores for datasets from CASP10. The bold number indicates the highest GR_score or TM-score for each target.
To better understand the results, the number of the targets for which each method produced the better results was counted. The results are shown in Figure 5, where the white bar represents the number of decoy sets for which our method produces better results than SPICKER, the gray bar represents the number of decoy sets for which our method produces worse results than SPICKER, and the black bar represents the number of the similar results produced by the two methods. It can be seen from the left part of Figure 5 that the proposed method selected more near-native structures with higher GR_scores, compared to the SPICKER method. However, when measuring the similarity using the TM-score, the SPICKER method produced more near-native structures with higher scores, as can be seen from the right part of Figure 5, although the difference was smaller compared to the GR_score result on the left part of Figure 5. This may be due to fact that the similarity measure used in the proposed method is GR_score, instead of the TM-score.
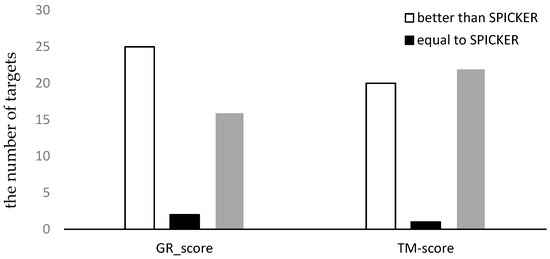
Figure 5.
The comparison of the two methods using both GR_score and TM-score for datasets from CASP10.
3.3.2. The Experimental Results for Datasets from CASP11.
To further evaluate the proposed method, it was also applied to the 54 decoy sets from CASP11. The near-native structure selected by the proposed method and the near-native structure generated by the SPICKER method used in I-TASSER sever were compared. The results of the GR_score are shown in the left scatter plot in Figure 6, while the results of the TM-score are shown in the left scatter plot in Figure 6.
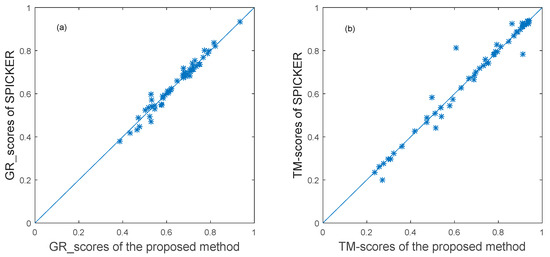
Figure 6.
The plot of GR_scores and TM-scores produced by two methods for datasets from CASP11.
Detailed results with scores for all the targets are shown in Table 2.
Table 2.
The Comparison of GR_scores and TM-scores for datasets from CASP11. The bold number indicates the highest GR_score or TM-score for each target.
To clearly represent the results, the number of the targets for which each method produces the better results was counted. The results are shown in Figure 7. It can be seen from the Figure 7 that the proposed method can select better near-native structures for more targets compared to the SPICKER method, evaluated either with GR_scores or with TM-scores.
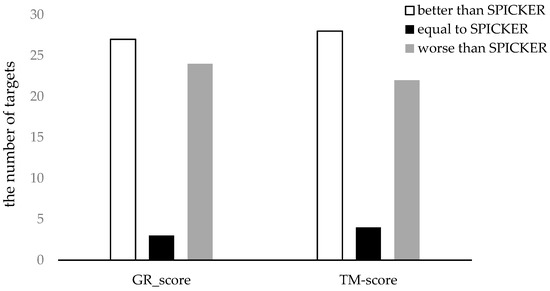
Figure 7.
The comparison of the two methods using both GR_score and TM-score for datasets from CASP11.
Taking target T0851 as an example, Figure 8 shows the superposition between the native structure and the near-native structure found by the proposed method and the near-native structure selected by SPICKER. The red model is the native structure and the blue is the structure selected by the proposed method in Figure 8a, the other blue structure is generated by SPICKER in Figure 8b. It can be seen from Figure 8 that the SPICKER model has an obvious mismatch in the right half part of the protein.
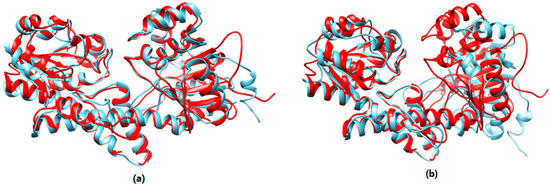
Figure 8.
(a) The superposition of T0851 native structure and the near-native structure selected by the proposed method. (b) The super-position of T0851 native structure and the model selected by SPICKER.
4. Conclusions
In this paper, we have proposed a new similarity score, GR_score, for comparing two protein structures based on both CMO and order graphlet degrees. The introduced GR_score can serve as a new assessment criterion for protein structure comparison. It is shown that the proposed GR_score along with the ensemble clustering can be used to select the near-native structures from the decoy sets. Compared to the state-of-the-art SPICKER method, the proposed method can select more high quality near-native structures if evaluated using the GR_score for datasets from both CASP10 and CASP11. In future work, we will continue to improve the computation of the similarity scores between protein structures, and to evaluate the similarity scores from more aspects.
Supplementary Materials
Following are available online at http://www.mdpi.com/2073-4425/10/2/132/s1, code and data used.
Author Contributions
Conceptualization, Y.L.; methodology, X.H., L.L., and Y.L.; software, X.H., and L.L.; validation X.H.; formal analysis, X.H.; investigation, X.H..; resources, X.H..; data curation, X.H.; writing—original draft preparation, X.H.; writing—review and editing, Y.L.; visualization, X.H.; supervision, Y.L.; project administration, Y.L.; funding acquisition, Y.L.
Funding
This research was funded by the National Key R&D Program of China (Grants number 2017YFE0111900, 2018YFB1003205).
Acknowledgments
We thank all the reviewers for their valuable comments, which helped us a lot in improving the writing of the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Collins, F.S.; Michael, M.; Aristides, P. The human genome project: Lessons from large-scale biology. Science 2003, 300, 286. [Google Scholar] [CrossRef] [PubMed]
- Crick, F. Central dogma of molecular biology. Nature 1970, 227, 561–563. [Google Scholar] [CrossRef] [PubMed]
- Pellegrini, M.; Marcotte, E.M.; Thompson, M.J.; Eisenberg, D.; Yeates, T.O. Assigning protein functions by comparative genome analysis: protein phylogenetic profiles. Proc. Natl. Acad. Sci. USA 1999, 96, 4285–4288. [Google Scholar] [CrossRef] [PubMed]
- Berman, H.M.; Westbrook, J.; Feng, Z.; Gilliland, G.; Bhat, T.N.; Weissig, H.; Shindyalov, I.N.; Bourne, P.E. The protein data bank. Nucl. Acids Res. 2000, 28, 235–242. [Google Scholar] [CrossRef] [PubMed]
- UniProtKB/TrEMBL Protein database release statisics. Available online: http://www.ebi.ac.uk/uniprot/TrEMBLstats (accessed on 16 January 2019).
- Zhang, Z. An overview of protein structure prediction: From homology to ab initio. Bioc218 2002, 1–10. [Google Scholar]
- Hasegawa, H.; Holm, L. Advances and pitfalls of protein structural alignment. Curr. Opin. Struct. Biol. 2009, 19, 341–348. [Google Scholar] [CrossRef]
- Yang, Z.; Jeffrey, S. Automated structure prediction of weakly homologous proteins on a genomic scale. Proc. Natl. Acad. Sci. USA 2004, 101, 7594–7599. [Google Scholar]
- Wang, S.; Sun, S.; Li, Z.; Zhang, R.; Xu, J. Accurate de novo prediction of protein contact map by ultra-deep learning model. PLoS Comp. Biol. 2017, 13, e1005324. [Google Scholar] [CrossRef]
- Hamilton, N.; Burrage, K.; Ragan, M.A.; Huber, T. Protein contact prediction using patterns of correlation. Proteins 2004, 56, 679–684. [Google Scholar] [CrossRef]
- Moult, J.; Pedersen, J.T.; Judson, R.; Fidelis, K. A large-scale experiment to assess protein structure prediction methods. Proteins 1995, 23, ii–iv. [Google Scholar] [CrossRef]
- The 11th critical assessment of techniques for protein structure prediction. Available online: http://predictioncenter.org/casp11 (accessed on 7 December 2014).
- The 10th critical assessment of techniques for protein structure prediction. Available online: http://predictioncenter.org/casp10 (accessed on 7 December 2012).
- The Yang Zhang Lab. Available online: https://zhanglab.ccmb.med.umich.edu/decoys/ (accessed on 30 June 2018).
- Shortle, D.; Simons, K.T.; Baker, D. Clustering of low-energy conformations near the native structures of small proteins. Proc. Natl. Acad. Sci. USA 1998, 95, 11158–11162. [Google Scholar] [CrossRef] [PubMed]
- Godzik, A. The structural alignment between two proteins: Is there a unique answer? Protein Sci. 2010, 5, 1325–1338. [Google Scholar] [CrossRef] [PubMed]
- Shindyalov, I.N.; Bourne, P.E. Protein structure alignment by incremental combinatorial extension (CE) of the optimal path. Protein Eng. 1998, 11, 739–747. [Google Scholar] [CrossRef] [PubMed]
- Zemla, A.; Venclovas, C.; Moult, J.; Fidelis, K. Processing and analysis of CASP3 protein structure predictions. Proteins 2015, 37, 22–29. [Google Scholar]
- Zhang, Y.; Skolnick, J. Scoring function for automated assessment of protein structure template quality. Proteins 2004, 57, 702–710. [Google Scholar] [PubMed]
- Ye, Y.; Godzik, A. Flexible structure alignment by chaining aligned fragment pairs allowing twists. Bioinformatics 2003, 19 (Suppl. 2), ii246. [Google Scholar] [CrossRef]
- Kliment, O.; Eleonora, K.; Ceslovas, V. CAD-score: A new contact area difference-based function for evaluation of protein structural models. Proteins 2013, 81, 149–162. [Google Scholar]
- Valerio, M.; Marco, B.; Alessandro, B.; Torsten, S. IDDT: A local superposition-free score for comparing protein structures and models using distance difference tests. Bioinformatics 2013, 29, 2722–2728. [Google Scholar]
- Manavalan, B.; Lee, J.; Lee, J. Random forest-based protein model quality assessment (RFMQA) using structural features and potential energy terms. PLoS ONE 2014, 9, e106542. [Google Scholar] [CrossRef]
- Manavalan, B.; Lee, J. SVMQA: Support-vector-machine-based protein single-model quality assessment. Bioinformatics 2017, 33, 2496. [Google Scholar] [CrossRef]
- Godzik, A.; Skolnick, J. Flexible algorithm for direct multiple alignment of protein structures and sequences. Bioinformatics 1994, 10, 587–596. [Google Scholar] [CrossRef]
- Przulj, N.; Corneil, D.G.; Jurisica, I. Modeling interactome: Scale-free or geometric? Bioinformatics 2004, 20, 3508–3515. [Google Scholar] [CrossRef] [PubMed]
- Malod-Dognin, N.; Przulj, N. GR-Align: Fast and flexible alignment of protein 3D structures using graphlet degree similarity. Bioinformatics 2014, 30, 1259–1265. [Google Scholar] [CrossRef] [PubMed]
- Murzin, A.G.; Brenner, S.E.; Hubbard, T.; Chothia, C. SCOP: A structural classification of proteins database for the investigation of sequences and structures. J. Mol. Biol. 1995, 247, 536–540. [Google Scholar] [CrossRef]
- Zhang, Y.; Skolnick, J. SPICKER: A clustering approach to identify near-native protein folds. J. Comput. Chem. 2004, 25, 865–871. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Lu, Y.; Yan, H. Selecting near-native protein structures from ab initio models using ensemble clustering. Quant. Biol. 2018, 6, 307–312. [Google Scholar] [CrossRef]
- Needleman, S.B.; Wunsch, C.D. A general method applicable to the search for similarities in the amino acid sequence of two proteins. J. Mol. Biol. 1970, 48, 443–453. [Google Scholar] [CrossRef]
- Yang, J.Y.; Yan, R.X.; Roy, A.; Xu, D.; Poisson, J.; Zhang, Y. The I-TASSER Suite: Protein structure and function prediction. Nat. Methods 2015, 12, 7–8. [Google Scholar] [CrossRef]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).